【视频课件】MicroSoft AutoGen 基础入门与开发实战
公开课内容节选自《大模型与Agent开发》完整版付费课程!
公开课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《大模型与Agent开发实战课》 :

《大模型与Agent开发实战课》 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
公开课直播特惠,全年最低价!低至 5 折 !扫码咨询课程信息哦👇

MicroSoft AutoGen 基础入门

1. AutoGen 框架介绍
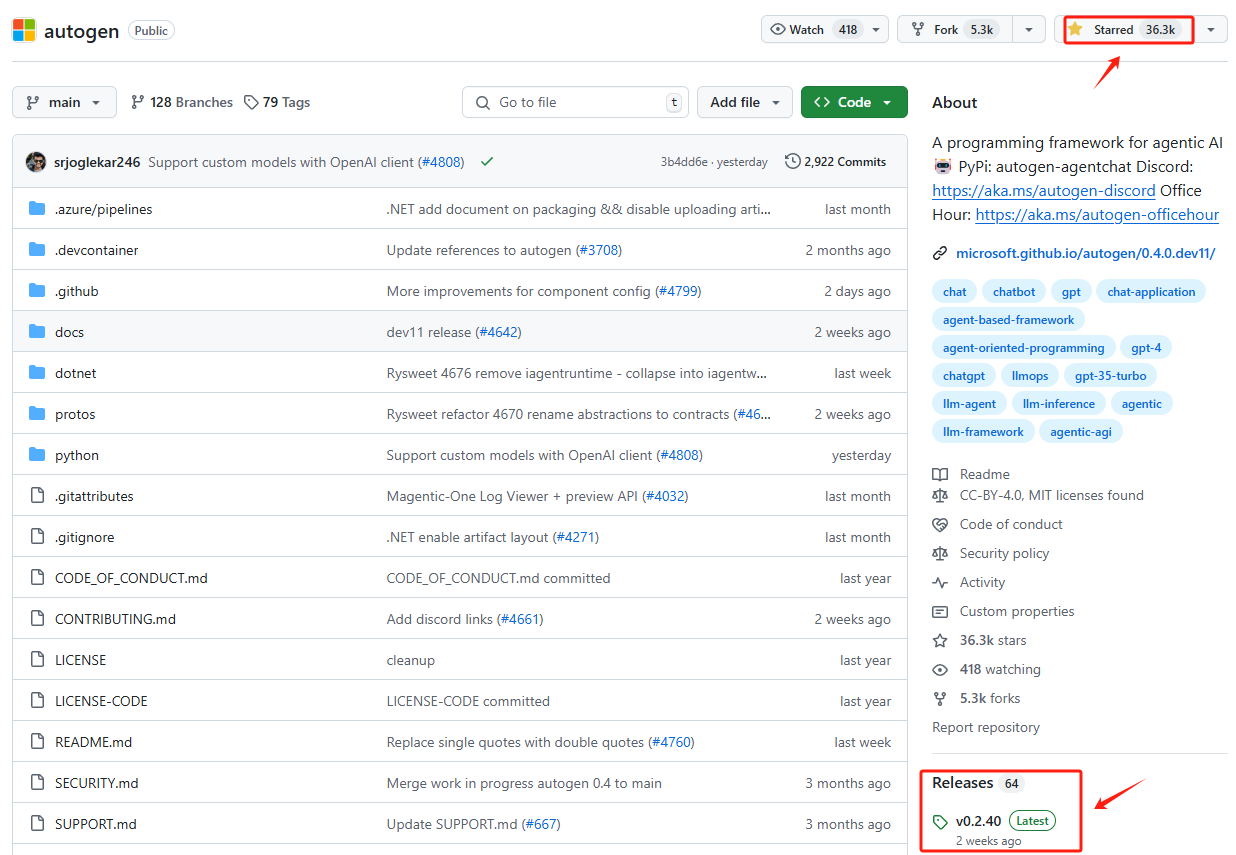
AutoGen 是 Microsoft 在大模型技术领域推出的开创性 AI Agent 开发框架,也是目前最受欢迎的AI Agent开发工具之一。自 2023 年 10 月发布以来,AutoGen 凭借其前沿的技术迭代目前在 GitHub 上已累计获得超过 36.3k 次的星标,同时截至2024年12月28日,AutoGen开源的最新版本是0.2.40,期间已经迭代了64个小版本,具有非常广泛的用户关注度和社区活跃度。如下图所示:
AutoGen 框架的一大特色是支持创建对话式应用。也就是说它构建多代理的方式是使多个智能体能够相互交流,从而促进不同智能体之间的合作以完成最终的任务。简单的理解就是这个框架可以让不同的Agent建立起通信的连接,然后它提供给开发者的使用方式是,其一可以为每个Agent自定义大模型、角色、工具及行为,其二可以创建不同的对话模式,包括一问一答、联合聊天、分层聊天等等,从而实现高度个性化的应用场景设计。如下图所示:
MicroSoft AutoGen Docs:https://microsoft.github.io/autogen/0.2/docs/Getting-Started
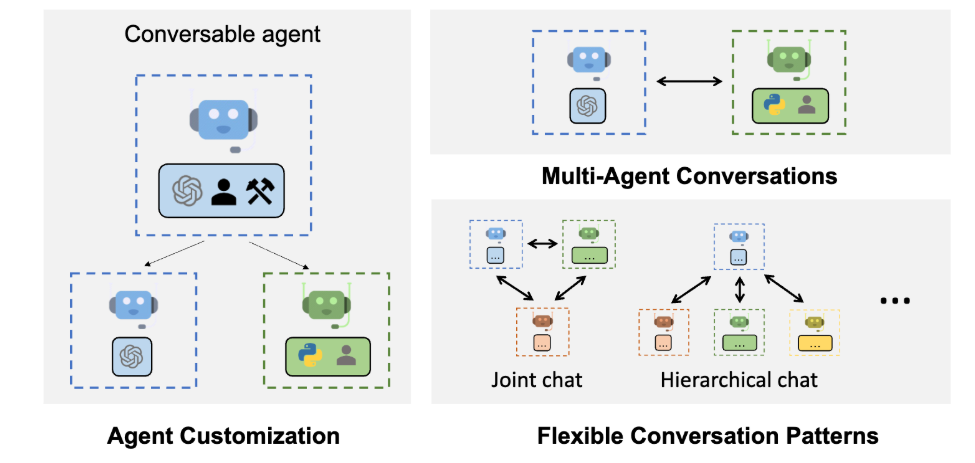
- Agent Customization
AutoGen支持开发者根据特定需求定制代理(Agent)。这种定制化允许开发者定义代理的行为、响应方式和功能,使其适应不同的应用场景。例如,我们可以创建自定义代理来执行特定的算术操作或其他任务。此外,AutoGen 还允许集成自定义的大模型,进一步增强代理的能力。
- Multi-Agent Conversations
AutoGen 支持多代理对话(Multi-Agent Conversations)。在 AutoGen 中,多个代理(Agents)可以通过对话相互交流,协作完成复杂任务。这些代理可以由大语言模型(LLMs)、人类输入或工具驱动,具备可定制和可对话的特性。
- Flexible Conversation Patterns
AutoGen 支持灵活的对话模式(Flexible Conversation Patterns),允许开发者根据应用需求设计多种代理交互方式。比如联合聊天(Joint Chat),在这种模式下,多个代理共同参与同一个对话线程,所有代理共享相同的上下文。而层次化聊天(Hierarchical Chat) 这种模式涉及将一个工作流封装为单个代理,以便在更大的工作流中重复使用。除此以外,像最基本的对话形式(Two-Agent Chat)用来构建两个代理之间的交流,顺序对话(Sequential Chat)通过上下文传递将前一次对话的摘要带入下一次对话等等多样化的对话模式,能够覆盖绝大部分的应用需求。
基于上述提到的这些功能和模式,AutoGen的开源仓库中提供了非常多如MathChat、文本分析等应用模板,可以在我们的项目中自由修改和部署,这也是它非常受欢迎的一个主要原因。
AutoGen框架的第二大优势,则是与其他AI Agent开发框架(如 LangChain、LangGraph)、RAG 以及函数调用等功能集成在一起,所以我们可以非常方便的通过额外的知识源去增强基于大模型的代理能力,从而使基于AutoGen构建的智能体可以解决相对复杂的问题和更多元化的应用场景。
在基本了解了 AutoGen 框架的核心特点后,接下来我们就尝试在本地的 Python 环境中实践,利用该框架构建一个实际的 AI Agent 应用程序。在学习框架使用方法的同时,也能直观体验最终应用的效果。
2. 安装AutoGen开发环境
如果使用 Microsoft AutoGen 进行AI Agent的开发,首先需要配置一个本地 Python 环境。MicroSoft 的官方要求是 Python 版本 >= 3.8并且< 3.13 ,我们建议建议 Python 版本 >= 3.10。为了方便管理项目依赖和隔离开发环境,我们这里使用 Anaconda3 作为环境管理工具。当然,大家也可以选择使用 Pycharm 或者 Vscode 工具。
- Step 1. 安装Anaconda 3
Anaconda3 官网:https://www.anaconda.com/ (注意:如果遇到安装问题,可以添加下面的二维码免费领取详细的安装教程)
- Step 2. 使用conda创建虚拟环境
首先打开Anaconda3的Anaconda Prompt,位置如下:
为AutoGen项目创建一个新的虚拟环境。使用conda安装项目依赖时,最好先创建一个虚拟环境,可以将项目的依赖与系统中的其他Python项目隔离开来。不同的Python项目可能需要同一库的不同版本。在虚拟环境中工作可以防止版本冲突。在 Conda 中创建虚拟环境的步骤相对简单。以下是创建虚拟环境的基本步骤:
首先,使用以下命令创建一个新的虚拟环境,其中 myenv 是给环境起的名字,python=3.11 指定该虚拟环境下使用的Python的版本,如果不指定Python版本,Conda将使用默认的Python版本创建环境。
FENCE0
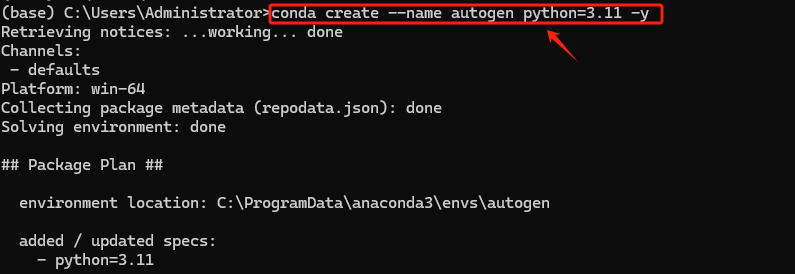
创建环境后,需要激活它才能开始使用。在 Windows 上,使用:
FENCE0
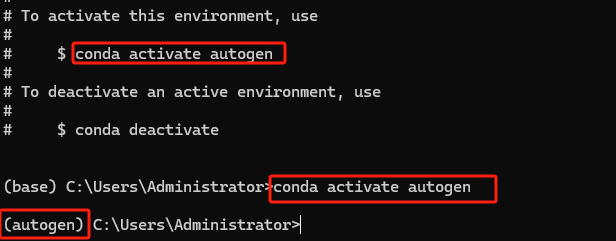
然后在激活的环境中,运行以下命令安装 Jupyter 和 ipykernel,命令如下:
FENCE0
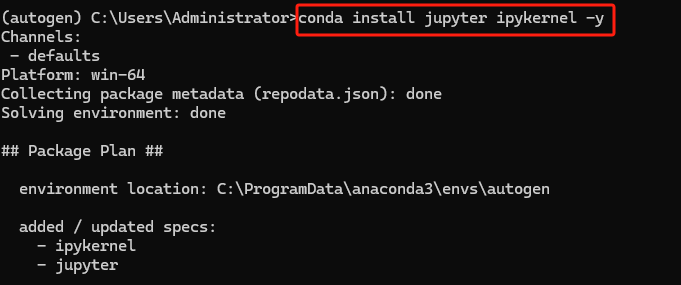
接下来将当前环境注册为 Jupyter 的内核,执行如下命令:
FENCE0

最后,启动 Jupyter Notebook 或 Lab, 在 命令提示符(CMD)中输入如下命令:
FENCE0
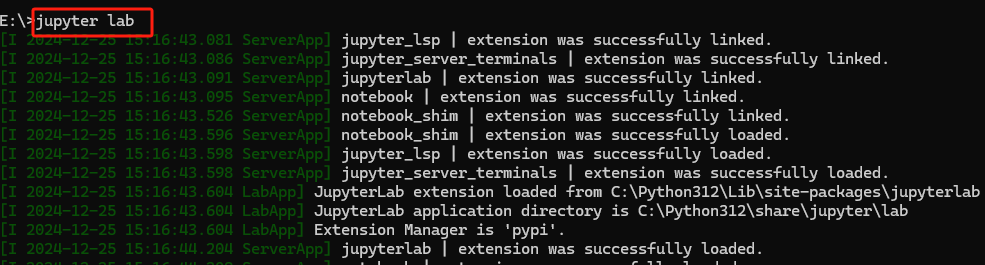
在 Jupyter Lab 前端中,创建一个新 Notebook,在右上角选择内核,确保显示 "Python 3.11 (autogen)"。
3. 安装AutoGen依赖
在准备好本地的Python运行环境后,使用 AutoGen 需要安装其相关的依赖包,其中包括 autogen-agentchat。这是 AutoGen 的核心组件之一,用于实现多代理协作和对话功能。根据 AutoGen 的当前版本信息,推荐安装的版本范围是 autogen-agentchat~=0.2。我们可以在当前的环境下执行如下命令:
# ! pip install autogen-agentchat~=0.2
4. 配置大模型代理
在 AutoGen 框架中,代理(Agent)可以由多种组件驱动,主要包括:
- 大语言模型(LLMs):例如
GPT-4、GLM 4等,用于自然语言处理和生成。 - 人类输入:代理可以接受人类的直接输入,进行交互或获取指令。
- 代码执行器:如 IPython 内核,允许代理执行代码,实现动态计算和任务处理。
- 其他可插拔和可定制的组件:根据具体需求,代理可以集成其他工具或功能模块,以扩展其能力。
这四种不同类型的代理之间能够进行对话交互,而 AutoGen做的事情就是提供多种不同的实现方法来支持这些交互。其中,我们需要优先学习和掌握的,是AutoGen框架内置的 ConversableAgent。该类作为一个基础的代理类,提供了非常灵活的接口,允许我们根据具体需求启用或禁用特定功能,并进行相应的配置。除此以外,AssistantAgent 和 UserProxyAgent 都是 ConversableAgent 的子类,分别用于执行任务处理、调用 API 和逻辑推理,以及模拟用户输入和执行代码等,我们将在后续的课程中再逐步的展开介绍。
AutoGen ConversableAgent:https://microsoft.github.io/autogen/0.2/docs/tutorial/introduction
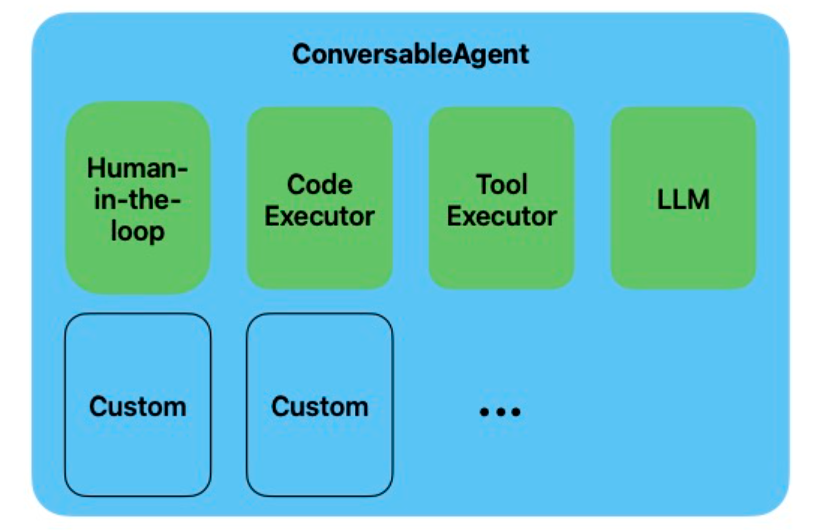
我们首先来进行实践:在大模型驱动下的ConversableAgent应该如何进行自然语言对话。
AutoGen 框架支持以下三种类型的大模型接入,分别是:
- OpenAI 模型:如
gpt-3.5-turbo、gpt-4等。 - Azure OpenAI 模型:通过
Azure平台提供的OpenAI服务。 - 其他兼容 OpenAI API 的模型:如
Anthropic的Claude系列模型,Ollama接入的本地开源大模型。
AutoGen LLM Configuration:https://microsoft.github.io/autogen/0.2/docs/topics/llm_configuration/

我们先通过OpenAI的GPT模型测试接入AutoGen的流程,首先,确保在本地的Python环境中可以正常访问到GPT模型。注意:在本地Python环境调用需要具备两个条件:1.一个有效的OpenAI API_Key。2. 魔法上网环境。
领取OpenAI GPT模型的注册及使用教程,可以扫码领取详细的课件资料哦👇
在准备好OpenAI API_Key后,在当前环境下先测试能否顺利调用OpenAI GPT大模型,测试代码如下:
! pip install openai
接下来需要通过如下命令将OpenAI API_Keys设置在Windows系统的环境变量中。
! setx OPENAI_API_KEY "your_api_key_here" # 这里替换成自己实际使用的 OpenAI API Keys
设置此环境变量的目的是为了在使用 OpenAI 的 API 时,程序能够自动读取该密钥进行身份验证。通过将 API 密钥存储在环境变量中,可以避免在代码中直接硬编码密钥,从而提高安全性和灵活性。注意:配置完成后,需要重启电脑,方可使环境变量生效。
from openai import OpenAI
client = OpenAI()
通过调用models.list()方法,可以查看到当前的API_key都可以调用哪些GPT模型。
print(client.models.list())
如果能正常返回结果,则说明当前的网络环境是正常的。接下来我们看一下如何在ConversableAgent中接入OpenAI的GPT模型进行交互。
4.1 使用在线大模型
class ConversableAgent(LLMAgent) 是通用可对话代理的类,它的核心功能是:收到每条消息后,代理将向发送者发送回复。同时,也可以直接针对用户输入的问题生成直接的响应。 使用 ConversableAgent 定义大模型实例的方式是需要借助llm_config参数来进行指定,比如如果接入的是OpenAI的GPT系列模型,代码如下图所示:
# ! pip install flaml[automl] # 不安装这个包会产生警告信息
import os
from autogen import ConversableAgent
agent = ConversableAgent(
name="chatbot",
llm_config={"config_list":
[{"model": "gpt-4o-mini",
"api_key": os.environ.get("OPENAI_API_KEY")}]},
)
config_list 允许指定不同的端点和配置 被使用。它支持OpenAI、Azure OpenAI、和其他OpenAI兼容的API端点,它是一个字典列表,其中可以指定的字段如下所示:
| 参数名称 | 类型 | 必需性 | 描述 |
|---|---|---|---|
model | str | 必需 | 要使用的模型的标识符,例如 'gpt-4','gpt-3.5-turbo'。 |
api_key | str | 可选 | 验证模型 API 端点请求所需的 API 密钥。 |
api_rate_limit | float | 可选 | 指定每秒允许的最大 API 请求数。 |
base_url | str | 可选 | API 端点的基本 URL,这是 API 调用所定向的根地址。 |
tags | List[str] | 可选 | 可用于过滤的标签。 |
如果想直接要求该代理针对输入的问题生成回复,可以使用generate_reply方法来实现。代码如下图所示:
# 调用代理生成回复
reply = agent.generate_reply(
messages=[
{
"role": "user",
"content": "你好,请你非常详细的介绍一下你自己"
}
]
)
# 打印生成的回复
print(reply)
agent.generate_reply方法会根据 messages 参数中的对话内容,调用底层模型或逻辑来生成响应。
4.2 使用开源大模型
如果大家想使用本地的开源大模型应用AutoGen框架构建Agent应用程序,因为AutoGen可以支持兼容 OpenAI API 的模型接入,因此最方便快捷的一种接入本地开源模型的方法就是使用Ollama。 该框架提供了与 OpenAI API 的兼容性,使得通过 Ollama 启动的开源模型可以与支持 OpenAI API 的应用程序进行集成。
领取Ollama本地部署详细指南,同时Ollama、vllm等框架的全体系介绍在正式课程《大模型与Agent开发实战课》 均有保姆级的讲解,想系统学习的小伙伴可以扫码咨询课程信息哦👇

这里我们使用Ollama启动的Qwen2.5:32B进行接入,我们只需要将 API 请求的主机名更改为 https://127.0.0.1:11434 , 即可通过本地运行的 Ollama 实例与这些模型进行交互。代码如下所示:
import os
from autogen import ConversableAgent
agent = ConversableAgent(
name="chatbot",
llm_config={"config_list":
[{"model": "qwen2.5:32b",
"base_url": "http://192.168.110.131:11434/v1/"}]},
)
您可以要求该代理使用以下命令生成对问题的答复 generate_reply方法:
# 调用代理生成回复
reply = agent.generate_reply(
messages=[
{
"role": "user",
"content": "你好,请你详细地介绍一下你自己",
}
]
)
# 打印生成的回复
print(reply)
可以看到:使用 AutoGen 集成 Ollama 模型时,虽然已成功接收到回复,但会出现以下警告:
FENCE0
出现此警告表示 AutoGen 未找到名为 qwen2.5:32b 的模型,因此无法计算相应的费用。如果想避免,我们可以在 config_list 中添加 price 字段,以指定每 1000 个提示(prompt)和完成(completion)标记的费用。
agent = ConversableAgent(
name="chatbot",
llm_config={
"config_list": [
{
"model": "qwen2.5:32b",
"base_url": "http://192.168.110.131:11434/v1/",
"price": [0.00, 0.00]
}
]
},
)
再次进行问答:
# 调用代理生成回复
reply = agent.generate_reply(
messages=[
{
"role": "user",
"content": "你好,请如何理解大模型",
}
]
)
# 打印生成的回复
print(reply)
从最终的回复中可以发现警告信息已经被消除。至此,我们就掌握了在AutoGen框架中如何接入在线大模型或者开源大模型。
4.3 模型配置过滤
接下来我们要考虑的是,AutoGen中的llm_config为什么要设计成一个列表?当llm_config是一个列表的时候,意味着我们定义代理的时候可以使用的多个模型。这在构建Agent的过程中非常有用,主要原因如下:
- 如果一个大模型超时或失败,代理可以尝试另一种模型。
- 有一个全局模型列表,可以根据某些键(例如名称、标签)对其进行过滤,以便将选择的大模型传递给某个代理(例如,使用更便宜的 GPT 3.5 来让代理解决更简单的任务)
- 某些专门代理具有根据当前任务选择最佳大模型的逻辑。
config_list中的工作原理是默认使用配置的第一个大模型,并针对该大模型进行调用。如果调用失败(例如 API 限制),代理将针对第二个大模型发起重试请求,依此类推,直到收到提示完成(或者如果没有大模型成功完成请求,则抛出错误)。因此,我们可以通过下面的形式进行定义:
llm_config = {
"config_list": [
{
"model": "gpt-4o-mini",
"api_key": os.environ.get("OPENAI_API_KEY"),
"tags": ["openai"]
},
{
"model": "qwen2.5:32b",
"base_url": "http://192.168.110.131:11434/v1/",
"price": [0.00, 0.00],
"tags": ["ollama"]
}
]
}
对于大模型实例的字典,我们在使用的时候可以基于某些标准来过滤该列表。如上所示,使用 tags参数来为不同的代理分配特定的大模型实例。通过在 llm_config 的 config_list 中为每个模型配置添加 tags,然后在创建代理时使用 filter_dict方法就可以进行筛选:
import autogen
# 过滤出包含 'ollama' 标签的模型配置
filter_model = {"tags": ["ollama"]}
config_model = autogen.filter_config(llm_config["config_list"], filter_model)
config_model
然后可以将config_model作为参数传递到ConversableAgent中,代码如下:
agent = ConversableAgent(
name="ollama_chatbot",
llm_config={"config_list": config_model} # 这里使用 config_model
)
reply = agent.generate_reply(messages=[{"role": "user", "content": "请问你是什么大模型",}])
print(reply)
同样也可以按照相同的方法去过滤OpenAI模型,代码如下:
import autogen
# 过滤出包含 'openai' 标签的模型配置
filter_model = {"tags": ["openai"]}
config_model = autogen.filter_config(llm_config["config_list"], filter_model)
agent = ConversableAgent(
name="openai_chatbot",
llm_config={"config_list": config_model}
)
reply = agent.generate_reply(messages=[{"content": "请问你是什么大模型", "role": "user"}])
print(reply)
掌握AutoGen框架中模型过滤的技巧非常关键,这种配置方式提供了非常便捷的灵活性,能够根据具体需求选择和定制模型。在实际应用中,合理配置 llm_config 可以实现多代理协作、自动代码生成、复杂任务处理等功能。这对于构建高效、智能的对话系统和自动化工作流具有重要意义。
5. AutoGen 实现Two-Agent Chat
在课程的开始我们已经重点强调过,AutoGen框架构建代理(Agent)的主要形式就是构建代理之间的对话/互动聊天,通过在对话过程中交换消息来推动任务的进展。 这里我们首先尝试在ConversableAgent中实现一个对话代理模式。比如在下面的示例中,我们通过设置system_message为两个代理分配不同的角色,并开启它们的聊天。
Two-Agent Chat是最简单的对话模式,目的就是让两个代理进行互相聊天。 在下面的场景中,我们使用 AutoGen 框架创建了两个 ConversableAgent 实例,分别代表相声表演中的捧哏演员和逗哏演员。
-
捧哏角色:名为“penggen”,系统消息设定为“你的名字是张三,你是相声表演中的捧哏演员,负责配合逗哏演员。”
-
逗哏角色:名为“dougen”,系统消息设定为“你的名字是李四,你是相声表演中的逗哏演员,负责引出笑点。”
每个代理都指定的是qwen2.5:32b 模型(LLM),通过这种设置,我们可以模拟相声表演中捧哏和逗哏之间的互动,研究他们的对话模式和协作方式。
import os
from autogen import ConversableAgent
# 定义捧哏角色
penggen = ConversableAgent(
name="penggen",
system_message="你的名字是张三,你是相声表演中的捧哏演员,负责配合逗哏演员。",
llm_config={
"config_list": [
{
"model": "qwen2.5:32b",
"base_url": "http://192.168.110.131:11434/v1/",
"price": [0.00, 0.00]
}
]
},
)
# 定义逗哏角色
dougen = ConversableAgent(
name="dougen",
system_message="你的名字是李四,你是相声表演中的逗哏演员,负责引出笑点。",
llm_config={
"config_list": [
{
"model": "qwen2.5:32b",
"base_url": "http://192.168.110.131:11434/v1/",
"price": [0.00, 0.00]
}
]
},
)
定义好了两个代理后(捧哏和逗哏)后,需要使用initiate_chat 方法启动两个代理(agents)之间的对话。
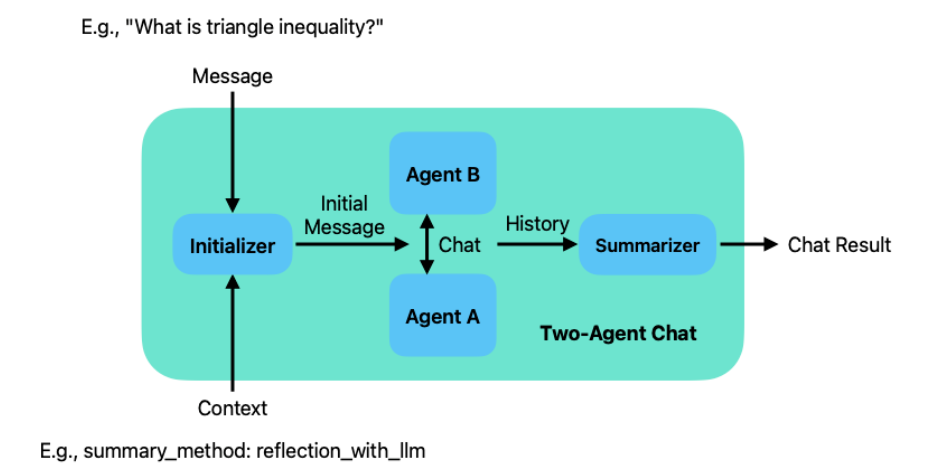
两个代理聊天需要两个输入:初始化输入的消息(由调用者提供)和上下文信息。发送方代理使用其聊天初始化方法(即 ConversableAgent的generate_init_message方法)从输入生成初始消息,并将其发送到接收代理以开始聊天。一旦聊天终止,聊天历史记录将由聊天摘要器处理。摘要器汇总聊天历史记录并计算聊天的Token使用情况。
https://microsoft.github.io/autogen/0.2/docs/reference/agentchat/conversable_agent/#initiate_chat
FENCE0
同时可以设置 max_turns参数,该参数用来指定两个代理之间聊天的最大轮数,一回合意味着一次对话往返。这里我们设置成5,让捧哏和逗哏发起5轮对话。完整代码如下:
result = dougen.initiate_chat(penggen, message="各位亲爱的观众朋友们,大家好。今天我们给大家带来一段关于宇宙牌香烟的相声。", max_turns=5)
同样,我们可以使用模型过滤方法,比如逗哏代理用gpt-4模型,捧哏代理用Qwen2.5:32b模型。
llm_config = {
"config_list": [
{
"model": "gpt-4o",
"api_key": os.environ.get("OPENAI_API_KEY"),
"tags": ["openai"]
},
{
"model": "qwen2.5:32b",
"base_url": "http://192.168.110.131:11434/v1/",
"price": [0.00, 0.00],
"tags": ["ollama"]
}
]
}
在为每个代理创建 llm_config 时,使用 filter_config 根据标签筛选所需的模型配置。
import autogen
# 过滤出包含 'ollama' 标签的模型配置
filter_dict_penggen = {"tags": ["ollama"]}
config_penggen = autogen.filter_config(llm_config["config_list"], filter_dict_penggen)
# 过滤出包含 'openai' 标签的模型配置
filter_dict_dougen = {"tags": ["openai"]}
config_dougen = autogen.filter_config(llm_config["config_list"], filter_dict_dougen)
config_penggen
在创建代理实例时,将筛选后的模型配置传递给 llm_config 参数。
# 定义捧哏角色
penggen = ConversableAgent(
name="penggen",
system_message="你的名字是张三,你是相声表演中的捧哏演员,负责配合逗哏演员。",
llm_config={"config_list": config_penggen}
)
# 定义逗哏角色
dougen = ConversableAgent(
name="dougen",
system_message="你的名字是李四,你是相声表演中的逗哏演员,负责引出笑点。",
llm_config={"config_list": config_dougen}
)
继续进行对话,代码如下:
result = dougen.initiate_chat(penggen, message="各位亲爱的观众朋友们,大家好.今天我和张三给大家带来一段相声。", max_turns=5)
print(result)
Two-Agent Chat(双智能体协作)的价值,不在于它只是两个聊天机器人在对话,而在于它能模拟多人协作、发挥不同角色的专长,进而自动化地解决更复杂的工作或学习任务。 通过引入“角色分工与对话迭代”机制,有效地模拟并增强了多角色间的协作能力,极大地提升了决策的精确性、创作的创新性、学习的深度和任务执行的效率。在现实生活中,这样的对话机制能够辅助用户从多维度评估情况,通过模拟不同角色的互动,帮助用户做出更加全面和客观的决策。在职场中,Two-Agent Chat 能够仿照专业团队的工作方式,进行项目规划、任务分配和质量审查,显著降低了重复沟通的时间与成本,同时提高了工作效率和成果质量。在教育与学习领域,它通过模拟教师与学生间的实时互动,提供即时反馈和个性化指导,使得学习过程更为精准和高效。同时这也是这种对话模式存在的实际价值。
比如下面是一个团队协作模拟与任务分解的实际工作场景。我们可以使用 AutoGen 的 Two-Agent 对话模式来模拟「项目经理(PM)」与「开发者(Dev)」在工作中的角色分工、任务拆解和对话流程。具体思路是:
- 让
PM代理负责需求分析、任务分解、进度规划等工作; - 让
Dev代理负责评估可行性、实现方案、编写代码/伪代码等。
import os
from autogen import ConversableAgent
# 定义项目经理(PM)角色
pm_agent = ConversableAgent(
name="pm_agent",
system_message=(
"你的名字是小王,你是一名项目经理。"
"你最擅长对需求进行分析、分解,规划进度,并督促团队成员完成开发任务。"
"当有人向你汇报问题时,你会耐心地提出解决思路或进行优先级调整。"
),
llm_config={
"config_list": [
{
"model": "gpt-4o",
"api_key": os.environ.get("OPENAI_API_KEY"),
"tags": ["openai"]
},
]
},
)
# 定义开发者(Dev)角色
dev_agent = ConversableAgent(
name="dev_agent",
system_message=(
"你的名字是小李,你是一名开发工程师。"
"你擅长将需求拆解为具体技术实现方案,并编写相应的代码。"
"如果遇到实现难点或需求不明确,你会主动与项目经理沟通。"
),
llm_config={
"config_list": [
{
"model": "gpt-4o",
"api_key": os.environ.get("OPENAI_API_KEY"),
"tags": ["openai"]
},
]
},
)
# 场景示例:
# PM(小王)向 Dev(小李)描述了一个新功能需求,比如要做一个“待办事项管理(To-Do List)”功能
# 开发者需要评估可行性,列出任务拆解,并进行简单的实现描述。
# init_message: PM 跟 Dev 的首次对话内容
init_message = (
"小李,我们有一个新需求:要在我们的应用里新增一个待办事项管理功能。"
"用户可以创建待办事项、设置优先级、标注完成情况,并进行搜索和过滤。"
"你这边看看技术上需要怎么做,工作量预估是多少?"
)
# 进行对话,max_turns 可以根据需要设定对话轮数
result = pm_agent.initiate_chat(
dev_agent,
message=init_message,
max_turns=6 # 设置对话轮数,避免无限循环
)
result
print("对话历史:")
for i, turn in enumerate(result.chat_history): # 注意这里使用 .chat_history
speaker = turn["role"]
content = turn["content"]
print(f"[{i} - {speaker}]: {content}")
# 如果你要查看“最终输出”,可以看看 chat_history 的最后一条消息
print("\n最终输出:")
print(result.chat_history[-1]["content"])
当然,在AutoGen框架中,Two-Agent Chat 还可以进一步与外部API、数据库及其他业务系统集成,不仅限于进行基本的对话交流,而是可以发展成为一个能够实际执行多样化任务的多角色智能合作平台,这将涉及到AutoGen框架更多的知识点讲解,即:
-
函数调用功能:AutoGen 支持通过函数调用与外部 API 交互,增强系统的整体功能和效率。例如,在对话过程中,根据需要调用天气 API 获取实时天气信息。
-
多代理协作:AutoGen 允许多个代理协作以实现共同目标。通过在多个代理之间初始化和协作,支持单聊以及群聊等多种对话模式,提升任务处理的效率和效果。
-
模块化设计:AutoGen 的模块化方法允许开发人员混合和匹配智能体、工具、任务和团队等组件,为构建人工智能系统提供了灵活性和定制选项。
-
快速原型开发:通过 AutoGen Studio 等工具,开发人员可以快速构建多智能体工作流,实现快速原型开发,展示人工智能系统的功能。
-
代码生成和执行:AutoGen 通过利用 Docker 容器进行隔离执行,简化了代码生成和执行的过程,提高了效率和可扩展性。
以上的内容构成了AutoGen完整的开发生态,也是我们在基于AutoGen框架进行Agent开发过程中必须掌握的技巧。大家可以关注我的B站账号:木羽Cheney 。我将继续更新AutoGen的相关课程。同时,AutoGen的系统性讲解以及其他AI Agent热门框架如LangGraph、CrewAI、Coze、Dify、Swarm等,在我们的正式课程中均有保姆级的讲解, 公开课直播特惠,全年最低价!低至 5 折 !扫码咨询课程信息哦👇
公开课内容节选自《大模型与Agent开发》完整版付费课程!
公开课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《大模型与Agent开发实战课》 :
《大模型与Agent开发实战课》 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
