ADK快速入门调用 (v2)
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(7月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(7月班)

《2025大模型Agent智能体开发实战》(7月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(夏季班)

两门大模型课程五周年特惠进行中!现在下单可享开课来最低特价+各期课程全部福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇



五周年庆特别直播
最强Agent开发框架:谷歌开源ADK框架快速入门实战
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/3088c0e4409fe7a1cc024ed7eb5321a5_raw.mp4", width=800, height=400)
一、谷歌 Agent Development Kit (ADK) 框架功能特性详解
1. 新一代Agent开发框架:ADK
Google Agent Development Kit (ADK) 是谷歌推出的一套开源框架,旨在帮助开发者高效构建、运行与调试智能体(Agents)。该项目以 统一的开发接口 和 模块化的设计理念 为核心,提供了从智能体编排、上下文管理、事件流处理,到工具调用与多智能体协作的完整支持。借助 ADK,开发者能够将大型语言模型(LLM)的推理能力,与外部 API、数据库及自定义工具无缝衔接,从而构建出具备更强推理、交互和执行能力的智能系统。
与传统的单一对话机器人框架不同,ADK 更强调 多智能体协作(multi-agent collaboration) 与 可扩展的事件驱动架构。它不仅支持单个智能体的对话和任务处理,还允许开发者通过灵活的编排机制,组合多个智能体以解决复杂问题。同时,ADK 内置了 事件追踪(event tracing)、调试工具(debugging utilities) 与 开发者工作流集成,大大降低了从实验到生产的落地门槛。
作为一个面向未来的智能体基础设施,Google ADK 试图在 标准化与可扩展性 之间取得平衡。它既能为研究者提供可快速迭代的原型环境,也能为企业开发者提供稳健的生产级部署方案,展现了谷歌在智能体生态构建方面的技术布局与战略愿景

- ADK项目说明文档:https://google.github.io/adk-docs/

2. 谷歌ADK框架核心功能特性
- 易于上手
- 兼容性强
ADK采用LiteLlm作为基座模型调用框架,能够适配目前市面上各类在线、开源大模型,以及模型中转平台(OpenRouter)。
- 便于开发
- 原生多模态功能
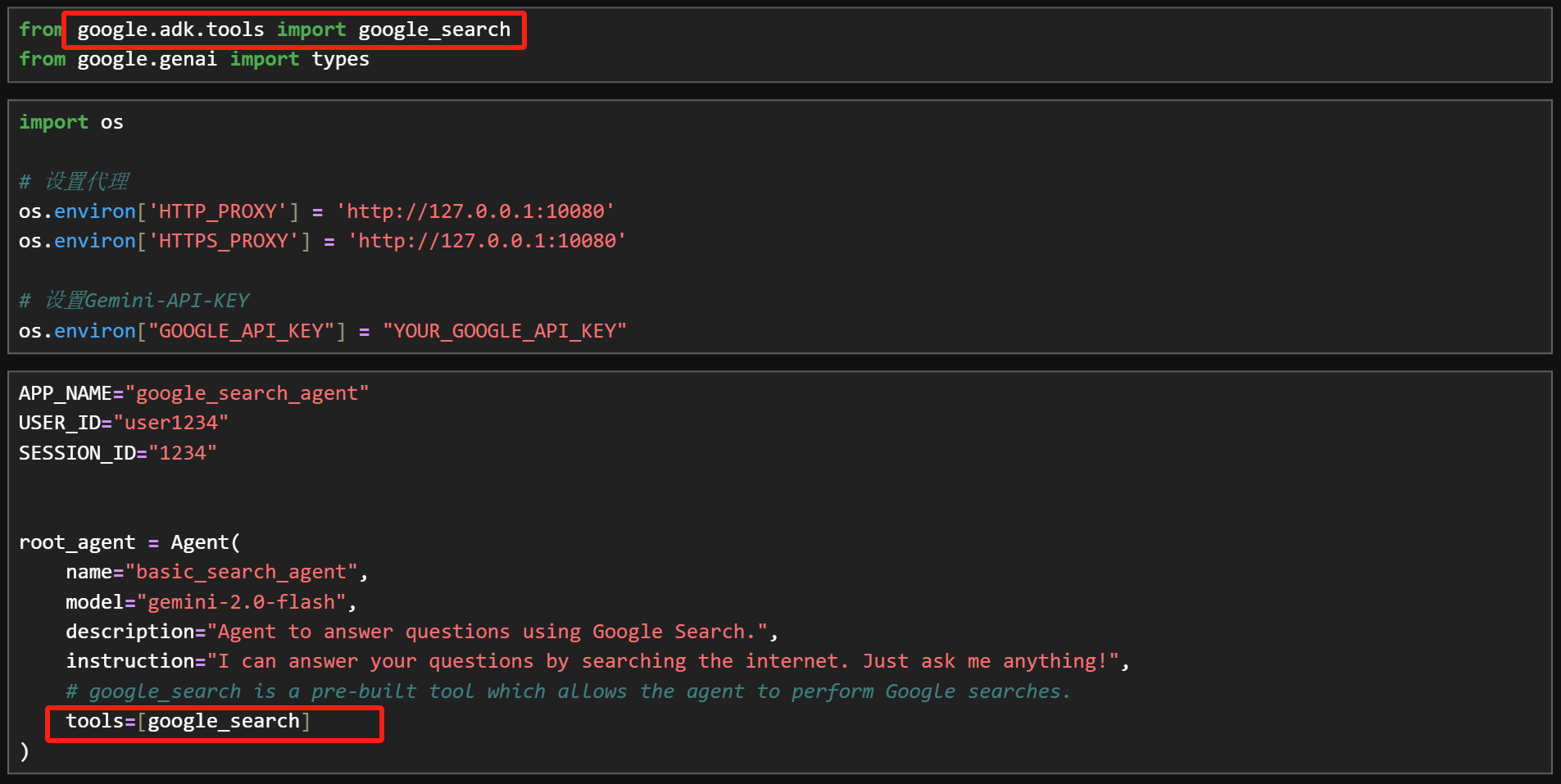
- 适配谷歌开发生态
原生支持谷歌云平台API、谷歌搜索以及VertexAI文档存储检索等各项功能。
注,付费课程中我们围绕谷歌ADK源码进行了修改,使得其更加适配各项开源工具。
2.1 灵活的编排能力(Flexible Orchestration)
ADK 提供了高度灵活的智能体编排机制。开发者既可以利用内置的工作流智能体(如 顺序执行 Sequential、并行执行 Parallel、循环执行 Loop),构建可预测、结构化的任务流水线;也可以借助 LLM 驱动的动态路由(LlmAgent transfer),让系统根据上下文与任务目标自动选择执行路径。这种双重机制既能满足生产场景下对确定性的严格需求,又能在探索性任务中体现出高度的适应性与灵活性,从而实现“稳健”与“灵活”的平衡。
2.2 多智能体架构(Multi-Agent Architecture)
ADK 鼓励以 模块化与层级化 的方式构建多智能体应用。开发者可以将不同专长的智能体进行组合,形成一个具备分工与协作机制的智能体层级体系。例如,一个顶层的“协调者智能体”可以将复杂任务拆解并分派给下层的“专长智能体”,后者则各自负责搜索、推理、编程、数据处理等子任务。这种架构不仅提升了系统的可扩展性和可维护性,还为构建大规模、复杂度高的多智能体系统提供了良好的技术基础。
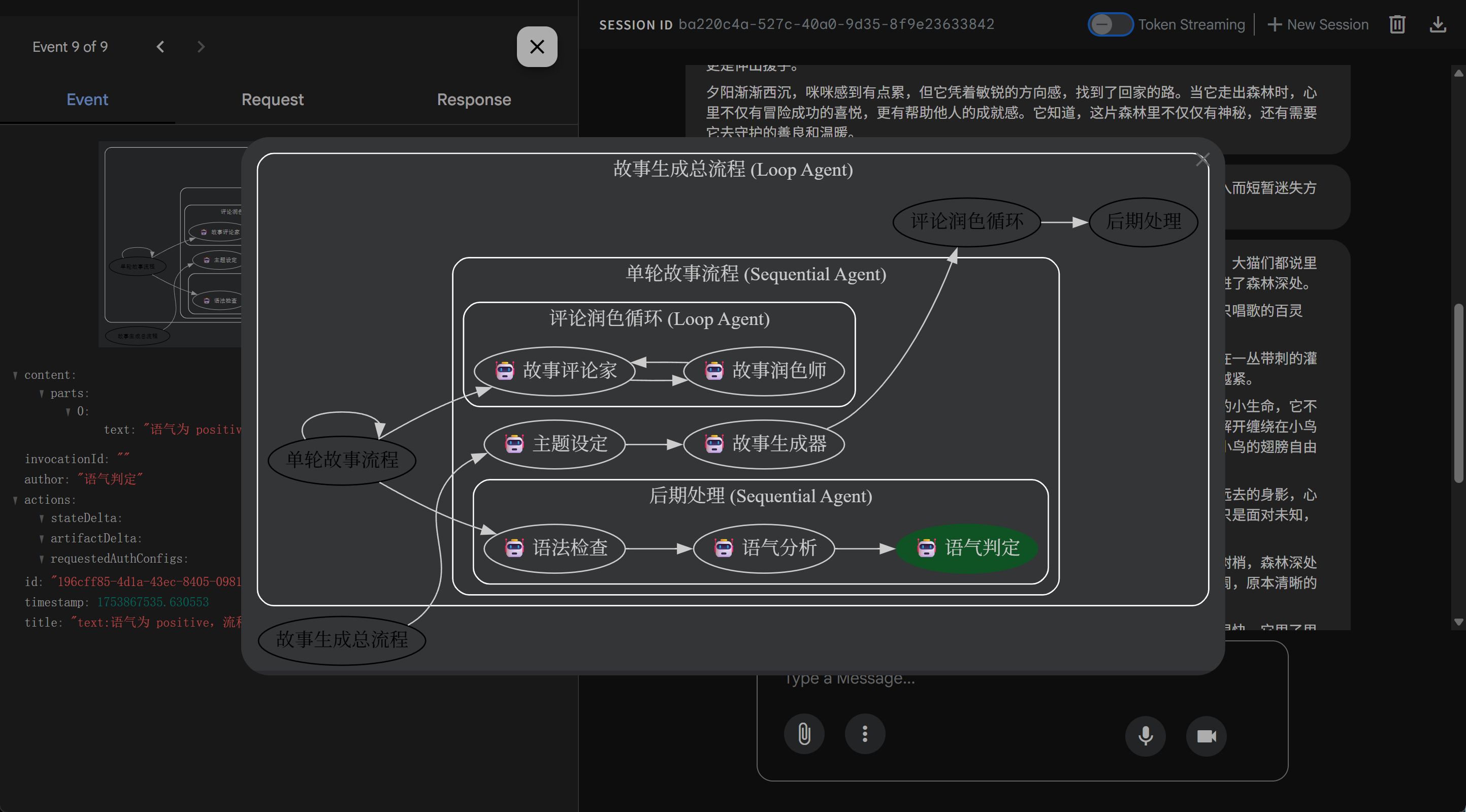
2.3 丰富的工具生态(Rich Tool Ecosystem)
ADK 内置了丰富的工具支持,使智能体能够获得多样化的能力扩展。开发者可以直接使用预构建工具(如 搜索 Search、代码执行 Code Exec),快速增强智能体的实用性;也可以灵活地注册自定义函数,满足特定业务需求。此外,ADK 还支持集成第三方生态(如 LangChain、CrewAI),甚至可以将其他智能体封装为“工具”,供当前智能体调用。这种开放且可组合的生态体系,使 ADK 智能体具备了更高的通用性和跨领域适配能力。

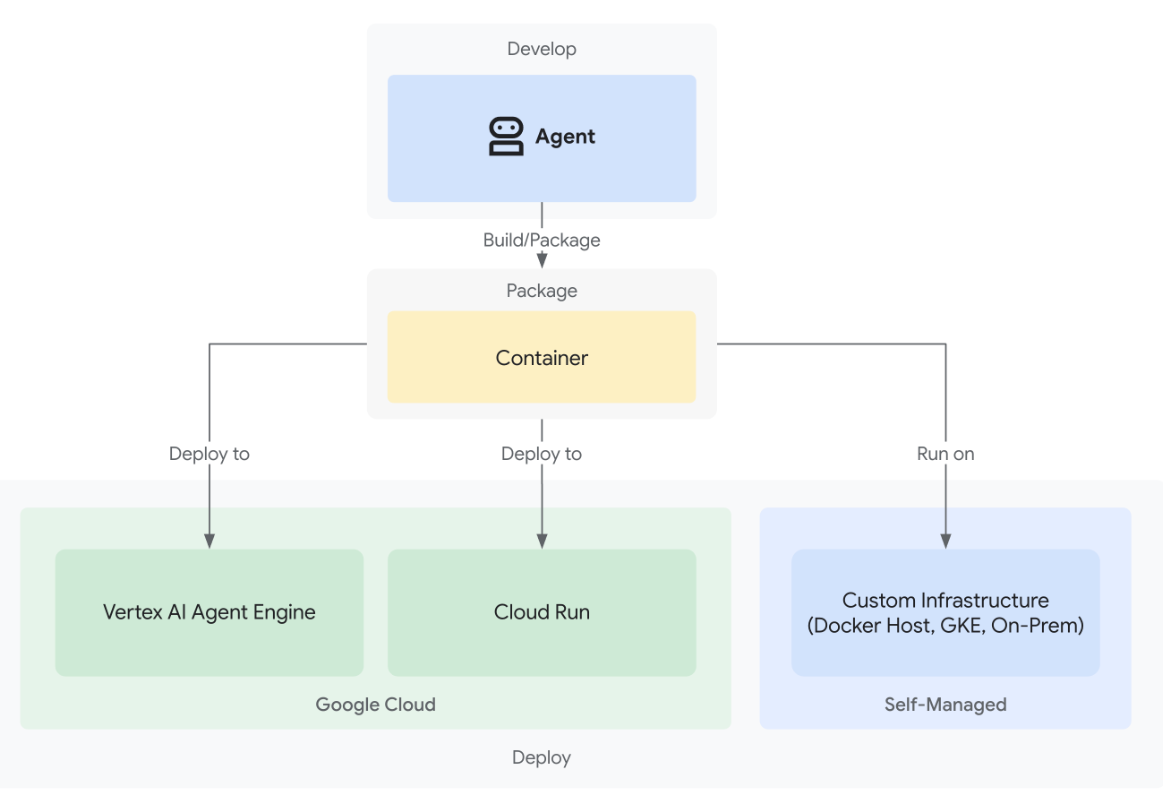
2.4 部署就绪(Deployment Ready)
ADK 充分考虑了从开发到部署的全流程落地需求。开发者可以将智能体以容器化的方式封装,并在多种环境中灵活运行:既可以在本地调试运行,也可以借助 Vertex AI Agent Engine 实现云端弹性扩展,还能通过 Cloud Run 或 Docker 集成进自定义的基础设施。这种灵活的部署模式,确保了 ADK 构建的智能体能够轻松适配从实验原型到大规模生产的不同阶段。
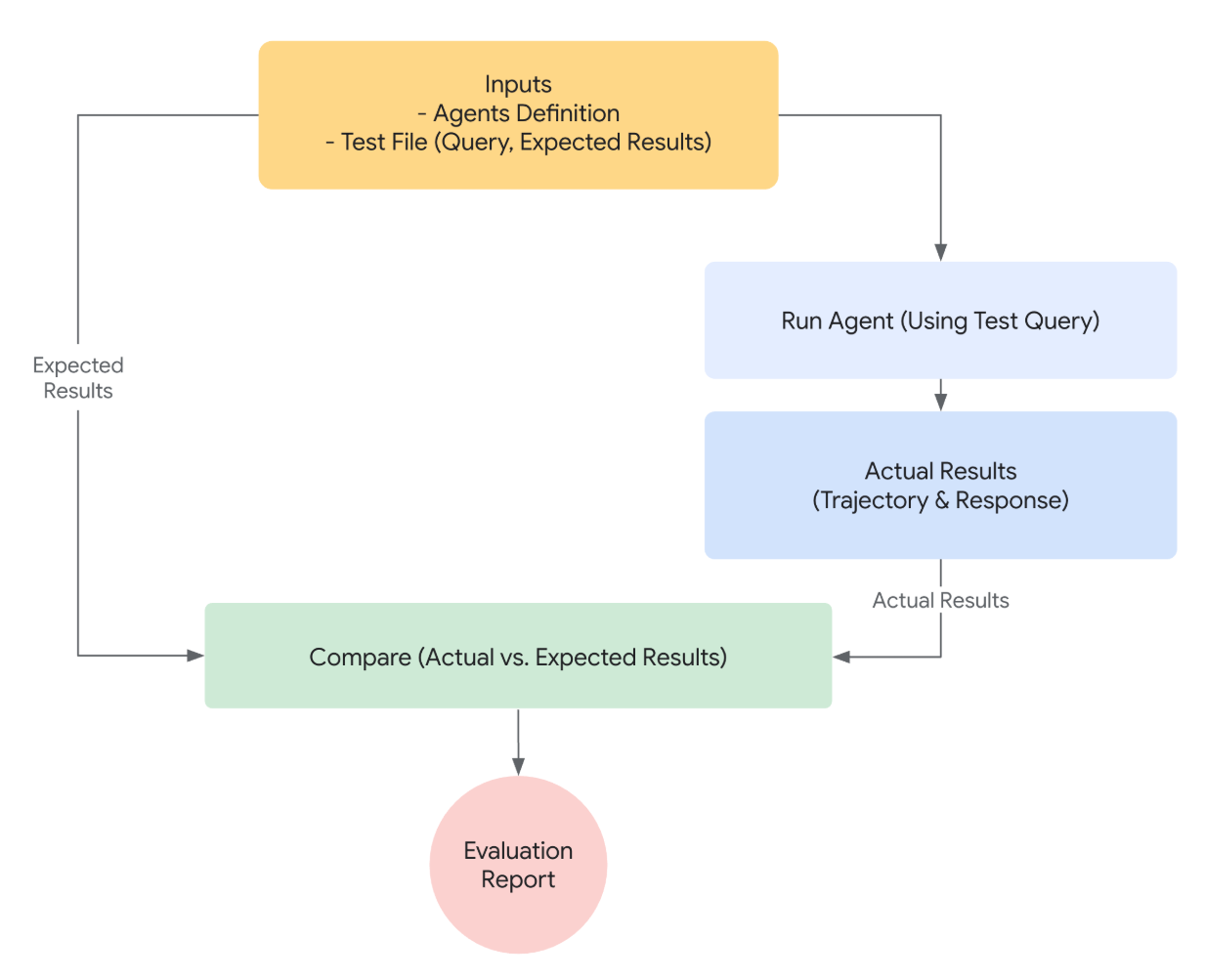
2.5 内置评估机制(Built-in Evaluation)
ADK 自带的评估框架能够帮助开发者系统化地衡量智能体的性能与可靠性。其评估不仅限于最终回复结果的质量,还涵盖了智能体在任务执行过程中的 逐步推理与动作轨迹,并可与预定义的测试用例进行对比。这种精细化的评估方式,为开发者提供了可量化的反馈,有助于持续优化智能体的决策逻辑与工具调用策略,从而提升整体系统的稳定性与可信度。
2.6 安全与可信设计(Building Safe and Secure Agents)
ADK 强调在智能体的设计过程中,必须将 安全性与可信性 作为核心考量。它为开发者提供了一系列安全模式(patterns)与最佳实践,帮助在系统中融入权限控制、异常防护、内容安全与用户隐私保护等机制。通过在架构层面强化安全设计,ADK 旨在确保开发者能够构建出不仅功能强大,而且符合伦理规范、可供长期信赖的智能体。
综合来看,谷歌 ADK 框架通过灵活的编排能力、多智能体架构、丰富的工具生态、灵活的部署模式、系统化的评估机制以及安全可信的设计理念,为智能体开发提供了一套从建模、执行到落地的完整解决方案。它既能满足开发者在探索性实验中对灵活性和开放性的需求,也能支撑企业在生产级应用中对可靠性、安全性和可扩展性的严格要求。借助 ADK,开发者不仅能够快速搭建功能强大的智能体系统,还能在实际应用中确保其运行的稳定性与可信度,从而推动智能体技术在更广泛的领域落地与发展。
3.谷歌 ADK、LangChain & LangGraph、OpenAI Agents SDK 功能对比表
| 对比维度 | 谷歌 ADK (Agent Development Kit) | LangChain & LangGraph | OpenAI Agents SDK |
|---|---|---|---|
| 定位与目标 | Google 官方框架,专为构建安全、可扩展、可监控的生产级多智能体系统设计,深度集成 GCP 环境 | LangChain:通用大模型开发框架,专注工具集成、RAG、对话式 AI;LangGraph:其工作流编排层,专注复杂多 Agent 协作与状态机建模 | OpenAI 官方开源 SDK,轻量级接口,快速构建工具驱动 agent,紧密结合 Responses API |
| 工作流控制结构 | 提供 Sequential / Parallel / Loop Workflow Agent,支持 LlmAgent transfer 实现动态调度 | LangGraph 提供 StateGraph,支持分支、循环、条件跳转、并发;LangChain 提供 Chains & Agents API,适合 RAG 与工具调用 | 采用 Python-native agent loop 管理工具调用,支持多轮迭代和输出校验 |
| 多 Agent 协作机制 | 支持层级化结构和 LlmAgent transfer(动态路由与控制流转移),适合复杂分工与协调 | LangGraph 提供 Supervisor/Worker 模式,支持多智能体协作与角色扮演,LangChain 可通过 ReAct、Multi-Action 实现多 Agent 流程 | 内建 handoffs 功能,支持在多个 agent 间任务递交与角色切换 |
| 工具扩展方式 | 内建 Search、Code Exec;可扩展第三方库(LangChain、CrewAI 等);agent 也可作为工具使用 | LangChain 提供丰富工具库(搜索、数据库、浏览器、代码执行等),支持自定义工具函数;LangGraph 可将外部工具嵌入节点调用 | 支持 Hosted Tools(WebSearchTool)、Function Tool(Python 函数)、Agents as Tools |
| 安全与 Guardrails | 提供安全与合规最佳实践指南,需手动实现(如权限控制、审计日志),强调企业级合规 | 提供部分 Guardrails(如 LangChain Guardrails、输出检查);LangGraph 可与安全策略结合,但实现依赖开发者 | 内置 Guardrails:输入/输出校验、tripwire 检测、Moderation API 集成,安全控制能力最完善 |
| 会话与状态管理 | 通过 InvocationContext 和 session.state 显式管理,开发者可控性高 | LangChain 提供 memory 模块(ConversationBufferMemory 等);LangGraph 用全局 StateGraph 记录状态流转 | 自动管理会话与上下文,提供 session API,支持连续交互和历史追踪 |
| Tracing 与调试能力 | 内建事件追踪,支持 CLI 与 Web UI 调试,查看 agent 执行轨迹 | LangSmith 提供全链路 tracing & eval,可视化链路与指标;LangGraph 也支持本地 debug 与事件跟踪 | 内建 tracing 系统,自动记录工具调用、handoff、guardrails 过程,可在 OpenAI Dashboard 可视化调试 |
| 部署与落地能力 | 强调 GCP 集成:支持 Vertex AI Agent Engine、Cloud Run、Docker 容器化部署 | 支持 LangServe 部署 API 服务;兼容 Docker/Kubernetes;LangGraph 可与 FastAPI/Streamlit 集成 | 依托 OpenAI Responses API 调用;SDK 本身可在 Python/TS 运行,暂无官方容器化方案 |
| 评估功能 | 内建测试框架,可对最终输出和中间执行轨迹进行对比与评估 | 提供 LangChain Eval、Synthetic Data Eval;支持模型响应质量评测、工具调用路径分析 | 内建 tracing + 评估 API,结合 OpenAI Fine-tuning/Eval 工具系统性评测 agent 表现 |
| 生态与语言支持 | 主要支持 Python;生态偏向 Google Cloud 体系,逐步扩展 | Python 生态成熟,支持 Node.js;LangGraph 用 Python 构建,LangChain 提供社区丰富扩展 | 支持 Python & TypeScript(JS SDK),生态主要面向 OpenAI API 应用场景 |
| 典型适用场景 | 企业级智能客服、合规审计、生产级自动化工作流、跨部门智能体协作 | RAG 系统、企业知识库问答、智能客服、Agent 工具调用、复杂多 Agent 工作流 | 快速原型开发、研究实验、客服机器人、工具驱动 agent 应用,适合中小规模生产场景 |
- ADK → 企业/生产级定位,安全合规、可追踪性与 GCP 集成是其最大优势,适合对安全性和可控性要求极高的团队。
- LangChain & LangGraph → 功能最全面,生态最丰富,尤其在 RAG 和多智能体编排方面成熟,适合快速开发和复杂 AI 应用场景。
- OpenAI Agents SDK → 最轻量,快速上手,内置 guardrails 与 tracing,适合工具驱动型 agent 和快速原型,但依赖 OpenAI API。
二、LiteLlm快速使用指南
在介绍ADK之前,我们需要系统介绍ADK默认的大模型调用工具——LiteLlm的使用方法。在后续使用ADK时,选择基础模型是最基础的环节,而ADK目前只支持使用LiteLlm进行模型调用,因此我们先详细介绍国内外在线模型、以及ollama和vLLM驱动下的开源模型如何接入LiteLlm,然后再讲解如何上手使用ADK。
1.LiteLLM 项目概述
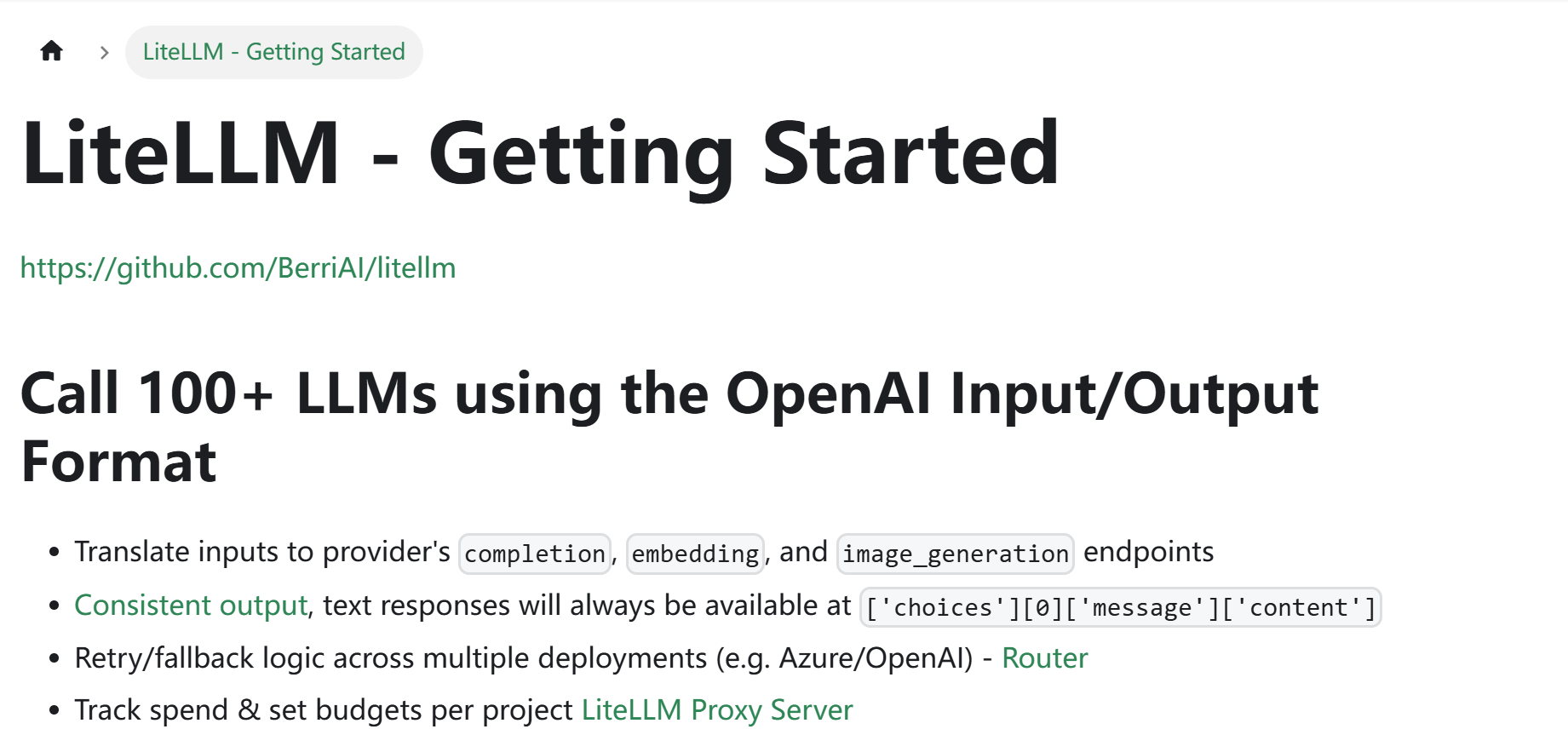
LiteLLM 是一个轻量级的 Python 库,旨在简化与各种大语言模型(LLM)进行交互的过程。它特别适用于开发者在多种云服务提供商(如 OpenAI、DeepSeek)或本地部署模型(如 Ollama)上运行大语言模型的需求。通过提供简洁的 API 和灵活的配置选项,LiteLLM 使得开发者可以轻松调用和集成各种不同的 LLM,同时支持模型的定制化扩展和高效调度。LiteLLM 核心功能如下:
-
跨平台模型兼容性:LiteLLM 使开发者能够通过统一接口调用多个大语言模型,无论是云端提供的 API(如 OpenAI)还是本地托管的模型(如 Ollama)。它内置支持常见的大型模型和多模型集成,如 GPT-3.5、GPT-4、DeepSeek 等,也能支持定制模型或自己托管的 LLM。
-
简化的 API 调用:LiteLLM 提供了一个简单直观的接口,使得开发者无需深入了解底层 API 细节即可实现与模型的交互。用户只需关注模型名称和输入输出内容,LiteLLM 会自动处理与模型的连接、API 调用以及响应解析工作。
-
多模型支持:LiteLLM 支持通过配置文件和代码直接切换不同的模型。它支持从 OpenAI、Anthropic、Meta、DeepSeek 等多个模型提供商调用,还允许开发者轻松集成自定义模型。例如,您可以在一个项目中同时使用 OpenAI 的 GPT 模型和 DeepSeek 的推理模型,而无需额外的集成工作。
-
灵活的代理支持:LiteLLM 可以配置为代理模型的 API,通过代理层进行调用,支持本地化部署和代理服务,例如与 Ollama 等工具结合,运行本地大语言模型。这使得 LiteLLM 在需要进行模型切换或构建跨平台服务时,能够提供极大的灵活性。
-
自定义 API 路由(Base URL):LiteLLM 允许用户设置自定义的
base_url,以支持通过代理或内部 API 调用模型。这为需要在多个环境中运行或通过私有部署调用 LLM 的企业应用提供了便利。 -
流式响应与事件处理:LiteLLM 支持流式响应(streaming responses),允许开发者在模型生成回复的同时进行处理。通过这种方式,开发者能够实时接收和处理模型输出,适用于需要低延迟响应的应用场景,如实时对话或多轮交互。
-
工具和任务管理:在集成外部工具(如搜索引擎、数据库查询等)时,LiteLLM 通过简洁的配置支持多任务执行。开发者可以将外部工具与模型结合,形成复杂的自动化任务流,例如通过模型生成的查询请求,调用外部 API 完成任务并返回结果。
-
灵活的配置和扩展性:LiteLLM 提供了多种配置选项,允许开发者根据具体需求调优模型的行为。用户可以通过传入配置文件来调整模型的推理设置、响应格式、温度参数等,此外,LiteLLM 还支持通过插件扩展其功能,适应更多的使用场景。
不难看出LiteLLM 是一款强大的模型调用工具,它的核心优势在于跨平台支持、简洁的 API 和灵活的配置选项。无论是调用云端大模型,还是集成本地托管的模型,LiteLLM 都能提供高效且简化的解决方案,使得开发者能够快速集成并灵活调度大语言模型。它特别适用于需要多模型集成、代理服务、任务管理和流式响应的场景,具有极高的可扩展性和适应性。通过 LiteLLM,开发者可以专注于业务逻辑和任务设计,而将模型调用、数据处理和通信细节交给框架来处理,从而大大提高开发效率并降低技术门槛。
2.LiteLlm安装部署调用流程
我们可以使用如下命令进行安装
FENCE0
安装完成后即可尝试调用DeepSeek模型在线API进行测试。
from litellm import completion
completion?
api_base = "https://api.deepseek.com"
api_key = "YOUR_DEEPSEEK_API_KEY"
# 使用 LiteLLM 调用 DeepSeek 模型
response = completion(
model="deepseek/deepseek-chat",
messages=[{"role": "user", "content": "你好,好久不见!"}],
api_base=api_base,
api_key=api_key
)
print(response)
print(response.choices[0].message.content)
由于后续我们主要借助ADK来调用LiteLlm,因此LiteLlm更多进阶功能就暂不介绍了,大家感兴趣的话可以参考官方说明文档。
3.各类大模型接入LiteLlm流程
接下来我们尝试使用LiteLlm调用更多模型,以及本地ollama、vLLM驱动的开源模型。
- 多模型API-KEY及Base_URL管理方法
在实际开发过程中,如果涉及到多个模型调用,可以考虑在当前项目文件内创建.env文件,用于保存不同模型的API-KEY和调用请求地址Base_URL,例如

然后写入如下内容:

也就是DeepSeek、OpenAI、Gemini等模型的API-KEY和Base_URL,之后即可使用如下方式进行导入:
import os
from dotenv import load_dotenv
load_dotenv(override=True)
# 读取模型们的API-KEY
DS_API_KEY = os.getenv("DS_API_KEY")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
# 读取模型们的BASE_URL
DS_BASE_URL = os.getenv("DS_BASE_URL")
OPENAI_BASE_URL = os.getenv("OPENAI_BASE_URL")
GEMINI_BASE_URL = os.getenv("GEMINI_BASE_URL")
- OpenAI/GPT-4.1模型调用流程
接下来测试GPT-4.1模型在LiteLlm中调用流程,在LiteLlm统一的模型调用框架下,同样也是只需要输入api_key和base_url即可调用:
openai_response = completion(
model="openai/gpt-4.1",
messages=[{"role": "user", "content": "你好,好久不见!"}],
api_base=OPENAI_BASE_URL,
api_key=OPENAI_API_KEY
)
print(openai_response.choices[0].message.content)
反向代理地址:
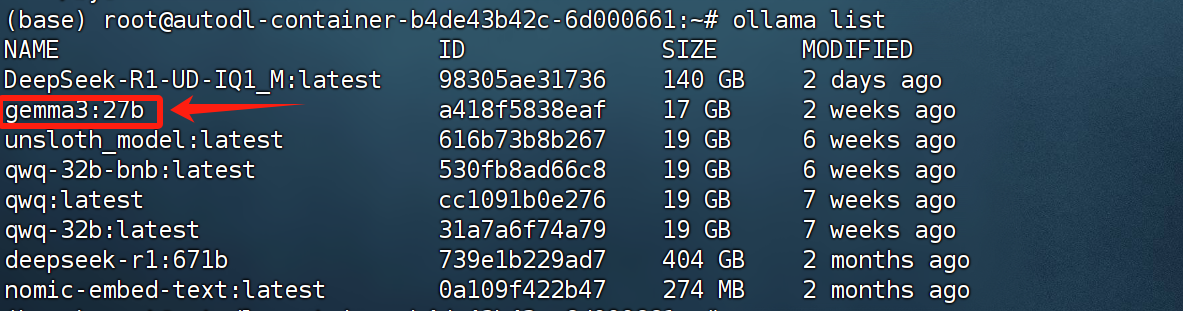
- ollama+开源模型调用流程
接下来继续测试使用LiteLlm调用本地开源模型,例如以Gemma-27B模型为例,首先需要确认模型已经下载并可以在ollama中顺利调用:

然后测试使用LiteLlm进行调用:
# 使用 LiteLLM 调用 Ollama 模型
ollama_response = completion(
model="ollama/gemma3:27b", # Ollama 模型
messages=[{"role": "user", "content": "你好,好久不见!"}],
api_base="http://localhost:11434" # 本地 Ollama API
)
print(ollama_response.choices[0].message.content)
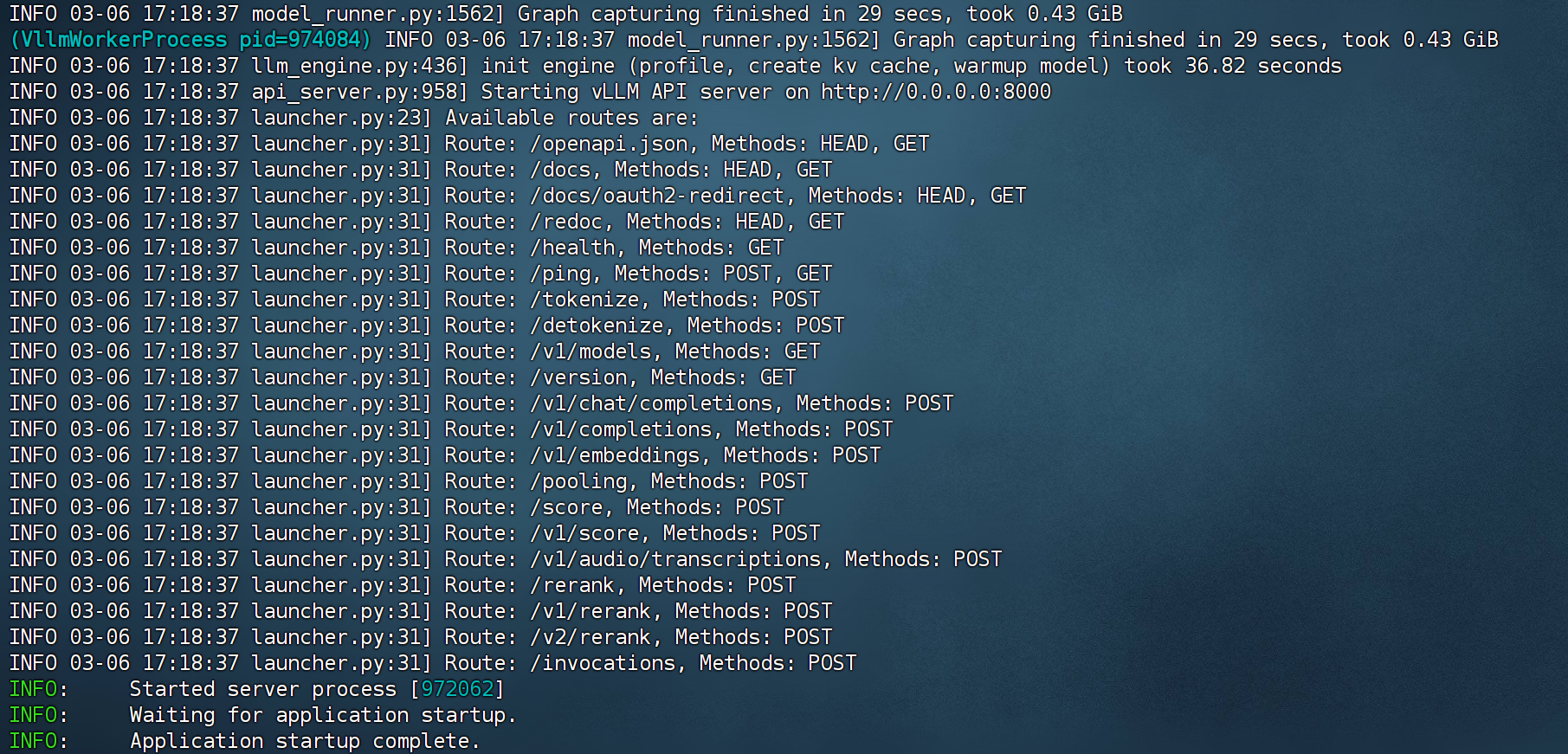
- vllm+开源模型调用流程
最后尝试使用vLLM调用本地QwQ-32B模型,并接入LiteLlm。首先需要启动vLLM:
然后输入如下代码进行测试:
# 使用 LiteLLM 调用 vLLM 模型
vllm_response = completion(
model="vllm/QwQ-32B", # vLLM 模型
messages=[{"role": "user", "content": "你好,好久不见!请介绍下你自己。"}],
api_base="http://localhost:8000" # 本地 vLLM API
)
print(vllm_response.choices[0].message.content)
能够顺利接入各类模型后,接下来即可进一步使用ADK来创建Agent了。
三、ADK(Agent Development Kit)调用流程详解
- ADK项目说明文档:https://google.github.io/adk-docs/
目前ADK处于快速迭代中,我们使用如下命令即可安装最新稳定版:
FENCE0
然后导入下列基础库:
import os
import asyncio
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
接下来即可简单进行测试和调用。作为工业级Agent开发框架,ADK的一个基本调用流程如下:
Step 1.配置模型
首先我们需要创建一个模型,也被称作ADK的模型调用适配器,这里需要采用ADK中封装的LiteLlm库来完成,需要注意的是,这个适配器负责配置好 model、认证、连接参数,然后统一管理模型调用接口。
LiteLlm?
其参数解释如下:
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
model | str 字符串 | ✅ 必填 | 指定要调用的模型名称(例如 openai/gpt-4o, deepseek/deepseek-chat, ollama/qwen2.5) |
llm_client | LiteLLMClient对象 | ❎ 可选 | 默认自动创建一个内部的客户端;高级用法允许你传自己定制的客户端(一般开发初期用不到) |
我们可以采用如下方法,创建一个ADK能够识别的DeepSeek模型:
model = LiteLlm(
model="deepseek/deepseek-chat",
api_base=DS_BASE_URL,
api_key=DS_API_KEY
)
需要注意的是,适配器创建模型的流程和使用completion函数调用模型类似,模型名称和参数都要相互匹配。
Step 2.定义一个极简Agent
接下来创建一个Agent对象。和一般Multi Agent框架类似,ADK也是通过Agent类来创建一个个能够独立完成一些功能的代理,而在实际工作中,会通过创建多个代理来协同完成复杂任务。
Agent是 Google ADK 中管理 LLM推理+工具使用+多Agent协作的标准组件,其功能概述如下:
- 封装一个模型(例如 LiteLlm 连接的模型)
- 定义这个Agent的指令说明(Instruction)
- 注册可以调用的工具(Tools)
- 支持子Agent管理(比如自己不能完成就转交子Agent)
- 支持调用前后回调(比如修改请求、监控日志)
- 支持输入输出Schema校验(结构化输入输出)
- 可以嵌套在更大系统中(比如成为子Agent)
Agent?
其核心参数解释如下:
| 参数名 | 类型 | 说明 | 中文解释 |
|---|---|---|---|
name | str | Agent的名称,必须唯一 | 代理的名字(必填) |
description | str | Agent的简短描述,通常在多Agent系统中用于路由/选择 | 代理的简短介绍 |
parent_agent | BaseAgent or None | 父Agent(如果这个Agent是子代理的话) | 父代理,默认无 |
sub_agents | list[BaseAgent] | 这个Agent下面挂载的子Agent们 | 子代理列表 |
before_agent_callback | Callable or None | 在Agent处理输入前,进行预处理的回调 | 处理前的自定义函数 |
after_agent_callback | Callable or None | 在Agent完成任务后,进行后处理的回调 | 处理后的自定义函数 |
model | str or BaseLlm | 关联的模型,可以是字符串名或模型实例(如LiteLlm) | 使用的模型(必填) |
instruction | str or Callable | 给Agent的详细指令,可以是固定文本,也可以是函数动态生成 | 指令说明(必填或推荐填写) |
global_instruction | str or Callable | 在整个Agent树范围共享的指令(全局指令) | 全局指令(少用) |
tools | list[Callable or BaseTool] | 这个Agent可以调用的外部工具列表 | 工具列表 |
generate_content_config | GenerateContentConfig or None | 控制模型生成内容时的一些配置,比如最大Token数、温度等 | 生成设置(选填) |
disallow_transfer_to_parent | bool | 禁止把任务转给父Agent(防止死循环) | 禁止转移到父代理 |
disallow_transfer_to_peers | bool | 禁止把任务转给同级Agent | 禁止转移到同级代理 |
include_contents | 'default' or 'none' | 是否在提示中包含历史对话内容 | 是否包含上下文 |
input_schema | pydantic.BaseModel or None | 限定输入必须符合某种结构(Pydantic模型) | 输入校验模型 |
output_schema | pydantic.BaseModel or None | 限定输出必须符合某种结构(Pydantic模型) | 输出校验模型 |
output_key | str or None | 指定模型输出结果中的哪个字段作为最终输出 | 输出字段名 |
planner | BasePlanner or None | 自定义计划器(比如动态规划步骤) | 规划器(进阶功能) |
code_executor | BaseCodeExecutor or None | 允许Agent执行代码(如Python沙盒环境) | 代码执行器(进阶功能) |
examples | list[Example] or BaseExampleProvider or None | 示例对话或行为示范,帮助模型更好完成任务 | 示例数据 |
before_model_callback | Callable or None | 在发送给模型推理前,修改请求内容 | 模型请求前回调 |
after_model_callback | Callable or None | 在收到模型响应后,修改或处理响应 | 模型响应后回调 |
before_tool_callback | Callable or None | 在调用工具前修改参数或做拦截 | 工具调用前处理 |
after_tool_callback | Callable or None | 在工具返回结果后做处理 | 工具调用后处理 |
其中四个核心参数:
model是必须指定的(不指定Agent就不会工作)instruction和description是推荐填写的(帮助大模型更好理解自己要干什么)tools是选填的(如果需要调用外部API、数据库等,就注册工具)sub_agents是选填的(需要多Agent协作时再用)
一个极简的Agent对象创建方法如下:
agent = Agent(
name="simple_agent",
model=model,
instruction="你是一个乐于助人的中文助手。",
description="回答用户的问题。"
)
Step 3.创建一个Session
紧接着创建一个Session对象,用于保存Agent运行过程中的多轮对话内容。ADK提供了一个InMemorySessionService类,其核心作用如下:
-
保存每轮用户输入(user messages)
-
保存每轮模型输出(assistant messages)
-
保存工具调用过程中的中间数据(如果有工具的话)
-
提供历史对话上下文,让模型能基于完整对话继续推理,而不是每次都从空白开始
InMemorySessionService?
在前期测试时,我们可以创建一个InMemorySessionService()实例:
session_service = InMemorySessionService()
这个对话管理示例实际会在内存中进行历史会话信息管理。而具体的会话信息会保存在.sessions属性里,默认为空:
session_service.sessions
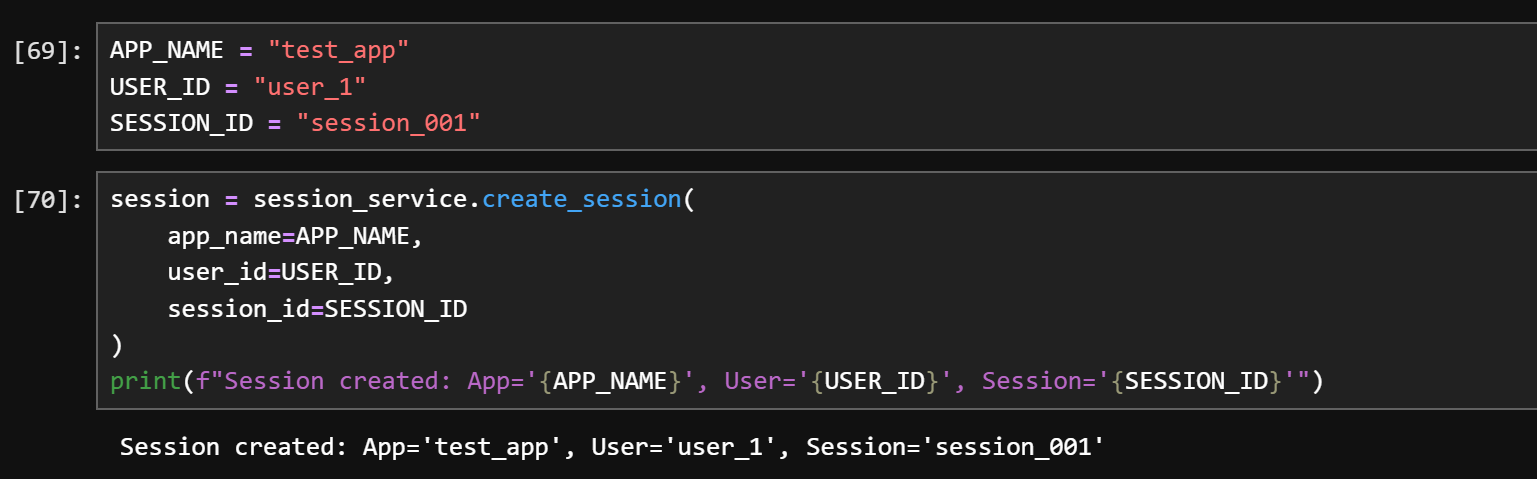
在正式开启对话之前,我们需要创建一个初始session对象,为了便于区分不同的会话,该对象需要设置APP名称、用户ID和对话ID,方便后续进行查找和调用:
APP_NAME = "test_app"
USER_ID = "user_1"
SESSION_ID = "session_001"
session = session_service.create_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID
)
print(f"Session created: App='{APP_NAME}', User='{USER_ID}', Session='{SESSION_ID}'")
需要注意的是,执行完上面的代码后,我们就获得了一个包含APP名称、用户ID和对话ID的session对象:
session
session.app_name
session.user_id
session.id
目前session对象是空的,而在后续执行过程中,伴随着上下文生成器存储了更多的会话信息,我们也可以将更多的上下文信息保存在session中。
不过这里需要注意的是,在创建session对象的同时,对话生成器session_service的.sessions也发生了变化,其内容与session基本一致:
session_service.sessions
而需要注意的是,在后续对话中,我们实际上是带入session_service进行对话,并读取session_service.sessions里面的历史对话信息作为上下文。这里可以将单独创建的session对象视作一个中间对象或者一个备份。
Step 4.创建智能体执行器(Runner)
接下来进一步创建Runner对象,简单说,Runner 是 ADK 中真正让 Agent“动起来”的引擎,其核心功能和Agents SDK中的Runner类似,具体职责如下:
| 职责 | 说明 |
|---|---|
| 会话管理 | 自动读取/写入 SessionService,维护历史 |
| Agent调用 | 调用指定的 Agent 完成推理和工具调用 |
| 输入输出流转 | 把用户输入交给Agent,把Agent输出返回 |
| 流程控制 | 支持多轮对话、子Agent委托、工具调用等 |
| 生命周期管理 | 处理每一次对话流程的完整生命周期 |
也就是说Runner:Agent的管理者,负责组织每一次对话交互的完整生命周期。
Runner?
其核心参数解释如下:
| 参数名 | 类型 | 说明 | 中文翻译 |
|---|---|---|---|
app_name | str | 应用程序的名称,用于标识不同的应用实例 | 应用名称 |
agent | BaseAgent | 要运行的根 Agent,负责执行实际的任务和推理 | 要运行的主代理 |
artifact_service | Optional[BaseArtifactService] | 可选的文件存储服务,用于处理生成的工件(如文件、模型) | 文件存储服务(可选) |
session_service | BaseSessionService | 必需的会话服务,用于管理和维护对话历史 | 会话服务(必须) |
memory_service | Optional[BaseMemoryService] | 可选的内存服务,用于长期和短期记忆管理 | 内存服务(可选) |
而Runner类有个直观重要的方法,Runner.run_async,其核心解释如下:
Runner.run_async?
runner.run_async 是 Runner 类的核心方法之一,用于以异步方式执行 Agent 的任务。这个方法接收用户输入的消息,并将其添加到会话中,随后启动 Agent 来处理该消息,并生成一系列的事件(Event)。
具体参数解释如下:
-
user_id(str):- 该参数表示用户的唯一标识,用于标记当前会话是属于哪个用户的。每个用户可以有多个会话实例。
- 示例:
user_id="user_123"
-
session_id(str):- 该参数表示会话的唯一标识,用于区分不同用户或同一用户的不同对话会话。每次创建会话时,都会为其分配一个唯一的
session_id。 - 示例:
session_id="session_456"
- 该参数表示会话的唯一标识,用于区分不同用户或同一用户的不同对话会话。每次创建会话时,都会为其分配一个唯一的
-
new_message(types.Content):- 这是 ADK 中的一个核心对象,表示传递给 Agent 的新消息。
types.Content是一个包含了消息的具体内容的对象,通常它包含role(角色)、text(消息文本)等字段。 - 示例:
new_message=types.Content(role="user", parts=[types.Part(text="今天天气如何?")])
- 这是 ADK 中的一个核心对象,表示传递给 Agent 的新消息。
-
run_config(RunConfig, 可选):- 这是一个配置对象,用于定制执行时的参数设置。可以根据需求设置一些如语音配置、响应方式、最大模型调用次数等参数。其默认值为
RunConfig(),这是一个内置的默认配置类。
RunConfig的核心字段解释:speech_config: 用于配置语音识别和语音输出的相关设置(例如语音转文本、语音输出等)。通常与语音助手相关。response_modalities: 配置响应的方式,例如,返回文本、语音等。save_input_blobs_as_artifacts: 是否将输入文件保存为工件(例如,将用户上传的图片保存为文件以供后续处理)。默认值为False。support_cfc: 是否支持 CFC(Custom Function Calling),即是否允许 Agent 调用自定义函数。streaming_mode: 设置流模式(例如是否开启流式输出),用于处理长时间生成的响应。output_audio_transcription: 配置输出的音频转录设置(如果支持语音输出)。max_llm_calls: 配置在一次会话中最大可以调用 LLM(大语言模型)次数的上限。默认值为 500。
- 这是一个配置对象,用于定制执行时的参数设置。可以根据需求设置一些如语音配置、响应方式、最大模型调用次数等参数。其默认值为
接下来我们创建Runner对象,而Runner.run_async方法会在之后用到。这里需要带入此前创建的session_service对象:
session_service
runner = Runner(
agent=agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=session_service # Uses our session manager
)
print(f"Runner created for agent '{runner.agent.name}'.")
ADK的runner和Agents SDK runner功能类似,本质上都是完成一个任务的循环,稍后会具体介绍。
Step 5.执行对话
接下来我们需要创建一个名为call_agent_async的函数来获得Agent响应,其代码如下:
async def call_agent_async(query: str, runner, user_id, session_id):
"""Sends a query to the agent and prints the final response."""
print(f"\n>>> User Query: {query}")
# Prepare the user's message in ADK format
content = types.Content(role='user', parts=[types.Part(text=query)])
final_response_text = "Agent did not produce a final response." # Default
# Key Concept: run_async executes the agent logic and yields Events.
# We iterate through events to find the final answer.
async for event in runner.run_async(user_id=user_id, session_id=session_id, new_message=content):
# You can uncomment the line below to see *all* events during execution
print(f" [Event] Author: {event.author}, Type: {type(event).__name__}, Final: {event.is_final_response()}, Content: {event.content}")
# Key Concept: is_final_response() marks the concluding message for the turn.
if event.is_final_response():
if event.content and event.content.parts:
# Assuming text response in the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate: # Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
# Add more checks here if needed (e.g., specific error codes)
break # Stop processing events once the final response is found
print(f"<<< Agent Response: {final_response_text}")
这段代码定义了一个 call_agent_async 异步函数,用来:
- 接收用户的查询(
query) - 调用 Agent 执行推理
- 获取并返回最终的 Agent 回复
其核心运行流程是:
- 将用户查询转换为 ADK 需要的格式
- 通过
runner.run_async()运行 Agent - 通过 事件驱动机制 获取和处理每一轮的消息、工具调用、回复
- 当 最终响应 到达时,停止循环并返回 Agent 的最终回答。
完整代码解释如下:
Part 1. 导入必要模块
FENCE0
- 这个
types模块是用于在 ADK 中创建消息内容的。它允许你定义消息的“角色”(如user或assistant),以及消息的内容部分。
Part 2. 定义 call_agent_async 函数
FENCE1
query: 用户输入的查询问题。runner: 你之前创建的 Runner 对象,负责启动 Agent 并管理会话。user_id和session_id: 用于标识特定用户和会话,确保模型能够维持会话上下文。
FENCE2
- 这里将用户的查询(
query)格式化为 ADK 消息格式,并通过types.Content和types.Part封装成可以传递给 Agent 的内容。role='user'表明消息是由用户发送的。
Part 3. 准备获取 Agent 的最终回复
FENCE3
- 默认情况下,
final_response_text被初始化为一个错误信息字符串,表明Agent没有最终响应。后续会被更新为真正的回答。
Part 4. 调用 Agent 并监听事件
FENCE4
runner.run_async()是一个异步生成器,负责执行Agent推理并生成一系列 事件(Events),每个事件代表了交互中的一步操作(如用户消息、模型回复、工具调用等)。- 你可以通过
async for循环来迭代所有事件,并逐一检查它们的内容。
Part 5. 检查是否是最终响应
FENCE5
- 关键点:
event.is_final_response()用来判断当前事件是否是最终回复。这个判断标志着Agent已经完成了对用户问题的处理,可以停止进一步处理。
FENCE6
- 如果事件的
content存在,并且包含了parts(模型回复的文本部分),就将 最终回复 保存到final_response_text变量中。
FENCE7
- 如果
event.actions.escalate为True,表示 错误发生或需要升级,比如模型不能处理问题,或者需要人工干预。这时,我们会将相应的错误信息记录在final_response_text。
FENCE8
- 一旦获取到最终的响应,
break语句会停止事件处理,不再继续监听其他的事件。
Part 6. 打印最终响应
FENCE9
- 最后将 Agent 的最终回复输出到控制台。
这里有以下几点需要注意:*
- 为什么要定义这个辅助函数?在这段代码中,我们通过
call_agent_async这个辅助函数来实现与 Agent 的交互。它的作用不仅是简单地给用户回复答案,而是通过 事件驱动 机制,来处理与 Agent 的复杂交互和状态管理。 - 为什么不直接调用
runner.run_async?这里的设计其实是为了让我们能够更方便地处理和监控整个过程,尤其是在多轮对话或复杂交互中。将这些复杂逻辑封装到一个函数里,使得代码更加清晰、可维护,并且容易扩展。
也就是说,我们可以把call_agent_async 想象成一个管控器,它负责管理这个异步对话的过程,并确保每一部分顺利完成。这个过程很复杂,因为:
- 它不是一次性任务,可能涉及多步推理、外部工具调用、错误处理等环节。
- 我们需要逐步监控每一个事件(可能有很多中间状态、工具调用等)。
- 只有当所有步骤完成,最终的模型回复才算“最终回应”。
实际运行流程如下:
query='你好,我叫陈明,好久不见!'
USER_ID, SESSION_ID
runner
await call_agent_async(query, runner, USER_ID, SESSION_ID)
此时输出内容如下:
-
Author:
simple_agent— 这个事件是由 simple_agent 发出的,表示当前响应来自于我们定义的 Agent。 -
Type:
Event— 表明这是一个事件对象,表示某个状态发生。 -
Final:
True—True表示这是最终的响应,模型已经完成任务并准备返回最终结果。 -
Content:
content.parts=[Part(...)]— 这里包含了模型回复的实际内容。它是一个Part对象,其中text字段就是最终的文本回答:'你好!我是你的智能助手,专门用来回答你的问题、提供帮助或陪你聊天。我可以帮你查询信息、解答疑问、提供建议,或者只是随便聊聊。有什么我可以帮你的吗? 😊' -
role:
'model'— 这个角色是 模型,意味着这条消息是从模型生成的,不是用户输入。
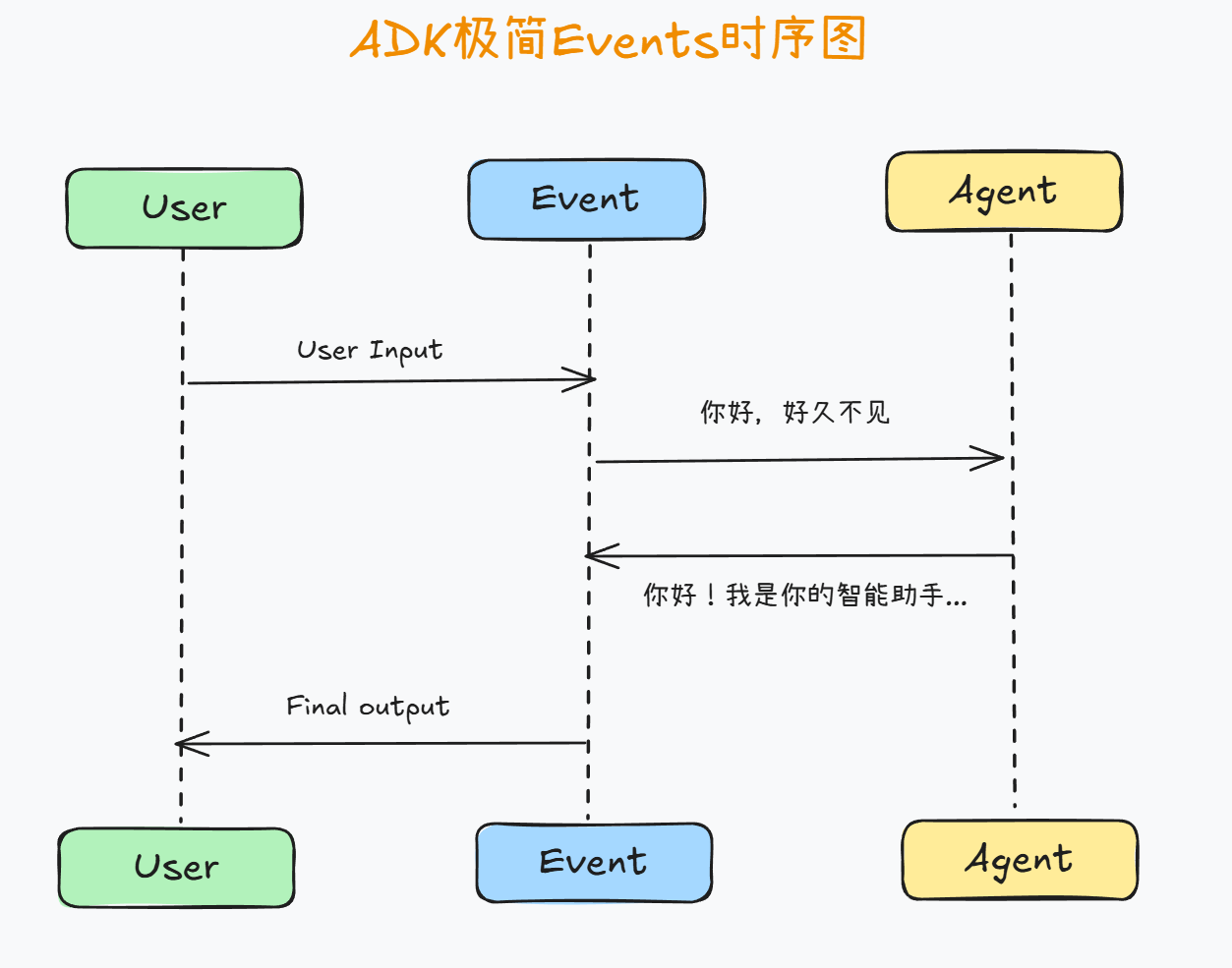
也就是说,在普通的问答过程中,事件流会经过以下几个关键步骤:
-
用户输入:
- 用户提交一个查询请求(例如:“你好,好久不见,请介绍下你自己。”)
-
生成事件:
- 系统触发一个 事件,表示用户输入已到达,准备交给 Agent 处理。
-
Agent 处理:
- Agent 接收用户的输入,开始进行推理(基于
instruction和模型的推理能力),并生成相应的回答。
- Agent 接收用户的输入,开始进行推理(基于
-
工具调用(可选):
- 如果 Agent 需要外部工具(例如查询天气、数据库、搜索引擎等),会触发工具调用事件。
-
最终响应:
- 最终响应(如
final=True)被标记为完成,且不会有更多的事件生成。此时,Agent 将答复用户,结束本轮对话。
- 最终响应(如
四、ADK历史对话信息保存机制与构建多轮对话机器人
1.ADK历史对话保存机制
需要注意的是,我们无需任何额外设置,ADK的历史对话信息就保存在session_service.sessions对象中:
session_service.sessions
因此无需任何额外操作,我们直接再进行新的对话,就会带入历史上下文进行对话:
query='很高兴认识你,你还记得我叫什么名字么?'
USER_ID, SESSION_ID
await call_agent_async(query, runner, USER_ID, SESSION_ID)
而新的会话信息会继续存储在session_service.sessions中。
session_service.sessions
据此查看test_app里面的对话信息:
session_service.sessions['test_app']
进一步查看用户user_1的对话信息:
session_service.sessions['test_app']['user_1']
进一步查看用户user_1的session_001对话信息:
session_service.sessions['test_app']['user_1']['session_001']
由此可见ADK本身的对话管理非常完整细致。我们只需要重复调用await call_agent_async(query, runner, USER_ID, SESSION_ID),这个流程本身就是在执行多轮对话。
2.ADK会话容器与会话管理器
谷歌ADK的企业级用户会话管理功能的实现,主要依托于InMemorySessionService和Session两个类,此前我们曾经分别使用过,接下来详细介绍这两个对象的基本功能。
from google.adk.sessions import InMemorySessionService, Session
InMemorySessionService?
2.1 会话容器Session
在此前我们首次创建会话管理器session_service的时候,曾经使用create命令初始化过一个会话容器:
而伴随着对话的进行,多轮对话信息都保存在session_service.sessions中,而最开始创建的会话容器session还保留着最初始的状态:
session
相比每次对话时都会带入的session_service.sessions对象,会话容器session更像是一种备份、或者充当保存点的角色,我们可以使用session_service.get_session内容创建一个包含当前对话全部信息的会话容器:
session_all = session_service.get_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID
)
此时session_all就包含了全部会话信息:
session_all
而我们现在就有两个会话容器了,其中session是个空的容器,而session_all是一个包含了好几轮对话信息的容器:
session
而如果我们想要回到最初始的状态(清空全部历史消息),则可以使用如下方法恢复到session保留的记忆:
session_service.sessions['test_app']['user_1']['session_001']
session_service.sessions['test_app']['user_1']['session_001'] = session
此时我们会话生成器的历史对话就和session同步了:
session_service.sessions
此时再进行对话,则不会有任何历史对话信息:
query = '你好,你还记得我叫什么名字么?'
await call_agent_async(query, runner, USER_ID, SESSION_ID)
而本次对话信息会继续保留在session_service.sessions中:
session_service.sessions
而如果我们想要恢复此前session_all的会话内容,则可以使用如下方法:
session_service.sessions['test_app']['user_1']['session_001'] = session_all
session_service.sessions
然后测试模型对话记忆:
query = '你好,你还记得我叫什么名字么?'
await call_agent_async(query, runner, USER_ID, SESSION_ID)
由此不难发现对话容器的核心用途,便于进行更加灵活的会话管理。
此外我们还可以通过session_id、user_id和app_name来进行会话管理。更多进阶内容会在付费课程中进行讲解。
2.2 会话生成器session_service
从此前的介绍中不难看出,会话生成器session_service的核心作用是伴随着会话进程,时刻保存会话信息。而实际上会话生成器还有更多的会话生命周期管理的功能:
session_service?
总的来说ADK的会话生成器有三种,其一是我们前文介绍的InMemorySessionService类:
from google.adk.sessions import InMemorySessionService
该类实例化的会话生成器,是基于内存的会话生成与保存,使用更加轻量便捷,但并不能持久化保存,一旦环境重启(或进程终止),历史会话就会消失。因此ADK还提供了另外两种能够持久化保存会话信息的方法,分别是使用数据库(PostgreSQL、MySQL、SQLite)进行保存的库DatabaseSessionService:
from google.adk.sessions import DatabaseSessionService
以及可以在谷歌云平台Vertex AI上进行存储的VertexAiSessionService类:
from google.adk.sessions import VertexAiSessionService
若采用持久化的会话生成器,则每次生成的会话内容(包括events流)则都会自动存储在指定数据库中。整个过程要求新进行数据库安装下载配置,并创建响应的存储表。以DatabaseSessionService+MySQL为例,基本执行流程如下:
- 第一步:设计数据库表结构
根据 ADK 的要求,我们需要在 MySQL 中创建四张表:sessions、events、app_states 和 user_states。
- 第二步:安装和配置 ADK
紧接着在 Python 环境中安装 Google ADK:
FENCE0
然后,安装支持 MySQL 的扩展:
FENCE1
- 第三步:配置
DatabaseSessionService
然后在 Python 代码中,使用以下方式配置 DatabaseSessionService:
FENCE2
这里需要将 username、password 和 localhost 替换为您的 MySQL 数据库的实际用户名、密码和主机地址。
- 第四步:创建会话并添加事件
在创建会话时,您可以初始化会话状态并添加事件:
from google.adk.sessions import Session
from google.adk.events import UserMessage, AgentResponse
# 创建会话
session = session_service.create_session(
app_name="MySQL_test",
user_id="user_1",
session_id="session_1",
state={"history": []}
)
之后的对话就和此前无异。
---
### ** 更多ADK会话信息持久化方法详见正课**
  **更多关于持久化具体实操流程,以及更多ADK进阶内容讲解,详见[《2025大模型Agent智能体开发实战》(7月班)](https://ix9mq.xetslk.com/s/3Zfsc8) 付费课程。<span style="color:red;">详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇</span>**
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/06661cb459aa3e4b655aface404435d.png" alt="06661cb459aa3e4b655aface404435d" style="zoom:15%;" />
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/38d63edff0bc82053aa281cf63f4079c_.png" alt="38d63edff0bc82053aa281cf63f4079c_" style="zoom: 50%;" />
---
## 五、ADK内置前端调用流程
### 1.ADK内置前端功能介绍
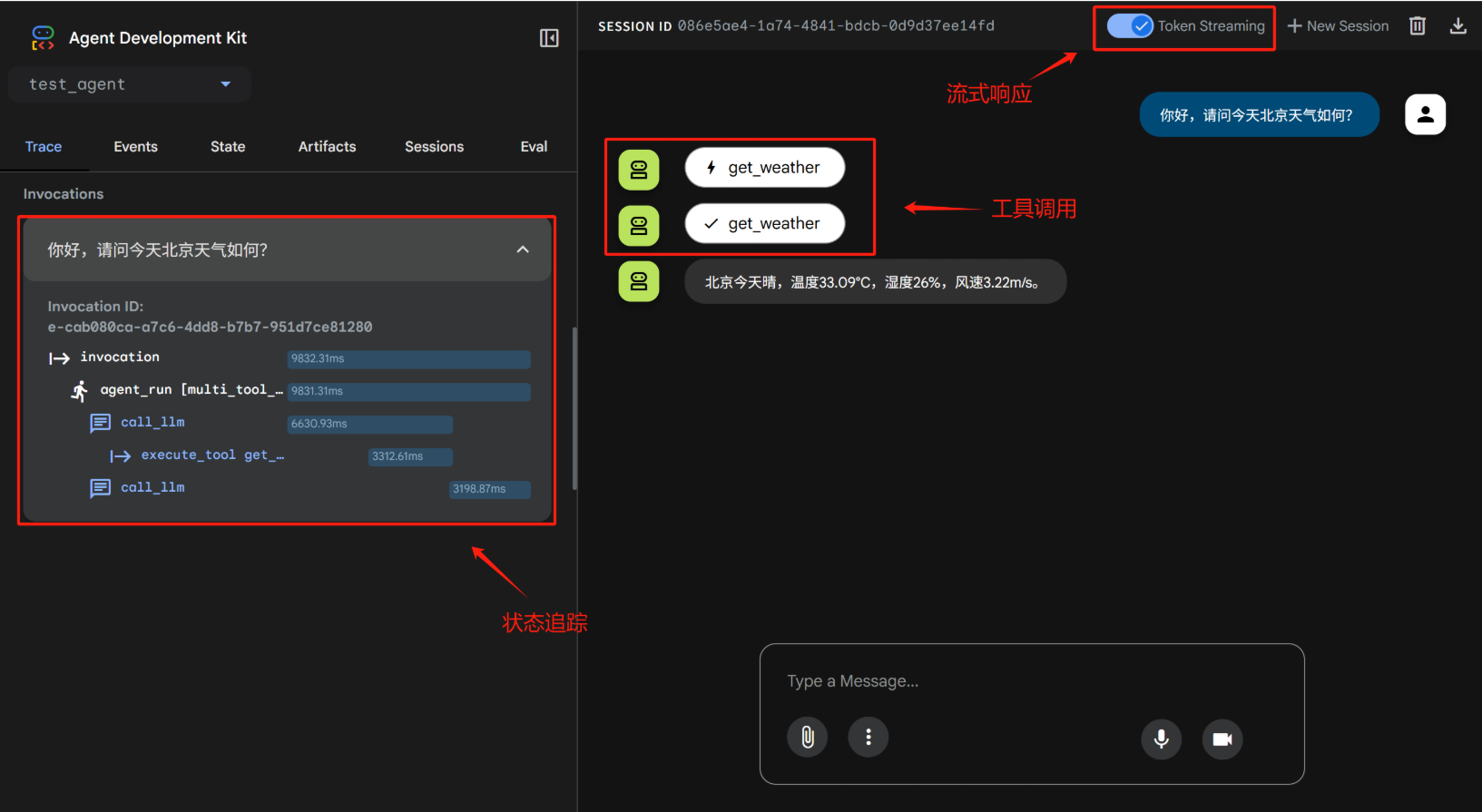
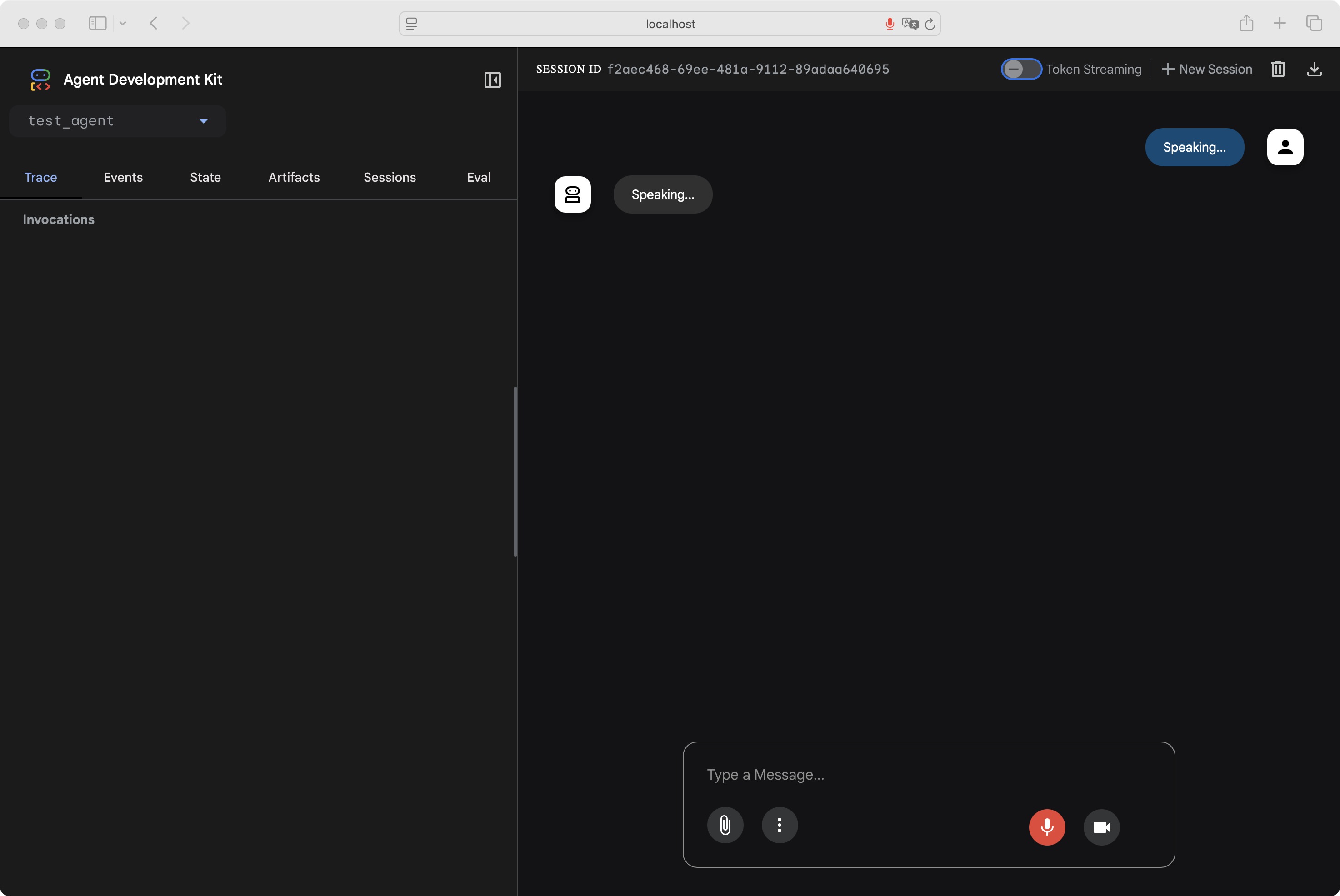
  ADK作为最新一代Agent开发框架,不仅功能特性非常领先,而且还内置了非常多的工具,包括Gemini系列模型自带的谷歌搜索、文件检索和代码解释器等功能,同时ADK还拥有内置对话前端,方便开发者更加直观的感受Agent的对话流程,并且实时追踪Agent的events流。而如果Agent中存在外部工具调用,则在内置前端中,还能进一步观察到Agent调用外部工具完整流程,以及各环节调用信息,方便开发者即时debug。如果是使用Gemini模型,这个前端还支持语音和视频实时交互,基本展示效果如下:
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/7e1032040d5c3bd8447894629c9361e.png" alt="7e1032040d5c3bd8447894629c9361e" style="zoom:50%;" />
### 2.ADK内置前端开启流程
  而ADK内置前端开启流程也非常简单,这里我们需要创建一个项目文件,如创建一个ADK_Chat文件夹:
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20250428112014361.png" style="zoom: 50%;" />
然后创建基本文件结构:(注意,如果是Windows系统,官方推荐手动创建项目文件基本结构,而不是采用IDE如Cursor等进行创建,以避免出现字符乱码情况)
FENCE0
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20250428112454327.png" alt="image-20250428112454327" style="zoom:50%;" />
然后使用cursor或者其他IDE打开项目,准备写入代码。(也可以直接使用文本编辑器将代码拷贝进去)
- **__init__.py**
写入如下内容:`from . import agent`
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20250428112642693.png" alt="image-20250428112642693" style="zoom:50%;" />
- **.env**
  然后在`.env`中写入如下内容:
FENCE0
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20250428113114121.png" alt="image-20250428113114121" style="zoom:50%;" />
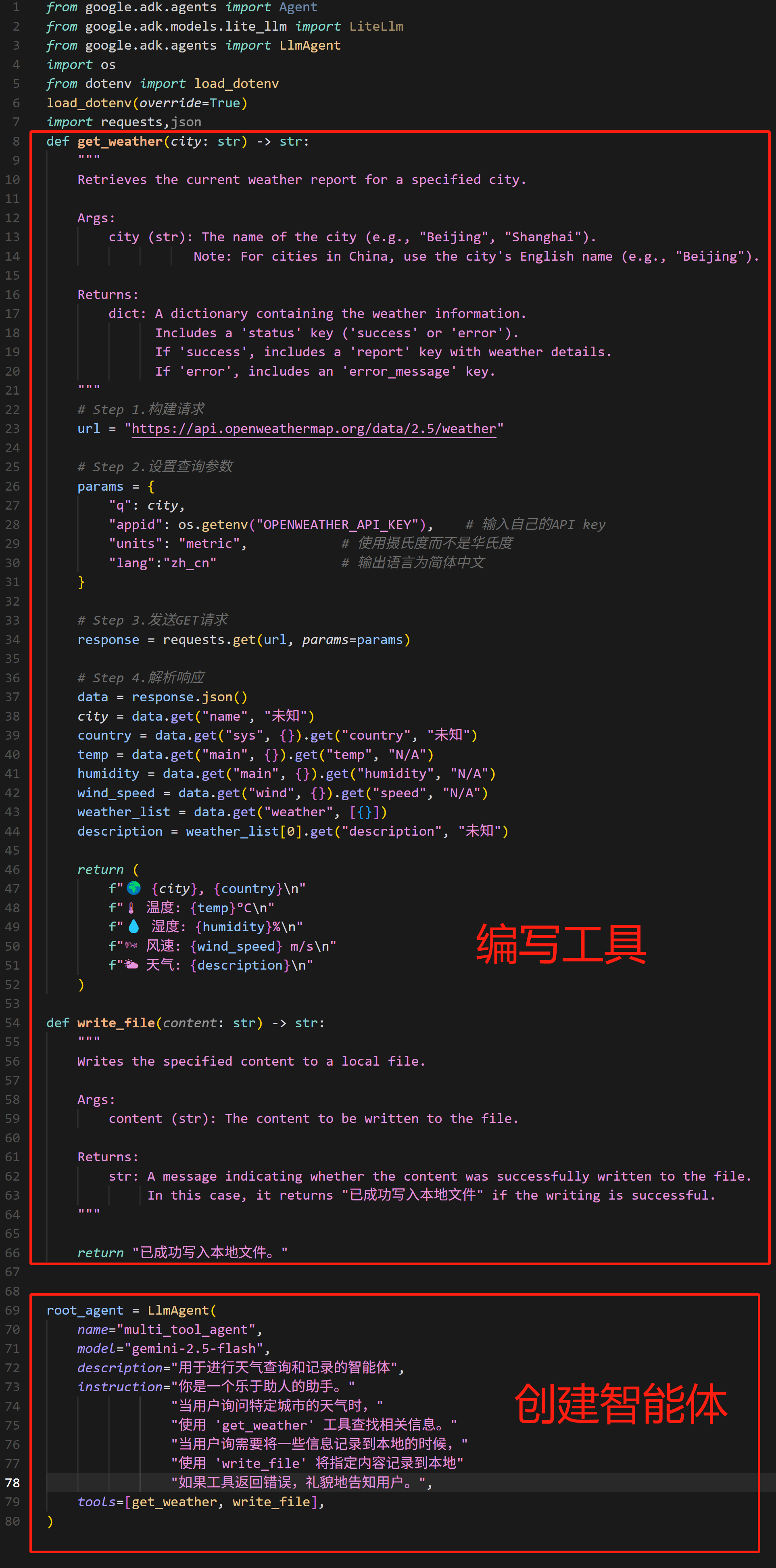
- **agent.py**
  写入如下内容:
FENCE0
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20250428113724937.png" alt="image-20250428113724937" style="zoom:33%;" />
然后再次确认当前环境是否安装adk和litellm两个库:
FENCE0
然后使用adk命令先进行Agent测试。我们在根目录下输入:
FENCE0
若能顺利进行对话,则说明Agent使用正常:
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20250428113650215.png" alt="image-20250428113650215" style="zoom:50%;" />
  由此不难看出,adk其实是伴随着安装包一起安装的调用测试命令。在使用adk命令时,我们无需单独设置主函数,只需要按照要求创建一个名为`root_agent`的主agent,即可顺利开启对话。同时当前项目结构中,`.env`文件用于保存一些关键变量信息,而`__init__.py`则负责将当前项目文件`test_agent`包装为一个可执行的Python文件。这也就是为何我们可以直接输入adk run test_agent的原因。
  接下来即可开启前端了,我们在项目根目录下输入:
FENCE0
> 注意选择一个未被使用的端口号
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20250428114255681.png" alt="image-20250428114255681" style="zoom:33%;" />
然后在浏览器输入:`http://0.0.0.0:8002/`即可开启对话:
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20250428121614162.png" alt="image-20250428121614162" style="zoom:50%;" />
在对话页面能够看到完整的历史对话消息,并且在左侧还能看到事件流的基本情况,以及每个事件的详细信息:
<img src="https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20250428121751965.png" alt="image-20250428121751965" style="zoom:50%;" />
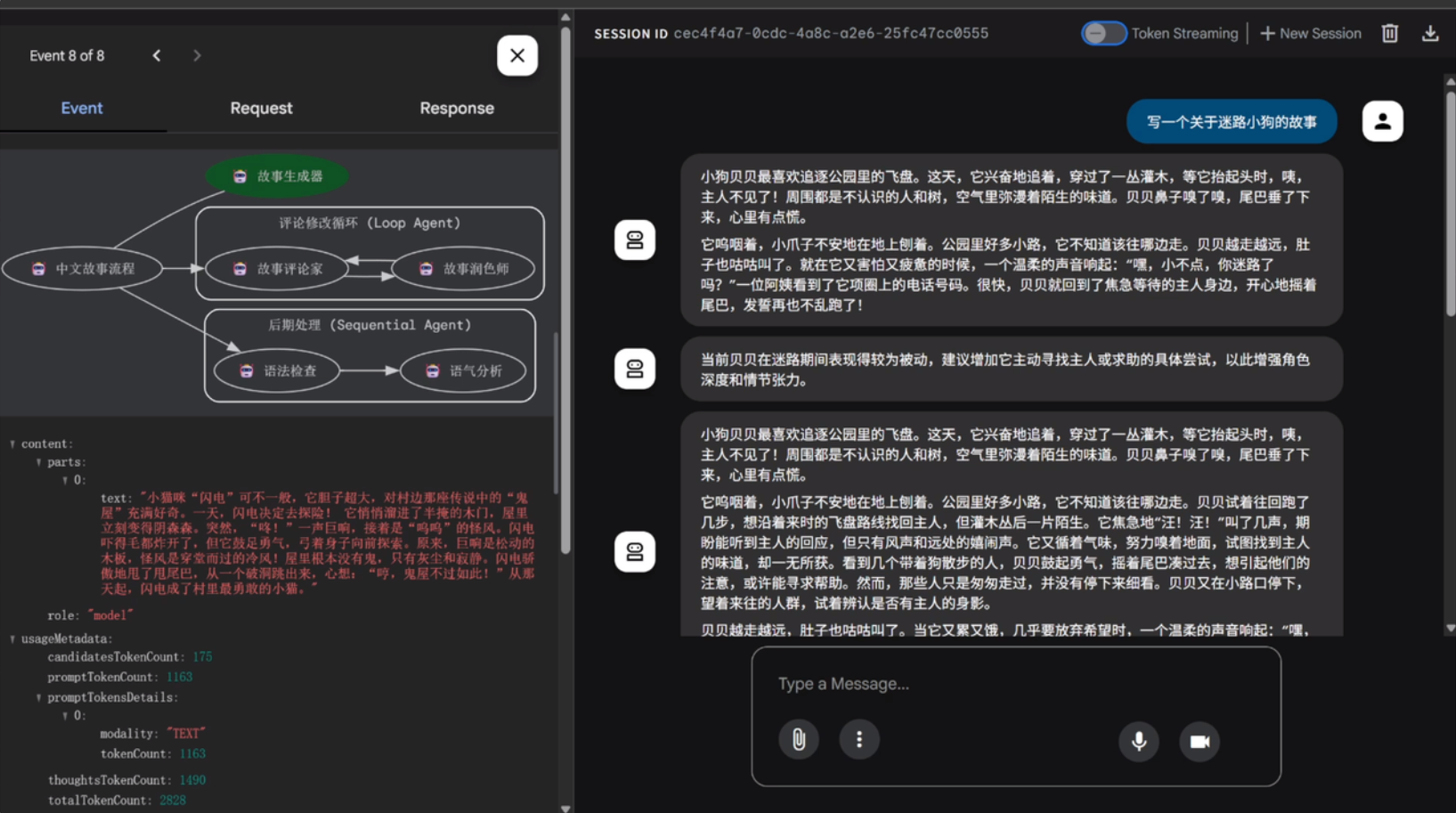
并且此时Agent也是能支持多轮对话的。具体演示效果如下:
```python
from IPython.display import Video
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2025-04-28%2012-12-22.mp4", width=800, height=400)
不难看出,尽管单独使用ADK代码环境创建Agent流程较为复杂,但如果是借助ADK run或者web等工具,则可以不进行任何额外其他设置,快速调用已经创建好的Agent并进行功能测试,期间关于会话ID、用户ID和APP ID等参数都会自动设置,且支持多轮对话并能打印详细的每个event信息,可以说是非常高效的开发工具了。
至此第一部分内容结束,下一部分我们将继续讲解ADK如何接入外部工具及MCP工具流程。