Google ADK 快速入门开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(秋招冲刺班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(秋招冲刺班)

《2025大模型Agent智能体开发实战》(秋招冲刺班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋招冲刺班)

两门大模型课程秋招冲刺班即将封班,直播间享五折特价+全套SVIP新班特定福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


《大模型Agent开发实战》(体验课)
Part 2. Google ADK 快速入门开发实战
Google Agent Development Kit是目前相较于其他Agent开发框架如LangGraph、AutoGen等,其设计理念最前沿的一个Agent开发框架,同时与OpenAI的Agents SDK框架相比,整体架构非常类似,但其模块化的程度更高,原生支持企业应用开发场景的组件也更多,综合来看,ADK框架是当前最值得推荐学习和使用的Agent开发框架,没有之一。
当我们想要使用ADK框架开发一个Agent应用时,一个基本的构建流程如下:
FENCE0
上述伪代码就是在ADK框架中,构建一个Agent应用的最简、且必备的五步流程。但这几行简单的代码调用其背后是有一套完整的事件驱动机制来支撑。
这里我们使用liteLLM接入DeepSeek模型,注意需要在同级目录下创建.env文件,并配置DS_API_KEY和DS_BASE_URL。同时,对于Agent的构建,我们使用最简模式,即只设置name和model。
# ! pip install litellm google-adk
注册一个 DeepSeek 的账号,并获取 API Key :https://platform.deepseek.com/api_keys
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
import os
from dotenv import load_dotenv
load_dotenv(override=True)
DS_BASE_URL = os.getenv("DEEPSEEK_API_BASE")
DS_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# 1. 通过 litellm 接入 DeepSeek 模型
model = LiteLlm(
model="deepseek/deepseek-chat",
api_base=DS_BASE_URL,
api_key=DS_API_KEY
)
# 2. 使用最简模式构建一个Agent代理
init_agent = Agent(
name="chatbot",
model=model,
instruction="你是一个乐于助人的中文助手。",
)
同样,因为session_service作为Runner的必填参数,我们这里先使用InMemorySessionService作为示例接入。
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
APP_NAME = "chatbot" # 手动定义应用名称
USER_ID = "user_1" # 手动定义用户ID
SESSION_ID = "session_001" # 手动定义会话ID
# 3. 创建内存会话缓存
session_service = InMemorySessionService()
# 4. 在内存中实际创建缓存数据
await session_service.create_session(app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID)
# 5. 创建Runner实例对象
runner = Runner(
app_name="chatbot",
agent=init_agent,
session_service=session_service
)
在Runner实例对象创建后,如果涉及运行启动,则需要调用其内部的方法,目前Runner类中提供的运行方法如下所示:
from google.genai import types
query = "你好,请你介绍一下你自己。"
# 将用户的问题转换为 ADK 框架的兼容格式
content = types.Content(
role='user',
parts=[types.Part(text=query)]
)
# 异步运行
async for event in runner.run_async(
user_id=USER_ID,
session_id=SESSION_ID,
new_message=content,
):
# 处理事件
print(event)
而如果要继续进行对话,并不需要我们手动去创建一些对话函数,只需要再次运行Runner,同时传递与上一次对话相同的user_id和session_id即可自动加载上一次的对话历史,并继续进行对话。
query = "我刚才问了你什么问题?"
# 将用户的问题转换为 ADK 格式
content = types.Content(role='user', parts=[types.Part(text=query)])
# 异步运行
async for event in runner.run_async(
user_id=USER_ID,
session_id=SESSION_ID,
new_message=content,
):
# 访问文本内容
if event.content and event.content.parts:
print(f"最终的响应结果为: {event.content.parts[0].text}")
这个执行过程并不复杂,只需要按照既定的规范依次定义SessionService和Runner实例对象,并调用Runner.run_async()方法即可快速在Google ADK框架中实现多轮对话。但其内部机制并不简单,我们接下来就快速的了解其架构的设计理念。
一、快速入门Google ADK框架
对新兴一代的Agent开发框架,其核心且必须具备的两个能力:其一是在构建Agent的时候能够灵活的赋予其工具调用/MCP Servers,其二是可以灵活的与其他Agent进行协作。 ADK 框架则是采用模块化设计,依次通过Agents模块、Tools模块、Sessions/State模块,以及回调与事件等组件构成的Runner模块来实现上述两个核心能力。
1.1 Google ADK 架构设计
我们可以先从官方提供的ADK架构图来了解一下ADK的架构设计。从宏观角度来看,在ADK框架的中一个会话的完整生命周期。如下图所示:(图片来源:https://google.github.io/adk-docs/runtime/#what-is-runtime )
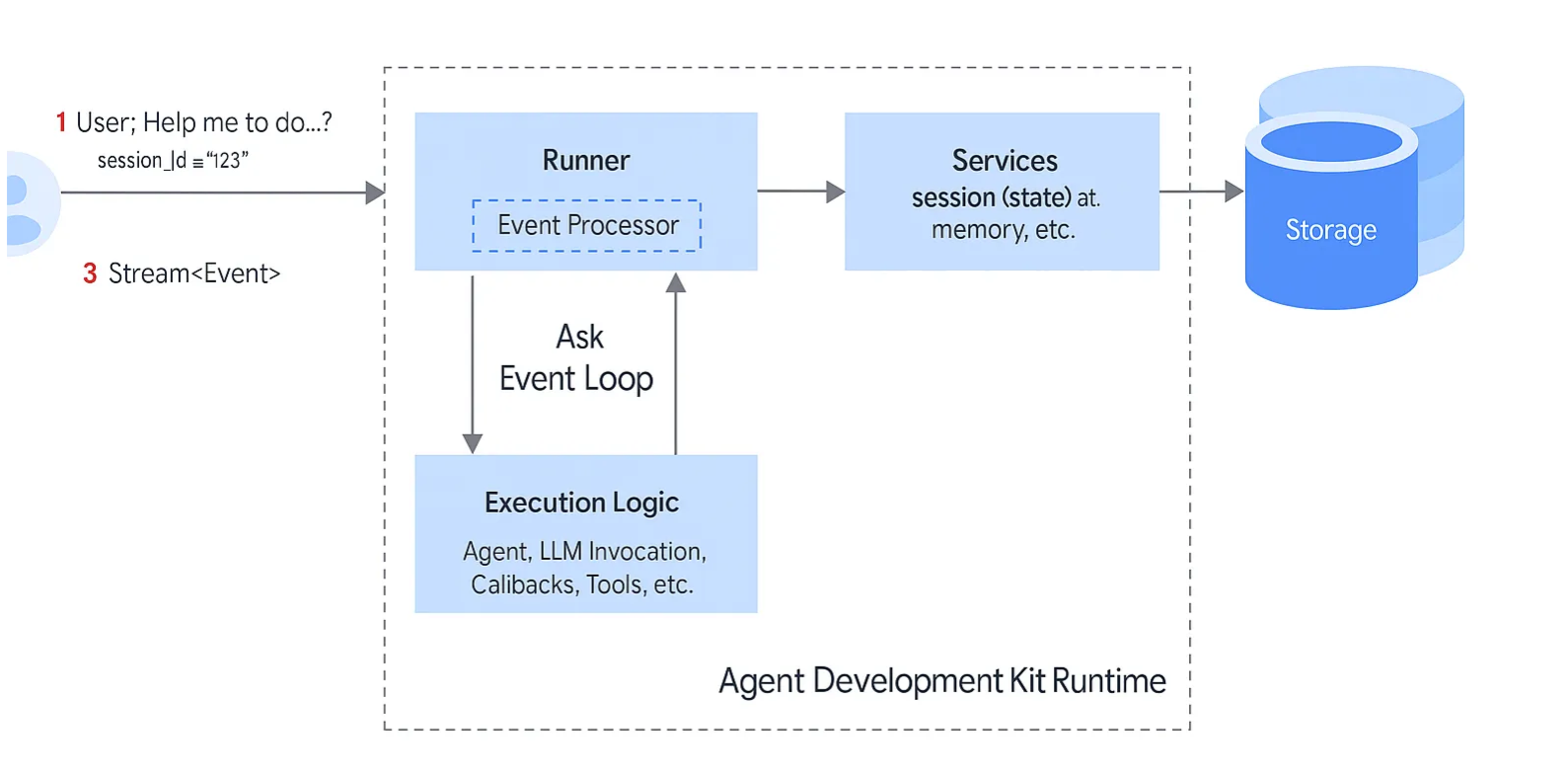
如上图所示,ADK 框架会将每一次与用户的交互过程抽象为一个会话 Session,并通过事件(Event)序列来驱动 Agent 生命周期。
Runner作为ADK 框架的运行管理模块,是让Agent能够“跑起来”的一个引擎。一个 Runner Processor 实例,(向左)接收用户输入并将其传递到Agent代理,(向右)与一个会话(Session)关联,管理该会话中从用户输入到Agent输出的整个过程。(向下)基于事件循环 (Event Loop) 运行,驱动 Agent 执行直到任务完成、调度处理执行过程中产生的事件,以及维护 Agent 执行的上下文与生命周期,这包括执行的工具调用、回调等之间的往返通信。
1.2 Agent 代理架构
ADK会在Agent组件的设计中,内置包含运行时状态,即接收用户的输入,并在内部处理生成最终的输入,或者调用外部工具的解析参数。同时也支持多种Agent对象类型,像LLM Agent 可以利用大模型根据指令和上下文动态决策下一步(包括是否使用工具或将任务转交其它 Agent),Workflow Agent可以按预定义流程执行,其子类包括顺序执行的 SequentialAgent、并行执行的 ParallelAgent、循环执行的 LoopAgent 等。
Google ADK中构建Multi-Agent系统并不复杂(复杂的是其底层的运行机制),ADK 将智能体抽象为 BaseAgent 基类,各个智能体通过共享信息协作完成任务。具体来说,ADK 通过会话状态 (Session State) 提供隐式数据传递机制,保证所有在同一会话/任务调用中的智能体可以共享一个 session.state 存储,前一个智能体可将处理结果写入 context.state['key'],后续智能体可读取该键值获取前置结果。除了状态共享,ADK 还通过事件 (Event) 机制报告每个智能体运行过程中的动作和结果,其他智能体通过监听这些事件来调整执行流程。此谓“LlmAgent” + 底层运行机制的协同。在这种协同机制下派生出几种不同的类型,即如下图所示:
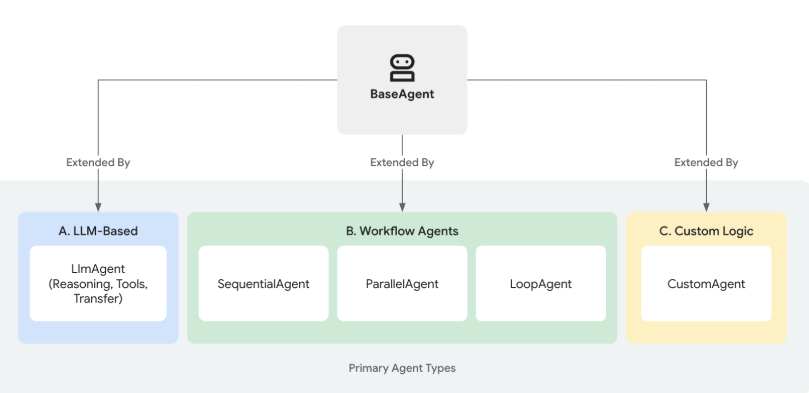
在 Google ADK 中,Agent 主要分为三类:LLM Agent、Workflow Agent和Custom Agent。这三类 Agent 各司其职,相互配合可构建复杂的应用。图片来源:https://google.github.io/adk-docs/agents/
LLM Agent:利用大模型对自然语言进行理解、推理和生成,能够动态决策下一步动作或调用何种工具;Workflow Agent:包含SequentialAgent、LoopAgent和ParallelAgent三种模式,不依赖大模型进行决策,而是按照预定义的流程执行其子Agent,确保可预测、可控制的执行路径;Custom Agent:通过继承BaseAgent并自定义其_run_async_impl执行逻辑,可以实现复杂的条件分支、外部系统调用或其他非标准流程。在内置的大模型/工作流模式无法满足需求时,可以选择编写自定义Agent;
核心区别可总结为:LLM Agent 非确定性、依赖 LLM 进行推理;Workflow Agent 确定性、依赖预设逻辑控制流程;Custom Agent 则灵活性最高,可实现独特流程。下表对比了三者的核心能力:
三种 Agent 类型对比
| Agent 类型 | 核心能力 | 驱动方式 | 执行特点 | 应用场景 |
|---|---|---|---|---|
| LLM Agent | 自然语言理解、推理与生成 | 大语言模型(LLM) | 非确定性,动态推理 | 对话生成、智能问答、工具调用、代码执行等 |
| Workflow Agent | 流程控制与任务编排 | 预定义逻辑结构 | 确定性,可预测 | 顺序处理(Sequential)、并行处理(Parallel)、迭代处理(Loop) |
| Custom Agent | 任意自定义逻辑与状态管理 | 自定义代码 | 灵活度最高,完全可控 | 复杂条件判断、动态流程、外部系统集成等 |
接下来我们就从LLM Agent 开始展开详细的介绍,同时也会结合特定的Agent实例重点讲解在ADK中关于工具调用、MCP接入,多代理协作等核心功能。
1.3 Session 会话管理
Session 表示用户与 Agent 的一次完整对话,用来存储用户与 Agent 的对话历史、当前对话的上下文、对话的配置信息、对话的运行时状态等。ADK实现了不同形式的Session,比如临时的内存存储以及持久化的数据库存储以满足不同的应用场景。
在业务场景中,一个Session对象可以简单的理解为一个独立的会话,这里我们以智谱清言 为例,如下所示:
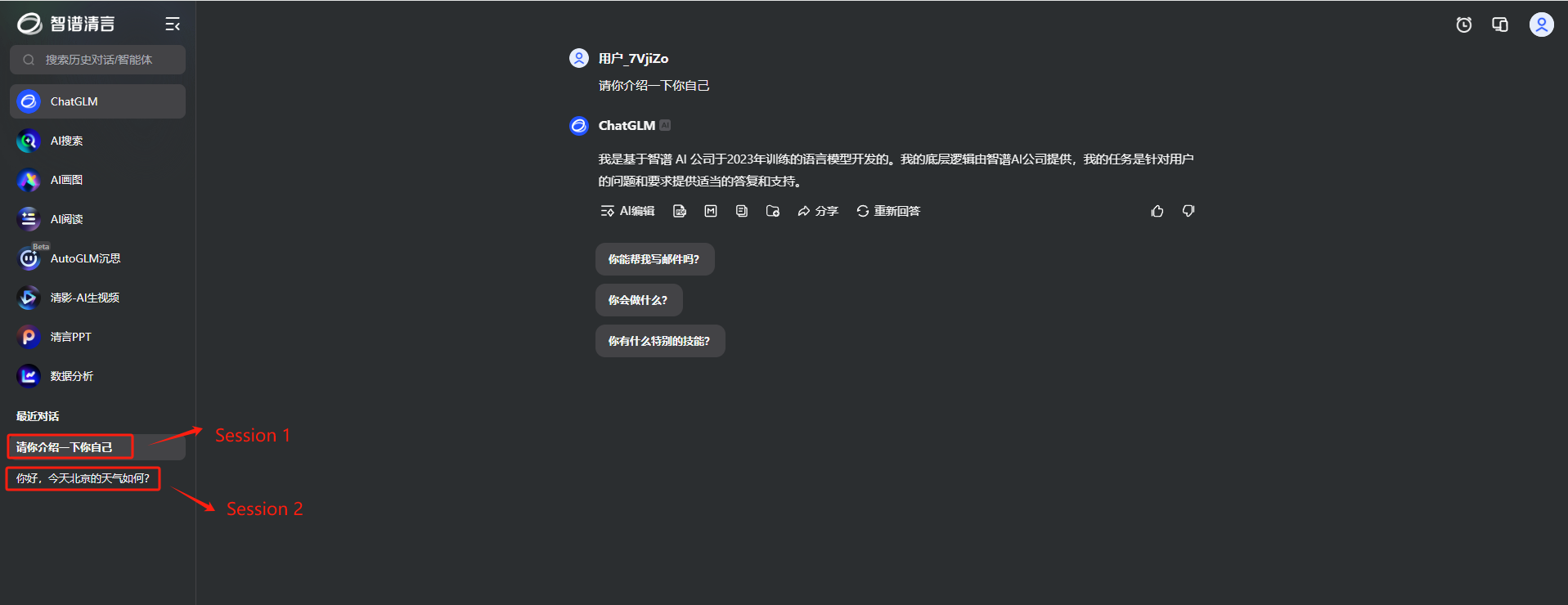
在每个独立的会话中(Session),都会包含特定的用户与代理之间的对话历史记录,以及代理的上下文等信息。这些信息则是通过Session对象的指定参数来进行管理。如下所示:
- id:对每个会话生成唯一的标识符,用于区分不同的会话。可以手动指定,如未手动指定,则会使用
uuid.uuid4()生成一个随机字符串作为Session ID; - app_name:应用的名称,用于区分不同的应用。比如一个应用产品中不仅包含普通对话功能,还包含知识库问答功能等,那么就可以通过
app_name来区分不同的功能模块,不同的功能模块彼此间的数据是隔离的,互不干扰; - user_id:用户的ID,用于区分不同的用户;主要是用来做用户级的状态管理,每个用户之间的对话信息是隔离的,互不干扰;
- events:会话的事件列表,比如用户的输入、大模型的响应、函数调用/响应等,其实就是一个历史会话列表。首次运行时为空列表,每当用户与代理进行一轮交互,就会根据交互的类型和内容生成相应的事件,不断地将事件追加进来;
- last_update_time:会话的最后更新时间,默认为0.0。每发生一次事件更新,就会更新一次。
1.4 Runner 运行组件
在 ADK 中,Runner是一个调度器,管理该会话中从用户输入到Agent输出的整个过程。核心职责包括:接收用户输入并将其引入 Agent、驱动 Agent 执行直到任务完成、调度处理执行过程中产生的事件,以及维护 Agent 执行的上下文与生命周期。而在调度过程中,是通过Event事件来驱动。Event是 ADK 中信息流通的基本单元,封装在对话过程中发生的各种内容:例如用户的提问消息、Agent 给出的回复、Agent 发出的工具使用请求(函数调用)、工具返回的结果、状态变化通知、控制信号以及错误信息等,因此大家可以简单理解为:ADK 框架是通过Runner 与 Event 的协作实现一个事件驱动的执行循环。
Runner 构造函数参数
| 参数名 | 类型 | 描述 | 必填/可选 |
|---|---|---|---|
app_name | str | 运行器的应用名称 | 必填 |
agent | BaseAgent | 要运行的初始代理 | 必填 |
artifact_service | Optional[BaseArtifactService] | 运行器的文件管理(可选) | 可选 |
session_service | BaseSessionService | 运行器的会话服务 | 必填 |
memory_service | Optional[BaseMemoryService] | 运行器的内存服务(可选) | 可选 |
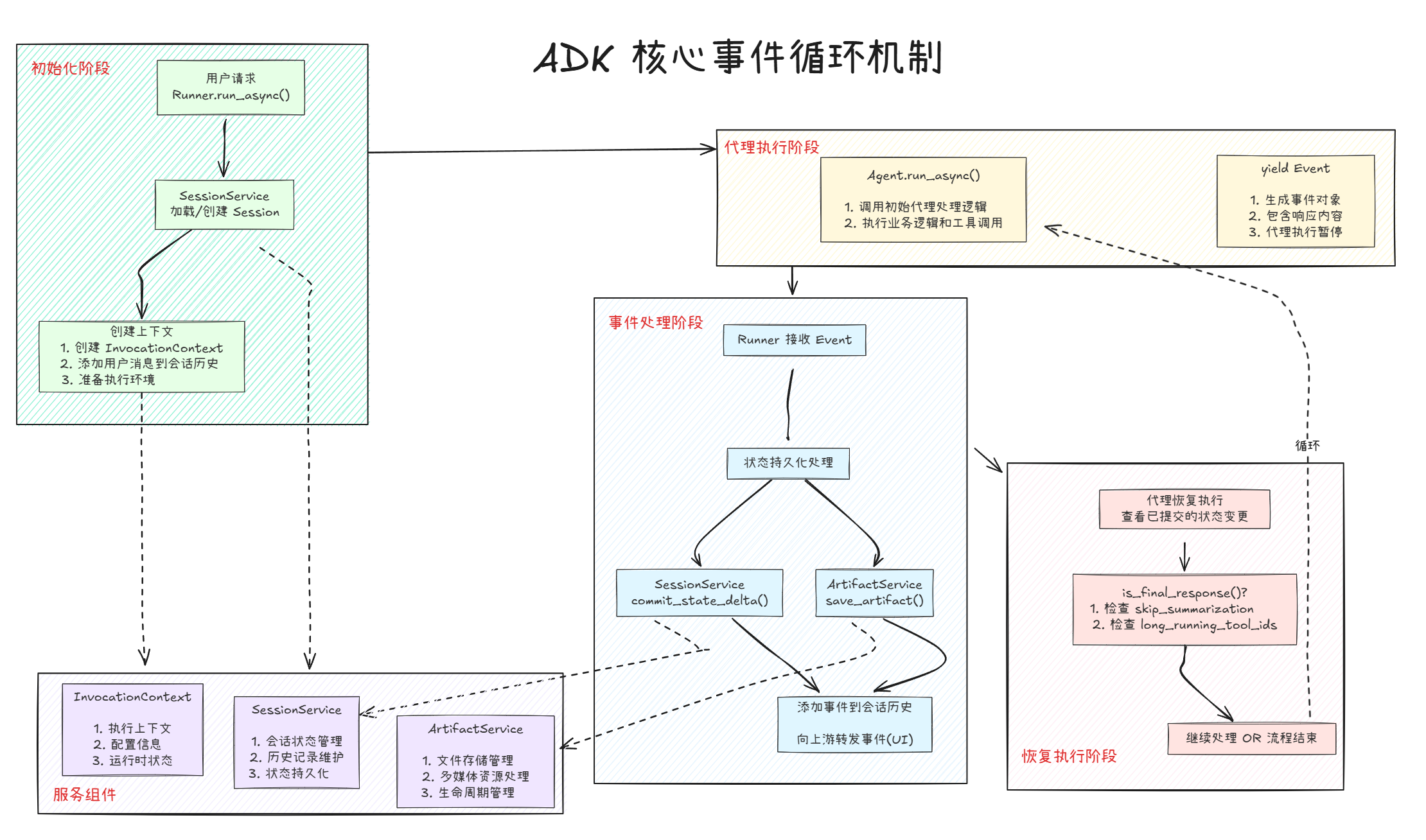
如上图所示,ADK(Agent Development Kit)采用高度模块化的事件循环机制来管理整个代理的执行流。其核心流程分为四个阶段:初始化阶段、代理执行阶段、事件处理阶段和恢复执行阶段,涵盖服务组件的数据流转。
首先,在初始化阶段,通过 Runner.run_async() 接收用户传递的请求,由 SessionService 加载或新建会话(Session),接着为本次请求创建执行上下文(InvocationContext),并把用户的输入消息添加到会话历史中,用于后续的对话过程,执行完以上流程后,进入正式的代理业务处理逻辑。
进入代理执行阶段后,会调用Agent代理的 run_async() 方法,正式进入业务逻辑处理。此过程中,代理会根据具体的业务推理和工具调用,动态地生成一个或多个 Event(事件)对象。每个 Event 代表代理推理的一个关键节点,事件中包含当前状态及响应内容,同时代理执行会在此阶段暂停,等待事件处理流程。
在事件处理阶段,Runner 会捕获代理产出的 Event。随后,系统会通过 SessionService.commit_state_delta() 将本轮的状态变更持久化,确保会话和流程状态得以保存;通过 ArtifactService.save_artifact() 将本次事件涉及的文件、媒资或其他工件(artifact)同步保存。同时,事件会被追加到会话历史当中,便于查询追溯,并可以向上游(如前端 UI)实时转发,实现可视化反馈和交互。
事件处理完成后,进入恢复执行阶段,代理会从暂停点恢复执行,继续后续推理和处理。此时,代理能够实时读取到所有已提交的状态变更,并以最新上下文为基础继续决策。系统会判断是否已经获得最终响应(通过 is_final_response() 检查),如果流程还未结束,则继续事件循环,直到所有流程节点处理完成。如果遇到特殊情况,例如需跳过总结或涉及长时间运行的工具调用,则会进入相应的分支逻辑进行处理。
从整体上理解,Runner 持续上述循环,直到 Agent 执行完毕不再产生事件。这种结构遵循典型的生产-消费循环模式,其中 Agent 是事件的生产者,Runner 是事件的消费者和处理者。同时,Runner 也充当任务调度器,通过协调 Agent 执行顺序、调用服务处理副作用、以及控制何时将结果输出或何时继续 Agent 执行,并且整个机制依赖于 InvocationContext、SessionService 和 ArtifactService 等服务组件的协同。InvocationContext 负责具体的执行上下文和参数配置,SessionService 负责会话级的状态管理和历史维护,ArtifactService 则负责文件、媒资及其他工件的全生命周期管理。通过事件驱动、状态持久化和工件管理三大核心服务组件实现高可扩展和高可靠的多轮对话及复杂业务流程。
理解了上述ADK的运行机制后,我们首先看Runner中run_async()方法的构造函数参数,如下所示:
run_async 构造函数参数
| 参数名 | 类型 | 描述 |
|---|---|---|
user_id | str | 会话的用户 ID |
session_id | str | 会话的 ID |
new_message | types.Content | 要添加到会话的新消息 |
run_config | RunConfig | 代理的运行配置(默认为 RunConfig()) |
其中user_id和session_id用于SessionService中会话的创建和维护。new_message是用户输入的消息内容,作用于InvocationContext中提供Agent执行过程中的上下文信息。而run_config是代理的运行配置,作为非必填参数用于更加灵活的控制Runner的运行配置。
1.5 Event 事件类型
事件(Event)是ADK中信息流的基本单元,承载代理交互生命周期中发生的每一次重要事件。在 ADK框架的设计模式中,事件驱动机制贯穿 Agent 执行的始终。Agent 的一切输出(无论是对用户的自然语言回答还是工具调用请求)都会被包装成 Event 并依次 yield 给 Runner 处理。Runner 对事件进行调度处理:例如,当 Event 指示需要调用某个工具时,Runner 会读取其中的 action 并实际调用相应工具函数,然后将工具执行结果再次封装为一个新的 Event供 Agent 后续处理。可以认为,每个 Event 就是一次 Agent 与外部环境(包括用户、工具和其他 Agent)的交互契机:它既携带了交互的内容,也携带了对框架的“请求”或“信号”。
事件流在系统中按顺序传递,例如,一个工具调用事件必须先由 Runner 完成工具执行并生成结果事件,Agent 才能继续推进自己的逻辑。通过这种事件调度机制,ADK 将智能体的连续对话过程离散化为一系列事件流,使得对话历史、状态演变和操作副作用都被显式地记录和管理。
从初始用户输入到最终响应,以及其间的所有步骤信息,包括:
- 内容载体:承载用户消息、模型回复、工具调用等,一切数据类型都以
Event类型流动; - 状态变更:通过
actions(事件行为)传递状态修改指令,比如状态发生了变更、代理发生了转移、执行持久化存储数据等; - 执行控制:控制代理的执行流程和转移,确定接下来运行哪个代理或循环是否应该终止;
- 元数据管理:记录事件的时间戳、来源、类型等,提供完整交互、按时间顺序排列的历史记录,用于逐步调试、审计和了解代理行为;
可以简单理解为:从用户的查询到代理的最终答案的整个过程都是通过 Event 对象的生成、解释和处理来协调的。
基础标识字段
| 参数名 | 类型 | 描述 |
|---|---|---|
invocation_id | str | 调用 ID,关联到特定的执行上下文 |
author | str | 事件作者:"user" 或代理名称 |
id | str | 事件唯一标识符(自动生成) |
timestamp | float | 事件时间戳(自动生成) |
author字段可以是user, 表示直接来自用户的输入。也可以是AgentName, 表示特定代理的输出或者操作。这里在ADK框架中匹配的就是用户消息事件,如下代码所示:
from google.adk.events import Event
# 用户输入
user_event = Event(
author="user",
content=types.Content(
role="user",
parts=[types.Part(text="你好,请帮我查询天气")]
)
)
print(f"用户消息事件的作者为:{user_event.author}")
print(f"用户消息事件id为:{user_event.id}")
print(f"用户消息事件时间戳为:{user_event.timestamp}")
在Part类型中,通用的内容主要关注的如下三个方面:
- text: 表示对话消息;
- function_call:表示是否存在工具调用请求,如果存在,内部会包含
.name和.args参数; - function_response:表示工具调用结果,如果存在,内部会包含
.name和.resonse参数;
因此,对于内容标识字段,在ADK框架中匹配的就是代理响应事件,如下代码所示:
# 代理文本响应
agent_event = Event(
author="weather_agent",
content=types.Content(
role="model",
parts=[types.Part(text="我来帮您查询天气信息")]
)
)
user_event
print(f"代理响应事件的作者为:{agent_event.author}")
print(f"代理响应事件内容为:{agent_event.content.parts[0].text}")
print(f"代理是否存在执行工具:{agent_event.content.parts[0].function_call}")
如果代理响应涉及工具调用,则function_call字段会存在,其对应的是工具调用事件,如下代码所示:
# 工具调用
tool_call_event = Event(
author="weather_agent",
content=types.Content(
role="model",
parts=[types.Part(
function_call=types.FunctionCall(
name="get_weather",
args={"city": "北京"}
)
)]
)
)
print(f"代理响应事件的作者为:{tool_call_event.author}")
print(f"代理响应事件内容为:{tool_call_event.content.parts[0].text}")
print(f"代理是否存在执行工具:{tool_call_event.content.parts[0].function_call}")
print(f"代理执行工具的结果为:{tool_call_event.content.parts[0].function_response}")
大模型函数调用的标准流程,是由大模型根据用户的输入意图,在工具列表中选择匹配的工具并根据该工具的Json Schema表示生成对应的参数,实际的去执行该工具,并将执行结果返回给大模型后,大模型才能继续根据执行结果进行后续的推理。因此,这里匹配的是工具响应事件。如下代码所示:
from google.genai.types import FunctionResponse
tool_response_event = Event(
author="weather_agent",
content=types.Content(
role="tool", # 工具响应角色是 tool
parts=[types.Part(function_response=types.FunctionResponse(name="get_weather", response={"temperature": "25°C", "condition": "晴天"}))]
),
)
print(f"代理响应事件的作者为:{tool_response_event.author}")
print(f"代理响应事件内容为:{tool_response_event.content.parts[0].text}")
print(f"代理是否存在执行工具:{tool_response_event.content.parts[0].function_call}")
print(f"代理执行工具的结果为:{tool_response_event.content.parts[0].function_response}")
比如对于函数调用事件来说,就是需要通过EventActions中的state_delta字段来更新执行外部工具后返回的实时数据,因此代码如下所示:
from google.adk.events import EventActions
state_update_event = Event(
author="weather_agent",
content=types.Content(
role="tool ", # 工具响应角色是 tool
parts=[types.Part(function_response=types.FunctionResponse(name="get_weather", response={"temperature": "25°C", "condition": "晴天"}))]
),
actions=EventActions(
state_delta={
"last_query_city": "北京",
"last_query_time": "2025-05-28 15:00:00"
}
)
)
print(f"代理响应事件的作者为:{state_update_event.author}")
print(f"代理响应事件内容为:{ state_update_event.content.parts[0].text}")
print(f"代理是否存在执行工具:{state_update_event.content.parts[0].function_call}")
print(f"代理执行工具的结果为:{state_update_event.content.parts[0].function_response}")
print(f"代理执行工具的状态更新为:{state_update_event.actions.state_delta}")
以上就是在ADK框架中,一个包含工具调用的Agent的完整执行。所有组件间通信都通过 Event 进行, 通过 actions.state_delta 实现状态的原子性更新(要么状态更新成功并被持久化,要么更新失败,状态保持不变), 以及通过 is_final_response() 明确回合边界。
FENCE0
以上是我们结合ADK的设计理念构造的分布执行流程,相信大家已经对ADK中的不同事件有了相对清晰的理解。现在再来看run_async方法执行Agent时,其实就是通过这个方法自动生成上述Event事件并进行处理。
所以当我们了解了ADK中的事件类型,自然就可以非常清晰且准确的提取和访问Runner过程中不同Event产生的相关数据。
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
import os
from dotenv import load_dotenv
load_dotenv(override=True)
DS_API_KEY = os.getenv("DS_API_KEY")
DS_BASE_URL = os.getenv("DS_BASE_URL")
model = LiteLlm(
model="deepseek/deepseek-chat",
api_base=DS_BASE_URL,
api_key=DS_API_KEY
)
init_agent = Agent(
name="chabot",
model=model,
instruction="你是一位乐于助人的智能助手,请根据用户的问题给出最合适的回答。"
)
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
APP_NAME = "chatbot"
USER_ID = "user_1"
SESSION_ID = "session_001"
session_service = InMemorySessionService()
await session_service.create_session(app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID)
runner = Runner(
app_name="chatbot",
agent=init_agent,
session_service=session_service
)
from google.genai import types
query = "你好,请你介绍一下你自己。"
# 将用户的问题转换为 ADK 格式
content = types.Content(role='user', parts=[types.Part(text=query)])
# 异步运行
async for event in runner.run_async(
user_id="user_1",
session_id="session_001",
new_message=content,
):
print(f"当前事件来自: {event.author}")
# 访问文本内容
if event.content and event.content.parts:
print(f"当前事件内容为: {event.content.parts[0].text}")
1.6 消息类型格式
这里的一个关键点是new_message,其类型为types.Content,其源码定义如下:
FENCE0
这里的Types是 Google ADK框架中的类型定义,用于表示消息序列的类型。正常对于OpenAI Chat API 标准格式下消息对话形式是这样的:
FENCE0
GPT Vs Gemini
| 特性 | OpenAI GPT 模型 | Google Gemini 模型 |
|---|---|---|
| 消息格式 | 结构化消息序列(system、user、assistant、tool) | 数组形式的消息(contents 数组,包含 role 和 parts) |
| 输出格式控制 | 通过 system 消息设定行为 | 通过 responseSchema 配置输出格式 |
| 多模态支持 | 支持(如 GPT-4o) | 原生支持(文本、图像、音频等) |
| 集成方式 | 通过 OpenAI API 或 Azure OpenAI 服务 | 通过 Vertex AI 或 Google Gen AI SDK |
二、Google ADK 接入外部工具
在Google ADK中,LlmAgent 的工具接入规范如下图所示:
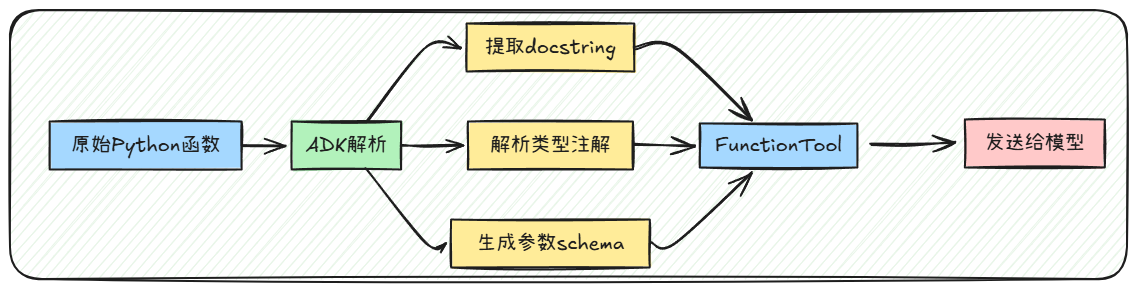
Google ADK 框架下创建Agent 时,可以通过tools 参数来添加工具,这里与其他框架不同的是:在ADK 框架中,可以直接将一个普通的Python函数添加到tools 参数中,ADK 会自动将其封装为FunctionTool,并不需要通过类似@tool 的装饰器来进行转化。比如我们定义两个普通的函数用来进行快速的测试:
from datetime import datetime
import psutil
import platform
# 实际有用的工具函数
def get_current_datetime() -> str:
"""获取当前精确的日期和时间,包括毫秒。"""
now = datetime.now()
return now.strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
def get_system_info() -> str:
"""获取当前系统的详细信息,包括CPU、内存使用率等。"""
try:
cpu_percent = psutil.cpu_percent(interval=1)
memory = psutil.virtual_memory()
disk = psutil.disk_usage('/')
info = f"""系统信息:
- 操作系统: {platform.system()} {platform.release()}
- CPU使用率: {cpu_percent}%
- 内存使用率: {memory.percent}% ({memory.used // (1024**3)}GB / {memory.total // (1024**3)}GB)
- 磁盘使用率: {disk.percent}% ({disk.used // (1024**3)}GB / {disk.total // (1024**3)}GB)
- Python版本: {platform.python_version()}"""
return info
except Exception as e:
return f"获取系统信息时出错: {str(e)}"
# 将函数直接添加到 Agent 的工具列表
capital_agent = Agent(
name="chatbot",
model=model,
instruction="你是一个多功能的助手,可以调用外部工具获取当前的日期和时间,以及系统的详细信息。",
tools=[get_current_datetime, get_system_info] # ADK 会自动封装此函数为 FunctionTool
)
接下来执行运行测试,看看效果如何。
# 创建会话
session = await session_service.get_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID,
)
# 创建 Runner 对象实例
runner = Runner(
agent=capital_agent,
app_name=APP_NAME,
session_service=session_service
)
# 创建用户消息
query = "现在几点了?"
content = types.Content(role='user', parts=[types.Part(text=query)])
# 运行
async for event in runner.run_async(user_id=USER_ID, session_id=SESSION_ID, new_message=content):
print(f"当前事件来自: {event.author}")
# 访问文本内容
if event.content and event.content.parts:
# 如果事件中存在工具调用,则打印执行的工具和参数
if event.get_function_calls():
print(f"需要执行外部工具:")
for call in event.get_function_calls():
tool_name = call.name
arguments = call.args
print(f" 执行的工具是: {tool_name}, 传递的参数是: {arguments}")
# 如果存在工具调用且工具调用成功,则打印工具调用的结果
if event.get_function_responses():
print(f"工具调用成功:")
for response in event.get_function_responses():
print(f" 工具:{response.name} 调用的结果是: {response.response}")
elif event.content.parts[0].text:
print(f"最终响应: {event.content.parts[0].text}")
通过Event事件类型的打印能够清晰的看到,LlmAgent在执行过程中是先执行的get_current_datetime函数获取到当前的时间才生成最终的响应。同样可以进行另一个工具的测试:
# 创建会话
session = await session_service.get_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID,
)
# 创建 Runner 对象实例
runner = Runner(
agent=capital_agent,
app_name=APP_NAME,
session_service=session_service
)
# 创建用户消息
query = "帮我获取一下系统信息"
content = types.Content(role='user', parts=[types.Part(text=query)])
# 运行
async for event in runner.run_async(user_id=USER_ID, session_id=SESSION_ID, new_message=content):
print(f"当前事件来自: {event.author}")
# 访问文本内容
if event.content and event.content.parts:
# 如果事件中存在工具调用,则打印执行的工具和参数
if event.get_function_calls():
print(f"需要执行外部工具:")
for call in event.get_function_calls():
tool_name = call.name
arguments = call.args
print(f" 执行的工具是: {tool_name}, 传递的参数是: {arguments}")
# 如果存在工具调用且工具调用成功,则打印工具调用的结果
if event.get_function_responses():
print(f"工具调用成功:")
for response in event.get_function_responses():
print(f" 工具:{response.name} 调用的结果是: {response.response}")
elif event.content.parts[0].text:
print(f"最终响应: {event.content.parts[0].text}")
三、Google ADK 流式输出实战
Google ADK 中实现流式输出只需要监测Event事件中的partial字段,即可实时的提取到增量产生的Token。当然,默认对于run_async方法是不开启流式输出功能的,我们需要在配置Runner时,通过RunConfig指定流式输出的模式。目前ADK支持指定两种流式化输出模式,分别是:SSE 和 BIDI (Bidirectional)
其中SSE 模式是使用标准的Server-Sent Events协议,单向的服务器向客户端发送流式数据,主要用于文本内容的逐步发送。而BIDI (Bidirectional) 模式是使用WebSocket协议实现双向通信,双向的客户端和服务器可以同时发送数据。但是目前通过LiteLlm接入的模型还不支持BIDI模式。只有使用Google的Gemini模型(google_llm.py)才能够进行使用。其配置方法如下所示:
FENCE0
这里大家可以通过stream_event.py文件查看完整的实现逻辑。其运行效果如下图所示:
FENCE0
同时,也基于ADK的流式接口封装了FastAPI接口,大家可以直接进行启动并通过Http Request进行服务访问。具体实现代码文件为stream_api.py。
四. Google ADK 接入 MCP 开发实战
从Google ADK的应用生态来看,该框架目前完全遵循 Model Context Protocol (MCP) 标准,支持Stdio、HTTP+SSE传输及Streamable HTTP三种传输协议的接入支持。如下表所示:
ADK 支持的 MCP 通信方式及对应实现
| 通信方式 | MCP 标准描述 | ADK 实现与配置 |
|---|---|---|
| Stdio | 客户端以子进程方式启动MCP服务器,通过 stdin/stdout 交换 JSON-RPC 消息。 | ADK 使用 StdioServerParameters,在 MCPToolset 中指定要运行的命令和参数,启动本地MCP服务器并通过标准IO通信。 |
| HTTP + SSE | 服务器独立运行,客户端通过HTTP POST发送请求,通过 SSE (HTTP GET) 建立长连接接收服务器推送的消息(需要两个端点)。 | ADK 使用 SseServerParams,提供远程 SSE 端点的 URL 及认证头等配置,实现与远程 MCP 服务的双通道通信。 |
| Streamable HTTP | 单一HTTP端点同时处理请求和响应的新协议(2025年推出),服务器通过一个端点即可接受请求并以流式方式返回多条消息,可选地使用 SSE 格式发送多部分响应。 | ADK 使用 StreamableHTTPConnectionParams(Python ADK)来连接支持 Streamable HTTP 的 MCP 服务器,以单端口方式进行交互(此为远程MCP的新推荐传输方式)。 |
在接入形式上,ADK 提供了统一的机制将 MCP 工具接入到Agent实例中,核心组件就是 MCPToolset 类。
MCPToolset 是 ADK 中用于与 MCP 服务器交互的核心类。该类中实现的核心功能就是将MCP实例加入Agents的 tools 列表后,便可连接 MCP 服务器、发现其工具并将这些工具适配为 ADK 工具。同时,根据不同的MCP通信协议,利用 MCPToolset 可以通过传递不同的连接信息connection_params 来实现不同的通信方式。如下图所示:
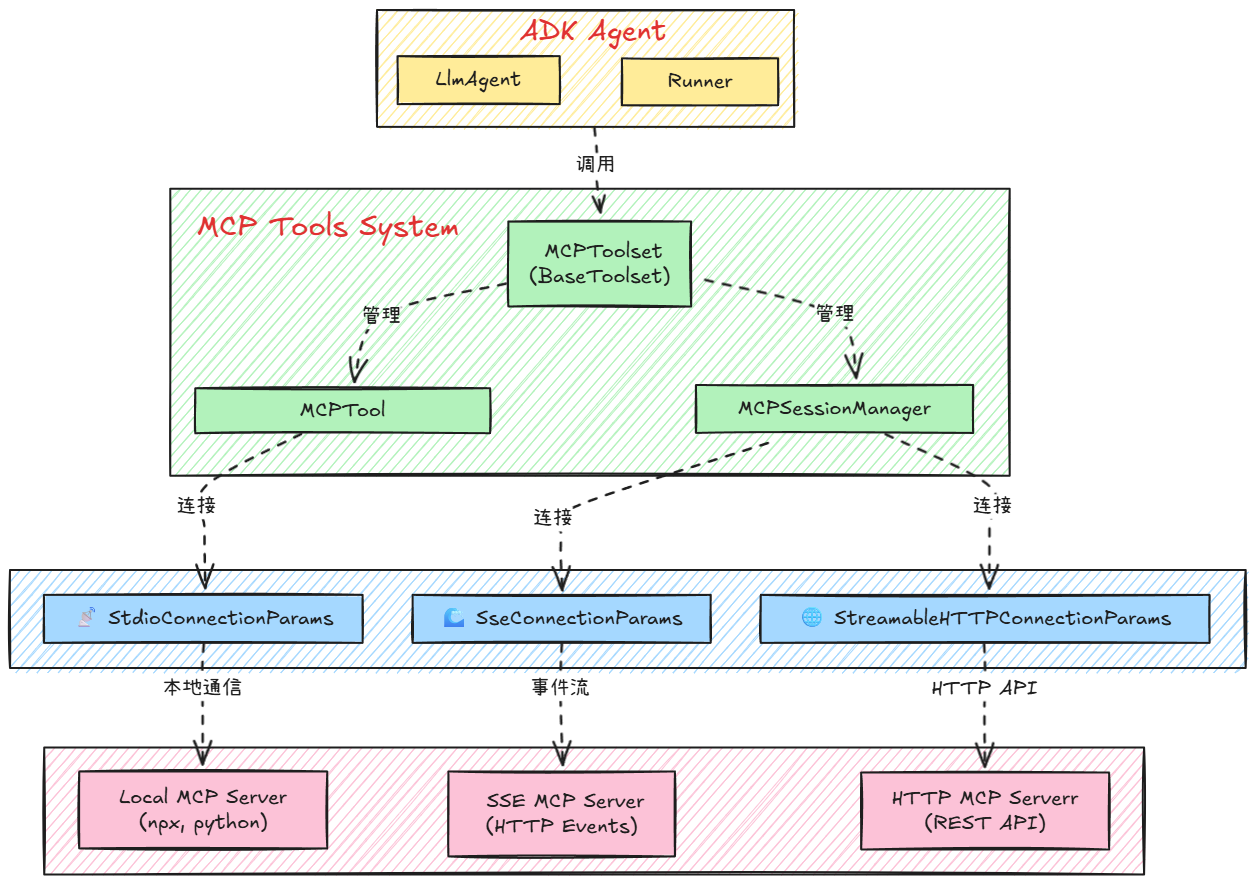
无论选择哪种连接方式,都可以通过统一的内置功能来实现与MCP服务器的交互,包含如下几个方面:
MCPToolset 功能
| 特征 (Feature) | 描述 |
|---|---|
连接管理 (Connection Management) | 支持 stdio、SSE 和 Streamable HTTP 方式连接 MCP 服务器 |
工具发现 (Tool Discovery) | 自动发现 MCP 工具并包装为 ADK 工具 |
工具过滤 (Tool Filtering) | 支持按名称或自定义条件过滤工具 |
身份验证 (Authentication) | 支持多种工具调用的身份验证方案 |
资源清理 (Resource Cleanup) | 自动管理连接的清理和资源释放 |
- 连接管理:
MCPToolset在初始化时建立与MCP服务器的连接,支持本地进程通信(StdioServerParameters)或远程SSE/HTTP连接(SseServerParams、StreamableHTTPConnectionParams),并在代理退出时会优雅地关闭连接; - 工具发现与适配:
MCPToolset调用list_tools方法从服务器获取工具列表,并将MCP工具模式转换为ADK的BaseTool实例,适配后的工具在代理中表现为本地工具,代理可直接调用,当代理调用这些工具时,MCPToolset会将请求转发给MCP服务器并返回结果; - 工具过滤:可通过
tool_filter指定要暴露的工具子集,避免将所有远程工具暴露给代理。
将MCP工具转化成ADK支持的工具类型的转化过程依次包括:先从 MCP JSON 模式到 ADK 内置函数声明的模式转换,再从 ADK 内置函数声明的模式到 ADK 的 BaseTool 实例,同时支持身份验证标头提取和管理,以及自动感知工具执行,在连接失败时会自动重试。
Google ADK与外部MCP服务进行交互时在会话管理、工具发现与适配、身份验证、资源清理等方面的实现原理。在这种模式下,我们需要重点了解的是,ADK 框架与 MCP 实现的是双向的交互模式,即ADK 可以作为 MCP 的客户端,也可以作为 MCP 的服务端。即:
-
作为
MCP客户端使用现有服务器:ADK代理通过MCPToolset访问外部MCP服务器提供的工具。这是最常见的方式,适合需要利用第三方能力的代理。例如,利用文件系统、谷歌地图、GitHub 等MCP服务器提供的功能。 -
将
ADK工具暴露为MCP服务器:开发者可用ADK+mcp/fastmcp库创建MCP服务器,将ADK工具包装并公开给其他MCP客户端。这种模式用于将自定义工具分享给更广泛的生态。
本节课,我们主要围绕ADK作为客户端接入外部MCP服务器的场景展开介绍。
目前主流MCP的使用形式可以归纳为两大类:自托管启动与平台托管直连。
- 自托管启动(Self-hosted)
这种方式主要是应用MCP官方的Python / TypeScript MCP SDK 把 Server 代码跑起来(FastAPI / Express 集成), 程序启动后会打印或返回一个本地或内网 SSE URL,然后便可以用这个 URL 建立事件流接入到OpenAI Agents SDK 框架中。如果需要使用MCP 官方的Python SDK构建SSE 模式的MCP 服务器,可以学习《【加餐】MCP SSE与流式HTTP开发实战】》课程模块,我们这里不再重复讲解。
- 平台托管直连(Platform-hosted)
诸如 ModelScope的 MCP 广场 、mcp.run 等社区维护大量 MPC 服务并支持一键启动MCP的SSE 模式。使用的方法非常简单,只需要在平台首页选好MCP Server → 生成一个API-Key,一键生成 SSE URL ,即可直接接入使用。
对于国内开发者,通过“一键复制 URL + API-Key”就能拿到 SSE 端点的热门网站大致可以分为四类:
- 专门的 MCP 服务市场/目录(如 MCP Market、AIbase、MCP Server Hub);
- 云厂商推出的 官方托管平台(阿里云 “百炼” 与 Higress Marketplace);
- 行业 API 已内置 MCP & SSE(百度地图、腾讯位置服务等);
- IDE / 客户端集市 把第三方 SSE URL 聚合到本地(Cherry Studio、Cursor)。
MCP 热门导航网站
| 平台 | 规模与特点 | 访问链接 |
|---|---|---|
| ModelScope MCP 广场 | 超过 3000+ 个中文托管 MCP;详情页右侧直接复制 SSE URL,部分服务需在“API Key”栏目填 Token | 点击进入 |
| MCP Market | 标榜“国内首个 MCP 服务市场”,已收录 1W+ SSE Server,并提供云托管与 Playground,一键生成专属 URL | 点击进入 |
| AIbase MCP 资源站 | 整理 GitHub 上的热门 MCP Server 并直接给出 SSE 地址与使用教程 | 点击进入 |
| MCP Server Hub | 国际化,标签筛选 + “Copy URL” 操作流畅,站内统计数千条 SSE Server | 点击进入 |
| 阿里云 百炼 | 官方托管“全周期 MCP 服务”,控制台能生成已鉴权的 SSE URL | 点击进入 |
Streamable HTTP 是 MCP (Model Context Protocol)在 2025-03-26 版规范中新引入的远程传输机制。该通信模式下可以用「同一个 HTTP 端点同时支持 POST + GET」取代了旧的「POST + SSE 双端点」模式,使客户端和服务器可以在一次 POST 里把 JSON-RPC 请求发过去,服务器必要时再把连接“升级”为 SSE 流,把多条响应、进度或反向请求实时推送回来。这让远程 MCP 服务器不必保持长连接,天然适合无状态 / Serverless 部署,也能与旧 SSE 模式共存。是目前效率最高,且最适用于企业环境下的通信模式。
在Google ADK框架下,StreamableHTTP 的通信方式借助于StreamableHTTPConnectionParams来实现,StreamableHTTPConnectionParams 一共只有五个参数属性,如下所示:
StreamableHTTPConnectionParams 参数
| 参数 | 类型 / 默认值 | 说明 | 常见用法示例 |
|---|---|---|---|
url | str (必填) | MCP SSE 服务器的 URL 地址 | "http://localhost:8000/mcp" |
headers | dict[str, Any] | None | MCP SSE 连接的请求头 | {"Authorization": "Bearer token"} |
timeout | float = 5.0 | 建立连接到 MCP SSE 服务器的超时时间(秒) | 10.0 |
sse_read_timeout | float = 300.0 | 从 MCP SSE 服务器读取数据的超时时间(秒) | 600.0 |
terminate_on_close | bool = True | 当连接关闭时是否终止 MCP 会话 | True |
StreamableHTTPConnectionParams 用于告诉 ADK 如何连接 MCP Streamable HTTP 服务器(单端点同时处理请求与 SSE 流)。参数与旧的 SseServerParameters 基本一致,但多了 terminate_on_close,这是 Streamable HTTP 独有的参数,控制当客户端断开连接时是否要求服务器端终止,以配合新版传输层的会话管理。具体协议细节可以参考:https://modelcontextprotocol.io/specification/2025-03-26/basic/transports ,我们这里不展开说明。
目前已经有越来越多的公开MCP Server 均支持Streamable HTTP通信模式,对于这类通信模式下的MCP Server其本质与Http + Sse通信模式下的MCP Server使用方法一样,我们依然需要先在本地服务器是启动MCP服务,然后通过StreamableHTTPConnectionParams来连接到MCP服务。
获取Firecrawl的MCP服务,可以参考:https://modelscope.cn/mcp/servers/@mendableai/firecrawl-mcp-server
获取Friework的API_KEY 地址:https://www.firecrawl.dev/app/api-keys
FENCE0
运行效果如下图所示:

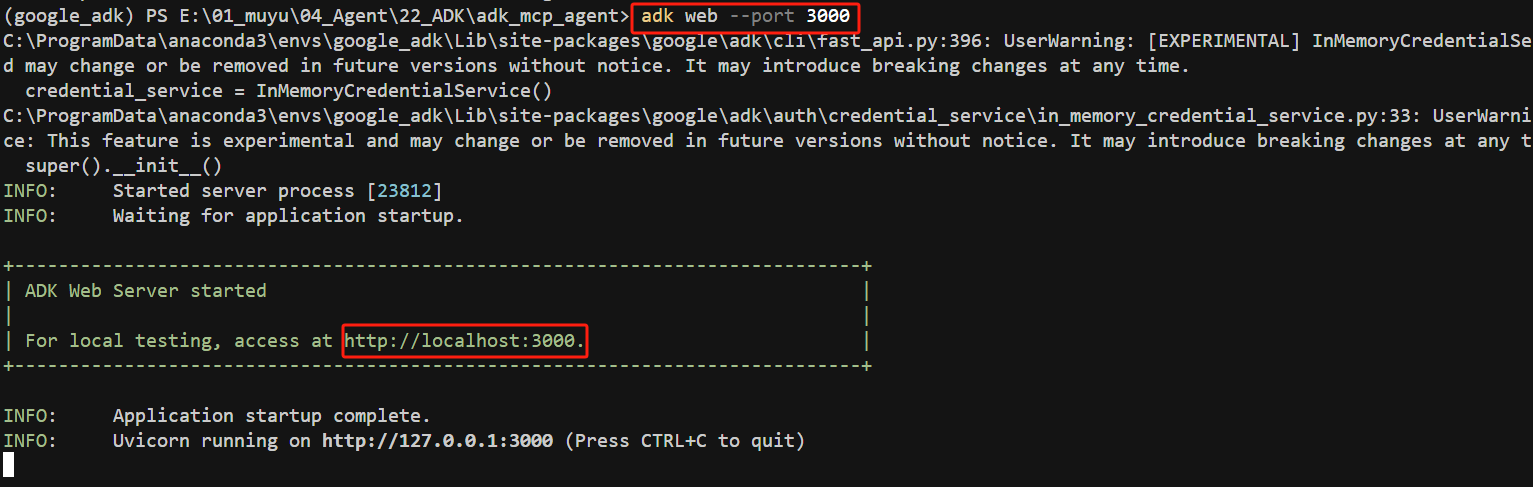
启动后,我们就可以通过StreamableHTTPConnectionParams来连接到MCP服务。具体的应用代码在adk_mcp_agent文件夹中的streamablehttp_agent文件夹中的agent.py文件中。同时需要注意的是:因为amap-mcp-server的服务器端口也是8000, 而adk web 的默认端口也是8000,所以可以通过--port 参数指定adk web的端口。如下所示:
FENCE1
启动后,我们就可以通过http://localhost:3000 访问adk web的界面。
在adk web的界面中,选择streamablehttp_agent,并进行测试。效果如下图所示:
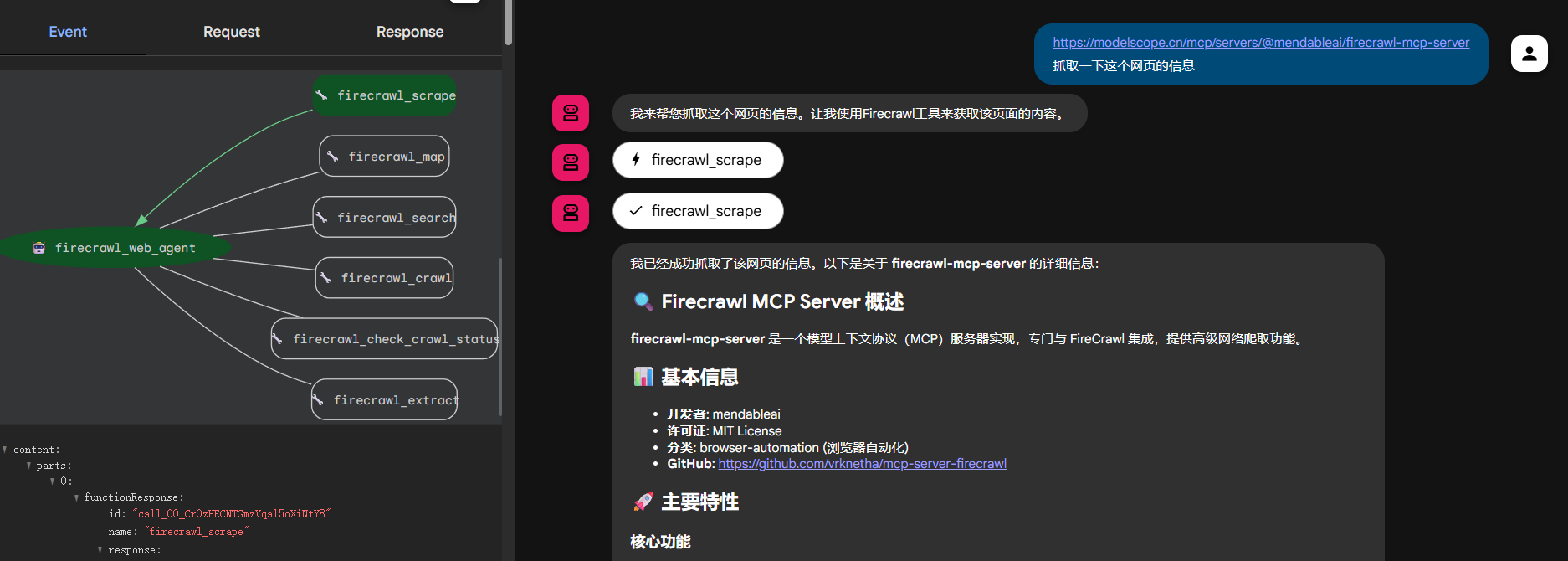

以上就是接入Streamable HTTP通信模式下的MCP Server的全部流程。对于多个MCP Server的接入也是一样,只需要在tools参数列表中添加多个MCPToolset即可。大家可以自行尝试。当然我们在课程后面的案例中也会涉及更多Multi-MCP的接入实战
对于Agent 接入MCP 的性能瓶颈,主要来源于传输协议的选择、工具元数据的体积、模型上下文膨胀及服务器启动与复用策略几个方面。如果采用stido模式,每次随代理进程一起启动,就会在首次调用时阻塞 0~N秒,复杂服务时间更长,这个冷启动的开销是很大的。此外,采用HTTP + Sse模式,虽然可以避免冷启动问题,但每次调用时都需要建立连接,一次list_tools就会把几十个工具、上百行的Json Schema都塞进上下文,直接加重token响应延时等多种情况。所以目前比较高效的就是Streamable HTTP模式 + 针对性的优化策略。