DeepSeek企业级智能体MiniManus开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(春季班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(春季班)

《2025大模型Agent智能体开发实战》(春季班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

重磅新增DeepSeek+QwQ+OpenAI responses API+MCP技术应用与智能体开发相关实战内容:

此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(3月班)

两门大模型课程春季班目前上新特惠中,立减2000起,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

DeepSeek智能体开发实战
Part 3.MiniManus开发实战
在了解了DeepSeek基本Function calling极其Agent能力后,最后我们尝试来搭建一个MiniManus智能体。
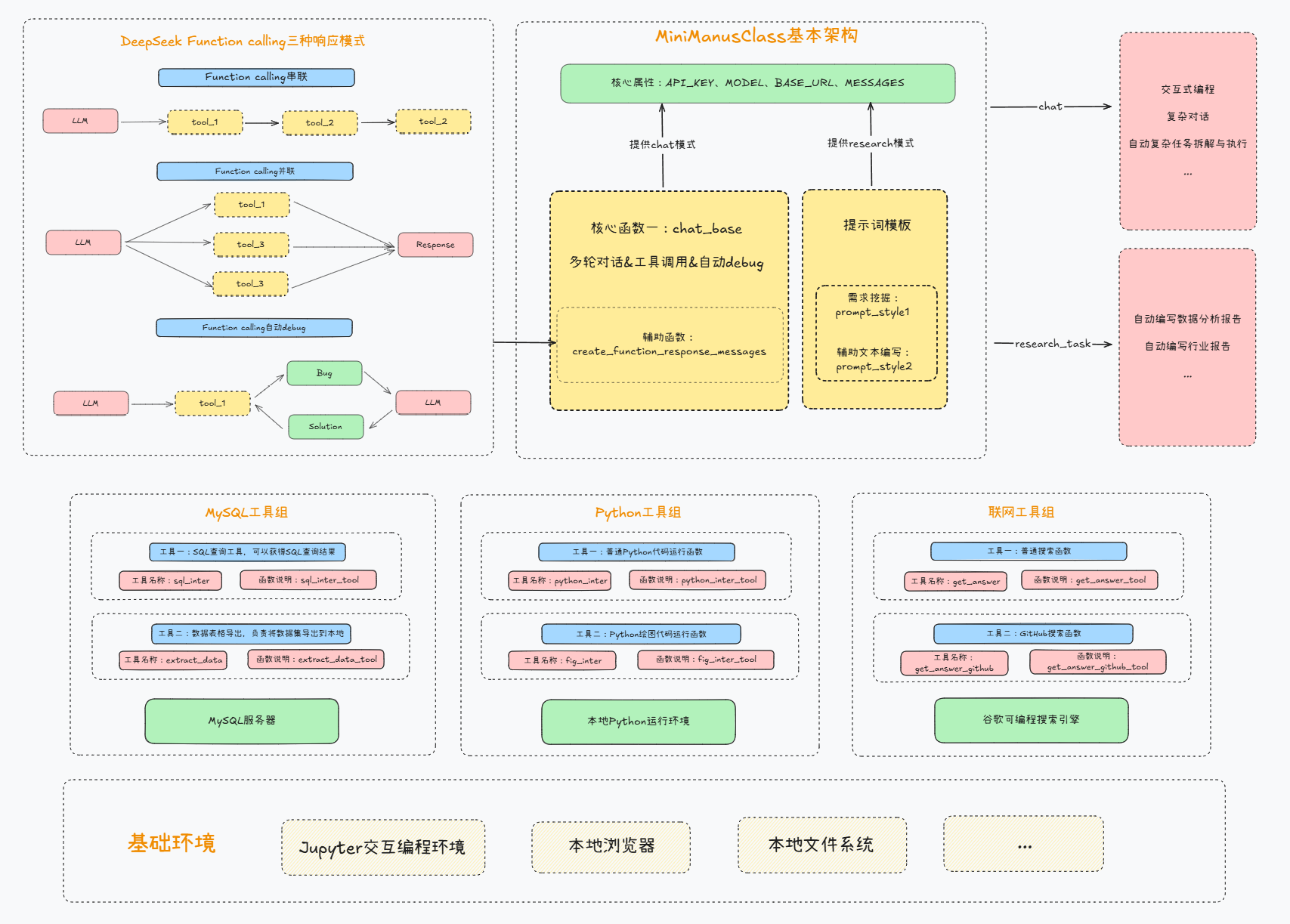
在此基础上,MiniManus能够自动浏览并搜索网络信息:
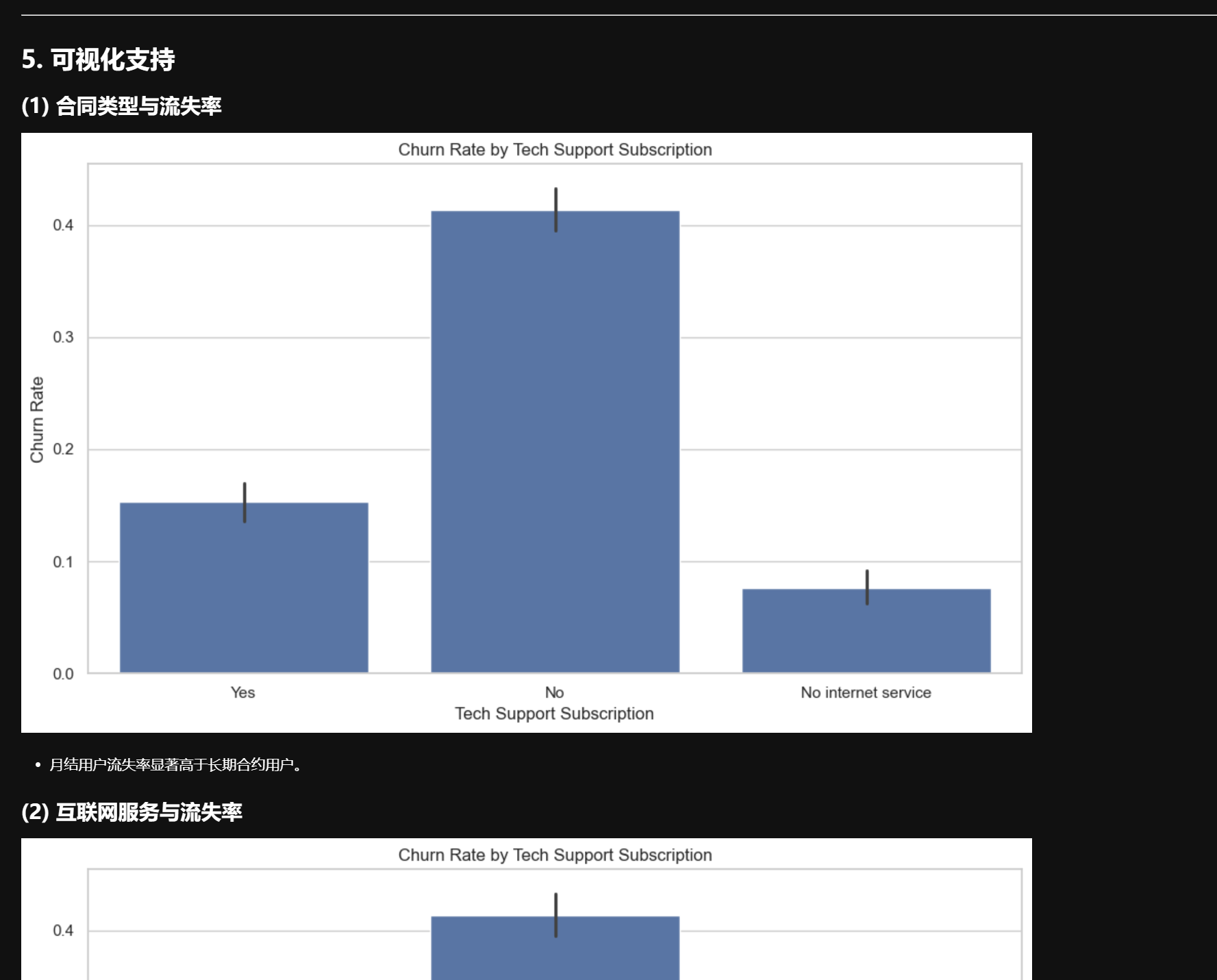
编写数据分析报告:
以及进行交互式Python编程、SQL查询取数等功能。
1.基础库导入与环境变量配置
- 导入相关的库
import os
import openai
import glob
import shutil
import numpy as np
import pandas as pd
import pymysql
import json
import io
import inspect
import requests
import re
import random
import string
import base64
from bs4 import BeautifulSoup
import dateutil.parser as parser
import tiktoken
from lxml import etree
import sys
from dotenv import load_dotenv
from openai import OpenAI
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import display, Code, Markdown, Image
from IPython import get_ipython
- 设置代理地址
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:10080'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:10080'
- 读取全部所需变量
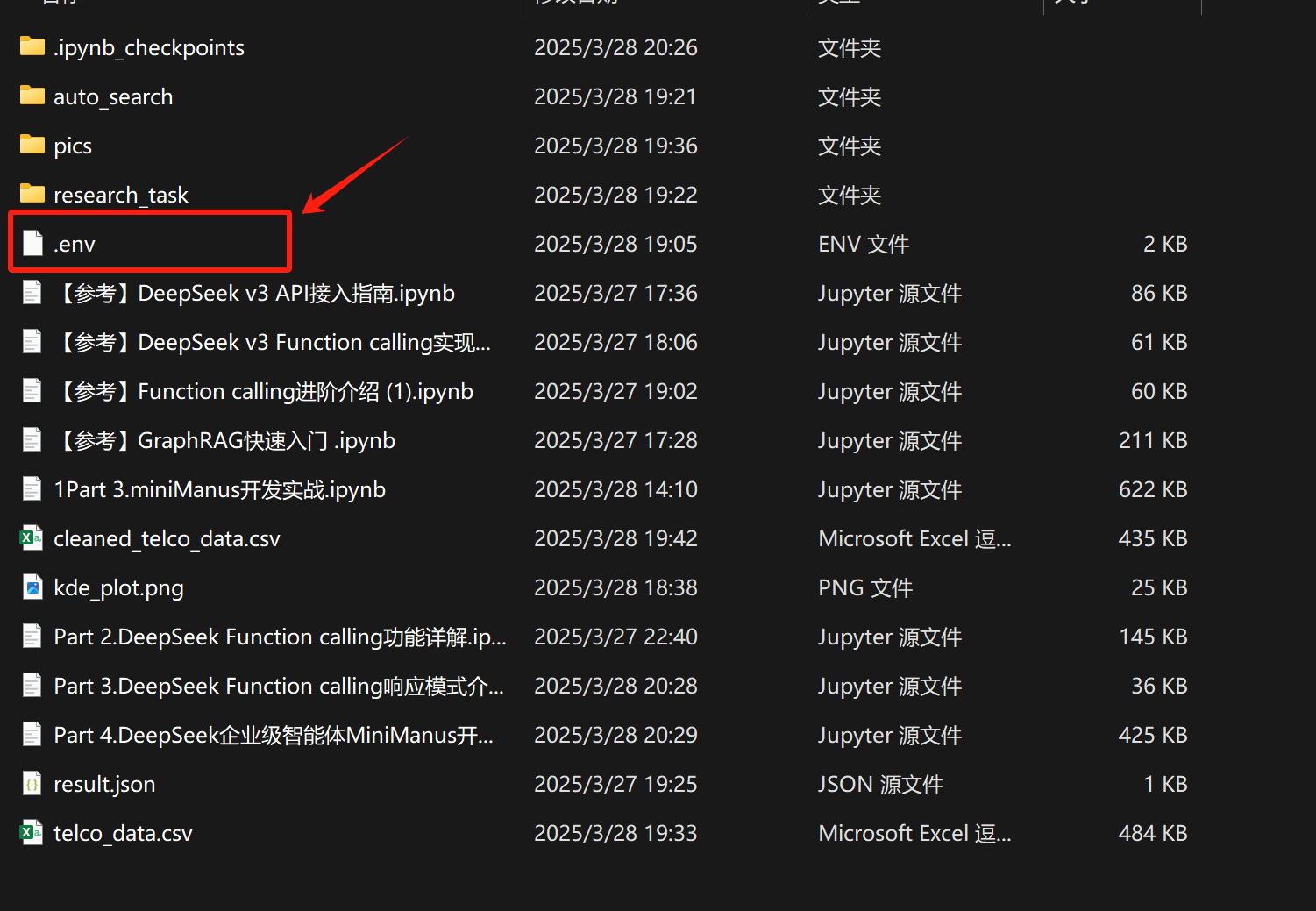
同时,需要在当前项目文件夹内创建一个.env文件,并写入如下变量:
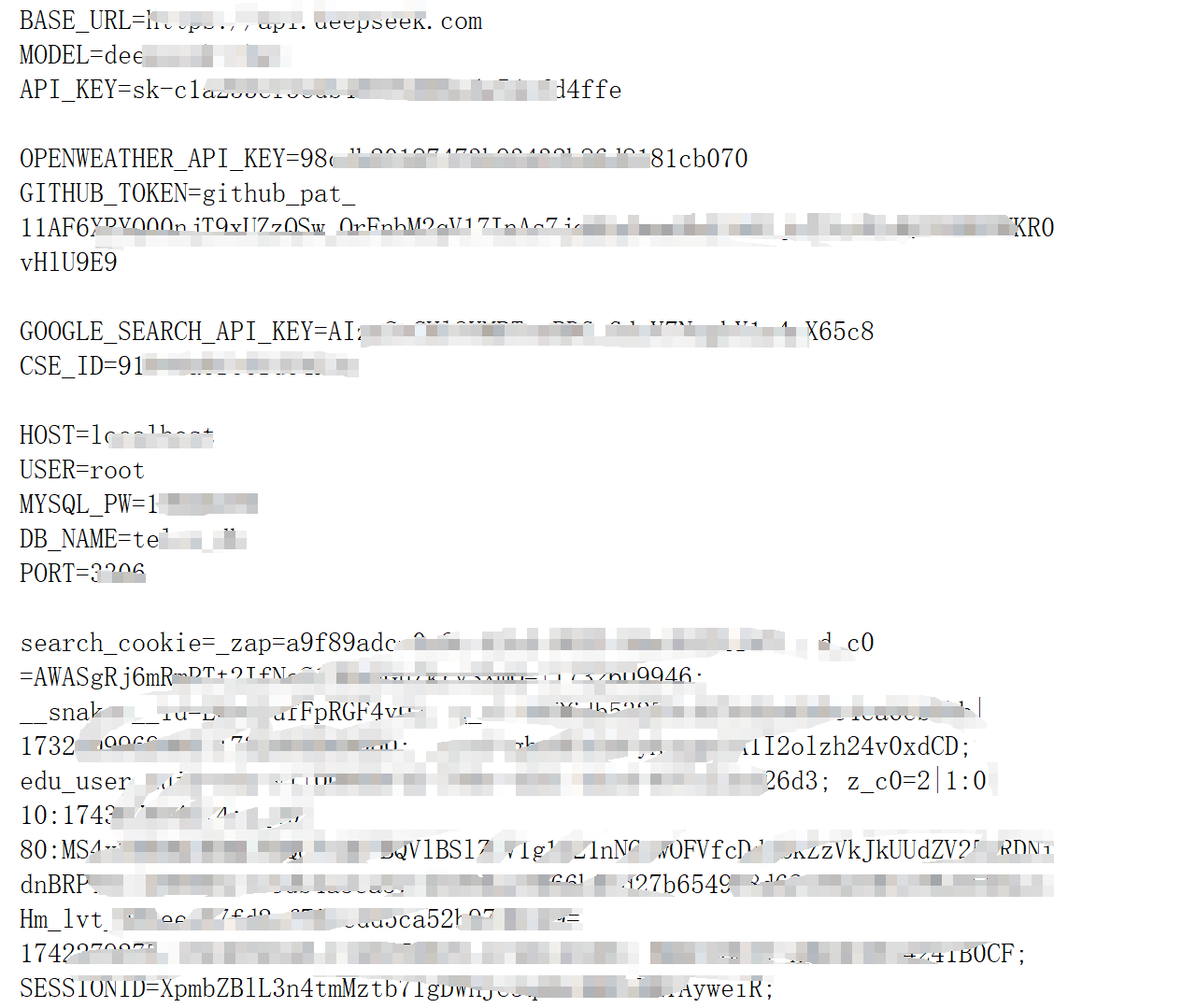
load_dotenv(override=True)
# 模型API-KEY及请求地址
API_KEY = os.getenv("API_KEY")
MODEL = os.getenv("MODEL")
BASE_URL = os.getenv("BASE_URL")
# 谷歌搜索服务器
google_search_key = os.getenv("GOOGLE_SEARCH_API_KEY")
cse_id = os.getenv("CSE_ID")
search_cookie = os.getenv("search_cookie")
search_ueser_agent = os.getenv("search_ueser_agent")
- 更多参考材料
- 测试模型调用
client = OpenAI(api_key=API_KEY, base_url=BASE_URL)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "user", "content": "你好,好久不见!"}
]
)
print(response.choices[0].message.content)
Python功能测试
- Python编程函数
def python_inter(py_code, g='globals()'):
"""
专门用于执行python代码,并获取最终查询或处理结果。
:param py_code: 字符串形式的Python代码,
:param g: g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可
:return:代码运行的最终结果
"""
print("正在调用python_inter工具运行Python代码...")
try:
# 尝试如果是表达式,则返回表达式运行结果
return str(eval(py_code, g))
# 若报错,则先测试是否是对相同变量重复赋值
except Exception as e:
global_vars_before = set(g.keys())
try:
exec(py_code, g)
except Exception as e:
return f"代码执行时报错{e}"
global_vars_after = set(g.keys())
new_vars = global_vars_after - global_vars_before
# 若存在新变量
if new_vars:
result = {var: g[var] for var in new_vars}
print("代码已顺利执行,正在进行结果梳理...")
return str(result)
else:
print("代码已顺利执行,正在进行结果梳理...")
return "已经顺利执行代码"
python_inter_args = '{"py_code": "import numpy as np\\narr = np.array([1, 2, 3, 4])\\nsum_arr = np.sum(arr)\\nsum_arr"}'
py_code = """
import numpy as np
arr = np.array([1, 2, 3, 4])
sum_arr = np.sum(arr)
sum_arr
"""
python_inter(py_code, g=globals())
python_inter_tool = {
"type": "function",
"function": {
"name": "python_inter",
"description": f"当用户需要编写Python程序并执行时,请调用该函数。该函数可以执行一段Python代码并返回最终结果,需要注意,本函数只能执行非绘图类的代码,若是绘图相关代码,则需要调用fig_inter函数运行。\n同时需要注意,编写外部函数的参数消息时,必须是满足json格式的字符串,例如如以下形式字符串就是合规字符串:{python_inter_args}",
"parameters": {
"type": "object",
"properties": {
"py_code": {
"type": "string",
"description": "The Python code to execute."
},
"g": {
"type": "string",
"description": "Global environment variables, default to globals().",
"default": "globals()"
}
},
"required": ["py_code"]
}
}
}
- Python绘图函数
def fig_inter(py_code, fname, g='globals()'):
print("正在调用fig_inter工具运行Python代码...")
import matplotlib
import os
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from IPython.display import display, Image
# 切换为无交互式后端
current_backend = matplotlib.get_backend()
matplotlib.use('Agg')
# 用于执行代码的本地变量
local_vars = {"plt": plt, "pd": pd, "sns": sns}
# 相对路径保存目录
pics_dir = 'pics'
if not os.path.exists(pics_dir):
os.makedirs(pics_dir)
try:
# 执行用户代码
exec(py_code, g, local_vars)
g.update(local_vars)
# 获取图像对象
fig = local_vars.get(fname, None)
if fig:
rel_path = os.path.join(pics_dir, f"{fname}.png")
fig.savefig(rel_path, bbox_inches='tight')
display(Image(filename=rel_path))
print("代码已顺利执行,正在进行结果梳理...")
return f"✅ 图片已保存,相对路径: {rel_path}"
else:
return "⚠️ 代码执行成功,但未找到图像对象,请确保有 `fig = ...`。"
except Exception as e:
return f"❌ 执行失败:{e}"
finally:
# 恢复原有绘图后端
matplotlib.use(current_backend)
fig_inter_tool = {
"type": "function",
"function": {
"name": "fig_inter",
"description": (
"当用户需要使用 Python 进行可视化绘图任务时,请调用该函数。"
"该函数会执行用户提供的 Python 绘图代码,并自动将生成的图像对象保存为图片文件并展示。\n\n"
"调用该函数时,请传入以下参数:\n\n"
"1. `py_code`: 一个字符串形式的 Python 绘图代码,**必须是完整、可独立运行的脚本**,"
"代码必须创建并返回一个命名为 `fname` 的 matplotlib 图像对象;\n"
"2. `fname`: 图像对象的变量名(字符串形式),例如 'fig';\n"
"3. `g`: 全局变量环境,默认保持为 'globals()' 即可。\n\n"
"📌 请确保绘图代码满足以下要求:\n"
"- 包含所有必要的 import(如 `import matplotlib.pyplot as plt`, `import seaborn as sns` 等);\n"
"- 必须包含数据定义(如 `df = pd.DataFrame(...)`),不要依赖外部变量;\n"
"- 推荐使用 `fig, ax = plt.subplots()` 显式创建图像;\n"
"- 使用 `ax` 对象进行绘图操作(例如:`sns.lineplot(..., ax=ax)`);\n"
"- 最后明确将图像对象保存为 `fname` 变量(如 `fig = plt.gcf()`)。\n\n"
"📌 不需要自己保存图像,函数会自动保存并展示。\n\n"
"✅ 合规示例代码:\n"
"```python\n"
"import matplotlib.pyplot as plt\n"
"import seaborn as sns\n"
"import pandas as pd\n\n"
"df = pd.DataFrame({'x': [1, 2, 3], 'y': [4, 5, 6]})\n"
"fig, ax = plt.subplots()\n"
"sns.lineplot(data=df, x='x', y='y', ax=ax)\n"
"ax.set_title('Line Plot')\n"
"fig = plt.gcf() # 一定要赋值给 fname 指定的变量名\n"
"```"
),
"parameters": {
"type": "object",
"properties": {
"py_code": {
"type": "string",
"description": (
"需要执行的 Python 绘图代码(字符串形式)。"
"代码必须创建一个 matplotlib 图像对象,并赋值为 `fname` 所指定的变量名。"
)
},
"fname": {
"type": "string",
"description": "图像对象的变量名(例如 'fig'),代码中必须使用这个变量名保存绘图对象。"
},
"g": {
"type": "string",
"description": "运行环境变量,默认保持为 'globals()' 即可。",
"default": "globals()"
}
},
"required": ["py_code", "fname"]
}
}
}
py_code = '''
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 生成一些示例数据
data = {
'x': [1, 2, 3, 4, 5],
'y': [10, 20, 25, 30, 40]
}
df = pd.DataFrame(data)
# 创建一个散点图
plt.figure(figsize=(8, 6))
sns.scatterplot(x='x', y='y', data=df)
plt.title('Scatter Plot Example')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
# 保存图形到一个变量
fig = plt.gcf()
'''
# 测试fig_inter功能的调用
fig_inter(py_code, 'fig', g=globals())
MySQL功能测试
- SQL函数
def sql_inter(sql_query, g='globals()'):
"""
用于执行一段SQL代码,并最终获取SQL代码执行结果,\
核心功能是将输入的SQL代码传输至MySQL环境中进行运行,\
并最终返回SQL代码运行结果。需要注意的是,本函数是借助pymysql来连接MySQL数据库。
:param sql_query: 字符串形式的SQL查询语句,用于执行对MySQL中telco_db数据库中各张表进行查询,并获得各表中的各类相关信息
:param g: g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可
:return:sql_query在MySQL中的运行结果。
"""
print("正在调用sql_inter工具运行SQL代码...")
load_dotenv(override=True)
host = os.getenv('HOST')
user = os.getenv('USER')
mysql_pw = os.getenv('MYSQL_PW')
db = os.getenv('DB_NAME')
port = os.getenv('PORT')
connection = pymysql.connect(
host = host,
user = user,
passwd = "19920229",
db = db,
port = int(port),
charset='utf8',
)
try:
with connection.cursor() as cursor:
sql = sql_query
cursor.execute(sql)
results = cursor.fetchall()
print("SQL代码已顺利运行,正在整理答案...")
finally:
connection.close()
return json.dumps(results)
sql_inter_args = '{"sql_query": "SHOW TABLES;"}'
sql_inter_tool = {
"type": "function",
"function": {
"name": "sql_inter",
"description": (
"当用户需要进行数据库查询工作时,请调用该函数。"
"该函数用于在指定MySQL服务器上运行一段SQL代码,完成数据查询相关工作,"
"并且当前函数是使用pymsql连接MySQL数据库。"
"本函数只负责运行SQL代码并进行数据查询,若要进行数据提取,则使用另一个extract_data函数。"
"同时需要注意,编写外部函数的参数消息时,必须是满足json格式的字符串,例如以下形式字符串就是合规字符串:"
f"{sql_inter_args}"
),
"parameters": {
"type": "object",
"properties": {
"sql_query": {
"type": "string",
"description": "The SQL query to execute in MySQL database."
},
"g": {
"type": "string",
"description": "Global environment variables, default to globals().",
"default": "globals()"
}
},
"required": ["sql_query"]
}
}
}
sql_query = "SHOW TABLES;"
sql_inter(sql_query, g=globals())
- SQL提取数据函数
def extract_data(sql_query, df_name, g='globals()'):
"""
借助pymysql将MySQL中的某张表读取并保存到本地Python环境中。
:param sql_query: 字符串形式的SQL查询语句,用于提取MySQL中的某张表。
:param df_name: 将MySQL数据库中提取的表格进行本地保存时的变量名,以字符串形式表示。
:param g: g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可
:return:表格读取和保存结果
"""
print("正在调用extract_data工具运行SQL代码...")
load_dotenv(override=True)
host = os.getenv('HOST')
user = os.getenv('USER')
mysql_pw = os.getenv('MYSQL_PW')
db = os.getenv('DB_NAME')
port = os.getenv('PORT')
connection = pymysql.connect(
host = host,
user = user,
passwd = mysql_pw,
db = db,
port = int(port),
charset='utf8',
)
g[df_name] = pd.read_sql(sql_query, connection)
print("代码已顺利执行,正在进行结果梳理...")
return "已成功创建pandas对象:%s,该变量保存了同名表格信息" % df_name
extract_data_args = '{"sql_query": "SELECT * FROM user_churn", "df_name": "user_churn"}'
extract_data_tool = {
"type": "function",
"function": {
"name": "extract_data",
"description": (
"用于在MySQL数据库中提取一张表到当前Python环境中,注意,本函数只负责数据表的提取,"
"并不负责数据查询,若需要在MySQL中进行数据查询,请使用sql_inter函数。"
"同时需要注意,编写外部函数的参数消息时,必须是满足json格式的字符串,"
f"例如如以下形式字符串就是合规字符串:{extract_data_args}"
),
"parameters": {
"type": "object",
"properties": {
"sql_query": {
"type": "string",
"description": "The SQL query to extract a table from MySQL database."
},
"df_name": {
"type": "string",
"description": "The name of the variable to store the extracted table in the local environment."
},
"g": {
"type": "string",
"description": "Global environment variables, default to globals().",
"default": "globals()"
}
},
"required": ["sql_query", "df_name"]
}
}
}
extract_data(sql_query="SELECT * FROM user_churn",
df_name="user_churn",
g=globals())
user_churn.head()
联网搜索功能开发
- 搜索测试
def google_search(query, num_results=10, site_url=None):
api_key = os.getenv("GOOGLE_SEARCH_API_KEY")
cse_id = os.getenv("CSE_ID")
url = "https://www.googleapis.com/customsearch/v1"
# API 请求参数
if site_url == None:
params = {
'q': query,
'key': api_key,
'cx': cse_id,
'num': num_results
}
else:
params = {
'q': query,
'key': api_key,
'cx': cse_id,
'num': num_results,
'siteSearch': site_url
}
# 发送请求
response = requests.get(url, params=params)
response.raise_for_status()
# 解析响应
search_results = response.json().get('items', [])
# 提取所需信息
results = [{
'title': item['title'],
'link': item['link'],
'snippet': item['snippet']
} for item in search_results]
return results
results = google_search(query="什么是MCP", num_results=5, site_url='https://www.zhihu.com/')
results
def windows_compatible_name(s, max_length=255):
"""
将字符串转化为符合Windows文件/文件夹命名规范的名称。
参数:
- s (str): 输入的字符串。
- max_length (int): 输出字符串的最大长度,默认为255。
返回:
- str: 一个可以安全用作Windows文件/文件夹名称的字符串。
"""
# Windows文件/文件夹名称中不允许的字符列表
forbidden_chars = ['<', '>', ':', '"', '/', '\\', '|', '?', '*']
# 使用下划线替换不允许的字符
for char in forbidden_chars:
s = s.replace(char, '_')
# 删除尾部的空格或点
s = s.rstrip(' .')
# 检查是否存在以下不允许被用于文档名称的关键词,如果有的话则替换为下划线
reserved_names = ["CON", "PRN", "AUX", "NUL", "COM1", "COM2", "COM3", "COM4", "COM5", "COM6", "COM7", "COM8", "COM9",
"LPT1", "LPT2", "LPT3", "LPT4", "LPT5", "LPT6", "LPT7", "LPT8", "LPT9"]
if s.upper() in reserved_names:
s += '_'
# 如果字符串过长,进行截断
if len(s) > max_length:
s = s[:max_length]
return s
def get_search_text(q, url):
cookie = os.getenv('search_cookie')
user_agent = os.getenv('search_ueser_agent')
code_ = False
headers = {
'authority': 'www.zhihu.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'max-age=0',
'cookie': cookie,
'upgrade-insecure-requests': '1',
'user-agent':user_agent,
}
# 普通问答地址
if 'zhihu.com/question' in url:
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
title = res_xpath.xpath('//div/div[1]/div/h1/text()')[0]
text_d = res_xpath.xpath('//div/div/div/div[2]/div/div[2]/div/div/div[2]/span[1]/div/div/span/p/text()')
# 专栏地址
elif 'zhuanlan' in url:
headers['authority'] = 'zhaunlan.zhihu.com'
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
title = res_xpath.xpath('//div[1]/div/main/div/article/header/h1/text()')[0]
text_d = res_xpath.xpath('//div/main/div/article/div[1]/div/div/div/p/text()')
code_ = res_xpath.xpath('//div/main/div/article/div[1]/div/div/div//pre/code/text()')
# 特定回答的问答网址
elif 'answer' in url:
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
title = res_xpath.xpath('//div/div[1]/div/h1/text()')[0]
text_d = res_xpath.xpath('//div[1]/div/div[3]/div/div/div/div[2]/span[1]/div/div/span/p/text()')
if title == None:
return None
else:
title = windows_compatible_name(title)
# 创建问题答案正文
text = ''
for t in text_d:
txt = str(t).replace('\n', ' ')
text += txt
# 如果有code,则将code追加到正文的追后面
if code_:
for c in code_:
co = str(c).replace('\n', ' ')
text += co
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
json_data = [
{
"link": url,
"title": title,
"content": text,
"tokens": len(encoding.encode(text))
}
]
# 自动创建目录,如果不存在的话
dir_path = f'./auto_search/{q}'
os.makedirs(dir_path, exist_ok=True)
with open('./auto_search/%s/%s.json' % (q, title), 'w') as f:
json.dump(json_data, f)
return title
url = 'https://www.zhihu.com/question/7762420288'
q = "什么是MCP"
get_search_text(q, url)
def get_search_result(q):
"""
当你无法回答某个问题时,调用该函数,能够获得答案
:param q: 必选参数,询问的问题,字符串类型对象
:return:某问题的答案,以字符串形式呈现
"""
# 默认搜索返回5个答案
results = google_search(query=q, num_results=5, site_url='https://zhihu.com/')
# 创建对应问题的子文件夹
folder_path = './auto_search/%s' % q
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 单独提取links放在一个list中
num_tokens = 0
content = ''
for item in results:
url = item['link']
title = get_search_text(q, url)
with open('./auto_search/%s/%s.json' % (q, title), 'r') as f:
jd = json.load(f)
num_tokens += jd[0]['tokens']
if num_tokens <= 12000:
# print(jd[0]['content'])
content += jd[0]['content']
else:
break
return(content)
get_search_result(q)
github_token = os.getenv('GITHUB_TOKEN')
github_token
def get_github_readme(dic):
github_token = os.getenv('GITHUB_TOKEN')
user_agent = os.getenv('search_user_agent')
owner = dic['owner']
repo = dic['repo']
headers = {
"Authorization": github_token,
"User-Agent": user_agent
}
response = requests.get(f"https://api.github.com/repos/{owner}/{repo}/readme", headers=headers)
readme_data = response.json()
encoded_content = readme_data.get('content', '')
decoded_content = base64.b64decode(encoded_content).decode('utf-8')
return decoded_content
def extract_github_repos(search_results):
# 使用列表推导式筛选出项目主页链接
repo_links = [result['link'] for result in search_results if '/issues/' not in result['link'] and '/blob/' not in result['link'] and 'github.com' in result['link'] and len(result['link'].split('/')) == 5]
# 从筛选后的链接中提取owner和repo
repos_info = [{'owner': link.split('/')[3], 'repo': link.split('/')[4]} for link in repo_links]
return repos_info
def get_search_text_github(q, dic):
title = dic['owner'] + '_' + dic['repo']
title = windows_compatible_name(title)
# 创建问题答案正文
text = get_github_readme(dic)
# 写入本地json文件
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
json_data = [
{
"title": title,
"content": text,
"tokens": len(encoding.encode(text))
}
]
# 自动创建目录,如果不存在的话
dir_path = f'./auto_search/{q}'
os.makedirs(dir_path, exist_ok=True)
with open('./auto_search/%s/%s.json' % (q, title), 'w') as f:
json.dump(json_data, f)
return title
def get_answer_github(q):
"""
当你无法回答某个问题时,调用该函数,能够获得答案
:param q: 必选参数,询问的问题,字符串类型对象
:return:某问题的答案,以字符串形式呈现
"""
# 调用转化函数,将用户的问题转化为更适合在GitHub上搜索的关键词
# q = convert_keyword_github(q)
# 默认搜索返回5个答案
# print('正在接入谷歌搜索,查找和问题相关的答案...')
search_results = google_search(query=q, num_results=5, site_url='https://github.com/')
results = extract_github_repos(search_results)
# 创建对应问题的子文件夹
folder_path = './auto_search/%s' % q
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# print('正在读取搜索的到的相关答案...')
num_tokens = 0
content = ''
for dic in results:
title = get_search_text_github(q, dic)
with open('./auto_search/%s/%s.json' % (q, title), 'r') as f:
jd = json.load(f)
num_tokens += jd[0]['tokens']
if num_tokens <= 12000:
content += jd[0]['content']
else:
break
# print('正在进行最后的整理...')
return(content)
q = 'DeepSeek-R1'
get_answer_github(q)
def get_answer(q, g='globals()'):
"""
当你无法回答某个问题时,调用该函数,能够获得答案
:param q: 必选参数,询问的问题,字符串类型对象
:param g: g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可
:return:某问题的答案,以字符串形式呈现
"""
# 默认搜索返回5个答案
print('正在接入谷歌搜索,查找和问题相关的答案...')
results = google_search(query=q, num_results=5, site_url='https://zhihu.com/')
# 创建对应问题的子文件夹
folder_path = './auto_search/%s' % q
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 单独提取links放在一个list中
num_tokens = 0
content = ''
for item in results:
url = item['link']
print('正在检索:%s' % url)
title = get_search_text(q, url)
with open('./auto_search/%s/%s.json' % (q, title), 'r') as f:
jd = json.load(f)
num_tokens += jd[0]['tokens']
if num_tokens <= 12000:
# print(jd[0]['content'])
content += jd[0]['content']
else:
break
return(content)
get_answer_tool = {
"type": "function",
"function": {
"name": "get_answer",
"description": (
"联网搜索工具,当用户提出的问题超出你的知识库范畴时,或该问题你不知道答案的时候,请调用该函数来获得问题的答案。该函数会自动从知乎上搜索得到问题相关文本,而后你可围绕文本内容进行总结,并回答用户提问。需要注意的是,当用户点名要求想要了解GitHub上的项目时候,请调用get_answer_github函数。"
),
"parameters": {
"type": "object",
"properties": {
"q": {
"type": "string",
"description": "一个满足知乎搜索格式的问题,用字符串形式进行表示。",
"example": "什么是MCP?"
},
"g": {
"type": "string",
"description": "Global environment variables, default to globals().",
"default": "globals()"
}
},
"required": ["q"]
}
}
}
get_answer(q="什么是MCP?", g=globals())
- Github搜索
def get_answer_github(q, g='globals()'):
"""
当你无法回答某个问题时,调用该函数,能够获得答案
:param q: 必选参数,询问的问题,字符串类型对象
:param g: g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可
:return:某问题的答案,以字符串形式呈现
"""
# 调用转化函数,将用户的问题转化为更适合在GitHub上搜索的关键词
# q = convert_keyword_github(q)
# 默认搜索返回5个答案
print('正在接入谷歌搜索,查找和问题相关的答案...')
search_results = google_search(query=q, num_results=5, site_url='https://github.com/')
results = extract_github_repos(search_results)
# 创建对应问题的子文件夹
folder_path = './auto_search/%s' % q
if not os.path.exists(folder_path):
os.makedirs(folder_path)
print('正在读取相关项目说明文档...')
num_tokens = 0
content = ''
for dic in results:
title = get_search_text_github(q, dic)
with open('./auto_search/%s/%s.json' % (q, title), 'r') as f:
jd = json.load(f)
num_tokens += jd[0]['tokens']
if num_tokens <= 12000:
content += jd[0]['content']
else:
break
print('正在进行最后的整理...')
return(content)
get_answer_github_tool = {
"type": "function",
"function": {
"name": "get_answer_github",
"description": (
"GitHub联网搜索工具,当用户提出的问题超出你的知识库范畴时,或该问题你不知道答案的时候,请调用该函数来获得问题的答案。该函数会自动从GitHub上搜索得到问题相关文本,而后你可围绕文本内容进行总结,并回答用户提问。需要注意的是,当用户提问点名要求在GitHub进行搜索时,例如“请帮我介绍下GitHub上的Qwen2项目”,此时请调用该函数,其他情况下请调用get_answer外部函数并进行回答。"
),
"parameters": {
"type": "object",
"properties": {
"q": {
"type": "string",
"description": "一个满足GitHub搜索格式的问题,往往是需要从用户问题中提出一个适合搜索的项目关键词,用字符串形式进行表示。",
"example": "DeepSeek-R1"
},
"g": {
"type": "string",
"description": "Global environment variables, default to globals().",
"default": "globals()"
}
},
"required": ["q"]
}
}
}
get_answer_github(q="DeepSeek-R1", g=globals())
搭建miniManus工作流
def print_code_if_exists(function_args):
"""
如果存在代码片段,则打印代码
"""
def convert_to_markdown(code, language):
return f"```{language}\n{code}\n```"
# 如果是SQL,则按照Markdown中SQL格式打印代码
if function_args.get('sql_query'):
code = function_args['sql_query']
markdown_code = convert_to_markdown(code, 'sql')
print("即将执行以下代码:")
display(Markdown(markdown_code))
# 如果是Python,则按照Markdown中Python格式打印代码
elif function_args.get('py_code'):
code = function_args['py_code']
markdown_code = convert_to_markdown(code, 'python')
print("即将执行以下代码:")
display(Markdown(markdown_code))
def create_function_response_messages(messages, response):
"""
调用外部工具,并更新消息列表
:param messages: 原始消息列表
:param response: 模型某次包含外部工具调用请求的响应结果
:return:messages,追加了外部工具运行结果后的消息列表
"""
available_functions = {
"python_inter": python_inter,
"fig_inter": fig_inter,
"sql_inter": sql_inter,
"extract_data": extract_data,
"get_answer": get_answer,
"get_answer_github": get_answer_github,
}
# 提取function call messages
function_call_messages = response.choices[0].message.tool_calls
# 将function call messages追加到消息列表中
messages.append(response.choices[0].message.model_dump())
# 提取本次外部函数调用的每个任务请求
for function_call_message in function_call_messages:
# 提取外部函数名称
tool_name = function_call_message.function.name
# 提取外部函数参数
tool_args = json.loads(function_call_message.function.arguments)
# 查找外部函数
fuction_to_call = available_functions[tool_name]
# 打印代码
print_code_if_exists(function_args=tool_args)
# 运行外部函数
try:
tool_args['g'] = globals()
# 运行外部函数
function_response = fuction_to_call(**tool_args)
except Exception as e:
function_response = "函数运行报错如下:" + str(e)
# 拼接消息队列
messages.append(
{
"role": "tool",
"content": function_response,
"tool_call_id": function_call_message.id,
}
)
return messages
- 创建工具
tools = [python_inter_tool,fig_inter_tool,sql_inter_tool,extract_data_tool,get_answer_tool,get_answer_github_tool]
- 单次对话函数
def chat_base(messages, client, model):
"""
获得一次模型对用户的响应。若其中需要调用外部函数,
则会反复多次调用create_function_response_messages函数获得外部函数响应。
"""
client = client
model = model
try:
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
)
except Exception as e:
print("模型调用报错" + str(e))
return None
if response.choices[0].finish_reason == "tool_calls":
while True:
messages = create_function_response_messages(messages, response)
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
)
if response.choices[0].finish_reason != "tool_calls":
break
return response
- SQL测试
messages=[{"role": "user", "content": "请帮我查询当前数据库中,总共有几张表。"}]
response = chat_base(messages=messages, client=client, model=MODEL)
display(Markdown(response.choices[0].message.content))
- 可视化功能测试
messages=[{"role": "user", "content": "请帮我模拟一组数据,并绘制核密度分布图"}]
response = chat_base(messages=messages, client=client, model=MODEL)
display(Markdown(response.choices[0].message.content))
- 联网测试
messages=[{"role": "user", "content": "请帮我介绍下最新大模型MCP技术。"}]
response = chat_base(messages=messages, client=client, model=MODEL)
display(Markdown(response.choices[0].message.content))
messages=[{"role": "user", "content": "请帮我介绍下GitHub上的DeepSeek-R1这个项目"}]
response = chat_base(messages=messages, client=client, model=MODEL)
display(Markdown(response.choices[0].message.content))
MiniManus主类创建
def save_markdown_to_file(content: str, filename_hint: str, directory="research_task"):
# 在当前项目目录下创建 research_task 文件夹
save_dir = os.path.join(os.getcwd(), directory)
# 如果目录不存在则创建
os.makedirs(save_dir, exist_ok=True)
# 创建文件名(取前8个字符并加上...)
filename = f"{filename_hint[:8]}....md"
# 完整文件路径
file_path = os.path.join(save_dir, filename)
# 将内容保存为Markdown文档
with open(file_path, 'w', encoding='utf-8') as file:
file.write(content)
print(f"文件已成功保存到:{file_path}")
save_markdown_to_file(content="测试文档", filename_hint="测试文档创建", directory="research_task")
class miniManusClass:
def __init__(self,
api_key=None,
model=None,
base_url=None,
messages=None):
load_dotenv(override=True)
if api_key != None:
self.api_key = api_key
else:
self.api_key = os.getenv("API_KEY")
if model != None:
self.model = model
else:
self.model = os.getenv("MODEL")
if base_url != None:
self.base_url = base_url
else:
self.base_url = os.getenv("BASE_URL")
if messages != None:
self.messages = messages
else:
self.messages = [{"role":"system", "content":"你miniManus,是一名助人为乐的助手。"}]
self.client = OpenAI(api_key=self.api_key, base_url=self.base_url)
try:
print("正在测试模型能否正常调用...")
self.models = self.client.models.list()
if self.models:
print("▌ MiniManus初始化完成,欢迎使用!")
else:
print("模型无法调用,请检查网络环境或本地模型配置。")
except Exception as e:
print("初始化失败,可能是网络或配置错误。详细信息:", str(e))
def chat(self):
print("你好,我是九天老师公开课制作的MiniManus,有什么需要帮助的?")
while True:
question = input("请输入您的问题(输入退出以结束对话): ")
if question == "退出":
break
self.messages.append({"role": "user", "content": question})
self.messages = self.messages[-20: ]
response = chat_base(messages=self.messages,
client=self.client,
model=self.model)
display(Markdown("**MiniManus**:" + response.choices[0].message.content))
self.messages.append(response.choices[0].message)
def research_task(self, question):
prompt_style1 = """
你是一名专业且细致的助手,你的任务是在用户提出问题后,通过友好且有引导性的追问,更深入地理解用户真正的需求背景。这样,你才能提供更精准和更有效的帮助。
当用户提出一个宽泛或者不够明确的问题时,你应当积极主动地提出后续问题,引导用户提供更多背景和细节,以帮助你更准确地回应。
示例引导问题:
用户提问示例:
最近,在大模型技术领域,有一项非常热门的技术,名叫MCP,model context protocol,调用并深度总结,这项技术与OpenAI提出的function calling之间的区别。
你应该给出的引导式回应示例:
在比较MCP(Model Context Protocol)与OpenAI的Function Calling时,我可以涵盖以下几个方面:
- 定义和基本概念:MCP和Function Calling的基本原理和目标。
- 工作机制:它们如何处理模型的输入和输出。
- 应用场景:它们分别适用于哪些具体场景?
- 技术优势与局限性:各自的优劣势分析。
- 生态和兼容性:它们是否能与现有的大模型和应用集成。
- 未来发展趋势:这些技术未来的发展方向。
请问你是否希望我特别关注某些方面,或者有特定的技术细节需要深入分析?
再比如用户提问:
请你帮我详细整理,华为910B2x鲲鹏920,如何部署DeepSeek模型。
你应该给出的引导式回应示例:
请提供以下详细信息,以便我能为您整理完整的部署指南:
1. 您希望部署的DeepSeek模型具体是哪一个?(例如DeepSeek-VL、DeepSeek-Coder等)
2. 目标系统环境(操作系统、已有软件环境等)?
3. 是否有特定的深度学习框架要求?(如PyTorch、TensorFlow)
4. 是否需要优化部署(如使用昇腾NPU加速)?
5. 期望的使用场景?(如推理、训练、微调等)
请提供这些信息后,我将为您整理具体的部署步骤。
记住,保持友好而专业的态度,主动帮助用户明确需求,而不是直接给出不够精准的回答。现在用户提出问题如下:{},请按照要求进行回复。
"""
prompt_style2 = """
你是一位知识广博、擅长利用多种外部工具的资深研究员。当用户已明确提出具体需求:{},现在你的任务是:
首先明确用户问题的核心及相关细节。
尽可能调用可用的外部工具(例如:联网搜索工具get_answer、GitHub搜索工具get_answer_github、本地代码运行工具python_inter以及其他工具),围绕用户给出的原始问题和补充细节,进行广泛而深入的信息收集。
综合利用你从各种工具中获取的信息,提供详细、全面、专业且具有深度的解答。你的回答应尽量达到2000字以上,内容严谨准确且富有洞察力。
示例流程:
用户明确需求示例:
我目前正在学习 ModelContextProtocol(MCP),主要关注它在AI模型开发领域中的具体应用场景、技术细节和一些业界最新的进展。
你的回应流程示例:
首先重述并确认用户的具体需求。
明确你将调用哪些外部工具,例如:
使用联网搜索工具查询官方或权威文档对 MCP 在AI模型开发领域的具体应用说明;
调用GitHub搜索工具,寻找业界针对MCP技术项目;
整理并分析通过工具获取的信息,形成一篇逻辑清晰、结构合理的深度报告。
再比如用户需要编写数据分析报告示例:
我想针对某电信公司过去一年的用户数据,编写一份详细的用户流失预测数据分析报告,报告需要包括用户流失趋势分析、流失用户特征分析、影响用户流失的关键因素分析,并给出未来减少用户流失的策略建议。
你的回应流程示例:
明确并确认用户需求,指出分析内容包括用户流失趋势、流失用户特征、关键影响因素以及策略建议。
明确你将调用哪些外部工具,例如:
使用数据分析工具对提供的用户数据进行流失趋势分析,生成趋势图表;
使用代码执行环境(如调用python_inter工具)对流失用户进行特征分析,确定典型特征;
通过统计分析工具识别影响用户流失的关键因素(如服务质量、价格敏感度、竞争对手促销),同时借助绘图工具(fig_inter)进行重要信息可视化展示;
使用互联网检索工具检索行业内最新的客户保留策略与实践,提出有效的策略建议。
记住,回答务必详细完整,字数至少在2000字以上,清晰展示你是如何运用各种外部工具进行深入研究并形成专业结论的。
"""
response = self.client.chat.completions.create(model=self.model,
messages=[{"role": "user", "content": prompt_style1.format(question)}])
display(Markdown("**MiniManus:**" + response.choices[0].message.content))
new_messages = [
{"role": "user", "content": question},
response.choices[0].message.model_dump()
]
new_question = input("请输入您的补充说明(输入退出以结束对话): ")
if new_question == "退出":
return None
else:
new_messages.append({"role": "user", "content":prompt_style2.format(new_question)})
second_response = chat_base(messages=new_messages,
client=self.client,
model=self.model)
display(Markdown("**MiniManus**:" + second_response.choices[0].message.content))
save_markdown_to_file(content=second_response.choices[0].message.content,
filename_hint=question)
def clear_messages(self):
self.messages = []
miniManus = miniManusClass()
- 基本多轮对话和自我认知测试
miniManus.chat()
- 调用外部工具测试
需要重新实例化一个miniManus,否则会继承之前的对话信息
miniManus_tools_test = miniManusClass()
miniManus_tools_test.chat()
telco_data
- 联网测试
miniManus_search_test = miniManusClass()
miniManus_search_test.chat()
- 任务模式测试
miniManus_task_test = miniManusClass()
question = "请帮我详细介绍下大模型最新MCP技术"
miniManus_task_test.research_task(question)
- 复杂数据分析测试
miniManus1 = miniManusClass()
miniManus1.chat()
miniManus1.messages
miniManus1.chat()
telco_data.head()
- 机器学习建模测试
miniManus1.chat()
miniManus1.chat()