大模型Multi-Agent架构设计及技术生态
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(秋招冲刺班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(秋招冲刺班)

《2025大模型Agent智能体开发实战》(秋招冲刺班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋招冲刺班)

两门大模型课程秋招冲刺班即将封班,直播间享五折特价+全套SVIP新班特定福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


《大模型Agent开发实战》(体验课)
Part 1. 大模型Multi-Agent架构设计及技术生态
一. 快速理解什么是AI Agent
AI Agent(人工智能代理)一般指一种结合大语言模型(LLM)与多种机制的智能体,可以自主地理解目标、规划步骤并执行任务。简单来说,AI Agent 就像一个聪明的数字助理:它不只是被动回答问题,还能够 “主动” 地想办法完成更复杂的任务。例如,当你让它安排一次旅行,它不会只给出建议,而是可以自主地规划行程、查询机票酒店(使用工具)、比较价格,最终给出完整方案。
下图来源于一个非常经典的多智能体开源项目 ChatDev,Github地址:https://github.com/OpenBMB/ChatDev 。

这张像素风海报用“虚拟软件公司”的方式展示了 ChatDev 的多智能体协作流程:
- 用户给出目标 “Develop a Gomoku game”(做一个五子棋游戏);
- 团队内不同角色的智能体分工协作,按软件工程流水线推进:Designing(需求/设计)→ Coding(编码)→ Testing(测试)→ Documenting(文档);
- 右上角的 Software 台展示最终产物:代码(Codes) 与 文档(Docs)。
简言之,它可视化了 ChatDev 让多个 AI 代理像一个小型软件公司那样协同完成从需求到交付的全过程。
二、AI Agent 的经典架构
一个典型的 AI Agent 系统通常包含四个关键组成::大语言模型(智能核心)、规划模块、工具使用接口,以及记忆模块。LLM提供了强大的通用智能和语言理解能力,而另外三个组件帮助弥补LLM自身的局限,使Agent具备更强的自主决策和执行能力。这些组件相互协作,使AI Agent能够感知环境(接受用户输入或观察结果)、决策下一步行动并付诸实施,形成感知 → 决策 → 执行 → 学习的循环。
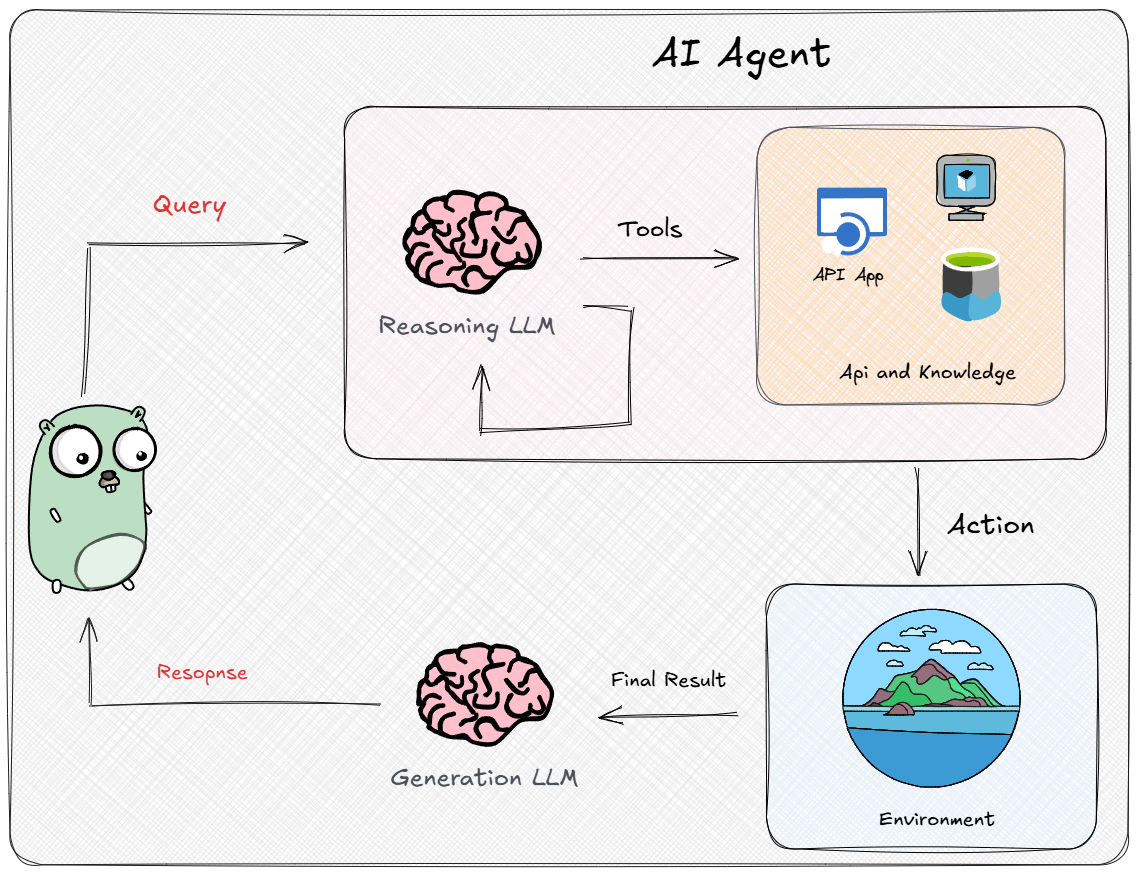
AI Agent之所以比单纯的LLM聊天机器人更强大,关键在于引入了规划、工具、记忆等模块。
2.1 Planning规划模块
规划模块(Planning)负责让AI Agent决定“下一步做什么”。当Agent接到一个复杂任务时,不可能直接凭一句回答就解决,需要把大任务分解成一系列可执行的子任务。规划模块的作用就是根据当前目标和环境,动态地产生解决问题的步骤或方案。这类似于人类在解决问题时先想策略:比如你让助理AI准备一份报告,它可能需要先计划查找资料、然后整理大纲、再撰写草稿,最后润色总结。
规划模块提高了Agent的灵活性和自主性。没有规划能力的Agent往往按部就班或 一问一答 地反应,遇到新情况就无从适应;而有了规划,Agent可以多步推理,根据中间结果调整后续行动。尤其在复杂任务中,规划模块连接了意图和行动:Agent通过规划把高层目标逐步细化为具体操作序列。规划可以通过硬编码规则实现(if-then的流水线),也可以利用LLM自身的推理能力来动态规划。后者往往通过让模型产生“思考过程”来决定下一步,例如链式思考(Chain-of-Thought)或树状的任务分解。
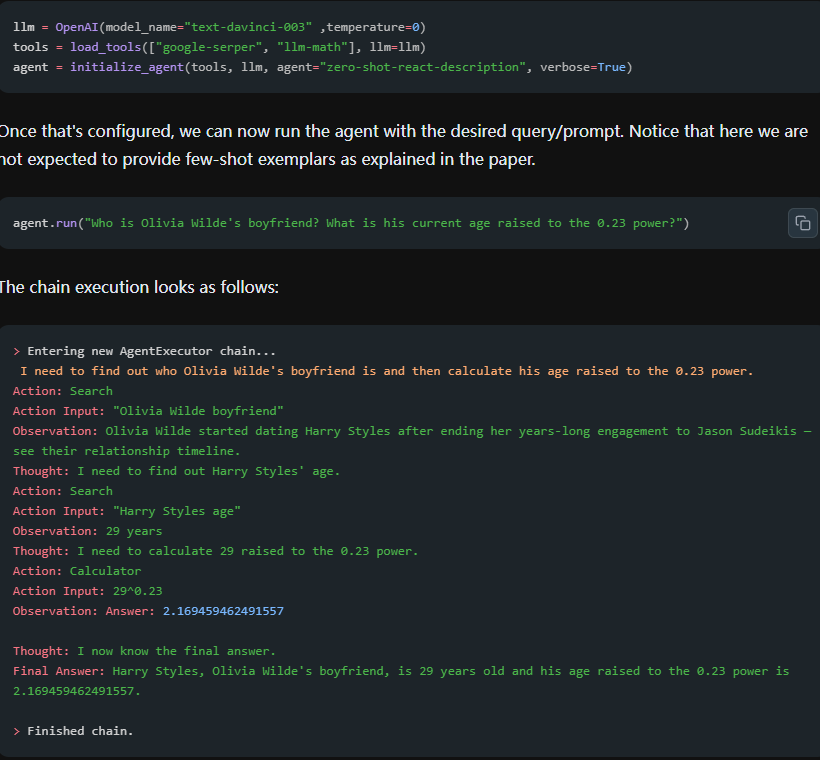
- ReACt框架
这是一种结合“推理(Reasoning)”和“行动(Acting)”的经典模式>在ReAct中,LLM会一边“思考”一边“行动”:先输出思考过程(例如分析问题、推理下一步需要的信息),然后决定调用某个工具或执行某个动作,再根据工具返回的观察结果继续思考,如此循环。这种交替进行“Thought→Action→Observation”的过程,相当于Agent在一步步制定和调整计划,直到最终得到答案

经典的应用就是LangChain开发框架的链式调用,如下所示:
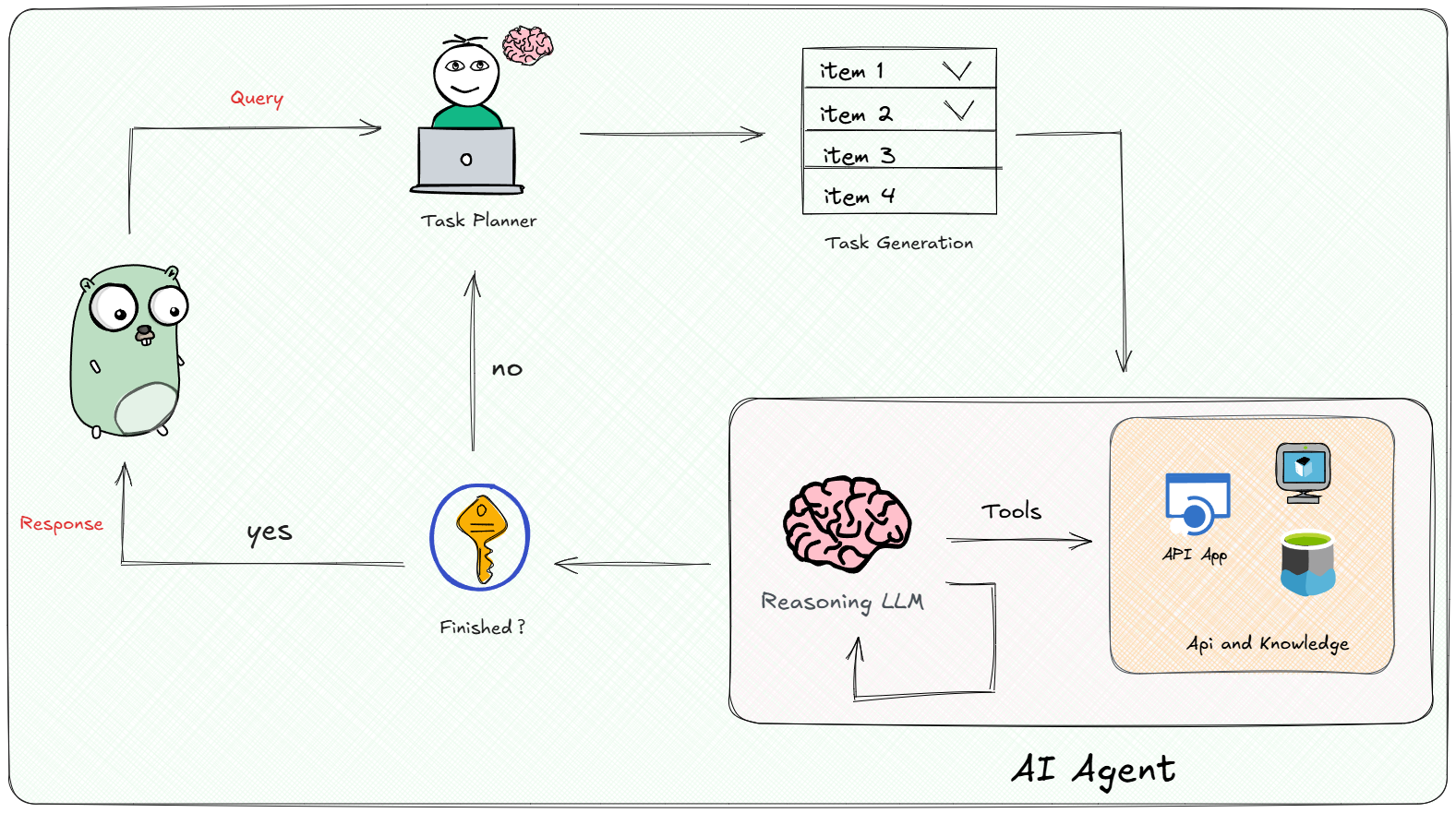
- Plan-and-Execute模式
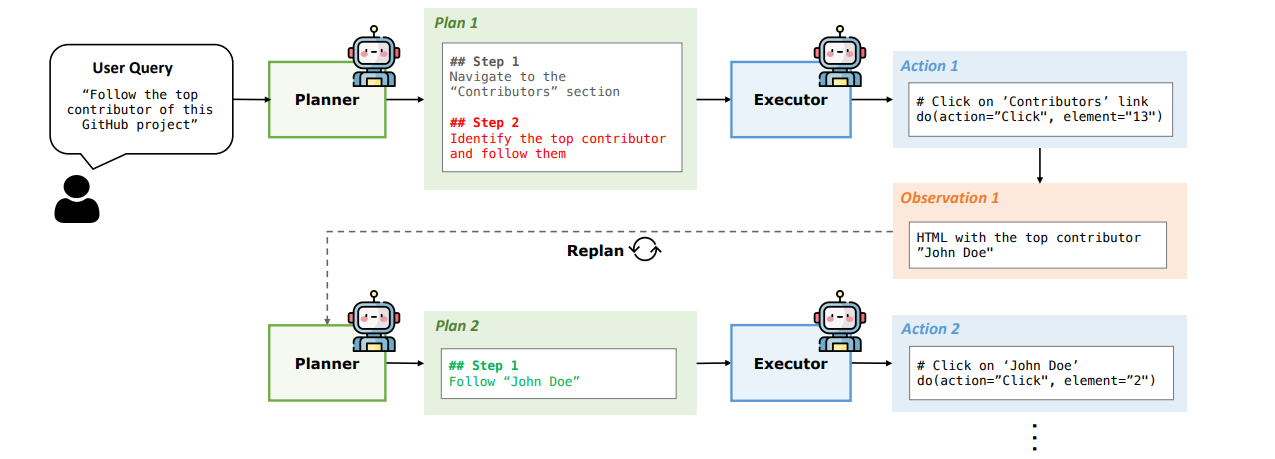
这种模式将规划与执行分离。例如先由LLM给出一个完整的计划清单(列出子任务序列),然后Agent按照清单逐一执行每个子任务(调用工具或子Agent)并收集结果,最后再由LLM综合结果输出。这种模式下,规划阶段产出的是整体方案,执行阶段严格按照方案实施。这适合某些结构明确的场景,但缺点是一开始计划如果不完善,中途缺乏调整。此外,OpenAI的函数调用接口也可以视为一种简单的Plan→Act模式:LLM先决定需要调用何种函数(计划),再调用执行函数并拿结果。
在大模型发展最初非常爆火的 BabyAGI 项目,就是规划代理架构的典型代表。https://github.com/yoheinakajima/babyagi
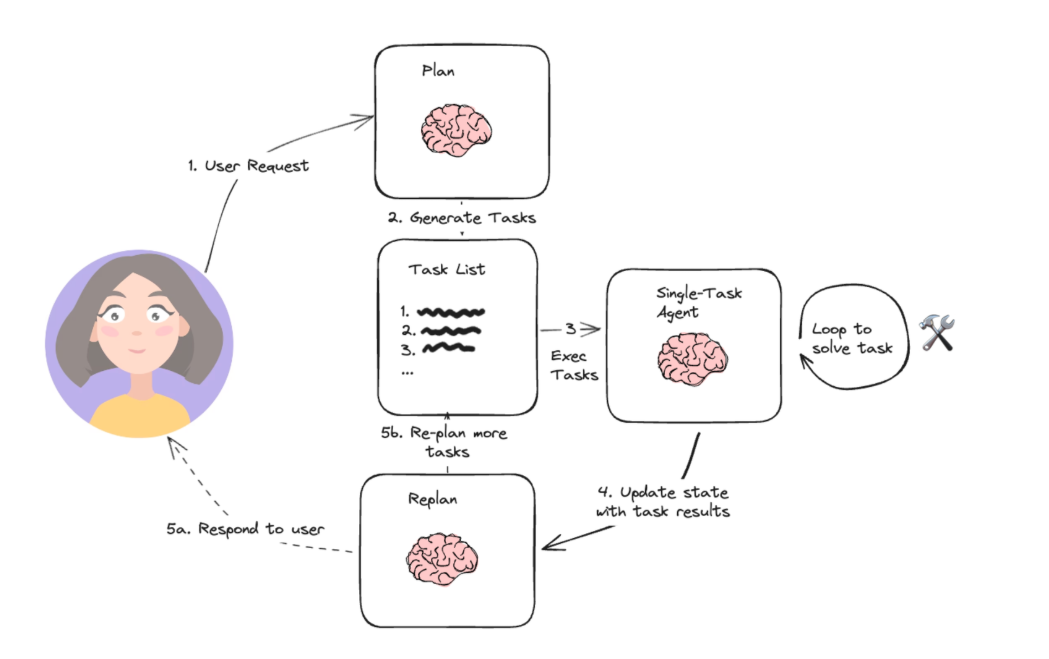
BabyAGI 是 Yohei Nakajima 在 2023 年发起的一个开源实验性项目,目标是构建一个“自主任务执行代理”(autonomous task agent),可以接收一个总体目标(objective),拆解出初始任务(initial task)然后进入一个循环。执行任务(execution),根据执行结果生成新的子任务(task creation),对任务队列进行优先级排序 / 管理(task prioritization),并利用“记忆”机制来保留之前执行任务的结果,以便在后续任务里能参考(context)或避免重复。
简而言之,它是一个轻量级的、自动循环的任务管理 agent,它自己不断地创造任务、执行任务、再创造,再排序,直到任务完成或满足某个终止条件。
同时像现在依然企业主流的Agent底层开发框架:LangGraph,也将其作为了核心的架构设计。
以及我们现在正在研发的多模态Manus课程项目:FuFanManus:
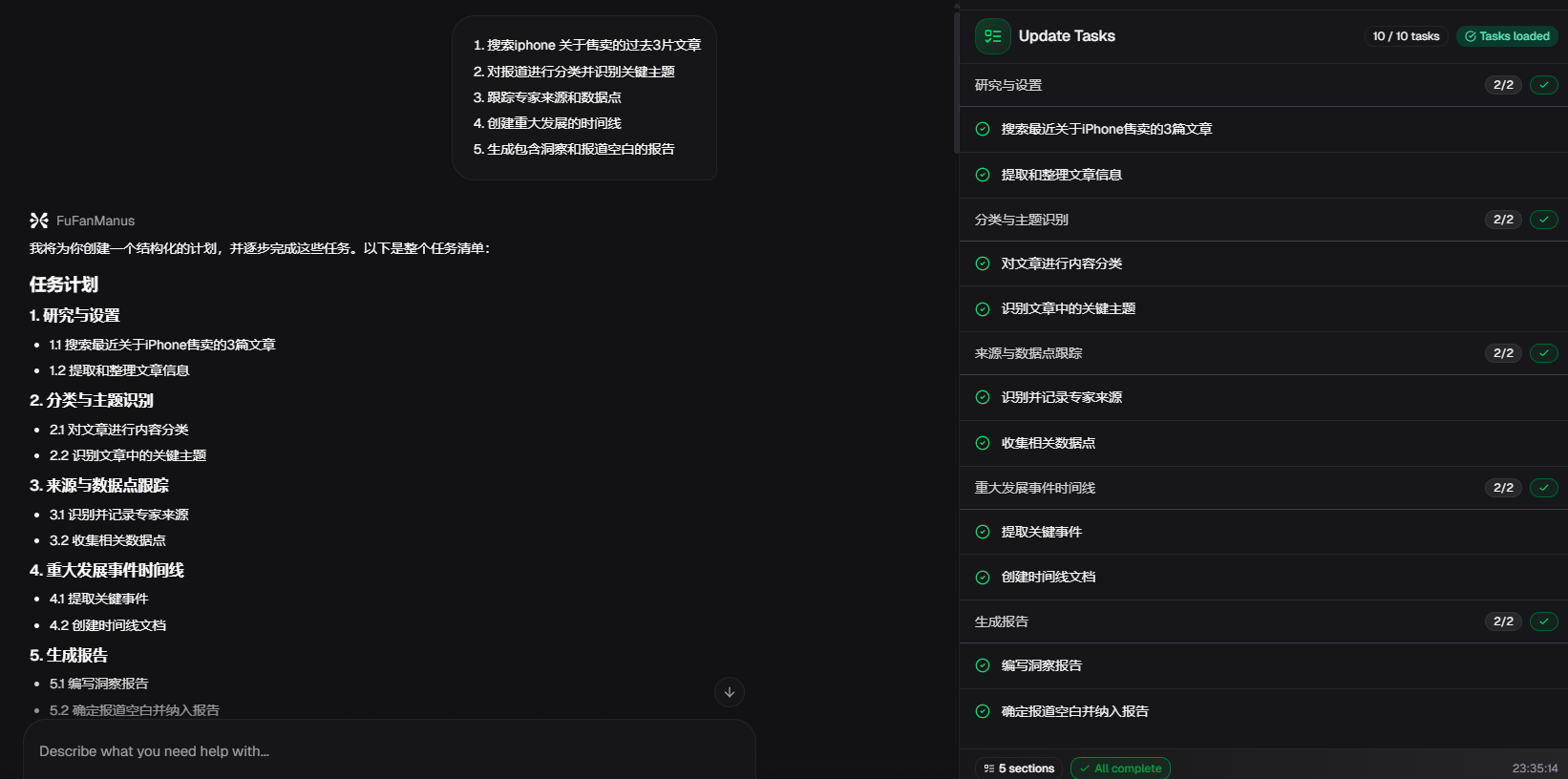
两门大模型课程秋招冲刺班即将封班,直播间享五折特价+全套SVIP新班特定福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇
- 自我反思与迭代改进
这是更高级的规划模式,Agent在执行过程中定期反思自己的方案和结果,必要时修改计划。例如Stanford提出的Reflection策略让Agent在遇到错误时暂停,调用自身检查上一步输出是否有误,再调整下一步行动。通过这种自我监督的循环,Agent的规划会越来越完善,逐步逼近正确解。这类似人类解决难题时不断检查和修正思路的过程。。通过这种自我监督的循环,Agent的规划会越来越完善,逐步逼近正确解。这类似人类解决难题时不断检查和修正思路的过程。
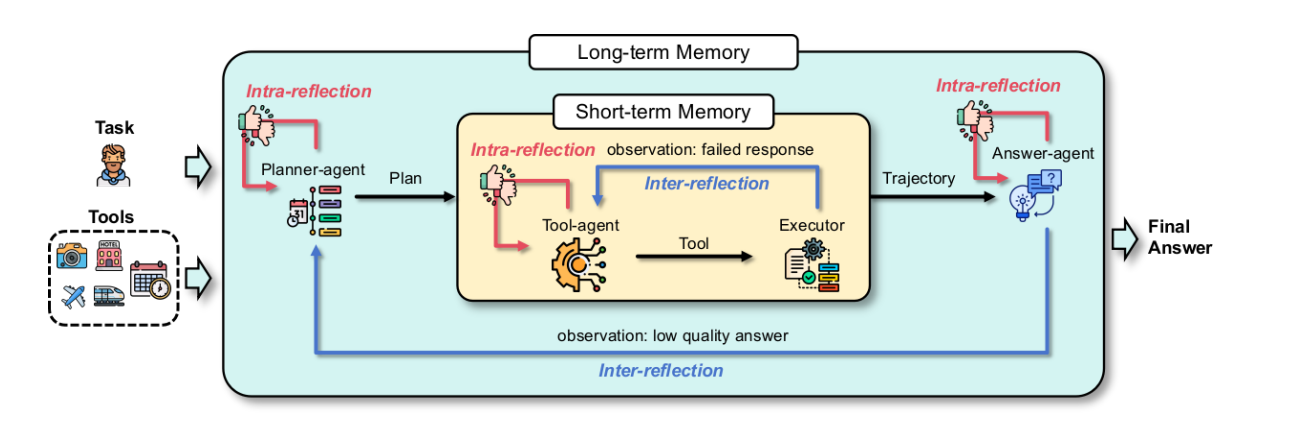
为什么需要反思(Reflection)?因为在多步任务中,大模型偶尔推理出错、工具调用出错、计划不完善。若没有反思机制,这些错误可能积累。 反思可以在任务执行前预测可能的问题(anticipatory)、执行中检查和反馈(post-action), 以及执行完成后总结经验用于下次(meta‐reflection)。模式类型:
-
事前反思(Anticipation):在做某动作前“预测”可能的失败或偏差;
-
事中反思 /即时修正(During execution):若某一步出结果与预期不符,停下来纠正;
-
事后总结 /经验积累(After completion):执行完任务后评估哪些步骤好/差,哪些原则适用于未来类似任务。
2.2 Agent 工具集成
工具(Tool)接口是AI Agent连接外部世界的桥梁。大语言模型本身只能“纸上谈兵”(生成文本),但现实任务往往需要执行操作、查询数据库、调用API等等。工具接口允许Agent在需要时调用外部的函数、API或者其他AI模型,从而扩展了Agent的能力范围。可以说,如果把LLM看作Agent的大脑,那么工具就是Agent可以使用的手脚和感官。
Function Calling(函数调用) 就是实现工具调用的最关键的技术。它解决的核心问题就是:如何让大语言模型"理解"并调用外部函数?
大语言模型本质上是文本处理器,它无法直接"看懂"Python函数。因此需要一个"翻译官"将人类编写的函数转换为模型能理解的格式。这个"翻译官"就是 JSON Schema。Function Calling 三步骤流程:

而大模型主要通过 JSON Schema 中的 description 字段来理解函数的用途和调用时机!
让我们通过一个具体例子来看这个转换过程:
# 步骤1:定义普通的Python函数
def get_weather(city: str, date: str = "today") -> str:
"""
获取指定城市的天气信息
Args:
city: 城市名称,如北京、上海
date: 日期,默认为today,也可以是tomorrow
Returns:
天气信息的文字描述
"""
# 模拟天气查询逻辑
weather_data = {
"北京": {"today": "晴天,15-25°C", "tomorrow": "多云,10-20°C"},
"上海": {"today": "小雨,18-22°C", "tomorrow": "晴天,20-28°C"},
"深圳": {"today": "晴天,25-30°C", "tomorrow": "雷阵雨,22-27°C"}
}
return weather_data.get(city, {}).get(date, "暂无该城市天气信息")
# 测试函数
print("测试普通函数调用:")
print(f"北京今天天气:{get_weather('北京', 'today')}")
print(f"上海明天天气:{get_weather('上海', 'tomorrow')}")
接下来,需要将函数转换为JSON Schema(也就是做成大模型的"说明书")。
import json
# 这就是大模型看到的函数描述!
weather_function_schema = {
"name": "get_weather",
"description": "获取指定城市的天气信息。",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,如北京、上海"
},
"date": {
"type": "string",
"description": "日期,默认为today,也可以是tomorrow",
"enum": ["today", "tomorrow"],
"default": "today"
}
},
"required": ["city"]
}
}
print("大模型看到的函数Schema:")
print(json.dumps(weather_function_schema, ensure_ascii=False, indent=2))
Description 是大模型的"理解密码"
-
函数触发条件:大模型通过
description判断什么时候调用这个函数- 糟糕的描述:
"get weather" - 良好的描述:
"获取指定城市的天气信息。当用户询问天气、气温、下雨等相关问题时使用此函数"
- 糟糕的描述:
-
参数理解:每个参数的
description告诉模型如何填充参数值- 模型看到用户问:"北京明天下雨吗?"
- 通过
city.description识别出 "北京" →city参数 - 通过
date.description识别出 "明天" →date: "tomorrow"
接下来模拟大模型的真实理解与调用过程:
def simulate_llm_function_calling(user_query: str, available_functions: dict):
"""
模拟完整的 Function Calling 流程,包括 Function Response 处理
"""
print(f"用户输入: '{user_query}'")
print(f"LLM第一轮分析:")
# 阶段1: LLM分析用户意图并决定是否调用函数
print(f" 分析用户意图...")
print(f" 扫描可用函数库...")
for func_name, func_schema in available_functions.items():
description = func_schema["description"]
print(f" • {func_name}: {description}")
# 阶段2: LLM决定调用函数并生成Function Call
if "天气" in user_query or "下雨" in user_query or "气温" in user_query:
print(f" 匹配到函数: get_weather")
print(f" 提取参数...")
# 提取城市
cities = ["北京", "上海", "深圳", "广州"]
city = None
for c in cities:
if c in user_query:
city = c
break
# 提取日期
if "明天" in user_query or "tomorrow" in user_query:
date = "tomorrow"
else:
date = "today"
print(f" 城市: {city}")
print(f" 日期: {date}")
if city:
# 阶段3: LLM生成Function Call
function_call = {
"name": "get_weather",
"arguments": {"city": city, "date": date}
}
print(f" LLM输出Function Call: {function_call}")
print()
# 阶段4: 系统执行函数并返回Function Response
print(f"系统执行函数:")
print(f" 调用 get_weather(city='{city}', date='{date}')")
function_response = get_weather(city, date)
print(f" Function Response: '{function_response}'")
print()
# 阶段5: LLM处理Function Response并生成最终回答
print(f"LLM第二轮处理:")
print(f" 接收Function Response: '{function_response}'")
print(f" 基于响应结果生成用户友好的回答...")
# 模拟LLM对响应的处理和润色
final_answer = f"根据查询结果,{city}{'今天' if date=='today' else '明天'}的天气情况是:{function_response}"
if "晴天" in function_response:
final_answer += " 天气不错,适合外出活动!"
elif "雨" in function_response:
final_answer += " 记得带伞哦!"
print(f" 生成最终回答: {final_answer}")
return final_answer
else:
print(f" 参数提取失败:未识别到有效城市")
return "抱歉,我无法识别您要查询的城市,请提供具体的城市名称。"
else:
print(f" 未匹配到合适的函数")
return "我目前只能查询天气信息,请尝试询问某个城市的天气情况。"
# 演示不同的用户输入
test_queries = [
"北京今天天气怎么样?",
"上海明天会下雨吗?",
"深圳的气温如何?",
"你好,请问现在几点了?" # 这个不会触发天气函数
]
available_functions = {
"get_weather": weather_function_schema
}
print("Function Calling 完整流程演示:")
print("=" * 60)
for query in test_queries:
result = simulate_llm_function_calling(query, available_functions)
print(f"{result}")
print("-" * 60)
Function Calling 的成功关键在于设计出"大模型友好"的 JSON Schema,特别是精心编写的 description 字段!
- MCP 的实现
而随着AI Agent生态的发展,涌现了一些标准和框架来统一工具接口,MCP(Model Context Protocol)就是目前最流行的工具接口标准。MCP由Anthropic提出,本质上是一个“模型-工具交互的标准协议”。可以将它类比为AI世界的USB-C接口:不同的Agent和不同的工具只要都支持MCP协议,就能即插即用地互相连接,而不需要针对每种新工具各写一套适配代码。这大大降低了集成海量工具的复杂度——在没有MCP时,每新增一个工具可能要单独集成,Agent数量和工具数量增加会导致接入工作爆炸式**增加;而采用MCP标准后,新工具和Agent通过统一接口对接,扩展的代价仅线性增长。
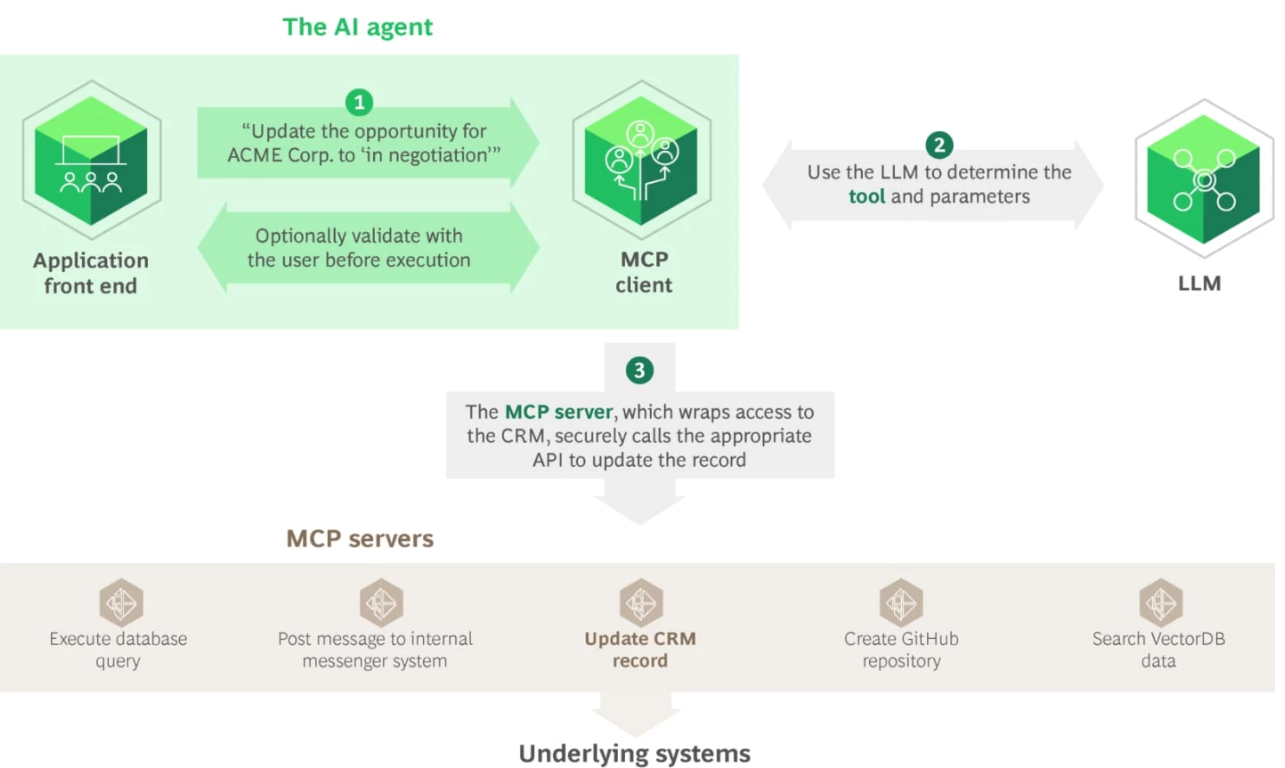
2.3 长短期记忆能力
当人类与AI Agent连续对话时,我们希望助手记得之前说过的话和提供的信息。同样,AI Agent若只有短期记忆(依赖LLM的上下文窗口),在跨越多轮对话或长时间后就会“失忆”。记忆模块(Memory)的引入正是为了解决LLM上下文窗口有限的问题,为Agent提供长期、一致的记忆能力。
我们可以将Agent的记忆分为两类:
-
短期记忆(Working Memory):维护当前对话或当前任务的上下文。它类似于人脑的工作记忆,容量有限但能记录最近的信息。例如,在一场对话中,短期记忆保存了用户刚才问过的问题、Agent自身已经采取的步骤等,以便后续回答保持连贯。在实现上,短期记忆通常是通过在Prompt中附加最近对话记录或摘要来实现(例如LangChain的ConversationBufferMemory会存储最近几轮对话并注入Prompt)。
-
长期记忆(Long-Term Memory):保存跨会话、跨任务、长时间的重要信息。这类似于人类的大脑长期记忆,可以跨天、跨周甚至更久地记住事实。对AI Agent而言,长期记忆可能包括:用户的偏好和背景知识、过去完成的任务结果、历史对话中提到的重要事实等。有了长期记忆,Agent就能“认识”老朋友和延续之前的谈话,而不会每次都从零开始
当前最常用的方案是结合向量数据库(Vector DB)来实现知识的存储与检索。核心思路是:把对话内容、重要事实等转化为向量嵌入并存入数据库,当需要记忆时,通过语义相似度检索找到相关记忆片段注入模型输入。这样Agent就能在需要时回忆起过去相关的信息。例如,用户曾告诉助理自己生日,那么以后再聊生日话题时,Agent可以通过检索记忆库找回用户的生日信息.
典型的就是 Google ADK 项目:
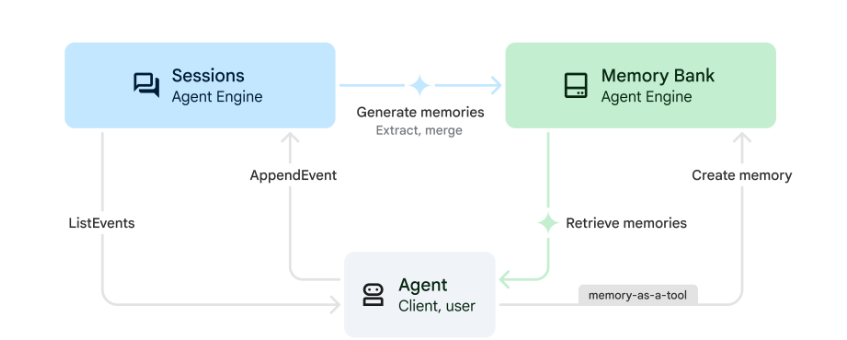
LangGraph 的实现:
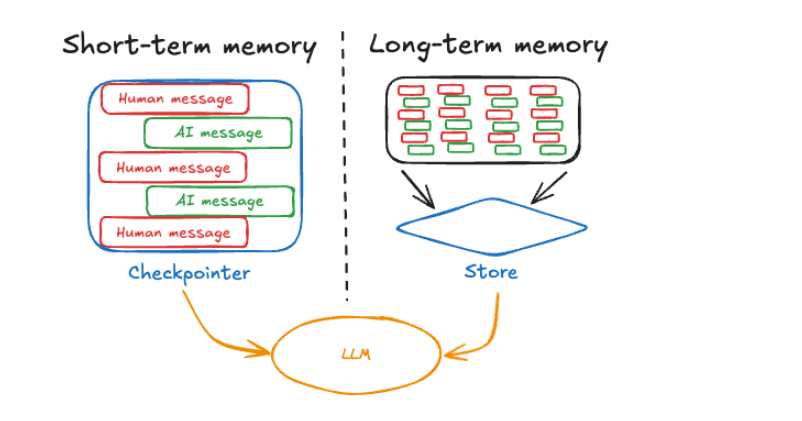
此外,提到长期记忆,不得不说比较热门的Mem0项目。Mem0被称为“AI应用的通用自改进记忆层”。它提供了一套用于Agent持久记忆的体系,包括动态提取、合并、检索关键信息,并可选用图数据库存储复杂关系。实验表明,使用Mem0的Agent在长对话问答等任务上准确率有显著提升,且大幅降低了延迟和token成本。
简单来说,Mem0通过更聪明的记忆管理(比如智能过滤不重要信息、定期淡忘过时内容、短期记忆与长期记忆动态转存等),让Agent真正做到持续学习,而不仅仅依赖一次性的上下文。 https://github.com/mem0ai/mem0

上下文工程包含许多技巧,例如:分层摘要(逐段总结以减少信息量但保留关键点)、工具输出压缩(去掉日志等冗余,只保留结果要点)、意图提炼(保留决策结论,省略冗长的推理过程)等。同时,定义结构化的Agent状态也很重要——相比无结构地把一长串对话当作上下文,一些框架让Agent维护结构化的状态对象(比如包含当前任务、已用工具、记忆摘要等字段)。这样Agent每轮只需要将状态里必要部分拼成Prompt,而非全部原始。通过精细的上下文管理,Agent能在有限窗口内实现更复杂的决策而不遗忘关键信息。
总之,记忆模块和上下文工程共同保障了Agent的状态保持和信息调度能力,让Agent不但能想到下一步怎么做,还能记住“过去发生了什么”和“目前应该关注什么”。随着对长期记忆和上下文管理研究的深入,我们离让AI Agent拥有类似人类连续对话的记忆力又更近了一步。
三、多智能体系统架构的设计模式
现实世界中,许多复杂任务需要团队合作才能完成。类似地,我们可以让多个AI Agent各司其职,协同解决问题。这就是**多智能体系统(MAS, Multi-Agent System)**架构。在这种架构下,不同Agent可以有不同专长或角色,通过通信与协作来完成单个Agent无法胜任的复杂任务。
多智能体系统有多种设计模式,以下介绍主要的几种:
3.1 模式一:主管-专家(Orchestrator-Experts)架构
这种模式下,引入一个主管Agent(也称路由器或仲裁者)来统筹全局。主管Agent的职责是:接收用户的请求后,根据请求内容将任务分派给合适的专长Agent,或在不同专长Agent之间切换。每个专家Agent负责一个子领域的任务,有各自独立的提示和工具集。例如在一个企业助理系统中,可能有"客户支持Agent"(会查知识库、处理退换货)、"数据分析Agent"(会写SQL、做数据摘要)等专能代理,而由一个高层的主管Agent决定用户的问题应交由谁处理。
这种架构类似现实中客服中心的分工:先有前台判断你的诉求需要哪个部门,然后转接到相应专家处理。其优点是模块化强:每个子Agent可以独立开发、独立维护,彼此通过标准接口通信。而且可以水平扩展出很多专家以覆盖不同领域。当一个用户请求涉及跨领域,主管Agent还能协调多个Agent按顺序合作(例如先由数据库查询Agent获取数据,再交由报告生成Agent撰写报告)。
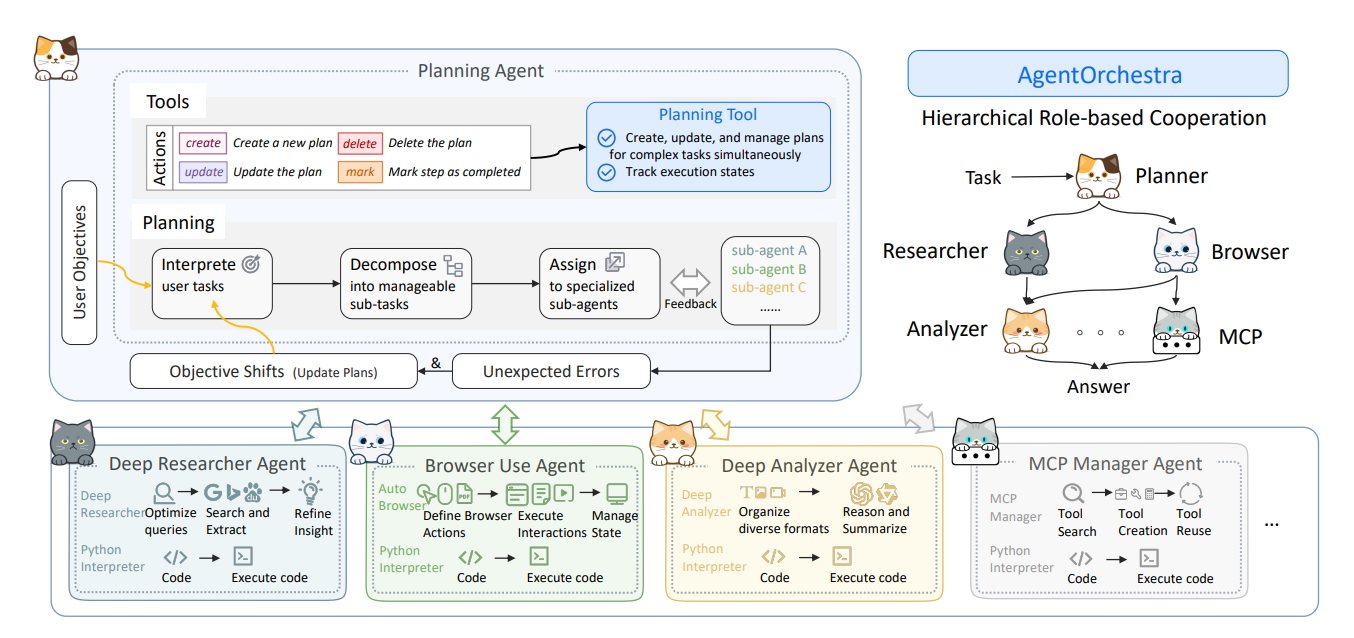
-
顶层 Planning Agent = Orchestrator,这里的 Planning Agent 就是“主管/调度者”。这相当于项目经理或调度员,掌握任务全局视图,负责分解、调度、监督。主要职责包括:
- 解释用户目标(Interpret user tasks):理解输入的任务需求。
- 分解任务(Decompose into sub-tasks):把复杂目标拆成可管理的子任务。
- 分派任务(Assign to sub-agents):把子任务交给不同的专家智能体处理。
- 监控反馈和计划更新:根据子Agent返回的结果,判断是否需要修改计划(Objective Shifts)或重新规划以处理异常。
-
底层 各类 Sub-Agents = Experts,图中列出 Deep Researcher、Browser Use、Deep Analyzer、MCP Manager 等专家 Agent。每个专家都有自己的专业技能:
- Researcher:优化查询、搜索资料、提炼洞见。
- Browser:自动浏览网页、执行点击和交互。
- Analyzer:对收集到的数据进行整合、推理和总结。
- MCP Manager:通过 MCP 协议管理外部工具的调用(创建、复用)。
这些 Agent 可以独立执行子任务,并通过反馈管道返回结果给 Planner。
然而,主管-专家模式的挑战在于:需要设计合理的任务路由策略,否则可能出现要么任务分配不当,要么多个Agent之间来回踢皮球、效率低下。为此,可引入一些措施:例如为每个Agent打标签标注其能力范围,主管Agent做意图分类来选择Agent;在多Agent协作中共享部分记忆或黑板,以避免信息割裂;设置超时和轮次数限制来防止两个Agent之间无限推诿等。
总体而言,Orchestrator-Experts模式适合企业应用,因为企业通常本身就有模块化的职能划分,可以自然映射到多个Agent上。此外,这种模式下每个Agent不用面面俱到,只需专注自己的领域,提示和工具都更精简,有助于提高准确性。
目前典型的具备Orchestrator-Experts模式的框架/项目有:
| 框架 /项目 | 具备 Orchestrator-Experts 模式 /怎样实现 |
|---|---|
| CrewAI | CrewAI 中 “Crew” 的设计就类似 Orchestrator-Experts 架构:一个 Crew(Orchestrator)管理多个 Agent(Experts),按角色分工(不同 Agent 负责不同子任务)并协调它们的执行。它支持顺序或分层流程模式,其中分层模式里 manager Agent 会分配任务给下属 Agent 并负责校验结果。这正是典型的主管-专家模式。 |
| AutoGen | 在多 Agent 协作中,也有 Orchestrator 类型的 Agent,用于管理任务分配、协调多个子 Agent 或工具。比如 AutoGen 的设计允许一个 Agent 作为调度/分派角色,其余作为执行或工具调用角色。这个角色分工与 Orchestrator-Expert 的思路相似。 |
| LangGraph | 虽然不是所有用例都严格 Orchestrator-Experts,但 LangGraph 支持图/状态机/工作流式的 Task Decomposition(任务拆解)与子 Agent/步骤机制。这可以组合出 Orchestrator + 专家 Agent 的流程。 |
3.2 模式二:多Agent协作(角色扮演团队)
另一种模式是让多个Agent以平等合作的方式直接交流,共同完成任务。这有点类似"脑暴会议",或者是在模拟一个团队不同角色各抒己见、互相配合。Andrew Ng将其称为"多智能体协作"设计模式,并举了写软件的例子:给定一个复杂的软件需求,不如让一组Agent分别扮演产品经理、设计师、程序员、测试工程师等角色,各自完成功能,然后交付给下一个角色检查或完善。最终这些Agent像一个虚拟的软件团队一样产出成品。这种方法在实践中效果相当惊人:研究发现多Agent分工合作往往比单Agent包办性能更好,因为每个Agent聚焦于自己擅长的子任务,从而整体上完成度更高。
一个实际案例就是ChatDev和MetaGPT项目。它们模拟了一家软件初创公司的工作流程:由产品经理Agent分析需求写PRD,架构师Agent设计架构,工程师Agent编写代码,测试Agent审查和改bug,最后交付软件。整个过程中,各Agent按照标准的SOP(Standard Operating Procedure,标准作业流程)沟通协作,有条不紊地把一个模糊需求变成了有源码、有文档的成品。MetaGPT框架正是支持这种多Agent流水线协作的开源项目,它将人类的软件开发流程知识注入Agent协作中,让每个Agent明确自己的职责范围和交付物,再通过消息协议交流。这样的多Agent系统被证明能够解决比单Agent更复杂的问题,并提高开发效率。

多Agent协作的另一个简单形式是"双Agent对话"。比如Camel方法让两个Agent一个扮演"用户"提出需求,另一个扮演"助手"来解答,两者通过对话不断澄清和细化问题,最后产生解决方案。这种角色扮演实际上利用了两个LLM彼此启发的机制,往往能碰撞出比单独思考更丰富的结果。此外,还有一种"对抗辩论"式的模式:让两个Agent一个提出方案,另一个充当审查者或挑错者,双方辩论直到收敛出高质量答案。这类似"双人检查",可以提高结果可靠性。
采用多Agent协作时,要注意沟通协议和共享知识的问题。如果Agent之间语言不通或信息不同步,可能各说各话,反而降低效率。为此,可以:约定统一的对话格式或通信协议,或者引入中央共享的记忆(例如所有Agent连到同一个Mem0长程记忆库)以同步关键信息。实际应用中,有时候会结合主管模式,即既有多个角色Agent,也有一个监督Agent来总结/协调(类似小组里推选的主持人)。
典型的技术框架:AutoGen、Google ADK 和 OpenAI Agents SDK。
3.3 模式三:竞争与博弈(对抗式、多Agent博弈)
除了上面以合作为主的模式,也有一些设计让Agent之间进行竞争或博弈,从而激发更优的结果。比如AI安全领域常用的红队/蓝队模式:一个Agent充当蓝队提供回答,另一个Agent作为红队寻找回答中的漏洞、偏见或错误。这有点像AlphaGo的自我对弈,用AI攻击AI,从而逼迫其改进。OpenAI的教材中也提到可以通过多Agent辩论来探究事实,两个Agent分别站在正反两方辩论一个问题,评审机制选择更有说服力的一方作为输出。
这类模式目前多用于研究或提升模型稳健性,实际产品中较少见。但它给我们启示:适度的内部竞争或多视角审查,可以提高Agent系统的可靠性和质量。例如,将协作和对抗结合:三个Agent,一个提方案,一个检查漏洞,第三个综合决策。这些都是多智能体可能的架构。
四、热门AI Agent开发框架盘点
构建一个功能完备的AI Agent涉及整合LLM、工具、记忆等诸多要素。幸运的是,社区和企业已经打造了许多Agent开发框架/库,大大简化了开发难度。下面我们介绍几类主流的框架,从低代码平台到灵活编程库乃至底层协议,帮助开发者以不同深度和方式构建AI Agent。
4.1 面向快速开发的低/无代码平台
如果你不熟悉编程或者希望快速搭建一个Agent原型,可以考虑一些低代码甚至无代码的平台。例如:
-
LangChain Hub / Langfuse:LangChain除了作为Python库,也有一些配套的可视化或模板工具。例如LangChain Hub提供了社区分享的Agent链模板;而LangFlow等第三方开源项目提供了拖拽界面,让你可以拼装LLM、Memory、Tool模块,设置好参数后生成一个Agent应用。这样即使不写代码,也能以配置方式组装出常见的Agent流程(类似搭积木)。
-
Dify/Coze/n8n:以Dify为代表的产品提供一个完全托管的Agent平台,用户只需通过自然语言或简单配置来描述需求,平台内部已经封装了规划、记忆、工具集成等全部逻辑。可以让非程序员也构建如"帮我管理日程并自动发送邮件"这样的Agent。这些平台本质上是把前沿Agent技术包装成了易用的SaaS。
-
商业RPA + LLM解决方案:传统RPA厂商也在集成LLM能力,推出所谓"智能流程自动化"工具。比如UiPath、Automation Anywhere等的AI插件,让业务流程中可以插入一个LLM判断节点或执行步骤。虽然不完全是Agent框架,但对于面向特定业务流程的自动化,这是低代码实现AI Agent的一种途径。
低/无代码的方案适合快速原型和非技术团队使用,但灵活性受限:复杂定制需求往往还是需要写代码或脚本来实现。因此对于开发者而言,更常用的是下一类代码级的Agent框架库。
4.2 开发者友好的Agent代码框架
这一类是为程序员准备的,用代码来构建和控制Agent逻辑的框架/库。它们提供了各种模块的Python或JS实现,开发者可以嵌入自己的业务代码,打造高度定制的Agent。主要有:
-
LangChain(Python/JS):提到Agent开发就不得不提LangChain。它是目前生态最丰富的开源库之一。LangChain提供了标准化的接口来连接LLM模型、Memory、各种Tool以及多步Chain。开发者可以用它几乎零起步地接入OpenAI/Anthropic等模型,用一行代码加载现成的工具(比如Google搜索API、Python REPL等),并选择不同的Agent决策逻辑(例如有内置的ReAct Agent、Conversational Agent等)。LangChain的优点在于组件齐全(向量库、工具、提示模板应有尽有)和社区活跃,有大量样例。但也有反馈指出LangChain用起来会出现层次复杂、调试困难的问题。特别是默认Agent的prompt较黑箱,新手可能摸不清Agent为何这样决策。不过凭借强大的生态,LangChain依然是当前最受欢迎的Agent开发库之一。
-
Semantic Kernel(C# / Python):微软推出的Semantic Kernel是一个针对企业应用的Agent框架。它强调与现有软件系统的集成,可将LLM嵌入到.NET等后台应用中。Semantic Kernel提供了Planner(规划器)和技能插件机制,开发者可以编写自己的函数作为Agent的技能,然后通过Kernel来让LLM调用这些函数完成任务。它适合有严格IT环境要求的场景,比如需要在本地运行、并发管理、安全审计等。相对来说社区资源不如LangChain多,但是如果你的技术栈在C#或Java上,Semantic Kernel是一个重要选择。
-
CrewAI / AutoGen / LangGraph等多Agent框架:随着多智能体需求增加,也出现了一些帮助构建多Agent系统的库。例如AutoGen(微软亚洲研究院开源)提供了让多个Agent基于对话进行协同的封装;AgentVerse框架支持多Agent的任务求解模式和模拟仿真模式,便于编排一组Agent的交互;LangGraph则是LangChain的一个扩展项目,提供了用状态机方式来组织复杂Agent流程,支持多Agent场景下的交互和同步。这些框架还在早期,但反映了多Agent系统的开发需求,适合愿意尝试前沿的开发者。
-
Google ADK 和 OpenAI Agents SDK:新一代的 Agent 开发框架越来越注重性能和可扩展性。Google ADK(Agent Development Kit)在设计上强调模块化和多 Agent 协作编排,支持异步执行、事件驱动和高并发场景,适合在生产环境中承载复杂工作流。OpenAI 的 Agents SDK 则简化了工具接入与上下文管理,使得构建“能调用工具、能记忆、能多步推理”的高性能 Agent 更加直接。这类框架通常提供流式输出、增量上下文管理和轻量级状态存储,能显著降低响应延迟并提高吞吐量
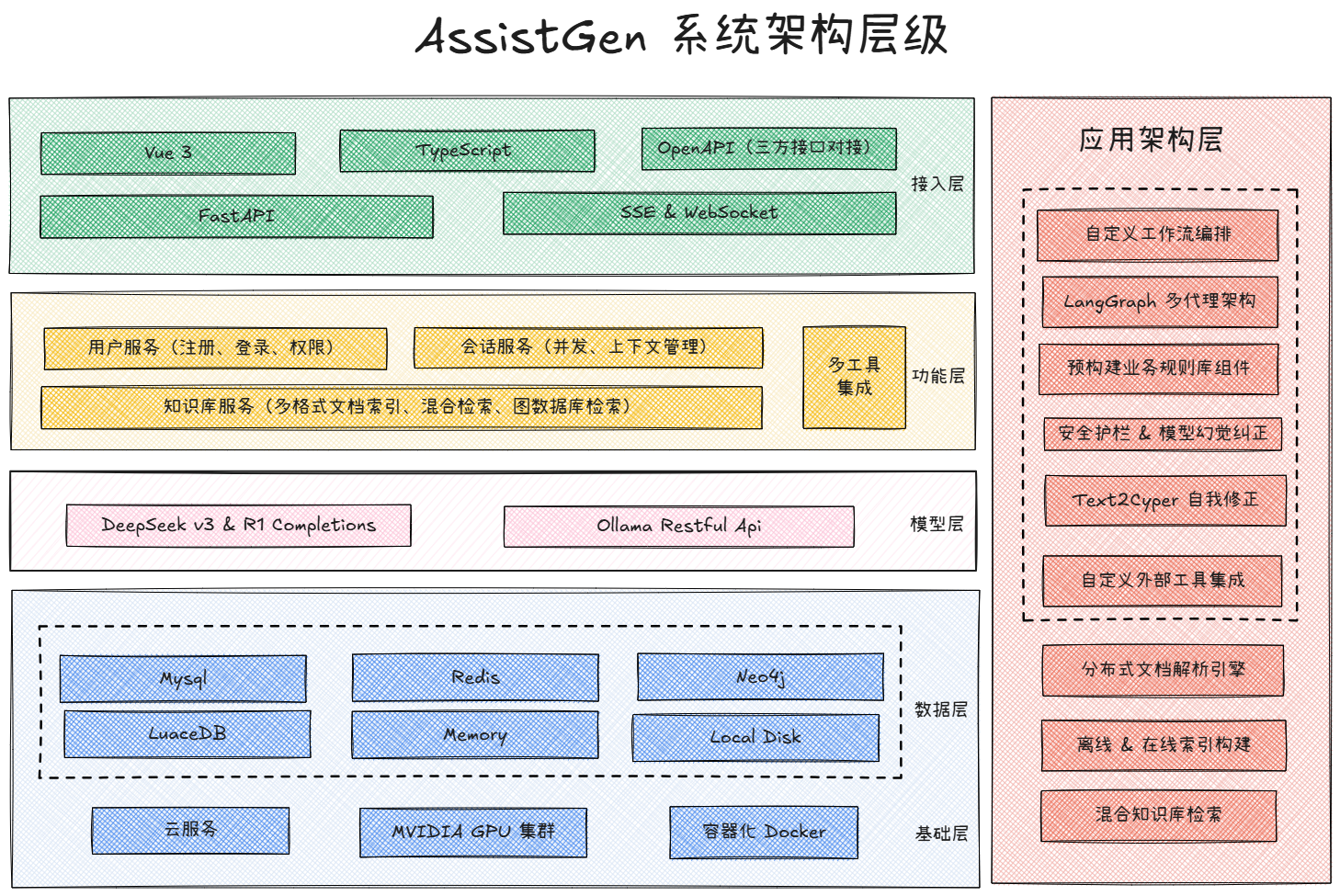
比如在智能客服领域,我们课程中的项目架构设计如下:
总的来说,这类代码框架面向开发者,自由度高。你可以深入定制Agent的每个细节(Prompt怎么写、Memory用什么数据库、Tools如何实现等等),也可以选择高度抽象的封装(如LangChain的高层接口)。对于追求敏捷开发的团队,可以先用这些框架里的现成模块迅速做出原型;然后再根据需要逐步替换或优化内部实现。正如有人总结的:Agent框架提供的是脚手架——它们加速了开发,但最终的精细打磨和责任仍在开发者自己手中。