课程说明:
同学们好呀~欢迎来到《2025大模型原理与训练》试学体验课!我是课程主讲老师,九天。本期体验课将带领各位同学手动从零到一完成miniDeepSeek大模型训练,完整介绍Ubuntu系统使用、分词器训练、大模型预训练、大模型全量指令微调,以及DPO强化学习微调完整流程!
- 体验课内容节选自《2025大模型原理与训练》完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我和菜菜老师主讲的《2025大模型原理与实战课程》 :


《2025大模型原理与实战课程》 上新特惠进行中!限量福利30席售罄即止!课程大纲获取、领取体验课学员专享优惠券,扫码添加课程助教,回复“训练”,即咨询课程信息哦👇



此外,miniDeepSeek-v3全部训练项目代码、数据、以及训练完的模型,都已上传至课件网盘,扫码联系助教即可领取。
《2025大模型原理与训练》体验课
从零手动复现DeepSeek v3
Ch.2 MiniDeepSeek v3 预训练过程
【补充介绍】大模型预训练基本概念与预训练数据集创建方法
- 大模型预训练与预训练数据集
在大模型训练的过程中,预训练阶段是至关重要的一步。预训练(Pre-training)是指在大规模无监督数据上进行初步模型训练,使模型能够学习到通用的语言模式、知识表征和统计特征。这一阶段不依赖于特定任务,而是通过在大规模、多样化的数据集上进行广泛的学习,帮助模型建立基础的语言理解能力。通过预训练,模型可以在后续的特定任务上(如分类、生成、翻译等)以更快的速度和更高的准确性进行微调(Fine-tuning)。
预训练的目标是使模型能够有效捕捉数据中的规律,学会高效的特征表示,从而为后续的任务奠定基础。这一阶段通常涉及训练深度神经网络,如Transformer架构,通过处理大规模文本数据,模型能够学会上下文依赖关系、词汇语义关系等复杂的语言特征。
而在选择预训练数据集时,需要特别关注以下几个关键因素:
-
数据规模
预训练数据集的规模对模型的性能具有直接影响。大模型通常需要数百亿甚至上千亿个参数,这要求使用海量数据来支持模型训练。在数据量较少的情况下,模型可能无法充分学习复杂的语义关系,进而影响预训练的效果。因此,数据集的规模应足够大,以便涵盖广泛的语言模式和知识。 -
数据多样性
数据集的多样性同样至关重要。预训练过程中,模型需要接触各种类型的文本内容,包括新闻、书籍、博客、技术文档等,以确保其能够广泛适应不同语言风格、领域知识和应用场景。如果数据过于单一,模型在后续应用于其他任务时,可能会表现出偏差或局限性。因此,选取多样化的数据源有助于提升模型的泛化能力。 -
数据质量
数据质量直接影响模型预训练的有效性和稳定性。高质量的数据应具有较少的噪声、语法错误和不完整的句子。若数据质量较差,模型可能会学习到错误的模式或产生不合理的输出。因此,需对数据集进行预处理和清洗,以剔除错误、冗余或低质量的部分。 -
领域相关性
尽管预训练通常是在通用数据集上进行,但在某些情况下,特定领域的数据可能更为重要。例如,若大模型的目标是用于医学或法律领域的应用,预训练数据集中应包含该领域的相关内容,以帮助模型建立更为准确的领域知识。这种数据的领域适配性可以在后续任务中显著提高模型的表现。
综上所述,预训练阶段的数据集选取是大模型成功的关键环节之一,良好的数据规模、质量、多样性及领域适配性有助于提高模型的泛化能力和应用效果。同时,数据的合规性与道德责任也不容忽视。通过精心选择和处理数据集,可以为后续的任务微调提供坚实的基础。
- 大模型预训练数据集构建方法
在大模型的开发中,构建高质量的预训练数据集是至关重要的一环。如果现有的公开数据集无法完全满足特定需求,研究人员或开发团队可能会选择自构预训练数据集,以便更好地适配模型的任务或领域。在构建过程中,不仅需要考虑数据的收集和处理,还应确保遵循数据的伦理、质量和多样性原则。
构建预训练数据集的步骤
-
确定数据来源
数据集的质量和多样性主要取决于数据来源的选择。常见的数据来源包括:- 公开数据集:如维基百科、Common Crawl等大型通用文本数据集。这类数据资源庞大且容易获取。
- 领域特定数据:从技术文献库、领域文献、研究论文或行业报告中收集数据,适用于特定领域(如医学、法律、金融等)模型的预训练。
- 网络抓取:通过网络爬虫工具从特定网站抓取数据,尤其适合于需要最新或领域特定信息的场景。需要注意遵守网站的隐私政策及数据使用协议。
- 自有数据:如企业内部的技术文档、客户服务记录等,这些数据能够使模型专门针对企业应用场景进行优化。
-
数据清洗与预处理
收集到的原始数据往往包含很多噪声和冗余信息,如广告、格式错误、拼写错误、重复内容等。为了提高预训练的有效性,必须对数据进行清洗和预处理,主要包括:- 去重处理:消除重复的文本片段,以避免模型过度学习某些特定模式。
- 去除噪声:如无意义的文本、HTML标签、标点符号过度堆积等。这些信息会干扰模型的训练,降低训练效果。
- 文本规范化:标准化文本格式,如统一的编码格式、消除特殊符号、处理数字或单位等。
- 句子分割与标注:确保文本中的句子分割合理,特别是对于连续文本段落的处理。根据需要,也可以对文本进行标注(如词性、句法等),以增加模型训练的多样性和丰富性。
-
数据分布与多样性检查
数据集的多样性和分布平衡性是影响模型泛化能力的重要因素。应尽量确保不同领域、不同风格、不同语言或不同语境下的数据均有适当的比例,以避免模型在某些特定领域或语言风格上产生偏见。可以通过统计分析工具对数据进行分布检查,确保数据涵盖广泛的上下文和主题。 -
数据格式化与存储
预训练数据通常需要转换为模型能够直接使用的格式,如标准化的纯文本文件(.txt)、序列化数据(JSON、CSV等),或者特定的分词和标注格式。确保数据的文件组织结构清晰,便于在训练时进行高效加载。
此外,预训练数据集往往非常庞大,因此需要合理的存储策略。常见的存储方式包括分片存储、大数据存储系统(如HDFS)、云存储等,以确保在大规模训练时的数据读取速度。 -
数据增强(可选)
在某些情况下,数据增强技术可以进一步提高数据集的多样性和丰富性,尤其是在数据规模不足的情况下。常见的数据增强技术包括:- 同义词替换:在不改变语义的前提下,用同义词替换句子中的部分词汇。
- 句子顺序打乱:对文本中的句子顺序进行随机调整,增加训练数据的复杂性。
- 生成式增强:利用已有模型生成新的语料,通过多种生成方式扩展训练数据的规模。
注意事项
-
合法性与伦理合规
在数据收集的过程中,必须遵守相关法律法规,特别是数据隐私保护和版权问题。未经授权采集的数据可能涉及法律风险,尤其是涉及个人隐私信息或受版权保护的内容时,必须确保有合法使用许可。此外,数据集中应避免包含有害或偏见性的内容,如种族、性别、文化等方面的歧视性语言。 -
数据平衡与去偏
数据集中的偏见可能会导致模型输出中的偏差,例如如果训练数据集中某类文本(如某一性别、民族或职业)过度代表,模型可能会倾向于此类文本。为减少这种偏差,数据集的构建应尽量平衡不同类型的内容,确保模型学习到的知识更加中立和广泛。 -
数据质量控制
数据的质量直接决定了模型预训练的效果。低质量的数据(如拼写错误、语法错误、不完整的句子等)会导致模型学习到不可靠的模式,因此需要在数据清洗阶段严格控制数据质量。此外,数据标注的准确性也是模型表现的关键,特别是在需要监督信号或标注信息时,必须确保标注的一致性和正确性。 -
数据规模与计算资源匹配
自构数据集时需要考虑数据集的规模与计算资源的匹配问题。大规模的数据集需要与之匹配的计算资源,如多GPU/TPU架构、高速存储系统等。若计算资源有限,建议采取渐进式预训练策略,逐步扩大数据集规模或降低模型复杂度,以提高计算效率。
- 其他常见问题
1. 能否用企业内部数据直接训练大模型?
如果企业内部的数据量足够大且多样化,完全可以用企业数据训练一个大模型。通过在企业私有数据上训练,模型可以学习到企业内部的专业知识和特定领域的任务,从而在企业专属的应用场景中表现出色。然而,通常情况下,企业的内部数据在规模和多样性上可能有限,直接用于训练大模型时,可能无法充分发挥大模型的潜力。
大模型的优势在于它能够通过海量数据捕捉广泛的语言和知识模式。如果企业内部数据量有限,模型可能无法学习到足够多的通用知识,进而在泛化能力上表现较弱。尤其是现代的大模型往往拥有上亿甚至上千亿的参数,它们需要大量的数据来支撑训练。因此,在企业内部数据量不足的情况下,单独依赖这些数据可能会导致模型性能欠佳。
2. 如果企业数据量较少,是否应混合互联网数据集进行训练?
对于数据量有限的企业,混合使用公开的互联网数据集是一个常见且有效的策略。通过将企业的专业数据与互联网中的大规模通用数据集(如Wikipedia、Common Crawl等)相结合,模型可以同时学习到通用的语言模式和领域特定的知识。这样,模型不仅在企业任务上有较好的表现,也能在通用任务中展现出优异的泛化能力。
这种混合训练的基本思想是:
- 通用数据为模型提供广泛的语言理解能力,包括基本的词汇、语法、常识性知识等。
- 企业私有数据则为模型注入特定领域的专业知识,如企业的业务流程、技术文档或客户服务记录。
然而,混合训练也存在潜在的风险——模型可能会“遗忘”企业私有数据背后的关键信息,尤其是在通用数据量相对庞大且与企业数据差异较大的情况下。
3. 如何防止大模型“遗忘”企业私有数据?
为了防止大模型在训练过程中遗忘企业私有数据背后的关键信息,有几种方法可以增强企业私有数据的作用,确保其在模型中的有效保留和强化:
3.1 微调(Fine-tuning)
- 微调是一个常见的方法。你可以先使用大规模的互联网数据进行预训练,获取模型的基础能力,然后在企业私有数据上进行微调。微调阶段专注于企业的数据,允许模型在保持通用能力的同时,强化与企业特定任务相关的知识。
- 微调的核心思想是在预训练的大模型基础上,通过额外的训练使模型对企业领域的数据更加敏感,而不会完全依赖于通用数据。这种方式可以让模型在保持通用能力的同时,深入掌握企业的专业知识。
3.2 知识蒸馏(Knowledge Distillation)
- 知识蒸馏是一种通过训练一个“小”模型来压缩和保留大模型知识的方法。在企业场景下,可以通过蒸馏技术将企业数据上训练的大模型信息提取出来,并浓缩到一个轻量化的模型中。这可以使模型在特定任务上更加高效且不易遗忘关键信息。
- 这种方法的优势在于,模型可以专注于企业数据的细节,而不必牺牲性能或增加计算资源的负担。
3.3 数据采样与加权训练
- 在训练过程中,可以使用数据采样或加权策略,给企业私有数据更大的权重。这意味着,在每个训练批次中,企业的数据可能比公开数据被更频繁地选择或赋予更高的损失函数权重。通过这种方式,模型会对企业数据给予更多的关注,进而减少遗忘。
- 这种加权训练可以通过超参数调整实现,使模型更加倾向于学习企业特定领域的知识。
3.4 混合训练中的对比学习(Contrastive Learning)
- 对比学习是一种无监督学习的方法,可以用于增强企业数据的重要性。在混合训练的过程中,企业私有数据可以被作为一种“对比”的参考,模型可以通过区分企业数据和通用数据来学习到领域特有的表示。这种方法可以帮助模型更清晰地理解哪些信息是企业独有的,哪些是通用知识。
- 对比学习的目标是通过将企业数据作为正样本,让模型学习到其特殊的语义特征,从而减少遗忘。
3.5 连续学习(Continual Learning)
- 在动态环境中,企业数据往往是逐步生成和更新的。通过连续学习方法,可以让模型在新的企业数据生成时逐步适应,而不会遗忘先前学到的信息。通过增量式更新训练,模型能够保留历史数据的知识,同时吸收新的信息。
- 这可以防止模型在引入更多通用数据或新数据时,遗忘早期学习的企业数据。
4. 增强企业私有数据的方法
除了上述防止遗忘的方法,还有一些技术可以进一步增强企业私有数据在大模型中的权重和价值:
-
数据增强:可以对企业私有数据进行增强,尤其是在数据量较少的情况下。例如,通过同义词替换、文本生成等技术扩展数据量,使企业数据的多样性得到提升,进而增强模型对该数据的敏感性。
-
生成对抗网络(GANs):使用生成对抗网络可以在企业私有数据上生成新的数据样本。这种方法不仅可以扩展数据量,还能捕捉企业数据中的潜在模式,丰富模型的知识储备。
-
跨领域预训练:如果企业的领域数据与其他领域存在部分相似性,可以尝试使用与该领域相关的公开数据进行初步预训练,然后再在企业数据上进行微调。这种方法能够加速模型对企业特定知识的适应。
对于数据量较少的企业,可以通过混合互联网数据集和企业私有数据来训练大模型,这能够提高模型的通用性和专业性。然而,模型在训练过程中确实可能遗忘企业特有的数据,为了防止这种情况,可以通过微调、加权训练、对比学习、连续学习等方法来增强企业私有数据的权重。此外,数据增强等技术也可以进一步丰富和扩展企业数据,确保模型对这些数据的关注度。
一、MateConv预训练数据集清洗与创建【可选】
注:本部分为可选操作,我为大家准备了清洗完的数据,可以直接使用。
1.预训练数据集获取
- 中文公开预训练数据集一览
| 中文预训练语料 | 描述 |
|---|---|
| Wiki中文百科:wikipedia-cn-20230720-filtered | 中文Wikipedia的数据 |
| BaiduBaiKe:百度网盘 提取码: bwvb | 中文BaiduBaiKe的数据 |
| C4_zh:百度网盘 part1 提取码:zv4r;百度网盘 part2 提取码:sb83;百度网盘 part3 提取码:l89d | C4是可用的最大语言数据集之一,收集了来自互联网上超过3.65亿个域的超过1560亿个token。C4_zh是其中的一部分 |
| WuDaoCorpora:智源研究院BAAI:WuDaoCorpora Text文本预训练数据集 | 中文悟道开源的200G数据 |
| shibing624/medical:shibing624/medical | 源自shibing624的一部分医学领域的预训练数据 |
| seq-monkey-data:seq-monkey-data | 是由多种公开来源的数据(如网页、百科、博客、开源代码、书籍等)汇总清洗而成。整理成统一的JSONL格式,并经过了严格的筛选和去重,确保数据的全面性、规模、可信性和高质量。总量大约在10B token,适合中文大语言模型的预训练。 |
| Skywork:Skywork | 可公开访问部分包含约2.33亿个独立网页,每个网页平均包含1000多个汉字。数据集包括大约150B token和620GB的纯文本数据。 |
- 获取预训练数据集
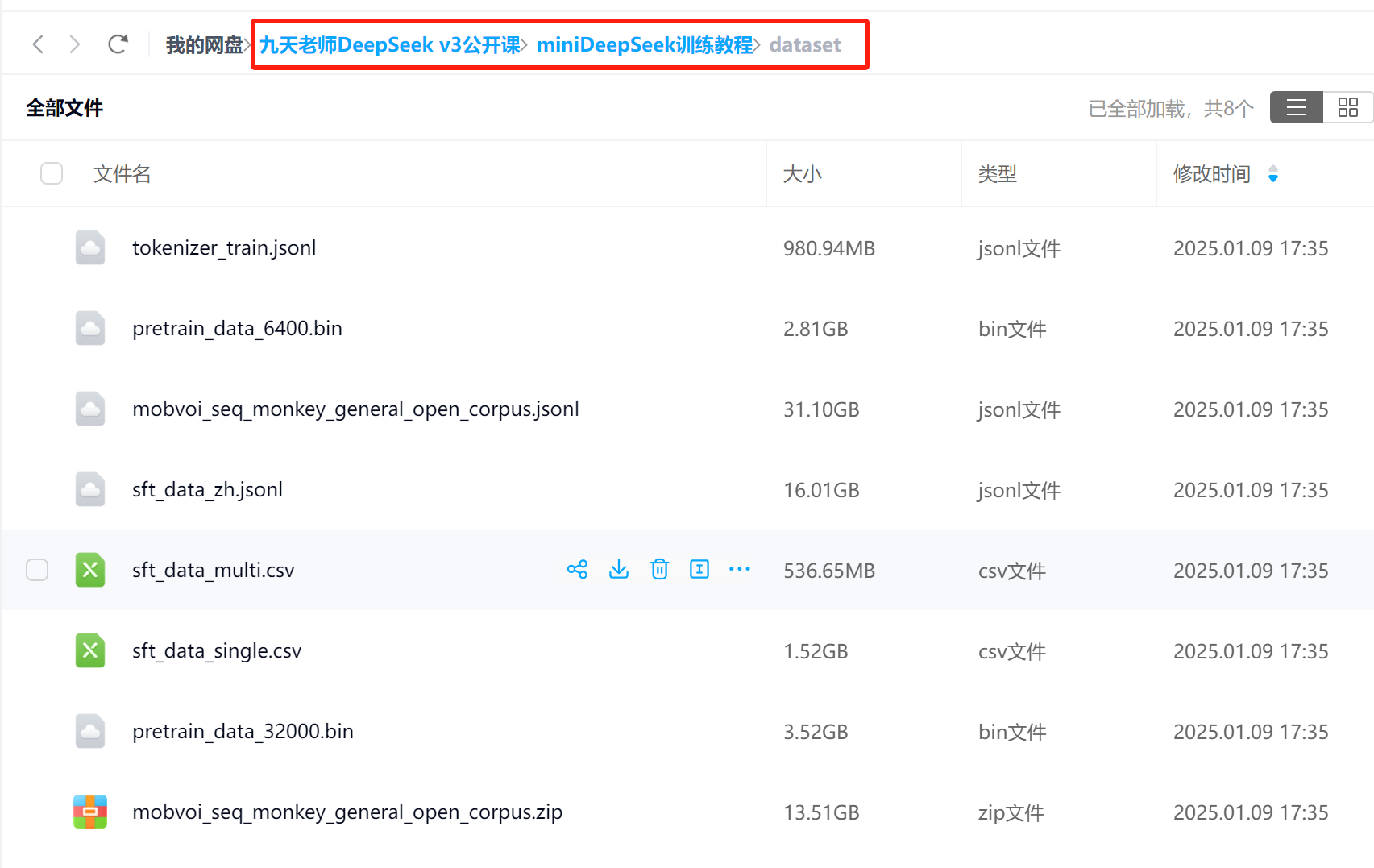
本次模型选择序列猴子通用文本数据集作为预训练数据集mobvoi_seq_monkey_general_open_corpus,该数据集介绍如下:https://github.com/mobvoi/seq-monkey-data/blob/main/docs/pretrain_open_corpus.md

数据集需要手动下载mobvoi_seq_monkey_general_open_corpus.zip文件并上传至项目data文件夹内。
- 文件解压缩
接下来则需要在服务器上运行如下命令:
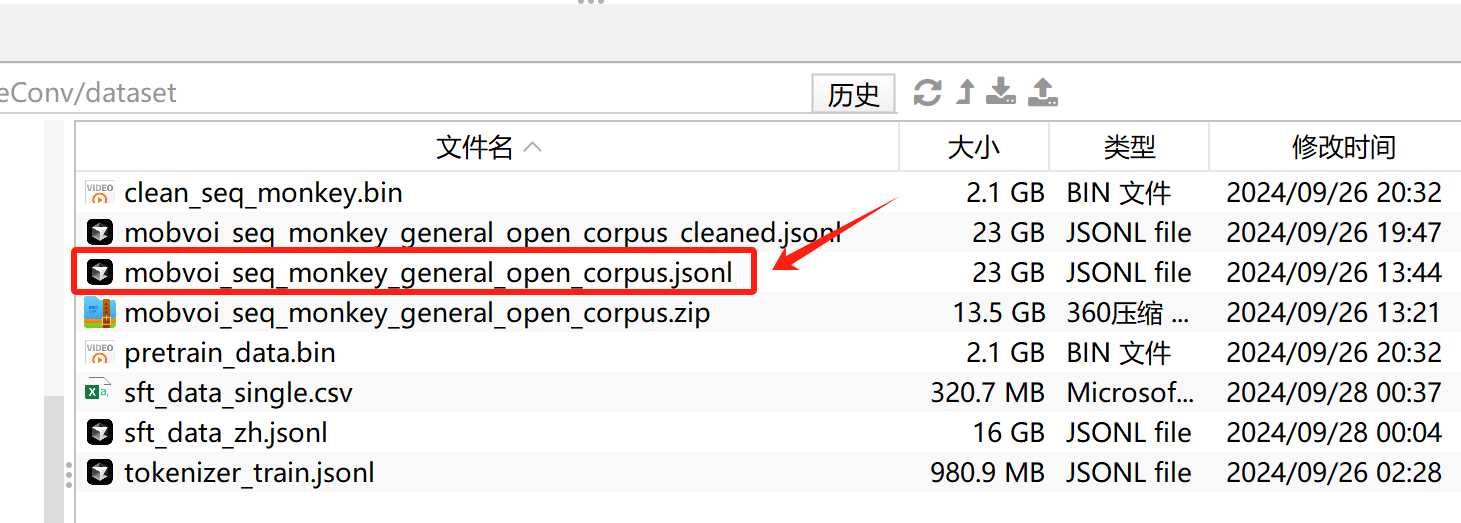
FENCE0
解压缩后就会得到文件mobvoi_seq_monkey_general_open_corpus.jsonl
2.预训练集清洗与二进制转化
- Step 1.导入库
import itertools
import re
import json
import jsonlines
import psutil
import ujson
import numpy as np
import pandas as pd
from transformers import AutoTokenizer
from datasets import load_dataset
import os
from tqdm import tqdm
- Step 2.定义BOS和EOS标记,并加载分词器
# 定义BOS和EOS标记
bos_token = "<s>"
eos_token = "</s>"
# 加载训练好的分词器路径
tokenizer = AutoTokenizer.from_pretrained('/root/autodl-tmp/MateConv/model/mateconv_tokenizer', use_fast=False)
print(f'加载的tokenizer词表大小: {len(tokenizer)}')
- Step 3.读取部分数据
def preview_dataset(file_path, num_lines=5):
"""
读取并展示数据集的前 num_lines 行
"""
# 检查文件是否存在
if not os.path.exists(file_path):
raise FileNotFoundError(f"{file_path} 文件不存在,请检查路径!")
# 逐行读取并展示前 num_lines 行
with jsonlines.open(file_path) as reader:
for idx, obj in enumerate(reader):
print(f"第 {idx + 1} 行数据: {obj}")
if idx + 1 >= num_lines:
break
# 指定文件路径和需要展示的行数
file_path = './dataset/mobvoi_seq_monkey_general_open_corpus.jsonl'
preview_dataset(file_path, num_lines=5)
JSONL(JSON Lines):是一种逐行存储 JSON 对象的文件格式,每行是一个独立的 JSON 对象,行与行之间并没有特定的结构。每行的 JSON 对象独立存在,不属于同一个数组或对象。例如:
{"name": "Alice", "age": 25}
{"name": "Bob", "age": 30}
- 什么样的 JSONL 中会携带无效的 JSON 格式?
在 JSONL 文件中,每一行都应当是有效的 JSON 对象,但有以下几种常见情况会导致无效的 JSON 行:
-
缺少必要的符号:JSON 对象必须用
{}括起来,且键值对之间要用逗号分隔。例如,缺少结束花括号:{"name": "Alice", "age": 25 -
引号问题:JSON 的键和值(非数字类型)必须使用双引号。如果使用了单引号或忘记引号,都会导致无效格式:
{'name': 'Alice', 'age': 25} # 错误的引号 -
数据未完整写入:例如由于文件写入中断,某一行可能是不完整的 JSON 对象:
{"name": "Alice", "age": -
额外的标点符号或换行符:一些 JSONL 文件可能错误地加入了多余的标点符号或不正确的换行符,导致解析错误:
{"name": "Alice", "age": 25},{"name": "Bob", "age": 30}这里的逗号在 JSONL 中是不需要的,因为每一行都是独立的。
-
字符编码问题:文件可能存在编码不一致的情况,特别是非 UTF-8 编码时,可能会引发解码错误,例如你的错误提示中看到的 "codec can't decode byte"。
- 无效的 JSON 格式示例
例如,以下 JSON 数据格式就是无效的:
-
缺少关闭括号:
{"name": "Alice", "age": 25 -
键名未加双引号:
{name: "Alice", "age": 25} -
值部分使用了错误的引号:
{"name": 'Alice', "age": 25} -
Step 4.统计与清理数据
def get_total_lines(file_path):
"""
获取 JSONL 文件的总行数,不忽略错误,保证能够全面统计。
"""
with open(file_path, 'rb') as f: # 使用二进制模式避免编码问题
return sum(1 for _ in f)
def check_jsonl_format(file_path):
"""
检查 JSONL 文件中的每一行是否是有效的 JSON 格式,带进度显示,并统计所有有问题的行。
"""
total_lines = get_total_lines(file_path) # 获取文件总行数
valid_lines = 0
invalid_lines = 0
# 使用逐行读取,捕获 JSON 和编码错误
with open(file_path, 'rb') as f: # 使用二进制读取避免编码问题
# 使用 tqdm 进度条显示检查进度
for idx, line in tqdm(enumerate(f), total=total_lines, desc="Checking JSONL format"):
try:
# 先尝试将每行数据解码为 UTF-8
decoded_line = line.decode('utf-8')
# 然后检查是否是有效的 JSON 格式
obj = jsonlines.Reader([decoded_line]).read()
valid_lines += 1
except UnicodeDecodeError as e:
print(f"Encoding error at line {idx + 1}: {e}")
invalid_lines += 1
except jsonlines.InvalidLineError as e:
print(f"Invalid JSON at line {idx + 1}: {e}")
invalid_lines += 1
print(f"检查完成,文件中共有 {valid_lines} 行有效的 JSON 数据,{invalid_lines} 行无效的 JSON 数据。")
return valid_lines, invalid_lines
valid_lines, invalid_lines = check_jsonl_format(file_path)
def remove_invalid_line(file_path, output_path, invalid_line_num):
"""
读取文件,跳过指定的无效行,并将结果写入新文件
"""
with open(file_path, 'rb') as infile, open(output_path, 'wb') as outfile:
for idx, line in enumerate(infile):
if idx + 1 != invalid_line_num: # 跳过无效行
outfile.write(line)
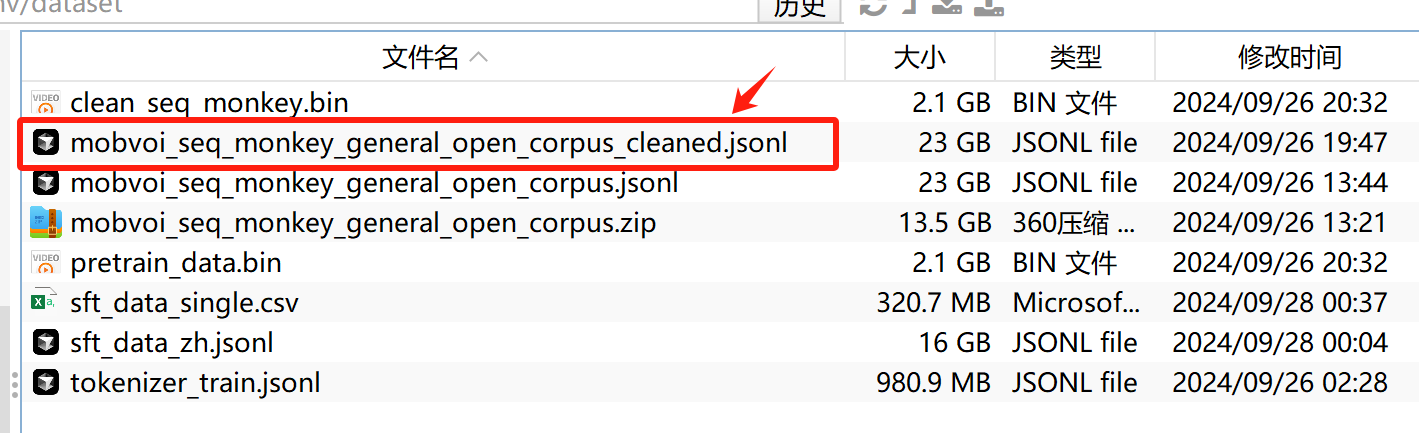
# 使用该函数删除第 9598787 行并保存为新文件
remove_invalid_line('./dataset/mobvoi_seq_monkey_general_open_corpus.jsonl',
'./dataset/mobvoi_seq_monkey_general_open_corpus_cleaned.jsonl',
invalid_line_num=9598787)
- Step 5.定义处理函数(逐块处理数据)
def process_seq_monkey(chunk_size=50000):
"""
逐块读取 mobvoi_seq_monkey_general_open_corpus.jsonl 文件,
对文本进行分词,并将分词结果保存为二进制文件,支持跳过无效行,并显示处理进度。
"""
doc_ids = []
chunk_idx = 0
total_lines = 0
# 先计算总行数以便显示进度
with open('./dataset/mobvoi_seq_monkey_general_open_corpus_cleaned.jsonl', 'r', encoding='utf-8') as f:
total_lines = sum(1 for _ in f)
# 打开jsonlines文件逐行读取
with jsonlines.open('./dataset/mobvoi_seq_monkey_general_open_corpus_cleaned.jsonl') as reader:
# 使用 tqdm 进度条显示进度
with tqdm(total=total_lines, desc="Processing lines") as pbar:
while True:
try:
# 使用 itertools.islice 按块读取文件,每次读取 chunk_size 行数据
chunk = list(itertools.islice(reader, chunk_size))
except jsonlines.InvalidLineError as e:
print(f"Skipping invalid chunk at chunk {chunk_idx}: {e}")
continue
if not chunk: # 如果读取到文件末尾,则停止
break
# 遍历块中的每一行数据
# 逐行对数据进行编码(按token进行编码)
for idx, obj in enumerate(chunk):
try:
# 从每一行数据中提取'text'字段(即文本内容)
content = obj.get('text', '')
# 跳过长度超过512的文本
if len(content) > 512:
continue
# 对文本进行分词,将其转为 token ids 序列,并加上BOS和EOS标记
text_id = tokenizer(f'{bos_token}{content}{eos_token}').data['input_ids']
# 将分词结果添加到 doc_ids 列表中
doc_ids += text_id
except UnicodeDecodeError as e:
# 如果遇到编码错误,跳过该行,并打印错误信息
print(f"Skipping invalid line {chunk_idx * chunk_size + idx + 1}: {e}")
continue
# 每处理完一块数据,更新 chunk_idx 并打印进度信息
chunk_idx += 1
pbar.update(len(chunk)) # 更新进度条
# 如果累积的 token ids 超过 1,000,000 个,保存到文件中
if len(doc_ids) > 1000000:
arr = np.array(doc_ids, dtype=np.uint16)
with open(f'./dataset/clean_seq_monkey.bin', 'ab') as f:
f.write(arr.tobytes())
doc_ids = []
# 如果处理完所有数据后 doc_ids 中还有未保存的内容,最后再保存一次
if doc_ids:
arr = np.array(doc_ids, dtype=np.uint16)
with open(f'./dataset/clean_seq_monkey.bin', 'ab') as f:
f.write(arr.tobytes())
def pretrain_process():
"""
函数的作用是调用 process_seq_monkey() 函数生成数据,
然后整合所有生成的二进制文件,并将其合并保存为一个总的预训练数据文件。
"""
# 调用 process_seq_monkey 函数处理数据
process_seq_monkey()
# 数据文件路径列表,目前只处理 clean_seq_monkey.bin 文件
data_path_list = [
'./dataset/clean_seq_monkey.bin'
]
data_lst = []
# 读取生成的二进制文件
for data_path in data_path_list:
with open(data_path, 'rb') as f:
# 将二进制文件中的内容加载到 numpy 数组中
data = np.fromfile(f, dtype=np.uint16)
data_lst.append(data)
# 将所有读取到的数据合并为一个大数组
arr = np.concatenate(data_lst)
print(f"合并后的数据大小: {arr.shape}")
# 将合并后的数据保存为最终的预训练数据文件
with open('./dataset/pretrain_data.bin', 'wb') as f:
f.write(arr.tobytes())
- 为什么要将数据转换为二进制文件:
-
高效存储和读取:二进制文件相比文本文件具有更高的存储和读取效率,尤其是对于大规模的数据集。由于二进制文件是以原始的机器可读格式存储的,不需要进行字符编码转换,因此读取速度更快。对于预训练阶段通常需要处理大量数据,二进制文件可以显著减少读取时间。
-
减少文件大小:二进制格式的数据比常规的文本格式更紧凑,占用的磁盘空间更少。这对存储大数据集尤其重要,能够显著节省存储资源。
-
与深度学习框架兼容:深度学习框架(如 PyTorch、TensorFlow 等)在训练时往往需要数据以某种高效的格式加载到内存中。将数据保存为二进制格式有助于快速载入到 NumPy 数组或直接作为模型输入,避免了每次都需要重新转换。
-
跨平台一致性:二进制文件可以跨平台使用而不丢失精度和数据信息,适合在不同的硬件和操作系统环境中使用。
- 这个函数的具体作用:
process_seq_monkey()函数负责处理原始数据并生成单个或多个二进制文件。- 然后这些生成的二进制文件通过
np.fromfile读取并存入 NumPy 数组,所有的二进制数据都会被拼接到一起。- 最后,通过
np.concatenate合并所有的 NumPy 数组,生成一个总的数据数组,并将其存储为一个大的二进制文件 (pretrain_data.bin),供后续的模型预训练使用。
总结来说,这种处理方式主要是为了提高效率,方便在大规模预训练任务中快速加载数据并减少磁盘和内存的占用。
- 运行数据处理
pretrain_process()
运行结束后会创建一个名为pretrain_data.bin的二进制数据文件,该文件也就是接下来进行模型预训练的文件:
3. 检查预训练数据集【必要】
当我们清洗完数据后,即可检查数据集然后开启预训练过程。这里需要下载pretrain_data.csv数据文件,并导入查看:
import pandas as pd
# 读取CSV文件
pretrain_df = pd.read_csv('./dataset/pretrain_data.csv')
# 打印前5行数据(默认)
print(pretrain_df.head())
# 如果你想打印前n行,可以传递一个参数
print(pretrain_df.head(n=10)) # 打印前10行
二、MiniDeepSeek预训练开启、打断与中继过程
1.MiniDeepSeek基础模型架构代码编写
在准备好了数据集之后,接下来即可开启大模型的预训练过程。公开课里我们不深入探讨模型结构和相关代码,总的来说MiniDeepSeek采用了DeepSeek v3 MoE架构的文本大模型,具体代码如下:
FENCE0
我们需要在/root/autodl-tmp/miniDeepSeek文件夹内创建一个名为model.py的文件,并写入上述代码:
FENCE0
写入完成后保存并退出。
以下是MiniDeepSeek模型架构的基本解释:
1. RMSNorm 类
RMSNorm(Root Mean Square Normalization)是一个归一化层,它与常见的层归一化(LayerNorm)类似,但是使用了均方根(RMS)来计算标准差。该类的实现如下:
__init__:初始化时接受输入的维度dim和一个小常数eps用于防止除零错误。_norm:对输入进行 RMS 归一化。forward:对输入数据x进行归一化操作,并通过可训练的weight参数缩放输出。
2. precompute_pos_cis 函数
这个函数用于预计算位置编码的复数形式(pos_cis),在模型中用于增强位置感知能力。
dim:表示嵌入空间的维度。end:序列的最大长度。theta:频率的缩放因子。- 这个函数生成了一个与输入序列长度和模型维度相对应的复数位置编码。
3. apply_rotary_emb 函数
该函数应用旋转位置编码(rotary embedding)到查询 xq 和键 xk 上,以便增强模型的位置信息。
xq,xk:查询和键,分别来自注意力机制的输入。pos_cis:预计算的复数位置编码。apply_rotary_emb会对查询和键进行旋转编码,使得相对位置关系能够被更好地建模。
4. Attention 类
Attention 类实现了一个多头自注意力机制(Multi-head Attention)。其中包含:
n_kv_heads:表示键值对的头数,可以与查询头数不同。wq,wk,wv,wo:用于映射输入的线性层,分别用于查询、键、值和输出。mask:用于实现因果遮蔽(causal masking),防止模型看到未来的词。forward:计算注意力分数并应用于值(value)。其中使用了旋转位置编码(apply_rotary_emb)来增强位置信息。
5. FeedForward 类
这是标准的前馈神经网络(FeedForward Network),包含了两层线性变换和一个激活函数(silu,类似于gelu):
forward:执行输入数据的前向传播,经过线性变换和激活函数。
6. MoEGate 类
MoEGate 实现了一个门控机制,用于选择一个或多个专家(专家模型通常用于大规模任务,能够提高模型的计算效率)。具体步骤如下:
scoring_func:定义了如何计算门控函数的得分(比如使用 Softmax)。top_k:表示每个 token 会选择哪些top_k个专家进行处理。forward:根据计算的得分,选择专家并返回加权结果。
7. MOEFeedForward 类
该类结合了 MoE(混合专家网络)和前馈神经网络,在输入上应用 MoE 门控机制选择不同的专家进行计算:
forward:在训练时,根据门控机制对输入数据进行专家选择,并加权专家的输出;在推理时,选择最优的专家进行处理。
8. TransformerBlock 类
TransformerBlock 是标准的 Transformer 层,包含了多头自注意力和前馈神经网络。具体来说:
attention:多头自注意力层。feed_forward:前馈神经网络,支持普通的前馈网络或者 MoE(通过use_moe参数选择)。forward:执行该层的前向传播,即先进行注意力计算,然后进行前馈神经网络计算。
9. Transformer 类
这是模型的主要类,继承自 PreTrainedModel:
__init__:初始化模型,包括词嵌入层、若干个TransformerBlock层、位置编码、归一化层等。forward:执行模型的前向传播,处理输入的tokens和targets,返回模型的输出。训练时计算交叉熵损失,推理时返回生成的 logits。generate:生成文本的函数,支持温度采样、Top-k 采样等生成策略。eval_answer:在推理模式下,根据输入idx计算下一个 token 的 logits。
MiniDeepSeek通过集成多种先进的技术,如多头注意力(Attention)、旋转位置编码(Rotary Embedding)、混合专家网络(MoE)等,旨在提升大规模语言模型的计算效率和表现。每个模块的设计都为处理长序列和多任务提供了灵活的功能,特别是 MoE 和自定义的门控机制使得模型可以选择性地激活部分计算资源,从而减少计算量。
2.MiniDeepSeek模型配置文件编写
同时,model.py中预留了很多模型参数接口,可以统一通过继承一个transformers中的PretrainedConfig类来设置这些参数。这里我们在model这个文件夹内再创建一个名为LMConfig.py的文件,来设置MateConv的模型参数。
FENCE0
并在LMConfig.py文件中输入如下内容:
FENCE0
然后保存并退出:
LMConfig 类用于定义和控制模型架构中的一系列关键参数。它继承自PretrainedConfig,允许用户通过配置参数来灵活地调整模型的结构和行为。以下是对LMConfig中相关参数的解释,以及这些参数如何影响原始模型架构和运行流程。
class LMConfig(PretrainedConfig):
- 继承自
PretrainedConfig,意味着这个配置类是用来定义一个预训练模型的配置,能够被 Hugging Face 的模型管理工具加载和使用。
model_type = "miniDeepSeek":
- 这是模型的名称,告诉 Hugging Face 框架这个配置是针对
miniDeepSeek模型的。
def __init__(...):
- 这是类的初始化方法,定义了多个参数,它们控制着
miniDeepSeek模型的不同方面。所有参数都具有默认值,可以在实例化时修改。
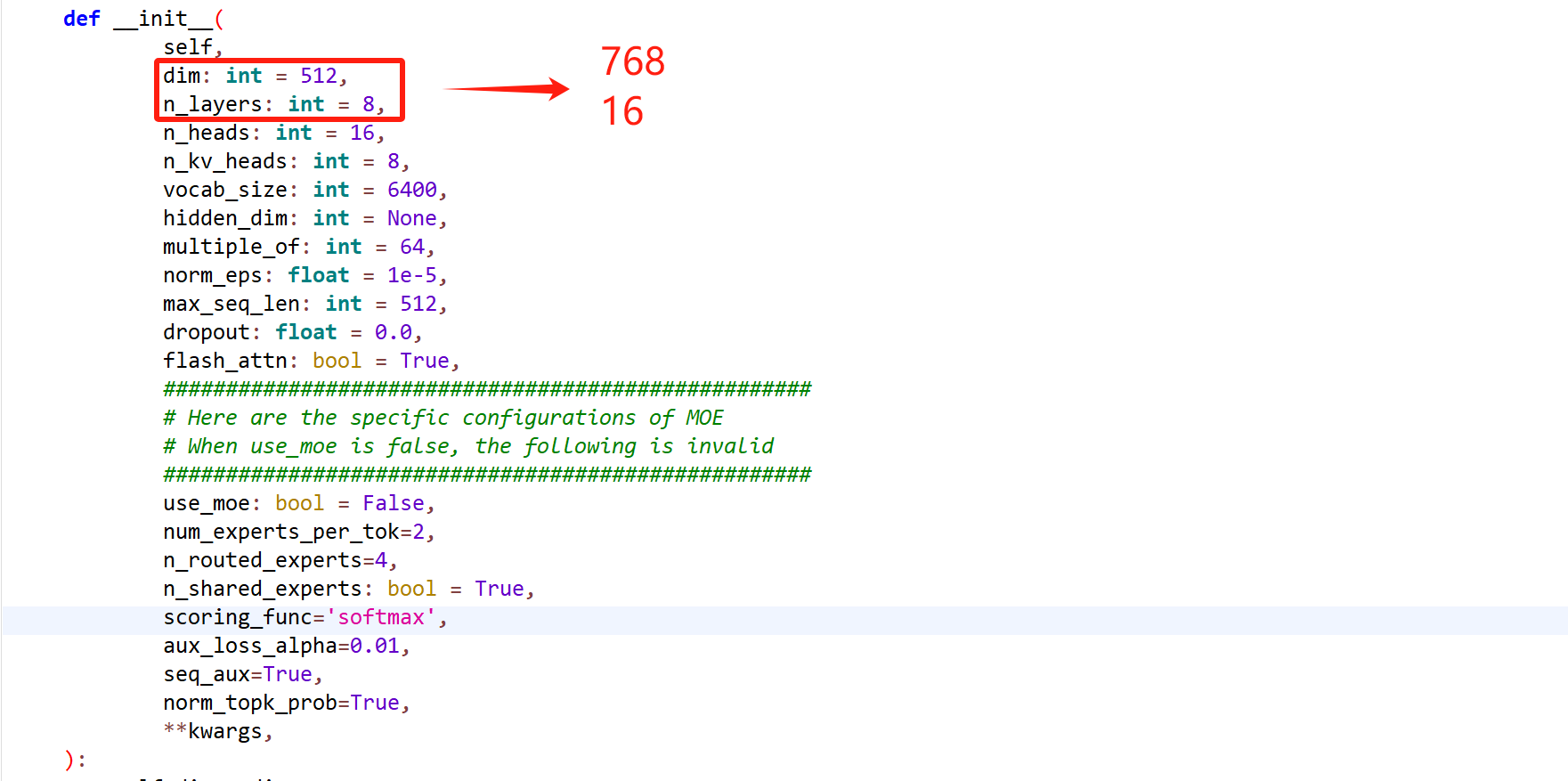
参数解释:
dim: int = 512: 模型的隐藏层维度,即每层的神经元数量。n_layers: int = 8: 模型的层数,指定模型包含多少个 transformer 层。n_heads: int = 16: 自注意力机制中的头数,决定了每个 transformer 层的并行计算量。n_kv_heads: int = 8: KV(Key-Value)头数,用于处理注意力机制中的键和值。vocab_size: int = 6400: 词汇表的大小,定义了词嵌入层的输入大小。hidden_dim: int = None: 隐藏层的维度,如果没有指定,则默认是 4 倍的dim。multiple_of: int = 64: 一个对隐藏层维度的约束,保证该维度是某个数字的倍数。norm_eps: float = 1e-5: 用于归一化的 epsilon 值,防止数值不稳定。max_seq_len: int = 512: 最大输入序列长度,决定模型能处理的最长文本的长度。dropout: float = 0.0: 用于防止过拟合的 dropout 比例。flash_attn: bool = True: 是否启用 Flash Attention 技术,提高注意力机制的效率。use_moe: bool = True: 是否使用 Mixture of Experts(MoE)机制,允许模型选择不同的专家来处理不同的输入。num_experts_per_tok: int = 2: 每个 token 所选择的专家数量,和 MoE 机制相关。n_routed_experts: int = 4: 总的专家数量,MoE 机制下使用的专家数目。n_shared_experts: bool = True: 是否共享专家。scoring_func: str = 'softmax': 用于 MoE 的评分函数,默认为softmax。aux_loss_alpha: float = 0.01: 辅助损失的权重因子,用于 MoE 的训练。seq_aux: bool = True: 是否计算序列级别的辅助损失。norm_topk_prob: bool = True: 是否标准化 top-k 概率,通常与 MoE 机制一起使用。
super().__init__(**kwargs):
- 这行代码调用父类
PretrainedConfig的构造函数,并将额外的参数传递给它,确保配置类与 Hugging Face 框架兼容。
LMConfig 类提供了对 miniDeepSeek 模型各项超参数的控制,涵盖了模型结构(如维度、层数、头数等)、优化和训练设置(如 dropout、MoE 配置、辅助损失等)。这些参数允许在创建模型时进行灵活配置,使得该模型可以根据不同的任务需求进行调整。。
- 数据读取与脚本
同时,我们需要在model文件夹内创建一个名为dataset.py的脚本,用于在训练时读取数据:
FENCE0
3.编写MiniDeepSeek预训练脚本
在准备好了模型架构和参数代码之后,接下来我们就可以开始编写模型的预训练脚本了,该脚本的核心功能是将数据带入模型,并且根据模型参数来完成模型的预训练过程。这里还是一样,我们首先需要在项目根目录下创建一个预训练脚本文件pretrain.py:
FENCE0
并在pretrain.py文件中输入如下内容:
FENCE0
然后保存并退出:
这段脚本用于启动语言模型的预训练过程,结合了PyTorch的多GPU并行训练(DistributedDataParallel)、梯度累积、学习率调度等功能,以优化大规模的训练任务。脚本的主要功能包括模型初始化、数据加载、分布式训练支持以及训练日志记录。下面详细解释代码中的核心功能和参数设置。
脚本功能解释如下
-
分布式训练支持 (
DistributedDataParallel)- 脚本可以通过分布式训练模式来加速模型训练。在分布式模式下,模型会通过多GPU并行计算实现数据并行。
init_distributed_mode函数负责初始化分布式环境,使用NCCL后端进行通信。 - 使用
torch.distributed模块的DistributedSampler确保数据在不同GPU之间合理分配,避免数据重叠。
- 脚本可以通过分布式训练模式来加速模型训练。在分布式模式下,模型会通过多GPU并行计算实现数据并行。
-
模型初始化 (
init_model)- 该函数初始化模型,并打印模型的参数数量。在配置文件
LMConfig中设置的参数(如dim、n_layers等)将被用于初始化Transformer模型。参数的设置将影响模型的规模和计算量。 - 如果启用了
MOE(专家模型),则会根据配置初始化MOE相关的组件。 - 该模型支持在PyTorch 2.0及以上版本中通过
torch.compile进一步优化模型的推理性能。
- 该函数初始化模型,并打印模型的参数数量。在配置文件
-
学习率调度 (
get_lr)- 学习率调度器采用了余弦退火(Cosine Annealing)的方式来逐步降低学习率。在训练的早期阶段进行学习率预热(warm-up),然后逐步减小学习率,最终在训练结束时接近于零。这个策略可以在训练初期加快收敛速度,并在后期稳定地进行微调。
- 学习率由
get_lr函数动态计算,在每一步训练中通过迭代更新学习率。
-
训练过程 (
train_epoch)- 每个
epoch的训练过程包括以下步骤:- 将训练数据加载到设备上。
- 动态调整学习率。
- 使用
torch.cuda.amp.autocast()自动进行混合精度训练,减少显存使用,提高计算效率。 - 梯度累积:模型在每
accumulation_steps步之后更新参数,以减少显存开销,适用于大模型和小批次训练。 - 梯度裁剪:为了防止梯度爆炸,通过
torch.nn.utils.clip_grad_norm_对梯度进行裁剪。 - 训练日志记录:定期记录训练过程中的损失、学习率和时间,并将结果输出到控制台。
- 每个
-
模型保存
- 在每
save_interval步后保存模型的状态字典。保存时,根据配置选择是否包括MOE专家模型的参数。 - 如果是在分布式训练模式下(
DistributedDataParallel),则会保存主进程模型的参数。
- 在每
-
梯度放大与更新 (
GradScaler)- 通过
torch.cuda.amp.GradScaler来缩放梯度,进一步减少数值不稳定的风险并提高混合精度训练的效果。
- 通过
脚本参数解释如下:
-
--out_dir- 默认值:
"out" - 含义:模型保存的输出目录。预训练过程中生成的模型权重会保存在该目录下。
- 默认值:
-
--epochs- 默认值:
20 - 含义:训练的总轮数。每个轮次将使用整个训练数据集进行一次完整的模型更新。
- 默认值:
-
--batch_size- 默认值:
32 - 含义:训练时使用的批次大小。较大的批次可以提高模型的泛化性能,但也需要更多的计算资源。
- 默认值:
-
--learning_rate- 默认值:
2e-4 - 含义:初始学习率,控制模型的权重更新速度。余弦退火调度器将会逐步减少该值。
- 默认值:
-
--device- 默认值:
"cuda:0"(如果有GPU),否则为"cpu" - 含义:训练设备。可以是
CPU或GPU,通常在大规模训练中使用GPU。
- 默认值:
-
--dtype- 默认值:
"bfloat16" - 含义:指定数据类型(如
float16或bfloat16)以启用混合精度训练。bfloat16通常在GPU上使用,因为它可以提高训练速度并减少显存占用。
- 默认值:
-
--use_wandb- 默认值:
False - 含义:是否使用
Weights & Biases(WandB)工具来跟踪实验进度和记录训练指标。WandB 是一种实验跟踪和可视化工具。
- 默认值:
-
--wandb_project- 默认值:
"MateConv-Pretrain" - 含义:如果使用WandB,这是用于实验的项目名称。
- 默认值:
-
--num_workers- 默认值:
8 - 含义:用于数据加载的工作进程数量。更多的
num_workers可以加速数据加载,但会占用更多的CPU资源。
- 默认值:
-
--data_path- 默认值:
"./dataset/pretrain_data.csv"(也可根据实际情况改为.bin文件) - 含义:训练数据集的路径。该数据集应该是预处理后的二进制文件,用于模型预训练。
- 默认值:
-
--ddp- 默认值:
False - 含义:是否启用分布式数据并行(DistributedDataParallel)训练。如果启用,模型将分布到多个GPU上进行并行计算。
- 默认值:
-
--accumulation_steps- 默认值:
8 - 含义:梯度累积步数。通过累积多个批次的梯度,再进行一次参数更新,以减少显存压力并提高训练稳定性。
- 默认值:
-
--grad_clip- 默认值:
1.0 - 含义:梯度裁剪的阈值,用于限制梯度的最大范数,防止梯度爆炸。
- 默认值:
-
--warmup_iters- 默认值:
0 - 含义:学习率预热的迭代次数。在预热阶段,学习率从零逐渐增加到设定值。
- 默认值:
-
--log_interval- 默认值:
100 - 含义:日志记录的间隔步数。每经过
log_interval步会在控制台输出一次损失和学习率等信息。
- 默认值:
-
--save_interval- 默认值:
1000 - 含义:模型保存的间隔步数。每经过
save_interval步,模型的当前状态将被保存到指定的输出目录中。
- 默认值:
-
--local_rank- 默认值:
-1
- 默认值:
4.借助wandb进行训练过程记录【可选,但推荐】
在大规模模型训练中,我们往往需要监控和分析大量的训练数据,而WandB可以帮助我们实现这一目标。它提供了以下几个重要的功能:
实时可视化:WandB可以实时展示训练过程中关键指标的变化,如损失函数、学习率、训练时间等。通过这些可视化数据,我们能够直观地了解模型的训练进展,快速发现训练中的异常或瓶颈。
自动记录与日志管理:WandB会自动记录每次实验的参数、代码、输出结果,确保实验结果的可追溯性。无论是超参数的设置,还是模型的架构调整,WandB都能够帮助我们完整保留实验记录,方便后期对比与调优。
支持中断与恢复训练:在长时间的预训练任务中,系统中断或需要暂停是常见的情况。通过WandB的checkpoint功能,我们可以随时恢复训练,从上次中断的地方继续进行,避免数据和时间的浪费。
多实验对比:当我们尝试不同的模型配置或超参数时,WandB允许我们在多个实验之间轻松进行对比分析,帮助我们选择最优的模型配置。
团队协作:WandB还支持团队协作,多个成员可以共同查看实验结果,协同调试模型。这对研究和项目开发中团队的合作非常有帮助。
- 注册wandb:https://wandb.ai/site
- 安装wandb:
在命令行中输入如下代码安装wandb:
FENCE0
然后即可登录wandb,在命令行页面输入:
FENCE0
并根据提示输入API-KEY:

即可在当前电脑上保存wandb账号信息,之后即可直接在wandb home主页上看到训练过程。
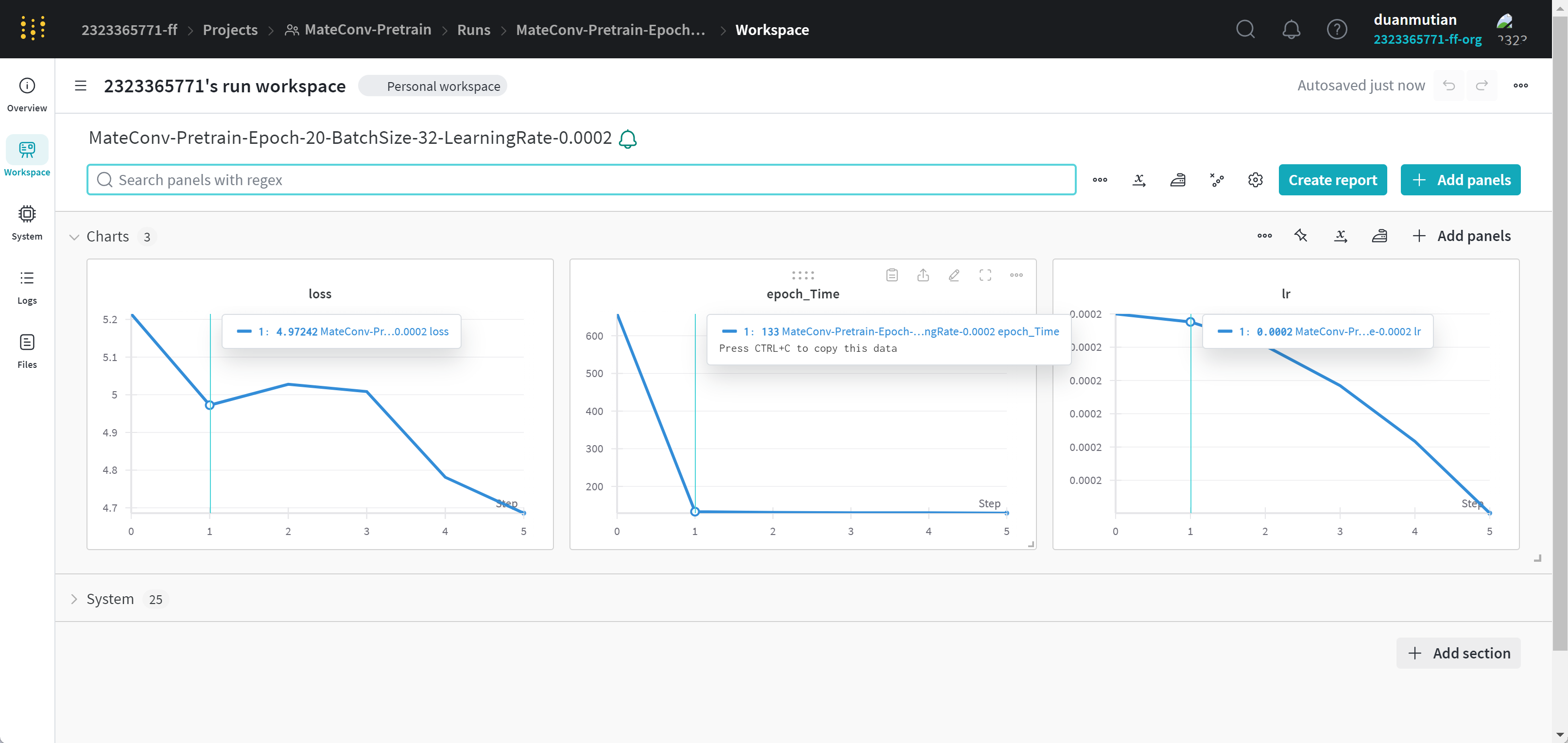
- 借助wandb监控当前运行效果
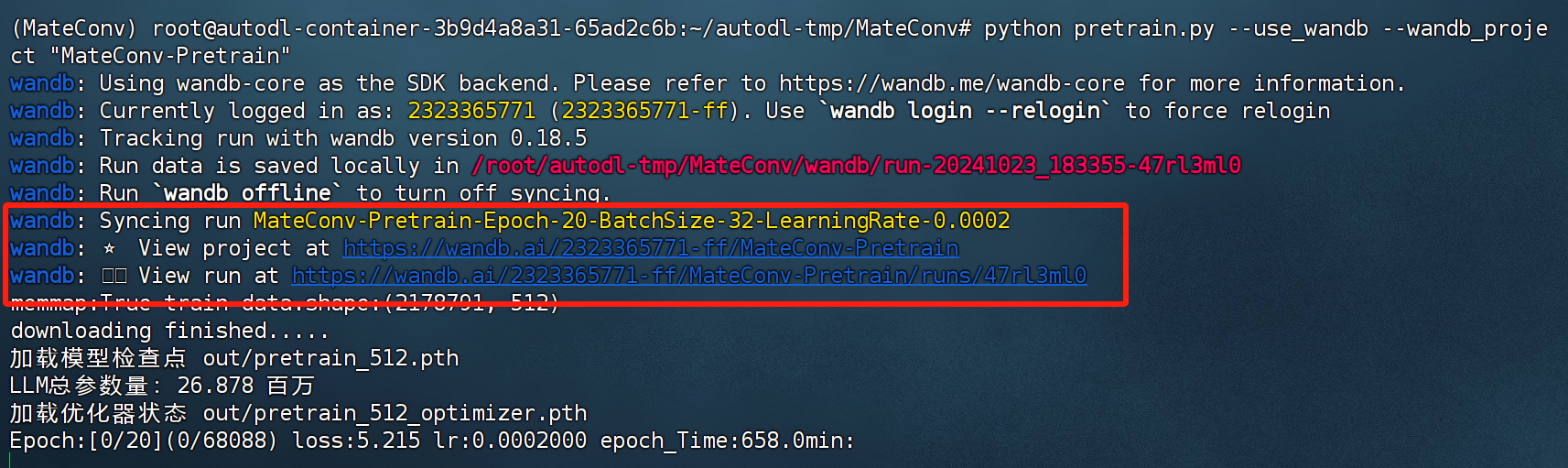
接下来在命令行中尝试运行该指令:
FENCE0
5.模型训练中断与重启
目前的pretrain.py脚本设置了断点保存功能,支持每各1000步保存一次,例如,当出现如下打印信息时,则说明当前模型部分训练结果已经保存:
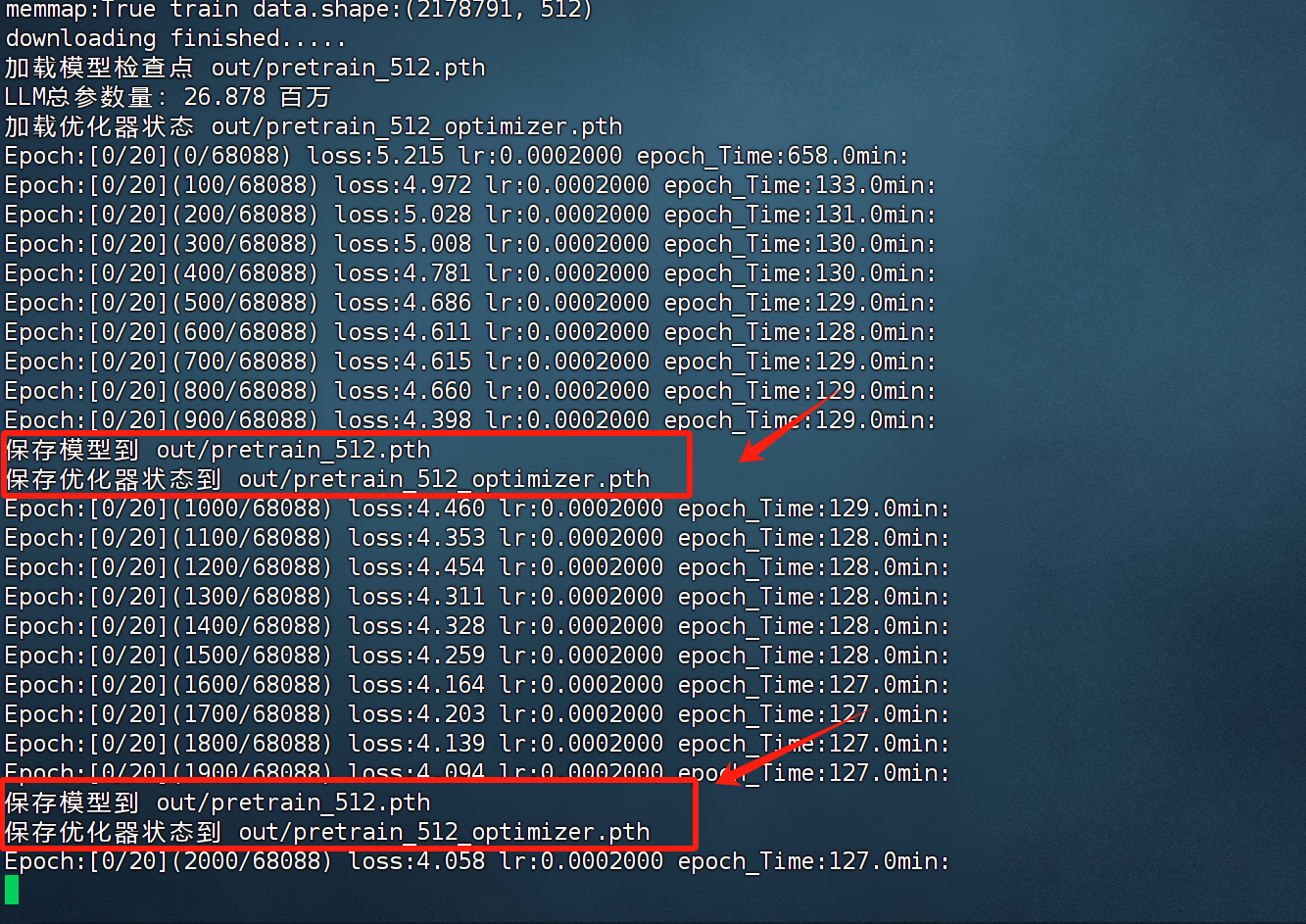
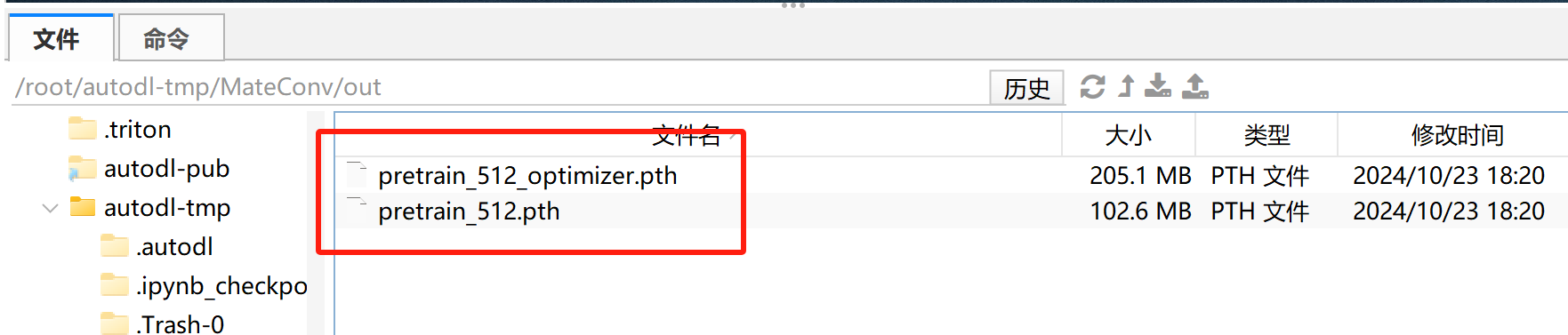
此时即可在./out文件夹中看到保存结果:
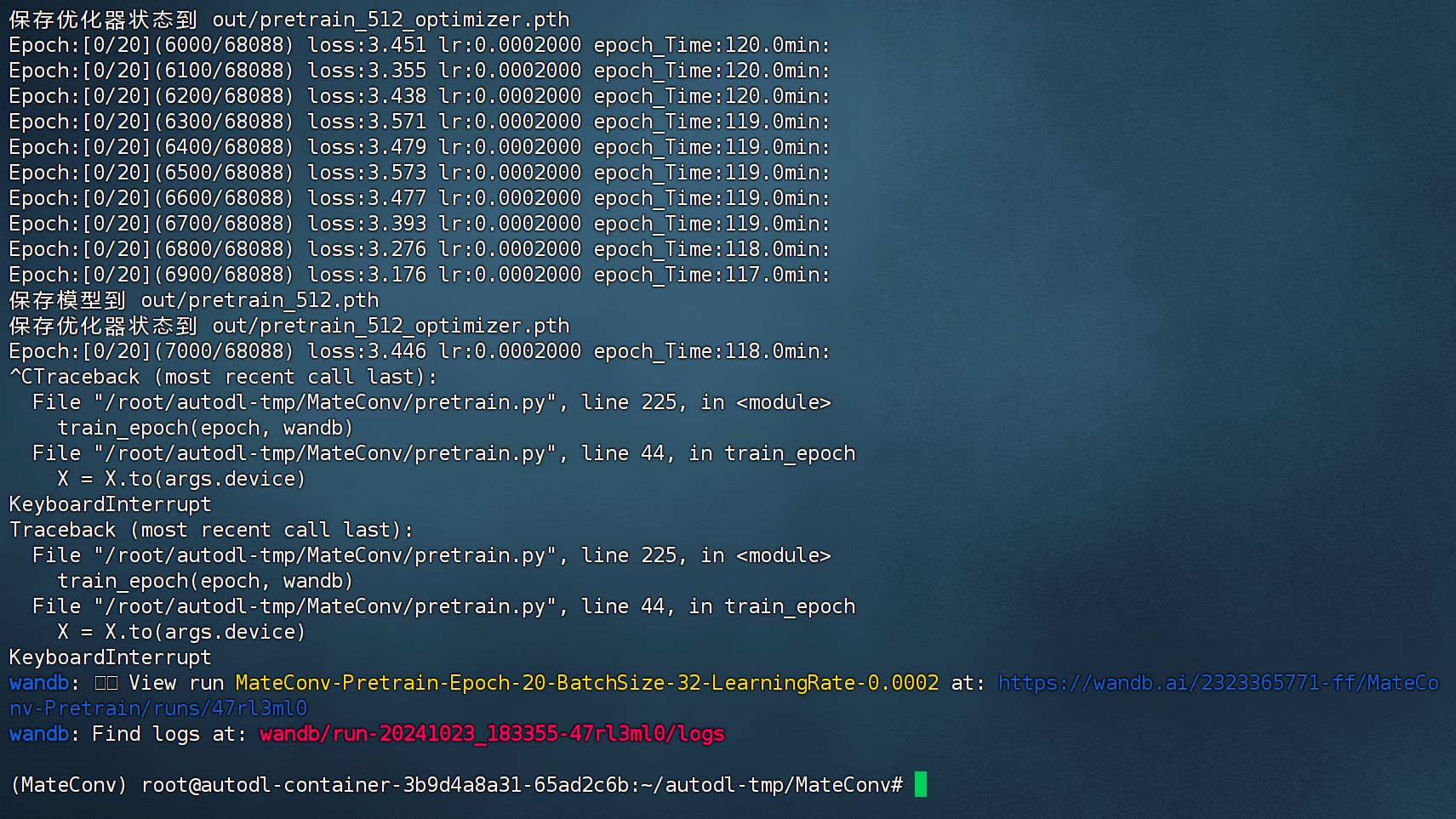
这里我们直接CTRL+C即可中断训练:
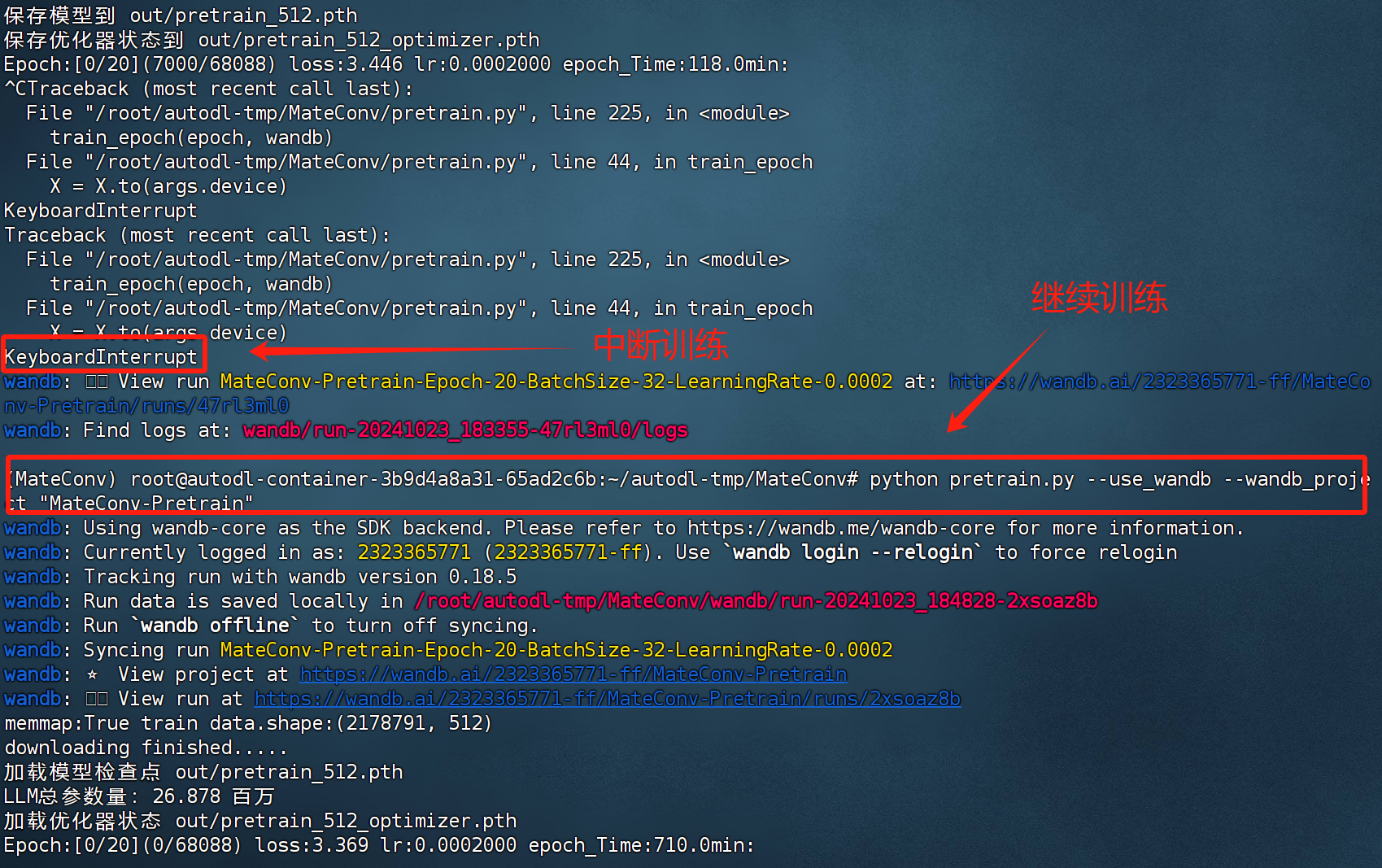
而我们只需要再次输入训练代码,即可从上次保存点开始继续训练:
四、MiniDeepSeek完整预训练过程
1.Ubuntu持久化会话方法
在做完基本准备工作之后,接下来就会进入到完整的模型训练过程中。这里需要注意的是,由于我们是使用finalshell连接远程服务器,所以在默认情况下,中途关闭对话会导致服务器当前进程运行终止,所以这里我们需要安装screen来持久化对话。
screen 是 Ubuntu(以及其他 Linux 系统)中一个非常有用的工具,特别适合长时间运行任务时使用。它可以让你在终端中启动一个独立的会话,并且即使你关闭了终端,任务仍然可以继续在后台运行。当你重新连接到服务器时,你可以恢复之前的 screen 会话,查看任务的进度或继续操作。
screen 的作用:
- 持久化会话:即使你断开了终端连接,
screen内的进程仍会继续运行。这对于需要长时间运行的任务(如训练模型、远程编译等)非常有用。 - 多任务处理:
screen允许你在一个终端会话中运行多个任务,每个任务在不同的screen窗口中独立运行。 - 会话恢复:你可以随时重新连接到
screen会话,继续查看任务输出或输入命令。
screen 的安装步骤:
-
更新系统软件包列表: 在开始安装之前,建议你先更新系统的软件包列表,以确保你安装的是最新版本的软件包。使用以下命令:
sudo apt update -
安装
screen: 安装screen非常简单,你可以通过 Ubuntu 系统的包管理器apt来安装:sudo apt install screen -
确认
screen安装成功: 安装完成后,你可以使用以下命令检查screen是否已经成功安装:screen --version如果安装成功,你会看到类似以下的版本信息:
Screen version 4.08.00 (GNU) 05-Feb-20
screen 的基本使用方法:
-
启动一个新的
screen会话:screen -S session_name这里的
session_name是你为这个会话起的名字,方便以后管理多个会话。例如:screen -S my_training_session -
在
screen会话中运行程序: 启动screen后,你可以在会话中运行任何命令或程序。即使你关闭了终端连接,程序也会继续运行。 -
断开
screen会话但保持后台运行: 在screen中按下以下键组合,即可暂时离开screen会话,保持后台运行:Ctrl + A, 然后按 D -
列出所有的
screen会话: 你可以查看当前系统中所有的screen会话:screen -ls -
恢复之前的
screen会话: 如果你想恢复之前的会话,使用以下命令:screen -r session_name或者,如果你只启动了一个
screen会话,直接输入:screen -r -
关闭
screen会话: 当你不再需要screen会话时,可以通过以下命令退出并关闭会话:exit
screen 的应用场景:
- 长时间模型训练:当你需要在远程服务器上训练大模型,可能需要数小时甚至数天时间。使用
screen,你可以在断开连接后让训练任务继续运行,稍后再重新连接以查看训练进度。 - 远程服务器管理:如果你在远程服务器上管理多个任务,
screen让你可以在不同的窗口中处理多个任务,而不会丢失任务进度。
screen 的常用快捷键:
- 断开但不关闭会话:
Ctrl + A, 然后 D - 恢复会话:
screen -r - 退出并关闭会话:
exit

- 功能测试
打开一个新的会话连接,输入screen -S my_training_session:
然后即可进入新的会话页面,输入任意内容留作标记:
然后关闭当前对话,再次打开一个新的会话:
然后输入screen -r my_training_session,便可恢复之前的会话:
此时my_training_session就是一个持久对话,并不会因为会话窗口关闭而关闭。接下来我们就在my_training_session中进行模型训练。
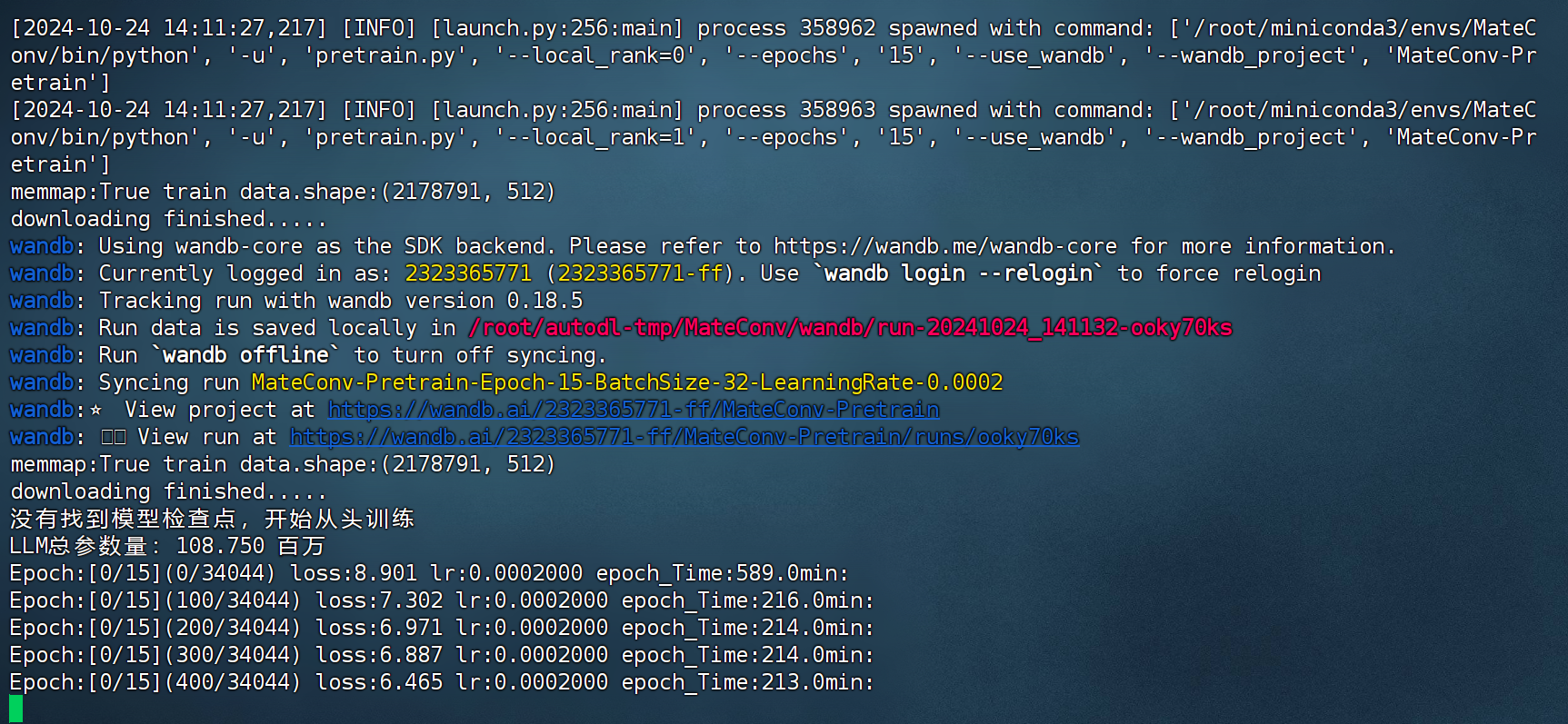
2.开启MiniDeepSeek预训练
- 确认进入到了my_training_session会话中:
FENCE0
- 准备开始训练
FENCE0
训练开启状态:
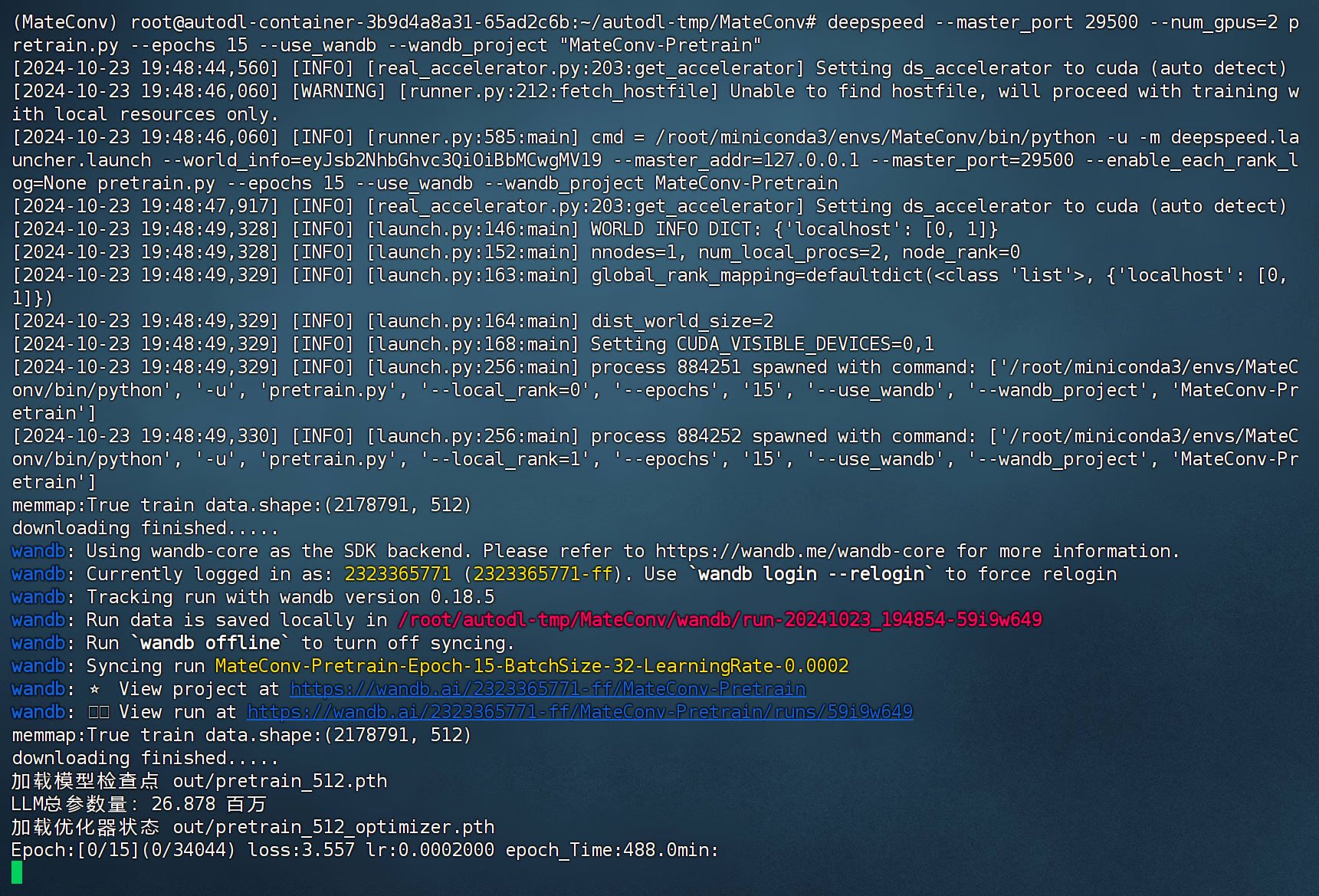
wandb显示状态:

训练结束状态:
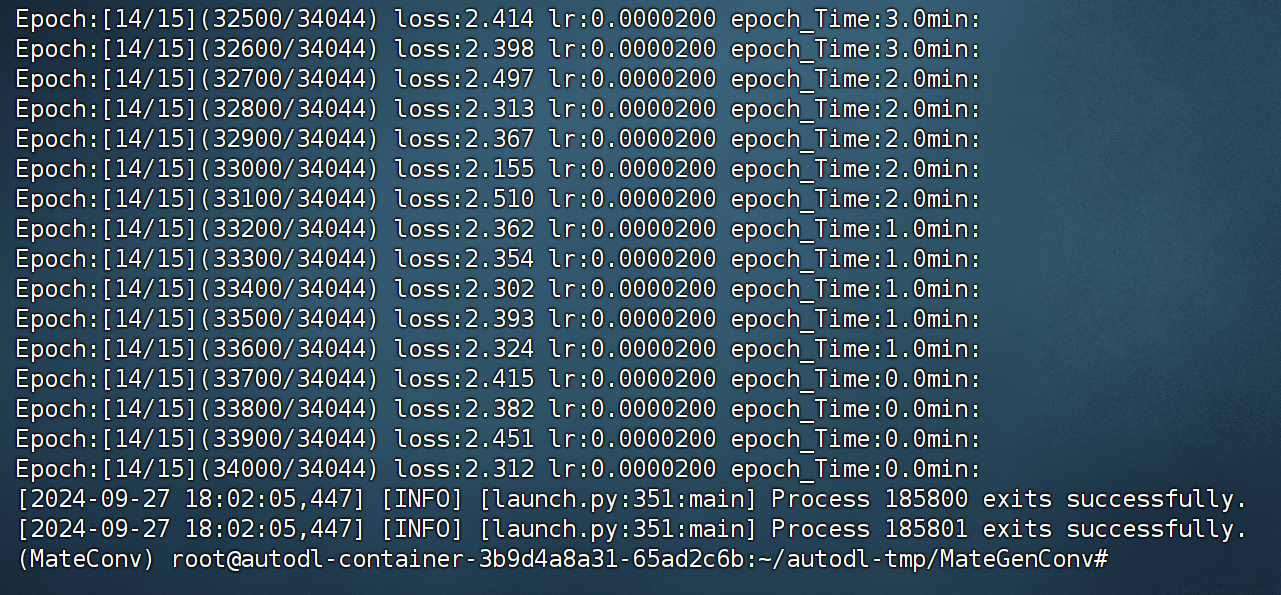
- 此时关闭会话并不会影响训练
FENCE0
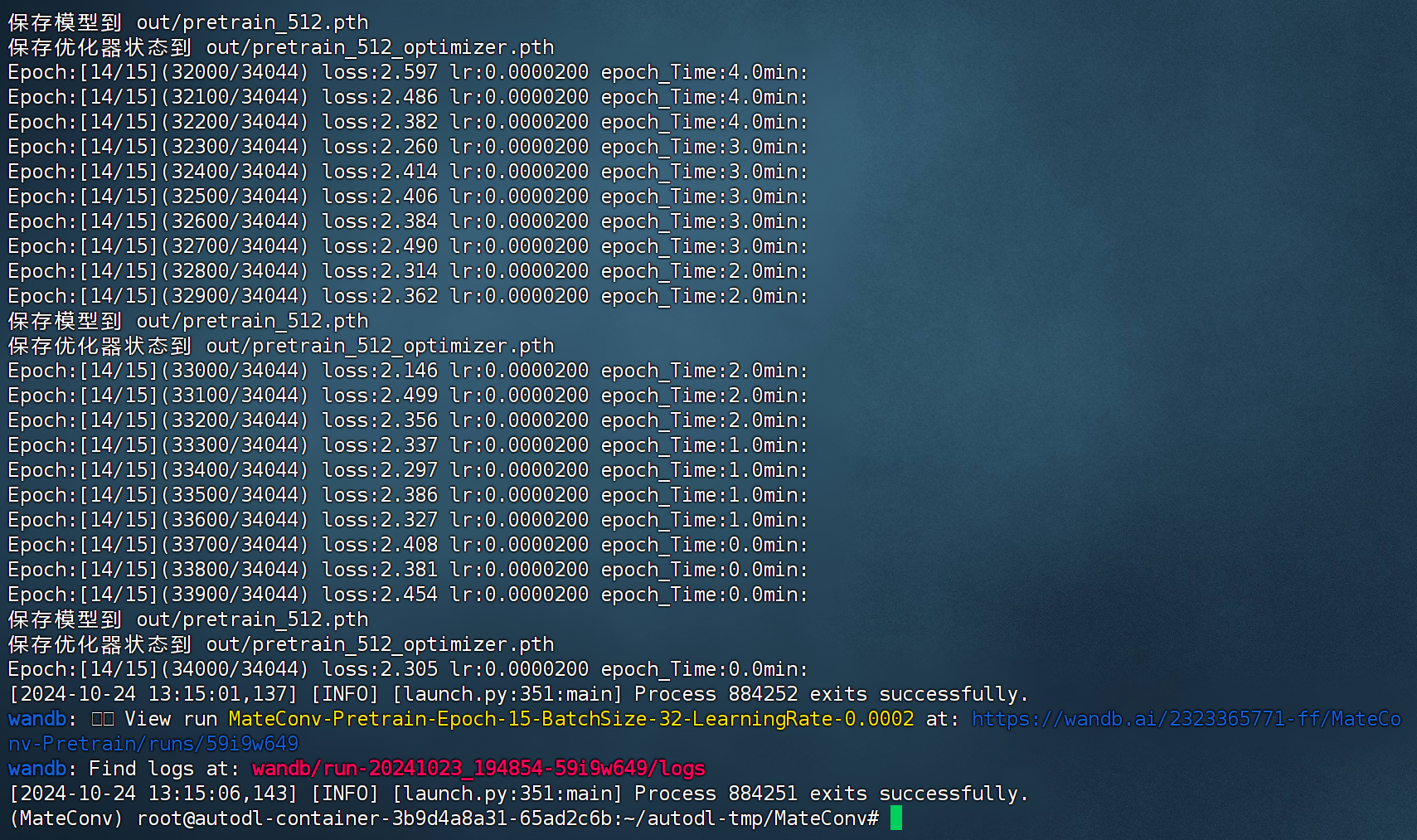
- 训练结束后截图
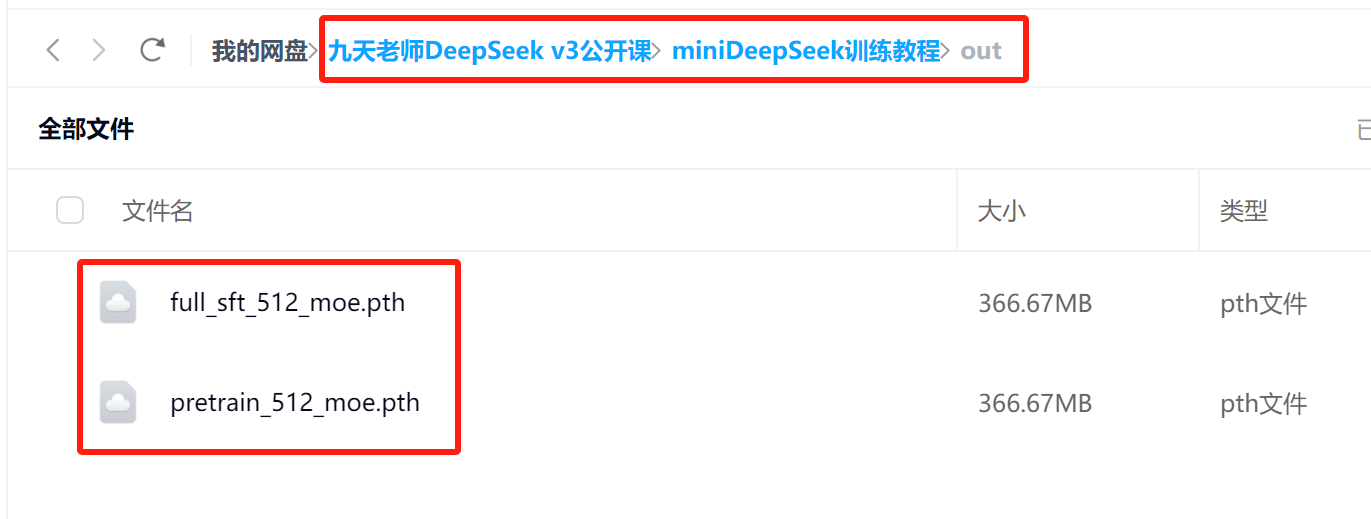
相关模型权重已上传至课件网盘,可直接下载使用。
3.MiniDeepSeek预训练后效果测试
- 训练结束后测试运行
import itertools
import re
import json
import jsonlines
import psutil
import ujson
import numpy as np
import pandas as pd
from transformers import AutoTokenizer
from datasets import load_dataset
import os
from tqdm import tqdm
# 定义BOS和EOS标记
bos_token = "<s>"
eos_token = "</s>"
# 加载训练好的分词器路径
tokenizer = AutoTokenizer.from_pretrained('/root/autodl-tmp/miniDeepSeek/model/miniDeepSeek_tokenizer', use_fast=False)
print(f'加载的tokenizer词表大小: {len(tokenizer)}')
# 导入必要的模块
import torch
from model.model import Transformer # 确保路径正确
from model.LMConfig import LMConfig # 导入 LMConfig
# 创建配置对象
lm_config = LMConfig()
# 初始化 Transformer 模型
model = Transformer(lm_config)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
model.to(device)
# 检查模型结构和参数
print(model)
# 加载模型权重【这里要修改为你的模型地址】
model.load_state_dict(torch.load('out/pretrain_512_moe.pth', map_location=device))
model.eval() # 切换到评估模式
# 准备输入文本
input_text = "长江是"
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
# 生成多个 token
num_tokens_to_generate = 2 # 要生成的 token 数量
generated_tokens = []
with torch.no_grad():
for _ in range(num_tokens_to_generate):
output = model(input_ids)
next_token = output.logits.argmax(dim=-1)[:, -1] # 获取最后一个 token 的预测
generated_tokens.append(next_token.item()) # 将 token ID 添加到列表中
input_ids = torch.cat([input_ids, next_token.unsqueeze(0)], dim=1) # 将新 token 添加到输入中
# 将生成的 token IDs 转换为文本
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
# 打印最终回复
print(generated_text)
# 准备输入文本
input_text = "长江、黄"
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
# 生成多个 token
num_tokens_to_generate = 1 # 要生成的 token 数量
generated_tokens = []
with torch.no_grad():
for _ in range(num_tokens_to_generate):
output = model(input_ids)
next_token = output.logits.argmax(dim=-1)[:, -1] # 获取最后一个 token 的预测
generated_tokens.append(next_token.item()) # 将 token ID 添加到列表中
input_ids = torch.cat([input_ids, next_token.unsqueeze(0)], dim=1) # 将新 token 添加到输入中
# 将生成的 token IDs 转换为文本
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
# 打印最终回复
print(generated_text)
5.更大规模参数训练方法
FENCE0
1. dim (模型维度):
- 含义:
dim是指模型中每层的特征维度,也就是 Transformer 中每个隐藏状态向量的大小。通常,dim越大,模型的表示能力越强。 - 调整建议:增大
dim将使模型能够捕捉到更加复杂和细致的特征。比如,从512调整到1024,可以提升模型的表达能力,但也会大大增加每层的计算量和显存需求。 - 影响:增大
dim会直接增加每层的计算复杂度和参数量,因为模型中很多计算都是基于这个维度进行的。
2. n_layers (层数):
- 含义:
n_layers是指模型中 Transformer block 的数量。每一层都包含自注意力机制和前馈神经网络等模块。 - 调整建议:增加
n_layers会让模型更深,从而能够学习更复杂的模式。例如,从8层增加到12或24层可以显著提升模型的表达能力,但计算复杂度也会显著上升。 - 影响:增加层数会直接增加模型的深度,更多的层意味着模型有更多机会处理上下文信息,但也会带来计算成本的显著增加。
3. n_heads (注意力头数):
- 含义:
n_heads是指每层中自注意力机制的多头注意力头数。多头注意力允许模型在不同的子空间中并行处理不同的注意力模式。 - 调整建议:增加
n_heads可以让模型在同一层中捕捉到更多的特征,提升自注意力的能力。比如从16增加到32会让注意力机制更加丰富,但也会增加计算和存储需求。 - 影响:更多的注意力头数将提升每层的并行计算能力,但头数增加的同时,每个头的维度(
dim // n_heads)会变小,可能会影响注意力的效果。
4. vocab_size (词汇表大小):
- 含义:
vocab_size是模型词汇表的大小,即模型可以处理的不同 token 的数量。较大的词汇表允许模型处理更多的词或符号,但也会增加嵌入层和输出层的参数量。 - 调整建议:如果你的任务涉及更多的词汇,可以增加
vocab_size,比如从6400增加到10000或30000。但这会显著增加嵌入层和输出层的大小。 - 影响:增加词汇表大小会直接影响嵌入矩阵的大小,特别是在处理大规模语料时,这可能是一个重要的调整点。
5. hidden_dim (隐藏层维度):
- 含义:
hidden_dim是前馈神经网络的隐藏层维度。如果hidden_dim没有设置,默认通常是4 * dim。 - 调整建议:增加
hidden_dim可以让前馈层处理更多的特征,提升模型的非线性表达能力。例如,可以将hidden_dim从4 * dim增加到8 * dim,但计算量和参数量也会增加。 - 影响:前馈网络的隐藏维度增加将直接影响每一层的计算复杂度。
6. max_seq_len (最大序列长度):
- 含义:
max_seq_len是模型能够处理的输入序列的最大长度。这个参数控制模型能处理多少个 token。 - 调整建议:如果需要处理更长的文本序列,可以增加
max_seq_len,比如从512增加到1024,以适应更长的输入文本。这样可以让模型处理更长的上下文信息,但也会增加每层的计算量。 - 影响:更大的
max_seq_len意味着每个序列中的 token 数量增加,因此自注意力机制的计算复杂度会增加(注意力机制的复杂度与序列长度平方成正比)。
7. dropout (丢弃率):
- 含义:
dropout是指模型训练时用于防止过拟合的丢弃比例。它帮助模型在训练过程中避免过拟合。 - 调整建议:增加
dropout比率(例如从0.1增加到0.3),可以在训练时防止模型过拟合,特别是在小数据集上训练时可能需要加大dropout。 - 影响:增大
dropout会让模型训练过程更加稳定,但在推理时并不使用dropout。
8. flash_attn (快速注意力):
- 含义:
flash_attn是一种加速注意力机制的技术。如果开启,模型会使用更高效的注意力机制来加速训练和推理。 - 调整建议:保持
True可以加速模型的训练和推理,特别是对于较大模型,启用flash_attn可以提升效率。
如何通过调整这些参数增加模型规模:
- 增加模型的表达能力:通过增加
dim和n_layers,你可以大大提升模型的表达能力,使其能够处理更复杂的任务。 - 增加并行处理能力:通过增加
n_heads,你可以让模型在自注意力机制中更加并行处理不同的上下文信息,适应更复杂的模式。 - 处理更长的输入文本:增大
max_seq_len可以让模型处理更长的文本序列,适合处理长文档或更复杂的对话任务。 - 增加词汇覆盖面:增大
vocab_size可以让模型处理更多种类的词汇,特别是在多语言任务或复杂领域任务中,这是一个重要的调整。
注意:
- 计算资源需求:随着这些参数的增加,模型的显存需求和训练时间也会成倍增加。因此,在调整这些参数时需要考虑硬件资源的限制。
- 参数之间的平衡:增加模型规模并不是简单地增大所有参数,而是需要根据任务的复杂性和资源的限制,选择性地调整关键参数。