Agents SDK+DeepSeek+MCP智能体开发实战(下)
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(春季班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(春季班)

《2025大模型Agent智能体开发实战》(春季班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

重磅新增DeepSeek+QwQ+OpenAI responses API+MCP技术应用与智能体开发相关实战内容:

此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(3月班)

两门大模型课程春季班目前上新特惠中,立减2000起,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

《2025大模型Agent智能体开发实战》体验课
OpenAI开源Agents SDK + DeepSeek + MCP智能体开发实战(下)
import openai
openai.__version__
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv(override=True)
from openai import AsyncOpenAI
from agents import OpenAIChatCompletionsModel,Agent,Runner,set_default_openai_client
from agents.model_settings import ModelSettings
from contextlib import AsyncExitStack
import openai
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv(override=True)
from openai import AsyncOpenAI
from agents import OpenAIChatCompletionsModel,Agent,Runner,set_default_openai_client
from agents.model_settings import ModelSettings
from agents import function_tool
import requests,json
import pymysql
from agents import (
Agent,
HandoffOutputItem,
ItemHelpers,
MessageOutputItem,
RunContextWrapper,
Runner,
ToolCallItem,
ToolCallOutputItem,
TResponseInputItem,
function_tool,
handoff,
trace,
)
from agents.extensions.handoff_prompt import RECOMMENDED_PROMPT_PREFIX
from IPython.display import display, Code, Markdown, Image
import os
import openai
import glob
import shutil
import numpy as np
import pandas as pd
import pymysql
import json
import io
import inspect
import requests
import re
import random
import string
import base64
from bs4 import BeautifulSoup
import dateutil.parser as parser
import tiktoken
from lxml import etree
import sys
from dotenv import load_dotenv
from openai import OpenAI
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import display, Code, Markdown, Image
from IPython import get_ipython
- DeepSeek API调用流程回顾
# 读取模型API-KEY
API_KEY = os.getenv("API_KEY")
# 实例化客户端
client = OpenAI(api_key=API_KEY,
base_url="https://api.deepseek.com")
# 调用 deepseekv3 模型
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "你好,好久不见!请介绍下你自己。"}
]
)
# 输出生成的响应内容
print(response.choices[0].message.content)
- Agents SDK基本调用流程回顾
external_client = AsyncOpenAI(
base_url = "https://api.deepseek.com",
api_key=API_KEY,
)
set_default_openai_client(external_client)
deepseek_model = OpenAIChatCompletionsModel(
model="deepseek-chat",
openai_client=external_client)
agent = Agent(name="Assistant",
instructions="你是一名助人为乐的助手。",
model=deepseek_model)
result = await Runner.run(agent, "请写一首关于编程中递归的俳句。")
print(result.final_output)
一、MCP入门介绍与接入Agents SDK基本流程
在3月27号,Agents SDK正式官宣支持MCP使用,这也使得Agents SDK的实际应用场景得到待拓展:

现在,我们仅需在创建Agent的时候,将MCP服务器视作为一项工具,即可顺利调用MCP服务器进行Agent开发。而实际在借助Agents SDK调用MCP的流程也非常简单,我们只需将MCP视作tools,即可进行调用。换而言之,就是如果使用Agents SDK作为Agent开发框架,则可以零门槛快速接入MCP海量服务器生态。
1.MCP技术回顾
MCP,全称是Model Context Protocol,模型上下文协议,由Claude母公司Anthropic于去年11月正式提出。

- Anthropic MCP发布通告:https://www.anthropic.com/news/model-context-protocol
- MCP GitHub主页:https://github.com/modelcontextprotocol
MCP的核心作用,是统一了Agent开发过程中,大模型调用外部工具的技术实现流程,从而大幅提高Agent开发效率。在MCP诞生之前,不同的外部工具各有不同的调用方法,要连接这些外部工具开发Agent,就必须“每一把锁单独配一把钥匙”,开发工作非常繁琐:
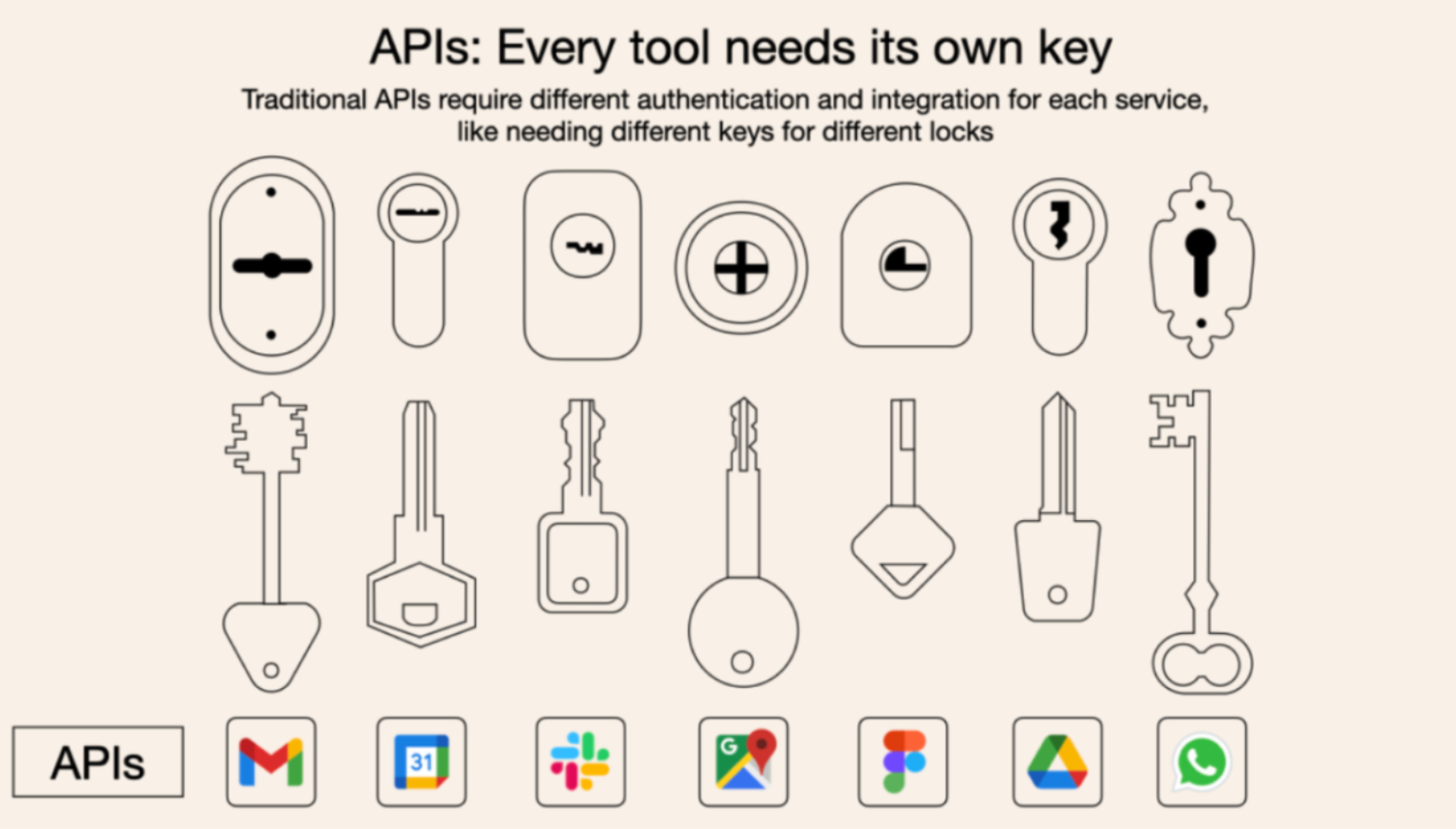
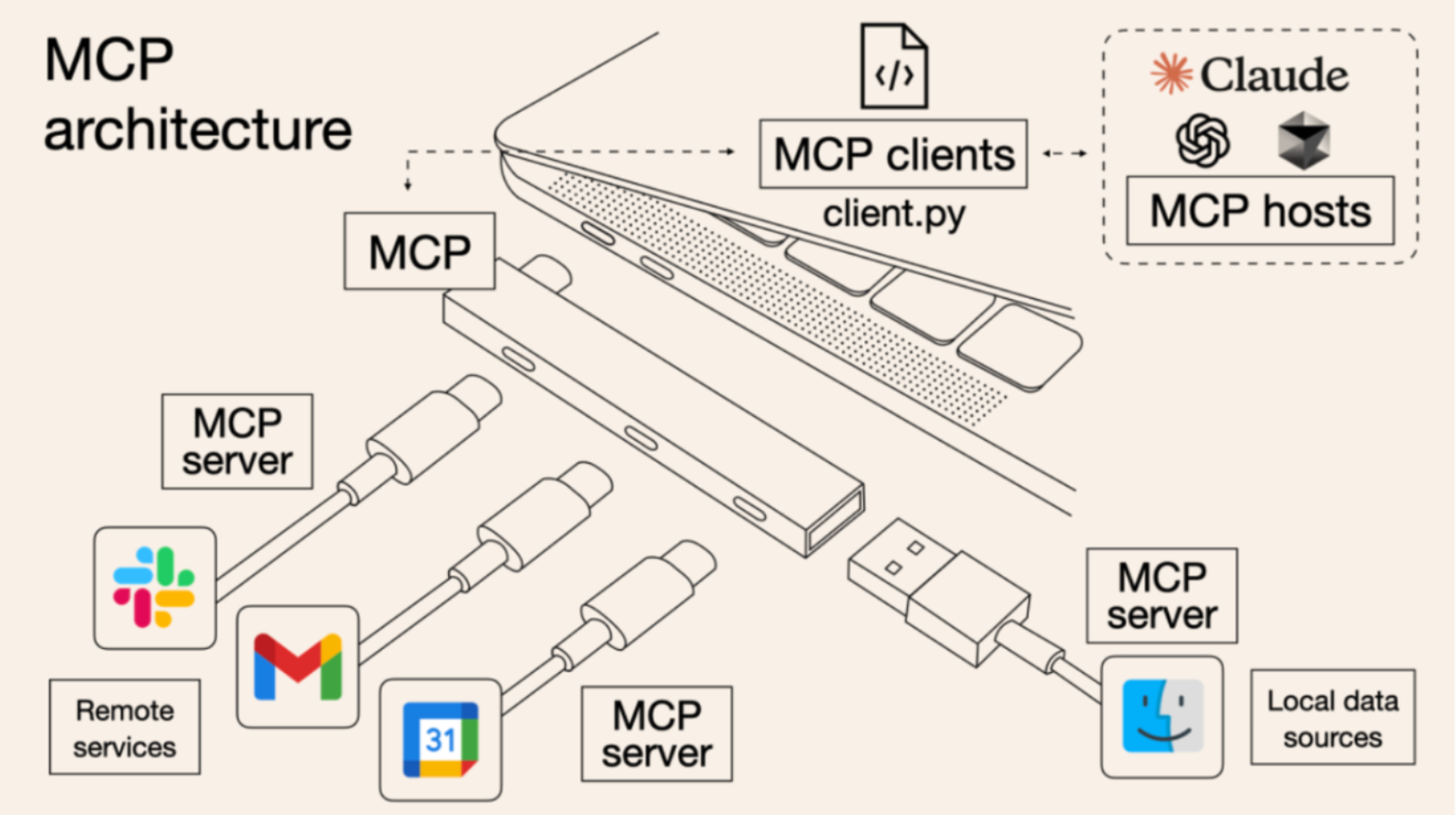
而MCP的诞生,则统一了这些外部工具的调用流程,使得无论什么样的工具,都可以借助MCP技术按照统一的一个流程快速接入到大模型中,从而大幅加快Agent开发效率。这就好比现在很多设备都可以使用type-c和电脑连接类似。
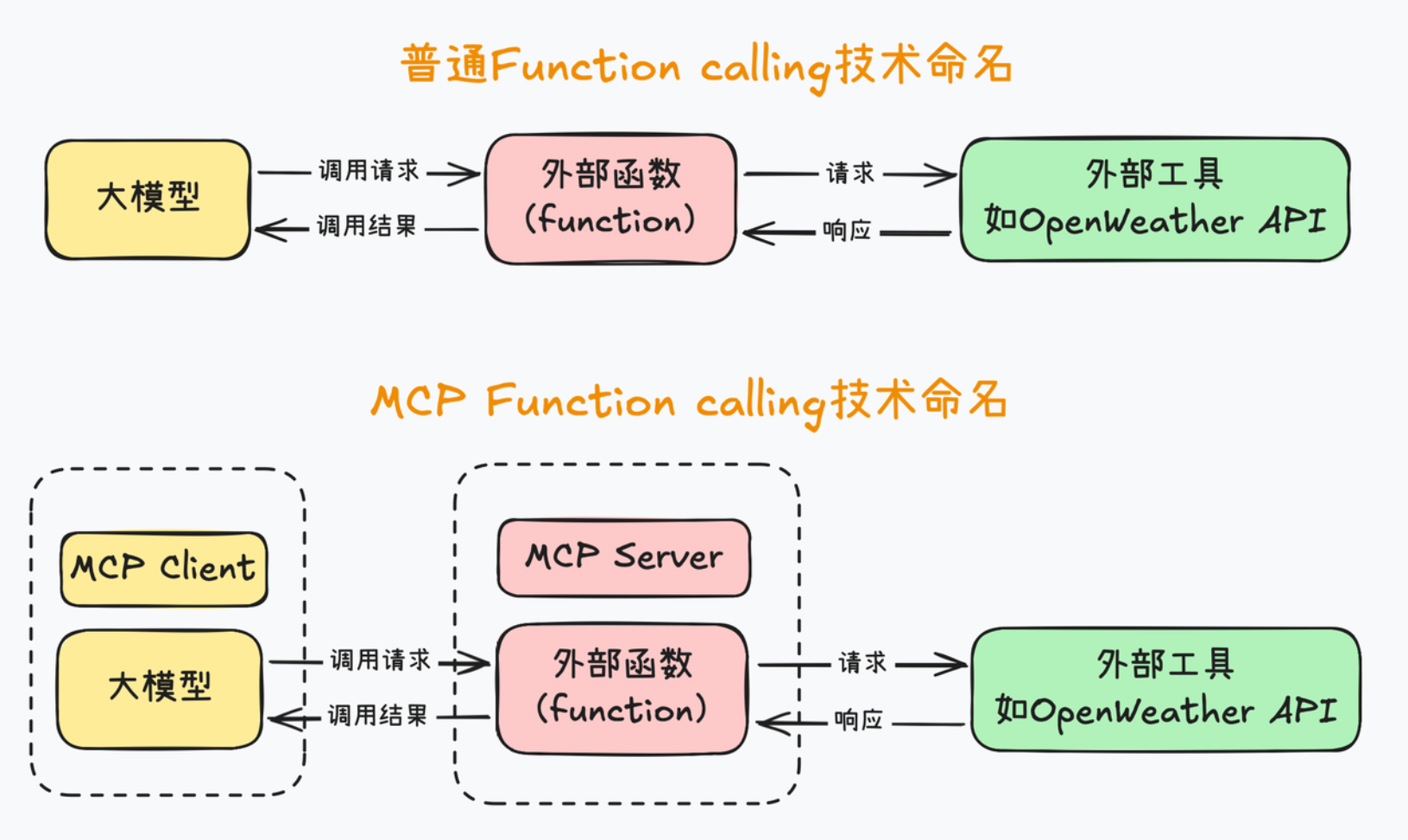
从技术实现角度来看,我们可以将MCP看成是Function calling的一种封装,通过server-client架构和一整套开发工具,来规范化Function calling开发流程。
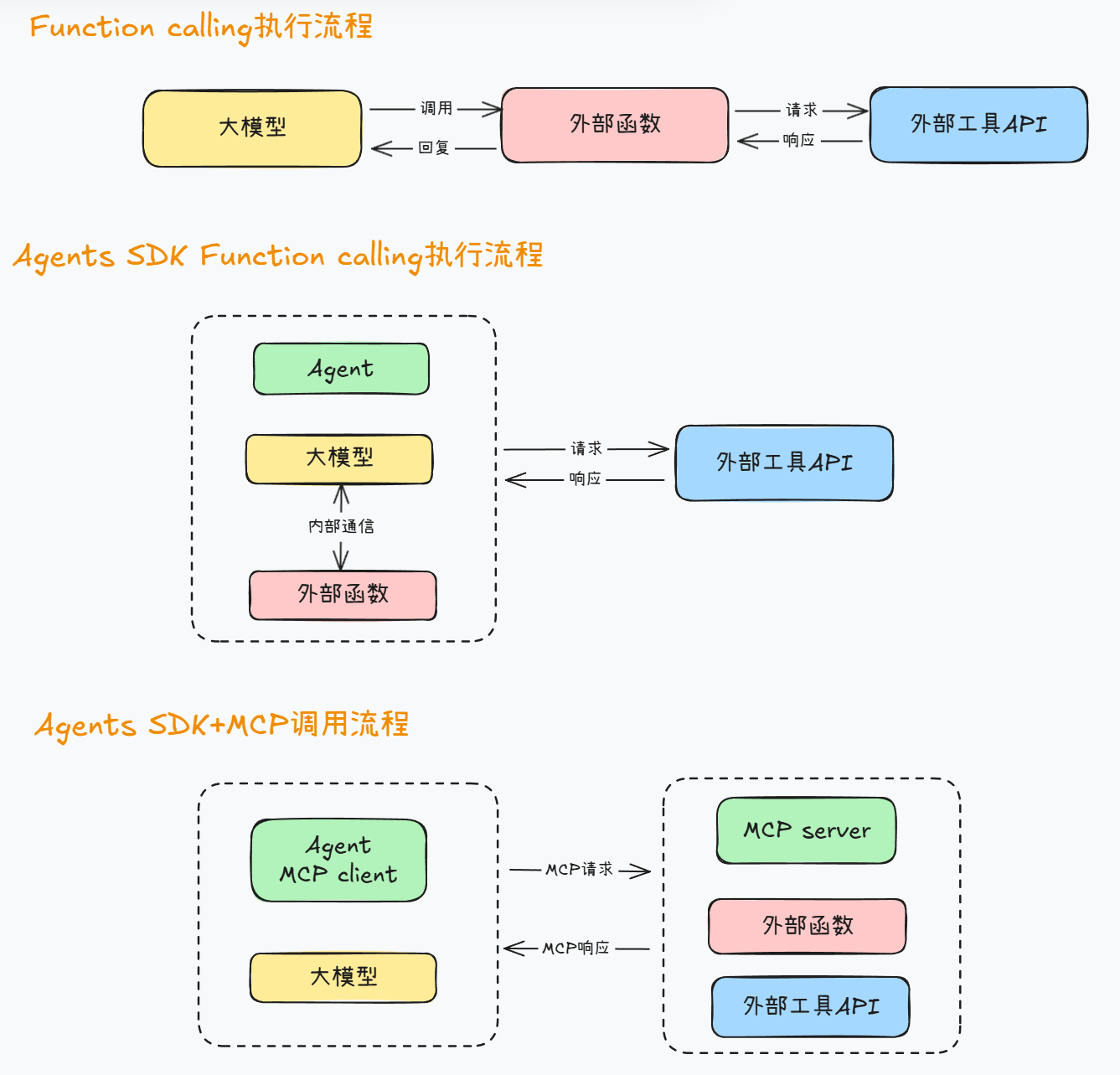
换而言之,Agents SDK实现MCP技术流程如下:
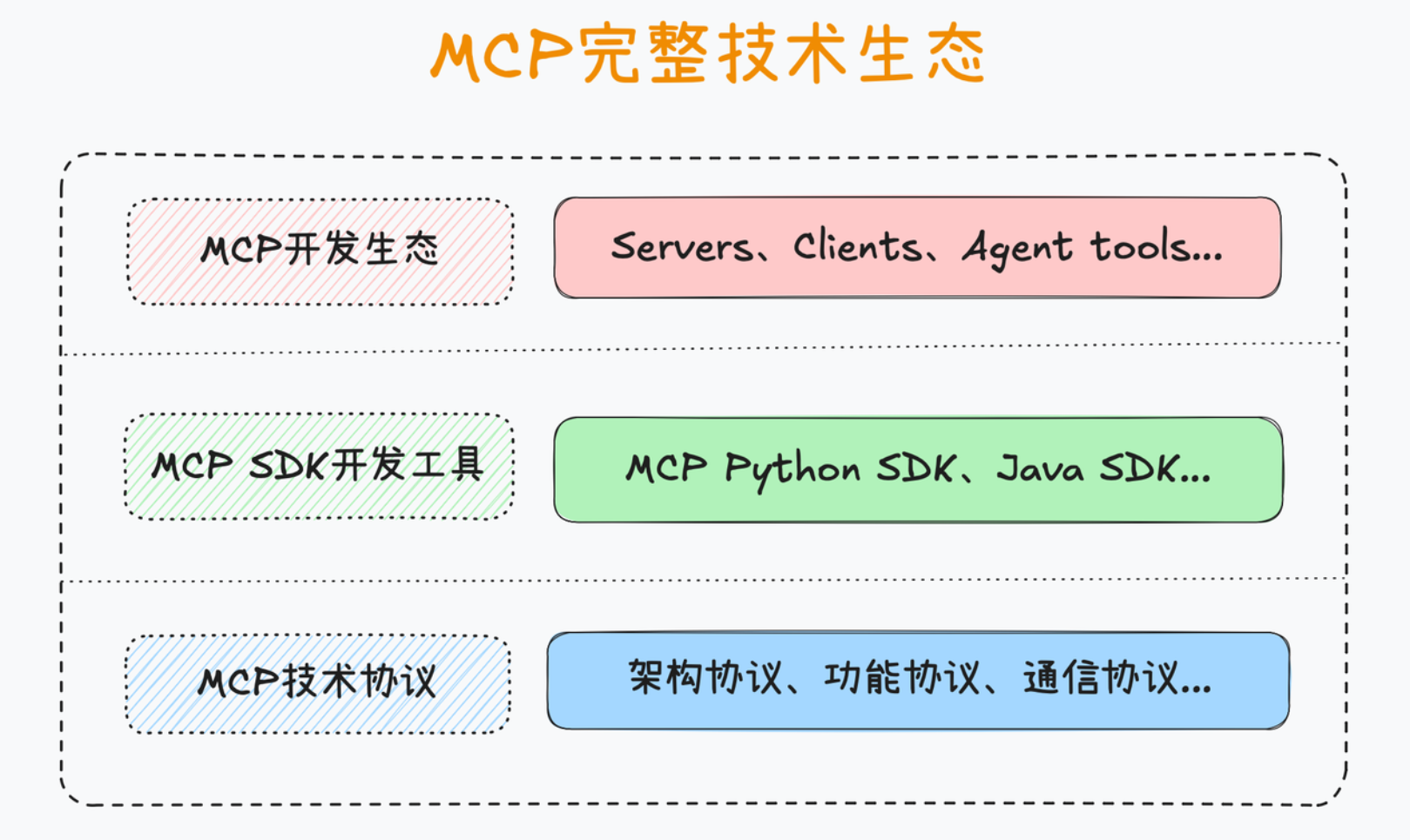
除此之外,实际上,MCP提供了三个方面的技术支持,其一是抽象的协议,也就是技术理论层面的设计;其二是一整套MCP的开发工具,也就是一些库,方便大家进行MCP工具(MCP Server)的开发并构建智能体;其三,MCP还提供了一整套非常丰富的开发生态,由于MCP是一套标准协议,任何MCP工具(MCP Server)都可以无缝接入任何MCP智能体中,也就是你开发的工具我也能用,我开发的工具你也能直接用。

2.MCP参考公开课
- 《7分钟讲清楚MCP是什么?》:https://www.bilibili.com/video/BV1uXQzYaEpJ/

- 《从零到一,MCP技术开发入门实战!》:https://www.bilibili.com/video/BV1NLXCYTEbj/

- 《MCP企业级智能体开发实战!》:https://www.bilibili.com/video/BV1n1ZuYjEzf/

从零到一MCP入门与智能体开发进阶课件合集:
下图扫码即可领取:
3.MCP基础实践流程
接下来,我们先尝试手动实现一遍MCP实践流程,然后再考虑将已经部署好的server带入Agents SDK中,作为tools进行调用。
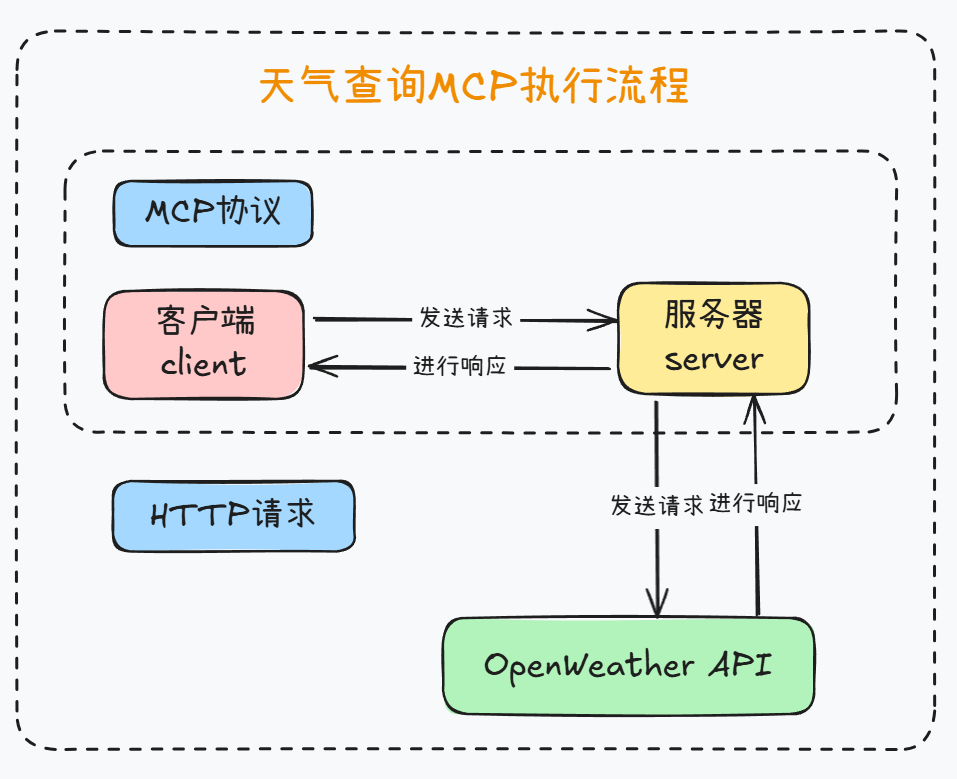
一个极简的天气查询MCP调用流程如下:
- 借助uv创建MCP运行环境
方法 1:使用 pip 安装(适用于已安装 pip 的系统)
FENCE0
方法 2:使用 curl 直接安装
如果你的系统没有 pip,可以直接运行:
FENCE1
这会自动下载 uv 并安装到 /usr/local/bin。
- 创建 MCP 客户端项目
FENCE0
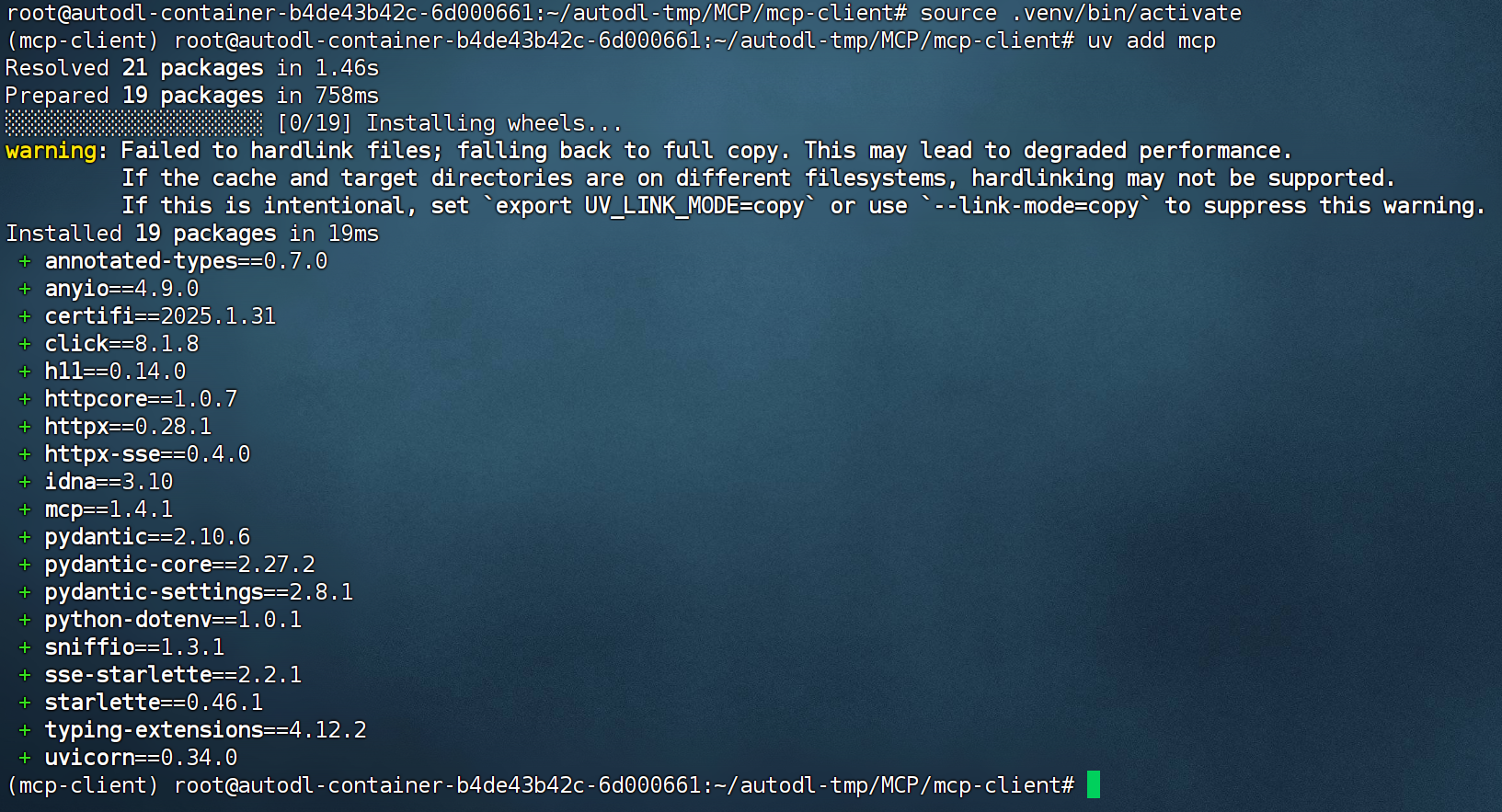
- 创建MCP客户端虚拟环境
FENCE0

然后即可通过add方法在虚拟环境中安装相关的库。
FENCE0
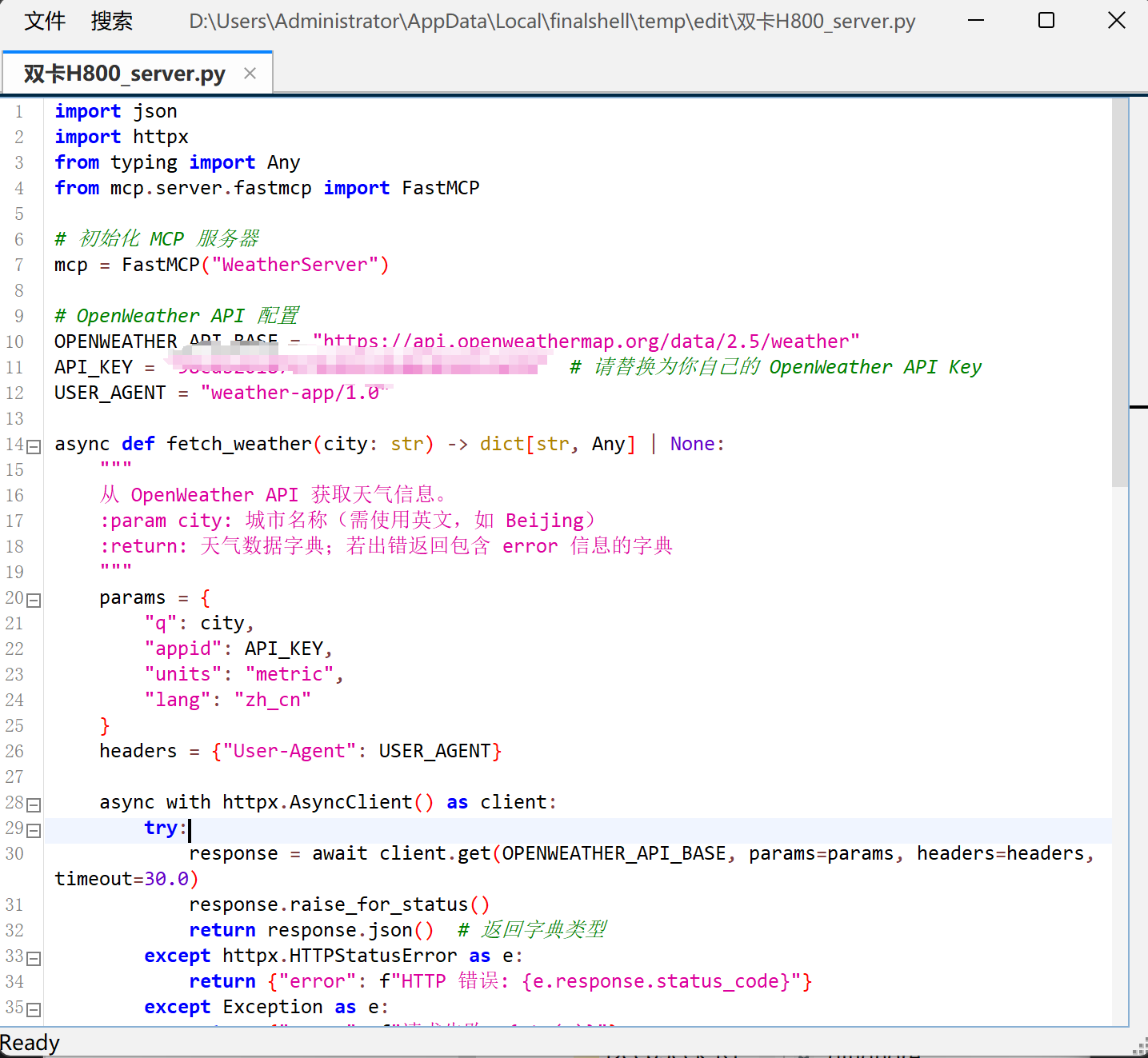
- 编写用于天气查询的server服务器代码:
这里我们需要在服务器上创建一个server.py,并写入如下代码:
FENCE0
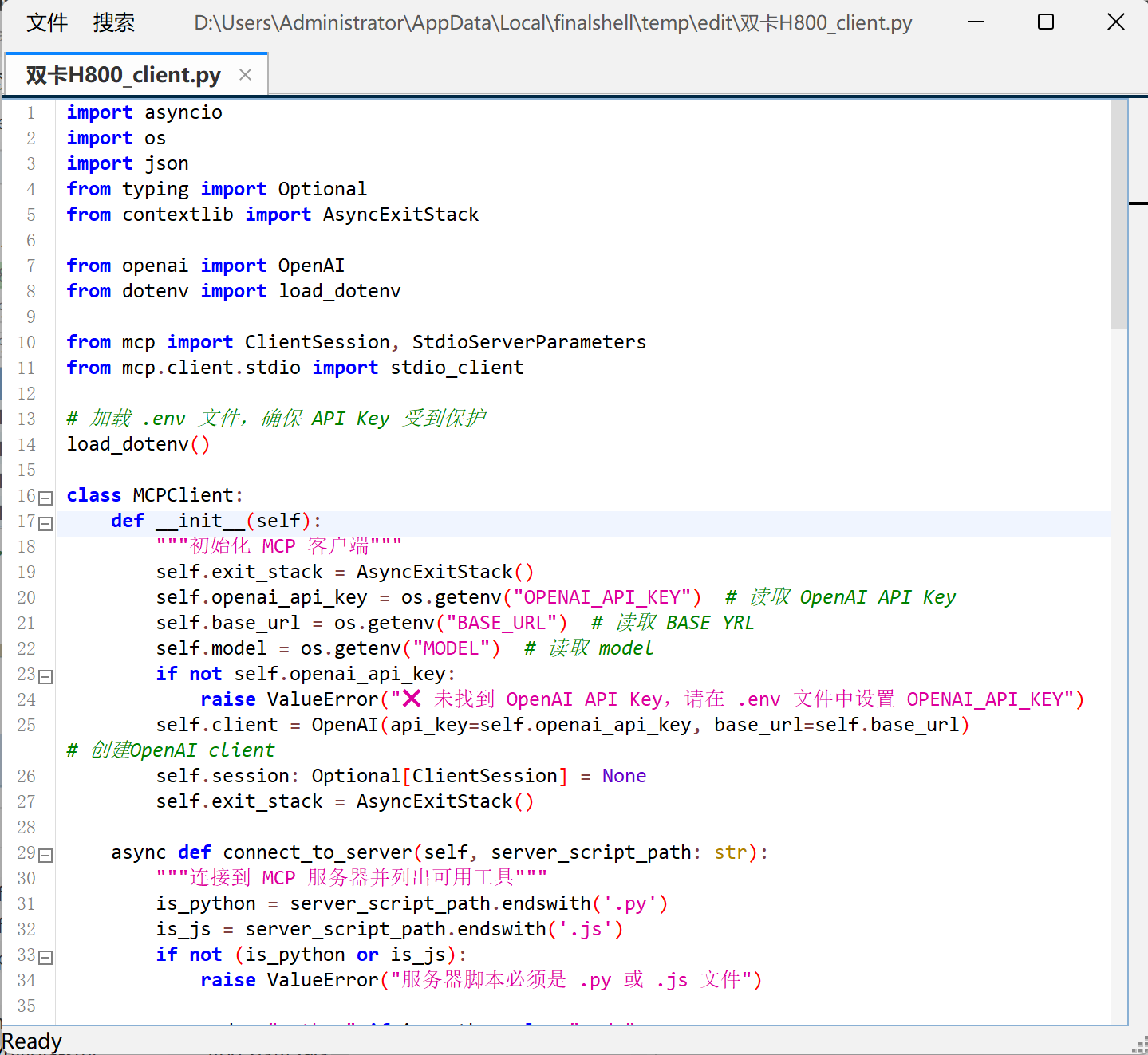
- 天气查询客户端client创建流程
然后创建一个可以和server进行通信的客户端,需要注意的是,该客户端需要包含大模型调用的基础信息。我们需要编写一个client.py脚本,聂荣如下:
FENCE0
- 创建.env文件
接下来继续创建一个.env文件,来保存大模型调用的API-KEY
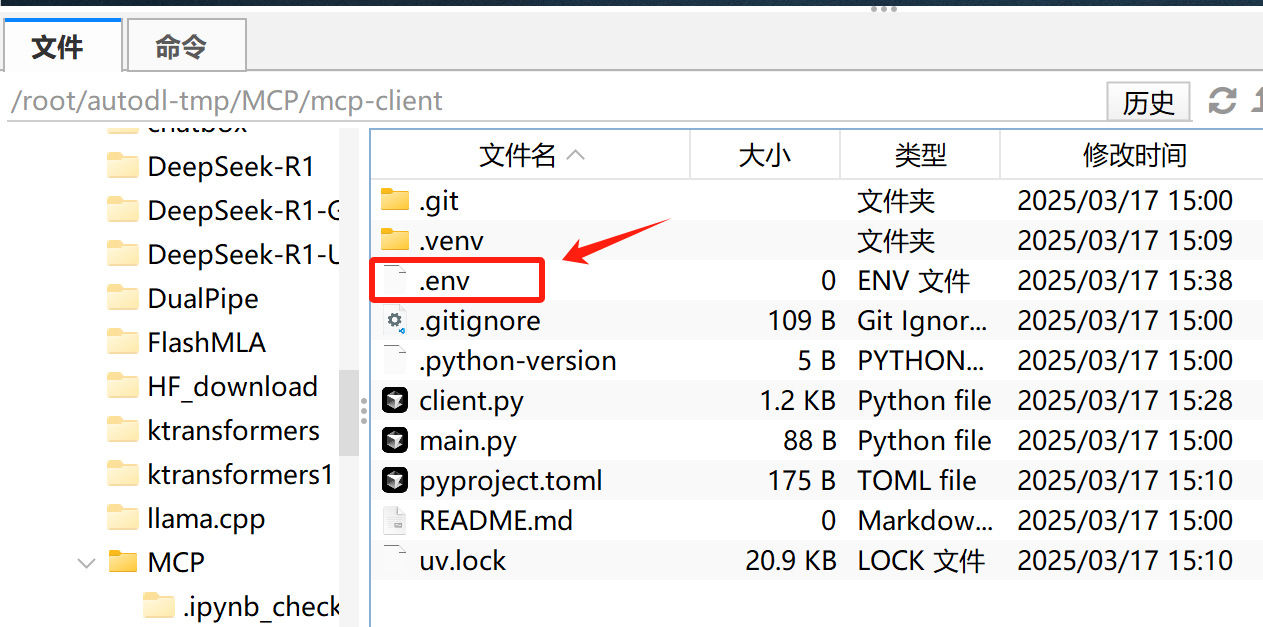
并写入如下内容:
FENCE0
此时项目结构如下:
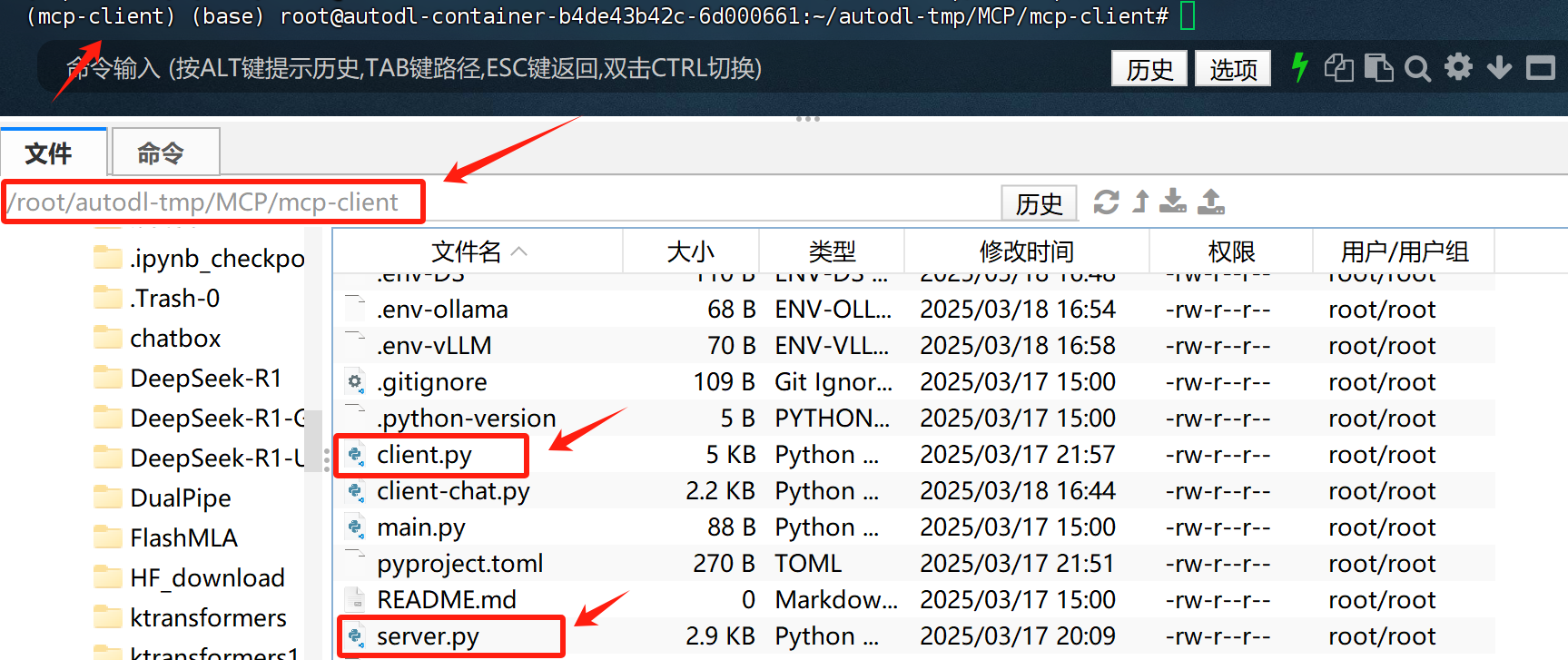
- 运行MCP客户端+服务器
最后在命令行中执行如下命令,即可开启对话:
FENCE0
直接提问请问北京今天天气如何?运行结果如下所示:
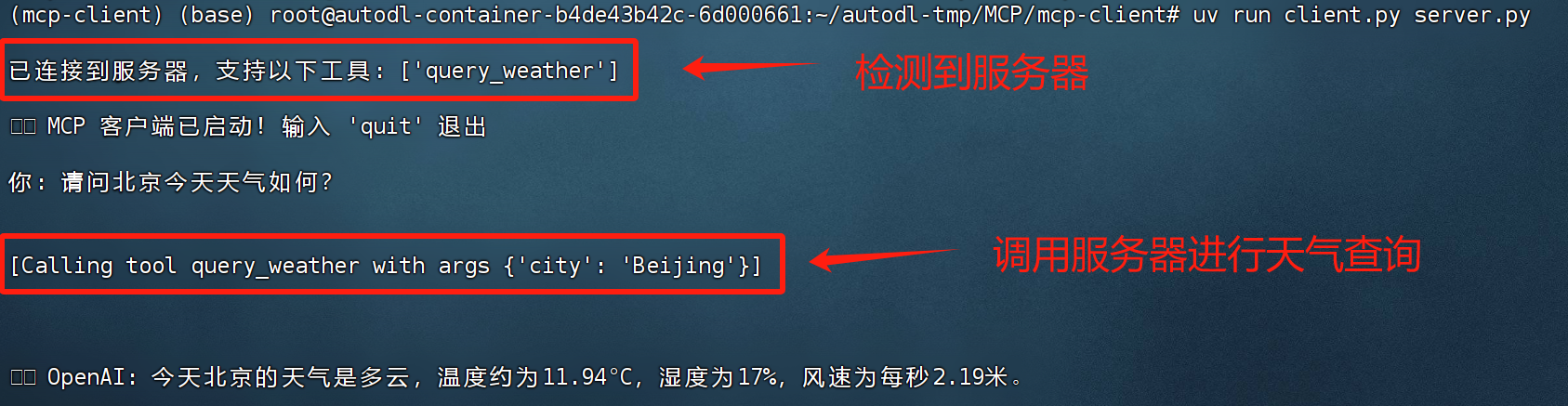
至此,即完成了一次简单的MCP执行流程。
4.MCP+Agents SDK基础调用流程
而在新版的Agents SDK中,Agents SDK可以将某个对应的Agent封装为client与外部定义好的server进行通信。基本实现流程如下,还是查询天气的server.py,现在将其复制到jupyter运行主目录下,并修改名称为weather_server.py:
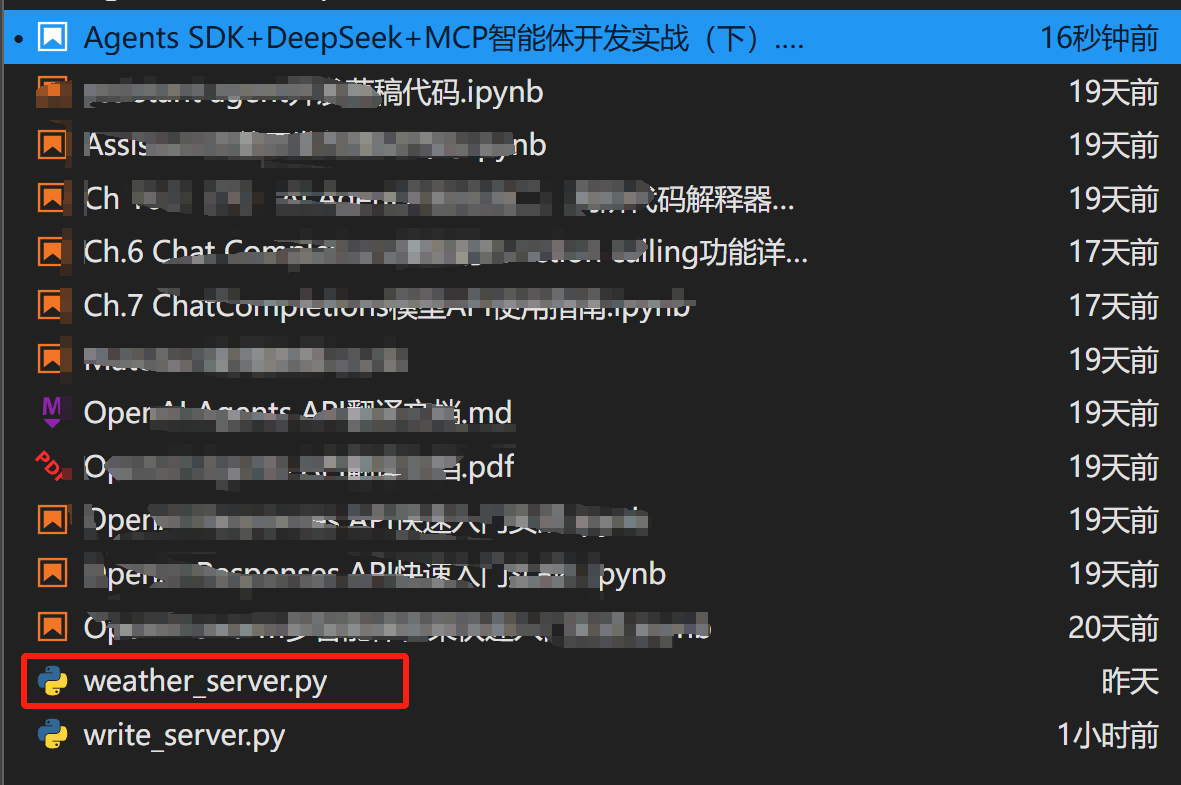
然后导入相关的库:
import asyncio
import os
import shutil
import subprocess
import time
from typing import Any
from agents import Agent, Runner, gen_trace_id, trace
from agents.mcp import MCPServer, MCPServerStdio
from agents.model_settings import ModelSettings
同时定义Agent+MCP运行函数,要求带入MCPServer对象,且带入mcp_servers中,作为类似tools参数带入到当前Agent运行过程中:
async def run(mcp_server: MCPServer):
agent = Agent(
name="Assistant",
instructions="你是一名助人为乐的助手",
mcp_servers=[mcp_server],
model=deepseek_model
)
message = "请帮我查询北京今天天气如何?"
print(f"Running: {message}")
result = await Runner.run(starting_agent=agent, input=message)
print(result.final_output)
然后创建mcp_run函数,负责开启外部server并运行Agent:
async def mcp_run():
async with MCPServerStdio(
name="Weather Server",
cache_tools_list=True,
params = {"command": "uv","args": ["run", "weather_server.py"]}
) as server:
await run(server)
✅ 关键组件解释:
-
async with MCPServerStdio(...) as server:
启动一个 MCP 工具服务器进程,使用标准输入输出(stdio)作为通信协议,并在上下文中运行(退出时会自动关闭)。 -
name="Weather Server"
给这个 MCP Server 起名为“天气服务器”,这只是用于日志和识别用的标识符。 -
cache_tools_list=True
意思是:首次加载工具时缓存工具列表,后续不需要重新请求工具元数据(提升效率)。 -
params = {"command": "uv", "args": ["run", "weather_server.py"]}
这是启动 MCP 工具服务器的 命令行参数,等价于在命令行里运行:uv run weather_server.pyuv:同样使用uv ,是一个快速的 Python 包和环境管理器,比 pip/venv 更高效。run weather_server.py:运行一个你定义好的MCP server。
最后测试运行:
await mcp_run()
从零到一MCP入门与智能体开发进阶课件合集:
二、Agents SDK+MCP进阶技术实践
1.Agents SDK接入更多开源MCP服务器流程
若要采用MCP技术栈,最核心的便利就在于可以快速接入海量MCP开源服务器,无需反复开发,即可快速丰富当前Agent功能。热门MCP server合集地址如下:
-
Model Context Protocol servers: https://github.com/modelcontextprotocol/servers
-
Awesome MCP Servers: https://github.com/punkpeye/awesome-mcp-servers
-
MCP导航: https://mcp.so/
接下来我们就先尝试接入一个开源的、开发人员常用的MCP服务器——mcp-server-git。
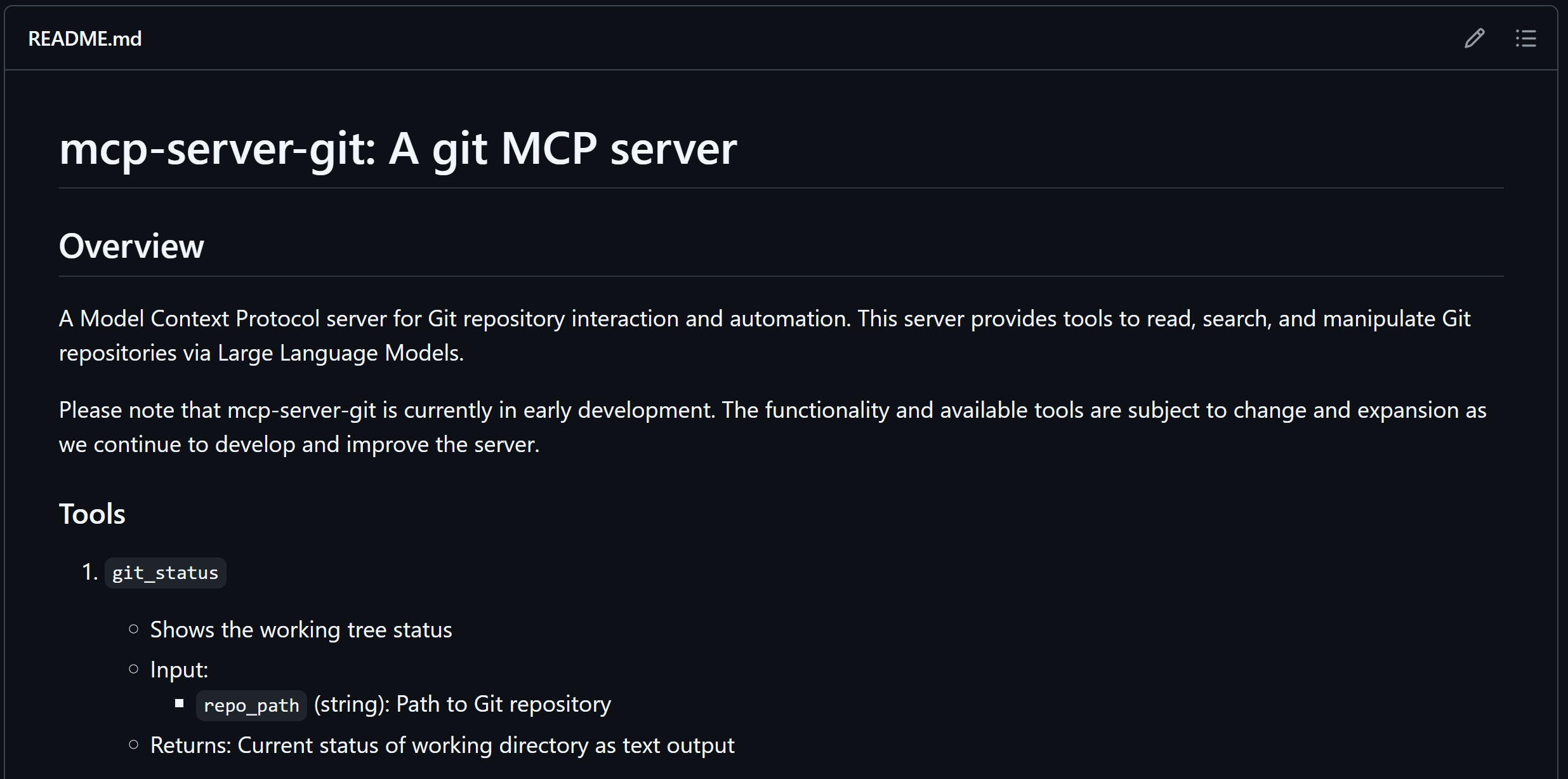
📌 MCP-Server-Git 简介
mcp-server-git 是一个遵循 Model Context Protocol (MCP) 的 Git 操作服务器,专为大语言模型与 Git 仓库的交互而设计。通过该服务,模型可以安全、结构化地完成 Git 操作,包括状态查询、差异比较、提交更改、分支管理等,从而实现自动化代码管理与协作。
✨ 核心功能包括:
- 查询仓库状态:获取当前工作区和暂存区的变动情况(
git_status、git_diff_unstaged、git_diff_staged) - 版本比较:支持分支或提交之间的差异查看(
git_diff) - 代码提交与暂存管理:支持新增、暂存、撤销暂存、更改提交(
git_add、git_reset、git_commit) - 日志查询与历史查看:获取提交历史、查看具体提交内容(
git_log、git_show) - 分支操作:新建分支、切换分支(
git_create_branch、git_checkout) - 仓库初始化:支持新建空 Git 仓库(
git_init)
🚀 调用方式
✅ 使用 uvenv 快速启动(推荐方式)
无需安装,只需一行命令即可运行:
FENCE0
首次运行会从 PyPI 下载并缓存,后续启动速度更快。
📡 接口调用格式(示例)
以 git_status 为例,MCP 工具调用格式如下:
FENCE1
服务将返回 Git 工作目录当前状态的文本描述。
- uvx(已弃用)/ uvenv 工具安装与使用指南(Ubuntu)
uvx(现已由 uvenv 取代)是一个基于 Python 的零安装运行工具,可快速运行 Python 包,而无需手动安装或污染系统环境。
- uvenv 安装方法(Ubuntu)
打开终端,运行以下命令自动安装最新版 uv(含 uvenv):
FENCE0
或使用 wget 命令安装:
FENCE1
安装完成后,验证是否安装成功:
FENCE2
🔁 可选:通过 pip 安装(不推荐)
FENCE3
虽然可以使用 pip 安装 uv,但官方推荐使用上面的安装脚本,因为:
- 安装的是预编译二进制版本,性能更好
- 功能更完整
- 自动将可执行文件添加到环境路径
- uvenv 功能说明
- 无需提前安装:
uvenv自动从 PyPI 拉取并运行 Python 包。 - 隔离环境:每次执行均为临时环境,避免污染系统全局环境。
- 缓存机制:首次拉取后自动缓存,后续使用直接读取缓存,提高运行速度。
- 用途广泛:适用于快速测试、命令行工具临时使用以及 Python 脚本的隔离执行。
- uvenv 基本使用方法
使用语法
FENCE4
示例:运行 mcp-server-git
首次运行会自动从 PyPI 下载并缓存:
FENCE5
再次运行则直接使用缓存,速度更快:
FENCE6
⚠️ 更新缓存中的包
默认情况下,uvenv 不会自动检测和使用 PyPI 上的新版本。如果想强制使用最新版本,可以:
- 清理缓存后重新运行:
FENCE7
- 常用操作
- 查看缓存位置:
FENCE8
- 清理缓存(若需要):
FENCE9
- 升级 uv/uvenv 工具:
FENCE10
- 从 uvx 迁移提示:如果你看到如下提示:
FENCE11
说明你已成功迁移到新版,请使用 uvenv run <package> 来代替原来的 uvx <package> 命令。
接下来尝试在Jupyter中创建Agent来完成调用:
async def run(mcp_server: MCPServer, directory_path: str):
agent = Agent(
name="Assistant",
instructions=f"Answer questions about the git repository at {directory_path}, use that for repo_path",
mcp_servers=[mcp_server],
model=deepseek_model
)
message = "请帮我介绍下这个项目。"
print(f"Running: {message}")
result = await Runner.run(starting_agent=agent, input=message)
print(result.final_output)
async def mcp_run(directory_path):
async with MCPServerStdio(
name="GitHub Server",
cache_tools_list=True,
params={"command": "uvenv", "args": ["run", "mcp-server-git"]},
) as server:
await run(server, directory_path=directory_path)
接下来我们查询DeepSeek大模型部署推理加速库Ktransformers的新版本特性:
directory_path = 'https://github.com/kvcache-ai/ktransformers'
# 可选,设置代理
# os.environ['HTTP_PROXY'] = 'http://127.0.0.1:10080'
# os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:10080'
# 取消代理设置
# os.environ.pop('HTTP_PROXY', None)
# os.environ.pop('HTTPS_PROXY', None)
# AutoDL学术加速
import subprocess
import os
result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():
if '=' in line:
var, value = line.split('=', 1)
os.environ[var] = value
⚠需要注意的是,mcp-server-git 是一个持续运行的 CLI 工具服务,而受限于jupyter环境,以下代码运行结束后并不会自动退出,需要重启jupyter-kernel才能关闭进程,请谨慎运行:
await mcp_run(directory_path)
而一种更加稳妥的方式,是定义py脚本并在命令行中运行:
FENCE0
2.Agents SDK接入多个MCP服务器流程
接下来我们继续介绍如何将Agents SDK同时接入多个MCP服务器,理论上,MCP一个服务器能同时运行多个外部函数,而一个MCP Client则可以连接多个MCP服务器:
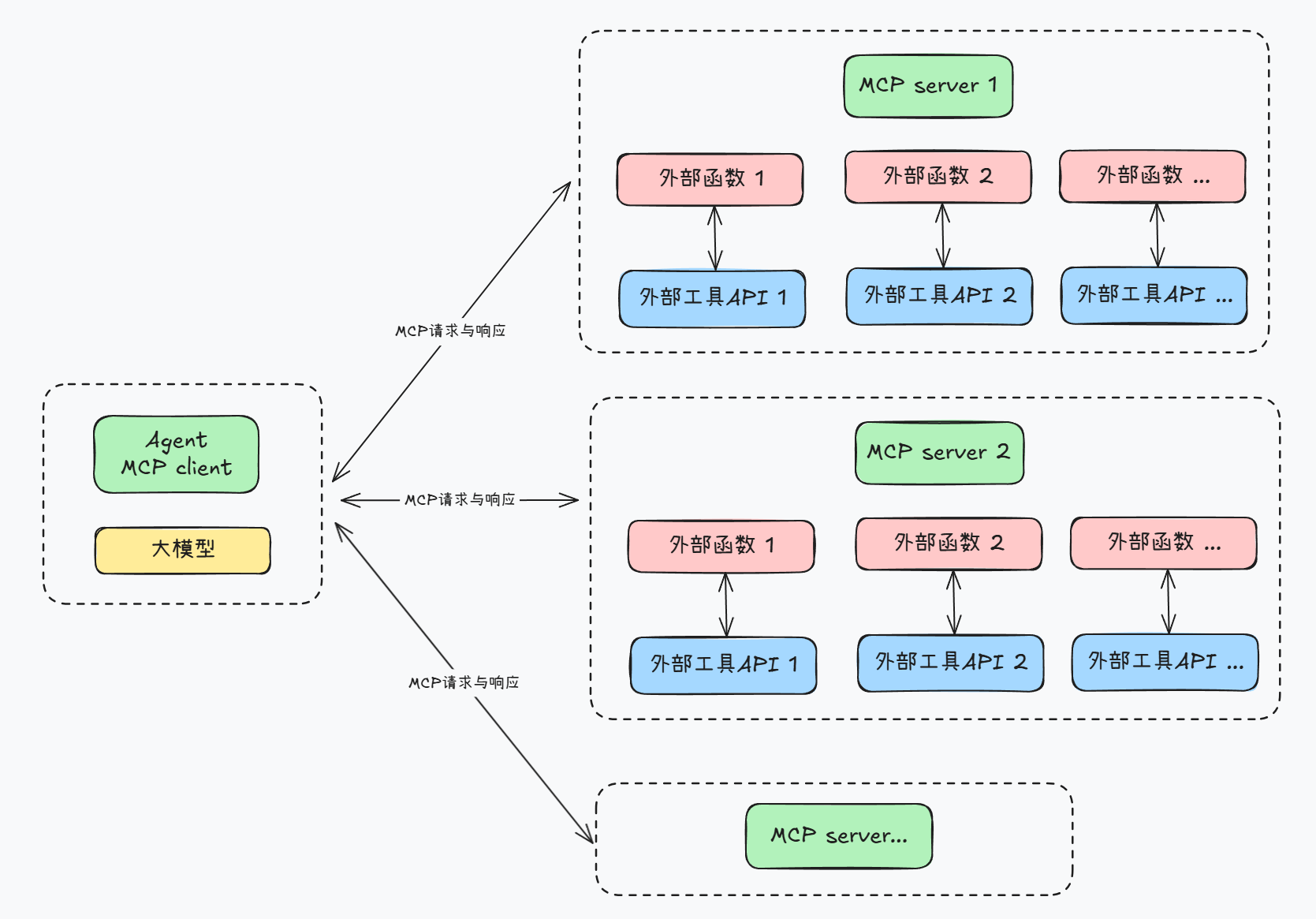
而Agents SDK本身也是可以作为MCP Client的,因此是完全可以连接多个MCP server,其基本实现函数如下:
async def mcp_run_multi(servers_params, message):
# 使用 AsyncExitStack 自动管理多个上下文退出
async with AsyncExitStack() as stack:
servers = []
# 创建并进入所有 server 上下文
for p in servers_params:
server = MCPServerStdio(
name=p.get("name", "Unnamed Server"),
cache_tools_list=True,
params={
"command": "uv",
"args": ["run", p["script"]],
},
)
entered_server = await stack.enter_async_context(server)
servers.append(entered_server)
# 构造 agent,传入多个 server
agent = Agent(
name="Assistant",
instructions="你是一名助人为乐的助手",
mcp_servers=servers,
model_settings=ModelSettings(tool_choice="required"),
model=deepseek_model
)
print(f"Running: {message}")
result = await Runner.run(starting_agent=agent, input=message)
print(result.final_output)
return result
这里我们尝试创建一个“写入本地文档”的MCP服务器:weather_server.py,代码如下:
FENCE0
并将其放在Jupyter主目录下:
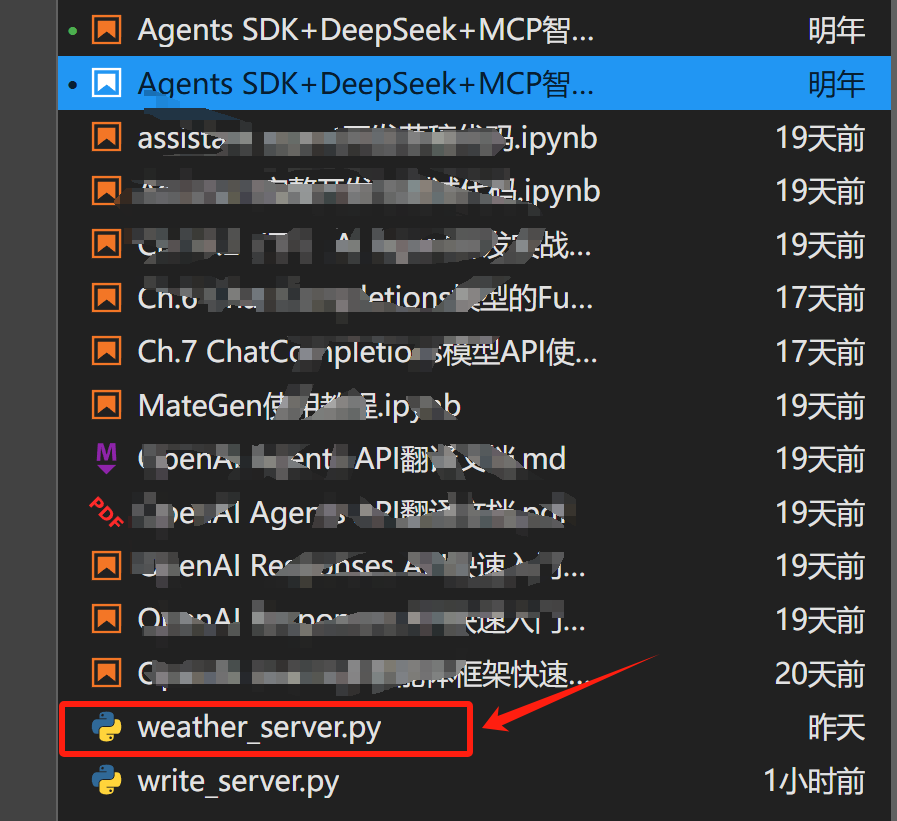
然后尝试同时调用多个server,结果如下:
# 示例调用:传入多个 server 的配置
result = await mcp_run_multi(
servers_params=[
{"name": "Weather Server", "script": "weather_server.py"},
{"name": "Writer Server", "script": "write_server.py"}
],
message="请帮我查询北京天气,并写入本地文档。"
)
len(result.new_items)
result.new_items[0].raw_item
result.new_items[1].raw_item
result.new_items[2].raw_item
result.new_items[3].raw_item
result.new_items[4].raw_item
result.to_input_list()
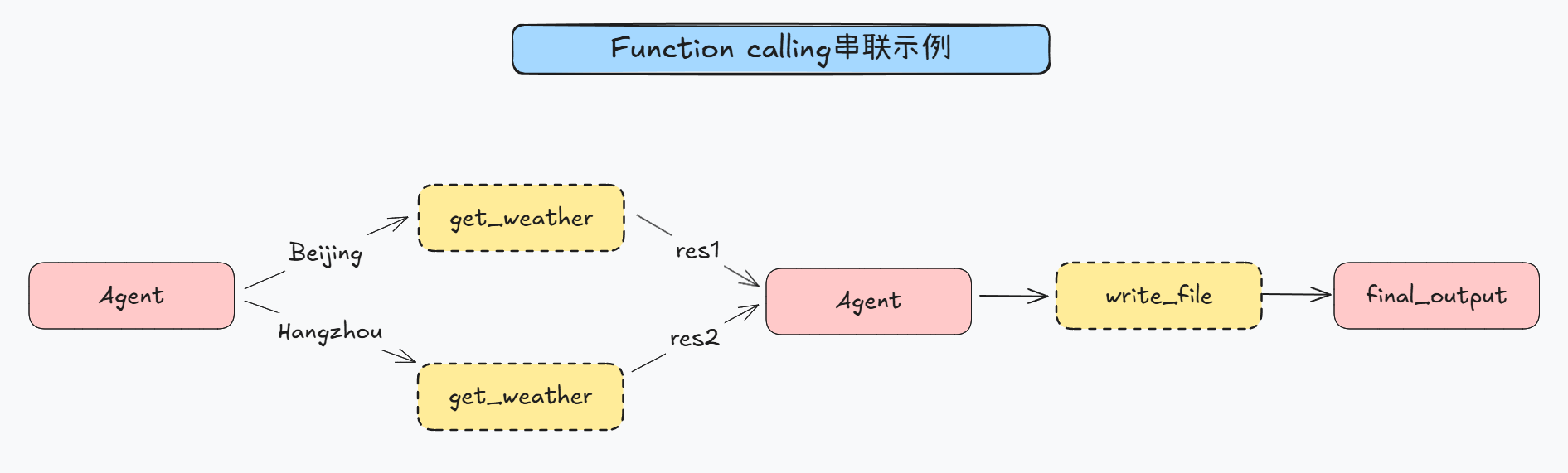
不难看出,Agents SDK对于MCP实现过程基本遵照Function calling来执行。
# 示例调用:传入多个 server 的配置
result = await mcp_run_multi(
servers_params=[
{"name": "Weather Server", "script": "weather_server.py"},
{"name": "Writer Server", "script": "write_server.py"}
],
message="请帮我查询北京和杭州天气,并写入本地文档。"
)
len(result.new_items)
result.to_input_list()
整体实现流程和上一小节介绍的Agents SDK Function calling执行流程完全一致:
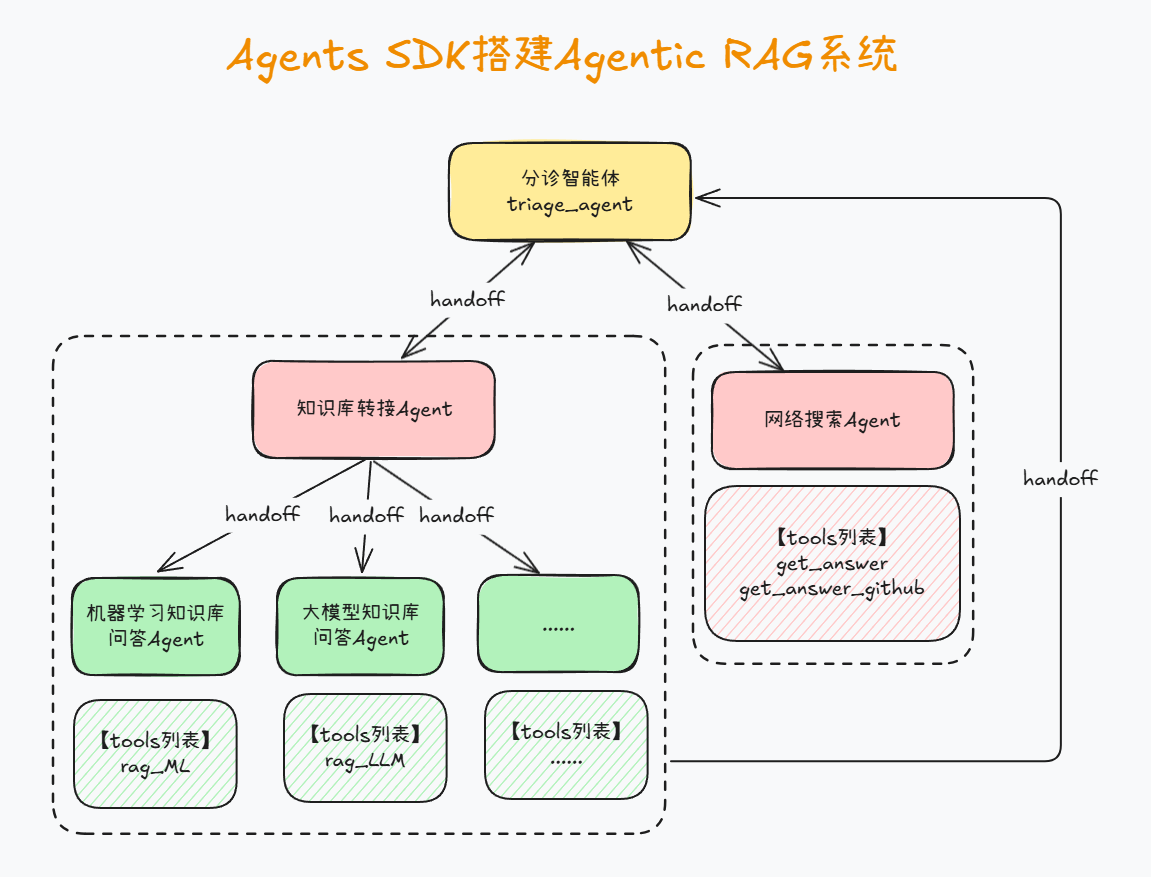
三、Agents SDK搭建Agentic RAG(1):GraphRAG API调用与外部函数封装
1.GraphRAG安装与项目创建
- Step 1.使用pip安装graphrag
FENCE0
Jupyter中可以使用如下方式进行安装:
pip install graphrag
需要注意的是,本次公开课采用GraphRAG最新版 2.1.0进行教学
pip show graphrag
最新版GraphRAG特性如下:
- 架构升级与知识图谱构建优化
-
智能化的知识图谱构建
GraphRAG 2.0 在数据预处理阶段,通过大模型自动抽取文本中的实体及关系,构建出层次化的知识图谱。相比传统的简单文本片段检索,构建后的图谱能够以“社区”(topic-based clusters)的方式对数据进行组织,这样不仅可以覆盖全局信息,也能针对局部查询给出更精准的答案。 -
动态社区选择机制
新版本引入了动态社区选择流程。系统会在生成响应之前,对知识图谱中不同“社区”的相关性进行评估,从而仅保留与当前查询最匹配的部分。这种机制能有效“丢弃”噪声数据,提高检索效率和答案的准确性。
- 查询流程与成本优化
-
两阶段查询流程
GraphRAG 2.0 将整个流程拆分为“索引阶段”和“查询阶段”:- 在索引阶段,系统利用大模型对原始数据进行结构化处理,提取实体及其关系,构建分层知识图谱;
- 在查询阶段,则先进行初步的相关性测试,再利用经过动态社区筛选的信息来生成上下文丰富、精准的回答。
这种分步处理不仅提高了检索的广度和深度,还能根据查询需求灵活调用大模型。
-
Token消耗大幅降低
为了应对大规模数据调用时高昂的成本,GraphRAG 2.0 对 LLM 的调用做了优化。据报道,在某些场景下整体 Token 消耗降低高达 77%,这使得系统在保证高质量回答的同时,也大幅提升了成本效率。 -
LazyGraphRAG 模式
新版本还推出了“LazyGraphRAG”模式——一种结合了向量检索和图结构检索优势的方案。该模式采用迭代深化的方式,只有在必要时才调用资源密集型的大模型进行深度分析,从而实现了与传统 GraphRAG 相比成本更低但效果相当的目标。
- 搜索结果质量与应用扩展
-
精准且上下文丰富的答案
利用层次化的知识图谱和动态社区筛选,GraphRAG 2.0 能够生成更具有可解释性和上下文关联的答案。无论是全局性问题(例如“核心主题是什么?”)还是局部性查询(如“谁、何时、何地”等),系统都能根据不同场景调整检索策略,返回最相关的信息。 -
多系统和多场景集成
此外,新版本在设计上也更注重与其它系统的集成能力,例如在数字营销场景中,通过与 URL 缩短服务、链接分析等工具相结合,为用户提供定制化且综合的查询反馈。 -
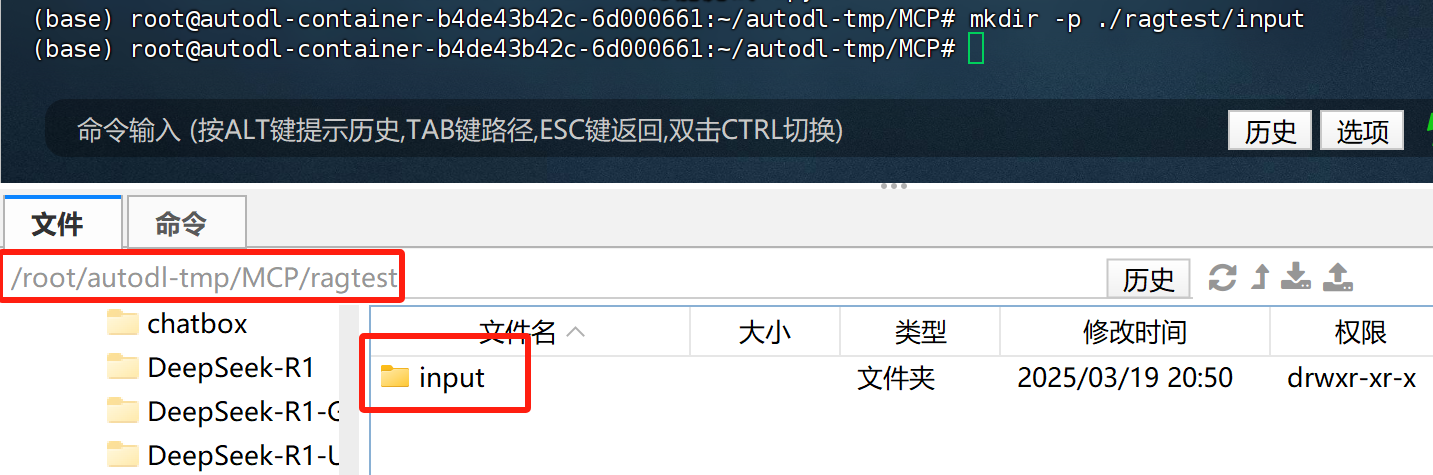
Step 2.创建检索项目文件夹
FENCE0
- Step 3.上传数据集
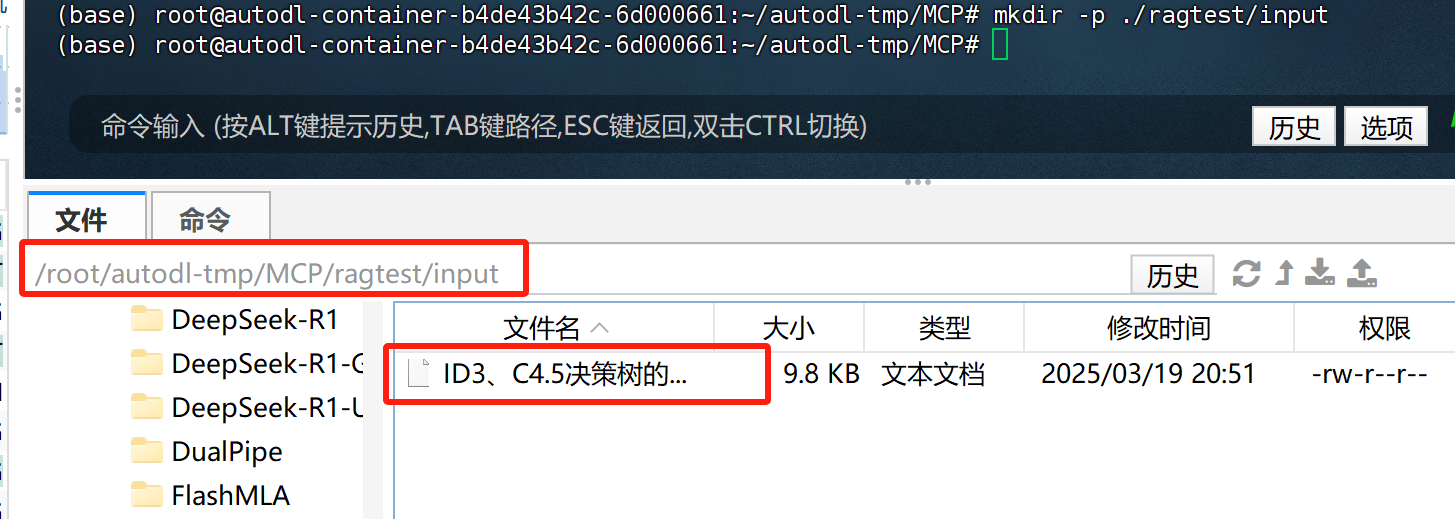

此外,目前GraphRAG只支持txt和csv两种文本格式,付费课程2025大模型Agent智能体开发实战》(春季班)https://whakv.xetslk.com/s/pxKHG 中会详细介绍如何修改源码,拓展支持文件类型。
- Step 4.初始化项目文件
FENCE0
!graphrag init --root ./ragtest
- Step 5.修改项目配置
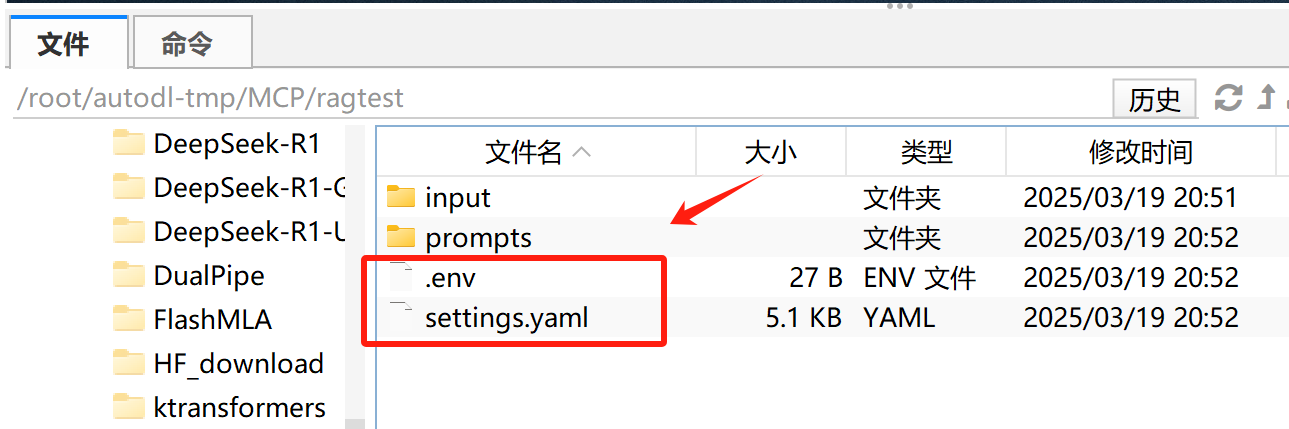
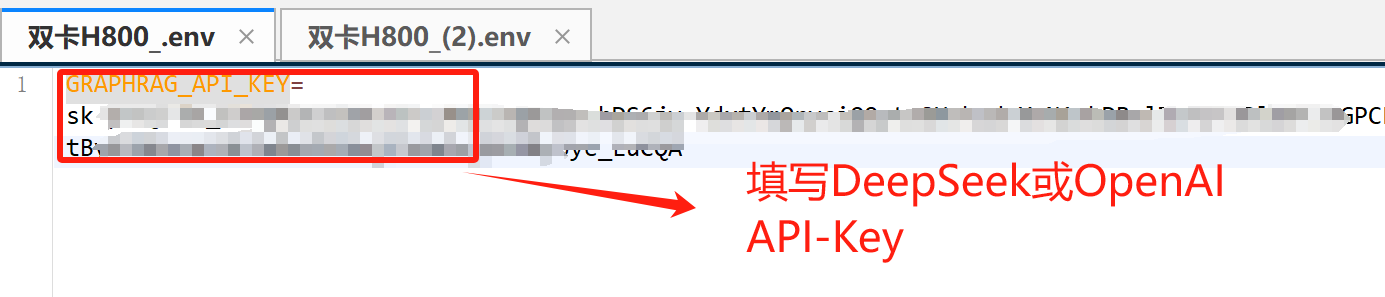
打开.env文件,填写DeepSeek API-KEY或OpenAI API-Key
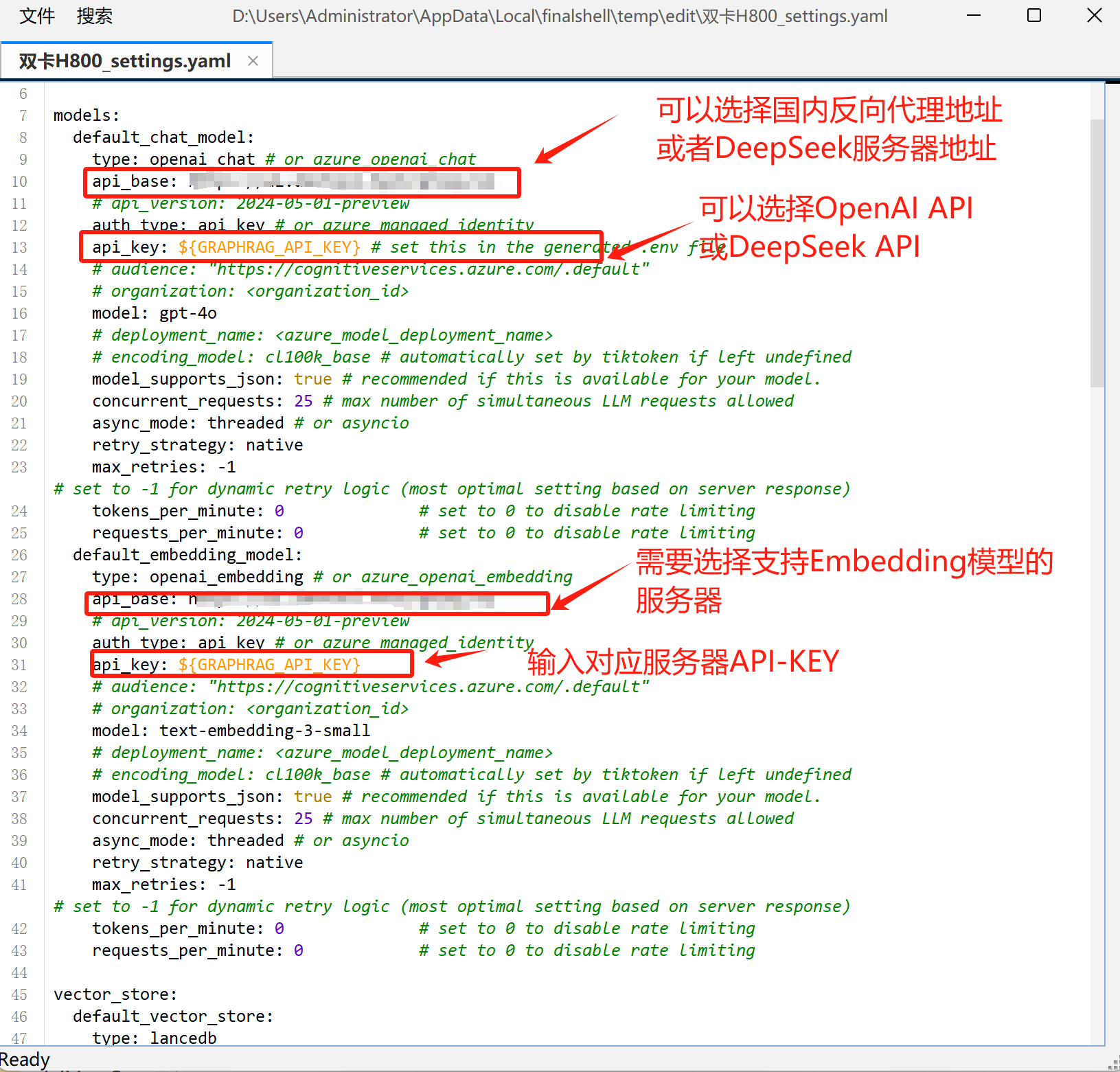
打开setting.yaml文件,填写模型名称和反向代理地址:
- 【可选】Step 6.验证API-KEY和反向代理地址是否可以正常运行
from openai import OpenAI
api_key = 'your-openai-api-key'
# 实例化客户端
client = OpenAI(api_key=api_key,
base_url="反向代理地址")
# 调用 GPT-4o-mini 模型
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "你好,好久不见!"}
]
)
# 输出生成的响应内容
print(response.choices[0].message.content)
然后查看当前API-KEY可以调用的模型:
models_list = client.models.list()
models_list.data
2.GraphRAG索引Indexing过程执行
一切准备就绪后,即可开始执行GraphRAG索引过程。
- Step 7.借助GraphRAG脚本自动执行indexing
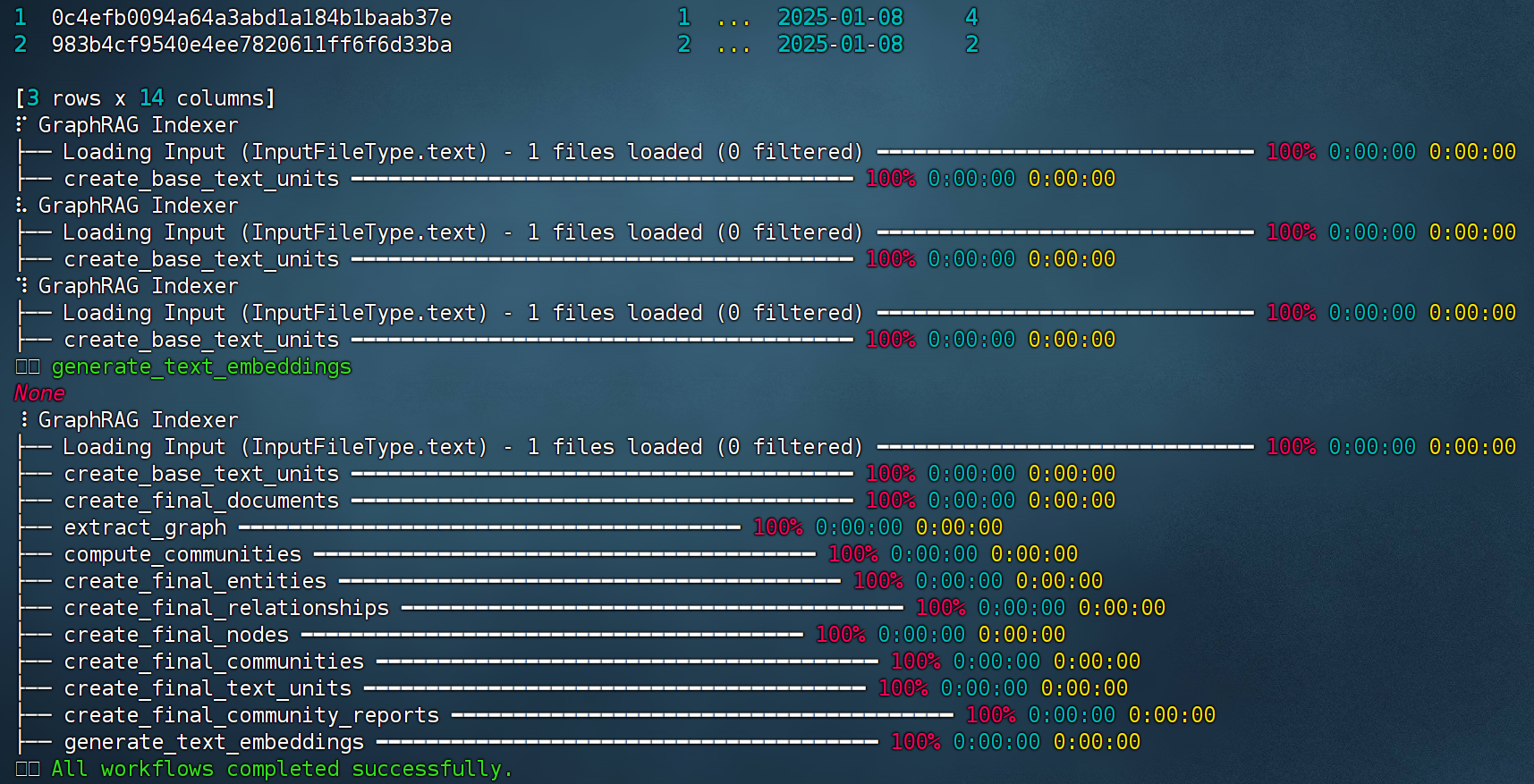
!graphrag index --root ./ragtest
该命令也可以在终端内运行,结果如图:
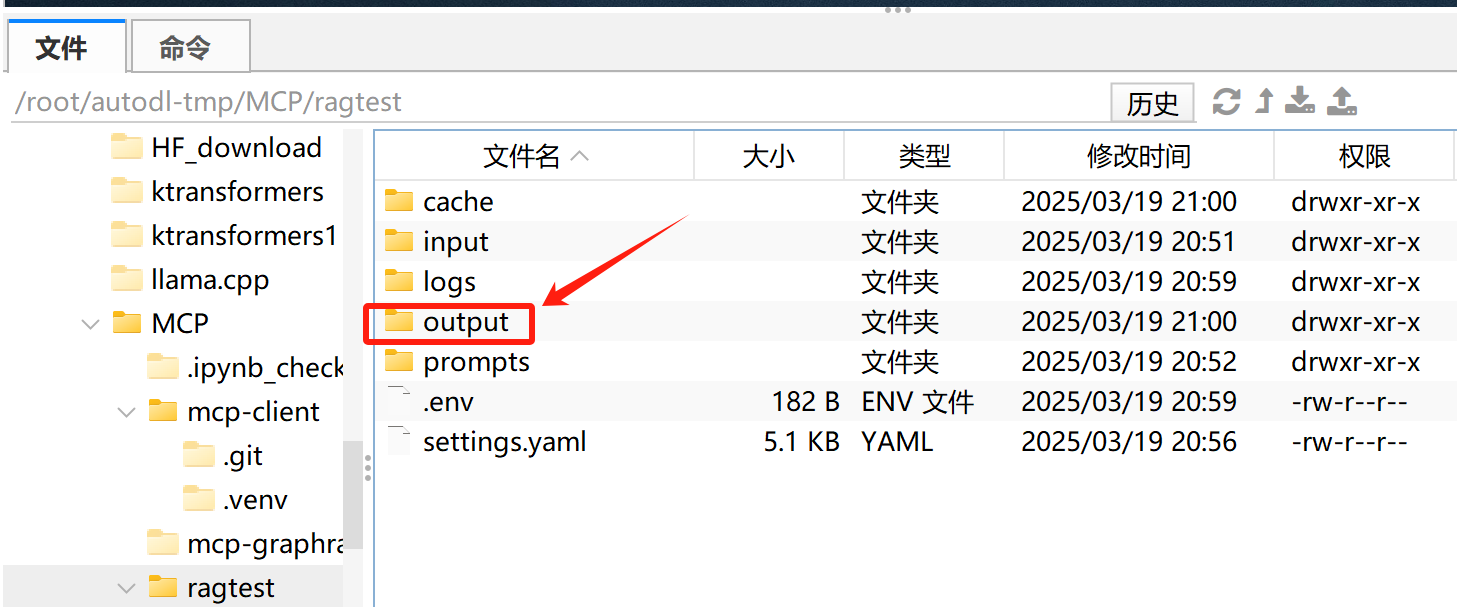
运行结束后,各知识图谱相关数据集都保存在output文件夹中:
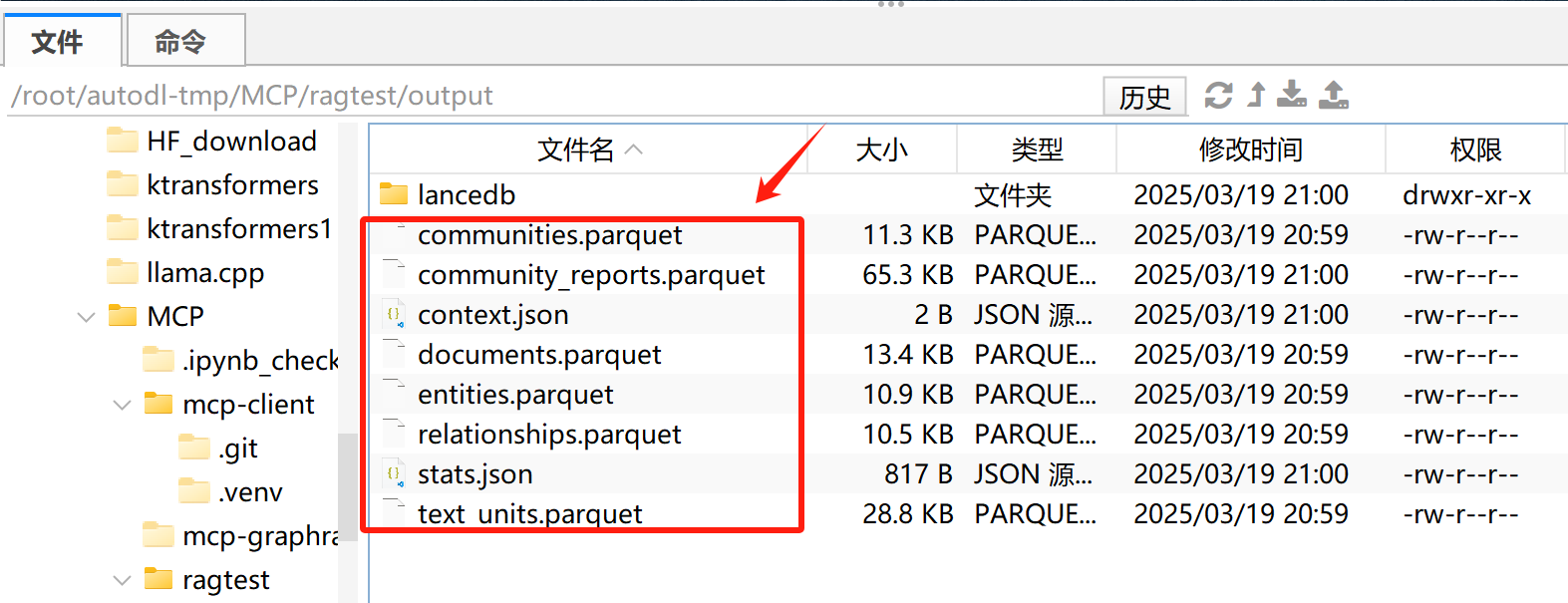
更多数据集介绍,详见:【6小时最强合集】GraphRAG从原理到实战技术精讲:https://www.bilibili.com/video/BV1uCifYLEQd/
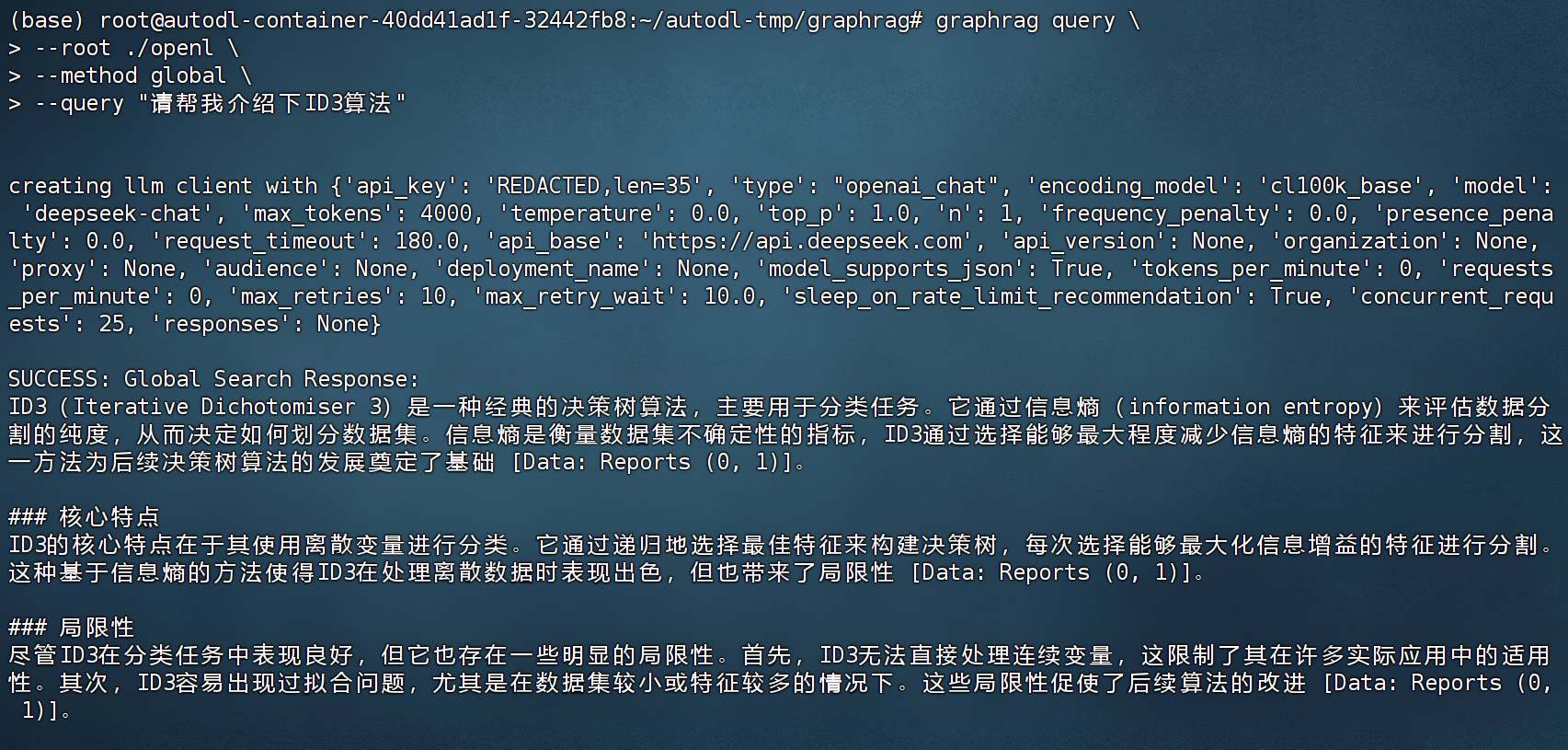
!graphrag query --root ./ragtest --method local --query "请帮我介绍下ID3算法"
Jupyter中可以直接输入如下内容进行Query:
!graphrag query --root ./ragtest --method local --query "请帮我介绍下ID3算法,请用中文回答。"
3.GraphRAG API 初始化项目
from pathlib import Path
from pprint import pprint
import pandas as pd
import graphrag.api as api
from graphrag.config.load_config import load_config
from graphrag.index.typing.pipeline_run_result import PipelineRunResult
FENCE0
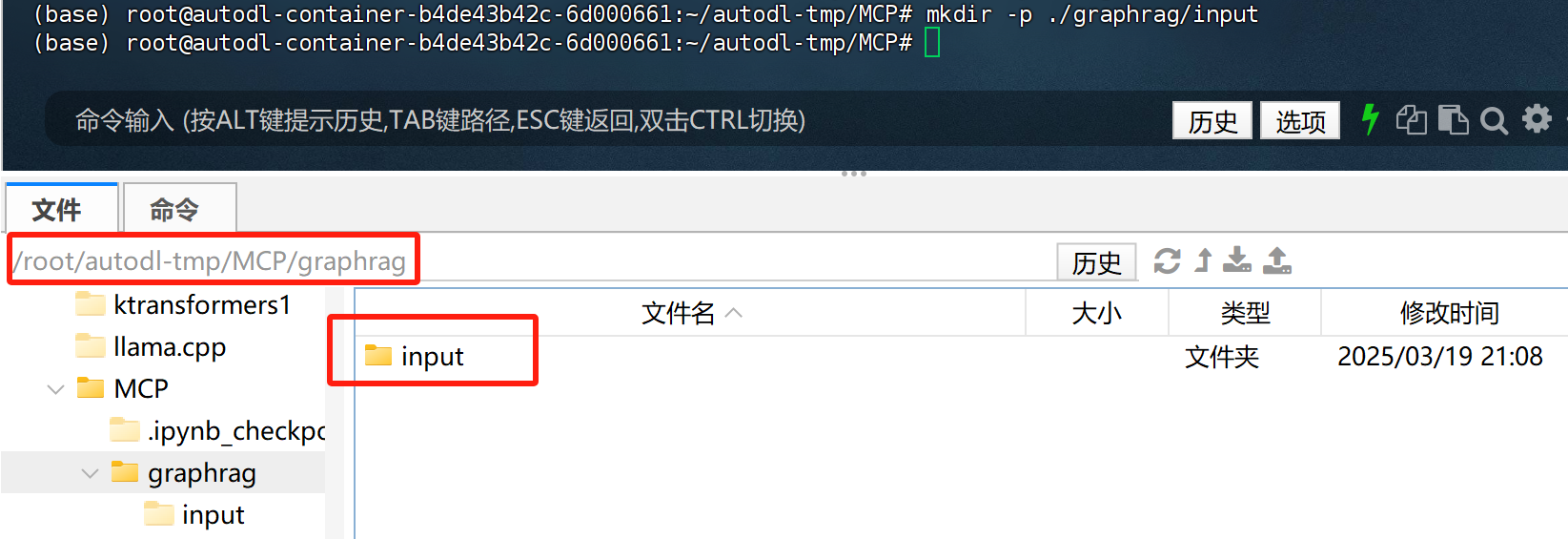
然后进行初始化
!graphrag init --root ./MLRAG
并修改配置文件(同上一部分)。
4.借助API进行Indexing过程
PROJECT_DIRECTORY = "./MLRAG"
生成 GraphRagConfig 对象
graphrag_config = load_config(Path(PROJECT_DIRECTORY))
索引 API
索引是指摄取原始文本数据并构建知识图谱的过程。GraphRAG 目前支持纯文本(.txt)和 .csv 文件格式。
构建索引
index_result: list[PipelineRunResult] = await api.build_index(config=graphrag_config)
index_result 是一个包含索引流水线各个工作流的列表,每个工作流代表一次索引构建过程。
for workflow_result in index_result:
status = f"error\n{workflow_result.errors}" if workflow_result.errors else "success"
print(f"Workflow Name: {workflow_result.workflow}\tStatus: {status}")
在此循环中,遍历 index_result 列表,并打印每个工作流的名称及其执行状态。如果工作流中存在错误,则输出错误信息,否则输出 "success"。
5.借助API进行Query过程
查询索引
在查询索引之前,必须先将多个索引文件加载到内存中,并传递给查询 API。
entities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/entities.parquet")
communities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/communities.parquet")
community_reports = pd.read_parquet(
f"{PROJECT_DIRECTORY}/output/community_reports.parquet"
)
上述代码读取 .parquet 格式的索引数据,包括 实体(entities)、社群(communities) 以及 社群报告(community_reports)。
执行全局搜索
query = "请帮我对比下ID3和C4.5决策树算法优劣势。并用中文进行回答。"
response, context = await api.global_search(
config=graphrag_config,
entities=entities,
communities=communities,
community_reports=community_reports,
community_level=2,
dynamic_community_selection=False,
response_type="Multiple Paragraphs",
query=query,
)
在这里,我们调用 global_search 方法,使用已加载的索引数据进行查询。
community_level=2:设定社群层级为 2 级。dynamic_community_selection=False:禁用动态社群选择。response_type="Multiple Paragraphs":设置返回的查询结果为多段落格式。query=query:查询问题为 "请帮我对比下ID3和C4.5决策树算法优劣势。并用中文进行回答。"。
解析查询结果
print(response)
response 变量是 GraphRAG 返回的正式查询结果。
pprint(context)
context 变量包含关于查询过程的详细元数据,包括:
- 查询过程中检索到的数据信息
- 被用于构建上下文的文本片段
- 其他元数据
深入分析 context 对象可以获取更精细的信息,比如LLM 模型最终使用的文本数据来源。
6.封装函数完成GraphRAG Query
@function_tool
async def rag_ML(query: str) -> str:
"""
输入ID3和C4.5决策树相关问题,可以获得精准答案。
:param query: 机器学习领域ID3和C4.5决策树的相关问题
:return: query问题对应的答案
"""
PROJECT_DIRECTORY = "./MLRAG"
graphrag_config = load_config(Path(PROJECT_DIRECTORY))
# 加载实体
entities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/entities.parquet")
# 加载社区
communities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/communities.parquet")
# 加载社区报告
community_reports = pd.read_parquet(
f"{PROJECT_DIRECTORY}/output/community_reports.parquet"
)
# 进行全局搜索
response, context = await api.global_search(
config=graphrag_config,
entities=entities,
communities=communities,
community_reports=community_reports,
community_level=2,
dynamic_community_selection=False,
response_type="Multiple Paragraphs",
query=query,
)
return response
query = '请帮我对比下ID3和C4.5决策树算法优劣势。并用中文进行回答。'
await rag_ML(query)
query
rag_ML(query)
- 机器学习知识检索智能体
RAG_agent = Agent(
name="机器学习知识库问答智能体",
instructions="可以通过调用rag_ML工具,进行机器学习ID3、C4.5等知识点高精度检索",
tools=[rag_ML],
model=deepseek_model
)
RAG_result = await Runner.run(RAG_agent, "请问ID3的建模流程是什么?")
RAG_result.final_output
四、Agents SDK搭建Agentic RAG(2):联网+知识检索功能实现
- 读取全部所需变量
同时,需要在当前项目文件夹内创建一个.env文件,并写入如下变量:
.env文件需要写入如下内容:
- BASE_URL:大模型请求端口;
- MODEL:大模型名称;
- API_KEY:大模型API-Key
- GITHUB_TOKEN:GitHub Token,若使用GitHub搜索,则需要设置;
- GOOGLE_SEARCH_API_KEY:谷歌搜索API-KEY;
- CSE_ID:谷歌搜索可编程引擎ID;
- search_cookie:网络爬虫所需本机cookie,需要注意的是,爬虫cookie失效很快,快的话几个小时就会失效,因此需要经常更新
- search_ueser_agent:爬虫所需本机信息;
- search_with_broswer:爬取网络信息时是否打开浏览器。
样例文件如下:
网盘下载地址,实际使用时将文件名改为.env,并填入对应变量名称即可:
- 搜索测试
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:10080'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:10080'
# 谷歌搜索服务器
google_search_key = os.getenv("GOOGLE_SEARCH_API_KEY")
cse_id = os.getenv("CSE_ID")
search_cookie = os.getenv("search_cookie")
search_ueser_agent = os.getenv("search_ueser_agent")
def google_search(query, num_results=10, site_url=None):
api_key = os.getenv("GOOGLE_SEARCH_API_KEY")
cse_id = os.getenv("CSE_ID")
url = "https://www.googleapis.com/customsearch/v1"
# API 请求参数
if site_url == None:
params = {
'q': query,
'key': api_key,
'cx': cse_id,
'num': num_results
}
else:
params = {
'q': query,
'key': api_key,
'cx': cse_id,
'num': num_results,
'siteSearch': site_url
}
# 发送请求
response = requests.get(url, params=params)
response.raise_for_status()
# 解析响应
search_results = response.json().get('items', [])
# 提取所需信息
results = [{
'title': item['title'],
'link': item['link'],
'snippet': item['snippet']
} for item in search_results]
return results
results = google_search(query="什么是MCP", num_results=5, site_url='https://www.zhihu.com/')
results
def windows_compatible_name(s, max_length=255):
"""
将字符串转化为符合Windows文件/文件夹命名规范的名称。
参数:
- s (str): 输入的字符串。
- max_length (int): 输出字符串的最大长度,默认为255。
返回:
- str: 一个可以安全用作Windows文件/文件夹名称的字符串。
"""
# Windows文件/文件夹名称中不允许的字符列表
forbidden_chars = ['<', '>', ':', '"', '/', '\\', '|', '?', '*']
# 使用下划线替换不允许的字符
for char in forbidden_chars:
s = s.replace(char, '_')
# 删除尾部的空格或点
s = s.rstrip(' .')
# 检查是否存在以下不允许被用于文档名称的关键词,如果有的话则替换为下划线
reserved_names = ["CON", "PRN", "AUX", "NUL", "COM1", "COM2", "COM3", "COM4", "COM5", "COM6", "COM7", "COM8", "COM9",
"LPT1", "LPT2", "LPT3", "LPT4", "LPT5", "LPT6", "LPT7", "LPT8", "LPT9"]
if s.upper() in reserved_names:
s += '_'
# 如果字符串过长,进行截断
if len(s) > max_length:
s = s[:max_length]
return s
def get_search_text(q, url):
cookie = os.getenv('search_cookie')
user_agent = os.getenv('search_ueser_agent')
code_ = False
headers = {
'authority': 'www.zhihu.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'max-age=0',
'cookie': cookie,
'upgrade-insecure-requests': '1',
'user-agent':user_agent,
}
# 普通问答地址
if 'zhihu.com/question' in url:
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
title = res_xpath.xpath('//div/div[1]/div/h1/text()')[0]
text_d = res_xpath.xpath('//div/div/div/div[2]/div/div[2]/div/div/div[2]/span[1]/div/div/span/p/text()')
# 专栏地址
elif 'zhuanlan' in url:
headers['authority'] = 'zhaunlan.zhihu.com'
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
title = res_xpath.xpath('//div[1]/div/main/div/article/header/h1/text()')[0]
text_d = res_xpath.xpath('//div/main/div/article/div[1]/div/div/div/p/text()')
code_ = res_xpath.xpath('//div/main/div/article/div[1]/div/div/div//pre/code/text()')
# 特定回答的问答网址
elif 'answer' in url:
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
title = res_xpath.xpath('//div/div[1]/div/h1/text()')[0]
text_d = res_xpath.xpath('//div[1]/div/div[3]/div/div/div/div[2]/span[1]/div/div/span/p/text()')
if title == None:
return None
else:
title = windows_compatible_name(title)
# 创建问题答案正文
text = ''
for t in text_d:
txt = str(t).replace('\n', ' ')
text += txt
# 如果有code,则将code追加到正文的追后面
if code_:
for c in code_:
co = str(c).replace('\n', ' ')
text += co
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
json_data = [
{
"link": url,
"title": title,
"content": text,
"tokens": len(encoding.encode(text))
}
]
# 自动创建目录,如果不存在的话
dir_path = f'./auto_search/{q}'
os.makedirs(dir_path, exist_ok=True)
with open('./auto_search/%s/%s.json' % (q, title), 'w') as f:
json.dump(json_data, f)
return title
url = 'https://www.zhihu.com/question/7762420288'
q = "什么是MCP"
get_search_text(q, url)
def get_search_result(q):
"""
当你无法回答某个问题时,调用该函数,能够获得答案
:param q: 必选参数,询问的问题,字符串类型对象
:return:某问题的答案,以字符串形式呈现
"""
# 默认搜索返回5个答案
results = google_search(query=q, num_results=5, site_url='https://zhihu.com/')
# 创建对应问题的子文件夹
folder_path = './auto_search/%s' % q
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 单独提取links放在一个list中
num_tokens = 0
content = ''
for item in results:
url = item['link']
title = get_search_text(q, url)
with open('./auto_search/%s/%s.json' % (q, title), 'r') as f:
jd = json.load(f)
num_tokens += jd[0]['tokens']
if num_tokens <= 12000:
# print(jd[0]['content'])
content += jd[0]['content']
else:
break
return(content)
get_search_result(q)
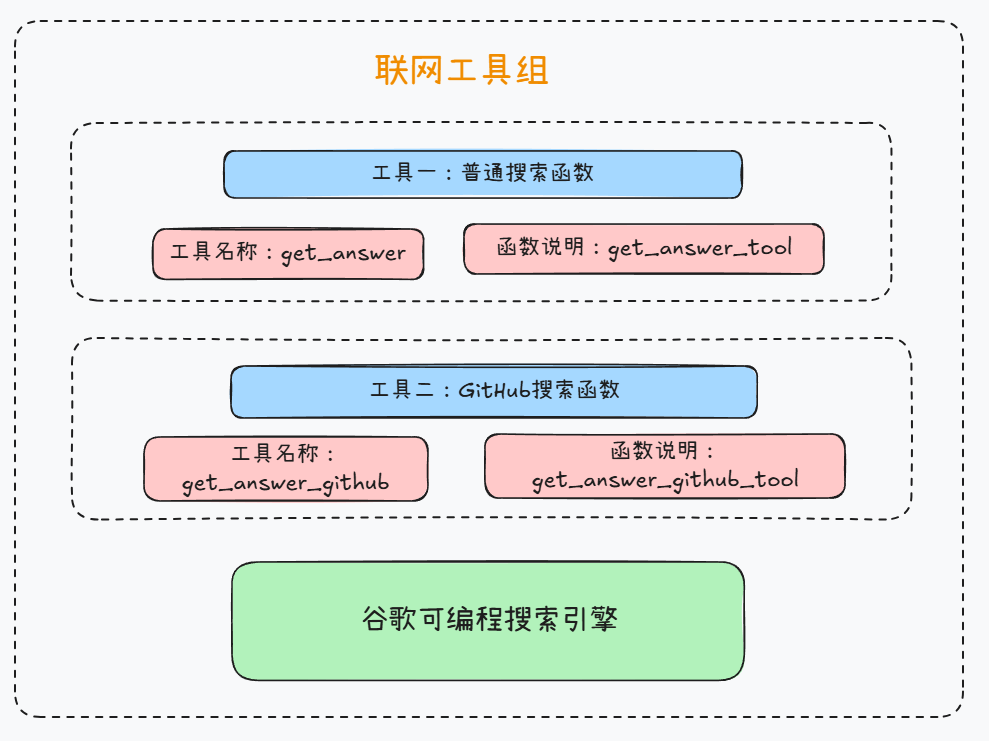
综上,联网搜索外部函数和GitHub搜索外部函数如下:
- 联网搜索外部函数
@function_tool
def get_answer(q):
"""
联网搜索函数,当用户提出的问题超出你的知识库范畴时,可以利用该函数在知乎上进行搜索,并返回相关答案。
:param q: 必选参数,和用户问题相关的知乎搜索的关键词,字符串类型对象
:return:某问题的答案,以字符串形式呈现
"""
# 默认搜索返回5个答案
print('正在接入谷歌搜索,查找和问题相关的答案...')
results = google_search(query=q, num_results=5, site_url='https://zhihu.com/')
# 判断是否需要自动打开浏览器
if os.getenv("search_with_broswer") == '1':
# Edge 浏览器的路径,需要找到你的浏览器地址,假设使用edge浏览器
edge_path = "C:/Program Files (x86)/Microsoft/Edge/Application/msedge.exe"
# 注册 Edge 浏览器
webbrowser.register('edge', None, webbrowser.BackgroundBrowser(edge_path))
# 创建对应问题的子文件夹
folder_path = './auto_search/%s' % q
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 单独提取links放在一个list中
num_tokens = 0
content = ''
for item in results:
url = item['link']
print('正在检索:%s' % url)
# 若打开浏览器,则停留3秒
if os.getenv("search_with_broswer") == '1':
webbrowser.get('edge').open(url)
time.sleep(3)
title = get_search_text(q, url)
with open('./auto_search/%s/%s.json' % (q, title), 'r') as f:
jd = json.load(f)
num_tokens += jd[0]['tokens']
if num_tokens <= 12000:
# print(jd[0]['content'])
content += jd[0]['content']
else:
break
return(content)
这里额外设置一个search_with_broswer参数,用于控制是否在搜索的时候同步打开浏览器,以达到如下效果:
需要注意的是,无搜索的时候是否同步打开浏览器,都对搜索结果没有影响,只是为了增加一个可视化效果。
search_with_broswer设置为1时代表打开浏览器,否则代表不打开浏览器。
get_search_result(q="什么是MCP?")
- 联网检索智能体search_agent创建流程
search_agent = Agent(
name="联网搜索智能体",
instructions="可以执行联网搜索功能,当用户提出的问题超出你的知识范畴时,请先进行搜索,再进行回答。",
tools=[get_answer],
model=deepseek_model
)
search_result = await Runner.run(search_agent, "请问什么是大模型MCP(模型上下文)技术。")
search_result.final_output
- 创建分诊智能体
triage_agent = Agent(
name="Triage Agent",
instructions="""
你是一个知识检索智能体,当用户提问机器学习ID3、C4.5相关问题时,请转交给RAG_result进行处理;
而当用户提出的问题超出你当前知识范畴时,请转交给search_agent进行处理。其他问题请自主进行回答。
""",
handoffs=[RAG_result, search_agent],
model=deepseek_model
)
RAG_agent.handoffs.append(triage_agent)
search_agent.handoffs.append(triage_agent)
- 对话效果测试
from agents import (
Agent,
HandoffOutputItem,
ItemHelpers,
MessageOutputItem,
RunContextWrapper,
Runner,
ToolCallItem,
ToolCallOutputItem,
TResponseInputItem,
function_tool,
handoff,
trace,
)
from agents.extensions.handoff_prompt import RECOMMENDED_PROMPT_PREFIX
async def chat_assistant():
input_items = []
current_agent = triage_agent
while True:
user_input = input("💬 请输入你的消息:")
if user_input.lower() in ["exit", "quit"]:
print("✅ 对话已结束")
break
input_items.append({"content": user_input, "role": "user"})
result = await Runner.run(current_agent, input_items)
for new_item in result.new_items:
agent_name = new_item.agent.name
if isinstance(new_item, MessageOutputItem):
print(f"🧠 {agent_name}: {ItemHelpers.text_message_output(new_item)}")
elif isinstance(new_item, HandoffOutputItem):
print(f"🔀 Handed off from {new_item.source_agent.name} to {new_item.target_agent.name}")
elif isinstance(new_item, ToolCallItem):
print(f"🔧 {agent_name}: Calling a tool...")
elif isinstance(new_item, ToolCallOutputItem):
print(f"📦 {agent_name}: Tool call output: {new_item.output}")
else:
print(f"🤷 {agent_name}: Skipping item: {new_item.__class__.__name__}")
input_items = result.to_input_list()
current_agent = result.last_agent
await chat_assistant()