基于LangChain1.0搭建NL2SQL数据分析系统
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(11月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(11月班)

《2025大模型Agent智能体开发实战》(11月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
11月班 · 重磅新增


11月班 · 重磅新增14项实战案例

完整课程介绍

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由九天老师亲自带队主讲的《大模型强化学习实战》(全网首发)


大模型11月班·双十一抢先购,直播间特惠进行时,直播间享五折特价+全套SVIP新班特定福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

《大模型Agent开发实战》(体验课)
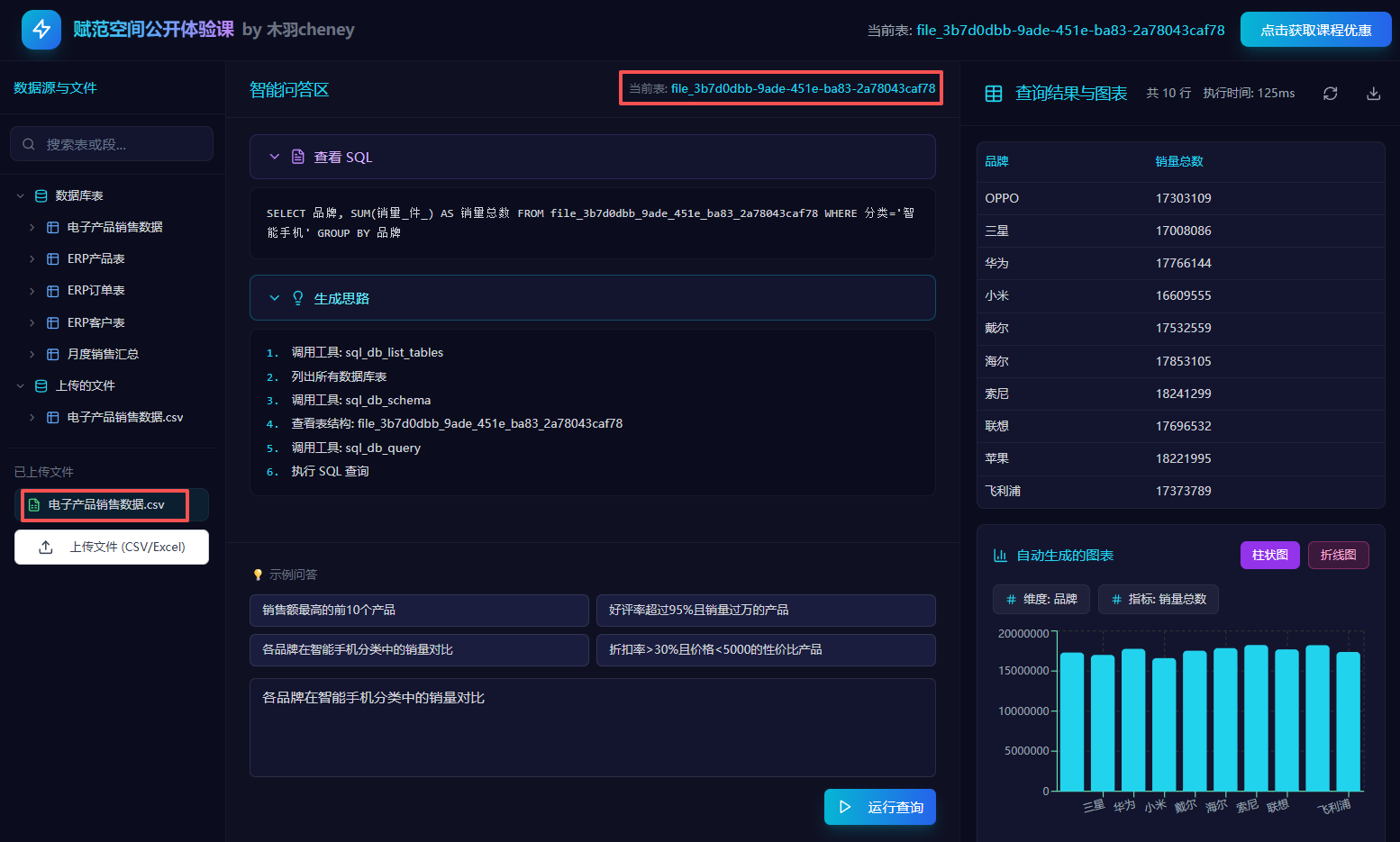
基于LangChain1.0搭建NL2SQL数据分析系统
让数据分析像聊天一样简单
本期公开课,我们将从零开始,手把手带大家搭建一个以NL2SQL技术为核心的SQL编程Agent数据分析系统。
- SQL编程Agent数据分析系统功能介绍
核心功能一:支持连接本地/云端的数据库,并选择数据库中的表,进行自然语言提问;
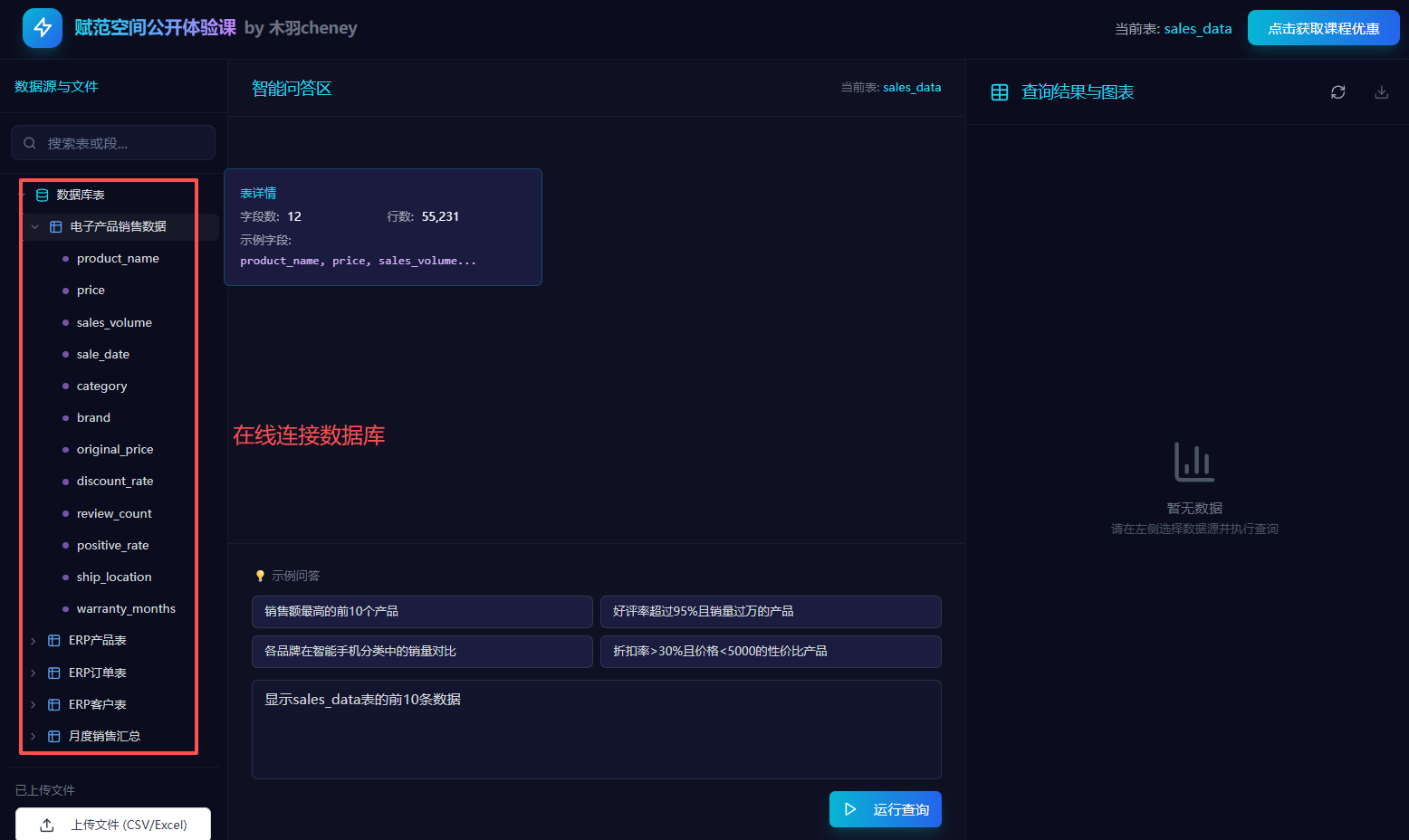
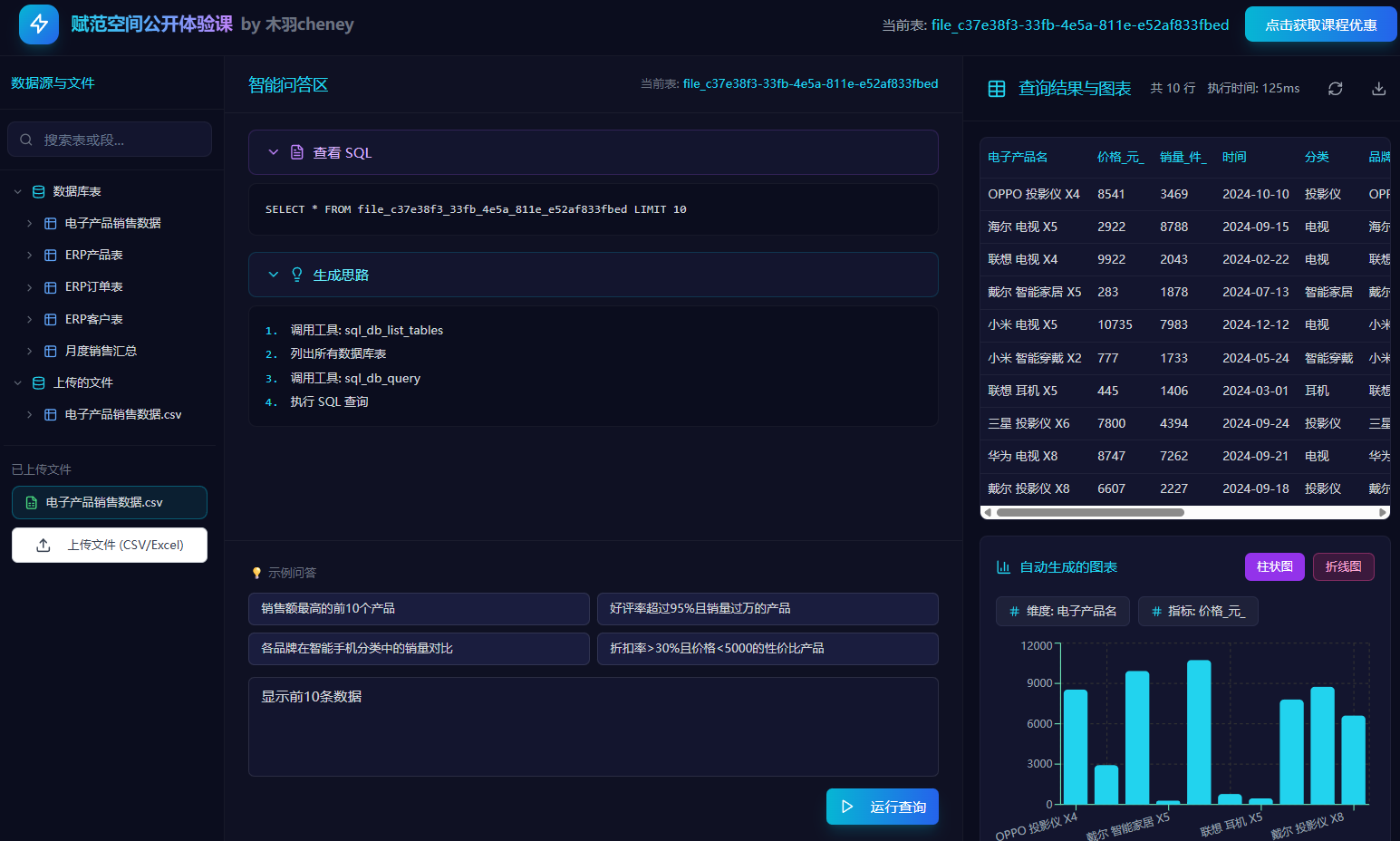
核心功能二:可以选择单表、多表的自动数据分析,实时生成查询SQL,并自动进行查询,同时还能基于查询结果进行可视化图表的生成;
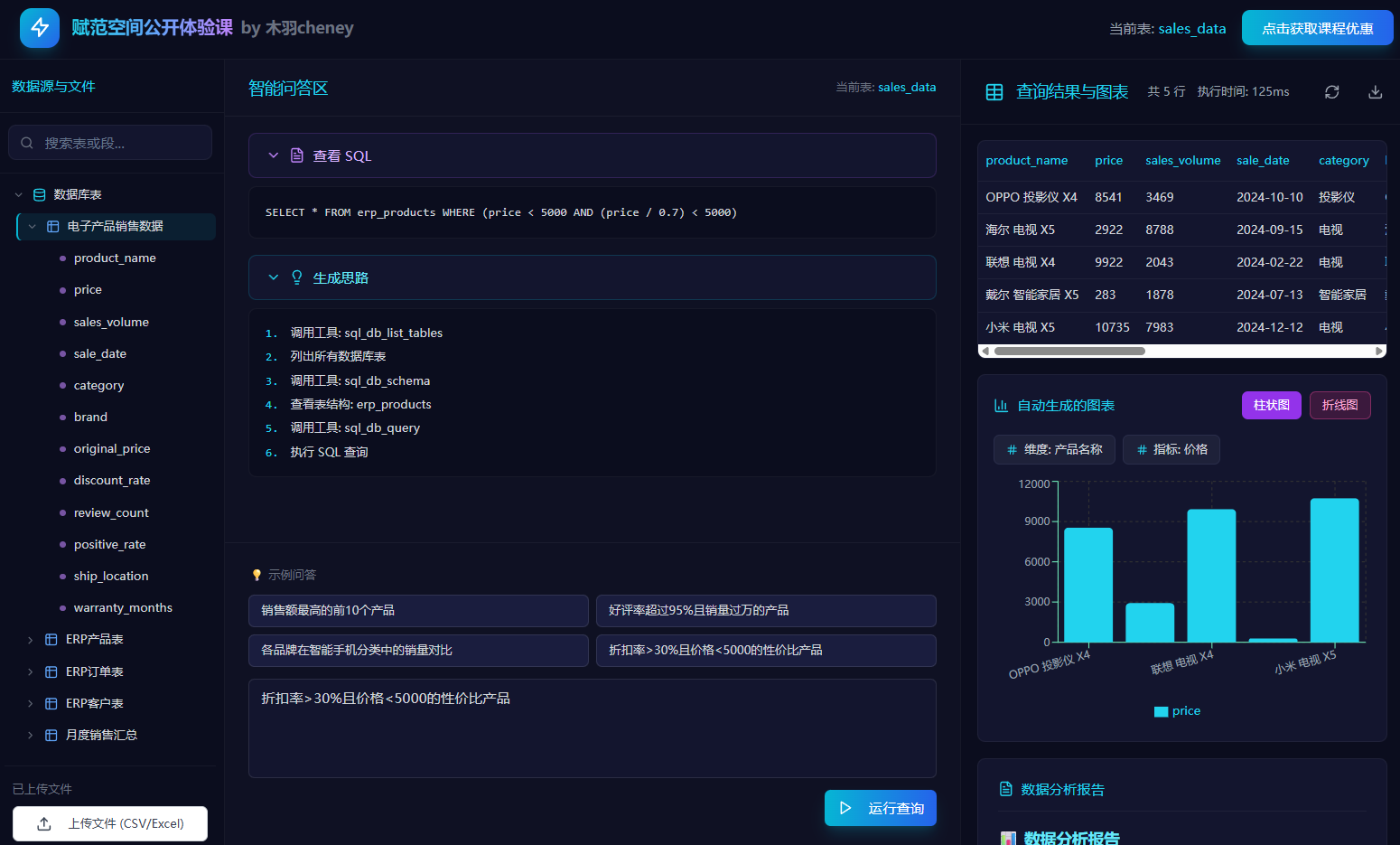
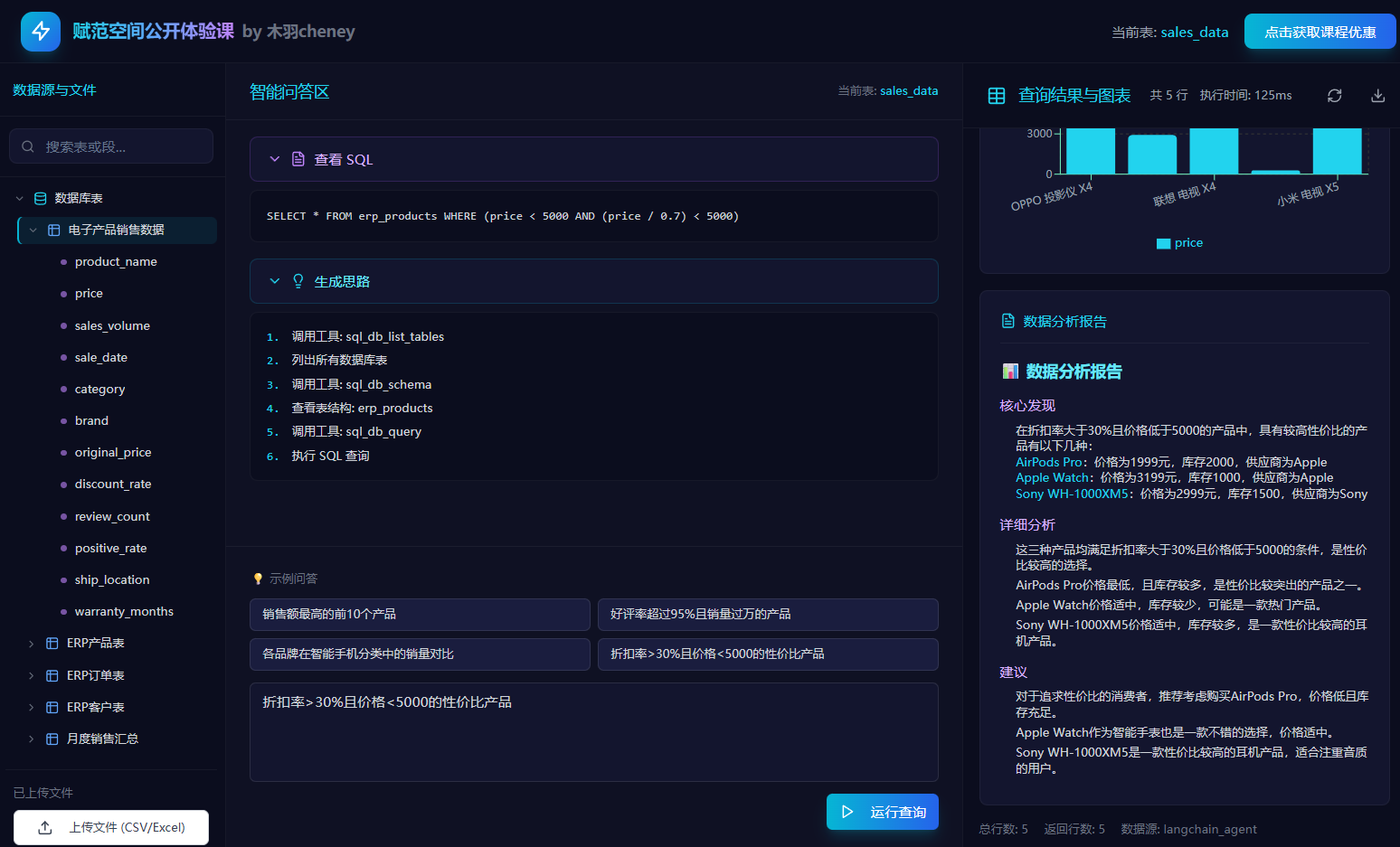
核心功能三:支持在线批量上传.csv/.excel文件,自动解析入库,并能够基于文件内容进行数据检索、可视化绘图及输出详细的数据分析报告;
如果大家正面临解决企业数据查询效率低下的痛点,或者想将大模型技术落地到数据分析场景,本期公开课提出的解决方案将为你提供非常有价值的技术落地。
系统适用业务场景
| 场景类型 | 典型问题 | 系统价值 |
|---|---|---|
| 企业数据民主化 | 业务人员不懂SQL,数据查询依赖技术团队 | 让业务人员通过自然语言直接查询数据,查询时间从"天"缩短到"秒" |
| 智能报表生成 | 周报、月报等报表需人工反复操作 | 自动生成SQL查询、数据分析和可视化图表,解放分析师重复劳动 |
| 运营与客服分析 | 需要快速获取留存率、转化率等业务指标 | 支持对话式追问,深入挖掘数据背后的业务洞察 |
| 数据中台建设 | 多系统数据分散,缺乏统一查询入口 | 企业AI+数据战略落地的理想切入点,投入小、见效快 |
当然,我们也会从AI数据分析系统的痛点、技术方案设计、技术实现细节、企业级实战落地等全面维度,为大家带来一场干货满满的实战分享。
一、AI数据分析系统解决的核心痛点
- 自 2023 年以来,NL2SQL 已成为生成式人工智能的顶级应用之一
自然语言到 SQL (NL2SQL) ,或称文本到 SQL,是指将用户用自然语言提出的问题自动翻译成可在关系数据库上执行的等效 SQL 查询。本质上,NL2SQL 系统充当了人与数据库之间的桥梁 ,使用户能够使用日常语言检索和分析数据,而无需具备专业的 SQL 技能。这尤其重要,因为世界上大量的结构化数据都存储在关系数据库中,但大部分潜在用户(业务分析师、领域专家等)缺乏 SQL 技能。通过降低数据库查询的门槛,NL2SQL 技术普及了结构化数据的访问 ,并加速了数据驱动的决策过程。例如,商业智能或分析领域的非技术用户可以提出诸如“上个季度我们收入排名前五的产品是什么?”之类的问题,并获得结果,而无需手动编写复杂的 SQL。
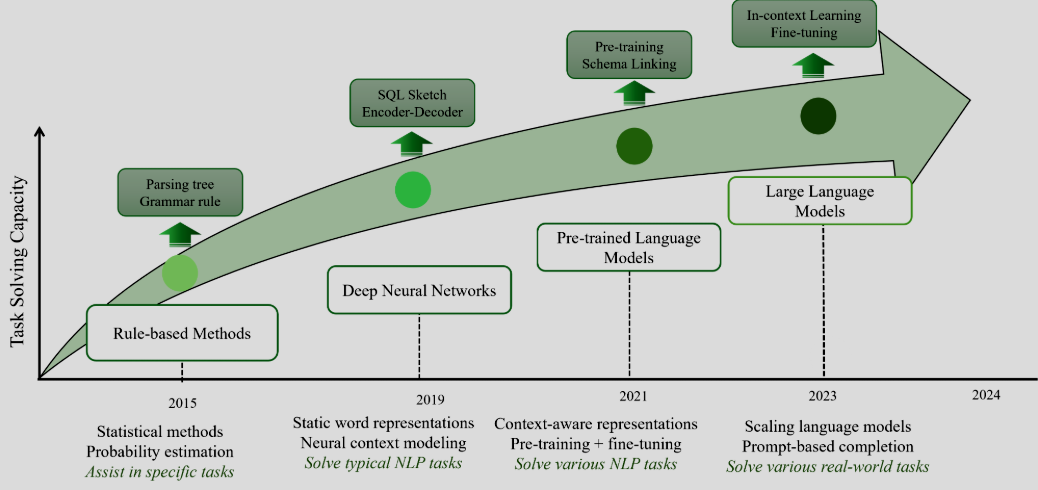
针对Text-To-SQL 的探索,从早期规则/语法解析方法,目前已经发展到基于大语言模型 (LLM) 的新方法。如下图所示:
- 基于语法规则与解析树,使用统计与概率估计,只能在特定任务中辅助。
- 引入静态词向量和上下文建模,可处理典型 NLP 任务,如 Seq2Seq SQL 生成。
- 预训练与微调结合,能处理多样化的 NLP 任务;引入 Schema Linking 增强数据库理解。
- 采用 In-context Learning 与 Prompt based completion,能够解决真实世界复杂任务。
在数据驱动的商业环境中,数据分析能力已经成为企业的核心竞争力。但现实情况是:业务人员想要获取数据,往往需要向技术团队提需求;技术人员写SQL,又需要理解业务语义;这种沟通成本极高,响应速度极慢。比如业务人员想要查询上季度销量最高的产品,却不得不找技术团队写SQL;运营同事想要生成一份用户增长报告,需要等待数据分析师几天才能拿到结果;客服经理想要统计某个渠道的投诉率,却因为不懂数据库而无从下手。这些痛点的本质就是:数据获取的门槛太高
传统的数据查询方式需要掌握SQL语言、理解数据库表结构、熟悉业务指标定义,这对非技术人员来说是巨大的障碍。如果业务人员能够用自然语言直接"问"数据,系统自动理解意图、生成SQL、返回结果,这将彻底改变企业的数据使用方式。而大模型的出现,则是可以实现用自然语言直接与数据库对话的可能性。
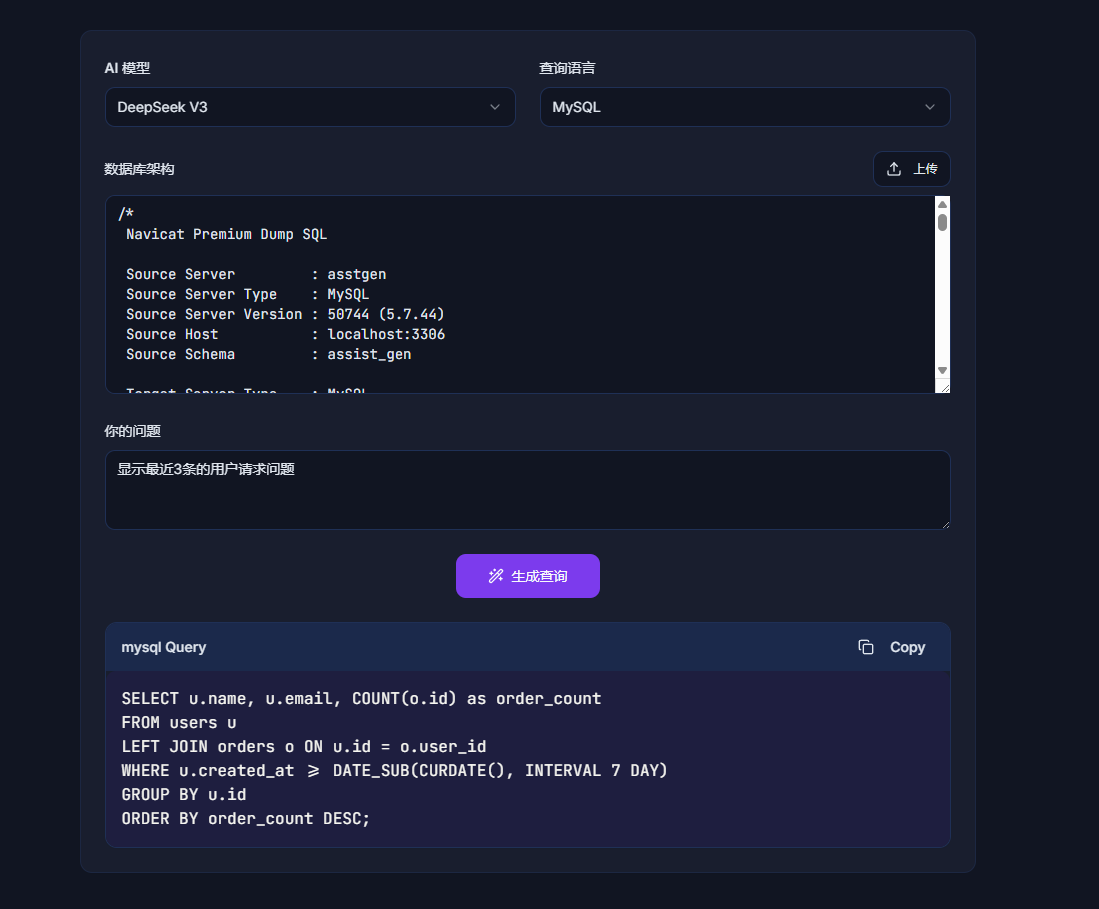
- 应用方向一:理解关系型数据库中的表结构,并能够根据自然语言并生成SQL语句 : https://query-gpt.com/?lang=zh
在这个需求背景下,可以让“非技术背景的人员通过简单自然语言输入生成复杂的 SQL 查询语句,可以参考QueryGPT的产品形态:
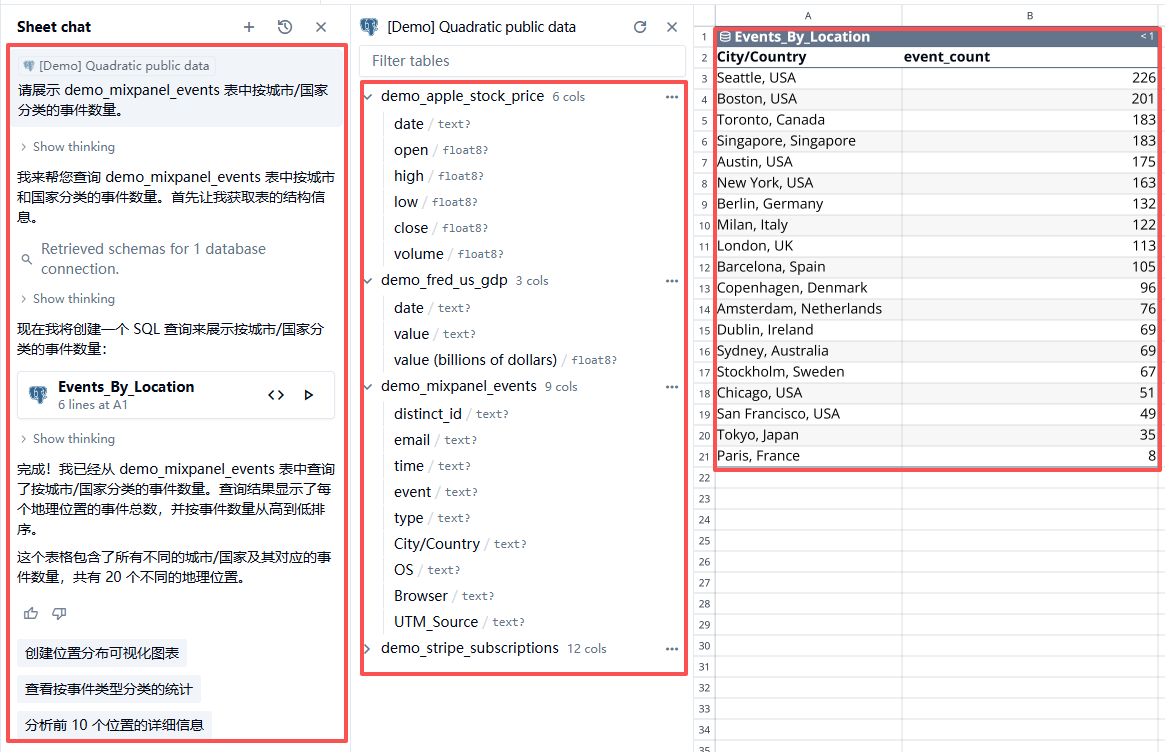
- 应用方向二:具备操作数据库,理解自然语言并生成SQL语句,同时还可以自主操作数据库。 其产品形式如下图所示:https://www.quadratichq.com/
- 应用方向三:具备操作数据库,理解自然语言并生成SQL语句的能力,并且可以自动绘制可视化图表及数据分析报告。
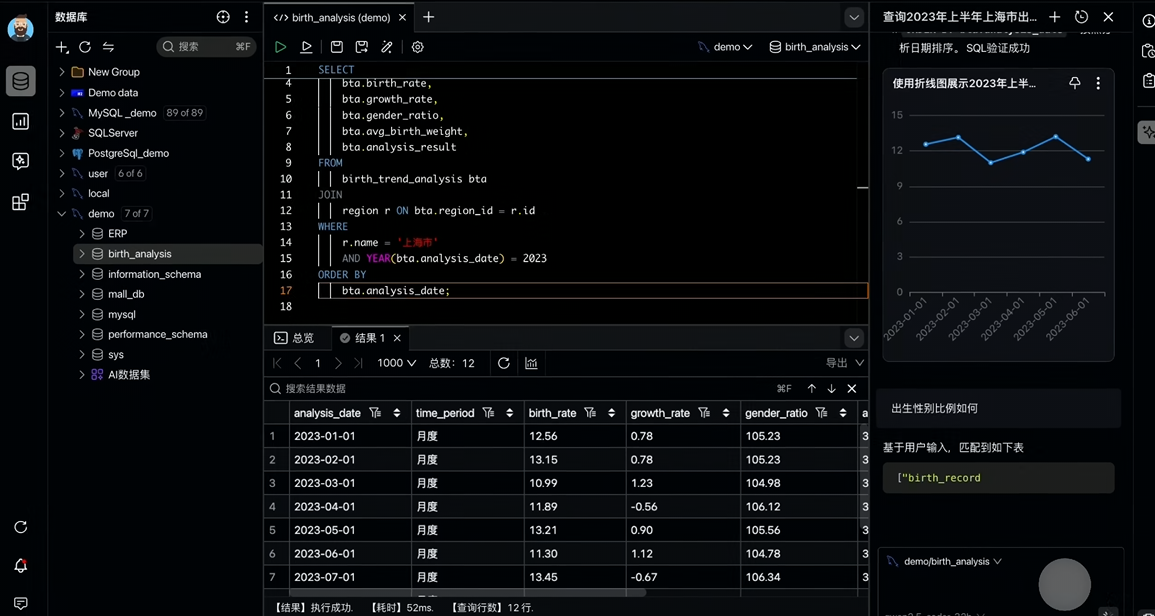
这些产品形态的背景其实是由一整套完整的技术体系支撑的,特别是在大模型(LLM)阶段,同时,不同的产品形态,也对应着不同的主流应用场景,我们可以将其分成如下三大类别:
NL2SQL核心应用场景对比
| 应用场景 | 场景描述 | 关键技术点 | 核心实现思路 |
|---|---|---|---|
| 数据自助分析 | 业务人员通过自然语言查询数据,无需懂SQL | • 自然语言理解与Schema映射 • NL2SQL生成与验证 • 数据库连接与结果呈现 | LLM Agent作为"SQL助手",通过链式思维(CoT)执行流程,利用Few-Shot示例库提高准确率,执行反馈循环逐步修正SQL |
| 智能报表生成 | 自动生成统计报表和可视化图表 | • 多步骤查询与分析 • 数据可视化生成 • 报告描述生成 | Agent作为"自动化数据分析师",规划分析流程,依次使用SQL工具、Python计算工具、可视化工具,形成图文并茂的报表 |
| 运营与客服分析 | 快速查询业务指标,支持对话追问 | • 复杂业务指标计算 • 多表关联与大数据性能 • 上下文记忆和追问细化 | 配置业务语义层定义指标,提供优化视图避免复杂JOIN,使用LangChain会话记忆支持多轮对话,拆解复杂分析任务 |
自然而然,这也是我们在探索NL2SQL技术落地的过程中需要深入了解和掌握的。
二、三大应用案例场景剖析
NL2SQL技术演进的核心在于:一方面让模型理解业务语义与背景(包括用户提问意图、业务指标定义、行业规则等);另一方面让模型理解数据库模式与字段结构(包括表/列/关系、字段命名、数据类型、示例值等)。这两者构成了从自然语言输入到 SQL 生成的完整闭环:自然语言 → 模型理解(业务 + 模式)→ 模式链接(模型识别相关表/列)→ SQL 生成 → 执行 & 返回结果。
整个流程我们可以梳理出如下三个关键环节。
- 环节一:自然语言理解与意图识别
系统收到用户的自然语言问题后,第一步要做的不是直接生成SQL,而是要深度理解用户的真实意图。这个过程包含三个层次的理解:
第一层:实体识别。从问题中提取出关键的业务实体。比如在"上周新注册用户中,来自抖音渠道的用户占比是多少"这个问题中,需要识别出:
- 时间维度:上周(需要转换为具体的日期范围)
- 用户类型:新注册用户(区别于活跃用户、付费用户等)
- 渠道维度:抖音渠道(需要知道在数据库中如何标识)
- 指标类型:占比(需要计算比例而非绝对数值)
第二层:关系理解。理解各个实体之间的逻辑关系。在上面的例子中:
- "新注册用户"是分母,"来自抖音渠道的新注册用户"是分子
- "上周"是一个时间筛选条件,需要同时应用于分子和分母
- "占比"意味着结果需要是百分比格式
第三层:隐含信息推断。很多时候用户的问题是不完整的,系统需要根据业务常识进行推断:
- 用户说"新注册用户",没有明确说是哪个平台(iOS/Android/Web),是否需要全平台汇总?
- 用户说"上周",是指自然周还是工作周?
- 如果结果为0,是真的没有数据,还是数据源有问题?
如下文的论文中提及,在生成 SQL 前,系统要先深度理解用户真实意图。其结构如下:
三层意图理解
| 层次 | 在此框架中的体现 | 说明 |
|---|---|---|
| 第一层:实体识别 | Reflector 的 Extraction 阶段 | Reflector 会从原 NL 中抽取关键 keywords(如 “Highschooler”、“Friend”、“student_id” 等),这些对应业务实体或数据库表字段。这一步是显式的 entity recognition — 系统需先识别语义中的对象。 |
| 第二层:关系理解 | Flaw Analysis + Action Revision 阶段 | 系统判断各实体关系是否逻辑合理:如“学生 没有 朋友” 对应的是 NOT IN 语句,关系应为反连接而非等连接。Reflector 会生成 “Flaw Type: Logical Mismatch between Entities” 的经验,属于关系推理层。 |
| 第三层:隐含信息推断 | Action Revision 阶段的 Reflection → Rewrite NL 过程 | 当用户的 NL 缺失上下文(如未提 “friend_id 和 student_id 之间的 外键关系”),系统会根据数据库 schema 自动补充。图中 Rewriter 把原句 “students who do not have any friends” 重写为 “entries who do not appear in Friend table as either student_id or friend_id” —— 这正是隐含信息推断的体现。 |
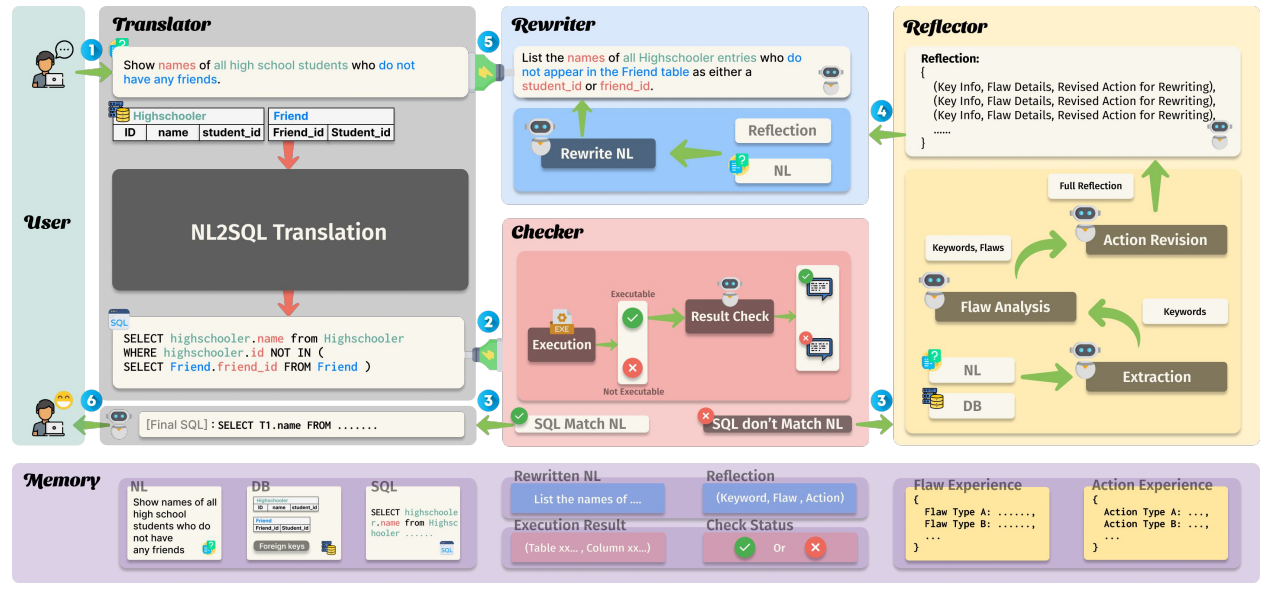
环节二:Schema映射与表字段定位
理解了用户意图后,下一步是最关键也是最容易出错的环节——将业务语言映射到数据库的表和字段。这是NL2SQL系统准确率的核心决定因素。但存在很多技术上的问题:
挑战1:业务术语与技术命名的鸿沟。用户说的是业务语言,数据库存储的是技术命名。比如:
- 用户说"新注册用户" → 数据库中可能叫 new_registered_users 或 user_registration 表
- 用户说"抖音渠道" → 数据库中可能是 source_channel='douyin' 或 acquisition_source='tiktok'
- 用户说"占比" → 需要知道分母是哪个字段,是 COUNT(*) 还是 SUM(user_count)
挑战2:一个业务概念可能对应多个表。在实际的企业数据库中,一个业务概念往往分散在多个表中。比如"用户信息"可能涉及:
- users 表(基本信息:用户ID、注册时间)
- user_profiles 表(详细信息:年龄、性别、地域)
- user_acquisition 表(获客信息:来源渠道、注册来源)
- user_behaviors 表(行为信息:最后登录时间、活跃度)
系统需要判断:对于当前问题,到底需要查询哪些表?需要如何关联这些表?
挑战3:同一个字段名在不同上下文有不同含义。比如 status 字段,在订单表中表示"订单状态"(待支付/已完成/已取消),在用户表中表示"用户状态"(正常/冻结/注销)。系统需要根据上下文正确理解字段含义。
如下论文所示:用户的自然语言查询 → 数据库结构映射 → SQL 生成过程中,因为自然语言有歧义 + 数据库模式可能变化,系统如何处理两种不同情境。首先,系统必须理解用户问 “哪些客户(实体)在劳动节 2023 借出图书(维度)并且类型为3 种不同的 genre(指标)”;其次,系统要找到数据库中对应的表(Customer/Account)、字段(Name、CustomerId、SubjectGenre)、外键关系(CustomerId ↔ BookOrder)等。如果其中任一步失败(用户意图歧义或模式结构变化未适应),最终生成的 SQL 就可能错误。
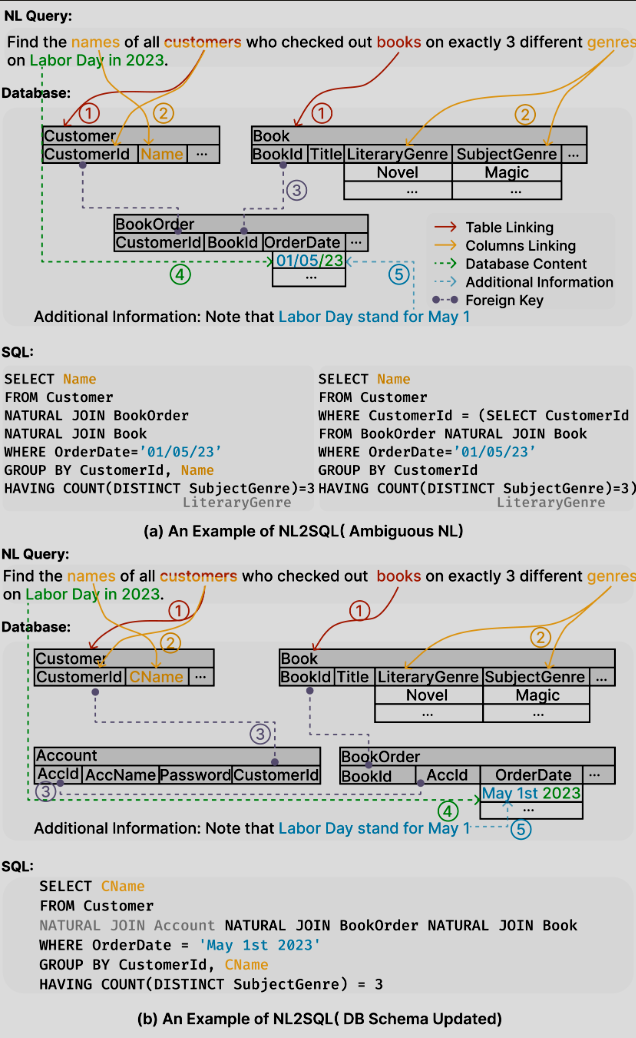
这张图说明了 NL2SQL 系统中两个关键流程:用户意图理解 + 数据库模式映射。首先,系统必须理解用户问 “哪些客户(实体)在劳动节 2023 借出图书(维度)并且类型为3 种不同的 genre(指标)”;其次,系统要找到数据库中对应的表(Customer/Account)、字段(Name、CustomerId、SubjectGenre)、外键关系(CustomerId ↔ BookOrder)等。如果其中任一步失败(用户意图歧义或模式结构变化未适应),最终生成的 SQL 就可能错误。
所以,一个相对健全的NL2SQL的链路往往会将意图识别+数据库模式映射作为关键的处理环节进行精细化的处理。
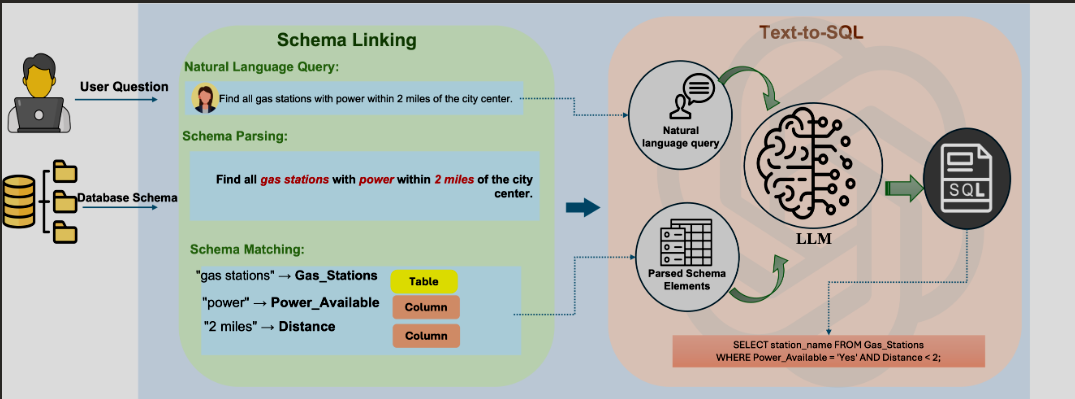
环节三:SQL迭代生成与校验
SQL的生成直接決定了NL2SQL系统的准确率以及可用性,一个标准的SQL生成链路要包含“先理解/生成 → 校验/反馈 →修正”这一迭代优化流程。正如下文所示:
- NL Query → NL2SQL Models:用户给出自然语言查询(NL Query),输入到一个 NL2SQL 模型(可以是 Seq2Seq 或大语言模型);
- 生成 SQL → 执行/获取 Query Result:模型生成初版 SQL,并将其执行(或采样执行)以获得查询结果(Query Result)。
- Data Tracker → Semantics Augmentor → Explanation Generator
- Data Tracker:追踪生成的 SQL 所执行的结果的 provenance(数据来源、哪些元组/列被用到)
- Semantics Augmentor:在获得 provenance 后,增强其语义,将操作语义(如 SQL 中的聚合、筛选)与数据 provenance 结合起来
- Explanation Generator:基于增强后的语义 + 数据 provenance,生成一段自然语言解释(NL explanation)说明查询结果为何如此、SQL 是怎样运作的。
- Translation Verifier → Feedback Loop:将生成的解释(NL explanation)与用户原始查询/SQL 结果一起输入到 Translation Verifier 模块,用于验证生成的 SQL 是否 正确对齐 用户意图、是否逻辑合理。图中 “④Verification”所在位置。
如果验证通过,就输出最终 SQL;若不通过,则进入反馈循环,可能回到 NL2SQL 模型阶段进行修正。整个流程形成一个 迭代优化反馈循环(Feedback Loop)。
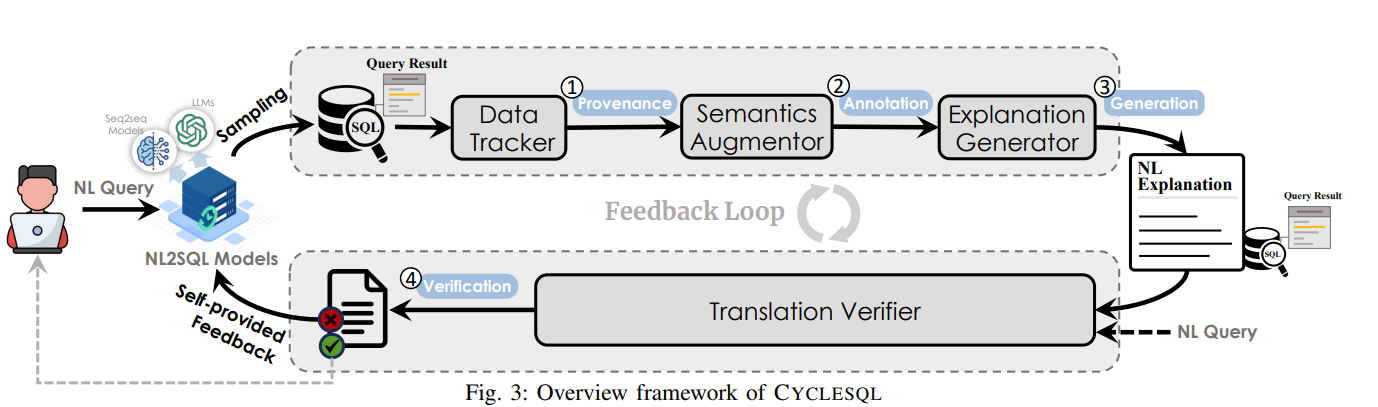
这里我们可以借助LangChain框架实现的ReAct思路来给大家直观的展示这个后端的设计思想:
FENCE0
接下来,我们就通过代码实战来展示上述介绍的NL2SQL的完整流程。
三、基于LangChain 1.0构建人在循环的SQL Agent智能问数系统
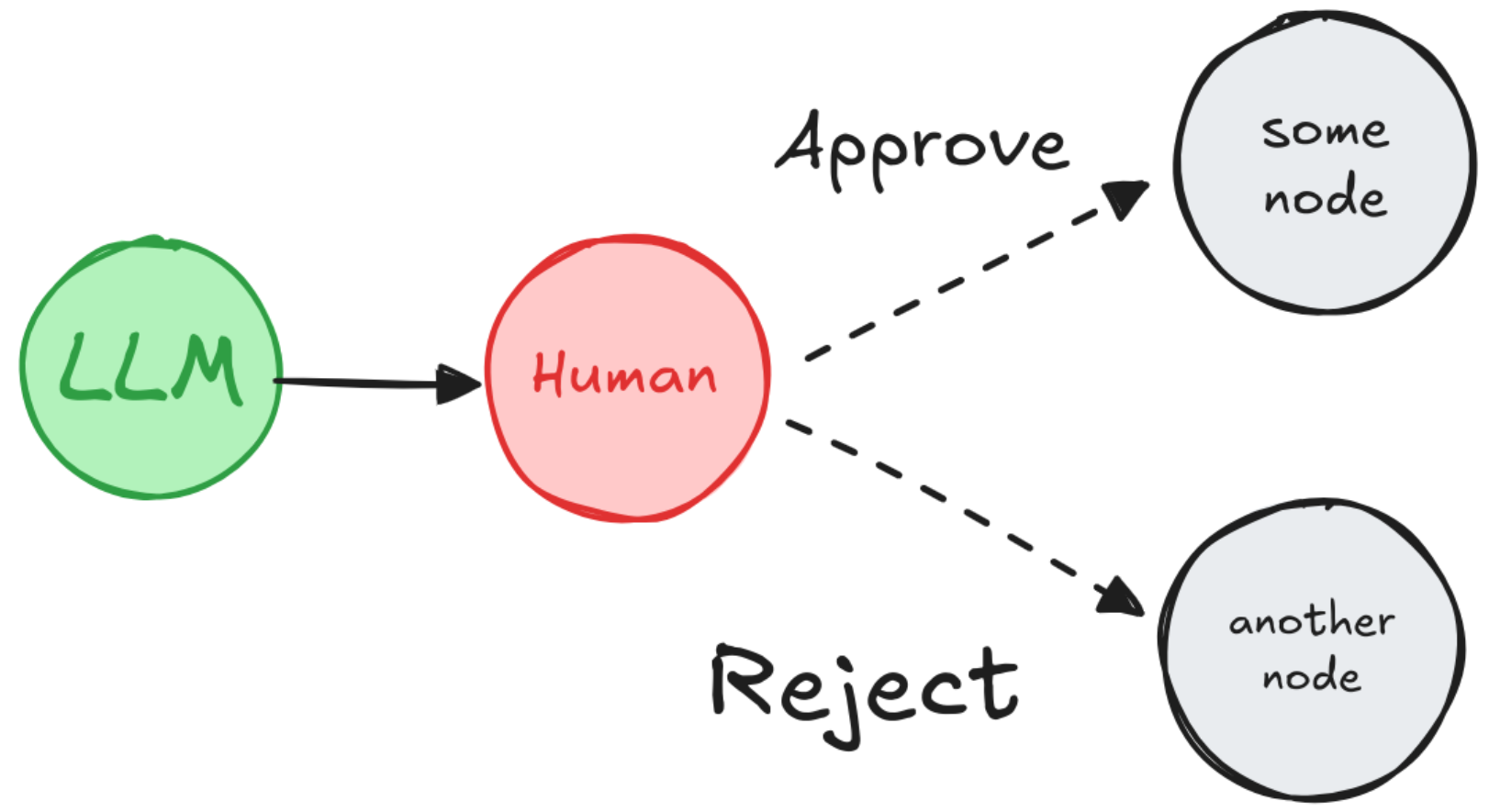
在实际的企业级NL2SQL应用中,直接执行大模型生成的SQL查询存在一定风险。可能会出现数据泄露、误删除数据或执行低效查询等问题。因此,**人在循环(Human-in-the-Loop)**机制成为了保障系统安全性和可靠性的关键技术。因此在本节案例中,我们将学习如何使用LangChain 1.0的最新API构建一个具有人工审核能力的SQL Agent。在这个系统中,当Agent生成SQL查询后,不会立即执行,而是先暂停并等待人工审核,只有在获得批准后才会继续执行。
核心知识点
| 技术点 | 说明 |
|---|---|
create_agent | LangChain 1.0 标准Agent创建方式 |
HumanInTheLoopMiddleware | 人在循环中间件,实现审核机制 |
InMemorySaver | 内存检查点,支持暂停和恢复 |
SQLDatabaseToolkit | SQL工具包,提供数据库交互能力 |
Command | 控制命令,用于恢复暂停的执行 |
Step 1: 环境准备与依赖安装
首先我们需要安装LangChain 1.0及其相关依赖包。LangChain 1.0是全新的架构,底层基于LangGraph构建,提供了更加简洁的API和更强大的功能。
注意: LangChain 1.0 与旧版本API不兼容,请确保使用最新版本。
# 安装核心依赖包
# %pip install -qU langchain langchain-openai langchain-community langgraph
# %pip install -qU sqlalchemy requests pandas matplotlib networkx
! pip show langchain
上述命令安装了以下核心组件:
langchain: LangChain 1.0 核心库,提供create_agent等标准APIlangchain-openai: OpenAI模型集成,支持GPT系列langchain-community: 社区工具包,包含SQLDatabaseToolkitlanggraph: 底层编排框架,提供人在循环等高级功能sqlalchemy: 数据库ORM,用于SQL操作- 其他工具库用于数据处理和可视化
Step 2: 导入必要模块
接下来导入本案例所需的所有模块。特别注意LangChain 1.0的新导入路径:
create_agent从langchain.agents导入 (新版核心API)HumanInTheLoopMiddleware从langchain.agents.middleware导入 (人在循环中间件)InMemorySaver从langgraph.checkpoint.memory导入 (检查点机制)
# LangChain 1.0 核心模块
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langchain.chat_models import init_chat_model
# LangGraph 模块 - 提供持久化和控制能力
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command
# SQL工具包
from langchain_community.utilities import SQLDatabase
from langchain_community.agent_toolkits import SQLDatabaseToolkit
# 标准库
import os
import pathlib
import requests
import warnings
warnings.filterwarnings('ignore')
print("模块导入成功!")
Step 3: 多模型配置 - GPT / Qwen / DeepSeek
LangChain 1.0提供了统一的模型接口init_chat_model,可以无缝切换不同的大模型提供商。比如对于GPT-5、Qwen3、DeepSeek等模型,我们只需要修改一行代码即可完成切换。
# ! pip install python-dotenv
# ==================== 配置 API Keys ====================
# 请在这里填入你的API密钥
from dotenv import load_dotenv
load_dotenv(override=True)
# OpenAI API Key (用于GPT模型)
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_API_BASE = os.getenv("OPENAI_BASE_URL")
OPENAI_API_MODEL = os.getenv("OPENAI_MODEL_NAME")
# 如果使用Qwen3,需要配置DashScope (阿里云百炼)
# DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY")
# 如果使用DeepSeek,需要配置DeepSeek API
#DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
print(f"OPENAI_API_MODEL: {OPENAI_API_MODEL}")
model = init_chat_model(
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE,
model=OPENAI_API_MODEL,
temperature=0, # 温度设为0,确保输出稳定
model_provider="openai" # 指定提供商
)
print(f"已加载模型:{OPENAI_API_MODEL}")
Step 4: 准备示例数据库
为了演示SQL Agent的功能,我们使用经典的Chinook数据库。这是一个音乐商店数据库,包含艺术家、专辑、曲目、客户、订单等多张表,非常适合用来测试NL2SQL能力。我们将从Google Cloud存储桶下载这个数据库,然后通过SQLAlchemy连接它。
# 下载Chinook示例数据库
url = "https://storage.googleapis.com/benchmarks-artifacts/chinook/Chinook.db"
local_path = pathlib.Path("Chinook.db")
if local_path.exists():
print(f"{local_path} 已存在,跳过下载")
else:
print(f"正在下载Chinook数据库...")
response = requests.get(url)
if response.status_code == 200:
local_path.write_bytes(response.content)
print(f"数据库下载成功: {local_path}")
else:
print(f"下载失败,状态码: {response.status_code}")
接下来使用LangChain的SQLDatabase包装器连接数据库。这个包装器提供了便捷的接口,可以获取表结构、执行查询等操作。
# 创建数据库连接
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(f"数据库连接成功!")
print(f"\n数据库方言: {db.dialect}")
print(f"可用表: {db.get_usable_table_names()}")
# 查看数据库结构
print("\n" + "="*60)
print("数据库Schema (前500字符):")
print("="*60)
print(db.get_table_info()[:500] + "...")
Chinook数据库包含11张表,涵盖了音乐商店业务的各个方面。Agent需要理解这些表的结构和关系,才能生成正确的SQL查询。
Step 5: 创建SQL工具包
SQLDatabaseToolkit是LangChain提供的专门用于SQL操作的工具集。它会自动创建多个工具,每个工具负责不同的数据库操作.这些工具将作为Agent的"技能",让它能够与数据库交互。
# 创建SQL工具包
toolkit = SQLDatabaseToolkit(db=db, llm=model)
tools = toolkit.get_tools()
print(f"SQL工具包创建成功,共 {len(tools)} 个工具:\n")
for tool in tools:
print(f" {tool.name}")
print(f" └─ 功能: {tool.description}")
print()
这些工具构成了Agent的工作流程:
- 用户提出问题
- Agent调用
sql_db_list_tables了解有哪些表 - Agent调用
sql_db_schema获取相关表的结构 - Agent生成SQL查询
- Agent调用
sql_db_query_checker验证SQL - 人工审核 (人在循环的关键步骤)
- 执行
sql_db_query获取结果 - 将结果转化为自然语言回答
Step 6: 配置系统提示词
系统提示词(System Prompt)是引导Agent行为的关键。一个好的提示词应该:
- 明确定义Agent的角色和职责
- 说明工作流程和注意事项
- 强调安全规则 (不执行DML语句)
- 提供最佳实践指导 (限制结果数、先查表、双重检查)
这里我们就使用COT思维链的提示词方式设计如下:
# 构建系统提示词
system_prompt = f"""
你是一个专业的SQL数据库智能助手,能够帮助用户查询{db.dialect}数据库。
## 工作流程
1. 当用户提出问题时,首先使用工具查看数据库中有哪些表
2. 然后查询相关表的Schema,了解字段信息
3. 基于表结构生成语法正确的{db.dialect}查询语句
4. 在执行查询前,使用query_checker工具验证SQL的正确性
5. 执行查询并获取结果
6. 将查询结果用自然语言总结并回答用户问题
## 重要规则
- **安全第一**: 绝对不允许执行INSERT、UPDATE、DELETE、DROP等修改数据的语句
- **限制结果**: 除非用户明确要求,查询结果最多返回 {5} 条记录
- **精准查询**: 只查询与问题相关的字段,避免SELECT *
- **智能排序**: 可以通过ORDER BY返回最有价值的结果
- **必须先探索**: 开始时一定要先查看表结构,不要跳过这一步
- **双重检查**: 执行查询前务必验证SQL语法
- **错误处理**: 如果查询出错,分析错误信息后重新生成查询
## 回答风格
- 用中文回答问题,语言简洁专业
- 如果查询结果为空,友好地告知用户
- 可以主动提供数据洞察和建议
"""
print("系统提示词配置完成")
print(f"\n提示词长度: {len(system_prompt)} 字符")
这个提示词包含了企业级SQL Agent的核心要素。特别是安全规则,在生产环境中至关重要。通过明确禁止DML操作,可以防止Agent误删除或修改数据。
Step 7: 创建人在循环的SQL Agent (核心)
这是本案例的核心部分!我们使用LangChain 1.0的create_agent API创建Agent,并通过HumanInTheLoopMiddleware中间件实现人在循环机制。其中:
- create_agent: LangChain 1.0的标准Agent创建方式,替代了旧版的
create_sql_agent - middleware: 中间件机制,可以在Agent执行过程中注入自定义逻辑
- HumanInTheLoopMiddleware: 专门用于人工审核的中间件
interrupt_on: 指定哪些工具调用需要人工审核description_prefix: 暂停时显示的提示信息
- checkpointer: 检查点机制,允许Agent暂停和恢复执行
InMemorySaver: 内存检查点,适合开发测试- 生产环境可使用
PostgresSaver等持久化方案
# 创建带人在循环的SQL Agent
agent = create_agent(
model=model,
tools=tools,
system_prompt=system_prompt,
# 配置中间件 - 实现人在循环
middleware=[
HumanInTheLoopMiddleware(
# 指定需要人工审核的工具
interrupt_on={
"sql_db_query": True, # SQL查询执行前需要审核
},
# 暂停时的提示信息
description_prefix="SQL查询待审核",
),
],
# 配置检查点 - 支持暂停和恢复
checkpointer=InMemorySaver(),
)
print(" SQL Agent创建成功!")
print("\nAgent配置:")
print(f" - 模型: {model.__class__.__name__}")
print(f" - 工具数量: {len(tools)}")
print(f" - 人在循环: 启用 (sql_db_query工具需要人工审核)")
print(f" - 检查点: InMemorySaver (内存持久化)")
创建完成后,当Agent尝试执行sql_db_query工具时,会自动暂停并等待人工审核。这确保了没有未经审核的SQL查询会被执行。
Step 8: 可视化Agent结构
LangChain 1.0基于LangGraph构建,因此我们可以将Agent的执行图可视化。这对于理解Agent的工作流程、调试问题非常有帮助。通过get_graph()方法可以获取Agent的内部图结构,然后使用draw_mermaid_png()生成可视化图像。
# 可视化Agent的执行图
from IPython.display import Image, display
try:
# 获取Agent的图结构并渲染
graph_image = agent.get_graph().draw_mermaid_png()
display(Image(graph_image))
print("\nAgent执行图可视化成功!")
except Exception as e:
print(f"可视化失败: {e}")
print("提示: 需要安装 pygraphviz 或在线Mermaid渲染器")
上图展示了Agent的完整执行流程:
- START: 开始节点,接收用户输入
- agent: Agent思考节点,决定下一步行动
- tools: 工具调用节点,执行具体操作
- human: 人工审核节点,在执行sql_db_query前暂停
- END: 结束节点,返回最终结果
这种图形化展示让我们清晰看到人在循环的位置:在工具执行前插入了人工审核环节。
Step 9: 执行查询 - 触发人在循环
现在让我们实际运行Agent,看看人在循环机制如何工作。我们将提出一个需要查询数据库的问题,观察Agent在生成SQL后如何暂停等待审核。
# 配置对话线程
config = {"configurable": {"thread_id": "sql-demo-001"}} # 每个对话需要一个唯一的线程ID,用于持久化状态
# 用户问题
user_question = "销售代表中,谁负责的客户平均购买金额最高?"
print(f"用户提问: {user_question}")
print("\n" + "="*60)
print("Agent开始处理...")
print("="*60 + "\n")
# 第一次调用 - 将会在SQL执行前暂停
result = agent.invoke(
{"messages": [{"role": "user", "content": user_question}]}, # 发起Agent调用,传入用户消息, 当Agent调用`sql_db_query`时,执行会自动暂停
config=config
)
print("\n" + "="*60)
print("⏸ Agent已暂停,等待人工审核")
print("="*60)
上述代码执行后,Agent会经历以下步骤:
- 理解用户问题:"销售额最高的员工"
- 调用
sql_db_list_tables查看有哪些表 - 识别相关表(可能是
Employee和Invoice表) - 调用
sql_db_schema获取表结构 - 生成SQL查询(JOIN、GROUP BY、ORDER BY等)
- 调用
sql_db_query_checker验证SQL - 准备执行
sql_db_query→ ⏸在此暂停!
此时Agent已经生成了SQL,但还未执行,正在等待我们审核。
Step 10: 查看待审核的SQL
在批准执行之前,我们需要查看Agent生成的SQL查询。通过检查Agent的状态,可以获取待执行的工具调用信息。get_state()方法返回当前的执行状态,包括所有等待审核的工具调用。
# 获取Agent当前状态
state = agent.get_state(config)
print("当前Agent状态:\n")
print(f" - 对话轮次: {len(state.values.get('messages', []))}")
print(f" - 下一步动作: {state.next}")
print(f"\n" + "="*60)
print("待审核的SQL查询:")
print("="*60 + "\n")
# 提取最后一条消息中的工具调用
messages = state.values.get('messages', [])
if messages:
last_message = messages[-1]
# 检查是否有工具调用
if hasattr(last_message, 'tool_calls') and last_message.tool_calls:
for tool_call in last_message.tool_calls:
print(f"工具名称: {tool_call.get('name', 'unknown')}")
print(f"\nSQL查询:")
# 获取SQL参数
args = tool_call.get('args', {})
if 'query' in args:
sql = args['query']
print(f"\n{sql}\n")
# 安全检查
dangerous_keywords = ['DELETE', 'DROP', 'UPDATE', 'INSERT', 'ALTER']
sql_upper = sql.upper()
print("\n 安全检查:")
has_danger = any(kw in sql_upper for kw in dangerous_keywords)
if has_danger:
print(" 警告: SQL包含危险操作!")
else:
print(" 安全: 仅包含SELECT查询")
else:
print(args)
else:
print(" 未发现工具调用")
else:
print(" 消息为空")
这段代码展示了人在循环的核心价值:在执行前透明化展示SQL,并进行安全检查。
我们可以看到:
- Agent生成的完整SQL语句
- 自动检测危险关键词(DELETE、DROP等)
- 为人工决策提供充分信息
在企业环境中,这个环节可以扩展为:
- 检查是否访问了敏感表
- 验证查询复杂度(避免慢查询)
- 记录审计日志
- 发送通知给相关负责人
Step 11: 审核决策 - 批准/拒绝/修改
LangChain 1.0的人在循环机制支持三种审核决策:
- 批准(approve): 直接执行Agent生成的SQL
- 拒绝(reject): 拒绝执行,Agent会重新思考
- 修改(edit): 修改SQL参数后再执行
这里我们演示最常用的场景:批准执行。通过Command对象的resume参数传递审核决策。
# ==================== 场景1: 批准执行 ====================
print("审核通过,批准执行SQL查询\n")
print("="*60)
print("继续执行Agent...")
print("="*60 + "\n")
# 使用Command恢复执行
result = agent.invoke(
Command(
resume={
"decisions": [{"type": "approve"}] # 批准决策
}
),
config=config # 使用相同的thread_id继续对话
)
print("\n" + "="*60)
print("查询结果:")
print("="*60 + "\n")
# 提取最终回答
if 'messages' in result:
for msg in result['messages']:
if hasattr(msg, 'content') and msg.content:
print(msg.content)
else:
print(result)
整个过程完全透明,我们可以追溯每一步操作。
# ==================== 场景2: 拒绝执行====================
# 如果发现SQL有问题,可以拒绝执行
result = agent.invoke(
Command(
resume={
"decisions": [
{
"type": "reject",
"feedback": "SQL查询可能返回过多结果,请添加LIMIT子句"
}
]
}
),
config=config
)
# Agent会根据反馈重新生成SQL
print("提示: 拒绝执行时,可以提供反馈信息指导Agent改进")
# ==================== 场景3: 修改后执行(可选演示) ====================
# 可以手动修改SQL参数
# result = agent.invoke(
# Command(
# resume={
# "decisions": [
# {
# "type": "edit",
# "args": {
# "query": "SELECT * FROM Employee LIMIT 3" # 修改后的SQL
# }
# }
# ]
# }
# ),
# config=config
# )
print("提示: 修改执行允许人工优化SQL查询")
Step 12: 多轮对话测试
人在循环的SQL Agent支持多轮对话。由于有checkpointer机制,Agent能够记住上下文,实现连续提问。让我们测试一个追问场景,看Agent如何在记忆上下文的同时,仍然保持人工审核机制。
# 追问:基于上一个问题继续提问
followup_question = "除了最高的,前10名都是多少?"
print(f"追问: {followup_question}")
print("\n" + "="*60)
print("Agent处理中(记住了上下文)...")
print("="*60 + "\n")
# 使用相同的thread_id,Agent会记住之前的对话
result = agent.invoke(
{"messages": [{"role": "user", "content": followup_question}]},
config=config # 相同thread_id
)
print("\n⏸再次暂停等待审核...")
print("提示: Agent已经知道'这些员工'指的是前面查询的员工")
# 查看新生成的SQL
state = agent.get_state(config)
messages = state.values.get('messages', [])
last_message = messages[-1]
if hasattr(last_message, 'tool_calls') and last_message.tool_calls:
for tool_call in last_message.tool_calls:
print("新的SQL查询:\n")
args = tool_call.get('args', {})
if 'query' in args:
print(args['query'])
# 批准执行
print("\n批准执行...\n")
result = agent.invoke(
Command(resume={"decisions": [{"type": "approve"}]}),
config=config
)
# 显示结果
print("="*60)
print("追问结果:")
print("="*60 + "\n")
if 'messages' in result:
for msg in result['messages']:
if hasattr(msg, 'content') and msg.content:
print(msg.content)
# 获取完整对话历史
state = agent.get_state(config)
messages = state.values.get('messages', [])
print("="*60)
print(f"对话历史 (共 {len(messages)} 条消息)")
print("="*60 + "\n")
for i, msg in enumerate(messages, 1):
msg_type = msg.__class__.__name__
if msg_type == "HumanMessage":
print(f"\n[{i}] 用户:")
print(f" {msg.content}")
elif msg_type == "AIMessage":
print(f"\n[{i}] AI:")
if hasattr(msg, 'tool_calls') and msg.tool_calls:
print(f" 调用工具: {[tc.get('name') for tc in msg.tool_calls]}")
if msg.content:
print(f" {msg.content[:100]}...") if len(msg.content) > 100 else print(f" {msg.content}")
elif msg_type == "ToolMessage":
print(f"\n[{i}] 工具返回:")
content_preview = str(msg.content)[:100]
print(f" {content_preview}...") if len(str(msg.content)) > 100 else print(f" {msg.content}")
print("\n" + "="*60)
通过对话历史,我们可以看到,从用户输入 → Agent思考 → 工具调用 → 人工审核 → 执行 → 结果返回,每个环节都有记录,形成完整的审计链,可以分析Agent的决策路径,优化提示词和工具配置。
使用LangChain 1.0构建人在循环的SQL Agent。相比传统NL2SQL系统,这种方案具有以下优势:
人在循环 vs 全自动执行对比
| 维度 | 全自动执行 | 人在循环 |
|---|---|---|
| 安全性 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 可控性 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 效率 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 审计能力 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 适用场景 | 低风险查询 | 企业生产环境 |
四、热门开源AI数据分析产品推荐
我们通过LangChain 1.0构建了人在循环的SQL Agent,并测试了其在企业级生产环境中的表现。虽然是作为快速入门的案例,但实质上已经解决了非常多的真实企业需求场景。但需要说明的是:NL2SQL 的Agent 在企业级生产环境中的应用,需要考虑的场景远不止于此,同时其落地技术方案的优化策略及架构也往往更加复杂,这里我们以一些主流的开源产品为例,介绍其在AI数据分析领域的构建思路和设计思想。
- Vanna:开源的 Text-to-SQL Agent 框架,让用户用自然语言直接与数据库对话。Github:https://github.com/vanna-ai/vanna
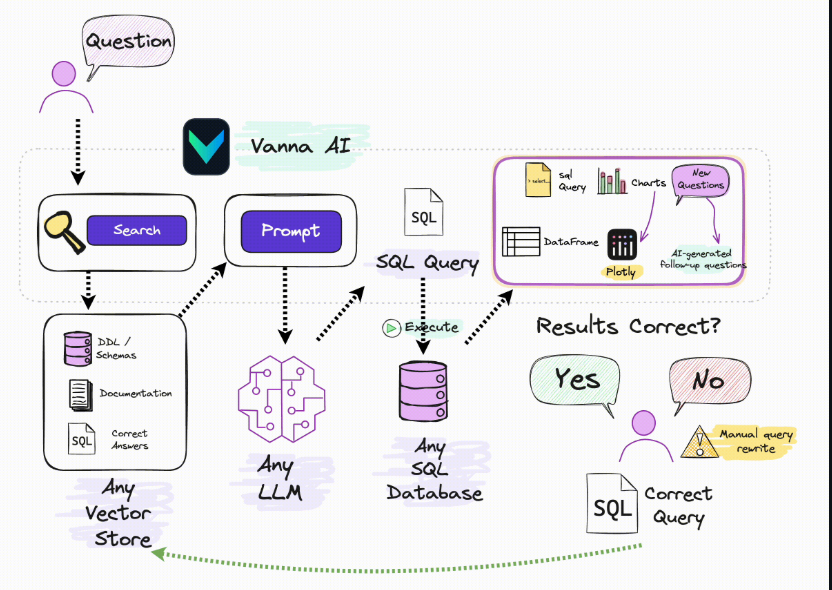
其设计架构较为复杂,当用户可以输入自然语言查询,Search 模块会从向量数据库检索相关知识(表结构 DDL、Schema、文档、历史 SQL 示例),提供上下文支持。同时还实现了结果反馈闭环:结合可视化与用户验证实现“生成-执行-校正”循环。
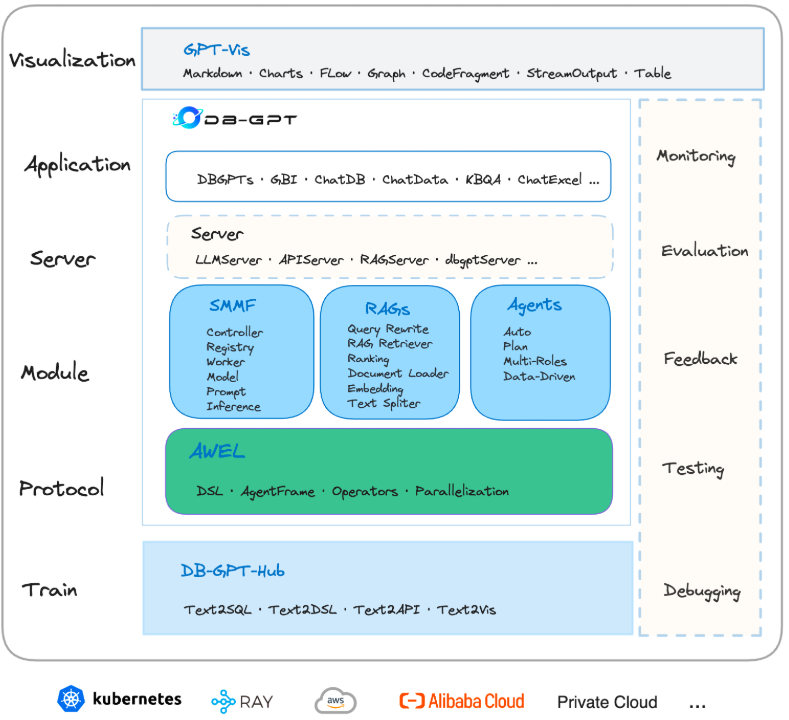
该项目是由 eosphoros‑ai(中国开源组织)开源的一个 “AI Native 数据应用开发框架” 项目。其目的在于:通过将大语言模型(LLM)与数据库、数据仓库、Excel 等多种数据源打通,降低数据交互的门槛、加速业务人员/开发者构建“自然语言 ↦ 数据查询/分析”应用。 其核心目标包括:Text2SQL 效能优化、RAG(检索增强生成)能力、多智能体协作(Multi-Agents)、Agentic Workflow Expression Language (AWEL) 等。

DB-GPT是一个面向企业级数据交互的多智能体系统,论文《Demonstration of DB-GPT》指出它通过多层架构实现从自然语言到数据洞察的全流程自动化,在 Application 层:包括 ChatDB、ChatData、ChatExcel 等端到端应用。同时借助RAG技术支持知识构建、查询重写、文档重排与嵌入生成。整体运行于 Kubernetes / Ray / AWS / 阿里云等环境,可支持私有化部署与可视化分析
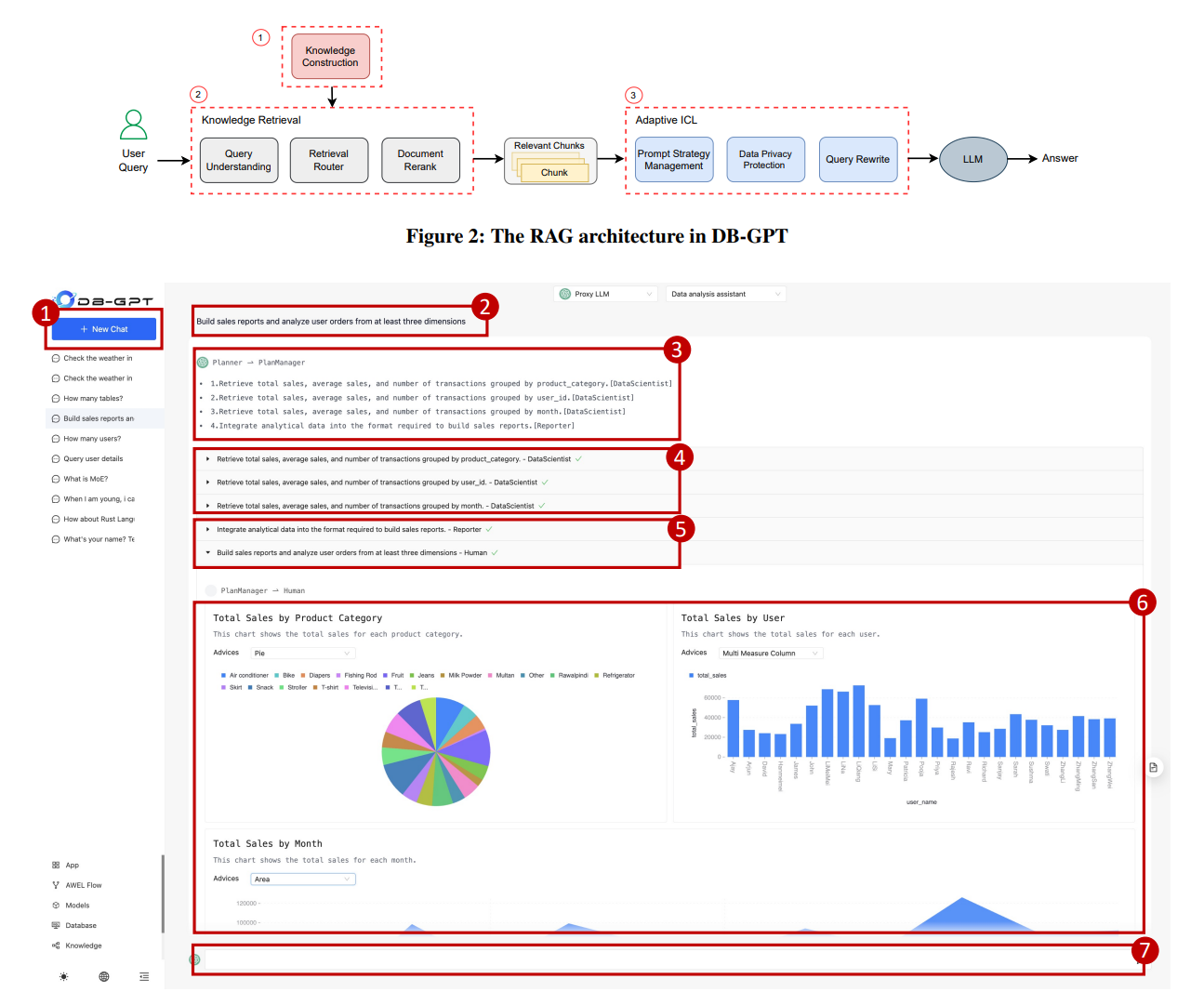
整套架构包含从 数据交互 → 语义理解 → 模型生成 → 结果展示 → 反馈优化 的完整闭环,是典型的 “AI Native Data Interaction System”,同时也是一个非常具有学习价值的开源项目。
人在循环 vs 全自动执行对比
| 项目名称 | GitHub Stars | 核心定位 | 主要技术特点 | 适用场景 | 核心优势 | 局限性 |
|---|---|---|---|---|---|---|
| PandasAI | 22.3k | AI 辅助数据分析库 | • DataFrame NL 操作 • 数据可视化生成 • 支持多种数据库 • Jupyter 友好 | 临时分析、小型数据探索、Notebook 场景 | 同时支持 SQL 和本地数据分析 | 缺少企业级功能(权限、多用户) |
| Vanna | 20.9k | 轻量级 NL2SQL 组件库 | • Agentic Retrieval (工具增强型 RAG) • 轻量级,易嵌入 • 面向开发者 | 后端服务嵌入、定制 Chatbot | 简单灵活,易集成 | 缺乏语义层,复杂业务一致性较弱 |
| Chat2DB | 18.3k | AI 数据库客户端 | • AI SQL Copilot • 支持 20+ 数据库 • 自然语言问答 + 仪表盘 • 本地化,数据不出企业 | 技术+业务人员的数据库管理分析 | 安全性强,本地部署,GUI + AI | 更偏工具型,平台化能力待验证 |
| DB-GPT | 12.7k | 大模型原生数据应用开发框架 | • 生成式 BI (GBI) • Text2SQL 微调框架 (Spider 82.5%) • 多 Agent 协作 + AWEL 工作流 • 数据工厂与多数据源 | 企业数据智能平台、复杂多 Agent 协作 | All-in-One,功能全面,社区活跃 | 复杂度高,学习曲线陡 |
| Wren AI | 12.3k | 开源生成式商业智能平台 | • Semantic-First 架构,完整语义层 • Text-to-Chart 自动图表 • dbt/数据工具集成 • Slack/Teams 集成 | 企业级 BI 系统、完整分析流程 | 语义层一致性强,Text-to-Chart | 相对较新,生态待成熟 |
| Dataherald | 3.6k | 开源 NL2SQL 引擎 | • RAG Agent + Fine-tuned Agent • Schema-Linking • 自动错误重试 • Few-shot 示例检索 | 生产就绪的端到端 NL2SQL 方案 | 基于 LangChain,生产就绪 | 商业托管版才有完整 UI |
五、基于LangChain 1.0构建CSV/Excel数据分析Agent系统
接下来我们再看一个数据分析场景。
在企业数据分析场景中,业务人员经常需要从CSV或Excel文件中提取洞察,但大多数人不熟悉编程。传统的BI工具虽然强大,但学习成本高,无法满足临时性、探索性的数据分析需求。
本小节内容,我们将学习如何使用LangChain 1.0构建一个智能数据分析Agent,它能够:
- 自动读取和理解CSV/Excel文件结构
- 接受自然语言提问,自动生成Pandas代码查询数据
- 自动生成可视化图表和分析报告
- 处理超大数据集(避免上下文溢出)
而整体的设计思路我们参考PandaAI中的处理流程,即为避免超大CSV文件超出LLM上下文限制,采用**"元数据优先"**策略:
- 不直接传递全部数据: 只传递表结构(列名、数据类型、前5行样本)
- 代码生成模式: Agent生成Pandas代码,由工具执行并返回结果
- 按需加载: 仅在需要时读取和处理特定数据片段
Step 1: 环境准备与依赖安装
首先安装必要的依赖包。除了LangChain 1.0核心库,还需要数据处理和可视化相关的库。
注意: 确保安装LangChain 1.0及以上版本以使用最新的Agent API。
# 安装核心依赖
# %pip install -qU langchain langchain-openai langgraph
# %pip install -qU pandas openpyxl matplotlib seaborn numpy
! pip show langchain
依赖说明:
langchain&langchain-openai: LangChain 1.0核心框架和OpenAI集成langgraph: Agent底层编排框架pandas: 数据处理核心库openpyxl: Excel文件读取支持matplotlib&seaborn: 数据可视化库numpy: 数值计算库
Step 2: 导入必要模块
导入LangChain 1.0的@tool装饰器和create_agent API,以及数据处理相关的库。
# LangChain 1.0 核心模块
from langchain.tools import tool
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
# LangGraph
from langgraph.checkpoint.memory import InMemorySaver
# 数据处理与可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from typing import Dict, List, Any
import json
import os
import warnings
warnings.filterwarnings('ignore')
# IPython显示
from IPython.display import Image, display
print("模块导入成功!")
Step 3: 配置模型与全局设置
配置OpenAI API密钥并初始化LLM模型。同时设置Matplotlib的可视化样式。
重要: 可视化时不使用中文,避免字体显示问题(方框乱码)。
from dotenv import load_dotenv
load_dotenv(override=True)
# OpenAI API Key (用于GPT模型)
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_API_BASE = os.getenv("OPENAI_BASE_URL")
OPENAI_API_MODEL = os.getenv("OPENAI_MODEL_NAME")
# 初始化模型
model = init_chat_model(
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE,
model=OPENAI_API_MODEL,
temperature=0, # 确保代码生成的稳定性
model_provider="openai"
)
# 设置可视化样式
plt.style.use('seaborn-v0_8-darkgrid')
sns.set_palette("husl")
# 全局变量存储数据
DATAFRAMES = {} # 存储加载的DataFrame
PLOT_COUNTER = 0 # 图表计数器
print("模型初始化完成")
Step 4: 创建数据加载工具
使用@tool装饰器创建第一个工具:加载CSV/Excel文件。
这个工具只返回元数据(表结构、列类型、前5行样本),而不是全部数据,从而避免超出上下文限制。
@tool
def load_data_file(file_path: str) -> str:
"""
Load a CSV or Excel file and return its metadata (structure, not full data).
Args:
file_path: Path to the CSV or Excel file
Returns:
JSON string containing:
- columns: list of column names
- dtypes: data types of each column
- shape: (rows, columns)
- sample: first 5 rows as dict
- statistics: basic statistics for numeric columns
"""
global DATAFRAMES
try:
# 根据文件类型加载
if file_path.endswith('.csv'):
df = pd.read_csv(file_path)
elif file_path.endswith(('.xlsx', '.xls')):
df = pd.read_excel(file_path)
else:
return f"Error: Unsupported file type. Only CSV and Excel files are supported."
# 存储DataFrame
DATAFRAMES[file_path] = df
# 构建元数据
metadata = {
"file_name": file_path,
"shape": {"rows": len(df), "columns": len(df.columns)},
"columns": df.columns.tolist(),
"dtypes": {col: str(dtype) for col, dtype in df.dtypes.items()},
"sample_data": df.head(5).to_dict('records'),
"numeric_stats": df.describe().to_dict() if len(df.select_dtypes(include=[np.number]).columns) > 0 else {},
"missing_values": df.isnull().sum().to_dict()
}
return json.dumps(metadata, indent=2, default=str)
except Exception as e:
return f"Error loading file: {str(e)}"
print("数据加载工具创建完成")
print(" 工具名称: load_data_file")
print(" 功能: 加载CSV/Excel并返回元数据")
这个工具仅传递元数据,即不返回全部数据,只返回结构信息。
Step 5: 创建Pandas代码执行工具
创建第二个工具:执行Pandas代码进行数据查询。Agent生成Pandas代码,这个工具负责安全执行并返回结果。
@tool
def query_data_fixed(file_path: str, pandas_code: str) -> str:
"""Execute Pandas code to query data from the loaded DataFrame."""
global DATAFRAMES
if file_path not in DATAFRAMES:
return f"Error: File '{file_path}' not loaded. Please load it first using load_data_file."
try:
df = DATAFRAMES[file_path]
# 添加 print 到安全内置函数
safe_builtins = {
'len': len,
'str': str,
'int': int,
'float': float,
'bool': bool,
'list': list,
'dict': dict,
'tuple': tuple,
'set': set,
'isinstance': isinstance,
'range': range,
'enumerate': enumerate,
'zip': zip,
'min': min,
'max': max,
'sum': sum,
'abs': abs,
'round': round,
'sorted': sorted,
'reversed': reversed,
'any': any,
'all': all,
'print': print, # 添加 print 支持
'True': True,
'False': False,
'None': None,
}
local_vars = {
'df': df,
'pd': pd,
'np': np,
'_result': None # 用于捕获执行结果
}
# 先尝试作为单行表达式执行(eval),如果失败则作为多行代码执行(exec)
try:
# 尝试单行表达式
result = eval(pandas_code, {"__builtins__": safe_builtins}, local_vars)
except (SyntaxError, TypeError):
# 多行代码:使用 exec 执行
lines = pandas_code.strip().split('\n')
if len(lines) == 1:
# 单行但不是表达式(如赋值语句),直接执行
exec(pandas_code, {"__builtins__": safe_builtins}, local_vars)
# 尝试从常见的变量名获取结果
result = local_vars.get('_result') or local_vars.get('result') or local_vars.get('res')
if result is None:
# 如果还是没有,返回 df(可能用户只是想操作 df)
result = local_vars.get('df', df)
else:
# 多行代码:将最后一行作为表达式赋值给 _result
last_line = lines[-1].strip()
# 检查最后一行是否是赋值语句
if '=' in last_line and not last_line.startswith('_result'):
# 如果最后一行是赋值,保持原样
exec_code = '\n'.join(lines)
else:
# 如果最后一行是表达式,赋值给 _result
lines[-1] = f"_result = {last_line}"
exec_code = '\n'.join(lines)
exec(exec_code, {"__builtins__": safe_builtins}, local_vars)
result = local_vars.get('_result')
# 如果 _result 还是 None,尝试从其他变量获取
if result is None:
for var_name in ['result', 'res', 'data', 'output']:
if var_name in local_vars:
result = local_vars[var_name]
break
# 如果还是 None,返回 df
if result is None:
result = local_vars.get('df', df)
# 格式化结果
if isinstance(result, pd.DataFrame):
if len(result) > 20:
return f"Result (showing first 20 rows):\n{result.head(20).to_string()}\n\nTotal rows: {len(result)}"
else:
return f"Result:\n{result.to_string()}"
elif isinstance(result, pd.Series):
if len(result) > 20:
return f"Result (showing first 20 rows):\n{result.head(20).to_string()}\n\nTotal rows: {len(result)}"
else:
return f"Result:\n{result.to_string()}"
else:
return f"Result: {result}"
except Exception as e:
return f"Error executing code: {str(e)}\n\nPlease check your pandas code syntax."
# 替换旧的 query_data
query_data = query_data_fixed
print("query_data 工具已修复!")
print(" - 添加了 print 支持")
print(" - 修复了 exec 返回 None 的问题")
print(" - 支持单行表达式和多行代码")
Step 6: 创建数据可视化工具
创建第三个工具:生成数据可视化图表。Agent生成绘图代码,工具执行并保存图表。
注意: 所有标签使用英文,避免中文显示为方框。
from langchain.tools import tool
@tool
def create_visualization_fixed(file_path: str, plot_code: str, title: str = "Data Visualization") -> str:
"""Execute plotting code to create data visualization."""
global DATAFRAMES, PLOT_COUNTER
if file_path not in DATAFRAMES:
return f"Error: File '{file_path}' not loaded. Please load it first."
try:
df = DATAFRAMES[file_path]
# 创建新图表
plt.figure(figsize=(12, 6))
#
safe_builtins = {
'len': len,
'str': str,
'int': int,
'float': float,
'bool': bool,
'list': list,
'dict': dict,
'tuple': tuple,
'set': set,
'isinstance': isinstance,
'range': range,
'enumerate': enumerate,
'zip': zip,
'min': min,
'max': max,
'sum': sum,
'abs': abs,
'round': round,
'sorted': sorted,
'reversed': reversed,
'any': any,
'all': all,
'print': print,
'__import__': __import__, # 添加 __import__ 支持(matplotlib 需要)
'True': True,
'False': False,
'None': None,
}
local_vars = {
'df': df,
'pd': pd,
'np': np,
'plt': plt,
'sns': sns
}
# 执行绘图代码
exec(plot_code, {"__builtins__": safe_builtins}, local_vars)
# 设置标题
plt.title(title, fontsize=14, fontweight='bold')
plt.tight_layout()
# 保存图表
PLOT_COUNTER += 1
plot_path = f"plot_{PLOT_COUNTER}.png"
plt.savefig(plot_path, dpi=150, bbox_inches='tight')
plt.close()
return f"Visualization saved to: {plot_path}\nTitle: {title}"
except Exception as e:
plt.close()
return f"Error creating visualization: {str(e)}"
# 替换旧的 create_visualization
create_visualization = create_visualization_fixed
print("create_visualization 工具已修复!")
print(" - 添加了 __import__ 支持")
print(" - 添加了 print 支持")
print(" - matplotlib/seaborn 现在可以正常工作")
Step 7: 配置系统提示词
编写详细的系统提示词,指导Agent如何使用这些工具进行数据分析。我们在提示词中需要说明:
- 工作流程(先加载→查询→可视化)
- Pandas代码编写规范
- 可视化最佳实践
- 英文标签要求
system_prompt = """
You are an expert Data Analyst Agent with deep knowledge of Pandas and data visualization.
## Your Tools
1. **load_data_file**: Load CSV/Excel and get metadata (structure, sample data, statistics)
2. **query_data**: Execute Pandas code to query and analyze data
3. **create_visualization**: Generate charts using matplotlib/seaborn
## Workflow
1. **Always start with load_data_file** to understand data structure
2. Use query_data for calculations, filtering, grouping, aggregations
3. Use create_visualization for charts (bar, line, scatter, pie, etc.)
4. Provide insights and interpretations in plain English
## Pandas Code Guidelines
**DO**:
- Use efficient pandas operations: groupby(), pivot_table(), merge()
- Handle missing values appropriately
- Use descriptive variable names in code
- Limit results with .head() if output is large
**DON'T**:
- Don't use loops when pandas vectorization is possible
- Don't return full datasets (use aggregations/summaries)
- Don't use Chinese characters in code or plot labels
## Visualization Best Practices
**Chart Selection**:
- Bar chart: Compare categories
- Line chart: Show trends over time
- Scatter plot: Show relationships
- Pie chart: Show proportions (use sparingly)
- Heatmap: Show correlations
**Styling Rules**:
- **ALL labels/titles MUST be in English** (avoid font rendering issues)
- Use clear, descriptive titles
- Add axis labels
- Use appropriate colors
- Include legends when needed
## Example Queries
User: "What are total sales by product?"
You:
1. query_data: df.groupby('Product')['TotalSales'].sum().sort_values(ascending=False)
2. create_visualization: df.groupby('Product')['TotalSales'].sum().plot(kind='bar')
3. Provide insight: "Laptop has the highest sales at $X, followed by..."
## Error Handling
- If code fails, explain the error and try a different approach
- Check data types before operations
- Validate that required columns exist
Remember: Be concise, accurate, and always use English for visualizations!
"""
print("系统提示词配置完成")
print(f" 长度: {len(system_prompt)} 字符")
对应的中文版本:
FENCE0
Step 8: 创建数据分析Agent
使用create_agent API创建数据分析Agent,集成所有工具。
# 工具列表
tools = [load_data_file, query_data, create_visualization]
# 创建Agent
agent = create_agent(
model=model,
tools=tools,
system_prompt=system_prompt,
checkpointer=InMemorySaver() # 支持对话记忆
)
print("数据分析Agent创建成功!")
print("\nAgent能力:")
print(" - 加载CSV/Excel文件")
print(" - 执行Pandas数据查询")
print(" - 生成可视化图表")
print(" - 自然语言交互")
print("\n工具数量:", len(tools))
for tool in tools:
print(f" - {tool.name}")
Step 9: 可视化Agent结构
使用get_graph()方法获取Agent的执行图,并进行可视化展示。这有助于理解Agent的工作流程和工具调用链路。
# 可视化Agent执行图
try:
graph_image = agent.get_graph().draw_mermaid_png()
display(Image(graph_image))
print("\nAgent执行图可视化成功!")
except Exception as e:
print(f"可视化失败: {e}")
Step 10: 测试案例1 - 基础数据查询
测试Agent的数据查询能力。提出一个简单的问题,观察Agent的运行过程:
# 配置对话线程
config = {"configurable": {"thread_id": "data-analysis-001"}}
# 测试问题1: 基础查询
question1 = "请分析电子产品销售数据.csv文件,告诉我产品总销售额。"
print("="*80)
print("测试案例1: 产品销售统计")
print("="*80)
print(f"\n用户: {question1}\n")
print("Agent处理中...\n")
print("-"*80)
# 执行Agent
result1 = agent.invoke(
{"messages": [{"role": "user", "content": question1}]},
config=config
)
# 提取回答
print("\n" + "="*80)
print("Agent回答:")
print("="*80 + "\n")
if 'messages' in result1:
for msg in result1['messages']:
if hasattr(msg, 'content') and msg.content and not hasattr(msg, 'tool_calls'):
print(msg.content)
print()
Step 11: 测试案例2 - 数据可视化
测试Agent的可视化能力。要求生成图表,观察Agent的运行过程:
# 测试问题2: 可视化
question2 = "创建一个折线图,显示最新的100条产品总销售额变化趋势"
print("\n" + "="*80)
print("测试案例2: 销售可视化")
print("="*80)
print(f"\n用户: {question2}\n")
print(" Agent处理中...\n")
print("-"*80)
# 执行Agent (使用同一thread_id,保持对话上下文)
result2 = agent.invoke(
{"messages": [{"role": "user", "content": question2}]},
config=config
)
# 提取回答
print("\n" + "="*80)
print("Agent回答:")
print("="*80 + "\n")
if 'messages' in result2:
for msg in result2['messages']:
if hasattr(msg, 'content') and msg.content and not hasattr(msg, 'tool_calls'):
print(msg.content)
print()
当然,也可以测试Agent处理复杂分析需求的能力。比如我们要求进行多维度分析并生成多个可视化。
# 测试问题3: 复杂分析
question3 = """根据电子产品销售数据,分析各地区销售情况:
1. 显示各地区总销售额
2. 创建一个折线图,比较各地区销售表现
3. 识别各地区销售冠军"""
print("\n" + "="*80)
print("测试案例3: 区域销售分析")
print("="*80)
print(f"\n用户:\n{question3}\n")
print("Agent处理中...\n")
print("-"*80)
# 执行Agent
result3 = agent.invoke(
{"messages": [{"role": "user", "content": question3}]},
config=config
)
# 提取回答
print("\n" + "="*80)
print("Agent回答:")
print("="*80 + "\n")
if 'messages' in result3:
for msg in result3['messages']:
if hasattr(msg, 'content') and msg.content and not hasattr(msg, 'tool_calls'):
print(msg.content)
print()
加载并显示Agent生成的所有可视化图表。
# 展示所有生成的图表
import glob
from IPython.display import Image, display
plot_files = sorted(glob.glob("plot_*.png"))
if plot_files:
print("="*80)
print(f"生成的图表 (共 {len(plot_files)} 张)")
print("="*80 + "\n")
for i, plot_file in enumerate(plot_files, 1):
print(f"[图表 {i}] {plot_file}")
display(Image(filename=plot_file))
print("\n" + "-"*80 + "\n")
else:
print("未找到生成的图表")
分析Agent的完整执行历史,了解工具调用情况和推理过程。
# 获取Agent状态
state = agent.get_state(config)
messages = state.values.get('messages', [])
print("="*80)
print(f"Agent执行历史 (共 {len(messages)} 步)")
print("="*80 + "\n")
# 统计工具调用
tool_calls_count = {}
for msg in messages:
if hasattr(msg, 'tool_calls') and msg.tool_calls:
for tc in msg.tool_calls:
tool_name = tc.get('name', 'unknown')
tool_calls_count[tool_name] = tool_calls_count.get(tool_name, 0) + 1
print("工具调用统计:")
for tool, count in sorted(tool_calls_count.items(), key=lambda x: x[1], reverse=True):
print(f" - {tool}: {count} 次")
print(f"\n数据概览:")
print(f" - 对话轮次: {len([m for m in messages if m.__class__.__name__ == 'HumanMessage'])}")
print(f" - Agent响应: {len([m for m in messages if m.__class__.__name__ == 'AIMessage'])}")
print(f" - 工具执行: {len([m for m in messages if m.__class__.__name__ == 'ToolMessage'])}")
print(f" - 总步骤数: {len(messages)}")
逐步展示Agent的推理和工具调用过程,清晰看到每一步的输入输出。
# 详细展示执行过程
print("="*80)
print("详细执行过程")
print("="*80 + "\n")
for i, msg in enumerate(messages, 1):
msg_type = msg.__class__.__name__
if msg_type == "HumanMessage":
print(f"\n{'─'*80}")
print(f"[步骤 {i}] 用户提问")
print(f"{'─'*80}")
print(f"{msg.content}\n")
elif msg_type == "AIMessage":
print(f"\n{'─'*80}")
print(f"[步骤 {i}] Agent决策")
print(f"{'─'*80}")
if hasattr(msg, 'tool_calls') and msg.tool_calls:
print("工具调用:")
for tc in msg.tool_calls:
tool_name = tc.get('name', 'unknown')
args = tc.get('args', {})
print(f"\n {tool_name}")
print(f" 参数:")
for key, value in args.items():
value_str = str(value)[:150] if len(str(value)) > 150 else str(value)
print(f" - {key}: {value_str}")
if msg.content:
print(f"\n思考: {msg.content[:200]}...")
elif msg_type == "ToolMessage":
print(f"\n[步骤 {i}] 工具返回")
content = str(msg.content)
preview = content[:300] if len(content) > 300 else content
print(f"{preview}")
if len(content) > 300:
print(f"\n... (共 {len(content)} 字符)")
print()
print("\n" + "="*80)
六、基于LangChain 1.0构建AI数据分析系统
最后,我们将使用LangChain 1.0的ReAct Agent架构,结合FastAPI后端和React前端,构建一个完整的智能SQL问答系统。该系统支持自然语言查询数据库表和CSV文件,并自动生成数据分析报告和可视化图表。
项目架构技术点
| 技术点 | 说明 |
|---|---|
ReAct Agent | 思考-行动-观察循环,自动选择合适的工具 |
SQLDatabaseToolkit | LangChain的SQL工具包,提供4个核心工具 |
CSV转SQLite | 将CSV文件动态转换为临时数据库 |
FastAPI流式响应 | 实时返回查询结果和分析报告 |
自动可视化 | 基于数据类型智能选择图表类型 |
系统核心价值是可以让用户用自然语言查询和分析数据,而不需要学习SQL语法,即时返回查询结果、可视化图表和数据分析报告。

6.1 系统架构设计
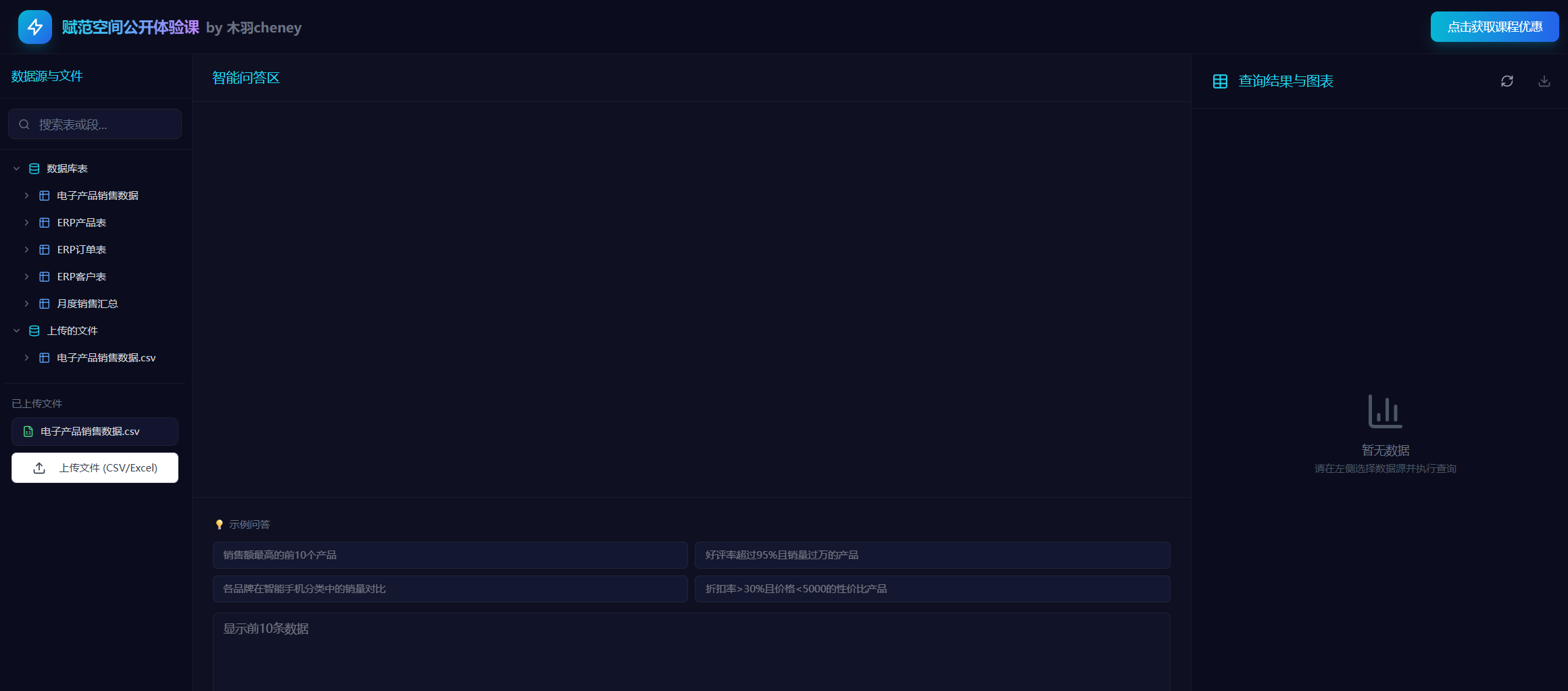
在开始编码之前,我们先了解整个系统的架构设计。这是一个典型的三层架构:前端展示层、后端API层、业务逻辑层。
FENCE0
技术栈
| 层级 | 技术选型 | 版本 | 核心作用 |
|---|---|---|---|
| 前端 | React + TypeScript | 18.3 + 5.2 | 用户交互界面 |
| 前端 | TailwindCSS + Radix UI | 3.4 | 现代化UI组件 |
| 前端 | Recharts | 2.15+ | 数据可视化 |
| 后端 | FastAPI | 0.115+ | 高性能异步API |
| 后端 | LangChain | 1.0.3+ | AI Agent框架 |
| 后端 | SQLAlchemy + Pandas | 2.0.30+ | 数据处理 |
| 数据 | SQLite | - | 轻量级数据库 |
系统的核心是SQLAgentManager类,它封装了LangChain的SQL Agent逻辑。其核心设计思路是基于 ReAct (Reasoning + Acting) 架构:
- Thought (思考): 分析用户问题,决定下一步操作
- Action (行动): 调用工具(如查看表结构、执行SQL)
- Observation (观察): 获取工具返回的结果
- 循环: 重复上述过程,直到得到最终答案
6.2 核心Agent设计思路
核心代码位置:
核心提示词如下:
# ==================== 继续实现 SQLAgentManager ====================
class SQLAgentManager:
# ... 前面的代码 ...
def _create_prompt(self):
"""
创建 ReAct Prompt
这是Agent的核心"指令",决定了:
1. Agent的行为方式
2. SQL生成的质量
3. 分析报告的专业度
"""
# 获取数据库中的表名
available_tables = self.db.get_usable_table_names() if self.db else []
template = f"""你是一个专业的数据分析师,专门帮助用户查询和分析 SQLite 数据库。
**数据库中的表: {available_tables}**
你有以下工具可以使用:
- sql_db_list_tables: 列出数据库中的所有表
- sql_db_schema: 查看特定表的结构和示例数据
- sql_db_query: 执行 SQL 查询并返回结果
- sql_db_query_checker: 在执行前检查 SQL 查询的正确性
**执行步骤:**
1. **重要**: 使用 sql_db_list_tables 查看数据库中实际的表名(绝对不要猜测表名)
2. 使用 sql_db_schema 查看表的结构和列名
3. 仔细理解用户问题,提取关键信息:
- 如果用户要求"前N条"、"显示N条"、"N个",SQL 必须使用 LIMIT N
- 如果用户没有指定数量,默认使用 LIMIT 10
4. 根据实际表名和列名,生成准确的 SQL 查询
5. 使用 sql_db_query_checker 检查 SQL 正确性
6. 使用 sql_db_query 执行查询
**输出格式:**
查询完成后,请根据用户的具体问题,用 Markdown 格式输出针对性的数据分析报告,包含:
## 📊 数据分析报告
### 核心发现
- 总结最重要的 2-3 个发现(用具体数据支撑)
### 详细分析
- 深入分析查询结果,回答用户的问题
- 分析数据的分布、趋势或特征
### 建议
- 基于查询结果给出 1-2 条可执行的建议
**重要提示:**
1. 分析报告必须直接回答用户的问题,不要使用通用模板
2. 引用查询结果中的具体数据
3. 不要在报告中列出原始数据,数据会自动显示在表格中
{{tools}}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{{tool_names}}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {{input}}
Thought: {{agent_scratchpad}}"""
return PromptTemplate.from_template(template)
# 添加到 SQLAgentManager 类中
SQLAgentManager._create_prompt = _create_prompt
print("系统提示词设计完成")
print(" - 包含角色定位、工具说明、执行步骤")
print(" - 强制要求使用 LIMIT 避免返回大量数据")
print(" - 输出 Markdown 格式的专业分析报告")
此外,对于上传.CSV / .Excel 文件,需要进行动态转换为临时SQLite数据库,并创建SQLAgentManager对象。其转换过程为:CSV文件上传 → Pandas读取 → 清理列名 → 写入SQLite → 创建Agent → 执行查询,核心的关键点在于:
技术栈
| 问题 | 解决方案 | 原因 |
|---|---|---|
| 中文列名 | 保留原样,SQLite支持 | 用户友好 |
| 特殊字符列名 | 转为下划线 | SQL标识符规范 |
| UUID表名 | 预先清理连字符 | 避免表名不一致 |
| 临时数据库 | 使用内存或临时文件 | 提高性能 |
核心难点: 表名一致性问题!
UUID格式:
8d67c87a-b3e2-4865-85be-8bb57b83bf6b如果不预先清理,LangChain会自动将
-转为_,导致表名不匹配!
有了Agent和数据库,接下来实现查询执行逻辑。这里的核心是从Agent的推理步骤中提取SQL和数据。
用户问题: "销售额最高的前5个产品"
FENCE0
6.3 Agent API接口服务
有了核心的SQLAgentManager,我们需要用FastAPI封装成Web API,供前端调用。
技术栈
| 端点 | 方法 | 功能 | 请求参数 |
|---|---|---|---|
/health | GET | 健康检查 | - |
/datasources | GET | 获取数据源列表 | - |
/upload | POST | 上传CSV文件 | file (文件) |
/query | POST | 智能查询(核心) | query, file_id/table_name |
/files/{file_id} | DELETE | 删除文件 | file_id (路径参数) |
核心代码如下:
6.4 前后端服务启动
完整的系统需要同时启动后端和前端两个服务。首先对于后端服务启动,需要依次执行如下操作:
FENCE0
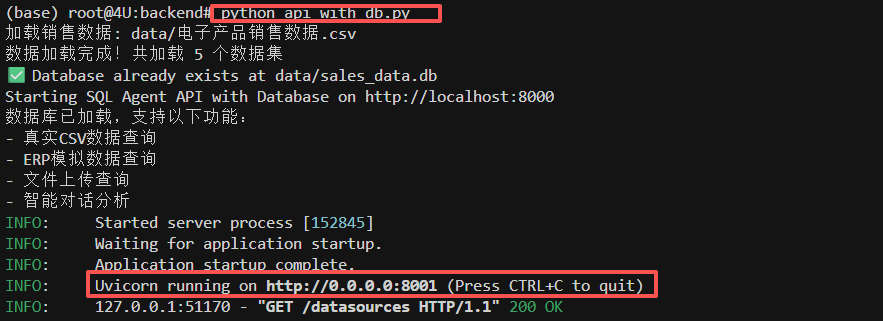
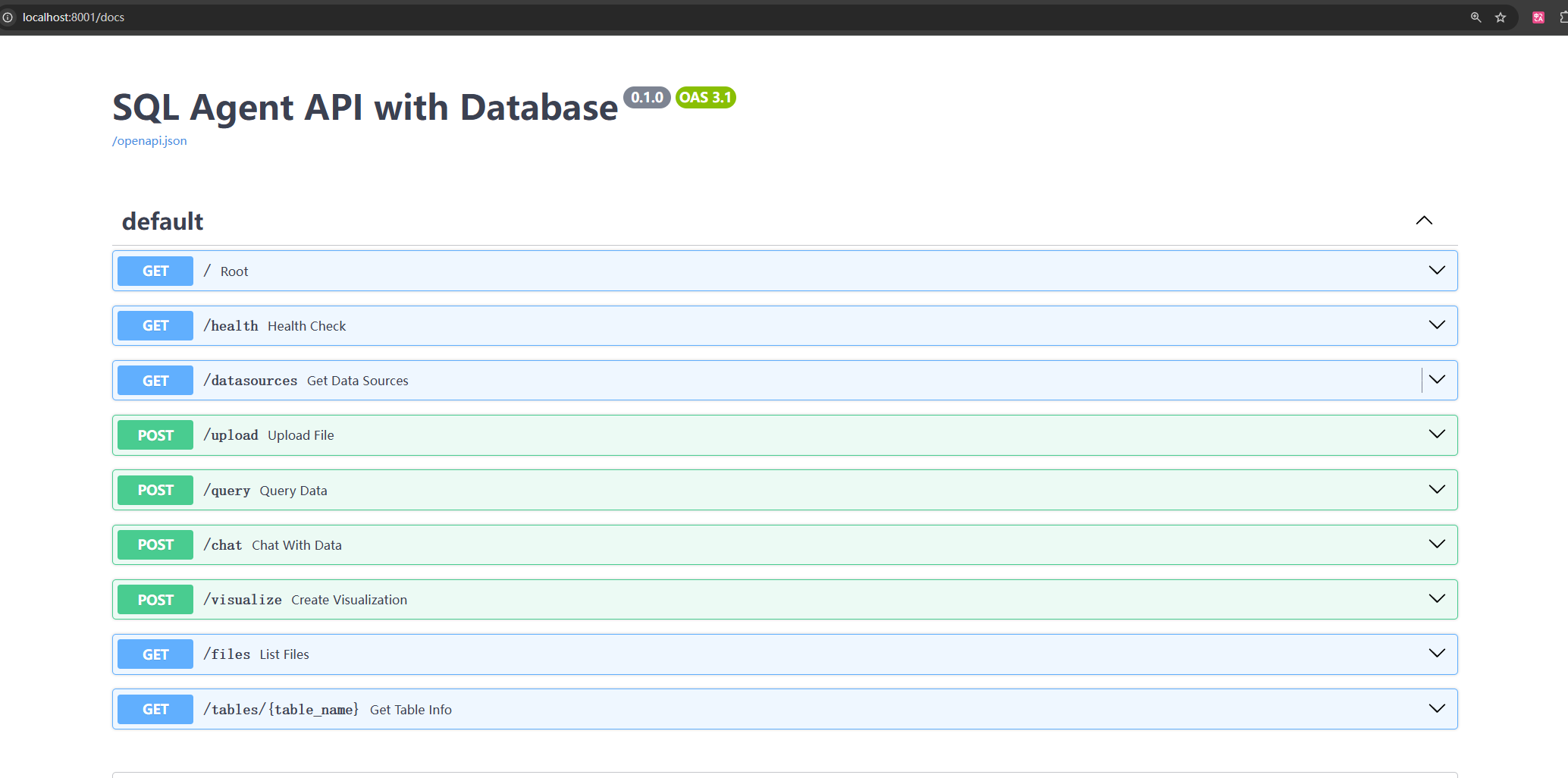
启动成功后,即可通过http://localhost:8001/docs访问FastAPI的自动文档。
前端服务启动,需要依次执行如下操作:
FENCE0
启动成功后,即可通过http://localhost:3000访问应用。
我们下期公开课,再见! 👋