LangGraph快速入门 (v2)
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(夏季班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(夏季班)

《2025大模型Agent智能体开发实战》(夏季班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(夏季班)

两门大模型课程夏季班目前上新特惠+618年中钜惠双惠叠加,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


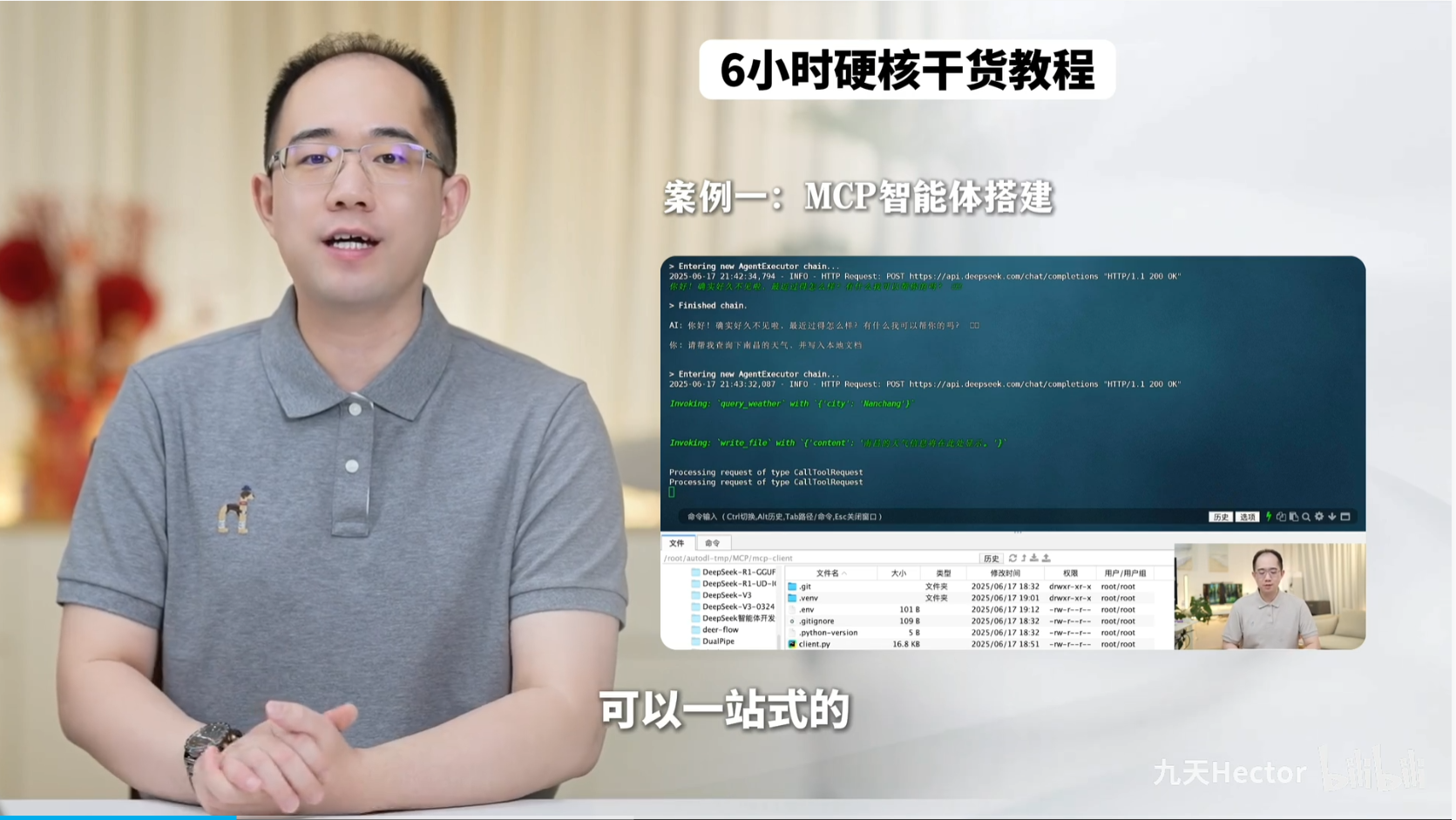
LangGraph快速入门与Agent开发实战
Part 1.LangGraph智能体开发快速入门
本期公开课,我们来深入系统讲解目前最通用、同时也是最实用的Agent开发框架:LangGraph。

LangGraph官网:https://langchain-ai.github.io/langgraph/
一、LangGraph入门介绍
1. LangGraph:超越LangChain的全新一代Agent开发框架
- Agent开发首选框架:LangChain
说到现阶段目前最流行、最通用的Agent开发框架,毫无疑问,肯定是LangChain。LangChain作为2022年就已经开源的元老级开发框架,历经数年的发展,其功能和生态都已非常完善,并且拥有数量众多的开发者。在我们团队统计的今年第一季度大模型岗位JD中,有90%以上的Agent开发岗位要求掌握LangChain,可以说LangChain就是目前最通用、最流行的Agent开发框架没有之一。
- LangChain的技术架构思路
不过,由于LangChain诞生时间较早,在2022年末,GPT-3.5刚诞生之时,开发者对大模型的想象主要是希望用其搭建一个又一个工作流,而这也成为LangChain的核心技术目标,LangChain中“Chain”就是指链、也就是搭建工作流的意思。
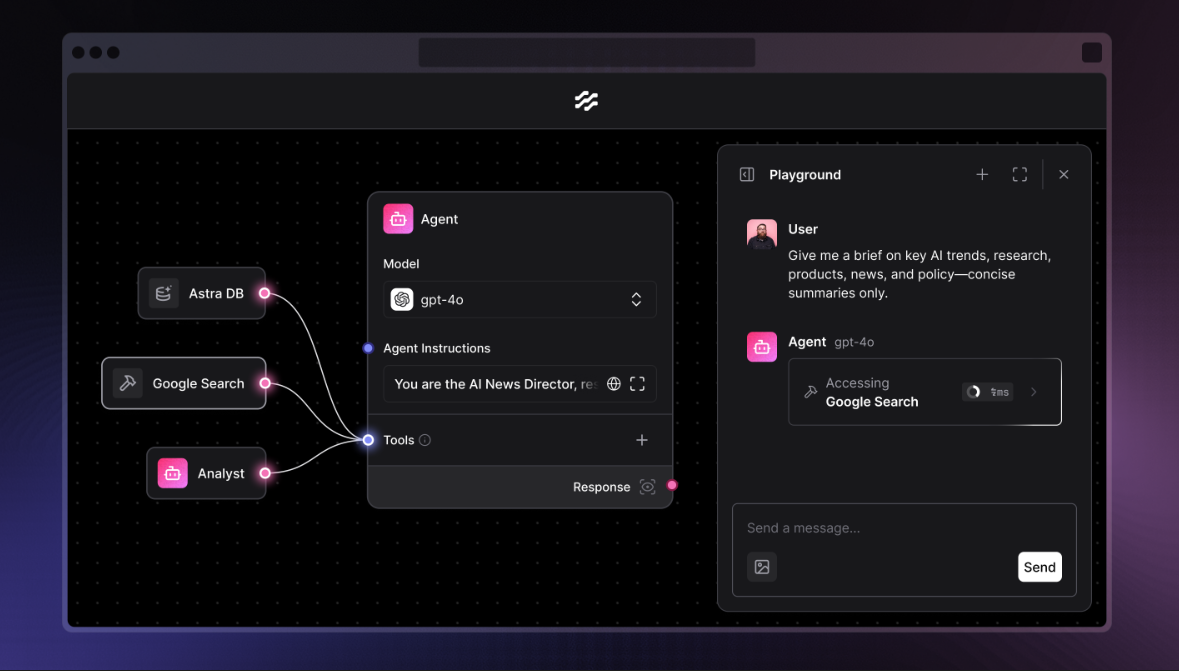
而且当时Function calling功能尚未诞生、大模型普遍性能较弱,并且2023年各类大模型百花齐放,但接口混乱、且上下文很短,开发者调用和开发都非常麻烦。因此,LangChain初始的核心架构有两层,第一层是围绕各类模型接入设置统一的接口,而为了让各类模型接入更加统一和稳定,LangChain不惜为不同的模型单独开发一个库,例如要接入Claude模型,我们就需要提前安装langchain-anthropic,而如果要接入DeepSeek模型,则需要安装langchain-deepseek。这么做虽然过程麻烦,但却能很好的保障开发过程的稳定性。
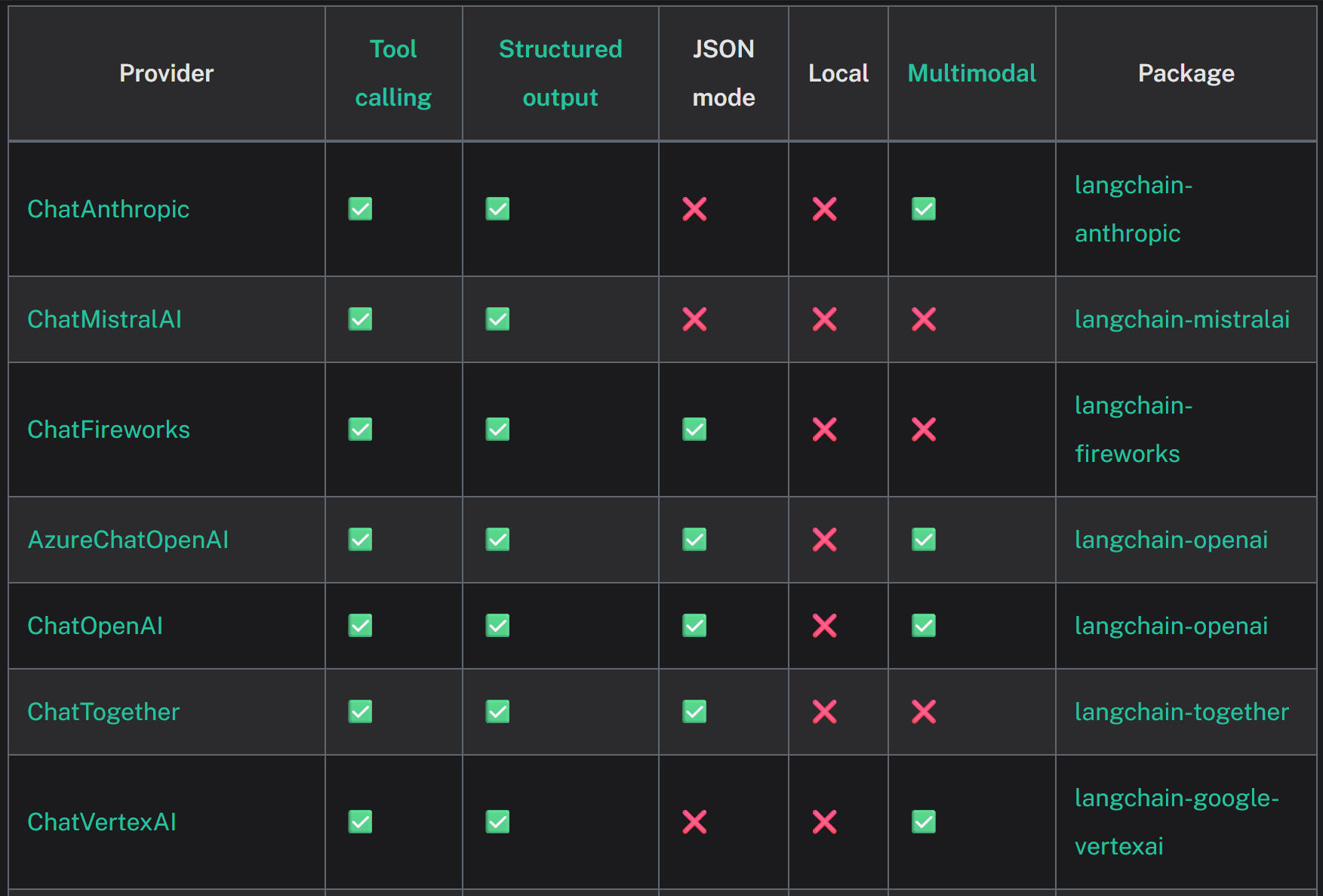
各类模型接入列表:https://python.langchain.com/docs/integrations/chat/
此外需要注意的是,LangGraph也需要使用和LangChain一样的模型接入流程。
而相比之下,OpenAI的Agents SDK则统一要求基座模型以OpenAI风格API进行接入,这必然会导致一些兼容性问题,而谷歌ADK则借助第三方库LiteLlm来调用基座模型,而这就会导致两个库功能不匹配的问题。因此从底层模型接入角度来看,LangChain也是最完善和最稳定的。
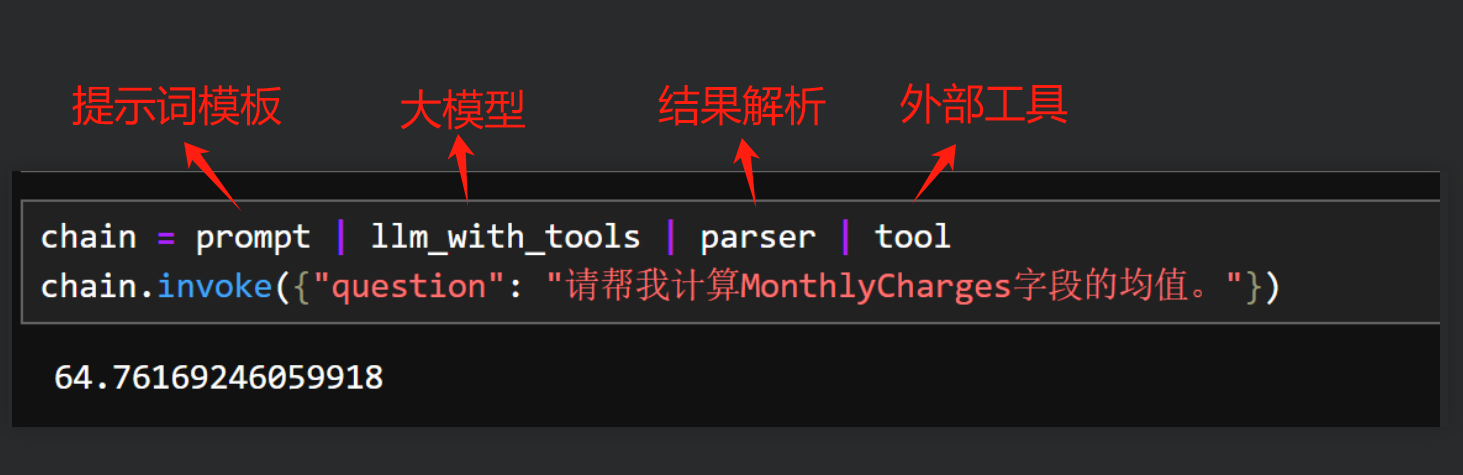
而在确保模型能够稳定接入后,LangChain紧接着定义了一整套LCEL(LangChain Expression Language)的语法规则,基于这个语法,开发者能够非常便捷的将提示词模板、大模型以及一些外部工具进行组合拼装,搭建一些大模型工作流,其功能定位和现在的n8n非常类似。
但是,大模型基座模型能力在飞速进化,例如目前最新一代的大模型,不仅拥有非常强悍的外部工具识别和调用能力,还原生就支持多工具并联和串联调用,而开发者对于大模型应用开发的需求也在快速变化,单纯的构建这种线性的工作流,可拓展性并不强。当前开发者更偏好的是“用AI开发AI”的思路,也就是我们不用定死工作流,而可以让大模型自主判断每一步该怎么做,然后实时创建一些链路,并根据运行情况随时调整。这也就是目前Agent智能体开发的核心思路。
为此,LangChain又进行了第三层封装,在Chain基础上,LangChain设置了一整套能够实时根据用户需求灵活创建Chain来完成工作的API——Agent API。借助这些API,开发者仅需将模型、提示词模板和外部工具“放一起”创建Agent,该Agent就能自动根据用户需求创建一些链来完成工作。从而避免开发者反复编写各种链的复杂工作,大幅加快的了开发效率。
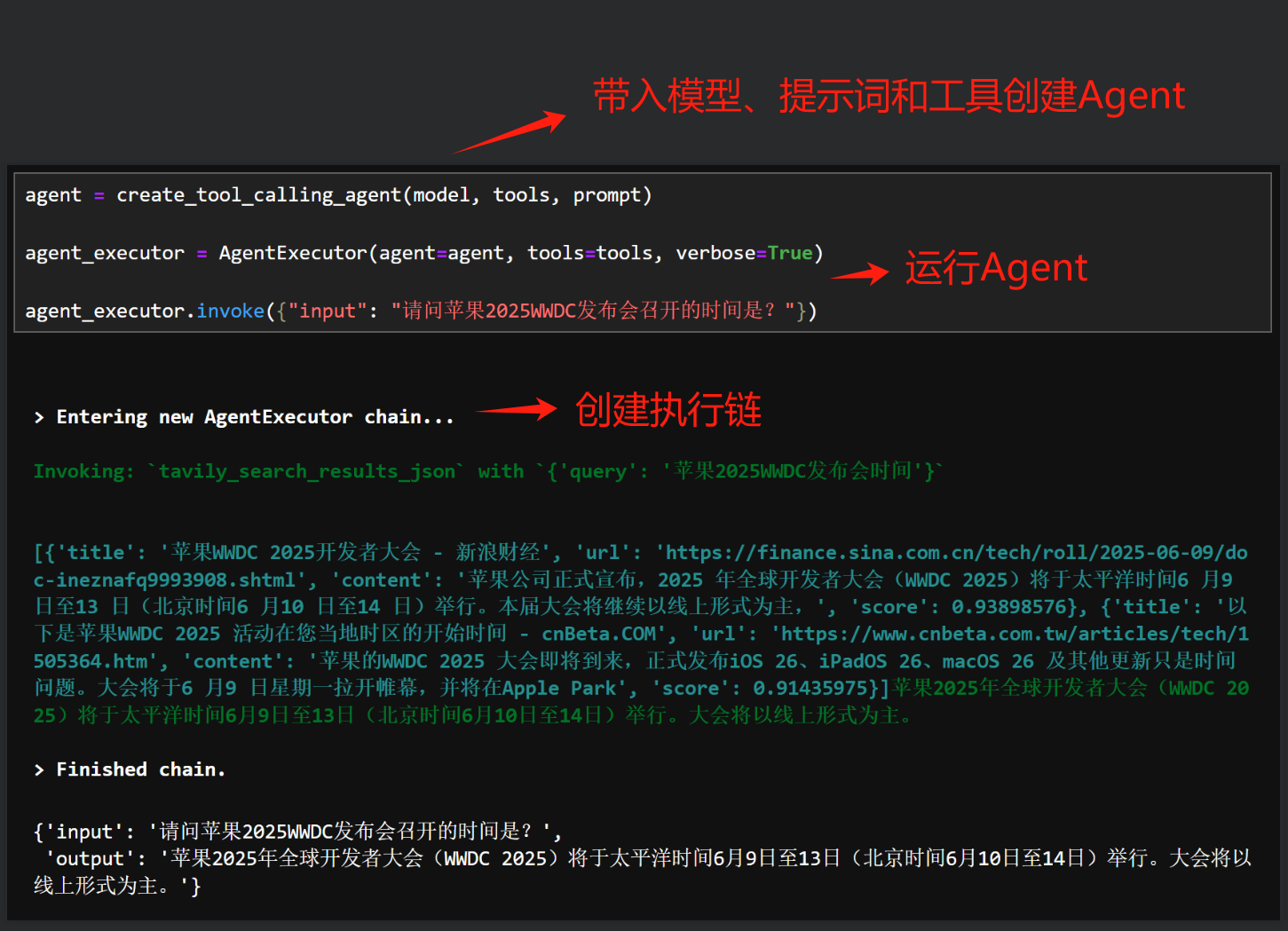
这种开发模式也就是目前OpenAI Agents SDK和谷歌ADK遵循的开发模式。
因此,LangChain整体架构如下:
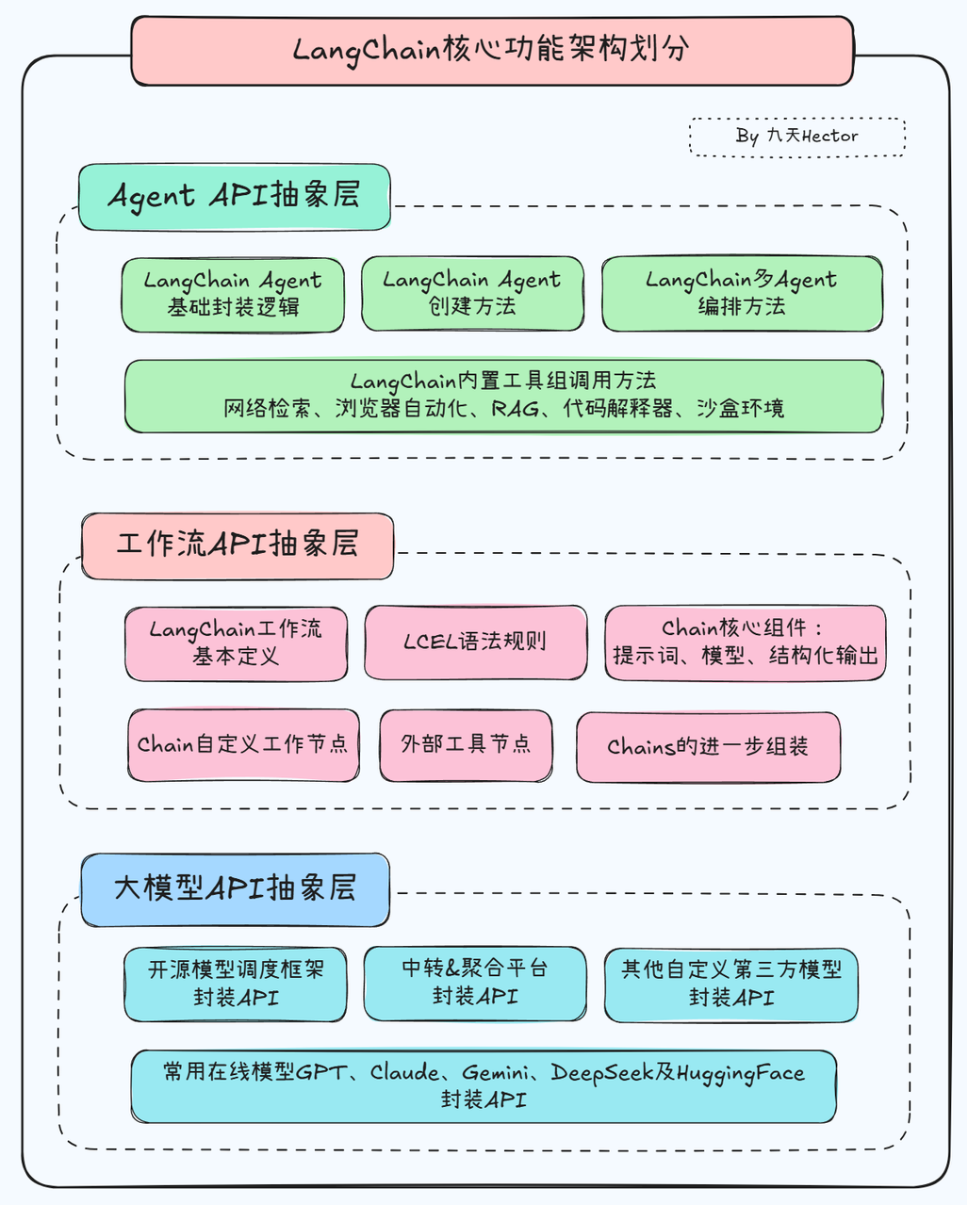
不过,伴随着Agent开发飞速发展,很快LangChain就意识到,要真正满足新一代Agent开发需求,仅靠Agent API是完全不够的,因此在23年下半年,LangChain开源了一个实验性质项目——LangGraph。
- LangGraph核心技术概念
LangGraph和LangChain同宗同源,底层架构完全相同、接口完全相通。从开发者角度来说,LangGraph也是使用LangChain底层API来接入各类大模型、LangGraph也完全兼容LangChain内置的一系列工具。换而言之,LangGraph的核心功能都是依托LangChain来完成。但是和LangChain的链式工作流哲学完全不同的是,LangGraph的基础哲学是构建图结构的工作流,并引入“状态”这一核心概念来描绘任务执行情况,从而拓展了LangChain LCEL链式语法的功能灵活程度。
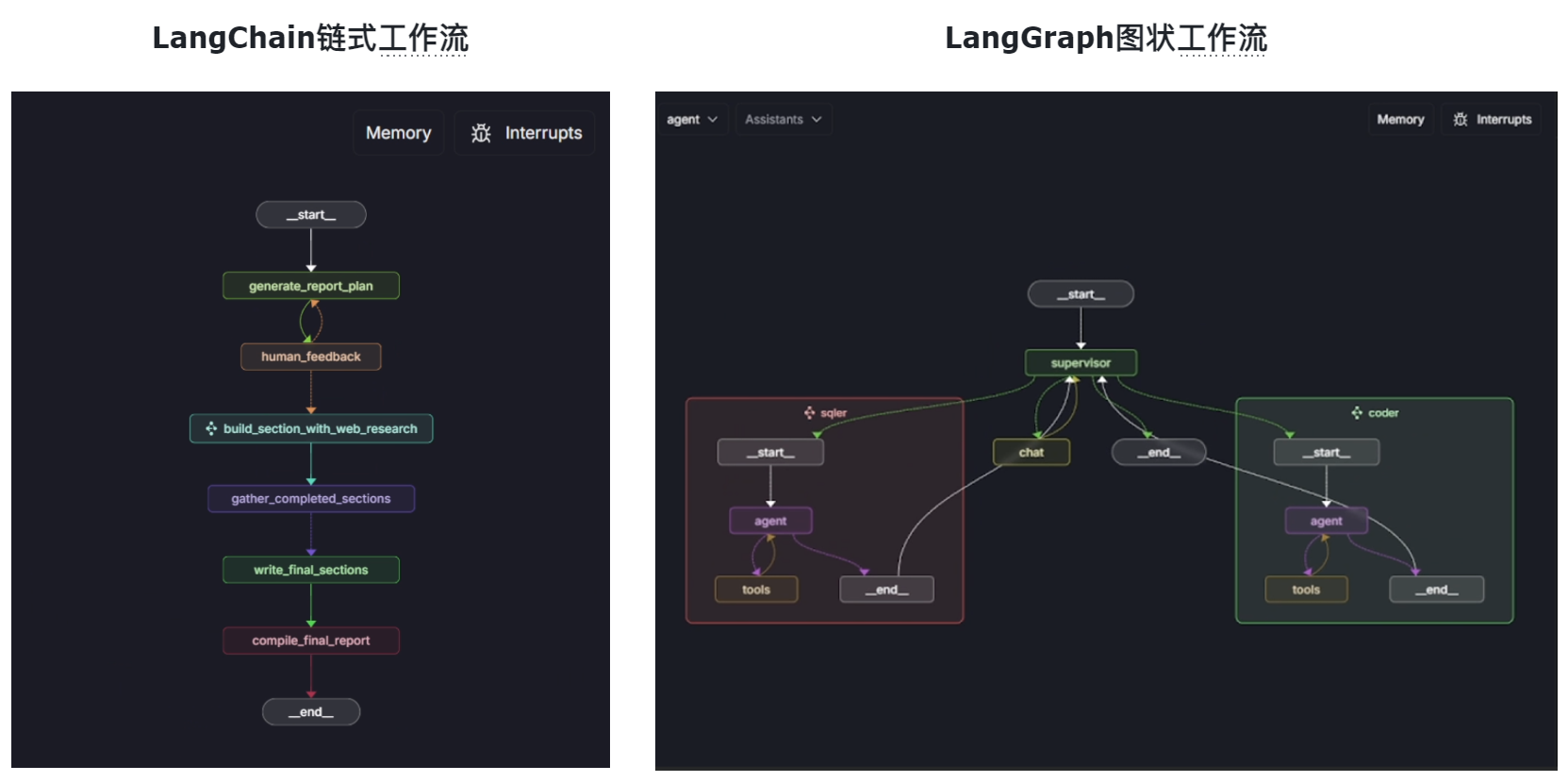
很明显,图状工作流肯定比链式工作流功能要更加灵活,功能可拓展性也更强。
用于创建图结构的工作流,这也是LangGraph中Graph一词的由来。
- LangGraph的本质:LangChain的高级编排工具
不过需要注意的是,LangGraph是基于LangChain进行的构建,无论图结构多复杂,单独每个任务执行链路仍然是现行的,其背后仍然是靠着LangChain的Chain来实现的。因此我们可以这么来描述LangChain和LangGraph之间的关系,LangGraph是LangChain工作流的高级编排工具,其中“高级”之处就是LangGraph能按照图结构来编排工作流。
- LangGraph的技术架构
尽管图结构看起来比链式结构灵活很多,但在实际开发过程中,要创建一个图结构却绝非易事。大家可以试想一下,要在代码环境中描述清楚一个图,至少需要清晰的说明图中有哪些节点,不同节点之间是什么关系(边如何连接),同时还需要设置各节点功能,然后才能测试上线,这个流程其实是非常复杂的,哪怕是简单的一个图也需要用很多代码才能描述清楚:
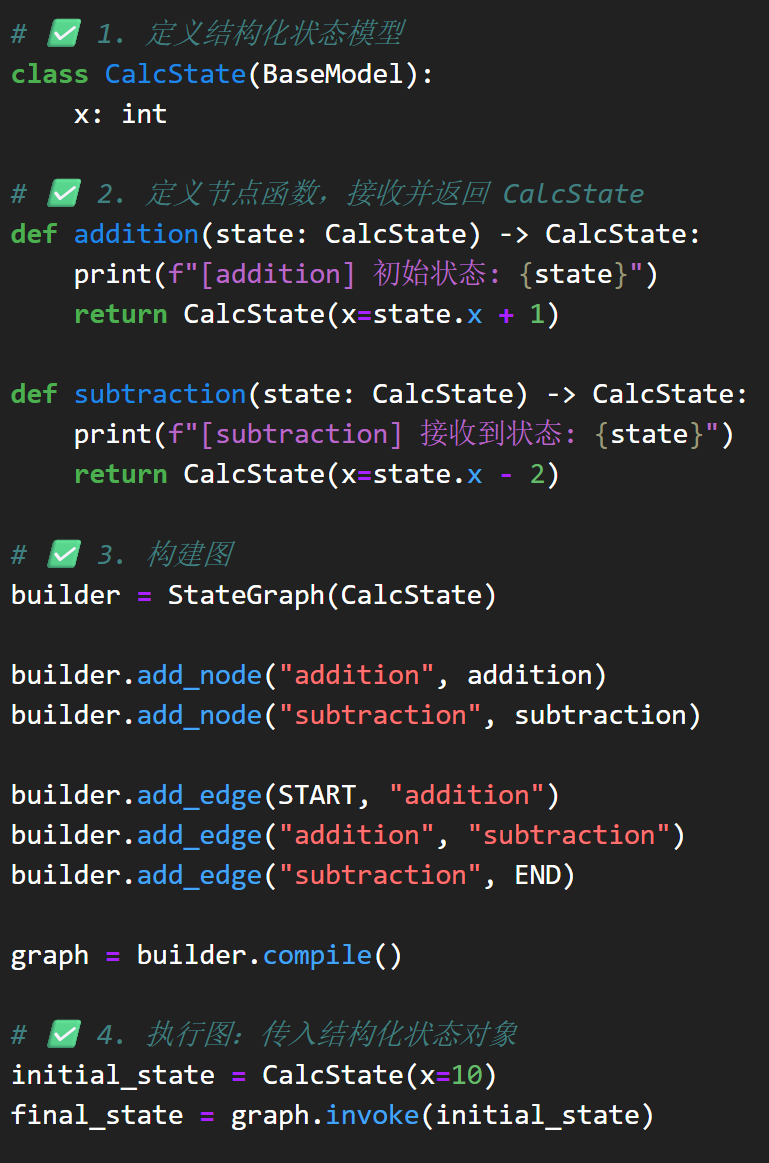
这就会导致开发效率受到影响。
LangGraph的本质是DAG(有向无环图),但它扩展支持了“有状态循环图”,本质上是一种 可控状态机(State Machine)。
- LangGraph的高层封装API
不过这对于LangChain来说并不难解决。LangChain生态各框架的核心思路都是“既要有底层API来定义基础功能,同时也要有高层API来加快开发效率”,就好比LangChain中既有LCEL语法、同时也有Agent API一样,LangGraph也提供了基于图结构基础语法的高层API。
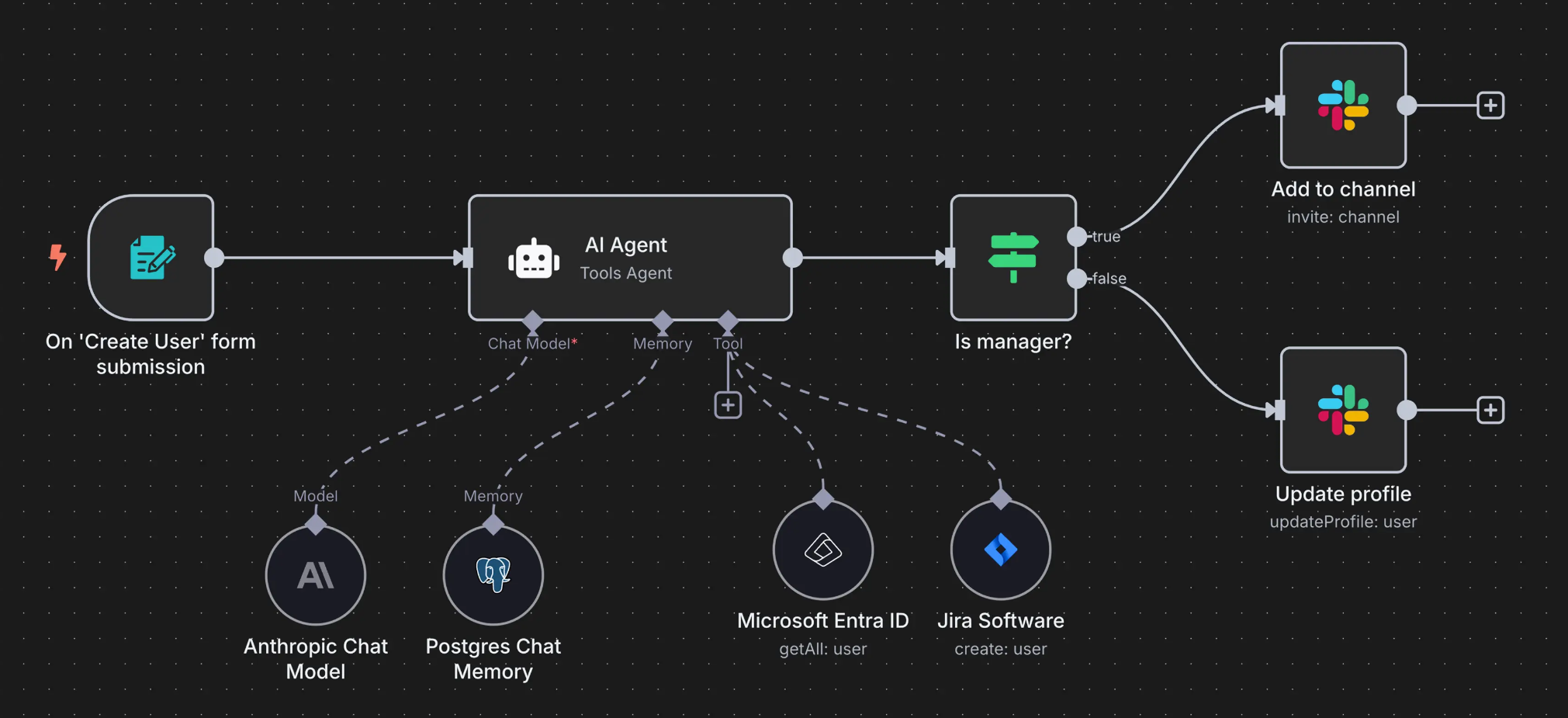
LangGraph的高层API主要分为两层,其一是Agent API,用于将大模型、提示词模板、外部工具等关键元素快速封装为图中的一些节点,而更高一层的封装,则是进一步创建一些预构建的Agent、也就是预构建好的图,开发者只需要带入设置好要带入的工具和模型,三行代码就能借助这些预构建好的图,创建一个完整的Agent:
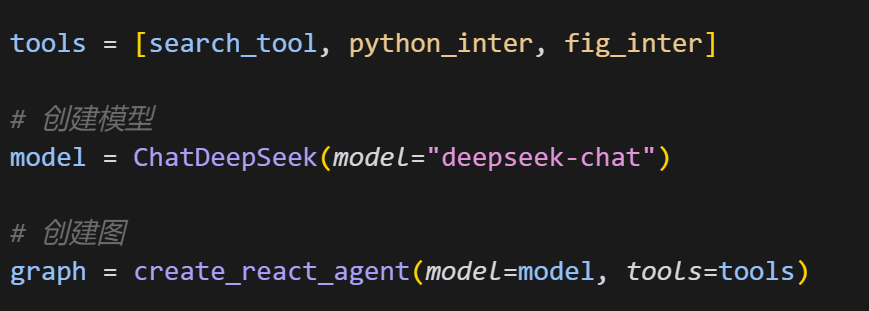
开发效率得到极大提升。
完整的LangGraph三层API架构图如下所示:
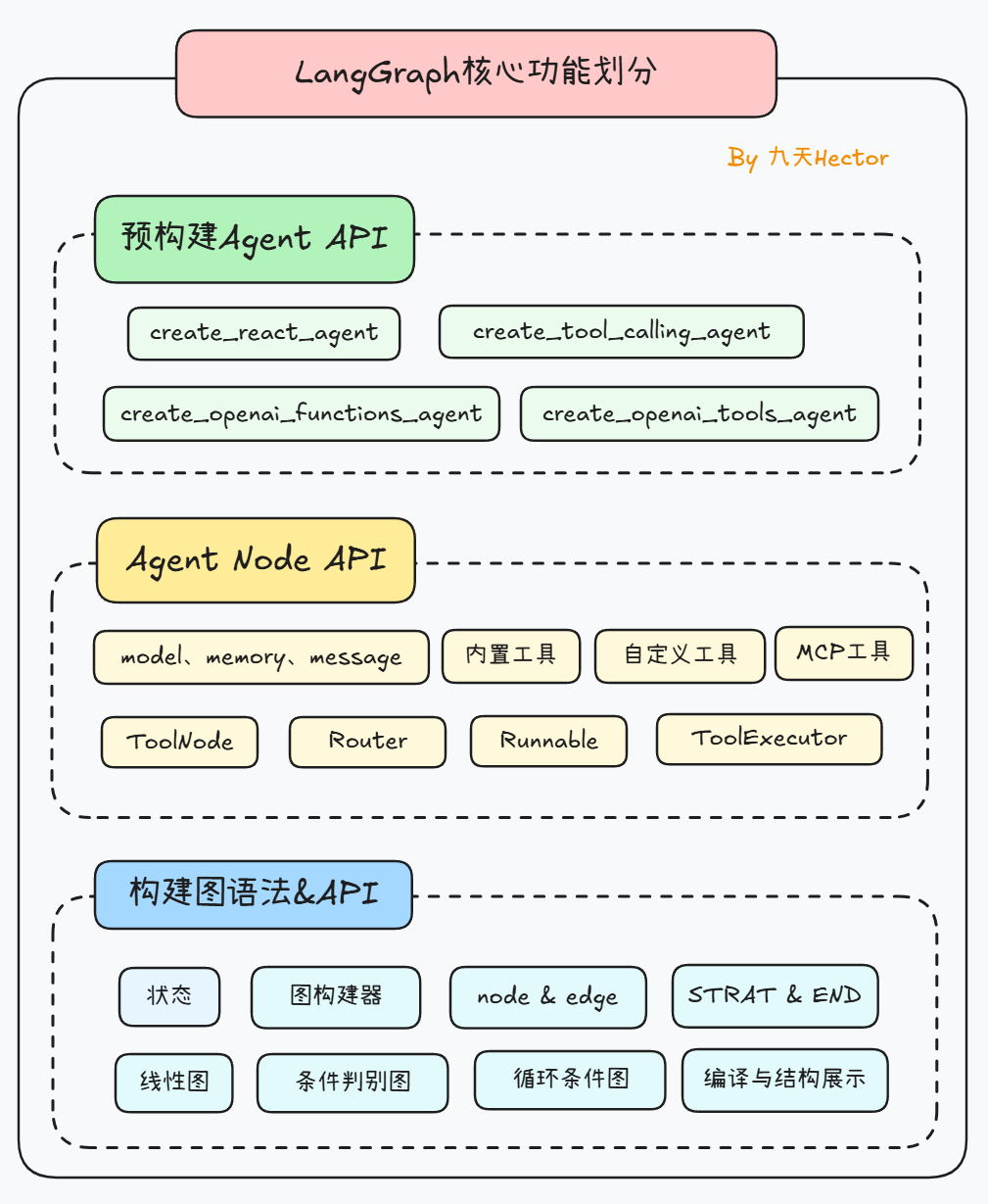
依托LangChain完善的生态、拥有丰富稳定的API架构、以及便捷上手等特性,使得LangGraph成为目前超越LangChain的新一代Agent开发框架。
2. LangGraph开发必备工具套件
在对LangGraph有了一定的基础了解之后,对于开发者来说,还需要进一步了解和掌握LangGraph必备的开发者套件。分别是LangGraph运行监控框架LangSmith、LangGraph图结构可视化与调试框架LangGraph Studio和LangGraph服务部署工具LangGraph Cli。可以说这些开发工具套件,是真正推动LangGraph的企业级应用开发效率大幅提升的关键。同时监控、调试和部署工具,也是全新一代企业级Agent开发框架的必备工具,也是开发者必须要掌握的基础工具。
- LangGraph运行监控框架:LangSmith
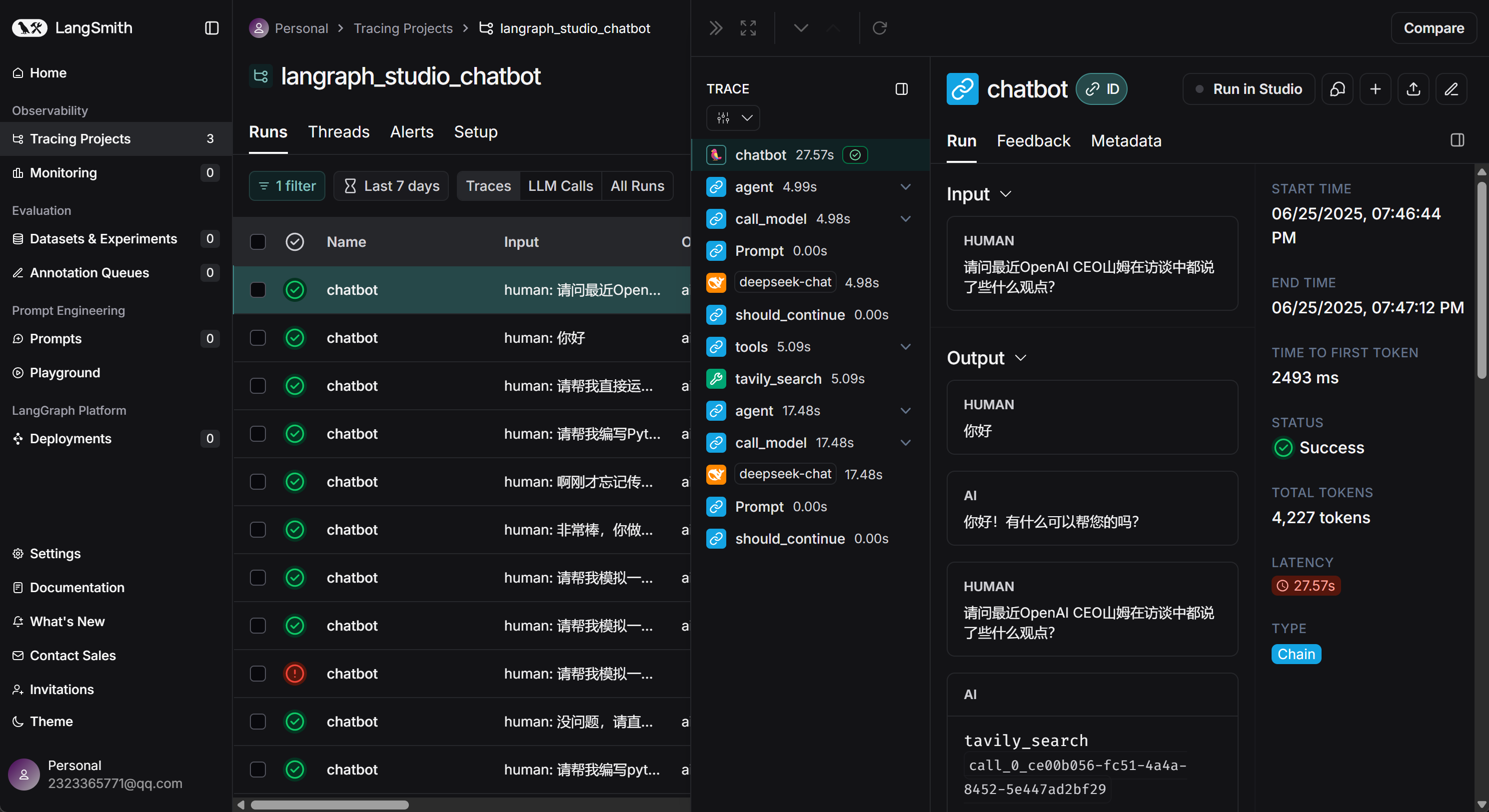
LangSmith官网地址:https://docs.smith.langchain.com/
LangSmith 是一款用于构建、调试、可视化和评估 LLM 工作流的全生命周期开发平台。它聚焦的不是模型训练,而是我们在构建 AI 应用(尤其是多工具 Agent、LangChain/Graph)时的「可视化调试」、「性能评估」与「运维监控」。
| 功能类别 | 描述 | 场景 |
|---|---|---|
| 🧪 调试追踪(Trace Debugging) | 可视化展示每个 LLM 调用、工具调用、Prompt、输入输出 | Agent 调试、Graph 调用链分析 |
| 📊 评估(Evaluation) | 支持自动评估多个输入样本的回答质量,可自定义评分维度 | 批量测试 LLM 表现、A/B 对比 |
| 🧵 会话记录(Sessions / Runs) | 每次 chain 或 agent 的运行都会被记录为一个 Run,可溯源 | Agent 问题诊断、用户问题分析 |
| 🔧 Prompt 管理器(Prompt Registry) | 保存、版本控制、调用历史 prompt | 多版本 prompt 迭代测试 |
| 📈 流量监控(Telemetry) | 实时查看运行次数、错误率、响应时间等 | 在生产环境中监控 Agent 质量 |
| 📁 Dataset 管理 | 管理自定义测试集样本,支持自动化评估 | 微调前评估、数据对比实验 |
| 📜 LangGraph 可视化 | 对 LangGraph 中每个节点运行情况进行实时可视化展示 | Graph 执行追踪 |
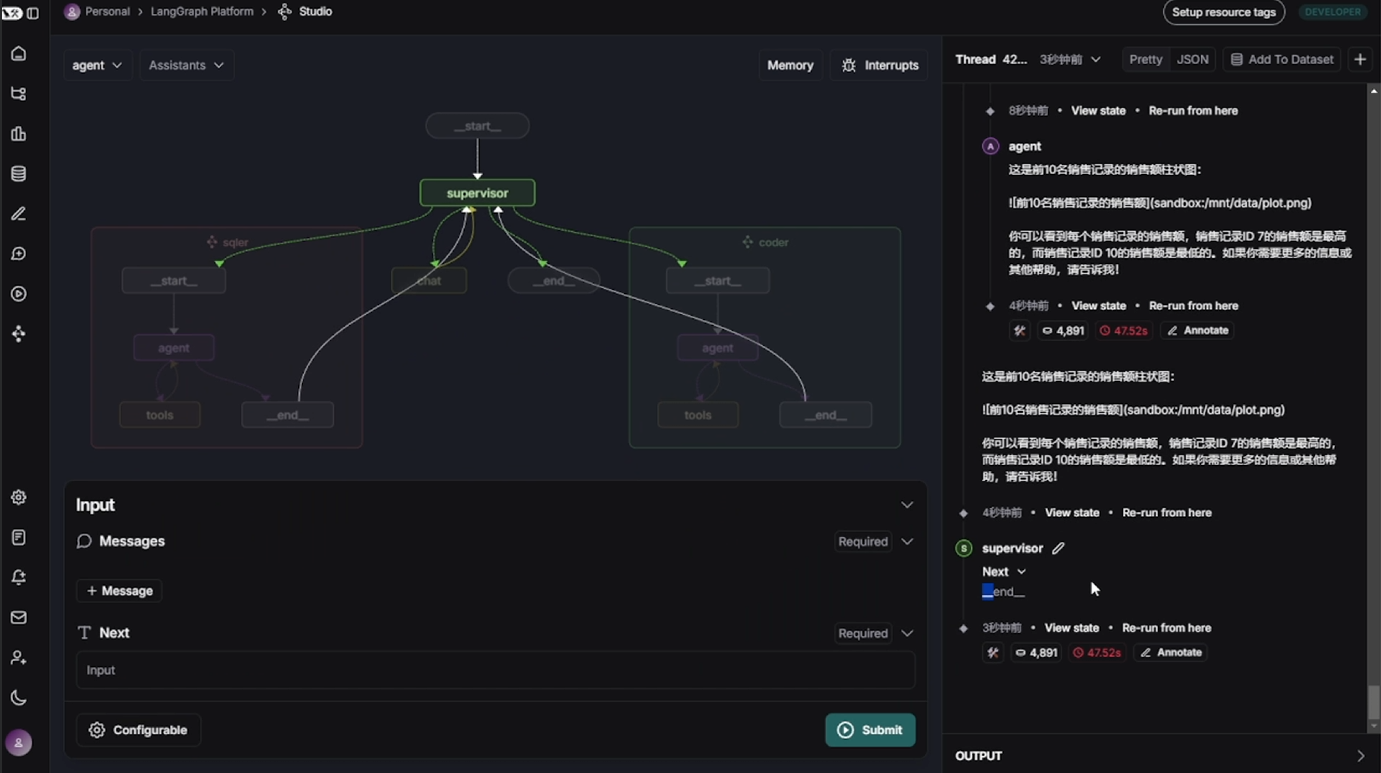
- LangGraph图结构可视化与调试框架:LangGraph Studio
LangGraph Studio官网地址:https://www.langgraph.dev/studio
LangGraph Studio 是一个用于可视化构建、测试、分享和部署智能体流程图的图形化 IDE + 运行平台。
| 功能模块 | 说明 | 应用场景 |
|---|---|---|
| 🧩 Graph 编辑器 | 以拖拽方式创建节点(工具、模型、Router)并连接 | 零代码构建 LangGraph |
| 🔍 节点配置器 | 每个节点可配置 LLM、工具、Router 逻辑、Memory | 灵活定制 Agent 控制流 |
| ▶️ 即时测试 | 输入 prompt 可在浏览器中运行整个图 | 实时测试执行结果 |
| 💾 云端保存 / 分享 | 将构建的 Graph 保存为公共 URL / 私人项目 | 团队协作,Demo 分享 |
| 📎 Tool 插件管理 | 可连接自定义工具(MCP)、HTTP API、Python 工具 | 插件式扩展 Agent 功能 |
| 🔁 Router 分支节点 | 创建条件分支,支持 if/else 路由 | 决策型智能体 |
| 📦 上传文档 / 多模态 | 可以上传文件(如 PDF)并嵌入进图中处理流程 | RAG 结构、OCR、图文问答等 |
| 🧠 Prompt 输入/预览 | 编辑 prompt 并观察其运行效果 | Prompt 工程调试 |
| 📤 一键部署 | 将 Graph 部署为可被 Agent Chat UI 使用的 Assistant | 快速集成到前端 |
- LangGraph服务部署工具:LangGraph Cli
LangGraph Cli官网地址:https://www.langgraph.dev/ (需要代理环境)
LangGraph CLI 是用于本地启动、调试、测试和托管 LangGraph 智能体图的开发者命令行工具。
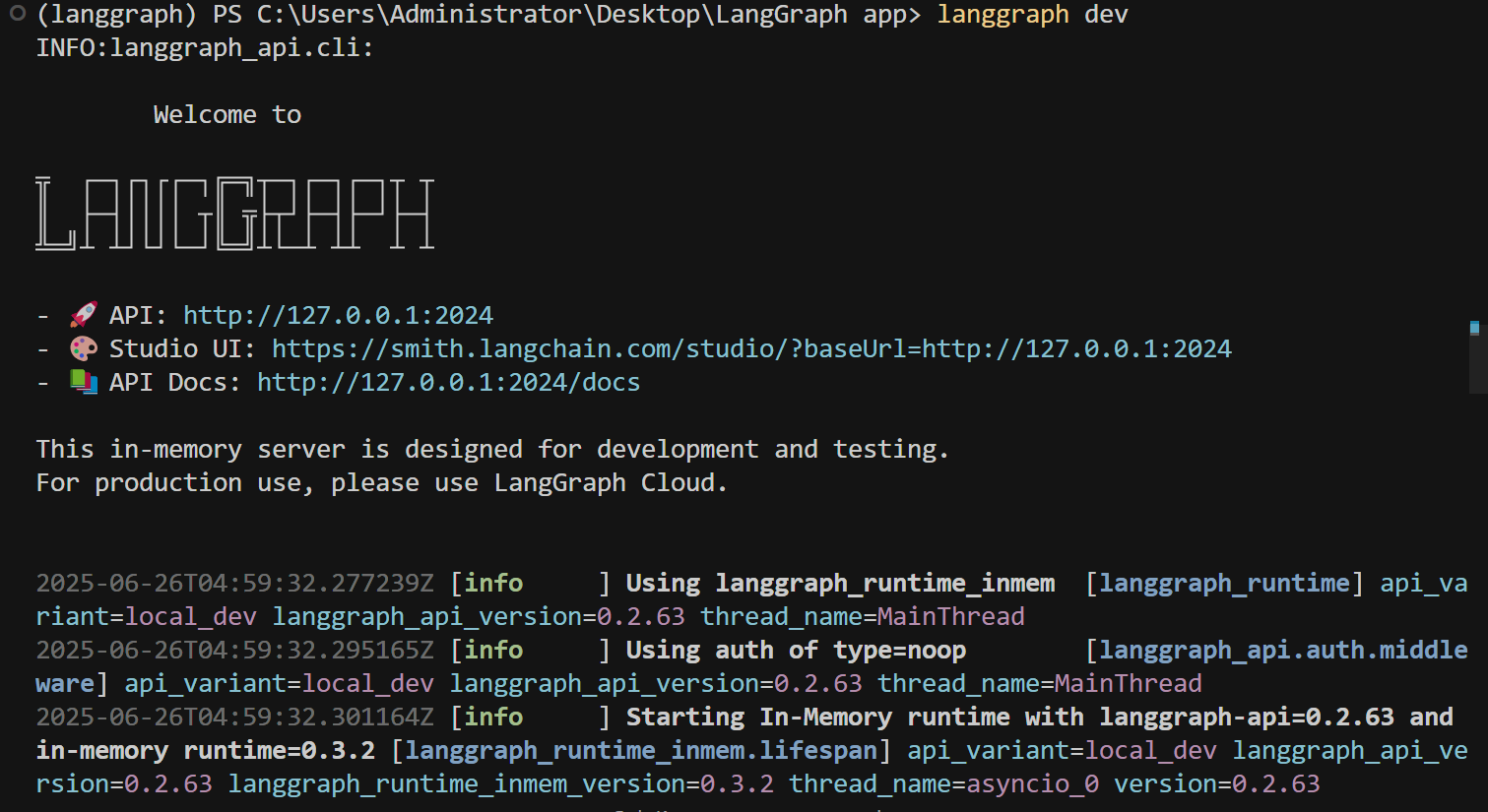
| 功能类别 | 命令示例 | 说明 |
|---|---|---|
| ✅ 启动 Graph 服务 | langgraph dev | 启动 Graph 的开发服务器,供前端(如 Agent Chat UI)调用 |
| 🧪 测试 Graph 输入 | langgraph run graph:graph --input '{"input": "你好"}' | 本地 CLI 输入测试,输出结果 |
| 🧭 管理项目结构 | langgraph init | 初始化一个标准 Graph 项目目录结构 |
| 📦 部署 Graph(未来) | langgraph deploy(预留) | 发布 graph 至 LangGraph 云端(已对接 Studio) |
| 🧱 显示 Assistant 列表 | langgraph list | 显示当前 graph 中有哪些 assistant(即 entrypoint) |
| 🔄 重载运行时 | 自动热重载 | 修改 graph.py 时,dev 模式自动重启生效 |
而一旦应用成功部署上线,LangGraph Cli还会非常贴心的提供后端接口说明文档:
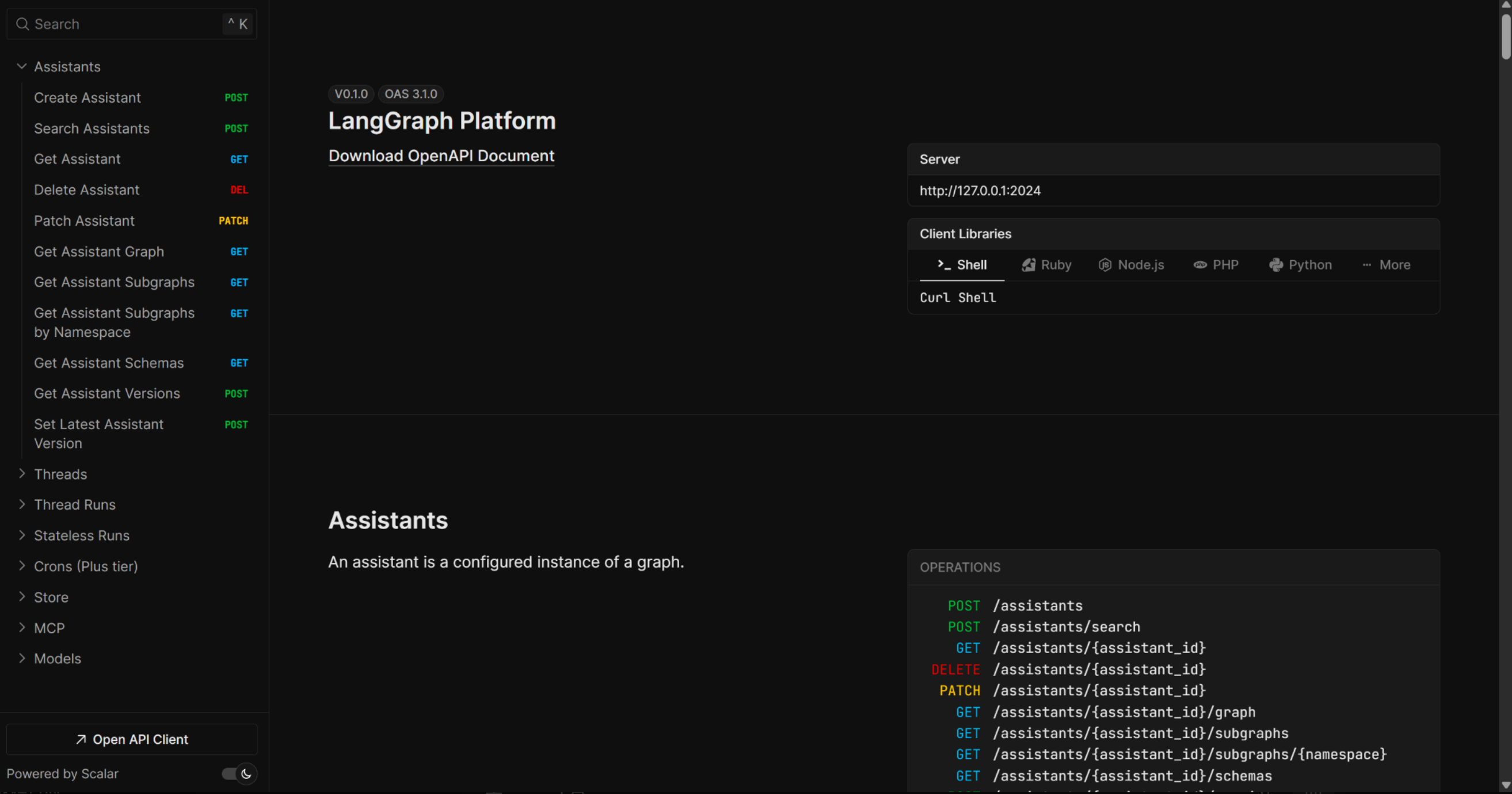
而对于LangGraph构建的智能体,除了能够本地部署外,官方也提供了云托管服务,借助LangGraph Platform,开发者可以将构建的智能体 Graph部署到云端,并允许公开访问,同时支持支持长时间运行、文件上传、外部 API 调用、Studio 集成等功能。
- LangGraph Agent前端可视化工具:Agent Chat UI
Agent Chat UI 是 LangGraph/LangChain 官方提供的多智能体前端对话面板,用于与后端 Agent(Graph 或 Chain)进行实时互动,支持上传文件、多工具协同、结构化输出、多轮对话、调试标注等功能。
Agent Chat UI官网地址:https://langchain-ai.github.io/langgraph/agents/ui/
| 功能模块 | 描述 | 应用场景 |
|---|---|---|
| 💬 多轮对话框 | 类似 ChatGPT 的输入区域,支持多轮上下文 | 用户提问,Agent 回复 |
| 🛠 工具调用轨迹显示 | 显示每个调用的工具、参数、结果(结构化) | Agent 推理透明化 |
| 📄 上传 PDF / 图片 | 支持上传文档、图片、嵌入多模态输入 | RAG、OCR、图像问答 |
| 📁 文件面板 | 可查看上传历史文件、删除、重新引用 | 管理文档输入 |
| 🧭 Assistant 切换 | 支持切换不同 Assistant(Graph entry) | 一键切换模型能力(如 math / weather) |
| 🧩 插件支持 | 与 MCP 工具、LangGraph 图打通 | 工具式 Agent 调用 |
| 🔍 调试视图 | 显示每轮 Agent 的思维过程和中间状态 | Prompt 调试、模型行为分析 |
| 🌐 云部署支持 | 支持接入远端 Graph API(如 dev 服务器) | 前后端分离部署 |
| 🧪 与 LangSmith 对接(可选) | 若后端启用 tracing,可同步显示运行 trace | 调试闭环 |
- LangGraph内置工具库与MCP调用组件
除了有上述非常多实用的开发工具外,LangGraph还全面兼容LangChain的内置工具集。LangChain自诞生之初就为开发者提供了非常多种类各异的、封装好的实用工具,历经几年发展时间,目前LangChain已经拥有了数以百计的内置实用工具,包括网络搜索工具、浏览器自动化工具、Python代码解释器、SQL代码解释器等。而作为LangChain同系框架,LangGraph也可以无缝调用LangChain各项开发工具,从而大幅提高开发效率。
LangChain工具集:https://python.langchain.com/docs/integrations/tools/
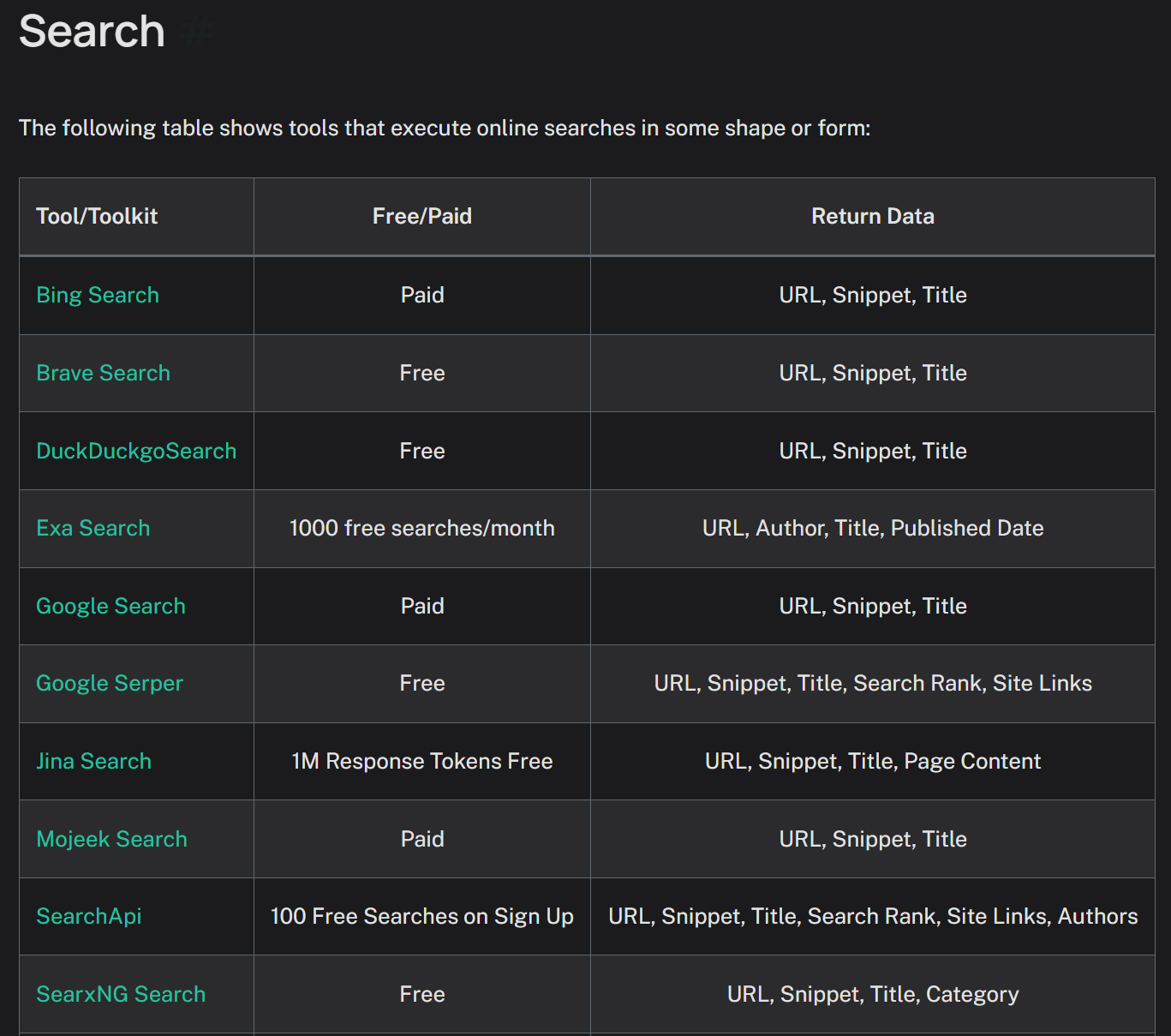
此外,LangChain是最早支持MCP的开发框架之一,借助langchain-mcp-adapters,LangChain和LangGraph便可快速接入各类MCP工具。

并且LangGraph也同样支持谷歌的A2A(跨Agents通信协议)。
3. LangGraph VS 其他开发框架
而关于LangGraph框架与其他开发框架的对比,其实从上面对于LangGrpah的技术介绍不难看出,依托LangChain的强大生态,LangGraph可以说是目前功能最完善、性能最强的开发框架没有之一。
- LangGraph VS LangGraph
首先,如果要对比LangGraph和LangChain,其实二者定位有本质的区别。从目前LangChain工具功能划分来看,LangChain未来将继续专注于更加底层的API开发与维护,以及链式基础功能的维护,而作为LangChain链式功能更高级编排工具,LangGraph未来将承担更多Agent开发的重任。
因此如果要从LangChain和LangGraph中挑选一项进行学习的话,推荐优先学习更高层的LangGraph API,而在实际使用LangGraph的过程中,将会用到非常多的LangChain基础功能,届时再补充LangChain基础知识即可。另外,如果希望一站式深入学习LangChain&LangGraph技术体系,也可以先从底层API开始学习,先学习LangChain打好基础,然后再学习LangGraph,这样的学习路径将有助于搭建更加扎实的技术和技能体系。
LangChain公开课参考:https://www.bilibili.com/video/BV1pYKgzAE5C/
- LangGraph VS OpenAI Agents SDK
目前来看,OpenAI的Agents SDK最核心的优势还是在于和OpenAI的GPT系列模型深度集成,能够非常便捷的调用GPT模型的很多内置工具(如网络搜索、RAG、Computer use等),并且上手难度非常低,能够非常简单的完成Agent创建。因此如果是GPT模型开发者,Agents SDK还是非常合适的。
但Agents SDK本身并不能算是企业级的Agent开发框架,其很多功能设计较为简单,且稳定性不足,因此Agents SDK更加适用于小规模智能体功能探索或前期demo开发或者用于科研性质的智能体开发。
- LangGraph VS 谷歌ADK
相比OpenAI的Agents SDK,谷歌的ADK功能更加丰富、运行更加稳定,并且谷歌ADK也提供了调试前端UI页面以及智能体运行追踪等功能,同时支持一键部署上线,因此尽管ADK上手难度更高,但确实是目前能够用于企业级Agent开发的框架。
但相比LangGraph,谷歌ADK起步时间较晚,很多功能细节丰富程度不如LangGraph,并且内置工具也远不如LangChain更加丰富。但ADK的优势在于和Gemini多模态功能深度适配,可以说是原生的多模态Agent开发框架,原生就支持图像、文本、音频等多模态交互功能,并且和谷歌云在线API深度集成,可以直接调用谷歌云API(例如谷歌云盘、谷歌邮箱API、谷歌搜索等)来完成智能体开发。并且由于ADK采用了和LangGraph完全不同的设计思路,具体何种思路会在未来的竞争中胜出犹未可知。
因此,就目前来看,我们推荐的适用于企业级应用的Agent框架学习路线是LangChain&LangGraph>ADK>Agents SDK。而如果是出于科研目的,或者前期希望进行一些尽量快速的尝试和探索,并不考虑工业环境部署上线,则优先推荐Agents SDK。
4. LangGraph最佳学习路线与本期公开课大纲
虽然从技术架构的角度来说,是LangGraph图结构语法—>Agent Node API—>预构建的Agent API,但对于学习者来说,更推荐反过来的学习顺序,也就是预构建的Agent API—>Agent Node API—>LangGraph图结构语法,这也是本期公开课的内容顺序。
二、从零构建LangGraph智能体
1. LangGraph接入大模型流程
- LangGraph安装
本次公开课使用的版本是:langgraph==0.4.8
! pip install langgraph -i https://pypi.tuna.tsinghua.edu.cn/simple
! pip show langgraph
- LangGraph接入DeepSeek模型流程
接下来以DeepSeek为例,介绍LangGraph接入大模型流程。
! pip install python-dotenv openai
这里我们使用DeepSeek官方的API_KEK进行调用。如果初次使用,需要现在DeepSeek官网上进行注册并创建一个新的API_Key,其官方地址为:https://platform.deepseek.com/usage
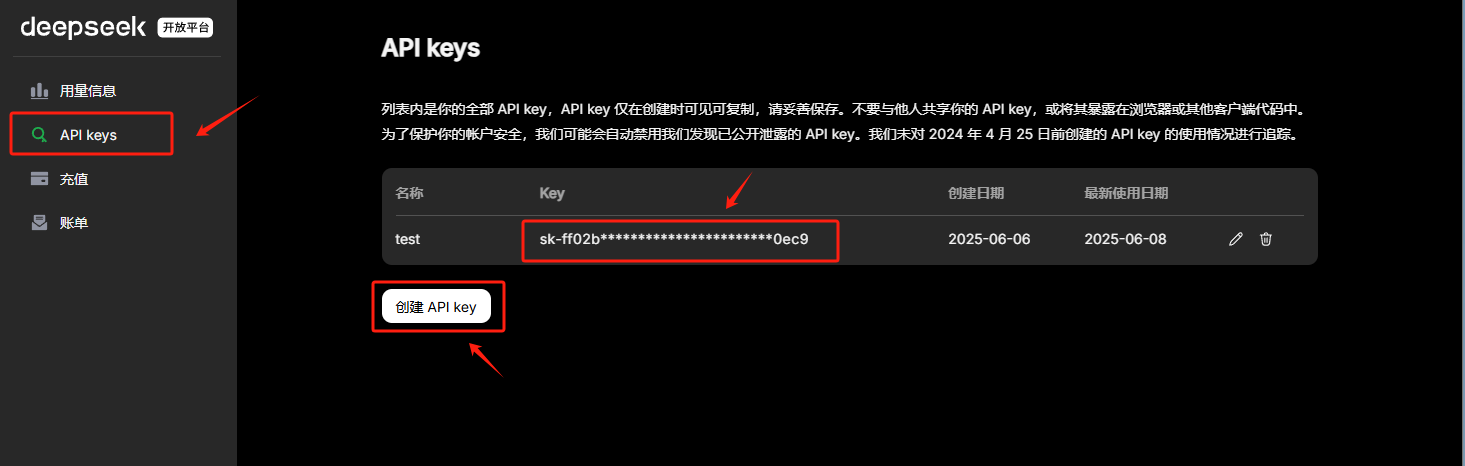
注册好DeepSeek的API_KEY后,首先在项目同级目录下创建一个env文件,用于存储DeepSeek的API_KEY,如下所示:
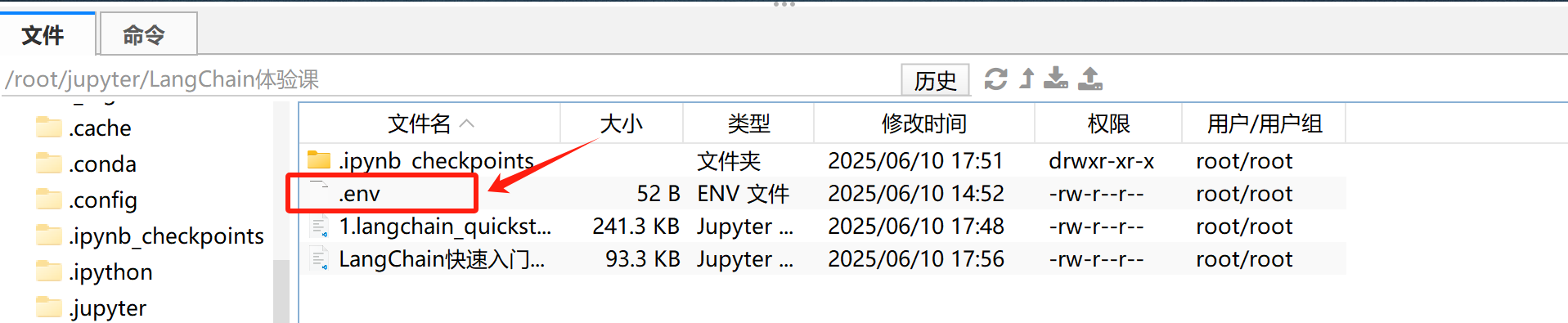

接下来通过python-dotenv库读取env文件中的API_KEY,使其加载到当前的运行环境中,代码如下:
import os
from dotenv import load_dotenv
load_dotenv(override=True)
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# print(DeepSeek_API_KEY) # 可以通过打印查看
from openai import OpenAI
# 初始化DeepSeek的API客户端
client = OpenAI(api_key=DeepSeek_API_KEY, base_url="https://api.deepseek.com")
# 调用DeepSeek的API,生成回答
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是乐于助人的助手,请根据用户的问题给出回答"},
{"role": "user", "content": "你好,请你介绍一下你自己。"},
],
)
# 打印模型最终的响应结果
print(response.choices[0].message.content)
接下来我们要考虑的是,对于这样一个DeepSeek官方的API,如何接入到LangGraph中呢?其实非常简单,我们只需要使用LangChain中的一个DeepSeek组件即可向像述代码一样,直接使用相同的DeepSeek API KEY与大模型进行交互。因此,我们首先需要安装LangChain的DeepSeek组件,安装命令如下:
! pip install langchain-deepseek
安装好LangChain集成DeepSeek模型的依赖包后,需要通过一个init_chat_model函数来初始化大模型,代码如下:
from langchain.chat_models import init_chat_model
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
其中model用来指定要使用的模型名称,而model_provider用来指定模型提供者,当写入deepseek时,会自动加载langchain-deepseek的依赖包,并使用在model中指定的模型名称用来进行交互。
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
result
model = init_chat_model(model="deepseek-reasoner", model_provider="deepseek")
result = model.invoke(question)
print(result.content)
result.additional_kwargs
result.additional_kwargs['reasoning_content']
这里可以看到,仅仅通过两行代码,我们便可以在LangChain中顺利调用DeepSeek模型,并得到模型的响应结果。相较于使用DeepSeek的API,使用LangChain调用模型无疑是更加简单的。同时,不仅仅是DeepSeek模型,LangChain还支持其他很多大模型,如OpenAI、Qwen、Gemini等,我们只需要在init_chat_model函数中指定不同的模型名称,就可以调用不同的模型。其工作的原理是这样的:
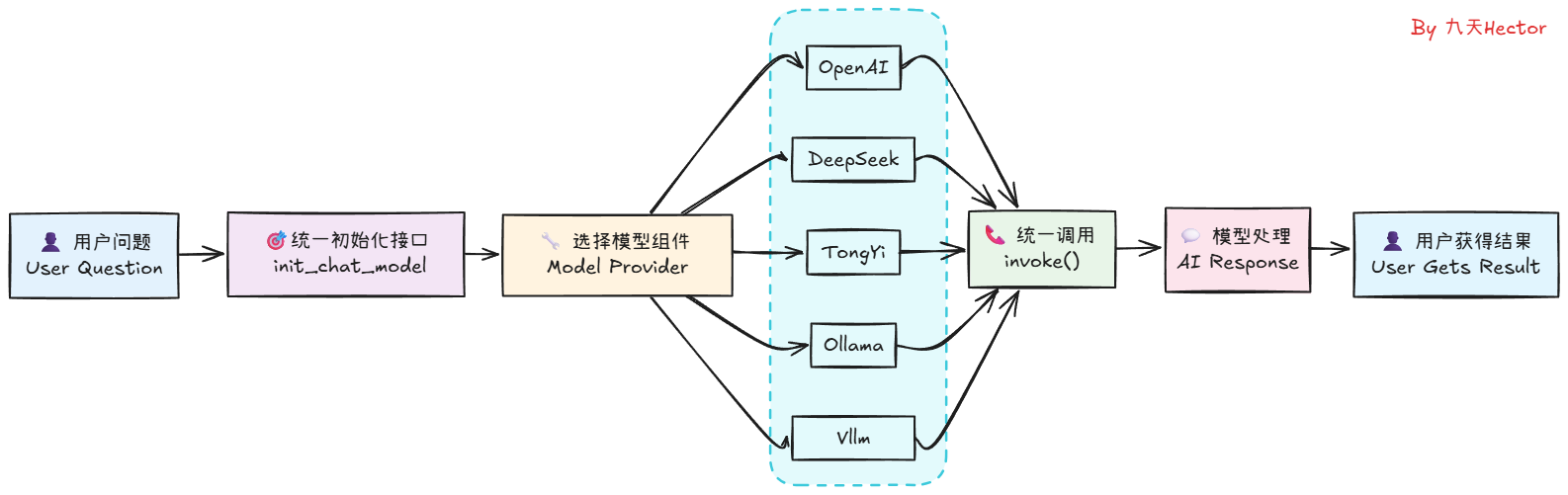
理解了这个基本原理,如果大家想在用LangGraph进行开发时使用其他大模型如Qwen3系列,则只需要先获取到Qwen3模型的API_KEY,然后安装Tongyi Qwen的第三方依赖包,即可同样通过init_chat_model函数来初始化模型,并调用invoke方法来得到模型的响应结果。关于LangChain都支持哪些大模型以及每个模型对应的是哪个第三方依赖包,大家可以在LangChain的官方文档中找到,访问链接为:https://python.langchain.com/docs/integrations/chat/
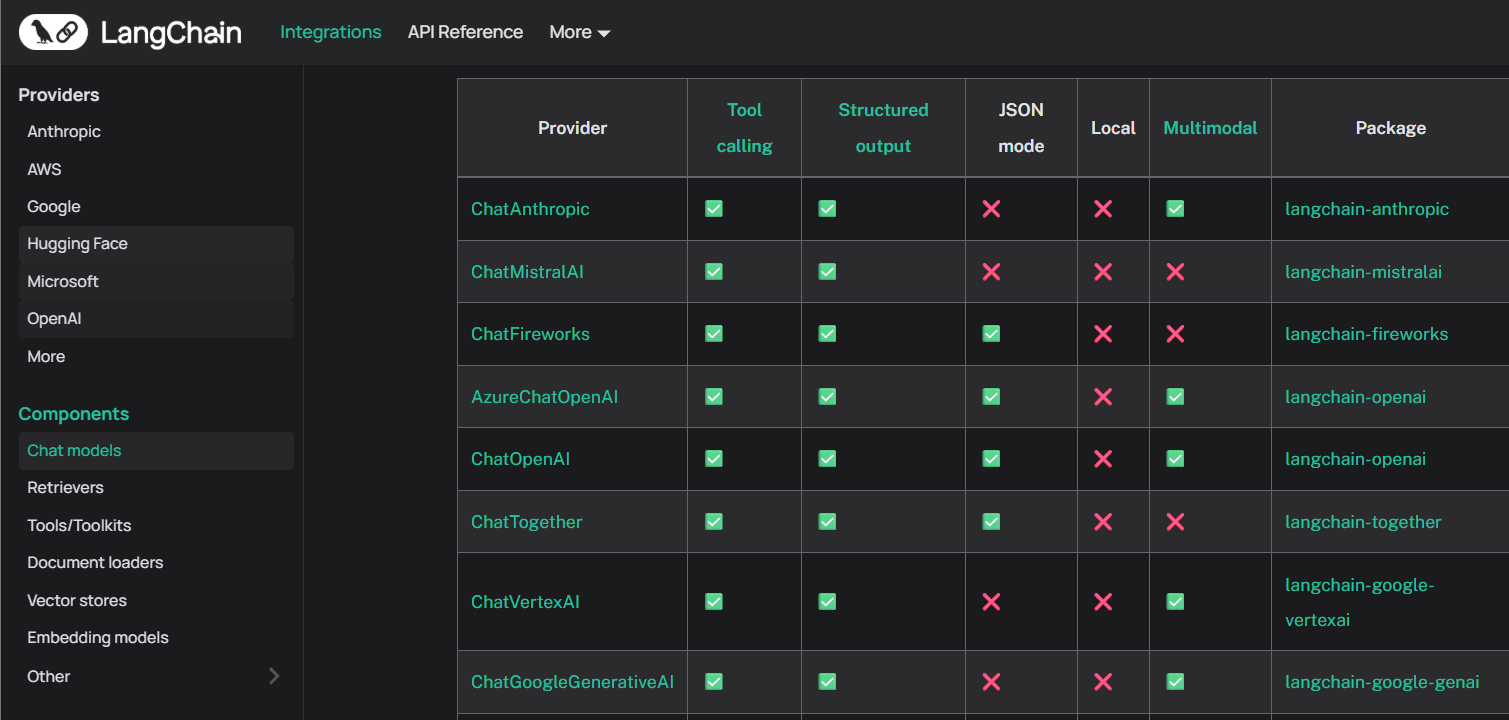
更多关于LangChain&LangGraph接入各类大模型的基本流程,可以参考LangChain公开课相关资料,本节公开课不再赘述。

2. 借助预构建的智能体API快速创建LangGraph智能体
正如开篇所说,我们先尝试用最高层的API快速构建智能体,然后在后续的课程讲解中,将逐渐深入到其背后的底层原理及更底层的API进行讲解。
在LangGraph所有的顶层API中,最常见的预构建智能体API就是create_react_agent,借助该API,开发者仅需将大模型、工具和提示词模板(可选)以参数形式带入,即可快速创建一个拥有完整功能、并且能够串联并联调用多个外部工具的智能体。
- 创建自定义工具
import requests,json
import os
from dotenv import load_dotenv
load_dotenv(override=True)
def get_weather(loc):
"""
查询即时天气函数
:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing';
:return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\
返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息
"""
# Step 1.构建请求
url = "https://api.openweathermap.org/data/2.5/weather"
# Step 2.设置查询参数
params = {
"q": loc,
"appid": os.getenv("OPENWEATHER_API_KEY"), # 输入API key
"units": "metric", # 使用摄氏度而不是华氏度
"lang":"zh_cn" # 输出语言为简体中文
}
# Step 3.发送GET请求
response = requests.get(url, params=params)
# Step 4.解析响应
data = response.json()
return json.dumps(data)
get_weather("Beijing")
在LangGraph中,我们可以直接使用上述外部工具带入到LangGraph中创建智能体,不过更为稳妥的形式,是通过一个结构化工具函数来说明外部函数的参数输入(包括参数类型),以确保在实际调用过程中大模型能够准确识别外部函数的参数类型及其实际含义:
from langchain_core.tools import tool
from pydantic import BaseModel, Field
class WeatherQuery(BaseModel):
loc: str = Field(description="The location name of the city")
@tool(args_schema = WeatherQuery)
def get_weather(loc):
"""
查询即时天气函数
:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing';
:return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\
返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息
"""
# Step 1.构建请求
url = "https://api.openweathermap.org/data/2.5/weather"
# Step 2.设置查询参数
params = {
"q": loc,
"appid": os.getenv("OPENWEATHER_API_KEY"), # 输入API key
"units": "metric", # 使用摄氏度而不是华氏度
"lang":"zh_cn" # 输出语言为简体中文
}
# Step 3.发送GET请求
response = requests.get(url, params=params)
# Step 4.解析响应
data = response.json()
return json.dumps(data)
print(f'''
name: {get_weather.name}
description: {get_weather.description}
arguments: {get_weather.args}
''')
其中Pydantic 提供的 BaseModel 负责定义外部函数的参数结构,相当于是告诉模型外部函数参数名是 loc、类型是字符串(str)、描述为“城市名称”,有了这个结构,模型能更好地理解如何调用该函数。
- 创建LangGraph智能体
# 封装外部函数列表
tools = [get_weather]
from langchain.chat_models import init_chat_model
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(model=model, tools=tools)
response = agent.invoke({"messages": [{"role": "user", "content": "你好,请介绍下你自己。"}]})
response
response["messages"]
response["messages"][-1].content
然后测试外部工具调用
response = agent.invoke({"messages": [{"role": "user", "content": "请问北京今天天气如何?"}]})
print(response["messages"][-1].content)
response['messages']
而这背后其实就是一次完整的Function calling调用流程:
len(response['messages'])
response['messages'][0]
response['messages'][1]
response['messages'][2]
response['messages'][3]
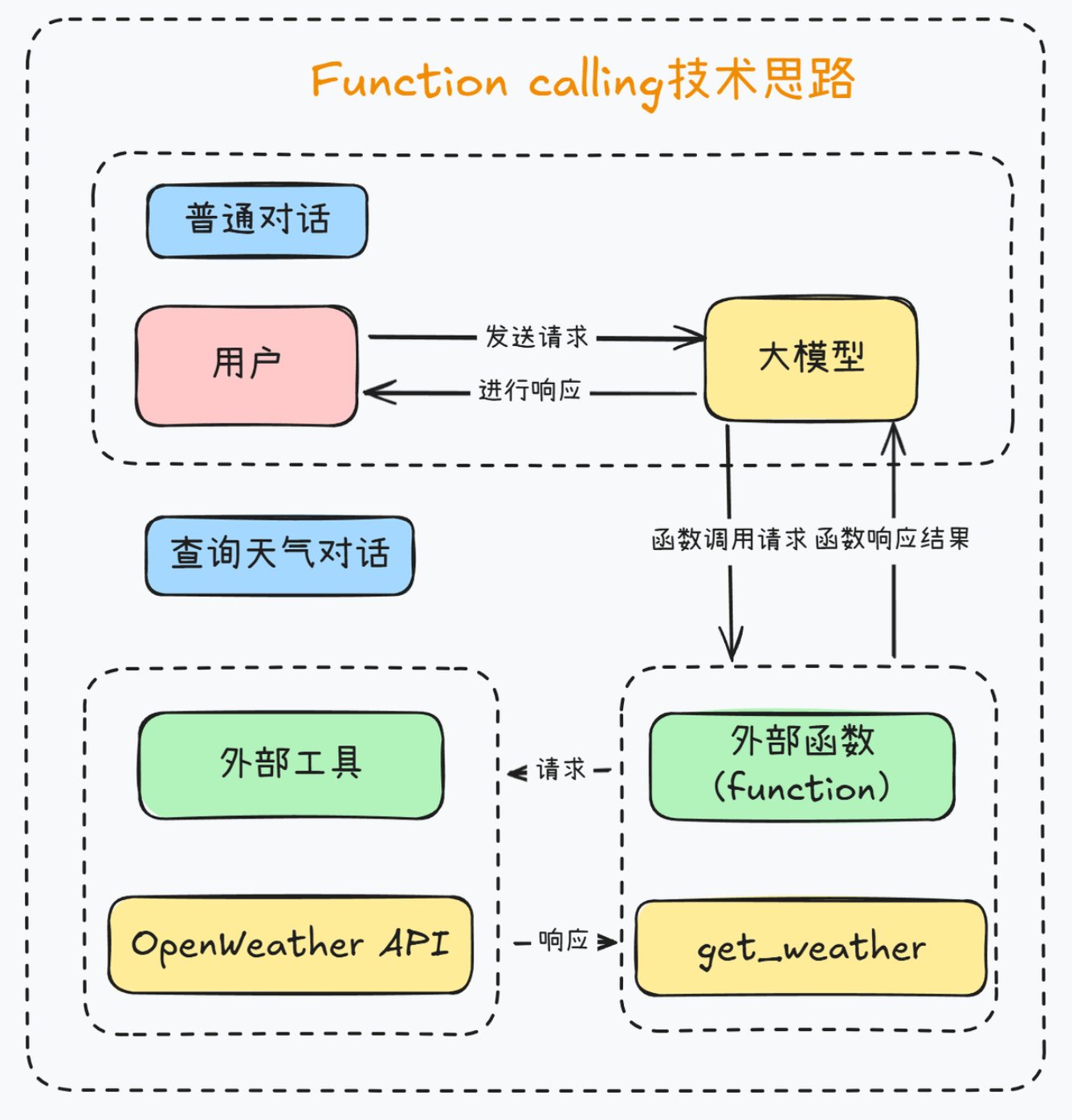
更加完整的Function calling执行链路
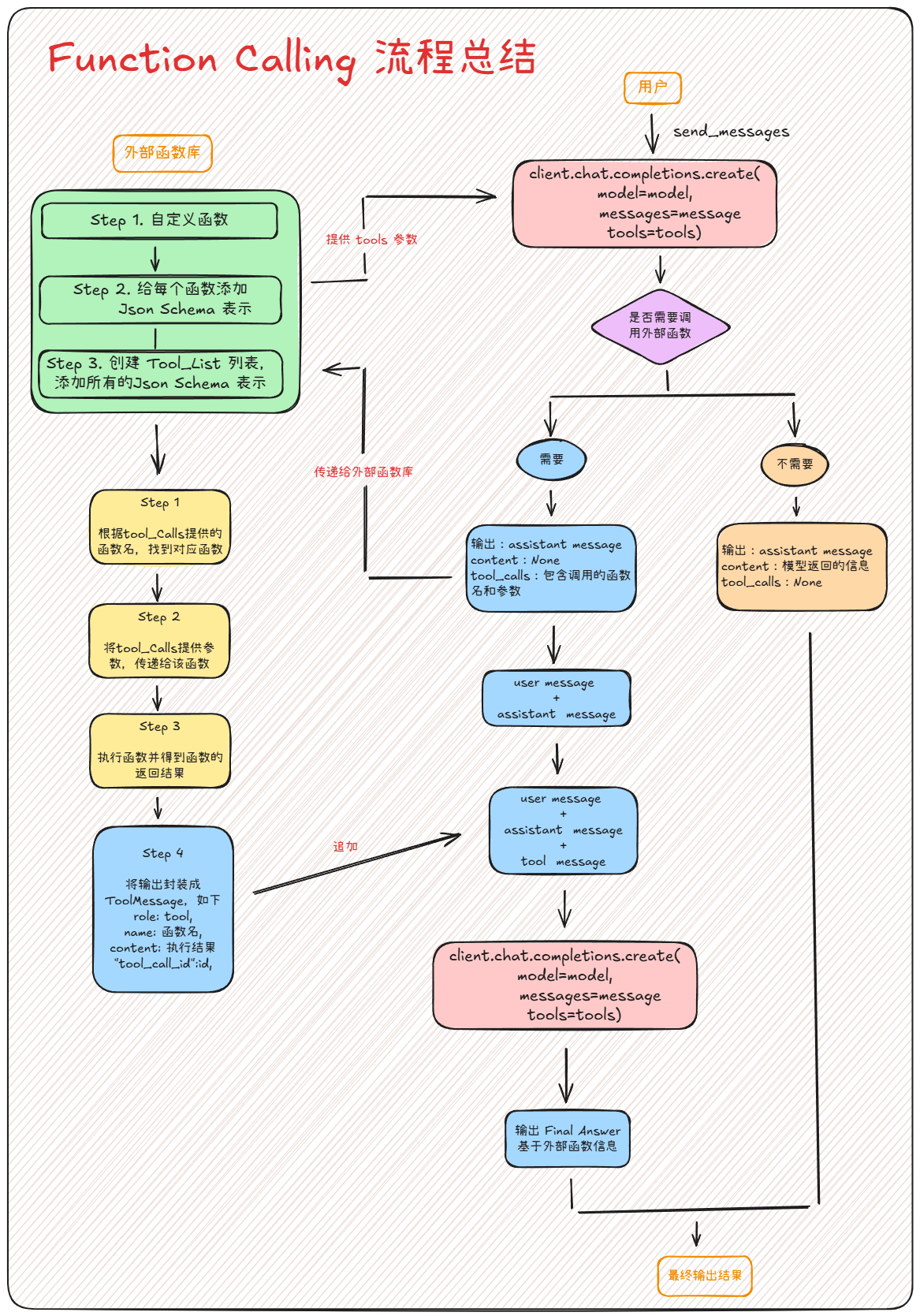
3. LangGraph React Agent外部工具响应形式
借助LangGraph React Agent,无需任何额外设置,即可完成多工具串联和并联调用。
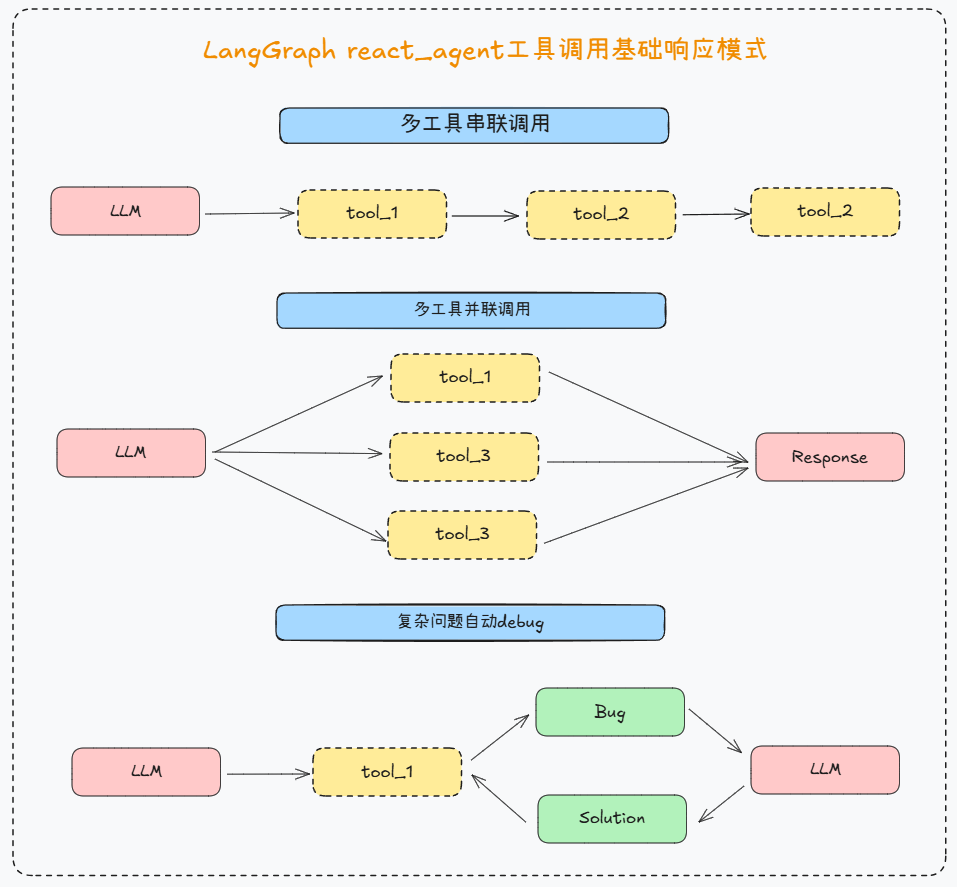
response = agent.invoke({"messages": [{"role": "user", "content": "请问北京和杭州今天哪里更热?"}]})
response
from langchain_core.tools import tool
from pydantic import BaseModel, Field
class Write_Query(BaseModel):
content: str = Field(description="需要写入文档的具体内容")
@tool(args_schema = Write_Query)
def write_file(content: str) -> str:
"""
将指定内容写入本地文件。
:param content: 必要参数,字符串类型,用于表示需要写入文档的具体内容。
:return:是否成功写入
"""
return "已成功写入本地文件。"
# 封装外部函数列表
tools = [get_weather, write_file]
agent = create_react_agent(model=model, tools=tools)
response = agent.invoke({"messages": [{"role": "user", "content": "你好,请帮我查询北京和杭州的天气,并将其写入本地文件中。"}]})
print(response["messages"][-1].content)
len(response['messages'])
response['messages']
能够看出,此时Agent能够顺利完成多工具的多次调用,并最终完成用户需求。需要注意的是,此时react agent的执行逻辑是先发起了一次并联调用工具的请求,然后第二次再发起调用write函数的调用请求,因此总共是7条消息。
4. LangGraph React Agent接入内置工具流程
当然对于LangGraph智能体来说,除了能够灵活接如自定义工具,还能够接入LangChain丰富的内置工具,快速完成智能体开发。
在 LangChain 框架中,**工具(Tools)**是实现语言模型与外部世界交互的关键机制。LangChain 提供了大量内置与可扩展的工具接口,使得智能体(Agent)能够执行函数调用、访问 API、查询搜索引擎、调用数据库等任务,从而超越纯语言生成的能力,真正实现“能行动的智能体”。LangChain 官方文档将这些工具按照其用途进行了模块化划分,涵盖了以下主要类别:
| 功能类别 | 工具名称 | 简要说明 |
|---|---|---|
| 🔎 搜索工具 | TavilySearchResults | 快速搜索实时网络信息 |
SerpAPIWrapper | 基于 SerpAPI 的搜索结果工具 | |
GoogleSearchAPIWrapper | 调用 Google 可编程搜索引擎 | |
| 🧠 计算工具 | PythonREPLTool | 执行 Python 表达式并返回结果 |
LLMMathTool | 结合 LLM 和数学推理能力 | |
WolframAlphaQueryRun | 基于 Wolfram Alpha 的计算引擎 | |
| 🗂 数据工具 | SQLDatabaseToolkit | 构建 SQL 数据库查询工具集 |
PandasDataframeTool | 用于在 Agent 中操作表格数据 | |
| 🌐 网络/API | RequestsGetTool / RequestsPostTool | 执行 HTTP 请求 |
BrowserTool / PlaywrightBrowserToolkit | 自动化网页浏览与抓取 | |
| 💾 文件处理 | ReadFileTool | 读取本地文件内容 |
WriteFileTool | 写入文本到指定文件中 | |
| 📚 检索工具 | FAISSRetriever | 基于向量的文档检索工具 |
ChromaRetriever | 使用 ChromaDB 的检索器 | |
ContextualCompressionRetriever | 上下文压缩检索器,适合长文档 | |
| 🧠 LLM 工具 | ChatOpenAI / OpenAIFunctionsTool | 使用 OpenAI 模型作为工具调用 |
ChatAnthropic | Anthropic Claude 模型封装工具 | |
| 🔧 自定义工具 | @tool 装饰器 | 任意函数可封装为 Agent 可调用工具 |
Tool 类继承 | 自定义更复杂逻辑的工具实现 |
LangChain工具集:https://python.langchain.com/docs/integrations/tools/
- 创建带搜索功能的Agent
这里我们尝试借助LangChain内置的Tavily搜索引擎工具,搭建能够进行网络搜索的智能体。首先需要在tavily官网进行注册并获取API-KEY:https://www.tavily.com/

并继续将tavily的API-KEY写到.env文件中:

然后安装对应的库:
!pip install -U langchain-tavily
然后即可导入该工具,并快速将其封装为LangGraph智能体工具:
from langchain_tavily import TavilySearch
search_tool = TavilySearch(max_results=5, topic="general")
tools = [search_tool]
search_agent = create_react_agent(model=model, tools=tools)
response = search_agent.invoke({"messages": [{"role": "user", "content": "请帮我搜索最近OpenAI CEO在访谈中的核心观点。"}]})
print(response["messages"][-1].content)
5. LangGraph React Agent限制最大迭代次数
LangChain工具集:https://python.langchain.com/docs/integrations/tools/
5. LangGraph React Agent限制工具调用次数
对于任何全自动的代理,合理控制调用次数都是至关重要的一环,对于LangGraph React Agent来说,我们只需要在Agent运行的时候设置{"recursion_limit": X},即可限制智能体自主执行任务时的步数。
try:
response = agent.invoke(
{"messages": [{"role": "user", "content": "请问北京今天天气如何?"}]},
{"recursion_limit": 4},
)
except GraphRecursionError:
print("Agent stopped due to max iterations.")
response['messages'][-1].content
response['messages']
len(response['messages'])
try:
response = agent.invoke(
{"messages": [{"role": "user", "content": "请问北京今天天气如何?"}]},
{"recursion_limit": 2},
)
except GraphRecursionError:
print("Agent stopped due to max iterations.")
response['messages']
response['messages'][-1].content
response = agent.invoke(
{"messages": [{"role": "user", "content": "请问北京今天天气如何?"}]},
{"recursion_limit": 4},
)
response["messages"][-1].content
len(response["messages"])
response = agent.invoke(
{"messages": [{"role": "user", "content": "请问北京今天天气如何?"}]},
{"recursion_limit": 2},
)
len(response["messages"])
response["messages"][-1].content
三、LangGraph React智能体记忆管理与多轮对话方法
在实际进行Agent开发时,还有一项工作至关重要,那就是需要管理智能体的记忆。
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
tools = [get_weather]
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
agent = create_react_agent(model=model,
tools=tools,
checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
response = agent.invoke(
{"messages": [{"role": "user", "content": "你好,我叫陈明,好久不见!"}]},
config
)
response['messages']
response['messages'][-1].content
此时记忆就自动保存在当前Agent和线程中:
latest = agent.get_state(config)
latest
当我们再次进行对话时,直接带入线程ID,即可带入此前对话记忆:
response = agent.invoke(
{"messages": [{"role": "user", "content": "你好,请问你还记得我叫什么名字么?"}]},
config
)
response['messages']
response['messages'][-1].content
latest = agent.get_state(config)
latest
而如果更新线程ID,则会重新开启对话:
config2 = {
"configurable": {
"thread_id": "2"
}
}
response2 = agent.invoke(
{"messages": [{"role": "user", "content": "你好,你还记得我叫什么名字么?"}]},
config2
)
response2['messages']
此外,关于记忆的管理,往往还涉及记忆持久化存储、跨线程记忆管理、修建&总结历史记录、设置用户偏好记忆、记忆修改、语义搜索、数据加密、快照回复、人机交互(Human in loop)等功能,受限于公开课时间,无法具体展开介绍,感兴趣的同学可以参与付费课程进行更深入的学习,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(夏季班) ,下图扫码即可咨询。