LangChain1.0 + OCR 多模态PDF解析实战 (v3)
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(11月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(11月班)

《2025大模型Agent智能体开发实战》(11月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
11月班 · 重磅新增


11月班 · 重磅新增14项实战案例

完整课程介绍

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由九天老师亲自带队主讲的《大模型强化学习实战》(全网首发)


大模型11月班·双十一抢先购,直播间特惠进行时,直播间享五折特价+全套SVIP新班特定福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

《大模型Agent开发实战》(体验课)
LangChain1.0 + OCR 多模态PDF解析实战
MinerU & Paddle-OCR & DeepSeek-OCR 深度集成
本期公开课,我们将从零开始,手把手带大家将目前行业内性能最强的OCR解析项目:MinerU、DeepSeek-OCR和PaddleOCR-VL通过vLLM推理框架进行高性能部署,并实现具有统一解析服务接口的多模态数据分析系统。
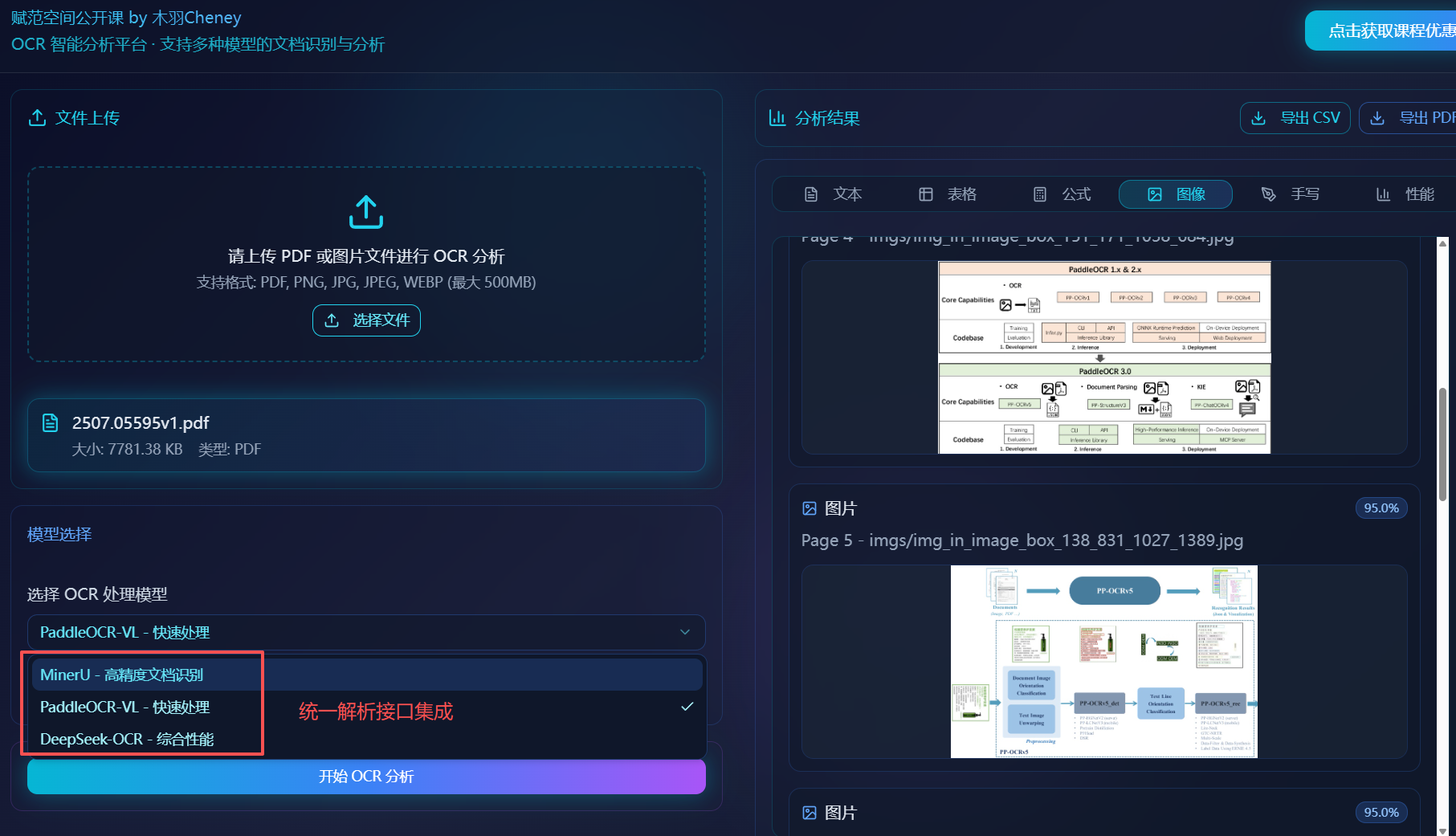
核心功能一:源码部署 MinerU,使用 vLLM 启动推理服务,并以 MCP Server方式与LagnChain完成集成,支持批量解析多模态PDF、图片格式文件;
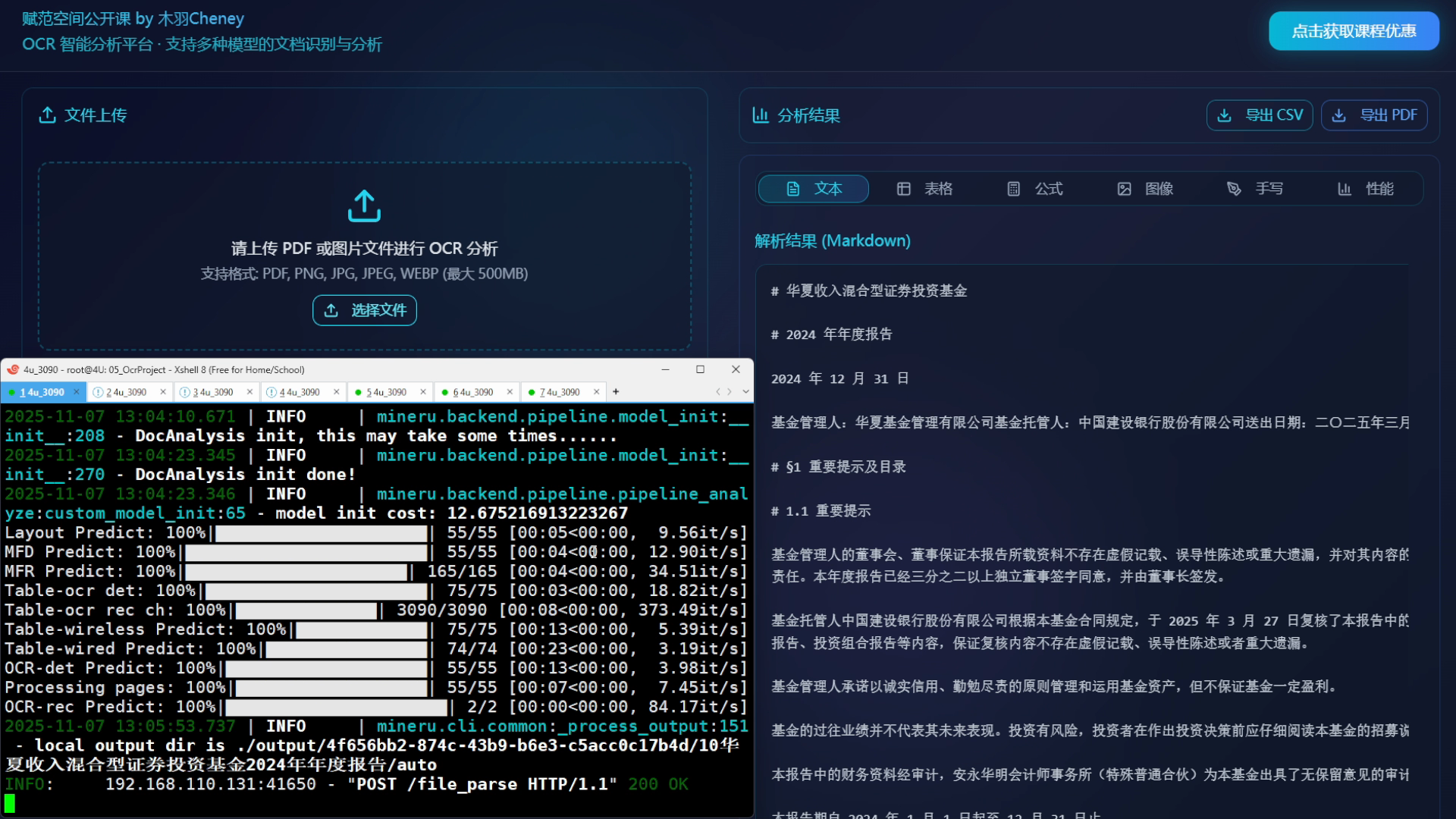
核心功能二:使用 vLLM 推理框架部署启动 DeepSeek-OCR 解析服务接口,并支持批量解析PDF和图像文件格式;
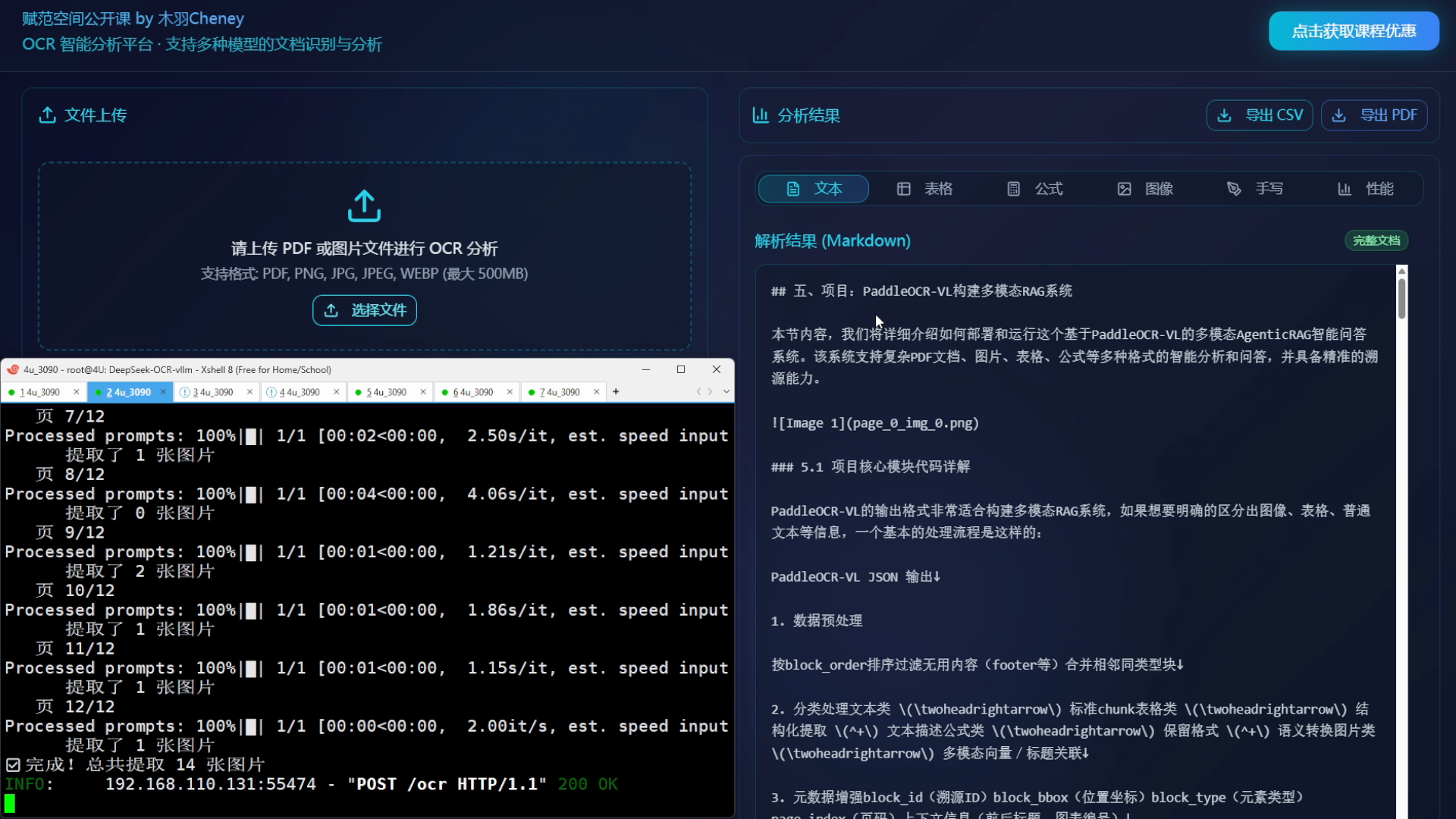
核心功能三:本地部署 PaddleOCR-VL ,并通过 PaddleOCR CLI 工具挂载 vLLM 推理服务,提供极高性能的OCR解析服务,支持批量解析PDF和图像文件格式;
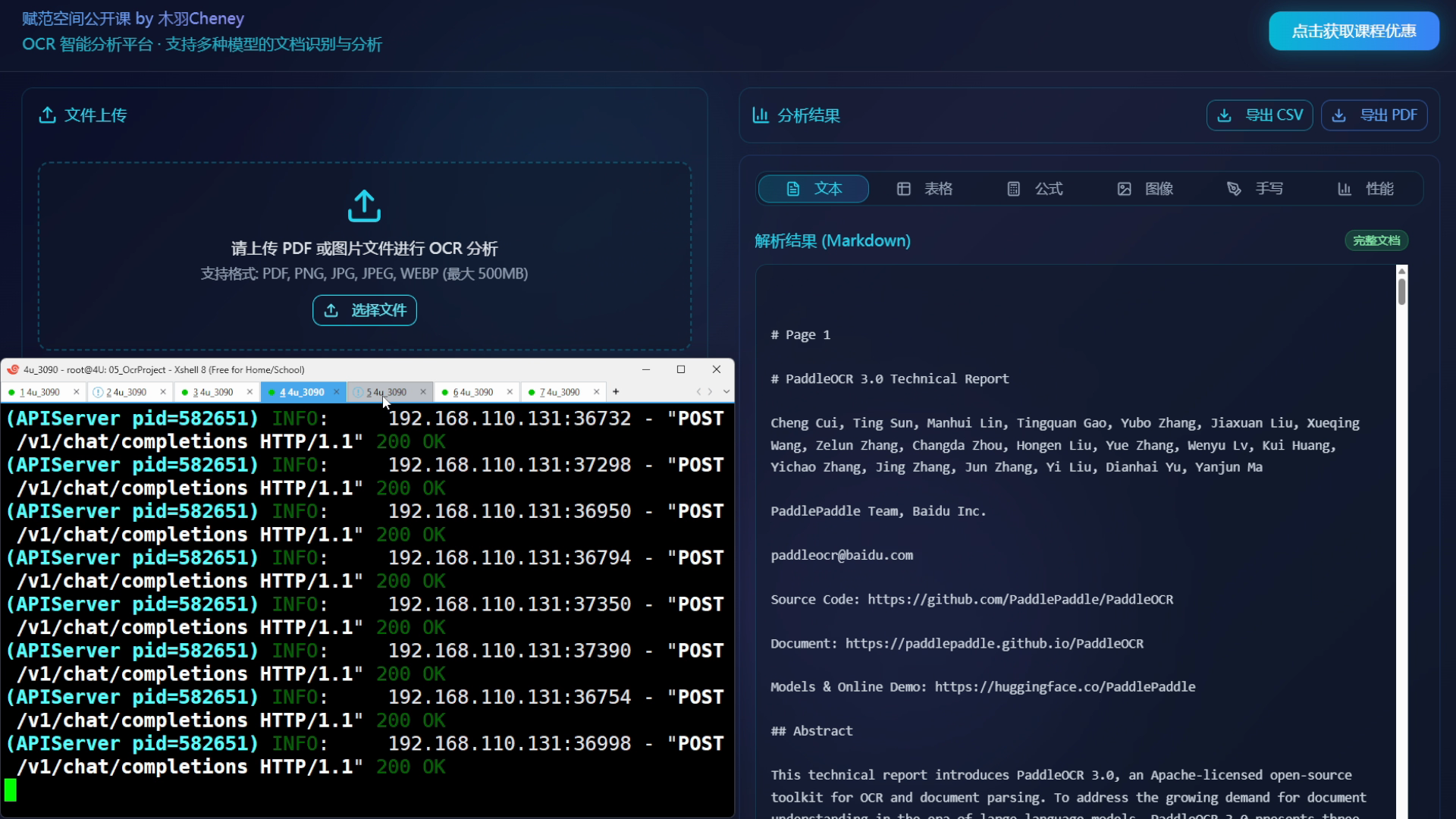
该项目包含我们针对DeepSeek-OCR、MinerU等服务接口的独家自研代码程序,及完整的本地部署流程。同时,我们也将提供全部的前后端源码供大家学习和使用,是真正可以直接在企业中落地的项目。
一、PDF文件难点与解析方法总览
目前,无论是做Agent智能体应用,还是专注于做RAG知识库问答,PDF格式文件都是最难处理的文件类型,没有之一。主要原因在于PDF格式文件的结构非常复杂,包含文本、图像、表格等多种类型的数据,很多上下文信息都是通过标题、图片、图表和格式等来传达的,我们需要保留这些信息并进行有效的存储,才能够保证在应用阶段正确识别出有效的文本,从而使大模型能够更好地确定如何“思考”给定内容中提供的信息。
我们这里以RAG应用方向为例。
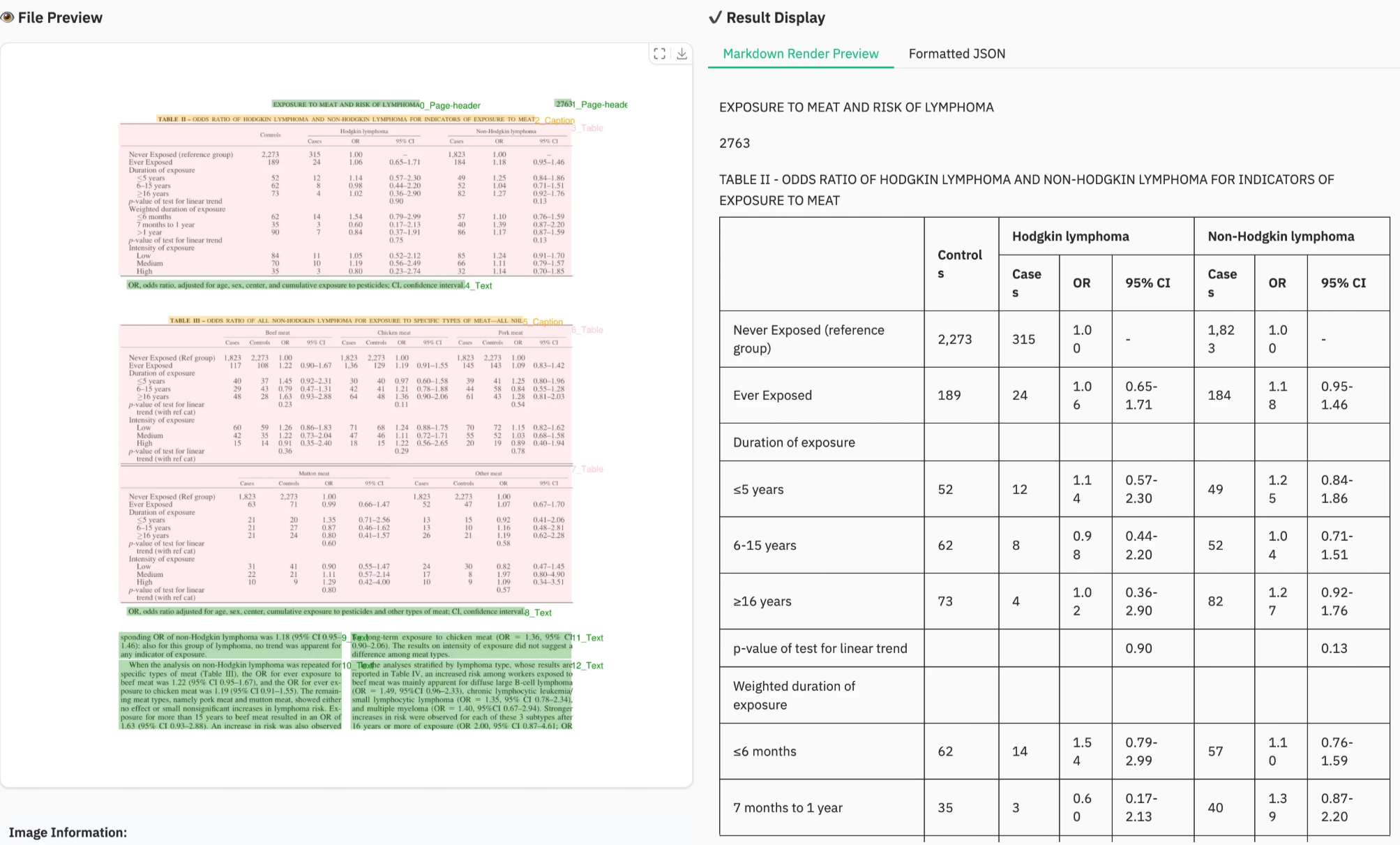
RAG系统往往是需要依靠高质量的结构化数据来生成准确且与文本相关的输出。PDF 通常用于官方文件、业务报告和法律合同,包含大量信息,但其布局复杂且数据结构不合理。如果做不到精确的 PDF 解析,关键数据就会丢失,从而导致结果不准确并直接影响 RAG 应用程序的有效性。因此,PDF格式文件的索引和检索的流程,在RAG框架中的实现过程如下图所示:
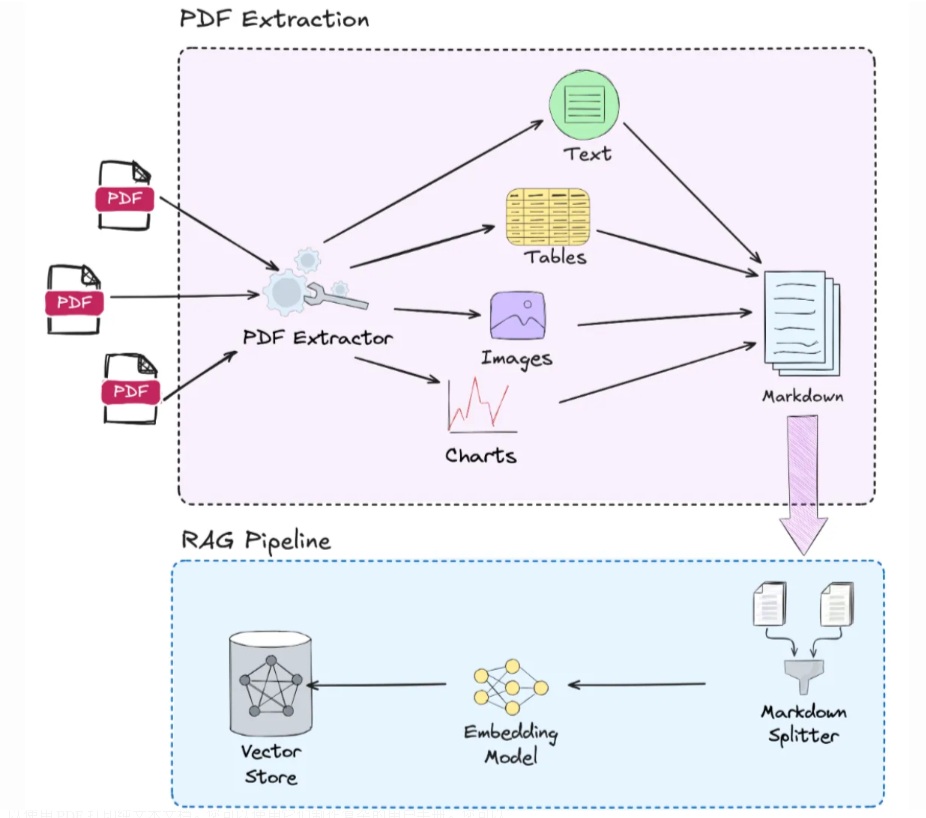
我们在实际构建RAG的第一步,往往是先做PDF Parsing,即PDF解析。所谓的PDF Parsing,指的是提取 PDF 文件中的内容并将其转换为结构化格式的过程,对于PDF格式的这种文件特点,就不能像处理.txt、.csv、.json等文件那样,直接使用Python的open函数打开文件,然后逐行读取文件内容,然后进行处理。它涉及分析 PDF 文件的结构和内容以提取有意义的信息,即把PDF文件中的文本、图像、表格和元数据等正确的识别出来,同时还需要解析出PDF文件的结构信息,比如:页眉、页脚、页码、章节、段落、标题等。
在RAG处理PDF格式文件的解析过程中,将其先转换为Markdown文件再做后处理是目前通用的做法。 Markdown 格式文件自2023年起就一直是在大模型领域的最流行格式,像ChatGPT、DeepSeek等聊天机器人格式化其响应的方式都是使用的Markdown语法,包括我们课程中的所有项目案例Fufan_chat、MateGen Pro和AssistGen,采取的做法都是后端实现流式输出,通过SSE协议将结果返回给前端,前端再通过Markdown语法进行展示。如下所示:DeepSeek的响应会以大而粗的字体呈现标题,以及通过使用粗体文本表示关键字。

如下是 Markdown 语法的一些基本示例:
FENCE0
这种结构优势很明显,比如能给标题、表格、列表、链接等提供结构化的信息,添加了印刷强调元素,例如粗体或斜体,还能提供代码块、数学公式、图片、图表等,即易于编写,又易于阅读,即可以保留文档的原始结构,这包括保留布局、顺序以及不同部分(例如页眉、脚注、表格)之间的连接。对大模型来说,阅读和理解这种类型的输入文档上下文中是非常有效的。也正是因为Markdown格式文件的这种优势,所以现在主流的处理PDF格式文件的库、框架、工具,都是优先针对PDF --> Markdown 提取策略展开研究和优化。
- OCR技术兴起的背景
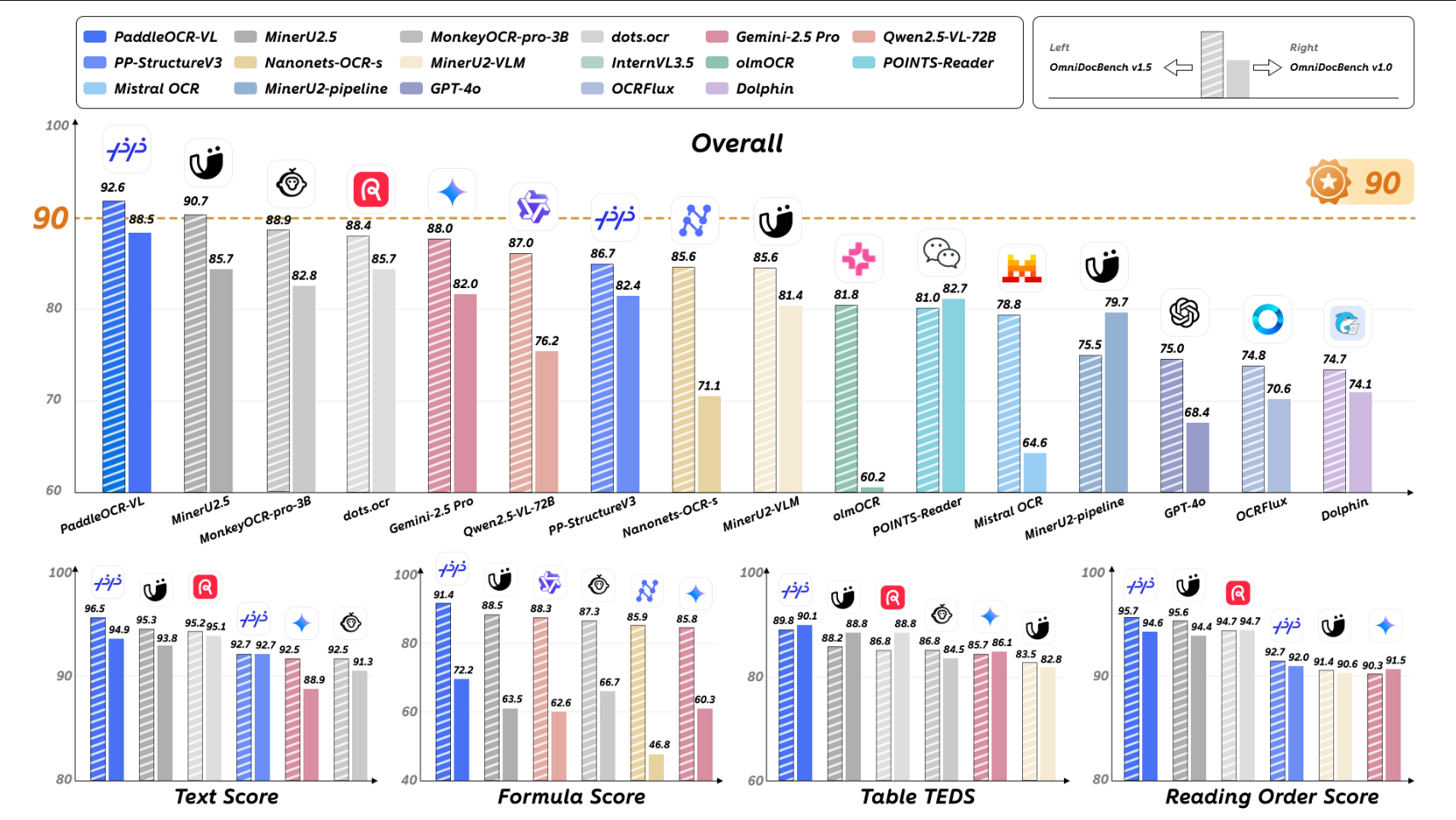
也正是随着这种多模态数据难处理的困境,OCR 技术也迎来了新的快速发展机遇。2025年10月16日发布的 PaddleOCR-VL 模型直接屠榜,在全球权威榜单OmniDocBench V1.5中以92.6分夺得综合性能第一,横扫文本识别、公式识别、表格理解与阅读顺序四项SOTA。

而紧接其后,DeepSeek 也于 2025年10月21日发布了 DeepSeek-OCR 模型,仅需7G的显存,就能完成高精度的表格、公式识别,图片语义识别,并且在多项评测指标中一举拿下SOTA成绩。
这类模型的兴起,完全是源于真实应用需求的驱动。
OCR(全称:Optical Character Recognition,光学字符识别)是将包含文本的图像(如扫描文档、照片、表单、书页)转换成 机器可读的文本格式的技术,如下图所示:

这类模型并不是传统的OCR模型,而是拥有大模型多模态能力的OCR模型,这种模型被称为VLM(Vision-Language Model)模型、或者OCR 2.0模型。其中最本质的区别,就是多模态大模型在进行图像识别之前,会借助一个名叫视觉编码器的算法,将图像视觉信息映射到文本空间中,然后再借助大模型对文本语义的理解能力,间接的去理解图像信息。
简单理解就是:你有一张扫描的图片,上面写满了打印或手写的文字,OCR 技术可以把这些“文字图像”变成“真实的文本数据”(可以编辑、搜查、分析)而不是只是“一个图片”而已。
目前企业在做的大部分业务场景都是以正确识别不同文档类型的内容为前提,比如处理大量纸质文档(发票、合同、报表、表单、收据等),需要通过 OCR 可以把这些纸质/图像文档转换为电子数据,从而更便于存储、检索、分析。 在数字化、智能化流程(例如自动化数据输入、档案管理、人工智能分析)中,它同样也是一个基础环节。
二、企业级OCR项目适用场景及优劣势分析
就目前的发展来看,OCR 与 RAG 的技术结合并不像简单的传统 OCR 是“你给我一张图像,我把文字提取出来”就可以了,重点不能仅仅放在去提取文字,而是要在 OCR 的基础上,不仅仅是“图像中的文字”被识别,还需要结合 视觉(图像)、语言(文本)、版面结构(布局)、场景环境/上下文 等多个模态(modalities)一起分析,使得识别和理解更强、更智能。
现代文档不仅仅是文本。它们包含多列布局、数学公式、半扫描表格、多语言文本以及分辨率奇数的图表。像 GPT-4o 或 Qwen-VL 这样的端到端模型可以解析它们,但它们速度慢、布局混乱,并且耗费 GPU 内存。所以企业环境下往往会选择更小、更紧凑的视觉模型来为解析工作提供支持。主流的企业级OCR项目应用如下:
- MinerU:点击进入
MinerU 是由 OpenDataLab(上海人工智能实验室下属团队)发起的一个开源工具,目标是将 PDF(含扫描件、复杂版式、多栏、多表格、多公式)转换为可机读的结构化格式(如 Markdown、JSON)以便进一步下游使用。项目的定位更偏「文档内容抽取/结构化」而不仅仅是传统 OCR。其取向是“将 PDF → Markdown/JSON”这一流程,而不仅“图片 → 文字”。
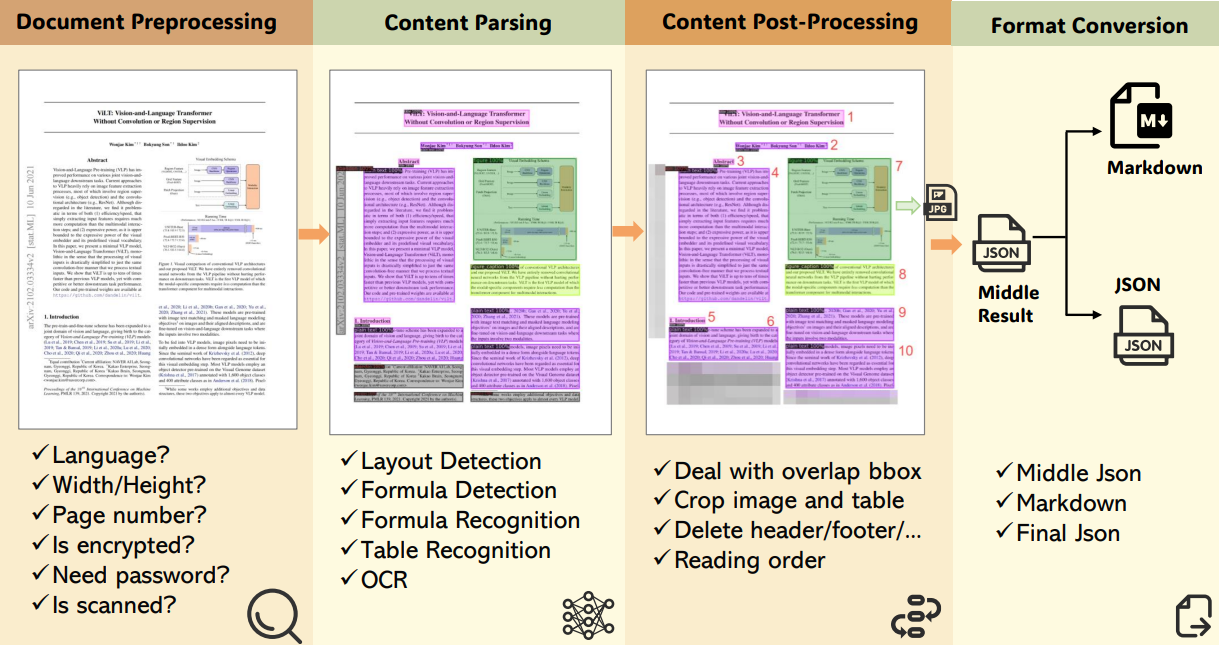
MinerU的主要工作流程分为以下几个阶段:
- 输入:接收
PDF格式文本,可以是简单的纯文本,也可以是包含双列文本、公式、表格或图等多模态PDF文件; - 文档预处理(Document Preprocessing):检查语言、页面大小、文件是否被扫描以及加密状态;
- 内容解析(Content Parsing):
- 局分析:区分文本、表格和图像。
- 公式检测和识别:识别公式类型(内联、显示或忽略)并将其转换为
LaTeX格式。 - 表格识别:以
HTML/LaTeX格式输出表格。 - OCR:对扫描的
PDF执行文本识别。
- 内容后处理(Content Post-processing):修复文档解析后可能出现的问题。比如解决文本、图像、表格和公式块之间的重叠,并根据人类阅读模式重新排序内容,确保最终输出遵循自然的阅读顺序。
- 格式转换(Format Conversion):以
Markdown或JSON格式生成输出。 - 输出(Output):高质量、结构良好的解析文档。
如下是MinerU项目官方给出的配置参考:
VLM-Transformer则是直接利用transformers库中的Vision-Language模型处理图像+文本的多模态输入,其流程如下:

而VLM-Sglang后端则是利用sglang高性能推理引擎,优化了GPU加速及分布式部署的基础上同时支持实时流式输出,其流程如下:

MinerU 项目非常适用于:
-
需要从大量 PDF 文档中抽取结构化内容(例如学术文献、技术白皮书、报告)用于知识库或训练语料。
-
对版式结构(如章节、列表、表格、公式)要求较高,而不只是 OCR 文本识别。
-
希望输出 Markdown/JSON 供后续自动化流水线使用。
-
PaddleOCR:点击进入
PaddleOCR 是由 Baidu (及其生态) 基于其深度学习框架 PaddlePaddle 提供的开源 OCR 工具箱。支持从 PDF 或图像文档转为结构化数据(适配 AI 场景),支持 100+ 语言。最新版本 3.0 在其技术报告中提出:PP-OCRv5、PP-StructureV3、PP-ChatOCRv4 三大解决方案,覆盖文字识别、多版式文档解析、关键 信息提取。

在早期版本(如 PP-OCRv3)中,其结构可概括为:“检测 (Detection) → 分类 (Classification of orientation) → 识别 (Recognition)”。使用多种模型,例如检测模型(DBNet 等)、识别模型(如 SVTR),在 3.0 版本中,其“PP-StructureV3”整合了布局分析、表格识别、结构抽取。同时还最新推出了还推出了PaddleOCR-VL 的 Vision-Language 模型版本(0.9B 参数的 VLM),用于多语种文档解析。
PaddleOCR-VL 是推出的一个专注于“文档解析/视觉-语言模型 (Vision-Language Model, VLM)”功能的新模块,采用了视觉-语言模型架构以应对更高阶的需求。在解析多模态数据方面,PaddleOCR将这项工作分为两部分:
- 首先检测并排序布局元素。
- 使用紧凑的视觉语言模型精确识别每个元素。
该系统分为两个明确的阶段运行。
第一阶段是执行布局分析(PP-DocLayoutV2),此部分标识文本块、表格、公式和图表。它使用:
- RT-DETR 用于物体检测(基本上是边界框 + 类标签)。
- 指针网络 (6 个转换器层)可确定元素的读取顺序 ,从上到下、从左到右等。
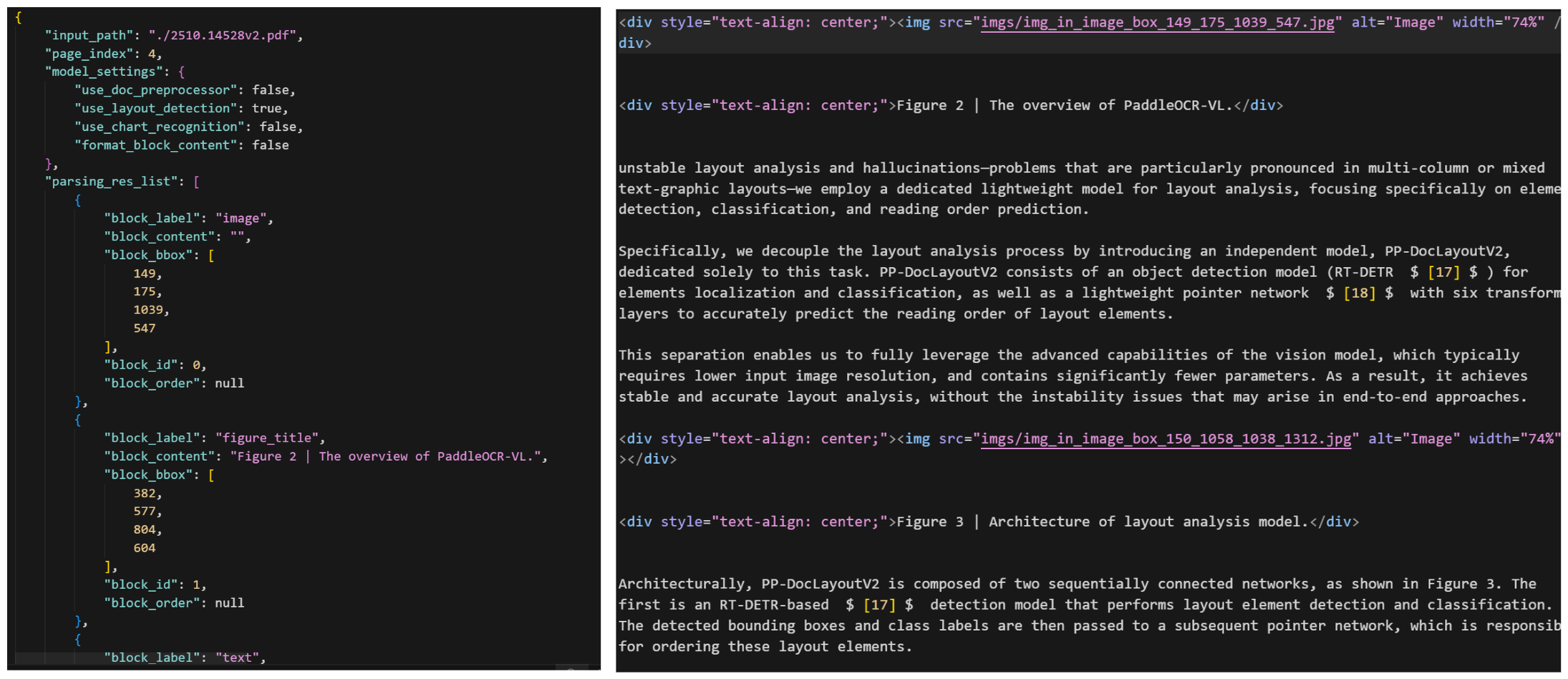
最终输出统一模式的图片标注数据,如下图所示:

第二阶段则是元素识别(PaddleOCR-VL-0.9B),这就是视觉语言模型发挥作用的地方。它使用:
- NaViT 风格编码器 (来自 Keye-VL),可处理动态图像分辨率。无平铺,无拉伸。
- 一个简单的 2 层 MLP, 用于将视觉特征与语言空间对齐。
- ERNIE-4.5–0.3B 作为语言模型,该模型规模虽小但速度很快,并且采用 3D-RoPE 进行位置编码
最终模型输出结构化 Markdown 或 JSON 格式的文件用于后续的处理。
这个小小的设计决策, 将布局和识别分离,使得 PaddleOCR-VL 比通常的一体化系统更快、更稳定。同时根据实际的测试,其运行和解析速度也更快。在 A100 GPU 上, 吞吐量为 1.22 页/秒,。比 MinerU2.5 快 15.8%, VRAM 比 dots.ocr 少约 40%。
- DeepSeek-OCR:点击进入
DeepSeek 于 2025年10月21日发布了 DeepSeek-OCR 模型,仅需7G的显存,就能完成高精度的表格、公式识别,图片语义识别,并且在多项评测指标中一举拿下SOTA成绩。其 Github 相较于其他项目相对比较"简陋",仅仅提供了Transformers 和 vLLM 启动 DeepSeek-OCR的服务示例代码文件:
- dots.ocr:点击进入
dots.ocr 是由 rednote‑hilab(HiLab团队)开源的多语种文档布局解析工具。官方介绍中强调:“一个统一的 Vision-Language 模型(≈1.7 B 参数)即可完成布局检测 + 内容识别 +阅读顺序排序”。支持文本、表格、公式、以及多语言输入。

dots.ocr 的特点是用一个 VLM(1.7 B 参数)来统一布局解析+内容识别,而不是传统将检测、识别、结构分开。用户可通过不同 prompt 来切换任务(如“请输出版式元素的 bbox、类别、文本”)→ 即说明模型采用 prompt + VLM 的方式。
非常适合需要快速处理多语种、混版式文档,且希望用一个统一模型/prompt 来搞定。虽然表现不错,但对于极复杂的表格(如跨页表、合并单元格)或特殊版式效果并不是很理想。
三、MinerU 项目概览与vllm 服务接口
MinerU是一个非常典型的基于管道的解决方案 (Pipeline-based solution) ,并且是一个开源文档解析项目,一共四个核心组件,通过Pipeline的设计无缝衔接,实现比较高效、准确的文档解析。如下图所示:(下图来源官方论文:https://arxiv.org/pdf/2409.18839v1 )
MinerU的主要工作流程分为以下几个阶段:
- 输入:接收
PDF格式文本,可以是简单的纯文本,也可以是包含双列文本、公式、表格或图等多模态PDF文件; - 文档预处理(Document Preprocessing):检查语言、页面大小、文件是否被扫描以及加密状态;
- 内容解析(Content Parsing):
- 局分析:区分文本、表格和图像。
- 公式检测和识别:识别公式类型(内联、显示或忽略)并将其转换为
LaTeX格式。 - 表格识别:以
HTML/LaTeX格式输出表格。 - OCR:对扫描的
PDF执行文本识别。
- 内容后处理(Content Post-processing):修复文档解析后可能出现的问题。比如解决文本、图像、表格和公式块之间的重叠,并根据人类阅读模式重新排序内容,确保最终输出遵循自然的阅读顺序。
- 格式转换(Format Conversion):以
Markdown或JSON格式生成输出。 - 输出(Output):高质量、结构良好的解析文档。
目前在Github 上,MinerU 的Star 数为48.2K,Fork 数为4K,拥有非常良好的社区支持和活跃的贡献者,且一直处于active development状态。
MinerU 提供了在线Demo 页面,我们可以直接线进行测试。试用地址:https://opendatalab.com/OpenSourceTools/Extractor/PDF/
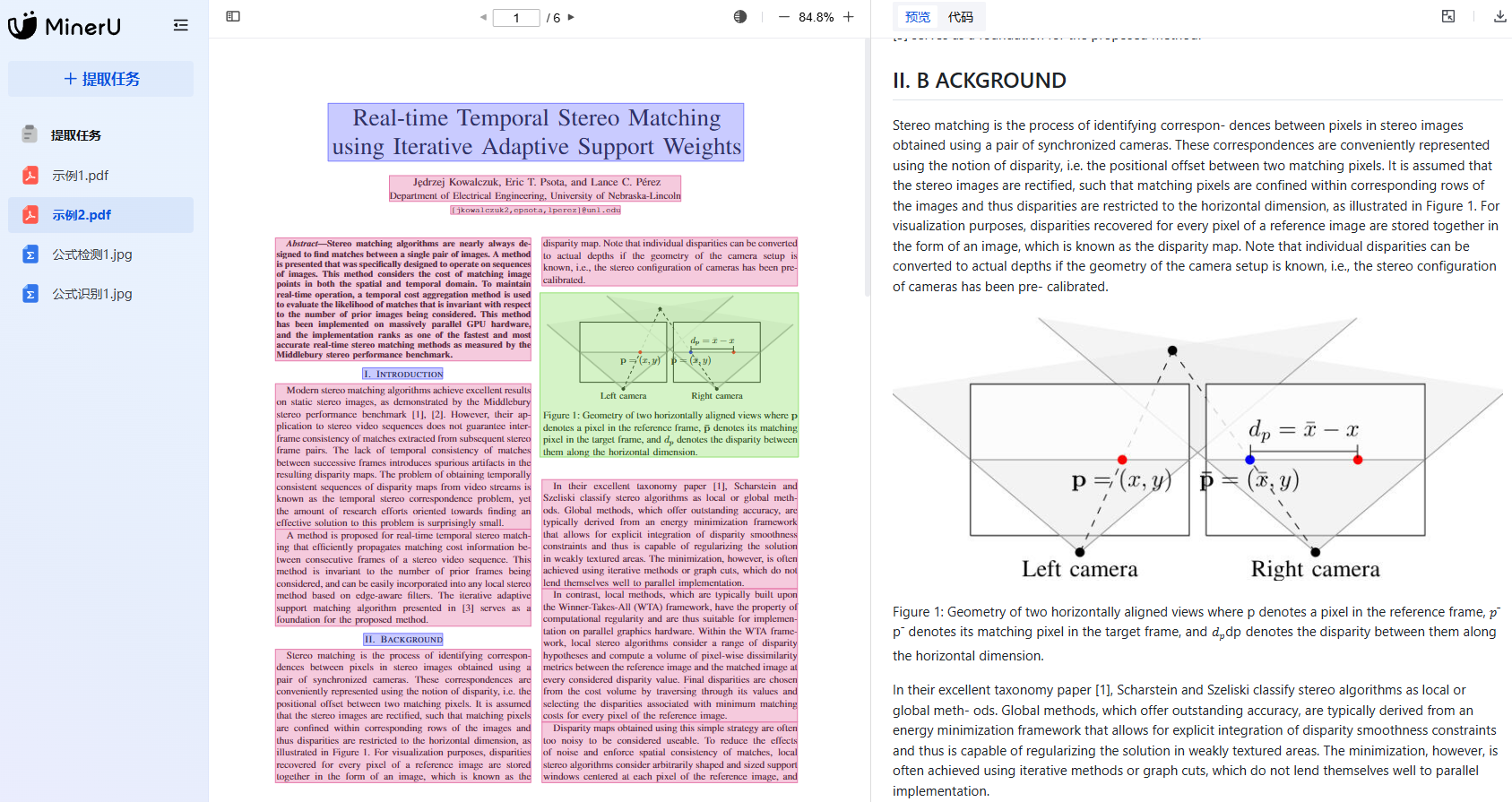
同时,MinerU 项目于2024年07月05日首次开源,底层主要是集成 PDF-Extract-Kit 开源项目做PDF的内容提取,PDF-Extract-Kit同样是一个开源项目:https://github.com/opendatalab/PDF-Extract-Kit

PDF-Extract-Kit这个项目主要针对的是PDF文档的内容提取,通过集成众多SOTA模型对PDF文件实现高质量的内容提取,其中应用到的模型主要包括:
PDF-Extract-Kit 应用的模型类型
| 模型类型 | 模型名称 | GitHub 链接 | 模型下载链接 | 任务描述 |
|---|---|---|---|---|
| 布局检测模型 | LayoutLMv3 / DocLayout-YOLO | GitHub / GitHub | 模型下载 / 模型下载 | 定位文档中不同元素位置:包含图像、表格、文本、标题、公式等 |
| 公式检测模型 | YOLO | GitHub | 模型下载 | 定位文档中公式位置:包含行内公式和行间公式 |
| 公式识别模型 | UniMERNet | GitHub | 模型下载 | 识别公式图像为latex源码 |
| 表格识别模型 | StructEqTable | GitHub | 模型下载 | 识别表格图像为对应源码(Latex/HTML/Markdown) |
| OCR模型 | PaddleOCR | GitHub | 模型下载 | 提取图像中的文本内容(包括定位和识别) |
MinerU与PDF-Extract-Kit的关系是:MinerU 结合PDF-Extract-Kit输出的高质量预测结果,进行了专门的工程优化,使得文档内容提取更加便捷高效,处理底层原理的优化细节外,主要提升点在以下几点:
- 加入了自研的
doclayout_yolo(2501)模型做布局检测,在相近解析效果情况下比原方案提速10倍以上,可以通过配置文件与layoutlmv3自由切换使用; - 加入了自研的
unimernet(2501)模型做公式识别,针对真实场景下多样性公式识别的算法,可以对复杂长公式、手写公式、含噪声的截图公式均有不错的识别效果; - 增加
OCR的多语言支持,支持84种语言的检测与识别,支持列表:https://paddlepaddle.github.io/PaddleOCR/latest/ppocr/blog/multi_languages.html#5 - 重构排序模块代码,使用
layoutreader进行阅读顺序排序,确保在各种排版下都能实现极高准确率 : https://github.com/ppaanngggg/layoutreader - 表格识别功能接入了
StructTable-InternVL2-1B模型,大幅提升表格识别效果,模型下载地址:https://huggingface.co/U4R/StructTable-InternVL2-1B
在部署和使用方面,MinerU 支持Linux、Windows、MacOS 多平台部署的本地部署,并且其中用的到布局识别模型、OCR 模型、公式识别模型、表格识别模型都是开源的,我们可以直接下载到本地进行使用。而且,MinerU 项目是完全支持华为昇腾系列芯片的,可适用性非常广且符合国内用户的使用习惯。
因此,接下来我们将重点介绍如何在Linux 系统下部署MinerU 项目并进行PDF 文档解析流程实战。注意:这里强烈建议大家使用Linux 系统进行部署,其支持性和兼容性远高于Windows 系统。如果大家想选择其他操作系统,可以参考如下链接进行自行实践:Windows 10/11 + GPU ,Docker 部署 ,
3.1 MinerU 源码安装
针对MinerU这个项目,其提供了 MCP 服务的配置文件,但是存在很多BUG, 我们必须手动修改相关的源码才能适配如LangChain等框架中,所以这里我们建议大家采用Linux系统下的源码安装方式。如下是MinerU项目官方给出的配置参考:

MinerU 实现了三个不同的处理后端,每个后端针对不同的用例和硬件配置进行了优化。其中Pipeline后端是默认的,也是最通用的后端,其采用传统的机器学习流程:
- 输入:接收
PDF格式文本,可以是简单的纯文本,也可以是包含双列文本、公式、表格或图等多模态PDF文件; - 文档预处理(Document Preprocessing):检查语言、页面大小、文件是否被扫描以及加密状态;
- 内容解析(Content Parsing):
- 局分析:区分文本、表格和图像。
- 公式检测和识别:识别公式类型(内联、显示或忽略)并将其转换为
LaTeX格式。 - 表格识别:以
HTML/LaTeX格式输出表格。 - OCR:对扫描的
PDF执行文本识别。
- 内容后处理(Content Post-processing):修复文档解析后可能出现的问题。比如解决文本、图像、表格和公式块之间的重叠,并根据人类阅读模式重新排序内容,确保最终输出遵循自然的阅读顺序。
- 格式转换(Format Conversion):以
Markdown或JSON格式生成输出。 - 输出(Output):高质量、结构良好的解析文档。
VLM-Transformer则是直接利用transformers库中的Vision-Language模型处理图像+文本的多模态输入,其流程如下:
而VLM-Sglang后端则是利用sglang高性能推理引擎,优化了GPU加速及分布式部署的基础上同时支持实时流式输出,其流程如下:
各个后端的默认模型配置为:
MinerU 后端默认模型配置
| 后端类型 | 默认模型 | 适用场景 | 资源需求 |
|---|---|---|---|
| VLM-Transformer | MinerU2.5-2509-1.2B | 高精度解析 | 中等 GPU |
| VLM-SGLang | MinerU2.5-2509-1.2B | 高速推理 | 高端 GPU |
| Pipeline | PDF-Extract-Kit-1.0 | 轻量部署 | CPU 友好 |
MinerU 的 VLM 后端默认使用的是自研的 MinerU2.5-2509-1.2B 模型,这是一个基于 Qwen 架构、专门为文档解析优化的 1.2B 参数多模态模型。而PDF-Extract-Kit-1.0,则是沿用了旧版本的基于 YOLO、OCR、表格识别等传统独立 CV 子模型的模块化架构。
MinerU 的新版本不再严格限制python 3.10版本,但建议大家使用python 3.11或者python 3.12,python 3.13可能存在兼容问题。
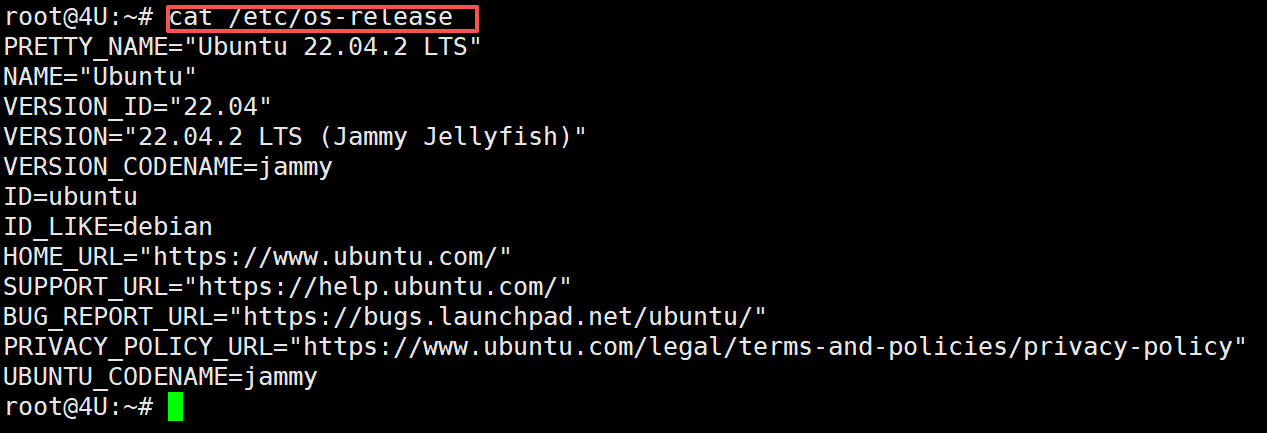
- Step 1. 确认系统版本
我们使用的是Ubuntu 22.04 系统,可以通过cat /etc/os-release 命令查看系统版本,如下图所示:
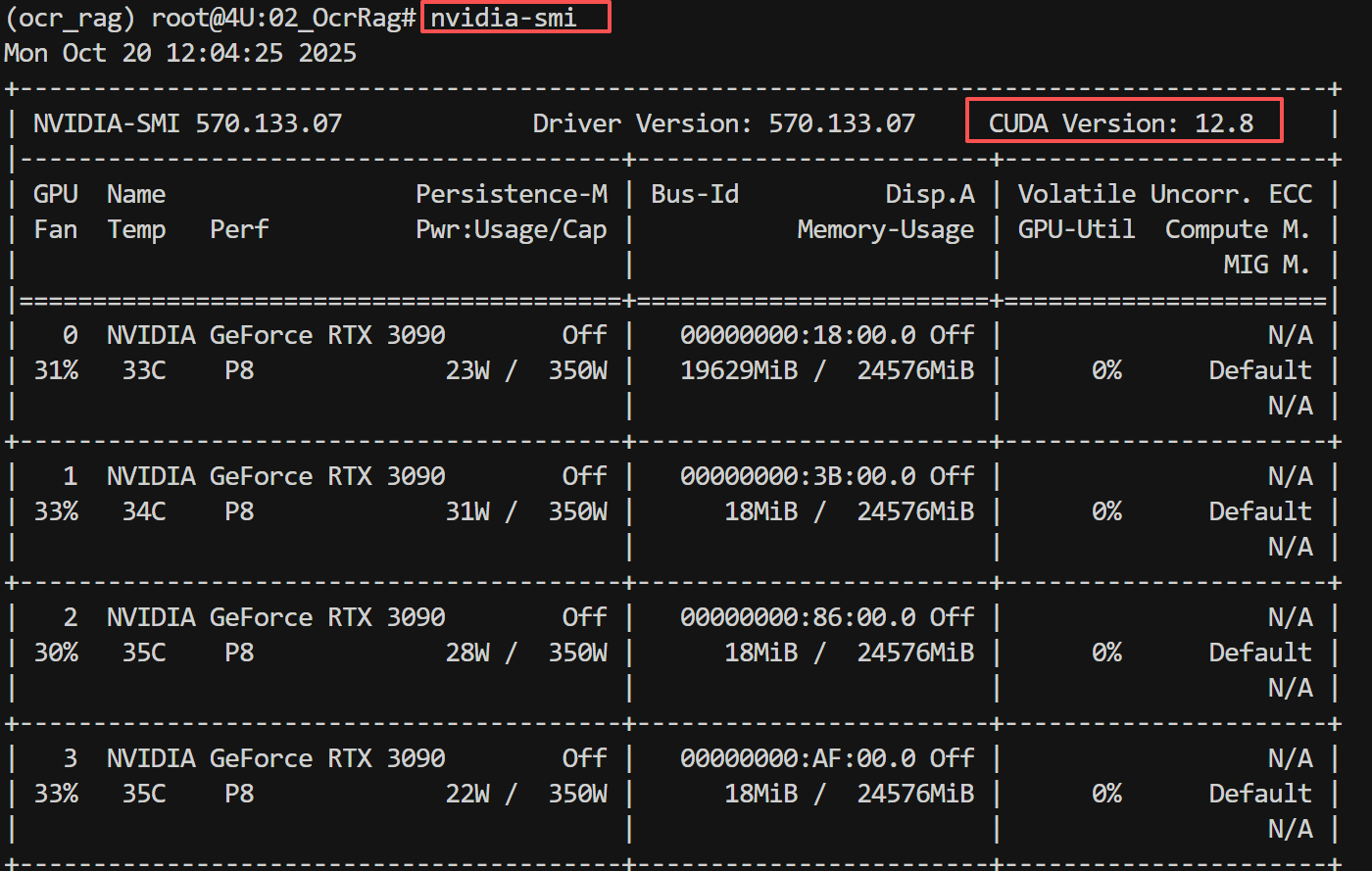
- Step 2. 确认
CUDA版本
在Linux 系统下,可以通过nvidia-smi 命令查看CUDA 版本,这里的服务器配置是四卡的RTX 3090 显卡,如下图所示:
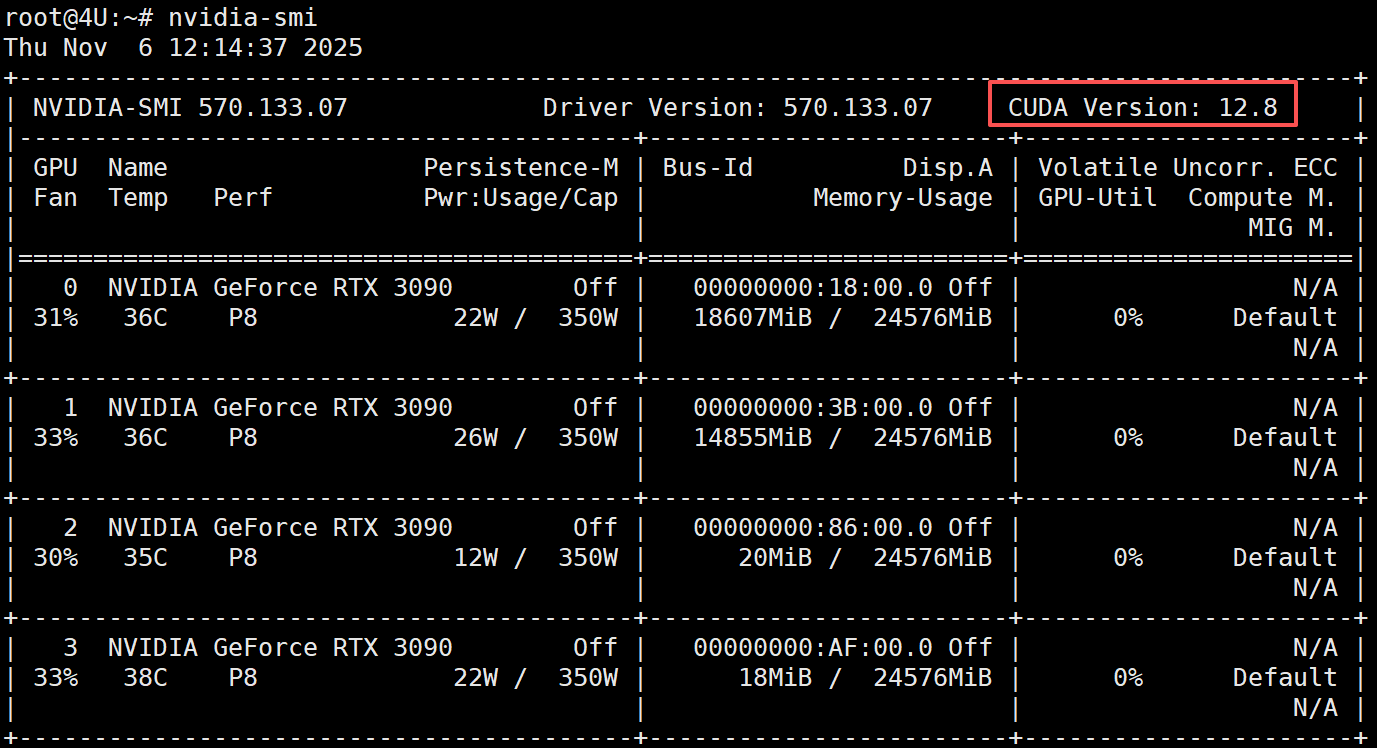
CUDA Version 显示的版本号必须 >= 12.1,如显示的版本号小于12.1,需要自行升级CUDA 版本。
- Step 3. 确认
Conda版本
我们使用的是Anaconda 安装的Conda 环境,可以通过conda --version 命令查看Conda 版本,如下图所示:

如果出现Conda not found 等报错,需要先安装Conda 环境,再执行接下来的步骤。
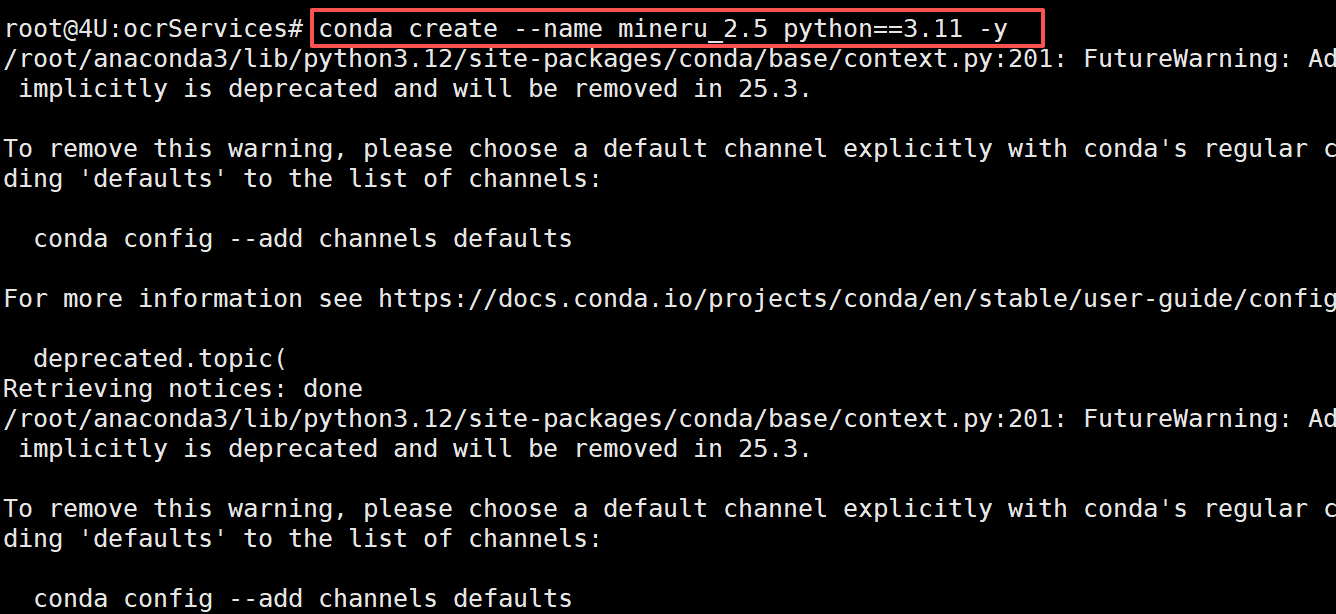
- Step 4. 使用
Conda创建Python 3.11版本的虚拟环境
执行如下命令创建一个全新的虚拟环境
FENCE0
- Step 5. 激活虚拟环境
创建完虚拟环境后,使用Conda 激活虚拟环境,通过conda activate mineru_2.5 命令激活,如下图所示:

- Step 6. 下载MinerU源码文件
截止目前最新的MinerU项目源码版本为是:2.6.4-released,但当前版本的源码在使用MCP Server时存在一些Bug,所以我们针对源码做了一些修改。因此大家一定要下载我们课程网盘中的源码文件进行部署和使用。下载后上传至服务器中,解压文件,并进入解压后的文件夹,如下图所示:
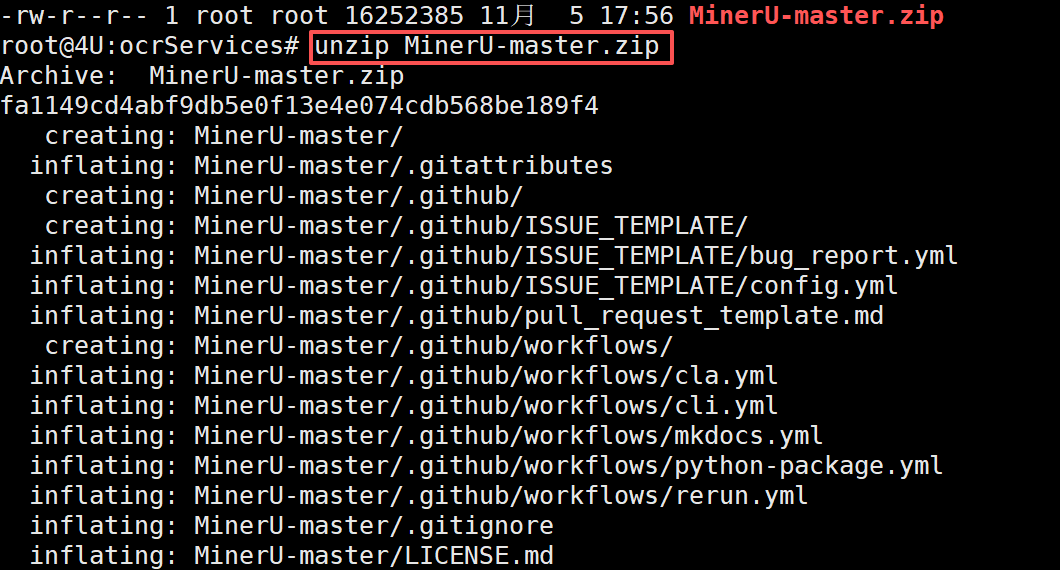
注意,大家这里一定要使用我们课程提供的源码版本,因为我们对源码进行了非常多的修改才能适配MCP服务下使用MinerU vllm解析服务。

- Step 7. 安装
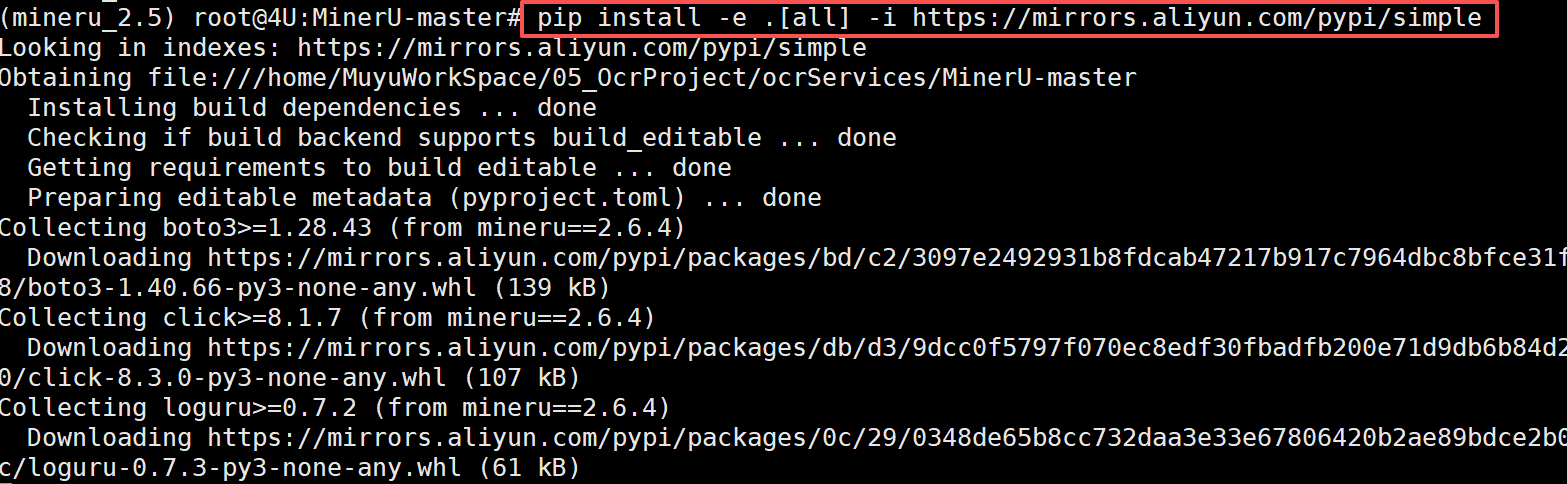
MinerU项目依赖
使用Conda 安装MinerU 项目依赖,需要通过如下命令在新建的mineru 虚拟环境中安装运行MinerU 项目程序的所有依赖,命令如下:
FENCE0
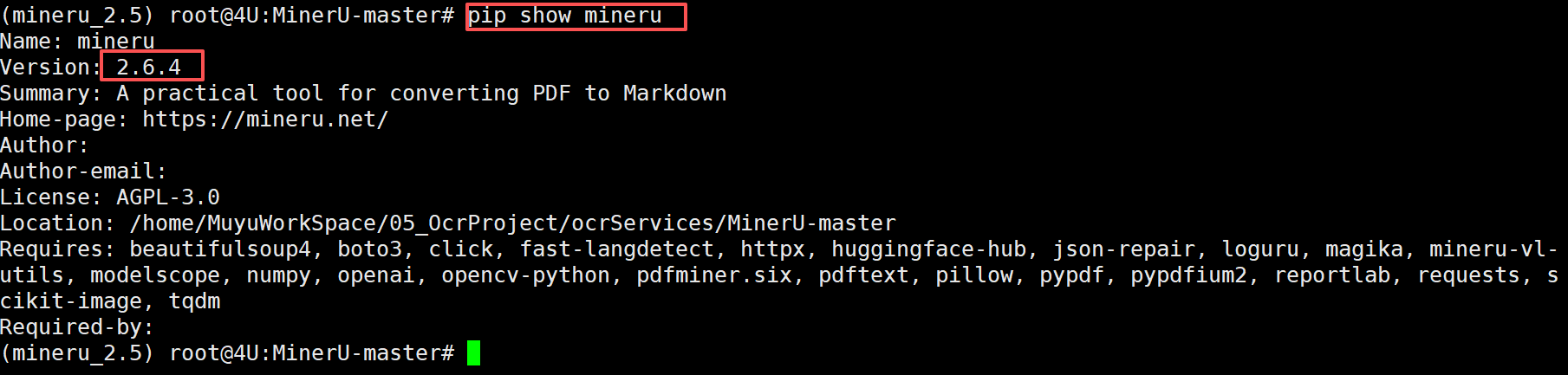
通过pip show mineru 命令查看MinerU 项目的版本:
至此,基础的MinerU 项目依赖就安装完成了,接下来我们需要下载MinerU 项目中用到的模型文件,并进行项目配置。
- Step 8. 下载
MinerU项目中用到的模型文件
新版本的MinerU 项目提供了一键下载所有模型文件的脚本,我们只需要执行如下命令即可:
FENCE0
执行该命令需要我们根据自己的需求灵活的选择要下载到本地的模型。其中modelscope 和 huggingface 是两个不同的模型下载源,我们只需要选择其中一个即可。(注意:国内用户建议使用modelscope 下载模型文件)。其次,pipeline指的是用于文档解析的一系列模型,而vlm指的是用于视觉语言模型的模型,即MinerU2.0-2505-0.9B 模型。如果是all,则会全部下载。
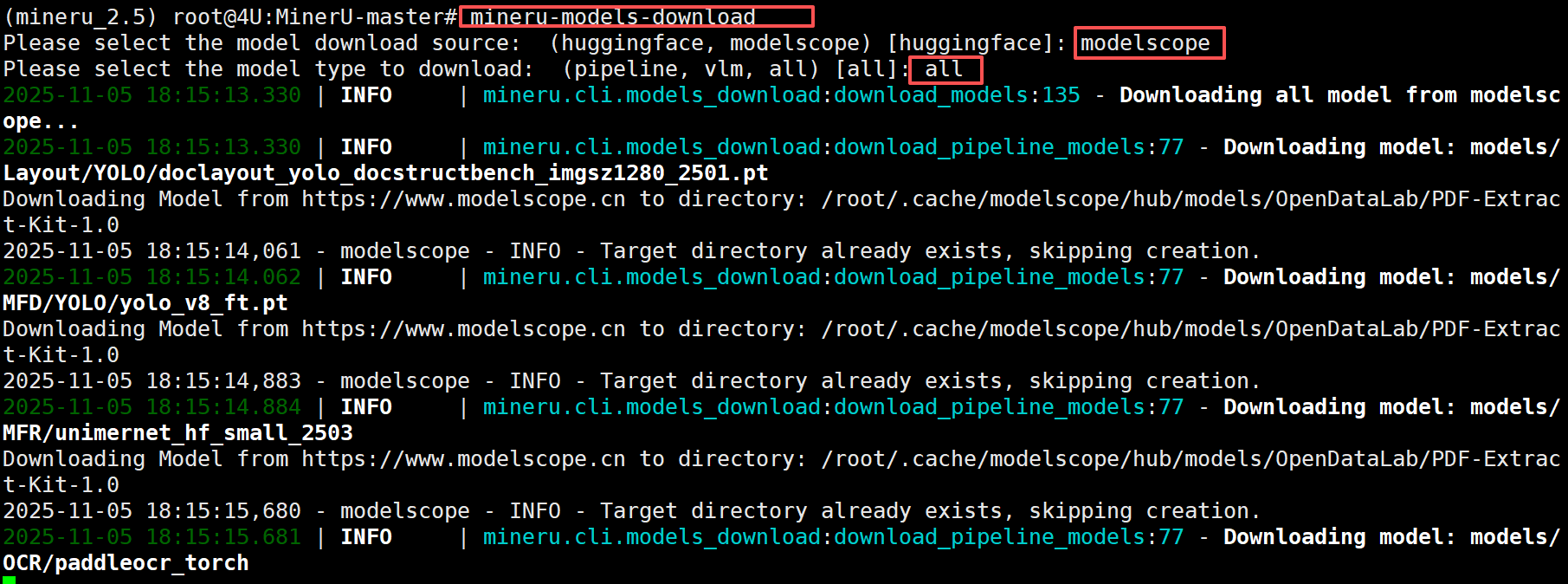
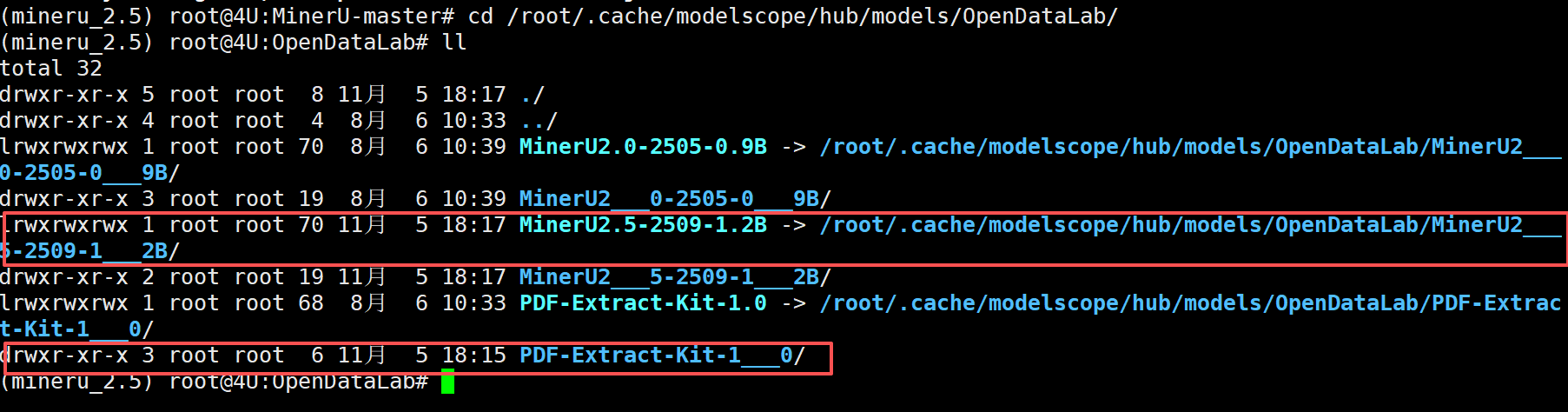
等待下载完成后,所有模型文件的默认存储路径是:
FENCE1
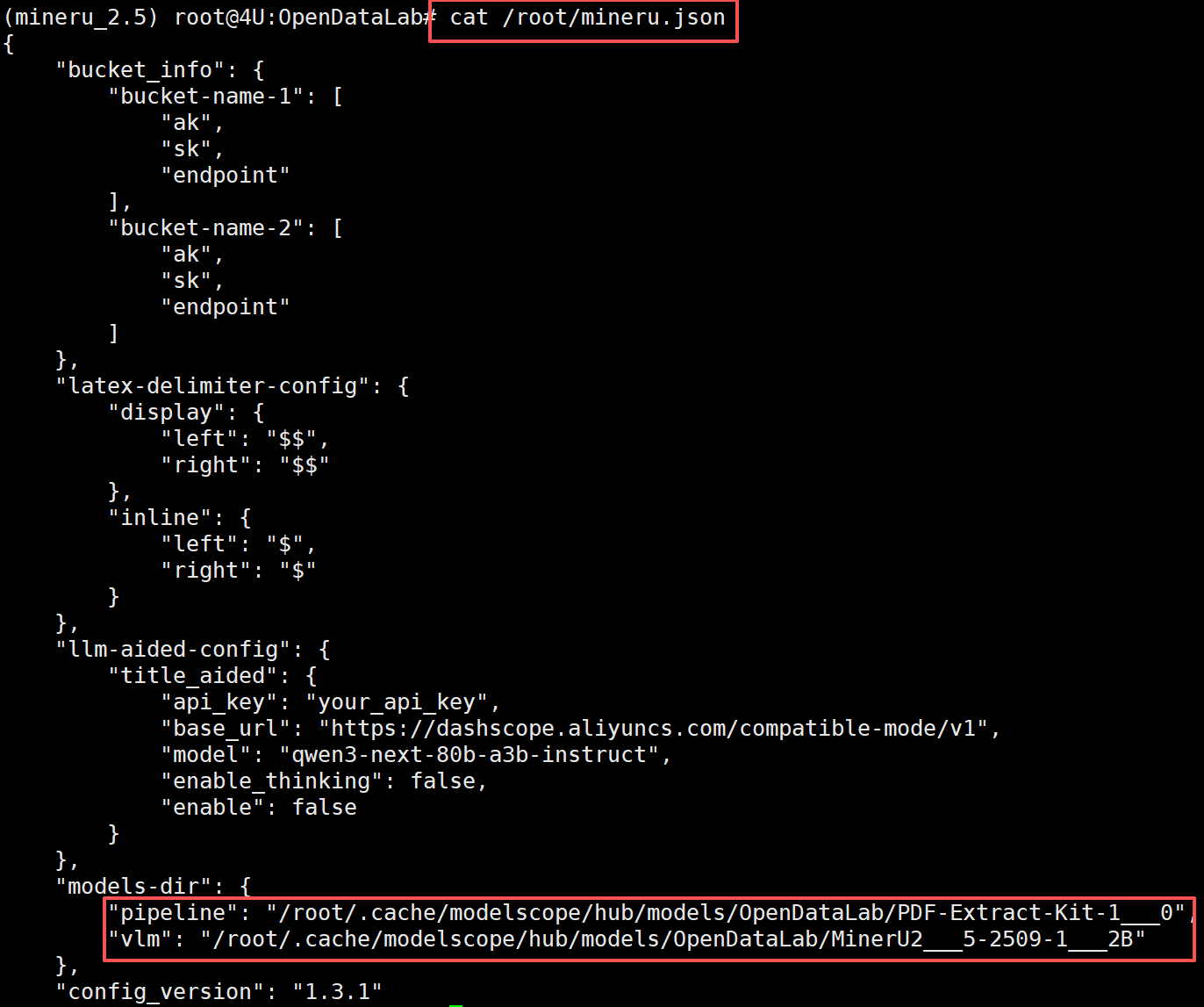
并且,也会自动在/root/mineru.json 文件中配置用于后续使用的模型路径。
至此,MinerU 项目的本地配置就全部完成了,接下来我们可以尝试运行MinerU 项目并进行PDF 文档解析测试。
3.2 MinerU 启动vLLM API 推理服务
接下来新打开一个终端,启动mineru-api 服务:
FENCE0
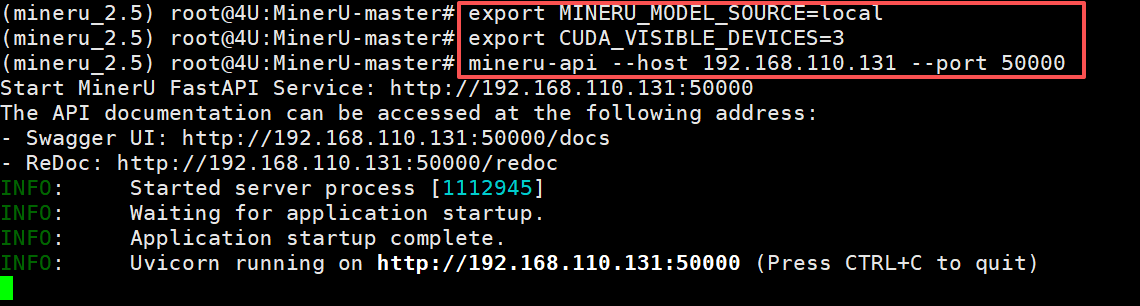
启动后,在192.168.110.131:50000/docs中可以看到接口服务:
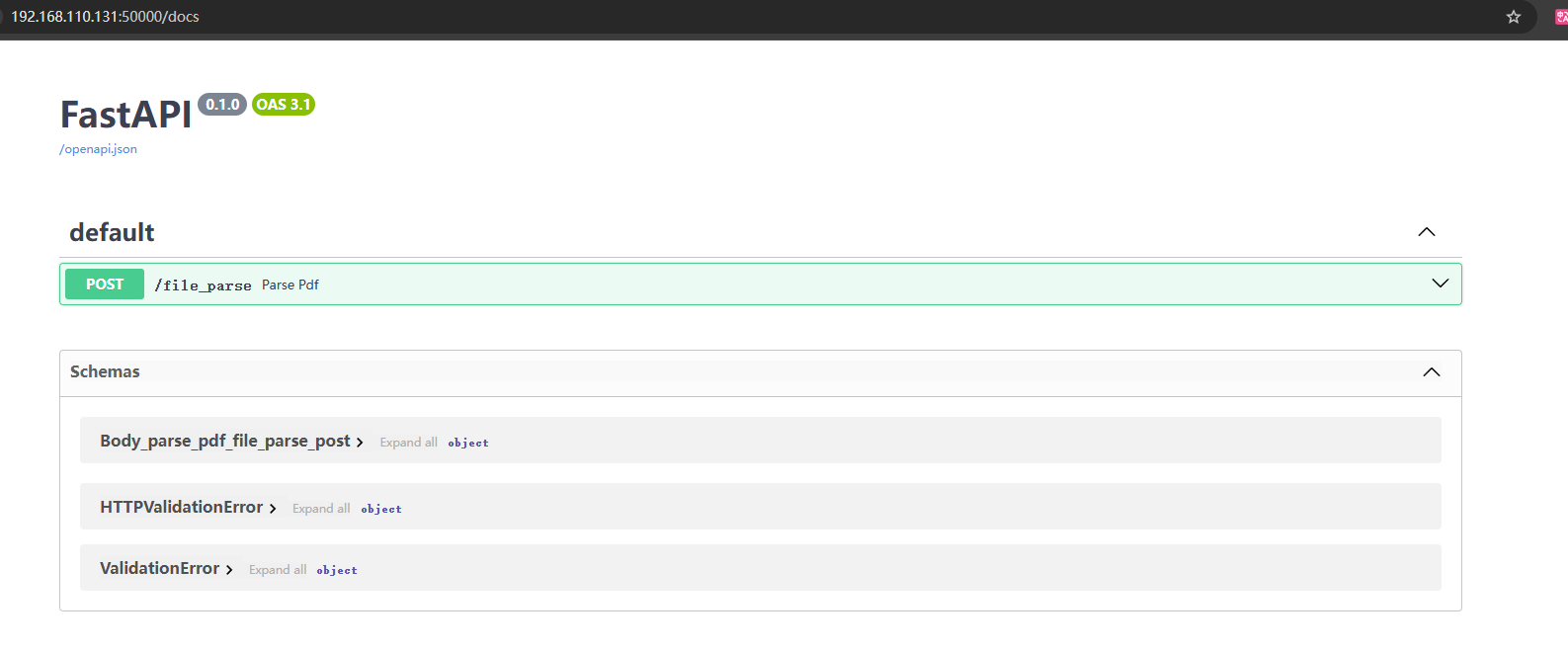
3.3 MinerU vLLM API服务连接测试
#!/usr/bin/env python3
"""
测试 MinerU API 的不同 backend
通过 50000 端口调用,传递不同的 backend 参数来使用不同的模型
"""
import requests
import sys
from pathlib import Path
def test_mineru_api(pdf_path: str, backend: str = "pipeline"):
"""
测试 MinerU API
Args:
pdf_path: PDF 文件路径
backend: 后端类型,可选值:
- "pipeline" (默认,使用本地 PyTorch)
- "vlm-vllm-async-engine" (使用 vLLM 加速)
"""
api_url = "http://192.168.130.4:50000/file_parse"
print(f"\n{'='*60}")
print(f"测试 MinerU API with backend: {backend}")
print(f"{'='*60}")
print(f"API URL: {api_url}")
print(f"PDF 文件: {pdf_path}")
print(f"Backend: {backend}")
print()
# 检查文件是否存在
if not Path(pdf_path).exists():
print(f"错误: 文件不存在 - {pdf_path}")
return None
try:
# 打开文件并发送请求
with open(pdf_path, 'rb') as f:
files = [('files', (Path(pdf_path).name, f, 'application/pdf'))]
data = {
'backend': backend,
'parse_method': 'auto',
'lang_list': 'ch',
'return_md': 'true',
'return_middle_json': 'false',
'return_model_output': 'false',
'return_content_list': 'false',
'start_page_id': '0',
'end_page_id': '1', # 只处理前2页,快速测试
}
print("发送请求...")
response = requests.post(
api_url,
files=files,
data=data,
timeout=300
)
# 检查响应
if response.status_code != 200:
print(f"请求失败: HTTP {response.status_code}")
print(f"响应: {response.text[:500]}")
return None
# 解析 JSON 响应
result = response.json()
# 提取信息
backend_used = result.get('backend', 'unknown')
version = result.get('version', 'unknown')
results = result.get('results', {})
print(f"请求成功!")
print(f" 使用的 backend: {backend_used}")
print(f" 版本: {version}")
print(f" 结果数量: {len(results)}")
# 提取 markdown 内容
if results:
file_key = list(results.keys())[0]
md_content = results[file_key].get('md_content', '')
print(f"\nMarkdown 内容预览 (前500字符):")
print("-" * 60)
print(md_content[:500])
print("-" * 60)
# 保存 markdown 到文件
output_file = f"output_{backend}.md"
with open(output_file, 'w', encoding='utf-8') as f:
f.write(md_content)
print(f"\n完整 Markdown 已保存到: {output_file}")
return md_content
else:
print("未找到结果")
return None
except Exception as e:
print(f"测试失败: {e}")
import traceback
traceback.print_exc()
return None
def main():
# 默认测试文件
pdf_path = "./2507.05595v1.pdf"
print(f"\n开始测试 MinerU API 的不同 backend")
print(f"测试文件: {pdf_path}\n")
# 测试 1: pipeline backend (本地 PyTorch)
print("\n" + "="*60)
print("测试 1: pipeline backend (本地 PyTorch)")
print("="*60)
result_pipeline = test_mineru_api(pdf_path, backend="pipeline")
# 测试 2: vLLM backend (vLLM 加速)
print("\n" + "="*60)
print("测试 2: vlm-vllm-async-engine backend (vLLM 加速)")
print("="*60)
result_vllm = test_mineru_api(pdf_path, backend="vlm-vllm-async-engine")
# 总结
print("\n" + "="*60)
print("测试总结")
print("="*60)
print(f"Pipeline backend: {'成功' if result_pipeline else '失败'}")
print(f"vLLM backend: {'成功' if result_vllm else '失败'}")
if result_pipeline and result_vllm:
print("\n所有测试通过! MinerU 可以通过 backend 参数切换不同模型")
print("\n💡 提示:")
print(" - pipeline: 使用本地 PyTorch,适合调试")
print(" - vlm-vllm-async-engine: 使用 vLLM 加速,速度更快")
if __name__ == "__main__":
main()
当然,上述代码也是LangChain1.0 + OCR 多模态PDF解析实战项目中MinerU 的核心代码逻辑:
当然,MinerU 提供了命令行离线解析、Gradio/WebUI、独立 FastAPI 服务(mineru-api)等多种启动方式。不同方式适合的场景、端口、性能与依赖各不相同,如下所示:
MinerU 启动方式
| 启动方式 | 典型命令/镜像 | 端口 & 路径 | 适用场景 | 依赖 |
|---|---|---|---|---|
| SGLang 后端服务 | mineru-sglang-server --host 0.0.0.0 --port 30000 | POST /file_parse | 高并发、GPU 推理、本地私有化 | Python + CUDA/SGLang |
| Docker 一键 | docker run -p 30000:30000 opendatalab/mineru:latest mineru-sglang-server | 同上 | 免环境配置、快速试用 | Docker (GPU 可选) |
| 命令行离线解析 | mineru -p <输入> -o <输出> | 无服务;直接落盘 | 批处理、无网络、脚本化 | 纯 Python CLI |
| Gradio WebUI | mineru-gradio --enable-sglang-engine | 浏览器 UI | 交互演示、无代码使用 | Gradio 前端 |
| FastAPI API 服 务 | git clone .../mineru-api && docker compose up | PUT /api/parse | 需要依托自定义业务接口 | FastAPI + Uvicorn |
| MCP-Server(外壳) | uv run mineru-mcp --transport streamable-http | /mcp 或 /sse | 给 ADK/Agent 暴露工具 | fastmcp 框架 |
| n8n/Serverless 封装 | n8n「MCP Client」节点或 Runpod 镜像 | 由平台分配 | 无代码工作流 | 平台函数 |
实际上,MinerU 会输出非常丰富的信息,主要是:
-
images:这是一个文件夹,里面存储了
PDF文档中出现的所有图片; -
.origin.pdf:进行解析的原始
PDF文件; -
.markdown:
PDF文档的解析结果,输出为xxx.md的Markdown格式; -
.layout.pdf:这个文件用不同的背景色块圈定不同的内容块,以此来区分整体的布局识别结果;
-
.model.json:这个文件的主要作用是将
PDF从像素级别的展示转换为结构化的数据,使计算机能够"理解"文档的组成部分。主要存储的信息是:
- 文档布局识别:存储文档中的各种元素(标题、正文、图表等)及其在页面上的精确位置
- 内容分类:将识别出的元素分类为不同类型(如标题、表格、公式等)
- 特殊内容解析:对于公式、表格等特殊内容,提供其结构化表示(如LaTeX、HTML格式)
其示例数据如下:
FENCE0
其中每一个layout_dets 中存储了PDF 文档中每一页的布局识别结果,poly 是四边形坐标, 分别是 左上,右上,右下,左下 四点的坐标,形式为:[x0, y0, x1, y1, x2, y2, x3, y3], 分别表示左上、右上、右下、左下四点的坐标,page_info 是PDF 文档中每一页元数据,包含页码、高度、宽度信息,而category_id 为PDF 文档中每一页的布局识别结果的类型,分别为:
category_id 的类别
| 类别 ID | 类别名称 | 描述 |
|---|---|---|
| 0 | title | 标题 |
| 1 | plain_text | 文本 |
| 2 | abandon | 包括页眉页脚页码和页面注释 |
| 3 | figure | 图片 |
| 4 | figure_caption | 图片描述 |
| 5 | table | 表格 |
| 6 | table_caption | 表格描述 |
| 7 | table_footnote | 表格注释 |
| 8 | isolate_formula | 行间公式 |
| 9 | formula_caption | 行间公式的标号 |
| 13 | embedding | 行内公式 |
| 14 | isolated | 行间公式 |
| 15 | text | OCR 识别结果 |
这个.json文件主要可以内容提取,比如精确提取特定类型的内容(如所有表格或公式),搜索,比如实现对文档内容的结构化搜索,文档分析,比如分析文档的结构特征(如有多少图表、公式密度等)等需求场景。
- _middle.json:这个文件的核心作用是存储
PDF文档解析过程中多层次结构化数据,它比model.json提供了更详细的层次结构和内容信息, 其示例数据是这样的:
FENCE0
解析结果是一个多层嵌套,从大到小依次为:PDF 文档 → 包含多个页面 → 包含多个区块(blocks) → 分为一级区块和二级区块 → 每个区块包含多行 → 每行包含多个最小单元, 其中para_blocks内存储的元素为区块信息, span是所有元素的最小存储单元。大家理解了这个结构后,可以结合下图对每个字段进行理解,我们这里不再赘述。
一级
| 字段名 | 解释 |
|---|---|
| pdf_info | list,每个元素都是一个 dict,这个 dict 是每一页 PDF 的解析结果,详见下表 |
| _parse_type | ocr |
| _version_name | string,表示本次解析使用的 magic-pdf 的版本号 |
二级
| 字段名 | 解释 |
|---|---|
| preproc_blocks | PDF 预处理后,未分段的中间结果 |
| layout_bboxes | 布局分割的结果,含有布局的方向(垂直、水平),和 bbox,按阅读顺序排序 |
| page_idx | 页码,从 0 开始 |
| page_size | 页面宽度和高度 |
| _layout_tree | 布局树状结构 |
| images | list,每个元素是一个 dict,每个 dict 表示一个 img_block |
| tables | list,每个元素是一个 dict,每个 dict 表示一个 table_block |
| interline_equations | list,每个元素是一个 dict,每个 dict 表示一个 interline_equation_block |
| discarded_blocks | list,模型返回的需要 drop 的 block 信息 |
| para_blocks | 将 preproc_blocks 进行分段之后的结果 |
三级(最外层block)
| 字段名 | 解释 |
|---|---|
| type | block 类型(table 或 image) |
| bbox | block 矩形框坐标 |
| blocks | list,里面的每个元素都是一个 dict 格式的二级 block |
四级(内层block)
| 字段名 | 解释 |
|---|---|
| type | block 类型 |
| bbox | block 矩形框坐标 |
| lines | list,每个元素都是一个 dict 表示的 line,用来描述一行信息的构成 |
| ----------------------- | -------------------------- |
| 其中 type 类型 | 描述 |
| image_body | 图像的本体 |
| image_caption | 图像的描述文本 |
| image_footnote | 图像的脚注 |
| table_body | 表格本体 |
| table_caption | 表格的描述文本 |
| table_footnote | 表格的脚注 |
| text | 文本块 |
| title | 标题块 |
| index | 目录块 |
| list | 列表块 |
| interline_equation | 行间公式块 |
五级(lines)
| 字段名 | 解释 |
|---|---|
| bbox | line 的矩形框坐标 |
| spans | list,每个元素都是一个 dict 表示的 span,用来描述一个最小组成单元的构成 |
六级(spans)
| 字段名 | 解释 |
|---|---|
| bbox | span 的矩形框坐标 |
| type | span 的类型 |
| content | img_path |
| ----------------------- | -------------------------- |
| 其中 type 类型 | 描述 |
| type | 描述 |
| image | 图片 |
| table | 表格 |
| text | 文本 |
| inline_equation | 行内公式 |
| interline_equation | 行间公式 |
该.json文件除了能像model.json一样提取特定类型的内容,因为其内容的丰富程度,可以做更精细化的文本分析,比如段落级别的文本分析,建立更精确的搜索索引,支持按内容类型搜索等。
7. span.pdf:根据 span 类型的不同,采用不同颜色线框绘制页面上所有 span。该文件可以用于质检,可以快速排查出文本丢失、行间公式未识别等问题。
最后一个 .content_list.json 文件,是PDF 文档中所有内容的列表,使用 JSON 格式存储数据,每个元素都是一个字典,包含了不同类型的内容(文本、图像等)。
FENCE0
字段说明
| 字段名 | 出现位置 | 数据类型 | 说明 |
|---|---|---|---|
| type | 所有内容块 | 字符串 | 内容块的类型,可能的值有:"text"、"image"、"table" |
| page_idx | 所有内容块 | 整数 | 内容所在的页码,从0开始计数 |
| text | 文本类型块 | 字符串 | 文本内容 |
| text_level | 部分文本类型块 | 整数 | 文本的层级,通常用于标题,1表示一级标题 |
| img_path | 图像和表格类型块 | 字符串 | 图像或表格截图的文件路径 |
| img_caption | 图像类型块 | 数组 | 图像的说明文字,通常为空数组 |
| img_footnote | 图像类型块 | 数组 | 图像的脚注,通常为空数组 |
| table_caption | 表格类型块 | 数组 | 表格的说明文字,通常为空数组 |
| table_footnote | 表格类型块 | 数组 | 表格的脚注,通常为空数组 |
| table_body | 表格类型块 | 字符串 | 表格的HTML内容,包含完整的表格结构 |
以上是对MinerU解析结果的说明,通过这些文件,我们基本上可以获取到PDF文档中所有内容的位置、类型、内容等信息,理解各个文件的结构,也是我们后续进行自定义处理的关键,所以这里大家务必明确文件及其内部结构的组成。除此以外,除了PDF格式,该流程也可以支持图像(.jpg及.png)、PDF、Word(.doc及.docx)、以及PowerPoint(.ppt及.pptx)在内的多种文档格式的解析,大家可以进行尝试。
四、PaddleOCR项目介绍及vLLM服务启动
本小节课程,我们将从零开始,详细介绍如何在本地环境中完整部署 PaddleOCR-VL 并通过 vLLM 服务启动 PaddleOCR API 服务。
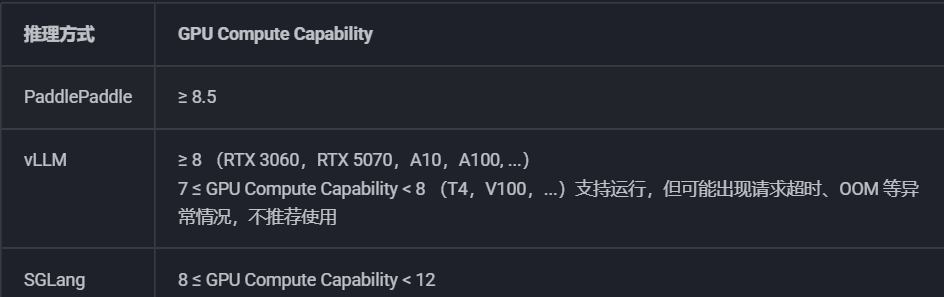
对于硬件要求,官方给出了如上说明。其中使用原生的PaddlePaddle方式,需要GPU算力≥8.5(RTX 3090/4090、A100 等),最稳定。使用vLLM方式,需要GPU算力≥8(RTX 3060 及以上),速度最快,但算力7-8之间(T4/V100)虽可运行但不推荐,易超时或OOM。使用SGLang方式,需要GPU算力8-12之间(RTX 3060-4090),性能与稳定性的平衡选择。
注意:表格里的 "≥8" 指的是 GPU Compute Capability(GPU 算力版本号),不是显存大小!根据实测,根据PaddleOCR-VL-0.9B 模型(模型文件约 3.8GB):
- 最低要求:6GB 显存(勉强够用,单张图)
- 推荐配置:8GB+ 显存(运行舒适)
- 理想配置:12GB+ 显存(可以批处理多张图)
所以:8GB 显存 + RTX 30 系列以上达到高效运行是完全没问题的。整个过程主要包括以下几个核心步骤:
- 创建 Python 虚拟环境 - 隔离项目依赖,避免环境冲突;
- 安装 PaddlePaddle 深度学习框架 - PaddleOCR 的底层依赖;
- 安装 PaddleOCR 库 - 核心 OCR 功能库;
- 下载预训练模型 - PaddleOCR-VL-0.9B 和 PP-DocLayoutV2;
- 验证安装 - 运行测试确保环境正常;
公开课所使用的硬件环境为:Ubuntu 22.04 + 4 * 3090,共计显存96G显存,运行起来非常流畅。
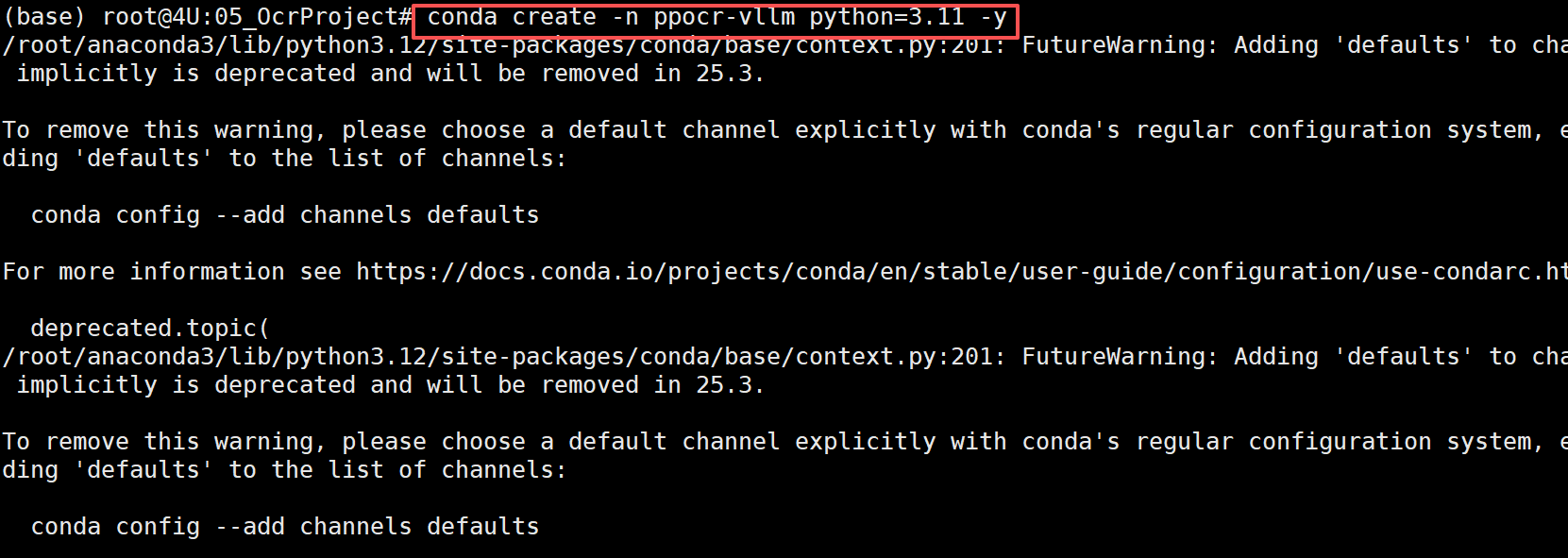
4.1 创建虚拟环境
首先,我们需要创建一个独立的 Python 虚拟环境。虚拟环境可以隔离项目依赖,避免与系统其他 Python 项目产生冲突。执行如下命令 FENCE0
其中:
--name ppocr-vllm:虚拟环境名称,可以自定义python==3.11:指定 Python 版本为 3.11(PaddleOCR 推荐版本)
执行效果如下图所示:
接下来激活虚拟环境: FENCE0
激活后,命令行提示符前会显示 (ppocr-vllm),表示已进入虚拟环境。

4.2 安装 PaddleOCR 工具框架
首先需要区分PaddleOCR 和 PaddleOCR-VL 两个之间的区别和联系。首先。PaddleOCR 是一个较为成熟、功能全面的 OCR+文档理解开源工具库,其开源地址:https://github.com/PaddlePaddle/PaddleOCR/tree/main
PaddleOCR-VL 是在这个生态内新发布的一个专注于“文档解析/视觉-语言模型 (Vision-Language Model, VLM)”功能的新模块。
简单来说,PaddleOCR 是一个“全面且成熟”的 OCR+文档理解工具箱,而 PaddleOCR-VL 是在这个工具箱里“专门为复杂文档解析”设计的新模块,采用了视觉-语言模型架构以应对更高阶的需求。
因此,在使用PaddleOCR-VL 时,我们首先需要安装 PaddleOCR 工具框架。https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html
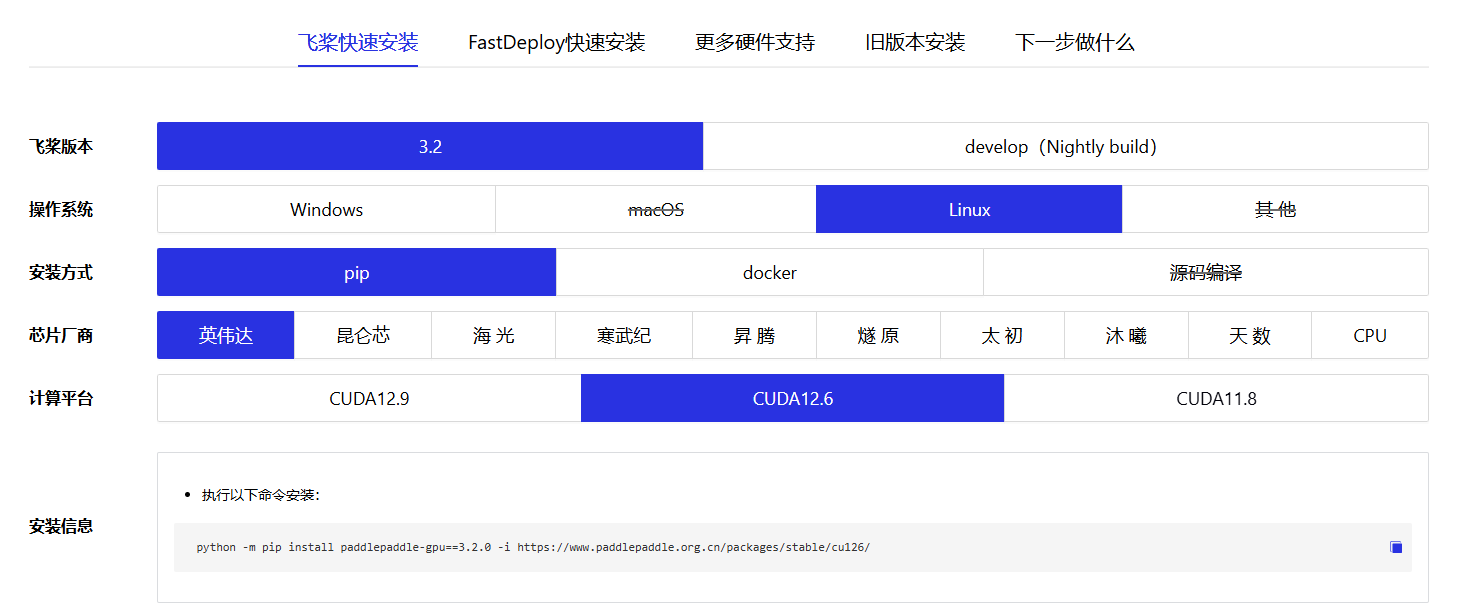
这里安装 PaddlePaddle 3.2.0 版本。执行如下命令:
FENCE0
其中:
paddlepaddle-gpu==3.2.0:GPU 版本的 PaddlePaddle 3.2.0-i https://...:使用百度官方镜像源,下载速度更快cu126:对应 CUDA 12.6 版本
安装过程如下图所示:
安装结束后,需要验证 PaddlePaddle 安装状态,依次运行以下命令验证:
FENCE0
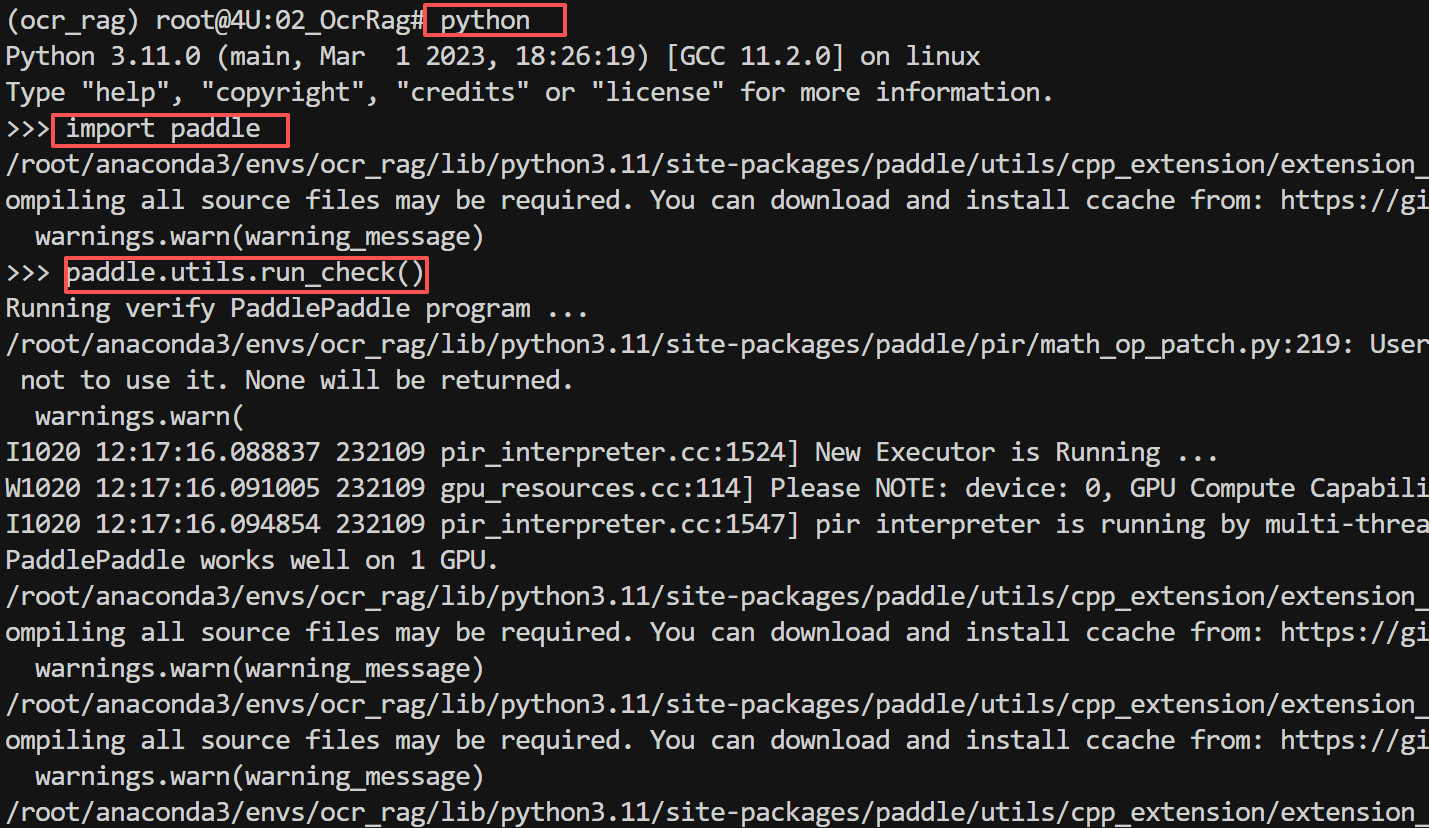
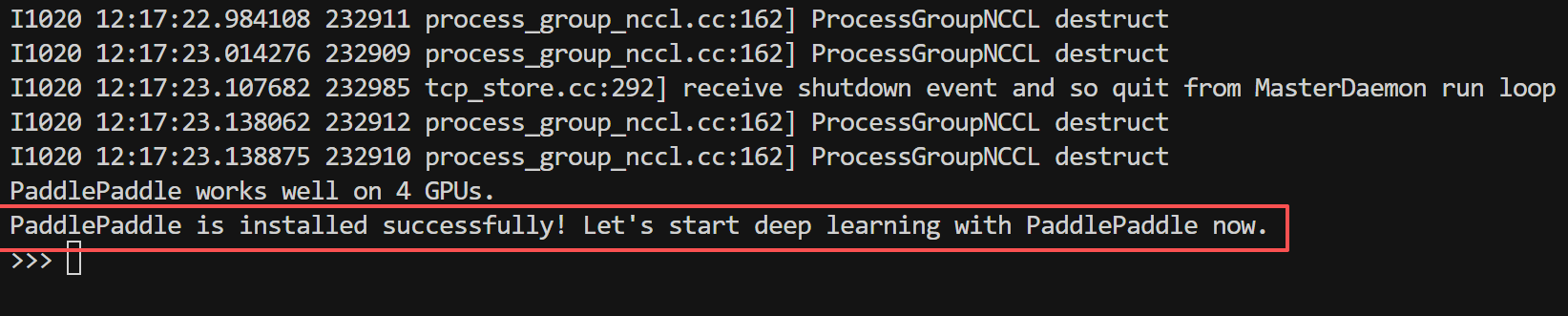
如果看到如下“”信息,说明 PaddlePaddle 已成功安装。
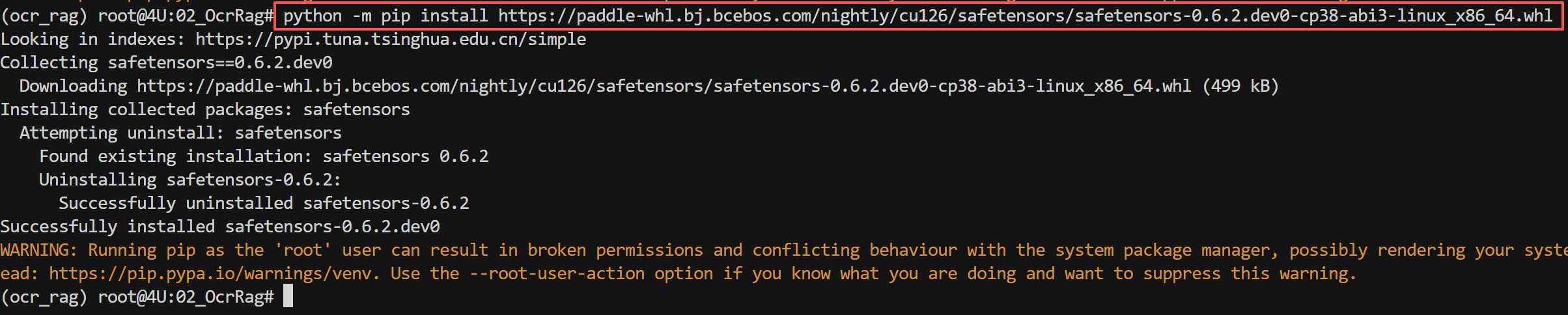
接下来要重点关注的是:PaddleOCR-VL 使用 safetensors 格式存储模型权重,需要额外安装,同时需要安装指定版本的,执行如下命令
FENCE0
这是兼容最新PaddleOCR-Vl 的 safetensors 版本,安装很快。
4.3 下载PaddleOCR-VL模型
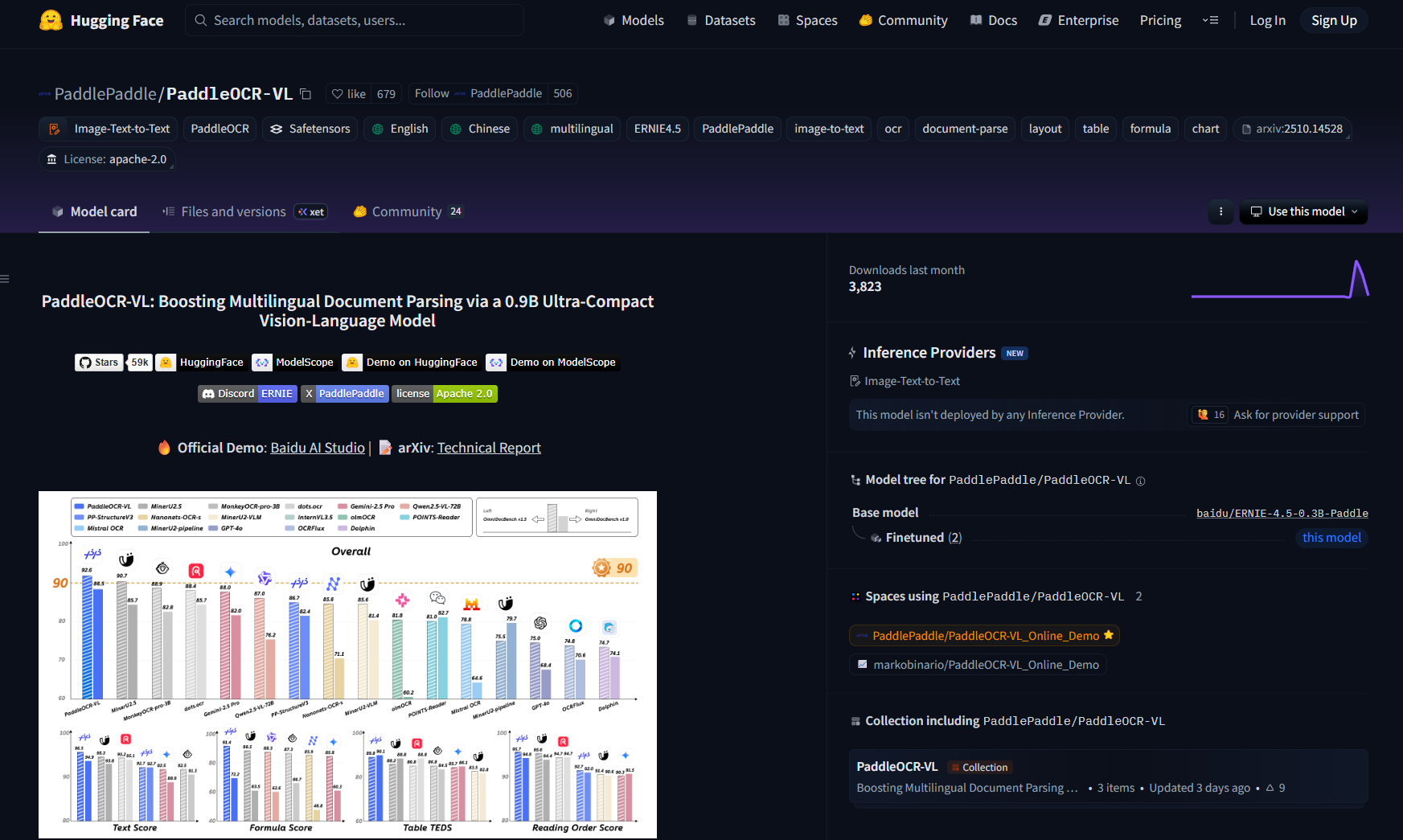
使用 PaddleOCR-VL 解析功能需要两个预训练模型,其中:
- PaddleOCR-VL-0.9B - 视觉语言模型(用于文本识别)
- PP-DocLayoutV2 - 文档布局检测模型(用于布局分析)
该模型权重的HuggingFace 地址为:https://huggingface.co/PaddlePaddle/PaddleOCR-VL ,
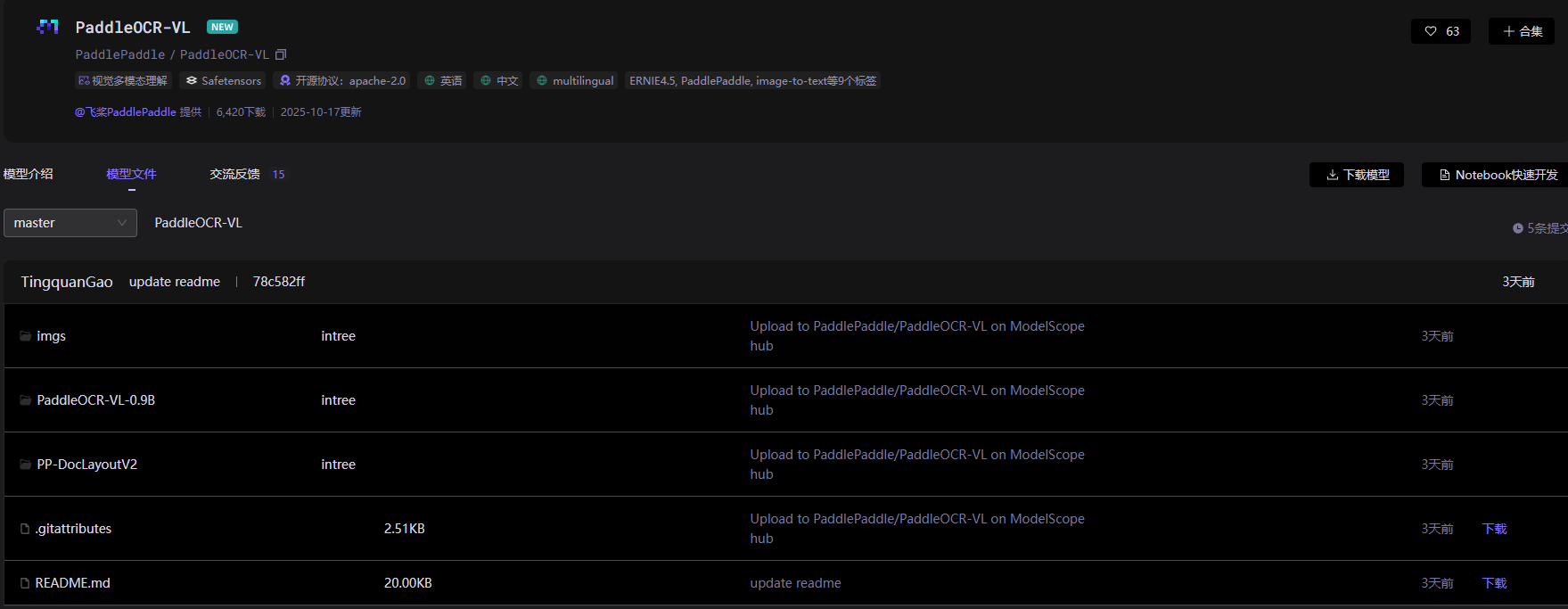
此外,对于我们国内用户来说,更建议通过 ModelScope 下载(推荐)。https://modelscope.cn/models/PaddlePaddle/PaddleOCR-VL/summary
ModelScope 是阿里云的模型托管平台,国内访问速度快。首先执行如下命令:
FENCE0
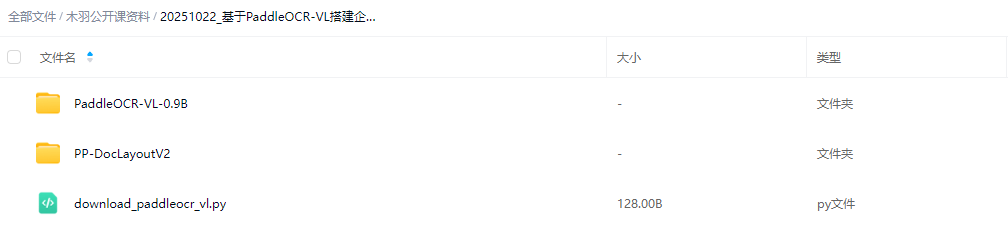
新建一个 download_paddleocr_vl.py 文件,写入如下代码:
FENCE0
其中:
'PaddlePaddle/PaddleOCR-VL':模型仓库 IDlocal_dir='.':下载到当前目录(也可以指定其他路径,如'./models')
接下来执行如下代码进行模型权重安装:
FENCE0
下载完成后的模型目录结构如下所示:
其中 PaddleOCR-VL-0.9B 文件夹中存储的就是本次最新开源的超紧凑视觉语言模型,具有以下特点:
PaddleOCR-VL-0.9B 模型特性
| 特性 | 说明 |
|---|---|
| 模型规模 | 0.9B 参数(极小,推理速度快) |
| 语言支持 | 109 种语言(包括中文、英文、日语、韩语等) |
| 识别能力 | 文本、表格、公式、图表等复杂元素 |
| 输出格式 | Markdown、JSON、HTML |
| 资源消耗 | GPU 显存 4GB+,推理速度 1.22 页/秒(A100) |
| 优势 | 比 MinerU 快 15.8%,显存占用比 dots.ocr 少 40% |
接下来,在进行运行前需要依次安装依赖包,首先是paddleocr[all], 其中:

FENCE0
这里我们安装doc-parser,如下图所示:

然后,使用 PaddleOCR CLI 安装 vLLM 的推理加速服务依赖:
FENCE0
安装完成后,继续安装 flash-atten 编译包:
FENCE1
接下来,就可以启动vLLM 服务器服务器了。如下代码所示:
FENCE0
vLLM 服务启动后,保持这个终端窗口运行,不要关闭。同时打开一个新的终端,使用paddlex连接启动的paddleocr-vl服务,首先进行初始化服务配置:
FENCE0
然后生成 .yaml 配置文件:
FENCE1

找到 genai_config 配置项,修改为如下所示:
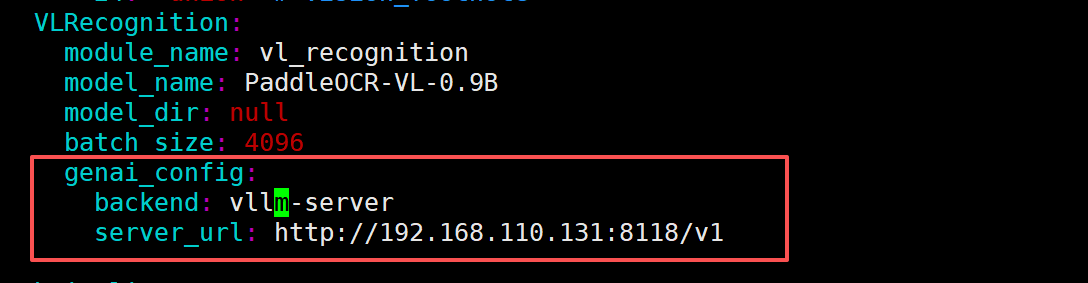
最后,启动 PaddleOCR API 服务:
FENCE2
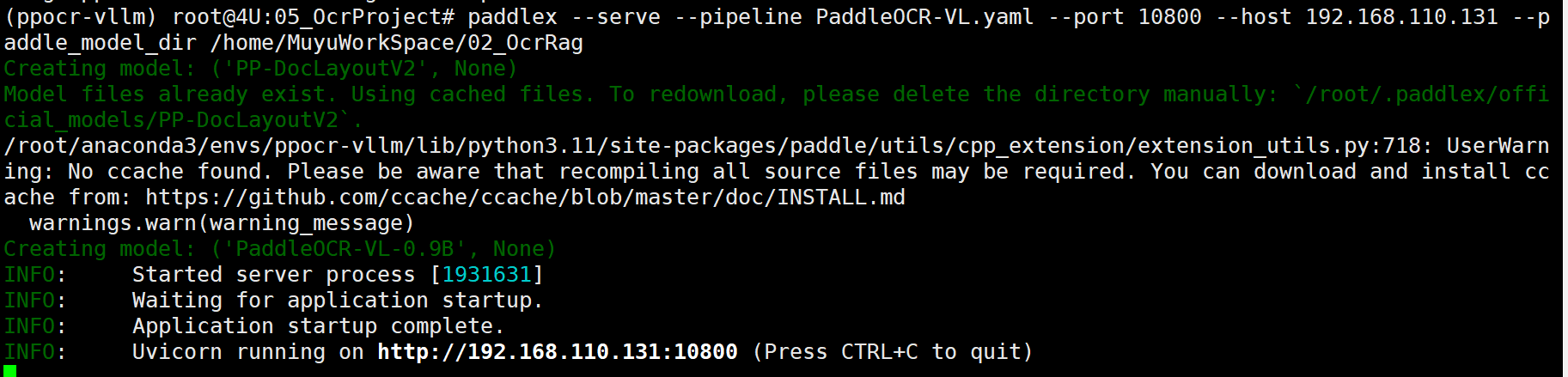
成功启动后,在浏览器中访问 http://192.168.110.131:10800/docs 查看API文档,如下图所示:
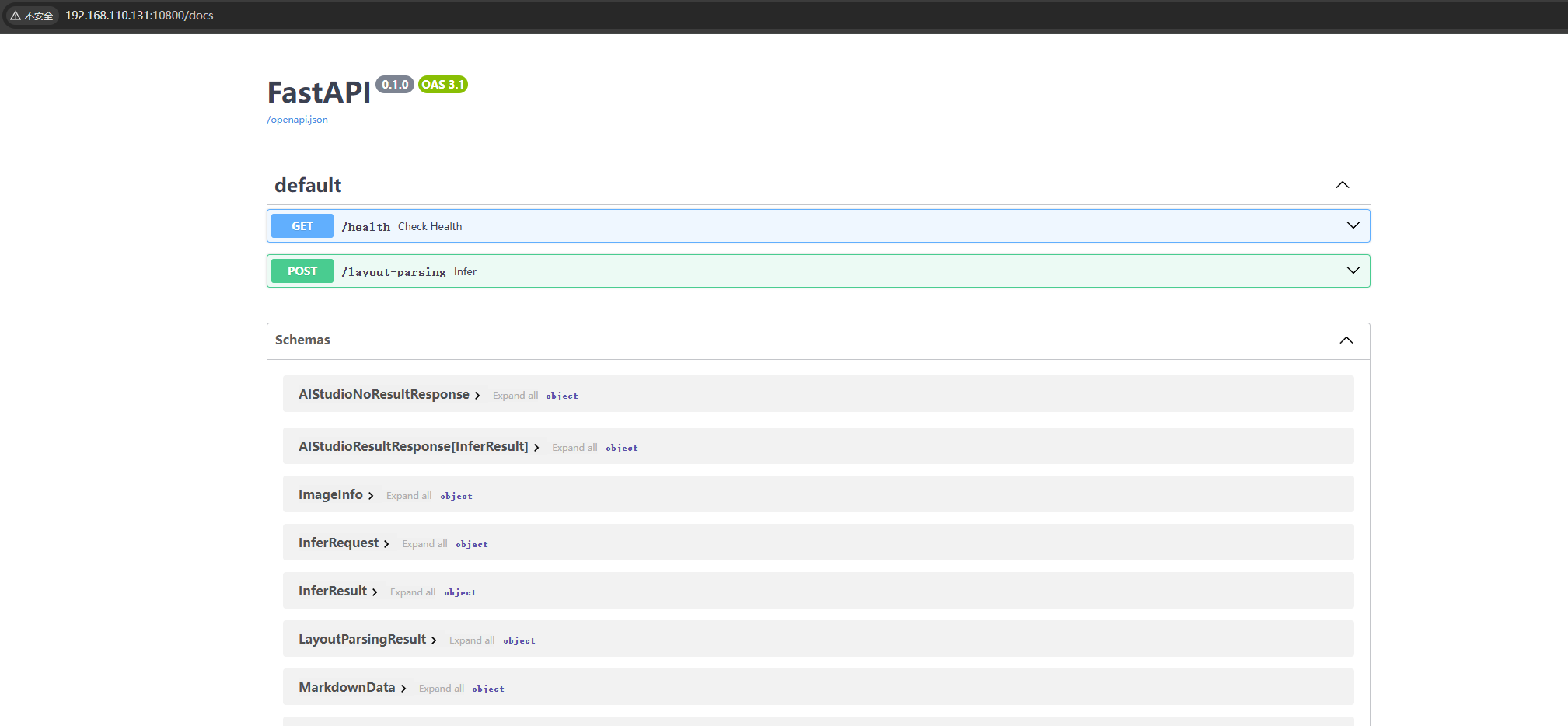
至此,PaddleOCR API 服务启动成功。
4.4 PaddleOCR vLLM API服务连接测试
import base64
import json
import requests
import os
# === 1. 服务端地址 ===
SERVER_URL = "http://192.168.130.4:10800/layout-parsing"
# === 2. 待处理文件路径 ===
input_path = "./course.pdf" # 也可以是 test.png
output_md = "result.md"
# === 3. 读取文件并转为 Base64 ===
with open(input_path, "rb") as f:
file_base64 = base64.b64encode(f.read()).decode("utf-8")
# === 4. 构造 JSON 请求体 ===
payload = {
"file": file_base64,
"fileType": 0 if input_path.lower().endswith(".pdf") else 1,
"prettifyMarkdown": True,
"visualize": False,
}
headers = {"Content-Type": "application/json"}
# === 5. 发送请求 ===
resp = requests.post(SERVER_URL, headers=headers, data=json.dumps(payload))
# === 6. 解析响应 ===
if resp.status_code == 200:
data = resp.json()
if data.get("errorCode") == 0:
# PDF 的结果在 layoutParsingResults 数组中
results = data["result"]["layoutParsingResults"]
md_text = ""
for i, page in enumerate(results, 1):
md_text += f"\n\n# Page {i}\n\n"
md_text += page["markdown"]["text"]
with open(output_md, "w", encoding="utf-8") as f:
f.write(md_text)
print(f"成功生成 Markdown:{output_md}")
else:
print(f"服务端错误:{data.get('errorMsg')}")
else:
print(f"HTTP 错误:{resp.status_code}")
print(resp.text)
PaddleOCR Doc Parser 命令参数如下表所示:
基础参数
| 参数名 | 说明 |
|---|---|
-i INPUT, --input INPUT | 输入路径或 URL(必需) |
--save_path SAVE_PATH | 输出目录路径 |
布局检测参数
| 参数名 | 说明 |
|---|---|
--layout_detection_model_name | 布局检测模型名称 |
--layout_detection_model_dir | 布局检测模型目录路径 |
--layout_threshold | 布局检测模型的分数阈值 |
--layout_nms | 是否在布局检测中使用 NMS(非极大值抑制) |
--layout_unclip_ratio | 布局检测的扩展系数 |
--layout_merge_bboxes_mode | 重叠框过滤方法 |
VL识别模型参数
| 参数名 | 说明 |
|---|---|
--vl_rec_model_name | VL 识别模型名称 |
--vl_rec_model_dir | VL 识别模型目录路径(指定本地 PaddleOCR-VL-0.9B 模型路径) |
--vl_rec_backend | VL 识别模块使用的后端(native, vllm-server, sglang-server) |
--vl_rec_server_url | VL 识别模块使用的服务器 URL |
--vl_rec_max_concurrency | VLM 请求的最大并发数 |
文档处理模型
| 参数名 | 说明 |
|---|---|
--doc_orientation_classify_model_name | 文档图像方向分类模型名称 |
--doc_orientation_classify_model_dir | 文档图像方向分类模型目录路径 |
--doc_unwarping_model_name | 文本图像矫正模型名称 |
--doc_unwarping_model_dir | 图像矫正模型目录路径 |
功能开关参数
| 参数名 | 说明 |
|---|---|
--use_doc_orientation_classify | 是否使用文档图像方向分类 |
--use_doc_unwarping | 是否使用文本图像矫正 |
--use_layout_detection | 是否使用布局检测 |
--use_chart_recognition | 是否使用图表识别 |
--format_block_content | 是否将块内容格式化为 Markdown |
--use_queues | 是否使用队列进行异步处理 |
VLM生成参数
| 参数名 | 说明 |
|---|---|
--prompt_label | VLM 的提示标签 |
--repetition_penalty | VLM 采样中使用的重复惩罚系数 |
--temperature | VLM 采样中使用的温度参数 |
--top_p | VLM 采样中使用的 top-p 参数 |
--min_pixels | VLM 图像预处理的最小像素数 |
--max_pixels | VLM 图像预处理的最大像素数 |
硬件与性能参数
| 参数名 | 说明 |
|---|---|
--device | 用于推理的设备,例如 cpu、gpu、npu、gpu:0、gpu:0,1。如果指定多个设备,将并行执行推理。注意:并非所有情况都支持并行推理。默认情况下,如果可用将使用 GPU 0,否则使用 CPU |
--enable_hpi | 启用高性能推理 |
--use_tensorrt | 是否使用 Paddle Inference TensorRT 子图引擎。如果模型不支持 TensorRT 加速,即使设置此标志也不会使用加速 |
--precision | 使用 Paddle Inference TensorRT 子图引擎时的 TensorRT 精度(fp32, fp16) |
--enable_mkldnn | 为推理启用 MKL-DNN 加速。如果 MKL-DNN 不可用或模型不支持,即使设置此标志也不会使用加速 |
--mkldnn_cache_capacity | MKL-DNN 缓存容量 |
--cpu_threads | 在 CPU 上用于推理的线程数 |
--paddlex_config | PaddleX 管道配置文件路径 |
当然,上述代码也是LangChain1.0 + OCR 多模态PDF解析实战项目中PaddleOCR 的核心代码逻辑:
五、DeepSeek-OCR vLLM 服务接口启动
DeepSeek-OCR 作为刚刚开源的小型多模态视觉模型,经过我们团队大量的测试,其不仅识别精度高,同时对中文的支持也非常出色,同时也能够输出结构化的 Markdown 格式文档。
5.1 环境配置要求
在开始部署之前,我们首先需要确认自己的服务器是否满足运行条件。
硬件配置要求(建议)
| 硬件类型 | 最低要求 | 推荐配置 | 说明 |
|---|---|---|---|
| GPU | NVIDIA RTX 3090 | RTX 4090 或更高 | 必须是NVIDIA显卡,支持CUDA |
| 显存 | 24GB | 24GB+ | 显存越大,处理速度越快 |
| 内存 | 32GB | 64GB+ | 用于图像预处理和数据缓存 |
| 硬盘 | 50GB可用空间 | 100GB+ | 模型文件较大,需要足够空间 |
除了硬件,我们还需要准备相应的软件环境:主要包括操作系统:建议使用 Ubuntu 22.04,同时需要 CUDA 12.0+,而Python 环境建议使用 Python 3.10+。
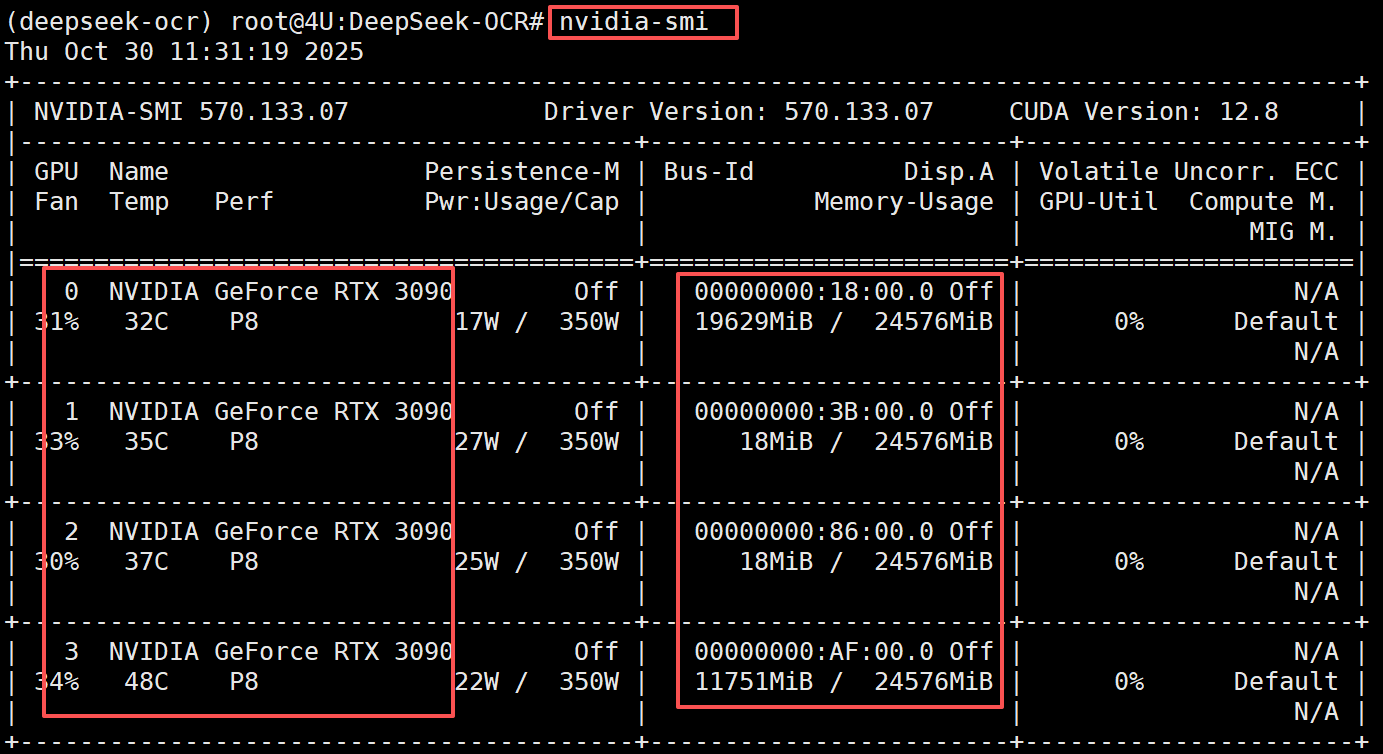
课程使用的配置环境为:Ubuntu 22.04 + 四卡 3090。大家在使用 vLLM 启动DeepSeek-OCR时,首先需要做如下配置校验:
FENCE0
执行上述命令后,如果看到类似下面的输出,说明GPU正常工作:
接下来检查 Conda 是否安装,执行如下命令:
FENCE0
如果看到类似 conda XXX 的版本号,说明conda已经安装。如果提示命令不存在,需要先安装 miniconda 或者 anaconda3。

5.2 DeepSeek-OCR模型下载
环境准备好之后,接下来我们需要下载 DeepSeek-OCR 模型文件,并进行相应的配置。这一步是整个部署过程的核心。国内用户强烈建议大家使用 ModelScope 下载模型,没有网络限制,同时速度也会快很多。
首先,我们需要创建一个独立的 Python 虚拟环境。虚拟环境可以隔离项目依赖,避免与系统其他 Python 项目产生冲突。执行如下命令 FENCE0
其中:
--name deepseek-ocr-vllm:虚拟环境名称,可以自定义python==3.10:指定 Python 版本为 3.10(PaddleOCR 推荐版本)
执行效果如下图所示:
接下来激活虚拟环境: FENCE0
激活后,命令行提示符前会显示 (deepseek-ocr-vllm),表示已进入虚拟环境。

接下来,在ModelScope 平台下载 DeepSeek-OCR 模型文件。地址:https://modelscope.cn/models/deepseek-ai/DeepSeek-OCR
ModelScope 是阿里云的模型托管平台,国内访问速度快。首先执行如下命令:
FENCE0
然后执行如下代码:
FENCE0
其中:
'deepseek-ai/DeepSeek-OCR':模型仓库 IDlocal_dir='.':下载到当前目录(也可以指定其他路径,如'./models')
接下来执行如下代码进行模型权重安装:
FENCE0
下载完成后的模型目录结构如下所示:
5.3 Deepseek-OCR vLLM 项目文件
DeepSeek-OCR通过 vLLM 平台启动,我们是借助DeepSeek-OCR官方提供的项目代码,并做了一些优化和调整,其官方源码下载地址:https://github.com/deepseek-ai/DeepSeek-OCR/tree/main/DeepSeek-OCR-master/DeepSeek-OCR-vllm
我们将项目文件下载到本地并上传到服务器上:
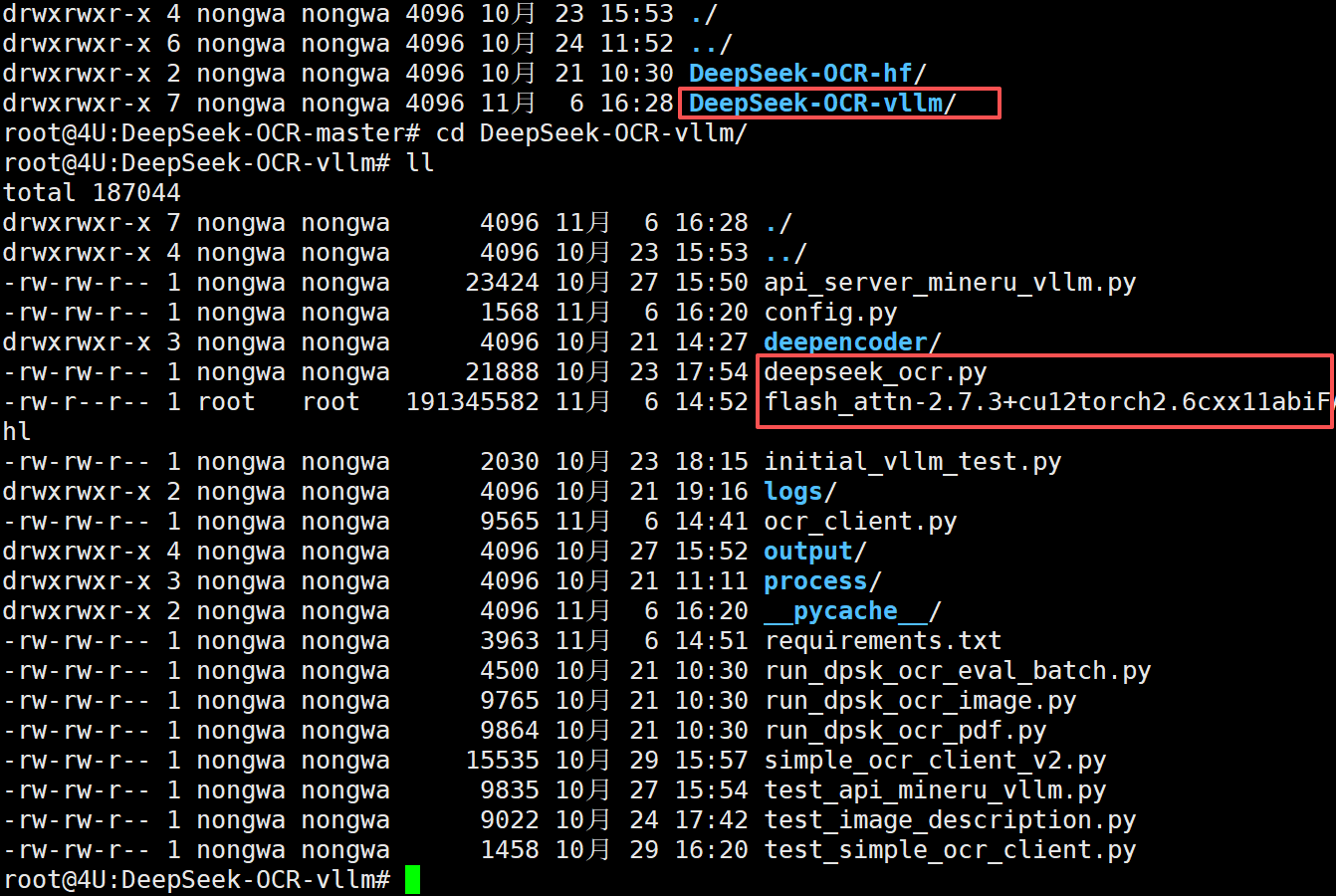
其中deepseek_ocr.py 和 flash_attn-2.7.3+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl 使我们给大家提供的两个核心文件,一个用于封装 DeepSeek OCR API 接口,另一个则是离线安装的 fla_ttn 的离线安装包。
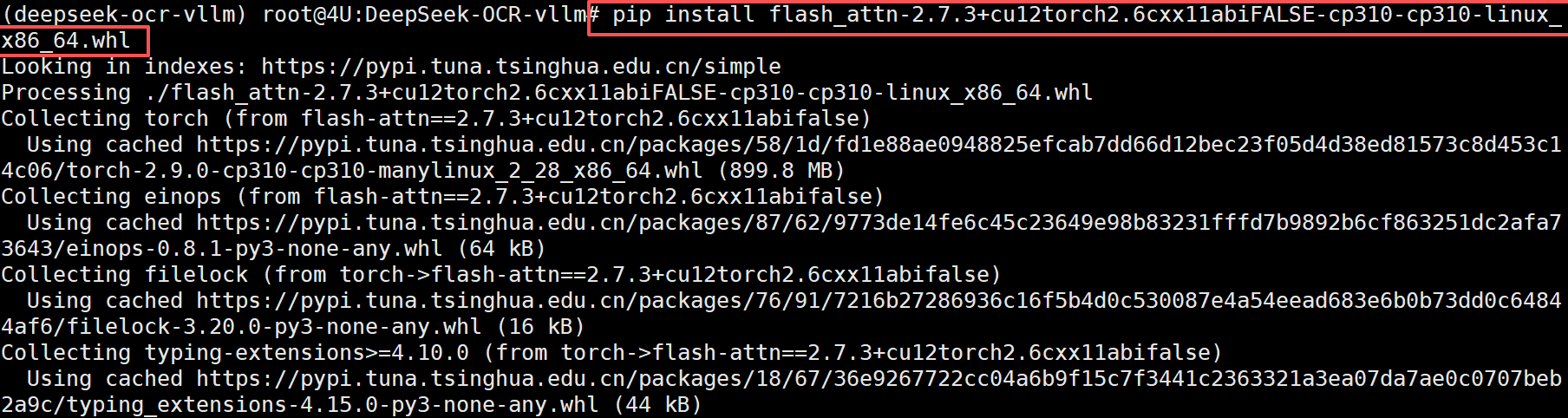
接下来一键安装 vLLM 运行 DeepSeek-OCR的依赖包:

安装结束后,使用我们给大家提供的deepseek_ocr.py文件,启动 DeepSeek OCR API 接口 服务。
启动命令如下:
FENCE0
启动成功后,会显示如下:
接下来,便可以在网页端查看到 FastAPI 接口:
5.4 DeepSeek-OCR API 连接测试
前面我们完成了服务的部署和启动,接下来我们要学习如何在实际项目中调用这个 OCR 服务。本节将通过完整的代码示例,带领大家掌握图片识别和 PDF 文档处理的全流程。
在开始编写调用代码之前,我们先来了解一下 OCR 服务提供的 API 接口规范。
OCR API 接口规范
| 项目 | 说明 |
|---|---|
| 接口地址 | http://localhost:8797/ocr |
| 请求方式 | POST |
| 内容类型 | multipart/form-data |
| 文件参数 | file(支持 jpg, png, pdf 等格式) |
| 可选参数 | enable_description(是否生成图片描述,默认 False) |
返回的数据格式如下:
FENCE0
返回的 markdown 字段就是我们需要的识别结果,它保留了原文档的格式结构,包括标题、列表、表格等。
下面我们通过一个完整的代码示例,来演示如何调用 OCR 服务。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
测试 DeepSeek-OCR API
直接调用 API 并保存返回的 markdown 和图像数据
"""
import requests
import json
import sys
from pathlib import Path
def test_deepseek_ocr(pdf_path: str, output_dir: str = "./test_output"):
"""
测试 DeepSeek-OCR API
Args:
pdf_path: PDF 文件路径
output_dir: 输出目录
"""
# API 配置
api_url = "http://192.168.130.4:8797/ocr"
# 确保输出目录存在
output_path = Path(output_dir)
output_path.mkdir(parents=True, exist_ok=True)
print(f"测试文件: {pdf_path}")
print(f"API 地址: {api_url}")
print(f"输出目录: {output_dir}")
print("-" * 60)
# 读取 PDF 文件
try:
with open(pdf_path, 'rb') as f:
files = {'file': (Path(pdf_path).name, f, 'application/pdf')}
# API 参数
data = {
'enable_description': 'false', # 是否生成图片描述
}
print("发送请求到 DeepSeek API...")
# 发送请求
response = requests.post(
api_url,
files=files,
data=data,
timeout=300
)
if response.status_code != 200:
print(f"API 返回错误: {response.status_code}")
print(f"错误信息: {response.text[:500]}")
return False
# 解析响应
result = response.json()
print(f"API 响应成功")
print(f"响应包含的字段: {list(result.keys())}")
print("-" * 60)
# 提取数据
markdown_content = result.get("markdown", "")
page_count = result.get("page_count", 0)
images_data = result.get("images", {})
print(f"Markdown 长度: {len(markdown_content)} 字符")
print(f"页数: {page_count}")
print(f"图像数量: {len(images_data)}")
if images_data:
print(f"图像列表:")
for img_key in list(images_data.keys())[:10]:
img_size = len(images_data[img_key])
print(f" - {img_key}: {img_size} 字符 (base64)")
print("-" * 60)
# 保存 Markdown
md_file = output_path / f"{Path(pdf_path).stem}_deepseek.md"
with open(md_file, 'w', encoding='utf-8') as f:
f.write(markdown_content)
print(f"Markdown 已保存: {md_file}")
# 保存完整响应
json_file = output_path / f"{Path(pdf_path).stem}_response.json"
with open(json_file, 'w', encoding='utf-8') as f:
# 为了避免文件过大,只保存图像的部分信息
simplified_result = {
"markdown": markdown_content,
"page_count": page_count,
"images_count": len(images_data),
"image_keys": list(images_data.keys())
}
json.dump(simplified_result, f, ensure_ascii=False, indent=2)
print(f"响应摘要已保存: {json_file}")
# 保存图像数据(可选,如果需要)
if images_data:
images_file = output_path / f"{Path(pdf_path).stem}_images.json"
with open(images_file, 'w', encoding='utf-8') as f:
json.dump(images_data, f, ensure_ascii=False, indent=2)
print(f"图像数据已保存: {images_file}")
# 统计信息
print("-" * 60)
print("统计信息:")
# 统计表格数量
import re
table_count = len(re.findall(r'<table>', markdown_content, re.IGNORECASE))
print(f" - HTML 表格: {table_count} 个")
# 统计图片引用
img_ref_count = len(re.findall(r'!\[.*?\]\(.*?\)', markdown_content))
print(f" - Markdown 图片引用: {img_ref_count} 个")
# 统计行数
line_count = len(markdown_content.split('\n'))
print(f" - Markdown 行数: {line_count} 行")
print("-" * 60)
print("测试完成!")
return True
except FileNotFoundError:
print(f"文件不存在: {pdf_path}")
return False
except requests.exceptions.Timeout:
print(f"请求超时")
return False
except Exception as e:
print(f"发生错误: {e}")
import traceback
traceback.print_exc()
return False
def main():
"""主函数"""
success = test_deepseek_ocr(
pdf_path='./course.pdf',
output_dir='./')
if __name__ == "__main__":
main()
通过不同的提示词,对输入的PDF文档的每一页做格式化提取:
FENCE0
当然,上述代码也是LangChain1.0 + OCR 多模态PDF解析实战项目中DeepSeek-OCR 的核心代码逻辑:
六、OCR 多模态解析系统本地部署
完整的系统需要同时启动后端和前端两个服务。首先对于后端服务启动,需要依次执行如下操作:
FENCE0
启动服务执行如下代码:
FENCE0
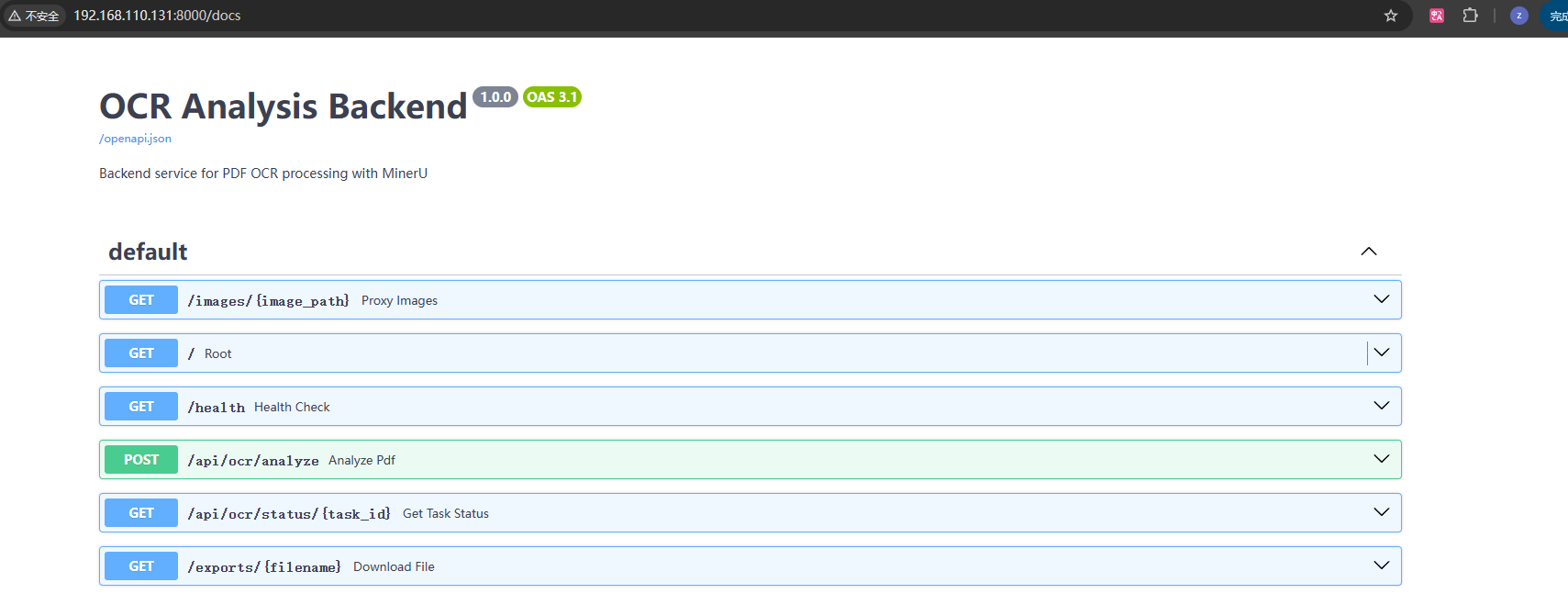
然后,便可以在 http://192.168.110.131:8000/docs 查看 API 文档:
前端服务启动,需要依次执行如下操作:
FENCE0
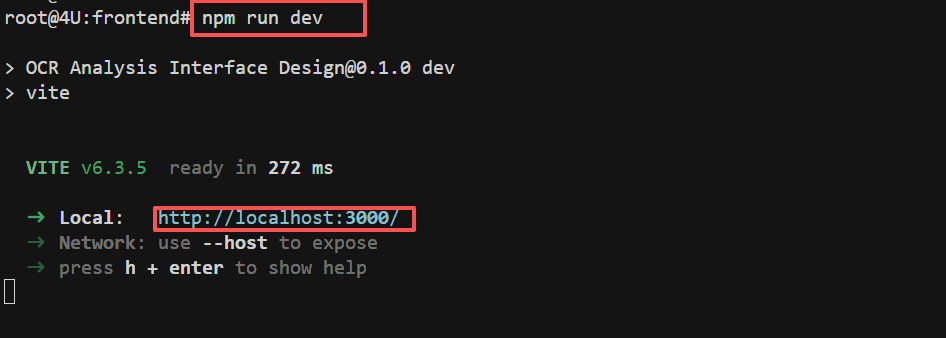
启动成功后,即可通过http://localhost:3000访问应用。
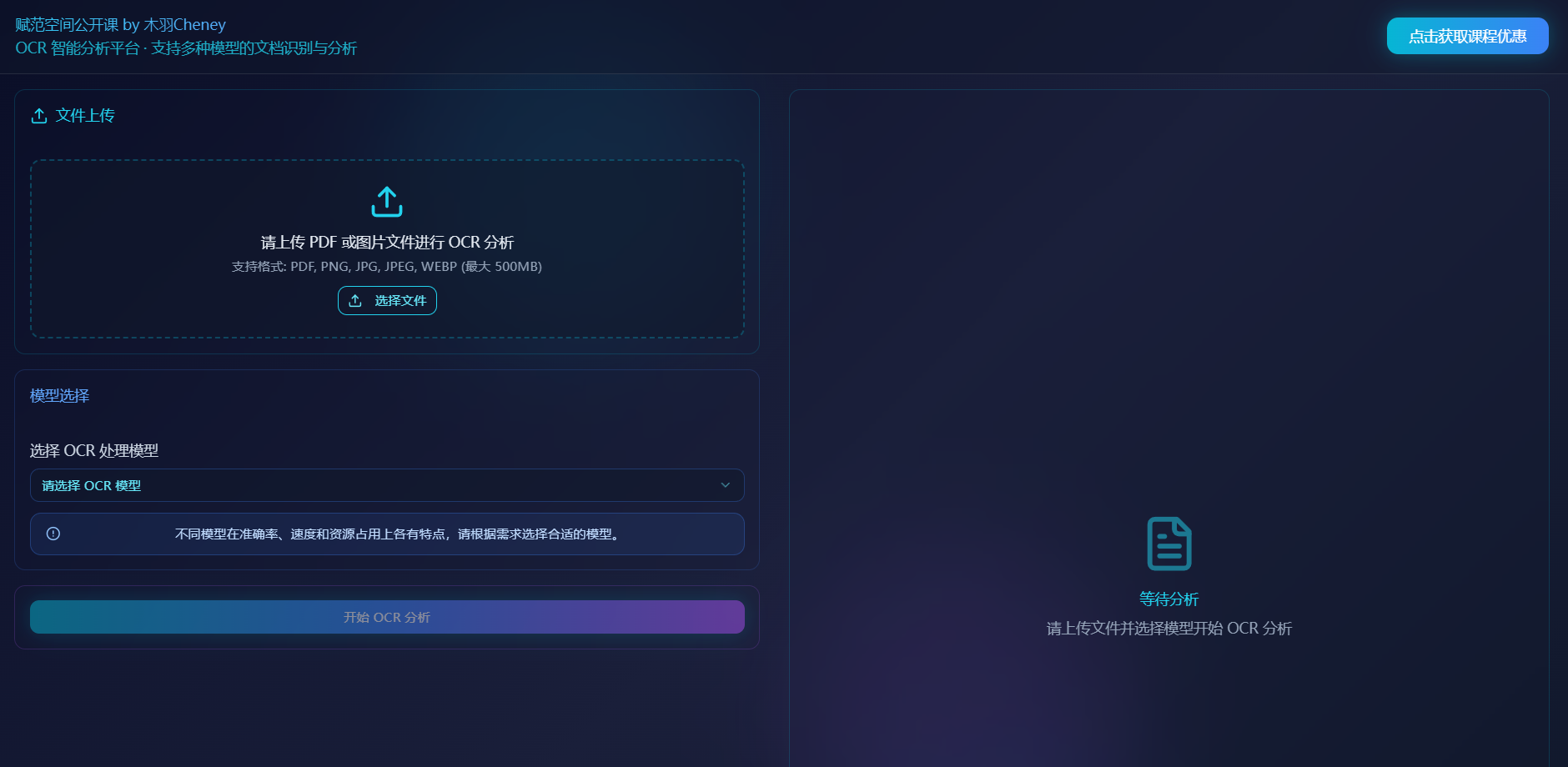
【加餐】 LangChain1.0 接入 MinerU MCP Server
随着MinerU项目的发展,除了解析性能上进一步提升,同时也支持了MCP协议,可以通过stdio、Http + Sse和 Streamable Http三种通信模型进行访问。因此,本小节我们重点讲解MinerU项目在MCP协议下的使用,并基于LangChain 1.0 新版本实现MinerU MCP的接入。
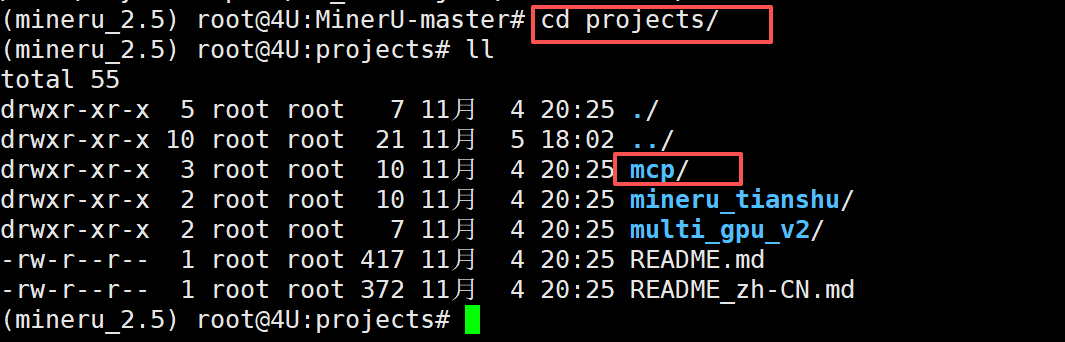
最新版本的MinerU 项目中内置了MCP Server 服务,我们可以通过该服务将MinerU 的解析服务暴露给ADK 或 Agent 使用。与常规的MCP Server 构建方式一样,也是通过 FastMCP 外放FastAPI 服务并支持stdio、Http+Sse和StreamableHttp 三种传输方式。源码位置如下:
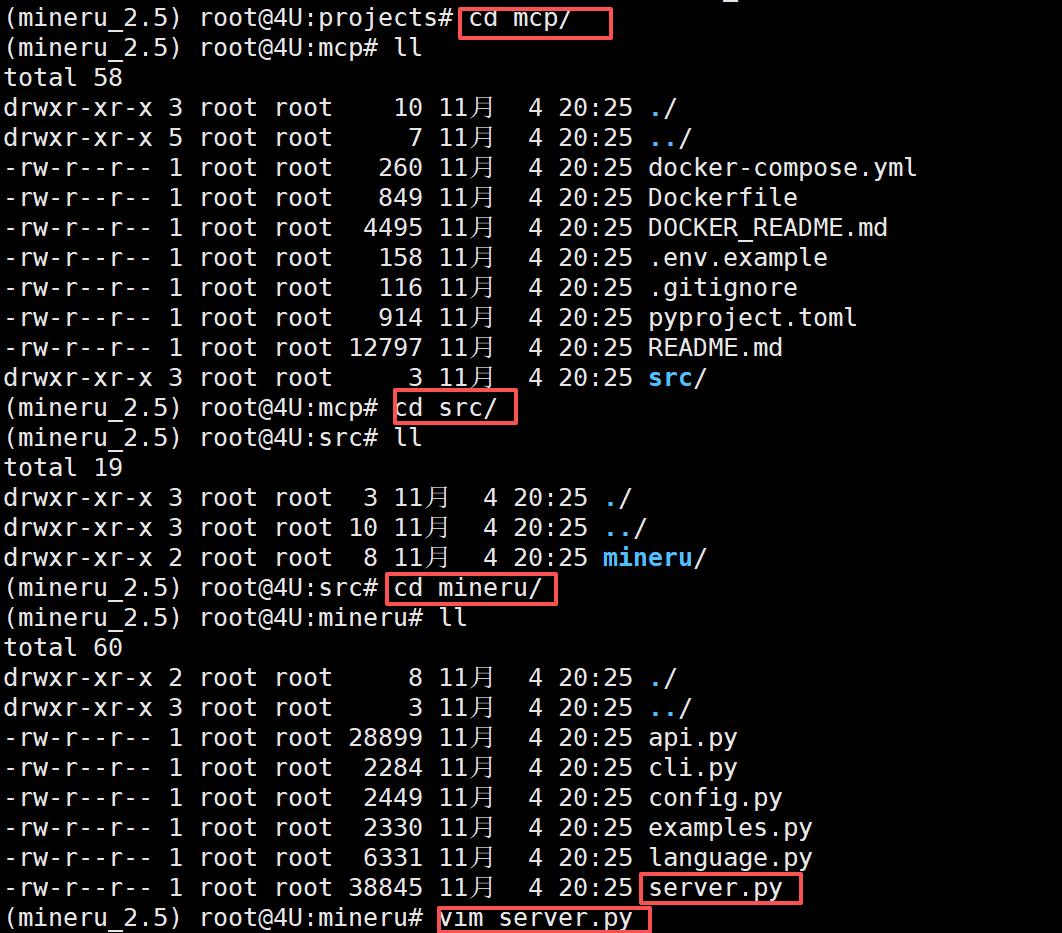
这里我们使用StreamableHttp 传输方式,并且在启动前,修改下源码,使其可以加载我们通过命令行传递的host参数,否则只能使用默认的localhost 地址。如下所示:
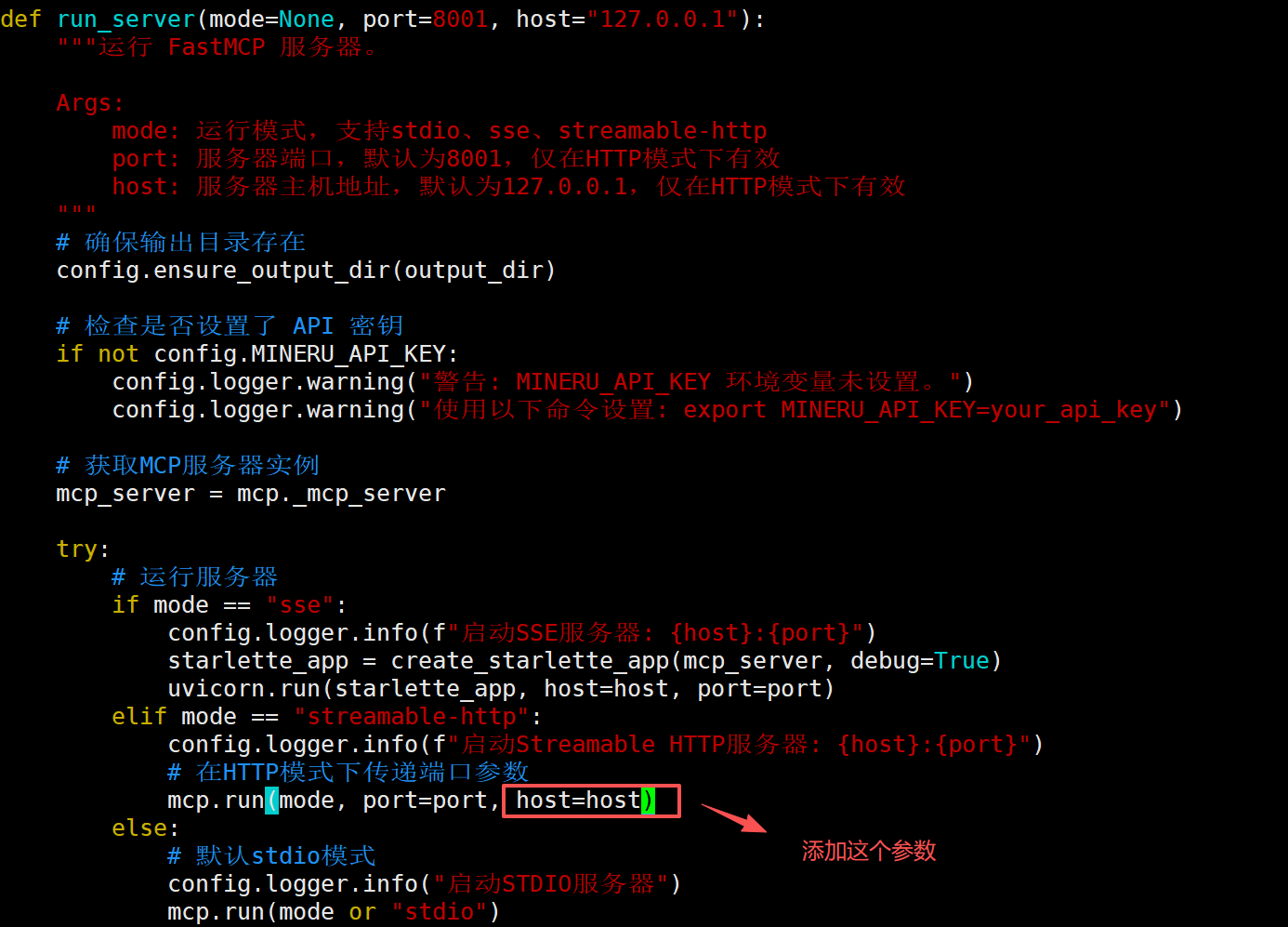
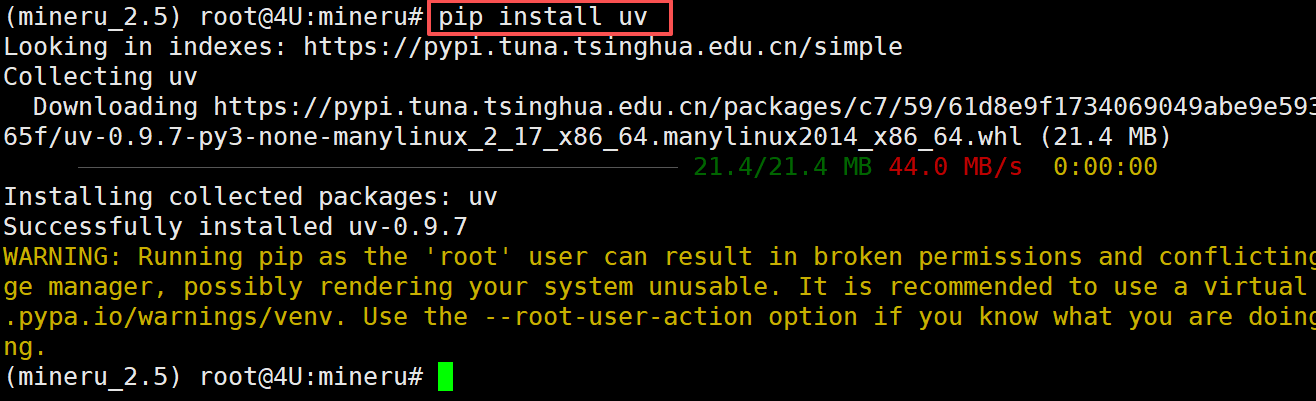
接下来创建MCP的uv环境,首先通过pip 安装 uv:
FENCE0
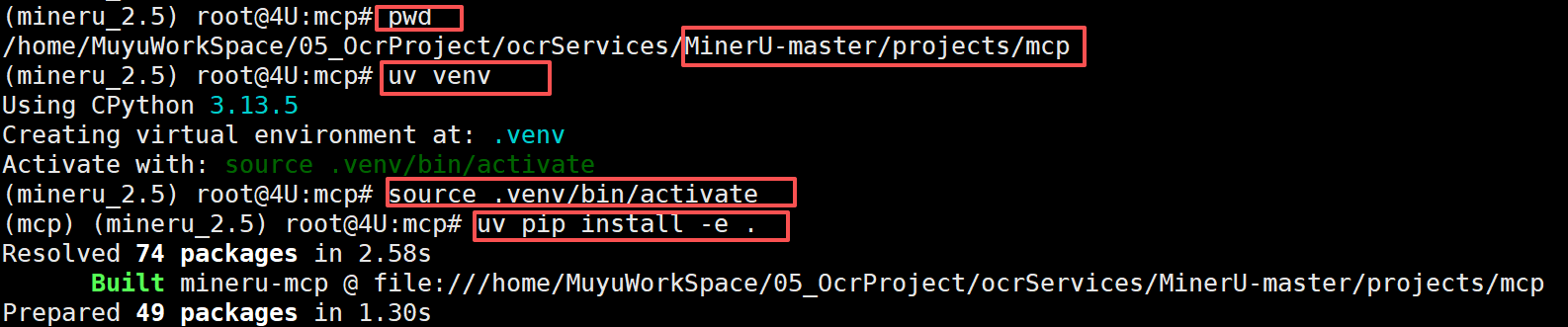
然后通过uv 创建MCP 的uv 环境,并安装MinerU 项目中用到的依赖:
FENCE1
安装完成后,我们就可以通过uv 启动MCP 服务了:
FENCE2
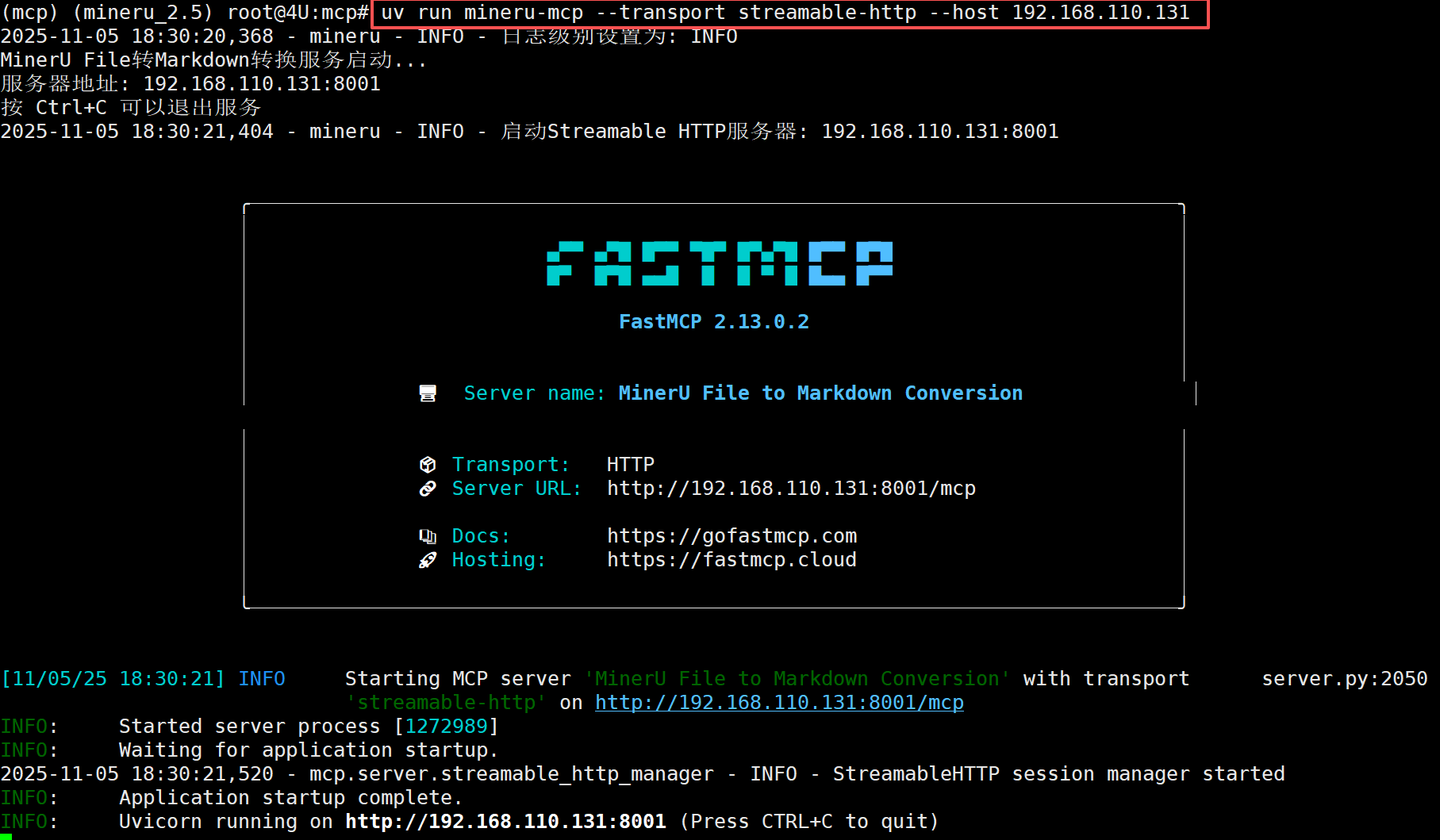
启动后,我们可以在浏览器中访问http://192.168.110.131:8000/mcp快速进行验证:
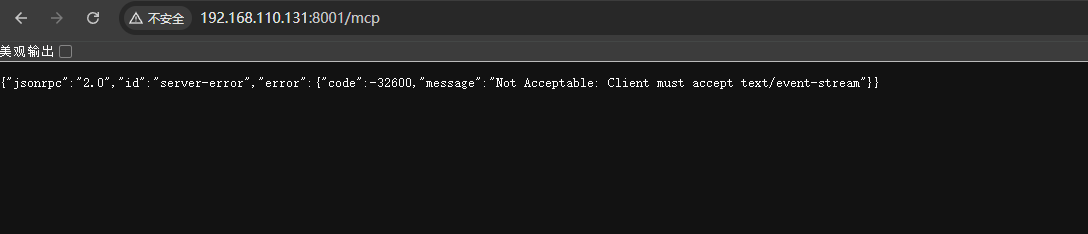
需要重点注意的是:parse_documents 工具是MinerU 项目中通过FastAPI 外放的工具接口,其本质上,调用的是mineru-api 服务中的/api/parse 接口。所以,大家要理解的逻辑是:
FastMCP 负责暴露parse_documents和get_ocr_languages 工具协议,而真正做 PDF→Markdown 的逻辑在 MinerU 的“本地解析服务”里,并通过 /file_parse 路由完成。MCP 只是一个工具“壳”,真正干活的是mineru-api。因此,我们首先需要修改MinerU MCP Server的配置文件,让其找到解析服务。如下所示:
FENCE0
修改如下:
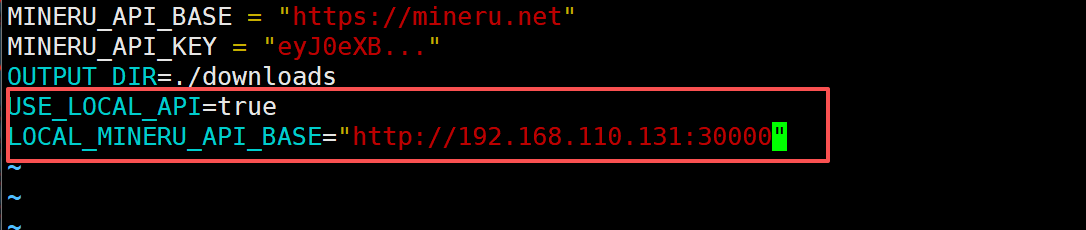
其中USE_LOCAL_API=true 表示使用本地解析服务,LOCAL_API_URL 表示本地解析服务的地址。修改完成后重新启动MinerU MCP Server 服务。
FENCE1
FENCE2
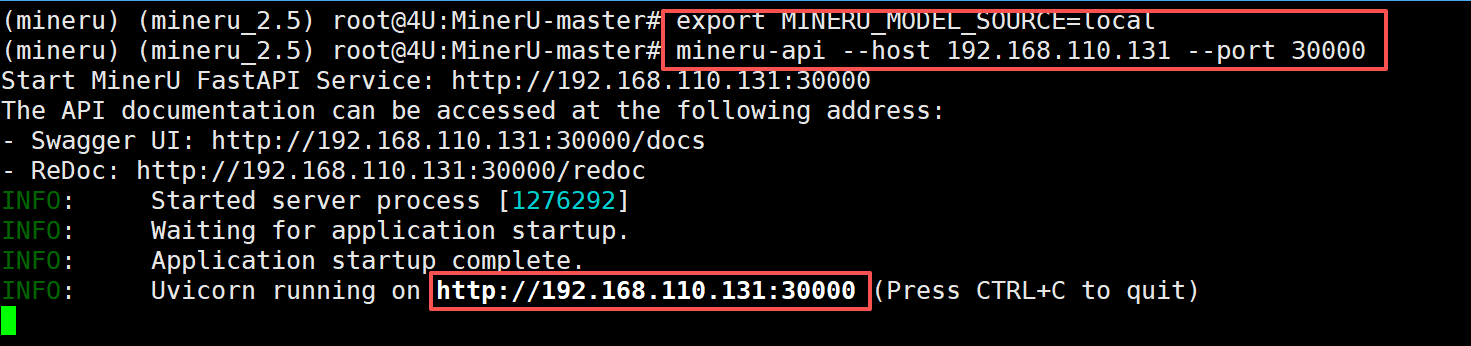
启动后,在192.168.110.131:30000/docs中可以看到接口服务:
全部验证成功后,我们就可以在LangChain中使用MCP 服务了。代码如下:
! pip install langchain>=1.0.0 langchain-core>=1.0.0 langchain-mcp-adapters mcp httpx -q
安装完成后,让我们导入必要的模块:
# 导入必要的库
import asyncio
from pathlib import Path
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
from langchain_mcp_adapters.tools import load_mcp_tools
print("所有库导入成功!")
现在,配置连接到 MinerU MCP 服务的参数。根据服务启动日志,
- 协议类型: streamable-http
- 服务地址: http://192.168.110.131:8001/mcp 首先定义服务器配置参数:
# 配置 MinerU MCP 服务器参数
MCP_SERVER_URL = "http://192.168.110.131:8001/mcp"
server_params = {
"url": MCP_SERVER_URL,
# 如果需要认证,可以在这里添加 headers
# "headers": {
# "Authorization": "Bearer your_token"
# }
}
print(f"MCP 服务器地址: {MCP_SERVER_URL}")
print("服务器参数配置完成")
在实际解析 PDF 之前,我们先要了解 MCP 服务器提供了哪些工具。这就像进入一个工具箱,先看看里面有什么工具可用。如下函数来列出所有可用的 MCP 工具:
async def list_mcp_tools(server_params):
"""
列出 MCP 服务器提供的所有工具
Args:
server_params: 服务器连接参数
Returns:
tools: LangChain 工具列表
"""
print("🔌 正在连接 MCP 服务器...")
# 使用 streamable-http 客户端建立连接
async with streamablehttp_client(**server_params) as (read, write, _):
# 创建 MCP 会话
async with ClientSession(read, write) as session:
# 初始化会话(握手)
await session.initialize()
print("MCP 会话初始化成功\n")
# 加载所有 MCP 工具
tools = await load_mcp_tools(session)
print(f"发现 {len(tools)} 个可用工具:\n")
print("=" * 80)
# 打印每个工具的详细信息
for i, tool in enumerate(tools, 1):
print(f"\n工具 {i}: {tool.name}")
print(f" 描述: {tool.description}")
# 打印工具参数(如果有)
if hasattr(tool, 'args_schema') and tool.args_schema:
print(f" 参数结构:")
if hasattr(tool.args_schema, 'schema'):
schema = tool.args_schema.schema()
if 'properties' in schema:
for param_name, param_info in schema['properties'].items():
param_type = param_info.get('type', 'unknown')
param_desc = param_info.get('description', '无描述')
print(f" - {param_name} ({param_type}): {param_desc}")
print("\n" + "=" * 80)
return tools
# 执行函数(在 Jupyter 中运行异步代码)
tools = await list_mcp_tools(server_params)
接下来,构建一个完整的客户端类,封装所有的功能,使其更易用。客户端类将包含以下功能:
- 连接管理
- 工具列表查询
- PDF 文档解析
- 结果保存
class MinerUClient:
"""
MinerU MCP 客户端封装类
提供简洁的 API 来调用 MinerU 文档解析服务
"""
def __init__(self, mcp_url: str = "http://192.168.110.131:8001/mcp"):
"""
初始化客户端
Args:
mcp_url: MCP 服务器地址
"""
self.mcp_url = mcp_url
self.server_params = {"url": self.mcp_url}
print(f"MinerU 客户端已初始化")
print(f"服务器地址: {self.mcp_url}")
async def get_tools(self):
"""
获取所有可用的 MCP 工具
Returns:
tools: 工具列表
"""
async with streamablehttp_client(**self.server_params) as (read, write, _):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await load_mcp_tools(session)
return tools
async def parse_pdf(self, pdf_path: str, output_format: str = "markdown"):
"""
解析 PDF 文件
Args:
pdf_path: PDF 文件路径(支持相对路径和绝对路径)
output_format: 输出格式,默认为 markdown
Returns:
解析结果(Markdown 文本)
"""
# 检查文件是否存在
pdf_file = Path(pdf_path)
if not pdf_file.exists():
raise FileNotFoundError(f"PDF 文件不存在: {pdf_path}")
print(f"开始解析 PDF: {pdf_file.name}")
print(f"文件路径: {pdf_file.absolute()}")
print(f"文件大小: {pdf_file.stat().st_size / 1024:.2f} KB\n")
# 连接 MCP 服务器并解析
async with streamablehttp_client(**self.server_params) as (read, write, _):
async with ClientSession(read, write) as session:
await session.initialize()
# 加载工具
tools = await load_mcp_tools(session)
print(f"已加载 {len(tools)} 个工具\n")
# 查找合适的解析工具
parse_tool = None
for tool in tools:
# 根据工具名称特征查找
tool_name_lower = tool.name.lower()
if any(keyword in tool_name_lower for keyword in
['convert', 'parse', 'markdown', 'pdf', 'file']):
parse_tool = tool
print(f"找到解析工具: {tool.name}")
print(f" 工具描述: {tool.description}\n")
break
if not parse_tool:
print("未找到合适的解析工具,可用工具列表:")
for i, tool in enumerate(tools, 1):
print(f" {i}. {tool.name}")
# 如果没找到特定工具,尝试使用第一个工具
if tools:
parse_tool = tools[0]
print(f"\n尝试使用第一个工具: {parse_tool.name}")
else:
raise ValueError("MCP 服务器没有提供任何工具")
# 调用工具进行解析
print("正在调用 MCP 工具解析文档...")
try:
# 构建工具调用参数 - 参数是字符串格式(支持单个文件或逗号分隔的多个文件)
tool_input = {
"file_sources": str(pdf_file.absolute())
}
# 调用工具
result = await parse_tool.ainvoke(tool_input)
print("解析完成!\n")
return result
except Exception as e:
print(f"解析失败: {str(e)}")
raise
# 创建客户端实例
client = MinerUClient(mcp_url=MCP_SERVER_URL)
print("客户端创建成功!")
在实际运行之前,我们需要准备一个 PDF 文件用于测试。
# 使用 LangChain Agent 自动调用 MCP 工具
from pathlib import Path
print("=" * 80)
print("创建 LangChain Agent 自动调用 MCP 工具")
print("=" * 80)
# 1. 加载 MCP 工具
print("\n加载 MCP 工具...")
async with streamablehttp_client(**server_params) as (read, write, _):
async with ClientSession(read, write) as session:
await session.initialize()
mcp_tools = await load_mcp_tools(session)
print(f"已加载 {len(mcp_tools)} 个 MCP 工具")
for tool in mcp_tools:
print(f" - {tool.name}: {tool.description[:60]}...")
# 2. 直接使用工具解析 PDF
print("\n" + "=" * 80)
print("使用 parse_documents 工具解析 PDF")
print("=" * 80)
pdf_file_path = "./course.pdf"
pdf_file = Path(pdf_file_path)
if not pdf_file.exists():
print(f"文件不存在: {pdf_file_path}")
else:
print(f"\n文件: {pdf_file.name}")
print(f"大小: {pdf_file.stat().st_size / 1024:.2f} KB")
# 找到 parse_documents 工具
parse_tool = None
for tool in mcp_tools:
if tool.name == "parse_documents":
parse_tool = tool
break
if not parse_tool:
print("未找到 parse_documents 工具")
else:
print("\n调用 parse_documents 工具...")
try:
# 调用工具,可以指定 backend 和 enable_ocr
result = await parse_tool.ainvoke({
"file_sources": str(pdf_file.absolute()),
"backend": "vlm-vllm-async-engine", # 可选: pipeline, vlm-transformers, vlm-vllm-engine, vlm-http-client
"enable_ocr": True, # 启用 OCR,对应 parse_method="ocr"
"language": "ch", # 文档语言
"device": "cuda:3"
})
print("解析完成!\n")
# 处理结果 - 正确解析 JSON 结构
import json
import urllib.parse
if isinstance(result, str):
# 尝试解析 JSON 字符串
try:
result = json.loads(result)
except:
content = result
result = None
if isinstance(result, dict):
if result.get("status") == "success":
# 检查是否有 content 字段(直接返回)
content = result.get("content", "")
# 如果没有 content,检查 result 字段(嵌套结构)
if not content:
result_data = result.get("result", {})
if result_data:
results_dict = result_data.get("results", {})
if results_dict:
# 提取第一个结果(即使键是 URL 编码的)
# results_dict 的键可能是 URL 编码的中文文件名
for encoded_key, file_result in results_dict.items():
md_content = file_result.get("md_content", "")
if md_content:
content = md_content
# 解码文件名(用于日志)
try:
decoded_name = urllib.parse.unquote(encoded_key)
print(f" 解码文件名: {decoded_name}")
except:
pass
break
# 如果还是没有,检查是否有 results 列表
if not content:
results_list = result.get("results", [])
if results_list:
content = results_list[0].get("content", "")
elif result.get("status") == "error":
print(f"解析失败: {result.get('error')}")
content = None
else:
content = str(result)
elif result is None:
# 已经是字符串了
pass
else:
content = str(result)
if content:
print("=" * 80)
print("解析结果统计")
print("=" * 80)
print(f"总字符数: {len(content):,}")
print(f"总行数: {content.count(chr(10)) + 1:,}")
# 保存结果到当前工作目录
import os
current_dir = Path(os.getcwd())
output_file = current_dir / f"{pdf_file.stem}_parsed.md"
output_file.write_text(content, encoding='utf-8')
print(f"\n结果已保存到: {output_file.absolute()}")
print(f"当前工作目录: {current_dir.absolute()}")
print(f"文件大小: {output_file.stat().st_size / 1024:.2f} KB")
# 显示预览
print("\n" + "-" * 80)
print("解析结果预览(前 1500 字符):")
print("-" * 80)
print(content[:1500])
if len(content) > 1500:
print("\n... (后续内容已省略)")
print("-" * 80)
print("\n" + "=" * 80)
print("成功!")
print("=" * 80)
else:
print("解析结果为空")
except Exception as e:
print(f"调用失败: {e}")
import traceback
traceback.print_exc()
同时也可以看到后端的服务运行情况:
我们下期公开课,再见! 👋