GPT-5实战公开课
Part 1.GPT-5模型快速上手与接入指南
一、OpenAI最新旗舰:GPT-5模型入门
1. GPT-5模型入门介绍
当地时间8月7号,OpenAI正式发布最新一代旗舰大模型GPT-5,这是两年以来(自GPT-4发布以来)GPT系列模型的最大更新,同时也是OpenAI基座模型研发方面的一次重大创新突破。

GPT-5模型同时拥有Multi-Function calling、多模态、可控推理程度以及可控输出详细程度等各项最顶尖的基座模型特性,并且在推理、编程、工具调用、长文本等能力刷爆各大评分榜单榜单,而且在第三方评测榜单上也以绝对优势登顶第一。
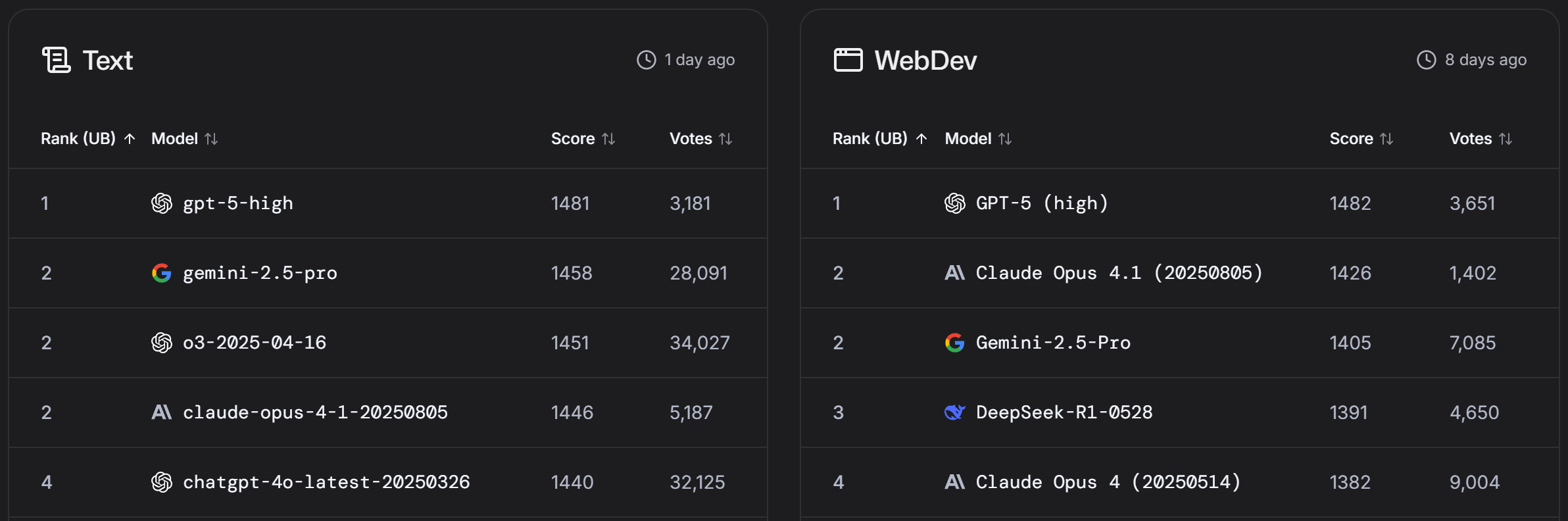
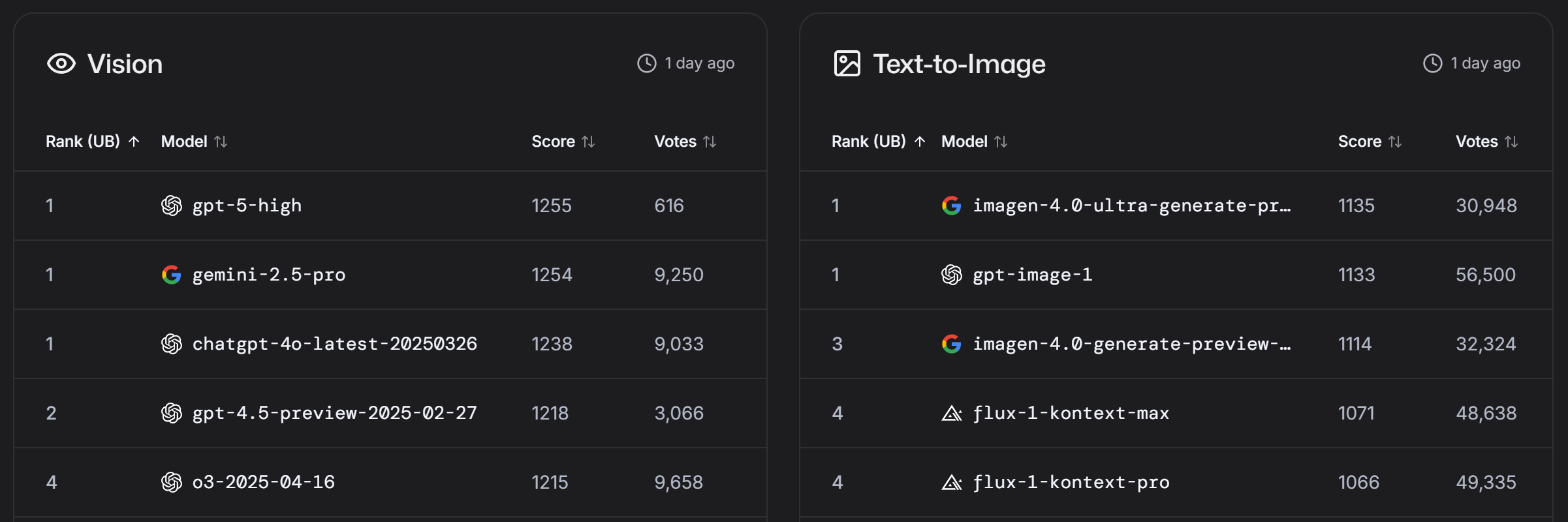
大模型竞技场地址:https://lmarena.ai/leaderboard
此外,GPT-5模型拥有三个尺寸,可以灵活应用于不同场景,

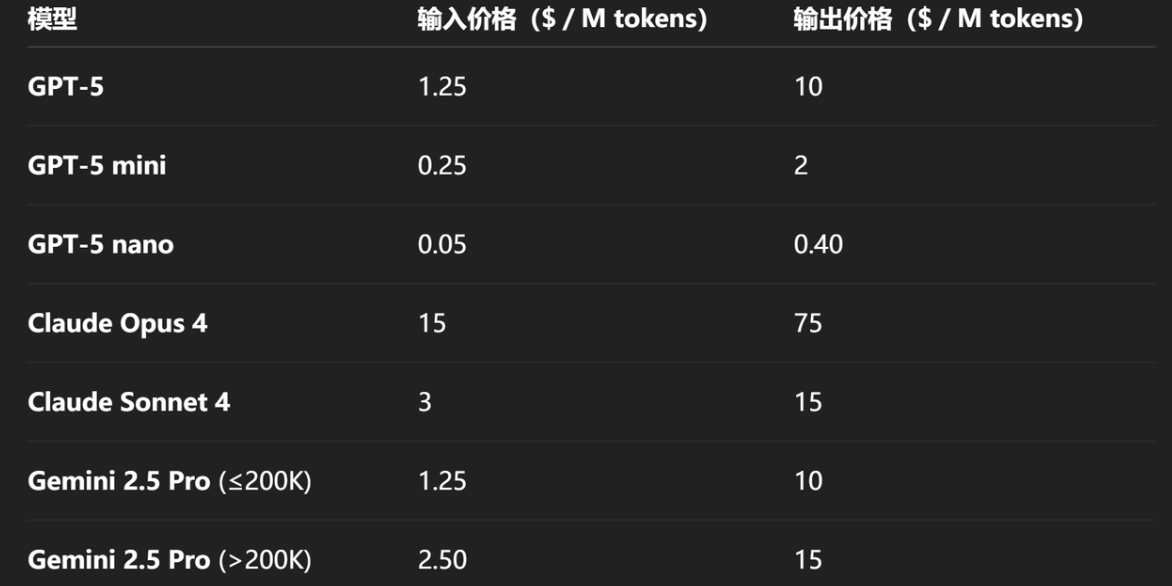
并且模型价格也非常亲民,与旗舰款模型与Gemini 2.5 Pro模型同价,并且仅为Claude 4 Opus的1/5。
总的来说,GPT-5模型是目前同价位下性能最强大模型,并且拥有最顶尖的开发特性以及稳定的并发调用,是Vibe Coding、Agent开发的不二之选。
本期公开课,我就将为大家系统介绍GPT-5模型特性,详细介绍如何上手使用GPT-5模型,以及如何借助GPT-5模型搭建RAG知识库问答系统与Agent系统。
2. GPT-5模型相关资料
-
GPT-5官网介绍:https://openai.com/gpt-5/
-
GPT-5深度解读:https://www.bilibili.com/video/BV18YtCzoEue/

-
GPT-5模型性能测试:https://www.bilibili.com/video/BV1kLtmzREMr/

3. GPT-5公开课资料与赠送材料
-
公开课课件领取:
包含《GPT-5账号注册与API-KEY获取指南》、《GPT-5模型调用方法》、《GPT-5模型Agent开发指南等》各项资料。

-
公开课配套附赠资料:
-
GPT-5模型测试提示词模板
-
OpenAI国内反向代理地址使用方法
粉丝&学员专享,无需网络门槛和其他任何费用,即可直连OpenAI官方服务器调用GPT-5大模型:
-
-
公开课目录:
[toc]
二、GPT-5模型介绍
1. GPT-5模型官方评分
1.1 GPT-5模型智力方面评分
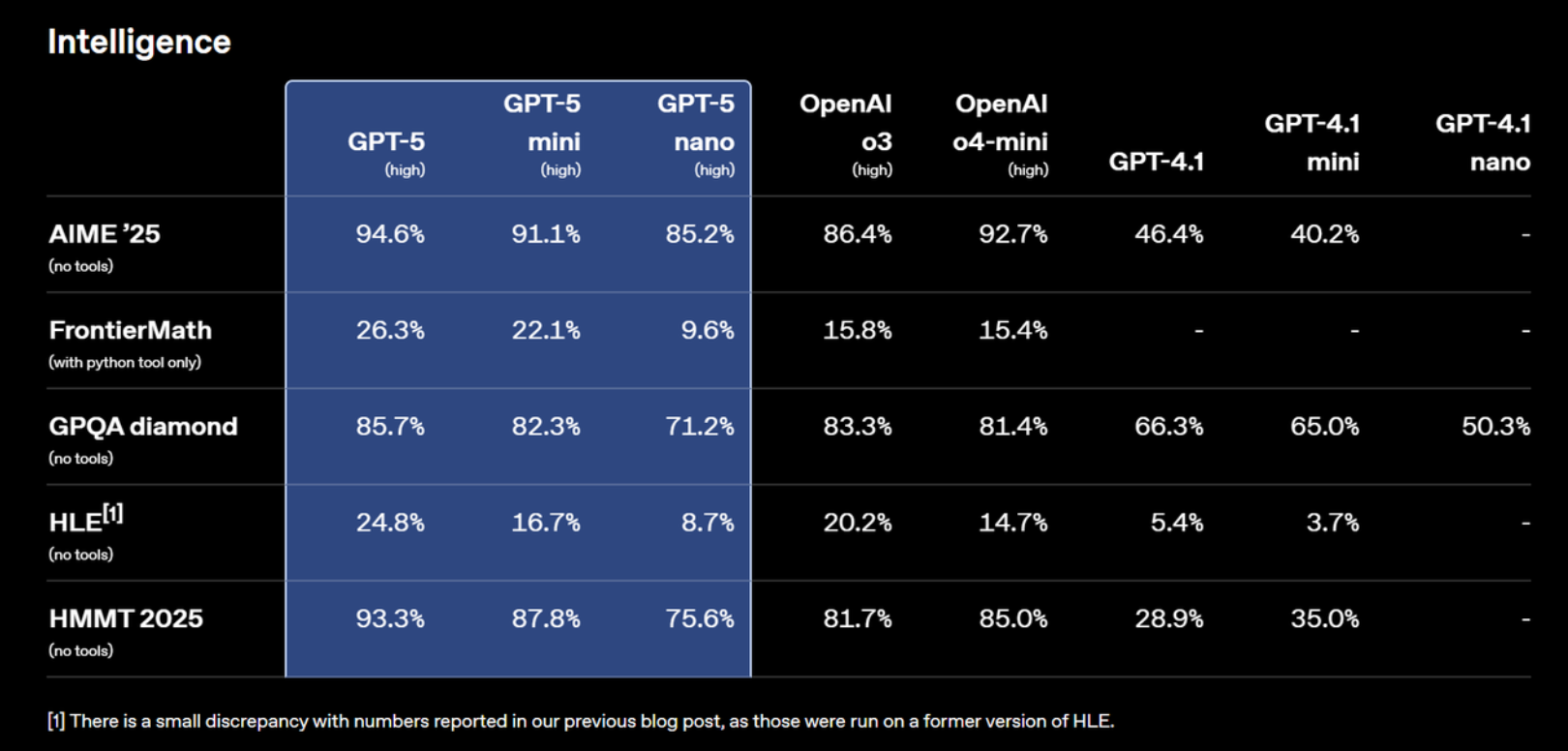
GPT-5在 AIME ’25(数学竞赛题,无工具)中,GPT-5(high 配置)取得了 94.6% 的高分,较 GPT-4.1(46.4%)和 o3(86.4%)均有明显提升,尤其在 GPT-5 mini 与 nano 版本中依旧保持了 91.1% 与 85.2% 的领先水平,展现了模型在数学推理与精确计算领域的强大稳健性。
在 FrontierMath(仅可调用 Python 工具)任务中,GPT-5 high 的得分为 26.3%,相较 o3 的 15.8% 提升显著,这表明 GPT-5 在需要工具配合的复杂数学场景下,具备更高的计算与推理效率。尽管 mini 与 nano 版本得分相对较低(22.1% 与 9.6%),但仍优于多数非推理专用模型。
GPQA diamond(高难度知识问答,无工具)结果进一步印证了 GPT-5 的综合知识能力。GPT-5 high 在此项中取得 85.7%,明显优于 GPT-4.1(66.3%)及 o3(83.3%),而 mini 与 nano 版本也分别达到 82.3% 与 71.2%,表现稳健。
在代表极端推理难度的 HLE(无工具)测试中,GPT-5 high 的成绩为 24.8%,虽绝对数值仍有提升空间,但已高于 GPT-4.1(5.4%)与 o3(20.2%),显示其在长链路复杂推理场景中的进步。
HMMT 2025(高阶数学团队竞赛题,无工具)是另一项高门槛测试,GPT-5 high 取得 93.3%,接近满分水准,大幅领先 GPT-4.1(28.9%)与 o3(81.7%)。mini 与 nano 版本也保持了 87.8% 与 75.6% 的优异成绩。
总体来看,GPT-5 在数学推理、知识问答以及高难度逻辑推理任务中均展现出跨版本的性能优势,不仅高配版本在绝对得分上遥遥领先,轻量化的 mini 与 nano 版本也延续了较高的性能下限。这意味着 GPT-5 系列在不同计算资源条件下,均能为用户提供稳定、强大的智力支持,特别适合需要高准确率与广覆盖知识能力的应用场景。
1.2 GPT-5模型代码能力评分
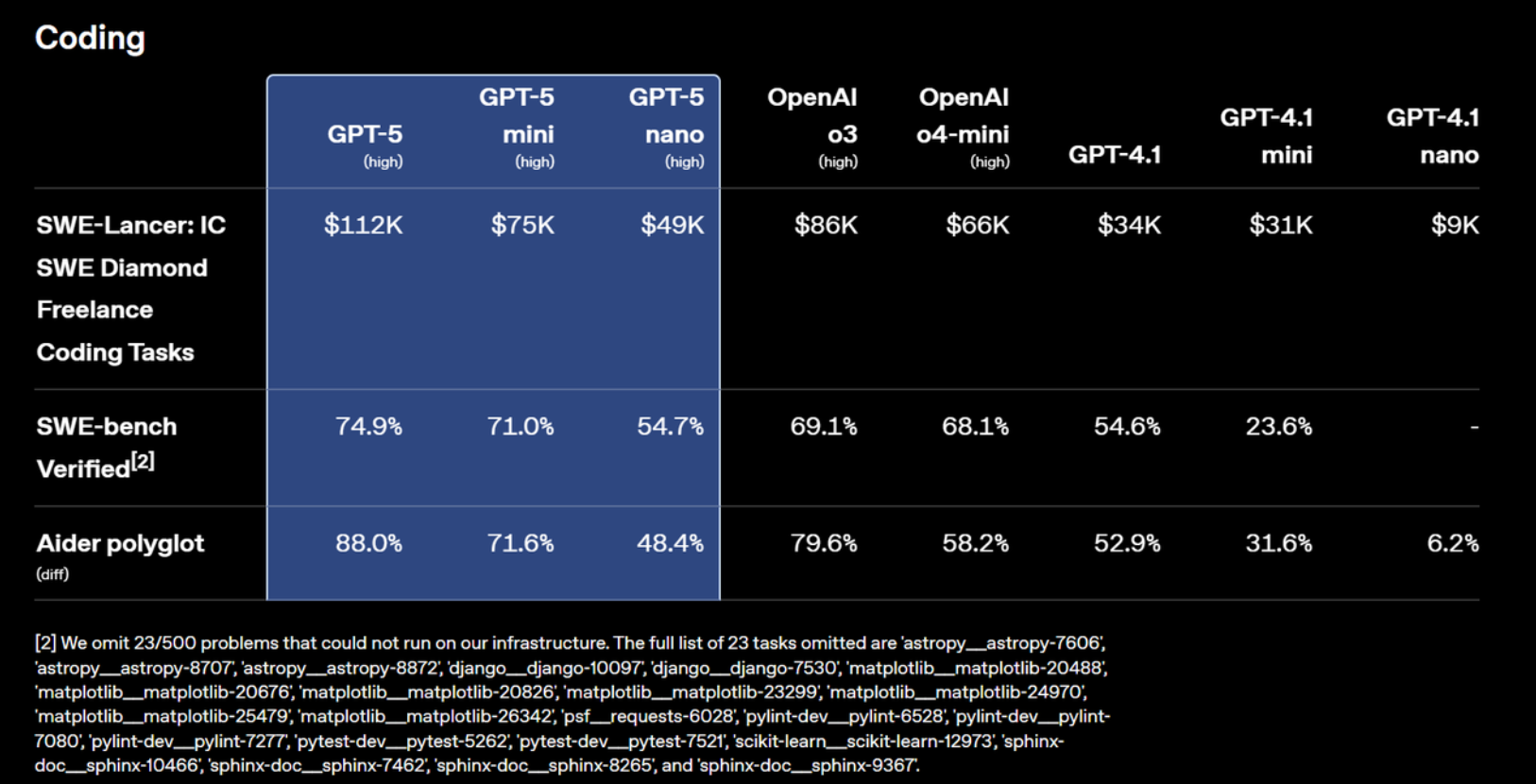
从编程与软件工程相关的测试结果来看,GPT-5 系列在多项高强度代码生成与修复任务中展现出了全面的优势。尤其是在 SWE-Lancer: IC SWE Diamond Freelance Coding Tasks 这一高度模拟真实自由职业开发任务的基准中,GPT-5(high 配置)实现了 $112K 的虚拟收益评估,显著高于 o3($86K)与 o4-mini($66K),并远超 GPT-4.1($34K)。即便是资源占用更低的 GPT-5 mini 与 nano 版本,也分别达到 $75K 和 $49K,在效率与成本之间保持了优异的平衡。
在被视为代码自动化能力黄金标准的 SWE-bench Verified 测试中,GPT-5 high 的准确率达到了 74.9%,较 o3 的 69.1% 和 GPT-4.1 的 54.6% 有明显提升,显示出其在实际软件缺陷修复与集成测试场景中的稳定性与成功率。GPT-5 mini 也能维持在 71.0%,而 nano 版本虽有所下降(54.7%),但依旧超过了 GPT-4.1 mini 的 23.6%。
在跨语言、多样化代码编辑与差异合并任务 Aider polyglot 测试中,GPT-5 high 获得了 88.0% 的高分,较 o3(79.6%)和 GPT-4.1(52.9%)均有显著优势。这一结果表明,GPT-5 不仅在单一语言环境中具备出色能力,在需要多语言混合与上下文切换的复杂软件维护场景中同样表现卓越。
整体来看,GPT-5 在软件工程领域的优势不仅体现在高配版本的绝对性能,还在于轻量版本依旧保持了竞争力。这意味着,无论是在高算力场景下追求极致性能,还是在资源受限的条件下部署高效模型,GPT-5 系列都能提供高水准的代码生成、缺陷修复与跨语言协作能力,为自动化软件开发、代码审查以及智能编程助手等应用提供了坚实的技术支撑。
1.3 GPT-5模型指令跟随能力评分
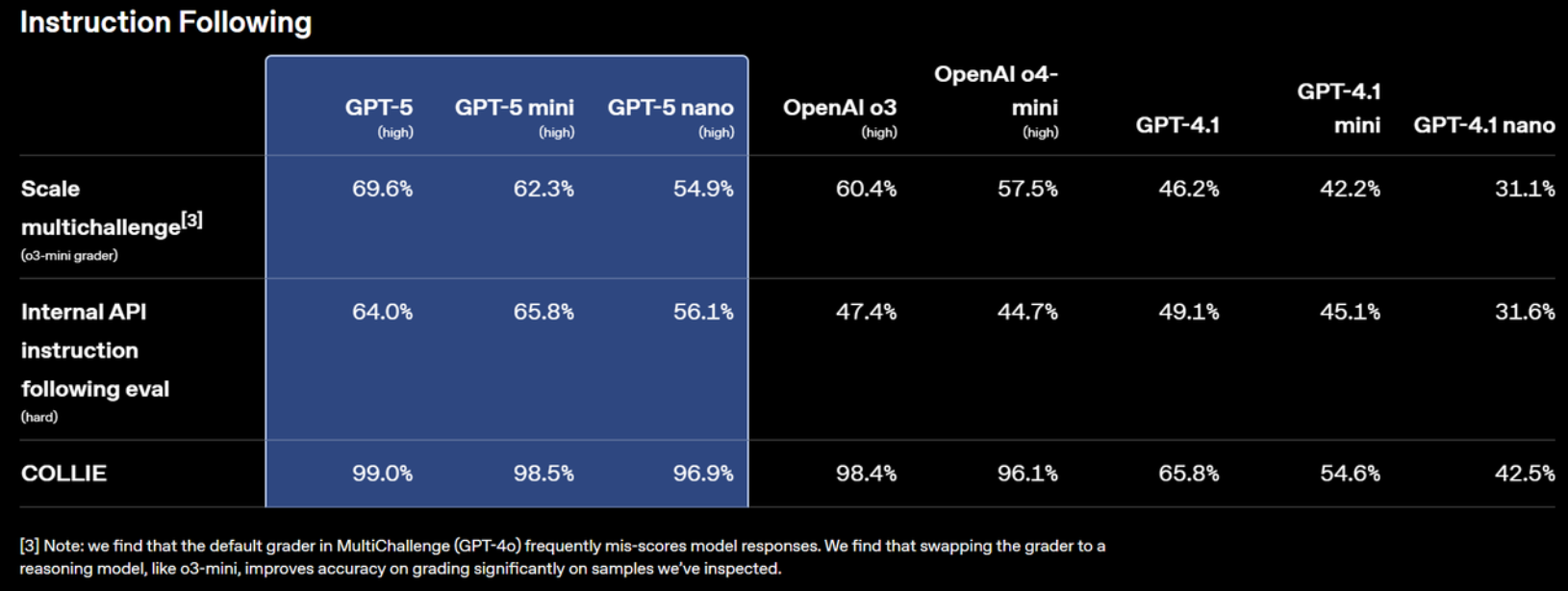
在指令跟随(Instruction Following)方面,GPT-5 系列在多项严苛评测中均展现了显著优势,延续并扩大了相较前代模型的性能领先幅度。
在 Scale multichallenge(多任务规模化挑战)测试中,GPT-5 high 取得 69.6% 的成绩,明显高于 o3(60.4%)及 GPT-4.1(46.2%),充分体现了其在多任务、跨领域指令执行中的适应性与稳定性。即便在轻量化版本中,GPT-5 mini 依然保持 62.3%,nano 版本为 54.9%,在同类尺寸模型中也处于领先水平。
在 Internal API instruction following eval(内部 API 高难度指令跟随评测)中,GPT-5 系列的表现同样突出。GPT-5 high 达到 64.0%,而 GPT-5 mini 更是达到 65.8%,均显著优于 o3(47.4%)与 GPT-4.1(49.1%)。这一结果表明,GPT-5 在高复杂度、规则严格的指令场景下,能更准确地理解需求并执行响应。
在强调一致性与可靠性的 COLLIE 测试中,GPT-5 high 几乎达到了满分 99.0%,接近人类专家级的稳定性。GPT-5 mini 和 nano 版本也分别获得 98.5% 与 96.9% 的高分,远超 GPT-4.1(65.8%)及其衍生版本。这表明 GPT-5 在长对话、多轮指令执行、需要持续保持上下文一致性的任务中,具备极高的可靠性。
综合来看,GPT-5 系列在指令跟随任务中不仅显著领先于前代和同类模型,而且在不同计算规格下都保持了高水准的表现。这种在高精度、多任务及一致性方面的全面优势,使得 GPT-5 在企业自动化流程控制、复杂 API 调用编排以及多步骤任务管理等领域的应用潜力更加突出。
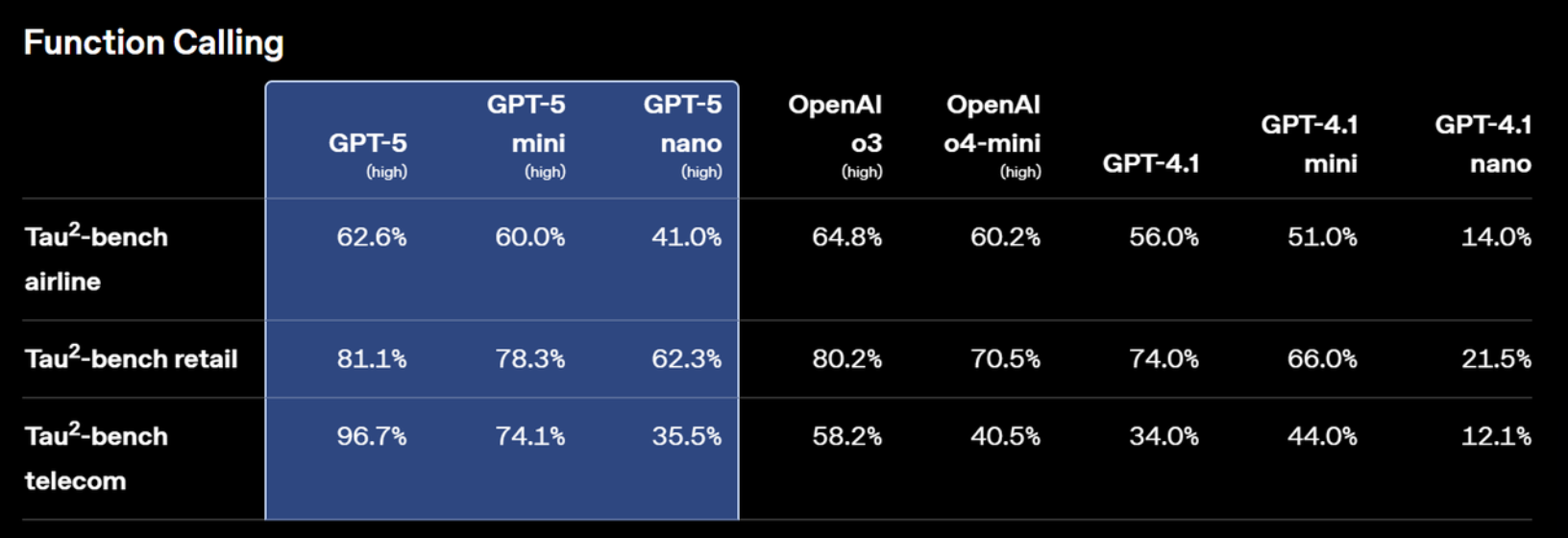
1.4 GPT-5模型工具调用能力评分
在指令跟随(Instruction Following)方面,GPT-5 系列在多项严苛评测中均展现了显著优势,延续并扩大了相较前代模型的性能领先幅度。
在 Scale multichallenge(多任务规模化挑战)测试中,GPT-5 high 取得 69.6% 的成绩,明显高于 o3(60.4%)及 GPT-4.1(46.2%),充分体现了其在多任务、跨领域指令执行中的适应性与稳定性。即便在轻量化版本中,GPT-5 mini 依然保持 62.3%,nano 版本为 54.9%,在同类尺寸模型中也处于领先水平。
在 Internal API instruction following eval(内部 API 高难度指令跟随评测)中,GPT-5 系列的表现同样突出。GPT-5 high 达到 64.0%,而 GPT-5 mini 更是达到 65.8%,均显著优于 o3(47.4%)与 GPT-4.1(49.1%)。这一结果表明,GPT-5 在高复杂度、规则严格的指令场景下,能更准确地理解需求并执行响应。
在强调一致性与可靠性的 COLLIE 测试中,GPT-5 high 几乎达到了满分 99.0%,接近人类专家级的稳定性。GPT-5 mini 和 nano 版本也分别获得 98.5% 与 96.9% 的高分,远超 GPT-4.1(65.8%)及其衍生版本。这表明 GPT-5 在长对话、多轮指令执行、需要持续保持上下文一致性的任务中,具备极高的可靠性。
综合来看,GPT-5 系列在指令跟随任务中不仅显著领先于前代和同类模型,而且在不同计算规格下都保持了高水准的表现。这种在高精度、多任务及一致性方面的全面优势,使得 GPT-5 在企业自动化流程控制、复杂 API 调用编排以及多步骤任务管理等领域的应用潜力更加突出。
1.5 GPT-5模型幻觉
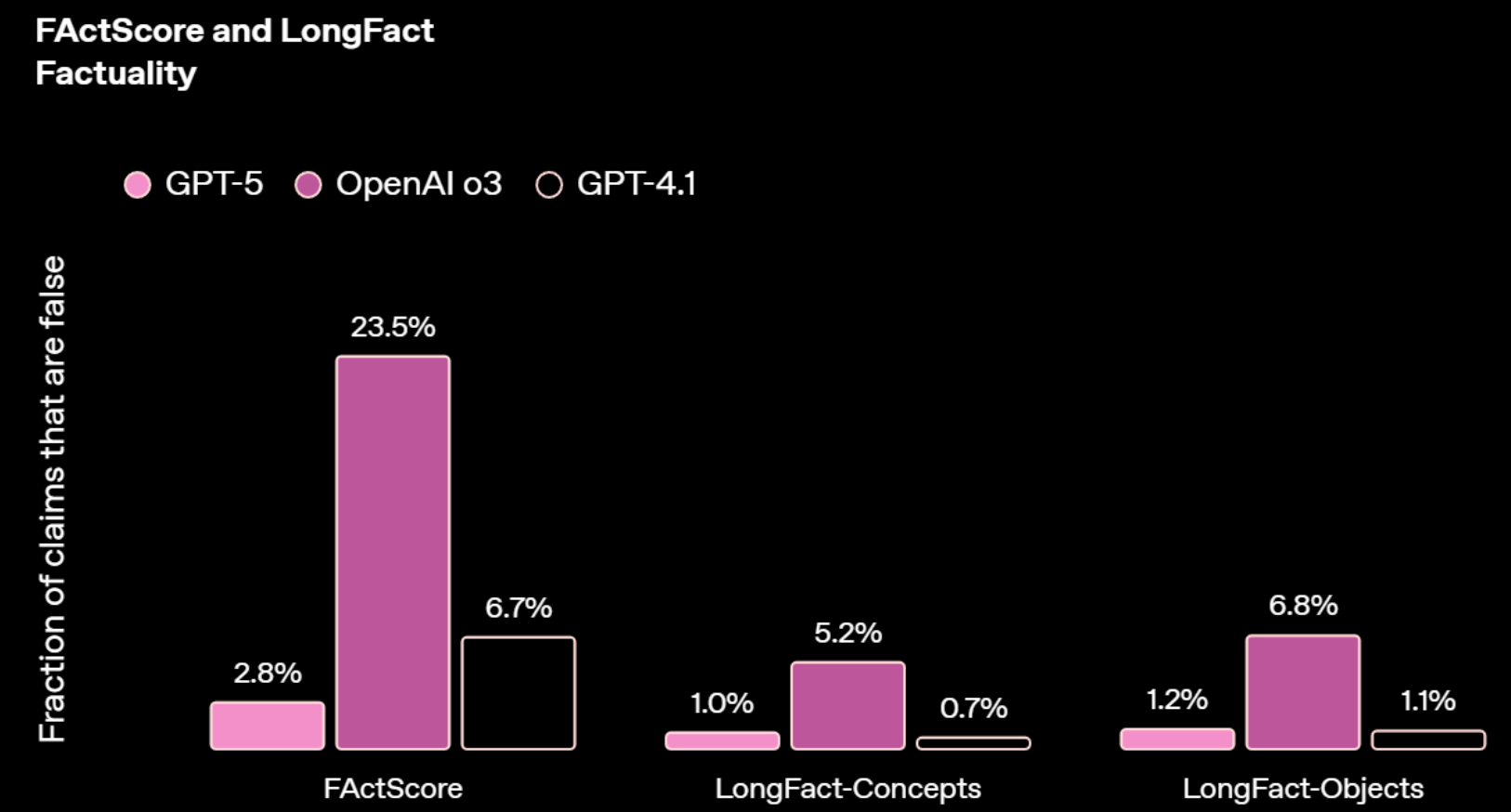
在 FActScore(事实准确性综合评分)指标中,GPT-5 的虚假陈述比例仅为 2.8%,显著低于 o3 的 23.5% 以及 GPT-4.1 的 6.7%。这一结果表明,GPT-5 在一般事实性任务中几乎消除了绝大多数幻觉现象,输出的内容高度可靠。
在更具挑战性的 LongFact-Concepts(长文本概念性事实验证)测试中,GPT-5 的虚假陈述比例仅为 1.0%,同样显著低于 o3(5.2%)和 GPT-4.1(0.7%)。虽然 GPT-4.1 在此项的幻觉率略低于 GPT-5,但两者的差距非常微小,均表现出较强的长文本概念理解与事实保持能力。
在 LongFact-Objects(长文本客体事实验证)任务中,GPT-5 的虚假陈述比例为 1.2%,大幅优于 o3(6.8%)和 GPT-4.1(1.1%)。这表明 GPT-5 在长篇生成中对具体实体与对象相关事实的准确性控制处于领先水平。
综合来看,GPT-5 在事实准确性上相较前代有显著进步,尤其在通用事实性任务中将幻觉率降至接近可忽略的水平。在长文本场景中,GPT-5 依旧能够稳定保持信息的真实性,对减少误导性内容、提升生成可信度具有重要意义。这使得 GPT-5 在需要高可靠性输出的领域(如法律文书生成、医学知识问答、新闻撰写等)中具备更高的实用价值和安全性。
1.6 GPT-5大模型竞技场评分
- 大模型竞技场地址:https://lmarena.ai/leaderboard
2. GPT-5与其他主流模型比较
2.1 GPT-5与其他模型评分对比
| Benchmark / 任务 | GPT-5 (high) | Gemini 2.5 Pro | Grok 4 (Heavy) / Grok 4 | Claude Opus (4.1) |
|---|---|---|---|---|
| Humanity’s Last Exam (HLE) | ≈ 25.3% | ≈ 18.8% | ≈ 44.4% | — (~11.5%) |
| AIME 2025 (数学竞赛,高难度) | ≈ 94.6% (图中) | ≈ 86.7% | ≈ 100% (Heavy)/ 91.7% | ≈ 75.5% |
| GPQA Diamond (PhD 级科学问答) | ≈ 85.7% (图中) | ≈ 84.0% | ≈ 87.5% | ≈ 79.6% |
| SWE-bench Verified (Agentic Coding) | ≈ 74.9% | ≈ 63.8% | ~— | ≈ 72.7% |
| LiveCodeBench / LiveCodeBench v5 | — | ≈ 70.4% | ≈ 79.4% | — |
| MRCR / 长上下文理解能力 | — | ≈ 91.5% (128k context) | — | — |
2.2 GPT-5模型代码能力评测
GPT-5模型性能测试:https://www.bilibili.com/video/BV1kLtmzREMr/

完整提示词包含在课程课件中,扫码即可领取:

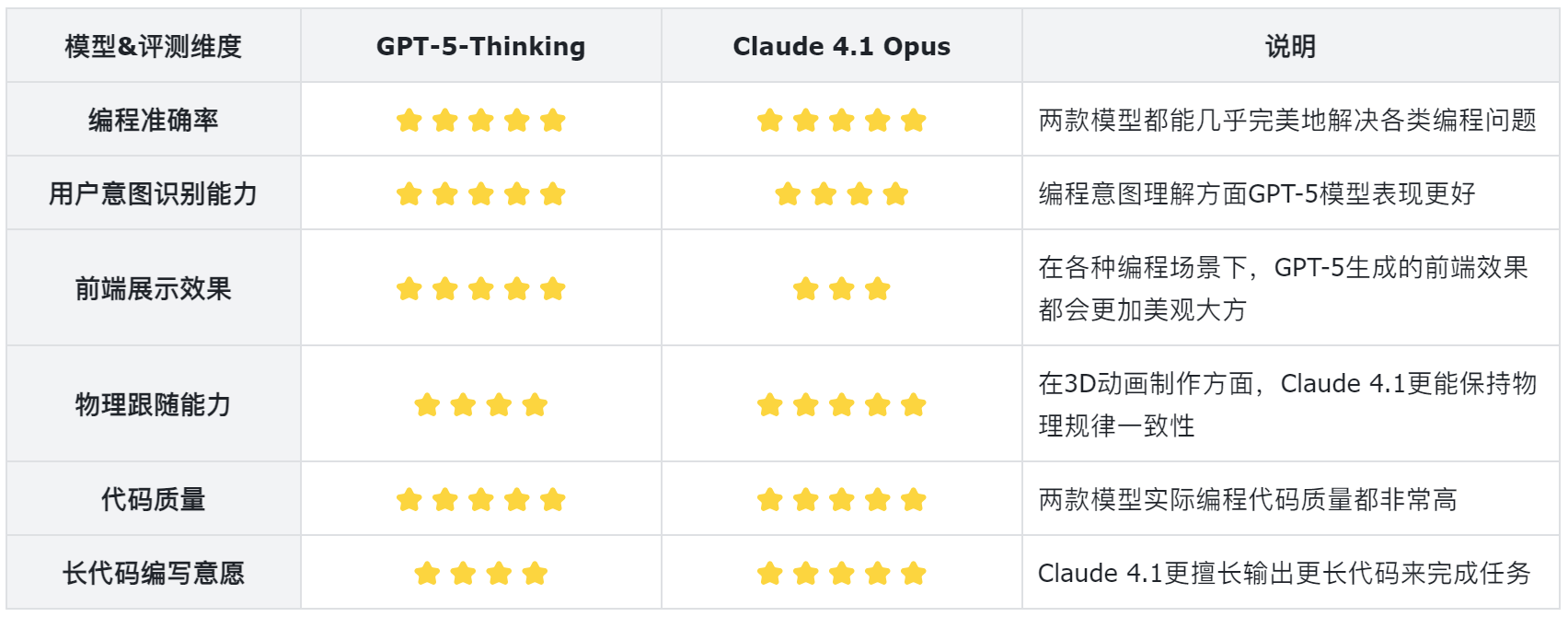
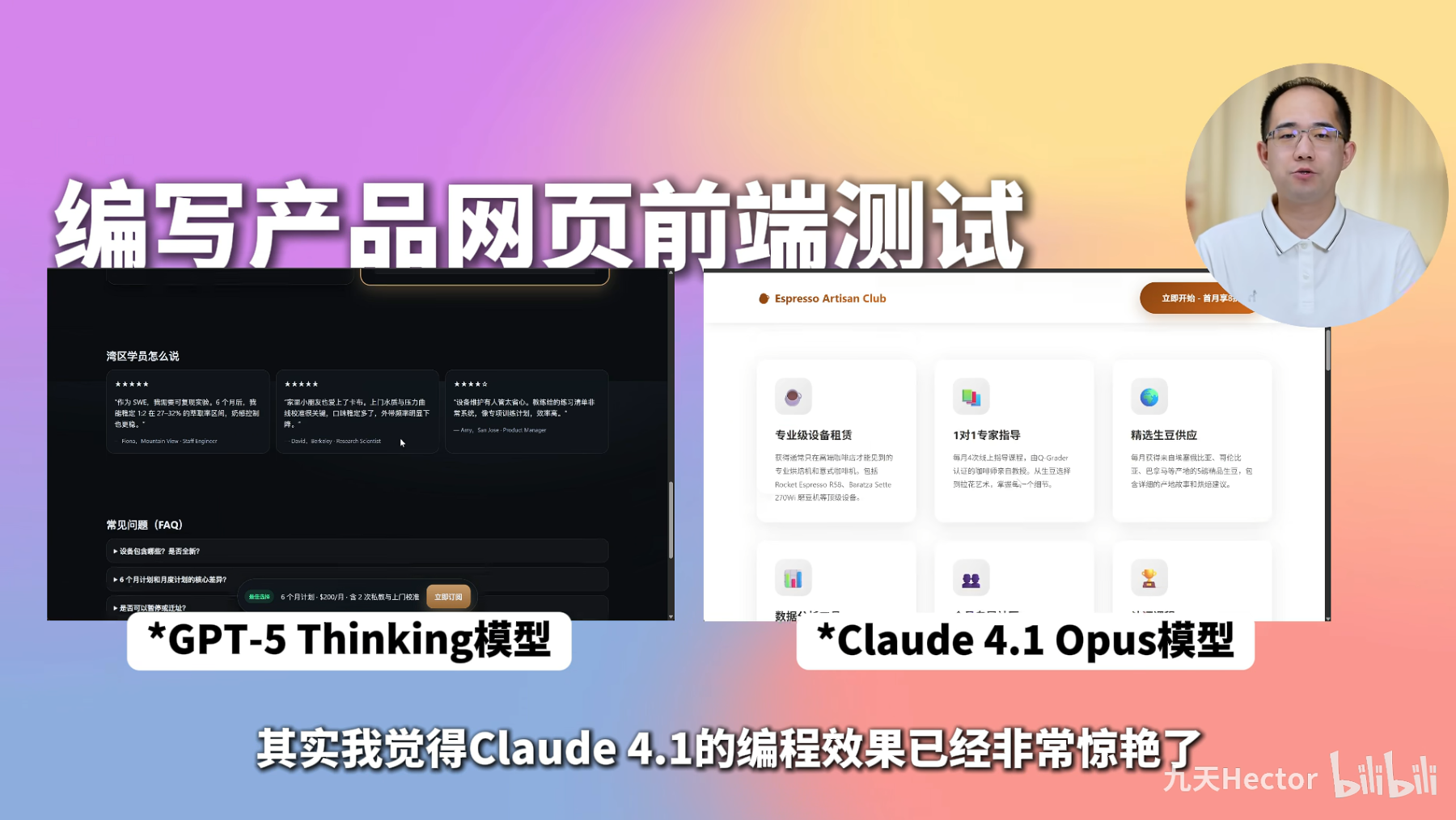
2.3 GPT-5 VS Claude 4.1代码能力评测
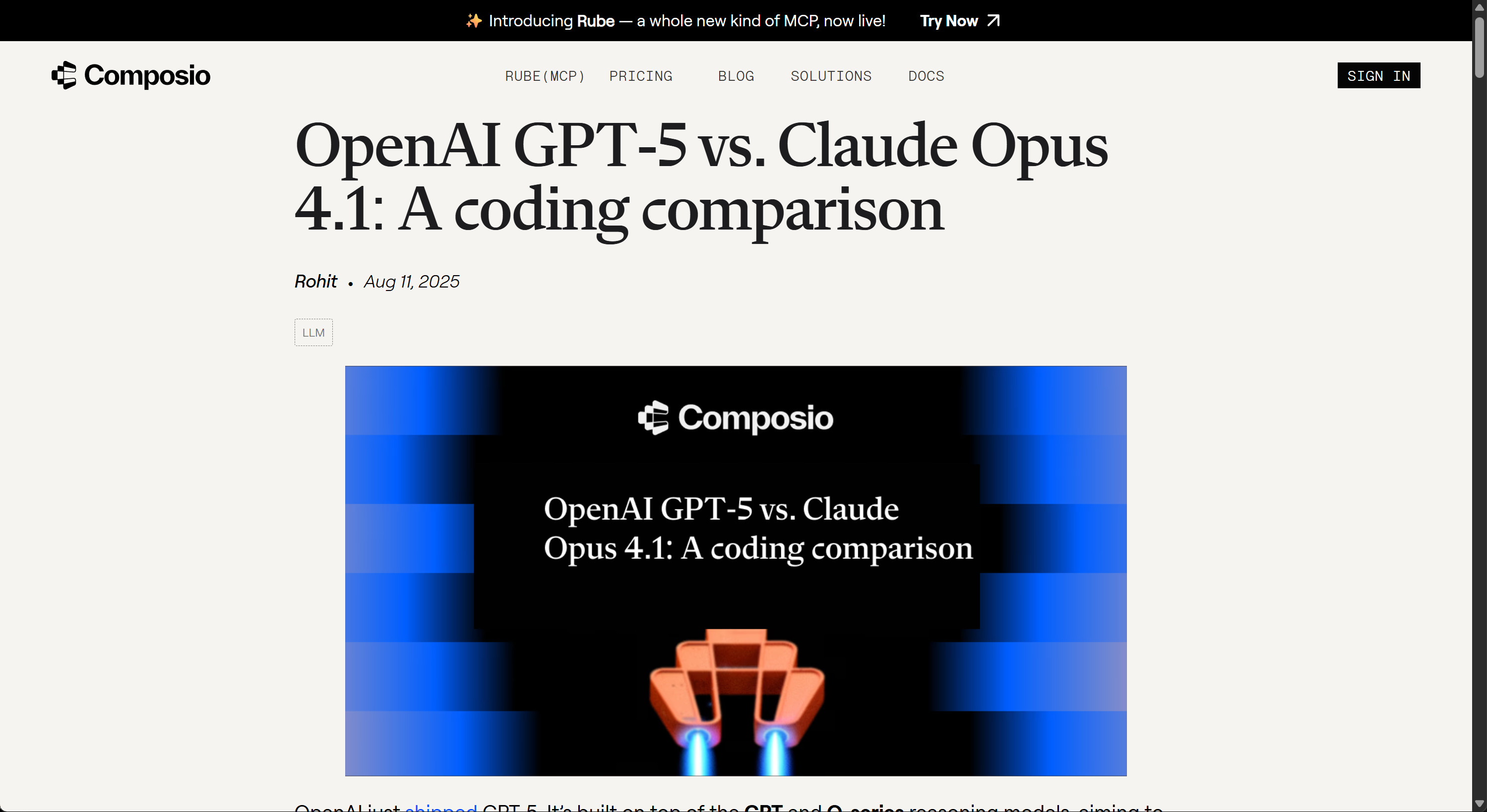
2.3.1 性能与效率对比
- 算算法任务(Algorithm Challenges) GPT‑5 明显胜出,仅使用 8 K tokens 完成测试,而 Claude Opus 4.1 则消耗了约 79 K tokens。这表明 GPT‑5 在算法类问题上更快速且节省计算资源(token)。(composio.dev, composio.dev)
- 基于 Figma 的 Web 开发任务 虽然 Claude Opus 4.1 在将 Figma 设计还原成代码方面展现出更高的“设计还原度”(fidelity),但其使用的 tokens 数量高达 900 K,而 GPT‑5 仅需约 1.4 M+ tokens,耗费更少且更具成本效益 (composio.dev)
- 总体成本对比 根据估算,使用“Thinking”模式下 GPT‑5 的总费用约为 $3.50,而 Claude Opus 4.1 在“双模式(Thinking + Max)”下则需要约 $7.58,GPT‑5 成本仅为对方的 2.3 倍 (composio.dev)
2.3.2 使用场景优劣建议
- GPT‑5 的优势 快速完成算法任务,适用于日常开发与原型构建,成本更低,令其成为“日常开发工作伙伴”的理想选择。(composio.dev, composio.dev)
- Claude Opus 4.1 的优势 更适合注重视觉精度与结构严格度的任务(如客户导向的界面代码),同时提供更清晰的逐步解释,适用于高预算下追求质量与审美一致性的场景 (composio.dev)
3. GPT-5 模型功能特性介绍
3.1 GPT-5 模型混合推理特性
GPT-5 模型作为 OpenAI 最新一代旗舰产品,标志着公司此前“基座模型发展战略”的一次全面收官与升级:将原本相互独立的推理模型(o 系列)与对话模型(GPT 系列)功能彻底融合,打造出一款 All-in-One 的统一模型架构。由此,GPT-5 不再仅仅是对话式语言模型,而是一款同时具备高效交互能力与深度推理能力的混合推理模型(Hybrid Reasoning)。
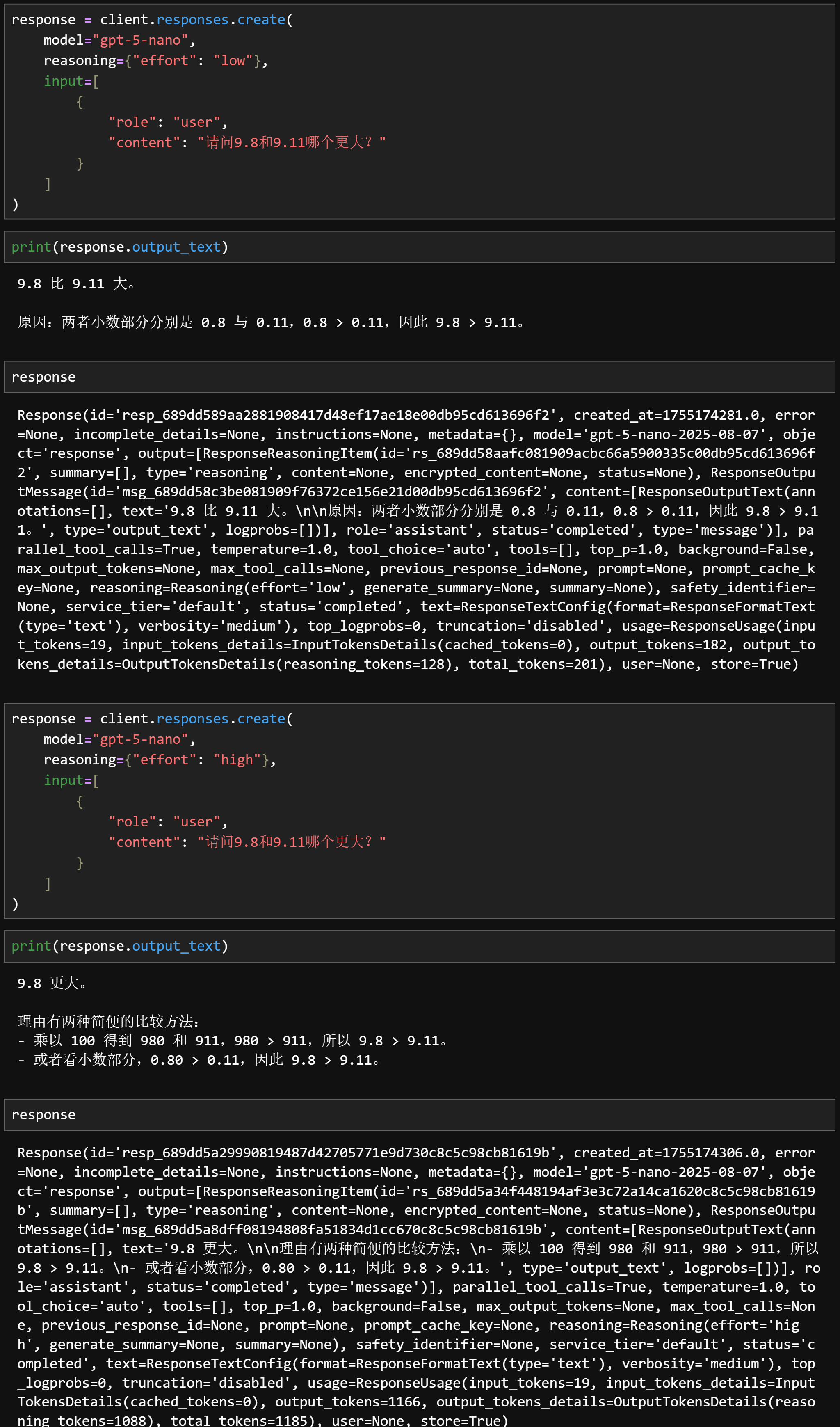
与 Claude 3.7 所采用的“思考预算(Thinking Budget)”机制不同——后者主要通过预设最大思考链(Chain of Thought)Token 数量来限制推理深度——GPT-5 在混合推理模式的设计上更为灵活与自动化。用户既可以通过 API 参数 reasoning.effort 明确指定推理力度(如 minimal、low、medium、high 等),也可以完全交由系统的 智能路由器(Router) 自动判定当前任务的复杂度,并动态切换至最适合的推理路径。
这种混合推理机制带来了以下几个显著优势:
- 任务适配自动化 在日常问答、轻量分析等低复杂度场景中,GPT-5 会优先采用快速模式(Fast Path)以降低延迟和成本;在多步骤推导、复杂代码生成或跨领域推理等高复杂度任务中,则自动切换至深度推理模式(Reasoning Path),确保输出的准确性与逻辑一致性。
- 推理力度可控化
开发者可以通过
reasoning.effort参数直接影响推理链的长度与复杂度。例如,设置为high可让模型生成更完整的中间推理步骤,而minimal则更适合快速响应场景。相比 Claude 的固定 Token 上限机制,这种方式能更细腻地平衡性能、延迟与成本。 - 路由与多模态协同 GPT-5 的混合推理能力不仅局限于文本任务,还可在需要工具调用、代码执行、图像分析等多模态场景下进行智能模式切换。例如,在复杂数据分析任务中,模型可先在推理路径中生成调用工具的计划,再切回快速路径进行结果汇总与自然语言表达,从而在准确性与效率之间实现最优平衡。
- 与推理摘要(Reasoning Summary)结合 在深度推理模式下,GPT-5 支持输出推理摘要,便于开发者理解模型的思考逻辑并进行调试。这种摘要是对内部思考链的安全化提炼,不会泄露完整的原始推理过程,但能提供足够的可解释性。
GPT-5 的混合推理特性不仅在技术架构上实现了对话与推理的无缝融合,还在交互体验上提供了自动化与可控化的双重选择。这种设计为不同使用场景下的性能优化提供了更大弹性,也为未来的多模态协作与复杂任务自动化奠定了坚实基础。
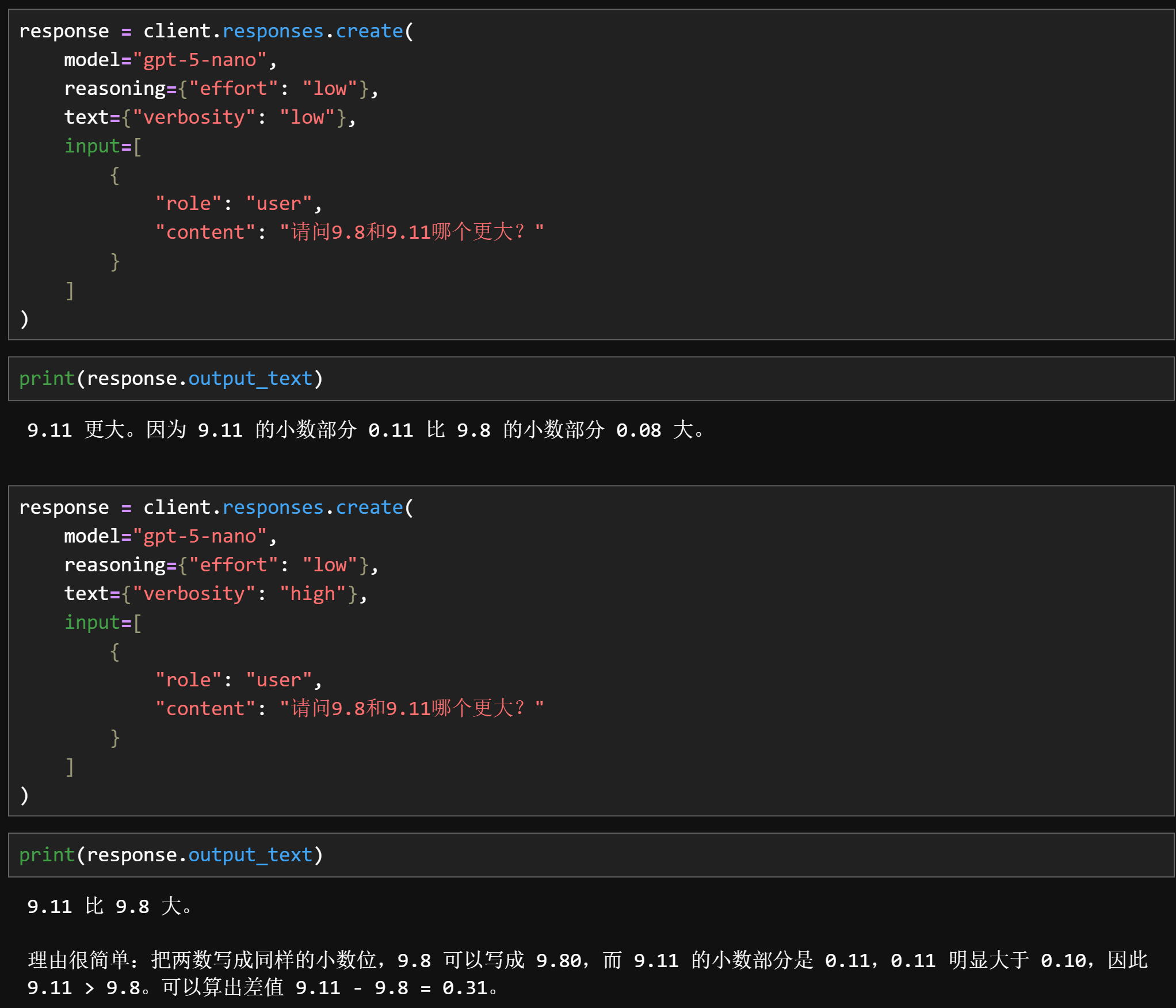
此外,我们还可以通过设置verbose参数来调整模型输出结果的详细程度:
3.2 GPT-5 模型多模态特性
作为 OpenAI 最新一代的旗舰模型,GPT-5 在多模态能力上实现了显著跃升,不仅继承了前代模型在文本与图像理解上的成熟能力,还在输入与输出的模态范围、跨模态推理的深度以及交互体验的连贯性方面做出了系统性优化。
首先,在输入维度上,GPT-5 支持多种类型的模态数据,包括自然语言文本、静态图像以及结构化数据格式(如 JSON、CSV 等)。相比于 GPT-4 系列,GPT-5 在图像理解的细粒度上有明显提升,能够更准确地解析图像中的细节元素(如图表、代码截图、界面布局)并将其映射到高层语义。这一能力对于诸如文档解析、UI/UX 设计审查、图表生成与解释等任务尤为重要。
其次,在跨模态推理方面,GPT-5 能够在单一对话或调用流程中灵活切换不同模态的数据处理。例如,当用户提供一张流程图时,模型不仅可以对其内容进行识别,还能结合上下文中的文本指令生成代码实现或优化建议。这种跨模态链式推理得益于其内部统一的语义表示(Unified Embedding Space),使得不同模态信息在推理过程中能够无缝融合。
在输出能力上,GPT-5 除了生成高质量的自然语言文本外,还可以输出结构化数据(如标准化 JSON)、可执行代码片段、Markdown 格式的技术文档以及自然语言和图像混合的回答形式。在 API 场景下,结合 response_format 参数,开发者可以要求模型在多模态输出中严格遵循指定的结构规范,从而直接对接下游的自动化处理流程。
值得注意的是,GPT-5 在多模态任务中的性能不仅体现在静态任务上,也能与其实时交互能力结合。例如,在配合 OpenAI Realtime API 或其他低延迟传输方案时,GPT-5 可以实现图像上传后的即时解析与响应,这对于现场问答、在线教育和协作设计等场景具有极高的实用价值。
最后,得益于混合推理(Hybrid Reasoning)的集成,GPT-5 在处理多模态数据时能够动态调整推理深度。当图像内容简单且指令明确时,模型会优先使用快速模式以减少延迟;而在图像信息复杂、需多步分析推导的情况下,则会自动切换至深度推理模式,确保输出的完整性与准确性。
总体而言,GPT-5 的多模态特性不仅在感知精度与生成质量上超越前代,更在跨模态推理的一致性、结构化输出的可控性以及低延迟交互体验方面实现了全面升级。这使其在智能文档处理、跨媒体信息检索、视觉编程助手、在线教育辅导等多元化应用中具备了广阔的落地潜力。
- 普通视觉功能
- 视觉推理功能:根据架构图还原并创建整个项目框架

3.3 GPT-5 模型函数调用与工具链支持特性
GPT-5 在函数调用(Function Calling)与工具链(Tool Use)能力方面延续并强化了前代模型的设计,使其不仅能够理解自然语言指令,还能在对话或 API 调用中精准地触发外部函数、接口及复杂工具工作流。这一特性使得 GPT-5 能够在企业级自动化、数据分析、知识检索、API 集成等场景中实现高度的可编程性与可扩展性。
首先,在函数调用精确性方面,GPT-5 的自然语言到函数参数的映射能力得到显著提升。在面对包含多参数、嵌套结构或条件逻辑的复杂函数时,模型能够正确识别参数类型、默认值和约束条件,从而显著减少调用错误率。这种高精度映射不仅提升了交互效率,也降低了后端 API 校验与异常处理的负担。
其次,GPT-5 对**多工具编排(Tool Orchestration)**的支持更加灵活。在单次会话或 API 请求中,模型可根据任务需求调用多个不同类型的工具,并自动规划调用顺序与依赖关系。例如,在数据分析任务中,GPT-5 可先调用检索工具获取数据集,再调用计算引擎执行分析,最后生成可视化图表或结构化报告。这种多工具协同能力尤其适用于多步骤工作流(Multi-step Workflows)与智能体(Agent)系统。
在接口定义与调用格式方面,GPT-5 完全兼容 OpenAI Responses API 的 tools 参数和 JSON Schema 描述方式。开发者可以通过精确定义函数签名、参数类型与约束,让模型在推理过程中自动生成符合规范的调用请求。在生成调用结果后,模型还能够根据工具返回值继续推理,实现闭环的任务执行。例如,在天气查询场景中,模型可以先调用 get_weather(city) 函数,再根据返回的温度与降水概率为用户提供出行建议。
值得一提的是,GPT-5 的混合推理机制在函数调用场景中也表现出色。当模型判断当前任务需要外部工具支持时,会自动进入深度推理模式,以确保调用逻辑的正确性和结果的完整性;在无需复杂分析的简单调用中,则会使用快速模式减少响应时间与成本。
此外,GPT-5 在与多模态输入结合的工具调用上也展现出新能力。例如,用户上传一张图像并询问“帮我统计图表中各类产品的销量并生成柱状图”,模型可先调用图像解析工具提取数据,再调用绘图库生成可视化结果。这种跨模态与函数调用的结合,大幅扩展了 GPT-5 在数据处理、报告生成、知识管理等领域的应用边界。
总体而言,GPT-5 在函数调用与工具链支持方面不仅延续了前代的可编程优势,更在调用精度、多工具协作、跨模态集成以及推理模式自适应等方面进行了系统性强化。这使得其能够在更广泛的生产环境中充当“任务执行核心引擎”,支撑从简单 API 查询到复杂业务流程自动化的全链路智能化实现。