LangChain 1.1 实现 Claude Skills 动态工具过滤
从原理到实践的完整教学指南
学习目标:
- 理解 Claude Skills 的设计理念和核心价值
- 掌握 LangChain 1.1 Middleware 机制的工作原理
- 实现一个完整的动态工具过滤系统
- 通过实际运行观察工具数量的动态变化
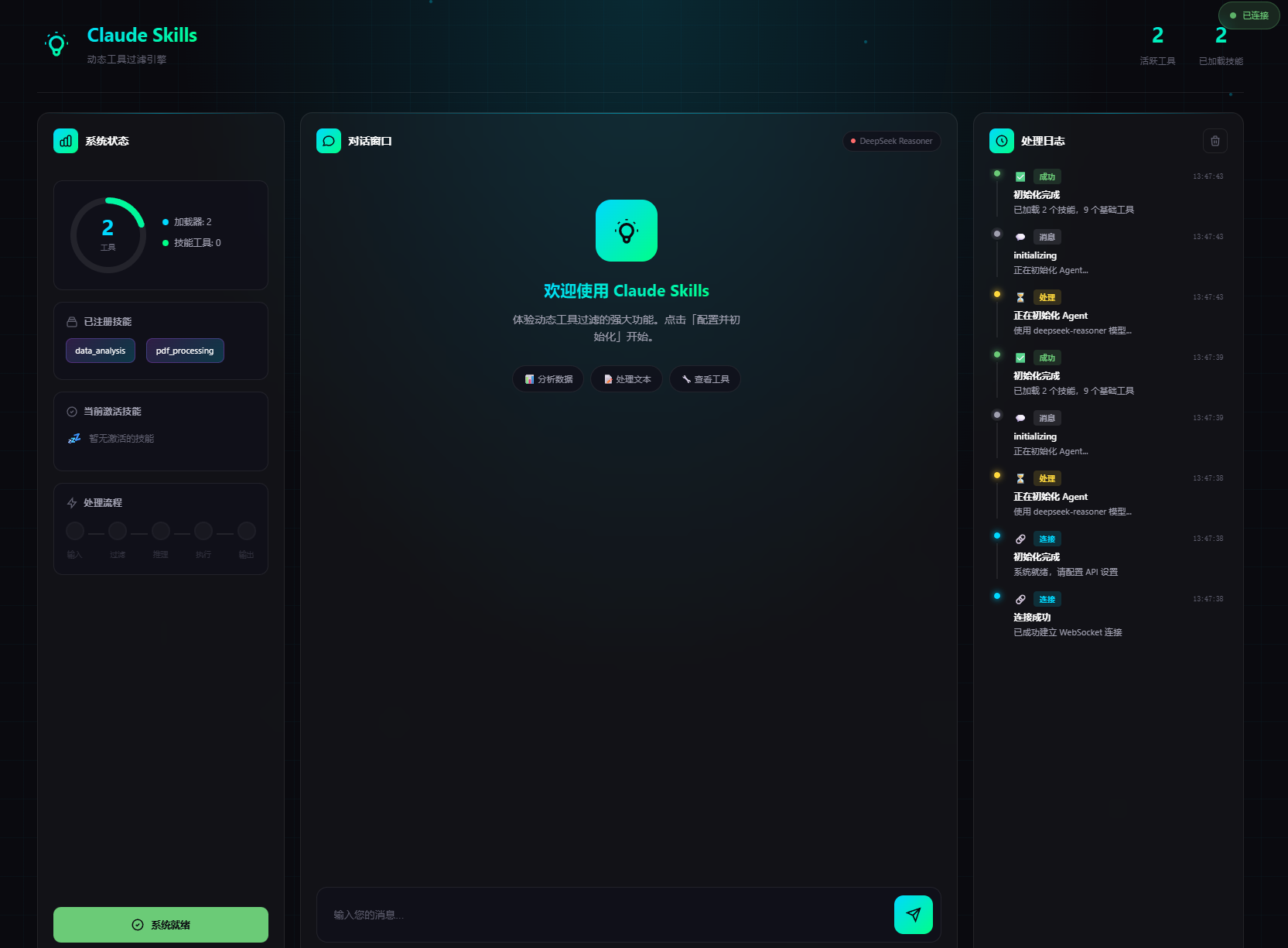
本期课程将带大家从零开始,深入理解并实现 Claude Skills 的核心功能——动态工具过滤。通过学习可以帮助大家深刻理解如何让 AI Agent 在运行时智能地选择需要的工具,而不是一次性加载所有工具。

1. Claude Code Skills 背景介绍
Vibe Coding(氛围编程) 大家应该都听过,那它是怎么发展而来的呢?
第一代 AI 编码工具主要依赖于基于统计的补全技术,随后发展为以 GitHub Copilot 为代表的“中间填充”(Fill-in-the-Middle)预测模型,这些工具本质上是被动的,依赖开发者提供明确的上下文和光标位置。然而,随着模型推理能力的飞跃,特别是 Anthropic Claude 系列模型在长上下文处理和逻辑推理方面的突破,一种新的范式即代理式编程(Agentic Coding)应运而生。
Claude Code 的出现,其不仅仅是一个运行在终端中的 CLI 工具,而是一个具备自主规划与执行能力的智能代理 。与传统的 CLI 工具不同,Claude Code 被设计为能够理解自然语言指令,并将其转化为一系列复杂的系统操作,包括文件编辑、代码运行、Git 版本控制管理以及错误调试 。它遵循 Unix 哲学,具有高度的可组合性(Composable)和可脚本化(Scriptable)特征,能够与其他命令行工具通过管道(Pipe)进行交互 。
Claude Code 的核心竞争力在于其“全栈意识”。它不仅仅关注当前打开的文件,而是能够通过索引和检索机制理解整个代码库的架构、依赖关系以及业务逻辑 。这种能力使得开发者可以从繁琐的语法细节中解脱出来,转向更高层次的架构设计和意图表达,这种工作流在社区中被形象地称为“氛围编程”(Vibe Coding)
from IPython.display import Video
Video("https://muyu20241105.oss-cn-beijing.aliyuncs.com/images/202512111044143.mp4", width=1500, height=400)
在 Claude Code 的架构中,Skill(技能) 扮演着至关重要的角色。如果说 Claude 模型是大脑,MCP 是连接外部世界的手脚,那么 Skill 就是存储特定领域专业知识的操作手册。
虽然 Claude Opus 4.5 拥有广泛的编程知识,但它并不了解某家特定初创公司的内部部署脚本、某种冷门框架的特殊配置,或者某个团队特定的代码审查规范。传统的解决方案是将这些信息全部塞入系统提示词(System Prompt)或上下文窗口中,但这会导致两个问题:一是上下文窗口迅速耗尽,增加了推理成本(Token Economics);二是过多的无关信息会干扰模型的注意力,导致“迷失中间”(Lost in the Middle)现象。
from IPython.display import Video
Video("https://muyu20241105.oss-cn-beijing.aliyuncs.com/images/202512021352519.mp4", width=1500, height=400)
Skill 通过引入动态加载(Dynamic Loading)和渐进式披露(Progressive Disclosure) 机制,优雅地解决了这一难题。它允许开发者将海量的程序性知识(Procedural Knowledge)封装在本地文件系统中,Agent 仅在识别到用户意图与某个 Skill 匹配时,才会按需加载相关的指令和脚本 。这种架构不仅极大地扩展了 Agent 的能力边界,还保证了推理的高效性和准确性。
from IPython.display import Video
Video("https://muyu20241105.oss-cn-beijing.aliyuncs.com/images/202512111128060.mp4", width=1500, height=400)
官方介绍:https://support.claude.com/en/articles/12512176-what-are-skills
2. Claude Skills 给予Agent的启发
- 大模型的工具调用流程
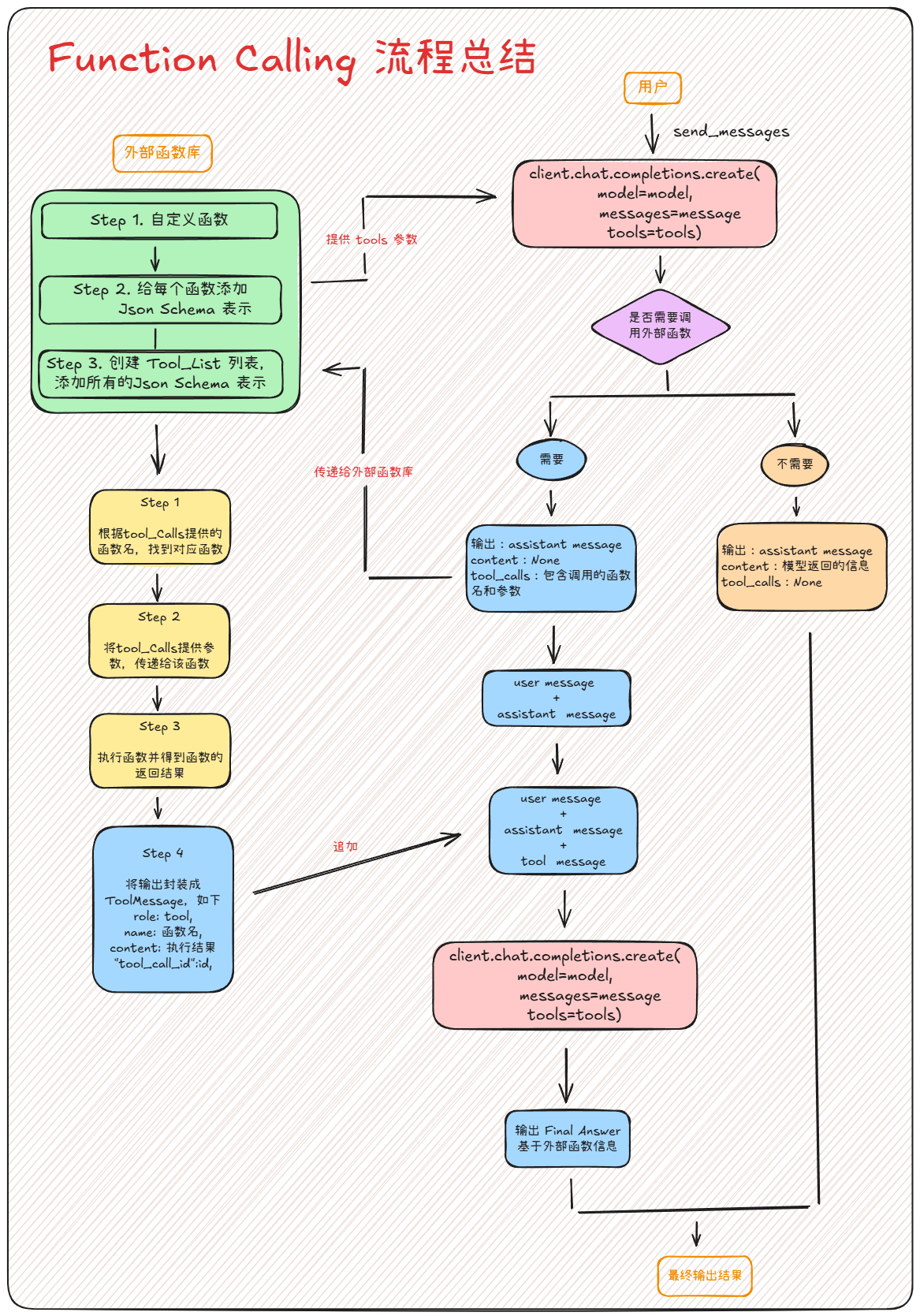
传统的 AI Agent 在处理任务时,会将所有可用的工具(Tools)一次性暴露给大语言模型。想象一下,如果你有 50 个工具,每次模型调用都需要处理这 50 个工具的描述信息,
FENCE0
这会带来几个严重问题:
- Token 消耗巨大:每个工具的描述可能有几百个 token,50 个工具就是上万个 token;
- 大模型困惑:面对过多选择,模型容易选错工具或产生幻觉;
- 响应延迟:处理大量工具描述需要更长时间;
- 成本高昂:API 调用按 token 计费,浪费严重;
Claude Skills 的核心思想是:让模型在每次调用时只看到「相关的」工具,而不是全部工具。这就像一个智能助手,只有当你说"我要分析数据"时,才会把数据分析相关的工具拿出来;说"我要处理 PDF"时,才会展示 PDF 处理工具。
FENCE1
接下来,我们就通过底层技术来复现这个非常高价值的Agent开发模式。
- 为什么选择 LangChain 1.0
LangChain 1.1 版本最大的优势就是在LangGraph之上构建并集成了革命性的 Middleware API。
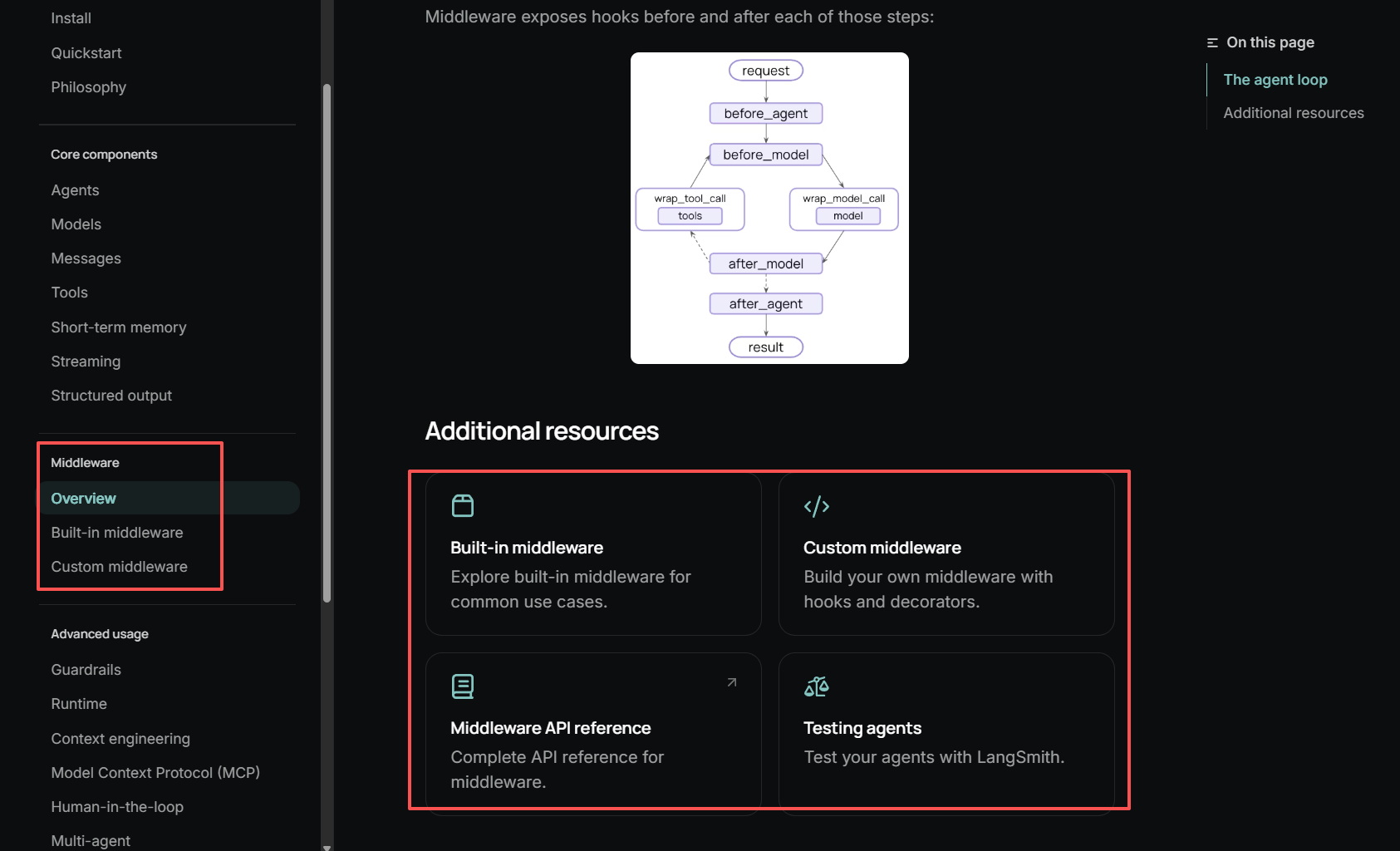
图片来源:https://docs.langchain.com/oss/python/langchain/middleware/overview
这个 Middleware API 允许我们在 Agent 的执行流程中插入自定义逻辑,实现:
- 动态工具过滤:在每次模型调用前修改工具列表
- 状态管理:通过
state_schema追踪运行时状态 - 请求拦截:使用
request.override()修改请求参数
在 LangChain 1.1 之前,实现动态工具过滤需要复杂的 hack,比如重写 Agent 类或修改工具列表。现在,通过官方支持的 Middleware API,我们可以优雅地实现这一功能。
LangChain 版本对比
| 特性 | LangChain 0.x | LangChain 1.0 |
|---|---|---|
| 工具过滤 | 需要 hack | 官方 Middleware 支持 |
| 状态管理 | 手动实现 | state_schema 内置 |
| 请求修改 | 不支持 | request.override() |
下面这张图展示了使用LangChain 1.0 复现 Claude Skills 的核心工作流程:
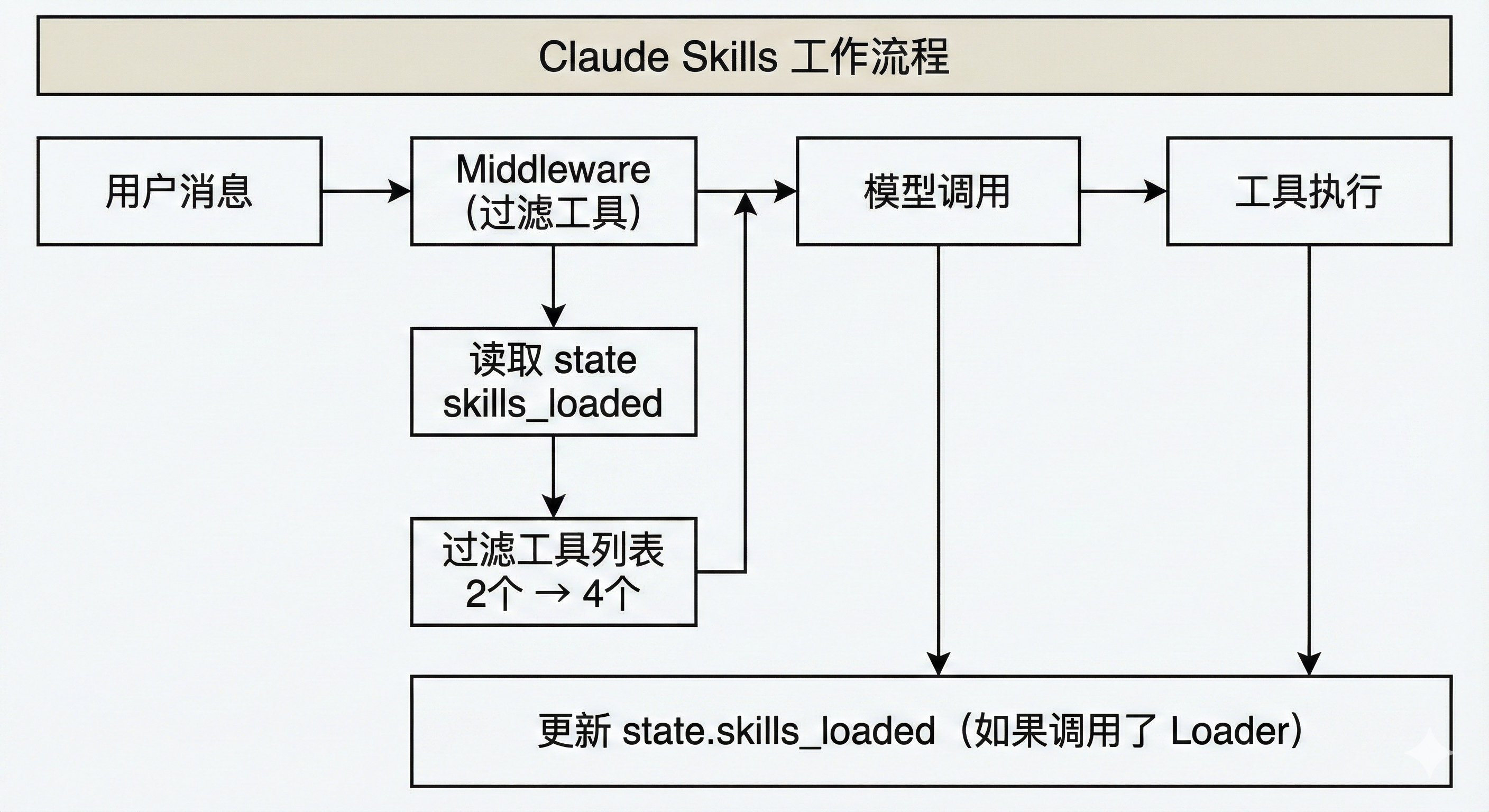
从图中可以看到,Middleware 是整个系统的核心。它在模型调用之前拦截请求,根据当前状态(skills_loaded)动态过滤工具列表,然后将过滤后的请求传递给模型。
3. 从零复现 Claude Skills 动态工具过滤
3.1 LangChain 1.1 本地运行与配置
首先,让我们导入实现 Claude Skills 所需的核心库。这里我们会用到 LangChain 1.0 的几个关键模块:
langchain.agents:提供create_agent和 Middleware 相关类langchain_core.tools:工具定义的基类typing_extensions:用于定义状态 Schema 的 TypedDict
执行如下代码:
%pip install -U langchain langgraph langchain-openai pdfplumber pandas numpy matplotlib python-dotenv
! pip show langchain
# 基础库导入
import os
import sys
from pathlib import Path
from typing import List, Callable, Any, Optional
from typing_extensions import TypedDict
# 加载环境变量
from dotenv import load_dotenv
load_dotenv(override=True)
# LangChain 1.0 核心导入
from langchain.agents import create_agent
from langchain.agents.middleware import (
AgentMiddleware,
ModelRequest,
ModelResponse,
)
from langchain_core.tools import BaseTool, tool
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
print("核心库导入成功")
上面的代码导入了我们需要的所有核心组件。特别注意 langchain.agents.middleware 模块,这是 LangChain 1.0 新增的关键模块,包含了:
AgentMiddleware:中间件基类,我们需要继承它;ModelRequest:封装了模型调用请求的所有信息(消息、工具、状态等);ModelResponse:模型调用的响应;
3.2 配置 DeepSeek-v3.2 模型
在本教程中,我们使用 DeepSeek 的 deepseek-reasoner 模型作为底层 LLM。这个模型的特点是支持「推理过程」输出,可以让我们看到模型的思考过程。
提示:你也可以替换为 OpenAI、Anthropic 或其他兼容 LangChain 的模型。核心的 Middleware 机制是通用的。
这里我们使用的是最新发布的 DeepSeek-v3.2 推理模型。但需要说明的是:因为 DeepSeek-v3.2 模型刚刚发布,其推理模式在langChian 1.0的新版本中存在兼容性问题,在进行工具调用过程中会报错如下:

因此,我们团队也是完全重写了 DeepSeek-v3.2-reasoner 的模型适配器,大家扫码即可领取项目文件:
# 添加项目路径(用于导入自定义模型)
PROJECT_ROOT = Path.cwd()
sys.path.insert(0, str(PROJECT_ROOT))
# 导入自定义的 DeepSeek 模型适配器
from skill_system.models import DeepSeekReasonerChatModel
# 检查 API Key
api_key = os.getenv("DEEPSEEK_API_KEY")
if not api_key:
print("未设置 DEEPSEEK_API_KEY")
print(" 请在 .env 文件中添加: DEEPSEEK_API_KEY=your-key")
else:
print(f"API Key 已配置 (前8位: {api_key[:8]}...)")
# 创建模型实例
model = DeepSeekReasonerChatModel(
api_key=api_key,
model_name="deepseek-reasoner",
temperature=0.7
)
print(f"DeepSeek 模型已创建")
DeepSeekReasonerChatModel 是我们自定义的模型适配器,它继承自 LangChain 的 BaseChatModel,并添加了对 DeepSeek 推理模型的支持。关键特性是它会保留模型返回的 reasoning_content(推理过程),这对于调试和理解模型行为非常有帮助。
3.3 配置LangChain1.1 Middleware
中间件(Middleware)是一个非常常见的设计模式。它允许你在请求处理的过程中插入自定义逻辑,而不需要修改核心代码。
LangChain 1.0 引入的 Agent Middleware 遵循同样的理念:
FENCE0
在 Agent 的上下文中,Middleware 可以:
- 拦截模型调用请求:在模型被调用之前获取请求信息
- 修改请求参数:比如修改工具列表、系统提示等
- 传递给下一个处理器:调用
handler(request)继续执行 - 处理响应:可以在返回之前修改响应(可选)
这正是实现动态工具过滤的关键!我们可以在 Middleware 中检查当前状态,然后只把相关的工具传递给模型。
在LangChain 1.1中AgentMiddleware 基类的结构如下:
FENCE0
wrap_model_call 参数说明
| 参数名 | 类型 | 描述 | 说明 |
|---|---|---|---|
| request | ModelRequest | 模型调用请求 | 包含 messages, tools, state 等 |
| handler | Callable | 下一个处理器 | 调用它来继续执行链 |
| 返回值 | ModelResponse | 模型响应 | handler 执行后的结果 |
ModelRequest 是 Middleware 中最重要的对象,它封装了模型调用的所有信息:
FENCE0
request.override() 是实现动态过滤的核心方法。它允许我们创建一个新的请求对象,其中某些参数被修改了,而其他参数保持不变。例如:
FENCE1
3.4 实现一个简单的日志 Middleware
在实现复杂的工具过滤之前,我们先写一个简单的日志 Middleware,帮助大家理解整个流程:
class LoggingMiddleware(AgentMiddleware):
"""
日志中间件 - 记录每次模型调用的信息
这是一个最简单的 Middleware 示例,用于理解基本工作流程
"""
def __init__(self, name: str = "Logger"):
super().__init__()
self.name = name
self.call_count = 0
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""
拦截模型调用,打印日志信息
"""
self.call_count += 1
# 1. 调用前:记录请求信息
print(f"\n{'='*60}")
print(f"[{self.name}] 第 {self.call_count} 次模型调用")
print(f"{'='*60}")
# 打印工具信息
if hasattr(request, 'tools') and request.tools:
tool_names = [t.name for t in request.tools]
print(f"可用工具 ({len(tool_names)}个): {tool_names}")
# 打印状态信息
if hasattr(request, 'state') and request.state:
print(f"当前状态: {request.state}")
# 2. 调用下一个处理器(这里是实际的模型调用)
response = handler(request)
# 3. 调用后:可以处理响应(这里只是打印)
print(f"模型调用完成")
print(f"{'='*60}\n")
return response
print("LoggingMiddleware 类已定义")
上面的 LoggingMiddleware 展示了 Middleware 的基本结构:
- 继承
AgentMiddleware:这是必须的 - 重写
wrap_model_call:这是核心方法 - 调用
handler(request):必须调用,否则模型不会被执行 - 返回响应:必须返回 handler 的结果
注意:如果你不调用
handler(request),整个 Agent 链条就会中断!
3.5 定义工具与状态 Schema
在 LangChain 1.1 中,State Schema 用于定义 Agent 运行时需要追踪的状态信息。它使用 Python 的 TypedDict 来定义,提供类型安全和清晰的结构。
对于 Claude Skills,我们需要追踪一个关键状态:skills_loaded - 当前已加载的技能列表。这个状态会被 Middleware 读取,用于决定哪些工具应该暴露给模型。
# # 使用 MessagesState 而不是 TypedDict
from langgraph.graph import MessagesState
from typing import Annotated, List
# 第一种模式:替换模式
# # 定义 reducer 函数
# def skill_list_reducer(current: List[str], new: List[str]) -> List[str]:
# """替换模式:用新列表替换旧列表"""
# return new
# # 使用 MessagesState 作为基类
# class SkillState(MessagesState):
# """
# Skill 状态 Schema
# 使用 MessagesState 作为基类,它已经包含了 messages 字段
# 我们只需要添加 skills_loaded 字段
# """
# skills_loaded: Annotated[List[str], skill_list_reducer] = []
# 第二种模式:累计模式
# 修改 reducer 函数为累积模式
def skill_list_accumulator(current: List[str], new: List[str]) -> List[str]:
"""
累积模式:合并已加载的 Skills
保持所有已加载的技能,而不是替换
"""
if not current:
return new
# 合并并去重,保持顺序
combined = current + [s for s in new if s not in current]
return combined
# 使用累积模式的 reducer
class SkillState(MessagesState):
"""
Skill 状态 Schema
"""
skills_loaded: Annotated[List[str], skill_list_accumulator] = [] # 改为累积模式
SkillState 定义了两个关键字段:
messages:消息历史,这是 LangChain Agent 的标准字段,用于存储对话历史;skills_loaded:已加载的技能列表,这是我们自定义的字段,用于追踪当前激活的技能;
重要:TypedDict 在运行时本质上就是一个普通的
dict,所以在 Middleware 中我们使用request.state.get("skills_loaded", [])来访问它。
3.6 定义外部工具
现在,我们需要定义一组示例工具来实际展示动态过滤流程。我们会创建三类工具:
- Loader 工具(始终可见):用于加载技能;
- 数据分析工具:只有加载了
data_analysis技能后才可见; - 文本处理工具:只有加载了
text_processing技能后才可见;
执行如下代码:
# ==================== Loader 工具 ====================
# 这些工具始终可见,用于加载其他技能
from langgraph.types import Command
from langchain_core.messages import ToolMessage
@tool
def skill_data_analysis(runtime) -> Command:
"""
加载数据分析技能。
"""
instructions = """数据分析技能已成功加载!
现在你可以使用以下工具:
• calculate_statistics(numbers): 计算一组数字的统计信息
• generate_chart(data, chart_type): 生成数据图表
请继续使用这些工具完成用户的数据分析任务。"""
return Command(
update={
"messages": [ToolMessage(
content=instructions,
tool_call_id=runtime.tool_call_id
)],
"skills_loaded": ["data_analysis"] # 关键:直接更新状态
}
)
@tool
def skill_text_processing(runtime) -> Command:
"""
加载文本处理技能。
调用此工具后,你将获得以下文本处理相关的工具:
- summarize_text: 生成文本摘要
- extract_keywords: 提取关键词
使用场景:当用户需要处理文本、生成摘要或提取关键信息时,
请先调用此工具加载文本处理技能。
"""
instructions = """文本处理技能已成功加载!
现在你可以使用以下工具:
• summarize_text(text, max_length): 生成文本摘要
• extract_keywords(text, num_keywords): 提取关键词
请继续使用这些工具完成用户的文本处理任务。"""
return Command(
update={
"messages": [ToolMessage(
content=instructions,
tool_call_id=runtime.tool_call_id
)],
"skills_loaded": ["text_processing"] # 关键:直接更新状态
}
)
# ==================== 数据分析工具 ====================
# 这些工具只有在加载了 data_analysis 技能后才可见
@tool
def calculate_statistics(numbers: List[float]) -> str:
"""
计算一组数字的统计信息,包括平均值、最大值、最小值、标准差等。
Args:
numbers: 要分析的数字列表
"""
import statistics
if not numbers:
return "错误: 数字列表为空"
result = {
"count": len(numbers),
"sum": sum(numbers),
"mean": statistics.mean(numbers),
"median": statistics.median(numbers),
"min": min(numbers),
"max": max(numbers),
}
if len(numbers) > 1:
result["stdev"] = statistics.stdev(numbers)
return f"统计结果: {result}"
@tool
def generate_chart(data: List[float], chart_type: str = "bar") -> str:
"""
根据数据生成图表(模拟)。
Args:
data: 数据列表
chart_type: 图表类型 (bar, line, pie)
"""
return f"已生成 {chart_type} 图表,包含 {len(data)} 个数据点"
# ==================== 文本处理工具 ====================
# 这些工具只有在加载了 text_processing 技能后才可见
@tool
def summarize_text(text: str, max_length: int = 100) -> str:
"""
生成文本摘要。
Args:
text: 要摘要的文本
max_length: 摘要最大长度
"""
if len(text) <= max_length:
return f"摘要: {text}"
return f"摘要: {text[:max_length]}..."
@tool
def extract_keywords(text: str, num_keywords: int = 5) -> str:
"""
从文本中提取关键词。
Args:
text: 要分析的文本
num_keywords: 要提取的关键词数量
"""
# 简单模拟:取前几个单词
words = text.split()[:num_keywords]
return f"关键词: {', '.join(words)}"
# 组织工具
LOADER_TOOLS = [skill_data_analysis, skill_text_processing]
DATA_ANALYSIS_TOOLS = [calculate_statistics, generate_chart]
TEXT_PROCESSING_TOOLS = [summarize_text, extract_keywords]
ALL_TOOLS = LOADER_TOOLS + DATA_ANALYSIS_TOOLS + TEXT_PROCESSING_TOOLS
print("工具定义完成")
print(f" Loader 工具 ({len(LOADER_TOOLS)}): {[t.name for t in LOADER_TOOLS]}")
print(f" 数据分析工具 ({len(DATA_ANALYSIS_TOOLS)}): {[t.name for t in DATA_ANALYSIS_TOOLS]}")
print(f" 文本处理工具 ({len(TEXT_PROCESSING_TOOLS)}): {[t.name for t in TEXT_PROCESSING_TOOLS]}")
print(f" 总计: {len(ALL_TOOLS)} 个工具")
上面的代码定义了 6 个工具,分为三类:
-
Loader 工具(2个):
skill_data_analysis,skill_text_processing- 这些工具始终可见,因为用户需要通过它们来加载其他技能
-
数据分析工具(2个):
calculate_statistics,generate_chart- 只有当
skills_loaded包含"data_analysis"时才可见
- 只有当
-
文本处理工具(2个):
summarize_text,extract_keywords- 只有当
skills_loaded包含"text_processing"时才可见
- 只有当
关键洞察:在传统 Agent 中,模型会一次性看到全部 6 个工具。但通过动态过滤,初始状态下模型只看到 2 个 Loader 工具。
3.7 定义工具映射
为了实现动态过滤,我们需要定义一个映射关系:哪些工具属于哪个技能。
# 技能到工具的映射
SKILL_TOOL_MAPPING = {
"data_analysis": DATA_ANALYSIS_TOOLS,
"text_processing": TEXT_PROCESSING_TOOLS,
}
def get_tools_for_skills(skills_loaded: List[str]) -> List[BaseTool]:
"""
根据已加载的技能列表,返回应该暴露给模型的工具
核心逻辑:
1. Loader 工具始终包含
2. 根据 skills_loaded 添加对应的技能工具
Args:
skills_loaded: 已加载的技能名称列表
Returns:
过滤后的工具列表
"""
# 始终包含 Loader 工具
tools = list(LOADER_TOOLS)
# 根据已加载的技能添加对应工具
for skill_name in skills_loaded:
if skill_name in SKILL_TOOL_MAPPING:
tools.extend(SKILL_TOOL_MAPPING[skill_name])
return tools
# 测试工具过滤函数
print("测试 get_tools_for_skills 函数:")
print(f"\n1. skills_loaded = []")
tools = get_tools_for_skills([])
print(f" 返回 {len(tools)} 个工具: {[t.name for t in tools]}")
print(f"\n2. skills_loaded = ['data_analysis']")
tools = get_tools_for_skills(['data_analysis'])
print(f" 返回 {len(tools)} 个工具: {[t.name for t in tools]}")
print(f"\n3. skills_loaded = ['data_analysis', 'text_processing']")
tools = get_tools_for_skills(['data_analysis', 'text_processing'])
print(f" 返回 {len(tools)} 个工具: {[t.name for t in tools]}")
从测试结果可以看到:
- 当没有加载任何技能时,只有 2 个 Loader 工具可用
- 加载
data_analysis后,变成 4 个工具(2 Loaders + 2 数据分析) - 加载全部技能后,变成 6 个工具
这就是动态工具过滤的核心逻辑!接下来我们要做的,就是在 Middleware 中实现这个过滤。
3.8 实现 SkillMiddleware(核心)
现在我们来实现整个系统的核心组件:SkillMiddleware。它的工作流程如下:

代码实现如下:
class SkillMiddleware(AgentMiddleware):
"""
Skill 中间件 - 实现动态工具过滤
这是 Claude Skills 的核心组件!
工作原理:
1. 在每次模型调用前拦截请求
2. 从 request.state 中读取 skills_loaded 列表
3. 根据 skills_loaded 过滤工具列表
4. 使用 request.override() 替换工具列表
5. 传递给下一个 handler
这样,模型在每次调用时只会看到相关的工具!
"""
def __init__(self, verbose: bool = True):
"""
初始化 SkillMiddleware
Args:
verbose: 是否打印详细日志(用于调试和演示)
"""
super().__init__()
self.verbose = verbose
self.call_count = 0
def _get_skills_from_state(self, request: ModelRequest) -> List[str]:
"""
从请求状态中提取 skills_loaded
注意:AgentState 是 TypedDict,本质上是 dict
所以我们使用字典方式访问
"""
skills_loaded = []
if hasattr(request, 'state') and request.state is not None:
# TypedDict 本质是 dict,使用 .get() 方法
if isinstance(request.state, dict):
skills_loaded = request.state.get("skills_loaded", [])
else:
# 兼容其他类型
skills_loaded = getattr(request.state, "skills_loaded", [])
return skills_loaded
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""
【核心方法】拦截模型调用,动态过滤工具
这是整个 Claude Skills 系统最关键的方法!
"""
self.call_count += 1
# Step 1: 从状态中获取已加载的 Skills
skills_loaded = self._get_skills_from_state(request)
# Step 2: 获取过滤后的工具
filtered_tools = get_tools_for_skills(skills_loaded)
# Step 3: 打印日志
if self.verbose:
print(f"\n{'─'*60}")
print(f"[SkillMiddleware] 第 {self.call_count} 次模型调用")
print(f"{'─'*60}")
print(f"skills_loaded: {skills_loaded}")
print(f"过滤后工具 ({len(filtered_tools)}个): {[t.name for t in filtered_tools]}")
# 对比原始工具数量
if hasattr(request, 'tools') and request.tools:
original_count = len(request.tools)
print(f"工具数量变化: {original_count} → {len(filtered_tools)}")
# Step 4: 【关键】使用 request.override() 替换工具列表
# 这会创建一个新的 ModelRequest,其中 tools 被替换为过滤后的列表
filtered_request = request.override(tools=filtered_tools)
if self.verbose:
print(f"已将过滤后的工具传递给模型")
print(f"{'─'*60}\n")
# Step 5: 调用下一个 handler(实际的模型调用)
return handler(filtered_request)
async def awrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""
异步版本 - 与同步版本逻辑相同
LangChain 可能使用异步调用,所以需要同时实现两个版本
"""
self.call_count += 1
skills_loaded = self._get_skills_from_state(request)
filtered_tools = get_tools_for_skills(skills_loaded)
if self.verbose:
print(f"\n{'─'*60}")
print(f"[SkillMiddleware] (async) 第 {self.call_count} 次模型调用")
print(f"skills_loaded: {skills_loaded}")
print(f"过滤后工具: {[t.name for t in filtered_tools]}")
print(f"{'─'*60}\n")
filtered_request = request.override(tools=filtered_tools)
return await handler(filtered_request)
print("SkillMiddleware 类已定义")
print("\n关键方法说明:")
print(" • wrap_model_call(): 同步拦截模型调用")
print(" • awrap_model_call(): 异步拦截模型调用")
print(" • request.override(): 创建修改后的请求对象")
上面的 SkillMiddleware 实现了动态工具过滤的核心逻辑。需要重点理解几个关键点:
FENCE0
这是整个系统最关键的一行代码!request.override() 方法会创建一个新的 ModelRequest 对象,其中 tools 参数被替换为我们过滤后的工具列表,而其他参数保持不变。
设计模式:
override()方法遵循「不可变性」原则,它不会修改原始请求,而是返回一个新的请求对象。这是函数式编程的最佳实践。
3.9 创建 Agent 并测试
现在我们已经准备好了所有组件,接下来使用 LangChain 1.1 的 create_agent 函数来创建 Agent。这个函数接受以下关键参数:
create_agent 参数说明
| 参数名 | 类型 | 描述 | 必填 |
|---|---|---|---|
| model | BaseChatModel | 语言模型实例 | 是 |
| tools | List[BaseTool] | 工具列表 | 是 |
| middleware | Tuple[AgentMiddleware] | 中间件列表 | 否 |
| state_schema | TypedDict | 状态 Schema | 否 |
| system_prompt | str | 系统提示 | 否 |
# 创建 SkillMiddleware 实例
skill_middleware = SkillMiddleware(verbose=True)
# 定义系统提示
SYSTEM_PROMPT = """
你是一个智能助手,可以使用各种技能来帮助用户完成任务。
## 工作方式
1. 你有两类工具:
- **Skill Loader**(技能加载器):用于加载特定技能,名称以 skill_ 开头
- **功能工具**:执行具体任务的工具
2. 当用户请求某个功能时:
- 首先检查是否有对应的功能工具
- 如果没有,调用相应的 Skill Loader 加载技能
- 加载后,使用新获得的工具完成任务
3. 可用的 Skill Loaders:
- skill_data_analysis:加载数据分析相关工具
- skill_text_processing:加载文本处理相关工具
请根据用户的需求,灵活使用工具完成任务。
"""
print("准备创建 Agent...")
print(f" 模型: DeepSeek Reasoner")
print(f" 工具数量: {len(ALL_TOOLS)}")
print(f" 中间件: SkillMiddleware")
print(f" 状态 Schema: SkillState")
# 创建 Agent
try:
agent = create_agent(
model=model,
tools=ALL_TOOLS, # 注册所有工具(但 Middleware 会动态过滤)
middleware=(skill_middleware,), # 关键:添加 SkillMiddleware
state_schema=SkillState, # 使用我们定义的状态 Schema
system_prompt=SYSTEM_PROMPT,
)
print("\nAgent 创建成功!")
print("\n关键配置:")
print(f" • 注册工具总数: {len(ALL_TOOLS)}")
print(f" • 初始可见工具: {len(LOADER_TOOLS)} (仅 Loaders)")
print(f" • Middleware: SkillMiddleware (动态过滤)")
except TypeError as e:
print(f"创建时遇到参数问题: {e}")
print("尝试简化版本...")
agent = create_agent(
model=model,
tools=ALL_TOOLS,
middleware=(skill_middleware,),
)
print("Agent 创建成功(简化版本)")
Agent 创建完成!注意几个关键点:
-
tools 参数:我们传入了所有 6 个工具,但这不代表模型会看到全部。Middleware 会在每次调用前过滤。
-
middleware 参数:必须是一个元组(tuple),即使只有一个中间件也要写成
(middleware,)。 -
state_schema 参数:告诉 Agent 我们的状态结构,这样它就知道如何管理
skills_loaded字段。
4. LangChain Skills Agent运行测试
让我们先测试一个简单的问候,看看初始状态下模型能看到多少工具:
print("="*60)
print("测试场景 1:初始状态 - 简单问候")
print("="*60)
print("\n预期行为:")
print(" • skills_loaded: [] (空)")
print(" • 可见工具: 2 个 (仅 Loaders)")
print("\n" + "-"*60)
# 构造输入 - 使用 HumanMessage 对象
from langchain_core.messages import HumanMessage
test_input = {
"messages": [HumanMessage(content="你好,请告诉我你现在有哪些工具可用?")],
"skills_loaded": [] # 初始状态:没有加载任何技能
}
# 调用 Agent
result = agent.invoke(test_input)
print("-"*60)
print("\nAI 响应:")
for msg in result.get("messages", []):
if msg.__class__.__name__ == "AIMessage" and msg.content:
print(msg.content)
从上面的测试可以看到,Middleware 的日志显示 skills_loaded: [],所以模型只能看到 2 个 Loader 工具。这正是我们期望的行为!
现在让我们测试核心功能:当用户请求数据分析时,观察工具的动态加载过程。
print("="*60)
print("测试场景 2:动态加载数据分析技能")
print("="*60)
print("\n预期行为:")
print(" 1. 第一次调用: skills_loaded=[] → 2 个工具")
print(" 2. AI 调用 skill_data_analysis → 加载数据分析技能")
print(" 3. 第二次调用: skills_loaded=['data_analysis'] → 4 个工具")
print(" 4. AI 使用 calculate_statistics 完成任务")
print("\n" + "-"*60)
# 重置 Middleware 计数
skill_middleware.call_count = 0
# 构造输入 - 使用 HumanMessage 对象而不是字典格式
from langchain_core.messages import HumanMessage
test_input = {
"messages": [HumanMessage(content="我有一组销售数据 [150, 200, 180, 220, 190],请帮我计算统计信息")],
"skills_loaded": [] # 初始状态:没有加载任何技能
}
# 调用 Agent
result = agent.invoke(test_input)
print("-"*60)
print("\n最终状态:")
print(f" skills_loaded: {result.get('skills_loaded', [])}")
print("\nAI 响应:")
for msg in result.get("messages", []):
if msg.__class__.__name__ == "AIMessage" and msg.content:
print(msg.content)
从测试结果可以清晰地看到动态工具过滤的工作过程:
- 第一次模型调用:
skills_loaded: [],模型只能看到 2 个 Loader 工具 - AI 决策:发现需要数据分析功能,调用
skill_data_analysis - 技能加载:
skills_loaded更新为['data_analysis'] - 第二次模型调用:
skills_loaded: ['data_analysis'],模型看到 4 个工具 - 任务完成:使用
calculate_statistics计算统计信息
这就是 Claude Skills 的核心价值:模型在每次调用时只看到相关的工具,大大减少了 token 消耗和错误率。
最后,再测试一个更复杂的场景:同时需要数据分析和文本处理。
print("="*60)
print("测试场景 3:多技能组合")
print("="*60)
print("\n预期行为:")
print(" • 加载多个技能")
print(" • 工具数量逐步增加: 2 → 4 → 6")
print("\n" + "-"*60)
# 重置计数
skill_middleware.call_count = 0
# 构造输入 - 需要多种技能
test_input = {
"messages": [{
"role": "user",
"content": """请帮我完成以下任务:
1. 计算这组数据的统计信息: [85, 92, 78, 95, 88]
2. 从这段文本中提取关键词: "人工智能正在改变各行各业的工作方式"
"""
}],
"skills_loaded": []
}
# 调用 Agent
result = agent.invoke(test_input)
print("-"*60)
print("\n最终状态:")
print(f" skills_loaded: {result.get('skills_loaded', [])}")
print("\nAI 响应:")
for msg in result.get("messages", []):
if msg.__class__.__name__ == "AIMessage" and msg.content:
print(msg.content)
5.总结与最佳实践
通过本节课给大家介绍了如何使用 LangChain 1.1 的 Middleware 机制实现 Claude Skills 动态工具过滤。核心概念如下:
-
Middleware 机制
- 作用:在 Agent 执行流程中插入自定义逻辑
- 核心方法:
wrap_model_call(request, handler) - 关键操作:
request.override(tools=filtered_tools)
-
State Schema
- 作用:定义 Agent 运行时需要追踪的状态
- 实现:使用
TypedDict定义结构 - 访问:通过
request.state.get("key")获取
-
动态工具过滤
- 原理:根据当前状态(
skills_loaded)决定暴露哪些工具 - 好处:减少 token 消耗、降低错误率、提升响应速度
- 实现:在 Middleware 中过滤并替换工具列表
- 原理:根据当前状态(
同时,我们也给大家提供了工业场景下真实应用落地的 LangChain 1.0 实现 Claude Skills 动态工具过滤的完整代码,大家可以直接下载使用。