LangGraph 基础入门与 Agent 开发实战
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》 :

《2025大模型Agent智能体开发实战》 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

《2025大模型Agent智能体开发实战》2025 年新春班上新特惠,早鸟价入学,直降2000,木羽老师直播间专属叠加优惠券1000,仅需2999报名即学,【仅限前10名】详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇



《2025大模型智能体Agent开发实战》体验课
LangChain AI+ DeepSeek v3 企业 Agent 开发实战
Part 2. LangGraph 基础入门与 Agent 开发实战
1. LangGraph 接入 DeepSeek v3 模型
LangGraph 中的 StateGraph类,这个类允许我们创建图,其节点通过读取和写入共享状态进行通信。 StateGraph 类由开发者定义的 State 对象进行参数化,该对象表示图中的节点将通过其进行通信的共享数据结构。
from typing import Annotated
from langgraph.graph import StateGraph
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
定义模型实例,这里使用DeepSeek v3 模型。
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="deepseek-chat",
api_key='sk-98f37d04e1374105b31cb994ae0c9c96',
base_url='https://api.deepseek.com')
定义大模型对话节点。
def chatbot(state: State):
# print(state)
return {"messages": [model.invoke(state["messages"])]}
添加节点并编译图。同样,我们先看普通边。如果直接想从节点A到节点B,可以直接使用add_edge方法。注意:LangGraph有两个特殊的节点:START和END。START表示将用户输入发送到图的节点。使用该节点的主要目的是确定应该首先调用哪些节点。END节点是代表终端节点的特殊节点。当想要指示哪些边完成后没有任何操作时,将使用该节点。因此,一个完整的图就可以使用如下代码进行定义:
from langgraph.graph import START, END
# 添加自定义节点
graph_builder.add_node("chatbot", chatbot)
# 构建边
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
# 编译图
graph = graph_builder.compile()
LangGraph还提供了多种内置的图形可视化方法,能够将任何Graph以图形的形式展示出来,帮助我们更好地理解节点之间的关系和流程的动态变化。可视化最大的好处是:直接从代码中生成图形化的表示,可以检查图的执行逻辑是否符合构建的预期。LangGraph提供的三种图形可视化方法如下:
- Mermaid.Ink:一个开源服务,可以根据 Mermaid 代码生成图表的 URL。它通过 API 提供多种输出格式,包括 PNG、JPEG、SVG 和 PDF,并可以自定义尺寸、主题和背景颜色等选项。开源仓库👉:mermaid
- Mermaid + Pyppeteer:使用 Mermaid 结合 Pyppeteer 的主要区别在于如何将 Mermaid 图表转换成图像或其他格式。Mermaid 本身是一个轻量级的工具,用于通过文本描述生成图表的图形表示。而 Pyppeteer 是一个 Python 库,它提供了一个接口来控制 Chrome,自动打开包含 Mermaid 图表的网页,然后通过浏览器自动截图功能捕获这些图表,生成图像文件。
- Graphviz:Graphviz 是一个图形可视化软件,主要用于自动图形布局。它非常适合于复杂图形的生成,如有向图和无向图,而且它支持多种格式的图像输出,如 PNG、SVG、PDF 等,有更精细的布局控制。
https://langchain-ai.github.io/langgraph/how-tos/visualization/

如果是Linux操作系统,建议使用Graphviz工具。而Windows系统建议使用Mermaid + Pyppeteer方法,因为在Windwos中Graphviz并不能直接通过 pip install的形式安装,编译安装的方法较为复杂。这里我们就使用Mermaid + Pyppeteer来进行图的可视化操作。首先,在当前的虚拟环境中安装依赖包,执行如下代码:
# ! pip install pyppeteer ipython
生成图结构的可视化非常直接,只需一行代码即可完成。具体代码如下:
from IPython.display import Image, display
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
当通过 builder.compile() 方法编译图后,编译后的 graph 对象提供了 invoke 方法,该方法用于启动图的执行。我们可以通过 invoke 方法传递一个初始状态,这个状态将作为图执行的起始输入。代码如下:
input_message = {"messages": ["你好,请你介绍一下你自己"]}
result = graph.invoke(input_message)
print(result)
print(result["messages"][-1].content)
通过一个程序构建可交互式的聊天机器人。完整代码如下:
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [("user", user_input)]}):
for value in event.values():
print("模型回复:", value["messages"][-1].content)
while True:
try:
user_input = input("用户提问: ")
if user_input.lower() in ["退出"]:
print("下次再见!")
break
stream_graph_updates(user_input)
except:
break
掌握State的定义模式和消息传递是LangGraph中最关键,也是构建应用最核心的部分,所有的高阶功能,如工具调用、上下文记忆,人机交互等依赖State的管理和使用,所以大家务必理解并掌握上述相关内容。
2. 工具调用代理
Tool Calling Agent(工具调用代理)是LangGraph支持的一种AI Agent代理架构。这个代理架构是在Router Agent的基础上,大模型可以自主选择并使用多种工具来完成某个条件分支中的任务。 当我们希望代理与外部系统交互时,工具就非常有用。外部系统(例如API)通常需要特定的输入模式,而不是自然语言。例如,当我们绑定 API 作为工具时,我们赋予大模型对所需输入模式的感知,大模型就能根据用户的自然语言输入选择调用工具,并将返回符合该工具架构的输出。
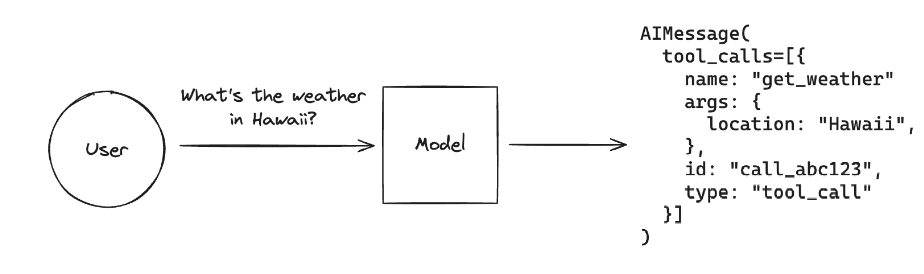
在LangGraph框架中,可以直接使用预构建ToolNode进行工具调用,其内部实现原理和我们之前介绍的手动实现的Function Calling流程思路基本一致,即:
LangGraph ToolNode 源码:https://langchain-ai.github.io/langgraph/reference/prebuilt/#langgraph.prebuilt.tool_node.ToolNode
FENCE0
2.1 使用ToolNode接入工具
经过ToolNode工具后,其返回的是一个LangChain Runnable对象,会将图形状态(带有消息列表)作为输入并输出状态更新以及工具调用的结果,通过这种设计去适配LangGraph中其他的功能组件。比如我们LangGraph预构建的更高级AI Agent架构 - ReAct,两者搭配起来可以开箱即用,同时通过ToolNode构建的工具对象也能与任何StateGraph一起使用。由此,对于ToolNode的使用,有三个必要的点需要满足,即:
- 状态必须包含消息列表。
- 最后一条消息必须是AIMessage。
- AIMessage必须填充tool_calls。
我们尝试进行一下实践。首先,既然是工具调用代理,我们就准备一下需要用的外部工具/函数。这里我们使用Serper API去构建实时联网检索的功能。
# ! pip install requests
import requests
import json
def fetch_real_time_info(query):
"""Get real-time Internet information"""
url = "https://google.serper.dev/search"
payload = json.dumps({
"q": query,
"num": 3,
})
headers = {
'X-API-KEY': 'd9c2c002085468d95712cbc71d76c4302b4f7342',
'Content-Type': 'application/json'
}
response = requests.post(url, headers=headers, data=payload)
data = json.loads(response.text) # 将返回的JSON字符串转换为字典
if 'organic' in data:
return json.dumps(data['organic'], ensure_ascii=False) # 返回'organic'部分的JSON字符串
else:
return json.dumps({"error": "No organic results found"}, ensure_ascii=False) # 如果没有'organic'键,返回错误信息
定义好实时联网检索函数后,我们可以先进行一下连通性测试:
# 使用示例
query = "DeepSeek v3 相关的新闻"
result = fetch_real_time_info(query)
print(result)
如果功能正常,该函数将根据用户的输入,返回实时的网页检索信息,这包括标题、链接、摘要等等有效的信息。而如果想要将普通的函数变成ToolNode可以应用的外部函数,只需要在函数定义时添加@tool装饰器。
from langchain_core.tools import tool
@tool
def fetch_real_time_info(query):
"""Get real-time Internet information"""
url = "https://google.serper.dev/search"
payload = json.dumps({
"q": query,
"num": 1,
})
headers = {
'X-API-KEY': 'd9c2c002085468d95712cbc71d76c4302b4f7342',
'Content-Type': 'application/json'
}
response = requests.post(url, headers=headers, data=payload)
data = json.loads(response.text) # 将返回的JSON字符串转换为字典
if 'organic' in data:
return json.dumps(data['organic'], ensure_ascii=False) # 返回'organic'部分的JSON字符串
else:
return json.dumps({"error": "No organic results found"}, ensure_ascii=False) # 如果没有'organic'键,返回错误信息
print(f'''
name: {fetch_real_time_info.name}
description: {fetch_real_time_info.description}
arguments: {fetch_real_time_info.args}
''')
接下来使用ToolNode对函数进行实例化,代码如下:
from langgraph.prebuilt import ToolNode
tools = [fetch_real_time_info]
tool_node = ToolNode(tools)
tool_node
ToolNode使用消息列表对图状态进行操作。所以它要求消息列表中的最后一条消息是带有tool_calls参数的AIMessage ,比如我们可以手动调用工具节点:
from langchain_core.messages import AIMessage
message_with_single_tool_call = AIMessage(
content="",
tool_calls=[
{
"name": "fetch_real_time_info",
"args": {"query": "DeepSeek v3 最新的新闻"},
"id": "tool_call_id",
"type": "tool_call",
}
],
)
tool_node.invoke({"messages": [message_with_single_tool_call]})
同时,如果将多个工具调用同时传递给AIMessage的tool_calls参数,仍然可以使用ToolNode进行并行工具调用:
@tool
def get_weather(location):
"""Call to get the current weather."""
if location.lower() in ["beijing"]:
return "北京的温度是16度,天气晴朗。"
elif location.lower() in ["shanghai"]:
return "上海的温度是20度,部分多云。"
else:
return "不好意思,并未查询到具体的天气信息。"
tools = [fetch_real_time_info, get_weather]
tool_node = ToolNode(tools)
tool_node
message_with_multiple_tool_calls = AIMessage(
content="",
tool_calls=[
{
"name": "fetch_real_time_info",
"args": {"query": "DeepSeek v3 最新的新闻"},
"id": "tool_call_id",
"type": "tool_call",
},
{
"name": "get_weather",
"args": {"location": "beijing"},
"id": "tool_call_id_2",
"type": "tool_call",
},
],
)
tool_node.invoke({"messages": [message_with_multiple_tool_calls]})
而Tool Calling Agent的本质原理是:让大模型根据用户的输入,自动的去判断应该使用哪个函数,并实际的执行,最后结合工具的响应结果 + 用户的原始问题作为完整的Prompt生成最终的问题。即如下图所示:
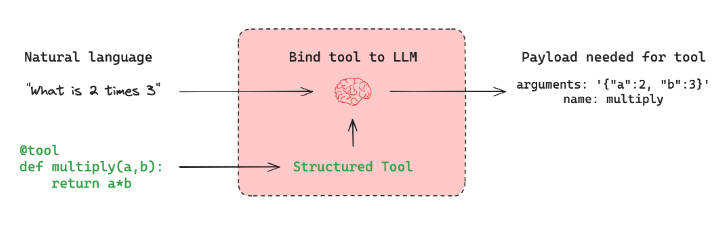
通过ToolNode(tools)可以根据参数来执行函数,并返回结果。而其前一步,根据自然语言生成执行具体某个函数必要参数的过程,则由大模型决定,所以一个完整的基于大模型的工具调用过程应该是,在实例化大模型的时候,就告诉大模型你都有哪些工具可以使用。这个过程可以通过bind_tools函数来实现。代码如下:
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="deepseek-chat",
api_key='sk-98f37d04e1374105b31cb994ae0c9c96',
base_url='https://api.deepseek.com')
tools = [fetch_real_time_info, get_weather]
model_with_tools = model.bind_tools(tools)
model_with_tools
model_with_tools.kwargs
model_with_tools.invoke("DeepSeek v3 最新的新闻").tool_calls
model_with_tools.invoke("北京现在多少度呀?").tool_calls
由此可见,借助大模型可以正确的填充tool_calls信息 ,因此我们可以将其直接传递给ToolNode,从而完成完整的Tool Calling Agent链路。代码如下:
tool_node.invoke({"messages": [model_with_tools.invoke("DeepSeek v3")]})
tool_node.invoke({"messages": [model_with_tools.invoke("北京现在多少度呀")]})
2.2 Tool Calling Agent的完整实现案例
接下来,我们来构建完整的Tool Calling Agent。这里我们对Router Agent实现的图做进一步的升级,即用户输入问题后,如果不需要外部工具的信息,则直接生成回复,否则,则进入一个工具库中,选择最合适的工具执行,并返回最终的响应。因此,我们首先来定义工具库:
- Step 2. 构建Mysql后台数据
首先,我们需要构造一份商家后台的模拟数据。那么,如何存储这些数据呢?对于结构化数据,通常使用关系型数据库来进行存储。常见的选择包括 SQLite、MySQL 和 MongoDB 等。我们这里选择使用 MySQL 作为数据存储的方案,然后再借助pymysql库在本地Python环境中进行连接。关于在Windows安装Mysql服务的过程,我们就不在直播过程中进行讲解,大家可以添加专属助理领取非常详细的安装教程:
按照上述教程安装完成并启动Mysql服务后,我们可以使用一些可视化的工具来进行直观的测试连接。常用的像 👉 workbench 、 DBeaver 、Navicat 等,大家按个人喜好选择就行。安装的方法非常简单,点击链接选择对应自己操作系统的版本执行傻瓜式安装即可。我们这里通过Navicat进行演示。
首先启动 Navicat 客户端,进入主界面,创建新的连接: 在 Navicat 主界面左上方,点击 “连接” 按钮,选择 MySQL:
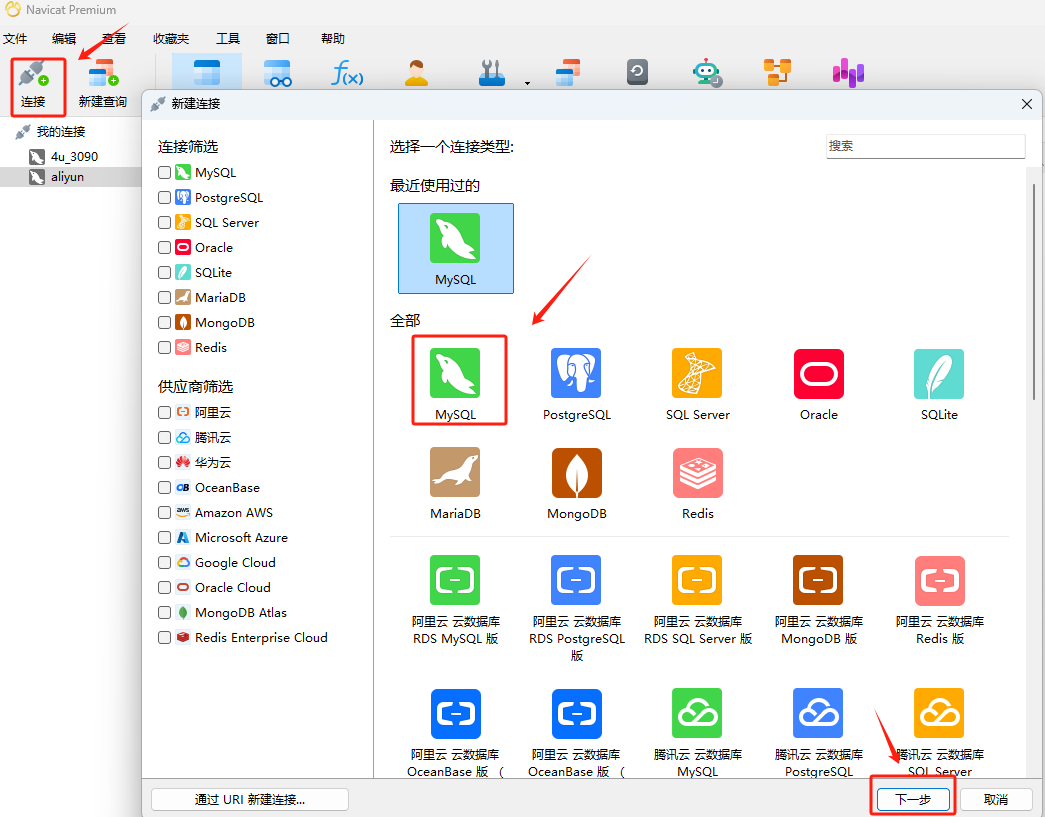
在弹出的连接设置窗口中,填写你的 MySQL 数据库连接信息,其中:
- 连接名称:给你的连接起个名字,方便识别(例如:智能客服系统)。
- 主机名/IP 地址:如果安装在本地计算机上,可以填写 localhost 或 127.0.0.1。
- 端口:默认情况下,MySQL 使用端口 3306,除非你有修改,保持默认即可。
- 用户名:输入你的 MySQL 用户名(例如:root,或者你设置的其他用户名)。
- 密码:输入对应的密码(如果是 root 用户,默认是你安装时设置的密码)。
填写完连接信息后,点击窗口下方的 “测试连接” 按钮。如果连接成功,Navicat 会显示 "连接成功" 的提示。如果连接失败,则需要上述配置是否填写正确。
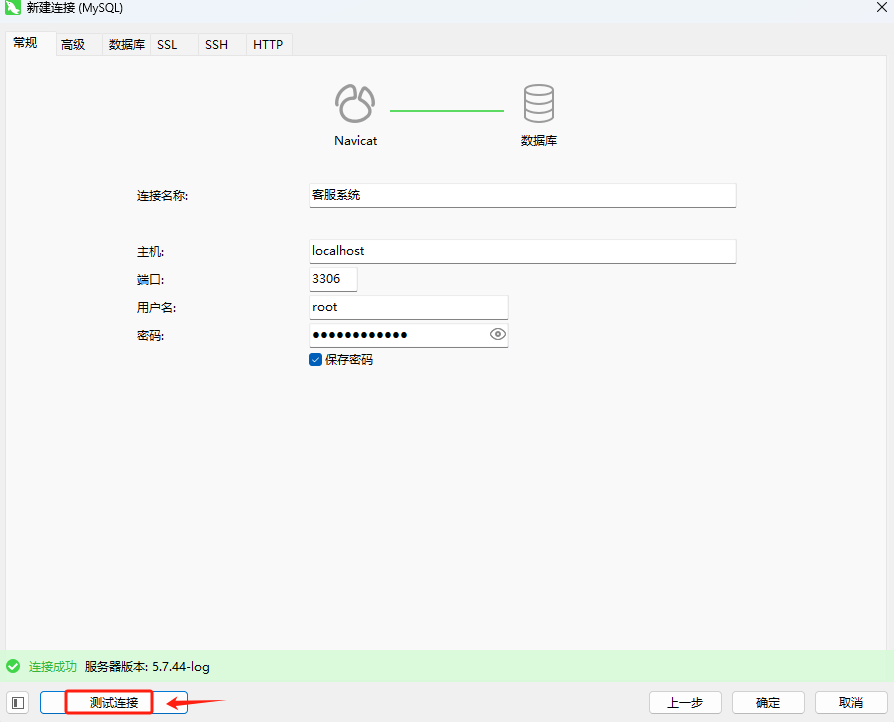
最后,如果测试连接成功,点击 “确定” 按钮,Navicat 会保存连接并尝试连接到你的 MySQL 数据库,并显示在左侧的数据库列表,至此就可以选择并管理该数据库了。
接下来,我们需要使用Python来连接本地的Mysql数据库,同时创建education_db库并插入生成的模拟数据,代码如下:
import pymysql
def create_and_populate_mysql():
# 连接到MySQL服务器(未指定数据库)
conn_mysql = pymysql.connect(
host='localhost', # 这里替换成你自己的 MySQL 主机地址
user='root', # 这里替换成你自己的用户名
password='snowball2019', # 这里替换成你自己的密码
charset='utf8mb4' # 字符集
)
cursor_mysql = conn_mysql.cursor()
# 创建数据库 education_db(如果不存在)
cursor_mysql.execute("CREATE DATABASE IF NOT EXISTS education_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci")
# 切换到 education_db 数据库
cursor_mysql.execute('USE education_db;')
# 创建课程信息表
create_courses_table_query = '''
CREATE TABLE IF NOT EXISTS courses (
course_id VARCHAR(20), -- 课程ID
course_name VARCHAR(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci, -- 课程名称
course_category VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci, -- 课程类别
chapter_number INT, -- 章节编号
chapter_name VARCHAR(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci, -- 章节名称
duration INT, -- 课程时长(小时)
keywords VARCHAR(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci, -- 关键词
PRIMARY KEY (course_id, chapter_number) -- 组合主键(课程ID + 章节编号)
);
'''
cursor_mysql.execute(create_courses_table_query)
# 插入示例数据
insert_data_query = '''
INSERT INTO courses (course_id, course_name, course_category, chapter_number, chapter_name, duration, keywords)
VALUES
('ML001', '机器学习基础', '机器学习', 1, '机器学习简介', 4, '监督学习,无监督学习'),
('ML001', '机器学习基础', '机器学习', 2, '线性回归', 6, '回归分析,模型训练'),
('DL001', '深度学习概论', '深度学习', 1, '神经网络基础', 5, '神经网络,激活函数'),
('DL001', '深度学习概论', '深度学习', 2, '卷积神经网络', 6, 'CNN,图像识别'),
('LM001', '大模型智能体开发', '大模型智能体开发', 1, '智能体基础', 5, 'Agent,FunctionCalling'),
('LM001', '大模型智能体开发', '大模型智能体开发', 2, '本地知识库问答', 7, 'RAG,VectorStore'),
('MLP001', '大模型原理', '大模型原理', 1, '大模型概念', 4, '大模型,计算资源'),
('MLP001', '大模型原理', '大模型原理', 2, '大规模训练', 6, '分布式训练,并行计算'),
('CI001', '因果推断导论', '因果推断', 1, '因果关系与相关性', 5, '因果推断,回归分析'),
('CI001', '因果推断导论', '因果推断', 2, '随机化实验设计', 5, '实验设计,干预实验');
'''
try:
cursor_mysql.execute(insert_data_query)
conn_mysql.commit() # 提交事务
print("数据插入成功!")
except pymysql.MySQLError as e:
print(f"插入数据时出错:{e}")
conn_mysql.rollback() # 回滚事务
# 提交更改并关闭连接
conn_mysql.close()
# 调用函数创建数据库并插入数据
create_and_populate_mysql()
上述代码的执行过程是:首先,程序通过 pymysql 连接到本地的 MySQL 服务器,并检查是否存在名为 education_db 的数据库。如果该数据库不存在,程序会创建一个新的数据库 education_db。然后,切换到该数据库并检查是否已经创建了名为 courses 的表,如果没有,会自动创建此表。接着,将一组预设的产品数据插入到 courses 表中。插入完成后,提交这些更改,并关闭数据库连接,最后输出提示信息,表示数据库和数据已经成功创建并插入 MySQL 中。接下来我们执行这个函数以生成模拟数据:
执行完上述函数后,将在本地 MySQL 数据库中创建一个名为 courses 的表。
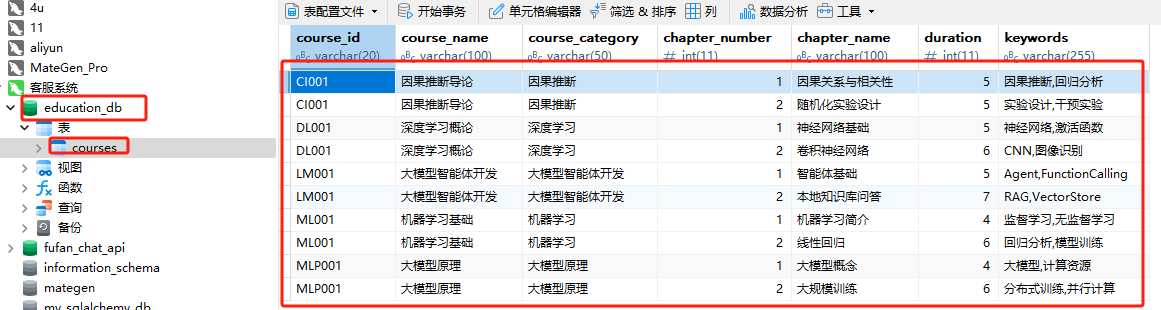
如果希望根据关键字来搜索数据,可以通过在查询中使用 LIKE 操作符来查找包含特定关键字的记录。我们可以对 SQL 查询进行修改,让它支持根据 keywords 字段进行搜索。
def query_by_keyword(keyword):
# 连接 MySQL 数据库
conn_mysql = pymysql.connect(
host='localhost',
user='root',
password='snowball2019',
database='education_db',
charset='utf8mb4'
)
cursor_mysql = conn_mysql.cursor()
# 使用 SQL 查询按关键字查找课程。'%'符号允许部分匹配。
cursor_mysql.execute("SELECT * FROM courses WHERE LOWER(keywords) LIKE %s", ('%' + keyword.lower() + '%',))
# 获取所有查询到的数据
rows = cursor_mysql.fetchall()
# 字段说明
field_descriptions = {
'course_id': '课程唯一标识符',
'course_name': '课程名称',
'course_category': '课程所属类别',
'chapter_number': '章节的编号',
'chapter_name': '章节名称',
'duration': '课程时长(小时)',
'keywords': '与课程相关的关键词'
}
# 关闭连接
conn_mysql.close()
# 返回数据和字段说明
return {
'data': rows,
'field_descriptions': field_descriptions
}
query_by_keyword("Agent")
将其封装成大模型可以调用的外部工具。
@tool
def fetch_real_time_info(query):
"""Get real-time Internet information"""
url = "https://google.serper.dev/search"
payload = json.dumps({
"q": query,
"num": 1,
})
headers = {
'X-API-KEY': 'd9c2c002085468d95712cbc71d76c4302b4f7342',
'Content-Type': 'application/json'
}
response = requests.post(url, headers=headers, data=payload)
data = json.loads(response.text) # 将返回的JSON字符串转换为字典
if 'organic' in data:
return json.dumps(data['organic'], ensure_ascii=False) # 返回'organic'部分的JSON字符串
else:
return json.dumps({"error": "No organic results found"}, ensure_ascii=False) # 如果没有'organic'键,返回错误信息
@tool
def query_by_keyword(keyword):
"""Search course details in local database according to keywords"""
# 连接 MySQL 数据库
conn_mysql = pymysql.connect(
host='localhost',
user='root',
password='snowball2019',
database='education_db',
charset='utf8mb4'
)
cursor_mysql = conn_mysql.cursor()
# 使用 SQL 查询按关键字查找课程。'%'符号允许部分匹配。
cursor_mysql.execute("SELECT * FROM courses WHERE LOWER(keywords) LIKE %s", ('%' + keyword.lower() + '%',))
# 获取所有查询到的数据
rows = cursor_mysql.fetchall()
# 字段说明
field_descriptions = {
'course_id': '课程唯一标识符',
'course_name': '课程名称',
'course_category': '课程所属类别',
'chapter_number': '章节的编号',
'chapter_name': '章节名称',
'duration': '课程时长(小时)',
'keywords': '与课程相关的关键词'
}
# 关闭连接
conn_mysql.close()
# 返回数据和字段说明
return {
'data': rows,
'field_descriptions': field_descriptions
}
tools = [query_by_keyword, fetch_real_time_info, get_weather]
tool_node = ToolNode(tools)
tool_node
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="deepseek-chat",
api_key='sk-98f37d04e1374105b31cb994ae0c9c96',
base_url='https://api.deepseek.com')
llm = model.bind_tools(tools)
from langgraph.prebuilt import create_react_agent
graph = create_react_agent(llm, tools=tools)
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
理解了上面的create_react_agent方法内部的构建原理后,其实就能明白:当通过create_react_agent(llm, tools=tools)一行代码的执行,现在得到的已经是一个编译后、可执行的图了。我们可以通过mermaid方法来可视化经过create_react_agent方法构造出来的图结构,代码如下所示:
返回的是编译好的LangGraph可运行程序,可直接用于聊天交互。调用方式则和之前使用的方法一样,我们可以依次针对不同复杂程度的需求依次进行提问。首先是测试是否可以不使用工具,直接调用大模型生成响应。
# query="你好,请你介绍一下你自己"
# input_message = {"messages": [HumanMessage(content=query)]}
# 可以自动处理成 HumanMessage 的消息格式
finan_response = graph.invoke({"messages":["你好,请你介绍一下你自己"]})
finan_response
finan_response["messages"][-1].content
加大输入问题的复杂度,接下来我们提问的问题希望它能够自动找到正确的工具函数,基于工具的执行结果作为既定的事实,引导生成最终的回复。
finan_response = graph.invoke({"messages":["课程中有没有Agent相关的内容?"]})
finan_response
finan_response["messages"][-1].content
finan_response = graph.invoke({"messages":["你知道 OpenAI 最近的动态吗?请用中文回复我"]})
finan_response
finan_response["messages"][-1].content
def stream_graph_updates(user_input: str):
# 初始化一个变量来累积输出
accumulated_output = []
for event in graph.stream({"messages": [("user", user_input)]}):
for value in event.values():
# 将模型回复的内容添加到累积输出中
accumulated_output.append(value["messages"][-1].content)
# 返回累积的输出
return accumulated_output
while True:
try:
user_input = input("用户提问: ")
if user_input.lower() in ["退出"]:
print("下次再见!")
break
# 获取累积的输出
updates = stream_graph_updates(user_input)
# 打印最后一个输出
if updates:
print("模型回复:")
print(updates[-1])
except:
break
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》 :
《2025大模型Agent智能体开发实战》 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
《2025大模型Agent智能体开发实战》2025 年新春班上新特惠,早鸟价入学,直降2000,木羽老师直播间专属叠加优惠券1000,仅需2999报名即学,【仅限前10名】详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇