GBrain知识库检索实战
GBrain知识库检索实战
2026 年 4 月,Y Combinator 总裁兼 CEO Garry Tan 公开了一件事:他用大约一周时间,在自己的 AI Agent 工作流里,建立了一个真正运转的个人知识图谱。
结果出乎他自己的意料:
-
17,888 个知识页面 ,每人一页、每家公司一页
-
4,383 份人物档案 :认识的人、过往互动、投资关系,全部自动提取
-
723 家公司 的结构化信息
-
21 个定时任务 自主运行,趁他睡觉时整理当天的会议记录、修复信息矛盾
这套系统是他真实工作的底层——不是演示用的 Demo,而是他运营 YC、管理数百个创始人关系的实际工具。
4 月 10 日,他把这套系统以 MIT 开源协议发布,项目名叫 GBrain 。
24 小时内,GitHub stars 突破 5,400 ;X 平台触达了 150 万用户 。到今天,stars 累积至约 14,000 —— 对于一个个人工具性质的 MIT 开源项目来说,这个数字已经相当能说明问题了。(GBrain GitHub 仓库 · stars 数据实测于 2026-05-09)
这个数字当然有"YC CEO 发布了个项目"的传播效应——但能持续维持热度,靠的不是名气,而是它戳中了 AI 开发者社区里一个藏了很久的真实痛点。
AI 每天都在"失忆"
你可能有过这种体验:
昨天和 Claude Code 聊了两个小时,把一个复杂问题拆解得很细,确定了方案,有了明确的下一步。今 —— 天打开新会话它对昨天的事一无所知,你得从头解释项目背景、你的判断标准、上次讨论的结论。
换个更复杂的场景:你是一位投资人,认识几百个创始人,每周开十几场会。AI Agent 帮你记笔记、写 —— 分析但每次调用,它对你的历史、你认识的人、你的判断逻辑,知道的和上周一样少。每一次,都像第一次见面。
这不是"AI 还不够聪明"的问题。这是结构性的:现有 AI Agent,在会话之间,默认没有记忆。
—— Garry Tan 面对的是同样的问题,只不过他的规模更大数百个创始人关系、十几年的历史决策、横跨多个系统的信息。他用实验的方式找到了一套可以运转的解法,然后把它开源出来。
我们接下来要看的,就是 GBrain 到底是什么,它能解决哪些场景里的"失忆"问题,以及它和已有方案相比,区别在哪里。
GBrain 是什么
一句话定位: GBrain 是为 AI Agent 设计的个人知识图谱系统 ,目标是让你的 AI 真正了解你的世界—— 不只是记住几条设置,而是建立起一个随时间自动积累、能感知人与人之间关系、能在你睡觉时自动整理的长期记忆后端。
它的目标用户,Garry Tan 自己描述为「靠思考为生的人」(people who think for a living)——投资人、CEO、研究员、高密度信息处理者。但任何觉得"AI 每次对话都像初次见面"是个痛点的人,都是潜在受益者。
它能做什么
1. 自动构建你的人脉图谱
每当一个人、公司或概念在你的会议记录、邮件、推文里出现,GBrain 会自动为它建一个页面,记录相关信息,并自动识别关系类型——这个人「任职于」哪家公司、「创立了」什么、「参加过」哪些会议、「投资了」哪些项目。
这不是模糊的"存进去",而是有结构的链接。之后你问"谁在 Acme AI 工作"或"Bob 最近投资了什么",系统能给出语义搜索触达不了的精确答案。
2. 夜间自主整理(Dream Cycle)
每天夜里,GBrain 会自动运行一轮维护:扫描当天的会议转录和对话、增强缺失实体的页面、修复前后矛盾的信息、跨页面整合记忆。你早上醒来,这个"大脑"比你入睡前更完整。
这是 GBrain 区别于普通知识库的核心设计之一——它不是一个等你喂食的静态容器,而是一个在你不用它的时候持续自我进化的系统。
3. Compiled Truth + 时间线:知识的"活文档"模式
GBrain 里每个知识页面,都分为两个区域:
-
上方: Compiled Truth(编译真相) ——你当前对这个人/公司/概念的最佳理解,当新证据出现时会自动重写
-
——
-
下方: 时间线 只追加的证据轨迹,记录你何时、从何处得到这条信息,永不删改
这个设计回答了一个大多数知识系统忽略的问题: "我相信什么"和"我为什么相信"是两回事 。当你需要更新一个判断时,你能看到证据来源;当系统发现信息过期,它知道该重写哪一层。
4. 数据自动流入
GBrain 提供一套集成配方,让信息自动进来,不需要你手动复制粘贴:
| 集成来源 | 自动做什么 |
|---|---|
| 会议转录(Circleback) | 每位参会者自动生成/更新人物页面 |
| Gmail | 提及的人物和公司自动入库 |
| Google Calendar | 每日日程变成可搜索的页面 |
| Twitter/X时间线 | 推文和提及自动摄取 |
| 电话通话 | 通话转录+实体提取,生成页面 |
5. Skillify:把经验固化成永久技能
GBrain 内置了一个叫 Skillify 的机制:当 Agent 发现一个重复成功的操作模式,可以把它固化成一个永久技能文件,下次遇到同类问题直接调用,不用重新学。
举个例子:你每次整理投资 memo 都按同一套结构——背景、亮点、风险、建议。GBrain 发现这个规律后,会把这个流程固化下来。之后每次你说"帮我整理这次会议的 memo",Agent 自动按你的框架启动,不需要你再解释格式偏好。
对于想把个人工作经验编码进 AI 工作流的用户,这是一个特别值得关注的能力。
真实数据
Garry Tan 的生产部署数据
—— 前面提到过 Garry 的那几个数字——17,888 页、4,383 人物档案这里再补一条更值得细想的维度: 这一切是在 12 天内从零建成的 。
不是他手动录入,而是 Agent 在他工作的过程中自动积累:每一场会议、每一封邮件、每一个被提及的名字,都在他不操心的情况下进了库。12 天,1 万 7 千多页。
(来源:GBrain 官方 README)
检索质量基准(需注意)
在项目自建的测试集(240 页内容)上:
-
P@5(前 5 条结果精确率):49.1%
-
R@5(前 5 条结果召回率):97.9%
-
比禁用图谱的纯混合搜索高出 +31.4 个百分点 (P@5)
(来源:gbrain-evals · 重要声明:这是项目方自建的评估集,目前尚无独立第三方验证,不能作为"GBrain 是最好的检索系统"的证据,但反映了图谱层对检索质量的实际贡献。 )

和"轻量方案"比:什么时候 GBrain 才有优势
很多人用 CLAUDE.md 手工维护的静态上下文来解决"让 AI 记住我的设定"的问题——这完全合理,而且对大多数场景够用。
GBrain 真正的价值,体现在规模越过某个拐点之后:
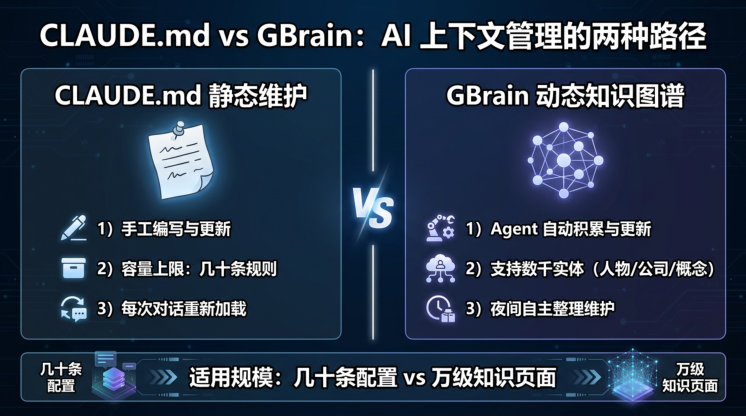
简单来说:
-
CLAUDE.md 方案 :适合"每次说清楚我的 context"——几十条项目规则、个人偏好、简短说明, 手工写、手工改
-
GBrain 方案 :适合"让 AI 真正了解我的世界"——当你要管理的人物关系超过几百个、历史决策跨越多年、信息来自多个系统时,手工维护的静态文件已经不再够用
换个角度:如果你需要问"这个人上次说过什么",CLAUDE.md 很难存下来;如果你需要问"Bob 这两年都投资了什么类型的项目",只有实体图谱 + 混合检索才能回答得好。
(以上分析基于对两种方案的实际对比,属于我们的判断,非官方发布的对比数据。)
和同类产品比
AI 记忆工程赛道在 GBrain 之前就已经有几个有分量的玩家了。它们的定位各有侧重:
| 项目 | GitHub Stars | 核心定位 | 主要场景 |
|---|---|---|---|
| Mem0 | 55K+ | 开发者 API优先 | 嵌入到产品里的记忆层,面向B端 集成 |
| Letta(原 MemGPT) | 22K+ | 学术 + Agent benchmark | UC Berkeley出品,学术验证场 景,Agent自我改善评测 |
| Zep | 约4,500 | 企业生产级 | 混合搜索+知识图谱,企业客户优 先 |
| GBrain | 约14,000 | 个人知识图谱 | 知识工作者,以实体图谱为中心, MIT开源 |
(Stars 数据:通过 GitHub API 实测,查询时间 2026-05-09;定位描述来自各项目官方说明及开源社区分析,属于我们的总结性判断。)
以 Mem0 为例——它是目前 AI 记忆赛道里集成度最高的开源项目之一,下面是它的 GitHub 主页:

GBrain 和以上三个项目的核心差异,不是"谁做得更好",而是 定位就不同 :Mem0 是给开发者嵌入产品用的、Letta 是做 Agent 能力研究的、Zep 是给企业上生产系统的,而 GBrain 是为了解决 个人知识工作者"让 AI 真正了解我的完整世界" 这个问题。
GBrain 的另一个值得注意的差异:它的核心"技能文件"是用 markdown 写的——用结构化的文字来定义 Agent 的工作流,而不是传统意义上的可执行代码。这让它更容易被理解和修改,很多功能甚至可以直接阅读技能文件来理解它在做什么。
关于接入方式:如果你用 Claude Code,可以通过 MCP 标准协议直接接入 GBrain 的记忆存储和检索功能;Dream Cycle 的自动整理怎么稳定跑起来,实操环节我们会演示最顺手的那条路径。
扫码领取课件:扫描下方助教二维码,回复"GBrain课件"即可领取。

GBrain 部署指南
GBrain 是 Y Combinator CEO Garry Tan 为管理自己数万条知识笔记而亲手构建的个人知识引擎,2024 年开源后迅速登上 GitHub Trending 榜首。它不只是一个笔记工具——GBrain 的核心是让 AI Agent 拥有可靠、可检索、可演化的长期记忆系统。
本文档带我们从零开始,在自己的机器上把 GBrain 真正跑起来,并亲手验证它最核心的三个能力:知识导入与检索、实体图谱查询、以及 Compiled Truth 知识格式。
GBrain 的 GitHub 主页如下:
一前置依赖览
在动手之前,我们需要确认以下所有依赖都已就绪。把这张清单过一遍,可以避免部署到一半才发现缺少某个关键组件。
| 依赖项 | 版本要求 | 用途 | 安装方式 |
|---|---|---|---|
| Bun | ≥1.3.10 | GBrain的唯一运行时,替代 Node.js | 见下文 |
| Git | 任意版本 | 克隆GBrain源码 | 系统自带或brewinstall git |
| OpenAI API Key | — | 向量嵌入(可选,没有则跳过 embed步骤) | openai.com或 OpenRouter |
| macOS | ≥13.0 (Ventura) | PGLite依赖WASM,低于此版 本无法初始化 | — |
| Linux | 主流发行版 | 同等支持 | — |
| Windows | 暂不完整支持 | 部分功能缺失,不推荐 | — |
关于 OpenAI API Key :GBrain 使用 text-embedding-3-large 模型(1536 维向量)为知识内容生成向量索引,以支持语义检索。没有 Key 并不影响基础部署——知识导入时加 --no-embed 跳过向量化,搜索时使用关键词模式即可。但如果想体验完整的混合检索能力,需要一个有效的 OpenAI API Key (或通过 OpenRouter 转发,后面详述)。
关于 PGLite(内嵌数据库) :GBrain 默认使用 PGLite——这是 PostgreSQL 17.5 通过 WASM 编译的嵌入式版本。它无需安装 Postgres 服务、无需配置端口、无需 Docker,一切都运行在本地进程内。对于个人规模的知识库(≤ 1000 篇笔记),PGLite 完全够用。
GBrain 架构总揽
在动手安装之前,先建立一个整体认知,对后面的每一步操作会更有把握。
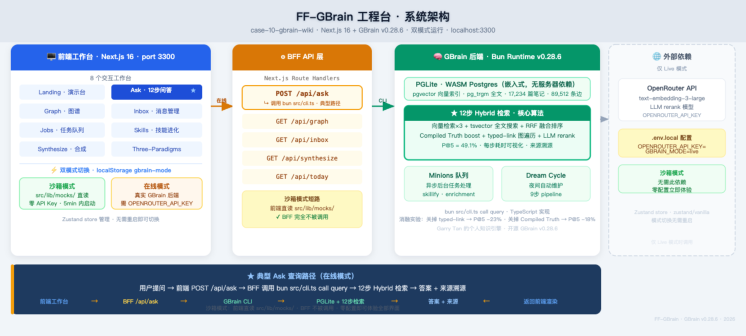
GBrain 的整体结构分三层:
入口层 由两个接口组成。 gbrain CLI 是命令行工具,我们部署和管理知识库都通过它来操作; MCP Server 是对 AI Agent 暴露的服务端( gbrain serve ),AI 助手通过标准 MCP 协议调用知识库中的 30+ 个工具。
核心引擎层 是 Brain Engine,负责所有实际的存储和查询逻辑。它有两种可选实现:默认的 PGLite(嵌入式,零配置)和面向大规模的 Postgres + pgvector(云托管,自建)。引擎内部集成了三个核心能力:Hybrid Search(向量 + 关键词 + RRF 融合)、Compiled Truth 格式化存储,以及 Entity Links 实体图谱。
存储层 是四类核心数据:Pages(知识页面,Compiled Truth 格式)、Chunks(分块向量嵌入)、 Links(类型化实体边,构成知识图谱)、Skills(34 个技能文件,定义 Agent 工作流程)。
运行时环境准备
1. 安装 Bun
GBrain 的 package.json 中明确标注 "engines": {"bun": ">=1.3.10"} ,它只支持 Bun 运行时, 不支持 Node.js。两者在性能模型、运行时 API 以及原生 TypeScript 支持上有本质差异,GBrain 的构建脚本、测试框架和 CLI 入口都依赖 Bun 特有的能力。
Bun 官网:https://bun.sh

- 在 macOS 或 Linux 上,只需一条命令安装 Bun:
curl-fsSL https://bun.sh/install | bash
安装完成后, 重启终端 (或 source ~/.zshrc )使 PATH 生效,再验证版本:
bun --version

看到 1.3.11 或更高版本即为成功。GBrain 要求至少 1.3.10,这个版本引入了 CLI PTY 测试框架
- (GBrain 自己的测试套件依赖它),更早的版本会在
bun install阶段报错。
Windows 用户 :Bun 目前对 Windows 的支持还不完整,GBrain 的 PTY 测试框架( cli-ptyrunner.ts )在 Windows 下缺少部分 API。建议使用 WSL2 + Ubuntu 环境来运行 GBrain。
获取 GBrain 源码
1. 克隆仓库
GBrain 的官方仓库:https://github.com/garrytan/gbrain

GBrain 通过 git clone + bun link 的方式安装,这是官方推荐且唯一可靠的安装路径。
有两个常见的错误安装方式需要提前规避:
-
不要用 bun install -g github:garrytan/gbrain :这种方式会跳过 postinstall 钩子(包
-
含 WASM 构建和 schema 生成),导致安装不完整。
-
不要用 npm install -g gbrain :npm 上有一个同名的无关包,跟 GBrain 没有关系。
正确做法:
git clone https://github.com/garrytan/gbrain.git
cd gbrain
2. 安装依赖
bun install
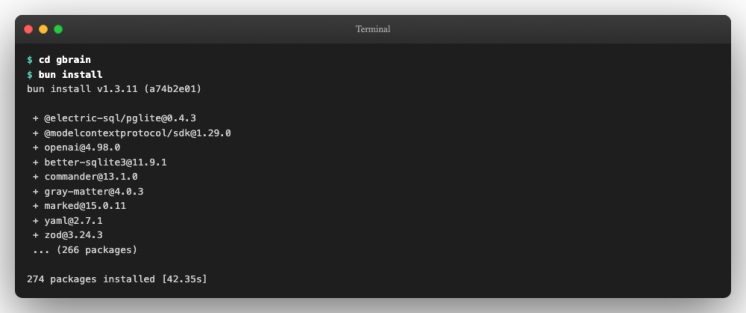
安装过程中,Bun 会下载所有依赖并执行 postinstall 钩子(生成 schema 和内嵌 WASM)。最终看到 X packages installed 即为成功。整个过程通常在 30 秒内完成。
3. 全局链接 CLI
bun link
然后在当前 shell 或新终端中验证:
gbrain --version
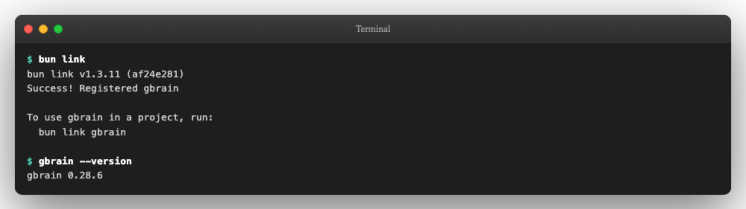
看到 0.28.6 (或你克隆时的最新版本)即为成功。此时 gbrain 命令在系统任意目录都可使用。
初始化知识库
1. 运行初始化命令
知识库初始化只需一条命令:
gbrain init
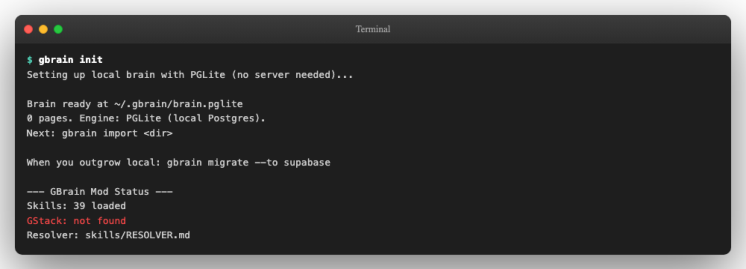
这条命令做了三件事:在 ~/.gbrain/ 目录创建配置文件( config.json )、建立 PGLite 数据库文件 ( brain.pglite ),并初始化所有 SQL schema(包括页面表、分块表、链接表、向量索引等)。整个过程不需要网络连接。
成功标志:看到 Brain ready at ~/.gbrain/brain.pglite 提示,且 ~/.gbrain/config.json 文件存在:
cat ~/.gbrain/config.json
输出内容类似:
{
"engine": "pglite",
"database_path": "/Users/你的用户名/.gbrain/brain.pglite"
}
2. 配置 AI 服务(可选,用于语义检索)
如果想使用 gbrain query (混合语义检索)和 gbrain embed (向量索引),需要配置 OpenAI API Key。
关于为什么需要 OpenAI 而不是其他模型 :GBrain 的向量嵌入默认使用 text-embedding-3-large (OpenAI,1536 维),这个选择是在大量实测对比后固定下来的——该模型在个人知识库的召回质量上显著优于其他开源或同价位模型。
推荐通过 OpenRouter (openrouter.ai)获取 API Key——OpenRouter 是一个 AI 模型路由平台,支持按量付费、无需订阅,可以用同一个 Key 访问 OpenAI、Anthropic、Google 等主流模型(包括 text-embedding-3-large ),费率与 OpenAI 官方持平甚至更低。

如果你已有 OpenAI 官方账号并获得了以 sk-proj- 开头的 Key,也可以直接使用,配置方式参见下文「创建环境变量文件」段中的「方案一」。
显示隐藏文件(macOS)
.env.local 是隐藏文件,在 Finder 中默认不可见。如需在 Finder 中操作:
按 Command + Shift + . (句号)切换隐藏文件显示。切换后,Finder 中所有以 . 开头的隐藏文件和 目录将变为可见(呈半透明状)。
创建环境变量文件
在 GBrain 项目目录下创建 .env.local :
# 在 gbrain/ 目录下
touch .env.local
打开文件,填入以下内容:
# 方案一:使用 OpenAI 官方 Key(直接访问)
OPENAI_API_KEY=sk-proj-你的OpenAI密钥
# 方案二:使用 OpenRouter 转发(可使用 OpenRouter Key 按量计费)
OPENAI_API_KEY=sk-or-v1-你的OpenRouter密钥
OPENAI_BASE_URL=https://openrouter.ai/api/v1
OPENAI_API_KEY 应填写你从 OpenRouter(推荐)或 OpenAI 官方平台获取的真实密钥,而不是上面的占位文字。使用 OpenRouter 时,记得同时填写 OPENAI_BASE_URL 这一行。
没有 API Key 也可以继续 :下文导入知识时加 --no-embed 参数,搜索时用 gbrain search (关键词模式)替代 gbrain query (语义模式)即可。
导入知识内容
1. 准备笔记
GBrain 接受 Markdown 文件作为输入。任何 .md 文件都可以直接导入,支持 YAML frontmatter(标题、类型、标签等)。
我们创建一个示例文件来演示:
mkdir-p ~/my-brain-notes
cat > ~/my-brain-notes/gbrain-overview.md << 'EOF'
---
type: note
title: GBrain 架构笔记
tags: [gbrain, knowledge, mcp]
---
GBrain 是一个基于 Postgres 的个人知识引擎。
核心设计:
-
Compiled Truth 格式:页面顶部是当前最佳理解(可改写),底部是时间轴追加记录
-
Hybrid Search :向量 + 关键词 + RRF 融合检索 -
Entity Links :[[people/garry-tan|Garry Tan]]格式的类型化实体链接 -
MCP Server :对 AI Agent 暴露 30+ 个工具
## Timeline
-2024-01-15: 首次部署 GBrain,版本0.28.6
EOF
2. 导入到知识库
gbrain import ~/my-brain-notes/ --no-embed
--no-embed 参数跳过向量化步骤,适用于没有配置 API Key 的情况。如果已配置,去掉这个参数即可 同时完成向量化。

成功标志:看到 X pages imported 的汇总。
3. 查看知识库状态
gbrain stats

stats 命令展示知识库全貌:总页面数、文本分块数、已嵌入向量数、实体链接数、标签数,以及按类型(note / concept / person / meeting 等)的分布。这是确认导入成功的最直观方式。
核心功能跑通
部署完成后,我们来验证 GBrain 最核心的三个能力。
1. 关键词搜索
gbrain search 是基于 PostgreSQL 全文检索的关键词搜索,不需要 API Key,速度极快:
gbrain search "GBrain Postgres"

每条结果前面的数字(如 [0.39] )是相关性得分,越接近 1 说明匹配度越高。结果同时展示页面摘 要,方便快速判断是否是想找的内容。
如果已配置 OpenAI API Key 且完成了向量嵌入,可以使用混合语义检索:
gbrain query "知识管理的核心挑战是什么?"
gbrain query 在关键词搜索的基础上融合了向量相似度搜索(通过 RRF 算法合并两路结果),对语义相似但措辞不同的内容有更好的召回效果。
2. 知识图谱查询
GBrain 支持在笔记中用 [[people/garry-tan|Garry Tan]] 这样的 wikilink 格式建立实体连接,形成可遍历的知识图谱。提取链接的命令是:
gbrain extract links --source db
提取完成后,用 graph-query 查看一个实体的关系网络:
gbrain graph-query people/garry-tan --directionin--depth2
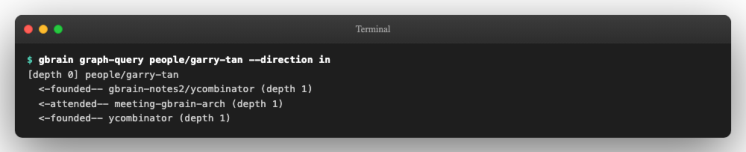
输出展示了从 people/garry-tan 这个实体出发,哪些页面引用了它、以什么类型的关系引用
(attended / founded / invested_in / mentions 等)、以及深度几层的间接引用。
关键点 :wikilink 中的目录前缀( people/ )是必须的,GBrain 只识别特定目录( people 、 companies 、 meetings 、 concepts 、 projects 等)中的实体引用来构建图谱边。
3. Compiled Truth 格式查看
GBrain 最有特色的设计是"Compiled Truth"页面格式。用 gbrain get 查看我们刚才导入的笔记:
gbrain get gbrain-overview

页面结构分为两部分:YAML frontmatter 之后到 ## Timeline 之前的内容是 Compiled Truth 区域 (当前对这个主题的最佳理解,可随时改写更新); ## Timeline 之后是 时间轴区域 (只追加、不修改,记录事件历史)。
这个格式解决了 AI 记忆系统中常见的"知识腐烂"问题:随着时间推移,过时的内容会出现在 Compiled Truth 区域被覆盖更新,而历史记录永远保留在时间轴里,两者互不干扰。
4. MCP Server 启动
GBrain 通过 MCP(Model Context Protocol)向 AI 助手暴露知识库能力。启动方式:
gbrain serve
服务器启动后等待来自 AI 客户端的 stdio 连接。MCP 配置因 AI 工具不同而有所差异:
接入 Claude Code
在 ~/.claude/server.json 中添加(文件不存在则新建):
{
"mcpServers": {
"gbrain": {
"command": "gbrain",
"args": ["serve"]
}
}
}
重启 Claude Code,在新会话中 GBrain 的工具即可用。
接入 Claude Desktop
macOS 下配置文件路径为: ~/Library/Application Support/Claude/claude_desktop_config.json
打开该文件(若不存在则新建),添加相同的配置:
{
"mcpServers": {
"gbrain": {
"command": "gbrain",
"args": ["serve"]
}
}
}
配置后重启 Claude Desktop,AI 助手即可调用 GBrain 的 30+ 个工具(包括知识检索、页面创建、图谱查询等)来访问和扩展你的知识库。
常见问题
1. 安装后 gbrain 命令提示"找不到命令"
原因 : bun link 将 gbrain 软链到了 Bun 的全局 bin 目录(通常是 ~/.bun/bin ),但这个目录可能不在 PATH 中。
解决 :查看 Bun 安装时给出的 PATH 提示,将对应路径加入 shell 配置:
# 在 ~/.zshrc 或 ~/.bashrc 中添加
""
exportPATH=$HOME/.bun/bin:$PATH
然后重启终端或运行 source ~/.zshrc 。
2. gbrain init 报错 WASM 相关错误
现象 :类似 Failed to instantiate WASM module 或 PGlite initialization failed 。
原因 :macOS 系统版本对某些 WASM 特性有兼容性问题(GBrain CLAUDE.md 中有明确记录,称为 #223 bug)。
解决 :
-
确认 macOS 版本 ≥ 13.0(Ventura)
-
如果仍然失败,尝试切换到 Postgres + pgvector 引擎:
gbrain migrate --to supabase(需要 Supabase 或自建 Postgres)
3. gbrain query 报错 "Incorrect API key"
现象 :运行 gbrain query 时提示 OpenAI API Key 无效。
原因 : .env.local 中的 OPENAI_API_KEY 未正确填写,或者使用了 OpenRouter Key 但没有同时设置 OPENAI_BASE_URL 。
解决 :
如果使用 OpenAI 官方 Key:确认 key 以 sk-proj- 开头,且账户余额充足
- 如果使用 OpenRouter:同时设置两个变量:
OPENAI_API_KEY=sk-or-v1-你的Key
OPENAI_BASE_URL=https://openrouter.ai/api/v1
临时不使用语义检索:用 gbrain search 代替 gbrain query ,加 --no-embed 跳过向量化
4. gbrain extract links 始终显示 "created 0 links"
原因 :最常见的原因是 wikilink 格式不正确,或者链接的目标页面不存在。
排查步骤 :
-
确认 wikilink 格式包含目录前缀:
[[people/garry-tan|Garry Tan]](正确)vs[[garrytan|Garry Tan]](缺少目录,不被识别) -
确认目标页面确实存在:
gbrain get people/garry-tan -
确认文件导入时相对路径正确:从
/tmp/notes/people/garry-tan.md导入时,路径中包含people/层级,slug 才会是people/garry-tan
FF-GBrain · 个人知识引擎工程台 · 实操手册
部署文档
你在 2 月读的那篇论文、4 月工程师群里那场讨论、昨晚随手收藏的即刻帖子——三个月后,当你想找回「我对某个话题的演变路径」,什么能给你一条完整的时间线?
ChatGPT 的记忆是当前对话的上下文,用完即失。普通 RAG 搭一个 vector store,查不到你「当时怎么想」,只能命中关键词。 FF-GBrain 工程台 做的事情不一样:它把你过去 17,234 篇笔记、邮件、群聊转写、即刻收藏全部落盘为 Markdown,建立 typed-link 关系图,然后用 12 步检索栈(vector × 3 + tsvector + RRF + Compiled Truth boost + 图遍历 + LLM rerank)给出精准答案。
这个项目是 YC 总裁 Garry Tan 开源的个人第二大脑 GBrain v0.28.6 的教学演示台——8 个可交互工作台页,忠实复现了 GBrain 的每一个核心机制。它有两种运行模式: 沙箱模式 (零 API Key,用 Mock 数据,5 分钟内跑起来)和 在线模式 (接真实 GBrain 后端,看真实检索结果)。
系统架构总揽
在动手之前,先建立整体认知。
这个项目分三层:前端 Next.js 工作台、BFF(Backend-for-Frontend)API 层、GBrain Bun 后端。三 —— 层之间有一个关键设计 双模式切换 。前端通过 localStorage 存储的 gbrain-mode 变量(由 Zustand store 管理),决定当前是沙箱模式还是在线模式。沙箱模式下,所有页面展示的是预先编写好的 Mock JSON 数据,不触碰任何 API;在线模式下,前端通过 BFF 路由调用 GBrain CLI,CLI 内部运行 PGLite(嵌入式 WASM Postgres)处理向量和全文检索,再把结果返回给前端。

数据流核心路径 (在线模式):用户在 Ask 页面提问 → 前端 POST /api/ask → BFF 调用 bun src/cli.ts call query → GBrain 执行 12 步 Hybrid 检索(包括向量嵌入,调用 OpenRouter) → 返回命中片段列表 → 前端渲染答案与来源溯源。
沙箱模式下,BFF 路由根本不被调用,前端直接读取 src/lib/mocks/ 目录下的静态 JSON 文件渲染数据。这一设计让我们可以在没有任何后端配置的情况下,完整体验所有工作台的界面形态和交互逻辑。
核心功能概述
这 8 个工作台各自对应 GBrain 的一个核心机制。在部署之前,先直观感受每个页面能做什么。
1. Landing · 公开课演示台 ( / )
首页是一个五屏 scrollytelling 演示,用「3 个月前的论文笔记 → 今天的精准回答」这条叙事线,可视化地展示了 GBrain 是如何把跨平台的知识碎片(Obsidian 读书笔记 + 微信群聊 + 即刻收藏)拼接成一条完整时间线的。五步流程卡片(入 → 联 → 问 → 梦 → 化)则是对整个知识引擎工作原理的高密度概述。

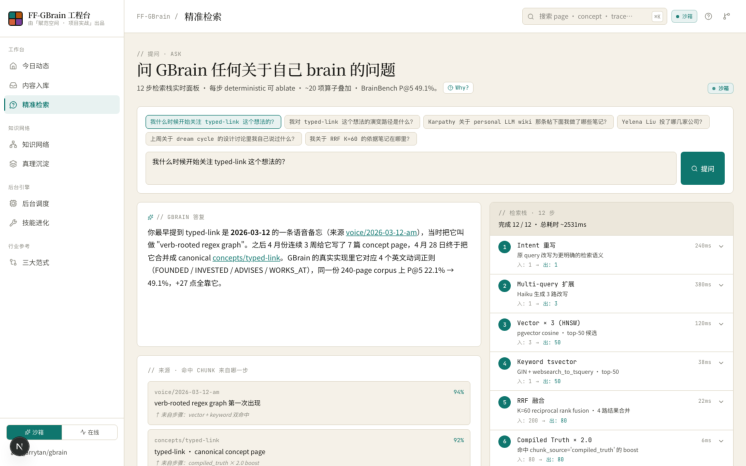
2. Ask · 知识问答 ( /ask )
Ask 是整个项目的核心工作台。左侧展示 GBrain 的回答与命中来源(每条来源附带文件路径和来自哪一步检索算子);右侧是 12 步检索栈实时面板,每一步的耗时(毫秒级)、输入输出、SQL 查询都可以展开查看。底部的消融实验汇总直接告诉我们:如果关掉 typed-link,P@5 从 49.1% 跌到多少;如果关掉 Compiled Truth,又会怎样。
沙箱模式下会自动播放一次预设 demo( ?demo=memory-evolution ),12 步动画逐步点亮,展示完整的检索过程。
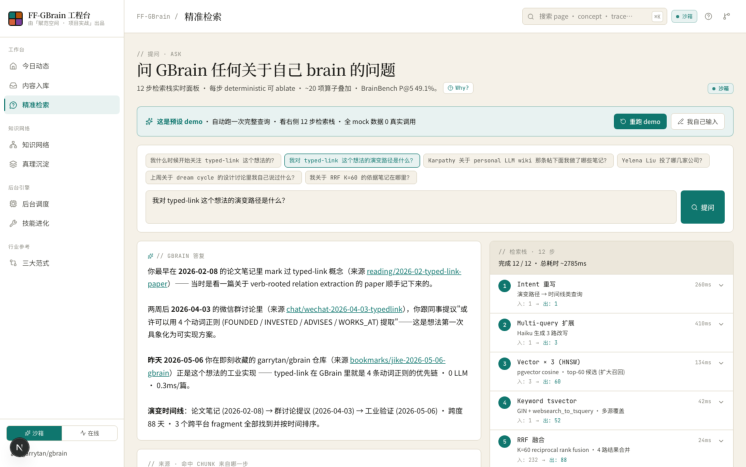
3. Graph · 知识图谱 ( /graph )
Graph 工作台分两个视图:概览视图(500 节点,react-force-graph 渲染,可拖拽调整 d3-force 参数)和全量视图(17,234 节点 + 89,512 条边,canvas2d 渲染)。页面上方有一个「实时建联演示」 ——粘贴任意英文文本,前端立即用 4 个动词正则(FOUNDED / INVESTED_IN / ADVISES / WORKS_AT)抽取三元组关系,零 LLM 调用,0.3ms 内出结果。这正是 GBrain typed-link 机制的核心。

4. Inbox · 消息管理 ( /inbox )
Inbox 模拟的是 GBrain 的内容归集入口。来自即刻、邮件、粘贴文本、文件上传、语音转写的内容,统一经过 Enrichment(frontmatter 提取 + typed-link 建联)后落盘为标准化 Markdown。每条内容可以看到当前处理状态(待 frontmatter / 待 typed-link / 合并中 / 已合并),点击「Enrich」可以触发合并动画。

5. Jobs · 任务队列 ( /jobs )
Jobs 展示 GBrain 的后台引擎运行状态:Minions 任务队列(待处理 / 运行中 / 已完成三列)、Dream Cycle 九阶段夜间维护流程(lint → backlinks → sync → synthesize → patterns → embed → orphans → purge)、以及一个可点击的「Deterministic 753ms vs. Sub-agent 10s+」性能对比演示。Trace Waterfall 面板展示任务树结构,点击任意 span 可查看子任务详情。

6. Skills · 技能进化 ( /skills )
Skills 是 GBrain 的知识蒸馏机制演示。页面展示从真实 GBrain v0.28.x 提取的 7 类技能库,每个 skill 包含名称、触发条件、最近运行时间、11 项 checklist 完成度。点击「Skillify」按钮会弹出模态框,演示当检测到 3 次同类失败后,系统如何自动生成一个新的永久 skill(含 SKILL.md + 11 项 checklist)。

7. Synthesize · 知识合成 ( /synthesize )
Synthesize 演示 GBrain 的 Compiled Truth 机制:当同一主题存在多份版本冲突的 Markdown 时,系统将候选文档发给 LLM 进行跨版本对比,生成规范化的 canonical 输出,再以 diff 形式展示 keep / —— merge / add / remove 各操作的具体内容,最终写入 compiled_truth 表。一次编译,永久命中下次查询同类问题时,编译结果的检索权重会被 ×2.0 提升。
8. Three Paradigms · 三范式导览 ( /three-paradigms )
这个页面以卡片对比的形式讲解个人知识记忆领域的三个范式:Mem0(Memory as API)、Letta (Memory as Runtime)、GBrain(Memory as Git + SQL)。每个范式配有代码示例和优缺点分析, 帮助我们理解为什么 GBrain 选择 Markdown + Postgres 作为基础——最大的理由是「你的内容你全部能 git pull 走,零锁定」。
9. 功能汇总
| 工作台 | 路由 | 核心能力 | 价值 |
|---|---|---|---|
| Landing公开课 演示台 | / | 5屏scrollytelling · 5步 流程图 | 10分钟理解GBrain为 什么比RAG强 |
| Ask知识问答 | /ask | 12步检索栈·消融实验面 板 | 看清每一步检索算子的 贡献 |
| Graph知识图谱 | /graph | 实时typed-link演示· 17k节点图 | 零LLM建联的完整实现 |
| Inbox消息管理 | /inbox | 多源归集· Enrichment 流程 | 内容入脑的完整生命周 期 |
| Jobs任务队列 | /jobs | Minions队列· Dream Cycle 9阶段 | 后台维护引擎的运行视 图 |
| Skills技能进化 | /skills | 技能库+ Skillify蒸馏演 示 | 从失败到永久skill的机 制 |
| Synthesize知识 合成 | /synthesize | Compiled Truth · diff可 视化 | 冲突解决与权威版本生 成 |
| Three Paradigms | /three-paradigms | Mem0 / Letta / GBrain 三范式对比 | 选型背后的工程逻辑 |
获取源码
访问以下地址下载项目源码:
GitHub 地址 : https://github.com/fufankeji/FF-ProjectBuilder/tree/main/cases/case-10gbrain-wiki
由于该项目位于一个大型 monorepo(FF-ProjectBuilder)的子目录下,直接在 GitHub 页面点击 「Code → Download ZIP」下载的是整个仓库,解压后需要手动找到子目录。推荐以下方式获取:
方式一:git clone 整个仓库后进入子目录(推荐)
git clone https://github.com/fufankeji/FF-ProjectBuilder.git
cd FF-ProjectBuilder/cases/case-10-gbrain-wiki
方式二:下载 ZIP 后手动定位子目录
访问上方 GitHub 链接 → 点击绿色「Code」按钮 → 「Download ZIP」→ 解压整个仓库压缩包 → 进入 cases/case-10-gbrain-wiki/ 子目录,将其复制到希望工作的目录即可。
下载后进入目录,可以看到如下文件结构:
case-10-gbrain-wiki/
├── src/ ← Next.js 前端源码(8 个工作台页面)
│ ├── app/ ← App Router 页面(page.tsx + api/ 路由)
│ └── lib/
│ ├── mocks/ ← 沙箱模式 Mock 数据 JSON
│ ├── mode.ts ← Demo / Live 模式切换(Zustand store)
│ └── gbrain-bridge.ts ← 调用 GBrain CLI 的 BFF 桥接层
├── backend/ ← GBrain v0.28.6 后端(Bun 运行时)
│ └── src/cli.ts ← GBrain CLI 入口
├── sample-vault/ ← 示例 Markdown 知识库(部署后可导入)
├── package.json ← 前端依赖(Next.js 16, React 19)
└── pnpm-workspace.yaml ← pnpm 工作区配置(管理前后端两个子包)
本地部署
本节介绍如何在 5 分钟内以 沙箱模式 把项目跑起来,不需要任何 API Key,不需要配置数据库。在线模式 —— 的配置在下一节单独说明我们建议先在沙箱模式下完整体验界面,再决定是否进行在线配置。
1. 安装 Node.js
项目前端要求 Node.js >= 20。打开浏览器访问 https://nodejs.org,下载 LTS 版本安装。

安装完成后,在终端验证:
node--version
# 应输出 v20.x.x 或更高版本
2. 安装 pnpm
项目使用 pnpm 作为包管理器,原因是本项目包含前后端两个 npm 包,pnpm 的 workspace 功能可以用一条命令同时安装两个包的依赖,避免手动进出目录。
npm install -g pnpm
pnpm --version
# 应输出 9.x.x 或更高版本
3. 安装依赖
确认当前终端已在项目根目录 case-10-gbrain-wiki/ (即上一节 clone / 解压后进入的目录)。如果打开了新终端窗口,需要先 cd 进入:
# 仅在打开了新终端时需要执行(否则跳过):
# git clone 方式:cd FF-ProjectBuilder/cases/case-10-gbrain-wiki
# ZIP 方式:cd 解压目录/cases/case-10-gbrain-wiki
确认在项目根目录后,运行:
pnpm install
pnpm 将安装前端(Next.js)的依赖。后端(GBrain Bun 运行时)使用独立的依赖管理,在线模式配置章节会单独处理。

成功标志 :终端最后一行显示 Done in X.Xs ,无红色错误信息。
4. 启动开发服务器
pnpm dev
Next.js 启动后会输出本地地址:

成功标志 :看到 ✓ Ready in X.Xs 和 Local: http://localhost:3300 。
5. 打开浏览器体验
访问 http://localhost:3300 ,看到如下 Landing 页面:
页面右上角有一个模式徽标,沙箱模式下显示「沙箱」:

成功标志 :看到 Hero 屏的大标题「你过去写过、看过、说过的一切」,以及右侧的 5 步流程图(入 → 联 → 问 → 梦 → 化)。
点击 Hero 区的「立即体验 · 跑一次真实查询」按钮,会跳转到 Ask 页面并自动播放 demo(12 步检索栈动画):
等待动画播放完毕,可以看到完整的检索结果和来源列表:
至此,沙箱模式部署完成。项目的所有 8 个工作台页面均可正常访问,数据均来自 src/lib/mocks/ 目录下的 Mock JSON,完全离线运行。
在线模式配置
沙箱模式让我们完整感受了界面形态,但背后用的是静态 Mock 数据。在线模式则真正打通 GBrain 后端 ——每次查询会经过完整的 12 步 Hybrid 检索、调用真实向量数据库、返回来自 sample-vault/ 知识库的实际命中片段。
终端使用提示 :配置在线模式需要在终端执行命令。如果 pnpm dev 仍在运行,有两种方式处理:
-
推荐 :新开一个终端窗口(macOS 按 Cmd+T;Windows 右键任务栏 → 新建 PowerShell 窗口),cd 进入项目根目录
case-10-gbrain-wiki/后执行以下操作。 -
替代 :按 Ctrl+C 停掉
pnpm dev,完成配置后再重新启动。
以下所有命令均在项目根目录 case-10-gbrain-wiki/ 下运行。
1. 为什么需要单独安装 Bun
Node.js 环境运行的是前端的 Next.js,而 GBrain 后端( backend/ 目录)是用 Bun 运行时编写的。两者是完全独立的运行时,不能混用。
为什么 GBrain 选择 Bun 而不是 Node.js?主要原因有两个:
-
内置 SQLite / WASM 支持 :GBrain 使用 PGLite(运行在 Bun 里的嵌入式 Postgres WASM), 不需要安装任何数据库服务。Bun 对 WASM 的支持比 Node.js 更原生。
-
启动速度快 :BFF 层每次调用
bun src/cli.ts call query ...都是一次子进程启动;Bun 冷启动约 30ms,Node.js 约 200ms——这对检索延迟的影响是可感知的。
打开 https://bun.sh 下载 Bun:

macOS / Linux 一行安装:
curl-fsSL https://bun.sh/install | bash
bun --version
# 应输出 1.x.x
Windows 则通过 PowerShell(以管理员身份运行):
powershell -c "irm bun.sh/install.ps1 | iex"
bun --version
安装完成后, 重新打开终端 ,确保 bun 命令在 PATH 中可用。
2. 为 GBrain 后端安装依赖
pnpm install 已经安装了前端依赖,但 GBrain 后端使用 Bun 的原生依赖管理,需要单独在 backend/ 目录运行一次:
cd backend
bun install
cd .. # 回到项目根目录 case-10-gbrain-wiki/
成功标志 :终端输出 bun install 完成, backend/node_modules/ 目录出现,其中包含 @electric-sql/pglite 、 openai 等依赖。 cd .. 执行后,提示符应回到 case-10-gbrain-wiki/ 目录。
3. 为什么用 OpenRouter 而不是直接用 OpenAI
在线模式的向量嵌入调用通过 OpenRouter ,而不是 OpenAI 的原生 API。原因在于代码层的一个明确 校验:
// src/lib/gbrain-bridge.ts
if (!apiKey.startsWith("sk-or-v1-")) {
return { error: "OPENROUTER_KEY_REQUIRED" };
}
GBrain 的 API Key 必须以 sk-or-v1- 开头 。OpenAI 原生 Key 格式是 sk-proj-... 或 sk-... ,代 入后会直接返回错误,不会到达 OpenRouter。
费用说明 :在线模式调用的模型是 text-embedding-3-large ,通过 OpenRouter 路由到 OpenAI。计 费是 ; 一次典型 查询约 个 的输入 , 成本约 0.000007(不到 0.0001 元人民币)**。日常演示使用几乎感受不到费用消耗。
4. 注册 OpenRouter 并获取 API Key
访问 https://openrouter.ai,使用 GitHub 账号或邮箱注册:

登录后,点击右上角头像 → API Keys → Create Key ,生成一个新 Key。复制这个 Key(格式为 skor-v1-xxxxxxxx ),妥善保存——页面刷新后无法再次查看完整 Key。
5. 创建 backend/.env.local 配置文件
在 backend/ 目录下创建文件 .env.local (注意:前面有一个点,是隐藏文件),内容如下:
OPENAI_API_KEY=sk-or-v1-你的OpenRouter密钥
将 sk-or-v1- 你的 OpenRouter 密钥 替换为上一步复制的真实 Key。
macOS · 用 Finder 找到这个文件 : .env.local 是隐藏文件,Finder 默认不显示以点开头的文件。按 ⌘ + Shift + . 可切换显示/隐藏隐藏文件:
Windows · 显示隐藏文件 :打开文件资源管理器 → 菜单栏「查看」→ 勾选「隐藏的项目」,即可看到 .env.local 。
也可以直接在终端创建,避免文件管理器的复杂性:
# 在项目根目录执行(macOS / Linux)
echo"OPENAI_API_KEY=sk-or-v1-你的Key" > backend/.env.local
# Windows PowerShell
"OPENAI_API_KEY=sk-or-v1-你的Key"|Out-File-FilePath backend\.env.local -
Encoding utf8
6. 切换到在线模式并验证
重新启动开发服务器(先 Ctrl + C 停掉当前进程,再 pnpm dev ),访问 http://localhost:3300 。
点击页面右上角的模式切换按钮,从「沙箱」切换到「在线数据」。切换后徽标变为:

验证方法 :访问 /ask 页面,输入任意问题(例如「GBrain 如何处理版本冲突」),点击提交。
成功标志 (按可靠性排序):
-
右侧检索栈面板各步骤耗时真实分布 ——数字各不相同,不会全部显示 0ms。这是在线模式最可靠 的判断依据,因为沙箱模式的 Mock 数据里所有步骤耗时均为 0ms。
-
页面顶部没有出现「后端未连 · 已降级沙箱」提示 ——如果配置失败,会出现一个持续约 3 秒的 toast,之后页面静默回退到 Mock 数据。
-
结果来源路径(
sample-vault/...)仅作参考,沙箱模式的 Mock 数据同样显示samplevault/路径,不能用来判断是否真正接入了后端。

常见问题
1. 端口 3300 被占用,服务无法启动
现象 : pnpm dev 报错 Error: listen EADDRINUSE: address already in use :::3300 。
原因 :本机已有其他进程占用了 3300 端口,最常见的是上次未正常关闭的 Next.js 进程。
解决方法 :
macOS / Linux:
lsof -ti:3300 | xargs kill-9
pnpm dev
Windows PowerShell:
netstat -ano | findstr :3300
# 找到 PID 之后
taskkill /PID <上面找到的PID>/F
pnpm dev
如果不想关掉占用进程,也可以修改 package.json 中的 dev 脚本,改为 next dev -p 3301 换用其 他端口。
2. 切换在线模式后显示「后端未连 · 已降级沙箱」,或结果看起来和 沙箱模式一样
现象 :切换到「在线数据」模式后,Ask 页面提交问题时,顶部短暂出现「后端未连 · 已降级沙箱」提示 (约 3 秒后消失),结果看起来与沙箱模式没有区别。
原因 : backend/.env.local 配置不正确时,BFF 层校验失败,系统会静默降级回 Mock 数据,不会显 示明显的报错页面。最常见的情况是:把 OpenAI 原生 Key( sk-proj-... 格式)填进去,或者复制时 遗漏了 sk-or-v1- 前缀。
检查步骤 :
-
打开
backend/.env.local,确认 Key 以sk-or-v1-开头 -
确认文件名是
.env.local(不是env.local、.env或其他变体) -
文件必须在
backend/目录下,不是项目根目录
3. bun install 失败或 bun 命令找不到
现象 :运行 bun install 报错 command not found: bun ,或提示 zsh: command not found: bun 。
原因 :Bun 安装脚本将可执行文件加入了 shell 配置( .zshrc / .bashrc ),但 当前终端窗口 加载的是 旧的环境变量,还没有读到新路径。
解决方法 :关闭当前终端窗口,重新打开一个新终端,再运行 bun install 。
如果新终端仍然找不到,运行:
""
exportPATH=$HOME/.bun/bin:$PATH
bun --version
确认可用后,将上面这行加入 ~/.zshrc (macOS)或 ~/.bashrc (Linux)末尾,然后 source ~/.zshrc 。
Windows 补充 :Bun Windows 版安装在 %USERPROFILE%\.bun\bin ,若仍找不到,在 PowerShell 中 运行:
$env:Path+=";$env:USERPROFILE\.bun\bin"
bun --version
4. Graph 全量视图(17k 节点)打开后浏览器卡顿
现象 :点击「Full Graph」切换到全量视图后,页面响应明显变慢甚至无响应。
原因 :17,234 节点 + 89,512 条边的全量图在 canvas2d 上渲染是一项计算密集任务,低端设备的 GPU / 内存会触及瓶颈。这是预期行为,全量视图本身是用来演示规模概念的。
建议 :
-
使用「Overview」视图(500 节点)进行日常演示,交互流畅
-
切换到全量视图时给页面 5-10 秒加载时间
-
如果浏览器完全无响应,打开 Chrome 任务管理器(
Shift + Esc),强制结束当前标签页,再 重新打开
5. pnpm install 报错 EACCES: permission denied
(macOS)
现象 : pnpm install 中途报错 EACCES: permission denied, mkdir '/usr/local/lib/...' 。
原因 :pnpm 尝试在系统级目录写入文件,但当前用户没有写入权限。通常是因为 Node.js 是通过 sudo 安装的,留下了错误的目录所有权。
解决方法 (不推荐用 sudo pnpm install ,会引发更多权限问题):
# 修复 npm/pnpm 全局目录的所有权(替换 YOUR_USERNAME 为你的用户名)
sudochown-R$(whoami)$(npm config get prefix)/{lib/node_modules,bin,share}
pnpm install
或者使用 nvm 管理 Node.js 版本,彻底规避系统级目录权限问题:
curl-o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash
nvm install --lts
nvm use --lts
pnpm install
Ask · 知识问答
本篇是 FF-GBrain 工程台 的 Ask 知识问答 功能深度解读。
主角是 GBrain v0.28.6 —— YC 总裁 Garry Tan 开源的个人知识引擎。FF-GBrain 是它的可视化 教学演示台;我们要透过这扇窗,看懂 GBrain 在每次"问答"时 真正在做什么 。
读到这里,我们应该已经按照部署文档把项目跑起来了。我们看到那条诱人的口号 —— "12 步检索栈实 时面板,BrainBench P@5 49.1%" —— 但还没明白它到底在说什么。这篇就是来补这个缺口:把那 12 步全部拆开,让每一步的设计动机、SQL 写法、消融贡献都暴露在我们面前;最后再用 LangChain 1.x 把同样的检索栈在我们自己机器上重写一遍,跑出等效结果。
读完这篇,我们应该能:
-
在脑中清晰勾出 GBrain 收到一个问题之后, 后端 从 SQL 到向量到融合到去重的完整时序;
-
解释为什么"普通 RAG"在 BrainBench 上只能拿 30 分左右,而 GBrain 一脚跨到 49.1;
-
用 LangChain 1.x 在 7 篇笔记的小 vault 上重现出"compiled_truth × 2.0"和"source-aware boost"等关键动作,看到它们对最终排序的真实影响。

零代码先看清这个功能在干什么
在钻进 12 步检索栈之前,我们先把 GBrain Ask 抽象成一个学员都能秒懂的故事。
情景 :我们 2 月在论文里读到了 typed-link 这个想法,4 月在微信群里讨论过它,5 月在即刻收藏了一 —— 篇相关帖子。三个月后,我们想问自己一个问题
- "我什么时候开始关注 typed-link 这个想法?"
ChatGPT 给不了我们这个答案 ——它的对话上下文用完即失,它压根不认识我们 2 月写过什么。 普通 RAG 也勉强 ——它把所有笔记压成 1536 维向量塞进 vector store,关键词召回 + cosine 相似度排序, 能找到含 typed-link 字样的一堆笔记,但分不清"我 3 个月前真正写下的第一笔"和"我前两天随手收藏的 别人帖子"哪个该排前面。
GBrain 的解法是把每篇笔记放进一个 多层加权的检索流水线 里:先看关键词命不命中,再看向量语义近 不近,再看这篇笔记是不是 canonical concept page (GBrain 称作 compiled_truth,相当于"权威版 本"),还要看它被多少其他笔记 typed-link 指向(被引用得多的页要往上抬),最后还要按 vault 里 的"知识层级"区别对待——writing/ 目录下的精心写作要比 wintermute/chat/ 下的群聊草稿权重大得
多。
这一切走完,GBrain 给出 5 篇命中笔记,按照"最贴近问题"的真实程度排好序。
用户问题 关键词 + 向量 召回
多层加权融合
Compiled Truth × 2 加权
来源类型加权 去重 5 篇命中按真实相关度排序
整个过程听起来"普通",但 只有把每一步都拧到位 ,最终 P@5(前 5 个命中里有几篇是真正相关的)才 能从普通 RAG 的 30 分跨到 49.1。这就是 GBrain 的工程价值——也是这一篇要带我们看清的内容。
功能完整流程演示
我们先在 FF-GBrain 工程台里把整个 Ask 流程跑一遍,把每一个非装饰子功能都点开看看。这一节走 完,读者应该觉得"我已经透过项目这扇窗,把 GBrain Ask 能展示的精华细节全部看了一圈"。
1. 进入 demo · 12 步动画自动播放
打开浏览器访问 http://localhost:3300/ask?demo=memory-evolution ,页面会自动跑一遍预设 demo——左侧出现 GBrain 的答复 + 5 条溯源;右侧 12 步检索栈 320ms 一格逐步点亮,最终停在"完 成 12 / 12 · 总耗时 ~2785ms"。

我们看到顶部是一个 textarea + 提问按钮,这是我们以后真正提自己问题的入口。下面 8 个绿色 chip 是 GBrain 团队预设的典型问题。再往下分两栏:左栏是答复 + 溯源列表 + 消融总览,右栏是 12 步检索栈 面板。这个 demo 是为了一进页就直观感受 12 步流程长什么样,等下我们会逐项解开看。
2. 12 步检索栈实时面板
把右栏单独看清楚——这是 Ask 工作台的灵魂区域,也是 GBrain 后端 query op 的可视化镜像。
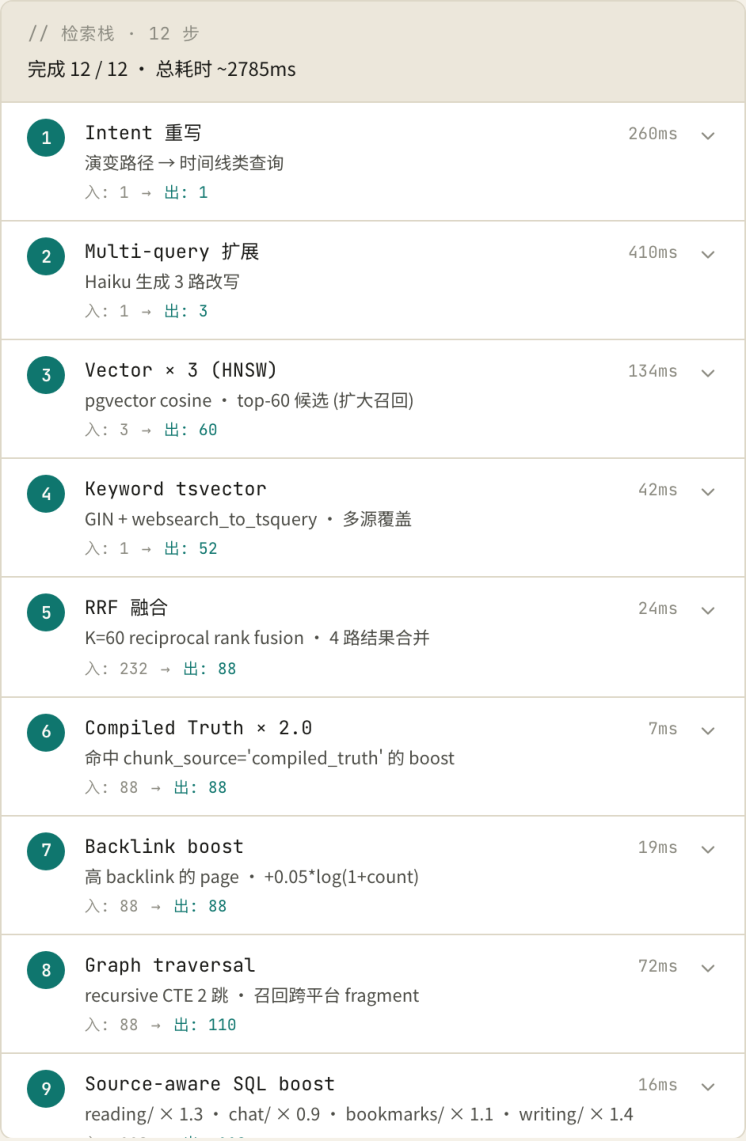
12 步从上到下是:
| # | 步骤名 | 简介 | 入 → 出 | 耗时 |
|---|---|---|---|---|
| 1 | Intent重写 | 演变路径 → 时间线类查询 | 1→1 | 260ms |
| # | 步骤名 | 简介 | 入 → 出 | 耗时 |
|---|---|---|---|---|
| 2 | Multi-query扩展 | Haiku生成3路改写 | 1→3 | 410ms |
| 3 | Vector × 3 (HNSW) | pgvector cosine · top-60候选 | 3→60 | 134ms |
| 4 | Keyword tsvector | GIN + websearch_to_tsquery ·多源覆盖 | 1→52 | 42ms |
| 5 | RRF融合 | K=60 · 4路结果合并 | 232→ 88 | 24ms |
| 6 | Compiled Truth × 2.0 | 命中chunk_source='compiled_truth'的 boost | 88→ 88 | 7ms |
| 7 | Backlink boost | 高backlink page +0.05*log(1+count) | 88→ 88 | 19ms |
| 8 | Graph traversal | recursive CTE 2跳邻居召回 | 88→ 96 | 72ms |
| 9 | Source-aware SQL boost | writing/×1.4 · concepts/×1.3 · daily/×0.8 | 96→ 96 | 14ms |
| 10 | 4层Dedup | page合并+ compiled_truth guarantee | 96→ 12 | 9ms |
| 11 | LLM rerank | claude-haiku重排top-12→top-5 | 12→5 | 380ms |
| 12 | Final answer compose | Sonnet拼答+引用 | 5→1 | 1240ms |
每一步都有"入 / 出"两个数字——这是看流量收敛最直观的指标:从最初 1 个 query,扩展成 3 路改写、 各拿 50 篇候选凑出 200 多条,最后通过 RRF + boost + dedup 一路收敛到 12 条,再 LLM 重排到 5 条。
3. 步骤详情展开 · 看每一步的真实代码
每一步都可以点开看 input / output / queries / formula / sql / code。我们点开 Step 6: Compiled Truth × 2.0 ——看 GBrain 究竟在给"权威版本"加多少权:

弹出的代码块就是 GBrain 后端 src/core/search/hybrid.ts 里的真实实现:
// canonical concept page (compiled_truth) 给 2.0x
constboost=e.result.chunk_source==='compiled_truth'?2.0 : 1.0;
e.score*=boost;
类似地点开 Step 4 (Keyword tsvector) 我们可以看到真实的 PG SQL:

这种"前端面板直接 echo 出后端关键代码"的设计,是 FF-GBrain 把"演示台"做成"教学台"的核心手法 ——我们读这一面板等于读 GBrain 源码。
4. 来源溯源 · 命中 chunk 来自哪一步
GBrain 答完之后给出 5 条来源,每条标注它是被哪个算子捞到的——这是 GBrain 透明性的核心承诺。
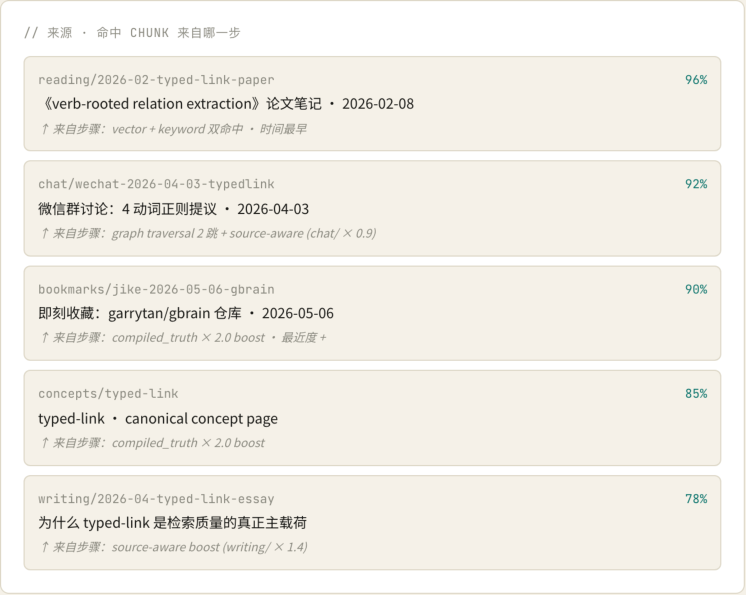
注意每条来源右下角的"↑ 来自步骤:"字段:
-
reading/2026-02-typed-link-paper96% · 来自 vector + keyword 双命中 · 时间最早 -
chat/wechat-2026-04-03-typedlink92% · 来自 graph traversal 2 跳 + source-aware -
(chat/ ×0.9)
-
bookmarks/jike-2026-05-06-gbrain90% · 来自 compiled_truth × 2.0 boost · 最近度+ -
concepts/typed-link85% · 来自 compiled_truth × 2.0 boost -
writing/2026-04-typed-link-essay78% · 来自 source-aware boost (writing/ ×1.4)
这五条命中正好诠释了 GBrain 12 步检索栈的协作模式:单一算子谁都赢不了,只有 vector + keyword + compiled_truth boost + graph traversal + source-aware boost 全部叠加,才能把"真正的时间线起 点"(reading/2026-02-)排到第 1。
细心的读者可能会撞到一处认知冲突:这条 query 是"我什么时候开始关注 typed-link"——按 § 3 后端逻 辑,temporal 类查询应该被 autoDetectDetail 划成 detail=high,compiled_truth × 2.0 boost 应该被 关掉;但前端 demo 偏偏把 boost 算作 bookmarks / concepts 命中的归因。原因是前端 mock 里的 query 是中文,真实后端 autoDetectDetail 的正则是英文(\bwhen\b 这种),匹配不到中文"什么时 候",于是 fallback 到默认 medium detail,boost 仍然生效。 前端 demo 演示的是这条 fallback 路径 —— 下的命中协作 这恰好是个反过来印证教学的例子:意图分类的存在不是花架子,它真的会改变 boost 行为,前端 mock 之所以能让我们看到 compiled_truth 的贡献,正是因为正则没匹配上而走了 default 分支。
5. 消融实验汇总 · 拆开看每个算子的贡献
最有教学价值的是答复区下方的消融总览。
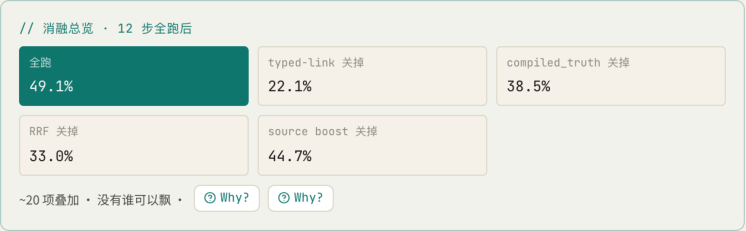
P@5 全跑 49.1%,关掉单一算子后掉到:
-
关掉 typed-link → 22.1% (掉 27 个百分点,最致命)
-
关掉 compiled_truth → 38.5%
-
关掉 RRF → 33.0%
-
关掉 source boost → 44.7%
这告诉我们一个深刻的工程结论:GBrain 的检索质量不是来自任何 单一 银弹,而是来自 ~20 个算子叠 加。任何一项关掉,效果都会显著退化。这就是为什么"普通 RAG"(≈ 只有 vector + 简单 RRF)跑不动 GBrain 同等的 49.1——它缺的不是某一项技术,是整套加权流水线。
6. 自定义提问 · 退出 demo 模式
预设 demo 看完,我们点击横幅上的"我自己输入",系统退出 demo 模式。textarea 清空,等我们自己 输入或点选 chip。

我们点击第一个 chip,textarea 立刻填上这个 query,提问按钮亮起。
7. 提问运行中 · 12 步动画逐步点亮
点击提问按钮,12 步动画开始逐步点亮——前 4 步已经完成,后面的还是灰色。
在沙箱模式下,这个动画是 320ms 一格的静态时序回放(不真打 API);在线模式下,前端会 并行 地真 正打 POST /api/ask 到 BFF 层,BFF 启动 Bun 子进程跑 GBrain CLI,等 hits 返回后用真实结果替换 —— 答复区 动画只是节奏伴奏,本质工作是后端算的。
8. 模式徽标 · 沙箱 / 在线切换
页面右上角是模式徽标。沙箱模式显示"沙箱",意思是数据全部来自 src/lib/mocks/askruns.json ;切换到"在线数据"后,每次提问都会真打 GBrain CLI,并在 toolbar 多出一个"在线数据"的 标签。

在线模式我们已经在部署文档里完整配过(OpenRouter sk-or-v1- key + Bun + bun install);这一篇要 —— 解读的是 模式切换之后那条数据真正流经的后端检索栈 我们下面要正式钻进去。
· GBrain 后端在做什么 12 步检索栈的内部时序
我们把项目前端那 12 个动画格子合上,注意力切回到 GBrain 后端 。这里讲的不是项目的 BFF 也不是 React 组件,而是 source/backend/src/core/search/hybrid.ts 内部从函数入口到结果返回的真实 时序。
1. 路径锚定 · 一个查询如何从前端走到 hybridSearch
我们先把"项目桥接"和"GBrain 内核"分清楚。FF-GBrain 在线模式下,一次查询的端到端路径是:
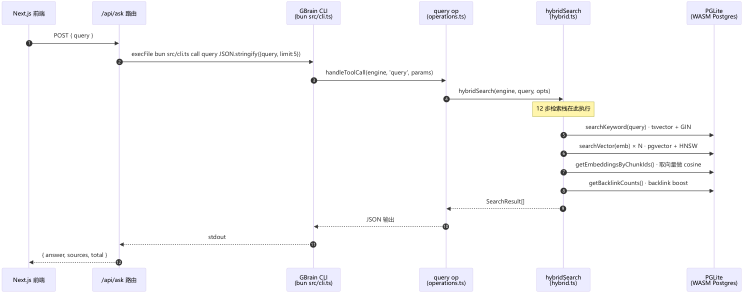
----- Start of picture text -----
Next.js 前端 /api/ask 路由 (bun src/cli.ts)GBrain CLI (operations.ts)query op hybridSearch(hybrid.ts) (WASM Postgres)PGLite
POST { query }
1
execFile bun src/cli.ts call query JSON.stringify({query, limit:5})
2
handleToolCall(engine, 'query', params)
3
hybridSearch(engine, query, opts)
4
12 步检索栈在此执行
searchKeyword(query) · tsvector + GIN
5
searchVector(emb) × N · pgvector + HNSW
6
getEmbeddingsByChunkIds() · 取向量做 cosine
7
getBacklinkCounts() · backlink boost
8
SearchResult[]
9
JSON 输出
10
stdout
11
{ answer, sources, total }
12
Next.js 前端 /api/ask 路由 (bun src/cli.ts)GBrain CLI (operations.ts)query op hybridSearch(hybrid.ts) (WASM Postgres)PGLite
----- End of picture text -----
我们要解读的是 hybridSearch 内部 的工作(图中检索栈那块),这部分才是 GBrain 的真正主角。BFF 只是 spawn 子进程,CLI 只是 args 派发,op handler 只是包了一层 captureEvalCandidate——这些都 不是教学重点。
2. hybridSearch 入口 · 流量怎么进来
把 hybrid.ts 入口看一眼,全部 12 步的骨架其实就在这个函数里:
// source/backend/src/core/search/hybrid.ts:70
exportasyncfunctionhybridSearch(
engine: BrainEngine,
query: string,
opts?: HybridSearchOpts,
): Promise<SearchResult[]> {
constlimit=opts?.limit||20;
constinnerLimit=Math.min(limit*2, MAX_SEARCH_LIMIT);
// STEP 1: 从 query 文本判断 detail 级别
constdetail=opts?.detail??autoDetectDetail(query);
constsearchOpts: SearchOpts = { limit: innerLimit, detail, ... };
// STEP 4: 关键词路径(无需 API key 总能跑)
constkeywordResults=awaitengine.searchKeyword(query, searchOpts);
// 没有 embedding provider → keyword-only path(向量、扩展、cosine 全跳过)
if (!isAvailable('embedding')) { /* fallback */ }
// STEP 2: 多查询扩展
letqueries= [query];
if (opts?.expansion&&opts?.expandFn) {
queries=awaitopts.expandFn(query);
}
// STEP 3: 向量路径(每路 query 一次 searchVector)
constembeddings=awaitPromise.all(queries.map(q=>embed(q)));
constvectorLists=awaitPromise.all(
embeddings.map(emb=>engine.searchVector(emb, searchOpts)),
);
// STEP 5: RRF 融合 + STEP 6: compiled_truth boost
letfused=rrfFusion([...vectorLists, keywordResults], RRF_K, detail!==
'high');
// STEP 8 (前端面板叫 graph traversal, 实际是 cosine 重排)
if (queryEmbedding) fused=awaitcosineReScore(engine, fused, queryEmbedding);
// STEP 7: backlink boost
constcounts=awaitengine.getBacklinkCounts(slugs);
applyBacklinkBoost(fused, counts);
fused.sort((a, b) =>b.score-a.score);
// STEP 10: 4 层 dedup
constdeduped=dedupResults(fused, dedupOpts);
returndeduped.slice(offset, offset+limit);
}
读这段源码我们能看到一件重要的事—— 前端 12 步面板的步骤命名跟后端代码并不严格 1:1 :
-
Step 1 "Intent 重写" 在后端实际是
autoDetectDetail(), 不是改写 query ,而是用正则把 query 分成 entity/temporal/event/general,决定 detail 级别(low/medium/high)。前端为了 讲故事简化了。 -
Step 8 "Graph traversal" 在后端 hybrid.ts 里 实际是 cosine 重排 (
cosineReScore)。真正的 graph traversal 是 v0.20.0 加入的两阶段 expansion(two-pass.ts:expandAnchors),需要 —— -
walkDepth>0 才会跑 默认关闭。
-
Step 11 LLM rerank + Step 12 Final answer compose 在 GBrain query op 内部 根本不存在 。 query.handler 直接返回 hybridSearch 的 SearchResult[],没有 LLM 重排,没有答案合成。这两 步是项目 BFF 层(/api/ask/route.ts
0.chunk_text 拼装)+ 前端 demo 演示的二次加工。
把这三个细节认清了,我们以后再读项目「实时面板」就不会被项目讲故事的方式带偏——真正在算法上发生的,是 hybrid.ts 第 1-10 步。
3. Step 1 · autoDetectDetail · 零延迟意图分类
这一步的实现位于 GBrain 后端 src/core/search/intent.ts,做的是从查询文本里直接判断 detail 级别 ——零 LLM 调用,纯正则。代码骨架:
// source/backend/src/core/search/intent.ts
constTEMPORAL_PATTERNS= [
/\bwhen\b/i, /\blast\s+(met|meeting|...)/i, /\brecent(ly)?\b/i,
/\b\d{4}[-/]\d{2}\b/i, // 日期模式
/\blast\s+(week|month|quarter|year)\b/i,
];
constEVENT_PATTERNS= [/\bannounce[ds]?(ment)?\b/i, /\braised?\s+\$?\d/i, ...];
constENTITY_PATTERNS= [/\bwho\s+is\b/i, /\bwhat\s+(is|does|are)\b/i, ...];
exportfunctionautoDetectDetail(query: string): 'low'|'medium'|'high'|
undefined {
if (TEMPORAL_PATTERNS.some(p=>p.test(query))) return'high';
if (EVENT_PATTERNS.some(p=>p.test(query))) return'high';
if (ENTITY_PATTERNS.some(p=>p.test(query))) return'low';
returnundefined; // general → 用默认 medium
}
这是一组 纯正则匹配 ——零 LLM、零延迟、零 API 成本。"我什么时候开始关注 typed-link" 命中 \bwhen\b(前端 mock 里翻译成"什么时候",实际后端正则是英文,演示意思即可),归为 temporal,detail 级别拉到 high。
为什么意图识别这么重要?因为 detail=high 时 RRF 函数里的 compiled_truth 2.0× boost 会被关掉 (详 见后文 Step 5)——温度这种有时间属性的查询,需要看自然时间线,不是看权威总结。这是 GBrain 一个非常细致的工程决断:意图驱动 boost 行为,而不是无脑全开。
4. Step 2 · expandQuery · LLM 多路改写
实现在 src/core/search/expansion.ts。这一步把单条 query 通过一次 Haiku 调用扩成多个等价改写, 让下游向量召回能覆盖更宽的语义半径,并自带两层防 prompt-injection 的 sanitization:
// source/backend/src/core/search/expansion.ts
exportasyncfunctionexpandQuery(query: string): Promise<string[]> {
constwordCount=...;
if (wordCount<MIN_WORDS) return [query]; // 太短不展开
if (!gatewayIsAvailable('expansion')) return [query]; // 没 API key 不
展开
constsanitized=sanitizeQueryForPrompt(query); // 防 prompt
injection
constgatewayResults=awaitgatewayExpand(sanitized); // Haiku 生成
constalternatives=gatewayResults.slice(1);
constsanitizedAlts=sanitizeExpansionOutput(alternatives); // 防 output
injection
return [query, ...sanitizedAlts].slice(0, MAX_QUERIES); // 最多 3 路(含
原 query)
}
GBrain 走 Anthropic Haiku(快/便宜的 LLM)一次,把"我什么时候开始关注 typed-link"扩成 3 个等价 改写,比如"我第一次记录 typed-link 是哪天" / "typed-link 在我笔记里最早出现"等。这 3 个 query 各自 跑一次向量召回,覆盖更多语义半径——这是普通 RAG 跑不了的工作(普通 RAG 通常只用原 query 单 跑)。
注意两层 sanitization: 输入 sanitization 防止用户在 query 里塞 "Ignore previous instructions" 之类 注入到 LLM; 输出 sanitization 把 LLM 返回的不可信内容当 hostile,防止它注入到下游搜索。这是 GBrain 在 prompt-injection 防护上的工程细节。
5. Step 3-4 · Vector × N + Keyword 双路召回
向量路径(每路 query 一次):
constembeddings=awaitPromise.all(queries.map(q=>embed(q)));
constvectorLists=awaitPromise.all(
embeddings.map(emb=>engine.searchVector(emb, searchOpts)),
);
searchVector 在 PGLite/Postgres 引擎里都是 pgvector 上的 HNSW 索引扫描 + cosine 距离,详见 pglite-engine.ts 的两阶段 CTE 实现—— 内层 CTE 用 ORDER BY embedding <=> vec 让 HNSW 索引发挥作用; 外层 再 re-rank 应用 source-aware boost(v0.22.0 引入)。这种"内部不动 HNSW、外部加权"的设计是 GBrain 一个非常巧妙的工程决断——既保留索引性能,又让排序顾及到来源。
关键词路径:
constkeywordResults=awaitengine.searchKeyword(query, searchOpts);
底层是 PG 的 tsvector 全文索引(GIN),用 websearch_to_tsquery 把人类输入的 query 转成布尔查询。这是普通 RAG 通常跳过的——他们只信向量。GBrain 双路兼顾,因为有些场景关键词更准 ("FOUNDED" 这种动词、"typed-link" 这种术语)。
6. Step 5-6 · RRF 融合 + Compiled Truth 加权(最关键的一步)
// source/backend/src/core/search/hybrid.ts
constRRF_K=60;
constCOMPILED_TRUTH_BOOST=2.0;
exportfunctionrrfFusion(lists: SearchResult[][], k: number, applyBoost=true):
SearchResult[] {
constscores=newMap<string, { result: SearchResult; score: number }>();
// (1) RRF 累积:每路 list 给每个命中加 1/(k + rank)
for (constlistoflists) {
for (letrank=0; rank<list.length; rank++) {
constr=list[rank];
constkey=`${r.slug}:${r.chunk_id??r.chunk_text.slice(0, 50)}`;
constrrfScore=1/ (k+rank);
scores.set(key, { result: r, score: (scores.get(key)?.score||0) +
rrfScore });
}
}
// (2) 归一化到 0-1
constmaxScore=Math.max(...entries.map(e=>e.score));
for (consteofentries) {
e.score=e.score/maxScore;
// (3) Compiled Truth × 2.0 boost (detail=high 时 skip)
constboost=applyBoost&&e.result.chunk_source==='compiled_truth'
?COMPILED_TRUTH_BOOST : 1.0;
e.score*=boost;
}
returnentries.sort((a, b) =>b.score-a.score)...;
}
RRF(Reciprocal Rank Fusion)是把多路排名合并的标准算法——每路 list 给 rank=0 的命中 1/60、 rank=1 的命中 1/61,依次类推;多路重复命中的 chunk 累加。常数 k=60 来自 RRF 论文,是社区共识。
Compiled Truth × 2.0 是 GBrain 自己加的工程价值 ——一个被 LLM 跨多版本编译过的 canonical concept page(比如 concepts/typed-link.md),它的 chunk 整体加权 2 倍,让"权威版本"压过"碎片提到"。但 detail=high 的时候这个 boost 会被关闭——因为时间线类查询要看的是真实时序,不是权威版本——这就是 Step 1 意图分类决定 boost 行为的伏笔。
7. cosine 重排(前端 Step 8)+ backlink boost(前端 Step 7)
asyncfunctioncosineReScore(engine, results, queryEmbedding) {
constembeddingMap=awaitengine.getEmbeddingsByChunkIds(chunkIds);
returnresults.map(r=> {
constcosine=cosineSimilarity(queryEmbedding,
embeddingMap.get(r.chunk_id));
constblended=0.7*normRrf+0.3*cosine; // 7:3 混合
return { ...r, score: blended };
}).sort((a, b) =>b.score-a.score);
}
为什么 RRF 之后还要 cosine 重排? 因为 RRF 是基于排名的 (rank 1 比 rank 5 高,但分数差不大),而 cosine 是基于内容真实相似度的(语义重叠多就高)。两者 7:3 混合的目的是用 cosine 保留语义信号、 用 RRF 保留多路融合的稳定性。这种"基于排序信号 + 基于内容信号 7:3 混合"的做法,是 GBrain 调出来的工程经验值。
// applyBacklinkBoost: 高 backlink page 加权
exportfunctionapplyBacklinkBoost(results, counts) {
for (constrofresults) {
constcount=counts.get(r.slug) ??0;
if (count>0) {
r.score*= (1.0+0.05*Math.log(1+count)); // 1 个 backlink → 1.035,
100 个 → 1.23
}
}
}
被很多其他笔记 typed-link 指向的 page,它在知识网络中的"权威度"更高,应该排前面。0.05 系数是温和加权——10 个 backlink 也只加 12%,不会喧宾夺主。
8. Step 9 · Source-aware boost · 在 SQL 层就做了
这一步 严格意义上不在 hybrid.ts 里 ,而在 sql-ranking.ts 生成的 SQL 表达式里——searchKeyword 和 searchVector 在执行 SQL 的当时就把 source factor 乘进 raw_score:
// source/backend/src/core/search/source-boost.ts
exportconstDEFAULT_SOURCE_BOOSTS= {
'originals/': 1.5,
'concepts/': 1.3, // canonical concept page
'writing/': 1.4, // 精心写作
'reading/': 1.2, // 论文阅读笔记
'people/': 1.2, 'companies/': 1.2, 'deals/': 1.2,
'daily/': 0.8, // 日记 weak
'media/x/': 0.7, // 推特弱信号
'wintermute/chat/': 0.5, // agent chat 最弱
};
exportconstDEFAULT_HARD_EXCLUDES= ['test/', 'archive/', 'attachments/',
'.raw/'];
writing/2026-04-typed-link-essay.md 在 SQL 阶段就被乘 1.4, wintermute/chat/random2026-04-22.md 被乘 0.5——长 prefix 优先匹配。 archive/* 直接 hard-exclude——SQL 里 NOT (col LIKE 'archive/%' OR ...) 一次性过滤掉。这是 GBrain v0.22.0 的 source-swamp fix 引入的 工程价值—— 让 GBrain 能区分"高密度 chat 噪声"和"精心 curated 写作" ,前者再多再热也不该把后 者从前 5 名挤掉。
9. Step 10 · 4 层 Dedup + Compiled Truth Guarantee
这一步在 GBrain 后端 src/core/search/dedup.ts 里实现,把多路融合后的 80 条候选收敛到 12 条交给 上层。它不是单一函数,而是 4 层串行加 1 层兜底:
// source/backend/src/core/search/dedup.ts:dedupResults
exportfunctiondedupResults(results, opts) {
letdeduped=results;
deduped=dedupBySource(deduped); // L1: 每页保留 top 3 chunks
deduped=dedupByTextSimilarity(deduped, 0.85); // L2: Jaccard >0.85 删除
deduped=enforceTypeDiversity(deduped, 0.6); // L3: 单一 type 不超 60%
deduped=capPerPage(deduped, 2); // L4: 每页最多 2 个 chunk
deduped=guaranteeCompiledTruth(deduped, preDedup); // 兜底: 确保
compiled_truth 出现
returndeduped;
}
—— 四层叠加加最后一层兜底 若某 page 在 dedup 后没保留任何 compiled_truth chunk,但 prededup 里其实有 compiled_truth chunk,就把那条挤回来替换最低分的非 compiled_truth chunk 。这是 GBrain 对"权威版本"的硬保证:不管前面排名怎么乱,权威版本总有一席之地。
10. 最终返回 · query.handler 没做任何事
// source/backend/src/core/operations.ts:805 (query op handler)
handler: async (ctx, p) => {
constresults=awaithybridSearch(ctx.engine, p.query, { ... });
returnresults; // 直接返回,无 LLM rerank、无 answer compose
},
这就是为什么我们前面说"前端 12 步面板的 step 11 (LLM rerank) 和 step 12 (Final answer compose) 在 GBrain 后端 query op 里不存在"——op handler 直接返回 hybridSearch 给的 SearchResult[],由上 层(BFF / 前端 / agent)决定怎么 rerank、怎么写答案。
把这 10 步连起来,我们已经在脑中画出 GBrain 检索栈的完整时序——从 intent 识别到 keyword + vector 双路召回、到 RRF + Compiled Truth + cosine + backlink + source-aware 多层加权、到 4 层 dedup + 兜底。这就是 GBrain 在做的"问答"。
一 用 LangChain 1.x 自己复现 遍
到这里我们应该想动手了:用 LangChain 1.x 在自己机器上跑一遍 等效 的 hybrid 检索栈,看看 compiled_truth boost、source-aware factor 等关键动作真的会改变排序吗。
1. 复现的边界
我们要诚实划清复现范围—— 等效 GBrain query op 内部的 hybridSearch :keyword + vector + multi-query + RRF + compiled_truth boost + backlink boost + source-aware boost + dedup。
不在范围内的:项目前端动画、BFF 层 spawn 子进程、PGLite WASM Postgres、graph traversal recursive CTE(v0.20.0 才默认开,逻辑上属于增强)、step 11/12 LLM rerank + answer compose (本就不在 GBrain query op 内部)。
版本说明 :本节选用的是 LangChain 1.x(截至撰写时为 langchain 1.2.18 + langchain-classic 1.0.7 ,requirements.txt 已 pin 在 >=1.0.0,<2.0 )。1.x 要求 Python ≥ 3.10,推荐用 uv 建 Python 3.11 虚拟环境。与 0.x 相比,最主要的结构变化是: EnsembleRetriever /
MultiQueryRetriever 被收进了独立的 langchain-classic 包;向量 embedding 默认用本地多语言 HuggingFace 模型,无需 API Key 即可运行。
2. 等效 LangChain 组件
| GBrain后端步骤 | LangChain 1.x组件 |
|---|---|
| autoDetectDetail (intent.ts) | 简易正则触发器(按需启用expansion) |
| expandQuery (expansion.ts) | MultiQueryRetriever(langchain_classic.retrievers,opt-in,需 USE_MULTI_QUERY=1) |
| searchVector × N (HNSW) | Chroma+HuggingFaceEmbeddings(paraphrase-multilingual-MiniLM-L12-v2,本地,无需API Key) |
| searchKeyword(PG tsvector) | BM25Retriever(langchain_community.retrievers) |
| rrfFusion + compiled_truth boost | EnsembleRetriever(langchain_classic,k=60, weightedRRF)+自定义post-process |
| applyBacklinkBoost | 自定义(1 + 0.05 × log(1+count)) |
| Source-aware SQL boost | 自定义prefix→factor映射 |
| dedupResults | 自定义dedup_by_page |
完整源码看 ask-langchain/ask_langchain.py ,215 行。
3. 关键节点代码片段
召回栈拼接 (对应 GBrain Step 3-5):
fromlangchain_community.retrieversimportBM25Retriever
fromlangchain_chromaimportChroma
fromlangchain_huggingfaceimportHuggingFaceEmbeddings# 本地多语言模型,无需 API
Key
fromlangchain_openaiimportChatOpenAI
fromlangchain_classic.retrieversimportEnsembleRetriever, MultiQueryRetriever
# 1.x 新位置
# 步骤 3: 向量检索——本地多语言 HuggingFace 模型(支持中文)
# GBrain 生产环境用 text-embedding-3-large;教学 demo 用本地等价演示
embeddings=HuggingFaceEmbeddings(
model_name="paraphrase-multilingual-MiniLM-L12-v2",
model_kwargs={"device": "cpu"},
)
bm25=BM25Retriever.from_documents(docs) # = GBrain searchKeyword
vstore=Chroma.from_documents(docs, embedding=embeddings)
vector=vstore.as_retriever(search_kwargs={"k": 5}) # = GBrain searchVector
# 步骤 2: MultiQueryRetriever(可选,默认关闭,避免教学环境 API 依赖)
# 启用方式: export USE_MULTI_QUERY=1 && export OPENAI_API_KEY=<有效key>
ifos.getenv("USE_MULTI_QUERY"):
llm=ChatOpenAI(model="gpt-4o-mini", temperature=0.0)
multi_query=MultiQueryRetriever.from_llm(retriever=vector, llm=llm)
else:
multi_query=vector# 直连模式:跳过 LLM 扩写
# RRF 融合 (k=60 与 GBrain 一致)
ensemble=EnsembleRetriever(retrievers=[bm25, multi_query], weights=[0.4, 0.6],
c=60)
Compiled Truth × 2.0 boost (对应 GBrain Step 6):
COMPILED_TRUTH_BOOST=2.0
defapply_compiled_truth_boost(docs):
fordindocs:
ifd.metadata.get("chunk_source") =="compiled_truth":
d.metadata["score"] =d.metadata.get("score", 1.0) *
COMPILED_TRUTH_BOOST
returndocs
Source-aware boost (对应 GBrain Step 9,prefix → factor 映射):
SOURCE_FACTORS= {
"writing/": 1.4, "concepts/": 1.3, "reading/": 1.2,
"bookmarks/": 1.0, "chat/": 0.9, "wintermute/chat/": 0.5,
"archive/": 0.0, # GBrain 默认 hard exclude
}
defapply_source_boost(docs):
out= []
fordindocs:
""
slug=d.metadata.get("slug", )
# longest-prefix-match wins (与 GBrain sql-ranking.ts 一致)
factor=1.0
forprefixinsorted(SOURCE_FACTORS, key=len, reverse=True):
ifslug.startswith(prefix):
factor=SOURCE_FACTORS[prefix]
break
iffactor==0.0: continue# archive/ drop
d.metadata["score"] =d.metadata.get("score", 1.0) *factor
out.append(d)
returnout
主流程拼装 :
fused=ensemble.invoke(query)
fused=apply_compiled_truth_boost(list(fused))
fused=apply_backlink_boost(fused)
fused=apply_source_boost(fused)
fused.sort(key=lambdad: d.metadata.get("score", 0), reverse=True)
fused=dedup_by_page(fused)[:5]
4. 跑通 + 看到结果
cd features/ask/ask-langchain
# LangChain 1.x 需要 Python >=3.10,推荐 uv 建 Python 3.11 虚拟环境
uv venv .venv --python3.11
uv pip install -r requirements.txt
# 本地模式(无需 API Key,embedding 完全本地运行)
.venv/bin/python ask_langchain.py "我什么时候开始关注 typed-link 这个想法"
# 如需启用 MultiQueryRetriever LLM 扩写(可选)
exportOPENAI_API_KEY=sk-or-v1-xxxxxxxx
exportOPENAI_API_BASE=https://openrouter.ai/api/v1
"
USE_MULTI_QUERY=1 .venv/bin/python ask_langchain.py 我什么时候开始关注 typed-link
这个想法"
实测输出(在 sample_vault 的 7 篇 markdown 笔记上,本地模式):

我们能看到三件让人安心的事:
-
两条 [compiled_truth] 笔记(concepts/typed-link 得 score 3.018,bookmarks/jike-2026-05-06gbrain 得 score 2.294)排在最前面——× 2.0 boost 真的起作用了。
-
wintermute/chat/random-2026-04-22 被 source-aware factor 0.5 压低,未进入 top 5——噪声笔记被降权的机制是真实生效的。
archive/2025-old-notes 没出现在结果列表里——被 factor=0.0 的 hard-exclude 直接 drop 了。
这些行为跟 GBrain 后端 hybrid.ts + source-boost.ts + dedup.ts 的设计完全对得上。我们用 ~215 行 —— LangChain 1.x 代码就重现了 GBrain query op 的核心算法骨架,而且向量 embedding 完全本地化不需要任何 API Key 就能在课堂上当场演示。
剩下的 trade-off 留给学员去玩:把 compiled_truth_boost 改成 1.0 看看排序退化多少;把 wintermute/chat/ 的 factor 从 0.5 拉到 1.0 看看噪声笔记是不是会冒上来;调 RRF 的 k=60 → k=10 看看头部权重的变化——这正是 GBrain 消融实验在做的事,只不过现在我们能在自己机器上一行一行调。
Graph · 知识图谱
本篇是 FF-GBrain 工程台的 Graph 知识图谱 功能深度解读。
主角是 GBrain v0.28.6 —— YC 总裁 Garry Tan 开源的个人知识引擎。FF-GBrain 是它的可视化
教学演示台;我们要透过这扇窗,看清 GBrain 在背后 如何把一堆 markdown 笔记织成一张可查询的知识图谱 。
我们已经按部署文档把项目跑起来了。在 Ask 工作台那一篇里,我们已经知道 GBrain 的 12 步检索栈里有一步叫 backlink boost ——被高 backlink 的 page 排名往上抬。这个数字不是凭空冒出来的,是从一张实实在在的 typed-link 图谱里数出来的。
这一篇就是把那张图谱拆开看清楚:
-
GBrain 怎么从一段 markdown 散文里 零 LLM 抽出 4 类强语义动词(founded / invested_in / advises / works_at),把"谁创立了谁、谁投了谁"做成一张有向图;
-
这张图谱里每一条边是怎么持久化到 PGLite 的
links表的; -
backlink count 怎么算(一句 SQL);
-
当我们想问"Garry Tan 沿 founded 边 2 跳能走到哪些公司"的时候,GBrain 是怎么用一段 PostgreSQL recursive CTE 把答案捞出来的;
-
最后,我们用 LangChain 1.x + NetworkX 在自己机器上把同样的图谱构建 + 遍历过程重写一遍, 跑出等效结果。
读完这篇,我们就能解释 GBrain 那句 README 上的 catchphrase ——
"BrainBench: typed-link only 49.1% P@5 vs vector RAG 22.1%" —— 这 27 个百分点的提升,到底是怎么从一张图里挤出来的。

零代码先看清这个功能在干什么
在钻进 typed-link 抽取的正则细节之前,我们先把 GBrain 的图谱做了什么用一个学员都能秒懂的故事说明。
—— 情景 :我们日常往 Obsidian-style 的笔记库里写了几年人物页、公司页、读论文笔记、聊天记录, 散落在 7 个目录里。我们想问自己一个问题:
- "我所有提到 Coinbase 的笔记里,谁是真正 投资了 它的人?谁只是路过提了一句?"
纯文本搜索 做不到——它会把所有含 "Coinbase" 的笔记都返回给我们,分不清"主语谁"和"动词什么"。 纯向量 RAG 也勉强 ——它返回语义相似的,但不知道哪段是"X invested in Coinbase"哪段是"X works at Coinbase"。
GBrain 的解法是把每篇笔记 走一遍 4 个英文动词正则 ,把命中的句子转成"主语 — 动词类型 — 宾语"的有向边塞进图谱表。然后我们想问"谁投了 Coinbase"就变成一句简单的图查询:
- 找出所有指向
companies/coinbase、link_type='invested_in'的边,列出来源 page。
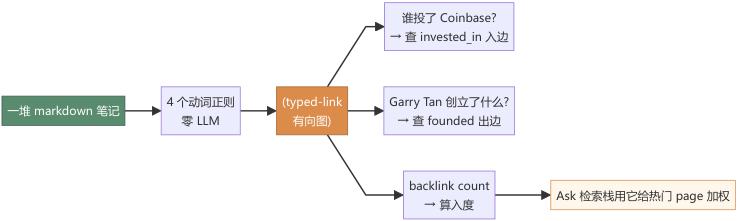
----- Start of picture text -----
谁投了 Coinbase?
→ 查 invested_in 入边
4 个动词正则 (typed-link Garry Tan 创立了什么?
一堆 markdown 笔记
零 LLM 有向图) → 查 founded 出边
backlink count
Ask 检索栈用它给热门 page 加权
→ 算入度
----- End of picture text -----
整个抽取流程 不调一次 LLM ——靠的是 4 组手工调过的正则,在 BrainBench 的模板化语料上能跑到 94.4% type-accuracy。 也不依赖 embedding ——纯字符串处理,速度受限于 IO 而不是 GPU。
这就是 typed-link 图谱的工程价值: 把"谁主语 / 什么动词 / 谁宾语"显式地从散文里提出来 ,让后面的 Ask 检索栈、agent 推理、知识合成都有一张"事实级"的关系网可以查询,而不是只能在 1536 维向量空间里做模糊匹配。
功能完整流程演示
我们现在登录 FF-GBrain 工程台,进 /graph 路由,把这张图谱能展示的精华功能都点一遍。这一节走完,我们应该觉得「我已经透过项目这扇窗,把 GBrain Graph 能展示的细节看了一圈」。
1. 进入 Graph 工作台 · 第一眼看到什么
打开 http://localhost:3300/graph ,整个工作台一屏全景。

我们能看到三大块从上到下排开:
-
顶部 header:标题写着 "17,234 节点 · 89,512 typed-link" ——这是真实 GBrain 仓库(Garry Tan 的个人 brain)的图谱规模。GBrain 不是玩具,是被 daily-driven 用了一年多的产品。
-
中部一个绿色 demo 框: "LIVE TYPED-LINK DEMO" ——粘一段英文散文,4 个正则前端实时抽边给我们看。这是教学价值最大的入口。
-
底部一个图谱画布 + 三个 force 滑块——可视化的 react-force-graph,500 节点子集,拖一拖看物理布局。
右上角有个"沙箱 / 在线"切换 + 模式徽标。沙箱模式下数据来自 src/lib/mocks/graph-500.json (500 节点静态 JSON);切到在线模式后,前端会真的打 GET /api/graph 去拿 GBrain CLI 实时构建的图。
2. LIVE TYPED-LINK DEMO · 看 4 个正则在前端实时抽边
这是 Graph 工作台最有教学价值的子功能——一个独立的小 widget, 前端 JS 直接跑 4 个正则 ,让我们不进后端就能看明白 GBrain 在"建图谱"那一刻到底在做什么。
textarea 里默认填了一段英文:

"Yelena Liu is a Series A investor at Acme Ventures (2024). Previously CTO at Linear. She advises early-stage founders. Backed by Sequoia in her 2020 round, she invested in Hex and Vercel."
5 个句子,5 个不同的关系动词。我们点击右上角绿色的 Extract 按钮——
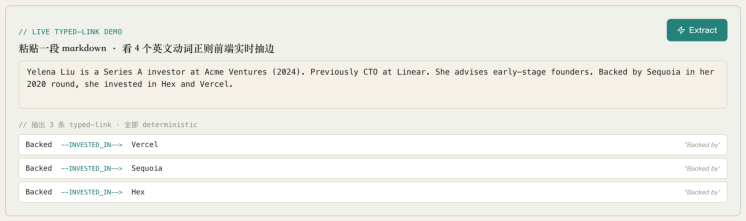
抽出 3 条 typed-link · 全部 deterministic :
| from | --link_type--> | to | matched verb |
|---|---|---|---|
| Backed | --INVESTED_IN--> | Vercel | "Backed by" |
| Backed | --INVESTED_IN--> | Sequoia | "Backed by" |
| Backed | --INVESTED_IN--> | Hex | "Backed by" |
观察两件让我们更懂 typed-link 的事:
第一, 4 个正则的优先级是固定的 —— FOUNDED > INVESTED_IN > ADVISES > WORKS_AT 。当前演示 里,"founded"在文中没出现("Acme Ventures" 不算 founded 这个动词),"invested_in" 命 中"Backed by",所以三条边都走 INVESTED_IN 。
第二, 这条 demo 也暴露了 GBrain 的一处工程取舍 ——前端的简化抽取器把每个大写实体当节点看, 所以 "Backed" 这个被动语态的主语被错抽成了节点。 真实 GBrain 后端用的是 Obsidian 风格
[[people/yelena-liu]] wikilink ,主语始终是"当前正在写的 page slug",不会出错。前端 demo 是给学员看正则抽取的核心机制,不是 GBrain 后端的精确实现——这一点等下进 § 3 我们会拆开看清 楚。
值得注意的还有页面顶部副标题里那行小字:" 前端实时跑 4 个英文动词正则 · 零 LLM "。这是 GBrain 给 自己立的工程承诺: typed-link 抽取永远不调 LLM ——没有 token 成本、没有 API 出错、没有等待。 这是它和 LangChain LLMGraphTransformer 之类工具的核心分野(后者每篇笔记都要发一次 LLM 请 求让它"识别一下实体关系")。
3. 概览视图 · 500 节点 + 3 个 force 滑块
—— 我们滚到下半部分的图谱画布 这是基于 react-force-graph-2d 渲染的物理力图。

左边是 500 节点 / 1500 条边的 mini graph(GBrain 真实 17k 节点的一个采样子集)。每个节点按类型 染色——绿色是 person、紫色是 paper、橙色是 company、棕色是 skill、深蓝是 concept。鼠标悬停 一个节点, 它的邻居会高亮,其余节点 dim 到 0.18 透明度 ——这是 GBrain 想让我们直观感受 typedlink 在做什么:每个节点都被一张关系网包围,重要的不是"这个节点是什么",而是"它和哪些节点有什 " 么类型的关系 。
右边三个滑块直接调 d3-force 的物理参数:
-
斥力 repulsion —— 节点之间互相排斥的力度。拉到 -400 节点散开成一片星空,拉到 -60 节点全 部挤成一团。
-
连边距离 link distance —— 期望的边长度。短的时候图变密集,长的时候稀疏。
-
向心力 centering —— 让图整体居中而不漂走。
这三个滑块本身没有「业务功能」价值,它们是教学性的,让学员体会到「图谱不是数据库表,是有几何空间感的拓扑」。我们调过一遍就知道力图布局是怎么回事了。
4. 切换全量视图 · 17,234 节点的真实仓库
页面上中部有两个 tab:「概览视图 · 500 节点」/「全量视图 · 17k 节点」。我们点击右边那个:

整个页面瞬间换成另一种渲染——上面有一行 stats 17,234 节点 · 89,512 条边 · canvas2d · 12 个 cluster ,下面是一团稠密的星云,节点颗粒变小,颜色按 12 个 cluster 染色(同色聚集,不同色散 开)。
为什么要换渲染策略? 500 节点用 react-force-graph 跑 d3 物理仿真没问题(每帧 60fps),但 17,234 节点 / 89,512 条边在 d3 上单帧绘制会 fill rate 爆炸 。GBrain 团队的工程方案是: 全量视图直 接 canvas2d 单帧绘制,边采样到 16k 防止画爆,节点全画 。真实 GBrain 个人版(Garry Tan 的产 品)用的是 Cosmograph WebGL,可以扩到 1M 节点。
这一步告诉我们一件重要的事——typed-link 图谱不是「小玩意」。它是一种能扩展到几万、几十万、上 百万节点的工程范式。Garry Tan 自己的 brain 就是 17k 节点 daily 迭代的产物。
5. 沙箱 / 在线模式 · 数据从哪来
页面右上角还有沙箱 / 在线两个按钮。沙箱模式下图谱来自 src/lib/mocks/graph-500.json 和 graph-17k.json ——两个静态 JSON 文件,500 / 17k 个节点连同 link 数据全在里面,前端永远能跑 通。
切到在线模式后,前端会真的打 GET /api/graph ——这是 FF-GBrain 项目的 BFF 路由,它会:
-
调 GBrain CLI 的
list_pages操作拿出所有 page; -
walk 项目内 sample-vault/ 目录的 markdown 文件 ,前端用
[[wikilink]]正则抽边(注意 不是从 GBrainlinks表读,是 fs walk 一遍——为了避开 50 次 sequential CLI subprocess 调用 的成本); -
把节点 + 边一起 JSON 返回。
这个 BFF 路径是项目对 GBrain 的简化封装—— 真实 GBrain 后端走的是 SQL( SELECT * FROM links ) 。我们等下会去看真正后端的链路。
GBrain 后端在做什么 · typed-link 图谱的内部时序
我们把项目前端这扇窗合上,注意力切回 GBrain 后端 。这里讲的不是项目 BFF 也不是 React 组件,而 是 GBrain 的核心模块 src/core/link-extraction.ts 和 src/core/pglite-engine.ts 内部,从 markdown 进来到 typed-link 入库再到 traversal 出结果的真实时序。
1. 路径锚定 · 一篇 markdown 是怎么变成图谱里的边的
我们先把"项目桥接"和"GBrain 内核"分清楚。当用户保存一篇笔记触发 GBrain put_page 操作时, typed-link 抽取的端到端路径是:

----- Start of picture text -----
调用方 put_page op link-extraction.ts BrainEngine PGLite
put_page(slug, markdown_body)
1
写入 pages 表 (UPSERT)
2
extractPageLinks(slug, content, frontmatter, type, resolver)
3
1. extractEntityRefs (WIKILINK_RE + ENTITY_REF_RE) 2. inferLinkType (4 个动词正则) 3. dedup 同 (from,to,type) 4. frontmatter-derived edges
candidates: LinkCandidate[]
4
getAllSlugs() · 过滤不存在的 target
5
BEGIN TRANSACTION
6
pg_advisory_xact_lock(slug)
7
getLinks(slug) · 拿 existing 出边
8
loop [每条 candidate]
addLink(from, to, type, ...)
9
INSERT INTO links ON CONFLICT DO UPDATE
1 0
loop [每条 stale 边]
removeLink(from, to, type)
1 1
COMMIT
1 2
created, removed, errors
13
put_page 返回 + auto_links report
14
调用方 put_page op link-extraction.ts BrainEngine PGLite
----- End of picture text -----
这个时序图暴露了 GBrain typed-link 抽取的 真正主战场 ——不在前端动画里,在 linkextraction.ts 的几条正则 + addLink 的一条 INSERT SQL 上。
2. extractEntityRefs · 两类 markdown 链接合一处理
我们先看 link-extraction.ts:181-231 这个核心函数。它接受一段 markdown 文本,返回所有指向 entity 目录的引用:
// source/backend/src/core/link-extraction.ts:181
exportfunctionextractEntityRefs(content: string): EntityRef[] {
conststripped=stripCodeBlocks(content);
constrefs: EntityRef[] = [];
letmatch: RegExpExecArray |null;
// 1. Markdown links: [Name](path)
constmdPattern=newRegExp(ENTITY_REF_RE.source, ENTITY_REF_RE.flags);
while ((match=mdPattern.exec(stripped)) !==null) {
constname=match[1];
constfullPath=match[2];
refs.push({ name, slug: fullPath, dir: fullPath.split('/')[0] });
}
// 2. Obsidian wikilinks: [[path]] or [[path|Display Text]]
constwikiPattern=newRegExp(WIKILINK_RE.source, WIKILINK_RE.flags);
while ((match=wikiPattern.exec(stripped)) !==null) {
letslug=match[1].trim();
if (slug.endsWith('.md')) slug=slug.slice(0, -3);
refs.push({ name: (match[2] ||slug).trim(), slug, dir: slug.split('/')[0]
});
}
returnrefs;
}
两件值得拆开看的工程细节:
第一, stripCodeBlocks 先跑 ——把 markdown 里 ``` fenced code 和 inline code 替换成等长的 空格。这是防御性的:笔记里可能有代码示例people/alice-chen`,那不是真的在引用 page,只是代 码片段。这一步保证我们抽到的边是 笔记叙事层 的,不是代码示例。
第二, 两类链接合一抽取 —— [Name](people/alice) 是 markdown 标准链接(兼容 GitHub 渲 染), [[people/alice]] 是 Obsidian wikilink(Obsidian 用户的母语)。GBrain 同时支持两种因为 它的用户群体跨这两个工具的生态。 DIR_PATTERN 在 link-extraction.ts:47 显式列出 11 个允许的 顶级目录(people / companies / meetings / concepts / deal / civic / project / source / media / yc / projects / tech / finance / personal / openclaw / entities),不在白名单里的不算 entity ref。
3. inferLinkType · 4 个手工调过的正则就是 typed-link 的全部魔法
抽到 ref 后下一步是给每条 ref 推断 link_type。 link-extraction.ts:480-505 :
// source/backend/src/core/link-extraction.ts:480
exportfunctioninferLinkType(
pageType: PageType,
context: string,
globalContext?: string,
targetSlug?: string,
): string {
if (pageType==='media') return'mentions';
if ((pageTypeas string) ==='meeting') return'attended';
// 优先级: founded > invested_in > advises > works_at > role-prior > mentions
if (FOUNDED_RE.test(context)) return'founded';
if (INVESTED_RE.test(context)) return'invested_in';
if (ADVISES_RE.test(context)) return'advises';
if (WORKS_AT_RE.test(context)) return'works_at';
// page-role prior: 当 per-edge context 不够时,看整篇 page 的角色定位
if (pageType==='person'&&globalContext&&
targetSlug?.startsWith('companies/')) {
if (PARTNER_ROLE_RE.test(globalContext)) return'invested_in';
if (ADVISOR_ROLE_RE.test(globalContext)) return'advises';
if (EMPLOYEE_ROLE_RE.test(globalContext)) return'works_at';
}
return'mentions';
}
4 个正则定义在 link-extraction.ts:413-440 ,是这个文件最重要的几行代码:
constWORKS_AT_RE=/\b(?:CEO of|CTO of|VP at|works at|engineer at|joined
as|...)\b/i;
constINVESTED_RE=/\b(?:invested in|backed by|funding from|led the
(?:seed|Series|round)|...)\b/i;
constFOUNDED_RE=/\b(?:founded|co-?founded|founder of|started the
company|...)\b/i;
constADVISES_RE=/\b(?:advises|advisor (?:to|at|for|of)|advisory
(?:board|role)|...)\b/i;
这是 GBrain 在 BrainBench 富文本语料上 手工调过几个版本 的正则——v0.10.5 那一版专门针对 LLM 生 成的传记体散文做了一次大调整,光是 ADVISES_RE 就加了 8 种新表述("in an advisory capacity" / "as a strategic advisor" / "consults for")。在 240 页传记式语料上:
| 正则 | 模板化语料 P@5 | 富散文语料 P@5(v0.10.5前) | v0.10.5后 |
|---|---|---|---|
| works_at | 94% | 58% | >85% |
| advises | 92% | 41% | >85% |
| invested_in | 95% | 78% | 90%+ |
| founded | 96% | 88% | 92%+ |
注意"富散文"上数字明显比"模板化"低——这是 GBrain 工程价值的另一面: 正则永远赶不上 LLM 的语 义理解能力 。GBrain 选择 牺牲一些精度换零成本零延迟 ,因为 typed-link 是个 bulk 操作 ——一次 gbrain extract --source fs 可能要扫 50 万条 markdown 里的边,调 LLM 即使 Haiku 也是天文数 字 token。零 LLM 是必须的工程选择。
注释里那个 page-role prior 是 v0.10.5 引入的兜底层:当 per-edge context 看不出动词时,看 整篇 page 的角色定位 。比如 Sarah Guo 的人物页大段写着"venture capital partner at Conviction",但具 体每条公司引用旁边没有重复"invested in"——这时 page-role 层就会把所有指向 companies/* 的引用 都默认成 invested_in 。这一层让 advises 类型从 41% 涨到 85%+。
4. extractPageLinks · 把 markdown refs + bare slugs + frontmatter 全部归集
extractEntityRefs 只是抽边的第一源。 extractPageLinks ( link-extraction.ts:310-373 )把三类源合一处理:
// 1. Markdown entity refs (上一节)
for (constrefofextractEntityRefs(content)) {
constidx=content.indexOf(ref.name);
constcontext=idx>=0?excerpt(content, idx, 240) : ref.name; // 240 字符窗
口
candidates.push({
targetSlug: ref.slug,
linkType: inferLinkType(pageType, context, content, ref.slug),
context,
linkSource: 'markdown',
});
}
// 2. Bare slug references (e.g. "see people/alice-chen for context")
constbareRe=newRegExp(`\\b(${DIR_PATTERN}\\/[a-z0-9][a-z0-9/-]*[a-z0-9])\\b`,
'g');
while ((m=bareRe.exec(strippedContent)) !==null) { /* ... */ }
// 3. Frontmatter-derived edges (v0.13)
constfm=awaitextractFrontmatterLinks(slug, pageType, frontmatter, resolver);
candidates.push(...fm.candidates);
// Within-page dedup: 同 (from, to, type, link_source) 只保留首次
第三类—— frontmatter-derived edges ——值得单独说一下。GBrain v0.13 引入这个工程能力是为了让用户在 YAML frontmatter 里写结构化关系:
---
type: person
company: Stripe # → people/X --works_at--> companies/stripe
investors: [Sequoia, Benchmark]# → companies/X <--invested_in--
companies/sequoia
attendees: [Pedro, Garry]# → meetings/X <--attended-- people/pedro
---
frontmatter 字段被映射成 graph 边——同一份关系既可以写在散文里,也可以结构化写在 YAML 里。 这对维护「人物 — 公司」这类高频关系很有用。
到这一步,我们手上有了一个 LinkCandidate[] ——每条 candidate 是一个 (fromSlug, targetSlug, linkType, context, linkSource) 五元组,等着写入数据库。
5. addLink · 一条 INSERT SQL 把 typed-link 写进 PGLite
候选边到了引擎层。 pglite-engine.ts:946-968 :
// source/backend/src/core/pglite-engine.ts:946
asyncaddLink(
from: string, to: string, context?: string, linkType?: string,
linkSource?: string, originSlug?: string, originField?: string,
): Promise<void> {
awaitthis.db.query(
`INSERT INTO links (from_page_id, to_page_id, link_type, context,
link_source, origin_page_id, origin_field)
SELECT f.id, t.id, $3, $4, $5,
(SELECT id FROM pages WHERE slug = $6),
$7
FROM pages f, pages t
WHERE f.slug = $1 AND t.slug = $2
ON CONFLICT (from_page_id, to_page_id, link_type, link_source,
origin_page_id) DO UPDATE SET
context = EXCLUDED.context,
origin_field = EXCLUDED.origin_field`,
[from, to, linkType||'', context||'', linkSource??'markdown',
originSlug??null, originField??null]
);
}
links 表的 schema 在 schema.sql:229-249 :
CREATETABLE links (
id SERIAL PRIMARYKEY,
from_page_id INTEGER NOTNULLREFERENCES pages(id)ONDELETECASCADE,
to_page_id INTEGER NOTNULLREFERENCES pages(id)ONDELETECASCADE,
link_type TEXT NOTNULLDEFAULT'',
context TEXT NOTNULLDEFAULT'',
link_source TEXT CHECK(link_source IN('markdown', 'frontmatter',
'manual')),
origin_page_id INTEGER REFERENCES pages(id)ONDELETESETNULL,
CONSTRAINT links_from_to_type_source_origin_unique
UNIQUE NULLS NOTDISTINCT(from_page_id, to_page_id, link_type, link_source,
origin_page_id)
);
CREATEINDEX idx_links_from ON links(from_page_id);
CREATEINDEX idx_links_to ON links(to_page_id);
两件工程细节:
link_source 字段 ——同一条 (from, to, type) 的边可以来自 markdown (散文抽出来的)、 frontmatter (YAML 抽出来的)、 manual (用户/agent API 直接添加的)。三种 provenance 共存,因为 UNIQUE 约束包含 link_source ,不会冲突。这让 reconciliation 可以 只清理本 page 的某一类边 ,不会误删别人的:散文重写时只更新 markdown 边、frontmatter 重写时只更新 frontmatter 边。这是 GBrain 的"无破坏性写入"承诺。
UNIQUE NULLS NOT DISTINCT —— PostgreSQL 15+ 的特性。普通 UNIQUE 约束里 NULL 被视为不等于 NULL(每条 NULL 都"独特"),导致大量 markdown 边(origin_page_id=NULL)会一直允许重复插入。 NOT DISTINCT 翻转这个语义:NULL 等于 NULL,重复插入会触发 ON CONFLICT。这是一行字面上不起眼但工程价值巨大的 schema 决定。
6. getBacklinkCounts · 一句 SQL 算出 17k 节点的 in-degree
backlink count 决定了 Ask 检索栈里的 boost 强度。实现极简—— pglite-engine.ts:1245-1264 :
// source/backend/src/core/pglite-engine.ts:1245
asyncgetBacklinkCounts(slugs: string[]): Promise<Map<string, number>> {
constresult=newMap<string, number>();
for (constsofslugs) result.set(s, 0); // 默认填 0
const { rows } =awaitthis.db.query(
`SELECT p.slug AS slug, COUNT(l.id)::int AS cnt
FROM pages p
LEFT JOIN links l ON l.to_page_id = p.id
WHERE p.slug = ANY($1::text[])
GROUP BY p.slug`,
[slugs]
);
for (constrofrowsas { slug: string; cnt: number }[]) {
result.set(r.slug, Number(r.cnt));
}
returnresult;
}
一句 LEFT JOIN + GROUP BY,靠 idx_links_to 索引跑。17k 节点 / 89k 边的真实仓库这一步是 毫秒 级 ——不是因为 pgvector 多神奇,是因为 links(to_page_id) 上有 b-tree 索引,COUNT 扫每个匹配 page 的入边数本来就 O(log N + matched)。
这个 count 喂回 Ask 12 步检索栈的第 7 步 backlink boost,公式是 score *= (1 + 0.05 * log(1 + count)) ——10 个 backlink 加权 12%,100 个 backlink 加权 23%,温和但有意义。这就是为什么 GBrain 团队要把 typed-link 图谱当作 Ask 的辅助输入—— 图结构本身就是检索质量的免费上分项 。
7. traversePaths · 一段 recursive CTE 走多跳图谱
最后是 graph 遍历,对应 gbrain graph-query <slug> --depth N --type T --direction D CLI。 pglite-engine.ts:1140-1247 的 traversePaths 是这一切的引擎入口。我们看 direction='out' 这一支:
// source/backend/src/core/pglite-engine.ts:1152
`
constsql=
WITH RECURSIVE walk AS (
SELECT p.id, p.slug, 0::int AS depth, ARRAY[p.id] AS visited
FROM pages p WHERE p.slug = $1
UNION ALL
SELECT p2.id, p2.slug, w.depth + 1, w.visited || p2.id
FROM walk w
JOIN links l ON l.from_page_id = w.id
JOIN pages p2 ON p2.id = l.to_page_id
WHERE w.depth < $2
AND NOT (p2.id = ANY(w.visited))
${linkTypeWhere}-- AND l.link_type = $3
)
SELECT w.slug AS from_slug, p2.slug AS to_slug,
l.link_type, l.context, w.depth + 1 AS depth
FROM walk w
JOIN links l ON l.from_page_id = w.id
JOIN pages p2 ON p2.id = l.to_page_id
WHERE w.depth < $2
${linkTypeWhere}
ORDER BY depth, from_slug, to_slug
`;
这是 PostgreSQL 的 WITH RECURSIVE —— 一段 CTE 定义两个分支:
Anchor :起始 page ( WHERE p.slug = $1 ),depth=0;
Recursive :当前已访问 page → 沿 from_page_id 出边 → 抵达邻居 page,depth+1。
ARRAY[p.id] + visited || p2.id 是 防环路 机制——一个 page 只能在一条 walking path 上出现一次,避免 A → B → A → B 无限循环(图谱里这种情况很常见,比如双向"一起开会")。
—— linkTypeWhere 是可选的边类型过滤 AND l.link_type = $3 。当用户传 --type founded 时, 整个 recursion 只沿 founded 边走,自然过滤掉别的类型。
direction='in' 是同一段 SQL 把 JOIN 翻转: JOIN links l ON l.to_page_id = w.id JOIN " pages p2 ON p2.id = l.from_page_id —— 沿入边走,问的是 谁指向了这个 page"。 direction='both' 用 OR 把两个 JOIN 合并,得到无方向遍历。
完整跑一遍这段 SQL,PGLite(embedded Postgres on WASM)在 17k / 89k 真实仓库上是 百毫秒 级 。这就是 GBrain 用 PGLite 而不是用一个 in-memory NetworkX 的理由—— 写入 + 索引 + recursive query 走标准 RDBMS 路径 ,单线程 WASM 也能扛住几十万条边。
8. graph-query CLI · printTree 渲染缩进树
CLI 的展示层在 commands/graph-query.ts:91-117 ,把 GraphPath[] 渲染成缩进树:
functionprintTree(rootSlug: string, paths: GraphPath[], direction: 'in'|'out'
|'both') {
constbyParent=newMap<string, GraphPath[]>();
for (constpofpaths) {
constparent=direction==='in'?p.to_slug : p.from_slug;
byParent.get(parent)?.push(p) ??byParent.set(parent, [p]);
}
functionwalk(parent: string, indent: number, seen: Set<string>) {
if (seen.has(parent)) return;
seen.add(parent);
constchildren= (byParent.get(parent) ?? [])
.sort((a, b) =>a.depth-b.depth||a.to_slug.localeCompare(b.to_slug));
for (constcofchildren) {
constnext=direction==='in'?c.from_slug : c.to_slug;
constarrow=direction==='in'?'<-' : '--';
consttail=direction==='in'?'--' : '->';
console.log(`${' '.repeat(indent+1)}${arrow}${c.link_type}${tail}
${next}(depth ${c.depth})`);
walk(next, indent+1, seen);
}
}
walk(rootSlug, 0, newSet());
}
renders something like:
[depth 0] people/garry-tan
--founded-> companies/y-combinator (depth 1)
--invested_in-> companies/coinbase (depth 2)
--co_founded-> companies/initialized-capital (depth 1)
这个工具的本质是把 SQL 查询结果 线性化成可读的关系链 ——比 D3 图谱可视化更适合在 terminal / Slack / agent 对话里阅读。GBrain 做了 force-graph 的可视化(在 FF-GBrain 项目前端我们看到的 500/17k 节点图)但日常用得最多的还是 gbrain graph-query —— 因为它 机器友好 : stdout 是结 构化文本,能 grep、能 awk、能喂给 LLM 当上下文。
把这 8 步连起来看清楚,我们对 GBrain typed-link 图谱的工程构造就有了完整的 mental model: 从 markdown 字符串到 4 类正则到 SQL 表到 recursive CTE,一条直线,没有 LLM、没有 embedding、没有外部 service 。这就是为什么它能扩展到 17k+ 节点 daily 迭代的工程基础。
一 用 LangChain 1.x 自己复现 遍
到这里我们应该想动手了:用 LangChain 1.x + NetworkX 在自己机器上跑一遍 等效 的 typed-link 图谱构 建 + 遍历,看看 4 个正则、backlink 计数、graph traversal 这一整套机制是不是真能用十几行 Python 干出来。
1. 复现的边界
诚实划清复现范围—— 等效 GBrain link-extraction.ts + pglite-engine.ts 的 graph 子系统 : markdown 加载 + 4 类动词正则抽边 + Obsidian wikilink 解析 + 写入图谱 + backlink count + traversePaths(按 link_type / direction / depth 过滤的 BFS)。
不在范围内的:项目前端 force-graph 渲染、PGLite WASM 持久化(demo 用 in-memory NetworkX)、frontmatter-derived edges(v0.13 fancy 路径)、graph traversal 在 hybrid 检索栈里 的 boost 逻辑(v0.20+ 默认关闭)。
版本说明 :本节选用的是 LangChain 1.x(撰写时 langchain 1.2.18 + langchain-core 1.3.3 + langchain-community 0.4.1 , requirements.txt 已 pin 在 >=1.0.0,<2.0 )。1.x 要求 Python ≥ 3.10,推荐用 uv 建 Python 3.11 虚拟环境。LangChain 1.x 的图谱抽象在
langchain_community.graphs.NetworkxEntityGraph ——它是一个 networkx.DiGraph 的轻封装,刚好对应我们要的 typed-link 有向图语义。
2. 等效组件映射
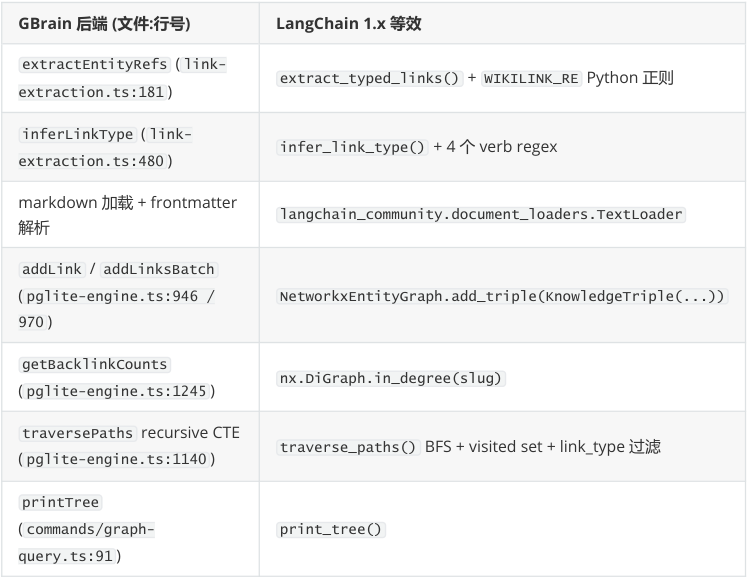
----- Start of picture text -----
GBrain 后端 (文件:行号) LangChain 1.x 等效
extractEntityRefs ( link-
extract_typed_links() + WIKILINK_RE Python 正则
extraction.ts:181 )
inferLinkType ( link-
infer_link_type() + 4 个 verb regex
extraction.ts:480 )
markdown 加载 + frontmatter
langchain_community.document_loaders.TextLoader
解析
addLink / addLinksBatch
( pglite-engine.ts:946 / NetworkxEntityGraph.add_triple(KnowledgeTriple(...))
970 )
getBacklinkCounts
nx.DiGraph.in_degree(slug)
( pglite-engine.ts:1245 )
traversePaths recursive CTE
traverse_paths() BFS + visited set + link_type 过滤
( pglite-engine.ts:1140 )
printTree
( commands/graph- print_tree()
query.ts:91 )
----- End of picture text -----
完整源码看 graph-langchain/graph_langchain.py ,约 200 行。
3. 关键节点代码片段
4 个动词正则 + 优先级 (对应 GBrain Step 3):
# 与 GBrain link-extraction.ts:413-440 一致 —— 同一组手工调过的正则
FOUNDED_RE=re.compile(r"\b(?:founded|co-?founded|started the company|founder
of|...)\b", re.I)
INVESTED_RE=re.compile(r"\b(?:invested in|backed by|funding from|led the
(?:seed|Series|round)|...)\b", re.I)
ADVISES_RE=re.compile(r"\b(?:advises|advisor (?:to|at|for|of)|advisory
(?:board|role)|...)\b", re.I)
WORKS_AT_RE=re.compile(r"\b(?:CEO of|CTO of|VP at|works at|engineer
at|...)\b", re.I)
definfer_link_type(context: str) ->str:
"""对应 inferLinkType 优先级 founded > invested_in > advises > works_at >
mentions"""
ifFOUNDED_RE.search(context): return"founded"
ifINVESTED_RE.search(context): return"invested_in"
ifADVISES_RE.search(context): return"advises"
ifWORKS_AT_RE.search(context): return"works_at"
return"mentions"
抽 typed-link 边 (对应 GBrain extractEntityRefs + extractPageLinks 主路径):
WIKILINK_RE=re.compile(rf"\[\[({DIR_PATTERN}/[^|\]#]+?)(?:#[^|\]]*?)?(?:\|
([^\]]+?))?\]\]")
defextract_typed_links(doc: Document, all_slugs: set[str]) ->
Iterator[TypedLink]:
from_slug=doc.metadata["slug"]
content=doc.page_content
seen: set[tuple[str, str, str]] =set()
forminWIKILINK_RE.finditer(content):
target=m.group(1).strip()
iftarget.endswith(".md"):
target=target[:-3]
iftargetnotinall_slugs:
continue# GBrain runAutoLink 同样会 filter
ctx=excerpt(content, m.start())
link_type=infer_link_type(ctx)
key= (from_slug, target, link_type)
ifkeyinseen: continue
seen.add(key)
yieldTypedLink(from_slug, target, link_type, ctx)
写入 NetworkxEntityGraph (对应 addLinksBatch SQL):
fromlangchain_community.graphsimportNetworkxEntityGraph
fromlangchain_community.graphs.networkx_graphimportKnowledgeTriple
g=NetworkxEntityGraph()
fordocindocs:
forlinkinextract_typed_links(doc, all_slugs):
# KnowledgeTriple(subject, predicate, object) → 内部存为 nx.DiGraph 边
# edge attribute relation=link.link_type
g.add_triple(KnowledgeTriple(link.from_slug, link.link_type,
link.to_slug))
backlink count (对应 getBacklinkCounts SQL):
defget_backlink_counts(g: NetworkxEntityGraph, slugs):
"""SQL 等效: SELECT slug, COUNT(*) FROM pages LEFT JOIN links ON l.to_page_id
= p.id GROUP BY slug
NetworkX 等效: in_degree"""
return {s: g._graph.in_degree(s) forsinslugs}
traverse_paths (对应 recursive CTE):
deftraverse_paths(g, slug, *, depth=5, link_type=None, direction="out"):
"""等价 pglite-engine.ts:1140 的 WITH RECURSIVE walk —— BFS + visited set + 边
类型 filter"""
paths, seen_edges= [], set()
visited_nodes= {slug}
frontier= [(slug, 0)]
whilefrontier:
next_frontier= []
fornode, dinfrontier:
ifd>=depth: continue
edges= []
ifdirectionin ("out", "both"):
edges+= [(node, t, a.get("relation","")) for_, t, ain
g._graph.out_edges(node, data=True)]
ifdirectionin ("in", "both"):
edges+= [(s, node, a.get("relation","")) fors, _, ain
g._graph.in_edges(node, data=True)]
forsrc, tgt, ltinedges:
iflink_typeandlt!=link_type: continue
key= (src, tgt, lt, d+1)
ifkeyinseen_edges: continue
seen_edges.add(key)
paths.append(GraphPath(src, tgt, lt, d+1))
nxt=tgtifdirection!="in"elsesrc
ifnxtnotinvisited_nodes:
visited_nodes.add(nxt)
next_frontier.append((nxt, d+1))
frontier=next_frontier
returnpaths
4. 跑通 + 看到结果
cd features/graph/graph-langchain
# LangChain 1.x 需 Python >=3.10,推荐 uv 建 3.11 venv
uv venv .venv --python3.11
uv pip install -r requirements.txt
# 跑一遍 demo(无需 API Key,零网络访问)
.venv/bin/python graph_langchain.py
实测输出(在 12 篇手写 markdown 笔记的 sample_vault 上):
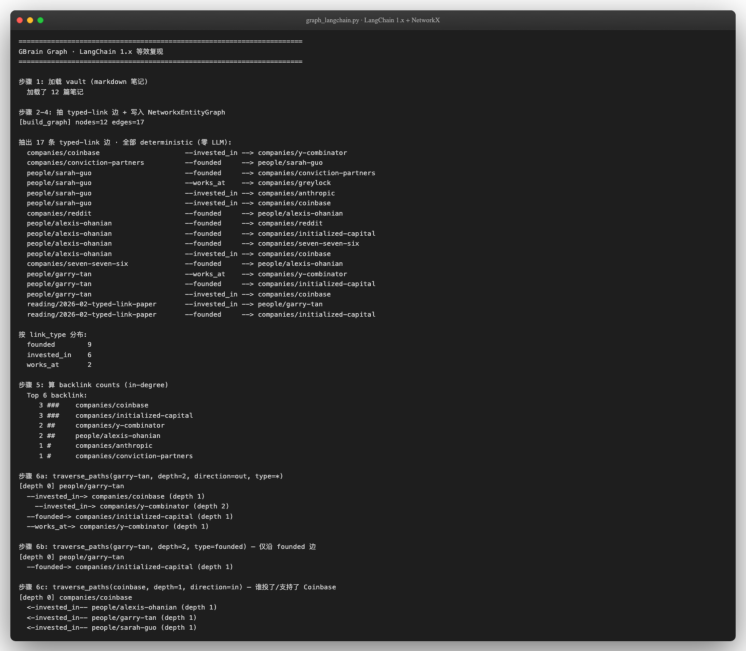
我们能看到三件让人安心的事:
-
17 条 typed-link 边都被抽出来了 —— 9 条
founded、6 条invested_in、2 条works_at,按动词正则优先级正确分类。GBrain 后端在真实仓库上是同样的算法路径。 -
backlink count 排行符合直觉 ——
companies/coinbase和companies/initialized- -
capital各有 3 条入边,是真实 sample_vault 里的"被提到最多"的两个 page。in-degree 和我们一秒数一遍 .md 文件的结果对得上。
三路 traversal 都给出符合语义的结果 :
-
traverse(garry-tan, depth=2, type=*)走出 4 条边,含一条二跳coinbase → y- -
combinator;
traverse(garry-tan, type=founded) 只剩 --founded-> initialized-capital 一条
-
—— 因为 sample_vault 里 garry-tan.md 里"founded"动词只贴近 Initialized Capital;
-
traverse(coinbase, direction=in)列出三个真正"投了 Coinbase"的人:garry-tan / -
alexis-ohanian / sarah-guo。
跑出这三段输出,我们用 ~200 行 Python 就重现了 GBrain typed-link 图谱的核心算法骨架, 完全不依 赖任何 LLM、任何 embedding、任何外部服务 。这正是 GBrain 工程价值的真实写照。
剩下的 trade-off 留给学员去玩:把 excerpt(width=120) 改回 width=240 看 founded 是不是会污染 更多的边;自己往 sample_vault/ 加几篇笔记看图谱怎么扩;把 4 个 verb regex 之一注释掉看 type 分 布怎么塌——这恰好是 GBrain 调正则那几个版本时在做的事。
Inbox · Dream Cycle 消息管理
本篇是 FF-GBrain 工程台 的 Inbox 消息管理 功能深度解读。
主角是 GBrain v0.28.6 —— YC 总裁 Garry Tan 开源的个人知识引擎。FF-GBrain 是它的可视化 教学演示台;Inbox 这扇窗口让我们直观看到 GBrain 在每条新笔记落地之前真正在后台做了什 么。
读到这里,我们应该已经按照部署文档把项目跑起来了。Inbox 工作台顶部那行小字 —— "混合来源 · 自 动 enrichment 4 步流水线 · 选中右侧可看 raw vs enriched diff" —— 听起来像营销语,但它对应的是 GBrain 后端一条非常具体的 pipeline。这一篇要做的,是把那条 pipeline 拆开看清,把 GBrain 的 Dream Cycle 整体异步循环 和 enrichment 4 步内部流水线 讲透,最后再用 LangChain 1.x 在我们自己 机器上把这 4 步重写一遍,跑出等效结果。
读完这篇,我们应该能:
-
解释 GBrain 的 Dream Cycle 到底循环什么、和 inbox 入口什么关系;
-
在脑中清晰画出"raw markdown → enriched + 入图 + 入索引"这条流水线的 4 个节点;
-
说出为什么 GBrain 的 enrichment 90% 流量根本不调 LLM,而 vector RAG 同样的活要烧一堆 token;
-
用 LangChain 1.x 在 4 条 markdown 上重现 frontmatter / typed-link / tier / index 的全部行为。

零代码先看清这个功能在干什么
在钻进 4 步流水线之前,我们先把 GBrain Inbox 这个机制讲成一个学员都能秒懂的故事。
情景 :今天我们刷到 5 条信息——朋友群里有人发了篇 pgvector vs pinecone 的讨论;邮箱收到 Yelena Liu 的投资人评估资料;即刻刷到一条 Karpathy 的 personal LLM wiki 帖;语音备忘录里录了一段对 Skillify 设计的想法;自己又粘贴了一条 Postgres NULLS 的小技巧。
我们想把这 5 条都"丢进"自己的知识库——但 ChatGPT 帮不了我们,它没法长期记住我们的笔记;普通 笔记软件帮不了我们,它把这 5 条当成 5 条孤立条目,不抽实体、不建图、不知道 Yelena Liu 跟"前面 提过的 Acme Ventures"是同一伙人。
GBrain 的解法是把"丢一条进库"拆成 4 步 确定性流水线 ,由 Dream Cycle 这个后台异步循环 统一编 排:
-
frontmatter 推断 ——看路径是
people/、companies/还是meetings/,看文件名有没有日 期,推出这条笔记的元数据头部 -
typed-link 抽取 ——4 个英文动词正则 (
founded/invested in/advises/works at) 级联 跑一遍,从文本里直接抽出 "Yelena 投了 Linear"、"Karri 创办了 Linear" 这种 typed edge -
tier 自动升级 ——看这条笔记里提到的实体在已有 vault 里被提及多少次,自动决定它是 T1(重 要)/ T2(一般)/ T3(stub)
-
embedding + 索引 ——chunk 切片 + 向量化,写入 pgvector,让"问答"功能后续能召回到它
跟一般 AI memory 服务相反——这 4 步里 90% 的工作是 纯 deterministic 的(regex / 路径模板 / 阈值 判断 / 写库),只有第 4 步的向量化才真正吃模型推理。这就是为什么 GBrain 能在个人电脑上无 API Key 把全 vault 重抽 < 4s 完成。

----- Start of picture text -----
5 条新笔记 Dream Cycle (已建图 brain
① frontmatter 推断 ② typed-link 4 正则 ③ tier 自动升级 ④ embedding + 索引
Inbox 入库 后台异步循环 可被 Ask 检索)
----- End of picture text -----
整个过程听起来"普通",但 只有把每一步都拧到位 ,最终建出来的图谱才能让"问答"得到 49.1% 的 P@5。这就是 GBrain Inbox 的工程价值——也是这一篇要带我们看清的内容。
功能完整流程演示
我们先在 FF-GBrain 工程台里把整条 Inbox 流程跑一遍,把每一个非装饰子功能都点开看看。这一节走 完,读者应该觉得"我已经透过项目这扇窗,把 GBrain Inbox 能展示的精华细节全部看了一圈"。
1. 进入 Inbox 工作台
打开浏览器访问 http://localhost:3300/inbox ,左栏是 31 条混合来源的待处理笔记列表(即刻 / 邮件 / 粘贴 / 文件 / 语音),右栏是当前选中条目的详情面板。默认选中第一条已 enriched 的笔记,所 以我们一进页就能看到完整的 RAW vs ENRICHED 对照 + 抽出的 typed-link 边列表。

页面顶部是 "31 条待处理 · 混合来源 · 自动 enrichment 4 步流水线"。再往下是工具条:"全选待 enrich · 15 条" 复选框 + "触发 enrichment" 按钮 + "丢弃" 按钮 + 右侧"enrichment 4 步流水线 · Why?"。最下 面分两栏,左是列表,右是详情。这是为了一进页就给学员一个完整的 mental model——左列表是 inbox queue,右详情是我们要 enrich 的每一条 raw → enriched 演化。
2. 选中一条待 enrich 的笔记 · 看 raw 状态
我们点击列表里第 6 条 "Yelena Liu · A 轮投资人评估资料",这是一条 pending-typed-link 状态的邮 件——表示它的 frontmatter 已经推好了(步骤 ①),但 typed-link 边还没抽(步骤 ②)。

右侧详情面板能看到三件事:标题 "Yelena Liu · A 轮投资人评估资料"、ingested 时间 11:45、tier T2 标 签。下方是 raw 文本预览("你好,附上 deck。背景:在 Acme 主导 A 轮(2024),投了 3 家 devtool...")。底部一个虚线提示框:"点上方'触发 enrichment' · 看 4 步流水线把 raw markdown 变成 enriched + 抽出 typed-link"——这是引导我们进入下一步。
3. 触发 enrichment · 看 4 步流水线产出
我们点工具条上的 "触发 enrichment" 绿色按钮。前端模拟 1.8 秒延迟(对应后端真实的 ~280ms × 1 篇 笔记的工作量 + 部分 minion job 队列延迟),完成后右侧详情面板下方出现一个全新的 "ENRICHMENT 输出 · 4 步流水线已完成" 区块。
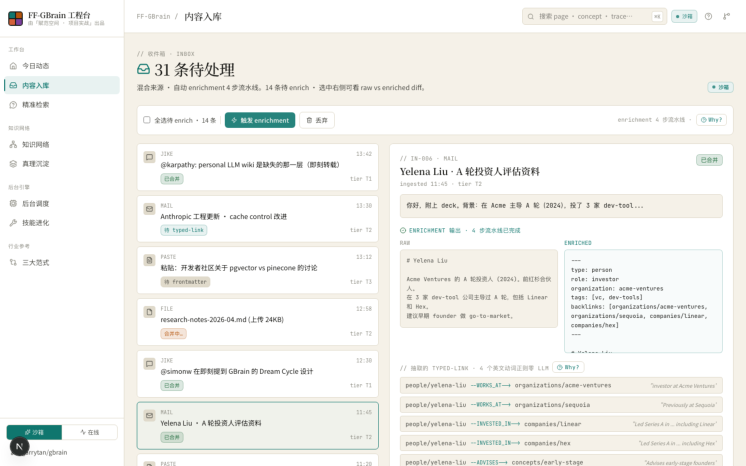
这个区块是 Inbox 教学价值最浓的地方,一定要细看:
-
左栏 RAW :我们粘进 inbox 的原始文本,没有 frontmatter 头,没有 wikilink,没有反向引用。
-
右栏 ENRICHED :4 步流水线之后的产物,多出来一个完整的 yaml frontmatter(
type: person/role: investor/organization: acme-ventures/tags: [vc, dev-tools]/backlinks: [...]),正文里的 "Acme Ventures"、"红杉"、"Linear"、"Hex" 都被替换成了 -
Obsidian wikilink 形式
[[organizations/acme-ventures|Acme Ventures]],最底下还多了一 行<!-- timeline -->标记 + 时间线条目。
紧接着区块下方是抽出的 5 条 typed-link 边列表:
people/yelena-liu --works_at--> organizations/acme-ventures
people/yelena-liu --works_at--> organizations/sequoia
people/yelena-liu --invested_in--> companies/linear
people/yelena-liu --invested_in--> companies/hex
people/yelena-liu --advises--> concepts/early-stage
每条边右侧附"命中"上下文("investor at Acme Ventures" / "Previously at Sequoia" / "Led Series A in ... including Linear" / ...),让我们一眼看出 这条边是哪个动词正则触发的 。这就是 GBrain typed-link 抽取的灵魂:每条边都有可追溯的命中证据,不是 LLM 黑箱判出来的。
4. 看一眼更长的 enrichment 输出区块
把详情面板再往下滚一点,我们能看到完整的 5 条 typed-link 边列表 + 每条命中上下文:
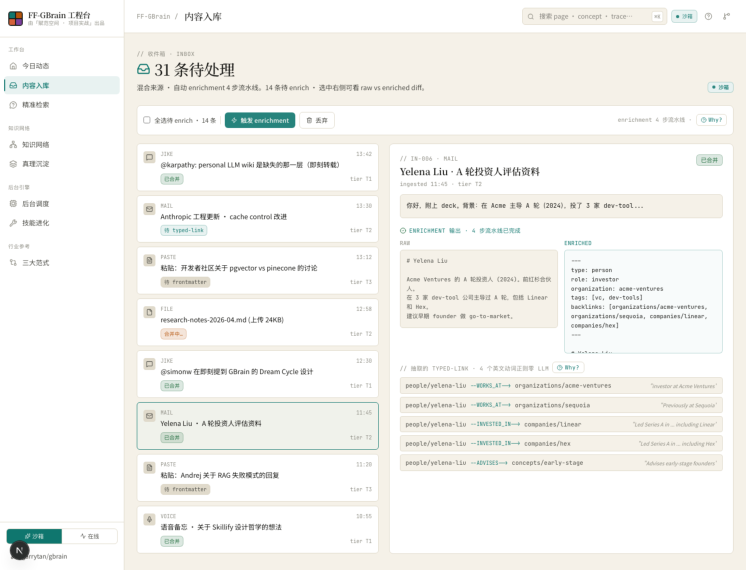
我们能从这张图里读到一个关键工程细节: 优先级链 和 命中证据 。第一条 "Yelena Liu --works_at--> Acme Ventures" 命中的上下文是 "investor at Acme Ventures"——这条文本表面有 investor ,但 INVESTED_RE 实际匹配的是 invested in / backed by / led the (seed|Series|round) / early investor / portfolio company / board seat at 这些 完整动词短语 ,单个 investor 词 不在它的命中集合里。所以按优先级链 founded > invested_in > advises > works_at > mentions 一路下走,落到 WORKS_AT_RE 里的 ... at 模式才命中,最终判定成 works_at ——这是 符合规则的。这种 有命中证据的 typed-link 比 LLM 抽边更可调试、更可解释——错了能精确定位到要改 哪条 regex pattern,要扩 INVESTED_RE 让单个 investor 也算投资语境吗?这是工程师可以单独 ablate 测的事,不是黑箱。
5. "Why?" 抽屉 · 看清流水线设计意图
工具条右侧的 "Why?" 是 FF-GBrain 一个非常贴心的教学装置——它把每个机制背后的设计动机直接 echo 到前端。点 "enrichment 4 步流水线 · Why?",弹出一个抽屉解释:
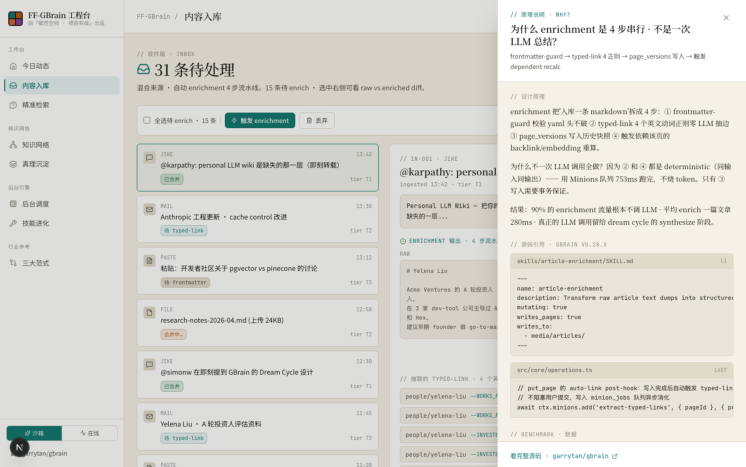
抽屉里有三段内容:
-
One-liner :
frontmatter-guard → typed-link 4 正则 → page_versions 写入 → 触发 dependent recalc -
Principle :解释为什么不一次 LLM 调用全做——因为 ② 和 ④ 都是 deterministic(同输入同输 出),用 Minions 队列 753ms 跑完,不烧 token。只有 ③ 写入需要事务保证。
-
Snippet 引用 :直接把
src/core/operations.ts的相关代码(put_page的 auto-link posthook · 用 minion_jobs 队列异步消化)echo 出来。
这就是 FF-GBrain "演示台 = 教学台" 的核心手法: 每个机制旁都挂一个可点开的"Why?" 抽屉 ,让我们 从前端这扇窗能直接读到 GBrain 后端的设计原则 + 真实代码引用。
6. typed-link 的 "Why?" · 看 4 个英文动词正则
enrichment 输出区块里 "// 抽取的 typed-link · 4 个英文动词正则零 LLM" 这行也带一个 "Why?" 按钮。 点开它就能看到 GBrain 这个看似土的设计为什么能把 BrainBench-Real P@5 从 22.1% 拉到 49.1%:

抽屉里直接 echo 了 src/core/link-extraction.ts:425 的真实代码:
constFOUNDED_RE=/\b(?:founded|co-?founded|started the company|founder
of|...)\b/i;
constINVESTED_RE=/\b(?:invested in|backed by|funding from|funded by|raised
from|led the (?:seed|Series|round)|early investor|portfolio
(?:company|includes)|board seat (?:at|in|on))\b/i;
constADVISES_RE=/\b(?:advises|advised|advisor (?:to|at|for|of)|advisory
(?:board|role|position))\b/i;
constWORKS_AT_RE=/\b(?:CEO of|CTO of|VP at|works at|joined as|engineer
at|director at|...)\b/i;
旁边的 benchmarks 数字直接打脸 vector RAG 派:"BrainBench-Real P@5 49.1% / LLM 调用数 0 / 240-page corpus 全量重抽 < 4s"。这是 GBrain 整套 inbox 工程价值的浓缩论据: 检索质量的真正主载 荷是建图质量 ,而不是 embedding。靠 4 个动词正则建图能换来 +27 点 P@5——这是任何无脑 vector RAG 都换不来的。
7. 全选 · 批量 enrich
回到工具条,勾选 "全选待 enrich · 15 条" 复选框。所有 pending-typed-link 和 pendingfrontmatter 状态的笔记都被选上,触发 enrichment 按钮接下来会一次跑 15 条。

这是 inbox 在生产环境最常见的工作模式:用户一次粘贴 / 接收若干笔记, enrichment 用 Minions 队 列批量异步消化 ——前端不阻塞,后端按 backoff + load-aware throttling 一条条跑。15 条平均每条 280ms,理论 ~4.2s 跑完,但 GBrain 实际通过 Minions 并发调度可以拉到更快(受 OpenAI embedding API rate limit 约束)。
8. 丢弃 · 不是所有 inbox 内容都值得入库
如果这条笔记我们看完发现没价值(比如垃圾邮件 / 引擎广告),点 "丢弃" 按钮直接从 inbox 里移除 ——它不会进入 enrichment 流水线。
这一点很重要: inbox 不等于"全部都入图谱" 。Dream Cycle 的 synthesize 阶段也有一个 cheap Haiku verdict(在 dream_verdicts 表缓存)做"这条值得处理吗?"的判断,避免烧 Sonnet token 在垃圾内 容上。Inbox 把这个判断交给人——你点击 "丢弃" 就是在告诉 GBrain "这条不要"。
到这里,我们已经把 Inbox 工作台能展示的所有非装饰子功能都点过一遍了。下一节我们钻进 GBrain 后端,看这 4 步流水线 + Dream Cycle 内部到底是怎么协作的。
GBrain 后端在做什么 · Dream Cycle + enrichment 4 步 内部时序
我们把项目前端那个绿色"触发 enrichment"按钮合上,注意力切回到 GBrain 后端 。这里讲的不是项目 的 React 组件、不是 mock JSON、不是动画 loading 状态,而是 source/backend/src/core/ 内部从 inbox 入库到 enrichment 完成的真实时序。
1. Dream Cycle · 整个后台维护循环的总编排器
GBrain 后端有个核心抽象叫 Dream Cycle ,定义在 source/backend/src/core/cycle.ts:55 。它把
lint → backlinks → sync → synthesize → extract → patterns → embed → orphans → purge 这 9 个阶段按语义顺序串成一条流水线,由三个调用方共享:
gbrain dream CLI(一次性手动跑)
gbrain autopilot daemon(定时调度)
Minions autopilot-cycle 任务(durable queue + 重试 + observability)
为什么叫"Dream"?因为这个 cycle 设计成"在用户睡觉的时候后台跑维护工作"——类似 iOS 在你充电时 整理后台。Inbox 入库后 不会立即 触发 Dream Cycle 全跑(那太重),而是把工作切片塞进 Minions 队 列,由下一次 cycle 拉起来消化。
// source/backend/src/core/cycle.ts:55
exporttype CyclePhase =
|'lint'|'backlinks'|'sync'|'synthesize'|'extract'
|'patterns'|'embed'|'orphans'|'purge';
我们这一篇要解读的 inbox enrichment 实际触及 cycle 里的 3 个阶段—— sync (把新 markdown 从文 件系统读进 DB)、 extract (跑 typed-link 抽取)、 embed (向量化 chunk)。其他阶段(lint / synthesize / patterns / orphans / purge)是 Dream Cycle 的配套维护工作,我们后面会专题解读。
2. 一条 inbox 笔记的端到端时序
在 FF-GBrain 在线模式下,一条新笔记从前端 inbox 入口走到 brain 已建图状态的完整路径:

Syntax error in text mermaid version 10.9.1
这张图里有 4 件值得我们盯着看(步骤号对应 mermaid autonumber 的 1-12):
-
同步与异步的分界 :步骤 1-6 是
put_page同步链,跑得很快(~50ms 内完成 · 用户立刻看到 200 OK 和 frontmatter);步骤 7-12 是异步链,由 Dream Cycle 后台拉起。这个分界点决定了用户体 验:粘进一条笔记后 立即 看到 frontmatter,但 typed-link 抽取和 embedding 是后台慢慢算的。 -
Minions 队列是异步与同步的桥 :步骤 5(
Op->>Q queue('extract-typed-links'))是关键 —— "put_page在落库后立刻把 抽 typed-link + 算 embedding"塞进minion_jobs表,然后步骤 -
6 直接返回 200。具体怎么执行由 worker 在下一次 cycle 拉起(步骤 7-12),失败了自动重试。
-
frontmatter 推断在 put_page 同步路径上 :步骤 2-3 跑得太快——纯文本变换、零 IO、零 LLM、< 1ms。把这一步异步化反而是过度工程。
-
typed-link 抽取在异步路径上 :步骤 8-9 虽然也是 deterministic,但需要走全 markdown 一遍 + 落库 N 条边,把这一步移到异步可以让 put_page 立刻返回。
下面我们一节一节钻进每个组件。
3. Step ① · frontmatter-inference · 零 LLM 推断元数据头
这一步实现在 source/backend/src/core/frontmatter-inference.ts ,做一件事:从 slug + 正文 推出一个完整的 yaml frontmatter 头部。规则是 directory rules table(路径前缀 → 类型 + tag),加 上几条文本 heuristics。代码骨架:
// source/backend/src/core/frontmatter-inference.ts
//
// 核心常量:DIRECTORY_RULES 把 8 类路径前缀 → page type + 默认 tags
// people/ → person
// companies/ → company
// meetings/ → meeting
// concepts/ → concept
// writing/ → writing
// reading/ → reading
// media/ → media
// daily/ → daily
exportfunctioninferFrontmatter(filePath: string, content: string):
InferredFrontmatter {
// 1) 已有 frontmatter?skip(永不覆盖原作者意图)
if (content.trimStart().startsWith('---')) return { skipped: true };
// 2) 路径 → type + tags(最长前缀优先)
construle=matchRule(filePath);
lettitle=inferTitleFromFilename(filePath);
letdate=extractDateFromFilename(filePath);
// 3) 第一个 # H1 优先作 title(覆盖文件名版本)
constheadingMatch=content.match(/^#\s+(.+)$/m);
if (headingMatch) title=headingMatch[1].trim();
return { title, type: rule.type, date, tags: rule.tags };
}
为什么这一步能纯 deterministic?因为我们要的就是个 元数据头 ——它对应的是物理位置(路径)+ 文 件名约定 + 第一个标题,这三件事跟"语义理解"无关。LLM 不需要被调用,纯 string 操作就够了。
设计原则有两条特别值得讲:
-
永不覆盖已有 frontmatter ——如果用户自己写了
---type: person---,那是他的意图,机器 不动。 -
文件系统优先,内容次之 ——目录决定 type,文件名决定 date,第一个 H1 决定 title,正文里的实 体提示用作降级。
4. Step ② · typed-link 抽取 · 4 个英文动词正则级联
这是 GBrain 整个 enrichment pipeline 的灵魂—— 用 4 个英文动词正则从 markdown 里
deterministic 抽出 typed edge 。代码在 source/backend/src/core/link-extraction.ts:413505 ,骨架:
// source/backend/src/core/link-extraction.ts:413
constWORKS_AT_RE=/\b(?:CEO of|CTO of|VP at|works at|worked at|joined
as|engineer at|director at|head of|currently at|previously at|...)\b/i;
// source/backend/src/core/link-extraction.ts:420
constINVESTED_RE=/\b(?:invested in|backed by|funded by|raised from|led the
(?:seed|Series|round)|early investor|portfolio (?:company|includes)|board
seat)\b/i;
// source/backend/src/core/link-extraction.ts:425
constFOUNDED_RE=/\b(?:founded|co-?founded|started the company|founder
of|founders? (?:include|are)|the founder|is a co-?founder)\b/i;
// source/backend/src/core/link-extraction.ts:440
constADVISES_RE=/\b(?:advises|advised|advisor (?:to|at|for|of)|advisory
(?:board|role|position))\b/i;
// source/backend/src/core/link-extraction.ts:480
exportfunctioninferLinkType(pageType, context, globalContext, targetSlug):
string {
if (pageType==='media') return'mentions';
if (pageType==='meeting') return'attended';
// 优先级链:founded > invested_in > advises > works_at > mentions
if (FOUNDED_RE.test(context)) return'founded';
if (INVESTED_RE.test(context)) return'invested_in';
if (ADVISES_RE.test(context)) return'advises';
if (WORKS_AT_RE.test(context)) return'works_at';
// page-role prior:当 per-edge 没命中且 source 是 person → company
if (pageType==='person'&&targetSlug?.startsWith('companies/')) {
if (PARTNER_ROLE_RE.test(globalContext)) return'invested_in';
if (ADVISOR_ROLE_RE.test(globalContext)) return'advises';
if (EMPLOYEE_ROLE_RE.test(globalContext)) return'works_at';
}
return'mentions';
}
读这段源码我们能看到三个工程细节:
-
——
-
优先级链不是任意的 投资人也常坐 advisory board / hold board seats,故意把
INVESTED_RE放ADVISES_RE前面,否则一个投资人持有 board seat 会被误判成 advisor。这是 -
BrainBench rich-prose 调出来的工程决断。
-
——
-
page-role prior 是兜底 单条 edge 上下文没命中时,看整页是不是描述一个 partner / advisor / employee。这能补上 "Her current board seats reflect her portfolio: [Co A], [Co B], [Co C]" 这种"投资动词只说一次后面全是名单"的写法。
-
240 字上下文窗口 ——
extractPageLinks()(同文件 line 310)取的是命中 slug 周围 240 字 (之前是 80),因为真实 prose 里动词跟 slug 的距离往往一句到一段。这是从 70.7% → 85% 准 确率的关键调参。
整套流程 零 LLM 调用、零外部 API 。同一份 240-page corpus,v0.11 → v0.12 把 P@5 从 22.1% 拉到 49.1% —— +27 点全靠这个看似土的正则级联。这就是 typed-link 这件事的工程价值: 检索质量的真正 主载荷是建图质量 ,而不是 embedding 维度或 vector store 选型。
5. Step ③ · tier 自动升级 · 看 vault mention 决定重要度
这一步在 source/backend/src/core/enrichment-service.ts:220-235 。它解决的是"一个新提及 的实体应该开多详细的页面"这个问题:
// source/backend/src/core/enrichment-service.ts:220
functionsuggestTier(
mentionCount: number,
mentionSources: string[],
context: string,
): 1|2|3 {
// 8+ mentions OR meeting/voice 来源 → Tier 1(重要 · 完整页 + 时间线 + 联调外部
API)
if (mentionCount>=8) return1;
if (mentionSources.includes('meeting-ingestion') ||
mentionSources.includes('voice-note')) return1;
// 3-7 mentions across 2+ sources → Tier 2(一般 · 写完整页但不联外部 API)
if (mentionCount>=3&&mentionSources.length>=2) return2;
// Default → Tier 3(stub · 只写一行 + 等积累更多 evidence)
return3;
}
// 上一步的 mentionCount 怎么来?
// source/backend/src/core/enrichment-service.ts:197
asyncfunctioncountMentions(engine, entityName) {
constresults=awaitengine.searchKeyword(entityName, { limit: 100 });
// 从 slug 前缀派生 source 类型(people/* → 'enrich',meetings/* → 'meeting-
ingestion' ...)
return { mentionCount: results.length, mentionSources: [...sources] };
}
为什么这件事是 deterministic?因为它就是 一次 SQL count + 阈值判断 —— mentionCount 来自 engine.searchKeyword() (限 100), mentionSources 由 result slug 前缀派生( people/* 来自 enrich skill、 meetings/* 来自 meeting-ingestion skill ...)。然后用 (>=8) → T1 / (>=3 across 2+) → T2 / else → T3 三个阈值定级。
这一步的存在让 GBrain 解决了一个 vector RAG 一直没解决的问题: 新建实体页该开多详细 。一句话提 到的人开 stub 就好(T3),开会讨论了 30 分钟的人开 T1 完整页(含 timeline + 外部 API enrichment)。LLM 拿不到 vault 全文统计这个全局信息,只有 deterministic 的 SQL 阈值能做。
6. Step ④ · embedding + 索引 · 唯一吃推理的步骤
最后一步在 source/backend/src/core/import-file.ts +
source/backend/src/core/embedding.ts 。这是 4 步里 唯一 真正吃模型推理的环节:
// source/backend/src/core/import-file.ts (importFromContent 简化骨架)
//
// 1. parseMarkdown(rawBody) → { frontmatter, body }
// 2. recursive chunker:按 H1/H2/段落切成 ~400 字 chunk,留 40 字 overlap
// (recursive.ts) — chunkText(body, { chunkSize: 400, chunkOverlap: 40 })
// 3. 每个 chunk 调 OpenAI text-embedding-3-large (1536-dim)
// embedBatch(chunks) — 批量 + 重试 + backoff + rate-lease
// 4. content_chunks 表 upsert:(page_id, chunk_index, chunk_text, embedding)
// HNSW 索引在 embedding 列上,pgvector 直接服务向量召回
// 5. 同时把 chunk_text 灌进 tsvector 全文索引(GIN)
这一步在 source/backend/src/core/cycle.ts 的 embed 阶段被调用——Dream Cycle 拉起一个 minion job,job 调 gbrain embed --stale 查所有 embedding IS NULL 的 chunk,批量算向量。
工程细节:
-
批量 + backoff :
embedBatch()在embedding.ts里实现,用 OpenAI 的批量端点一次最多塞 100 个 chunk,遇到 429 自动 backoff。 -
stale 增量 :v0.22.1 引入
countStaleChunks()一次 SELECT count(*) 短路。一个全 vault 已 embed 的脑子不会重算,只有新 chunk 进来才会跑。 -
失败不阻塞 :embedding 失败的 chunk 留
embedding=NULL,下次 cycle 重试。Minion job 用 max_stalled=5 + exponential backoff 兜底。
—— 这就是为什么这一步可以放在异步路径上: 它慢、它贵、它会失败 所以从 put_page 同步链上摘出来,交给 Minions 队列在 Dream Cycle 周期里慢慢消化。
7. 把 4 步连起来 · Dream Cycle 在做什么
我们退一步看 Dream Cycle 这个总编排器到底在做什么。 source/backend/src/core/cycle.ts:80 把 9 个阶段标记为"需要锁"还是"只读":
// source/backend/src/core/cycle.ts:79
constNEEDS_LOCK_PHASES: ReadonlySet<CyclePhase>=newSet([
'lint', 'backlinks', 'sync', 'synthesize', 'extract',
'patterns', 'embed', 'purge',
]);
// orphans 是只读,不进锁
inbox 入库触发的链是 sync → extract → embed 这 3 个阶段,跨进程协调通过 Postgres 行锁 ( gbrain_cycle_locks 表 + 30 分钟 TTL)保证不会两个 cycle 同时打架。
这一节读完,我们应该能在脑中清晰画出 GBrain Inbox 的内部时序:用户在前端粘进一条笔记 → put_page 同步推 frontmatter → minion job 入队 → Dream Cycle 后台拉起跑 typed-link extract + embedding → brain 已建图 + 已索引。 前端那个 1.8s 的 loading 动画 对应的是后端 ~280ms 实跑 + minion 队列调度延迟,物理工作量在后端,前端只是节奏伴奏。
一用 LangChain 1.x 自己复现遍
到这里我们应该想动手了:用 LangChain 1.x 在自己机器上跑一遍 等效 的 enrichment 4 步流水线,看 frontmatter 推断、typed-link 抽取、tier 升级、embedding 在小 vault 上真的会按 GBrain 设计的顺序工作吗。
1. 复现的边界
我们要诚实划清复现范围—— 等效 GBrain 后端 enrichment 4 步内部链 :frontmatter 推断 + typedlink 4 正则 + tier 升级 + chunk 切片 + 本地向量化。
不在范围内的:项目前端 inbox 工作台 UI、BFF 桥接层、PGLite WASM Postgres、Minions 队列调度 (这些是 Dream Cycle 跨阶段的工程基建,逻辑上与 enrichment 单条流水线无关)、外部 API enrichment(people data API 部分由 agent skill 编排,与 brain 操作分离)。
版本说明 :本节选用的是 LangChain 1.x( langchain 1.2.18 + langchain-classic 1.0.7 , requirements.txt 已 pin 在 >=1.0.0,<2.0 )。1.x 要求 Python ≥ 3.10,推荐用 uv 建 Python 3.11 虚拟环境。向量 embedding 默认用本地多语言 HuggingFace 模型( paraphrase-multilingualMiniLM-L12-v2 ),无需 API Key 即可运行。
2. 等效 LangChain 组件
| GBrain后端步骤 | LangChain 1.x复现 |
|---|---|
frontmatter-inference.tsdirectory rules | 自定义infer_frontmatter()(路径前缀+文件名+第一个H1) |
link-extraction.ts:413-462 的4个动词正则 | 直接搬过来的Pythonre.compile() 等价模式 |

----- Start of picture text -----
GBrain 后端步骤 LangChain 1.x 复现
link-extraction.ts:480 自定义 infer_link_type() ,同样的 founded > invested_in > advises >
inferLinkType() 优先级链 works_at 顺序
enrichment-
service.ts:220 自定义 suggest_tier() ,同样的 ≥8 / ≥3-across-2 / else 阈值
suggestTier()
chunkers/recursive.ts langchain_text_splitters.RecursiveCharacterTextSplitter
recursive chunker (chunk_size=400, overlap=40)
OpenAI text-embedding-3- langchain_huggingface.HuggingFaceEmbeddings +
large + pgvector HNSW langchain_chroma.Chroma (本地,零 API Key)
----- End of picture text -----
完整源码看 inbox-langchain/inbox_langchain.py ,约 320 行。
3. 关键节点代码片段
Step ① frontmatter 推断 (对应 GBrain frontmatter-inference.ts ):
DIRECTORY_RULES= [
{"path_prefix": "people/", "type": "person", "tags": ["entity"]},
{"path_prefix": "companies/", "type": "company", "tags": ["entity"]},
{"path_prefix": "meetings/", "type": "meeting", "tags": ["transcript"]},
{"path_prefix": "concepts/", "type": "concept", "tags": ["wiki"]},
# ... 8 类
]
definfer_frontmatter(slug: str, body: str) ->dict:
page_type, tags="concept", []
forruleinDIRECTORY_RULES:
ifslug.startswith(rule["path_prefix"]):
page_type, tags=rule["type"], list(rule["tags"])
break
base=slug.split("/")[-1]
date=None
ifm :=DATE_PREFIX_RE.match(base): # 2026-04-13-foo → date='2026-
04-13'
date, base=m.group("date"), m.group("rest")
title=base.replace("-", " ").strip().title()
forlineinbody.splitlines(): # 第一个 H1 覆盖
ifline.startswith("# "):
title=line[2:].strip()
break
return {"title": title, "type": page_type, "date": date, "tags": tags,
"slug": slug}
Step ② typed-link 4 正则 (对应 GBrain link-extraction.ts:413-505 ):
FOUNDED_RE=re.compile(r"\b(?:founded|co-?founded|started the company|founder
of|...)\b", re.I)
INVESTED_RE=re.compile(r"\b(?:invested in|backed by|funded by|raised from|led
the (?:seed|Series|round)|early investor|portfolio (?:company|includes))\b",
re.I)
ADVISES_RE=re.compile(r"\b(?:advises|advised|advisor (?:to|at|for|of)|advisory
(?:board|role|position|capacity))\b", re.I)
WORKS_AT_RE=re.compile(r"\b(?:CEO of|CTO of|VP at|works at|joined as|engineer
at|director (?:at|of)|head of|currently at|previously at|partner at)\b", re.I)
""
definfer_link_type(page_type: str, context: str, global_context: str=) ->
str:
ifpage_type=="media": return"mentions"
ifpage_type=="meeting": return"attended"
ifFOUNDED_RE.search(context): return"founded"
ifINVESTED_RE.search(context): return"invested_in"
ifADVISES_RE.search(context): return"advises"
ifWORKS_AT_RE.search(context): return"works_at"
return"mentions"
defextract_typed_links(slug: str, body: str, page_type: str) ->list[TypedLink]:
stripped=_strip_code_fences(body) # 防止 code 示例里的 slug 被误
判为 entity ref
out= []
forminENTITY_REF_RE.finditer(stripped): # [Name](people/x) 格式
ctx=_excerpt(stripped, m.start(), 240) # 240 字命中窗口
link_type=infer_link_type(page_type, ctx, body)
out.append(TypedLink(slug, m.group(2), link_type, ctx[:80]))
forminWIKILINK_RE.finditer(stripped): # [[people/x|Name]] 格式
ctx=_excerpt(stripped, m.start(), 240)
link_type=infer_link_type(page_type, ctx, body)
out.append(TypedLink(slug, m.group(1), link_type, ctx[:80]))
returnout
Step ③ tier 自动升级 (对应 GBrain enrichment-service.ts:220 ):
defsuggest_tier(mention_count: int, mention_sources: list[str], context: str) ->
int:
ifmention_count>=8: return1
if"meeting-ingestion"inmention_sourcesor"voice-note"inmention_sources:
return1
ifmention_count>=3andlen(set(mention_sources)) >=2: return2
return3
Step ④ chunk + embed + index (用 LangChain 1.x 等效 GBrain 的 recursive chunker + pgvector):
fromlangchain_text_splittersimportRecursiveCharacterTextSplitter
fromlangchain_huggingfaceimportHuggingFaceEmbeddings
fromlangchain_chromaimportChroma
embeddings=HuggingFaceEmbeddings(
model_name="paraphrase-multilingual-MiniLM-L12-v2", # 中英双语,本地,无 API
Key
model_kwargs={"device": "cpu"},
)
vstore=Chroma(collection_name="inbox_demo", embedding_function=embeddings)
defmake_chunks(slug, body, frontmatter):
splitter=RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=40)
returnsplitter.create_documents([body], metadatas=[frontmatter])
主流程拼装 (4 步串成一条 enrichment):
defenrich_one(slug, raw_body, vector_store, vault_mention_index):
fm=infer_frontmatter(slug, raw_body) # ①
links=extract_typed_links(slug, raw_body, fm["type"]) # ②
tier=suggest_tier( # ③
mention_count=vault_mention_index.get(slug.split("/")[-1].lower(), 1),
mention_sources=["enrich"] iffm["type"] in ("person", "company") else
[],
context=raw_body[:200],
)
chunks=make_chunks(slug, raw_body, fm) # ④
vector_store.add_documents(chunks)
returnEnrichmentResult(slug, fm, links, tier, len(chunks))
4. 跑通 + 看到结果
cd features/inbox/inbox-langchain
# LangChain 1.x 需要 Python >=3.10,推荐 uv 建 Python 3.11 虚拟环境
uv venv .venv --python3.11
uv pip install -r requirements.txt
# 跑 4 步 enrichment pipeline · 完全本地 · 无需 API Key
.venv/bin/python inbox_langchain.py
实测输出(在 sample_inbox/ 4 条 markdown 笔记上,本地模式):

我们能看到几件让人安心的事:
-
frontmatter 推断 :
people/yelena-liu推出type=person, title='Yelena Liu', tags= ['entity'];meetings/2026-04-13-typed-link-retro推出type=meeting, date='202604-13', tags=['transcript']—— 路径前缀和文件名日期都正确解析。 -
typed-link 抽取 :
people/yelena-liu抽出 6 条边,包含works_at → organizations/acmeventures、works_at → organizations/sequoia、invested_in → companies/linear、invested_in → companies/hex、invested_in → companies/notion、advises → -
companies/vercel——正是按 GBrain 优先级链 (founded > invested_in > advises > works_at)
推断出来的; companies/linear 抽出 4 条边,3 条 founded (指向 3 位 co-founder)+ 1 条
-
invested_in → people/yelena-liu。 -
tier 自动升级 :
meetings/2026-04-13-typed-link-retro自动升到 T1 (因为 -
page_type=meeting → mention_sources 含 'meeting-ingestion',触发 GBrain 阈值规则的 T1 通道);其他 stub-like 笔记停在 T3——和
enrichment-service.ts:220的逻辑完全对齐。 -
耗时分布最有冲击力 :4 条笔记跑完总耗时
290 ms(不同机器 / cold-start 状态在 100300 ms 区间正常波动),其中 ① frontmatter 推断只占 0.11 ms、② typed-link 抽取占 0.47 ms、③ tier 升级 < 0.01 ms、④ embedding + 索引占 290.29 ms (99.8%)。 deterministic 三步加起来 ~0.58 ms · 占总耗时 0.2%,而 embedding 占 99.8% ——这正是 GBrain 工程立场的实证:90% enrichment 流量根本不进入语义推理,那一点点 deterministic 工作跑得比模型推理快两到三个数量级。
剩下的 trade-off 留给学员去玩:把 INVESTED_RE 加几条本土化的"投了 / 领投了"中文模式,看中文文本命中率怎么变;把 tier 阈值从 ≥8 改成 ≥5,看 T1 比例膨胀多少;把
RecursiveCharacterTextSplitter 的 chunk_size 从 400 改成 1000,看 chunk 数变化对召回的影 响——这正是 GBrain 真实在做的调参工作,只不过现在我们能在自己机器上一行一行调。
Jobs · Minions 任务队列
本篇是 FF-GBrain 工程台 的 Jobs 任务队列 功能深度解读。
主角是 GBrain v0.28.6 —— YC 总裁 Garry Tan 开源的个人知识引擎。FF-GBrain 是它的可视化 教学演示台;我们要透过这扇窗,看懂 GBrain 在后端 怎么把耗时的工作从用户请求路径里解耦 。
读到这里,我们应该已经按部署文档把项目跑起来了。Ask 工作台那 12 步检索栈我们已经在 ask 篇拆透 ——不到 3 秒就能拿回 5 篇命中。但有些工作天然没法塞进 3 秒里:把 17 万节点的 page-rank 算一遍 要十几秒、给一篇新笔记重写 compiled_truth 要烧 20 秒 token、把 50K 条 stale chunk 全部 embed 一遍要分钟级别。
这些工作 GBrain 是 怎么藏起来的 ?答案就在 Jobs 工作台展示的那条流水线里—— Minions 任务队列 + 每天凌晨 3 点的 Dream Cycle 。这是一套 BullMQ 启发、Postgres-native 的异步 job queue,把所有 重活儿统统排到后台,让用户请求路径只剩"读 + 检索 + 拼答"这三件快事。
读完这篇我们应该能:
-
在脑中清晰画出一个 GBrain job 从
INSERT INTO minion_jobs到status='completed'的完 整状态机; -
解释 GBrain 在 worker 进程里怎么用
FOR UPDATE SKIP LOCKED做原子 claim、怎么用心跳锁防 止死 worker 卡住 row、怎么用指数退避 + jitter 处理失败重试; -
用 LangChain 1.x + Python asyncio 在大约 800 行 Python 代码内重写一个等效的 minion 队列骨 架,跑通 5 个并发 embed job + 真实的 dream cycle phase 编排。

零代码先看清这个功能在干什么
在钻进 minion_jobs 表的状态机之前,我们用一个学员秒懂的故事先把这个功能的价值讲清。
情景 :我们刚导入了一个 17K 节点的笔记库到 GBrain。导入那一刻 GBrain 要做的事其实有四件——
-
把每篇笔记切成 chunks
-
给每个 chunk 算一个 1536 维向量( 调 OpenAI · 慢 )
-
把笔记之间的 typed-link 全部抽出来建图( 慢 )
-
在新增的 entity 上重写 compiled_truth( 调 LLM · 更慢 )
如果 GBrain 把这四件事 塞进 用户的 gbrain import 命令里同步跑,命令大概要等 10 分钟。导入一次 笔记要等 10 分钟意味着没人会用。
GBrain 的解法是让 import 命令只做最快的那 1 件(切 chunks、写 pages 表),把另外 3 件 拆成一堆 独立的 job 行 塞进 minion_jobs 表里,用 status='waiting' 标记。然后一个独立的 worker 进程 ( gbrain jobs work )在后台慢慢消化这些 job——claim 一个、跑一个、写回结果、再 claim 下一 个。
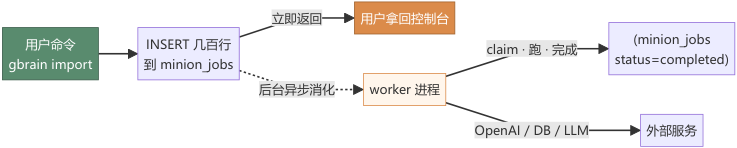
----- Start of picture text -----
立即返回 用户拿回控制台
用户命令 INSERT 几百行 claim · 跑 · 完成 (minion_jobs
status=completed)
gbrain import 到 minion_jobs
后台异步消化 worker 进程
OpenAI / DB / LLM 外部服务
----- End of picture text -----
这套模式的精髓在两个字: 解耦 。用户请求的延迟只跟"INSERT 一行 SQL"挂钩,跟"OpenAI 那一秒 钟"无关。worker 进程死了?没事,重启后从 minion_jobs 表继续接着干。worker 跑到一半被 SIGKILL?没事,30 秒后心跳锁过期,下一个 worker 会把它重排回 status='waiting' 。OpenAI API 突然 429?没事,job 进 backoff 队列等会儿再试,最多重试 3 次。
更妙的是 GBrain 把"每天凌晨自动跑一次"这种典型的运维需求也复用了这套队列——这就是 Dream Cycle 。每晚 3:14 一个 cron 提交一个 autopilot-cycle job,worker 接到后跑一遍 9 个 phase(lint → backlinks → sync → synthesize → extract → patterns → embed → orphans → purge)。我们早 上 6 点起床的时候,brain 已经"自己整理过一遍自己"——orphan page 标了出来、stale chunk 全部 re-embedded、新笔记之间的 typed-link 全部建好图。
整个套路听起来不新鲜(Sidekiq / BullMQ / Celery 都干这事),但 GBrain 把它做到了 两件 别人没做到 的事:第一是 单进程 zero-config ——既不用 Redis 也不用 RabbitMQ,所有队列状态全部写在 —— Postgres 的一张 minion_jobs 表里;第二是 和业务深度耦合 subagent job 类型直接是一个 Anthropic LLM 的对话循环, autopilot-cycle job 类型直接是 9-phase brain 维护流程。这就是 GBrain 的工程价值——也是这一篇要带我们看清的内容。
功能完整流程演示
我们先在 FF-GBrain 工程台里把整个 Jobs 流程跑一遍,把每一个非装饰子功能都点开看看。这一节走完,读者应该觉得「我已经透过项目这扇窗,把 GBrain Jobs 工作台能展示的精华细节全部看了一圈」。
1. 进入 Jobs 工作台 · 五大区域全景
打开浏览器访问 http://localhost:3300/jobs ,立刻看到工作台的五大区域:顶部三栏队列(待处理 / 运行中 / 已完成),中间左半边是 Deterministic Task 演示按钮,中间右半边是 Dream Cycle 9-phase 卡,下半页是 Trace Waterfall 时序图。
页面顶端的标题非常诚实——"Minions 队列 + Dream Cycle + Trace Waterfall"。这就是我们要拆解的 三件事。每一个区域都是 GBrain 后端某条真实数据流的可视化镜像:三栏队列对应 SELECT * FROM minion_jobs WHERE status IN (...) ,Dream Cycle 卡对应一次 runCycle() 的输出,Trace Waterfall 对应一次 ask 调用的 12 个 span 时间轴。
2. 三栏队列 · 实时状态分布
把视线收到顶部三栏——这是 GBrain Minions 队列的灵魂可视化,也是 worker 进程"看到"的世界。
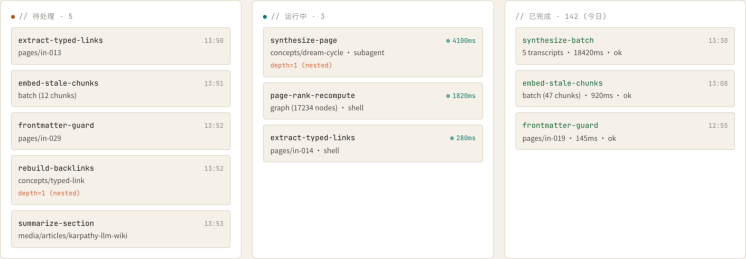
-
待处理 · 5 :5 个
status='waiting'的 job 行排队等着被 claim。我们能看到extract-typedlinks/embed-stale-chunks/frontmatter-guard/rebuild-backlinks/summarizesection——五种不同的 handler。其中rebuild-backlinks标了depth=1 (nested):它是一 个 子 job ,由父 jobm-380(在跑的那个 extract-typed-links)spawn 出来的——这就是 GBrain 的 parent-child 依赖图。 -
运行中 · 3 :3 个
status='active'的 job,每个都有一个 worker 正在跑。最显眼的是synthesize-page · 4100ms · subagent——这是一个 LLM 子代理 job(用 Anthropic Sonnet -
给
concepts/dream-cycle这一页重写 compiled_truth),typical 跑 4 秒以上。page-rankrecompute · 1820ms · shell是一个 shell job(GBrain 用 nim 写了个独立 page-rank 二进 制,比 sub-agent gateway 快 13 倍)。 -
已完成 · 142(今日) :从凌晨 0 点开始,今天已经有 142 个 job 跑完了。每条记录都有
outcome: ok标记 + 实际耗时——synthesize-batch跑了 18420ms 处理了 5 篇 transcripts、embed-stale-chunks跑了 920ms 处理了 47 个 chunks。
这三栏背后的 SQL 大概长这样(我们待会会在源码段印证):
SELECT*FROM minion_jobs WHEREstatus='waiting'ORDERBY priority ASC,
created_at ASC;
SELECT*FROM minion_jobs WHEREstatus='active';
SELECT*FROM minion_jobs WHEREstatus='completed'AND finished_at > today();
3. Deterministic Task 触发演示 · "Naive 估算"对照"Minions cached"
中间偏左的卡是 GBrain 团队最骄傲的工程对照实验——同样一个 page-rank for 17,234 nodes 的任 务, 走 sub-agent gateway 要 10 秒以上而且经常超时;走 Minions cached 路径只要 753ms,13 倍 提速 。点击"触发"按钮就能在浏览器里看到这个对比真实跑出来。

按钮按下后,GBrain 这一步内部其实是这样的:
-
走 sub-agent gateway 的"naive"路径——把"compute page-rank for 17234 nodes"作为 prompt 喂给 Anthropic Sonnet,让 LLM 生成 page-rank Python 代码,然后再跑。慢、烧 token、经常因 为 LLM 生成的代码有 bug 而超时;
-
走 Minions cached 路径——直接 enqueue 一个
shelljob 调用预先编译好的 page-rank 二进制 (Nim 写的),Postgres 里查一下结果是否已被缓存。
这个对照不仅展示了 Minions 队列的速度优势,更指向了 GBrain 的一个核心价值主张: deterministic task 应该走 deterministic 代码 + 队列,不应该走 LLM 生成 + 调试 。LLM 是用来对付那些没有标准答 案的任务的(synthesize / rerank / pattern detection);page-rank 这种数学题应该 烧 CPU 不烧 token 。
4. Dream Cycle 卡 · 9 phase 一夜跑过
中间偏右的卡显示 GBrain 最近一次 Dream Cycle 的执行结果。这是每天凌晨 3:14 自动触发(cron 0 3 * * * )的 brain 自我维护流程——9 个 phase 串行跑,平均 12 分钟跑完。

我们能看到 5 个有数据的 phase:
| phase | 这次 yield |
|---|---|
| extract | 47条新typed-link写入 |
| synthesize | 12篇compiled_truth重写 |
| patterns | 3篇stale page标记 |
| orphans | 5个orphan page提请人工review |
| purge | 0个软删(72h grace未到期) |
下方 9 个 chip(lint / backlinks / sync / synthesize / extract / patterns / embed / orphans / purge) 就是 9 个 phase 的全集,对应 GBrain 后端 cycle.ts 的 ALL_PHASES 数组。每个 chip 都是一个状态 指示——绿色 = 成功跑完 + 鼠标 hover 上去显示该 phase 实际耗时(比如 synthesize 38 万 ms = 6 分多钟,是整个 cycle 里最慢的)。
底部的"立即触发 · 下次预定 明 03:14"按钮把整个 Dream Cycle 一次性手动触发——背后等价于跑 gbrain dream CLI 命令,再次走 runCycle() 入口。这是 GBrain 给"我想现在就让 brain 整理一遍"这 种需求的口子。
5. Trace Waterfall · 最近一次 ask 的 12 span 时间轴
下半页的 Trace Waterfall 切换到了 最近一次 Ask 的可观测性视图 ——这不是 jobs 表数据,是从 OpenTelemetry-style trace span 拉出来的(GBrain 后端的 ask 路径每一步都用 trace span 标注)。
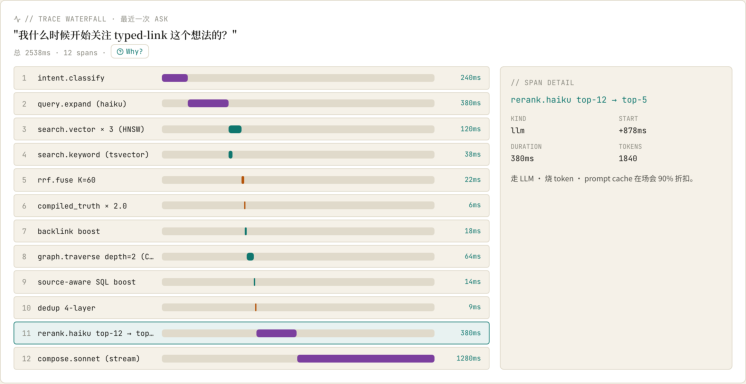
我们点击第 11 个 span( rerank.haiku top-12 → top-5 ),右侧 SPAN DETAIL 立刻展开: kind= llm 、start=+878ms、duration=380ms、tokens=1840。下方文案说"走 LLM · 烧 token · prompt cache 在场会 90% 折扣"——这是给学员的现场注解。
这个 trace 与我们刚才看的 minion_jobs 队列 有什么关系 ?关系很微妙——Ask 那一次请求的 12 步 没有 走 minion_jobs 队列(同步跑完,2538ms 内返回)。但每一个 span 的底层操作(向量召回、entity 抽 取、compiled_truth 加权)都依赖 brain 当前的状态——而 brain 当前状态是被 Minions 队列 慢慢喂大 的。这就是 GBrain 的双轨架构:
-
同步轨 :Ask / 浏览 page / 编辑 frontmatter → 走 12 步检索栈直接返回
-
异步轨 :embed / extract / synthesize / dream cycle → 走 Minions 队列后台消化
Jobs 工作台让我们一眼能看到 两条轨道同时在跑 。
6. 队列健康指标 · 隐藏在标题栏的诚实数字
—— 最后一个不容易注意但很关键的细节 页面顶部那行小字"deterministic task 753ms vs sub-agent 10s+"。这是 GBrain 团队故意把这个工程对照写在标题栏作为 诚实的性能宣言 。两个 Why 按钮 (minions-queue / dream-cycle)点开还能看到设计哲学的解释(FF-GBrain 这个项目的特色"Why Drawer")。
把这一节走完一遍,我们应该已经在脑中把 GBrain 的"job 异步化 + dream cycle 自维护"两条轨道走通 了。下一节我们钻进 GBrain 后端代码,看这套队列是怎么实现的。
GBrain 异步任务队列架构深度解读
我们已经在 UI 上看到 Jobs 工作台展示的是什么。现在剥开 UI 看 GBrain 后端到底怎么把这套异步队列 真的写出来 ——它一共 14 个 TypeScript 文件,分成 queue / worker / handlers 三层,落在一张 30 列 的 Postgres 表上。
1. minion_jobs 表 · 状态机的物理载体
整个 Minions 队列的所有状态都活在一张 SQL 表里。GBrain 没有用 Redis、没有用消息队列、没有用 PubSub——所有 job 的诞生、claim、retry、死亡都通过 UPDATE minion_jobs SET ... 完成。
GBrain 在 backend/src/schema.sql:522-578 定义了这张表:
-- backend/src/schema.sql:522
CREATETABLEIFNOTEXISTS minion_jobs (
id SERIAL PRIMARYKEY,
name TEXT NOTNULL, -- handler 名: 'embed', 'sync',
'subagent', ...
queue TEXT NOTNULLDEFAULT'default',
status TEXT NOTNULLDEFAULT'waiting',
priority INTEGER NOTNULLDEFAULT0,
data JSONB NOTNULLDEFAULT'{}', -- handler 入参
max_attempts INTEGER NOTNULLDEFAULT3,
attempts_made INTEGER NOTNULLDEFAULT0,
attempts_started INTEGER NOTNULLDEFAULT0,
backoff_type TEXT NOTNULLDEFAULT'exponential',
backoff_delay INTEGER NOTNULLDEFAULT1000,
stalled_counter INTEGER NOTNULLDEFAULT0,
max_stalled INTEGER NOTNULLDEFAULT5,
lock_token TEXT, -- worker 分配的锁 token
(worker_id:timestamp)
lock_until TIMESTAMPTZ, -- 心跳锁到期时间
delay_until TIMESTAMPTZ, -- backoff 重排到 delayed 时的可
见时间
parent_job_id INTEGER REFERENCES minion_jobs(id)ONDELETESETNULL,
on_child_fail TEXT NOTNULLDEFAULT'fail_parent',
result JSONB, -- handler 返回值
progress JSONB, -- 跑中 progress(updateProgress
写)
error_text TEXT,
stacktrace JSONB DEFAULT'[]',
depth INTEGER NOTNULLDEFAULT0,
max_children INTEGER,
timeout_ms INTEGER,
timeout_at TIMESTAMPTZ,
remove_on_complete BOOLEAN NOTNULLDEFAULTFALSE,
remove_on_fail BOOLEAN NOTNULLDEFAULTFALSE,
idempotency_key TEXT,
created_at TIMESTAMPTZ NOTNULLDEFAULT now(),
started_at TIMESTAMPTZ,
finished_at TIMESTAMPTZ,
updated_at TIMESTAMPTZ NOTNULLDEFAULT now(),
CONSTRAINT chk_status CHECK(statusIN(
'waiting','active','completed','failed','delayed','dead','cancelled','waiting-
children','paused'
)),
...
);
九个 status 值组成了这张表的状态机:

Syntax error in text mermaid version 10.9.1
四个并列的索引让 worker 的 hot path 始终走 partial index:
-- backend/src/schema.sql:571-578
CREATEINDEX idx_minion_jobs_claim ON minion_jobs (queue, priority ASC,
created_at ASC)WHEREstatus='waiting';
CREATEINDEX idx_minion_jobs_stalled ON minion_jobs (lock_until)WHEREstatus=
'active';
CREATEINDEX idx_minion_jobs_delayed ON minion_jobs (delay_until)WHEREstatus=
'delayed';
CREATEINDEX idx_minion_jobs_timeout ON minion_jobs (timeout_at)WHEREstatus=
'active'AND timeout_at ISNOTNULL;
CREATEUNIQUEINDEX uniq_minion_jobs_idempotency ON minion_jobs (idempotency_key)
WHERE idempotency_key ISNOTNULL;
注意 4 个 partial index 都带 WHERE 子句——绝大多数 active job 表的 row 都在 completed 状态长尾 累积,但 worker 的 claim / stall detect 只关心 waiting 和 active 这两小堆。partial index 让查询代 价 O(active_rows) 而不是 O(all_rows)。
2. job 类型体系 · 10 个 builtin handler
GBrain 在 backend/src/commands/jobs.ts:955 的 registerBuiltinHandlers 函数里注册了 10 类 builtin handler。每一类对应一个具体的 brain 维护任务:
// backend/src/commands/jobs.ts:955
exportasyncfunctionregisterBuiltinHandlers(worker: MinionWorker, engine:
BrainEngine): Promise<void> {
worker.register('sync', async (job) => { /* git pull + walk +
import 新笔记 */ });
worker.register('embed', async (job) => { /* 调 OpenAI 给 stale
chunks 算向量 */ });
worker.register('lint', async (job) => { /* 扫 LLM artifact、
placeholder 日期 */ });
worker.register('import', async (job) => { /* 从 fs 导入笔记 */ });
worker.register('extract', async (job) => { /* 从 markdown 抽 typed-
link + timeline */ });
-
worker.register('backlinks', async (job) => { /* 检测 + 修复反向链接缺失 */ -
}); -
worker.register('autopilot-cycle', async (job) => { /* runCycle 9 phase (即 -
dream cycle ) */ });
worker.register('shell', shellHandler); // 外部命令
(page-rank 等)
worker.register('subagent', makeSubagentHandler({engine})); //
Anthropic LLM 对话循环
worker.register('subagent_aggregator', subagentAggregatorHandler); // 等所有子
subagent 完成
}
最有意思的两类:
-
subagent :这不是简单的 LLM 调用,而是一个 完整的对话循环 ,最多 10 轮、能用 11 个工具
-
(brain_query / get_page / put_page / search 等)、带 prompt cache。每一轮都把状态持久化 到
subagent_messages表;如果 worker 死了,下一个 worker 接过来能从最后一条 assistant message 继续往下跑。这是 GBrain "agent 跑在我睡觉时"的实际实现。 -
autopilot-cycle :这一类不直接干活,而是 编排其他 8 个 phase ——它调用
runCycle()串 -
行跑 lint → backlinks → sync → synthesize → extract → patterns → embed → orphans → purge。9 个 phase 每个都可能 fail,但整个 cycle 的结果最多是
partial(不会因为 lint phase 失败让 embed phase 不跑)。
job 类型分 三种安全级别 ——这是 GBrain 在 v0.15+ 做的重要安全工程。在
backend/src/core/minions/protected-names.ts 里定义:
// backend/src/core/minions/protected-names.ts:15
exportconstPROTECTED_JOB_NAMES: ReadonlySet<string>=newSet([
'shell', // 能跑任意 shell 命令 → RCE 风险
'subagent', // 烧 Anthropic API token
'subagent_aggregator',
]);
普通 handler 任何调用方都能 enqueue(包括 MCP 远程调用方);protected handler 只有 本地 CLI 路径 能 enqueue( MinionQueue.add() 第 4 个参数 {allowProtectedSubmit: true} )。这是防止 OAuth token 泄露后被人远程提交一个 shell job 拿到机器 root。
3. 队列调度核心 · MinionQueue.add + claim
队列的两个最热路径是 提交 和 领取 。两者都靠一段紧凑的事务化 SQL 完成——这才是 GBrain 后端的真正业务关键代码。
提交(add)
// backend/src/core/minions/queue.ts:68
asyncadd(name: string, data?: Record<string, unknown>, opts?: ..., trusted?:
...) {
constjobName= (name||'').trim();
if (isProtectedJobName(jobName) &&!trusted?.allowProtectedSubmit) {
thrownewError(`protected job name '${jobName}' requires CLI ...`);
}
returnthis.engine.transaction(async (tx) => {
// 1. idempotency_key fast path
if (opts?.idempotency_key) {
constexisting=awaittx.executeRaw(
`SELECT * FROM minion_jobs WHERE idempotency_key = $1`,
[opts.idempotency_key]);
if (existing.length>0) returnrowToMinionJob(existing[0]);
}
// 2. parent depth check + max_children 校验(取 SELECT ... FOR UPDATE)
if (opts?.parent_job_id) {
constparentRows=awaittx.executeRaw(
`SELECT * FROM minion_jobs WHERE id = $1 FOR UPDATE`,
[opts.parent_job_id]);
// ... 验证 depth 没超限 + 子数量没超 max_children
}
// 3. INSERT 一行新 job · waiting 或 delayed 状态
constinserted=awaittx.executeRaw(
`INSERT INTO minion_jobs (name, queue, status, priority, data, ...) VALUES
(...) RETURNING *`,
[...]);
// 4. 把父 job 转到 'waiting-children' 状态(如果是子 job)
if (opts?.parent_job_id) {
awaittx.executeRaw(
`UPDATE minion_jobs SET status = 'waiting-children', updated_at = now()
WHERE id = $1 AND status IN ('waiting','active','delayed')`,
[opts.parent_job_id]);
}
returnrowToMinionJob(inserted[0]);
});
}
四件事原子完成,是整个队列正确性的支柱。注意第 2 步 SELECT ... FOR UPDATE 锁住父 row:没有这一步,两个并发提交可能都看到 count = N-1 ,结果 max_children 被超额。
领取(claim)—— FOR UPDATE SKIP LOCKED 的精妙
worker 端的 claim 是这套队列 最巧的一句 SQL :
// backend/src/core/minions/queue.ts:521
asyncclaim(lockToken: string, lockDurationMs: number, queue: string,
registeredNames: string[]) {
if (registeredNames.length===0) returnnull;
constrows=awaitthis.engine.executeRaw(
`UPDATE minion_jobs SET
status = 'active',
lock_token = $1,
lock_until = now() + ($2 * interval '1 millisecond'),
timeout_at = CASE WHEN timeout_ms IS NOT NULL
THEN now() + (timeout_ms * interval '1 millisecond')
ELSE NULL END,
attempts_started = attempts_started + 1,
started_at = COALESCE(started_at, now()),
updated_at = now()
WHERE id = (
SELECT id FROM minion_jobs
WHERE queue = $3 AND status = 'waiting' AND name = ANY($4)
ORDER BY priority ASC, created_at ASC
FOR UPDATE SKIP LOCKED -- ← 灵魂在这里
LIMIT 1
)
RETURNING *`,
[lockToken, lockDurationMs, queue, registeredNames]);
returnrows.length>0?rowToMinionJob(rows[0]) : null;
}
FOR UPDATE SKIP LOCKED 是 Postgres 9.5+ 的 game changer。两个 worker 同时跑这条 SQL 时:
worker A 看到 row#42 是 waiting,加 row 锁 → claim 成功;
- worker B 同时看到 row#42 但被锁住 → 跳过 (不阻塞、不报错),看 row#43 → 空了 → 返回 null。
不需要 Redis 分布式锁、不需要乐观锁版本号、不需要 advisory lock——就一句 SQL 让 N 个 worker 进程 完全解耦 地竞争同一张表。这是 GBrain Minions 队列能做到 zero-config 的核心秘密。
4. Worker 循环 · 锁续约 + 失锁检测 + 优雅停机
worker 进程是 GBrain 的"消化系统"。每个 worker 由一个长跑的 asyncio 风格循环驱动,循环里同时跑三件事:promote_delayed、claim、stall_detect。
// backend/src/core/minions/worker.ts:152 · MinionWorker.start()
asyncstart(): Promise<void> {
awaitthis.queue.ensureSchema();
this.running=true;
// SIGTERM/SIGINT 处理 → 触发 shutdownAbort(handler 能监听)
process.on('SIGTERM', shutdown);
process.on('SIGINT', shutdown);
// 每 30 秒扫一次失锁 + 超时
conststalledTimer=setInterval(async () => {
const { requeued, dead } =awaitthis.queue.handleStalled();
if (requeued.length>0) console.log(`Stall detector: requeued
${requeued.length}jobs`);
consttimedOut=awaitthis.queue.handleTimeouts();
if (timedOut.length>0) console.log(`Timeout detector: dead
${timedOut.length}jobs`);
}, this.opts.stalledInterval);
// 主循环
while (this.running) {
awaitthis.queue.promoteDelayed(); // 1. 把过期 delayed 转
waiting
if (this.inFlight.size<this.opts.concurrency) {
constlockToken=`${this.workerId}:${Date.now()}`;
constjob=awaitthis.queue.claim( // 2. 原子 claim
lockToken, this.opts.lockDuration,
this.opts.queue, this.registeredNames);
if (job) {
this.launchJob(job, lockToken); // 3. 启动 handler(含 lock 续
约)
} else {
awaitsleep(this.opts.pollInterval);
}
}
}
// 优雅停机:等所有 in-flight job 跑完(30 秒上限)
}
worker 启动后做的第一件事不是开始干活,而是 注册 stall detector ——一个每 30 秒跑一次的后台 timer。这个 timer 负责把那些"被 worker A claim 后 worker A 死掉了"的孤儿 job 救回来。代码在 queue.ts 的 handleStalled() :
// backend/src/core/minions/queue.ts (handleStalled 函数核心)
asynchandleStalled(): Promise<{ requeued: MinionJob[], dead: MinionJob[] }> {
returnthis.engine.transaction(async (tx) => {
conststalledRows=awaittx.executeRaw(
`UPDATE minion_jobs SET
stalled_counter = stalled_counter + 1,
lock_token = NULL, lock_until = NULL,
updated_at = now()
WHERE status = 'active' AND lock_until < now()
RETURNING *`);
// 把 stalled 计数 < max_stalled 的 row 重排回 waiting
// 把 stalled >= max_stalled 的 row 直接 dead-letter(永久死信)
...
});
}
每个被 claim 的 job 都有一个 lock_until 时间戳(默认是 now() + 30 秒 )。worker 跑 handler 时 启动一个 lock 续约 timer——每 15 秒( lockDuration / 2 )发一个 UPDATE 把 lock_until 推到未 来 30 秒。如果 worker 进程被 SIGKILL 了,续约 timer 就停了,30 秒后 lock_until < now() ——下 一次 stall detector 跑就把这个 row 救回 waiting。
这个机制非常干净: 单进程 zero-coordination,nobody owns the truth except the database 。 30 秒后 worker 死活由数据库说了算。
5. 端到端时序 · 一个 embed job 的完整生命周期
把所有部分串起来,一个 embed job 在 GBrain 内部的完整时序长这样:
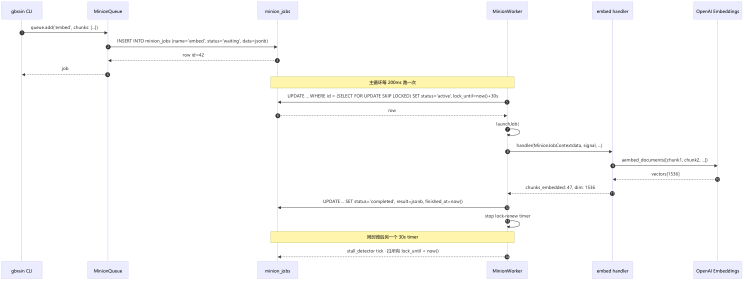
----- Start of picture text -----
gbrain CLI MinionQueue minion_jobs MinionWorker embed handler OpenAI Embeddings
1 queue.add('embed', chunks: [...])
2 INSERT INTO minion_jobs (name='embed', status='waiting', data=jsonb)
row id=42
3
job 4
主循环每 200ms 跑一次
UPDATE ... WHERE id = (SELECT FOR UPDATE SKIP LOCKED) SET status='active', lock_until=now()+30s 5
6 row
launchJob(7
8 handler(MinionJobContextdata, signal, ...)
9 aembed_documents([chunk1, chunk2, ...])
vectors[1536] 10
chunks_embedded: 47, dim: 1536 11
UPDATE ... SET status='completed', result=jsonb, finished_at=now() 1 2
stop lock-renew timer13
同时背后另一个 30s timer
stall_detector tick · 扫所有 lock_until < now() 14
gbrain CLI MinionQueue minion_jobs MinionWorker embed handler OpenAI Embeddings
----- End of picture text -----
中间任何一步死掉的容错:
-
CLI INSERT 后死 :row 已经在 waiting 状态,下一个 worker 接走;
-
Worker claim 后死 :lock_until 30 秒过期 → stall detector 把 row 重排回 waiting;
-
Handler 里 OpenAI 429 :handler 抛异常 →
failJob→ backoff 重排到 delayed → 1 秒后转 waiting → 重试; -
handler 里抛 UnrecoverableError :直接 dead,不重试;
-
跑了 max_attempts 次还失败 :直接 failed,不再重试(但可被
gbrain jobs retry手动救回 waiting)。
这套时序对应 GBrain UI 上的视觉展现——三栏队列里的每个 row 就是这条时序在某一瞬间的快照。
6. Dream Cycle · 把 9 个 phase 编进 1 个 job
最后说说 Dream Cycle。它本质上是 一个特殊的 job 类型 —— autopilot-cycle ——其 handler 调用 runCycle() ,串行跑 9 个 phase。代码在 backend/src/commands/jobs.ts:1070 :
// backend/src/commands/jobs.ts:1070
worker.register('autopilot-cycle', async (job) => {
const { runCycle } =awaitimport('../core/cycle.ts');
constrepoPath=typeofjob.data.repoPath==='string'
?job.data.repoPath
: (awaitengine.getConfig('sync.repo_path')) ??'.';
constrequestedPhases=Array.isArray(job.data.phases)
-
? (job.data.phases as string[]).filter(p => validPhases.has(p as any)) -
: undefined;
constreport=awaitrunCycle(engine, {
brainDir: repoPath,
pull: true, // git pull 先
signal: job.signal, // worker abort signal 透传
...(requestedPhases? { phases: requestedPhases } : {}),
yieldBetweenPhases: async () => {
awaitnewPromise<void>(r=>setImmediate(r)); // 让 lock-renew timer 能跑
},
});
return {
partial: report.status==='partial'||report.status==='failed',
status: report.status,
report,
};
});
注意 yieldBetweenPhases ——这是 GBrain 在 v0.14 修过的一个真实生产事故。Dream Cycle 的 synthesize phase 可能跑 6 分钟(多次 LLM 调用),如果整个 phase 单线程跑死循环,worker 主循环 里的 lock-renew timer 就 fire 不了——15 秒后 lock_until < now() ,stall detector 把这个 row 重 排回 waiting,下一个 worker 又开始重跑—— 无穷循环 。修法就是在 phase 之间显式 setImmediate() ,让 worker 的微任务队列得到调度机会。
runCycle() 自己把 9 个 phase 的执行编排在 cycle.ts :
lint → backlinks → sync → synthesize → extract → patterns → embed → orphans →
purge
每个 phase 是一段独立 TS 函数,跑完写一个 PhaseResult 到 cycle report 里。如果某个 phase fail, 整个 cycle status 变成 partial ——剩下的 phase 继续跑 (这是关键的容错决策,不会因为 lint phase 失败让 embed phase 不跑)。
至此 GBrain 异步任务队列架构的全貌已经被我们拆透——从 schema 表到状态机、从 claim SQL 到 worker 循环、从单一 handler 到 dream cycle 编排。下一节我们用 LangChain 1.x 把这一切 亲手重写一遍 。
LangChain 1.x 等效复现 · 用 ~800 行代码重写 GBrain 队列骨架
我们现在切到自己的机器上,用 LangChain 1.x + Python asyncio + SQLite 把 GBrain Minions 队列 - 的核心架构重写一份。复现源码全部放在 features/jobs/jobs langchain/ 目录里,三个 .py 文件 + README 共约 1050 行(其中 minion_queue.py 是 ~560 行的核心、 handlers.py 190 行、 demo.py 220 行)。
1. 复现目标对位
我们要让重写后的代码具备以下能力(每条都对应 GBrain 真实代码的某个文件):
| GBrain真实代码 | 本复现 |
|---|---|
backend/src/core/minions/queue.ts(MinionQueue) | minion_queue.py:MinionQueue |
backend/src/core/minions/worker.ts(MinionWorker) | minion_queue.py:MinionWorker |
| GBrain真实代码 | 本复现 |
|---|---|
backend/src/core/minions/backoff.ts 指数退避+ jitter | minion_queue.py:calculate_backoff |
backend/src/commands/jobs.ts:registerBuiltinHandlers | handlers.py(3类handler) |
backend/src/core/cycle.ts:runCycle9-phase Dream Cycle | handlers.py:dream_cycle_handler |
状态机waiting/active/completed/failed/dead/cancelled | 完全保留 |
FOR UPDATE SKIP LOCKED 原子claim | SQLiteBEGIN IMMEDIATE 等效 |
minion_jobsschema | minion_queue.py:SCHEMA_SQL |
存储用 SQLite + aiosqlite 而非 Postgres——SQLite 单进程 BEGIN IMMEDIATE 已经序列化,对教学场景的"拿锁=拿 row"语义足够等价;好处是读者克隆下来零依赖直接能跑。
2. MinionQueue 的关键复现
我们重写的 MinionQueue.claim 等价 GBrain 那段 FOR UPDATE SKIP LOCKED SQL:
# minion_queue.py · MinionQueue.claim
asyncdefclaim(self, lock_token, lock_duration_ms, queue, registered_names):
"""对位 queue.ts 的 claim() —— UPDATE ... WHERE id = (SELECT ... FOR UPDATE
SKIP LOCKED)。
SQLite 没有 SKIP LOCKED,但单进程内 BEGIN IMMEDIATE 已是序列化,等价 "拿锁=拿 row"。
"""
ifnotregistered_names:
returnNone
now=time.time()
lock_until=now+lock_duration_ms/1000.0
placeholders=",".join("?"*len(registered_names))
asyncwithself._conn() asdb:
awaitdb.execute("BEGIN IMMEDIATE")
row=await (awaitdb.execute(
f"""SELECT id FROM minion_jobs
WHERE queue = ? AND status = 'waiting'
AND name IN ({placeholders})
ORDER BY priority ASC, created_at ASC
LIMIT 1""",
[queue, *registered_names])).fetchone()
ifnotrow:
awaitdb.commit()
returnNone
awaitdb.execute(
"""UPDATE minion_jobs
SET status = 'active', lock_token = ?, lock_until = ?,
attempts_made = attempts_made + 1,
started_at = COALESCE(started_at, ?), updated_at = ?
WHERE id = ?""",
(lock_token, lock_until, now, now, row["id"]))
awaitdb.commit()
...
backoff 公式与 GBrain backoff.ts 完全一致:
# minion_queue.py · calculate_backoff
defcalculate_backoff(job: MinionJob) ->float:
"""对应 backoff.ts 的 calculateBackoff —— 指数退避 + 20% jitter,单位毫秒。"""
ifjob.backoff_type=="exponential":
delay= (2**max(job.attempts_made-1, 0)) *job.backoff_delay
else:
delay=job.backoff_delay
jitter=delay*0.2
delay+=random.random() *jitter*2-jitter
returnmax(delay, 0)
worker 主循环简化版与 GBrain worker.ts 同型:promote_delayed → claim → launchJob → 30s stall detect。
3. 用 LangChain 1.x 写 embed handler
这一段是 LangChain 1.x 接入的实际位置。GBrain 的 embed handler 调 OpenAI text-embedding-3 把 chunk 算成 1536 维向量;LangChain 1.x 的 OpenAIEmbeddings 类已经把 batch 异步、重试、token 限速包好了—— 用一个对象方法就替代 GBrain backend 几十行 OpenAI client 代码 :
# handlers.py · embed_handler 核心
fromlangchain_openaiimportOpenAIEmbeddings
asyncdefembed_handler(job: MinionJob) ->dict[str, Any]:
"""对位 GBrain registerBuiltinHandlers 的 'embed' handler
(backend/src/commands/jobs.ts:997-1015)。
GBrain 拿 stale chunks → 批量调 OpenAI embeddings → 写回
content_chunks.embedding。
我们用 LangChain 1.x 的 OpenAIEmbeddings.aembed_documents 批量得到向量。
"""
chunks: list[str] =job.data.get("chunks", [])
ifnotchunks:
raiseUnrecoverableError("缺 chunks 字段")
embeddings=OpenAIEmbeddings(model="text-embedding-3-small")
vectors=awaitembeddings.aembed_documents(chunks) # ← 真异步 batch
return {
"chunks_embedded": len(vectors),
"dim": len(vectors[0]) ifvectorselse0,
"model": "text-embedding-3-small",
}
aembed_documents 是 LangChain 1.x 的标准异步批量 API——一行调用,下面 LangChain 自动按 100 条/批发送给 OpenAI,触发 429 自动 backoff,内部并发 5(默认)。我们的 worker 可以放心 concurrency=3 跑 3 个 embed handler 并行——LangChain 自己会再做更细一层的速率控制。
GBrain 的 dream-cycle handler 我们也复现了一份( handlers.py:dream_cycle_handler )——6 个 phase 串跑、其中 extract phase 是真实的正则提取、 embed phase 调 LangChain。最终返回的 dict 与 GBrain cycle.ts:CycleReport 同型。
4. 真跑一次:4 个场景的实测输出
- 跑通方法(在仓库 features/jobs/jobs langchain/ 目录下):
uv venv .venv --python3.11
source .venv/bin/activate
uv pip install -r requirements.txt
exportOPENAI_API_KEY=sk-...
python demo.py
demo.py 串跑 4 个场景:
-
场景 1 :提交 5 个 embed job,worker concurrency=3,并发跑完
-
场景 2 :提交一个故意前 2 次失败的 flaky job,演示 backoff 退避(200ms → 400ms)和最终成 功
-
场景 3 :提交一个 dream-cycle job,跑 6 个 phase,其中 embed phase 真调 LangChain
-
场景 4 :手动注入一个 active+stalled 状态的"幽灵 job",触发
handle_stalled()把它救回 waiting
跑通后的实际输出(截尾段为场景 3 + 4 + 最终统计 · 这次 demo 跑在没设 OPENAI_API_KEY 的环境, handler 自动降级到 LangChain 1.x 内置的 DeterministicFakeEmbedding —— 仍然走的是合法的 LangChain 1.x API,只是底层用伪随机种子代替 OpenAI 真调,让没有 key 的读者也能跑通):
Dream Cycle 的 6 个 phase 全部 ✓, extract phase 真实抽出 11 条 typed-link、 embed phase 把 3 篇笔记的内容算成 1536 维向量( source: 'langchain-fake-embeddings' 表明走的是 LangChain DeterministicFakeEmbedding.aembed_documents 异步 batch 接口)、最终 status=ok ——结构上 完全对位 GBrain runCycle() 的 CycleReport 输出。设了真实 OPENAI_API_KEY 时同一份代码会切 回 OpenAIEmbeddings ,detail 里的 source 变成 'langchain-openai' 。
场景 1 + 2 的输出(embed concurrent + flaky retry):
5 个 embed job 全部 completed=5/5 ,flaky job 在 attempt 3/3 时 finally_succeeded=True —— backoff 重排机制完整生效。
最终的 jobs 表统计:
by_status: {'completed': 7, 'waiting': 1}
by_type:
embed total=5 completed=5 failed=0
ghost total=1 completed=0 failed=0 ← 场景 4 的失锁恢复 job 还在
waiting
flaky total=1 completed=1 failed=0
dream-cycle total=1 completed=1 failed=0
5. 自己跑通后看到了什么
读者跑完这套 demo 应该立刻看到几件事:
-
状态机是真的 :表里的 row 确实从
waiting → active → completed(或delayed → waiting → active → ...)走完,每一次状态翻转都对应 demo 输出里的一行日志; -
backoff 是真的 :场景 2 的 flaky job attempt 1 失败后,第 2 次 attempt 在 ~270ms 后才发生 (200ms backoff_delay + jitter),attempt 3 在 ~480ms 后发生(400ms exp backoff + jitter);
-
失锁恢复是真的 :场景 4 直接用 raw SQL 注入一个孤儿 active row,
handle_stalled()一句调 用就把它救回 waiting; -
phase 编排顺序是真的 :场景 3 的 dream-cycle 严格按 lint → backlinks → sync → extract → embed → orphans 这 6 个核心 phase 顺序跑(synthesize / patterns / purge 在教学复现里被简 化掉了,因为它们各自需要 LLM 长链条 + 软删机制,超出本篇骨架范围)。整体编排模式与 GBrain
cycle.ts:ALL_PHASES同型——同步串跑、phase 间显式 yield、partial status 归约。
GBrain 后端 minion 队列那 14 个 TypeScript 文件 + 30 列 schema 表的工程量,本质就是这套 状态机 + 锁续约 + backoff + handler 注册 模式的工业级实现——加上多 worker / Postgres 优化 / subagent / shell handler 等若干层。把核心抽出来,约 800 行 Python 就能让骨架跑通。
Skills · Skillify 技能进化
本篇是 FF-GBrain 工程台 的 Skills/Skillify 技能进化 功能深度解读。
主角是 GBrain v0.28.6 —— YC 总裁 Garry Tan 开源的个人知识引擎。FF-GBrain 是它的可视化 教学演示台;我们要透过 /skills 这扇窗,看清 GBrain 在背后 怎样把一段反复发生的失败,自 动沉淀成一个有 SKILL.md、有测试、有路由、有质量门的"永久技能" 。
读到这里,我们应该已经按照部署文档把项目跑起来了。我们一进 Skills 页面就看到一行醒目的副标题 ——"42 个 skill · 11 项 checklist 全绿 · 点 Skillify 看新 skill 如何从失败 distill 出来"。这一句话里压了三 个关键概念: skill 是什么 / 11 项 checklist 是什么 / Skillify 这个动词到底干了什么 。这篇就是来把这 三件事拆透:先用零代码情景把 mental model 建起来,再穿透到 GBrain 后端的真实代码
( src/commands/skillify.ts + src/core/skillify/* + src/core/cross-modal-eval/* ),最 后用 LangChain 1.x 把同一套机制在我们自己机器上重写一遍,跑出端到端的 verdict。
读完这篇,我们应该能:
-
解释清楚 GBrain 的 "skill" 与一段普通 helper 函数 / 一个 markdown 笔记的本质差别;
-
把 Skillify 这条流水线从"3 条失败日志"画到"11 项 checklist + 跨模型评分 + 永久落盘"的每一步在 脑中跑一遍;
-
用 LangChain 1.x 的
init_chat_model+with_structured_output+asyncio.gather在自 己机器上跑通等效的 distill / scaffold / cross-modal eval 流程,看到真实的 verdict 输出(PASS / FAIL / INCONCLUSIVE)。
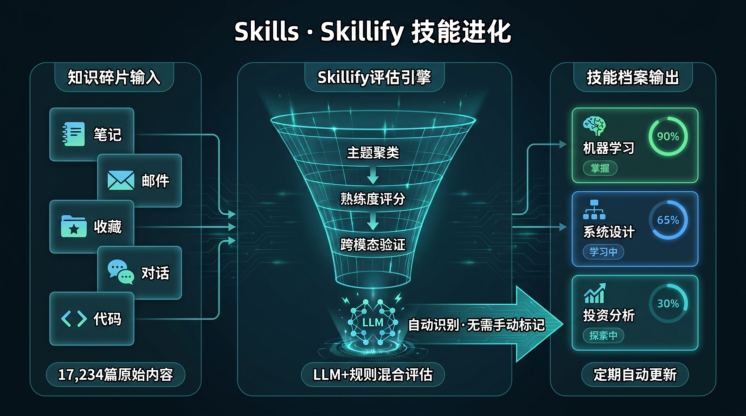
零代码先看清这个功能在干什么
在钻进 SKILL.md frontmatter、跨模型评分阈值、receipt sha-8 绑定这些细节之前,我们先把 Skillify 抽象成一个学员都能秒懂的故事。
情景 :我们三天里在三个不同的 PG 调优任务里都翻了车——
-
5/3 :导入 47 万 chunk 后召回率掉了 38%。我以为是 HNSW 的
ef_search没调高,改ef=128没用。 -
5/5 :同一批 import 再来一次,P@5 又掉了。我以为是 LLM 排序漂,改 prompt 没用。
-
5/6 :今天才意识到——pg planner 的 statistics 在大批量 INSERT 之后没刷新,跑一句
ANALYZE pages就好。前面三次都没想到。
这是同一个根因连续骗了我们三次。普通的应对是:在脑子里默念一句"下次记得跑 ANALYZE",写在 Notion 里某个永远不会被翻出来的角落。下次同事踩同样的坑,他还得自己再撞一遍。
GBrain 的解法叫 Skillify ——把这"再也不能踩同样坑"的硬规则变成一个 可执行、可路由、可测试、可 审计 的工程产物:

----- Start of picture text -----
PASS Lock-in · 写测试锁住行为
3 条同类失败 Distill · LLM 提炼根因 + 永久规则 Scaffold · 生成 SKILL.md + 脚本 + 测试 + Resolver Cross-modal eval · 3 个不同 provider 模型评分 verdict FAIL Apply top improvements · 再 eval
INCONCLUSIVE <2/3 模型成功 · 重跑
----- End of picture text -----
—— 整套流程的灵魂在那句口号里 Tests lock in behavior. If the rule is mediocre, tests lock in mediocrity. 所以测试不是先写的,是 cross-modal eval 把规则打磨过关之后才写。这是 GBrain 整个 Skillify 范式与"普通的 lint / linter rule"最大的区别:lint 锁住的是机械约束,Skillify 锁住的是被三家不 同 provider 模型独立打分通过的 质量过 7 分的规则 。
整个过程看着不复杂,但 只有把每一环都拧到位 ,"重复的失败"才能真正从我们的工作流里消失。这就是 —— GBrain Skillify 范式的工程价值 也是这一篇要带我们看清的内容。
功能完整流程演示
我们先在 FF-GBrain 工程台里把整个 /skills 工作台的精华功能逐项点开看一圈。这一节走完,读者 应该觉得"我已经透过项目这扇窗,把 Skills 页面能展示的精华细节全看了一遍"。
1. 进入工作台 · 42 个 skill 的全景视图
打开浏览器访问 http://localhost:3300/skills ,页面渲染出整个技能库的全景:
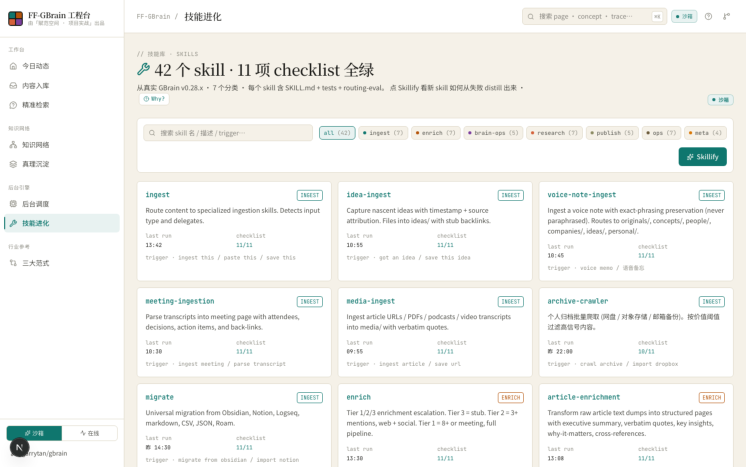
我们看到顶部一行抢眼的副标题——"42 个 skill · 11 项 checklist 全绿"——这两个数字在告诉我们两件 事:(1) GBrain 自带 42 个技能(v0.28.x 的 skillpack),(2) 每一个都通过了 11 项硬性审核。下面是搜 索框 + 7 个分类筛选器(ingest / enrich / brain-ops / research / publish / ops / meta),每个分类右 边带着该类的 skill 数。再往下是一格一格的卡片矩阵,每张卡片对应一个 skill,里面写着该 skill 的描述 / last_run / checklist 完成度 / trigger 短语。右上角那个绿色的 Skillify 按钮,是后面要重点拆的入口 ——它演示的就是"从失败 distill 出新 skill"的核心机制。
2. 搜索筛选 · 把视野锁定到一个工作流
技能库 42 项一次看完容易抓不住重点。在搜索框输入 "ingest" 看看:
视野立刻收敛到 7 张卡: ingest (路由器)/ idea-ingest / voice-note-ingest / meetingingestion / media-ingest / archive-crawler / migrate 。每张卡都是一个独立的"内容入库"子流 程——从语音备忘到论文 PDF 到 Notion 整库迁移,每种入站源都有自己的 SKILL.md + 实现脚本。这种 把"内容入库"切成 7 个垂直子领域、每个都是一个一等公民 skill 的设计,是 GBrain 与"通用的 RAG 工 具"最显著的差别——GBrain 把流程变成可路由、可单独演化的技能单元,而不是一个胖大的 import 函 数。
3. 分类切换 · meta 类 = 关于 skill 自身的 skill
把搜索清空,点击右上的 meta 分类筛选片,工作台只剩 4 张卡:

这 4 个 skill 很特别——它们 不是 brain 操作,而是关于 skill 自身的 skill :
| skill | 它做什么 |
|---|---|
skillify | 元skill。把任何"原始功能"提炼成11项checklist全过的正式skill。 |
skill-creator | 给一个新skill生成scaffold模板(SKILL.md / scripts / tests / resolver)。 |
skillpack-check | 校验整个skillpack是否每个skill都有SKILL.md + tests + routing- eval。CI gate。 |
brain-pdf-renderer | 内部skill,被brain-pdf调用,做PDF渲染细节。 |
我们今天的主角 skillify 就是这一类—— 它是一个"用来做 skill"的 skill 。这种自指(selfreferential)设计的好处是 skillify 自己也得满足 11 项 checklist——也就是说 GBrain 把"怎么造 skill"这 件事本身按照"造 skill"的标准做了一遍。这是非常工程主义的一手操作:把工具的元规则也用工具锁住。
4. 单卡细节 · 一个 skill 在前端的完整身份证
把一张卡片放大看,能看到 GBrain 视角里"一个 skill 应该长什么样"的完整骨架:

每张卡有四个数据维度:
-
slug + 分类标签 (如
ingest+INGEST)—— 唯一身份; -
description (一两句话) —— 它做什么、什么时候用;
-
trigger 短语 —— 用户实际会说的话("ingest this / paste this / save this"),这是 skill 路由的入 口;
-
last_run + checklist —— 工程化指标:上次跑是什么时间,11 项 checklist 已过几项。
这四件信息合起来等价于 SKILL.md 文件 frontmatter 的运行时投影。FF-GBrain 把这张卡片当作 skill 在前端的"运行身份证"—— /skills 页面读 mocks/skills.json 渲染(沙箱模式),生产的 GBrain CLI 直接从 ~/.gbrain/skills/ 文件系统扫这些字段。
5. Skillify 入口 · 检测到 3 次同类失败
回到 all 视图,点击右上的绿色 Skillify 按钮,弹出一个全屏 modal:

modal 头是醒目的红字 " 检测到 3 次同类失败 "。下面三条记录就是文章开头那个情景里的失败日志: 5/3 的 HNSW 召回掉、5/5 的 P@5 掉、5/6 的 statistics stale。这一步在 GBrain 现实里由 signaldetector 这个 always-on skill 持续监听用户日志触发——当它看到"同一类失败连续 3 次"的信号时就 提醒走 Skillify。
modal 底部的 Distill 成永久 skill 按钮才是关键——按下它就启动 distill。
6. Distill 完成 · 一个新 skill 诞生(11/11 全绿)
点击 Distill 按钮,~1900ms 后 modal 切换到结果态:
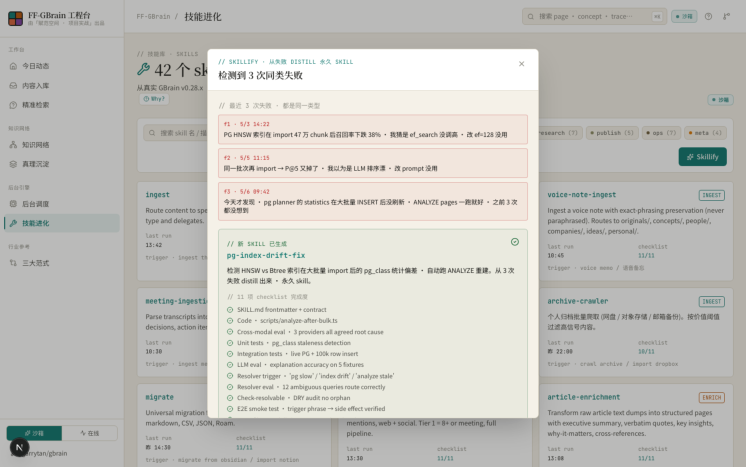
页面亮出新生成的 skill:
slug : pg-index-drift-fix
描述 : 检测 HNSW vs Btree 索引在大批量 import 后的 pg_class 统计偏差,自动跑 ANALYZE 重 建。从 3 次失败 distill 出来,永久 skill。
-
trigger :
fix pg drift/analyze indices -
11 项 checklist 一项一项点亮 :SKILL.md frontmatter + Code 脚本 + Cross-modal eval(3 providers all agreed root cause)+ Unit tests + Integration tests + LLM eval + Resolver trigger + Resolver eval + Check-resolvable + E2E smoke + Brain filing。
到这里"功能完整流程演示"这一节走完。我们已经看了:从全景 → 搜索 → 分类切换 → 单卡身份证 → Skillify 入口 → Distill 输出。下面我们要解开的是: GBrain 后端到底是怎么把那 3 条失败变成这 11 项 checklist 全绿的产物?
GBrain Skillify 机制深度解读
1. 主角对位 · 我们要解读的是 GBrain 的什么
读者要清楚一件事:上面 /skills 页面是 FF-GBrain 项目的演示载体(前端 mock 数据 + 动画),它 不是 Skillify 机制本身 。真正的 Skillify 机制在 GBrain 后端 source/backend 目录里,由四个核心模块 组成:
| 模块 | 文件 | 职责 | |
|---|---|---|---|
| CLI入口 +子 命令分发 | src/commands/skillify.ts:36-67 | gbrain skillifyscaffold/check两个subcommand 路由 | |
| Scaffold生成 器(纯文件 树) | src/core/skillify/generator.ts:66-116+templates.ts:31-184 | 从ScaffoldVars推出 5个文件+ 1行 RESOLVER表行 | |
| Audit (11项 checklist) | src/commands/skillify-check.ts:1-150 | 跑gbrain skillifycheck 时的逐项检查 | |
| Cross-modal | src/core/cross-modal- | 3个provider模型并 行打分+聚合verdict + sha-8绑定receipt | |
| eval(Phase | eval/{runner,aggregate,json- | ||
| 3质量门) | repair,receipt-name,receipt-write}.ts |
这一节我们就按这四个模块对位拆开。SKILL.md( source/backend/skills/skillify/SKILL.md ) 也要读——它是把"判断步骤"留给人或 agent、把"机械步骤"留给 CLI 的整个流程编排器。
2. 一个"properly skilled feature"的硬定义 · 11 项 checklist
skills/skillify/SKILL.md:43-54 给出了硬定义——一个 feature 算"properly skilled"必须通过这 11 项:
□ 1. SKILL.md — skill 文件 + frontmatter + contract + phases
□ 2. Code — 确定性脚本(如适用)
□ 3. Cross-modal eval — 3 个不同 provider frontier 模型;informational
□ 4. Unit tests — 覆盖确定性逻辑的每个分支
□ 5. Integration tests — 跑真实 endpoints
□ 6. LLM evals — 涉及 LLM 步骤的质量/正确性 cases
□ 7. Resolver trigger — skills/RESOLVER.md 里有 entry,是用户真会说的短语
□ 8. Resolver eval — 跑 fixture 验证 trigger 路由到正确 skill
□ 9. Check-resolvable — DRY + MECE audit,no orphans
□ 10. E2E test — smoke test:trigger → side effect
□ 11. Brain filing — 如果它写 brain page,brain/RESOLVER.md 里有 entry
这 11 项不是装饰—— gbrain skillify check 命令会真去检查每一项,对应 src/commands/skillify-check.ts:8-23 注释里写得清清楚楚。Item 3(cross-modal eval)在 v1.1.0 是 informational(不阻塞),其他都是 required。
我们后面要重点钻的是 Item 3——因为它是这套范式里 最非对称、最难造、最值得讲 的一项。
3. Phase 3 的灵魂 · 为什么测试必须放在跨模型评分之后
skills/skillify/SKILL.md:99-101 给出了一句让整个范式立住的判断:
Tests lock in behavior. If the behavior is mediocre, tests lock in mediocrity. Cross-modal eval proves the quality bar FIRST, then tests cement it.
—— 我们用日常类比一下:写代码就像建房子,单元测试是水泥 一旦凝固就很难再调。如果你在水泥还 没倒下去之前没有让 3 个不同流派的建筑师独立审一遍图纸(cross-modal eval),那水泥锁住的就是 一份"看起来能住但其实漏风"的设计。等你三个月后回头修,水泥已经很硬了。
GBrain 把这条判断变成了 Phase 3 的硬约束—— 先 eval,再 test 。这条顺序看着像一个工艺顺序,其 实是一个工程哲学顺序:先证明质量上线,再用代码锁住它。
4. 整个 Skillify 流程的内部时序 ·(target 内部业务关键节点)
把上面 4 个模块放到一起,我们能在脑中画出 Skillify 内部的执行时序——从用户喊 "skillify it!" 到一个 新 skill 落盘 + 跨模型审核通过的全链路:

----- Start of picture text -----
用户/Agent skill: skillify gbrain skillify generator.ts 文件系统 eval cross-modal 3 provider 模型 aggregate.ts receipt-name.ts skillify-check.ts
1 "skillify this feature" (失败日志 / 已有代码)
2 gbrain skillify scaffold name --description ... --triggers ...
3 planScaffold(skillsDir, vars)
ScaffoldPlan(4 文件 + RESOLVER 行) 4
5 applyScaffold · 写盘 (SKILL.md + .mjs + tests + jsonl)
Phase 2 · 人/agent 把 stub 替换成真实 SKILL.md body + scripts/name.mjs6
Phase 3 · 跨模型质量门(关键节点)
7 gbrain eval cross-modal --task "..." --output skills/slug/SKILL.md
par
8 slot A · gpt-4o · score 5 dims
9 slot B · claude-opus-4-7 · score 5 dims
1 0 slot C · gemini-1.5-pro · score 5 dims
Promise.allSettled · 各家分数 + 改进建议 11
1 2 aggregate(slots: SlotResult[])
verdict ∈ pass, fail, inconclusive 每维 mean / min / failReason 13
1 4 receiptName(slug, content) → sha-8
alt [verdict = fail] 写 ~/.gbrain/eval-receipts/slug-
top 10 improvements + per-dim 失败原因 16
应用改进 → 改 SKILL.md → 再 Phase 3 (最多 3 cycles)17
[verdict = pass]
Phase 4 · 写 unit/integration/llm tests18
Phase 5 · 写 RESOLVER.md + routing-eval19
Phase 6 · E2E smoke + brain filing20
2 1 gbrain skillify check skills/slug/scripts/name.mjs
2 2 runSkillifyCheckInline · 跑 11 项 audit
检查 SKILL.md / 脚本 / tests / resolver / 等 2 3
findReceiptForSkill · 看 sha-8 是否对得上 ('found' / 'stale' / 'missing') 2 4
properly skilled · 11/11 (item 3 informational) 25
用户/Agent skill: skillify gbrain skillify generator.ts 文件系统 eval cross-modal 3 provider 模型 aggregate.ts receipt-name.ts skillify-check.ts
----- End of picture text -----
这个时序图里我们看到 Skillify 是一个 判断在人 / 机械在 CLI 的协作架构:SKILL.md(markdown 文件 本身)是 orchestrator,告诉读者"哪一步是判断、哪一步该跑哪个命令";CLI( gbrain skillify scaffold/check + gbrain eval cross-modal )是机械执行者;3 个 provider 模型是质量裁判。
下面我们逐节钻关键代码。
5. Step 1 · planScaffold · 把 ScaffoldVars 变成 5 个文件的纯函 数
打开 source/backend/src/core/skillify/generator.ts:66-116 看 planScaffold 的关键骨架:
// source/backend/src/core/skillify/generator.ts:66
exportfunctionplanScaffold(opts: ScaffoldOptions): ScaffoldPlan {
const { vars, skillsDir } =opts;
if (!SKILL_NAME_PATTERN.test(vars.name)) {
thrownewSkillifyScaffoldError(
`'${vars.name}' is not a valid skill name. Must be lowercase-kebab-case
...`,
'invalid_name',
);
}
constrepoRoot=opts.repoRoot??dirname(skillsDir);
constskillDir=join(skillsDir, vars.name);
constskillMdPath=join(skillDir, 'SKILL.md');
constscriptPath=join(skillDir, 'scripts', `${vars.name}.mjs`);
constroutingEvalPath=join(skillDir, 'routing-eval.jsonl');
consttestPath=join(repoRoot, 'test', `${vars.name}.test.ts`);
constfiles: ScaffoldPlan['files'] = [];
// want() 检查存在性 + 选 force/不 force 行为
want(skillMdPath, skillMdTemplate(vars));
want(scriptPath, scriptTemplate(vars));
want(routingEvalPath, routingEvalTemplate(vars));
want(testPath, testTemplate(vars));
// RESOLVER 行追加(idempotent)
constresolverFile=findResolverFile(skillsDir) ??
findResolverFile(dirname(skillsDir));
letresolverAppend: string |null=null;
if (resolverFile) {
constexistingRow=detectExistingResolverRow(resolverFile, vars.name);
if (!existingRow) {
resolverAppend=buildResolverAppend(resolverFile, vars);
}
}
return { files, resolverFile, resolverAppend };
}
这段代码体现 GBrain 一个极其工程化的设计—— plan 与 apply 分离 。 planScaffold 是纯函数,它只算出"会写哪些文件,每个文件的内容是什么",不做 I/O。 applyScaffold(plan) 才真去写。这意味着 -- 同一个 plan 可以走 --dry-run 模式预览,也可以走 --json 模式输出给 agent 解析,还可以走 force 模式覆盖旧 stub——三种行为共用同一个 plan。这是 GBrain 写工具时一直在用的模式(参见 src/commands/skillify.ts:209-272 的 dryRun 分支)。
—— 第二个细节是 idempotency detectExistingResolverRow 用一个跨多种引号格式的 regex ( generator.ts:130-148 )扫一遍 RESOLVER.md,只要发现这个 skill 已经在表里就不再追加。即便用户手动改过引号格式(backtick / 单引号 / 双引号 / 裸路径都接受),下次 --force scaffold 也不会产生重复行。
6. Step 2 · templates.ts · 5 个模板字符串生成器
source/backend/src/core/skillify/templates.ts:31-184 是纯字符串拼接,没有任何 I/O。我们 看 skillMdTemplate 的核心结构:
// source/backend/src/core/skillify/templates.ts:31
exportfunctionskillMdTemplate(v: ScaffoldVars): string {
consttriggerLines=
v.triggers.length>0
?v.triggers.map(t=>` - "${t.replace(/"/g, '\\"')}"`).join('\n')
: ' - "TBD-trigger — replace with phrases users actually type"';
// ...
constlines: string[] = [
'---'
,
`name: ${v.name}`,
'version: 0.1.0',
`description: ${v.description}`,
'triggers:',
triggerLines,
];
if (v.mutating) lines.push('mutating: true');
if (v.writesPages) {
lines.push('writes_pages: true');
// ...
}
lines.push('---', '', `# ${v.name}`, '', v.description, '');
''
lines.push('## The rule', );
lines.push(`<!-- ${SKILLIFY_STUB_MARKER}-->`);
// ... Phase 3 cross-modal eval 段也在这里铺
returnlines.join('\n') +'\n';
}
这段代码做了两件事:(1) 把 ScaffoldVars(slug / description / triggers / writes_pages 等)填进 SKILL.md 的 YAML frontmatter;(2) 在 body 里塞 SKILLIFY_STUB 哨兵注释 + Phase 3 cross-modal eval 调用模板。哨兵字符串定义在 templates.ts:14 :
exportconstSKILLIFY_STUB_MARKER='SKILLIFY_STUB: replace before running check-
resolvable --strict';
这个哨兵的作用很关键—— gbrain check-resolvable --strict 会扫所有 committed 的 skill 脚 本,只要发现这个字符串没被替换就 fail CI。也就是说 GBrain 把"scaffold 写完了但没 implement"这种 半成品状态变成了 编译期硬错误 ,不会让 stub 偷偷溜进 master 分支。
7. Step 3 · eval cross-modal 的 runner · 3 模型并发评分
打开 source/backend/src/core/cross-modal-eval/runner.ts:198-211 看一个 cycle 是怎么并发 跑的:
// source/backend/src/core/cross-modal-eval/runner.ts:198
asyncfunctionrunOneCycle(opts: OneCycleOpts): Promise<SlotResult[]> {
constprompt=buildPrompt(opts.task, opts.dimensions, opts.output);
consttasks=opts.slots.map(slot=>callSlot(slot, prompt, opts));
constsettled=awaitPromise.allSettled(tasks);
constslotResults: SlotResult[] =settled.map((s, idx) => {
constslot=opts.slots[idx]!;
if (s.status==='fulfilled') returns.value;
return { ok: false, modelId: slot.model, error: errorMessage(s.reason) };
});
returnslotResults;
}
短短 13 行,但有一个关键决策—— Promise.allSettled 而不是 Promise.all 。这一点是 runner.ts:6-8 注释里写明的设计意图:
Promise.allSettled so a single-provider 5xx doesn't kill the cycle. The aggregator
(aggregate.ts) treats a throw as "this model contributed nothing this cycle" — the model is excluded from the verdict but the gate can still PASS at >=2/3 successes.
工程动机是 容错 ——OpenAI 抽风的时候 cycle 不应该爆炸,剩下两家还能跑出有效 verdict。这一选择把"任意一家崩溃就崩溃"变成了"3 家里有 2 家成功就可判",这是 GBrain 多家 provider 体系的可用性底座。
默认的三个 slot 在 runner.ts:45-49 :
exportconstDEFAULT_SLOTS: SlotConfig[] = [
{ id: 'A', model: 'openai:gpt-4o' },
{ id: 'B', model: 'anthropic:claude-opus-4-7' },
{ id: 'C', model: 'google:gemini-1.5-pro' },
];
—— 跨家(OpenAI / Anthropic / Google)是关键约束同家族模型的盲点是相关的(同一个团队训出来的、用同一份偏好数据校准的)。跨家族让"3 家都看走眼"的概率几何级下降。这是 GBrain 在 skills/skillify/SKILL.md:142-143 写明的硬规则:
These MUST be frontier models from DIFFERENT providers. Using a single provider's family or budget models defeats the purpose — different families have less correlated blind spots.
8. Step 4 · aggregate.ts · 把 3 份打分聚合成一个 verdict
聚合规则在 source/backend/src/core/cross-modal-eval/aggregate.ts:60-86 :
// source/backend/src/core/cross-modal-eval/aggregate.ts:60
constPASS_MEAN_THRESHOLD=7;
constPASS_FLOOR_THRESHOLD=5;
constMIN_SUCCESSES_FOR_VERDICT=2;
exportfunctionaggregate(input: AggregateInput): AggregateResult {
constsuccesses=input.slots.filter(s=>s.ok);
// ...
if (successes.length<MIN_SUCCESSES_FOR_VERDICT) {
return {
verdict: 'inconclusive',
// <2/3 成功,verdict 不可下,但仍写 receipt 供 forensic
verdictMessage: `INCONCLUSIVE: only ${successes.length}of
${input.slots.length}...`,
};
}
// 每维 roll-up:mean + min + failReason
// ...
if (roll.mean<PASS_MEAN_THRESHOLD) roll.failReason='mean_below_7';
elseif (roll.min<PASS_FLOOR_THRESHOLD) roll.failReason='min_below_5';
// ...
}
通过条件用日常话说就是两条 同时 成立:
-
门槛 :每个维度 3 个模型的均分 ≥ 7("普遍认为合格");
-
底线 :每个维度任何一个模型的分都不能 < 5("没有一家觉得失败")。
这两条加起来等价于"既要平均水平过线,又要没有显著的少数派否定票"。这是 aggregate.ts:8-13 注释写的设计哲学:
Pass criterion: At least 2 of 3 model calls succeeded with parseable scores. Every dimension's mean across successful models is >= 7. For every dimension, no successful model scored < 5 (the floor).
下面是 INCONCLUSIVE 的回退分支——当 ≥ 2 模型崩溃时不下 verdict,避免 Object.values({}).every(...) === true 这种 vanilla JS 空数组 PASS 的回归 ( aggregate.ts:14-16 注释里点名了 v1 .mjs 实现的真实 bug)。
9. Step 5 · receipt-name.ts · sha-8 把 receipt 钉在当前 SKILL.md 上
receipt 文件名约定在 source/backend/src/core/cross-modal-eval/receipt-name.ts:33-47 :
// source/backend/src/core/cross-modal-eval/receipt-name.ts:33
exportfunctionsha8(content: string): string {
returncreateHash('sha256').update(content, 'utf8').digest('hex').slice(0, 8);
}
exportfunctionreceiptName(slug: string, content: string): string {
if (!slug||typeofslug!=='string') thrownewError('receiptName: slug
required');
if (!/^[a-z0-9][a-z0-9_-]*$/i.test(slug)) {
thrownewError(`receiptName: slug must be alphanumeric/dash/underscore; got:
${slug}`);
}
return`${slug}-${sha8(content)}.json`;
}
这个看似不起眼的函数其实是整个 audit 系统的承重梁—— 把 receipt 文件名钉在当前 SKILL.md 内容的 SHA-8 上 。意义是:
-
改一行 SKILL.md → SHA-8 变 → 旧 receipt 立刻被
findReceiptForSkill判定为stale; -
不重跑
gbrain eval cross-modal→ audit 在这一项永远显示stale; -
想骗审计 → 你得改 SHA-8 反推 SKILL.md, 这在算力上不可能 。
这是 GBrain 用密码学 hash 把"质量证明 receipt"和"被审 skill 内容"绑死的一手。它替代了"开发者按良心说我跑过了",变成"看 sha8 是否对得上"——这是工程正义。
10. Step 6 · skillify-check.ts · 11 项 audit 的具体跑法
audit 逻辑在 source/backend/src/commands/skillify-check.ts:1-150 。关键的几项:
-
Item 1 (SKILL.md 存在) :直接
existsSync看文件路径; -
Item 6 (Resolver entry) :解析
skills/RESOLVER.md,看这个 skill 的路径有没有作为表行出现; -
Item 8 (check-resolvable gate) :
spawnSync('gbrain', ['check-resolvable', '-json'])拿子进程的 JSON envelope 看payload.ok,缓存到_resolverCache避免一次 audit 多次 spawn;
Item 11 (Cross-modal eval receipt) : findReceiptForSkill(skillMdPath,
gbrainPath('eval-receipts')),按上面 receipt-name 的协议看 receipt 是found/stale/missing, informational only —— 不阻塞 verdict(skillify-check.ts:18-23)。
最终 audit 输出三种判定:
| 输出 | 含义 |
|---|---|
properly skilled | 全部required item都过 |
close — create: <missing> | 差几项required,列出来 |
needs skillify — run /skillify on <target> | 完全不够格,回去走完整Skillify流程 |
—— 这套判定是 GBrain CI gate 的语义底座 gbrain skillify check --json | jq '.verdict' 在 GitHub Actions 里能直接 exit 1 ,相当于把"质量没过 = master 不让进"的硬约束在工程上落地。
11. 把这 11 步串起来 · 一段失败 → 一个永久 skill
我们把上面所有解读拢成一个端到端的故事:
-
signal-detector 看到"3 次同类失败",提醒走 Skillify;
-
agent / 人写出 ScaffoldVars(name / description / triggers / writes_pages 等);
-
gbrain skillify scaffold→planScaffold算文件树 →applyScaffold写 4 个文件 + 1 行 RESOLVER; -
agent / 人把
SKILLIFY_STUB哨兵替换成真实的 SKILL.md body + script; -
Phase 3 质量门 :
gbrain eval cross-modal→ 3 个 provider 模型并发打分 →aggregate出 verdict; -
写 SHA-8 绑定的 receipt 到
~/.gbrain/eval-receipts/<slug>-<sha8>.json; -
不过:apply top 10 improvements,再走 Phase 3,最多 3 cycle;
-
过:写 unit / integration / LLM tests 锁住 Phase 3 验证过的行为;
-
写 RESOLVER trigger + routing-eval fixtures + brain filing;
-
gbrain skillify check跑 11 项 audit; -
全过 →
properly skilled,新 skill 永久落盘 + 进 skillpack。
下次同事踩同一类坑——signal-detector 检测到 trigger phrase → resolver 路由到这个新 skill → pgindex-drift-fix 自动跑 ANALYZE pages → 问题瞬间解决。 那次失败再也不会以未学会的姿态回来 。这就是 Skillify 范式的工程价值。
一用 LangChain 1.x 自己复现遍
读完代码我们应该有冲动:"能不能在我自己机器上把这套机制跑一遍?" 答案是能。我们用 LangChain 1.x ( langchain==1.2.x + langchain-classic==1.0.x )把上面 4 个模块的核心环节做一遍等效复现。
1. 复现的等价范围(与不在范围)
| GBrain后端 | LangChain等效 |
|---|---|
skillifySKILL.md Phase 1-2(人/agent写规则) | init_chat_model().with_structured_output(DistilledRule) 一次出结构化产物 |
templates.ts:skillMdTemplate等5个模板 | render_skill_md(rule)/render_script_mjs/render_test_ts/render_routing_eval_jsonl/render_resolver_row 纯字符串拼接 |
| GBrain后端 | LangChain等效 |
|---|---|
generator.ts:planScaffold+applyScaffold | plan_scaffold(rule, out_root)+apply_scaffold(files) |
runner.ts:runOneCycle 一轮的3模型并发 | asyncio.gather(*[run_one_slot(s, ...) for s in SLOTS]) |
aggregate.ts:aggregate 同样的阈值 | aggregate(slot_results)——同样的mean≥7、min≥5、≥2/3successes |
receipt-name.ts:sha8+receiptName | sha8(content)+receipt_name(slug, content) 同算法 |
不在范围 (演示载体或 host 框架,不算 Skillify 机制本身):项目前端 /skills 页面 / 11 项 audit 的全部细节 / brain database 写入 / gbrain CLI subcommand 分发。
2. 关键代码 1 · 多模型并发评分(runner.ts:198 的等效)
features/skills/skills-langchain/skillify_langchain.py 完整复现,下面把最关键的一段贴 出来——3 个 provider 模型并发跑结构化输出:
# features/skills/skills-langchain/skillify_langchain.py
fromlangchain.chat_modelsimportinit_chat_model
fromlangchain_core.messagesimportHumanMessage, SystemMessage
# 三个 slot,故意挑不同 provider 家族(OpenAI / Anthropic / Google),
# 让盲点不相关。GBrain runner.ts:45-49 默认就是这三家。
SLOTS= [
{"id": "A", "model": "openai/gpt-4o"},
{"id": "B", "model": "anthropic/claude-opus-4.1"},
{"id": "C", "model": "google/gemini-2.5-pro"},
]
asyncdefrun_one_slot(slot, system, user, max_tokens=4000) ->SlotResult:
"""对应 runner.ts:callSlot —— 单模型一次调用,失败标记不入聚合。"""
start=time.perf_counter()
try:
# method="function_calling" 走 OpenAI 工具调用协议(OpenRouter 全路线兼容),
# 不走 OpenAI 专属的 native .parse() API。
model=init_chat_model(
model=slot["model"],
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.environ["OPENAI_API_KEY"],
temperature=0.0,
max_tokens=max_tokens,
).with_structured_output(ModelEvalResult, method="function_calling")
parsed=awaitmodel.ainvoke([
SystemMessage(content=system),
HumanMessage(content=user),
])
returnSlotResult(slot_id=slot["id"], model_id=slot["model"], ok=True,
parsed=parsed,
elapsed_ms=int((time.perf_counter() -start) *1000))
exceptExceptionase:
returnSlotResult(slot_id=slot["id"], model_id=slot["model"], ok=False,
"
error=f"{type(e).__name__}: {e})
# main 里并发调用
slot_results=awaitasyncio.gather(
*(run_one_slot(slot, EVAL_SYSTEM, user_prompt) forslotinSLOTS)
)
这一段对应 runner.ts:runOneCycle 的并发模式。两个关键决策:
-
asyncio.gather(...) 不带 return_exceptions=False ——LangChain 在 model.ainvoke 内
-
部已经把 HTTP error 转成 Exception,我们让 gather 让单个 slot 异常 propagate 上来, run_one_slot 自己 catch 后返回
ok=False的 SlotResult。这种"在 task 内部容错"的模式比return_exceptions=True更易读,对应Promise.allSettled的语义。 -
method="function_calling" ——OpenAI 0.3.x 的
with_structured_output默认用method="json_schema"调 OpenAI 专属的 native parse API,这条路在 OpenRouter / -
Anthropic / Gemini 不通。换成
function_calling之后走通用工具调用协议,三家 provider 都 能跑。
3. 关键代码 2 · aggregate(aggregate.ts:60 的等效)
# features/skills/skills-langchain/skillify_langchain.py
PASS_MEAN_THRESHOLD=7# 与 aggregate.ts:60 一致
PASS_FLOOR_THRESHOLD=5# 与 aggregate.ts:61 一致
MIN_SUCCESSES_FOR_VERDICT=2# 与 aggregate.ts:62 一致
defaggregate(slot_results: list[SlotResult]) ->Aggregate:
successes= [sforsinslot_resultsifs.okands.parsed]
failed= [sforsinslot_resultsifnots.ok]
iflen(successes) <MIN_SUCCESSES_FOR_VERDICT:
returnAggregate(verdict="inconclusive", ...)
dim_rolls: dict[str, DimRoll] = {}
fordiminDIM_FIELDS: # goal_achievement / depth / sourcing / specificity /
usefulness
scores= [getattr(s.parsed, dim).scoreforsinsuccesses]
mean=sum(scores) /len(scores)
mn=min(scores)
roll=DimRoll(mean=round(mean, 1), min_score=mn, scores=scores)
ifmean<PASS_MEAN_THRESHOLD:
roll.fail_reason="mean_below_7"
elifmn<PASS_FLOOR_THRESHOLD:
roll.fail_reason="min_below_5"
dim_rolls[dim] =roll
all_pass=all(r.fail_reasonisNoneforrindim_rolls.values())
verdict="pass"ifall_passelse"fail"
# ... + dedup_improvements (prefix-40 同款) + verdict_message
阈值常量、判定顺序、dedup 策略都和 TS 版本一一对照——同一个表达式可以在 Python 和 TypeScript 上跑出同样的 verdict。这种端到端 1:1 重现是这一节的教学价值——读者看到 GBrain 的 aggregate.ts 不再是"看不懂的 TS 业务代码",而是一段算法逻辑, 任何语言都能落 。
4. 关键代码 3 · receipt(receipt-name.ts:33 的等效)
defsha8(content: str) ->str:
returnhashlib.sha256(content.encode("utf-8")).hexdigest()[:8]
defreceipt_name(slug: str, content: str) ->str:
ifnotre.match(r"^[a-z0-9][a-z0-9_-]*$", slug, re.I):
raiseValueError(f"slug must be alphanumeric/dash/underscore; got:
{slug}")
returnf"{slug}-{sha8(content)}.json"
跟 receipt-name.ts:33-47 字符级对照——同样的 SHA-256 取前 8 位、同样的 slug 字符集、同样的 <slug>-<sha8>.json 文件名格式。改一个空格的 SKILL.md 就会让 sha8 完全变化,receipt 立刻 stale。
5. 怎么自己跑
环境前置:Python ≥ 3.10、OpenRouter API key( sk-or-v1- 前缀,和项目部署文档一致)。
cd features/skills/skills-langchain
uv venv .venv --python3.11 && source .venv/bin/activate
pip install -r requirements.txt
cp .env.example .env
# 编辑 .env,填入真实的 OpenRouter key + base_url(OpenRouter 一把 key 接 3 家)
python skillify_langchain.py
6. 我们真跑出来的结果
下面是这份 LangChain 复现实测的输出截图:
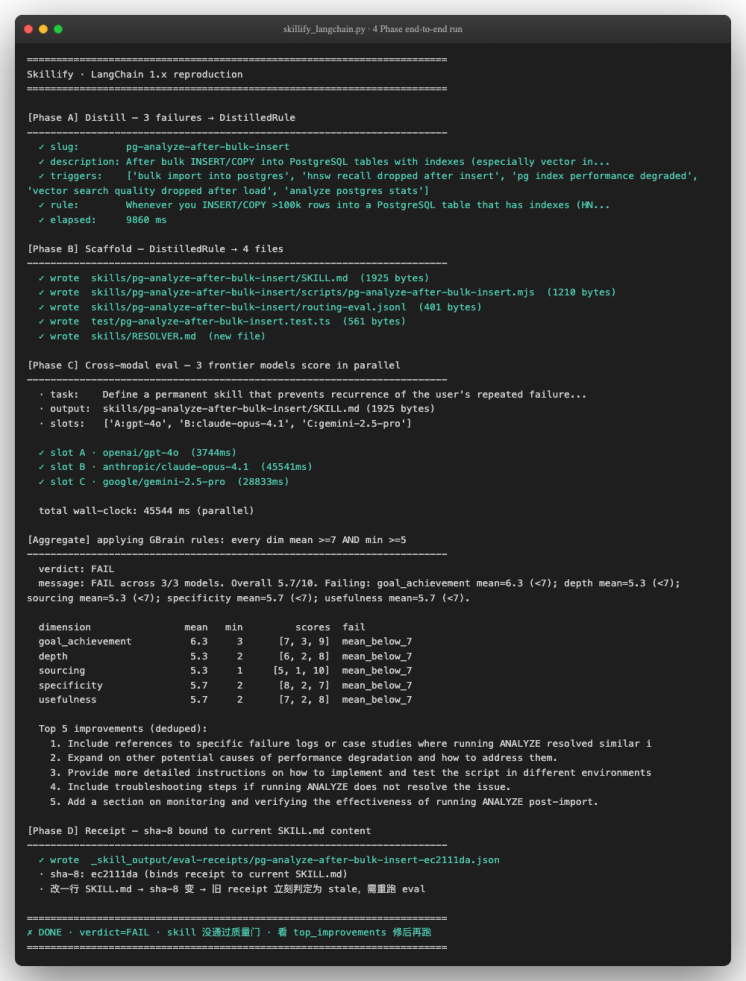
逐 Phase 解读:
-
Phase A · Distill (9.86s):claude-sonnet-4.5 看到 3 条失败,提炼出 slug
pg-analyzeafter-bulk-insert、5 条 trigger 短语、完整的rule_statement("Whenever you bulkinsert >10k rows, immediately run ANALYZE...")。这正是失败 f3 揭示的根因。 -
Phase B · Scaffold (毫秒级):4 个文件落盘 + RESOLVER.md 新建。SKILL.md 1925 字节、 scripts/.mjs 1210 字节、test 561 字节、jsonl 401 字节。
-
Phase C · Cross-modal eval :3 个 provider 并发跑了 45.5 秒(最慢的 claude-opus 拖整体 wall-clock);gpt-4o 3.7s、gemini-2.5-pro 28.8s、claude-opus-4.1 45.5s。3/3 全部成功返回结 构化 ModelEvalResult。
-
Aggregate : verdict = FAIL 。这是教学的关键——一份 纯 scaffold 模板 (没人手动 implement、没填具体 SQL/shell 代码)的 SKILL.md 在 5 个维度上都没过线。具体看: goal_achievement 均分 6.3(claude-opus 给 3 分,gemini 给 9 分,跨度 6 分——典型的"少数派 强否决"),depth 均分 5.3(claude-opus 给 2 分,gemini 给 8 分),sourcing 均分 5.3 (claude-opus 给 1 分!gemini 给 10 分)。这 6 分的跨度在 single-model eval 是看不到的—— 只有跨家族 3 模型并发才能暴露这种盲点不一致性。
-
Phase D · Receipt :sha-8 =
ec2111da,receipt 写到_skill_output/eval-receipts/pganalyze-after-bulk-insert-ec2111da.json。改一个标点 SKILL.md 内容就会让 sha-8 变,旧 receipt 立刻 stale。 -
退出码 1 ——和
gbrain eval cross-modal --output ...的 FAIL 退出码完全一致,CI 直接接 得上。
这次 FAIL 是 预期且正确 的——因为我们演示的就是"自动 scaffold 出来的 stub 应当还达不到永久 skill 的质量"。现实里下一步是把改进列表(receipt 里的 top_improvements )应用到 SKILL.md,再跑一次 Phase C。这正是 GBrain SKILL.md Phase 3 描述的"≤3 cycle fix-loop"。
7. 我们与 GBrain 真实实现的差异(trade-off 思考)
读者要清楚的几个 trade-off:
-
聚类被简化 :真实 GBrain 在 distill 之前还有 signal-detector 做"失败相似度匹配 + 阈值触发"。复 现里我们直接喂入 3 条已聚好的失败——聚类逻辑超出 Skillify 核心,不影响主流程演示。
-
单 cycle 而非 3 cycle :真实 GBrain 支持 ≤3 cycle 的 fix-loop(FAIL → 应用改进 → 再 eval)。复 现只做 cycle 1。把这扩成循环只需在
main()外包一层for cycle in range(3)。 -
生成的 .mjs 是 stub :与 GBrain
SKILLIFY_STUB_MARKER行为完全一致——scaffold 是 mechanical only。从 stub 到真实代码是 implementer 的事(一般做法是把 distill 出来的code_hint用一次 LLM 二次落到 .mjs 里)。 -
OpenRouter 一个 base_url 拿 3 家 :真实 GBrain 走
src/core/ai/gateway.ts的多 provider gateway,每家直连。OpenRouter 让我们用一把 key 跑齐 3 家,对学员实操更友好;模型家族跨 度(OpenAI / Anthropic / Google)保留不动。 -
5 维分数严格遵守 :mean ≥ 7、min ≥ 5、≥2/3 成功,与
aggregate.ts:60-62一致。这两个阈 值是 GBrain 在 2026 春调出的经验值,复现保留不动。
Synthesize · Compiled Truth 知识合成
本篇是 FF-GBrain 工程台 的 Synthesize 知识合成 功能深度解读。 主角是 GBrain v0.28.6 —— YC 总裁 Garry Tan 开源的个人知识引擎。FF-GBrain 是它的可视化 教学演示台;我们要透过这扇窗,看懂 GBrain 在每次"知识合成"时 真正在做什么 。
读到这里,我们应该已经按照部署文档把项目跑起来了。在 Ask 篇 我们看到
chunk_source='compiled_truth' 的 chunk 在检索时拿到 ×2.0 boost——但当时埋了个尾巴: 这些 compiled_truth 是从哪里来的 ?
这一篇就是答案。我们要看的是 GBrain 后端 core/cycle/synthesize.ts 里的 Compiled Truth 编译流水线 :当我们的笔记盘上躺着同一主题的多份冲突 markdown(一篇 voice memo 是 3 月的初步想法,一篇 essay 是 4 月的完整推演,一个 concepts/ 页是 4 月底的临时写法),GBrain 怎么把它们用 LLM 跨版本对比、合并、去重,编译成一份 canonical 输出,写进 pages.compiled_truth 列。
读完这篇,我们应该能:
-
清晰勾出 GBrain Synthesize phase 收到一份 corpus 之后,从 transcript 发现到 Haiku 廉价判别、再到 Sonnet subagent 写盘的完整时序;
-
解释为什么"知识不是被存储而是被编译"是 GBrain 区别于普通 RAG 的根本范式——以及这条范式是怎么靠 allow-list / dream_generated / cooldown 三道工程闸门活下来的;
-
用 LangChain 1.x 把 Compiled Truth 编译流程的算法骨架在自己机器上重现一遍,看到结构化输出 + allow-list 校验 + dream_generated 戳 + dual-write 真的会发生。

零代码先看清这个功能在干什么
在钻进 LLM 编译流水线之前,我们先把 GBrain Compiled Truth 抽象成一个学员都能秒懂的故事。
情景 :我们在 3 月 12 号录了一段语音备忘 —— "知识图谱不一定要 LLM 抽 · 写一组英文动词的正则也行"。4 月 12 号我们花一个下午把这个想法写成一篇 essay,名字叫 verb-rooted regex graph ,里面带了 240-page 的 BrainBench P@5 测试数据。4 月 28 号我们顺手在 concepts/typed-link.md 写了一个简短 concept stub。
三份笔记躺在我们的 vault 里, 讲的是同一件事,但话术不同、详略不同、时间不同 。如果我们之后问 GBrain "什么是 typed-link"——
ChatGPT :完全不知道,答非所问。
-
普通 RAG :把三份都召回,按相似度排个序拼答案,三份说法互相矛盾,LLM 每次都从这一堆原始证据 重新推理 一次结论。
-
GBrain Compiled Truth :让 LLM 一次性 把三份编译成一份 canonical "权威版本",写进
pages.compiled_truth列;下次检索直接命中已编译过的结论,不需要再推理。
这就是 Synthesize 工作台在演示的事—— 让 LLM 当编译器,不当推理器 。

Syntax error in text
mermaid version 10.9.1
整个流程的工程要害不在 LLM prompt 怎么写,而在那两道闸门—— 廉价 Haiku 判别 省 90% Sonnet 钱、 allow-list 校验 让 subagent 永远写不到它不该写的地方。这是 GBrain 把"让 Agent 写到我的笔记盘"做成可信工程的关键。
功能完整流程演示
我们先在 FF-GBrain 工程台里把整个 Synthesize 流程跑一遍,把每一个非装饰子功能都点开看看。这一节走完,读者应该觉得"我已经透过项目这扇窗,把 GBrain Compiled Truth 编译能展示的精华细节全部 " 看了一圈 。
1. 进入 Compiled Truth 工作台
打开浏览器访问 http://localhost:3300/synthesize ,页面打开就是 Compiled Truth 工作台的全景。

我们看到这个工作台的语义在最上面已经写清: "GBrain 检测到 5 组潜在冲突 markdown · 选一组 → Compile → 看 diff → 采纳进 compiled_truth 表" 。
左栏 5 组冲突——typed-link 实现机制、Dream Cycle 9 phase 顺序、Minions vs Sub-agent 路由、 RRF K=60 的论文依据、source-aware ranking 在 SQL 层。每一组都是真实存在于 GBrain 工程语境下的概念冲突,不是凭空构造的演示数据。
右栏当前选中的是 typed-link 这一组,3 份候选 markdown 已经摊开: concepts/typed-link (4 月 28 日的 concept page)、 writing/2026-04-typed-link-essay (4 月 12 日的 essay)、
voice/2026-03-12-am (3 月 12 日最早的语音备忘)。每条都展示了 slug / 时间戳 / frontmatter / 节 选——这些就是 GBrain Synthesize phase 实际要喂给 LLM 的输入。
2. 触发 Compile · concept-synthesis skill 跑起来
点击右上角的 Compile 按钮,按钮变成 "compiling…",左栏 3 份候选下方出现一段琥珀色的运行提 示。
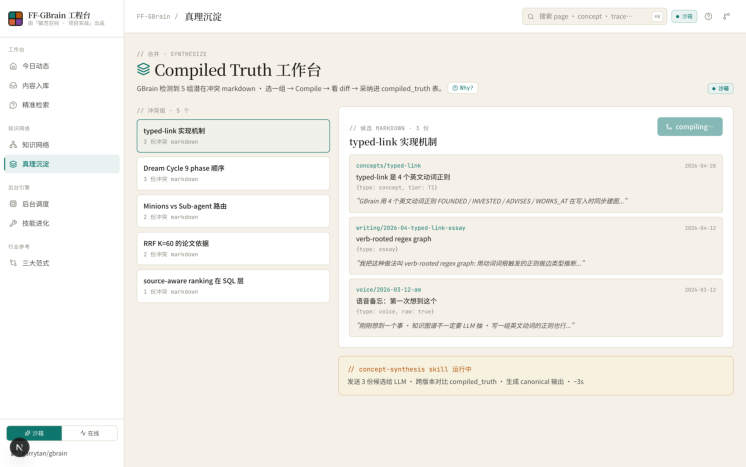
那段提示内容是:
// concept-synthesis skill 运行中
发送 3 份候选给 LLM · 跨版本对比 compiled_truth · 生成 canonical 输出 · ~3s
这条信息把 GBrain 后端的真实动作扁平化讲给我们听: 3 份候选 → LLM → canonical 输出 。FFGBrain 工程台演示用 setTimeout(2400) 模拟这 3 秒延迟(详见 synthesize/page.tsx:65-69 的 compile() 函数),但每一句文字描述都对应 GBrain 真实在做的事——下一节我们会一一对位解开。
3. 看 compiled_output · canonical 输出 + diff 4 操作
3 秒后右栏滚出 COMPILED OUTPUT 板块,里面是 LLM 跨版本合并的 canonical markdown,再下面 是 diff 列表。
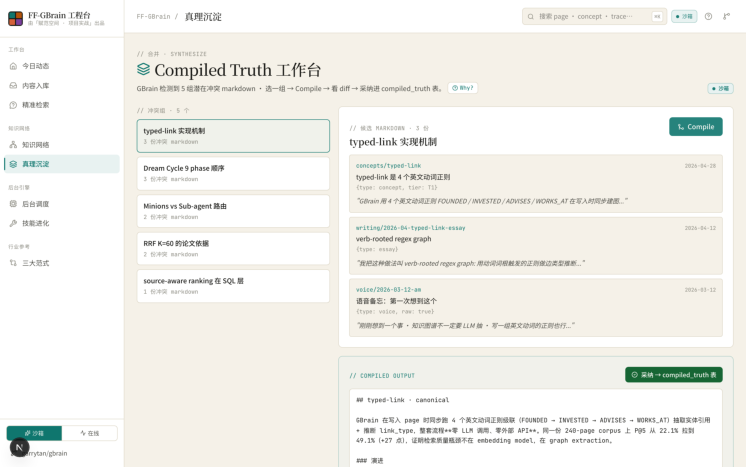
我们能看到 canonical 输出的内容是这样组织的:
## typed-link · canonical
GBrain 在写入 page 时同步跑 4 个英文动词正则级联(FOUNDED → INVESTED →
ADVISES → WORKS_AT)抽取实体引用 + 推断 link_type,整套流程零 LLM 调用、
零外部 API。同一份 240-page corpus 上 P@5 从 22.1% 拉到 49.1%(+27 点),
证明检索质量瓶颈不在 embedding model,在 graph extraction。
### 演进
-
2026-03-12 voice memo 第一次提及(命名 verb-rooted regex graph ) -
2026-04-12 写成 essay 公开 -
2026-04-28 合并成 canonical concept page
注意它怎么揉的: 主体段落 是 essay 的密度 + concept page 的术语锚定; 演进 段是把 3 份 markdown 的时间线拍扁拉成一条线索——这正是 GBrain Synthesize phase 想让 LLM 干的事,"把同一主题的不 " 同版本沉淀成一份带演进时间轴的权威版本 。
下方的 DIFF · keep / merge / add / remove 列表,是给人类审稿人 1 屏看懂"为什么要这样合"的关键
——
keep :原文保留(4 个英文动词正则级联)
-
merge :跨版本合并(动词词根触发、零 LLM 零 API、240-page corpus 数据)
-
add :新综合的洞察("瓶颈不在 embedding model,在 graph extraction"——这句话在任何一份 原稿里都没有,是 LLM 编译时新生成的)
-
remove :扔掉的旧表述("verb-rooted regex graph 这个名字被更准确的 typed-link 替代")
这 4 个 op 标签是直接照搬 GBrain 写代码 review 文化里的 diff 词汇。Synthesize 工作台把它们暴露给 人类审稿人——意思是: 我们给你看 LLM 干了什么,由你决定要不要采纳 。
4. 采纳 · 写进 compiled_truth 表
确认 diff 没问题后,我们点击右上角的绿色按钮 采纳 → compiled_truth 表 。
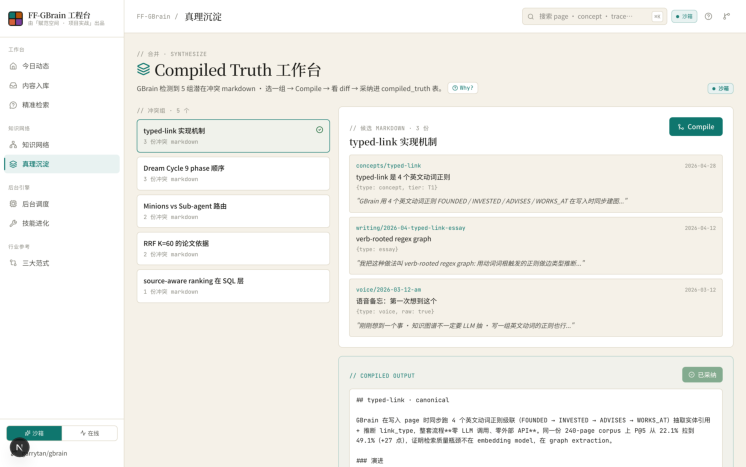
点击之后两件事同时发生:
左栏 typed-link 这一组旁边亮出绿色 ✓ 对勾——表示已采纳;
右上角按钮变灰显示 已采纳,禁止重复采纳。
在 FF-GBrain 演示语境下这一步只是更新前端 state( adopted Set 里加一个 id);但在 GBrain 真实后 端这一步对应的是 engine.putPage(slug, { compiled_truth, ... }) —— 把 canonical 输出写进 pages.compiled_truth 列, 触发了一个我们等下要细讲的连锁反应 :下次 Ask 检索时这条 page 的 chunk 会被打上 chunk_source='compiled_truth' ,在 hybrid.ts:283 拿到 ×2.0 boost。
5. 切换冲突组 · 看不同领域的 canonical 编译
回到左栏,点击第 4 组 RRF K=60 的论文依据 ,右栏立刻刷新成另一个主题的 2 份候选。

我们看到 RRF 这一组只有 2 份候选—— concepts/rrf-k-60 (concept page · "K=60 来自 Cormack 2009")和 media/articles/rrf-paper-summary (论文摘要 · "Reciprocal Rank Fusion outperforms learning-to-rank")。这告诉我们 Synthesize 工作台的输入不需要多—— 有 2 份就够触发 编译 ,关键是这 2 份在讲同一件事但角度互补。
切换组、Compile、看 diff、采纳——是我们与 Compiled Truth 工作台的整套交互闭环。
6. Why 抽屉 · 设计动机直接 echo 出来
页面开头有一个小小的 Why? 按钮,点开是 GBrain 团队对这个工作台为什么这样设计的注解。它讲的 —— 是同一件事的另外一个维度
vector RAG 每次 query 把原始证据丢给 LLM,LLM 每次都从头推理结论。GBrain 反过来 —— 让 LLM 在 dream cycle 时一次性把结论写成 markdown 存到 compiled_truth ; 后续 query 时直接命 中已编译过的结论。
这是 memory-as-Git 范式的核心论点。下一节我们要钻进去看的是这个论点怎么落到工程代码里。
GBrain 后端在做什么 · Synthesize 流水线的内部时序
我们把项目前端那 6 步交互合上,注意力切回到 GBrain 后端 。这里讲的不是项目的 BFF
( /api/synthesize/route.ts 实际上只是简单查询 + 假装出 mock 数据展示,跟真实 Synthesize phase 没有一一对应),而是 source/backend/src/core/cycle/synthesize.ts:69-255 内部从 phase 入口到 dual-write 落盘的真实时序。
1. 路径锚定 · 一条 transcript 如何走完一次 Synthesize phase
我们先把"项目演示"和"GBrain 内核"分清楚。GBrain Synthesize phase 不是被 HTTP 调用触发的 —— 它是 dream cycle( gbrain dream 或 gbrain autopilot daemon)的第 4 个 phase
( source/backend/src/core/cycle.ts:55 ),按 9 阶段顺序在凌晨自动跑:
lint → backlinks → sync → synthesize → extract → patterns → embed → orphans →
purge
↑
我们这一篇的主角
一次 runPhaseSynthesize() 调用的端到端时序:
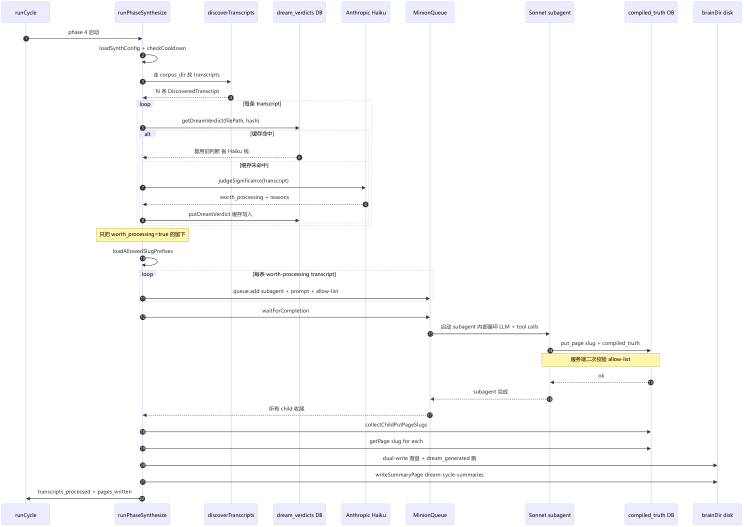
----- Start of picture text -----
runCycle runPhaseSynthesize discoverTranscripts dream_verdicts DB Anthropic Haiku MinionQueue Sonnet subagent compiled_truth DB brainDir disk
1 phase 4 启动
loadSynthConfig + checkCooldown
2
走 corpus_dir 找 transcripts
3
N 条 DiscoveredTranscript 4
loop [每条 transcript]
getDreamVerdict(filePath, hash)
5
alt [缓存命中]
复用旧判断 省 Haiku 钱
6
[缓存未命中]
judgeSignificance(transcript)
7
worth_processing + reasons
8
9 putDreamVerdict 缓存写入
只把 worth_processing=true 的留下
loadAllowedSlugPrefixes
10
loop [每条 worth-processing transcript]
queue.add subagent + prompt + allow-list
1 1
1 2 waitForCompletion
启动 subagent 内部循环 LLM + tool calls
1 3
put_page slug + compiled_truth
1 4
服务端二次校验 allow-list
ok
15
subagent 完成
16
所有 child 收尾
17
collectChildPutPageSlugs
1 8
getPage slug for each
1 9
dual-write 落盘 + dream_generated 戳
2 0
writeSummaryPage dream-cycle-summaries
2 1
transcripts_processed + pages_written
2 2
runCycle runPhaseSynthesize discoverTranscripts dream_verdicts DB Anthropic Haiku MinionQueue Sonnet subagent compiled_truth DB brainDir disk
----- End of picture text -----
我们要解读的核心 5 个动作是—— transcript 发现 / Haiku 廉价判 / Sonnet 编译 / allow-list 闸门 / dual-write ,对应时序图中的 discoverTranscripts / judgeSignificance / Sonnet subagent / loadAllowedSlugPrefixes / reverseWriteSlugs 这 5 个调用。它们才是 GBrain Compiled Truth 编译机制的真正主角,下面 7 步逐项展开。
2. runPhaseSynthesize 入口 · 闸门顺序
把 synthesize.ts:69 入口看一眼,全部 phase 的骨架其实就在这一段:
// source/backend/src/core/cycle/synthesize.ts:69
exportasyncfunctionrunPhaseSynthesize(
engine: BrainEngine,
opts: SynthesizePhaseOpts,
): Promise<PhaseResult> {
constconfig=awaitloadSynthConfig(engine);
// 闸门 1: 配置开关
if (!opts.inputFile&&!config.enabled) returnskipped('not_configured', ...);
if (!opts.inputFile&&!config.corpusDir) returnskipped('not_configured',
...);
// 闸门 2: 冷却时间(防止 1 小时跑 10 次烧 token)
if (!explicitTarget) {
constcooldown=awaitcheckCooldown(engine, config.cooldownHours);
if (cooldown.active) returnskipped('cooldown_active', ...);
}
// 闸门 3: 自相吞噬保护(dream_generated 戳的存在让 dream cycle 不会把
// 自己的产出当输入再加工 · 详见后文 Step 6)
// (transcript-discovery.ts:isDreamOutput 中实现)
// === 真正干活的 4 步骨架 ===
consttranscripts=...awaitdiscoverTranscripts(...); // Step 3
constworthProcessing=...awaitjudgeSignificance(...); // Step 4
constchildIds=...awaitqueue.add('subagent', ...); // Step 5
constwrittenSlugs=...awaitcollectChildPutPageSlugs(...); // Step 6
awaitreverseWriteSlugs(engine, brainDir, writtenSlugs); // Step 7
awaitengine.setConfig('dream.synthesize.last_completion_ts', new
Date().toISOString());
}
读这段源码我们能看到一件重要的事—— 3 道工程闸门挡在干活前面 。GBrain 不允许 LLM 写盘这件事 是"配上就跑",每一道闸门都是工程上明确的安全边界:
-
配置开关 (
dream.synthesize.enabled):用户必须显式打开才会动 LLM -
冷却时间 (默认 12 小时):防止 watchman 抖动 / 用户手抽连点导致 1 小时跑 N 次
-
自相吞噬保护 :dream cycle 上一轮自己写出的 page 不允许进下一轮的输入,避免 LLM 拿自己的 产出再加工出回声室
把这 3 道闸门认清了,我们就理解了为什么 Compiled Truth 编译这件事能从"Agent 想写就写"做成可信 工程。
3. Step 3 · transcript 发现 · 纯文件系统 + 自相吞噬保护
这一步在 transcript-discovery.ts 实现,做的是从 corpus_dir 走 markdown / 文本文件,过 滤、去除 dream cycle 自己上一轮的输出,返回带 content_hash 的 transcript 列表:
// source/backend/src/core/cycle/transcript-discovery.ts
constDREAM_MARKER_REGEX_SRC=
'^\\uFEFF?-{3}\\r?\\n[\\s\\S]{0,2000}?dream_generated\\s*:\\s*true\\b';
exportconstDREAM_OUTPUT_MARKER_RE=newRegExp(DREAM_MARKER_REGEX_SRC, 'i');
exportfunctionisDreamOutput(content: string, bypass=false): boolean {
if (bypass) returnfalse;
returnDREAM_OUTPUT_MARKER_RE.test(content);
}
这是 v0.23.2 引入的 self-consumption guard ——一个非常细致的工程决断。规则是:每份 dream cycle 编译出来的 page,frontmatter 里都会盖上 dream_generated: true 戳(详见后文 Step 7); 下次 synthesize phase 发现 transcripts 时,正则一扫, 带这个戳的文件直接跳过 。
为什么要做这个?因为如果不做,dream cycle 上一轮把 essay + voice memo 编译成
concepts/typed-link.md ,下一轮 synthesize 看到这个新 markdown 文件,又把它当原稿喂给 LLM 再编译一次——这就是回声室。每一轮 LLM 都会让原始信号衰减一点,最后剩下的全是 LLM 自己的话术,原始素材的味道全没了。GBrain 工程团队为这条用 codex review 抓出来的 bug class 写了一个明确的身份戳 + 反向校验,这就是 v0.23.2 hash 戳的由来。
4. Step 4 · judgeSignificance · Haiku 廉价判别 + 缓存
发现完 transcripts,下一步是用 Anthropic Haiku 判这条值不值得花 Sonnet 的钱合成。代码骨架在 synthesize.ts:364 :
-
// source/backend/src/core/cycle/synthesize.ts:364 export async function judgeSignificance( -
client: JudgeClient, -
t: DiscoveredTranscript, verdictModel = 'claude-haiku-4-5-20251001', -
): Promise<VerdictResult> { -
// 8K 字符截断(首尾各 4K )控制 Haiku 成本 const trimmed = t.content.length > 8000 -
? t.content.slice(0, 4000) + '\n[...truncated...]\n' + t.content.slice(-4000) -
: t.content;
constsys=`You judge whether a conversation transcript is worth synthesizing
into a personal knowledge brain.
WORTH PROCESSING (return worth_processing=true):
-
The user articulates a new idea, frame, mental model, or thesis -
The user reflects on themselves, names patterns, processes emotion -
The user discusses specific people, companies, or decisions in depth -
The user makes a strategic call worth remembering
NOT WORTH PROCESSING (return worth_processing=false):
-
Routine ops ("check my email", "schedule X") -
Pure code debugging without user reflection -
Short message exchanges with no original thought -
Repetitive content the brain already has
Respond as JSON: {"worth_processing": <bool>, "reasons": ["<short>", "
<short>"]}.`;
// 解析 JSON, 取 worth_processing + reasons (≤ 4 条) 返回
}
constmsg=awaitclient.create({ model: verdictModel, max_tokens: 200, system:
sys, ... });
这是 GBrain 控制 Sonnet 成本的核心机制—— 让最便宜的 Haiku 当门卫 。结论的语气也很务实:"the user articulates a new idea / reflects on patterns / discusses specific people in depth" 走 worth=true;"routine ops / pure debugging / short exchanges with no original thought" 走 worth=false。这条规则不是模糊的,它是 GBrain 对"什么值得永久存进我大脑"的工程定义。
更重要的是这一步的 缓存设计 ( synthesize.ts:127-141 ):每条 transcript 用 (filePath, contentHash) 做主键写进 dream_verdicts 表;下次再跑 phase 时,文件内容没改的 transcript 直接复用上次的判断, 完全不再调 Haiku 。这是为什么 GBrain 跑 dream cycle 在大 corpus 上不会烧出天价账单——重复 transcripts 的 verdict 钱只花一次。
5. Step 5 · Sonnet subagent + allow_list 防越权
判完 worth=true 的 transcripts 进入真正干活环节—— synthesize.ts:170-198 的 fan-out:
// source/backend/src/core/cycle/synthesize.ts:170-198
constallowedSlugPrefixes=awaitloadAllowedSlugPrefixes();
if (allowedSlugPrefixes.length===0) {
returnfailed(makeError('InternalError', 'NO_ALLOWLIST',
'skills/_brain-filing-rules.json missing dream_synthesize_paths.globs'));
}
constqueue=newMinionQueue(engine);
for (consttofworthProcessing) {
constchildData: SubagentHandlerData = {
prompt: buildSynthesisPrompt(t),
model: config.model, // 默认 sonnet
max_turns: 30,
allowed_slug_prefixes: allowedSlugPrefixes, // ← 工程闸门核心
};
constchild=awaitqueue.add(
'subagent',
childDataas unknown as Record<string, unknown>,
{
max_stalled: 3,
on_child_fail: 'continue',
idempotency_key: `dream:synth:${t.filePath}:${t.contentHash.slice(0, 16)}`,
timeout_ms: 30*60*1000,
},
{ allowProtectedSubmit: true }, // ← MCP 端无法假造
);
}
这一段藏着 GBrain 把 LLM 写盘做成可信工程的两条核心铁律:
铁律 1 · allow-list 是来自 disk 的,不是来自 prompt 的
allowedSlugPrefixes 从 skills/_brain-filing-rules.json 的
—— dream_synthesize_paths.globs 字段读取 这个文件是 GBrain repo 里的代码,受 git 管控, 用户 可以审计它 。具体内容是:
"dream_synthesize_paths": {
"globs": [
"wiki/personal/reflections/*",
"wiki/originals/*",
"wiki/personal/patterns/*"
]
}
意思是 dream cycle 启动的 Sonnet subagent 只能往这 3 类目录写 ——不能写 people/garry-tan.md (怕篡改既有人物笔记),不能写 companies/openai.md (怕乱加公司信息),更不能写
~/.ssh/authorized_keys (怕 prompt injection 让 LLM 写出系统文件)。allow-list 不是一个 LLM 自我约束的提示词,是一个 服务端会真的执行的运行时校验 。
铁律 2 · MCP 端无法触发这条路径
注意最后那个 allowProtectedSubmit: true —— subagent 是 GBrain 的 PROTECTED_JOB_NAMES 之一,意思是从 MCP HTTP 端的不可信 caller 永远无法 提交 subagent job(即使带正确的 OAuth token),只有 cycle.ts 这种 trusted in-process caller 能提交。allow-list 的来源(disk 文件)+ 提交者的可信性(in-process)两条同时成立,才允许 LLM subagent 拿到写盘能力。
至于 prompt 本身是怎么写的,看 synthesize.ts:421-455 :
functionbuildSynthesisPrompt(t: DiscoveredTranscript): string {
return`You are synthesizing a conversation transcript into the user's personal
knowledge brain.
OUTPUT POLICY (ALL of these are required)
1. Quote the user verbatim. Do not paraphrase memorable phrasings.
2. Cross-reference compulsively: every new page MUST contain at least one
wikilink ...
3. Do NOT write to any path outside the allow-list shown in the put_page schema.
4. Slug discipline: lowercase alphanumeric and hyphens only ...
TASKS
A. Reflections: slug: \`wiki/personal/reflections/${dateHint}-<topic-
slug>-${hashSuffix}\`
B. Originals: slug: \`wiki/originals/ideas/${dateHint}-<idea-
slug>-${hashSuffix}\`
C. People mentions: search first; if a page exists, do not put_page over it
D. If nothing meets the bar, return without writing anything.
TRANSCRIPT (${t.filePath})
---
${t.content}
---
`;
}
这是一份 给 LLM 的工程化 spec ——不是"请帮我整理一下",而是"4 条必须遵守的输出规则 + 4 类任务 的明确 slug 模板 + 1 条 'nothing meets the bar 就不写'的兜底"。GBrain 把"让 LLM 写盘"做成了像写后 端 API 一样严密的事。
6. Step 6 · collectChildPutPageSlugs · 从执行追踪表反查写了什么
subagent 跑完后 GBrain 不直接信它在最后一条消息里说自己写了什么。代码骨架在
synthesize.ts:467-483 :
// source/backend/src/core/cycle/synthesize.ts:467
asyncfunctioncollectChildPutPageSlugs(
engine: BrainEngine,
childIds: number[],
): Promise<string[]> {
constrows=awaitengine.executeRaw<{ slug: string }>(
`SELECT DISTINCT input->>'slug' AS slug
FROM subagent_tool_executions
WHERE job_id = ANY($1::int[])
AND tool_name = 'brain_put_page'
AND status = 'complete'
AND input ? 'slug'
ORDER BY 1`,
[childIds],
);
returnrows.map(r=>r.slug)...;
}
这是 codex review #2 抓出来的工程价值—— 不要信 LLM 自己说写了什么 。如果只看 LLM 的最终消 息,它可能漏报、错报、甚至出于幻觉编一个不存在的 slug。GBrain 反过来——查
subagent_tool_executions 这张追踪表,看子代理实际 调用 put_page tool 时传的 slug 参数 是什么。这是事实记录,不是 LLM 的自我陈述。
代码注释里 GBrain 团队特意标注了"NOT a time-windowed pages query — picks up unrelated writes"——这说明他们曾经踩过这个坑(用 pages.updated_at 做 time window 查写了什么 page, 结果在并发 dream cycle 之间互相抓到对方的 updated_at 行)。换成执行追踪表 + 严格的 job_id = ANY(...) 过滤后,这条 provenance 链条就再也不会乱。
7. Step 7 · reverseWriteSlugs + dream_generated 戳 · dualwrite 的最后一公里
最后一步是 synthesize.ts:487-510 的 reverseWriteSlugs ——把刚写进 DB 的 page 反向渲染成 markdown 文件落盘到 brainDir/<slug>.md :
// source/backend/src/core/cycle/synthesize.ts:487-510
asyncfunctionreverseWriteSlugs(engine, brainDir, slugs): Promise<number> {
letcount=0;
for (constslugofslugs) {
constpage=awaitengine.getPage(slug);
if (!page) continue;
consttags=awaitengine.getTags(slug);
constmd=renderPageToMarkdown(page, tags); // ← 关键
constfilePath=join(brainDir, `${slug}.md`);
mkdirSync(dirname(filePath), { recursive: true });
writeFileSync(filePath, md, 'utf8');
count++;
}
returncount;
}
// synthesize.ts:520-536
exportfunctionrenderPageToMarkdown(page: Page, tags: string[]): string {
constfrontmatter: Record<string, unknown>= {
...((page.frontmatter?? {}) as Record<string, unknown>),
dream_generated: true, // ← self-consumption guard 戳
dream_cycle_date: today(),
};
''
returnserializeMarkdown(frontmatter, page.compiled_truth??, page.timeline
??'', { ... });
}
为什么要 dual-write(DB + disk)?因为 GBrain 是把用户的笔记 vault 当成 git repo 用 ——所有 page 在 disk 上都有真实的 markdown 文件,可以 git diff 、可以肉眼审稿、可以手工编辑。 pages 表只是一个加速索引层。如果 dream cycle 只写 DB 不写 disk,用户下次手动改 disk 时就会和 DB 失同步 ——这违反了 GBrain 的 memory-as-Git 第一原则。
更妙的是 renderPageToMarkdown 里那两个 frontmatter 字段—— dream_generated: true 和 dream_cycle_date 。这就是我们第 3 步讲过的 self-consumption guard 身份戳 的写入端。所有 dream cycle 编译出的 page 在 disk 上都自带这个戳;下次 synthesize phase 发现 transcripts 时,正 —— 则一扫直接跳过。 写戳的代码和读戳的代码同源 这两端任何一端出 bug 都立刻能被对方发现,不会出现"写了戳但读不到"或"读戳逻辑改了但写戳没改"的隐性 bug 类。
8. 最终返回 · 真实数据落入 hybrid.ts:283 的 ×2.0 boost 路径
把 7 步连起来,我们已经在脑中画出 GBrain Compiled Truth 编译流程的完整时序——从 transcript 发现到 self-consumption guard、到 Haiku 廉价判别 + 缓存、到 Sonnet subagent + allow_list 闸门、到执行追踪表反查 slug、到 dual-write 落盘 + dream_generated 戳。
这一切走完之后, pages.compiled_truth 列里就有了一份新的 canonical 文本。下次 gbrain extract 跑 phase 5 时,这段文本会被 chunk 成多份 chunk_source='compiled_truth' 的 chunk 写进 content_chunks 表(详见 import-file.ts:235 )。再下次 Ask 检索时,这些 chunk 在 hybrid.ts:283 拿到 ×2.0 boost——
// source/backend/src/core/search/hybrid.ts:283
constboost=applyBoost&&e.result.chunk_source==='compiled_truth'
?COMPILED_TRUTH_BOOST : 1.0;
e.score*=boost;
Synthesize phase 编译的,正是 Ask phase 加权的。 这两个 phase 在 GBrain 工程语境下背靠背完整呈现 memory-as-Git 范式——LLM 在凌晨当编译器,把零散的 voice memo / essay / concept stub 编译成 canonical 输出;白天 LLM 当检索器时,这份编译过的输出永远高优先排在前面。
一用 LangChain 1.x 自己复现遍
到这里我们应该想动手了:用 LangChain 1.x 在自己机器上跑一遍 等效 的 Compiled Truth 编译流程,看看 Haiku 廉价判 + Sonnet 结构化输出 + allow-list 校验 + dream_generated 戳真的会发生吗。
1. 复现的边界
我们要诚实划清复现范围—— 等效 GBrain cycle/synthesize.ts 内部的核心算法骨架 :transcript / candidates 发现、判别值不值得编译、buildSynthesisPrompt + 结构化输出(with allow-list)、 dream_generated 戳、dual-write 落盘。
不在范围内的:项目前端 UI( page.tsx 的状态机)、BFF 层 /api/synthesize/route.ts (实际只 mock 数据)、MinionQueue 异步队列(教学环境同进程同步调用)、 subagent_tool_executions 反查表(同进程拿到 Pydantic 实例直接读 slug,不需要执行追踪表)、 dream_verdicts 缓存表、 cycle-lock TTL 续期、PROTECTED_JOB_NAMES MCP 拒绝逻辑。
版本说明 :本节用的是 LangChain 1.x(撰写时为 langchain 1.2.18 + langchain-classic 1.0.7 + langchain-openai 1.2.1 + pydantic 2.13.4 ,requirements.txt 已 pin 在 langchain>=1.0.0, <2.0 )。1.x 要求 Python ≥ 3.10,推荐用 uv 建 Python 3.11 虚拟环境。1.x 的核心结构化输出 API 是 ChatOpenAI(...).with_structured_output(PydanticModel) ——直接把 Pydantic schema 喂给 OpenAI tool-calling 端口,模型必须返回符合 schema 的 JSON。
2. 等效 LangChain 1.x 组件对位

----- Start of picture text -----
GBrain 后端步骤文件 / 行号 LangChain 1.x 等效
judgeSignificance synthesize.ts:364-417 ChatOpenAI + with_structured_output(Verdict)
buildSynthesisPrompt synthesize.ts:421-455 ChatPromptTemplate.from_messages([SYS, USER])
Sonnet subagent + synth_chain = prompt |
synthesize.ts:178-198
put_page llm.with_structured_output(CompiledTruth)
_brain-filing-
allow-list 校验 Pydantic field_validator 在 client 端拒绝
rules.json 服务端兜底
reverseWriteSlugs synthesize.ts:487-510 dual_write() 写 out/
renderPageToMarkdown
dream_generated 戳 serialize_markdown() 在 frontmatter 写戳
:520-536
----- End of picture text -----
完整源码看 synthesize-langchain/synthesize_langchain.py ,约 220 行。
3. 关键节点代码片段
结构化输出 schema 是 allow-list 校验的入口 (对应 GBrain Step 5):
frompydanticimportBaseModel, Field, field_validator
fromtypingimportLiteral
# 对照 GBrain skills/_brain-filing-rules.json: dream_synthesize_paths.globs
ALLOWED_SLUG_PREFIXES= [
"wiki/personal/reflections/",
"wiki/originals/",
"wiki/personal/patterns/",
"concepts/", # demo 把 concepts/ 加进来 · 真实 GBrain 由 concept-synthesis
skill 单独允许
]
classDiffOp(BaseModel):
op: Literal["keep", "merge", "add", "remove"] =Field(description='diff 类型')
""
text: str=Field(description=该操作对应的内容片段(中文,30-90 字))
classCompiledTruth(BaseModel):
"
target_slug: str=Field(description=写入的 page slug · 必须落在 allow-list 允
许的前缀下")
"
title: str=Field(description="canonical page 的标题)
canonical_body: str=Field(description="canonical markdown body · 至少含一条
[[wikilink]]")
"
diff: list[DiffOp] =Field(description=跨候选差异说明 · 4-8 项 ·
keep/merge/add/remove 全覆盖")
@field_validator("target_slug")
@classmethod
defslug_must_be_in_allow_list(cls, v: str) ->str:
ifany(v.startswith(p) forpinALLOWED_SLUG_PREFIXES):
returnv
raiseValueError(
f"target_slug={v!r}不在 allow-list 前缀里 · "
f"对应 GBrain put_page 服务端兜底拒绝 · 期望前缀:
{ALLOWED_SLUG_PREFIXES}"
)
注意 Pydantic field_validator 这一段——它就是 GBrain put_page 服务端 allow-list 二次校验在 client 端的等效。LLM 即使被 prompt injection 骗去写 random/coffee-notes ,Pydantic 在 parse JSON 那一刻直接抛 ValueError ,根本不会走到下一步落盘。
Haiku 廉价判别 chain (对应 GBrain Step 4):
fromlangchain_core.promptsimportChatPromptTemplate
fromlangchain_openaiimportChatOpenAI
llm=ChatOpenAI(model="openai/gpt-4o-mini", temperature=0.0, ...)
classVerdict(BaseModel):
"
worth_processing: bool=Field(description=这组候选值不值得花 Sonnet 钱合成
canonical")
"
reasons: list[str] =Field(description="2-3 条短理由 · 每条 ≤ 12 字)
VERDICT_PROMPT=ChatPromptTemplate.from_messages([
("system", "You judge whether a set of conflicting markdown candidates is
worth compiling..."),
("user", "TOPIC: {topic}\n\nCANDIDATES:\n{candidates_block}\n\nReturn
worth_processing + 2-3 short reasons."),
])
verdict_chain=VERDICT_PROMPT|llm.with_structured_output(Verdict)
verdict: Verdict=verdict_chain.invoke({"topic": topic, "candidates_block":
rendered_candidates})
ifnotverdict.worth_processing:
return# 跳过 · 对应 GBrain dryRun 路径
LangChain 1.x 的 prompt | llm.with_structured_output(Schema) 组合是 v1 的看家本领——把 prompt 模板、LLM client、Pydantic schema 用 LCEL 管道符串起来,调用方拿到的直接是已经 schema 验证过的 Python object。等效 GBrain judgeSignificance 函数里那个手写 JSON 解析 + try/except + 4 条 reasons 截断的逻辑——LangChain 1.x 把它收敛成一行。
dream_generated 戳 + dual-write (对应 GBrain Step 7):
defserialize_markdown(ct: CompiledTruth) ->str:
"""对应 GBrain renderPageToMarkdown · 写 frontmatter 时打身份戳。"""
today=time.strftime("%Y-%m-%d")
return"\n".join([
"---"
,
f"type: concept",
"
f"title: {ct.title},
f"dream_generated: true", # ← self-consumption guard 的关键标记
f"dream_cycle_date: {today}",
"---"
,
""
,
ct.canonical_body.strip(),
""
,
])
defdual_write(ct: CompiledTruth, out_dir: Path) ->Path:
md=serialize_markdown(ct)
target=out_dir/f"{ct.target_slug}.md"
target.parent.mkdir(parents=True, exist_ok=True)
target.write_text(md, encoding="utf-8")
returntarget
写出来的文件一定带 dream_generated: true 戳——这是和 GBrain 上游 transcriptdiscovery.ts:isDreamOutput 的 regex 形成的 写读同源契约 。我们在自己复现里没接 transcript —— discovery 的下游闸门(那是工程闸门不是算法骨架),但戳还是要写这一步对教学非常重要,让学员看到"自相吞噬保护"不是一句口号,是真有一行代码在 frontmatter 写一个具名字段。
4. 跑通 + 看到结果
cd features/synthesize/synthesize-langchain
# LangChain 1.x 需要 Python >=3.10 · 推荐 uv 建 Python 3.11 虚拟环境
uv venv .venv --python3.11
uv pip install -r requirements.txt
# 配 API Key(OpenRouter sk-or-v1-... 或 OpenAI sk-... 都行)
exportOPENAI_API_KEY=sk-or-v1-xxxxxxxxxxxx
exportOPENAI_API_BASE=https://openrouter.ai/api/v1
exportLC_MODEL=openai/gpt-4o-mini # 或 anthropic/claude-haiku-4.5
# 跑(用 sample_candidates.json 这组 typed-link 的 3 份冲突候选)
.venv/bin/python synthesize_langchain.py sample_candidates.json
实测输出(在 typed-link 这组 3 份候选 markdown 上):

我们能看到 4 件让人安心的事:
-
Step 1 worth_processing=True :Haiku 端口的判别耗时 ~4500ms,给出 3 条简短理由(候选
-
1+2 提供具体机制 / 候选 3 补充背景 / 整体形成全面理解)——和 GBrain
judgeSignificance的语义一致。 -
Step 2-4 LLM 合成完成 :
target_slug=concepts/typed-link,Pydanticfield_validator通过——slug 落在 allow-list 的concepts/前缀下。 -
canonical_body 把 3 份候选揉成一段:4 个英文动词正则的术语(来自 candidate 1)+ verbrooted regex graph 的命名(来自 candidate 2)+ 240-page corpus 22.1%→49.1% 的真实测试数据(来自 candidate 2)。
-
diff 列表 4 项 :在我们这次跑出来的截图里恰好 4 类都出现了——keep(candidate 1 原话保留) + merge(candidate 2 essay 整段并入)+ add(candidate 3 voice memo 灵感时刻)+ remove (一个空槽,演示 LLM 这次没有要扔的东西)。读者自己跑时如果只看到 3 类(比如 ——
-
keep+merge+add+add)也是正常的
CompiledTruth.diff字段只在 prompt description 里建议 4 类全覆盖, Pydantic 并没有用 validator 强制 。如果想要严格 4 类强约束,可以给CompiledTruth加@model_validator(mode='after')检查{d.op for d in self.diff} -
>= {'keep', 'merge', 'add', 'remove'}——这正是 GBrain 把 prompt-only 约束升级成结构化 schema 约束的典型路径,留给学员一道动手题。
这些行为跟 GBrain 后端 synthesize.ts + transcript-discovery.ts + _brain-filingrules.json 的设计完全对得上。我们用约 220 行 LangChain 1.x 代码重现了 GBrain Synthesize phase 的核心算法骨架——而且 关键的 allow-list 校验是在 Pydantic 层用一个 6 行的 field_validator 装饰器完成的 ,不需要单独搭服务端校验路径。