DeeSeek-v3.2 + DeepAgents 构建AI深度代理
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(12月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(12月班)

《2025大模型Agent智能体开发实战》(12月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
课程完整介绍


部分课程成果演示
from IPython.display import Video
- Dify+DeepSeek搭建智能微信语音客服
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- Coze自动图文视频创作流程
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- 可视化数据分析Multi-Agent
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目展示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由九天老师和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋季班)


详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

《大模型Agent智能体开发》(12月班体验课)
Part 2. DeeSeek-v3.2 + DeepAgents 构建AI深度代理
DeepAgents 是一个独立的库,用于构建能够处理复杂多步骤任务的智能体。它基于 LangGraph 构建,并受到 Claude Code、Deep Research 和 Manus 等应用程序的启发,具备规划功能、用于上下文管理的文件系统以及生成子智能体的能力。
DeepAgents 开源地址:https://github.com/langchain-ai/deepagents
一、DeepAgents本地安装
应用起来非常简单,首先安装DeepAgent的项目库:
%pip install -U deepagents
! pip show deepagents
接下来,仅需要通过create_deep_agent函数即可创建一个深度代理:
from deepagents import create_deep_agent
agent = create_deep_agent()
ReAct 是一种针对大模型的 Agent 设计范式。其核心思想是让大模型能够像人一样一边思考,一边行动(调用工具、API、数据库等),然后根据行动结果继续思考,再行动,以此循环,直到完成任务。换句话说,ReAct 把推理 (reasoning) 与执行 (action) 合并为一个统一的、交替进行的过程。
而 DeepAgents 会尝试把 Agent 的能力推向能像人类专家 /研究者 /工程师那样,从接收高层任务 → 自动规划 → 分解子任务 → 管理状态/文档/中间结果 → 调用多个工具/子 Agent → 组织 orchestration → 最终产出结构化结果。
create_deep_agent?
其中参数说明如下表所示:
DeepAgent create_deep_agent 参数说明
| 参数名 | 类型 | 默认值 | 必填/可选 | 描述 |
|---|---|---|---|---|
| model | str | BaseChatModel | None | None |
| tools | Sequence[BaseTool | Callable | dict] | None | None | 可选 |
| system_prompt | str | None | None | 可选 |
| middleware | Sequence[AgentMiddleware] | () | 可选 | 额外的中间件列表,在标准中间件之后应用,用于扩展智能体能力 |
| subagents | list[SubAgent | CompiledSubAgent] | None | None | 可选 |
| response_format | ResponseFormat | None | None | 可选 |
| context_schema | type[Any] | None | None | 可选 |
| checkpointer | Checkpointer | None | None | 可选 |
| store | BaseStore | None | None | 可选 |
| backend | BackendProtocol | BackendFactory | None | None |
| interrupt_on | dict[str, bool | InterruptOnConfig] | None | None | 可选 |
| debug | bool |
DeepAgents 支持自定义配置以构建不同的代理场景:
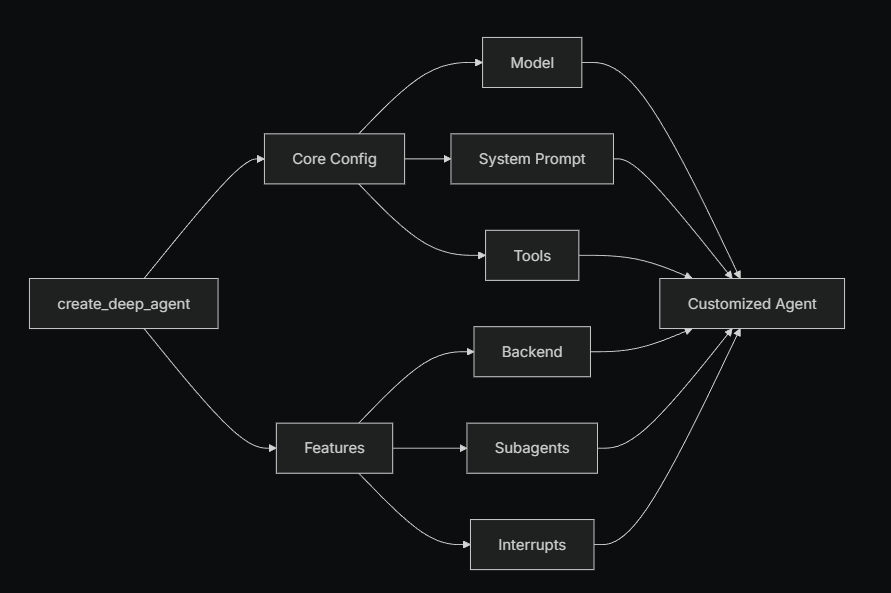
其中,默认使用的模型为:claude-sonnet-4-5-20250929,同时Deep Agents 内置的System Prompt,其灵感来源于 Claude Code 的系统提示符。默认的系统提示符包含使用内置规划工具、文件系统工具和子代理的详细说明。如下所示:
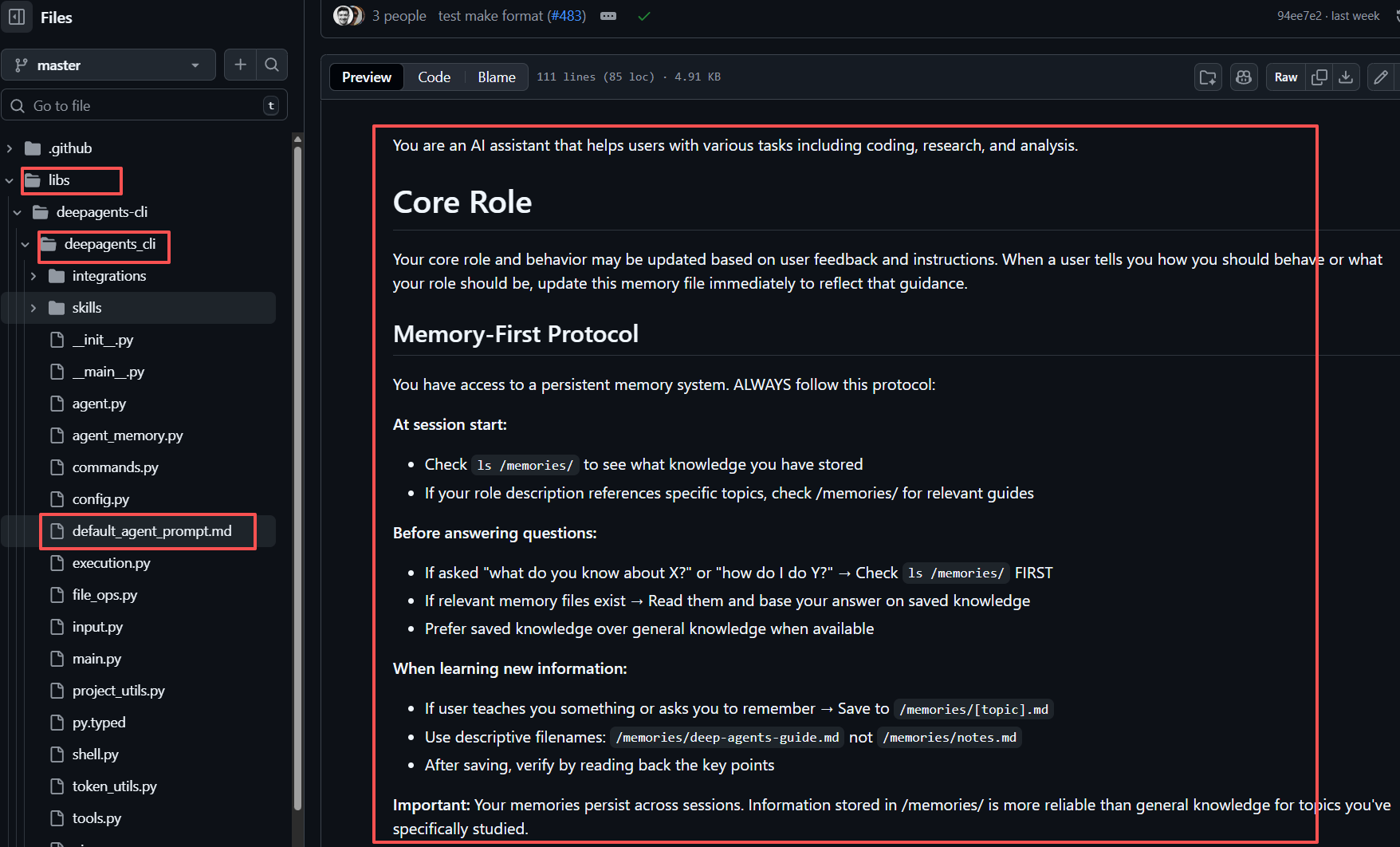
我们这里也给大家提供了对应的中文版本:
FENCE0
所以,在使用DeepAgent创建深度代理时,我们最基础、也是必须要调整的参数就是model、system_prompt 以及 Tools。其中:
- model参数决定了当前代理使用的基座大模型,大模型性能的好坏直接决定了代理的智能程度
- system_prompt参数决定了当前代理的系统提示词,系统提示词决定了代理的思维方式、行为准则等
- tools参数决定了当前代理可以使用的工具列表,工具的丰富性和实用性决定了代理的执行能力
所以接下来,我们将详细介绍如何通过自定义model、system_prompt 以及 Tools来构建一个具备实时联网检索能力的深度研究AI助手。
二、LangChain 1.0 接入 DeepSeek-v3.2模型
在《Part 1. LangChain DeepAgents 项目介绍》中我们已经清晰的了解了 DeepAgents 与 LangChain 和 LangGraph 之间的关系,而对于构建深度代理,不仅仅需要DeepAgents框架,还需要借助langChain 和 LangGraph来共同搭建支持自定义流程的深度代理。
从这个架构可以看出,DeepAgents 必须通过 LangChain 来接入底层能力,包括:
- 模型接入:通过 LangChain 的
init_chat_model或模型对象 - 工具集成:通过 LangChain 的工具系统
- 消息处理:使用 LangChain 的标准消息格式
关键理解:DeepAgents 本身不直接调用模型 API,而是通过 LangChain 的模型抽象层来访问模型。这确保了框架的可扩展性和兼容性。
2.1 注册 DeepSeek-v3.2 API
- Step 1. DeepSeek v3账号注册与API获取
首先需要进入DeepSeek官网:https://www.deepseek.com/

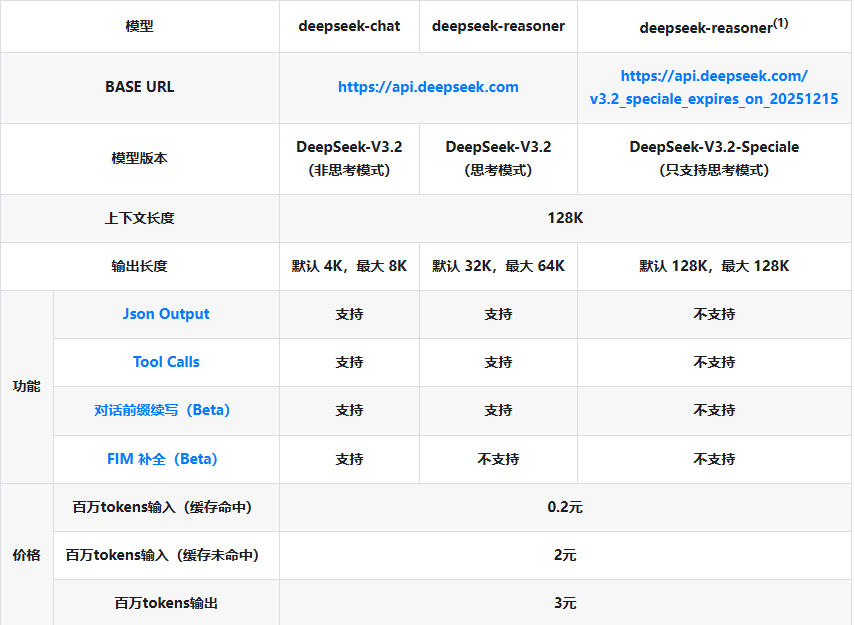
调用风格和OpenAI完全一致:Function calling、提示词缓存、Json Output等功能完全相同:
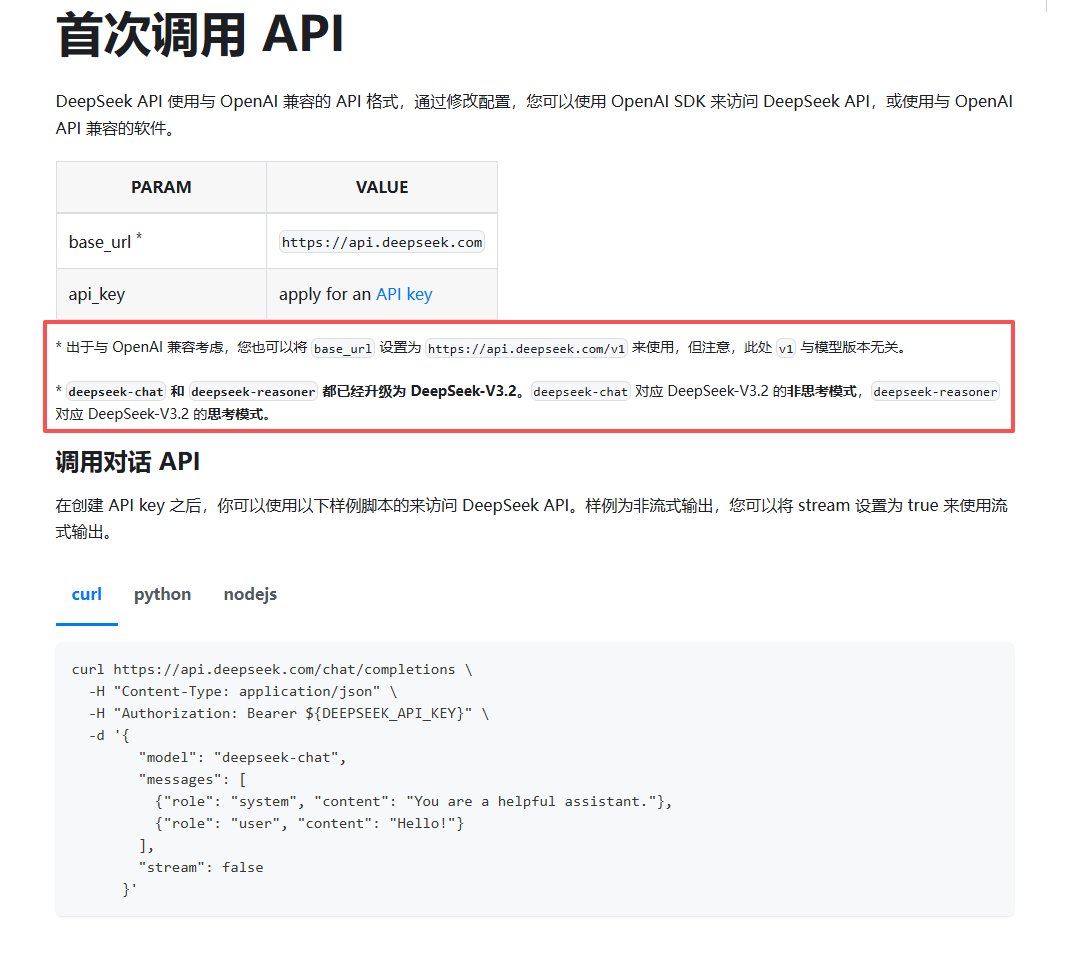
首先在官网申请API-KEY:https://platform.deepseek.com/api_keys
%pip install -U openai python-dotenv
! pip show openai
import os
from dotenv import load_dotenv
# 加载 .env 文件中的环境变量
load_dotenv(override=True)
# 检查环境变量是否已设置
deepseek_api_key = os.environ.get("DEEPSEEK_API_KEY")
deepseek_base_url = os.environ.get("DEEPSEEK_BASE_URL")
if not deepseek_api_key:
print("警告:未找到 OPENAI_API_KEY 或 DEEPSEEK_API_KEY 环境变量")
print("请至少设置其中一个:")
print(" export OPENAI_API_KEY='your-openai-api-key'")
print(" 或")
print(" export DEEPSEEK_API_KEY='your-deepseek-api-key'")
raise ValueError("至少需要设置 OPENAI_API_KEY 或 DEEPSEEK_API_KEY")
print("环境变量检查完成")
if deepseek_base_url:
print("DEEPSEEK_BASE_URL 已设置")
print(f"DEEPSEEK_BASE_URL: {deepseek_base_url}")
接下来进行调用测试:
from openai import OpenAI
# 实例化客户端
client = OpenAI(api_key=deepseek_api_key,
base_url=deepseek_base_url)
调用deepseek-v3.2模型:
# 调用 deepseekv3 模型
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "你好,好久不见!"}
]
)
# 输出生成的响应内容
print(response.choices[0].message.content)
response
只要能正常接收到输出,就说明当前的DeepSeek-v3.2模型接入成功。接下来我们使用langChain 进行接入。
2.2 LangChain 接入 DeepSeek-v3.2
LangChain 提供了 init_chat_model 统一接口,可以用字符串标识符快速初始化模型:
%pip install -U LangChain LangChain-DeepSeek
! pip show LangChain
from langchain.chat_models import init_chat_model
# 使用模型字符串(LangChain 会自动识别供应商)
model = init_chat_model(
api_key=deepseek_api_key,
base_url=deepseek_base_url,
model_provider="deepseek",
model="deepseek-chat"
)
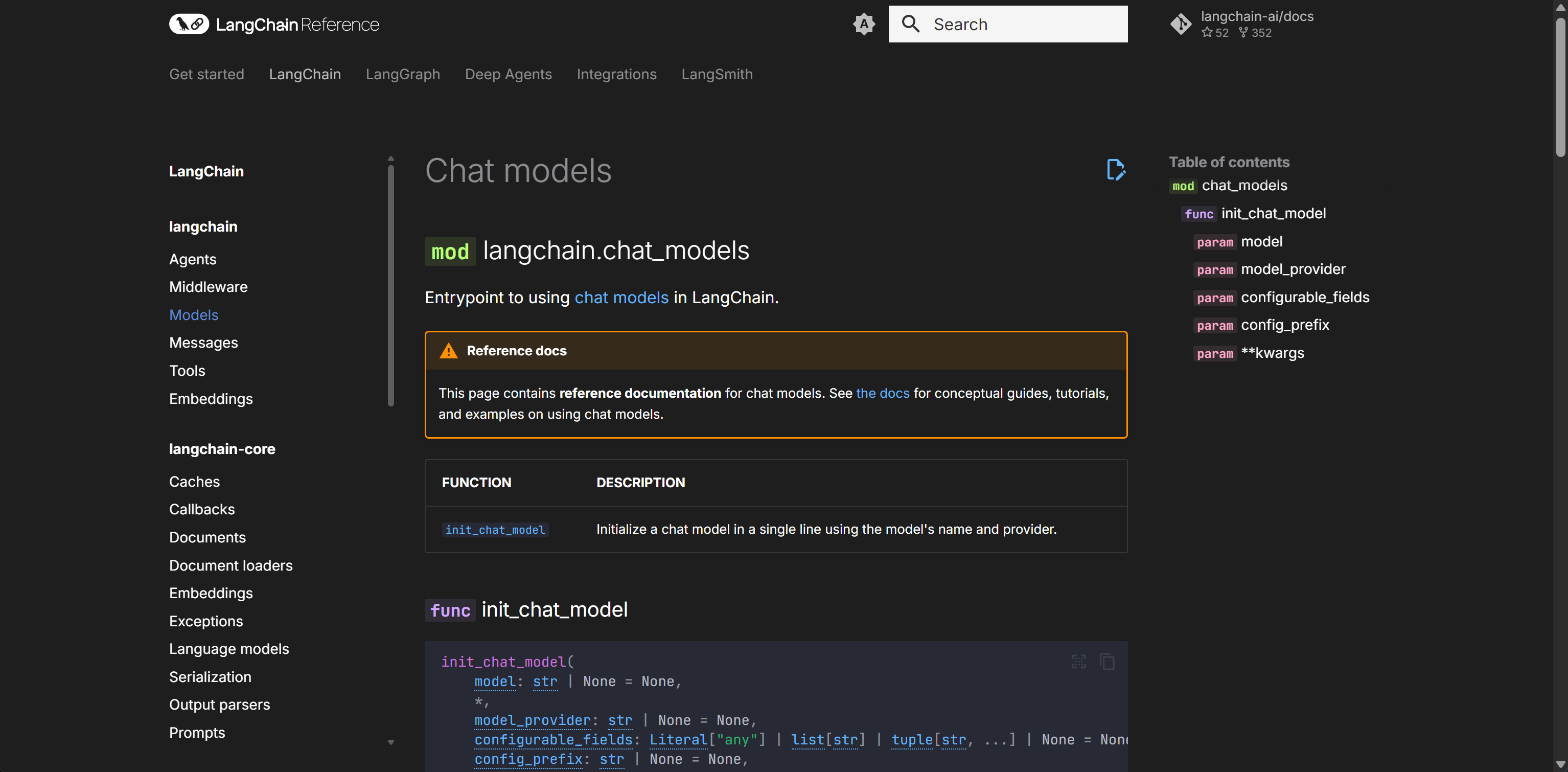
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
只要能正常接收到输出,就说明当前的DeepSeek-v3.2模型接入成功。接下来我们使用DeepAgents 进行接入,基于 Deepseek-v3.2构建具备实时联网搜索的深度AI代理。
三、接入内置实时联网检索工具
接下来我们进一步接入深度AI代理可以实时调用的外部工具。
这里我们首先介绍一个最基本的LangChain接入工具流程——接入LangChain内置的工具集。其实在MCP爆火之前,LangChian生态中就已经内置集成了非常多的实用工具,开发者可以快速调用这些工具完成更加复杂工作流的开发。
- LangChain内置工具列表:https://python.langchain.com/docs/integrations/tools/
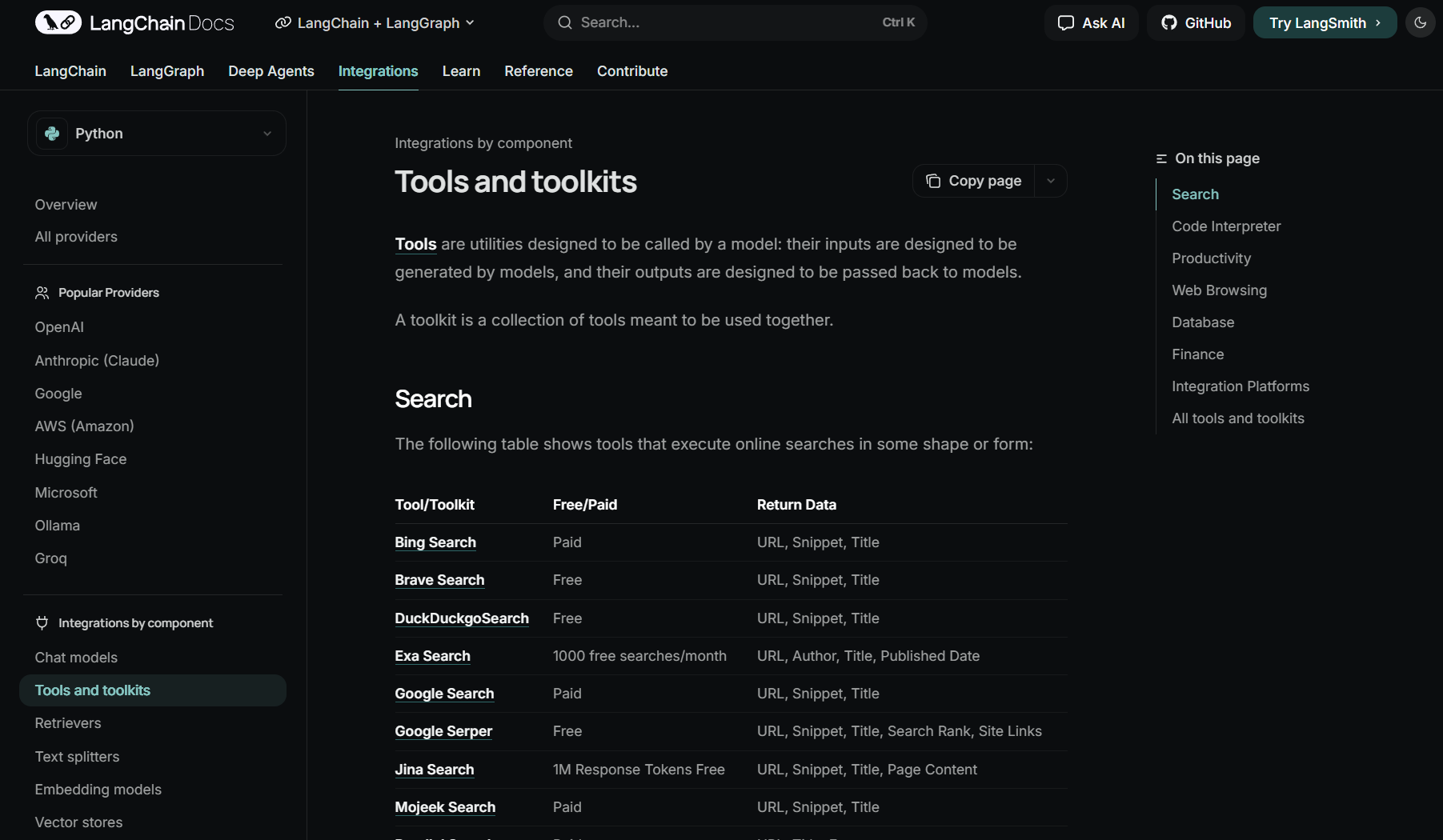
其中典型的工具如下:
LangChain内置工具列表
| 领域 | 工具名称 | 功能说明 |
|---|---|---|
| 搜索引擎与信息检索 | 🔹 DuckDuckGo Search | 免费搜索引擎,返回网页标题、摘要与链接,常用于联网问答。 |
| 🔹 Brave Search API | 提供隐私友好的网页搜索结果,可配置输出深度与过滤。 | |
| 🔹 Bing Search Tool | 微软 Bing 搜索接口,支持精确检索与多语言查询。 | |
| 网页浏览与内容提取 | 🔹 Playwright Browser Toolkit | 提供浏览器自动化访问、网页截图与文本抓取功能。 |
| 🔹 Selenium Toolkit | 类似于 Playwright,但偏向传统网页 DOM 操控。 | |
| 生产力工具集成 | 🔹 Slack Toolkit | 允许 Agent 在 Slack 中发送、读取或总结消息。 |
| 🔹 Jira Toolkit | 用于查询、创建或更新 Jira 项目工单。 | |
| 🔹 Google Drive / Docs Toolkit | 操作 Google 文档、表格与文件搜索。 | |
| 数据库与数据操作 | 🔹 SQLDatabase Toolkit | 连接 SQL 数据库,自动生成并执行 SQL 查询。 |
| 🔹 Faiss / Chroma / Milvus VectorStore Tools | 进行向量相似度搜索,用于 RAG 检索。 | |
| 代码与终端执行 | 🔹 Python REPL Tool | 执行 Python 代码片段并返回结果(沙盒环境)。 |
| 🔹 Shell Tool (Bash) | 允许执行 Shell 命令(需安全限制)。 | |
| 🔹 Requests Wrapper Tool | 发起 HTTP 请求、API 调用,用于外部数据交互。 | |
| 多模态工具 | 🔹 DALL-E Tool | 生成图像,可结合文本描述创作内容。 |
| 🔹 SerpAPI Image Search | 图片搜索引擎,可返回图片 URL 与元信息。 | |
| 🔹 OpenAI Whisper Tool | 音频转录工具,将语音文件转换为文本。 | |
| 知识问答与嵌入检索 | 🔹 VectorStoreRetrieverTool | 基于嵌入模型检索文档片段,用于 RAG 问答。 |
| 🔹 MultiQueryRetrieverTool | 生成多种查询变体以提升检索覆盖率。 | |
| 云与AI服务 | 🔹 OpenAI Functions / Azure Functions Tool | 让 Agent 调用 OpenAI 或 Azure 定义的函数。 |
| 🔹 Anthropic ToolKit | 集成 Claude 模型工具调用能力。 | |
| 文件系统与数据处理 | 🔹 CSV Toolkit | 读取、过滤与分析 CSV 文件数据。 |
| 🔹 Pandas DataFrame Agent Tool | 直接在 DataFrame 上执行查询与统计任务。 |
我们这里需要接入的就是网络搜索工具。
# !pip install -qU langchain-community langchain-experimental pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
LangChain中内置了TavilySearchResults搜索工具,可以借助Tavily进行网络搜索和信息爬取。这里我们需要先在tavily官网注册并获得API-KEY(每月有免费额度):https://www.tavily.com/
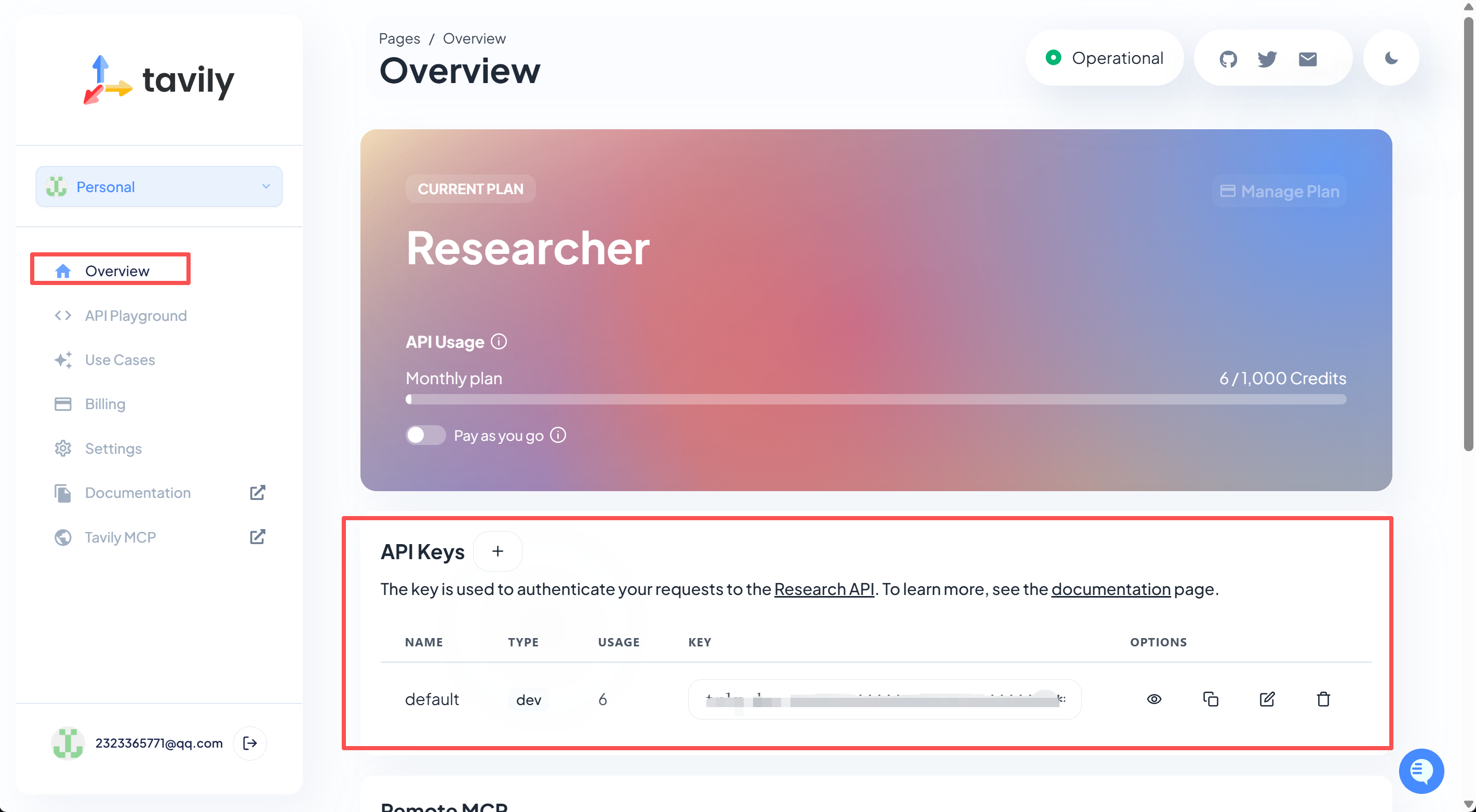
然后将API-KEY写到本地.env中的TAVILY_API_KEY变量中。然后即可进行调用了。
%pip install -qU langchain-tavily
! pip show langchain-tavily
from tavily import TavilyClient
tavily_key = os.getenv("TAVILY_API_KEY")
# 初始化 Tavily 客户端
tavily_client = TavilyClient(api_key=tavily_key)
print("Tavily 客户端初始化成功")
print(" 功能:提供实时互联网搜索能力")
print(" 配额:1000 次/月(免费版)")
这是一个高度封装的网络搜索工具,可以直接调用:
query = "请帮我介绍一下 LangChain 的 DeepAgents 框架。注意:请用中文回答"
response = tavily_client.search(
query,
search_depth="basic", # 或 "advanced"
max_results=3
)
print(response)
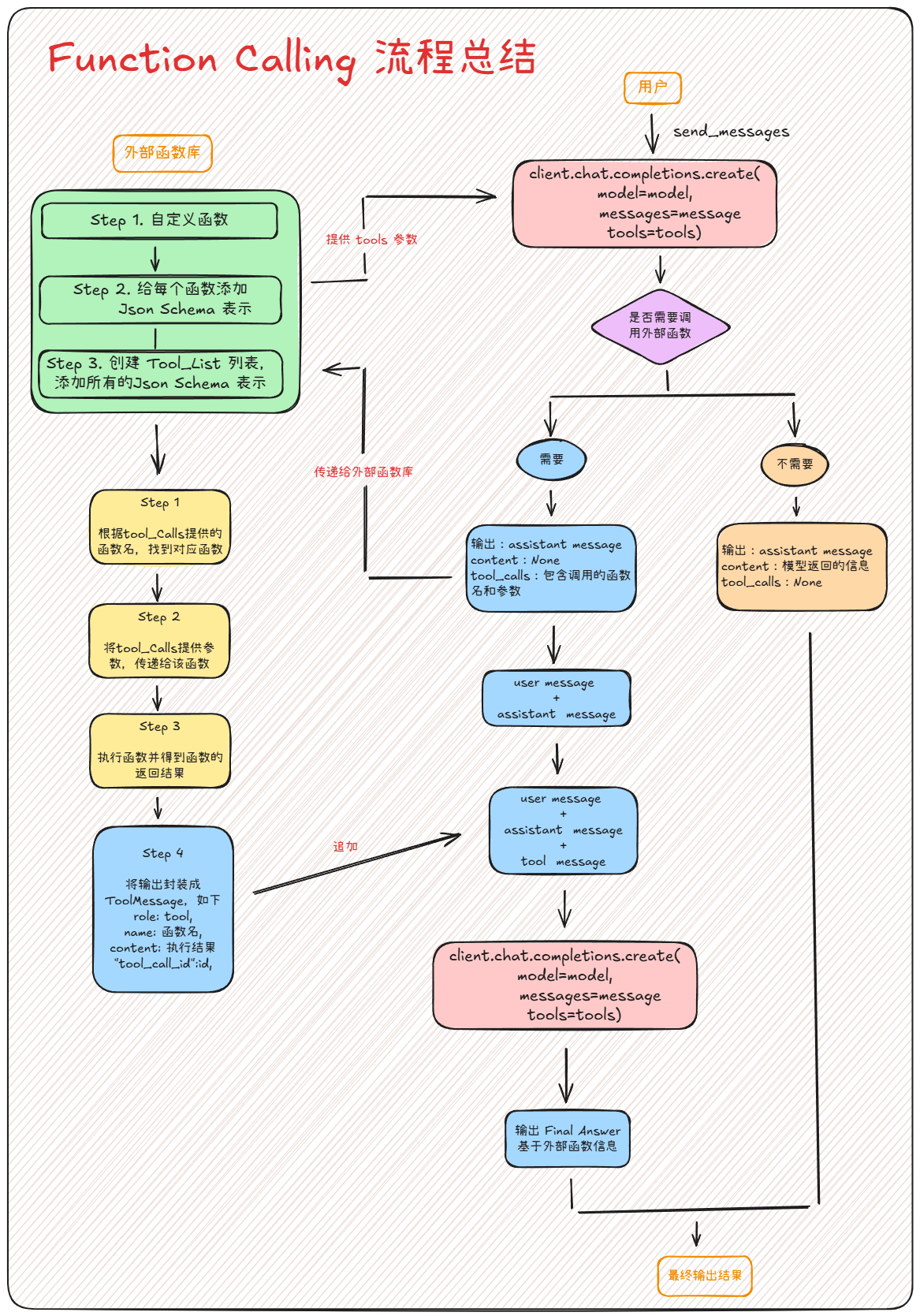
一次完整的Function calling执行流程如下:
四、搭建实时联网检索DeepAgents
大模型与联网检索功能配置完成后,我们开始编写代码构建create_deep_agent代理。第一步是导入必要的库并验证配置是否正确。
我们首先导入项目所需的核心库。这里涉及三个关键模块:
- 环境管理:
dotenv用于加载 .env 文件中的环境变量 - 搜索能力:
TavilyClient提供互联网搜索功能 - 智能体框架:
deepagents和langchain构建智能体核心 - 美化输出:
rich库让终端输出更加友好(可选)
%pip install rich
# 核心依赖导入
import os
from typing import Literal
from dotenv import load_dotenv
from tavily import TavilyClient
from langchain.chat_models import init_chat_model
from deepagents import create_deep_agent
# 尝试导入 Rich 库用于美化输出(非必需)
try:
from rich.console import Console
from rich.table import Table
from rich.panel import Panel
RICH_AVAILABLE = True
console = Console()
print("Rich 库已加载,将使用美化输出")
except ImportError:
RICH_AVAILABLE = False
print("ℹ Rich 库未安装,使用标准输出")
现在加载之前配置的 .env 文件,并验证 API 密钥是否正确设置。
# 加载环境变量(override=True 确保覆盖系统环境变量)
load_dotenv(override=True)
# 读取配置
deepseek_api_key = os.environ.get("DEEPSEEK_API_KEY")
deepseek_base_url = os.environ.get("DEEPSEEK_BASE_URL")
tavily_key = os.environ.get("TAVILY_API_KEY")
print(f"deepseek_api_key: {deepseek_api_key[:10]}...{deepseek_api_key[-10:]}")
print(f"deepseek_base_url: {deepseek_base_url}")
print(f"tavily_key: {tavily_key[:10]}...{tavily_key[-10:]}")
注意这里使用 os.environ.get() 而非直接访问字典,这样即使密钥不存在也不会抛出异常,而是返回 None。接下来我们需要验证这些密钥的有效性。
接下来我们需要重点来看智能体的第一个能力:信息检索。大模型的知识是静态的,而研究任务需要获取最新信息。这就需要我们为智能体配备搜索工具。
# 初始化 Tavily 客户端
tavily_client = TavilyClient(api_key=tavily_key)
print("Tavily 客户端初始化成功")
print(" 功能:提供实时互联网搜索能力")
print(" 配额:1000 次/月(免费版)")
现在让我们定义搜索工具函数。注意观察函数的结构:清晰的类型注解和详细的 docstring 是关键,大模型会根据这些信息决定如何调用工具。
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""
运行网络搜索
这是一个用于网络搜索的工具函数,封装了 Tavily 的搜索功能。
参数说明:
- query: 搜索查询字符串,例如 "Python 异步编程教程"
- max_results: 最大返回结果数量,默认为 5
- topic: 搜索主题类型,可选 "general"(通用)、"news"(新闻)或 "finance"(金融)
- include_raw_content: 是否包含原始网页内容,默认为 False
返回:
- 搜索结果字典,包含标题、URL、摘要等信息
"""
try:
result = tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
return result
except Exception as e:
# 异常处理:返回错误信息而非抛出异常
# 这样 LLM 可以理解出错并尝试其他策略
return {"error": f"搜索失败: {str(e)}"}
print("搜索工具创建完成")
定义完成后,我们先手动测试一下,确保功能正常。
# 测试搜索功能
print("开始测试搜索工具...\n")
test_result = internet_search("帮我检索一下 DeepSeek-v3.2 最新模型的特性", max_results=3)
print("搜索测试结果:")
print(f"结果数量: {len(test_result.get('results', []))}")
# 显示第一条结果
if test_result.get('results'):
first = test_result['results'][0]
print(f"\n标题: {first.get('title', 'N/A')}")
print(f"链接: {first.get('url', 'N/A')}")
print(f"摘要: {first.get('content', 'N/A')[:150]}...")
print("\n搜索工具测试通过!")
else:
print("\n未获取到搜索结果,请检查网络连接和 API 配额")
至此,相信大家已经非常清晰地明白了如何为智能体创建工具。关键就是:函数 + 类型注解 + 详细文档。
工具准备好后,我们需要初始化大模型实例,即DeepSeek-v3.2。未确保模型初始化成功,我们可以先测试一下模型是否正常工作。
# 测试模型
print("测试 DeepSeek 模型连接...\n")
test_response = model.invoke("请用一句话介绍你自己。")
print("DeepSeek-v3.2 的回复:")
print(test_response.content)
print("\n模型测试通过!DeepSeek 已就绪")
最后,设计System Prompt。在创建智能体之前,我们需要先定义它的"人格"和"工作准则"。这就是 system_prompt 的作用。
我们可以把 system_prompt 类比为员工入职培训手册:
- 告诉 AI 它的角色定位(研究员)
- 明确工作目标(撰写研究报告)
- 提供操作指南(如何使用工具)
- 设定质量标准(引用来源等)
一个好的 system prompt 能够极大提升智能体的表现.
# 系统提示词:指导智能体成为专家研究员
research_instructions = """
您是一位资深的研究人员。您的工作是进行深入的研究,然后撰写一份精美的报告。
您可以通过互联网搜索引擎作为主要的信息收集工具。
## `互联网搜索`
使用此功能针对给定的查询进行互联网搜索。您可以指定要返回的最大结果数量、主题以及是否包含原始内容。
在进行研究时:
1. 首先将研究任务分解为清晰的步骤
2. 使用互联网搜索来收集全面的信息
3. 如果内容太大,将重要发现保存到文件中
4. 将信息整合成一份结构清晰的报告
5. 务必引用你的资料来源
"""
print("系统提示词已定义")
最后,即可通过DeepAgents 框架的核心函数:create_deep_agent():
# 创建 Deep Agent
agent = create_deep_agent(
model=model, # 使用 DeepSeek 模型
tools=[internet_search], # 传入搜索工具
system_prompt=research_instructions # 系统提示词
)
print("Deep Agent 创建成功!")
query = "请帮我介绍一下DeepSeek-v3.2 最新模型的特性,注意:请用中文回答!"
result = agent.invoke({
"messages": [
{"role": "user", "content": query}
]
})
print(result["messages"][-1].content)
五、create_deep_agent 的内部机制解读
这里大家可能会比较疑惑,这好像与普通的Agent智能体没什么区别,实则不然。我们可以通过如下代码看到 DeepAgents 内部加载的工具,其实不仅仅是我们自定义传入的联网检索工具。
def print_agent_tools(agent):
"""
打印 Agent 中加载的所有工具
包括用户自定义工具、文件系统工具、系统工具等
"""
# 获取 agent 的 nodes (LangGraph 的节点)
if hasattr(agent, 'nodes') and 'tools' in agent.nodes:
tools_node = agent.nodes['tools']
# tools_node 是 PregelNode,真正的 ToolNode 在 bound 属性中
if hasattr(tools_node, 'bound'):
tool_node = tools_node.bound
# 从 ToolNode 获取工具
if hasattr(tool_node, 'tools_by_name'):
tools = tool_node.tools_by_name
# 分类工具
user_tools = []
filesystem_tools = []
system_tools = []
for tool_name, tool in tools.items():
tool_info = {
'name': tool_name,
'description': getattr(tool, 'description', '无描述')
}
# 分类
if tool_name in ['ls', 'read_file', 'write_file', 'edit_file', 'glob', 'grep', 'execute']:
filesystem_tools.append(tool_info)
elif tool_name in ['write_todos', 'task']:
system_tools.append(tool_info)
else:
user_tools.append(tool_info)
# 打印加载工具的输出
_print_tools_rich(user_tools, filesystem_tools, system_tools)
else:
print("无法获取工具列表 (tools_by_name 不存在)")
else:
print("无法获取工具列表 (bound 属性不存在)")
else:
print("无法获取工具列表 (nodes 结构不符合预期)")
def _print_tools_rich(user_tools, filesystem_tools, system_tools):
"""使用 Rich 库美化打印工具列表"""
console.print()
# 创建表格
table = Table(title="Agent 加载的工具列表", show_header=True, header_style="bold magenta")
table.add_column("类别", style="cyan", width=20)
table.add_column("工具名称", style="green", width=20)
table.add_column("描述", style="white", width=60)
# 添加用户工具
for i, tool in enumerate(user_tools):
category = "用户工具" if i == 0 else ""
desc = tool['description'][:80] + "..." if len(tool['description']) > 80 else tool['description']
table.add_row(category, tool['name'], desc)
# 添加文件系统工具
for i, tool in enumerate(filesystem_tools):
category = "文件系统工具" if i == 0 else ""
desc = tool['description'][:80] + "..." if len(tool['description']) > 80 else tool['description']
table.add_row(category, tool['name'], desc)
# 添加系统工具
for i, tool in enumerate(system_tools):
category = "系统工具" if i == 0 else ""
desc = tool['description'][:80] + "..." if len(tool['description']) > 80 else tool['description']
table.add_row(category, tool['name'], desc)
console.print(table)
# 打印统计
total = len(user_tools) + len(filesystem_tools) + len(system_tools)
console.print(Panel(
f"[bold green]共计 {total} 个工具[/bold green]\n\n"
f"• 用户工具: {len(user_tools)} 个\n"
f"• 文件系统工具: {len(filesystem_tools)} 个\n"
f"• 系统工具: {len(system_tools)} 个",
title="统计信息",
border_style="green"
))
console.print()
# 调用打印函数,查看智能体加载的所有工具
print_agent_tools(agent)
执行上面的代码后,我们会看到一个完整的工具清单,包括:
- 1 个用户工具:
internet_search(我们自定义的) - 7 个文件系统工具:
ls,read_file,write_file,edit_file,glob,grep,execute - 2 个系统工具:
write_todos,task
这就是 DeepAgents 的核心设计理念:中间件堆栈(Middleware Stack)。当我们调用 create_deep_agent() 时,框架会自动为智能体注入多层中间件,每层负责不同的功能增强:
DeepAgents 中间件堆栈
| 中间件名称 | 提供能力 | 注入工具 |
|---|---|---|
| TodoListMiddleware | 任务规划 | write_todos |
| FilesystemMiddleware | 文件系统操作 | ls, read_file, write_file, edit_file, glob, grep, execute |
| SubAgentMiddleware | 子代理管理 | task |
| SummarizationMiddleware | 上下文压缩 | (自动工作,无需工具) |
| AnthropicPromptCachingMiddleware | 提示词缓存优化 | (自动工作) |
| PatchToolCallsMiddleware | 工具调用错误修复 | (自动工作) |
这种设计让我们只需关注业务逻辑(搜索工具),框架自动处理基础设施。其运行过程如下:
FENCE0
至此,相信大家已经非常清晰地明白了 DeepAgents 的能力构成。这种透明化的设计让我们能够精确控制智能体的行为边界。
最后,为了让调用更加简洁,我们封装一个 run_research() 函数。
def run_research(query: str):
"""
运行研究任务
参数:
query (str): 研究查询字符串
返回:
str: 研究结果
"""
print(f"开始研究: {query}")
print("=" * 60)
# 调用 agent.invoke() 执行任务
result = agent.invoke({
"messages": [
{"role": "user", "content": query}
]
})
print("\n" + "=" * 60)
print("智能体的最终响应:")
print("=" * 60)
print(result["messages"][-1].content)
return result["messages"][-1].content
现在提出一个真实的研究需求,观察DeepAgents的表现。
# 定义研究任务
query = "详细调研 DeepSeek 大模型的最新技术进展,并写一份结构化的总结报告。"
try:
# 执行研究
result = run_research(query)
print("\n研究任务完成!")
except Exception as e:
print(f"\n发生错误: {str(e)}")
raise
当我们执行上面的代码时,智能体会经历以下步骤(虽然我们看不到中间过程):
- 第 1 步:任务规划
智能体会调用 write_todos 工具,将任务分解为:
- 搜索 DeepSeek-v3.2 最新发展的资料
- 整理关键技术点
- 撰写结构化报告
- 第 2 步:信息搜索
调用 internet_search 工具,查询 "DeepSeek-v3.2 大模型 2025 最新进展" 等关键词。
- 第 3 步:信息管理
如果搜索结果内容很多,智能体可能会调用 write_file 保存中间结果到虚拟文件系统。
- 第 4 步:综合输出
读取保存的信息,结合 system prompt 的要求,生成结构化报告。
整个过程可能涉及10+ 次工具调用和 LLM 推理,但对用户来说是完全透明的。这就是深度代理的魅力——自主完成复杂任务。
当然,我们也给大家提供了直接运行的.py文件,大家可以在百度网盘中领取: