工业级智能体记忆系统开发实践

《2026大模型Agent智能体开发实战》 体验课
工业级智能体记忆系统开发实践
[toc]

Part 1. 智能体记忆系统核心技术与主流架构演进
一、智能体记忆系统(Agent Memory)技术综述
1. OpenClaw爆火背后的工程:记忆管理与Skills系统
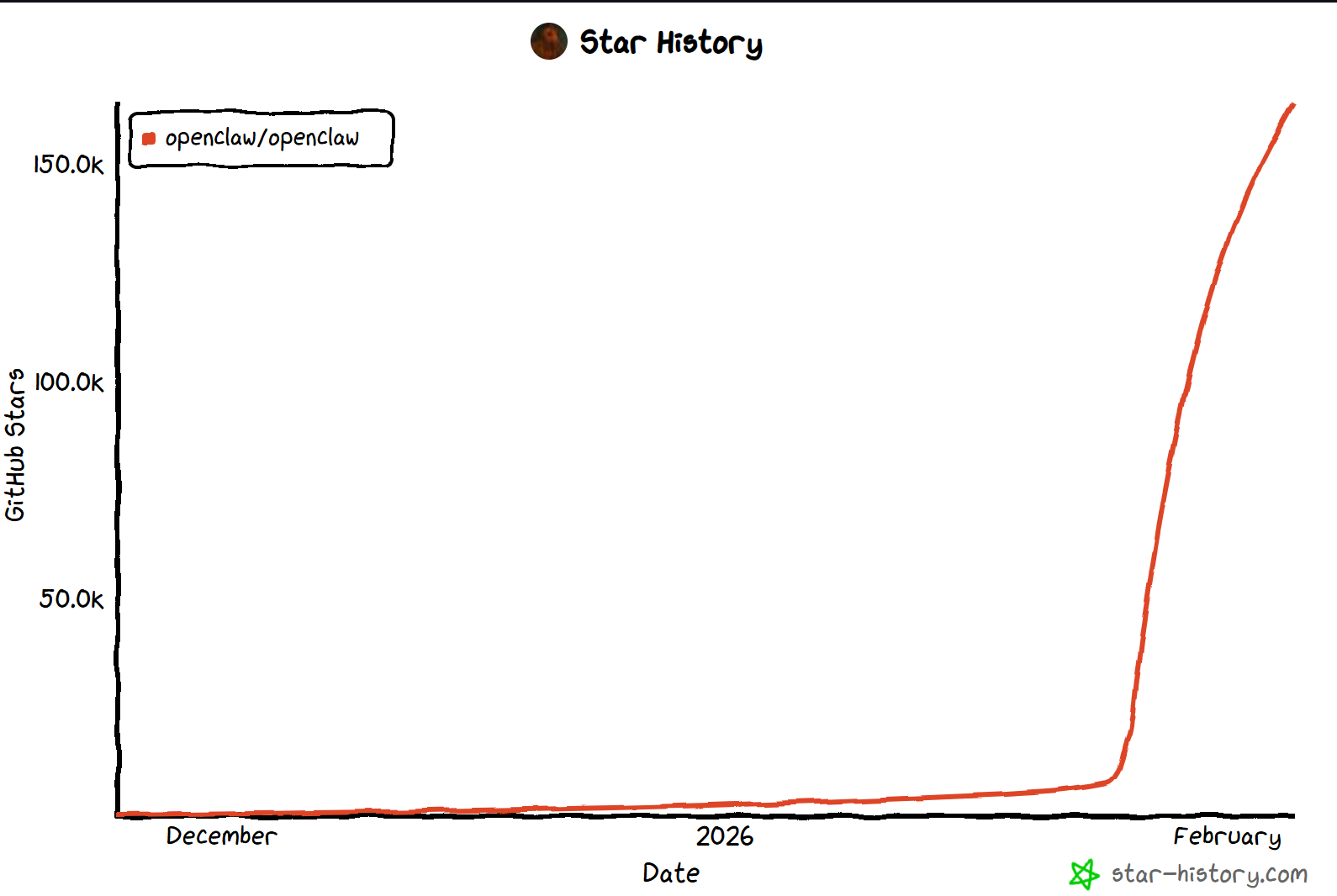
如果说 2025 年是 LLM 模型的“军备竞赛”,那么 2026 年初最引人注目的技术现象无疑是 OpenClaw 的横空出世。作为一个开源的自主智能体框架,OpenClaw 在 GitHub 上的 Star 数在短短两个月内突破了 150k 大关,不仅超越了老牌的 AutoGPT,更在开发者社区引发了关于“数字员工(Digital Employee)”的狂热讨论。
其影响力早已溢出技术圈:从有人利用 OpenClaw 开设“一人公司”实现全自动化的业务流转,到 Moltbook 社区中成千上万个 Agent 自主交互,甚至出现了 RentAHuman 这种由 AI Agent 主动雇佣人类来完成物理世界任务(如取快递、验证码识别)的逆向众包平台。OpenClaw 的成功证明了:一个具备极高自主性的智能体,已经不再是实验室里的玩具,而是具备了改变生产关系的潜力。
OpenClaw 之所以能给用户带来如此震撼的体验,核心功臣并非是其底层接入了多强的 LLM(它本质上是模型无关的),而在于其 工程化极致的记忆系统。用户在使用 OpenClaw 时,最大的感受是“贴心”与“连贯”:它不像传统的 Chatbot 那样聊几句就“断片”,而是能清晰地记住用户三周前的偏好设置、项目背景甚至是一次随口提及的 API Key。更重要的是,它具备**自我迭代(Self-Evolution)**的能力——能够将一次成功的工具调用经验沉淀为长期记忆(Skills),在下一次遇到类似任务时直接复用,而无需用户重复 Prompting。这种“无限上下文”的错觉和“越用越顺手”的成长性,正是得益于其底层精心设计的 Short-term(工作记忆) + Long-term(向量/图谱记忆) + Archival(归档记忆) 三级存储架构。
2. OpenClaw记忆系统架构简介:从“黑盒”回归“透明”
与市面上大多数依赖庞大云端向量数据库(如 Pinecone, Milvus)的 Agent 框架不同,OpenClaw 采取了一种极其独特的**“本地优先(Local-First)”与“文件即数据库(File-System as Database)”的设计哲学。它通过“Markdown 原生存储 + 嵌入式 SQLite 向量库”**的混合架构,在极低的资源占用下实现了极高的工程实用性。
2.1 双层记忆存储模型(Dual-Layer Memory)
OpenClaw 巧妙地将记忆划分为两个物理层级,完美模拟了人类的认知模式:
- Layer 1:每日流水账 (Daily Logs) 存储于
~/clawd/memory/YYYY-MM-DD.md。这相当于 Agent 的“日记本”,采用**追加写入(Append-only)**模式。Agent 会在这里记录当天的临时想法、任务执行流、工具调用结果以及对环境的观察。这种设计保证了“短期工作记忆”的高保真记录,且不会污染长期知识库。 - Layer 2:长期知识库 (Curated Knowledge) 存储于
~/clawd/MEMORY.md。这相当于 Agent 的“核心档案”,存放经过筛选和沉淀的高价值信息,如用户偏好(User Preferences)、项目核心事实(Project Facts)、已习得技能(Learned Skills)。Agent 会通过定期的“记忆刷盘(Flush)”机制,将 Daily Logs 中的精华提炼并写入此文件。
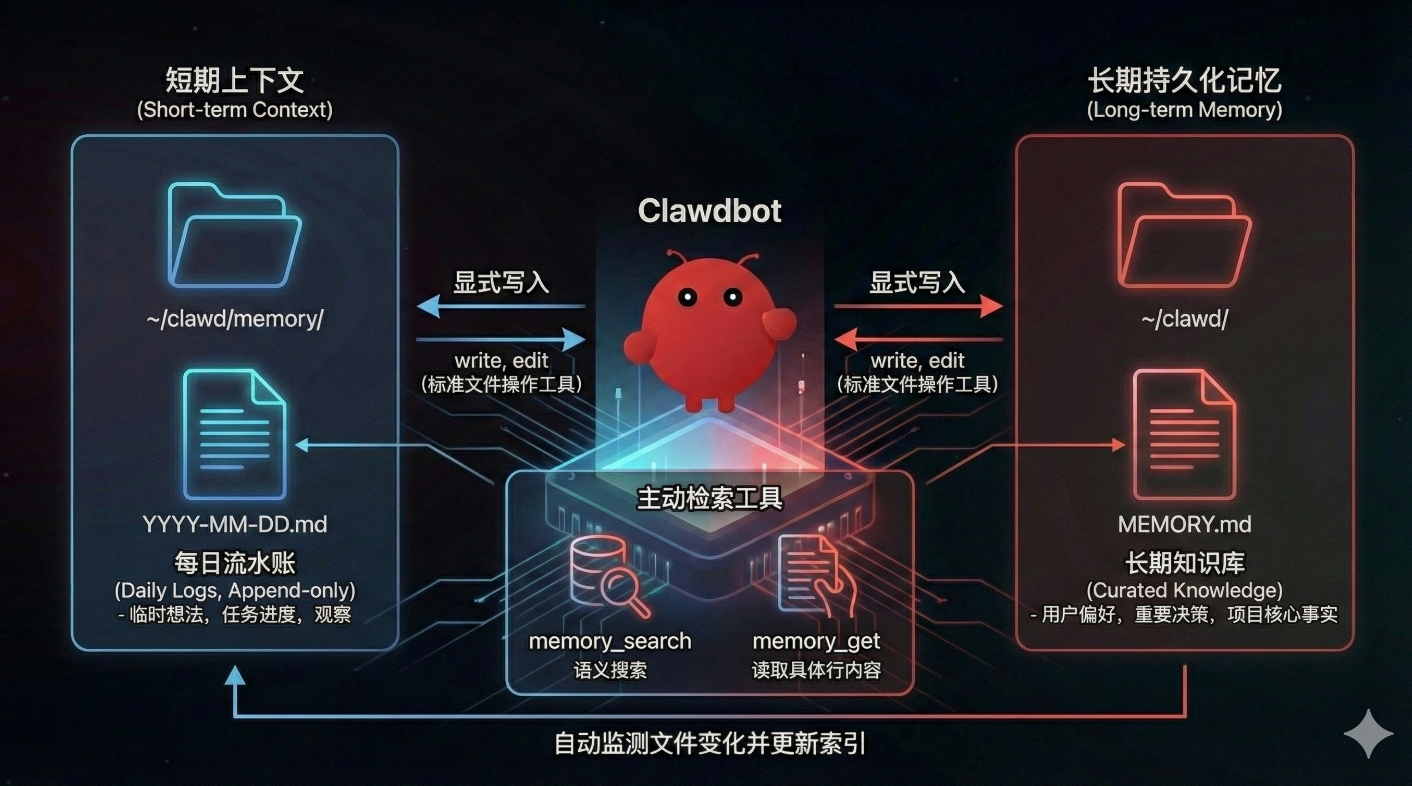
2.2 混合检索与透明化交互
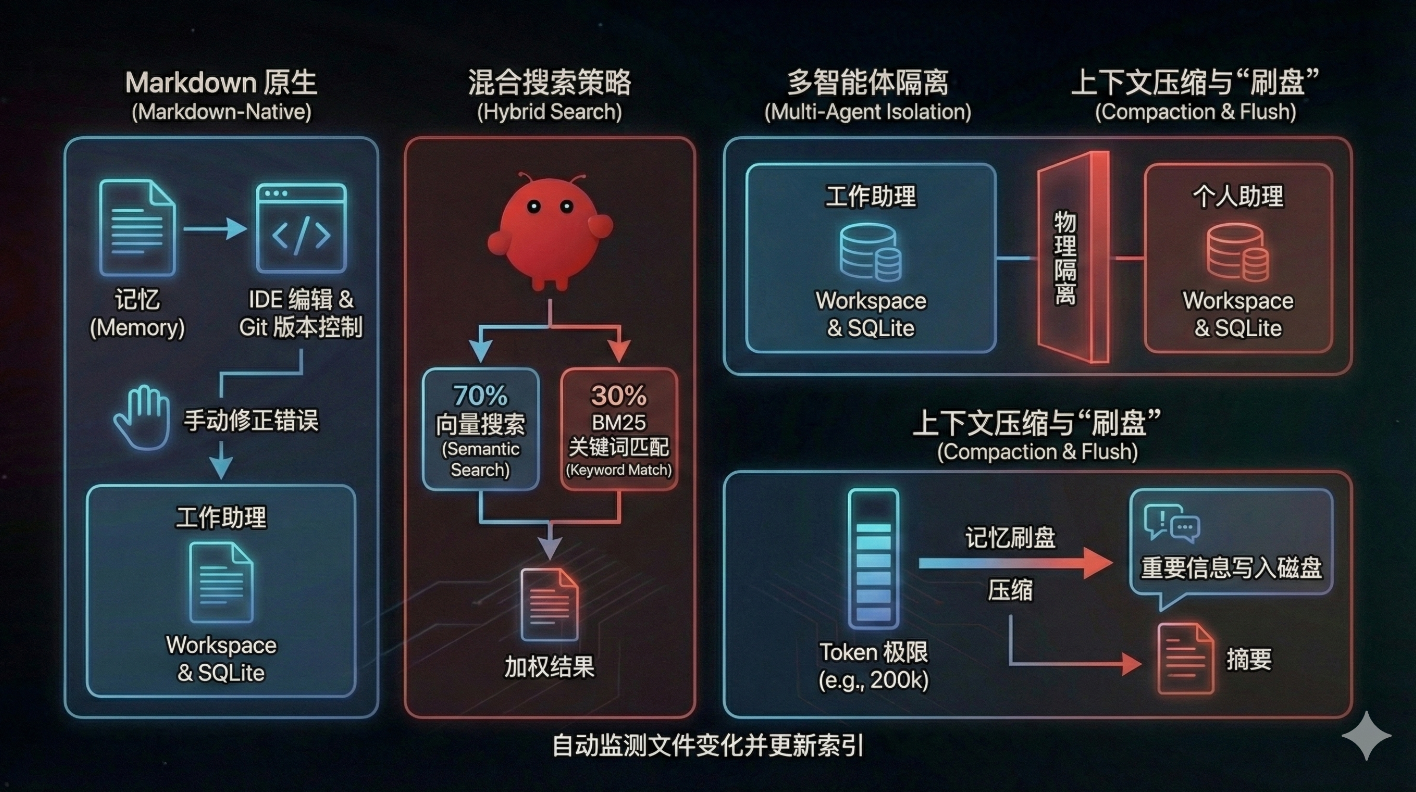
为了解决单一向量检索“查不准”的顽疾,OpenClaw 引入了加权混合搜索策略:
-
混合搜索 (Hybrid Search):系统采用 70% 向量语义搜索 (Semantic) + 30% BM25 关键词匹配 (Keyword) 的加权策略。这种组合拳既能通过语义模糊匹配找到“上次那个关于数据库的决定”,又能通过关键词精准定位到特定的 API Token 或变量名,大幅降低了记忆检索的幻觉率。
-
Markdown 原生带来的体验质变:这是 OpenClaw 体验超越竞品的关键。因为记忆本质上就是普通的 Markdown 文本文件,用户可以直接用 IDE 打开、编辑甚至 Git 版本控制 Agent 的记忆。
-
觉得 Agent 记错了? 直接手动修改
MEMORY.md。 -
想给 Agent 植入新技能? 直接 Copy 一段文本进去。
这种**“白盒化”**的设计,让用户第一次真正拥有了对智能体记忆的绝对掌控权,而非面对一个无法干预的黑盒数据库。
-
2.3 自我迭代的记忆和认知
OpenClaw 的记忆系统不仅仅是一个静态的存储库,它更是一个动态进化的有机体。这种进化能力主要得益于其独特的自我管理机制:
-
元认知指令驱动 (Meta-Cognitive Instructions):通过
AGENTS.md配置文件,用户不仅定义了智能体的人设,更定义了其“记忆筛选法则”。OpenClaw 能够在运行过程中,依据这些元指令(Meta-Instructions)自动判断当前交互中的信息价值。它不再是被动地记录所有对话,而是像一个经验丰富的助手一样,主动筛选出值得沉淀到MEMORY.md中的关键信息(如用户的代码风格偏好、特定项目的部署流程)。 -
全权限的自我修改 (Autonomous Self-Modification):OpenClaw 拥有对本地文件系统的完整读写权限(Command Line & File Ops)。这意味着它不仅能读取记忆,更能**“自己修改自己的大脑”。当它发现某条旧的技能描述不再准确,或者对用户的理解需要更新时,它会直接调用文件操作工具修改
MEMORY.md。这种无需人类干预的闭环更新机制,使得 OpenClaw 能够随着使用时长的增加,实现“越用越聪明、越用越懂你”**的体验飞跃。
3. 智能体记忆系统实际作用与价值
为何记忆系统被称为智能体的“灵魂”?在实际的工业级落地场景中,一个完善的记忆系统能为 Agent 带来四个维度的质变:
-
身份锚定与场景适应(Identity & Context):原生 LLM 是无状态的,但通过持久化的人设记忆(Persona Memory)和工作流记忆(Workflow Memory),智能体能够迅速“进入角色”。它不再是一个通用的聊天机器人,而是一个熟知内部 SOP、拥有特定语气风格的“资深员工”,能极大缩短在新工作场景下的冷启动适应期。
-
消除“上下文焦虑”(Infinite Context):通过合理的记忆切片与检索机制,记忆系统从根本上解决了 Token 上下文窗口限制带来的焦虑。用户无需在每次对话开头重复粘贴几千字的背景资料,Agent 能够根据当前任务,自动回溯并加载数月前的项目文档或决策记录,实现理论上的“无限上下文”。
-
跨线程的深度理解(Cross-Thread Continuity):真正的智能化体现在“越用越懂你”。通过跨会话的长期记忆(Episodic Memory),Agent 能够串联起用户在不同时间、不同对话线程中的碎片化信息。比如在线程 A 中提到“我喜欢 Python”,在线程 B 中让它写代码时,它会自动选择 Python 而无需额外提示。这种跨线程的连续性是构建“私人助理”体验的关键。
-
自主进化与技能沉淀(Autonomous Evolution):这是记忆系统的高级形态。智能体能够通过反思(Reflection)机制,将成功的工具调用链、错误修正经验沉淀为“程序性记忆”。随着使用时间的推移,它不仅记住了数据,更记住了“方法论”,从而实现从“新手”到“专家”的自我进化。
4. 智能体记忆管理开发核心技术体系
在理解了记忆系统的价值后,我们需要从工程视角解构其实现逻辑。开发一个工业级的记忆管理模块,绝非简单的“存数据库”那么简单,它涉及五个关键技术维度的协同设计:
-
分类存储架构设计(Taxonomy Strategy):首先要解决“存什么”和“怎么分”的问题。工业级记忆不能是一团混沌的文本,而必须分门别类:会话记忆(Session Memory,短期对话流)、人格记忆(Persona Memory,静态人设与元指令)、跨线程情景记忆(Episodic Memory,历史事件与用户画像)、程序性记忆(Procedural Memory,工作流与技能库)。合理的分类是高效检索的前提。
-
多级存储策略(Storage Strategy):根据数据的访问频率和隐私要求选择存储介质。对于个人助理(如 OpenClaw),本地文件系统 + SQLite 是兼顾隐私与速度的最佳选择;而对于企业级高并发场景,则需采用 Redis(热数据) + 向量数据库(Milvus/Pinecone,温数据) + 关系型数据库(PostgreSQL,冷数据) 的多级存储架构。
-
动态压缩与遗忘机制(Compression & Pruning):记忆不是越多越好,冗余信息是检索精度的杀手。系统必须具备自动压缩策略:包括剔除冗长的工具调用日志(如报错堆栈)、定期对长对话进行 LLM 摘要总结(Summarization)、以及基于时间衰减(Time-Decay)的遗忘机制,确保上下文窗口始终留给最关键的信息。
-
RAG 与混合检索技术(Advanced RAG Support):单一的向量检索往往不够用。开发中需要引入 混合检索(Hybrid Search),结合向量语义匹配(模糊查找)与关键词匹配(精准定位 ID/术语)。对于复杂场景,还需引入 重排序(Re-ranking) 模型,确保检索出的记忆片段与当前问题的相关性达到最高。
-
动态修改与热重载机制(Hot-Reloading & Modification):这是区别于传统数据库的关键点。Agent 在运行过程中,必须具备**即时读写(Read-Write)和热重载(Hot-Reload)**记忆的能力。无论是用户手动修正了记忆文件,还是 Agent 自主更新了认知,系统都应在毫秒级内感知变化并更新索引,而无需重启服务。这种“活”的记忆机制是实现 Agent 自主性的技术底座。
二、主流开发框架记忆管理机制深度解析
1. LangChain记忆模块(Memory Module)架构设计与源码分析
LangChain 无疑是目前全球最主流、生态最丰富的企业级 Agent 开发框架。它凭借极高的组件标准化程度(Chains, Agents, Tools)和广泛的 LLM 兼容性,成为了大模型应用开发的“Spring Boot”。然而,在“记忆管理”这一特定垂直领域,LangChain 的设计显得相对保守且基础,更多是作为“对话历史缓冲区”存在,而非真正的智能体“海马体”。
1.1 LangChain 原生记忆管理核心组件
LangChain 的记忆系统主要围绕 BaseMemory 抽象类构建,其本质是在 Chain 执行前后插入的两个 Hook(钩子函数):load_memory_variables(读取)和 save_context(写入)。其核心实现主要集中在短期对话管理上:
- 全量缓冲(ConversationBufferMemory):这是最基础的实现,简单粗暴地将所有历史对话记录在内存中。虽然完整保留了细节,但随着对话轮数增加,迅速消耗 Token 甚至撑爆上下文窗口,仅适用于短轮次演示 Demo。
- 滑动窗口(ConversationBufferWindowMemory):引入了简单的“遗忘机制”,仅保留最近 K 轮对话(k=N)。这虽然解决了 Token 爆炸问题,但会导致灾难性遗忘——Agent 会完全忘记 N 轮之前的重要指令或用户偏好。
- 摘要压缩(ConversationSummaryMemory):利用 LLM 自身的能力,定期对历史对话进行摘要总结。这是一种以时间换空间的策略,虽然压缩了 Token,但摘要过程会丢失关键细节(如代码参数、具体日期),且增加了额外的 LLM 调用成本。
- 向量检索(VectorStoreRetrieverMemory):这是 LangChain 尝试解决长期记忆的方案。它将历史对话向量化存入 VectorStore,并在新对话时检索最相关的 K 条片段。虽然具备了 RAG 的雏形,但其逻辑非常机械,缺乏对“记忆重要性”的评估和“混合检索”的支持。
1.2 工业级视角下的缺陷分析
对照前文提到的 OpenClaw 或理想的工业级记忆架构,LangChain 的记忆模块存在明显的“先天不足”:
- 被动式管理(Passive Management):LangChain 的记忆读写完全依赖于 Chain 的单次调用周期。它没有后台进程,无法像 OpenClaw 那样在系统闲置时自动进行“记忆整理”、“索引优化”或“过期清理”。这导致记忆库随着时间推移会变得越来越脏、越来越慢。
- 粒度单一(Coarse Granularity):LangChain 的记忆默认只处理无结构的“文本流”(HumanMessage/AIMessage)。它缺乏结构化设计,无法区分“用户画像”、“技能库”和“事实知识”。这种“一锅端”的存储方式,使得 Agent 难以实现复杂的身份锚定和跨任务迁移。
- 缺乏元认知与进化能力(No Meta-Cognition):LangChain 的记忆是“只读/追加”的,Agent 无法反思自己的记忆,也无法像 OpenClaw 那样主动修改或删除错误的记忆。这使得基于 LangChain 开发的 Agent 很难实现真正的自我进化。
2. 多智能体框架AgentScope的记忆交互机制与数据流转
AgentScope 是阿里达摩院(ModelScope Team)推出的多智能体协同框架。与 LangChain 的“链式调用”不同,AgentScope 的核心是**“消息传递(Message Passing)”。因此,其记忆系统的设计重心并不在于单个 Agent 的深度进化,而在于多 Agent 之间如何高效地共享、隔离和检索上下文**。
2.1 基于消息对象的短期记忆(RAM-Based Memory)
在 AgentScope 中,记忆被具象化为一个 Python 对象列表(List of Dicts)。每个 Agent 实例维护自己的 memory 属性,其核心操作逻辑如下:
- 结构化消息体:不同于 LangChain 的纯文本,AgentScope 的记忆单元是结构化的
Msg对象,包含name(发送者)、content(内容)、url(多模态链接)等元数据。这使得在复杂仿真中,Agent 能知道“谁”在“什么时候”说了“什么”。 - 显式过滤(Filter Strategy):由于多智能体对话会产生海量信息(例如 10 个 Agent 群聊),AgentScope 提供了显式的过滤机制。开发者可以通过配置,让 Agent 只“记住”(检索)特定角色的发言,或者只关注最近 N 条提及自己的消息。
- 瞬时性(Volatility):这种短期记忆主要驻留在内存(RAM)中。一旦 Python 进程结束,如果没有显式调用导出接口,记忆即刻消失。
2.2 基于 RAG 的长期记忆(Dict & Vector)
为了弥补短期记忆的易失性,AgentScope 引入了长期记忆模块,但这本质上是一个外挂的知识库接口:
- DictRAMMemory:一种简单的键值对存储,适合存储小规模的全局配置或黑名单。
- RAGMemory (Vector DB):这是其长期记忆的主力。AgentScope 封装了 Embeddings 和 Vector DB(如 LanceDB)的交互。当 Agent 需要长期记忆时,实际上是在执行一次标准的 RAG 流程:
Retrieve -> Augment -> Generate。 - 配置驱动:开发者需要在配置文件中显式定义
memory_config,指定使用哪种 Embedding 模型和数据库路径。
2.3 局限性:是“聊天记录管理器”而非“大脑”
尽管 AgentScope 在多智能体交互场景下表现出色,但从“独立智能体”的视角看,其记忆系统仍显得工程味过重,生物味不足:
- 割裂感:短期记忆(List)和长期记忆(RAG)是两套完全独立的代码逻辑。Agent 无法自动将短期记忆“沉淀”为长期记忆,必须依靠开发者手写逻辑来搬运数据。
- 缺乏自主性:AgentScope 的 Agent 更像是一个能够查数据库的 NPC。它没有内置的“反思”或“自我修改”机制。它记住了对话,但很难说它“学到了”什么。
- 交互复杂度:在 AgentScope 中,要实现一个具备复杂记忆的 Agent,往往需要编写大量的 Python 代码来管理消息流转,相比 OpenClaw 的“改个 Markdown 文件即生效”,其上手门槛和维护成本都要高得多。
三、新一代记忆即服务(MaaS)架构:Mem0项目简介
如果说 LangChain 和 AgentScope 是将记忆作为 Agent 的附属品,那么 Mem0(原名 EmbedChain 团队孵化)则试图定义一个全新的行业标准:MaaS (Memory As A Service)。它的愿景是将记忆系统彻底解耦,打造一个“LLM 时代的独立海马体”。
1. Mem0项目定位:从 RAG 到“智能体海马体”
Mem0 并不仅仅是一个增强版的 RAG 工具,它的核心定位是 "The Memory Layer for AI"。在 Mem0 的架构哲学中,应用逻辑(Chatbot)和记忆逻辑(Memory)应当是物理分离的:
- 解耦(Decoupling):无论你的 Agent 是基于 OpenAI、Anthropic 还是本地 Llama,无论你的框架是 LangChain 还是 AutoGen,都可以共享同一个 Mem0 记忆层。
- 持久化用户画像(User-Centric):Mem0 并不只关心“文档里写了什么”(RAG),它更关心“用户是谁”。它能够跨 Session、跨 App 追踪用户的偏好、习惯和历史行为,从而实现真正的个性化体验。
- Stripe for Memory:如同 Stripe 封装了复杂的支付逻辑,Mem0 试图封装复杂的向量检索、图谱构建和冲突消解逻辑,提供极简的
add()和search()API。
2. Mem0关键功能特性:多层级存储与自适应检索
Mem0 之所以被称为“新一代”方案,在于它在功能深度上远超传统的 VectorStore:
- 多层级/多维度记忆(User, Session, Agent): Mem0 原生支持多维度的记忆隔离与关联。你可以轻松指定某条记忆属于
user_id="alice",或者属于agent_id="travel_assistant"。这种原生的多租户设计,使其非常适合构建 SaaS 级应用。 - 图谱记忆(Graph Memory): 这是 Mem0 最具杀伤力的特性。除了传统的向量检索(Vector Search),Mem0 引入了知识图谱(Knowledge Graph)。它能自动提取对话中的实体(Entity)和关系(Relation),解决传统 RAG 难以处理的“多跳推理”问题。例如,当用户说“我搬家到了杭州”,Mem0 不仅更新向量,还会更新图谱中的
(User)-[LIVES_IN]->(Hangzhou)关系,确保逻辑的一致性。 - 自适应检索(Adaptive Retrieval): Mem0 并不只是简单的 Top-K 检索。它内置了一套评分机制,综合考量 Recency(时间新近度)、Relevance(语义相关性) 和 Importance(信息重要性)。这意味着 Agent 既能回忆起很久以前的关键大事,也能敏锐捕捉到刚刚发生的微小变动。
3. Mem0与传统RAG方案的差异化对比与局限性分析
3.1 优势:不仅仅是检索
| 维度 | 传统 RAG (LangChain) | Mem0 (MaaS) |
|---|---|---|
| 数据源 | 静态文档(PDF/Wiki) | 动态交互流(User Interactions) |
| 更新机制 | 定期全量索引(离线) | 实时增量更新(在线) |
| 冲突解决 | 无(新旧文档共存) | 有(自动去重、矛盾修正) |
| 记忆粒度 | 文本块(Chunks) | 实体、关系、偏好(Structured) |
3.2 局限性探讨:工业落地的“重”与“慢”
尽管 Mem0 功能强大,但在实际的工业级工程落地中,它也面临着不可忽视的挑战:
- 架构过于臃肿(Heavy Architecture): Mem0 为了实现上述炫酷功能,后端依赖极重。完整部署一套 Mem0,你需要维护 Vector DB (Qdrant/Milvus) 用于语义检索,Graph DB (Neo4j) 用于关系存储,还需要 LLM Service 用于记忆提取和去重。对于一个追求极致轻量化的端侧 Agent(如 OpenClaw 的本地模式),Mem0 显得“杀鸡用牛刀”,运维成本过高。
- 延迟问题(Latency): “智能”是有代价的。Mem0 的写入路径非常长:
Input -> LLM Extraction -> Deduplication -> Vector/Graph Embedding -> Storage。这一系列复杂的 ETL 流程导致记忆写入通常是异步的,无法做到毫秒级的“即存即用”。在对实时性要求极高的交互场景下,用户可能会感觉到“反应慢半拍”。 - 黑盒化焦虑(Black-Box Anxiety): 相比于 OpenClaw 那种“直接修改 Markdown 文件”的通透感,Mem0 将记忆封装在复杂的数据库和算法背后。当 Agent 出现幻觉或记错信息时,开发者很难像编辑文本文件那样快速定位并手动修正错误。调试和人工干预的难度随着系统复杂度的增加呈指数级上升。
Part 2.从零到一搭建工业级智能体记忆系统—mini Openclaw
一、内置工具
Mini-OpenClaw 在启动时,除了加载用户自定义的 Skills 外,必须内置以下 5 个核心基础工具(Core Tools)。根据“优先使用 LangChain 原生工具”的原则,技术选型更新如下:
1. 命令行操作工具 (Command Line Interface)
- 功能描述:允许 Agent 在受限的安全环境下执行 Shell 命令。
- 实现逻辑:
- 直接使用 LangChain 内置工具:
langchain_community.tools.ShellTool。 - 配置要求:
- 初始化时需配置
root_dir限制操作范围(沙箱化),防止 Agent 修改系统关键文件。 - 需预置黑名单拦截高危指令(如
rm -rf /)。
- 初始化时需配置
- 直接使用 LangChain 内置工具:
- 工具名称:
terminal。
2. Python 代码解释器 (Python REPL)
- 功能描述:赋予 Agent 逻辑计算、数据处理和脚本执行的能力。
- 实现逻辑:
- 直接使用 LangChain 内置工具:
langchain_experimental.tools.PythonREPLTool。 - 配置要求:
- 该工具会自动创建一个临时的 Python 交互环境。
- 注意:由于
PythonREPLTool位于experimental包中,需确保依赖项安装正确。
- 直接使用 LangChain 内置工具:
- 工具名称:
python_repl。
3. Fetch 网络信息获取
- 功能描述:用于获取指定 URL 的网页内容,Agent 联网的核心。
- 实现逻辑:
- 直接使用 LangChain 内置工具:
langchain_community.tools.RequestsGetTool。 - 增强配置 (Wrapper):
- 原生
RequestsGetTool返回的是原始 HTML,Token 消耗巨大。 - 必须封装:建议继承该类或创建一个 Wrapper,在获取内容后使用
BeautifulSoup或html2text库清洗数据,仅返回 Markdown 或纯文本内容。
- 原生
- 直接使用 LangChain 内置工具:
- 工具名称:
fetch_url。
4. 文件读取工具 (File Reader)
- 功能描述:用于精准读取本地指定文件的内容。这是 Agent Skills 机制的核心依赖,用于读取
SKILL.md的详细说明。 - 实现逻辑:
- 直接使用 LangChain 内置工具:
langchain_community.tools.file_management.ReadFileTool。 - 配置要求:
- 必须设置
root_dir为项目根目录,严禁 Agent 读取项目以外的系统文件。
- 必须设置
- 直接使用 LangChain 内置工具:
- 工具名称:
read_file。
5. RAG 检索工具 (Hybrid Retrieval)
- 功能描述:当用户询问具体的知识库内容(非对话历史)时,Agent 可调用此工具进行深度检索。
- 技术选型:LlamaIndex (此项保持不变,LangChain 内置检索在混合检索方面不如 LlamaIndex 灵活)。
- 实现逻辑:
- 索引构建:支持扫描指定目录(如
knowledge/)下的 PDF/MD/TXT 文件,构建本地索引。 - 混合检索:必须实现 Hybrid Search(关键词检索 BM25 + 向量检索 Vector Search)。
- 持久化:索引文件需持久化存储在本地(
storage/)。
- 索引构建:支持扫描指定目录(如
- 工具名称:
search_knowledge_base。
二、mini OpenClaw的Agent Skills系统
1. Agent Skills基础功能介绍
mini OpenClaw的Agent Skills遵循Anthropic提出的Skills基础范式,具体范式说明可参考:https://agentskills.io/home 。
Agent Skills的本质是一个个文件夹,一个文件夹就代表着一项技能,在项目根目录下有一个skills文件夹,其中保存着全部mini OpenClaw的各项技能。例如存在一个用于进行天气查询的skills,
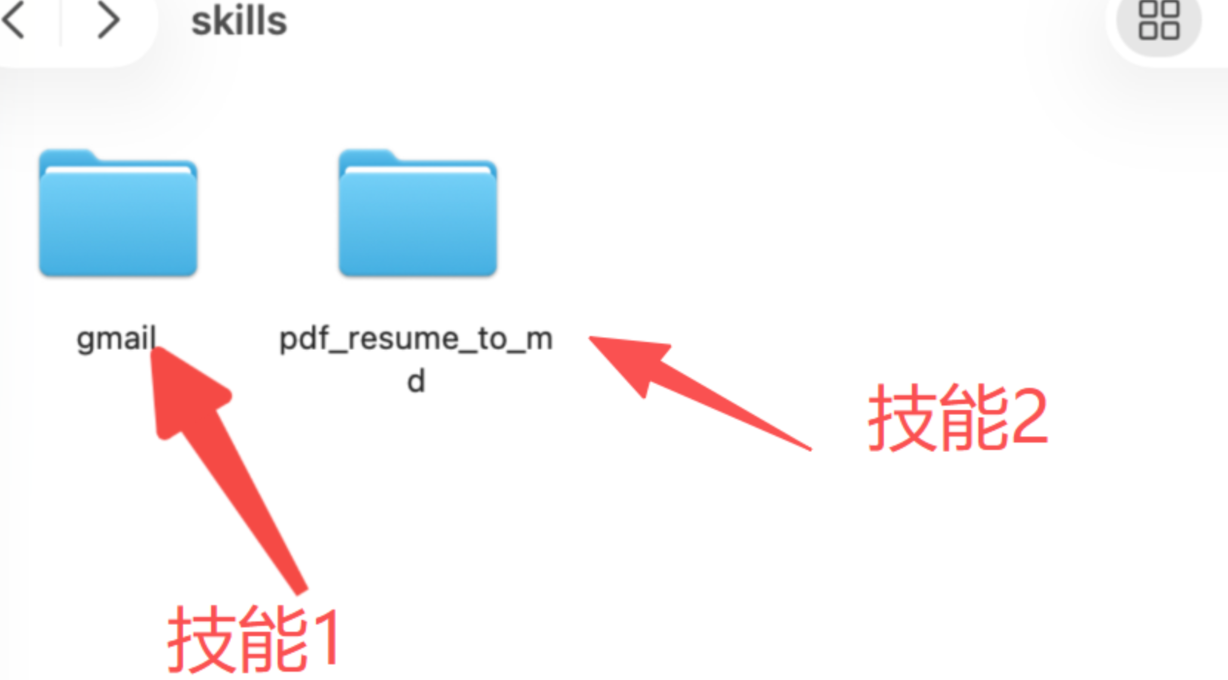
名叫get_weather,其具体的形式就是一个同名的文件夹get_weather,对于每个Agent Skills,都必须包含一个SKILL.md文件作为基础描述指令,其基本项目结构如下。
FENCE0
而对于天气查询的skill,一个典型的SKILL.md示例文档如下:
FENCE1
其中文档顶部为元数据,正文的内容则是关于技能的具体秒偶数。而必选的元数据包括:
name- 技能的名称description- 技能的描述
需要注意的是,在创建项目的时候,需要生成skills文件夹,但文件夹里面具体的skill,则是用户自行创建添加。
2. Agent Skills载入方法
2.1 Agent Skills读取流程
在Agent实际运行过程中,需要在每次对话开启的时候读取skills文件夹中全部的skill中的SKILL.md中的元数据,并将元数据以某种合适的格式拼接到SKILLS_SNAPSHOT.md文档中,该文档的情况会在下一小节介绍,该文档的核心功能是汇总所有的可调用的skills信息作为系统信息带入本次对话。具体汇总的方式如下,例如get_weather技能在被读取时,元数据信息汇总形式如下:
FENCE2
2.2 Agent Skills调用流程
而只要在系统信息中包含了可用的全部skills相关信息,就可以借助Function calling功能,在遇到相关问题时,自动读取对应的skill的SKILL.md文档,获得相关技能知识。例如,当用户想要查询天气的时候,就会自动触发读取get_weather/SKILL.md的行为,并将SKILL.md作为工具调用信息返回,而当Agent读取了SKILL.md之后,即可按照相关说明执行任务。
但是需要注意的是,skill真正触发的Function calling实际上是mini OpenClaw内置的文件读取工具,而传入的是SKILL.md的地址,返回的则是内置的读取工具读取到的md文件内容。
三、mini OpenClaw对话记忆管理系统设计
1.本地优先原则
mini OpenClaw遵循本地优先的记忆管理原则,既无论是历史对话系统指令,都优先以MarkDown或者json格式存储在本地。而在每次Agent运行之前,都会根据既定的流程从本地存储的历史对话和系统指令中进行读取、并拼接成当前会话的Message消息列表。
2.mini OpenClaw消息构成
mini OpenClaw项目中,Agent的消息构成主要由三部分,
- 其一是当前会话(Session)中的历史对话history:指的是本次会话中历史过往的消息,包括用户消息、模型回复消息、工具调用信息等;
- 其二则是系统提示system Prompt:mini OpenClaw的系统提示消息构成非常复杂,主要分为如下六个方面信息,实际运行的时候会将一下六部分信息进行拼接,作为system message,这六部分信息分别是:
SKILLS_SNAPSHOT.md:Agent的Skills列表SOUL.md:人格、语气与边界IDENTITY.md:名称、风格与表情USER.md:用户画像与称呼方式AGENTS.md:操作指令、记忆使用规则与优先级MEMORY.md:跨线程的长期记忆,Agent会根据其他的指示,把一些来自于其他对话的、非常重要的信息提取并写入到MEMORY.md文件中
- 其三则是当前用户消息,也就是用户发送出去的消息。
3.历史会话本地持久存储方案
3.1 历史会话存储方案说明
mini OpenClaw的历史会话统一存储在项目后端根目录的sessions文件夹中,每个会话都单独维护一个json文件,并以会话标题为文件名称,例如好久不见.json,其中json文件内部就包含了本次会话的全部历史对话信息,并在实际对话进行过程中不断追加和更新。除此之外,sessions文件夹中还有关于历史会话信息的元数据文件—sessions.json,用于记录每个会话的会话名称、最近一次对话时间、对话信息记录格式等。
3.2 sessions文件基本结构
sessions目录与基本示例结构如下:
FENCE3
4. 系统信息
mini OpenClaw的系统信息构成较为复杂,主要分为SKILLS_SNAPSHOT.md、SOUL.md、IDENTITY.md、USER.md、AGENTS.md、MEMORY.md总共6部分信息。以上6部分信息的存储位置在:
FENCE4
实际每次运行的时候会将这6部分md文档进行拼接,并组成系统消息。而如果这6部分消息过长,而每一部分信息的生成和基本格式如下说明。
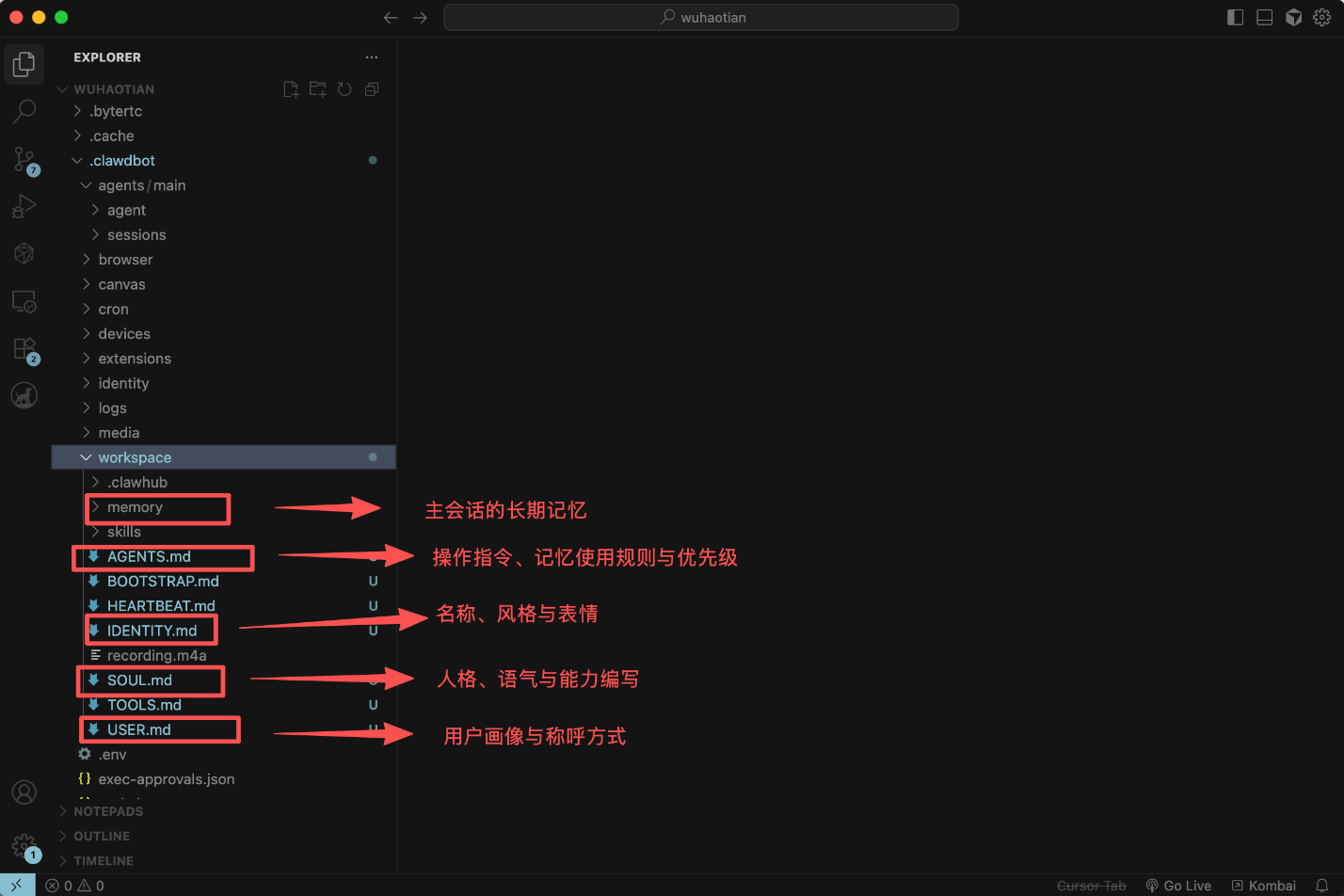
4.1 SKILLS_SNAPSHOT.md
SKILLS_SNAPSHOT.md(或SKILLS_INJECT.md)- 用途描述:用于在会话启动前手动或自动汇总当前可用技能(SKILLS)的 XML 元数据列表(读取根目录下的skills文件夹里面的每一个文件夹里面的SKILL.md里面的XML元数据),便于调试、审计或离线查看。同时也会包含如何调用这些Skill的基本说明。
- 简例:
FENCE5
4.2 SOUL.md:人格、语气与边界
-
解释:定义 Agent 的人格、语气与边界(persona, tone, and boundaries),每次会话加载
-
如何生成:由用户或模型编写;首次运行时 macOS 客户端会创建默认模板
-
简例:
# SOUL.md- 语气友好、专业- 不发送流式回复- 保护隐私
4.3 IDENTITY.md:名称、风格与表情
-
解释:记录 Agent 的名称、风格与表情(name, vibe, emoji),每次会话加载
-
如何生成:首次运行引导(BOOTSTRAP.md)完成后由模型写入;macOS 客户端提供默认模板
-
简例:
# IDENTITY.md- Name: Clawd- Creature: Lobster- Emoji: 🦞
4.4 USER.md:用户画像与称呼方式
-
解释:描述用户画像与称呼方式(who the user is and how to address them),每次会话加载 。
-
如何生成:首次运行引导时由模型写入,首次运行时提供默认模板。
-
简例:
# USER.md- Name: Alex- Preferred address: Alex- Timezone: UTC+8
4.5 AGENTS.md:操作指令、记忆使用规则与优先级
-
解释:包含操作指令、记忆使用规则与优先级(operating instructions, how to use memory, priorities)、以及mini OpenClaw内置的工具情况,每次会话加载 。
-
如何生成:用户编写,首次运行时提供默认模板
-
简例:
# AGENTS.md- 优先级:安全 > 效率- 记忆策略:重要决策写入 MEMORY.md- 每日日志写入 memory/YYYY-MM-DD.md
4.6 MEMORY.md:跨线程的长期记忆
-
解释:跨线程的长期记忆(curated long-term memory)
-
如何生成:由用户或模型主动写入(非自动生成);可在 AGENTS.md 中指示模型主动更新。
-
简例:
# 长期记忆## 偏好- 编程语言:Python、TypeScript## 决策- 2026-01-15:使用 SQLite 作为本地向量存储
5.mini OpenClaw消息队列拼接和处理方法
- 首次对话时,按照既定的格式创建json文件,用于持久本次存储对话内容,同时将本次会话的元数据填入session.json中;
- 首次对话时,会将系统消息的6个部分进行拼接,最终构成系统消息。而在拼接的过程中,如果任意某一部分的文档长度超过了20k,则暴力截断该部分文档内容(其他部分不变),同时在对应文档结尾部分加上阶段标识;
- 在实际对话过程中,需要将用户和模型的对话信息、以及工具调用信息等进行完整的消息队列拼接,同时系统信息位于消息队列的顶部,同样需要录入到对应的json文件中;
- 用户和模型的消息列表不可更改,但如果在对话的过程中可以根据用户的提示修改MEMORY.md文档,往里面注入一些用户觉得很重要的消息,并更新本次会话的系统消息;
- 在Agent运行过程中,允许实时新增Agent skills(也就是新增skills文件夹),系统不会自动检测有没有新增skills,只有当用户关键词触发的时候,系统才会重新扫描skills文件夹,并把新增的skill的xml加入到SKILLS_SNAPSHOT.md中,并更新本次会话的系统消息;
6.mini OpenClaw消息队列压缩与检索方法
- 历史对话超出阈值时,对一定比例50%的历史对话进行总结,并替换原始文本;
- 当MEMORY.md超出阈值时,采用混合检索RAG进行检索,而不是带全部MEMORY.md作为system_message。
四、系统消息文件说明
各项文档说明:
FENCE6
FENCE7
FENCE8
FENCE9
五、mini OpenClaw效果演示
- 体验课内容节选自《2026大模型Agent智能体开发实战》 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2026大模型Agent智能体开发实战》

《2026大模型Agent智能体开发实战》 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!**
课程完整介绍

部分课程成果演示
- Fufan Manus通用智能体开发实战