DeepAgents 应用开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(12月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(12月班)

《2025大模型Agent智能体开发实战》(12月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
课程完整介绍


部分课程成果演示
from IPython.display import Video
- Dify+DeepSeek搭建智能微信语音客服
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- Coze自动图文视频创作流程
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- 可视化数据分析Multi-Agent
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目展示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由九天老师和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋季班)


详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

《大模型Agent智能体开发》(12月班体验课)
Part 3. DeepAgents 应用开发实战
from IPython.display import Video
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2025-06-26%2019-29-04.mp4", width=1500, height=400)
from IPython.display import Video
Video("https://muyu20241105.oss-cn-beijing.aliyuncs.com/images/202512031242162.mp4", width=1500, height=400)
from IPython.display import Video
Video("https://muyu20241105.oss-cn-beijing.aliyuncs.com/images/202512041730948.mp4", width=1500, height=400)
在前面的课程中,我们已经成功构建了一个具备实时联网检索能力的 DeepAgents 研究智能体。但是,当我们运行智能体时,往往只能看到最终的结果,而无法观察到智能体内部的执行过程。
在本课程中,我们将学习三种方法来可视化和应用DeepAgents的执行过程:
- LangGraph Studio 可视化:使用 LangGraph 官方提供的可视化界面,实时观察智能体的执行流程;
- DeepAgents UI 可视化:使用 DeepAgents 官方提供的可视化界面,实时观察智能体的执行流程;
- 代码打印中间结果:通过编程方式打印智能体的每一步执行过程,包括 AI 思考、工具调用和工具响应
这三种方法各有优势,LangGraph Studio 提供了图形化的界面,DeepAgents UI 则提供了用户友好的应用形态,而代码打印则是能帮助大家理解如何提取DeepAgents的执行过程用于外部应用程序的集成。
一、DeepAgents 运行环境准备
为了进行可视化调试,我们首先需要确保已经创建了 DeepAgents 智能体。这里我们复用前面课程中已经配置好的代码。
# 核心依赖导入
import os
from typing import Literal
from dotenv import load_dotenv
from tavily import TavilyClient
from deepagents import create_deep_agent
# 加载环境变量
load_dotenv(override=True)
# 读取配置
deepseek_api_key = os.environ.get("DEEPSEEK_API_KEY")
deepseek_base_url = os.environ.get("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
tavily_key = os.environ.get("TAVILY_API_KEY")
print("环境变量加载完成")
from langchain.chat_models import init_chat_model
# 使用模型字符串(LangChain 会自动识别供应商)
model = init_chat_model(
api_key=deepseek_api_key,
base_url=deepseek_base_url,
model_provider="deepseek",
model="deepseek-chat"
)
# 初始化 Tavily 客户端
tavily_client = TavilyClient(api_key=tavily_key)
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""
运行网络搜索
这是一个用于网络搜索的工具函数,封装了 Tavily 的搜索功能。
参数说明:
- query: 搜索查询字符串,例如 "Python 异步编程教程"
- max_results: 最大返回结果数量,默认为 5
- topic: 搜索主题类型,可选 "general"(通用)、"news"(新闻)或 "finance"(金融)
- include_raw_content: 是否包含原始网页内容,默认为 False
返回:
- 搜索结果字典,包含标题、URL、摘要等信息
"""
try:
result = tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
return result
except Exception as e:
# 异常处理:返回错误信息而非抛出异常
# 这样 LLM 可以理解出错并尝试其他策略
return {"error": f"搜索失败: {str(e)}"}
print("搜索工具创建完成")
二、使用 LangGraph Studio 进行可视化
DeepAgents底层构建的是图结构,而图结构是由LangGraph支撑,大家可以思考一个问题:DeepAgents基于LangGraph框架可以开发出各种复杂的应用、Agent、Workflow等,那么这些应用、Agent、Workflow等在生产中如何部署和运行呢? 解决方案就是把它们部署成一个Server。 而对如何方便高效的把LangGraph的Graph部署成一个Server,LangGraph官方提供了LangGraph Platform,其完整架构如下所示:
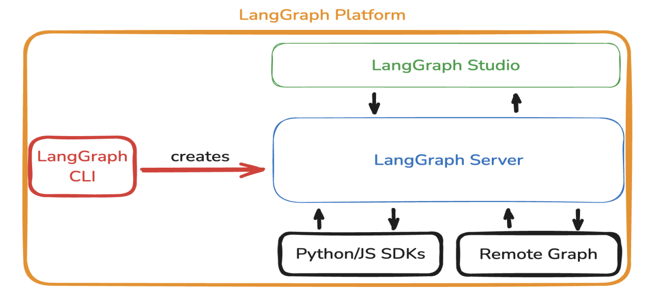
- LangGraph Studio:桌面版应用(
目前仅支持Mac)和本地运行(适用于所有操作系统); - LangServer:最终构建出来的服务,提供
Assistant API接口; - Python/JS SDK:通过接口可以直接和
LangServer提供的各个API接口连接; - Remote Graph:类似于之前
LangServe的用法,可以直接用Graph的接口去调用,这样拿到的Graph就是一个Runable对象,就可以去调用它的invoke,batch等。
LangGraph Studio 是专为 LangGraph 图式代理打造的本地/云端 IDE,具备可视化节点和状态及实时调试功能。LangGraph Studio 在本地可视化运行时会自动把调用过程上传到 LangSmith;而在 LangSmith 网页端查看任何 Trace 时,又能一键Run in Studio回放整条执行链,所以它是通过统一 Trace SDK 与 LangSmith 紧密集成。而LangGraph CLI则是构建这个项目的关键
首先,我们需要安装 LangGraph CLI 工具:
# 安装 LangGraph CLI(如果尚未安装)
%pip install -qU langgraph-cli
首先需要说明的是,如果想要把一个定义的Graph添加到LangGraph Studio中,需要严格按照官方要求的项目结构进行构建,需要执行的步骤依次是:
- Step 1. 创建一个
NetworkSearchAgent项目主文件夹
我们这里创建一个NetworkSearchAgent文件夹,如下图所示:
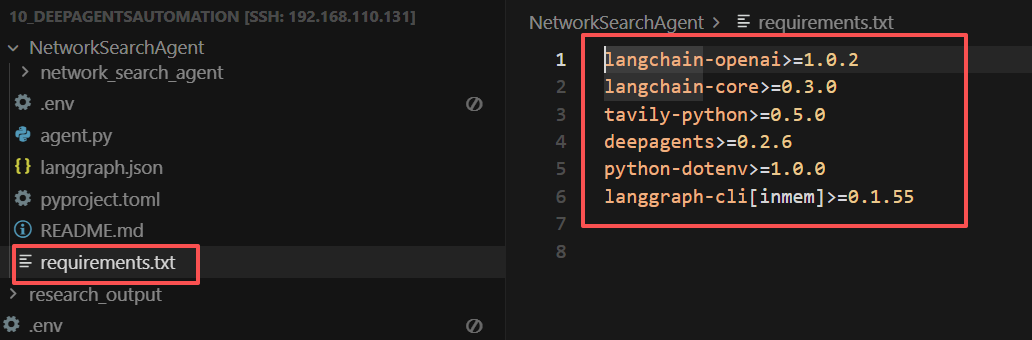
- Step 2. 创建
requirements.txt文件
在NetworkSearchAgent文件夹中,新建一个requirements.txt文件,里面需要填写在运行该项目时需要安装的依赖项,如下所示:
- Step 3. 注册LangSmith(可选)
对于企业级的Agent项目,为了更好的监控智能体实时运行情况,我们可以考虑借助LangSmith进行追踪(会将智能体运行情况实时上传到LangGraph官网并进行展示)。
要开始使用 LangSmith,我们需要创建一个帐户。可以在这里注册一个免费帐户进入LangSmith登录页面: https://smith.langchain.com/ , 支持使用 Google、GitHub、Discord 和电子邮件登录。
注册并等登录后,可以直接查看到仪表板:
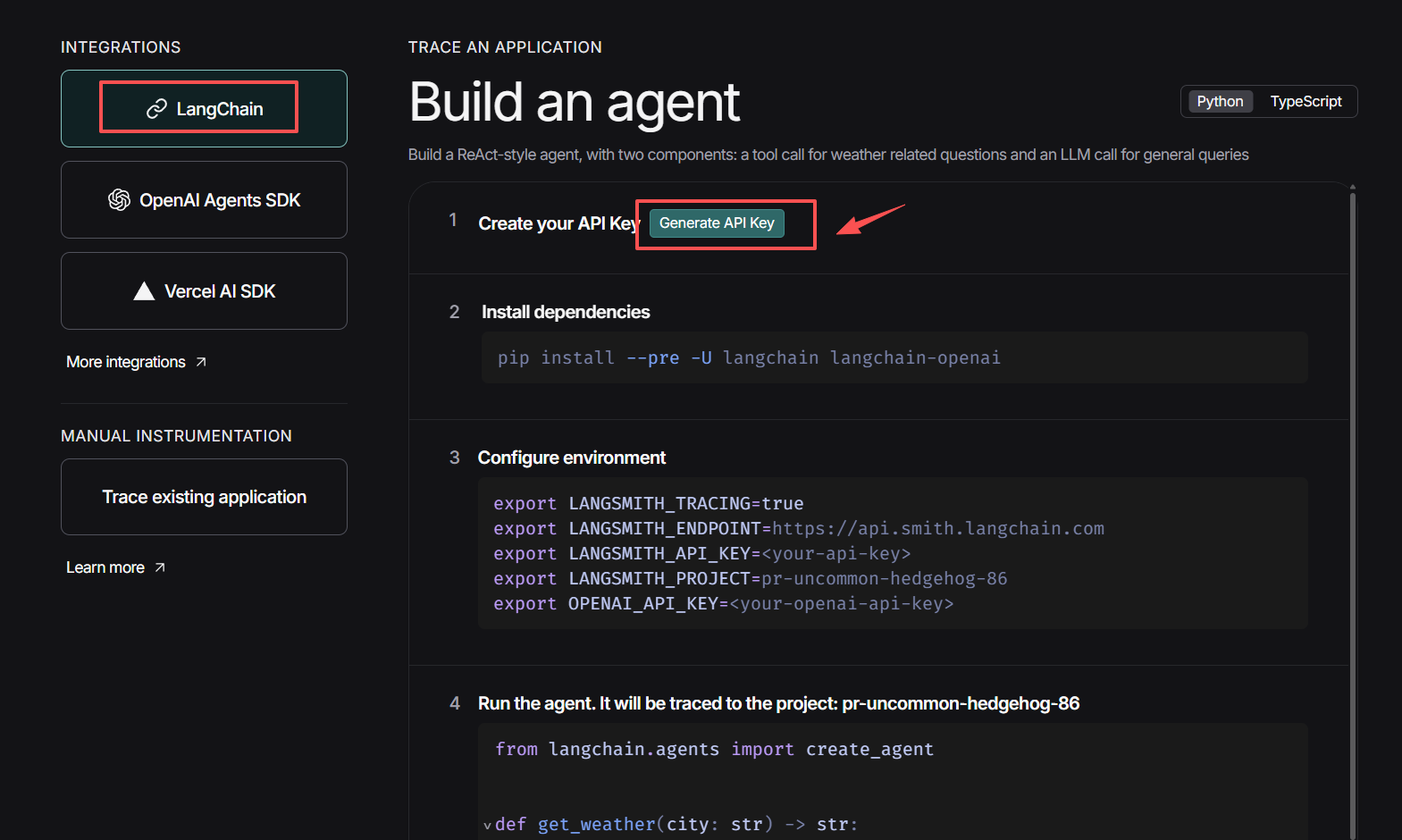
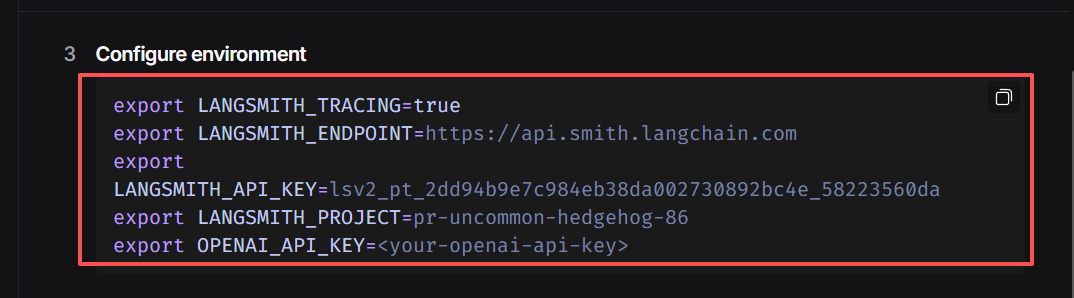
在构建程序跟踪前,首先需要创建一个 API 密钥,该密钥将允许我们的项目开始向 Langsmith 发送跟踪数据。创建完密钥后,在后续配置环境变量环节设置开启追踪、并输入密钥即可接入LangSmith。
- Step 4. 创建
.env配置文件
在NetworkSearchAgent文件夹中,新建一个.env文件,将敏感信息(如API密钥)放在环境变量中而不是硬编码。如下所示:
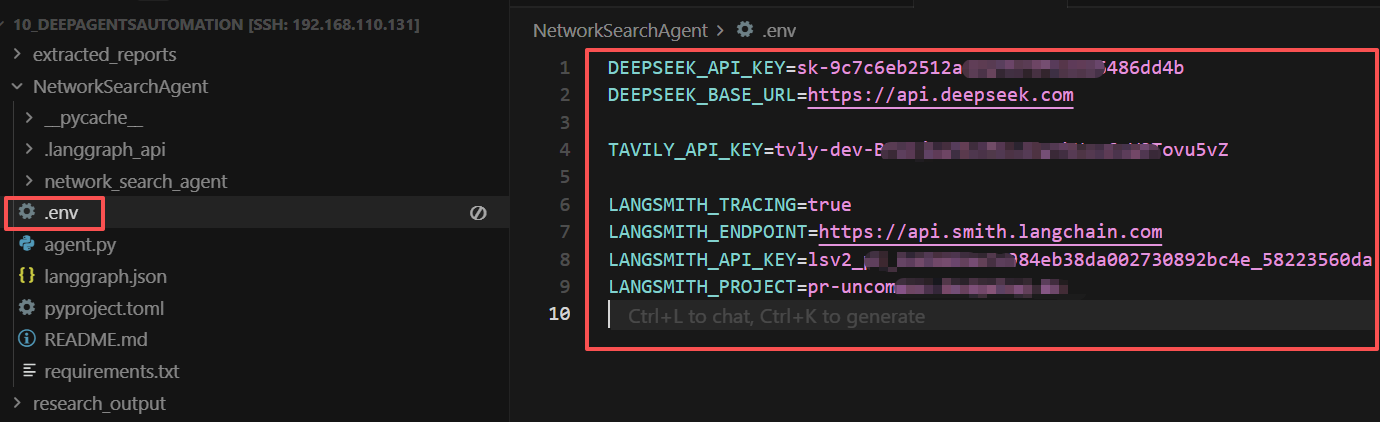
这里需要注意的是,如果不设置LangSmith,则无需设置中间三个环境变量,而具体工具也可以根据实际需求进行设置。
- Step 5. 创建
agent.py核心文件
在NetworkSearchAgent文件夹中创建agent.py文件,在该文件中编写构建图的具体运行逻辑,如状态、节点、变、图的编译等。此外,在使用LangGraph CLI创建智能体项目时,会自动设置记忆相关内容,并进行持久化记忆存储,无需手动设置。因此此时智能体代码如下所示:
FENCE0
- Step 6. 创建
langgraph.json文件
在NetworkSearchAgent文件夹中,新建一个langgraph.json文件,在该json文件中配置项目信息,遵循规范如下所示:
- 必须包含
dependencies和graphs字段 graphs字段格式:"图名": "文件路径:变量名"- 配置文件必须放在与Python文件同级或更高级的目录
注意: 项目文件的名称必须为langgraph.json。如下所示:
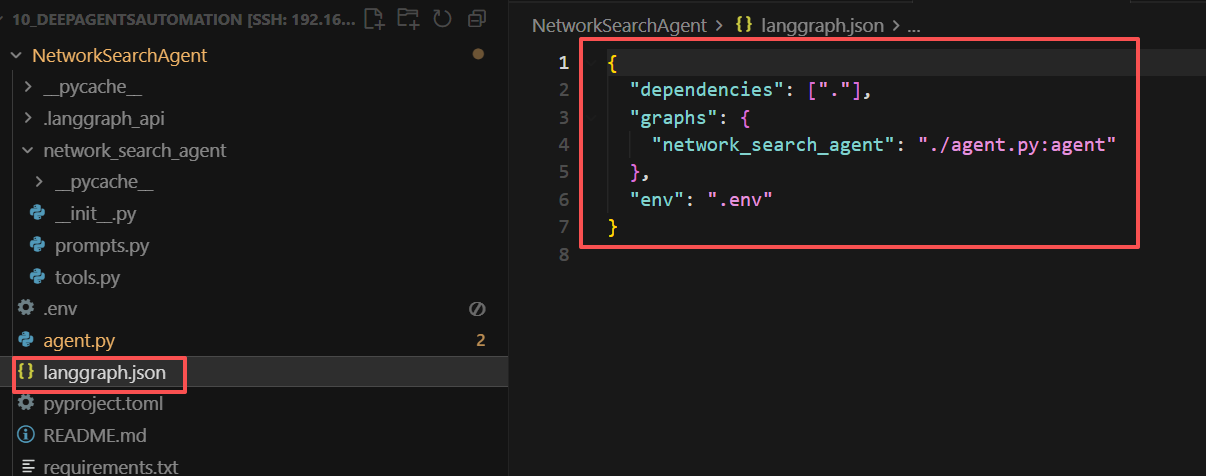
其中:
dependencies: ["./"] - 告诉LangGraph在当前目录查找依赖项(会自动读取requirements.txt)chatbot: "./graph.py:graph" - 定义图名为chatbot,来自graph.py文件中的graph变量env: ".env" - 指定环境变量文件位置
最终完整项目结构如下所示:
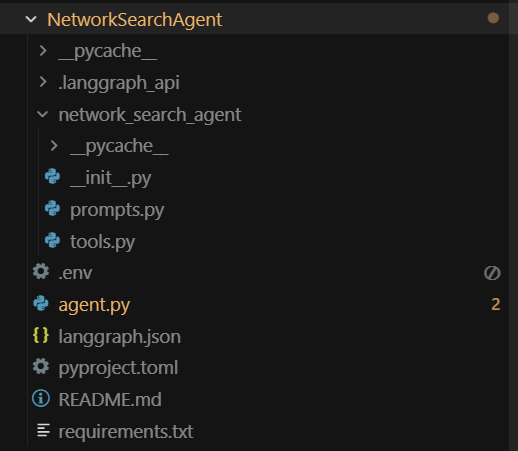
完整的代码已经上传至百度网盘中的NetworkSearchAgent文件夹中,大家可以扫描下方二维码免费领取
- Step 7. 安装
langgraph-cli以及其他依赖
然后,安装langgraph-cli依赖,执行如下代码:
FENCE0
然后进入到NetworkSearchAgent文件夹,安装相关基础依赖:
FENCE0
最后,进入到NetworkSearchAgent文件夹,执行LangGraph dev即可启动项目
FENCE0
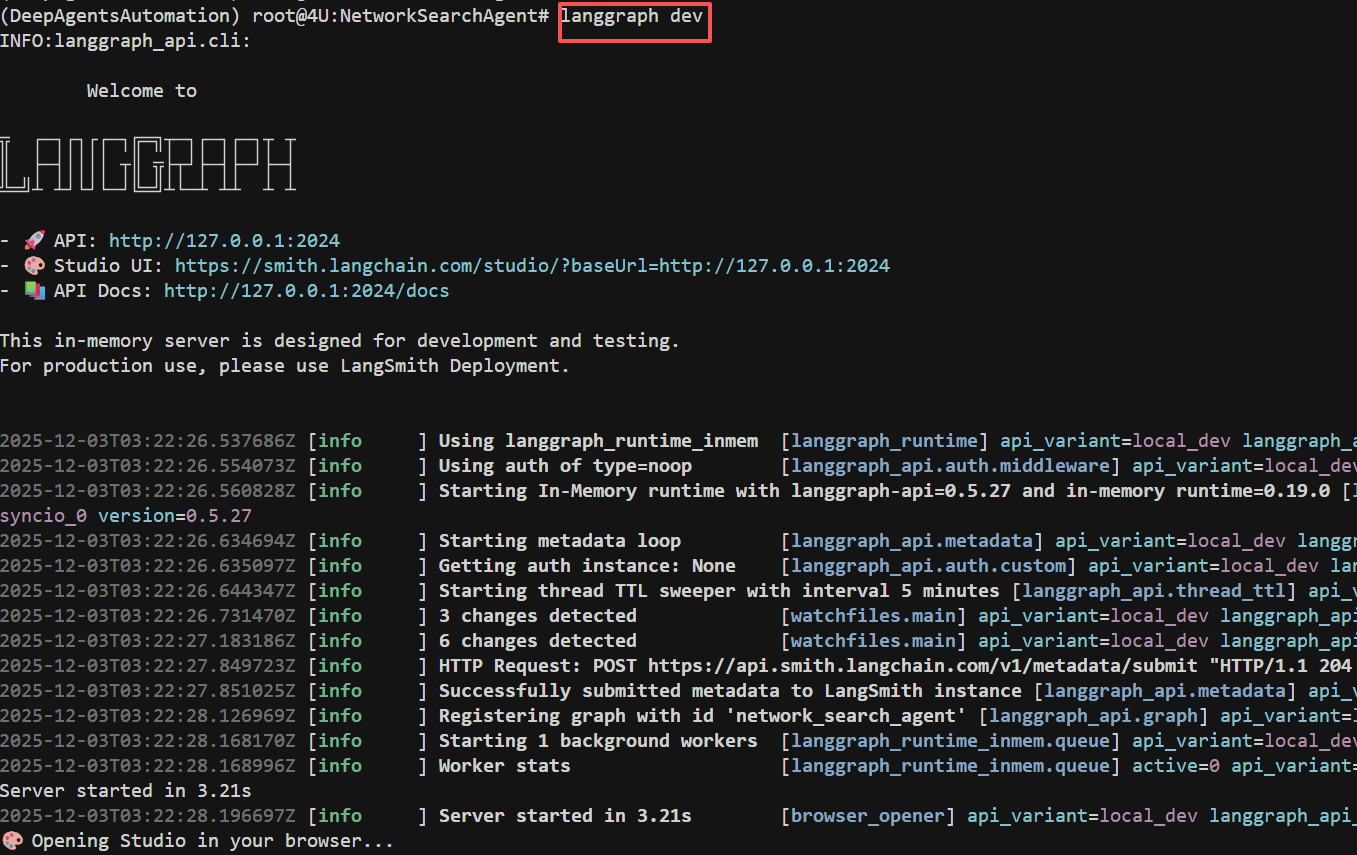
启动成功后能看到三个连接,其中第一个连接是当前部署完成后的服务端口,第二个是LangGraph Studio的可视化页面,第三个端口是端口说明。
三、DeepAgents部署后调用流程
- 后端服务接口
这里我们首先可以看下第三个连接,其中包含了详细的接口调用方法:
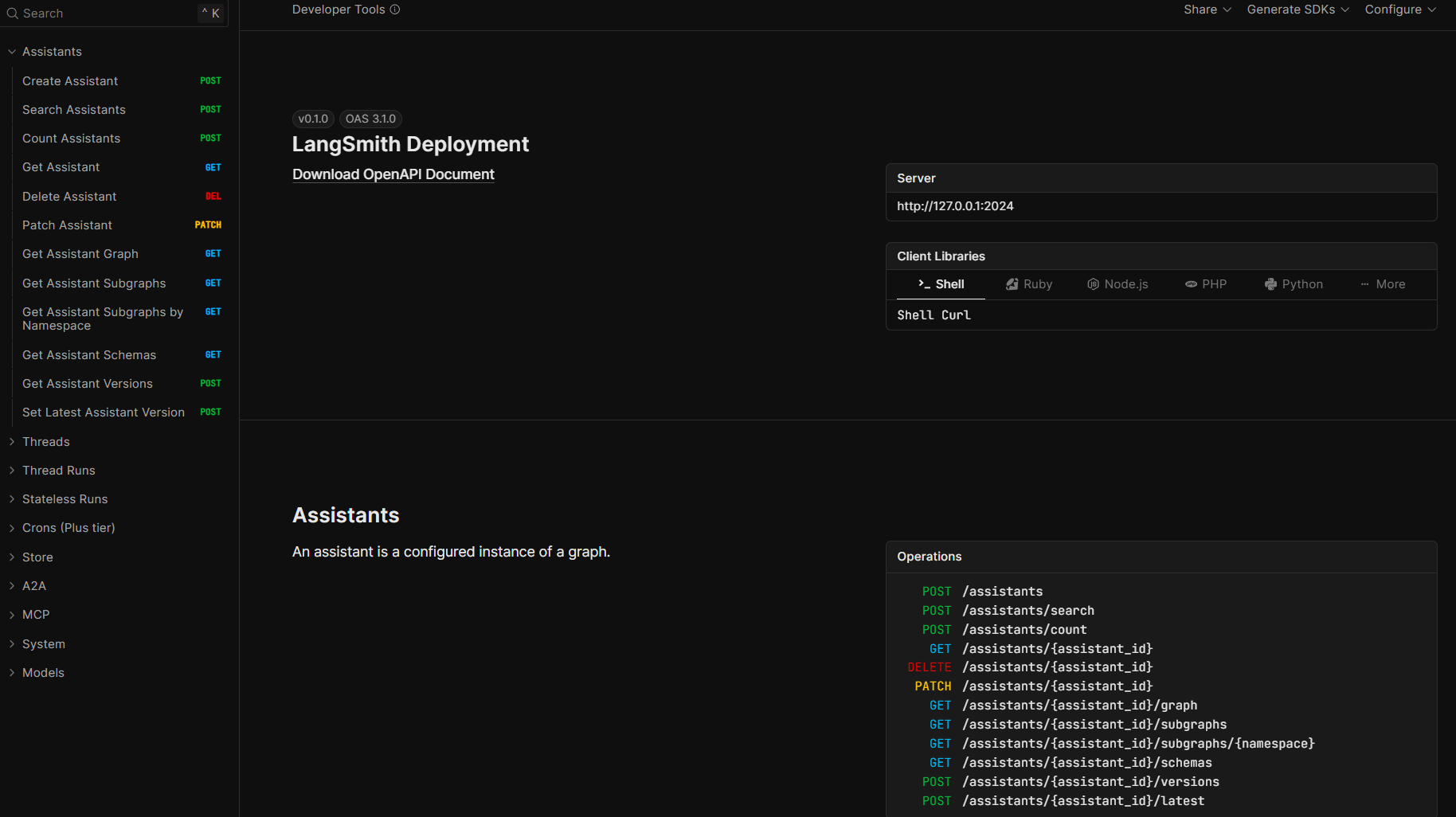
这些暴露的接口和调用方法,接下来就可以用于进行进一步开发和测试。
- LangGraph Studio
然后我们可点击Studio UI中显示的链接,在浏览器中打开并访问Studio,如下所示:
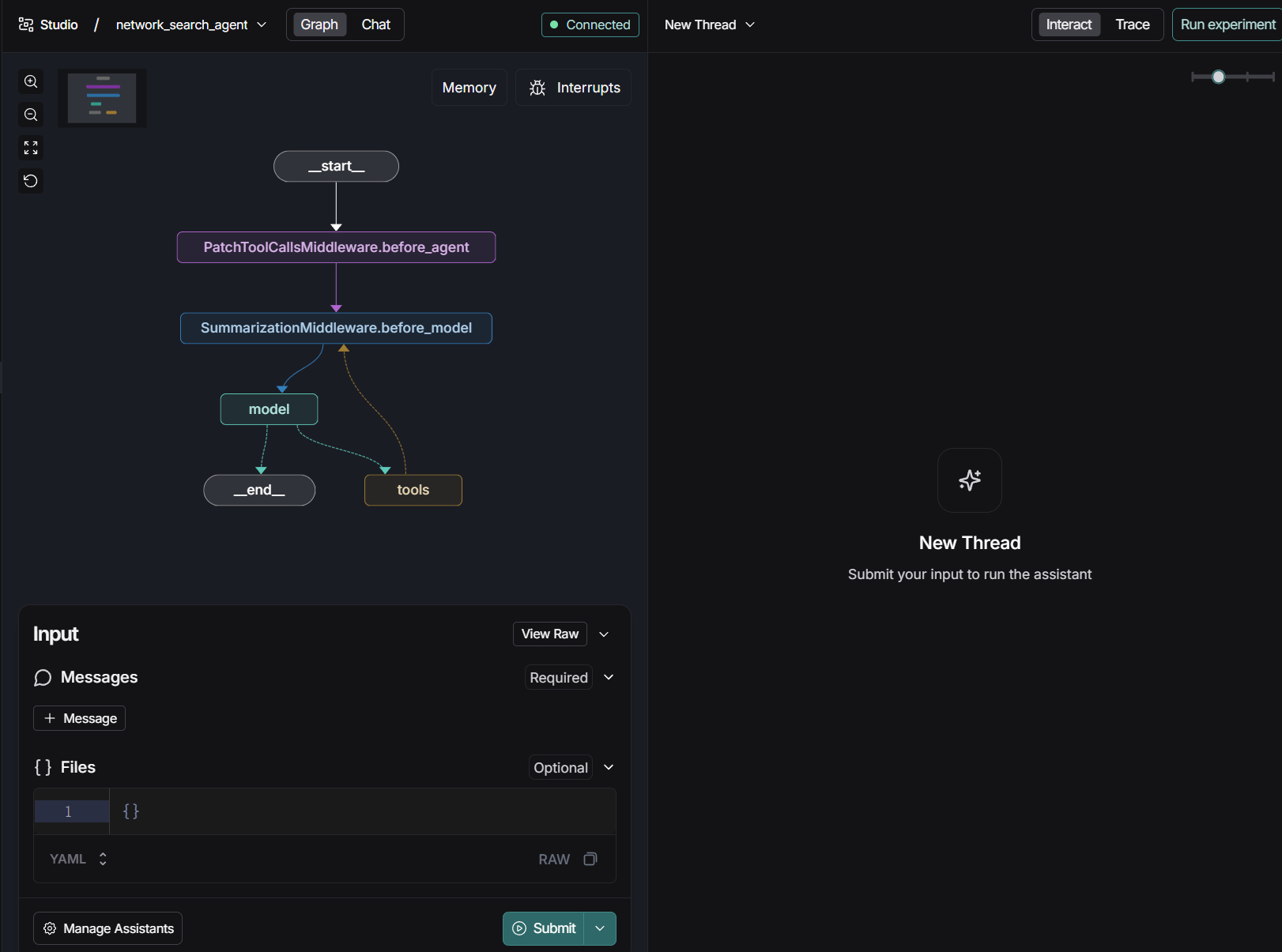
完整演示流程如下所示:
from IPython.display import Video
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2025-06-26%2019-29-04.mp4", width=1500, height=400)
四、Deep Agents UI 开发
除了 LangGraph Studio,我们还可以将 LangGraph 服务器连接到专为 deepagents 设计的 UI :https://github.com/langchain-ai/deep-agents-ui
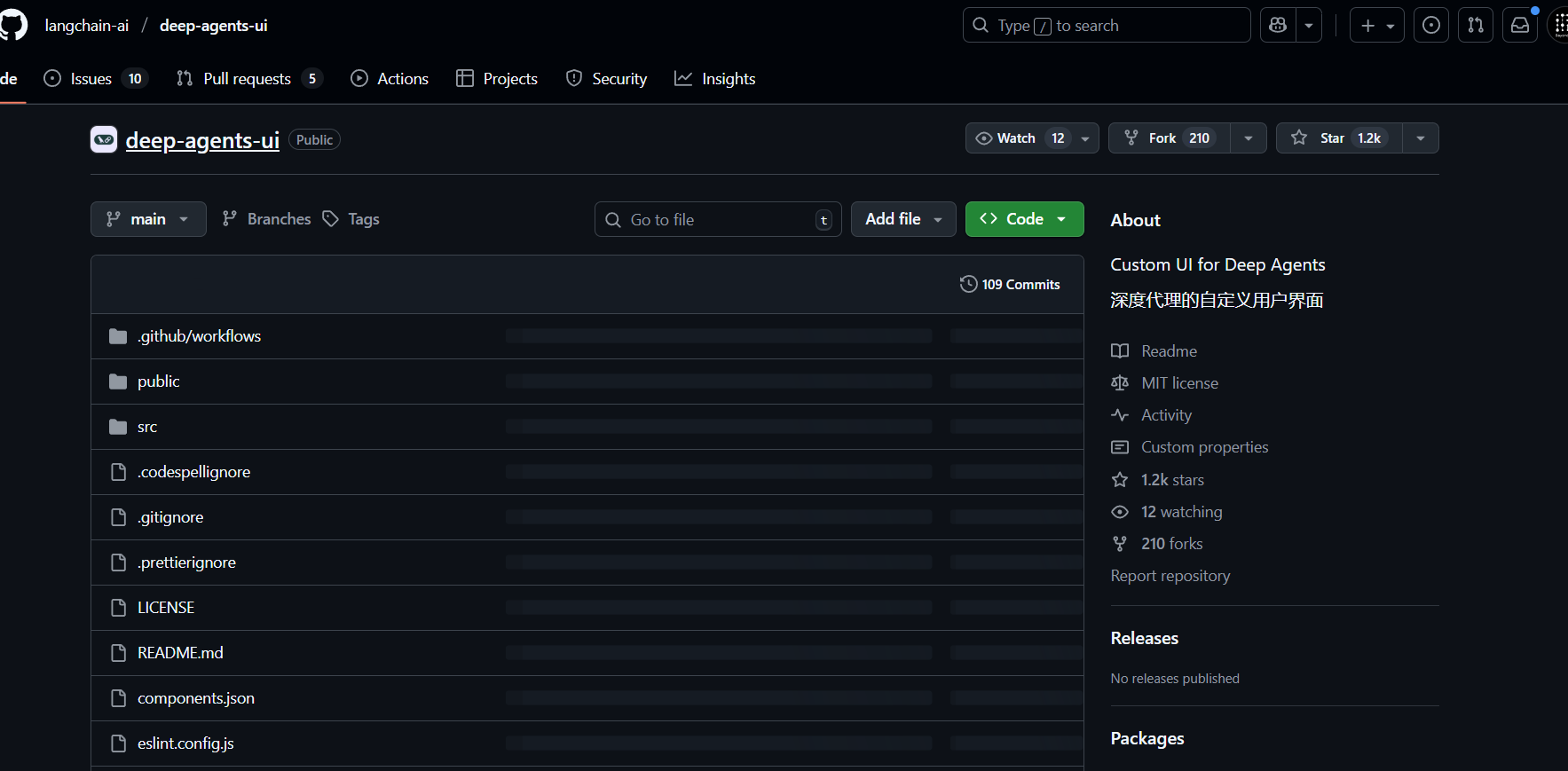
- Step 1. 克隆 Deep Agents UI 仓库
FENCE0

- Step 2. 安装依赖
执行如下代码安装依赖: FENCE0
- Step 3. 启动 UI
执行如下代码启动 UI:
FENCE0
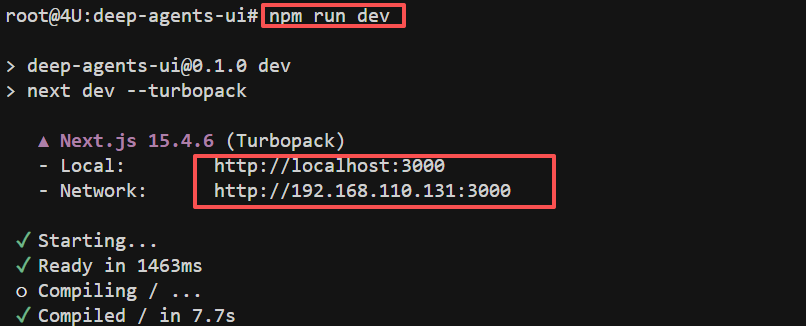
- Step 4. 连接到 LangGraph Server
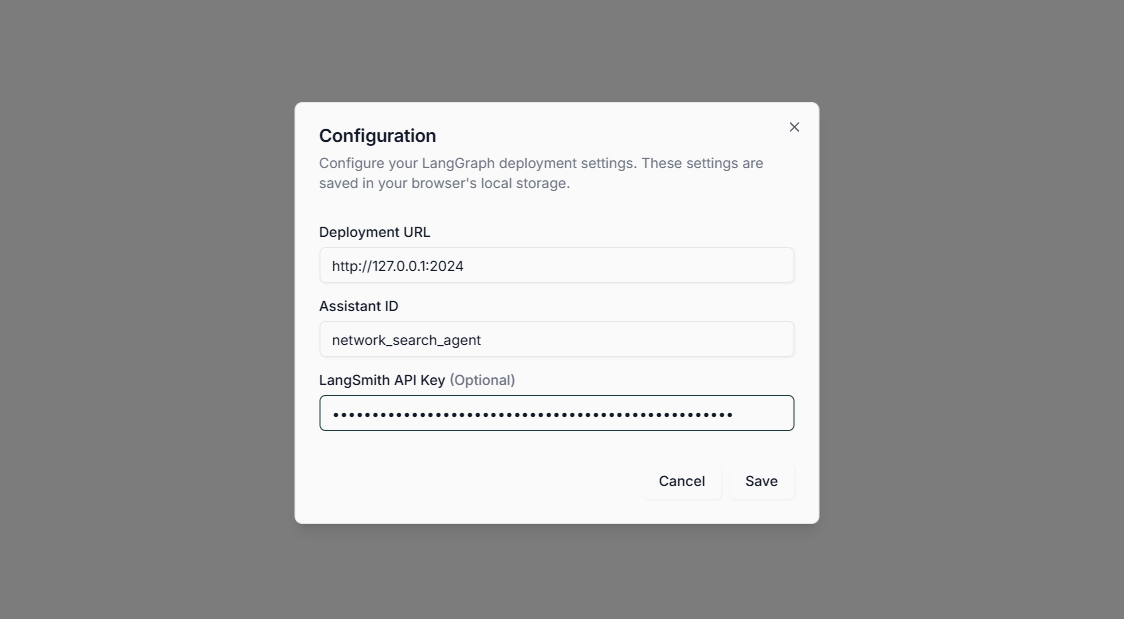
Deep Agents UI 提供了更友好的聊天界面和文件系统可视化功能。
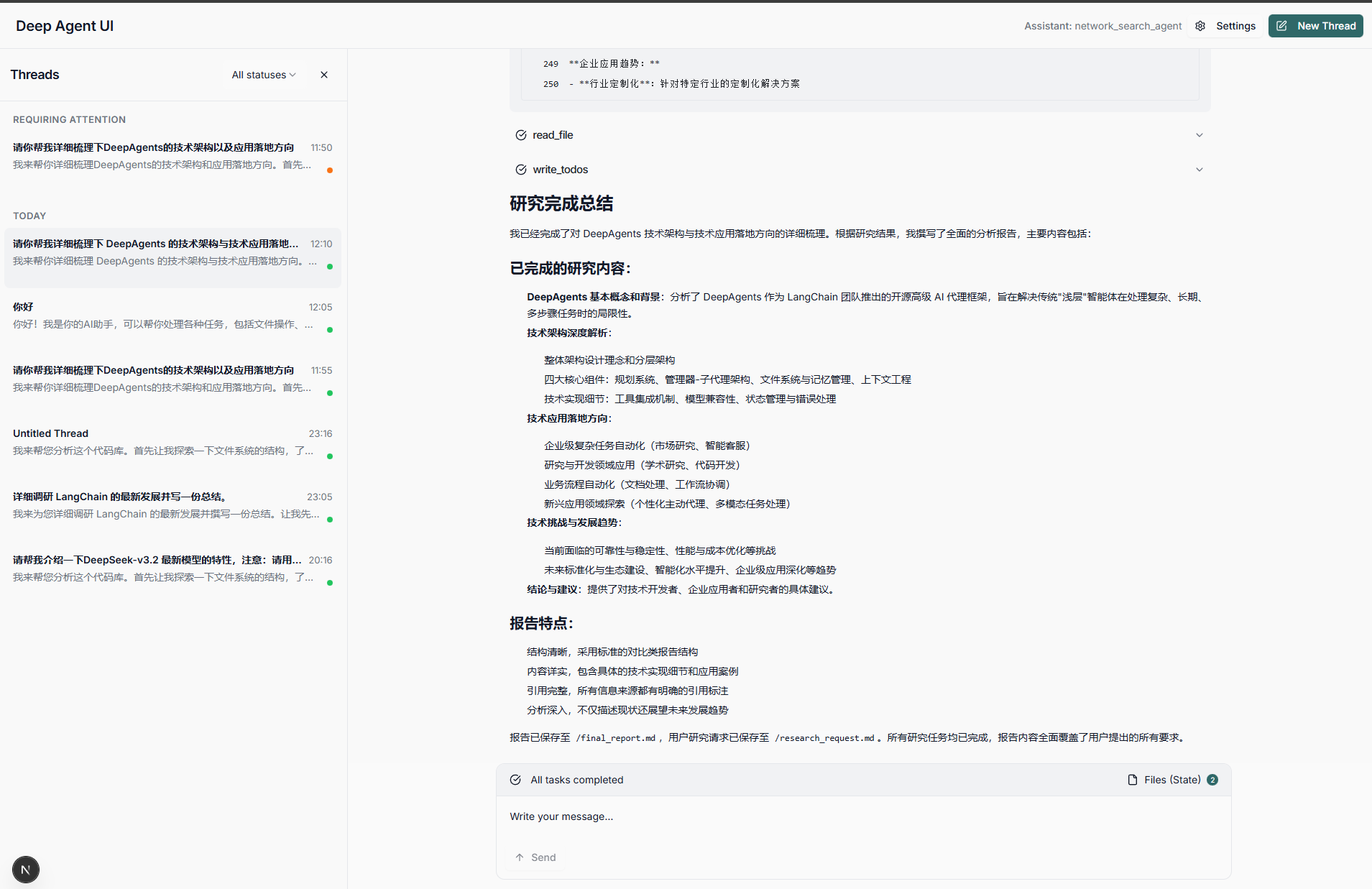
运行演示效果如下:
from IPython.display import Video
Video("https://muyu20241105.oss-cn-beijing.aliyuncs.com/images/202512031242162.mp4", width=1500, height=400)
五、【进阶实战】 代码环境提取DeepAgents运行状态
除了使用 LangGraph Studio,我们还可以通过编程方式打印智能体的执行过程。这种方法更适合在研发环境中进行调试和分析。DeepAgents 基于 LangGraph 构建,支持流式输出。我们可以使用 agent.stream() 方法来实时获取执行过程中的每一步。
# 核心依赖导入
import os
from typing import Literal
from dotenv import load_dotenv
from tavily import TavilyClient
from deepagents import create_deep_agent
# 加载环境变量
load_dotenv(override=True)
# 读取配置
deepseek_api_key = os.environ.get("DEEPSEEK_API_KEY")
deepseek_base_url = os.environ.get("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
tavily_key = os.environ.get("TAVILY_API_KEY")
print("环境变量加载完成")
from langchain.chat_models import init_chat_model
# 使用模型字符串(LangChain 会自动识别供应商)
model = init_chat_model(
api_key=deepseek_api_key,
base_url=deepseek_base_url,
model_provider="deepseek",
model="deepseek-chat"
)
# 初始化 Tavily 客户端
tavily_client = TavilyClient(api_key=tavily_key)
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""
运行网络搜索
这是一个用于网络搜索的工具函数,封装了 Tavily 的搜索功能。
参数说明:
- query: 搜索查询字符串,例如 "Python 异步编程教程"
- max_results: 最大返回结果数量,默认为 5
- topic: 搜索主题类型,可选 "general"(通用)、"news"(新闻)或 "finance"(金融)
- include_raw_content: 是否包含原始网页内容,默认为 False
返回:
- 搜索结果字典,包含标题、URL、摘要等信息
"""
try:
result = tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
return result
except Exception as e:
# 异常处理:返回错误信息而非抛出异常
# 这样 LLM 可以理解出错并尝试其他策略
return {"error": f"搜索失败: {str(e)}"}
print("搜索工具创建完成")
# 文件写入工具
def write_local_file(file_path: str, content: str) -> dict:
"""
将内容写入本地文件
这是一个用于将内容保存到本地文件的工具函数。
参数说明:
- file_path: 文件路径,例如 "report.md" 或 "./reports/research_report.md"
- content: 要写入文件的内容(字符串)
返回:
- 包含操作结果的字典,如果成功则返回 {"status": "success", "file_path": file_path}
- 如果失败则返回 {"status": "error", "error": "错误信息"}
"""
try:
# 确保目录存在
import os
directory = os.path.dirname(file_path)
if directory and not os.path.exists(directory):
os.makedirs(directory, exist_ok=True)
# 写入文件
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
return {
"status": "success",
"file_path": file_path,
"message": f"文件已成功保存到: {file_path}"
}
except Exception as e:
return {
"status": "error",
"error": f"写入文件失败: {str(e)}"
}
print("文件写入工具创建完成")
# 系统提示词
research_instructions = """您是一位资深的研究人员。您的工作是进行深入的研究,然后撰写一份精美的报告。
您可以通过互联网搜索引擎作为主要的信息收集工具。
## 可用工具
### `互联网搜索`
使用此功能针对给定的查询进行互联网搜索。您可以指定要返回的最大结果数量、主题以及是否包含原始内容。
### `写入本地文件`
使用此功能将研究报告保存到本地文件。当您完成研究并生成报告后,请使用此工具将完整的报告内容保存到文件中。
- 文件路径建议使用 .md 格式(Markdown),例如 "research_report.md" 或 "./reports/报告名称.md"
- 请确保报告内容完整、结构清晰,包含所有章节和引用来源
## 工作流程
在进行研究时:
1. 首先将研究任务分解为清晰的步骤
2. 使用互联网搜索来收集全面的信息
3. 将信息整合成一份结构清晰的报告
4. **重要**:完成报告后,务必使用 `写入本地文件` 工具将完整报告保存到本地文件
5. 务必引用你的资料来源
**注意**:请确保在完成研究后,将完整的报告内容保存到文件中,这样用户可以方便地查看和保存报告。
"""
# 创建 Deep Agent
agent = create_deep_agent(
model=model,
tools=[internet_search, write_local_file],
system_prompt=research_instructions
)
print("DeepAgents 创建成功!")
# 导入必要的库
import json
from rich.console import Console
from rich.panel import Panel
from rich.markdown import Markdown
from rich.json import JSON
# 导入 Rich 库
try:
from rich.console import Console
from rich.panel import Panel
from rich.markdown import Markdown
from rich.json import JSON
RICH_AVAILABLE = True
console = Console()
print("Rich 库已加载,将使用美化输出")
except ImportError:
RICH_AVAILABLE = False
console = None
print("Rich 库未安装,将使用标准输出")
我们创建一个调试函数,可以实时打印智能体的执行过程。这个函数会显示:
- AI 的思考过程
- 工具调用的详细信息
- 工具响应的内容
- 最终的研究报告
def debug_agent(query: str, save_to_file: str = None):
"""
运行智能体并打印中间过程(使用 Rich 美化输出)
参数:
query: 用户查询
save_to_file: 保存最终输出到文件(可选)
返回:
str: 最终的研究报告
"""
console.print(Panel.fit(
f"[bold cyan]查询:[/bold cyan] {query}",
border_style="cyan"
))
step_num = 0
final_response = None
# 实时流式输出
for event in agent.stream(
{"messages": [{"role": "user", "content": query}]},
stream_mode="values"
):
step_num += 1
console.print(f"\n[bold yellow]{'─' * 80}[/bold yellow]")
console.print(f"[bold yellow]步骤 {step_num}[/bold yellow]")
console.print(f"[bold yellow]{'─' * 80}[/bold yellow]")
if "messages" in event:
messages = event["messages"]
if messages:
msg = messages[-1]
# 保存最终响应
if hasattr(msg, 'content') and msg.content and not hasattr(msg, 'tool_calls'):
final_response = msg.content
# AI 思考
if hasattr(msg, 'content') and msg.content:
# 如果内容太长,只显示前300字符作为预览
content = msg.content
if len(content) > 300 and not (hasattr(msg, 'tool_calls') and msg.tool_calls):
preview = content[:300] + "..."
console.print(Panel(
f"{preview}\n\n[dim](内容较长,完整内容将在最后显示)[/dim]",
title="[bold green]AI 思考[/bold green]",
border_style="green"
))
else:
console.print(Panel(
content,
title="[bold green]AI 思考[/bold green]",
border_style="green"
))
# 工具调用
if hasattr(msg, 'tool_calls') and msg.tool_calls:
for tool_call in msg.tool_calls:
tool_info = {
"工具名称": tool_call.get('name', 'unknown'),
"参数": tool_call.get('args', {})
}
console.print(Panel(
JSON(json.dumps(tool_info, ensure_ascii=False)),
title="[bold blue]工具调用[/bold blue]",
border_style="blue"
))
# 工具响应
if hasattr(msg, 'name') and msg.name:
response = str(msg.content)[:500]
if len(str(msg.content)) > 500:
response += f"\n... (共 {len(str(msg.content))} 字符)"
console.print(Panel(
response,
title=f"[bold magenta]工具响应: {msg.name}[/bold magenta]",
border_style="magenta"
))
console.print("\n[bold green]任务完成![/bold green]\n")
return final_response
print("调试函数已创建")
现在让我们使用调试函数来运行一个研究任务,观察智能体的执行过程:
# 示例:使用调试函数运行研究任务
query = "详细调研 LangChain DeepAgents 框架的核心特性,并写一份结构化的总结报告。"
# 使用调试函数)
result = debug_agent(query)
当然,我们也给大家提供了直接运行的.py文件,大家可以在百度网盘中领取: