课程说明:
同学们好呀~欢迎来到《2025大模型原理与训练》试学体验课!我是课程主讲老师,九天。本期体验课将带领各位同学手动从零到一完成miniDeepSeek大模型训练,完整介绍Ubuntu系统使用、分词器训练、大模型预训练、大模型全量指令微调,以及DPO强化学习微调完整流程!
- 体验课内容节选自《2025大模型原理与训练》完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我和菜菜老师主讲的《2025大模型原理与实战课程》 :


《2025大模型原理与实战课程》 上新特惠进行中!限量福利30席售罄即止!课程大纲获取、领取体验课学员专享优惠券,扫码添加课程助教,回复“训练”,即咨询课程信息哦👇



此外,miniDeepSeek-v3全部训练项目代码、数据、以及训练完的模型,都已上传至课件网盘,扫码联系助教即可领取。
《2025大模型原理与训练》体验课
从零手动复现DeepSeek v3
Ch.1 MiniDeepSeek v3 分词器训练过程
一、分词器数据集准备
在大模型的训练过程中,分词器(Tokenizer)的训练和使用是非常关键的环节之一,直接影响到模型对文本的理解和生成能力。为了更好地理解为何需要训练分词器,以及分词器的概念和作用,下面我将详细解释这些内容。
1. 分词器的概念
分词器(Tokenizer)是将自然语言文本转换为模型可理解形式的工具,它将连续的文本字符串分解成模型能够处理的基本单位。这些基本单位可以是单词、子词(subword),甚至是单个字符。分词的目的是将原始文本映射为一系列的索引或标记(token),然后输入到模型中进行处理。
分词器的工作不仅限于切割文本,还包括将这些分割后的单位映射到模型词汇表中的索引。分词的粒度选择会影响模型的性能、训练时间和生成的结果,因此分词器在训练过程中扮演着重要角色。
2. 为什么需要训练分词器?
在大模型训练过程中,分词器是模型理解和生成文本的基础。如果没有合理的分词,模型无法有效地学习语言的规律和结构。以下是训练分词器的主要原因:
2.1 处理文本的必要性
计算机无法直接处理自然语言文本,需要将其转换为数字表示。而分词器就是完成这一步的工具,它将文本转换为一系列离散的标记,之后可以通过嵌入层将这些标记转换为向量输入模型。因此,训练分词器的首要任务是高效且准确地将文本分解成适合模型学习的标记。
2.2 减少模型的复杂性
如果直接使用单词作为标记,模型词汇表将变得极其庞大,因为自然语言中有海量的单词及其变体。词汇表过大不仅会导致训练时间增加,还会让模型难以泛化,尤其是当遇到词汇表中未包含的新词时,模型将无法处理。
通过训练分词器,尤其是使用子词分词(例如BPE或WordPiece算法),可以将词汇表的大小控制在一个合理的范围内,同时确保模型能够有效处理新词和变体。子词分词的思想是,将常见的词作为整体保留,但对不常见的词进行进一步分解,这样即使是未见过的词,也可以通过子词组合来表示。
2.2 提升模型的泛化能力
一个好的分词器能够帮助模型在面对未知或罕见词汇时保持良好的表现。训练好的分词器能够根据训练语料库中的频率、上下文等信息,对词语进行合理的拆分,让模型在推理和生成时具备更强的泛化能力。例如,遇到罕见或未见过的词时,分词器可以将其分解为多个子词,这样即使模型没有见过完整的单词,也能通过学习到的子词来理解其含义。
2.3 提高模型的效率
分词器还可以显著提高模型的计算效率。较小的词汇表可以减少嵌入矩阵的大小,从而减少模型的参数量和训练时间。此外,通过子词分解,还可以避免对整个单词进行处理,提高模型处理长文本时的效率。
3. 分词器的作用
3.1 将文本转换为标记序列
分词器的首要作用是将连续的自然语言文本转换为一系列的标记序列。模型需要处理的是这些离散的标记,而不是原始的字符串。不同的分词策略(如按单词、按子词、按字符等)会影响标记的数量和粒度。选择合适的分词策略对于提高模型的表现非常重要。
3.2 构建词汇表
分词器的另一个作用是基于训练语料库构建一个有限大小的词汇表。这个词汇表包含了模型能够处理的所有标记的集合,分词器在训练时通过分析语料库中的词频和词形变化,选择最适合的子词或词汇构建词汇表,确保词汇表足够小但仍能覆盖大部分文本。
3.3 处理未登录词(OOV问题)
自然语言的词汇是动态且丰富的,在训练数据中可能无法包含所有的词汇。分词器通过将未登录词(Out-Of-Vocabulary,OOV)拆解为子词,能够有效解决OOV问题。例如,对于一个未见过的复杂词汇,分词器可以将其拆分为更常见的子词,从而保证模型可以处理这些新词,而不会因为未登录词的出现导致模型无法理解。
3.4 保持文本的语义一致性
一个好的分词器不仅仅是将文本简单拆解,还需要考虑语义上的一致性。例如,分词器应该尽量避免将具有特定语义的词错误地分割,以免影响模型的语义理解能力。同时,分词器应通过合理的标记组合,使得模型能够在不同的上下文中准确理解词语的含义。
- 下载requirements.txt并安装相关依赖
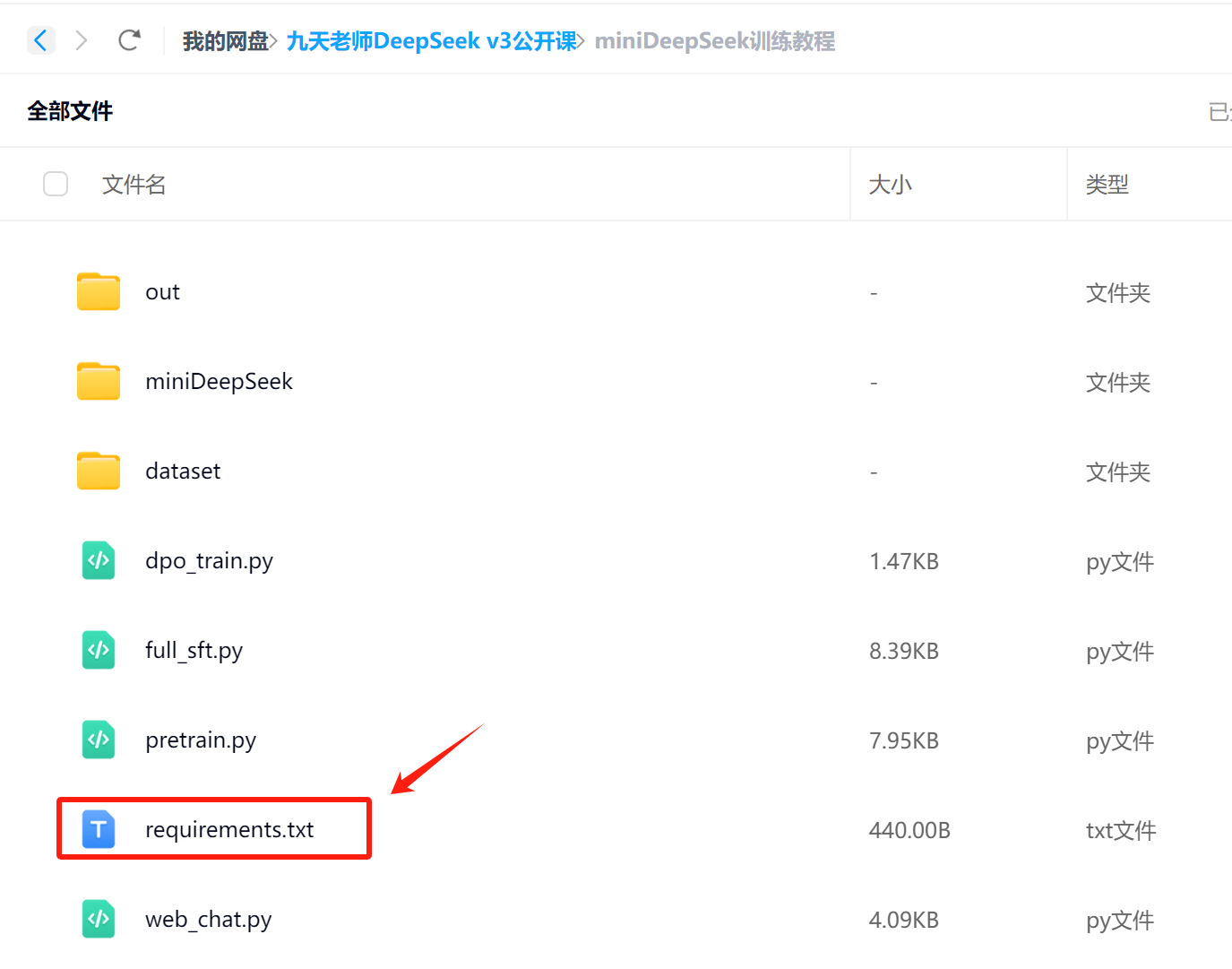
项目依赖列表如下:
FENCE0
安装项目依赖:
FENCE0
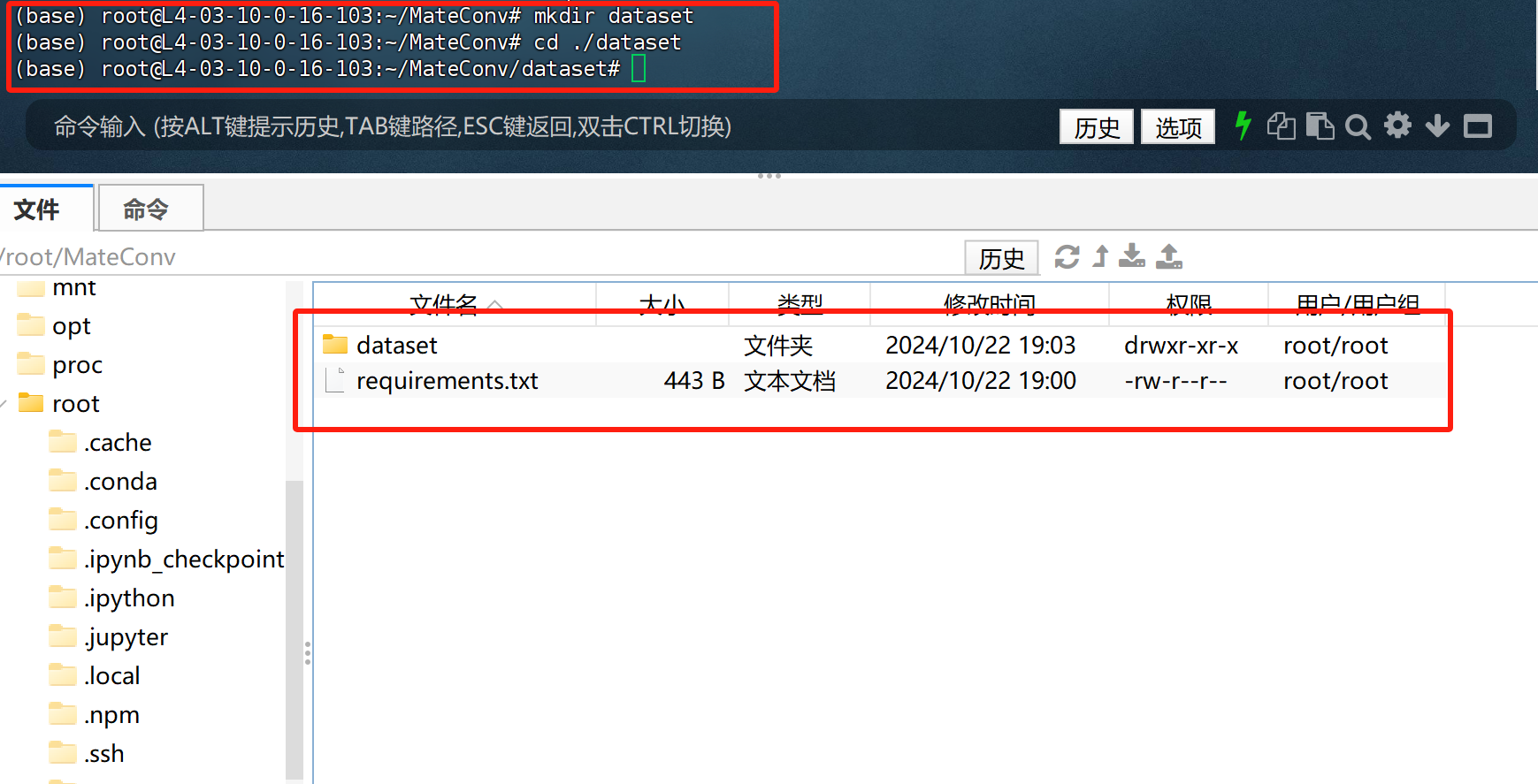
- 创建数据集存放文件夹
FENCE0
二、分词器训练流程
- Step 1.导入必要的库
import random
from tqdm import tqdm
from transformers import AutoTokenizer
import json
from datasets import load_dataset
from tokenizers import (
decoders,
models,
normalizers,
pre_tokenizers,
processors,
trainers,
Tokenizer,
)
import os
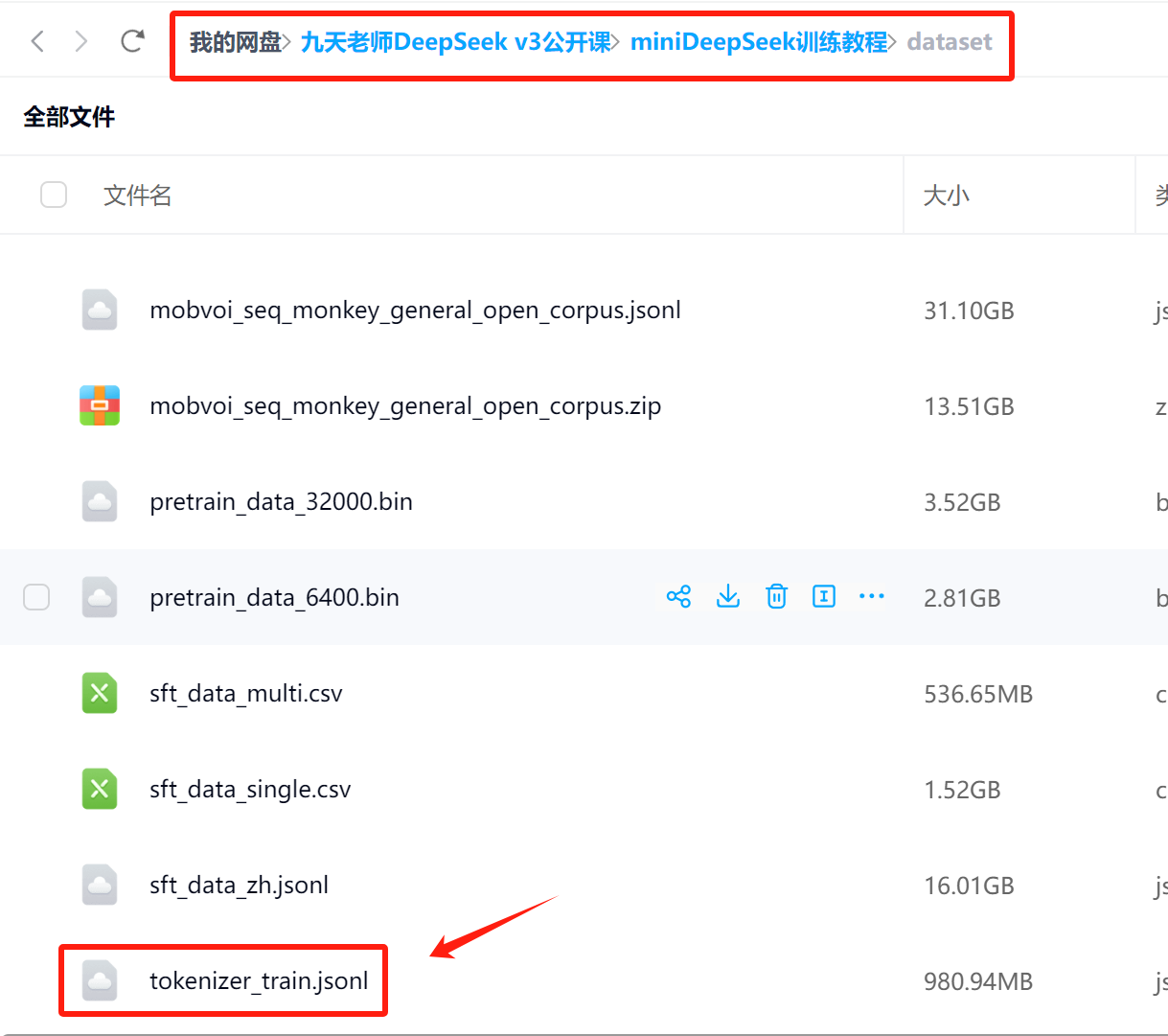
- Step 2.读取 tokenizer_train.jsonl 文件
def read_texts_from_jsonl(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
data = json.loads(line)
yield data['text']
# 测试读取数据
data_path = '/root/autodl-tmp/miniDeepSeek/dataset/tokenizer_train.jsonl'
texts = read_texts_from_jsonl(data_path)
# 打印前几行文本
for i, text in enumerate(texts):
if i < 5:
print(text)
else:
break
- Step 3.初始化分词器
首先,通过 models.BPE() 创建了一个基于 Byte-Pair Encoding (BPE) 模型的分词器。BPE 是一种常用于文本分词的子词分解算法,特别在自然语言处理任务中被广泛使用,如机器翻译和语言模型训练。BPE 的主要思想是通过将频繁出现的字符或字符对合并成一个新的子词单元,逐步构建一个子词级别的词汇表,从而处理词汇表稀疏性和未登录词问题。
# 初始化tokenizer
tokenizer = Tokenizer(models.BPE())
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)
# 定义特殊token
special_tokens = ["<unk>", "<s>", "</s>"]
# 设置训练器并添加特殊token
trainer = trainers.BpeTrainer(
vocab_size=6400,
special_tokens=special_tokens, # 确保这三个token被包含
show_progress=True,
initial_alphabet=pre_tokenizers.ByteLevel.alphabet()
)
print("分词器初始化成功,准备训练。")
- Step 4.训练分词器
【TIME Warning:5mins】
# 读取文本数据
texts = read_texts_from_jsonl(data_path)
# 训练tokenizer
tokenizer.train_from_iterator(texts, trainer=trainer)
print("分词器训练完成!")
- Step 5.保存分词器
在训练完毕之后,还需要设置解码器 (tokenizer.decoder = decoders.ByteLevel()) ,这是为了在生成文本时正确地将分词器产生的 token 序列还原回原始文本。
# 设置解码器
tokenizer.decoder = decoders.ByteLevel()
# 保存tokenizer
tokenizer_dir = "/root/autodl-tmp/miniDeepSeek/model/miniDeepSeek_tokenizer"
os.makedirs(tokenizer_dir, exist_ok=True)
tokenizer.save(os.path.join(tokenizer_dir, "tokenizer.json"))
tokenizer.model.save("/root/autodl-tmp/miniDeepSeek/model/miniDeepSeek_tokenizer")
# 手动创建配置文件
config = {
"add_bos_token": False,
"add_eos_token": False,
"add_prefix_space": True,
"added_tokens_decoder": {
"0": {
"content": "<unk>",
"lstrip": False,
"normalized": False,
"rstrip": False,
"single_word": False,
"special": True
},
"1": {
"content": "<s>",
"lstrip": False,
"normalized": False,
"rstrip": False,
"single_word": False,
"special": True
},
"2": {
"content": "</s>",
"lstrip": False,
"normalized": False,
"rstrip": False,
"single_word": False,
"special": True
}
},
"bos_token": "<s>",
"clean_up_tokenization_spaces": False,
"eos_token": "</s>",
"legacy": True,
"model_max_length": 1000000000000000019884624838656,
"pad_token": None,
"sp_model_kwargs": {},
"spaces_between_special_tokens": False,
"tokenizer_class": "PreTrainedTokenizerFast",
"unk_token": "<unk>",
"use_default_system_prompt": False,
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<s>user\\n' + content + '</s>\\n<s>assistant\\n' }}{% elif message['role'] == 'assistant' %}{{ content + '</s>' + '\\n' }}{% endif %}{% endfor %}"
}
# 保存配置文件
with open(os.path.join(tokenizer_dir, "tokenizer_config.json"), "w", encoding="utf-8") as config_file:
json.dump(config, config_file, ensure_ascii=False, indent=4)
print("Tokenizer 保存成功!")
- Step 6.评估分词器
from transformers import AutoTokenizer
# 加载预训练的tokenizer
tokenizer = AutoTokenizer.from_pretrained("./model/miniDeepSeek_tokenizer")
# 测试一段对话
messages = [
{"role": "system", "content": "你是一个优秀的聊天机器人,总是给我正确的回应!"},
{"role": "user", "content": '是椭圆形的'},
{"role": "assistant", "content": '456'},
{"role": "user", "content": '456'},
{"role": "assistant", "content": '789'}
]
# 使用模板进行文本处理
new_prompt = tokenizer.apply_chat_template(messages, tokenize=True)
print(new_prompt)