Agent开发进阶:工具组与数据分析Agent开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(11月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(11月班)

《2025大模型Agent智能体开发实战》(11月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
课程完整介绍

秋季班重磅新增14项实战案例

部分课程成果演示
from IPython.display import Video
- Dify+DeepSeek搭建智能微信语音客服
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- Coze自动图文视频创作流程
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- 可视化数据分析Multi-Agent
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目展示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋季班)



详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

国产开源AgentScope框架技术实战
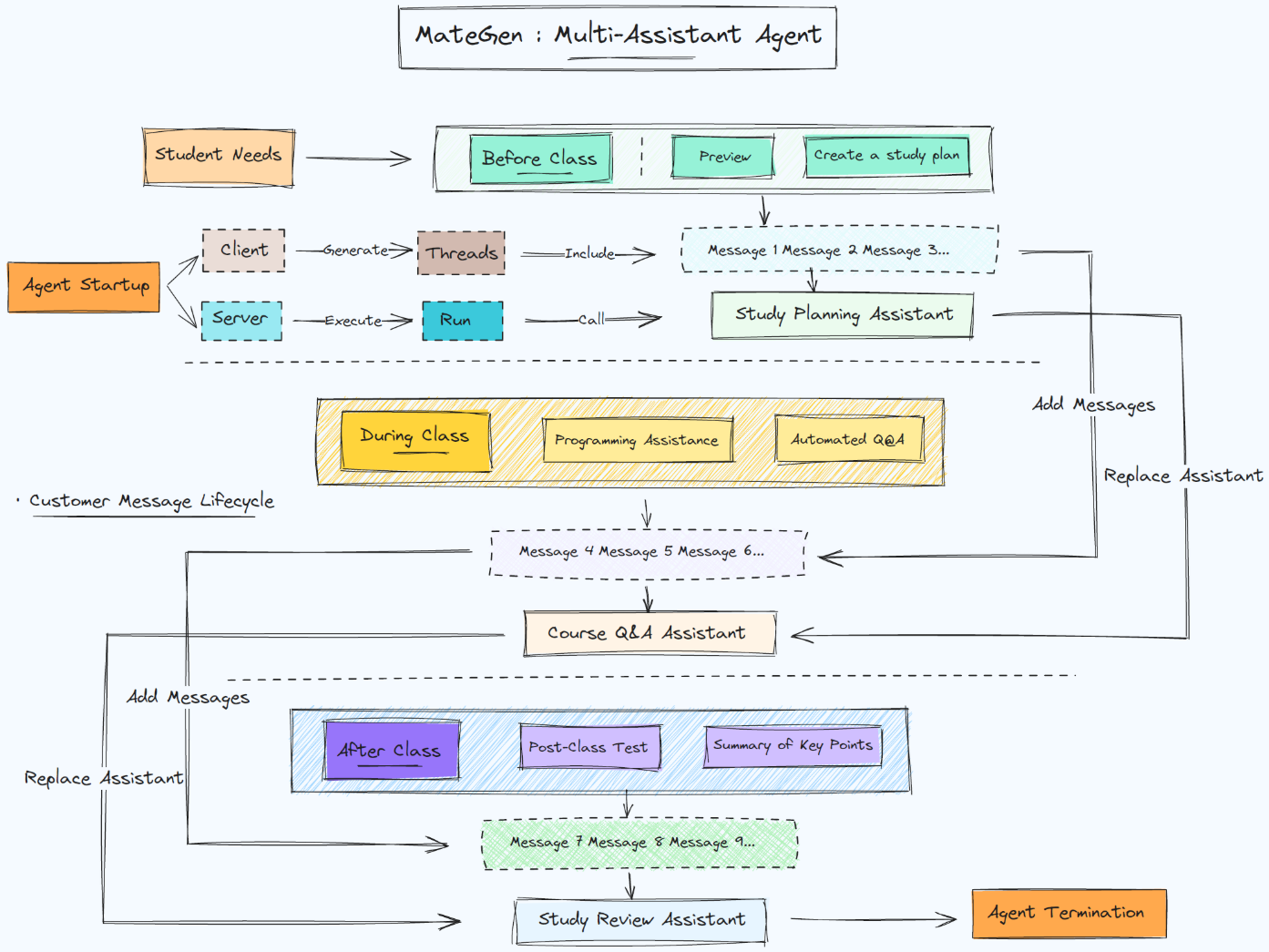
Part 4.Agent开发进阶:工具组与数据分析Agent开发实战
一、大模型技术热门应用方向:Data Agent
1. AI数据分析技术应用价值
数据是数字经济时代的石油,然而,如何低成本、高效率地“开采”和“精炼”这些石油,始终是困扰着无数企业的核心难题。传统的数据分析流程依赖于专业的BI工程师和数据科学家,他们就像是数据与业务决策者之间的“翻译官”,这个过程往往存在着沟通成本高、响应周期长、需求理解易偏差等痛点。
幸运的是,以大型语言模型(LLM)为核心的AI技术正以前所未有的力量,冲破这层障碍。AI数据分析,特别是自然语言到SQL(NL2SQL)和自然语言到Python(NL2Python)的技术,正在从根本上重塑我们与数据交互的方式。它的技术价值在于将复杂的数据查询和分析操作,转化为人类最自然的交流方式——对话。其应用前景更是不可限量:从让企业高管在会议室里用一句话调取实时销售报表,到赋能市场分析师通过多轮对话深挖用户行为模式,AI正在将数据分析的能力“民主化”,让每一个业务人员都能成为自己领域的数据专家。
放眼业界,这一赛道已涌现出不少先驱性的解决方案。开源社区的明星项目 DB-GPT 经过数年发展,已演进为一套综合性的私有化大模型数据解决方案。它强调在私有环境中,通过强大的RAG(检索增强生成)能力深度整合企业知识库(如数据字典、业务文档),并以多智能体(Multi-Agent)协作的模式,为用户提供精准、安全的数据服务。而在另一条技术路线上,微软的 TaskWeaver 项目则另辟蹊径,它以“代码优先”的理念为核心,将用户的请求精准地分解为一系列高可靠性的代码片段(Code Snippets)。TaskWeaver 强调规划与执行的分离,通过强大的状态管理,让数据(如 DataFrame)能够像接力棒一样在不同的代码步骤间无缝传递,展现了作为“代码生成式AI”的严谨与强大。
2. AI数据分析热门开源项目介绍
DB-GPT (https://github.com/eosphoros-ai/DB-GPT) 已经从一个单纯的Text-to-SQL项目,演进为一个一站式的私有化大模型数据解决方案平台。它的核心设计哲学是为企业提供一个安全、可控且功能全面的数据交互层,让大模型的能力能够在企业内部的防火墙之后安全、高效地释放。

由人大和清华大学共同发起的项目,聚焦构建“智能数据分析 Agent”,其核心技术要点包括:通过 AgentScope 实现 Agent 与外部工具(如 SQL 查询、Python 执行、绘图生成)高效协作;借助多模态知识库与 RAG 检索机制,将数据文本、可视化资产及查询历史统一纳入分析体系;采用模块化工具组管理,使 Agent 在“提取数据 → 分析计算 → 可视化展示”三大阶段之间具备流程控制与智能切换能力。项目特色在于将传统数据分析流程自动化为可被大模型驱动的 Agent 系统,让分析师从“写脚本”转向“提问题”,显著提高分析效率与知识复用能力。
如果说 DB-GPT 是一个功能全面的“数据应用航母”,TaskWeaver 是一个严谨的“数据任务总工程师”,那么 Vanna.ai (https://github.com/vanna-ai/vanna) 则更像一位专注、高效、可被轻松集成的“Text-to-SQL 外科手术专家”。它不追求大而全,而是聚焦于将“自然语言转换为SQL”这一核心任务做到极致的精准与便捷。
3. AI数据分析核心技术
NL2SQL:让人人都能与数据库“对话”
自然语言到SQL(Natural Language to SQL,简称NL2SQL),顾名思义,是一项旨在将人类的日常语言(如“查询上个季度北京地区所有产品的销售总额”)自动转换成数据库可以执行的、结构化的SQL查询语句的技术。这项技术的终极目标,是彻底拆除业务人员与底层数据之间的“技术壁垒”,让任何没有SQL编程背景的人,都能通过提问的方式,直观、快速地从海量数据中获取洞察。
在2025年的今天,NL2SQL早已超越了早期简单的模板匹配和关键词翻译。现代的NL2SQL系统更像一个具备深度理解能力的数据侦探。它面临的核心挑战主要有三方面:(1)数据库模式(Schema)的复杂性,成百上千的表和令人费解的字段名是第一道坎;(2)业务术语的鸿沟,例如“GMV”、“复购率”等词汇,模型本身并不理解其商业内涵和计算口径;(3)自然语言的模糊性,“大客户”究竟是指销售额大还是公司规模大?
为了克服这些挑战,最前沿的NL2SQL解决方案(正如Vanna和DB-GPT所展示的)普遍采用了**检索增强生成(RAG)**的架构。系统不再仅仅依赖大模型自身的通用知识去“猜”SQL,而是在生成SQL之前,先从一个专门构建的知识库(向量数据库)中,检索出与用户问题最相关的“备考资料”,包括:相关的表结构定义(DDL)、业务术语的官方解释、甚至是历史上相似的成功查询案例。通过将这些精准的上下文信息喂给大模型,NL2SQL的准确率和可靠性得到了指数级的提升,真正使“与数据对话”从一个美好的愿景,变为了触手可及的现实。
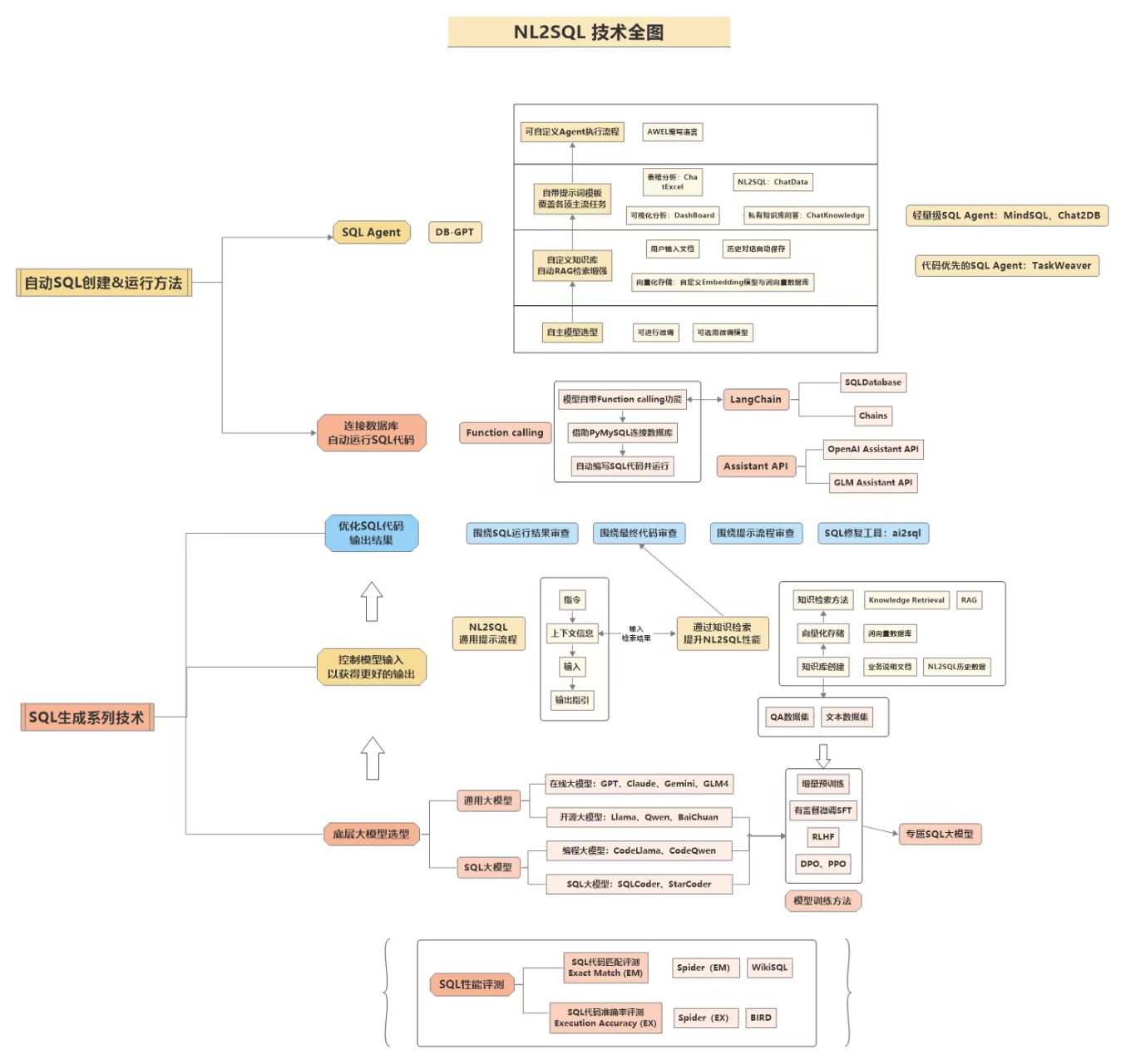
更多多模态NL2SQL相关技术,欢迎报名我主讲的《2025大模型Agent智能体开发实战》(11月班) 进行学习
NL2Python:从数据查询到智能自动化的飞跃
如果说NL2SQL是打开数据宝库大门的“钥匙”,那么**自然语言到Python(Natural Language to Python,简称NL2Python)**就是进入宝库后,对宝藏进行深度加工、分析、乃至创造新价值的“魔法棒”。它的范畴远超数据查询,旨在将用户描述的任务或目标,直接转换成可执行的Python代码,以完成更高级、更复杂的自动化流程。
与NL2SQL相比,NL2Python的能力边界要广阔得多。SQL的本质是数据查询,而Python则能实现真正意义上的数据计算与流程自动化。这包括:
- 复杂的数据处理:执行多表连接(Join)后的数据清洗、特征工程、数据重塑等。
- 高级统计与建模:运行统计检验、训练机器学习模型、进行预测分析。
- 动态数据可视化:根据分析结果,动态生成各种复杂的图表。
- 外部API交互:调用外部服务接口,用获取的数据丰富现有分析。
当然,其挑战也更为艰巨:(1)开放性问题,同一个任务可以用无数种方式和库来实现,如何生成最优、最高效的代码是一大难题;(2)状态管理,数据分析往往是多步骤的,如何让第二步生成的代码,正确地使用第一步代码产出的数据(如一个DataFrame),是实现复杂工作流的核心;(3)环境与安全,执行动态生成的代码需要考虑依赖库和安全沙箱的问题。
RAG:为AI数据分析注入“灵魂”的“大脑外挂”
我们必须认识到一个根本性的事实:像GPT-4或DeepSeek这样的通用大模型,它们是博学的通才,而非特定领域的专家。模型在预训练时学习了全世界的公开知识,它知道“销售额”的普遍概念,但它绝不可能知道在您公司的数据库里,“销售额”具体是指 transactions 表里的 sale_amount_rmb 字段,并且还需要排除掉 is_refunded 标记为 1 的订单。这便是通用AI在落地具体数据分析场景时遇到的最大鸿沟——上下文缺失(Context Gap)。
当缺乏这种 spezifische 上下文时,模型只能去“猜”,这直接导致了AI数据分析中最常见的失败:SQL查询幻觉(Hallucination),即模型编造出不存在的表名或字段名,生成无法执行或逻辑错误的查询。
检索增强生成(Retrieval-Augmented Generation,简称RAG)*技术,正是为了解决这一核心痛点而诞生的。它就像是为通用大模型配备了一个可以随时查阅的、针对特定数据库的*“大脑外挂”或“开卷考试小抄”。其工作原理优雅而强大:我们并不试图去改变或重新训练庞大的模型本身,而是在模型回答问题之前,先为它准备好所有必要的参考资料。
在AI数据分析的场景中,这个“大脑外挂”(通常是一个向量数据库)里存储的,正是关于您数据资产的一切核心知识:
- 数据库的DDL(Data Definition Language):即
CREATE TABLE语句,这是最精确、最无歧义的表结构和字段名信息。 - 数据字典与指标定义:对每一个字段、每一个业务核心指标(如“用户流失率”、“客单价”)的详尽文字说明和计算口径。
- 业务规则文档:任何描述数据处理逻辑、业务流程的内部文档。
- 高质量的SQL查询范例:一批由人类专家编写的、可供模型“模仿”和“学习”的优秀查询案例。
当用户提出一个问题时,RAG的工作流程分为两步:
- 检索(Retrieve):系统首先用用户的问题,从“大脑外挂”中快速检索出最相关的几条知识(例如,相关的表结构、指标定义、相似的查询范例)。
- 增强生成(Augmented Generation):然后,系统将这些检索到的、高度相关的上下文信息,连同用户的原始问题,一起“喂”给大模型。
有了这份“小抄”,模型便从一个需要“闭卷考试”的通才,变成了一个可以“开卷考试”的专家。它不再需要猜测,只需根据提供的精确信息,就能生成正确、可靠的SQL或Python代码。因此,RAG在AI数据分析中之所以如此重要,因为它直接带来了三大核心价值:极大地提升了查询的精准性、确保了AI的回答与企业业务口径的高度对齐、并通过展示参考来源,显著增强了整个系统的可信赖度与可解释性。
4. 团队自研工业级AI数据分析&AI编程项目:MateGen

- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
MateGen是基于一个**“多链协作”(Multi-Chain Collaboration)的流水线式架构**。它认为一次完整的数据分析,并非单一模型的任务,而是一个需要不同能力的AI模块有序协作的流程。MateGen核心特色如下:
- 🤖高易用性,零门槛调用:MateGen为用户提供在线大模型应用服务,无需任何硬件或网络代理门槛,即可一键安装并开启对话;
- 🚀强悍的高精度RAG系统:一键同步本地文档并进行RAG检索问答,最多支持1000篇文档以及10G文档内容进行检索,支持md、ppt、word、pdf等主流文档格式高精度问答,能够高效率实现包括海量文档总结、大海捞针内容测试、情感倾向测试问答等功能。MateGen可根据用户问题自动识别是否需要进行RAG检索;
- 🏅本地Python代码解释器:可连接用户本地Python环境完成编程任务,包括数据清洗、数据可视化、机器学习、深度学习、大模型开发等代码工作编写,支持先学习代码库再进行编程、能够根据实际情况debug,支持可视化图片自动上传图床等功能;
- 🚩高精度NL2SQL功能:可根据用户需求编写SQL,并连接本地MySQL环境自动执行,可自动debug,并且支持先检索数据字典、企业数据知识库再进行SQL编写,从而提高SQL编写精度;
- 🛩️视觉能力和联网能力:对话时输入图片网址即可开启MateGen视觉能力对图片内容进行识别,同时MateGen也具备联网能力,当遇到无法回答的问题时,可自动开启搜索问答模式;
- 🚅无限对话上下文:MateGen拥有无限上下文对话长度,MateGen会根据历史对话的未知信息密度进行合理处理,从而在节省token的同时实现无限对话上线文。
5.公开课Data Agent项目介绍
- 先查询数据文档,深度了解业务,再进行数据分析
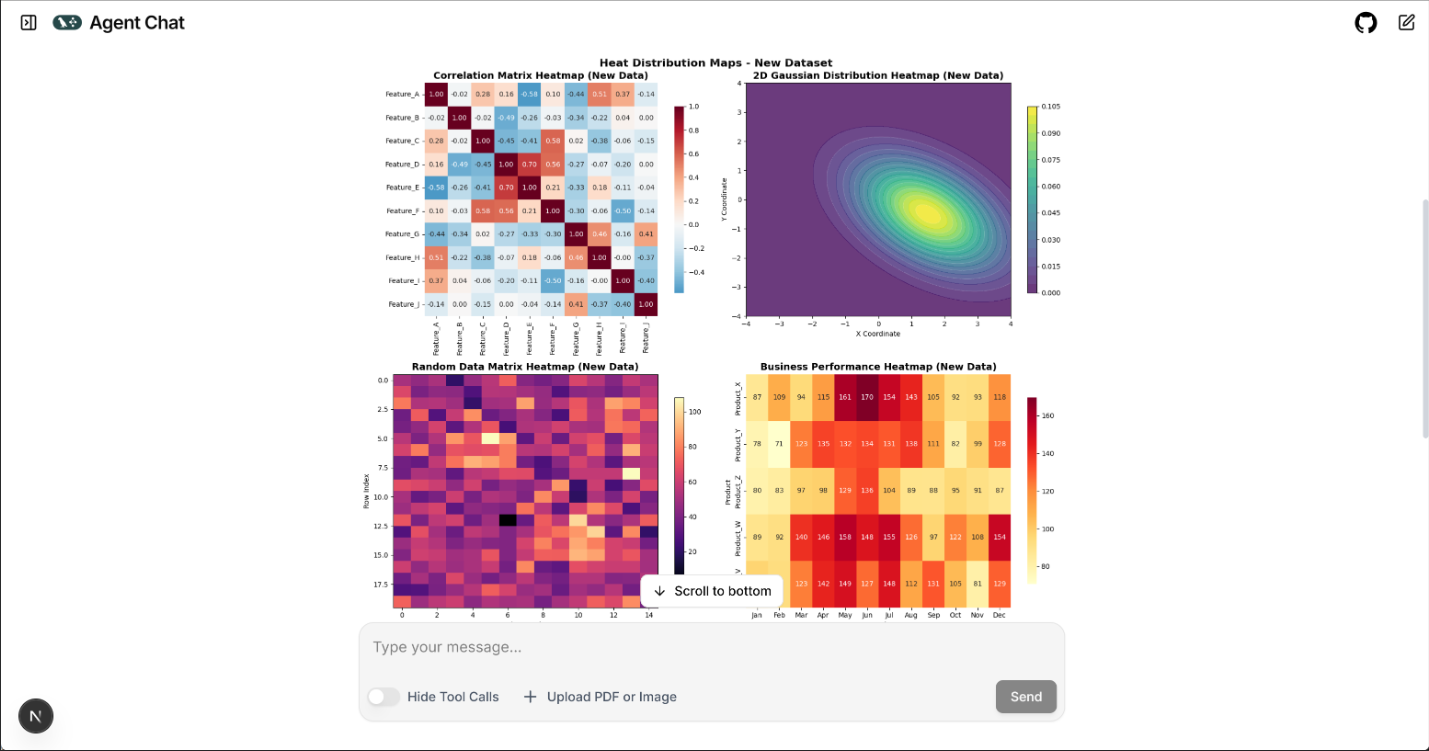
- 实现精美数据可视化分析
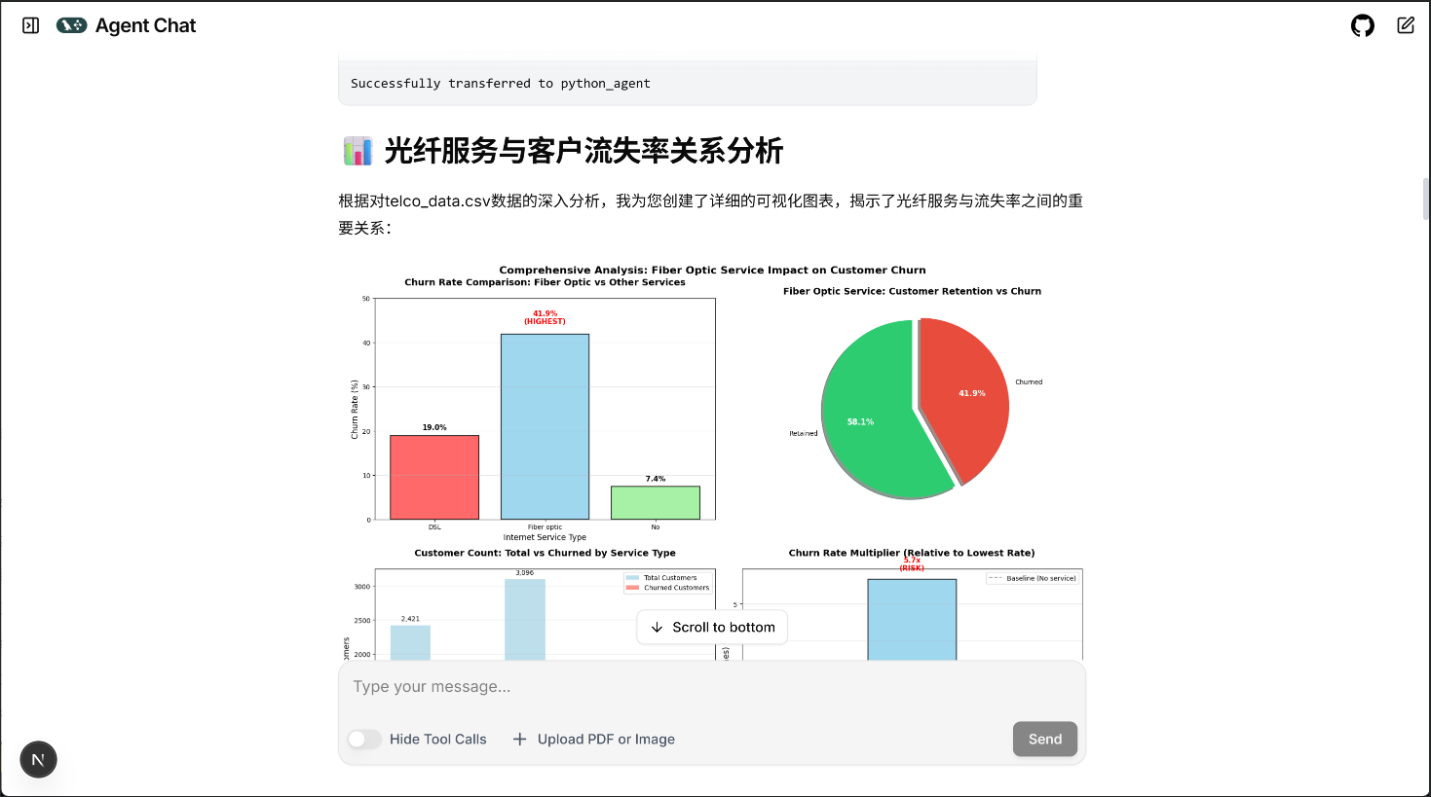
- 一键创建图文并茂的数据分析报告
- 快速上手编写数据分析专家文档

二、基于AgentScope的Data Agent开发流程
1. 数据分析 Agent 整体流程说明
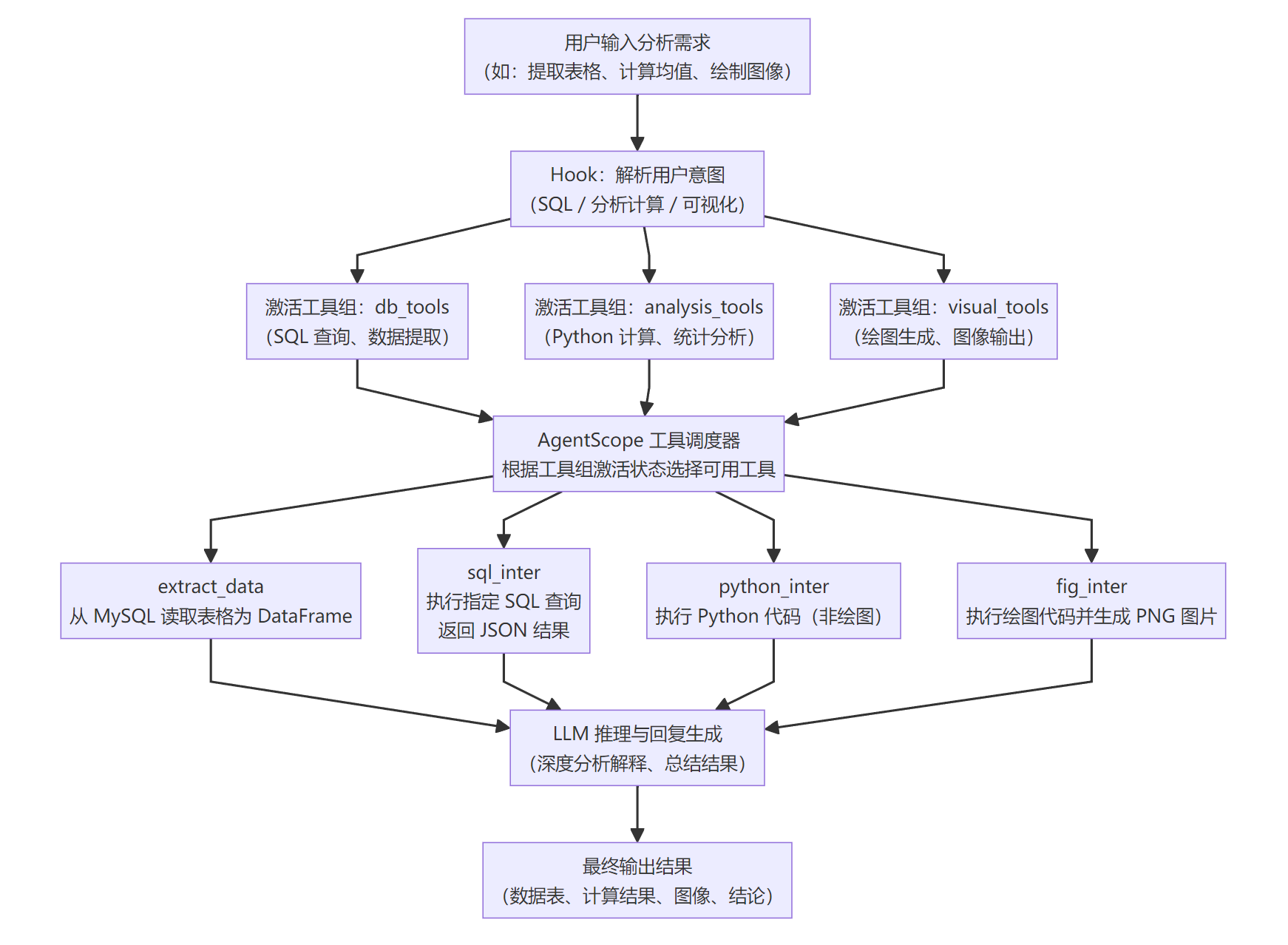
在数据分析场景中,用户往往需要完成多阶段任务,例如提取数据、进行统计计算、生成可视化图表等。因此,一个真正可用的数据分析 Agent,必须能够理解用户需求,并在多个工具链之间动态切换,形成稳定、可扩展的分析流程。本节将对整个系统运行机制进行完整讲解,帮助大家理解数据分析 Agent 的核心架构。
首先,当用户提出需求时(例如“提取 telco 表格并计算 Churn 列的流失率”),系统并不会立即调用具体的工具,而是通过 Hook 模块对用户意图进行初步解析。Hook 会针对输入内容识别用户是否需要进行数据库访问、执行 Python 计算,或生成可视化图像,再据此激活对应的工具组。这样可以有效避免不必要的工具暴露,也能够减少模型选择工具的歧义,使后续的调用更加稳定和确定。
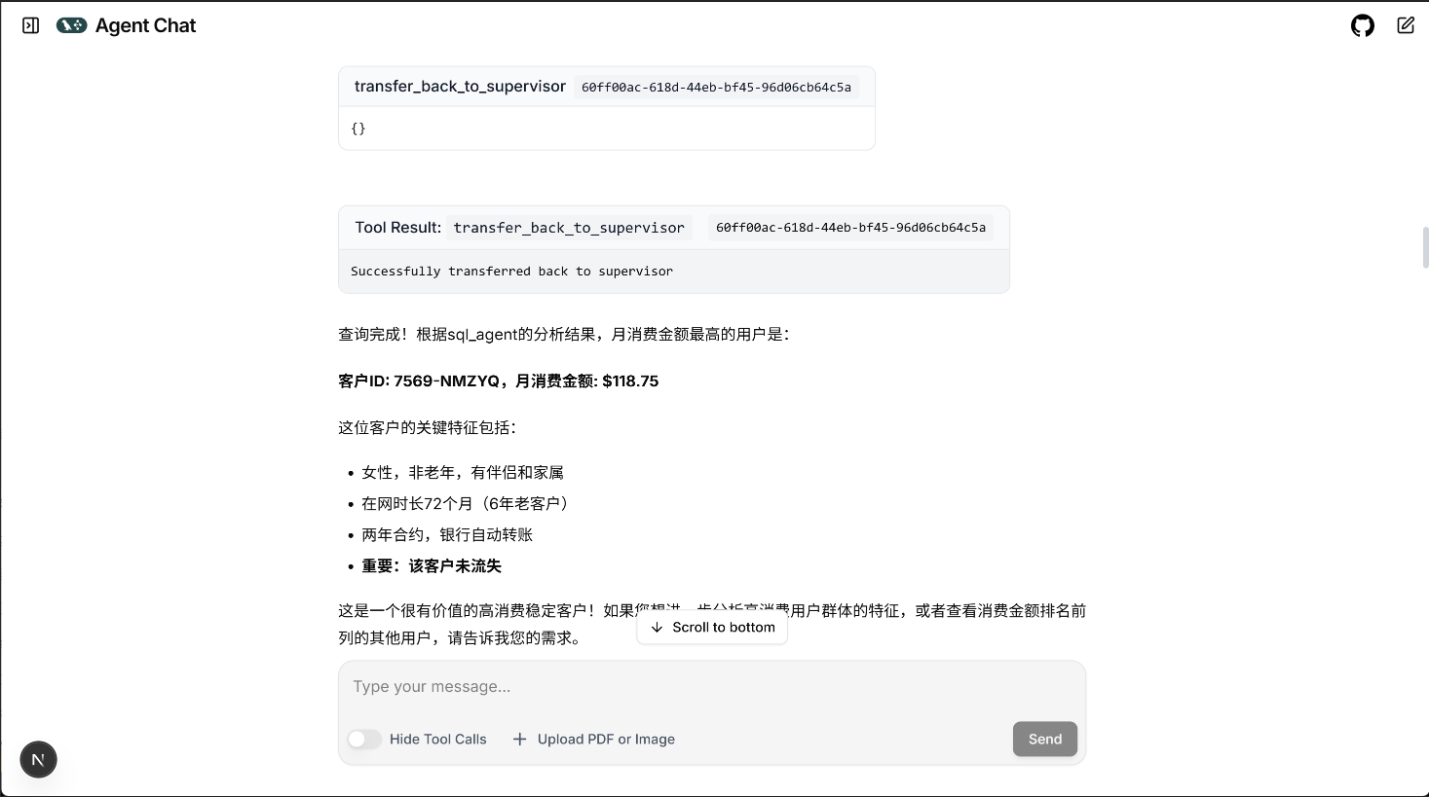
在工具组选择完成后,AgentScope 将进入工具调度阶段。调度器会根据哪些工具组被激活,动态选择可用的工具集合,并将其绑定到当前对话轮次中。对于涉及数据库的需求,系统会优先使用 SQL 工具链执行任务,其中包括 sql_inter(运行 SQL 查询)和 extract_data(将 MySQL 表格提取为 pandas DataFrame)等工具,用于完成数据读取与基础查询操作。
对于需要继续进行统计分析的任务,例如计算均值、方差、相关性等,系统会自动切换到 Python 计算工具链。此时,python_inter 负责执行模型生成的 Python 代码,通过全局变量共享机制访问 DataFrame 并完成实际计算。如果用户的分析需求还涉及绘图,如绘制分布图、趋势图、饼图等,则系统会进一步利用可视化工具链中的 fig_inter 执行绘图代码,并将生成的图像保存到本地路径中,以便在最终回答中引用。
所有工具执行完毕后,其结果(包括 JSON 输出、计算结果或生成的图像路径)会被统一传回 Agent,由大模型根据这些信息生成最终的解释性回答。大模型不仅会呈现工具输出,还会对计算过程进行补充说明,并给出分析性的自然语言总结,使回答内容不仅准确,而且具有可读性和专业性。
通过这样一套“意图识别 → 工具选择 → 工具执行 → 模型总结”的闭环机制,数据分析 Agent 能够高效、稳定地支持复杂的分析任务,使用户无需编写脚本,仅通过自然语言的方式即可完成端到端的数据分析过程。

import asyncio
import json
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv(override=True)
import agentscope
from agentscope.agent import ReActAgent
from agentscope.embedding import (
DashScopeTextEmbedding,
DashScopeMultiModalEmbedding,
)
from agentscope.formatter import DashScopeChatFormatter
from agentscope.message import Msg
from agentscope.model import DashScopeChatModel
from agentscope.rag import (
TextReader,
SimpleKnowledge,
QdrantStore,
Document,
ImageReader,
)
from agentscope.tool import Toolkit
from agentscope.memory import InMemoryMemory
1.单工具接入流程
from agentscope.tool import ToolResponse
from agentscope.message import TextBlock
import pymysql
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
def sql_inter(sql_query: str) -> ToolResponse:
"""在指定 MySQL 服务器上执行 SQL 查询语句。
本工具函数基于 pymysql 连接方式,用于在 MySQL 数据库中执行一段
SQL 查询代码,并返回查询结果(仅用于查询,不做数据提取操作)。
若需要对查询结果进行进一步的数据提取,请使用 extract_data 工具。
Args:
sql_query (str):
字符串格式的 SQL 查询语句,用于在环境变量指定的 MySQL 数据库中
执行查询操作,例如:
'SELECT * FROM customers LIMIT 10;'。
Returns:
ToolResponse:
返回数据库查询结果的 JSON 字符串(文本格式)。
"""
# 加载环境变量
load_dotenv(override=True)
host = os.getenv('HOST')
user = os.getenv('USER')
mysql_pw = os.getenv('MYSQL_PW')
db = os.getenv('DB_NAME')
port = os.getenv('PORT')
# 创建数据库连接(UTF-8 编码)
connection = pymysql.connect(
host=host,
user=user,
passwd=mysql_pw,
db=db,
port=int(port),
charset='utf8'
)
try:
with connection.cursor() as cursor:
cursor.execute(sql_query)
results = cursor.fetchall()
finally:
connection.close()
# 转 JSON 字符串
result_json = json.dumps(results, ensure_ascii=False)
# 按 AgentScope Tool 格式返回
return ToolResponse(
content=[TextBlock(type="text", text=result_json)]
)
toolkit = Toolkit()
toolkit.register_tool_function(sql_inter)
toolkit.clear()
model=DashScopeChatModel(
model_name="qwen-max",
api_key=os.environ["DASHSCOPE_API_KEY"],
stream=False,
enable_thinking=False,
)
data_agent = ReActAgent(
name="DataAgent",
sys_prompt="你是一个名助人为乐的数据分析师",
model=model,
formatter=DashScopeChatFormatter(),
memory=InMemoryMemory(),
toolkit=toolkit
)
msg = Msg(
name="user1",
content="请问我的数据库中总共有几张表?",
role="user",
)
res1 = await data_agent(msg)
2. 多工具接入流程
await data_agent.memory.clear()
def extract_data(sql_query: str, df_name: str) -> ToolResponse:
"""从 MySQL 数据库中提取表格数据并保存为 pandas DataFrame。
本工具函数基于 pymysql 和 pandas 的 read_sql 方法,
用于从 MySQL 数据库中提取完整数据表至当前 Python 环境中。
需要注意,本函数仅负责数据提取(即将表加载为 pandas DataFrame),
若需要执行 SQL 查询,请使用 sql_inter 工具函数。
Args:
sql_query (str):
SQL 查询语句,用于指定从 MySQL 数据库中提取哪张表的数据,
例如:'SELECT * FROM customers;'。
df_name (str):
用于在当前 Python 运行环境中保存提取后 DataFrame 的变量名,
例如:'customer_df'。
Returns:
ToolResponse:
包含成功或失败信息的文本内容。
"""
# 加载环境变量
load_dotenv(override=True)
host = os.getenv('HOST')
user = os.getenv('USER')
mysql_pw = os.getenv('MYSQL_PW')
db = os.getenv('DB_NAME')
port = os.getenv('PORT')
# 创建数据库连接
connection = pymysql.connect(
host=host,
user=user,
passwd=mysql_pw,
db=db,
port=int(port),
charset='utf8'
)
try:
# 执行 SQL 并保存到全局变量
df = pd.read_sql(sql_query, connection)
globals()[df_name] = df
message = (
f"✅ 成功创建 pandas 对象 `{df_name}`,"
"包含从 MySQL 提取的表格数据。"
)
except Exception as e:
message = f"❌ 数据提取失败:{str(e)}"
finally:
connection.close()
# 返回 AgentScope Tool 标准格式
return ToolResponse(
content=[TextBlock(type="text", text=message)]
)
def python_inter(py_code: str) -> ToolResponse:
"""执行一段纯 Python 代码,并返回运行结果。
本工具用于执行非绘图类的 Python 代码,包括表达式求值、变量赋值、
数据预处理、数学计算、字符串处理等任意合法 Python 语句。
若要执行绘图相关代码,请使用 fig_inter 工具。
执行逻辑如下:
1. 若代码为表达式,则尝试使用 eval 执行并返回表达式值;
2. 若 eval 失败,则使用 exec 执行;
3. 若 exec 产生新变量,则将新变量以字典形式返回;
4. 若 exec 未产生新变量,则返回“已顺利执行代码”。
Args:
py_code (str):
一段合法的 Python 代码字符串,例如:
'2 + 2'
'x = 3\\ny = x * 2'
'import math\\nresult = math.sqrt(16)'
Returns:
ToolResponse:
返回 Python 代码执行的结果(字符串形式)。
"""
g = globals()
try:
# 若是表达式(如 2+2),直接返回结果
result = eval(py_code, g)
message = str(result)
return ToolResponse(content=[TextBlock(type="text", text=message)])
except Exception:
# 如果表达式失败,则尝试执行代码块
global_vars_before = set(g.keys())
try:
exec(py_code, g)
except Exception as e:
message = f"❌ 代码执行时报错:{e}"
return ToolResponse(content=[TextBlock(type="text", text=message)])
global_vars_after = set(g.keys())
new_vars = global_vars_after - global_vars_before
# 若产生新变量,返回新变量内容
if new_vars:
result_dict = {var: g[var] for var in new_vars}
message = json.dumps(result_dict, ensure_ascii=False)
else:
message = "✅ 已顺利执行代码。"
return ToolResponse(content=[TextBlock(type="text", text=message)])
def fig_inter(py_code: str, fname: str) -> ToolResponse:
"""执行 matplotlib 绘图代码并将图像保存为 PNG 文件。
本工具用于运行 Python 绘图代码,生成图像文件并保存到指定目录。
所有绘图代码必须创建图像对象,并将其赋值给指定变量名 fname。
图像对象通常通过 `fig = plt.figure()` 或 `fig = plt.subplots()` 创建。
注意事项:
1. 必须将图像对象赋值给 fname 对应的变量名,例如 fname='fig'。
2. 不要在代码中调用 plt.show()。
3. 请确保绘图代码最后包含 fig.tight_layout()。
4. 图像中的标签、标题、legend 等文本必须使用英文。
5. 保存路径固定为 base_dir/images/fname.png。
Args:
py_code (str):
一段 matplotlib 绘图代码,例如:
'fig = plt.figure(); plt.plot([1,2],[3,4]); fig.tight_layout()'
fname (str):
图像对象的变量名,例如 'fig'。
Returns:
ToolResponse:
返回相对路径 'images/xxx.png' 或错误提示。
"""
# 保存当前后端
current_backend = matplotlib.get_backend()
matplotlib.use('Agg')
# 本地可用变量
local_vars = {"plt": plt, "pd": pd, "sns": sns}
# 你项目中的图像保存路径(保持你的原始逻辑)
base_dir = r"C:\Users\Administrator\AppData\Roaming\npm\node_modules\@agentscope\studio\dist\public"
images_dir = os.path.join(base_dir, "images")
os.makedirs(images_dir, exist_ok=True)
try:
g = globals()
# 执行绘图代码
exec(py_code, g, local_vars)
g.update(local_vars)
# 获取图像对象
fig = local_vars.get(fname, None)
if fig is None:
message = "⚠️ 图像对象未找到,请确认变量名正确并为 matplotlib 图对象。"
return ToolResponse(content=[TextBlock(type="text", text=message)])
# 保存图片
image_filename = f"{fname}.png"
abs_path = os.path.join(images_dir, image_filename)
rel_path = os.path.join("images", image_filename)
fig.savefig(abs_path, bbox_inches="tight")
message = f"✅ 图片已成功保存,路径为:{rel_path}"
except Exception as e:
message = f"❌ 绘图代码执行失败:{e}"
finally:
plt.close("all")
matplotlib.use(current_backend)
return ToolResponse(content=[TextBlock(type="text", text=message)])
toolkit.clear()
toolkit = Toolkit()
toolkit.register_tool_function(python_inter)
toolkit.register_tool_function(fig_inter)
toolkit.register_tool_function(sql_inter)
toolkit.register_tool_function(extract_data)
prompt = """
你是一名经验丰富的智能数据分析助手,擅长帮助用户高效完成以下任务:
1. **数据库查询:**
- 当用户需要获取数据库中某些数据或进行SQL查询时,请调用`sql_inter`工具,该工具已经内置了pymysql连接MySQL数据库的全部参数,包括数据库名称、用户名、密码、端口等,你只需要根据用户需求生成SQL语句即可。
- 你需要准确根据用户请求生成SQL语句,例如 `SELECT * FROM 表名` 或包含条件的查询。
2. **数据表提取:**
- 当用户希望将数据库中的表格导入Python环境进行后续分析时,请调用`extract_data`工具。
- 你需要根据用户提供的表名或查询条件生成SQL查询语句,并将数据保存到指定的pandas变量中。
3. **非绘图累任务的Python代码执行:**
- 当用户需要执行Python脚本或进行数据处理、统计计算时,请调用`python_inter`工具。
- 仅限执行非绘图类代码,例如变量定义、数据分析等。
4. **绘图类Python代码执行:**
- 当用户需要进行可视化展示(如生成图表、绘制分布等)时,请调用`fig_inter`工具。
- 你可以直接读取数据并进行绘图,不需要借助`python_inter`工具读取图片。
- 你应根据用户需求编写绘图代码,并正确指定绘图对象变量名(如 `fig`)。
- 当你生成Python绘图代码时必须指明图像的名称,如fig = plt.figure()或fig = plt.subplots()创建图像对象,并赋值为fig。
- 不要调用plt.show(),否则图像将无法保存。
5. **网络搜索:**
- 当用户提出与数据分析无关的问题(如最新新闻、实时信息),请调用`search_tool`工具。
**工具使用优先级:**
- 如需数据库数据,请先使用`sql_inter`或`extract_data`获取,再执行Python分析或绘图。
- 如需绘图,请先确保数据已加载为pandas对象。
**回答要求:**
- 所有回答均使用**简体中文**,清晰、礼貌、简洁。
- 如果调用工具返回结构化JSON数据,你应提取其中的关键信息简要说明,并展示主要结果。
- 若需要用户提供更多信息,请主动提出明确的问题。
- 如果有生成的图片文件,请务必在回答中使用Markdown格式插入图片,如:
- 不要仅输出图片路径文字。
**风格:**
- 专业、详细、以数据驱动。
- 不要编造不存在的工具或数据。
请根据以上原则为用户提供精准、高效的协助。
"""
data_agent = ReActAgent(
name="DataAgent",
sys_prompt=prompt,
model=model,
formatter=DashScopeChatFormatter(),
memory=InMemoryMemory(),
toolkit=toolkit
)
msg = Msg(
name="user1",
content="请问我的数据库中总共有几张表?",
role="user",
)
res1 = await data_agent(msg)
msg = Msg(
name="user1",
content="请问telco表中总共有几个特征?",
role="user",
)
res1 = await data_agent(msg)
3. AgentScope工具组技术概念介绍
- 在 AgentScope 中,工具函数(Tool)是可调用对象,返回
ToolResponse。 - 这些工具函数由
Toolkit类统一管理。 - 工具组(Tool Group) 是 “一组相关工具函数的集合”,例如一组浏览器操作工具、地图服务工具等。
- 每个工具组有 激活(active)状态。只有当一个工具组被激活时,其内的工具才对智能体可见(即
toolkit.get_json_schemas()会展示这些工具)。 - 官方还说明,一个特殊的工具组
basic默认处于激活状态,若你注册工具时未指定组名,则该工具默认归入basic组。 - 此外,
Toolkit提供一个 元工具函数reset_equipped_tools,用于智能体动态决定 激活哪些工具组。
而工具组允许开发者按 “功能类别” 划分工具,并通过激活/停用机制动态控制智能体可用工具集。这样的好处包括:
- 管理工具的可见性、权限和生命周期
- 智能体根据当前任务场景,仅暴露相关工具,减少混乱
- 更好地分离工具模块(模块化、可维护性高)
- 支持在运行时切换工具集 — 提高灵活性
目前我们定义了四个工具:
sql_inter— 用于执行 SQL 查询extract_data— 用于将 SQL 查询结果提取为 pandas DataFramepython_inter— 用于执行任意 Python 代码(非绘图)fig_inter— 用于执行绘图代码并保存图像
因为它们本身可以按 “功能类别” 划分为不同组:
- 数据库访问组db_tools:包括
sql_inter,extract_data - 代码执行组analysis_tools:包括
python_inter - 可视化组visual_tools:包括
fig_inter
这样做的优势:
- 当智能体面对“数据库查询”任务时,只激活
db_tools组,避免误用绘图工具。 - 当智能体要做“数据分析”任务(显式运行 Python/绘图)时,再激活
analysis_tools+visual_tools。 - 在系统提示(system prompt)中,可明确告知智能体当前可用组。例如:“当前激活工具组:数据库访问组、分析组”。
- 你也可以基于任务场景,动态切换工具组(利用
reset_equipped_tools),比如从数据提取转向可视化阶段时。
toolkit.clear()
toolkit = Toolkit()
# 创建工具组
toolkit.create_tool_group(
group_name="db_tools",
description="MySQL 数据库访问与提取工具。",
active=False # 初始状态可能不激活,按任务激活
)
toolkit.create_tool_group(
group_name="analysis_tools",
description="执行 Python 代码分析的工具。",
active=False
)
toolkit.create_tool_group(
group_name="visual_tools",
description="绘图与可视化工具。",
active=False
)
# 注册工具函数并指定所属组
toolkit.register_tool_function(sql_inter, group_name="db_tools")
toolkit.register_tool_function(extract_data, group_name="db_tools")
toolkit.register_tool_function(python_inter, group_name="analysis_tools")
toolkit.register_tool_function(fig_inter, group_name="visual_tools")
import re
from typing import Any
from agentscope.agent import ReActAgentBase
from agentscope.message import Msg
def auto_tool_group_pre_reply(self, kwargs):
"""
根据用户输入自动激活多个工具组,支持复合型问题:
例如:
“请提取 telco 表,并计算 tenure 均值。”
将同时激活 db_tools + analysis_tools。
"""
toolkit = getattr(self, "toolkit", None)
if toolkit is None:
return None
msg = kwargs.get("msg", None)
if msg is None:
return None
# 解析用户输入文本
text = ""
if isinstance(msg, list):
for m in msg:
if hasattr(m, "content") and isinstance(m.content, str):
text = m.content
else:
if hasattr(msg, "content") and isinstance(msg.content, str):
text = msg.content
lower = text.lower()
# 要激活的工具组列表
groups_to_activate = []
# --- 数据库相关 ---
if any(k in lower for k in ["mysql", "select", "from", "where", "提取", "数据库"]):
groups_to_activate.append("db_tools")
# --- 数据分析相关 ---
if any(k in lower for k in ["均值", "计算", "平均", "统计", "分析", "describe", "dataframe", "mean"]):
groups_to_activate.append("analysis_tools")
# --- 可视化相关 ---
if any(k in lower for k in ["画图", "plot", "hist", "figure", "可视化", "图像", "图", "展示"]):
groups_to_activate.append("visual_tools")
# ---- 激活对应工具组 ----
if groups_to_activate:
# 先全部关闭
toolkit.update_tool_groups(
group_names=["db_tools", "analysis_tools", "visual_tools"],
active=False,
)
# 再激活需要的
toolkit.update_tool_groups(
group_names=groups_to_activate,
active=True,
)
print(f"[HOOK] activated groups: {groups_to_activate}")
return None
data_agent = ReActAgent(
name="DataAgent",
sys_prompt=prompt,
model=model,
formatter=DashScopeChatFormatter(),
memory=InMemoryMemory(),
toolkit=toolkit
)
data_agent.register_instance_hook(
hook_type="pre_reply",
hook_name="auto_tool_group_switcher",
hook=auto_tool_group_pre_reply,
)
msg = Msg(
name="user1",
content="请问我的数据库中总共有几张表?",
role="user",
)
res1 = await data_agent(msg)
msg = Msg(
name="user1",
content="请帮我将telco表格提取到本地,并对Churn列进行数值转化,然后计算流失率。",
role="user",
)
res1 = await data_agent(msg)
telco_df
msg = Msg(
name="user1",
content="非常棒,请将计算的到的churn流失率绘制柱状图进行展示。",
role="user",
)
res1 = await data_agent(msg)
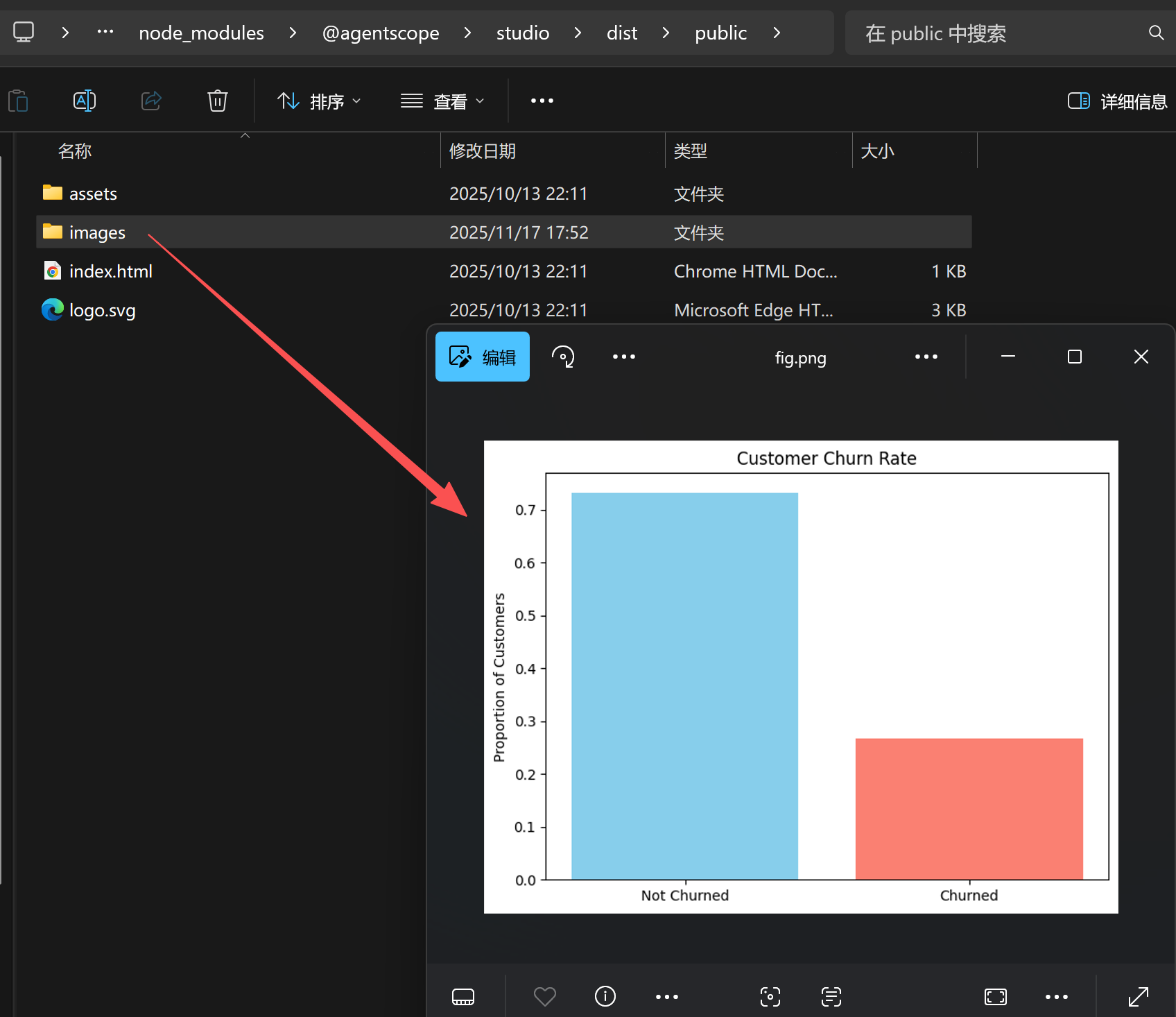
注:图片保存地址为:C:\Users\Administrator\AppData\Roaming\npm\node_modules@agentscope\studio\dist\public\images,为了方便后续进行前端展示。
4. 先RAG后分析流程实现

import asyncio
import json
import os
from matplotlib import pyplot as plt
import agentscope
from agentscope.agent import ReActAgent, UserAgent
from agentscope.embedding import (
DashScopeTextEmbedding,
DashScopeMultiModalEmbedding,
)
from agentscope.formatter import DashScopeChatFormatter
from agentscope.message import Msg
from agentscope.model import DashScopeChatModel
from agentscope.rag import (
TextReader,
SimpleKnowledge,
QdrantStore,
Document,
ImageReader,
)
from agentscope.tool import Toolkit
from bs4 import BeautifulSoup
import markdown
import uuid
class MdChunk:
def __init__(self, type, content=None, meta=None):
self.id = str(uuid.uuid4())
self.type = type # text / image / table / code
self.content = content
self.meta = meta or {}
def __repr__(self):
return f"<MdChunk type={self.type}, meta={self.meta}, content={str(self.content)[:20]}...>"
def parse_markdown_file(md_path, image_base_url=None):
with open(md_path, "r", encoding="utf-8") as f:
md_text = f.read()
html = markdown.markdown(md_text, extensions=["tables", "fenced_code"])
soup = BeautifulSoup(html, "html.parser")
md_dir = os.path.dirname(os.path.abspath(md_path))
chunks = []
# 遍历 HTML 所有 block element(而不是 children)
for block in soup.find_all(['p', 'h1', 'h2', 'h3', 'h4', 'h5', 'table', 'pre']):
# 1) 表格
if block.name == "table":
chunks.append(MdChunk(type="table", content=str(block)))
continue
# 2) 代码块
if block.name == "pre":
chunks.append(MdChunk(type="code", content=block.get_text()))
continue
# 3) 图片(可能在 block 内部)
images = block.find_all("img")
if images:
for img in images:
src = img.get("src")
abs_path = os.path.abspath(os.path.join(md_dir, src))
url = None
if image_base_url:
url = f"{image_base_url}/{src}".replace("\\", "/")
chunks.append(
MdChunk(
type="image",
meta={
"src": src,
"abs_path": abs_path,
"url": url
}
)
)
# 4) 文本内容
text = block.get_text().strip()
if text:
chunks.append(MdChunk(type="text", content=text))
return chunks
async def ingest_chunks_into_knowledge(
chunks,
knowledge: SimpleKnowledge,
chunk_size: int = 2048,
split_by: str = "paragraph",
):
"""
将 Markdown 解析出的 chunks 依序写入 AgentScope 的 SimpleKnowledge.
参数:
chunks: parse_markdown_file(...) 返回的列表,每个元素类似 MdChunk
- c.type in {"text", "image", "table", "code"}
- c.content / c.meta["src"]
knowledge: 已初始化好的 SimpleKnowledge 实例
chunk_size: TextReader 的切分长度
split_by: TextReader 的切分策略("paragraph" / "sentence" 等)
"""
text_reader = TextReader(chunk_size=chunk_size, split_by=split_by)
image_reader = ImageReader()
for idx, c in enumerate(chunks):
# ---- 文本类:text / table / code 都统一按文本处理 ----
if c.type in ("text", "table", "code"):
if not c.content or not str(c.content).strip():
continue
try:
# TextReader 是 async __call__,返回 List[Document]
docs = await text_reader(c.content)
if docs:
await knowledge.add_documents(docs)
print(f"[OK] Added {c.type.upper()} chunk #{idx} -> {len(docs)} docs")
except Exception as e:
print(f"[ERROR] Failed to add {c.type} chunk #{idx}")
print(e)
# ---- 图片类:用 ImageReader,直接喂 URL(src) ----
elif c.type == "image":
src = (c.meta or {}).get("src")
if not src:
print(f"[WARN] Image chunk #{idx} missing src, skipped")
continue
# 这里按你的设定:src 就是可访问的 URL(图床地址)
# 不再使用 abs_path,也不依赖本地文件
try:
docs = await image_reader(src)
if docs:
await knowledge.add_documents(docs)
print(f"[OK] Added IMAGE chunk #{idx} -> {len(docs)} docs, url={src}")
except Exception as e:
print(f"[ERROR] Failed to add image chunk #{idx}, url={src}")
print(e)
else:
print(f"[WARN] Unknown chunk type: {c.type}, idx={idx}, skipped")
knowledge = SimpleKnowledge(
embedding_model=DashScopeMultiModalEmbedding(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="multimodal-embedding-v1",
dimensions=1024,
),
embedding_store=QdrantStore(
location=":memory:",
collection_name="test_collection",
dimensions=1024,
),
)
chunks = parse_markdown_file("./课程项目/Telco 电信用户流失预测数据集专家文档.md")
await ingest_chunks_into_knowledge(chunks, knowledge)
toolkit.clear()
toolkit = Toolkit()
# 创建工具组
toolkit.create_tool_group(
group_name="db_tools",
description="MySQL 数据库访问与提取工具。",
active=False # 初始状态可能不激活,按任务激活
)
toolkit.create_tool_group(
group_name="analysis_tools",
description="执行 Python 代码分析的工具。",
active=False
)
toolkit.create_tool_group(
group_name="visual_tools",
description="绘图与可视化工具。",
active=False
)
# 注册工具函数并指定所属组
toolkit.register_tool_function(sql_inter, group_name="db_tools")
toolkit.register_tool_function(extract_data, group_name="db_tools")
toolkit.register_tool_function(python_inter, group_name="analysis_tools")
toolkit.register_tool_function(fig_inter, group_name="visual_tools")
data_agent = ReActAgent(
name="DataAgent",
sys_prompt=prompt,
model=model,
formatter=DashScopeChatFormatter(),
memory=InMemoryMemory(),
toolkit=toolkit,
kn
)
data_agent.register_instance_hook(
hook_type="pre_reply",
hook_name="auto_tool_group_switcher",
hook=auto_tool_group_pre_reply,
)
msg = Msg(
name="user1",
content="我想对用户流失率进行分析,有什么好的建议没?",
role="user",
)
res1 = await data_agent(msg)
三、借助AgentScope Studio进行Data Agent部署与调用
核心DataAgent代码如下:
FENCE0
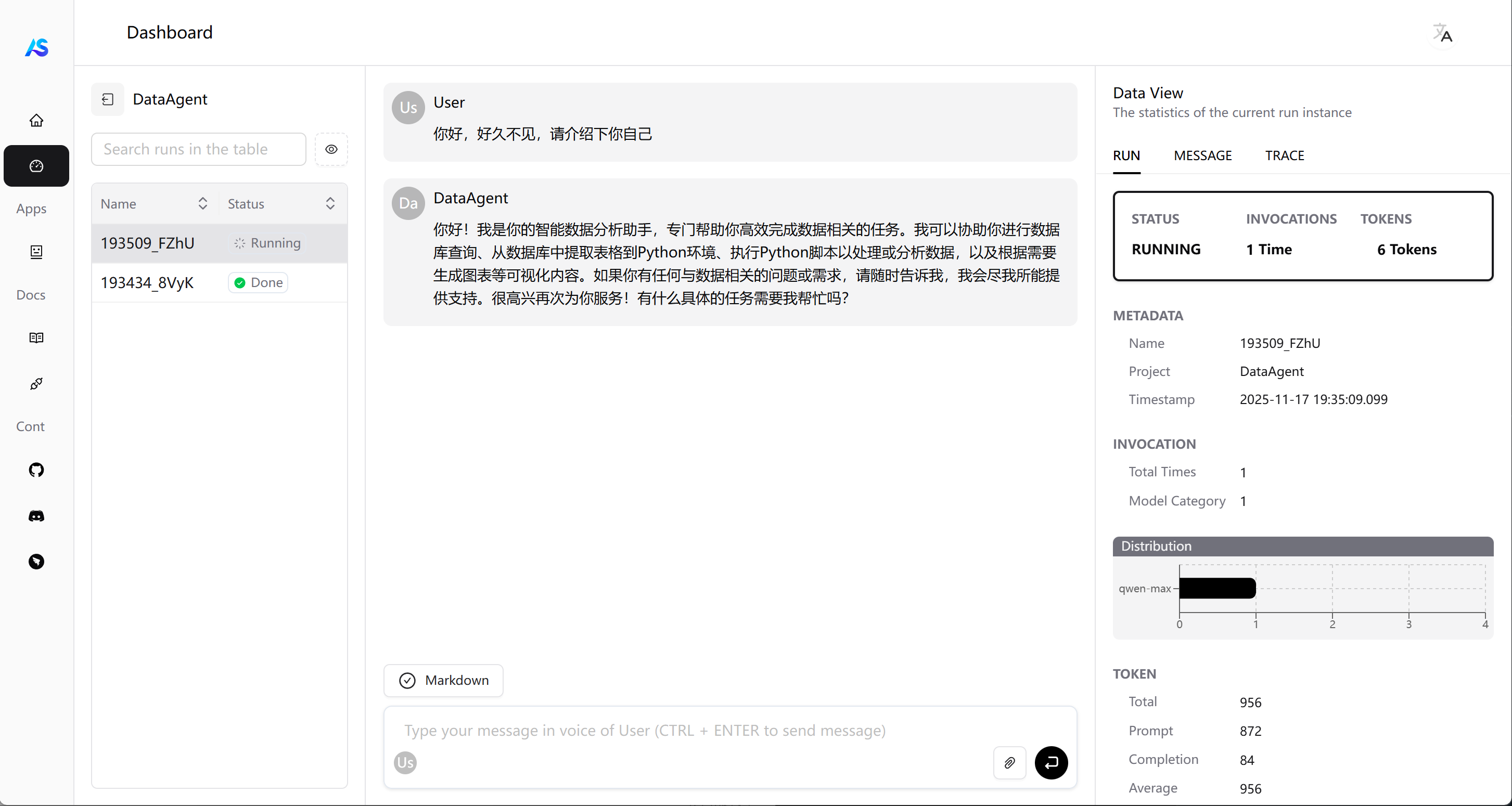
输入python DataAgent.py即可启动项目:
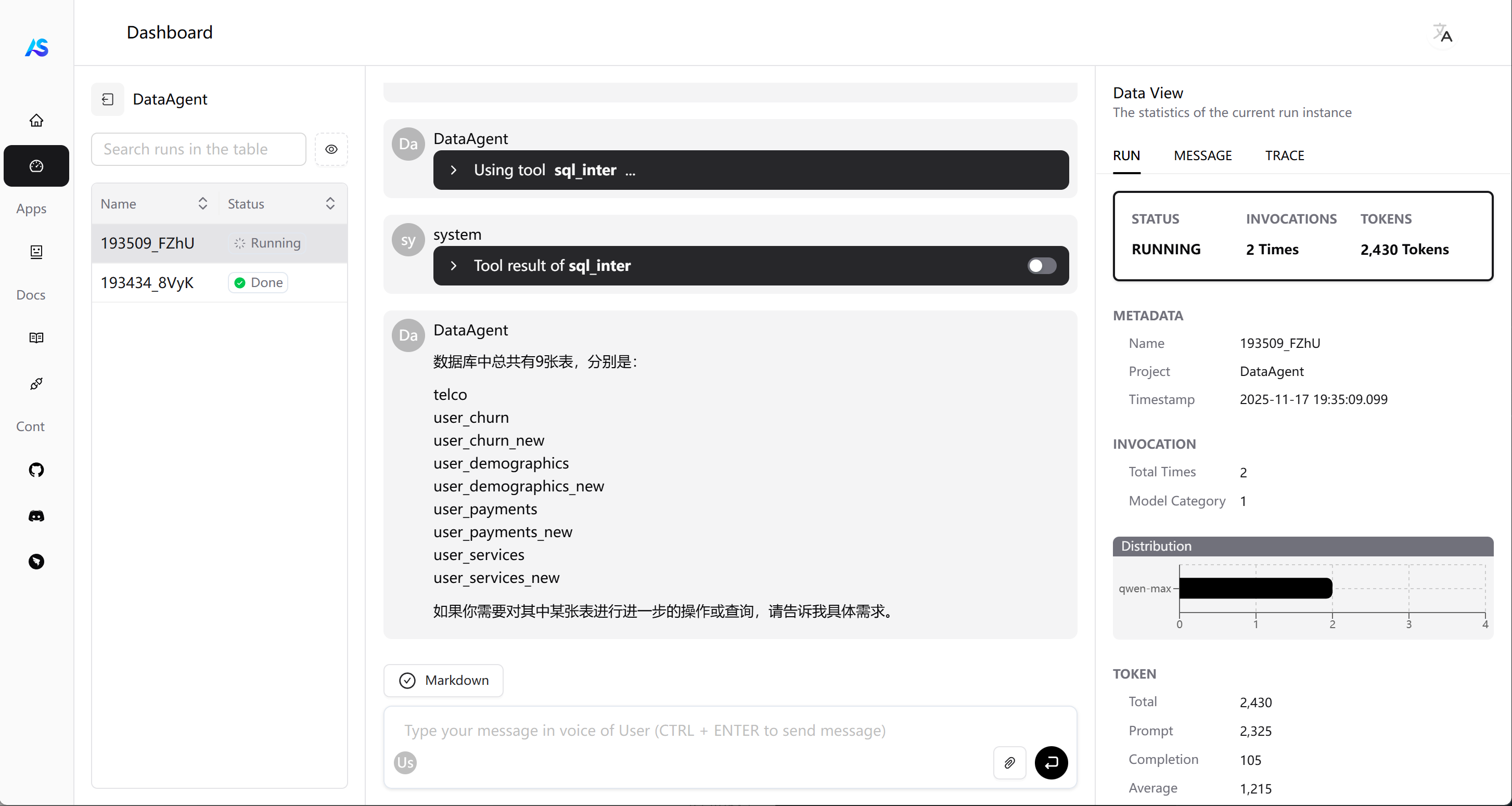
- 更多参考项目