OpenAI Responses API调用GPT-5流程
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(7月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(7月班)

《2025大模型Agent智能体开发实战》(7月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(夏季班)

两门大模型课程五周年特惠进行中!现在下单可享开课来最低特价+各期课程全部福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


GPT-5技术实战公开课
Part 2.OpenAI Responses API调用GPT-5流程
一、OpenAI Responses API介绍
Responses API 是 OpenAI 在最新 API 架构中推出的统一式接口,旨在为多种类型的模型调用(文本生成、代码生成、多模态推理等)提供一致的开发体验。与传统的 chat.completions API 相比,Responses API 的设计更贴近真实的任务流程:它不仅能完成文本对话,还能直接调用多模态能力、结构化输出模式以及 OpenAI 内置的工具服务,例如文档检索、联网搜索、代码执行等。这种统一接口避免了开发者在不同任务之间频繁切换 API,从而显著提升了集成效率与代码可维护性。
在调用形式上,Responses API 依旧沿用 input 参数作为主入口。开发者可以在一次请求中同时传入多种输入类型,包括纯文本、图片 URL、本地图片文件流,甚至是音频或视频数据。模型会自动解析并生成相应的多模态推理结果。对于需要高可控性的场景,Responses API 还提供了 reasoning 参数(如 reasoning.effort)来调整模型的推理深度,从而在响应速度与思考精度之间取得平衡。
Responses API 的另一个显著优势是与内置服务的无缝集成。例如,使用官方企业认证的 API Key 时,可以直接启用 OpenAI 官方的网络搜索、知识库检索或其他 Agent 工具链,而无需额外部署或编写中间层逻辑。这使得开发者能够更轻松地构建具备实时信息获取能力的智能应用。
综合而言,Responses API 不仅是一个多模态输入输出的统一入口,更是未来 OpenAI 生态中各种智能功能的集成枢纽。在实际应用中,如果用户需要同时利用 GPT-5 的多模态能力、可控推理模式以及官方工具服务,Responses API 是首选方案。
对此,我曾专门录制视频进行入门介绍,感兴趣的同学可以戳此观看:https://www.bilibili.com/video/BV1SVQEYqERV/

接下来我就为大家详细介绍这款专门为GPT系列模型量身定制的开发工具如何使用,并借助GPT-5模型进行高效率AI应用开发。
- 公开课OpenAI版本申明
import openai
openai.__version__
from openai import OpenAI
- 传统chat.completion API调用方法回顾
import os
from dotenv import load_dotenv
load_dotenv(override=True)
from openai import OpenAI
client = OpenAI(
base_url=os.getenv("BASE_URL"),
api_key=os.getenv("OPENAI_API_KEY"),
)
response = client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "user", "content": "你好,好久不见!"}
]
)
response
print(response.choices[0].message.content)
二、Responses API基本调用方法介绍
Responses API 是 OpenAI 为智能代理(Agents)提供的全新 API 基础构件,它结合了 Chat Completions API 的简洁性 与 Assistants API 的内置工具能力,使得代理能够更智能地执行任务。
📌 核心特点
- ✅ 简洁易用:继承了 Chat Completions API 的易用性。
- ✅ 增强功能:支持内置工具(Tools),如函数调用(Function Calling)、Web 搜索、文件搜索、计算机控制等。
- ✅ 适用于代理(Agents):可用于构建智能化任务执行系统。
🔗 未来发展:Responses API 旨在成为 OpenAI 代理系统的核心 API,结合 Agents SDK,提供更灵活的任务编排能力。

1.基本响应流程
使用 OpenAI API,你可以通过一个 简单的提示(prompt) 让模型生成文本,类似于 ChatGPT 的工作方式。
response = client.responses.create(
model="gpt-5",
input="你好,好久不见,请介绍下你自己!"
)
response
response.output_text
其中不难看出,OpenAI 的 API 响应包含一个内容数组(output),每个内容项具有以下结构:
FENCE0
📌 重要说明:
output可能包含多个结果,在多轮对话或批量生成时尤其明显。- 一些 SDK 提供
output_text属性,可以直接获取所有文本输出,方便访问文本数据。 - 除了纯文本,模型还可以返回 JSON 结构化数据(称为 Structured Outputs)。
response.output
response.output[1]
response.output[1].content
response.output[1].content[0]
response.output[1].content[0].text
2. 消息角色与指令控制
我们可以使用不同的方式给模型提供指令:
- 使用
instructions参数 提供全局行为指令,如语气、目标等。(权重最高) - 使用
input数组,指定不同角色的消息。
response = client.responses.create(
model="gpt-5",
instructions="用海盗的口吻说话。",
input="JavaScript 中的分号是可选的吗?",
)
print(response.output_text)
📌 在 instructions 中定义“说话像海盗”后,模型会以海盗风格回答。
此外,也可以使用 input 数组还可以指定多种角色,例如使用developer角色,developer 角色类似于 系统设定,用户输入 user 角色的内容,最终 模型按 developer 设定风格回答。
response = client.responses.create(
model="gpt-5",
input=[
{
"role": "developer",
"content": "用海盗的口吻说话。"
},
{
"role": "user",
"content": "JavaScript 中的分号是可选的吗?"
}
]
)
print(response.output_text)
其中OpenAI 规定不同角色的优先级如下:
| 角色 | 优先级 | 说明 |
|---|---|---|
developer | 最高 | 由开发者提供的指令,优先级最高,类似 system。 |
user | 次高 | 由最终用户提供的输入,次于 developer。 |
assistant | 最低 | 由模型生成的响应。 |
- 设置推理程度
response = client.responses.create(
model="gpt-5-nano",
reasoning={"effort": "low"},
input=[
{
"role": "user",
"content": "请问9.8和9.11哪个更大?"
}
]
)
print(response.output_text)
response
response = client.responses.create(
model="gpt-5-nano",
reasoning={"effort": "high"},
input=[
{
"role": "user",
"content": "请问9.8和9.11哪个更大?"
}
]
)
print(response.output_text)
response
- 设置输出详细程度
response = client.responses.create(
model="gpt-5-nano",
reasoning={"effort": "low"},
text={"verbosity": "low"},
input=[
{
"role": "user",
"content": "请问9.8和9.11哪个更大?"
}
]
)
print(response.output_text)
response = client.responses.create(
model="gpt-5-nano",
reasoning={"effort": "low"},
text={"verbosity": "high"},
input=[
{
"role": "user",
"content": "请问9.8和9.11哪个更大?"
}
]
)
print(response.output_text)
3. Responses API中多模态与结构化输出能力
- GPT-5模型视觉推理能力测试
resp = client.responses.create(
model="gpt-5",
input=[{
"role":"user",
"content":[
{"type":"input_text","text":"请帮我规划用于实现这张图上Agent架构的核心代码。"},
{"type":"input_image","image_url":"https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/202310292019679.png"}
]
}]
)
print(resp.output_text)
- GPT-5模型结构化输出方法
在 OpenAI 的 Responses API 中,通过结合 Pydantic 模型 或 JSON Schema,可以:
-
明确约束模型生成内容的字段和类型;
-
自动将输出解析为可直接调用的 Python 对象;
-
降低解析出错风险,实现“零样板代码”的结构化数据流。
这种方式不仅让大模型成为“会说话的专家”,更让它具备了“会输出代码可直接用的数据工程师”的能力,使 AI 在数据驱动型场景中的落地变得更加高效和稳健。
from pydantic import BaseModel
class BookInfo(BaseModel):
书名: str
作者: str
出版年份: int
类别: str
response = client.responses.parse(
model="gpt-5",
input=[
{"role": "system", "content": "请提取指定事件的相关信息。"},
{
"role": "user",
"content": "《三体》,作者刘慈欣,出版年份2008年,属于科幻类小说。",
},
],
text_format=BookInfo,
)
event = response.output_parsed
event
- responses API参数列表
| 参数名 | 类型 | 必填/可选 | 默认值 | 说明 |
|---|---|---|---|---|
| model | string | 必填 | 无 | 指定要使用的模型 ID,例如 gpt-4o 或 gpt-4o-mini。 |
| store | boolean or null | 可选 | false | 是否存储本次对话的输出,供模型精炼或评估产品使用。 |
| metadata | object or null | 可选 | null | 开发者自定义的标签和值,用于过滤仪表盘中的补全结果。 |
| frequency_penalty | number or null | 可选 | 0 | 数值在 -2.0 到 2.0 之间,正值减少重复生成内容的可能性。 |
| logit_bias | map | 可选 | null | 调整某些特定 tokens 出现的可能性,值在 -100 到 100 之间。 |
| logprobs | boolean or null | 可选 | false | 是否返回生成的每个 token 的对数概率。 |
| top_logprobs | integer or null | 可选 | null | 指定返回最有可能出现的前几个 tokens 及其概率,需开启 logprobs。 |
| max_completion_tokens | integer or null | 可选 | null | 指定模型生成的最大 token 数,包括可见文本和推理 tokens。 |
| n | integer or null | 可选 | 1 | 每个输入生成的对话补全选项数量,值越大,生成的回复越多。 |
| presence_penalty | number or null | 可选 | 0 | 数值在 -2.0 到 2.0 之间,正值鼓励生成新的主题和内容。 |
| response_format | object | 可选 | null | 指定生成结果的格式,可以设置为 json_schema 以确保结构化输出,或 json_object 用于 JSON 格式。 |
| seed | integer or null | 可选 | null | 保持生成的一致性,重复相同请求将尽量生成相同的结果。 |
| service_tier | string or null | 可选 | auto | 指定服务延迟等级,适用于付费订阅用户,默认为 auto。 |
| stop | string / array / null | 可选 | null | 最多指定 4 个序列,API 遇到这些序列时会停止生成进一步的 tokens。 |
| stream | boolean or null | 可选 | false | 是否启用流式响应,若启用,生成的 tokens 将逐步返回。 |
| stream_options | object or null | 可选 | null | 流式响应的选项,仅当 stream 为 true 时设置。 |
| temperature | number or null | 可选 | 1 | 控制生成输出的随机性,值越高生成的文本越随机。建议调整此值或 top_p,而不是同时调整。 |
| top_p | number or null | 可选 | 1 | 使用核采样方法,选择最有可能的 tokens,总概率达到 top_p 百分比。建议与 temperature 二选一。 |
| tools | array | 可选 | null | 模型可以调用的工具列表,目前仅支持函数调用。 |
| user | string | 可选 | null | 表示最终用户的唯一标识符,用于监控和检测滥用行为。 |
3. 基于Responses API构建多轮对话
response = client.responses.create(
model="gpt-5",
input="你好,我叫陈明,好久不见!",
)
print(response.output[1].content[0].text)
Response API 的一个关键特性是它具有状态。这意味着我们无需自行管理对话状态,API 会为您处理。例如,我们可以随时检索响应,其中包含完整的对话历史记录。
response.id
fetched_response = client.responses.retrieve(
response_id=response.id)
print(fetched_response.output[1].content[0].text)
我们可以参考之前的回复继续对话。
response_two = client.responses.create(
model="gpt-5",
input="好的,请问你还记得我叫什么名字么?",
previous_response_id=response.id
)
print(response_two.output[1].content[0].text)
三、Responses API的Web Search(网页搜索)功能实现
OpenAI Agents SDK 支持网页搜索,允许模型在生成回答之前查询最新的信息,类似于 ChatGPT 的搜索功能,并提供清晰的引用来源。
response = client.responses.create(
model="gpt-5",
tools=[{"type": "web_search_preview"}], # 启用 Web 搜索工具
input="请问近期有哪些关于AI的新闻?"
)
print(response.output_text)
- 该 API 请求会调用
web_search_preview,允许模型在回答前搜索最新的新闻。 - 但模型可以自行决定是否使用该工具。
response
而如果用户提出的问题无需搜索即可解决,则不会调用搜索引擎:
response1 = client.responses.create(
model="gpt-4o",
tools=[{"type": "web_search_preview"}], # 启用 Web 搜索工具
input="请帮我讲个笑话吧。"
)
print(response1.output_text)
此外,如果希望确保模型一定使用 Web 搜索(避免它仅使用内部知识回答),可以设置 tool_choice 参数:
FENCE0
3. 输出格式与引用
如果模型调用了 Web 搜索,API 响应将包含两部分:
- Web 搜索调用的 ID
- 模型的回答,并带有网页来源的引用信息
📌 示例输出:
FENCE0
response
response.output
len(response.output)
response.output[0]
response.output[-1]
response.output[-1].content
response.output[-1].content[0]
response.output[-1].content[0].annotations
response.output[-1].content[0].text
4. 指定位置搜索
Web 搜索可以根据用户的位置优化搜索结果。你可以指定:
country(国家):两字母 ISO 代码,如"US"(美国)、"GB"(英国)。city(城市):如"London"(伦敦)。region(地区):如"California"(加州)。timezone(时区):如"America/Chicago"(芝加哥时间)。
response = client.responses.create(
model="gpt-4o",
tools=[{
"type": "web_search_preview",
"user_location": {
"type": "approximate",
"country": "CN",
"city": "Beijing",
"region": "Beijing",
}
}],
input="北京三里屯附近最好吃的餐厅有哪些?",
)
print(response.output_text)
import base64
from IPython.display import Image, display
url = "https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20241009205714055.png"
display(Image(url=url, width=400))
response_multimodal = client.responses.create(
model="gpt-5",
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text":
"先根据图片内容想出相关的关键词,用这些关键词在网上搜索相关新闻,总结搜索结果,并引用信息来源。"},
{"type": "input_image", "image_url": "https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20241009205714055.png"}
]
}
],
tools=[
{"type": "web_search"}
]
)
response_multimodal.output_text
import json
print(json.dumps(response_multimodal.__dict__, default=lambda o: o.__dict__, indent=4))
四、文件搜索(File Search)
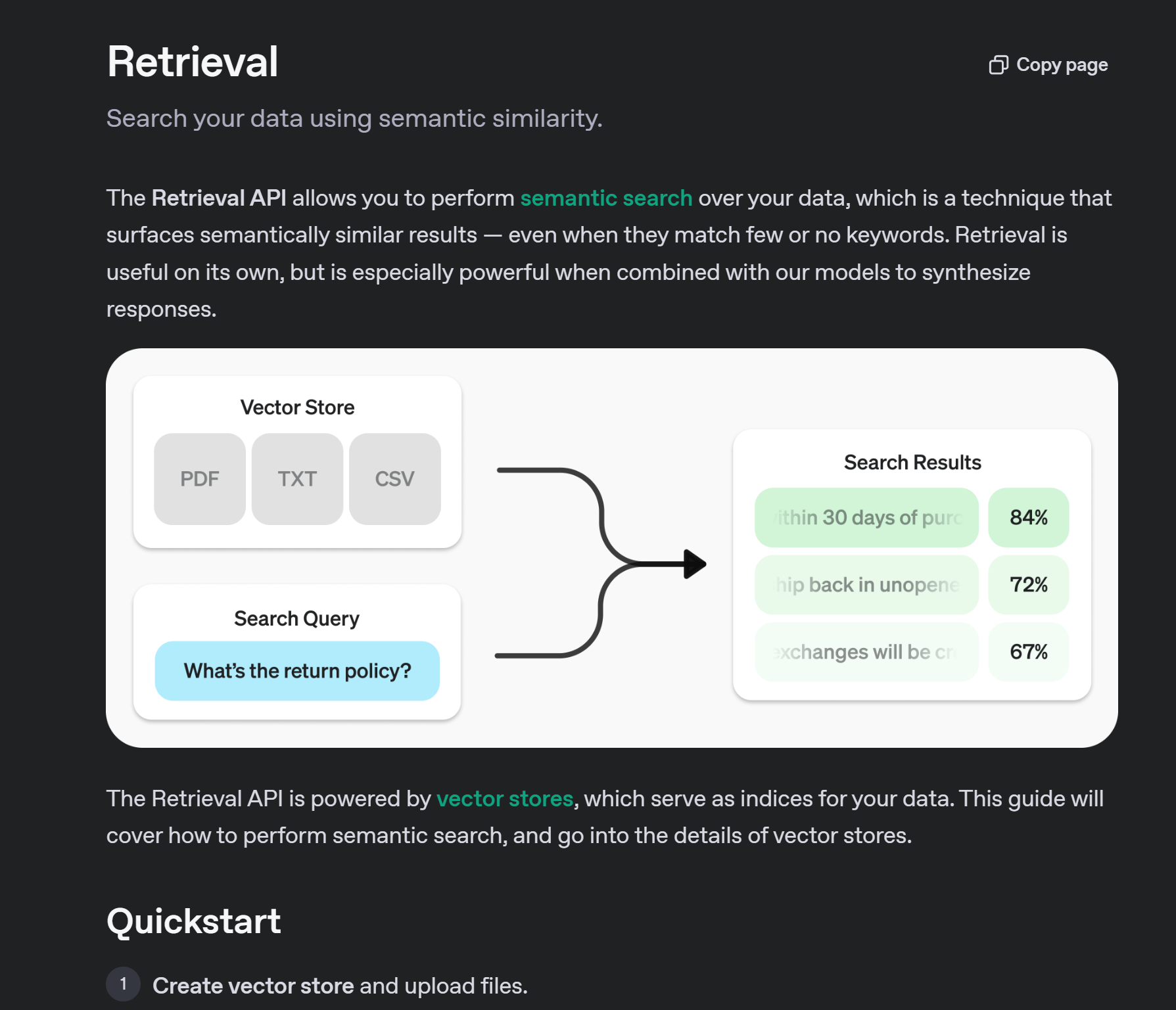
OpenAI Agents SDK 支持文件搜索功能,允许模型在生成回答之前检索用户上传的文件中的相关信息。
- OpenAI文档检索技术文档:https://platform.openai.com/docs/guides/retrieval
-
创建向量库
-
Vector store:https://platform.openai.com/docs/api-reference/vector-stores
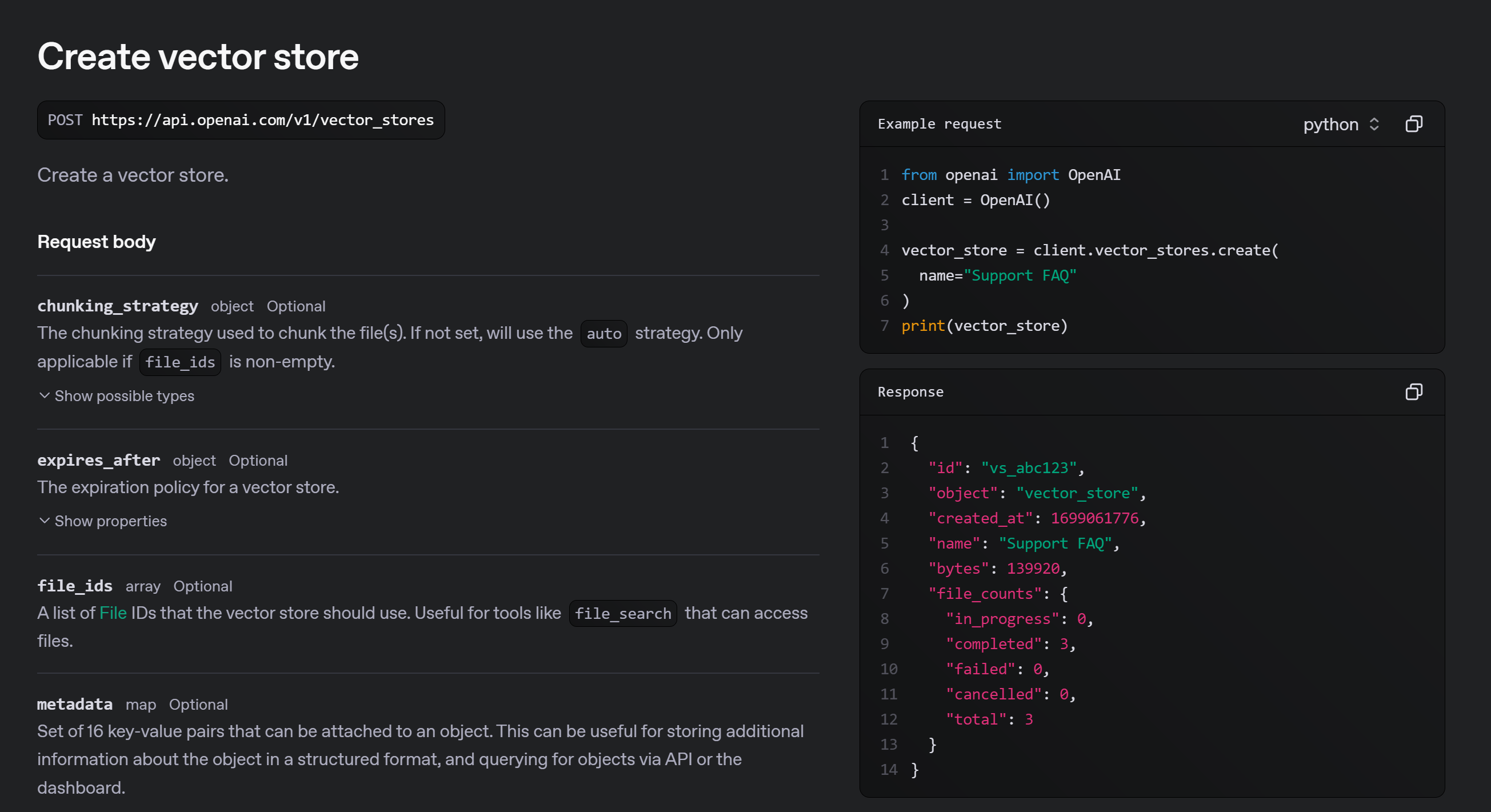
vector_store = client.vector_stores.create(
name="test-file"
)
print(vector_store)
vector_store.id
- 上传文档

# 准备上传到OpenAI的文件
file_paths = ["OpenAI Agents API翻译文档.md"]
file_streams = [open(path, "rb") for path in file_paths]
file_streams
file_batch = client.vector_stores.file_batches.upload_and_poll(
vector_store_id=vector_store.id, files=file_streams
)
print(file_batch.status)
print(file_batch.file_counts)
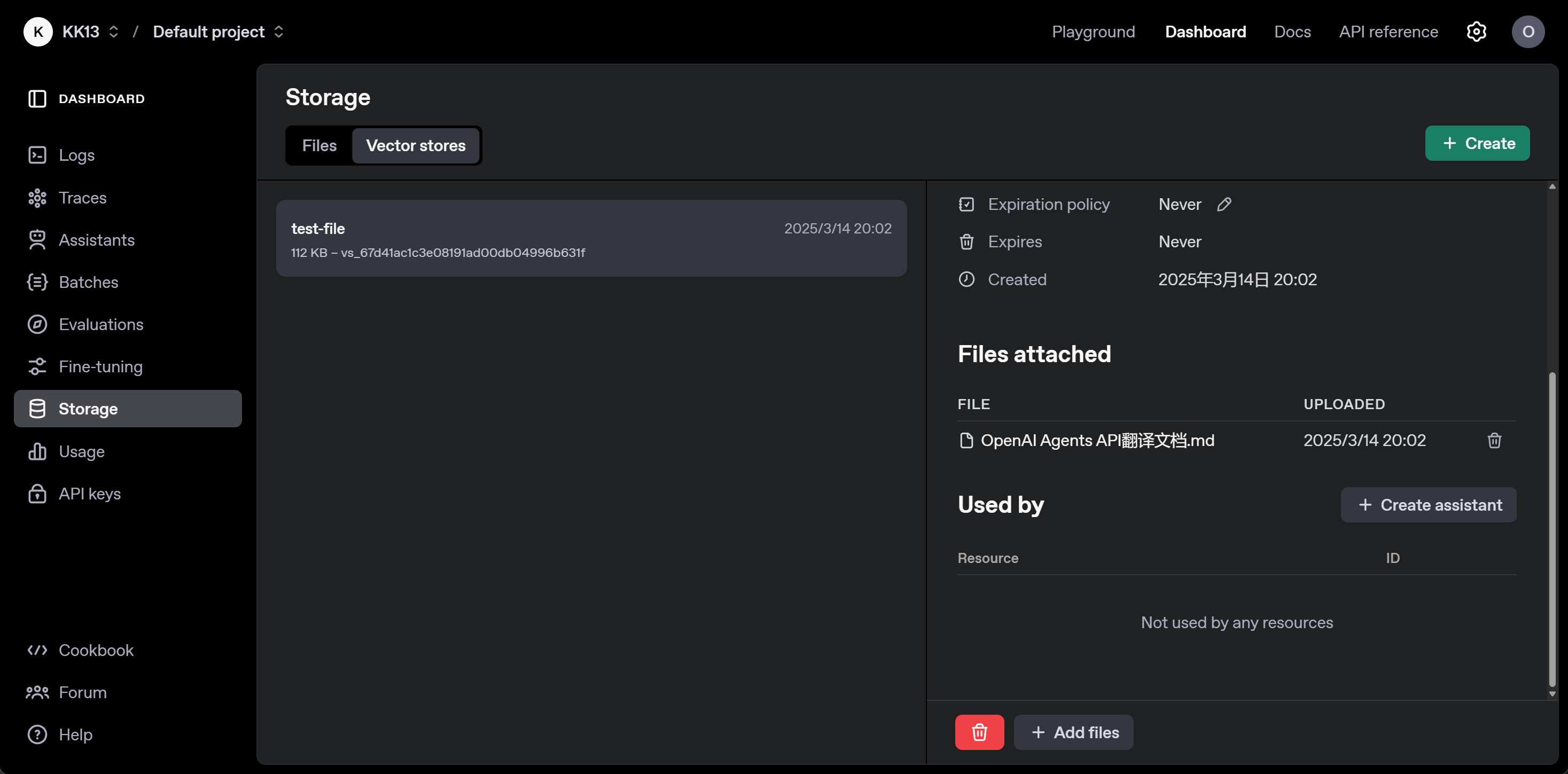
1. 文件搜索功能概述
file_search 工具可以让模型在已上传的文件知识库(vector stores)中进行语义搜索和关键词搜索,从而扩展模型的内在知识。
📌 特点:
- 托管工具(由 OpenAI 负责管理,无需用户自行实现搜索逻辑)。
- 自动调用:模型决定何时使用该工具进行检索。
- 向量存储支持:通过创建向量存储并上传文件来增强模型的知识。
📌 相关概念:
- Vector Store(向量存储):一个可存储文本向量化数据的数据库,支持语义检索。
- Semantic Search(语义搜索):利用向量表示进行相似性匹配,而不仅仅是关键字匹配。
📌 学习更多:可参考 OpenAI Retrieval Guide(检索指南)。
2. 使用文件搜索
在使用文件搜索前,用户需要:
- 创建向量存储(Vector Store)。
- 上传文件到向量存储。
- 在 API 调用中启用
file_search,并指定向量存储 ID。
📌 ⚠️ 限制:
- 目前 一次搜索仅支持一个向量存储(
vector_store_ids只能包含一个 ID)。
3.启用文件检索
response = client.responses.create(
model="gpt-5",
input="你知道OpenAI的responses API是什么么?",
tools=[{
"type": "file_search",
"vector_store_ids": ["vs_689dc6a26db4819189d36167f92b1766"] # 指定要搜索的向量存储
}]
)
print(response.output_text)
4. API 响应结构
当 file_search 工具被调用后,API 响应将包含两部分:
file_search_call:存储搜索请求的 ID 和查询内容。message:存储模型的回答,并包含文件引用信息(file citations)。
response
📌 解析:
-
file_search_call:存储搜索请求的 ID、状态和查询内容。 -
message:output_text:模型生成的文本。annotations:提供引用文件信息,包括file_id和filename,标明信息的来源。
让 API 响应包含搜索结果
response = client.responses.create(
model="gpt-5",
input="你知道OpenAI的responses API是什么么?",
tools=[{
"type": "file_search",
"vector_store_ids": ["vs_67d41ac1c3e08191ad00db04996b631f"]
}],
include=["output[*].file_search_call.search_results"]
)
📌 作用:
include参数指定要包含search_results,以便直接获取搜索的原始数据。
print(response)
response.output_text
此时检索到的20个文档片段如下:
response.output[0].results