Qwen-3本地部署与调用详解(下)
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(5月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(5月班)

《2025大模型Agent智能体开发实战》(5月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

同时,5月班重磅新增DeepSeek+Agents SDK+谷歌ADK+MCP技术应用与智能体开发相关实战内容,并计划新增Qwen-3模型实战教学:

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/4.MateGen%20Pro%20%E9%A1%B9%E7%9B%AE%E5%8A%9F%E8%83%BD%E6%BC%94%E7%A4%BA.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E6%BC%94%E7%A4%BA.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(5月班)

两门大模型课程5月班目前上新特惠中,立减2000起,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

Qwen-3本地部署与调用详解(下)
3. ollama API本地调用Qwen3
在部署完ollama之后,即可借助ollama API(也就是OpenAI风格API)在代码环境中调用模型。
- 导入OpenAI库及实例化OpenAI客户端
from openai import OpenAI
client = OpenAI(
base_url='http://192.168.110.131:11434/v1/',
api_key='ollama', # 必须传递该参数
)
prompt = "在单词\"strawberry\"中,总共有几个R?"
messages = [
{"role": "user", "content": prompt}
]
- 创建消息并获得回复
response = client.chat.completions.create(
messages=messages,
model='qwen3:14b',
)
print(response.choices[0].message.content)
因为Qwen3刚刚发布,所以Ollama目前还不支持在API调用时通过enable_thinking参数禁用思考过程,这里有一种策略是先用/no_think 提示不要进入思考过程。如下所示:
prompt = "/no_think 在单词\"strawberry\"中,总共有几个R?"
messages = [
{"role": "user", "content": prompt}
]
response = client.chat.completions.create(
messages=messages,
model='qwen3:14b',
)
print(response.choices[0].message.content)
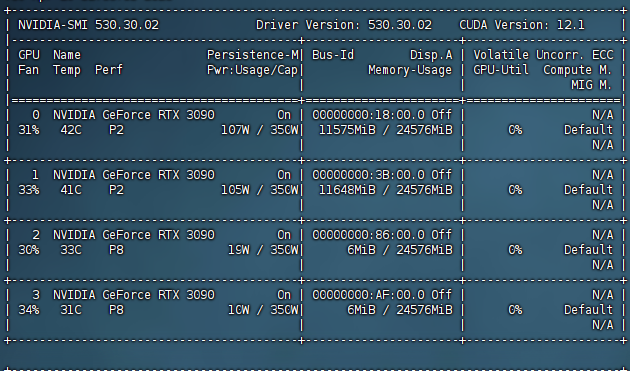
而此时显存占用约22G左右(14B Q4量化模型):
四、Qwen3模型接入vLLM与推理流程
接下来继续介绍Qwen3-14B模型借助vLLM进行推理的完整流程。相比ollama,vLLM更加适合企业级高并发应用场景,但对应的,显存占用也会更高,vLLM项目主页:https://github.com/vllm-project/vllm`Vllm` 底层是基于Pytorch 构建,其Gtihub 开源地址为:https://github.com/vllm-project/vllm

从各种基准测试数据来看,同等配置下,使用 vLLM 框架与 Transformer 等传统推理库相比,其吞吐量可以提高一个数量级,这归功于以下几个特性:
- 高级 GPU 优化:利用
CUDA和PyTorch最大限度地提高GPU利用率,从而实现更快的推理速度。Ollama其实是对CPU-GPU的混合应用,但vllm是针对纯GPU的优化。 - 高级内存管理:通过
PagedAttention算法实现对KV cache的高效管理,减少内存浪费,从而优化大模型的运行效率。 - 批处理功能:支持连续批处理和异步处理,从而提高多个并发请求的吞吐量。
- 安全特性:内置
API密钥支持和适当的请求验证,不像其他完全跳过身份验证的框架。 - 易用性:
vLLM与HuggingFace模型无缝集成,支持多种流行的大型语言模型,并兼容OpenAI的API服务器。
4.1 vLLM安装与启动
使用vllm框架部署Qwen3模型,同样需要先安装Python运行环境,这里我们可以复用之前安装的Anaconda环境,具体执行命令如下:
FENCE0
注意:vllm官方要求的是Python 3.9 ~ Python 3.12 之间的版本,所以如果Anaconda环境版本不在此范围内,请务必重新创建符合要求的Anaconda环境。
然后,安装vLLM框架,具体执行命令如下:
FENCE0
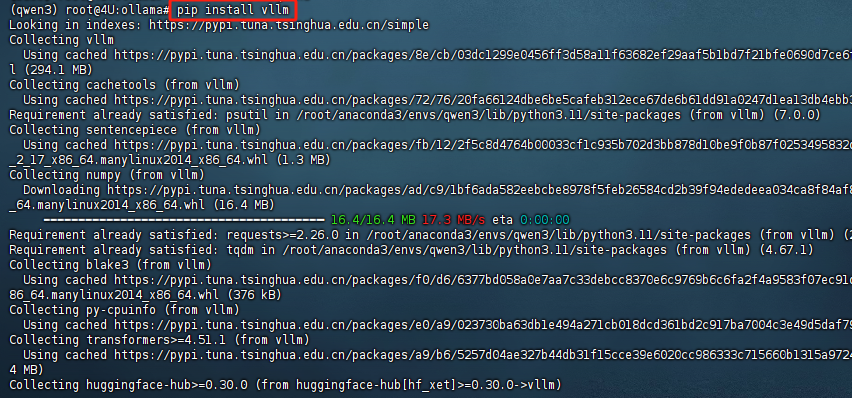
此时耐心等待安装完成即可。待安装完成后,可以使用pip show vllm 命令查看vllm 框架的安装信息,可以明确看到当前安装的vllm 版本号。如下图所示:
目前vLLM已支持Qwen3模型调用,可以在模型支持列表中查看模型关键字:https://docs.vllm.ai/en/latest/models/supported_models.html
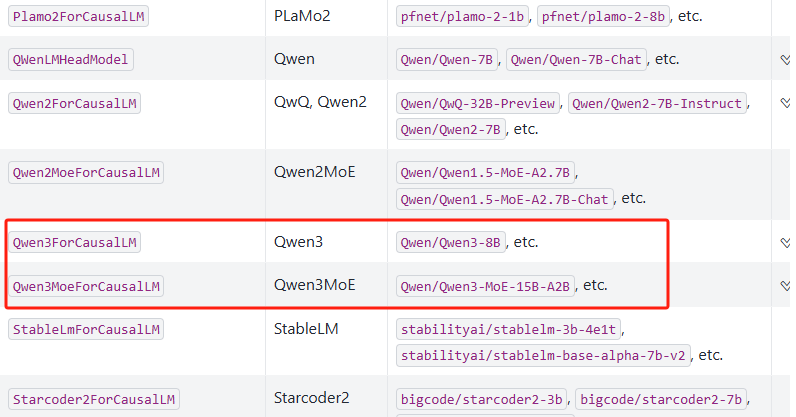
接下来即可按照如下流程进行调用。
4.2 OpenAI风格API响应模式
需要注意的是,随着模型上下文越长,所需要占用的显存也越大。根据测试,14B模型在32K上下文时,运行需要约30G显存。实际运行命令类似如下形式:
FENCE0
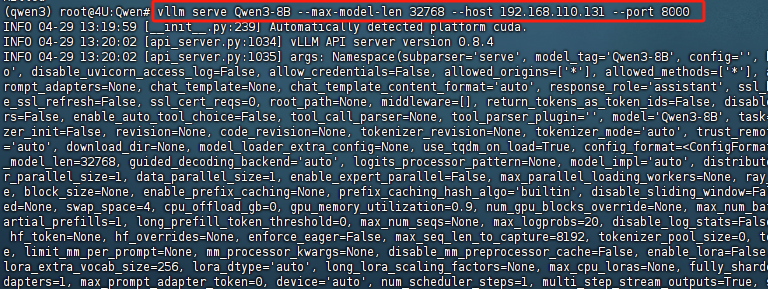
启动vLLM时候需要谨慎的设置最大上下文和对应的运行GPU数量。
- 单GPU运行命令
FENCE0
- 双GPU运行命令
FENCE1
启动成功后,即可在Jupyter中进行调用。
- 导入OpenAI库并实例化OpenAI客户端
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://192.168.110.131:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
- 创建消息获得回复
prompt = "在单词\"strawberry\"中,总共有几个R?"
messages = [
{"role": "user", "content": prompt}
]
response = client.chat.completions.create(
model="Qwen3:8B",
messages=messages,
)
print(response.choices[0].message.content)

五、基于llama.cpp的QwQ模型CPU推理
Qwen3系列模型目前也是可以使用llama.cpp进行纯CPU推理或者CPU+GPU混合推理的。接下来介绍如何使用llama.cpp调用模型权重进行推理和对话。
1. llama.cpp下载与编译
- llama.cpp项目主页:https://github.com/ggml-org/llama.cpp

由于llama.cpp是个C语言项目,因此实际调用过程需要先构建项目,然后设置参数进行编译,然后最终创建可执行文件(类似于脚本),再运行本地大模型。借助llama.cpp可以实现纯CPU推理、纯GPU推理和CPU+GPU混合推理。
-
依赖下载
apt-get updateapt-get install build-essential cmake curl libcurl4-openssl-dev -y
这条命令安装了一些常用的构建和开发工具,具体的每个部分的含义如下:
-
build-essential:安装一组构建必需的工具和库,包括:- 编译器(如 GCC)
make工具- 其他一些常见的构建工具,确保你的系统能进行编译。
-
cmake:安装 CMake 工具,它是一个跨平台的构建系统,允许你管理项目的编译过程。 -
curl:安装 cURL 工具,它是一个命令行工具,用于通过 URL 发送和接收数据。它在很多开发场景中都很有用,尤其是与网络交互时。 -
libcurl4-openssl-dev:安装 libcurl 库的开发版本。它是 cURL 的一个库文件,允许你在编程中通过 cURL 发送 HTTP 请求。libcurl4-openssl-dev是与 OpenSSL 配合使用的版本,提供了 SSL/TLS 加密支持,用于安全的 HTTP 请求。 -
llama.cpp源码下载
若是AutoDL服务器,可以先开启学术加速:
FENCE0
如果是其他服务器或者本地服务器,则可以直接进行源码下载:
git clone https://github.com/ggerganov/llama.cpp
也可以直接在课件网盘中找到代码文件,直接上传服务器并解压缩:
准备好后,即可在服务器中看到llama.cpp项目文件夹:
接下来,即可开始进行项目构建与编译。
-
项目构建与编译
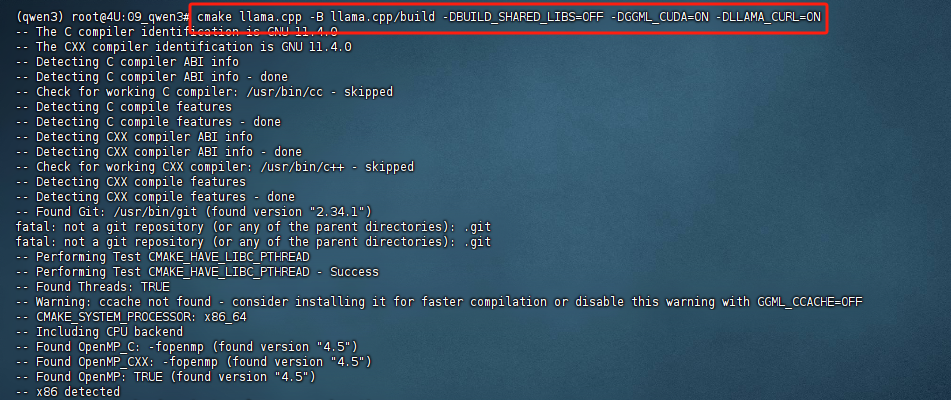
cmake llama.cpp -B llama.cpp/build \-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON -
cmake:运行 CMake 工具,用于配置和生成构建文件。 -
llama.cpp:指定项目的源代码所在的目录。在这个例子中,llama.cpp是项目的根目录。 -
-B llama.cpp/build:指定生成构建文件的目录。-B参数表示构建目录,llama.cpp/build是生成的构建目录。这是 CMake 将生成的文件存放的地方(例如 Makefile 或 Ninja 构建文件)。 -
同时还指定了一些编译选项:
-
禁用共享库(
-DBUILD_SHARED_LIBS=OFF),生成 静态库。 -
启用 CUDA 支持(
-DGGML_CUDA=ON),以便在有 GPU 的情况下使用 GPU 加速。 -
启用 CURL 库支持(
-DLLAMA_CURL=ON),以便支持网络请求。
然后需要进一步进行编译:
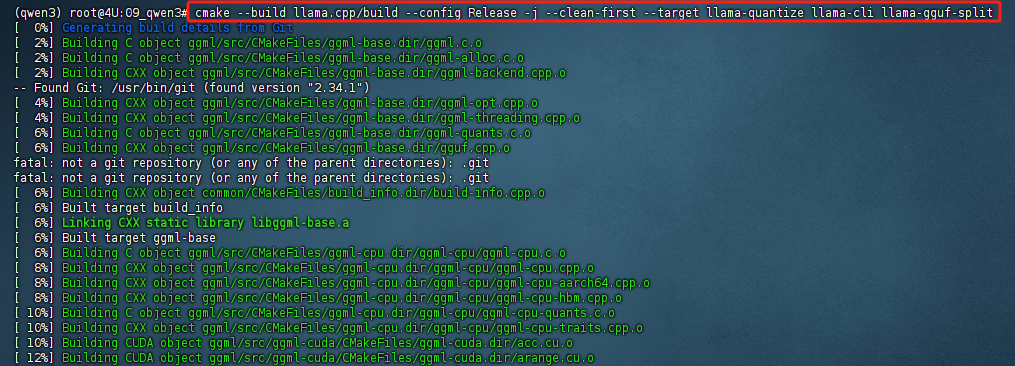
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split
--build llama.cpp/build:告诉 CMake 使用llama.cpp/build目录中的构建文件来执行构建过程。这个目录是在之前运行cmake llama.cpp -B llama.cpp/build命令时生成的,包含了所有构建所需的文件(例如 Makefile 或 Ninja 构建文件)。--config Release:指定构建的配置为 Release 配置。- Release 配置通常意味着启用更多的 优化,生成的程序运行速度较快,适合发布。
- 在 CMake 中,通常有两种常见的构建配置:
- Debug:用于调试版本,包含调试信息且没有做过多优化。
- Release:优化后的发布版本,去除调试信息,运行时性能更高。
-j:表示并行构建,允许 CMake 使用多个 CPU 核心来加速构建过程。- 如果没有指定数字,CMake 会使用默认的并行级别,通常是可用的所有 CPU 核心。你也可以指定并行的作业数,例如
-j 8表示使用 8 个并行作业进行编译。
- 如果没有指定数字,CMake 会使用默认的并行级别,通常是可用的所有 CPU 核心。你也可以指定并行的作业数,例如
--clean-first:表示在构建之前先清理掉之前的构建结果。这可以确保每次构建时都是从一个干净的状态开始,避免由于缓存或中间文件引起的编译错误。- 如果你之前运行过构建并且有问题,或者希望重新构建而不使用任何缓存文件,这个选项非常有用。
--target:指定构建的目标(target)。通常,一个项目会定义多个目标(比如库、可执行文件等),通过这个参数可以告诉 CMake 只编译特定的目标。llama-quantize:可能是与模型量化相关的目标。量化(quantization)是将模型的精度从浮点数降低到整数,从而减少内存占用和提高推理速度。llama-cli:可能是一个命令行工具,用于运行模型或与用户交互。llama-gguf-split:可能是一个用于拆分模型文件的目标,通常用于将一个大模型文件拆分成多个小文件,方便存储和加载。
-
复制可执行文件
cp llama.cpp/build/bin/llama-* llama.cpp将 所有生成的可执行文件 从构建目录
llama.cpp/build/bin/复制到项目的根目录llama.cpp下。这样可以更方便地在项目根目录下执行这些可执行文件,而无需每次都进入构建目录。

在准备完成后,接下来即可进行调用和推理测试了。
2.借助llama.cpp运行Qwen3模型
- 纯CPU推理流程【1token/s】
首先是纯CPU推理测试。此时系统只调用内存+CPU进行计算,此时不会用到GPU。
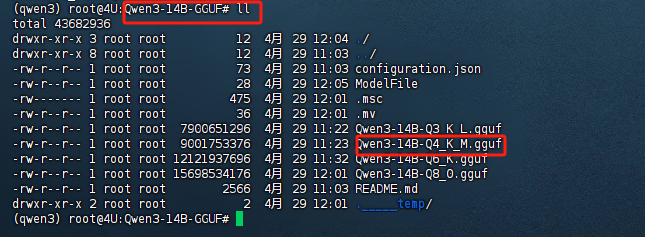
此时模型运行门槛很低,但运行速度非常慢,只有不到1tokens/s。具体推理代码实现流程如下:
FENCE0
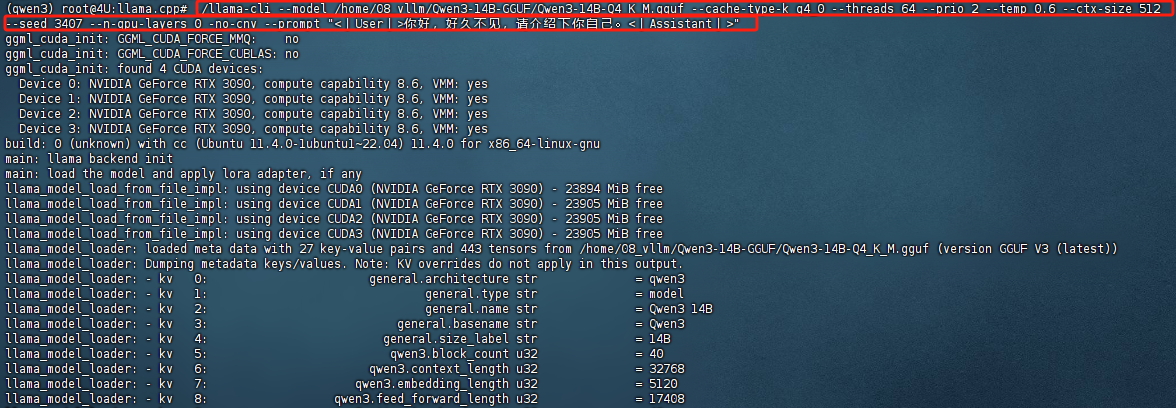
其中命令行核心参数说明:
--threads:CPU 核心数;--ctx-size:输出的上下文长度;--n-gpu-layers:需要卸载到 GPU 的层数,设置为0时代表完全使用CPU进行推理;--temp:模型温度参数;-no-cnv:不进行多轮对话;--cache-type-k:K 缓存量化为 4bit;--seed:随机数种子;
实际运行效果如下所示:

- CPU+GPU混合推理
接下来进一步尝试CPU+GPU混合推理,我们只需要合理的设置--n-gpu-layers参数,即可灵活的将模型的部分层加载到GPU上进行运行。并且无需手动设置,llama.cpp会自动识别当前GPU数量以及可以分配的显存,自动将模型权重加载到各个不同的GPU上。例如,我们这里考虑将30层加载到GPU上,运行效果如下所示:
FENCE0
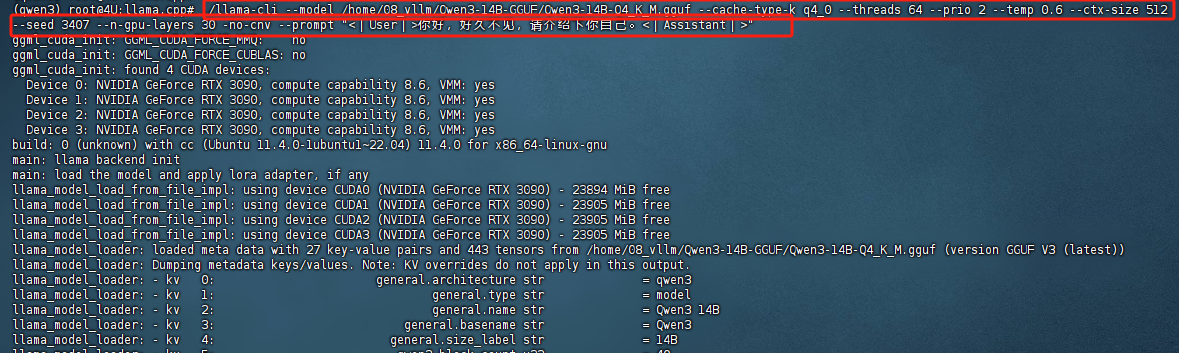
此时显存占用不到10G:
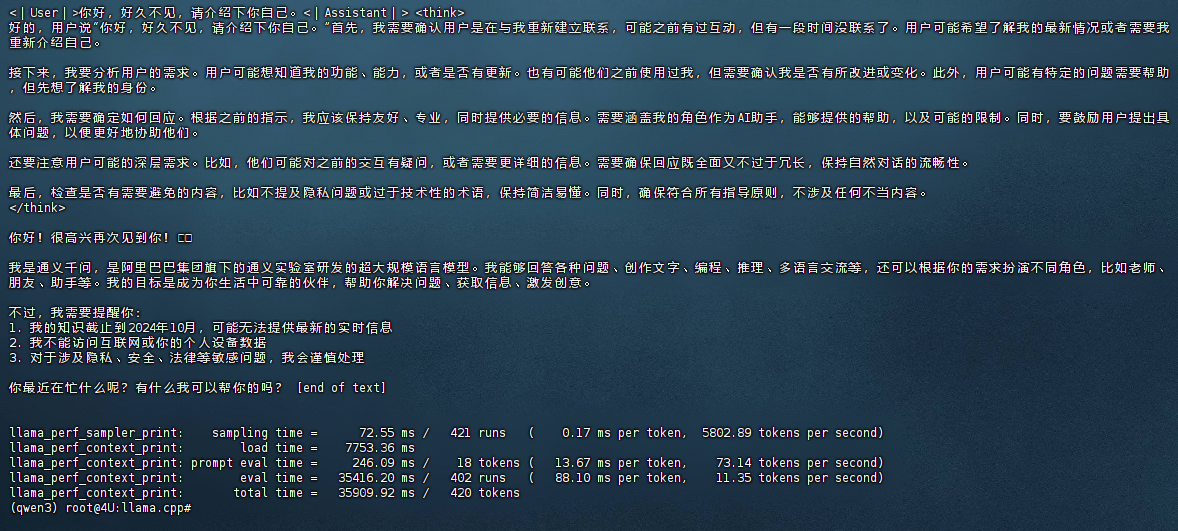
推理速度略微有所提升,能达到接近2tokens/s
- 纯GPU推理
最后,我们更进一步,尝试把全部的模型权重都放在GPU上进行推理。
FENCE0
此时GPU占用约11G:

推理速度则能达到14tokens/s。
六、Qwen3 接入OpenWeb-UI
1.Open-WebUI部署流程
首先需要安装Open-WebUI,官网地址如下:https://github.com/open-webui/open-webui 。
我们可以直接使用pip命令快速完成安装:
FENCE0
可以直接使用在GitHub项目主页上直接下载完整代码包,并上传至服务器解压缩运行:
此外,也可以在课件网盘中领取完整代码包,并上传至服务器解压缩运行:
在确保ollama正常运行的情况下,进行后续操作。
2. Open-WebUI启动与对话流程
在准备好了Open-WebUI和一系列模型权重后,接下来我们尝试启动Open-WebUI,并借助本地模型进行问答。
首先需要设置离线环境,避免Open-WebUI启动时自动进行模型下载:
FENCE0
然后启动Open-WebUI
FENCE1
需要注意的是,如果启动的时候仍然报错显示无法下载模型,是Open-WebUI试图从huggingface上下载embedding模型,之后我们会手动将其切换为本地运行的Embedding模型。
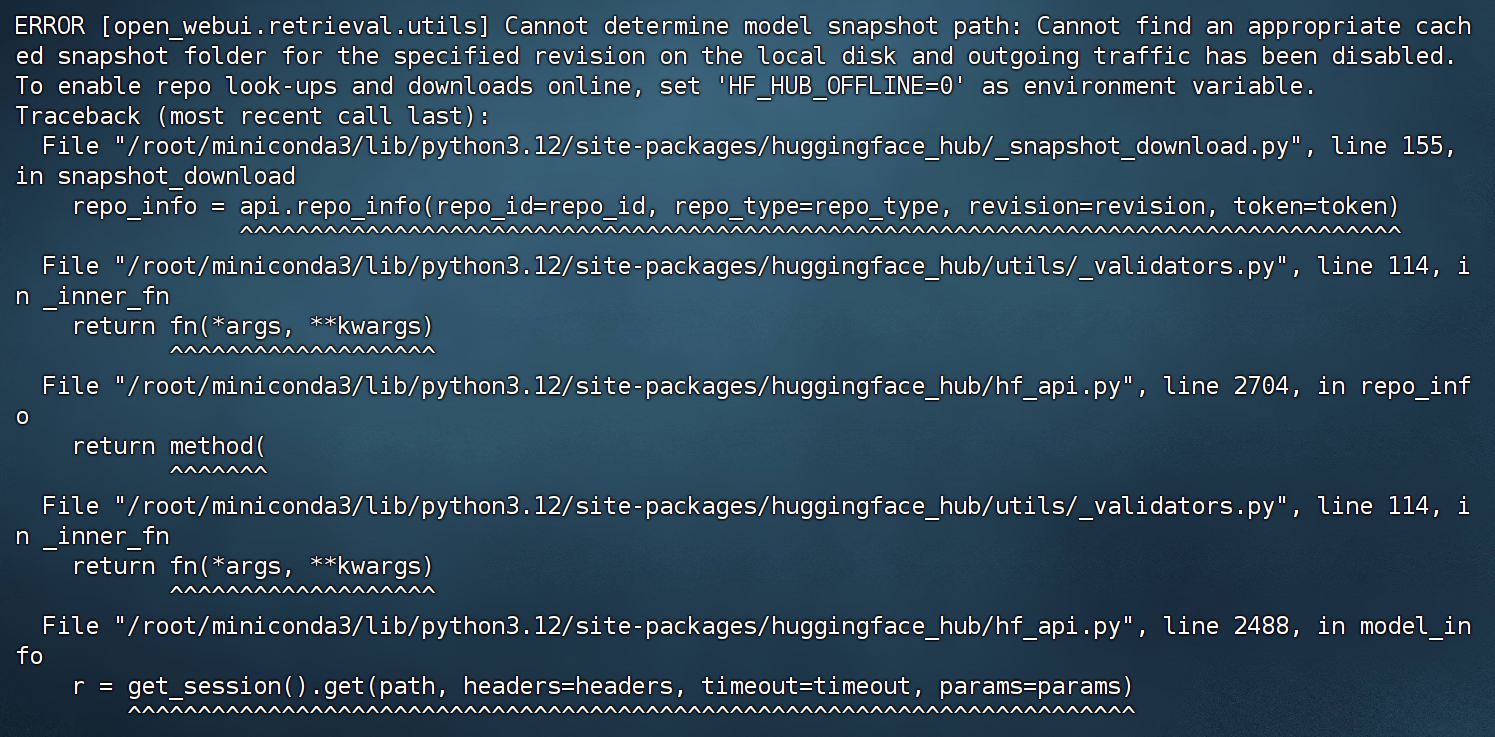
然后在本地浏览器输入地址:8080端口即可访问:

若使用AutoDL,则需要使用SSH隧道工具进行地址代理
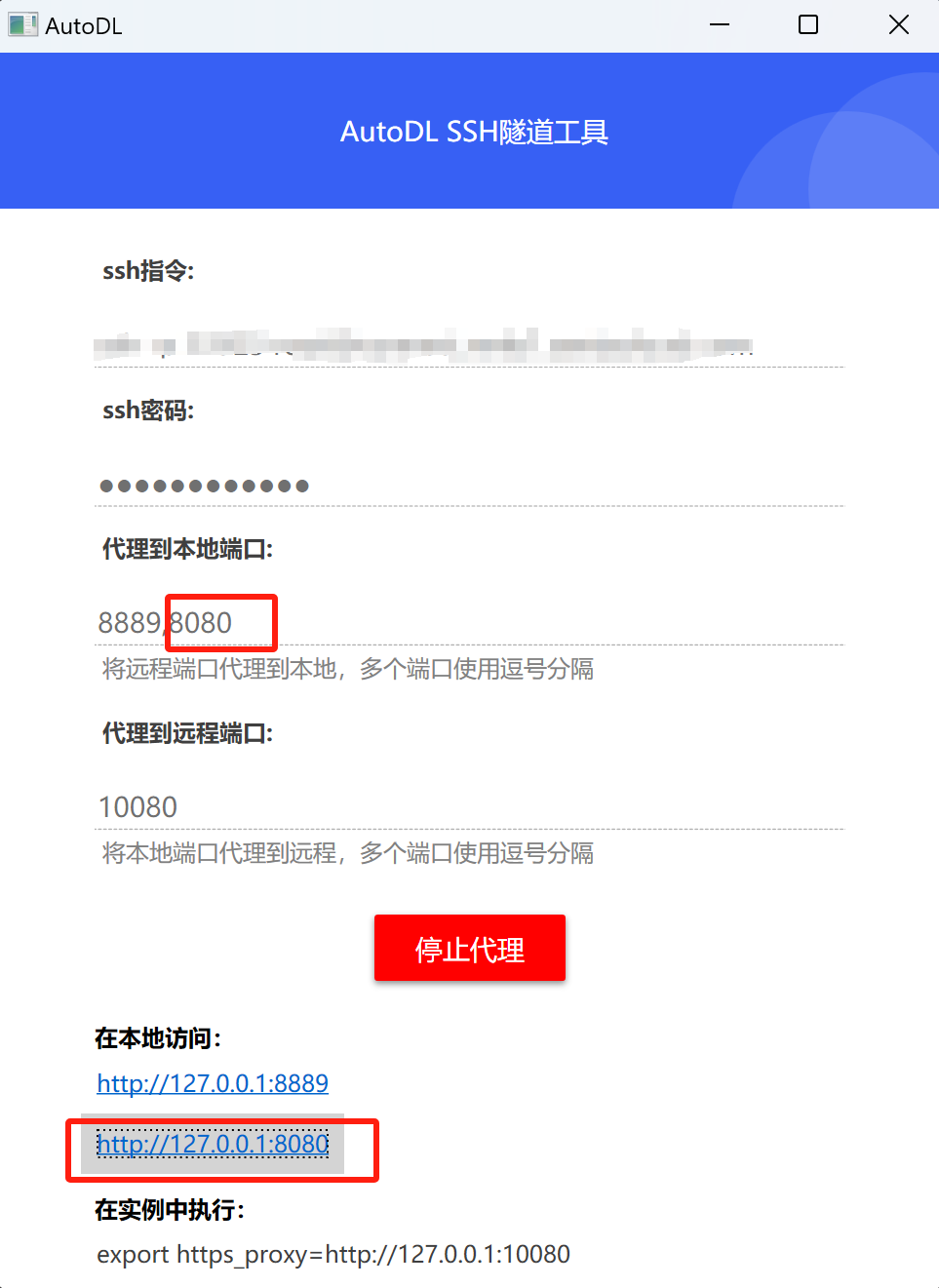
更多AutoDL相关操作详见公开课:《AutoDL快速入门与GPU租赁使用指南》|https://www.bilibili.com/video/BV1bxB7YYEST/
然后首次使用前,需要创建管理员账号:
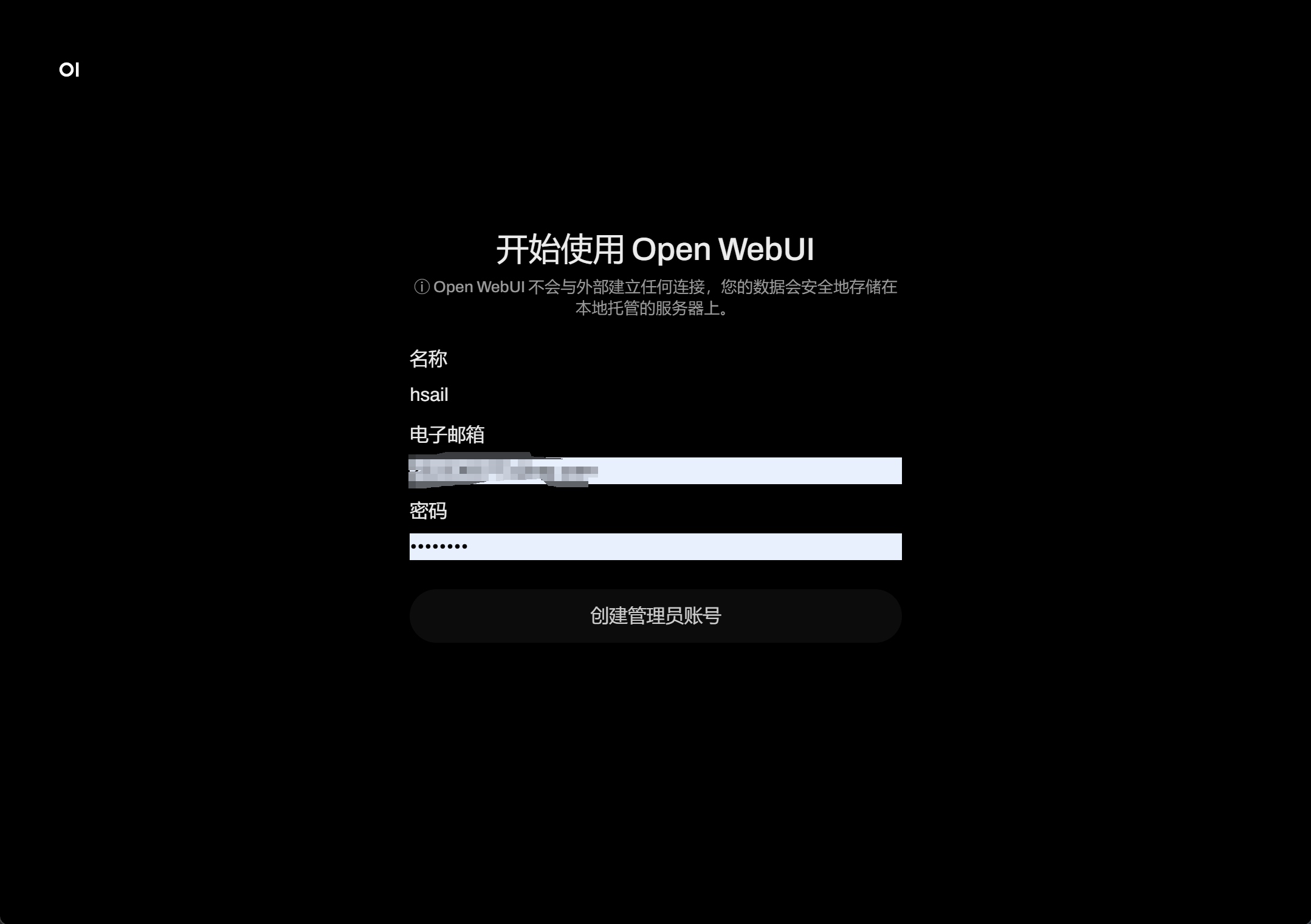
然后点击登录即可。需要注意的是,此时Open-WebUI会自动检测后台是否启动了ollama服务,并列举当前可用的模型。稍等片刻,即可进入到如下页面:
接下来即可进入到对话页面:
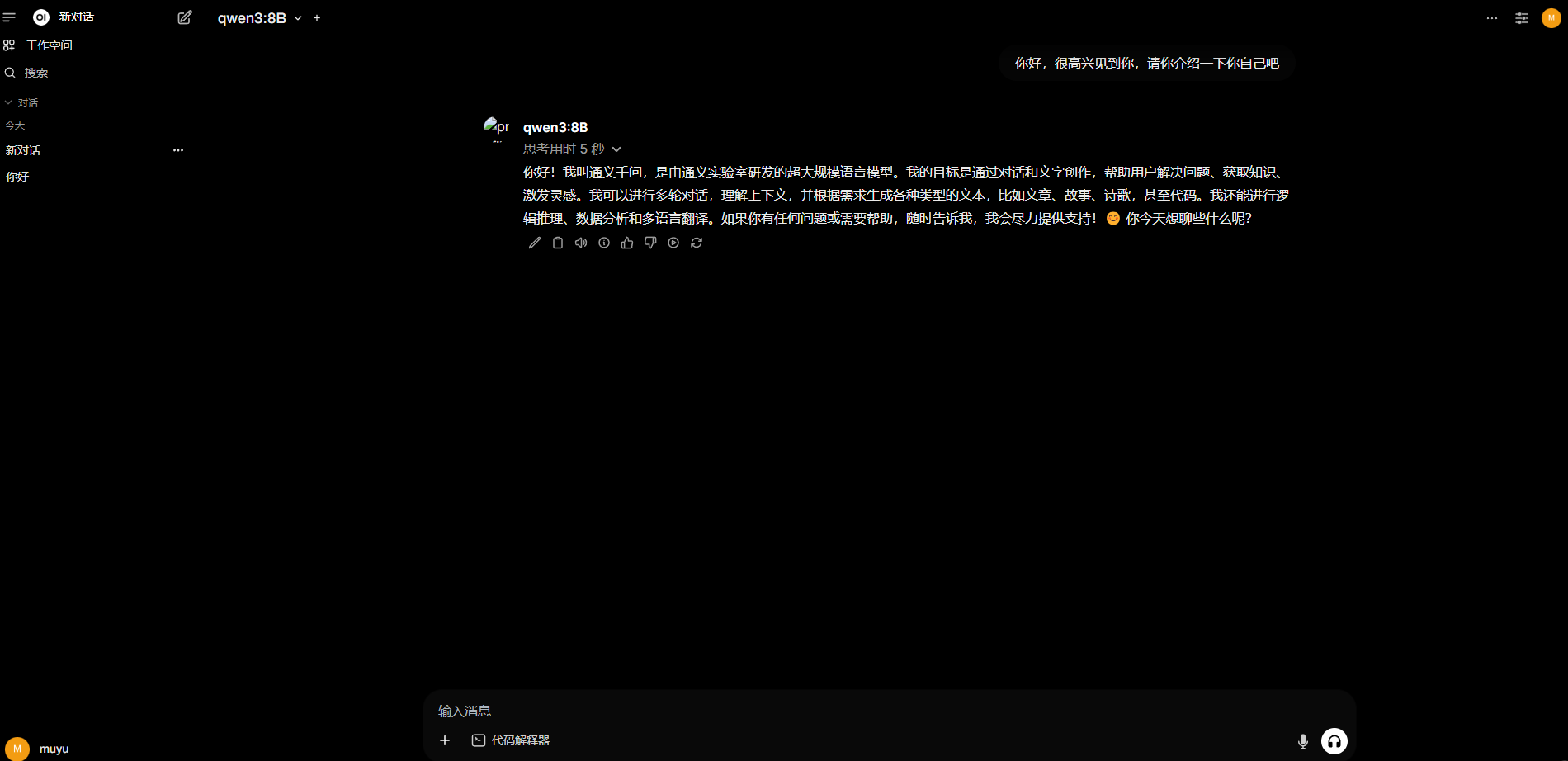
对话效果如下所示:
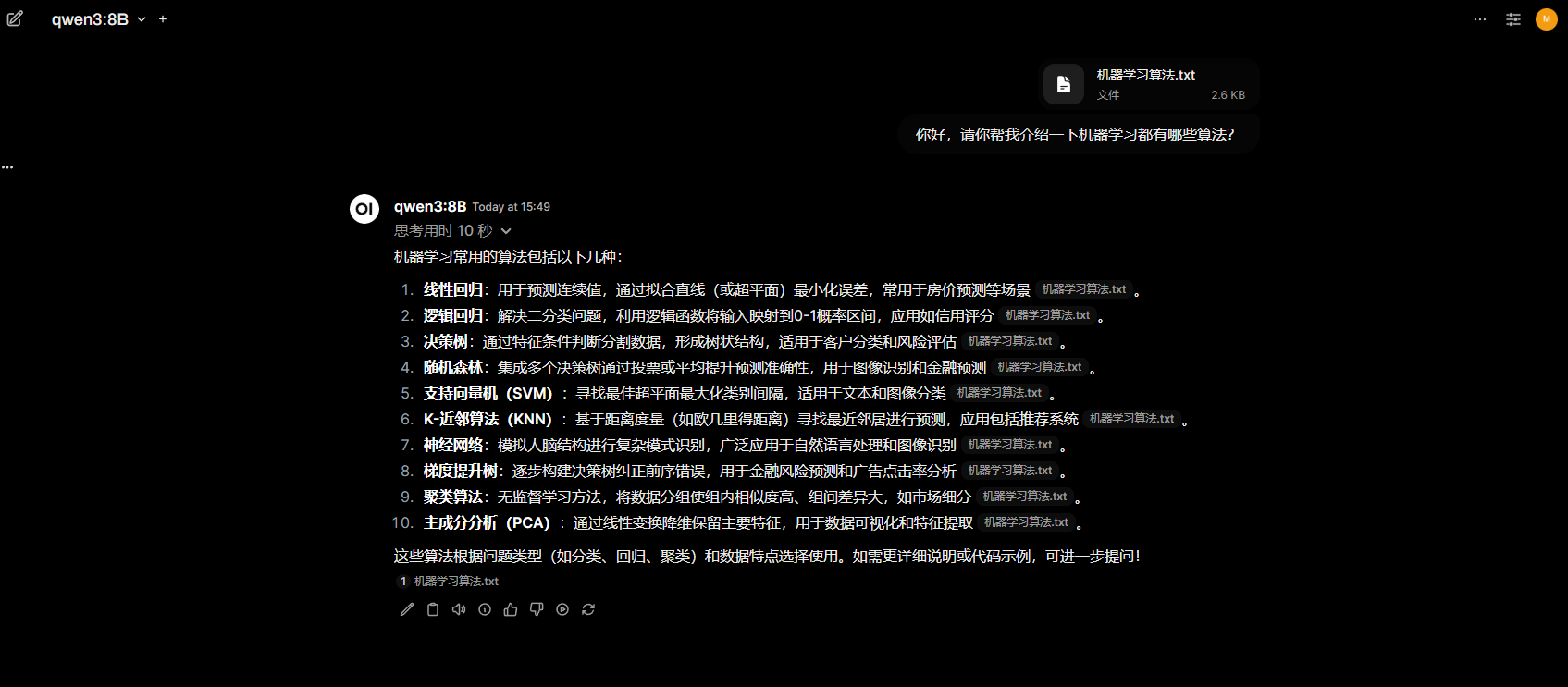
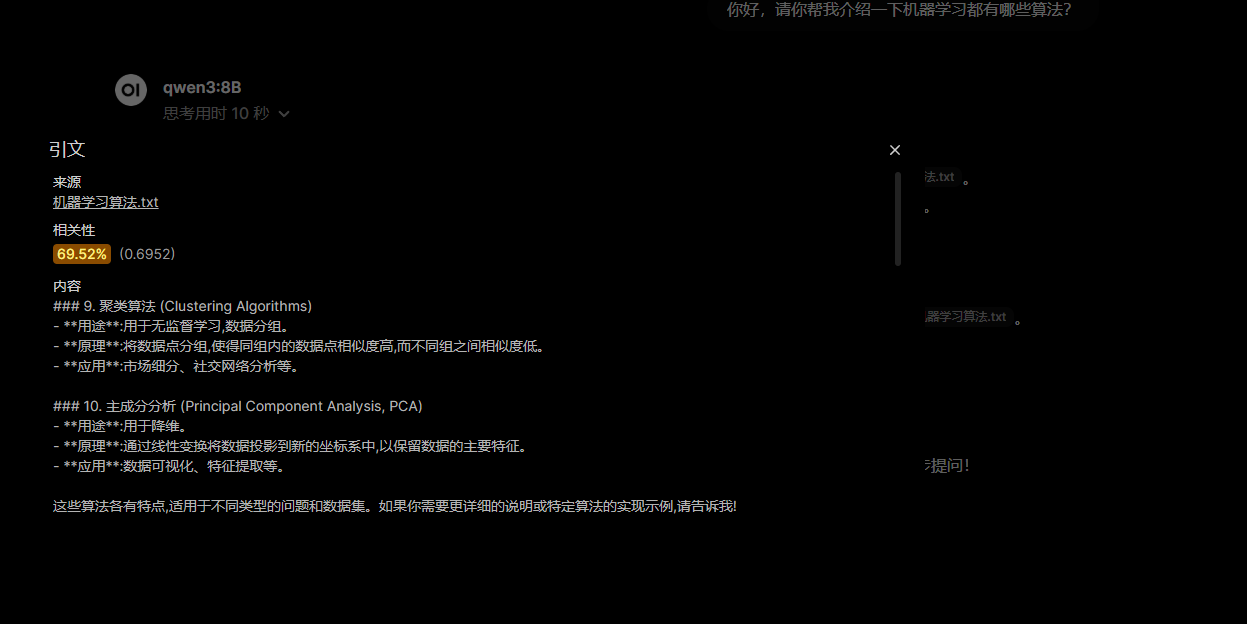
3. 本地知识库检索

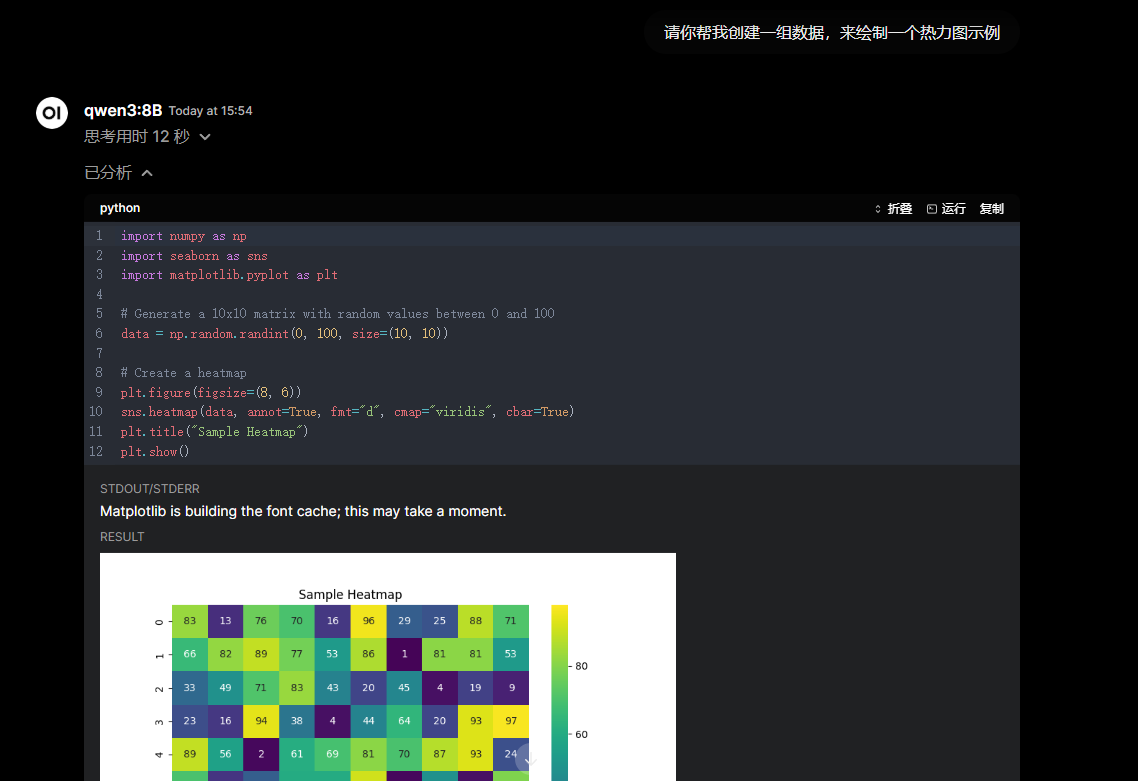
4. 代码解释器

5. 调用外部工具
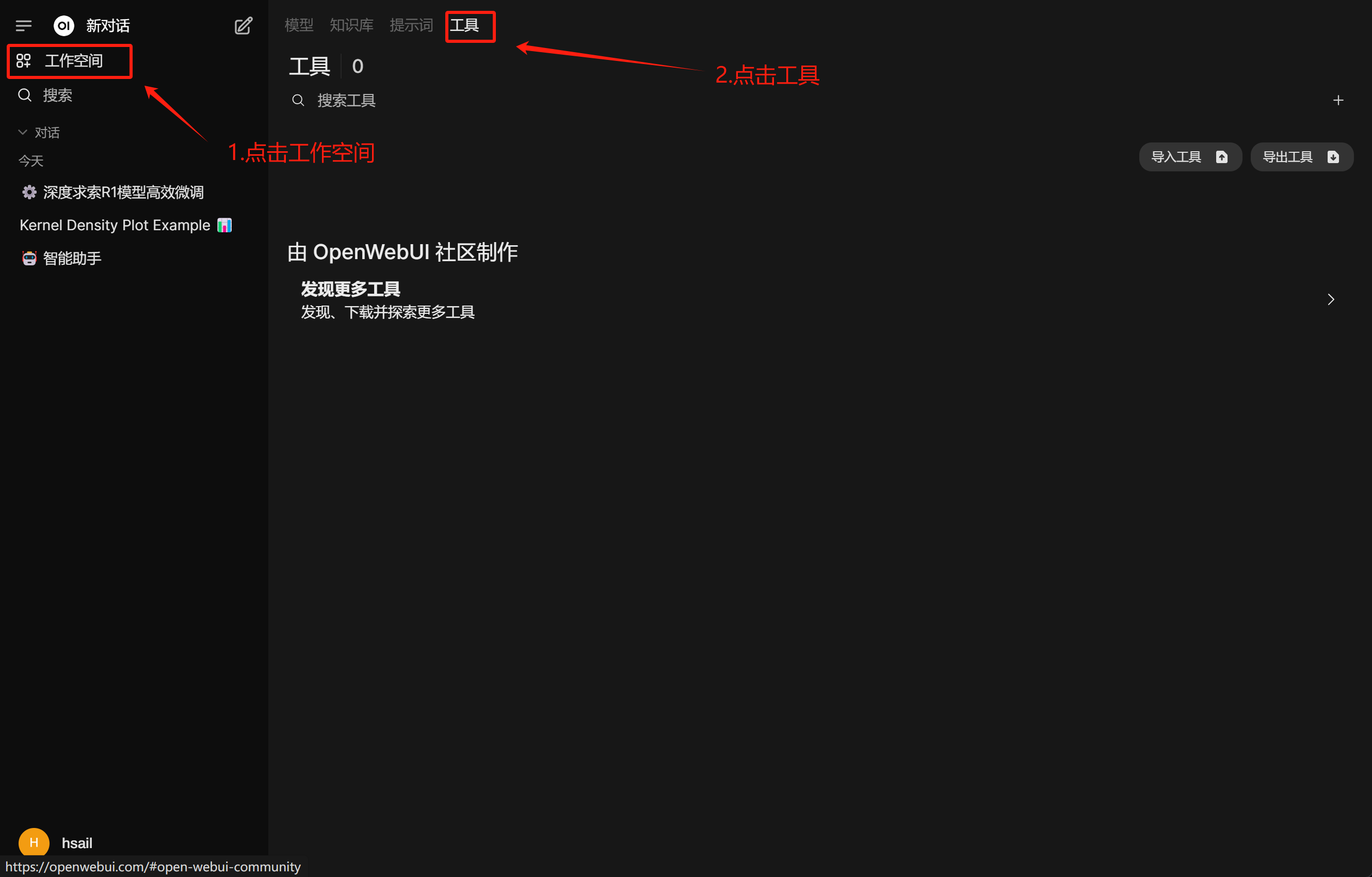
Qwen3全系列支持Function calling,因此我们可以基于此完成Open-WebUI的外部工具调用工作。
- Open-WebUI工具调用功能实现
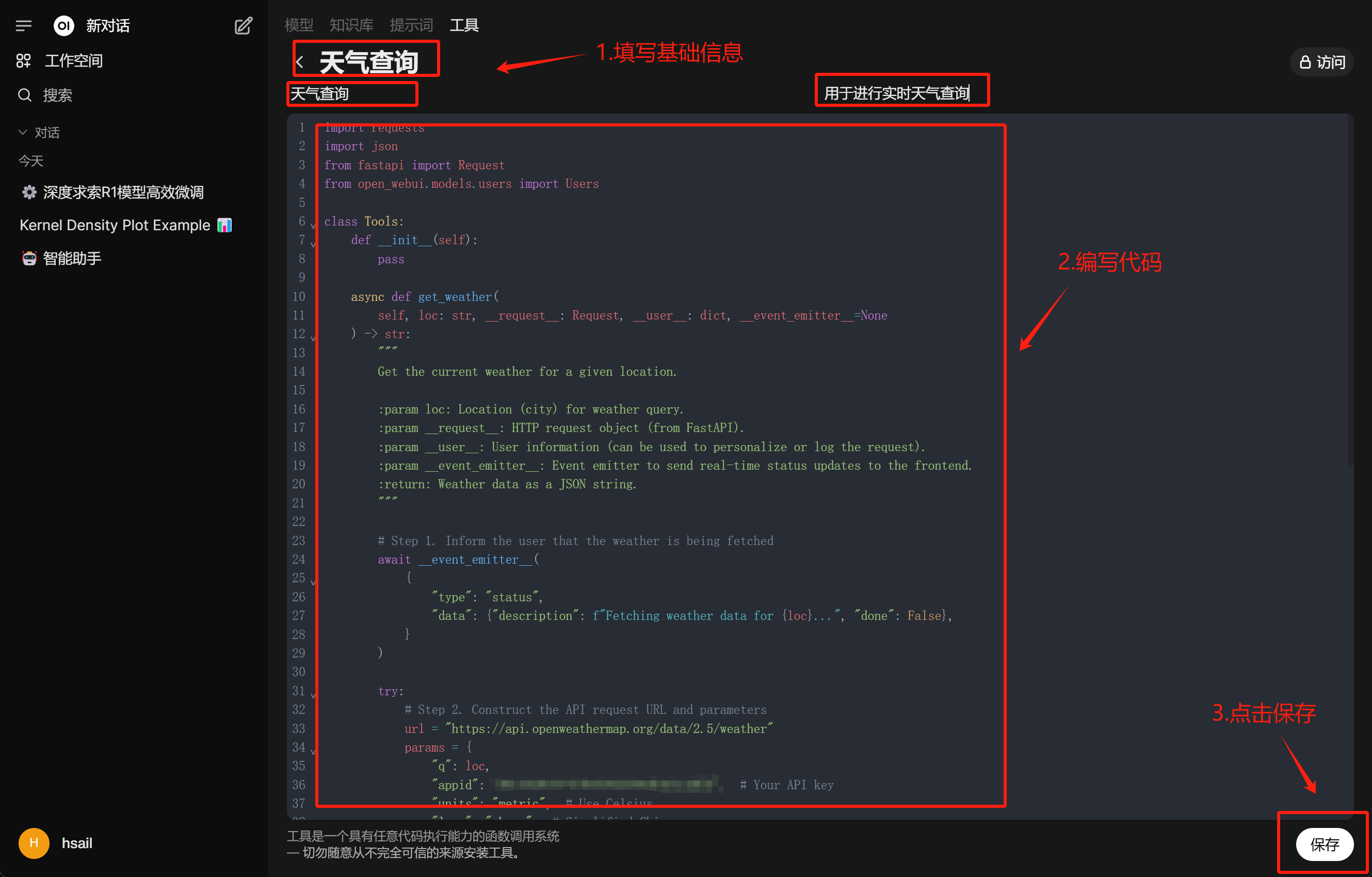
然后编写天气查询函数:
FENCE0
并将函数进行写入:
完成后即可看到新的工具:
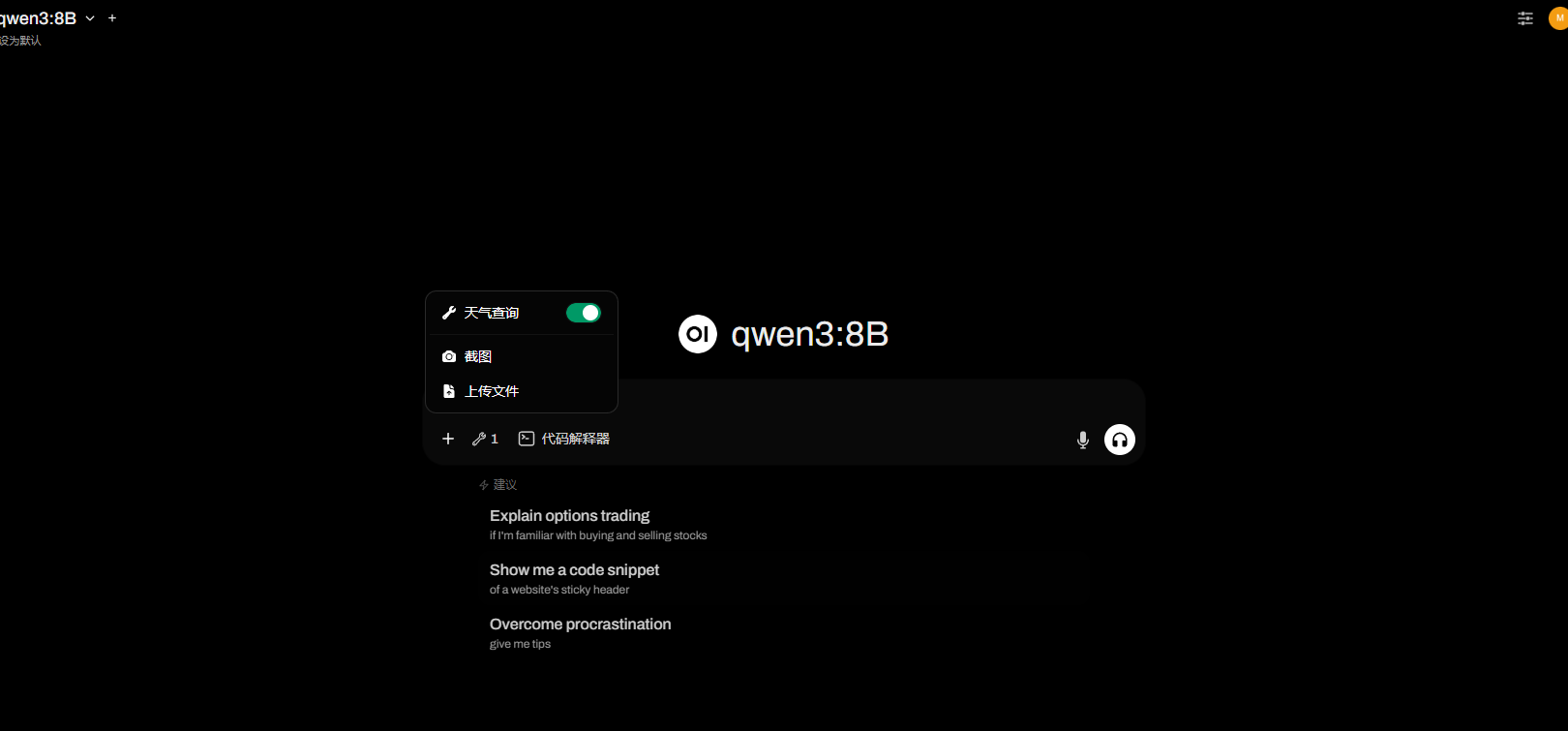
在对话时可以开启天气查询函数:
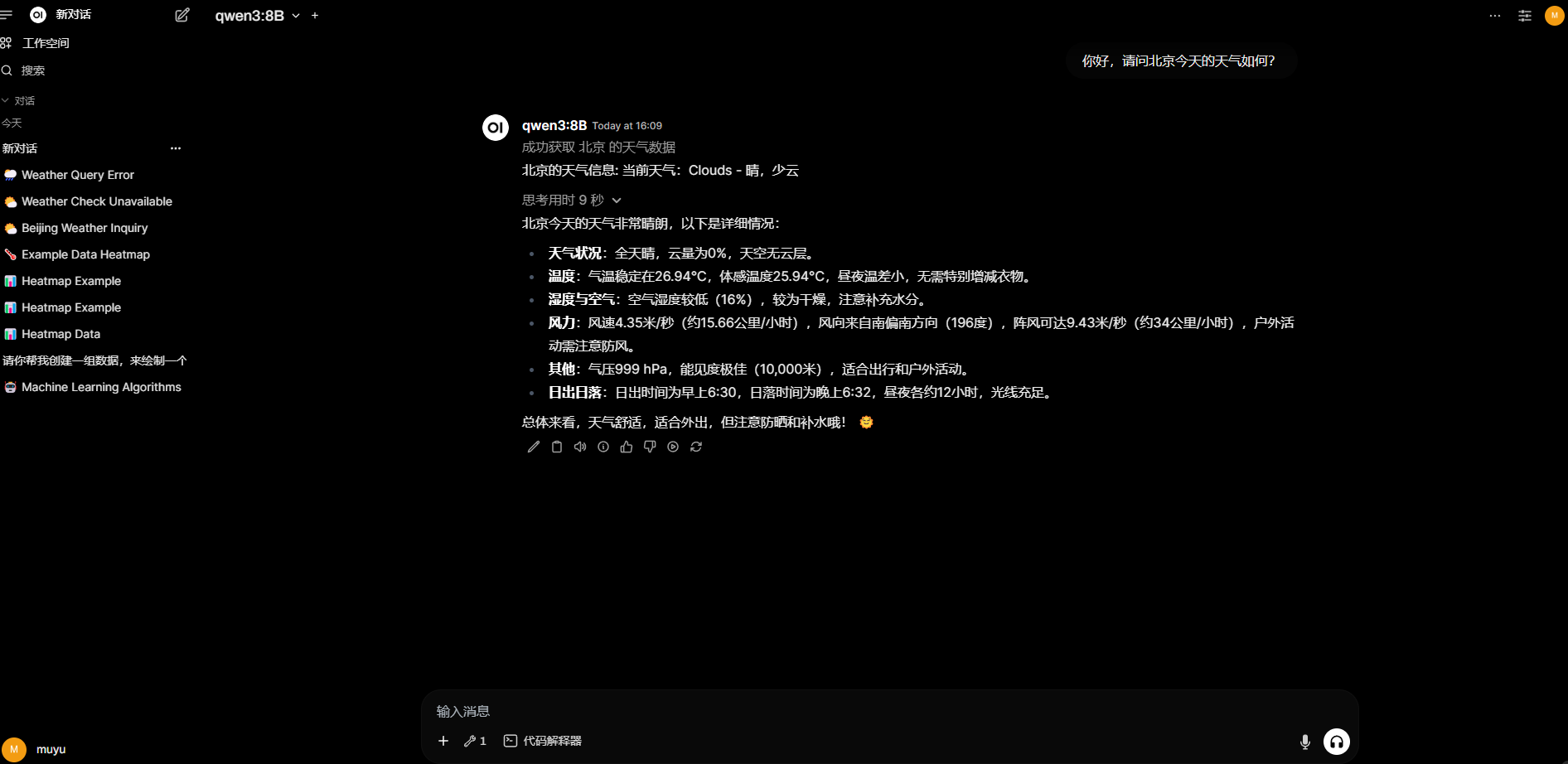
至此,我们就详细介绍了QwQ模型的各类本地部署与调用方法。