模型调用、记忆管理与工具调用流程
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(秋季班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(秋季班)

《2025大模型Agent智能体开发实战》(秋招冲刺班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
课程完整介绍

秋季班重磅新增14项实战案例

部分课程成果演示
from IPython.display import Video
- Dify+DeepSeek搭建智能微信语音客服
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- Coze自动图文视频创作流程
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- 可视化数据分析Multi-Agent
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目展示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋季班)



详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

LangChain 1.0入门实战
Part 3.模型调用、记忆管理与工具调用流程
在LangChain 1.0中,抛弃了此前版本LangChain的专门用于构建工作流的LCEL管道语言,转而大幅增强了基础模型的调用灵活度,因此学会使用LangChain API完成模型调用、对话、记忆管理以及工具调度等,也成了学习LangChain的非常核心的一部分内容。
import os
from dotenv import load_dotenv
load_dotenv(override=True)
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# print(DeepSeek_API_KEY) # 可以通过打印查看
1.LangChain 1.0基础模型消息格式说明与模型调用流程
在 LangChain 1.0 中,Message(消息)是模型交互的最基本单元。它既代表模型接收到的输入(Input),也代表模型生成的输出(Output)。
简单来说,每一轮与大模型的对话,都由一条或多条 Message 构成。每个 Message 不仅包含文字内容,还携带描述上下文状态的元信息(metadata),用于保持对话的一致性和可追踪性。通过这种结构化方式,LangChain 可以让模型在多轮交互中理解“谁在说话”“说了什么”“这条信息属于哪一轮对话”。
| 字段 | 说明 | 示例 |
|---|---|---|
| Role(角色) | 指明消息的类型或来源。常见的有:system(系统提示)、user(用户输入)、assistant(模型回复) | "role": "user" |
| Content(内容) | 消息的实际内容,可包含文本、图像、音频、文档等多模态数据 | "content": "你好,请帮我总结以下段落。" |
| Metadata(元数据) | 可选字段,存储额外信息,如:消息ID、响应时间、token消耗量、消息标签等 | "metadata": {"message_id": "abc123", "tokens": 54} |
同时,LangChain 在 1.0 中提供了跨模型统一的 Message 标准。无论你使用的是 OpenAI、Anthropic、Gemini 还是本地模型,这一标准都能保持一致的行为。这种统一抽象带来三个好处:其一是,兼容性强:不同模型的消息格式自动对齐。其二是可扩展性高:方便添加多模态内容或自定义字段。其三是可追踪性好:为 LangSmith 等调试工具提供一致的上下文数据结构。
基本使用方法如下:
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-chat")
from langchain.messages import HumanMessage, AIMessage, SystemMessage
system_msg = SystemMessage("你叫小智,是一名助人为乐的助手。")
human_msg = HumanMessage("你好,好久不见,请介绍下你自己。")
messages = [system_msg, human_msg]
messages
response = model.invoke(messages)
# 返回的结果也是一条message
response
返回的内容结果解释如下:
| 字段名称 | 示例值 / 类型 | 说明与作用 |
|---|---|---|
| content | '你好呀!我是小智,一个乐于助人的智能助手。我的主要功能是回答问题、提供建议、协助解决问题,或者陪你聊天。无论是学习、工作、生活琐事,还是想找点有趣的话题,我都可以帮忙!如果有任何需要,随时告诉我哦~ 😊' | 模型生成的主要文本内容。即对话中 AI 的自然语言回复。 |
| additional_kwargs | {'refusal': None} | 附加参数字段,通常存放模型的拒答原因、补充说明等。此处为 None 表示没有拒答。 |
| response_metadata | {...}(字典对象) | 响应元数据,用于记录模型调用的底层信息,如 token 使用量、模型来源、运行 ID 等。详解如下👇 |
↳ token_usage | {'completion_tokens': 60, 'prompt_tokens': 25, 'total_tokens': 85, ...} | 记录生成所消耗的 token 统计信息:输入 25,输出 60,总计 85。 |
↳ model_provider | 'deepseek' | 表示模型提供方(此处为 DeepSeek)。 |
↳ model_name | 'deepseek-chat' | 模型的具体名称。 |
↳ system_fingerprint | 'fp_ffc7281d48_prod0820_fp8_kvcache' | 模型版本或运行实例指纹,用于调试和追踪。 |
↳ id | '311d2a0e-7fa2-4543-a8d6-374b201db854' | 当前响应在 LangChain 运行中的唯一标识符。 |
↳ finish_reason | 'stop' | 模型生成结束的原因,stop 表示自然结束(无截断或超长)。 |
| id | 'lc_run--0d38df6a-0aa7-41fd-9b33-a9ecae16cb80-0' | LangChain 内部为此消息生成的唯一 运行 ID。 |
| usage_metadata | {...}(字典对象) | LangChain 层的 统一 token 计量信息,与 response_metadata.token_usage 相呼应。详解如下👇 |
↳ input_tokens | 25 | 输入 token 数量。 |
↳ output_tokens | 60 | 输出 token 数量。 |
↳ total_tokens | 85 | 总 token 数量(输入 + 输出)。 |
↳ input_token_details | {'cache_read': 0} | 输入部分缓存命中信息,用于优化推理性能统计。 |
↳ output_token_details | {} | 输出部分的补充统计(此处为空)。 |
据此,我们就能通过拼接消息列表来创建多轮对话或者进行Few-shot提示:
messages = [
SystemMessage("你叫小智,是一名助人为乐的助手。"),
HumanMessage("你好,我叫陈明,好久不见,请介绍下你自己。"),
AIMessage("你好呀!我是小智,一个乐于助人的智能助手。我的主要功能是回答问题、提供建议、协助解决问题,或者陪你聊天。无论是学习、工作、生活琐事,还是想找点有趣的话题,我都可以帮忙!如果有任何需要,随时告诉我哦~ 😊"),
HumanMessage("你好,请问你还记得我叫什么名字么?"),
]
response = model.invoke(messages)
response.content
除此之外,如果只需要输入一个简答你的文本提示,也可以采用类似第二部分的调用方法,在invoke中直接输入文本,即可自动转化为user message并进行对话:
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
2.基础模型的流式响应和批处理
在 LangChain 中,大多数模型都支持流式生成(Streaming Generation),即在模型输出完整回答之前,边生成边输出结果。这种机制使得:
- 响应速度更快 — 用户不必等待完整输出;
- 交互体验更流畅 — 尤其在长文本或复杂推理场景下;
- 可实时展示模型思考过程。
在LangChain 1.0中,可以通过调用stream()来进行流式响应,当使用stream()方法后,模型不会一次性返回完整结果,而是返回一个迭代器(iterator),每次迭代都会生成一个 AIMessageChunk,包含部分生成内容,运行结果会实时打印模型输出的 token:
for chunk in model.stream("你好,好久不见"):
print(chunk.text, end="|", flush=True)
每个 AIMessageChunk 都可以通过加法 + 操作符拼接。LangChain 内部为此设计了“消息块相加(chunk summation)”机制。
full = None # 初始值为空
for chunk in model.stream("你好,好久不见"):
full = chunk if full is None else full + chunk
print(full.text)
拼接完成后,可以查看完整内容块:
print(full.content_blocks)
需要注意的是:
- 流式输出依赖于整个程序链路都支持“逐块处理”。如果程序中的某个环节必须等待完整输出(如需一次性写入数据库),则无法直接使用 Streaming;
- angChain 1.0 进一步优化了流式机制,引入 自动流式模式(Auto-streaming)。例如在Agent中,如果整体程序处于 streaming 模式,即便节点中调用 model.invoke(),LangChain 也会自动流式化模型调用。
此外,LangChain 还支持通过 astream_events() 对语义事件进行异步流式监听,适合需要过滤不同事件类型的复杂场景。
而在使用大模型时,如果需要同时处理多条独立请求(例如多个问题或多段文本),则可以使用 批量调用(Batch) 方法一次性提交这些请求。LangChain 中的 batch() 方法允许你同时发送一组请求,模型会在后台并行处理,然后返回所有结果:
responses = model.batch([
"请介绍下你自己。",
"请问什么是机器学习?",
"你知道机器学习和深度学习区别么?"
])
for response in responses:
print(response)
| 特性 | 说明 |
|---|---|
| 执行位置 | batch() 在客户端(Client-side)并行调用模型,而非调用模型提供商的批量API(如OpenAI或Anthropic自带的batch API)。 |
| 返回结果 | 默认会在所有任务完成后,统一返回完整结果列表。 |
| 并行优势 | 多条独立请求可同时执行,无需等待彼此完成。 |
| 适用场景 | 文档摘要、批量问答、数据预处理、多样本分类等。 |
当然,我们也可以进行流式批处理,也就是每个每个任务完成后就立即获取结果(而不是等待全部完成),可以使用 batch_as_completed() 方法。
for response in model.batch_as_completed([
"请介绍下你自己。",
"请问什么是机器学习?",
"你知道机器学习和深度学习区别么?"
]):
print(response)
注意:结果可能不按原输入顺序返回,因为不同请求完成时间不同,并且每个返回项都包含原始输入的 index 索引,可根据索引重新排序。
而为了更好的控制并发,我们还可以在config参数中设置批处理的并发数,例如 FENCE0
更多config参数解释如下:
| 属性名 | 类型 | 说明 |
|---|---|---|
max_concurrency | int | 最大并行执行数 |
timeout | float | 每个请求的最大超时时间(秒) |
callbacks | list | 触发事件回调,用于日志或监控 |
metadata | dict | 额外的上下文信息,可用于追踪 |
3.基础模型的结构化输出方法
LangChain 1.0为所有模型都设置了结构化输出方法,可以让模型的回复严格匹配一份给定的 Schema(模式),便于解析与后续处理。结构化输出能避免“自然语言歧义”,让下游流程(数据库写入、API调用、连环任务)稳、准、可测。
目前LangChain 1.0支持多种Schema与结构化输出方式:
- Pydantic(字段校验、描述、嵌套结构,功能最丰富)
- TypedDict(轻量类型约束)
- JSON Schema(与前后端/跨语言接口最通用)
其中Pydantic 提供字段校验、默认值、描述信息、多层嵌套等高级能力,是生产场景首选。
from pydantic import BaseModel, Field
class Movie(BaseModel):
"""A movie with details."""
title: str = Field(..., description="The title of the movie")
year: int = Field(..., description="The year the movie was released")
director: str = Field(..., description="The director of the movie")
rating: float = Field(..., description="The movie's rating out of 10")
这里我们使用 Pydantic 的 BaseModel 定义一个严格的数据结构。每个字段都明确了类型(如 str、int、float),并用 Field(..., description="...") 提供语义描述。据此,模型回复时,LangChain 会要求 LLM 的输出必须能填充这些字段。
然后使用with_structured_output即可引导模型进行结构化输出:
model_with_structure = model.with_structured_output(Movie)
response = model_with_structure.invoke("Provide details about the movie Inception")
print(response)
response
而如果想要获得模型的完整回复,则可以设置include_raw=True
model_with_structure = model.with_structured_output(Movie, include_raw=True)
resp = model_with_structure.invoke("Provide details about the movie Inception")
resp
此外,LangChain 1.0还有非常多的对基础模型调用的方法设置,例如创建内容块(content block,主要用于传递多模态信息)、设置Rate Limit、以及设置Base_URL等等。公开课时间有限,我们就不展开一一介绍了,对更深度内容感兴趣的同学欢迎报名《2025大模型Agent智能体开发实战》(秋季班) 付费课程进行学习。
4.【入门实践】搭建流式响应的多轮问答机器人
在本小节结束前,我们再通过一个简单的示例,帮大家更加深刻的理解LangChain 1.0中模型调用方法、流式响应以及通过消息队列的拼接来创建多轮聊天对话机器人的流程。
from langchain_deepseek import ChatDeepSeek
from langchain.messages import HumanMessage, AIMessage, SystemMessage
# 1️⃣ 初始化模型(LangChain 1.0 接口)
model = ChatDeepSeek(model="deepseek-chat")
# 2️⃣ 初始化系统提示词(System Prompt)
system_message = SystemMessage(
content="你叫小智,是一名乐于助人的智能助手。请在对话中保持温和、有耐心的语气。"
)
# 3️⃣ 初始化消息历史
messages = [system_message]
print("🔹 输入 exit 退出对话\n")
# 4️⃣ 主循环(支持多轮对话 + 流式输出)
while True:
user_input = input("👤 你:")
if user_input.lower() in {"exit", "quit"}:
print("🧩 对话结束,再见!")
break
# 追加用户消息
messages.append(HumanMessage(content=user_input))
# 实时输出模型生成内容
print("🤖 小智:", end="", flush=True)
full_reply = ""
# ✅ LangChain 1.0 标准写法:流式输出
for chunk in model.stream(messages):
if chunk.content:
print(chunk.content, end="", flush=True)
full_reply += chunk.content
print("\n" + "-" * 40) # 分隔线
# 追加 AI 回复消息
messages.append(AIMessage(content=full_reply))
# 保持消息长度(只保留最近50轮)
messages = messages[-50:]
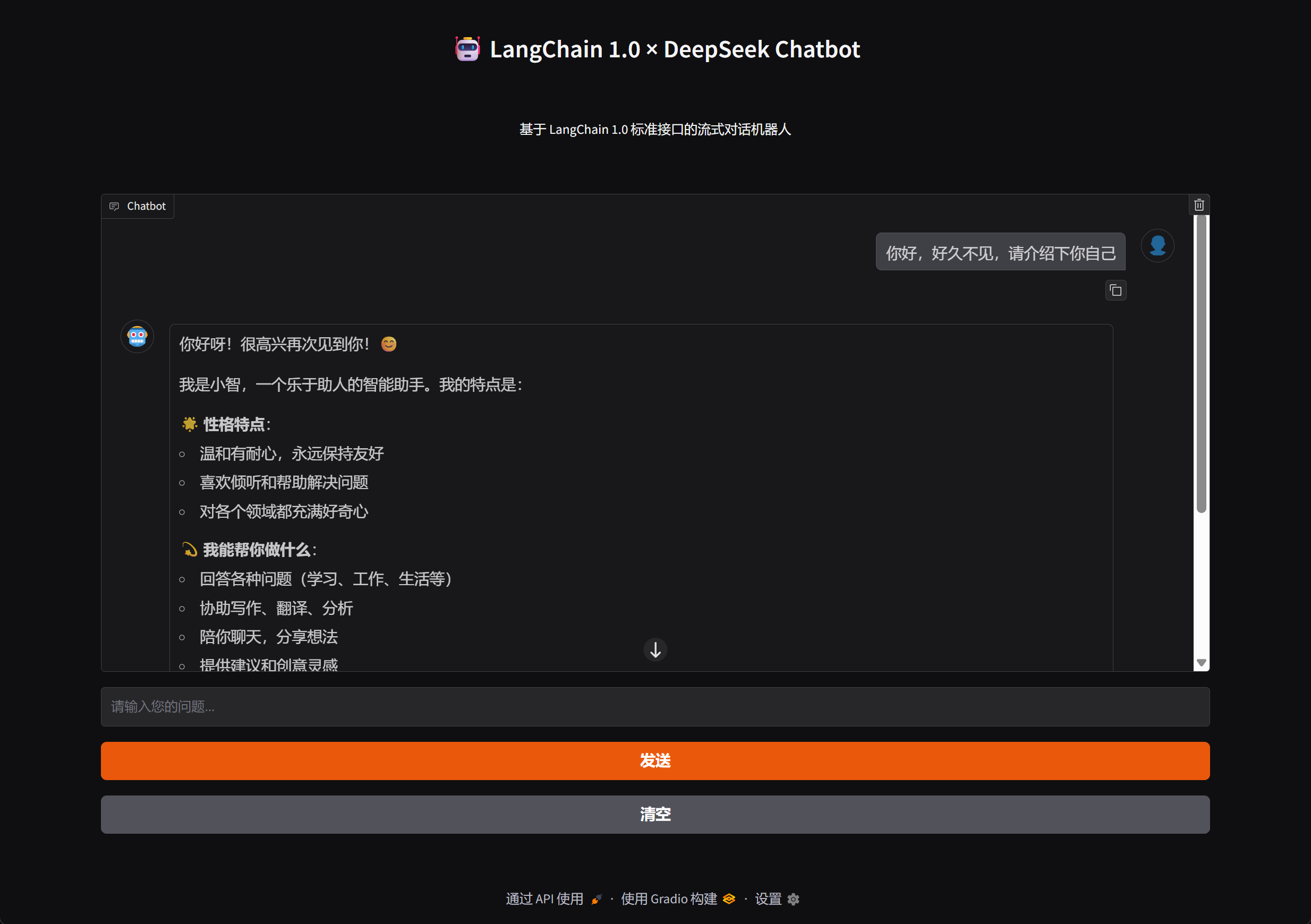
如上所示展示的问答效果就是我们在构建大模型应用时需要实现的流式输出效果。接下来我们就进一步地,使用gradio来开发一个支持在网页上进行交互的问答机器人。
首先需要安装一下gradio的第三方依赖包,
# 安装 Gradio
# !pip install gradio
import gradio as gr
from langchain_deepseek import ChatDeepSeek
from langchain.messages import HumanMessage, AIMessage, SystemMessage
# ──────────────────────────────────────────────
# 1️⃣ 初始化模型与系统设定
# ──────────────────────────────────────────────
# 使用 LangChain 1.0 接口创建 DeepSeek 模型
model = ChatDeepSeek(model="deepseek-chat")
# 定义系统角色(System Prompt)
system_message = SystemMessage(
content="你叫小智,是一名乐于助人的智能助手。请在对话中保持友好、有耐心、温和的语气。"
)
# ──────────────────────────────────────────────
# 2️⃣ 定义 Gradio 界面
# ──────────────────────────────────────────────
CSS = """
.main-container {max-width: 1200px; margin: 0 auto; padding: 20px;}
.header-text {text-align: center; margin-bottom: 20px;}
"""
def create_chatbot() -> gr.Blocks:
with gr.Blocks(title="DeepSeek Chat", css=CSS) as demo:
with gr.Column(elem_classes=["main-container"]):
gr.Markdown("# 🤖 LangChain 1.0 × DeepSeek Chatbot", elem_classes=["header-text"])
gr.Markdown("基于 LangChain 1.0 标准接口的流式对话机器人", elem_classes=["header-text"])
chatbot = gr.Chatbot(
height=500,
show_copy_button=True,
avatar_images=(
"https://cdn.jsdelivr.net/gh/twitter/twemoji@v14.0.2/assets/72x72/1f464.png",
"https://cdn.jsdelivr.net/gh/twitter/twemoji@v14.0.2/assets/72x72/1f916.png",
),
)
msg = gr.Textbox(placeholder="请输入您的问题...", container=False, scale=7)
submit = gr.Button("发送", scale=1, variant="primary")
clear = gr.Button("清空", scale=1)
# 状态:保存消息历史(LangChain Message 对象)
state = gr.State([])
# ─────────────── 主响应函数(流式输出) ───────────────
async def respond(user_msg: str, chat_hist: list, messages_list: list):
# 1️⃣ 输入为空则直接返回
if not user_msg.strip():
yield "", chat_hist, messages_list
return
# 2️⃣ 构建消息上下文(包括系统提示)
if not messages_list:
messages_list = [system_message]
messages_list.append(HumanMessage(content=user_msg))
chat_hist = chat_hist + [(user_msg, None)]
yield "", chat_hist, messages_list # 先显示用户消息
# 3️⃣ 流式生成模型回复
partial = ""
for chunk in model.stream(messages_list):
if chunk.content:
partial += chunk.content
chat_hist[-1] = (user_msg, partial)
yield "", chat_hist, messages_list
# 4️⃣ 保存完整 AI 回复并截断历史(保留50轮)
messages_list.append(AIMessage(content=partial))
messages_list = messages_list[-50:]
yield "", chat_hist, messages_list
# ─────────────── 清空对话函数 ───────────────
def clear_history():
return [], "", []
# ─────────────── Gradio 事件绑定 ───────────────
msg.submit(respond, [msg, chatbot, state], [msg, chatbot, state])
submit.click(respond, [msg, chatbot, state], [msg, chatbot, state])
clear.click(clear_history, outputs=[chatbot, msg, state])
return demo
# ──────────────────────────────────────────────
# 3️⃣ 启动 Gradio 应用
# ──────────────────────────────────────────────
demo = create_chatbot()
demo.launch(server_name="0.0.0.0", server_port=7860, share=False, debug=True)
具体运行效果如下: