GPT-OSS Agent性能微调
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(秋招冲刺班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(秋招冲刺班)

《2025大模型Agent智能体开发实战》(秋招冲刺班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋招冲刺班)

两门大模型课程秋招冲刺班预售进行中,直播间可享超值特价+全套学习福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


GPT-OSS高效微调实战
Part 4.GPT-OSS Agent性能微调
在熟悉了Unsloth核心功能以及基础的微调数据集准备方法之后,接下来我们尝试进行一项更加复杂的微调工作——围绕GPT-OSS模型进行Agent性能微调。
九、Agent性能微调数据集准备
1. Hermes tool use数据集介绍
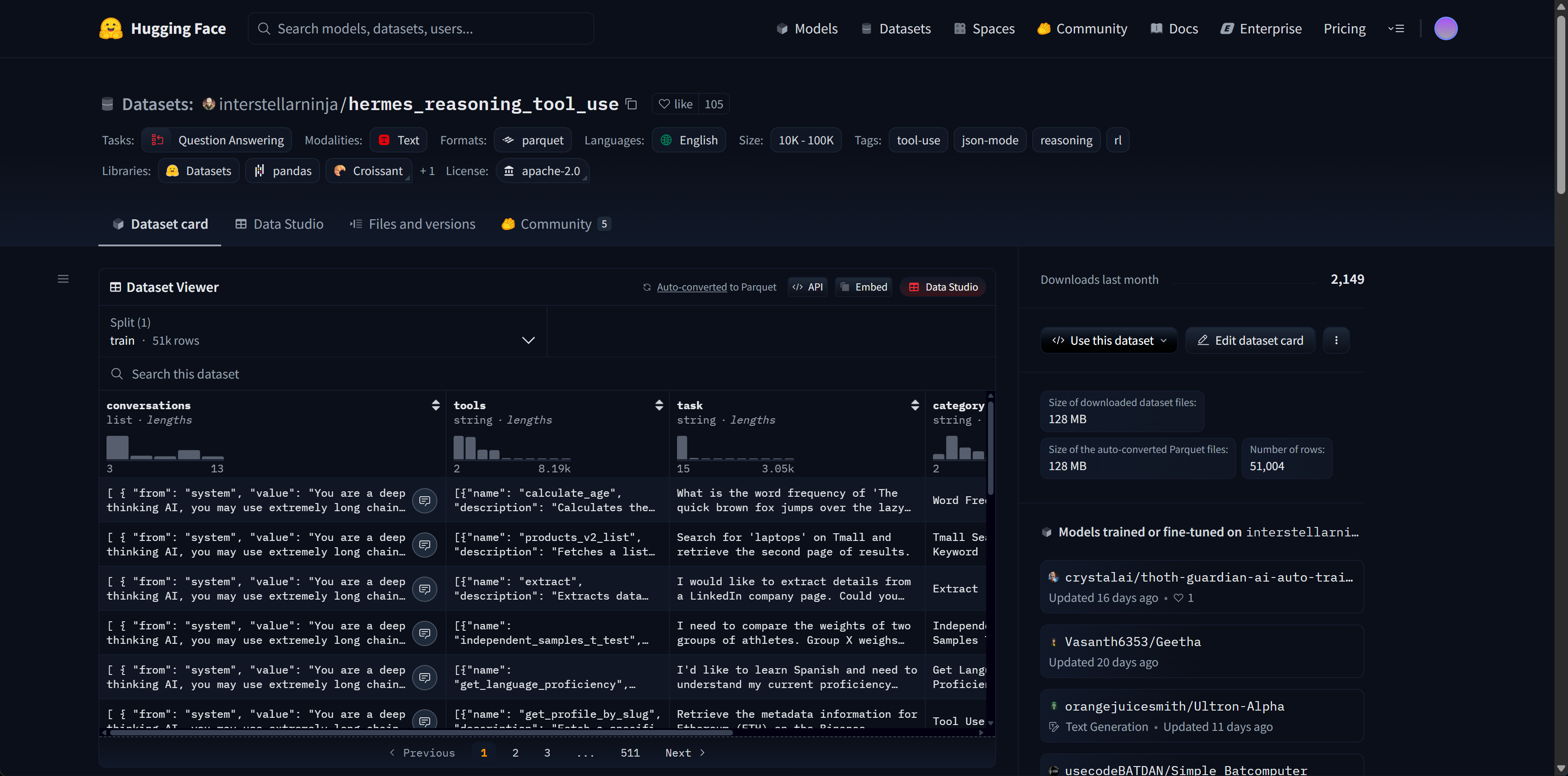
interstellarninja / hermes_reasoning_tool_use 是一个围绕“会思考、会用工具”的开源数据集:采用 Apache-2.0 许可、单一 train 切分约 51,004 条样本(约 392 MB),以 ShareGPT 会话格式存储(Parquet),字段含 conversations / tools / task / category / source / scenario_category,便于直接用 Datasets/axolotl 加载微调。其对话模板在 system 中明确要求将内在推理写入 <think>…</think>,并以 <tool_call>…</tool_call> 输出 OpenAI 风格的函数调用 JSON(含 pydantic schema),非常契合“思考链 + 函数调用”的监督信号。
样本覆盖 BFCL v3 的四类场景:single_turn、multi_turn、multi_step 与 relevance(无合适工具时应拒绝),有助于训练模型“何时/如何/是否”调用工具。构建流程基于 Nous Research 的 Atropos RL 栈,在自定义 MultiTurnToolCallingEnv 中进行 GRPO roll-outs,并通过奖励塑形与严格校验(如 _validate_think_plus_calls、_check_sequential_tools)仅保留结构与语义均合格的轨迹。
并且,数据集包含四种调用格式,single_turn(单轮单调用)、multi_turn(多轮多调用)、multi_step(单轮内**≥2 顺序调用**)、relevance(无合适工具应拒绝)。这天然覆盖了“何时/如何/是否”调用工具的决策学习。
总体而言,这是一个兼具长链推理标注与工具调用轨迹的实用数据集,既可用于 SFT,也可作为 GRPO 预热或评测基座,快速提升模型在真实代理场景下的工具使用稳健性。
- 数据集读取
from datasets import load_dataset, Dataset, Features, Value
import random, json, os
# 原始数据
ds_full = load_dataset("interstellarninja/hermes_reasoning_tool_use", split="train")
ds_full[0]
Hermes Reasoning Tool Use 是一个 “推理 + 工具调用(function calling)” 的教学/微调数据集。它不仅包含自然语言对话,还显式标注了:
- 系统提示(system)里提供的工具签名(函数名、参数等);
- 模型在对话中调用工具的动作(函数名 + 参数);
- 工具的返回结果(带
<tool_response>); - 模型的思维过程(使用
<think>…</think>包裹的内在推理)。
因此它特别适合训练/评估: 何时调用哪个工具、如何构造参数、如何把工具结果融入最终答复、以及多步工具调用的策划与执行。
ds_full
ds_full['task'][:10]
ds_full['source'][:10]
ds_full['scenario_category'][:10]
数据集每条样本通常包含以下顶层字段:
-
conversations:对话轮次(list)。每轮有:-
from:system/human/gpt/tool -
value:该轮文本。- system 轮里常见
<tools> … </tools>(提供函数签名) - gpt 轮里可能含
<think>…</think>与一个或多个<tool_call> … </tool_call> - tool 轮里含
<tool_response> … </tool_response>
- system 轮里常见
-
-
tools:工具清单(有时是 字符串化 JSON,有时是 list[dict])。与 system 里的<tools>一致或互补。 -
task:该样本的人类任务简述。 -
category:任务类别(如Is Hotel Available、Tool Use、Get Stock Price等)。 -
source:来源(如Nvidia-When2Call、ToolAce、Glaive、Nous-Hermes、Salesforce-Xlam)。 -
scenario_category:场景类型:single:单轮对话 + 单次或多次调用(在一轮内发起多个工具调用)multiturn:多轮往返multistep:需要按顺序完成多个工具步骤relevance:强调选择相关工具(干扰项较多)
⚠️ 真实数据里 类型并不总统一:
tools可能是字符串,也可能是对象数组;parameters.type可能写成"dict"(理想应为"object");required可能放在工具外层而不是parameters.required;- 有的属性缺失
description。 这就是我们清洗规范化要解决的。
- 单工具调用示例
ds_full[0]['conversations']
- 多工具并行调用示例
ds_full[1]['conversations']
- 多轮对话+工具调用示例
ds_full[2]['conversations']
- 无干预下多轮工具调用示例
ds_full[4]['conversations']
2. Hermes tool use数据集清洗
import re, json, ast
from copy import deepcopy
from datasets import load_dataset
# ========= 1) 类型映射:把简写类型转为 JSON Schema =========
def _map_type(t: str):
t = (t or "").strip()
if t.lower() in ("str", "string"):
return {"type": "string"}
if t.lower() in ("int", "integer"):
return {"type": "integer"}
if t.lower() in ("float", "number"):
return {"type": "number"}
if t.lower() in ("bool", "boolean"):
return {"type": "boolean"}
if t.startswith("List[") and t.endswith("]"):
inner = t[5:-1].strip()
inner_schema = _map_type(inner)
return {"type": "array", "items": {"type": inner_schema.get("type", "string")}}
# 兜底
return {"type": "string"}
import json, ast, re
# 1) 兜底的类型映射
def _map_base_type(t: str) -> str:
t = (t or "string")
if isinstance(t, str):
t = t.strip().lower()
else:
t = str(t).strip().lower()
# 去掉 like "bool, optional"
t = t.split(",")[0].strip()
MAP = {
"str": "string", "string": "string",
"int": "integer", "integer": "integer",
"float": "number", "number": "number",
"bool": "boolean", "boolean": "boolean",
"dict": "object", "object": "object",
"array": "array", "list": "array",
}
return MAP.get(t, "string")
# 2) 将各种 parameters 归一化为 JSON Schema
def _normalize_parameters_to_jsonschema(params) -> dict:
if not isinstance(params, dict):
return {"type": "object", "properties": {}}
if params.get("type") in ("object", "dict") and "properties" in params:
schema = dict(params)
if schema["type"] == "dict":
schema["type"] = "object"
props = {}
for p, spec in (schema.get("properties") or {}).items():
if not isinstance(spec, dict):
spec = {}
base = _map_base_type(spec.get("type", "string"))
props[p] = {
"type": base,
"description": spec.get("description", ""), # ← 必有描述
}
req = schema.get("required")
if not isinstance(req, list):
req = list(props.keys())
return {"type": "object", "properties": props, "required": req}
# 简写 -> 正规化
props, required = {}, []
for p, spec in (params.items() if isinstance(params, dict) else []):
if not isinstance(spec, dict):
spec = {}
base = _map_base_type(spec.get("type", "string"))
props[p] = {
"type": base,
"description": spec.get("description", ""), # ← 必有描述
}
required.append(p)
return {"type": "object", "properties": props, "required": required}
# 3) Hermes tools → gpt-oss tools(超稳健版)
def hermes_tools_to_gptoss_tools(hermes_tools):
out = []
if not hermes_tools:
return out
for t in hermes_tools:
if isinstance(t, str):
try:
t = json.loads(t)
except Exception:
try:
import ast
t = ast.literal_eval(t)
except Exception:
continue
if not isinstance(t, dict):
continue
fn = t["function"] if (t.get("type") == "function" and isinstance(t.get("function"), dict)) else t
name = (fn.get("name") or "").strip()
if not name:
continue
desc = fn.get("description") or "" # ← 必有 description
params = fn.get("parameters") or {}
schema = _normalize_parameters_to_jsonschema(params)
# ---- 补齐 properties 里的 type/description ----
if schema.get("type") == "object" and isinstance(schema.get("properties"), dict):
for p, spec in list(schema["properties"].items()):
if not isinstance(spec, dict):
spec = {}
spec.setdefault("type", "string")
spec.setdefault("description", "")
schema["properties"][p] = spec
# ---------------------------------------------
out.append({
"type": "function",
"function": {
"name": name,
"description": desc,
"parameters": schema,
},
})
return out
# ========= 3) 从 system 文本里提取/去掉 <tools>... 块 =========
_TOOLS_BLOCK_RE = re.compile(r"<tools>(.*?)</tools>", re.DOTALL)
def strip_tools_block(text: str) -> str:
if not text:
return text
return _TOOLS_BLOCK_RE.sub("", text).strip()
def extract_tools_from_system(text: str):
"""尽力从 <tools>...</tools> 中解析出 Python 列表或 JSON 列表;失败则返回 []."""
if not text:
return []
m = _TOOLS_BLOCK_RE.search(text)
if not m:
return []
raw = m.group(1).strip()
# 尝试 JSON
try:
return json.loads(raw)
except Exception:
pass
# 尝试 Python 字面量(Hermes 常用单引号)
try:
val = ast.literal_eval(raw)
return val if isinstance(val, list) else []
except Exception:
return []
# ========= 4) 解析 assistant 的 <think> 与 <tool_call> =========
_THINK_RE = re.compile(r"<think>(.*?)</think>", re.DOTALL)
_TOOLCALL_RE = re.compile(r"<tool_call>\s*(\{.*?\})\s*</tool_call>", re.DOTALL)
def parse_assistant_content(value: str):
"""返回 (thinking:str|None, tool_calls:list[{'function':{'name', 'arguments'}}])"""
if not value:
return None, []
thinking = None
m = _THINK_RE.search(value)
if m:
thinking = m.group(1).strip()
calls = []
for m in _TOOLCALL_RE.finditer(value):
blob = m.group(1)
try:
obj = json.loads(blob)
except Exception:
# 单引号风格
try:
obj = ast.literal_eval(blob)
except Exception:
continue
name = obj.get("name")
args = obj.get("arguments", {})
if not isinstance(args, dict):
# 再试一次解析
try:
args = json.loads(args) if isinstance(args, str) else {}
except Exception:
args = {}
if name:
calls.append({"function": {"name": name, "arguments": args}})
return thinking, calls
# ========= 5) 解析 tool 的 <tool_response> JSON 内容为字符串 =========
_TOOLRESP_RE = re.compile(r"<tool_response>\s*(\{.*?\})\s*</tool_response>", re.DOTALL)
def parse_tool_response_value(value: str) -> str:
"""
输入 Hermes 的 tool.value,输出一个 JSON 字符串(尽量规范化)。
"""
if not value:
return ""
m = _TOOLRESP_RE.search(value)
raw = (m.group(1).strip() if m else value.strip())
# 尝试 JSON
try:
obj = json.loads(raw)
return json.dumps(obj, ensure_ascii=False)
except Exception:
pass
# 尝试 Python 字面量
try:
obj = ast.literal_eval(raw)
return json.dumps(obj, ensure_ascii=False)
except Exception:
# 留原文(让模板做 tojson),至少是字符串
return raw
DEV_NOISE_PATTERNS = [
r"Here are the available tools:.*",
r"Use the following pydantic model.*",
r"Each function call should be enclosed.*",
r"You are a function calling AI model\..*",
r"within\s*<tools>\s*</tools>\s*XML tags.*",
]
DEV_NOISE_RE = re.compile("|".join(DEV_NOISE_PATTERNS), re.DOTALL)
def clean_developer_text(s: str) -> str:
s = _TOOLS_BLOCK_RE.sub("", s or "") # 先去掉 <tools>…</tools>
s = DEV_NOISE_RE.sub("", s).strip()
s = re.sub(r"\n{3,}", "\n\n", s)
return s
import re
# 原有噪音模式
DEV_NOISE_PATTERNS = [
r"Here are the available tools:.*",
r"Use the following pydantic model.*",
r"Each function call should be enclosed.*",
r"You are a function calling AI model\..*",
r"within\s*<tools>\s*</tools>\s*XML tags.*",
# 新增:清理 <think> 相关说明
r"You should enclose.*?<think>.*?</think>.*?(solution|response).*",
r"enclose your thoughts.*?<think>.*?</think>.*",
r"internal monologue.*?<think>.*?</think>.*",
]
DEV_NOISE_RE = re.compile("|".join(DEV_NOISE_PATTERNS), re.DOTALL | re.IGNORECASE)
def final_clean_developer_text(s: str) -> str:
"""
清理 Hermes system 提示,去掉工具声明、pydantic schema、<think> 标签说明,
只保留干净的通用 developer 提示。
"""
if not s:
return ""
# 先去掉 <tools>...</tools> 块
s = _TOOLS_BLOCK_RE.sub("", s)
# 去掉定义的噪音段落
s = DEV_NOISE_RE.sub("", s).strip()
# 压缩多余空行
s = re.sub(r"\n{3,}", "\n\n", s)
return s
import re, json
_UNPAIRED_THINK_OPEN = re.compile(r"<think>\s*", re.IGNORECASE)
_UNPAIRED_THINK_CLOSE = re.compile(r"\s*</think>", re.IGNORECASE)
def _strip_unpaired_think_tags(text: str) -> str:
if not isinstance(text, str):
return "" if text is None else str(text)
# 去掉单独出现(或未配对)的 <think> / </think> 标签
text = _UNPAIRED_THINK_OPEN.sub("", text)
text = _UNPAIRED_THINK_CLOSE.sub("", text)
return text
def _drop_none_fields(msg: dict) -> dict:
# 删掉值为 None 的键
return {k: v for k, v in msg.items() if v is not None}
def sanitize_messages_for_gptoss(messages: list) -> list:
cleaned = []
for m in messages:
m = dict(m) # 复制一份
role = m.get("role")
# 1) 去掉 thinking=None
if "thinking" in m and (m["thinking"] is None or m["thinking"] == ""):
m.pop("thinking", None)
# 2) 对 content 做兜底清洗(移除残留 think 标签)
if "content" in m:
m["content"] = _strip_unpaired_think_tags(m["content"])
# 3) tool 消息的 content 必须是字符串
if role == "tool":
c = m.get("content", "")
if not isinstance(c, str):
try:
m["content"] = json.dumps(c, ensure_ascii=False)
except Exception:
m["content"] = str(c)
# 4) assistant+tool_calls 情况:不能带 content
if role == "assistant" and "tool_calls" in m and m.get("tool_calls"):
m.pop("content", None) # 保守起见清掉
# 5) 删除 None 字段
m = _drop_none_fields(m)
# 6) 丢弃完全空的消息(极少数脏数据)
if role and (m.get("content") or m.get("tool_calls") or m.get("thinking") or role == "tool"):
cleaned.append(m)
return cleaned
# ========= 6) 单条样本转换:Hermes → gpt-oss (messages + tools) =========
def hermes_to_gptoss_example(ex: dict):
conv = ex.get("conversations") or []
top_tools_raw = ex.get("tools") # 可能是 str / list[str] / list[dict] / dict / None
messages = []
idx = 0
sys_text = ""
if len(conv) and conv[0].get("from") == "system":
sys_text = conv[0].get("value", "") or ""
# 若顶层无 tools,从 system 的 <tools>... 抽
if not top_tools_raw:
extracted = extract_tools_from_system(sys_text)
if extracted:
top_tools_raw = extracted
dev_text = final_clean_developer_text(sys_text)
if dev_text.strip():
messages.append({"role": "developer", "content": dev_text.strip()})
idx = 1
# 1) 工具归一化(你已有)
top_tools_norm = parse_tools_any(top_tools_raw)
gptoss_tools = hermes_tools_to_gptoss_tools(top_tools_norm or [])
# 2) 主循环(加一点点健壮性)
for turn in conv[idx:]:
who = (turn.get("from") or "").lower()
val = turn.get("value", "")
if not isinstance(val, str): # 防御:确保是字符串
val = str(val)
if who in ("human", "user"):
if val.strip():
messages.append({"role": "user", "content": val})
elif who in ("gpt", "assistant"):
thinking, calls = parse_assistant_content(val)
if calls:
for j, call in enumerate(calls):
msg = {"role": "assistant", "tool_calls": [call]}
if j == 0 and thinking: # 只有第一条带 thinking
msg["thinking"] = thinking
messages.append(msg)
else:
# 非工具调用回合
content = val
if thinking is not None:
content = _THINK_RE.sub("", val).strip()
messages.append(
{"role": "assistant", **({"thinking": thinking} if thinking else {}), "content": content}
)
elif who == "tool":
tool_payload = parse_tool_response_value(val) # -> JSON 字符串
messages.append({"role": "tool", "content": tool_payload})
# 3) 收尾清理(你已有)
messages = sanitize_messages_for_gptoss(messages)
return {"messages": messages, "tools": gptoss_tools}
# ========= 7) 批量映射 + 渲染成 text(用于 SFT) =========
def convert_hermes_dataset_to_gptoss_text(ds, tokenizer, reasoning_effort="low"):
"""
输入:datasets.Dataset(Hermes),以及已加载好的 gpt-oss tokenizer
输出:新的 Dataset,包含:
- messages(供调试)
- tools_obj(供调试)
- text(喂给 SFTTrainer 的列)
"""
def map_one(ex):
r = hermes_to_gptoss_example(ex)
return {"messages": r["messages"], "tools_obj": r["tools"]}
ds2 = ds.map(map_one)
def render_batch(batch):
out = []
for msgs, tools in zip(batch["messages"], batch["tools_obj"]):
txt = tokenizer.apply_chat_template(
msgs,
tools=tools, # ← 关键:工具通过参数传入
add_generation_prompt=False, # 训练集通常 False
reasoning_effort=reasoning_effort, # "low"/"medium"/"high"
tokenize=False,
)
out.append(txt)
return {"text": out}
ds3 = ds2.map(render_batch, batched=True)
return ds3
import json, ast
def parse_tools_any(obj):
"""
把 Hermes 的 tools 字段归一化为 [dict, ...]:
- 支持 str(JSON 或 Python 字面量,含单引号)
- 支持 dict(单个工具,转成 [dict])
- 支持 list(其中元素可为 str 或 dict)
- 其他类型返回 []
"""
if obj is None:
return []
# 纯字符串:尝试 json -> ast
if isinstance(obj, str):
s = obj.strip()
if not s:
return []
for loader in (json.loads, ast.literal_eval):
try:
val = loader(s)
return parse_tools_any(val) # 递归归一化
except Exception:
pass
return [] # 实在解析不了就空
# 字典:包成单元素列表
if isinstance(obj, dict):
return [obj]
# 列表:逐个元素解析
if isinstance(obj, list):
out = []
for it in obj:
if isinstance(it, dict):
out.append(it)
elif isinstance(it, str):
it_s = it.strip()
ok = None
for loader in (json.loads, ast.literal_eval):
try:
val = loader(it_s)
ok = val
break
except Exception:
pass
if isinstance(ok, dict):
out.append(ok)
elif isinstance(ok, list):
out.extend(parse_tools_any(ok))
# 其他情况丢弃这个元素
return out
# 其他类型丢弃
return []
定义好了数据清洗函数之后,接下来测试能否将原始数据转化为gpt-oss模型能够用于训练的文本格式:
ds_full
# 2) 随便取一条(比如第 0 条)
sample = ds_full[0]
print("原始 Hermes 数据:")
print(sample)
# 3) 单条转换(不用整个 map)
converted = hermes_to_gptoss_example(sample)
print("\n转换后的 gpt-oss messages:")
for m in converted["messages"]:
print(m)
from unsloth import FastLanguageModel
import torch
max_seq_length = 8192
dtype = None
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "./gpt-oss-20b-bf16",
dtype = dtype,
max_seq_length = max_seq_length,
load_in_4bit = True,
full_finetuning = False,
)
# 4) 渲染成 gpt-oss 文本
text = tokenizer.apply_chat_template(
converted["messages"],
tools=converted["tools"],
add_generation_prompt=False,
reasoning_effort="low",
tokenize=False,
)
print("\n渲染后的训练文本:")
text
sample = ds[15]
print("原始 Hermes 数据:")
print(sample)
converted = hermes_to_gptoss_example(sample)
print("\n转换后的 gpt-oss messages:")
for m in converted["messages"]:
print(m)
text = tokenizer.apply_chat_template(
converted["messages"],
tools=converted["tools"],
add_generation_prompt=False,
reasoning_effort="low",
tokenize=False,
)
print("\n渲染后的训练文本:")
text
接下来,我们抽取200条数据进行批量转化与快速微调效果验证:
from datasets import load_dataset, Dataset, Features, Value
import random, json, os
# 随机采样 200 条(可换成你想要的索引集合)
seed = 42
random.seed(seed)
idxs = random.sample(range(len(ds_full)), 200)
ds_sample = ds_full.select(idxs)
print(ds_sample) # sanity check
ds_sample[0]
# 注意:不要返回列名 'tools',用新名字避免与原始列冲突
def map_convert_to_strings(ex):
out = hermes_to_gptoss_example(ex) # -> {"messages": [...], "tools": [...]}
return {
"messages_json": json.dumps(out["messages"], ensure_ascii=False),
"tools_json": json.dumps(out["tools"], ensure_ascii=False),
}
# 显式声明 features 为 string,杜绝 Arrow 猜类型
features = Features({
"messages_json": Value("string"),
"tools_json": Value("string"),
})
# 移除原始所有列,只保留我们需要的两列,避免同名冲突
ds_conv = ds_sample.map(
map_convert_to_strings,
remove_columns=ds_sample.column_names,
features=features,
)
print(ds_conv[0])
ds_conv[1]
save_path = "hermes_200_gptoss.jsonl"
with open(save_path, "w", encoding="utf-8") as f:
for ex in ds_conv:
f.write(json.dumps({
"messages_json": ex["messages_json"],
"tools_json": ex["tools_json"],
}, ensure_ascii=False) + "\n")
print("Saved to:", os.path.abspath(save_path))
tokenizer
def _fix_tools_for_template(tools):
out = []
for t in tools or []:
if not isinstance(t, dict):
continue
fn = t.get("function") if (t.get("type") == "function" and isinstance(t.get("function"), dict)) else t
fn.setdefault("description", "")
params = fn.get("parameters") or {}
if isinstance(params, dict):
if params.get("type") == "dict":
params["type"] = "object" # ① dict -> object
if params.get("type") == "object":
props = params.setdefault("properties", {})
if not isinstance(props, dict):
params["properties"] = {}
# 把外层 required 并进去
if "required" not in params and isinstance(fn.get("required"), list):
params["required"] = fn["required"] # ② 合并 required
# 保证每个属性有 type/description
for k, spec in list(props.items()):
if not isinstance(spec, dict):
spec = {}
spec.setdefault("type", "string")
spec.setdefault("description", "")
props[k] = spec
out.append({"type": "function", "function": fn})
return out
def _fix_tool_messages(messages):
for m in messages:
if m.get("role") == "tool" and isinstance(m.get("content"), str):
s = m["content"]
try:
m["content"] = json.loads(s) # ③ 字符串 -> 对象
except Exception:
try:
import ast
m["content"] = ast.literal_eval(s)
except Exception:
pass
return messages
def render_batch(batch):
texts = []
for m_str, t_str in zip(batch["messages_json"], batch["tools_json"]):
messages = json.loads(m_str)
tools = json.loads(t_str)
messages = _fix_tool_messages(messages)
tools = _fix_tools_for_template(tools)
txt = tokenizer.apply_chat_template(
messages,
tools=tools,
add_generation_prompt=False,
reasoning_effort="low",
tokenize=False,
)
texts.append(txt)
return {"text": texts}
ds_text = ds_conv.map(render_batch, batched=True)
ds_text
完整数据集地址:

我们抽取其中几条数据进行查看:
ds_text[0]['text']
ds_text[1]['text']
ds_text[2]['text']
ds_text[3]['text']
ds_text[5]['text']
ds_text[6]['text']
【微调实战二】微调GPT-OSS模型Agent性能微调
当我们准备好了微调数据集之后,实际的微调过程并不会太复杂。
- Step 1.读取数据集
from datasets import load_dataset
dataset = load_dataset("json", data_files="hermes_200_gptoss.jsonl", split="train")
print(dataset[0]) # 查看第一条
- Step 2.数据格式转化
有了数据集之后,我们还需要将数据集转化为gpt-oss能够识别的数据格式,首先第一步是需要将其转化为gpt-oss的基本消息格式:
ds_text = dataset.map(render_batch, batched=True)
ds_text
其中'text'字段中就保存着可以用于微调的完整文本结构,其中assistant之前是输入,之后是输出:
print(ds_text[0]['text'])
- Step 3.LoRA参数灌注
model = FastLanguageModel.get_peft_model(
model,
r = 8, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
基本参数说明如下:
| 参数 | 含义 | 推荐值/当前设置 | 作用与说明 |
|---|---|---|---|
| r | LoRA 秩(rank) | 8(可选 8/16/32/64/128) | 控制新增参数规模;值越大表达能力越强,但显存占用也随之上升。中文推理链推荐从 8/16 起步。 |
| target_modules | 注入的线性层 | q/k/v/o 投影 + MLP (gate/up/down) | 指定在哪些层挂 LoRA。覆盖注意力 + MLP → 更好适配中文句法与逻辑;若显存不足可只保留 q/k/v/o。 |
| lora_alpha | LoRA 缩放系数 | 16 | 放大 LoRA 分支输出,等效调整学习率。常用范围 16–32,r 小时可适当调高。 |
| lora_dropout | LoRA dropout 概率 | 0 | 控制 LoRA 分支的随机丢弃率。0 在 Unsloth 中优化过,更快更省;若过拟合可尝试 0.05–0.1。 |
| bias | Bias 参数训练策略 | "none" | 是否对注入层 bias 可训练。"none" 开销最小且优化最好。 |
| use_gradient_checkpointing | 梯度检查点 | "unsloth" | 节省 ~30% 显存,支持更长上下文和更大 batch;推荐开启。 |
| random_state | 随机种子 | 3407 | 保证实验可复现;任意固定值均可。 |
| use_rslora | Rank-Stabilized LoRA | False | 在大 r(≥64)时可提高稳定性;一般场景不必启用。 |
| loftq_config | LoftQ 量化配置 | None | 结合量化训练 LoRA,在 4/8bit 推理时更稳。默认关闭;若目标是低比特部署,可配置启用。 |
- Step 4.设置微调参数
ds_text
from trl import SFTConfig, SFTTrainer
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = ds_text,
args = SFTConfig(
max_seq_length = 4096,
dataset_text_field = "text", # 你上一步 map 生成了 text 列
packing = False, # 一般先关掉 packing,避免拼接样本
per_device_train_batch_size = 1,
gradient_accumulation_steps = 4,
warmup_steps = 5,
num_train_epochs = 1, # Set this for 1 full training run.
learning_rate = 2e-4,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to="tensorboard", # 📌 启用 TensorBoard
logging_dir="./logs", # 日志目录
logging_strategy="steps",
logging_steps=1, # 记录频率
),
)
- Step 5.开始微调
trainer_stats = trainer.train()
- Step 7.微调后模型导出
最后,我们还可以将模型合并导出,以便下次使用:
model
model.save_pretrained_merged(save_directory = "GPT-OSS-finetuned",
tokenizer = tokenizer,
save_method = "merged_16bit")
- Step 8.微调效果对比
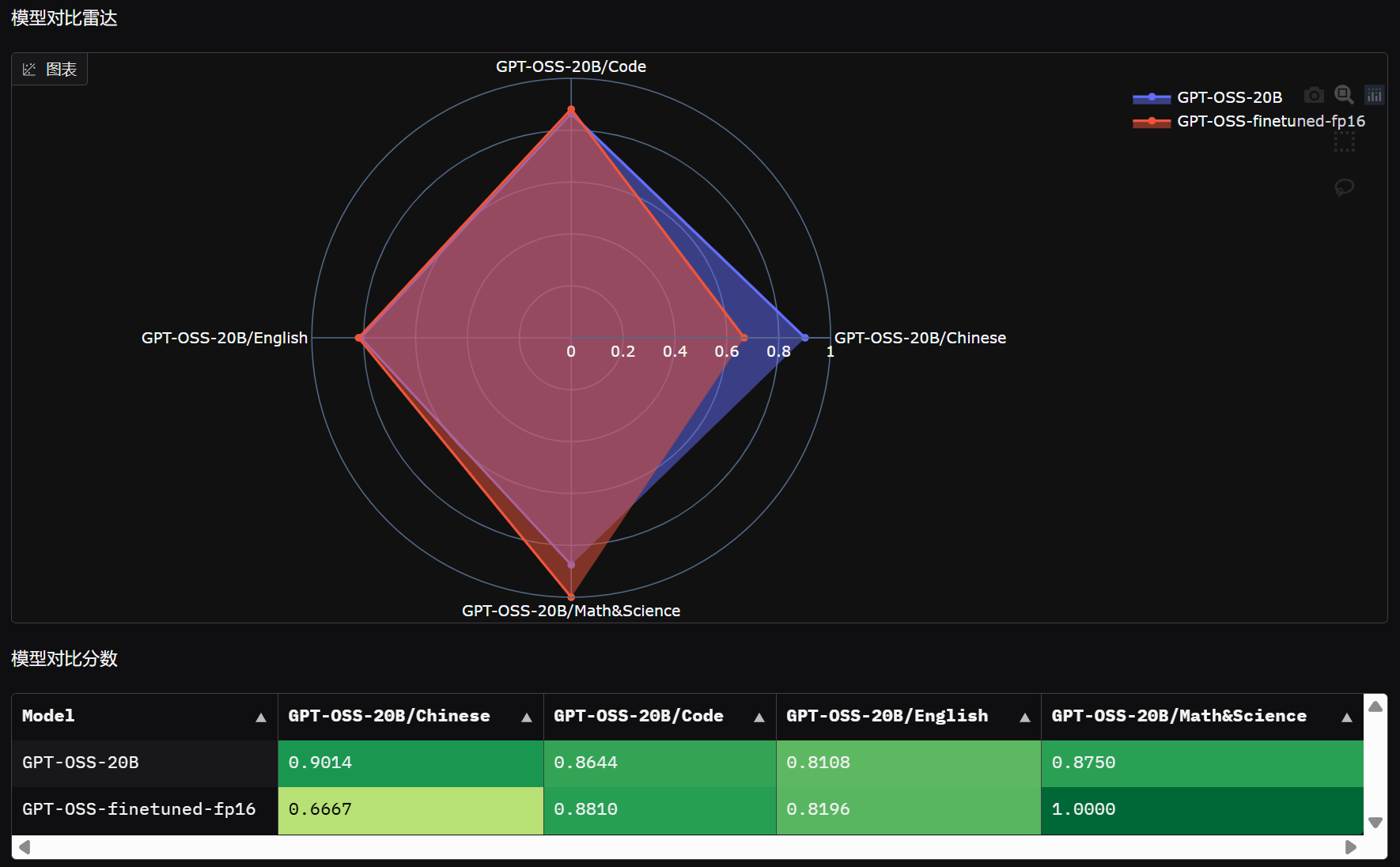
接下来即可使用vllm对其进行调用,并借助EvalScope进行测试。需要借助vLLM调用导出后的模型,然后借助evalscope进行测试。
FENCE0
测试后即可在前端中观察测评报告: FENCE0
原始模型评分:
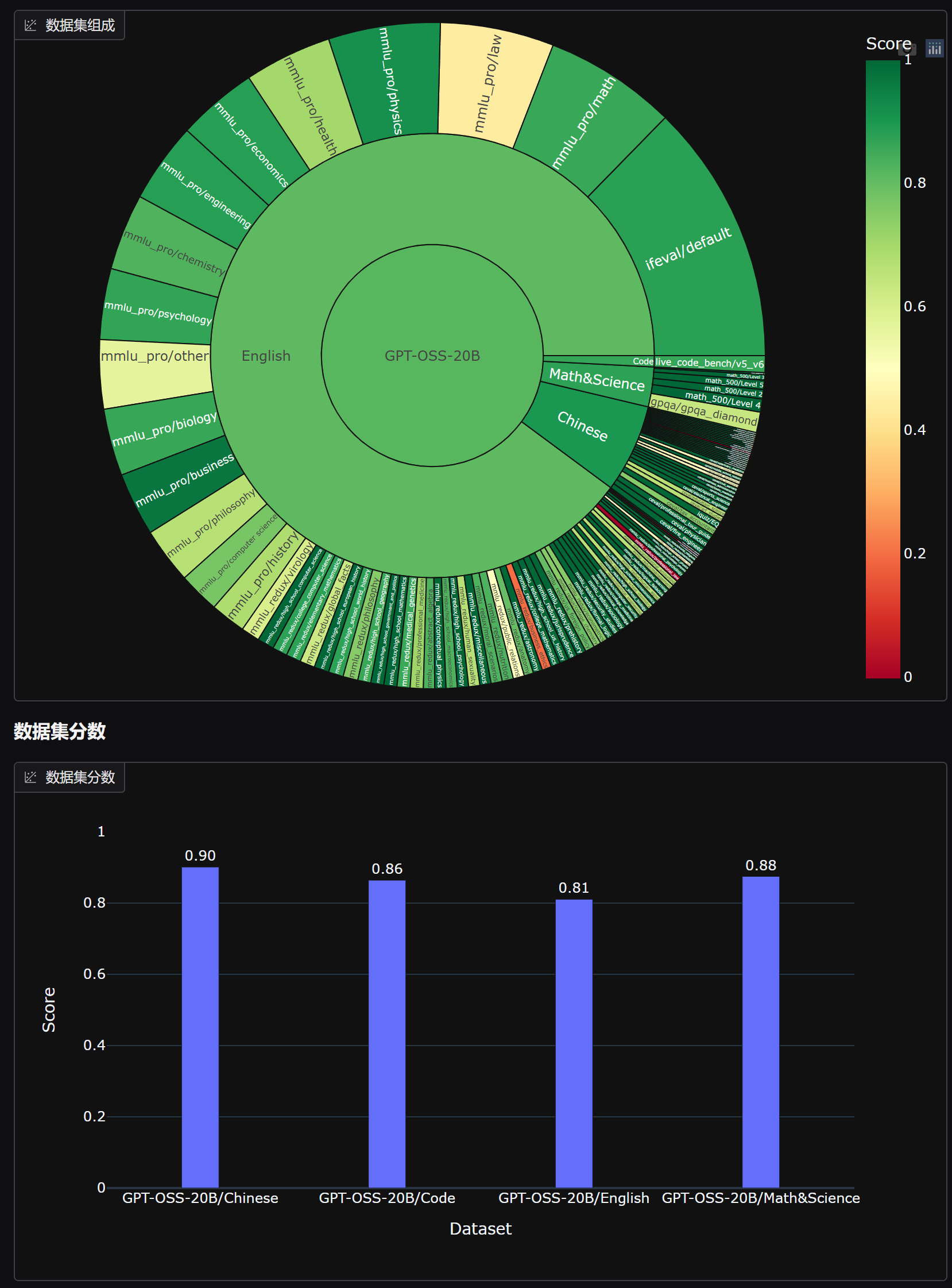
微调后模型评分:
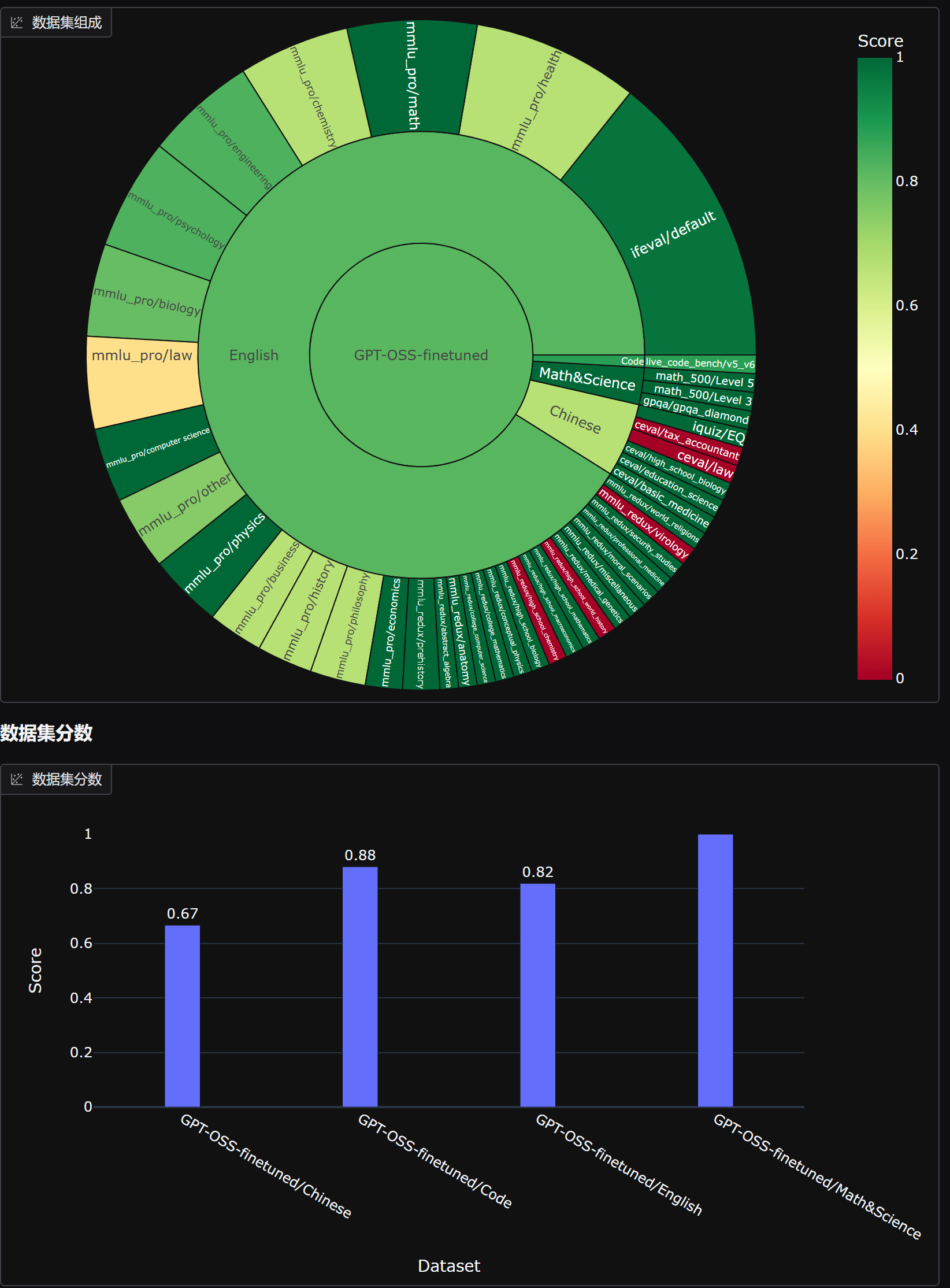
两个模型对比: