Nano Banana Pro文生图设计系统开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(11月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(11月班)

《2025大模型Agent智能体开发实战》(11月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
11月班 · 重磅新增


11月班 · 重磅新增14项实战案例

完整课程介绍

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由九天老师亲自带队主讲的《大模型强化学习实战》(全网首发)


大模型11月班·双十一抢先购,直播间特惠进行时,直播间享五折特价+全套SVIP新班特定福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

《大模型Agent开发实战》(体验课)
Nano Banana Pro文生图设计系统开发实战
欢迎大家参与本期公开课课程的学习!在本课程中,我们将深入学习如何通过 LiteLLM + OpenRouter 接入 Google 最新发布的 Gemini 3 Pro Image Preview 模型(也称为 Nano Banana Pro),并基于该模型完整实现一个具备国内网络环境应用 + 完全私有化部署的文生图设计系统。
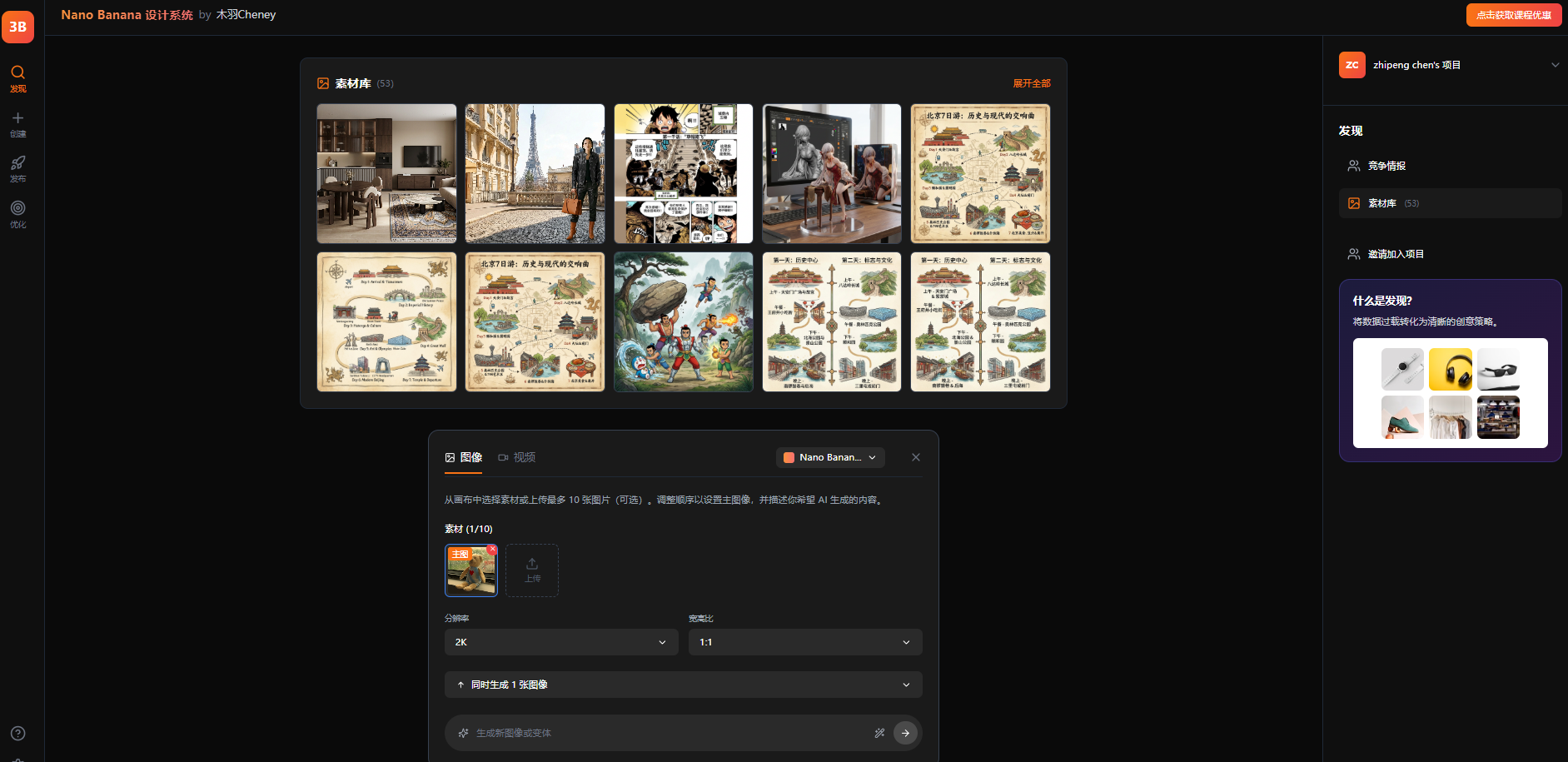
核心功能一:无需担心因网络限制无法调用 Nano Banana Pro 模型,通过 LiteLLM + OpenRouter 接入,最低一张图仅需 8 毛钱(人民币);
核心功能二:支持不同分辨率(2k)、不同长宽高比、以及单次请求同时生成多张图片;
核心功能三:支持自然语言描述生图、在线上传图片并基于图片生图,以及可以针对生成后的图片进行多轮修复;
在这节课中,我们将从模型特性、接入方法、到实战应用,全方位带大家掌握这个最先进的 AI 图像生成工具。无论你是想学习 AI 绘图技术,还是想将其集成到实际项目中,这节课都会给你带来巨大的收获。
一、Nano Banana Pro 模型介绍
谷歌在很早的3个月前就发布了Nano Banana 横空出世,当时直接颠覆了 AI 图像生成技术领域,而现在发布的 Nano Banana Pro 的正式发布,再次把 AI 生图技术推向全新的高度
Nano Banana Pro 相比前代实现了以下 9大核心技术突破:
Nano Banana Pro 九大核心技术突破
| 序号 | 技术突破 | 核心能力描述 |
|---|---|---|
| 1 | 图像生成质量大幅提升 | 整体图像质量相比前代有显著提升,细节更加丰富,色彩更加自然 |
| 2 | 多语种文本生成能力 | 能够生成更加清晰的多语种文字,解决了传统 AI 模型在文字生成上的痛点 |
| 3 | 原生图像推理能力 | 具备强大的图像推理能力,能够理解图像之间的逻辑关系和上下文 |
| 4 | 真实物理世界理解 | 对真实物理世界的理解能力大幅增强,生成的图像更加符合物理规律 |
| 5 | 专业摄影级图像控制 | 可自由切换图片色彩、光线效果、背景环境等专业摄影级别的图像细节参数 |
| 6 | 4K 高清分辨率支持 | 最高支持 4K 分辨率 的图片生成,大幅提升图像清晰度 |
| 7 | 任意比例调整与扩写 | 可任意调整图片比例、对图片进行扩写(画幅拓展),确保扩展前后风格高度一致 |
| 8 | 主题一致性大幅提升 | 精准识别图像中最多十几个实体 并进行组合绘图,保持主题和风格的高度一致性 |
| 9 | 写实感大幅提升 | 写实图像的 "AI 味" 大幅下降,真实感大幅提升(例如红眼树蛙照片几乎可以以假乱真) |
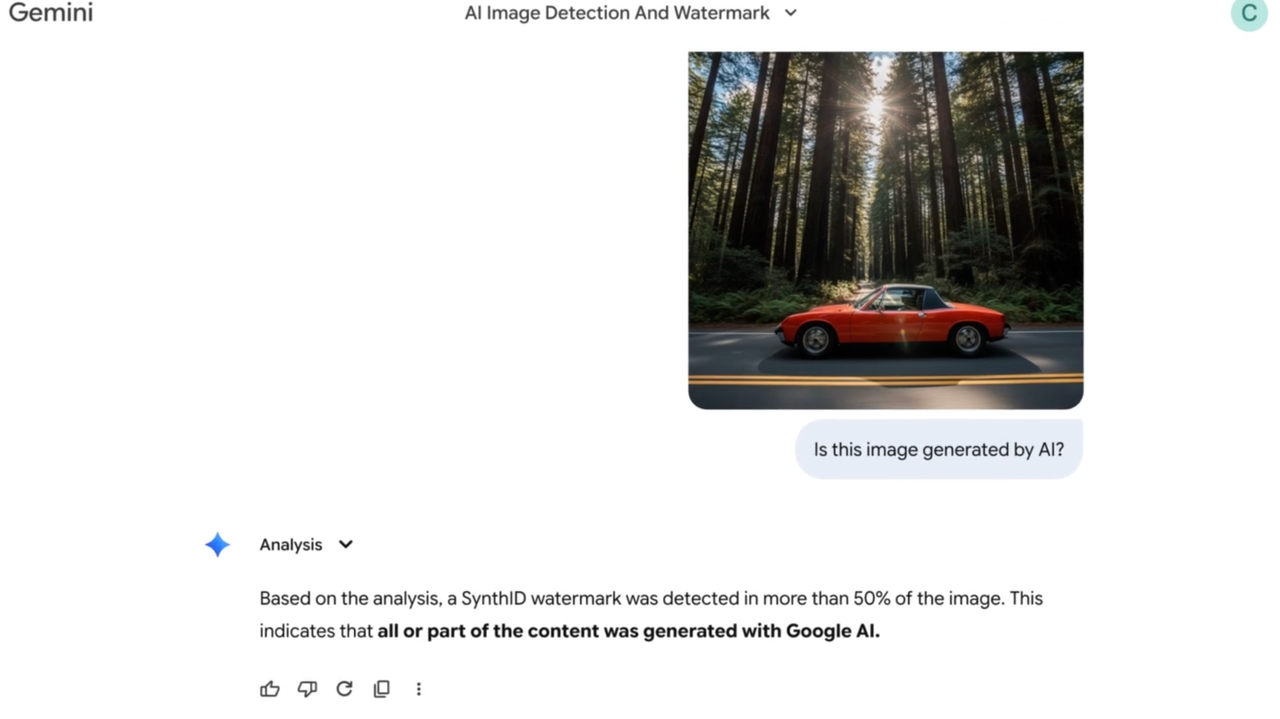
当然,考虑到 Nano Banana Pro 的图像太过逼真,Google 还在 Gemini 中同步上线了 AI 照片识别功能,基于 SynthID 隐形水印技术来判断图片是否由 Nano Banana 生成。
除此以外,Nano Banana Pro 本身也是 Gemini 模型生态的重要一员,可以与其他 Gemini 系列模型无缝协作。Nano Banana Pro 可以和 Gemini 3 搭配使用,实现更加强大的多模态能力;借助 Voe 3 视频生成模型,可以一键将静态图片转换为动态视频,真正让图片"活起来",此外结合 Gemini 3 的 GenUI 功能,可以一键创建各类应用。
此外,我们还为大家准备了各场景下图像的提示词、Gemini 3和Nano Banana的零门槛接入指南、以及更加进阶的AI图文创作工作流开发教程,大家扫码即可领取:
二、Nano Banana Pro 模型使用方式
Nano Banana Pro 模型已经全面上线,提供了多种接入方式,满足不同场景的需求。
- 方式一:Gemini 主页调用
最简单直接的使用方式,无需编程基础。在Gemini主页(https://gemini.google.com/ )开发者只需在工具栏选择制作图片,然后模型选择思考模型,即可调用Nano Banana Pro模型。
from IPython.display import Video
Video("https://muyu20241105.oss-cn-beijing.aliyuncs.com/images/202511271057927.mp4", width=800, height=400)
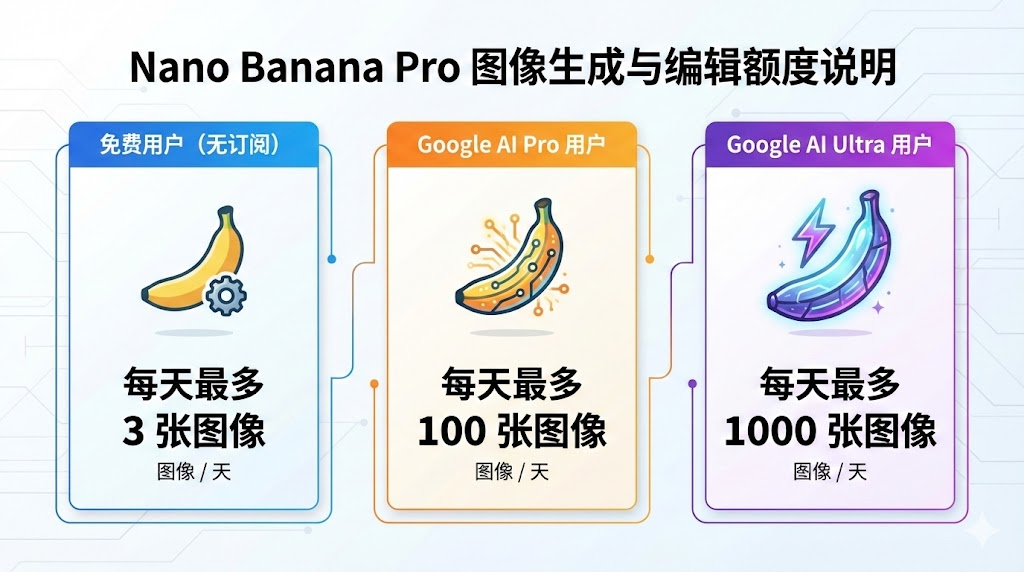
目前免费用户每天可以创建或编辑3张图片,Pro用户的额度则是100张,Ultra用户的额度是每天1000张(没错这张图片就是Nano Banana Pro生成的)。
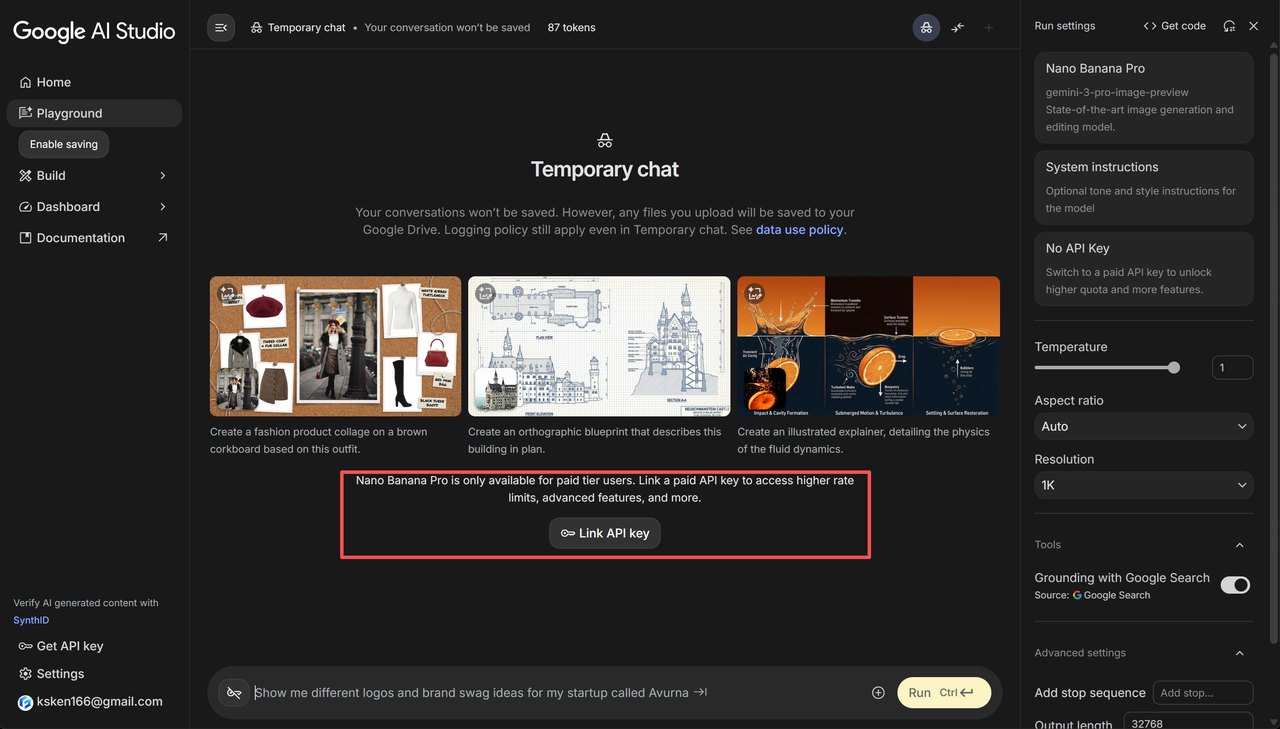
- 方式二:Google AI Studio
此外,开发者也可以在谷歌AI Studio进行尝试,但并没有免费的额度,需要输入API-KEY才能使用。
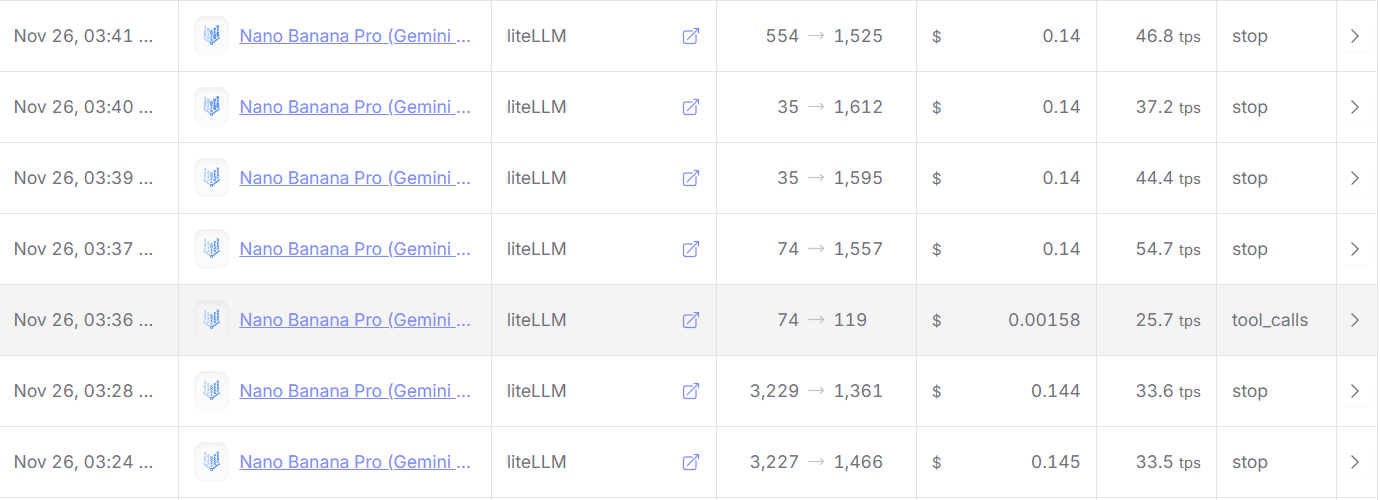
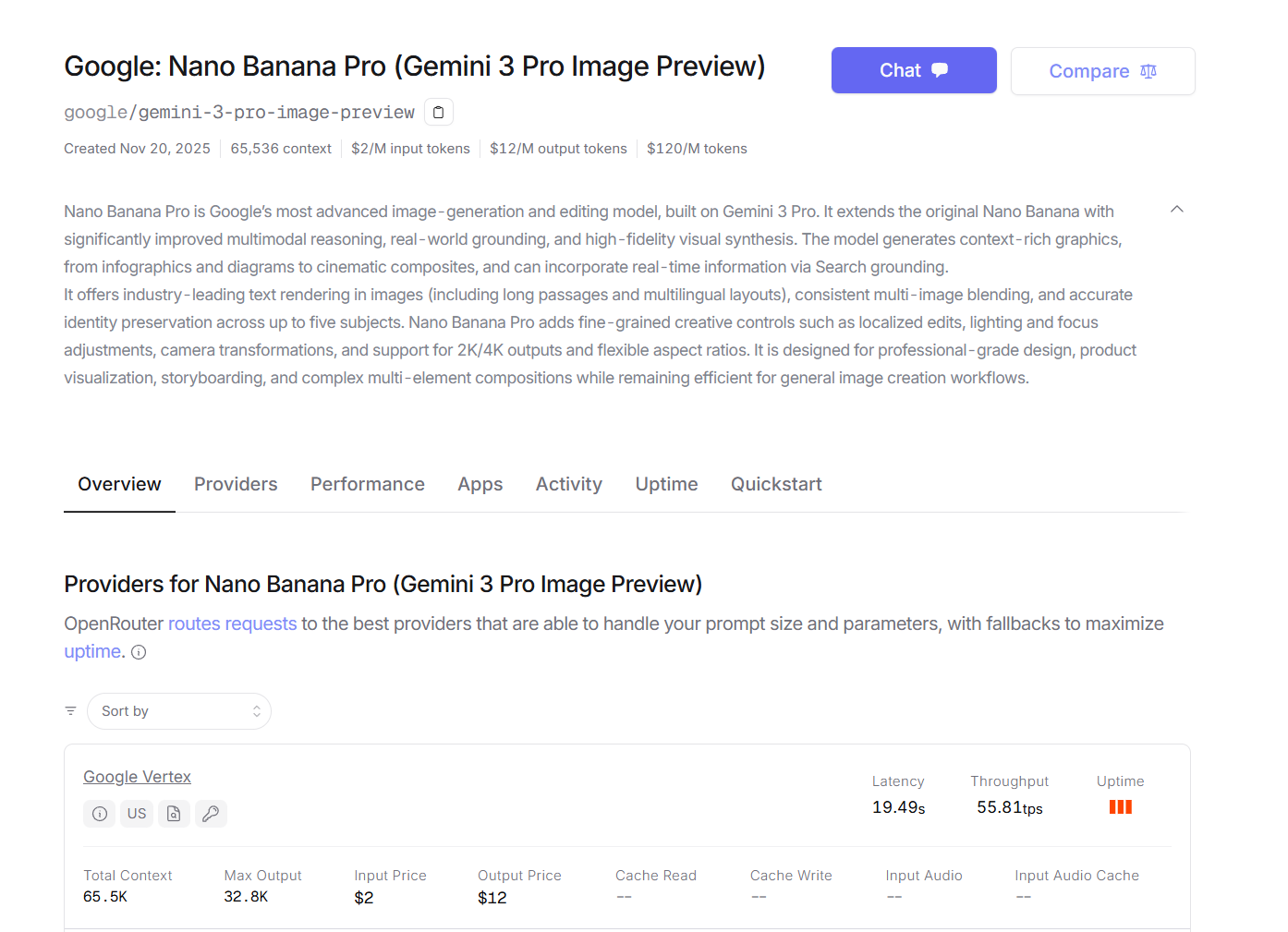
而与此同时Nano Banana Pro模型的API也已经全面上线,模型名称和定价如图所示:

调用代码示例:
FENCE0
当然,上述所有的使用方法,均需要魔法上网环境,且Google的监测会非常严,这会导致很多我们国内的开发者在上手使用时门槛会比较高。
因此,本节课我们主要做的就是借助LiteLLM + OpenRouter 接入Nano Banana Pro模型,并实现完整的调用流程,解决网络限制以及想私有化本地部署的应用两大难题。
基于 Nana Banana Pro 模型构建的文生图设计系统已经免费开源,大家扫码即可领取:
三、技术架构与核心概念
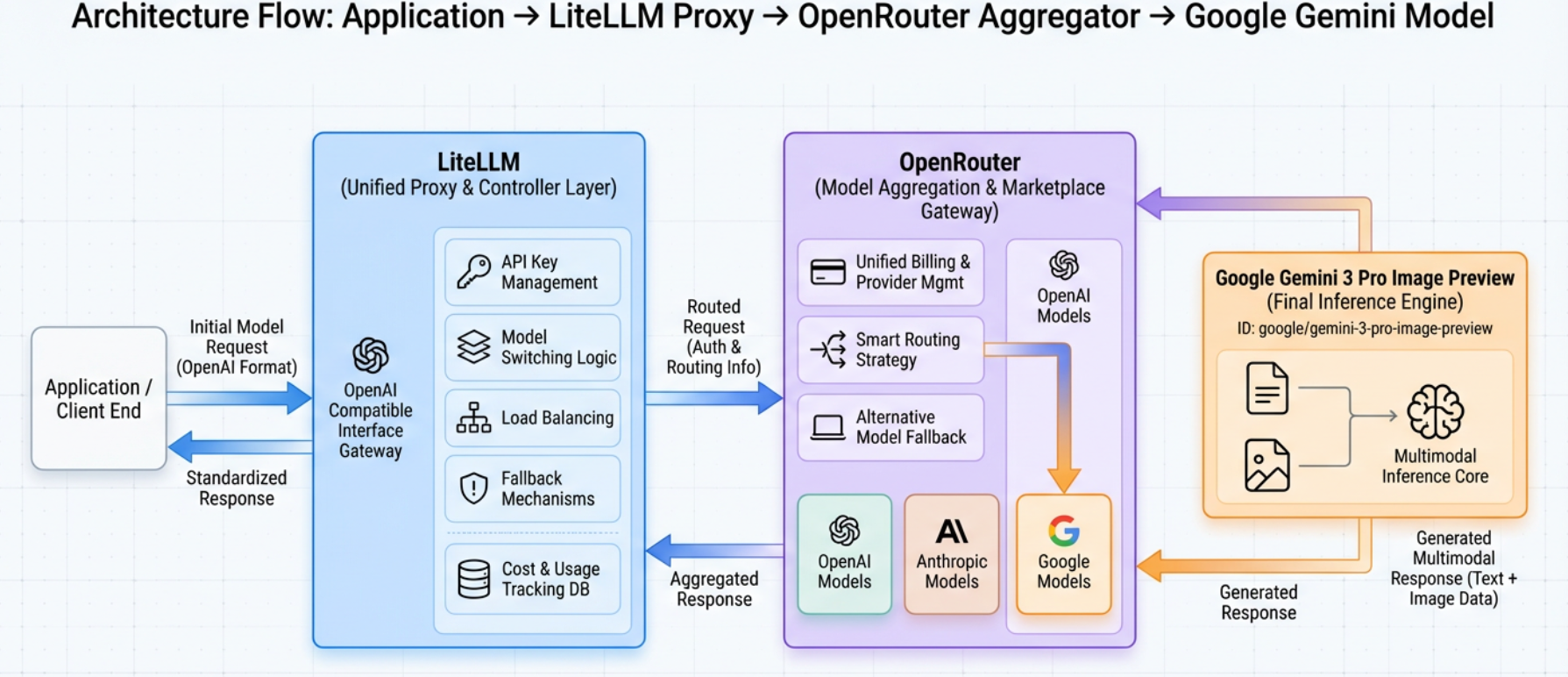
OpenRouter 是一个 AI 模型的统一网关服务。它的作用类似于一个"中转站":
FENCE0
通过 OpenRouter,我们只需要一个 API Key,就可以访问多家模型提供商的服务,大大简化了开发流程。
- 为什么需要 LiteLLM?
在实际的 AI 应用开发中,经常会遇到这样的问题:不同的大语言模型提供商有着各自不同的 API 接口格式。例如:
- OpenAI 有自己的 API 格式
- Anthropic Claude 有不同的调用方式
- Google Gemini 又是另一套接口
如果我们想在项目中灵活切换不同的模型,就需要为每个模型编写不同的适配代码,这显然非常繁琐。LiteLLM 应运而生,它提供了一个统一的接口,让我们可以用同样的代码调用不同的模型。
我们的技术架构如下:
FENCE0
这种架构的好处是:如果将来想切换到其他模型,只需要修改模型名称,而不需要改动业务逻辑代码。同时还能解决网络限制的问题。
了解到这里,接下来我们就来开始动手实践,实现一个完整的文生图设计系统。
四、Nano Banana Pro 调用环境准备
- Step 1:安装必要的 Python 包
在开始调用Nano Banana 模型生成图像之前,我们需要先安装几个核心的 Python 库。主要如下:
litellm:提供统一的 LLM 调用接口python-dotenv:用于管理环境变量(如 API Key)Pillow:用于图片处理(后续生成图片时会用到)
现在在当前的运行环境中执行安装命令:
# 安装依赖包
# ! pip install litellm python-dotenv Pillow
安装完成后,我们可以验证一下是否安装成功:
! pip show litellm
- Step 2:配置 OpenRouter API Key
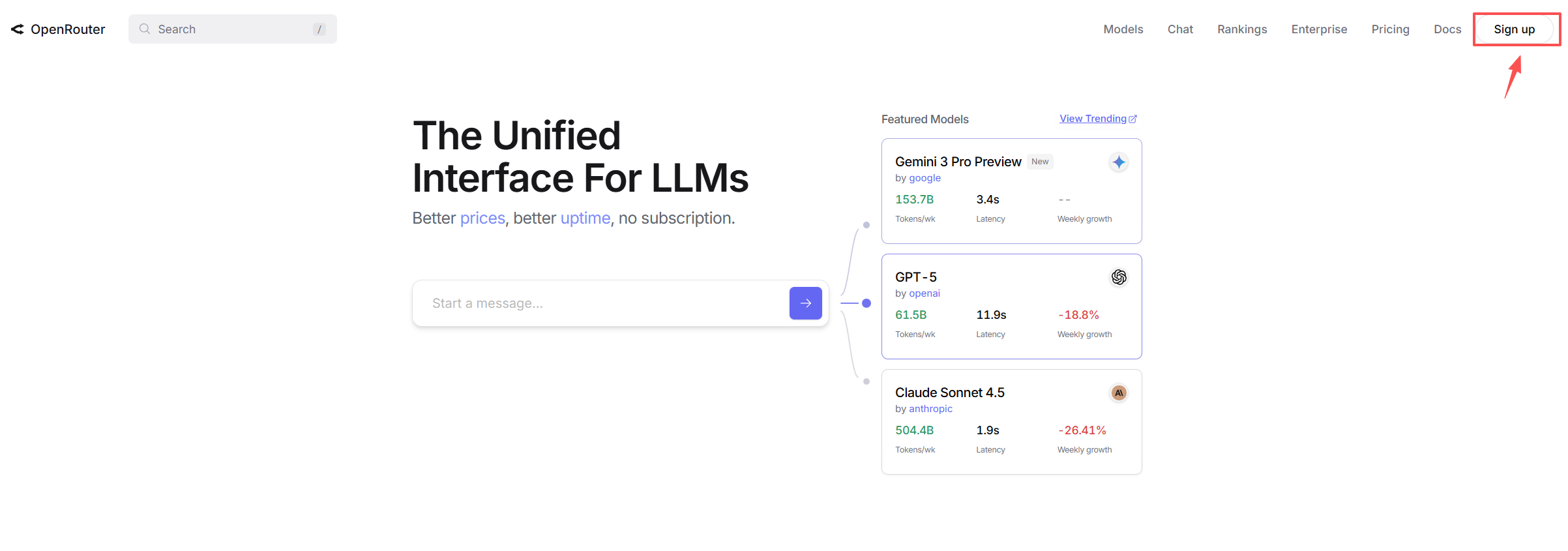
要使用 OpenRouter 服务,我们需要先获取 API Key。首先需要注册 OpenRouter 账号,访问 https://openrouter.ai/ 注册账号,首次登录需要点击右上角 "Sign Up" 注册账号。
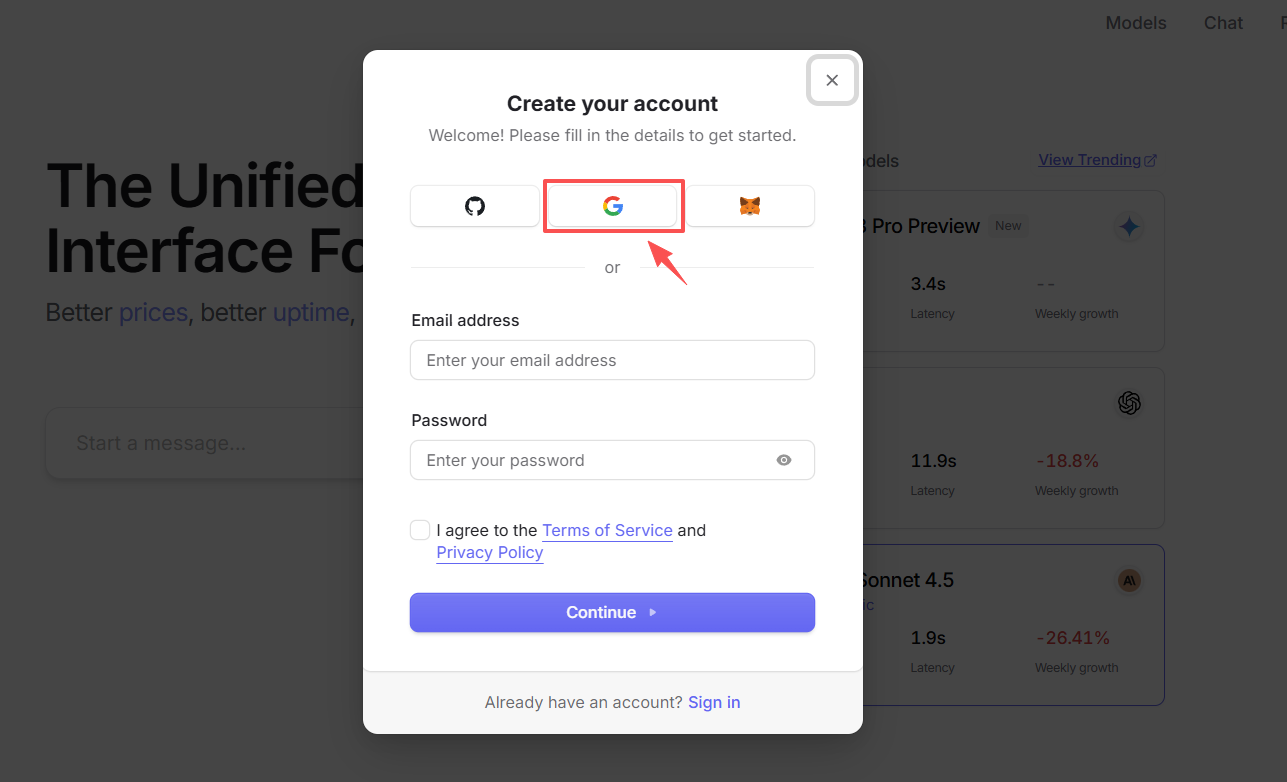
可以通过Google 邮箱一键登录:
登录后需要先绑定信用卡,并进行预付充值,
这里可以直接使用国内的任意信用卡进行开始绑定:
绑定信用卡后,需要进行预付充值,可以根据自己的需求灵活选择充值的金额。接下来,回到 Dashboard,点击 "Keys" 菜单,创建新的 API Key 并复制:
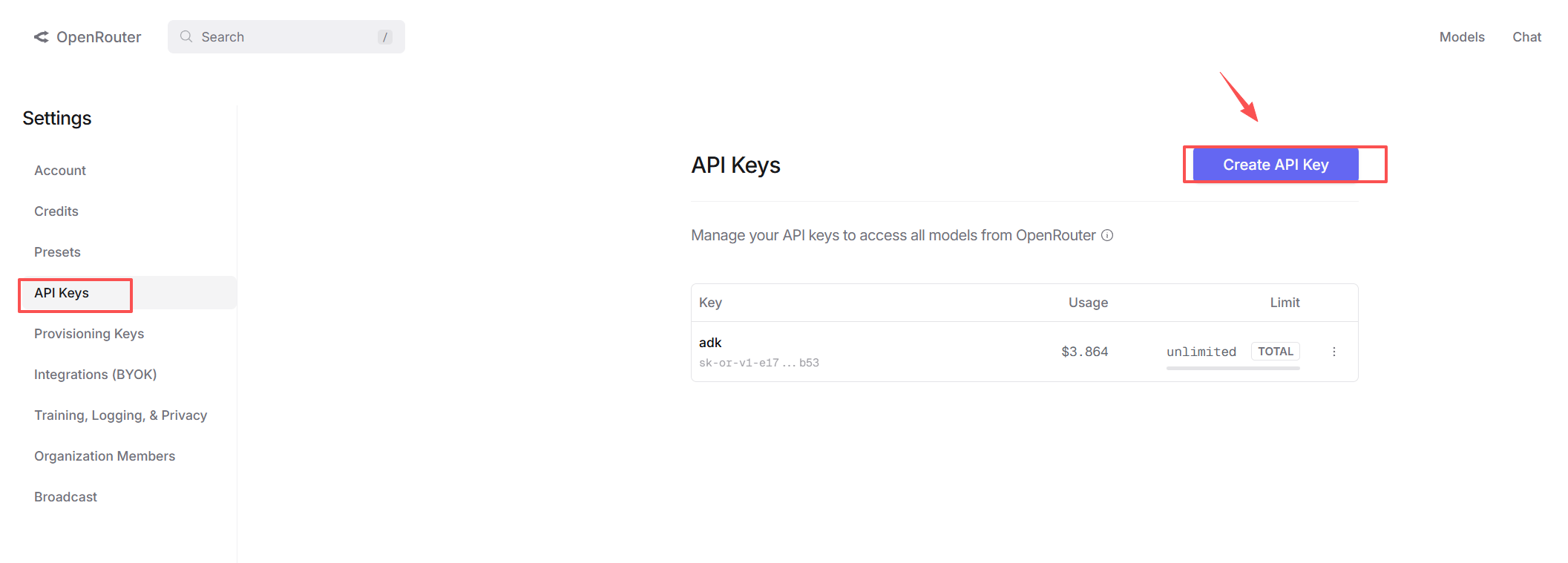
至此,我们就可以在项目中使用 OpenRouter 的 API Key 了。
- Step 3:配置环境变量
在实际的开发中,为了安全起见,我们一般不会将 API Key 直接写在代码中,而应该使用环境变量。因此在项目根目录创建一个 .env 文件,内容如下:
FENCE0
然后在代码中加载:
from dotenv import load_dotenv
import os
# 加载 .env 文件中的环境变量
load_dotenv(override=True)
# 读取 API Key
api_key = os.getenv("OPENROUTER_API_KEY")
# 验证是否成功读取
if api_key:
print(f"API Key 已加载(前10位): {api_key[:10]}...")
else:
print(" 未找到 OPENROUTER_API_KEY,请检查 .env 文件")
如果你只是想快速测试,也可以直接在代码中设置。(当然不推荐这种使用方式)
import os
# 临时设置 API Key
os.environ["OPENROUTER_API_KEY"] = "your-api-key-here"
print("注意:这种方式仅用于测试,生产环境请使用 .env 文件")
Nano Banana Pro 是 Google 基于 Gemini 3 Pro 构建的最先进图像生成模型,通过 OpenRouter 平台统一接入。该模型支持文本输入、图像和文本输出的多模态能力,其在OpenRouter 平台上的模型名称为 openrouter/google/gemini-3-pro-image-preview。
接下来,我们就可以开始调用这个模型了。
五、Nano Banana Pro 实现文本对话功能
现在环境已经准备好了,我们开始实现第一个功能:文本对话。LiteLLM 提供了一个非常简洁的 API:completion()。这个函数的核心参数如下:
completion() 函数核心参数说明
| 参数名 | 类型 | 描述 | 必填/可选 |
|---|---|---|---|
model | str | 模型名称,格式为 "openrouter/provider/model-name" | 必填 |
messages | list | 对话消息列表,包含 role 和 content | 必填 |
temperature | float | 控制输出随机性,范围 0-1,越高越随机 | 可选 |
max_tokens | int | 最大输出 token 数量 | 可选 |
modalities | list | 指定输出模式,如 ["text", "image"] | 可选 |
接下来我们逐步实现完整的文本对话功能。先从最简单的例子开始。
import os
from litellm import completion
from dotenv import load_dotenv
# 加载环境变量
load_dotenv(override=True)
# 配置模型信息
model_name = "openrouter/google/gemini-3-pro-image-preview"
api_key = os.getenv("OPENROUTER_API_KEY")
# 设置环境变量(LiteLLM 需要)
os.environ["OPENROUTER_API_KEY"] = api_key
print("=" * 60)
print("第一个对话示例")
print(f"使用模型: {model_name}")
print("=" * 60)
注意到我们使用的模型名称是 openrouter/google/gemini-3-pro-image-preview,这种命名方式让 LiteLLM 知道:"我要通过 OpenRouter 调用 Google 的 gemini-3-pro-image-preview 模型"。
# 构建消息列表
question = "你好!请介绍一下你自己。"
messages = [
{"role": "user", "content": question}
]
print(f"\n用户: {question}")
print("-" * 60)
# 调用模型
response = completion(
model=model_name,
messages=messages,
temperature=0.7,
max_tokens=2048,
)
# 提取并显示回复
if response and response.choices:
answer = response.choices[0].message.content
print(f"\nGemini: {answer}")
else:
print("\n未收到有效回复")
其中消息格式解析:messages 是一个列表,每个元素都是一个字典,包含两个关键字段:
FENCE0
通过 response.choices[0].message.content 来获取 AI 的回复内容。
更进阶地,在实际应用中,我们通常需要实现多轮对话,让 AI 能够记住之前的对话内容。这需要我们维护一个对话历史列表。
# 初始化对话历史
conversation_history = []
def chat(user_message):
"""
发送消息并获取回复
参数:
user_message: 用户输入的消息
返回:
AI 的回复内容
"""
# 将用户消息添加到历史
conversation_history.append({
"role": "user",
"content": user_message
})
# 调用模型
response = completion(
model=model_name,
messages=conversation_history, # 传入完整的对话历史
temperature=0.7,
max_tokens=2048,
)
# 提取 AI 回复
ai_message = response.choices[0].message.content
# 将 AI 回复也添加到历史
conversation_history.append({
"role": "assistant",
"content": ai_message
})
return ai_message
print("多轮对话功能")
print("=" * 60)
现在让我们测试一下多轮对话:
# 第一轮对话
print("\n【第一轮对话】")
user_msg_1 = "你好,我是木羽,我正在学习 Nano Banana Pro 模型的应用方法"
print(f"用户: {user_msg_1}")
ai_reply_1 = chat(user_msg_1)
print(f"AI: {ai_reply_1}")
# 第二轮对话 - 测试 AI 是否记住了之前的内容
print("\n【第二轮对话】")
user_msg_2 = "你还记得我叫什么名字吗?"
print(f"用户: {user_msg_2}")
ai_reply_2 = chat(user_msg_2)
print(f"AI: {ai_reply_2}")
# 查看完整的对话历史
print("\n【对话历史】")
print("=" * 60)
for i, msg in enumerate(conversation_history, 1):
role = "用户" if msg["role"] == "user" else "AI"
print(f"{i}. {role}: {msg['content'][:50]}...")
通过这个例子,相信大家已经理解了多轮对话的核心原理。关键要点就是:
- 维护对话历史:每次对话都要保存用户消息和 AI 回复
- 传入完整历史:调用 API 时要传入整个
conversation_history - 顺序很重要:消息必须按时间顺序排列
注意事项:
- 对话历史越长,消耗的 token 越多,成本也越高
- 建议定期清理过早的对话记录,只保留最近的几轮对话
- 可以通过
conversation_history = conversation_history[-10:]只保留最近 10 条消息
六、Nano Banana Pro 实现文本生成图片功能
在完成了基础的文本问答调用后,Gemini 3 Pro Image Preview 不仅能理解文本,还能根据文本描述生成图片。这就是所谓的"多模态文生图"能力。在 AI 领域,"模态"指的是信息的不同形式:
- 文本模态:文字、对话
- 图像模态:图片、照片
- 音频模态:声音、语音
- 视频模态:动态影像
而要让模型生成图片而不是文本,关键在于一个参数:modalities。当我们设置 modalities=["text", "image"] 时,就是告诉模型:"请输出文本和图片"。接下来我们就一步一步实现图片生成功能。
import base64
from PIL import Image
import io
from datetime import datetime
from pathlib import Path
# 创建输出目录
output_dir = Path("generated_images")
output_dir.mkdir(exist_ok=True)
print("图片生成功能初始化")
print(f"输出目录: {output_dir.absolute()}")
print("=" * 60)
现在让我们编写生成图片的核心函数:
def generate_image(prompt, filename=None):
"""
根据文本描述生成图片
参数:
prompt: 图片描述文本
filename: 保存的文件名(可选)
返回:
保存的图片路径
"""
print(f"\n开始生成图片...")
print(f"描述: {prompt}")
print("-" * 60)
try:
# 步骤 1: 调用 API 生成图片
response = completion(
model=model_name,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
],
modalities=["text", "image"], # 关键:指定输出图片
temperature=0.7,
)
# 步骤 2: 从响应中提取图片数据
message = response.choices[0].message
# 检查是否有图片
if not hasattr(message, 'images') or not message.images:
print("未能生成图片")
return None
# 步骤 3: 解码图片数据
image_data = message.images[0]
# 处理不同格式的图片数据
if isinstance(image_data, dict):
# OpenRouter 返回的格式
url = image_data['image_url']['url']
if url.startswith('data:image'):
# 提取 base64 部分
image_data = url.split(',', 1)[1]
image_bytes = base64.b64decode(image_data)
elif isinstance(image_data, str):
# 直接的 base64 字符串
if image_data.startswith('data:'):
image_data = image_data.split(',', 1)[1]
image_bytes = base64.b64decode(image_data)
else:
image_bytes = image_data
# 步骤 4: 保存图片
image = Image.open(io.BytesIO(image_bytes))
# 生成文件名
if not filename:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
prompt_preview = prompt[:20].replace(" ", "_").replace("/", "_")
filename = f"generated_{prompt_preview}_{timestamp}.png"
save_path = output_dir / filename
image.save(str(save_path))
print(f"\n图片生成成功!")
print(f"保存路径: {save_path}")
print(f"图片尺寸: {image.size}")
return str(save_path)
except Exception as e:
print(f"\n生成图片失败: {e}")
import traceback
traceback.print_exc()
return None
这段代码虽然有点长,但逻辑非常清晰。与文本对话相比,图片生成有两个重要区别:
content使用了结构化格式(列表+字典),而不是直接的字符串- 添加了
modalities=["text", "image"]参数
返回的 message.images 包含了健壮性的处理逻辑,针对多种格式均做了兼容处理:
- 字典格式:
{"image_url": {"url": "data:image/png;base64,..."}} - 字符串格式:直接的 base64 编码
- 字节格式:原始的图片字节数据
最终使用 PIL (Pillow) 库来处理图片,它可以从字节数据创建 Image 对象,并获取图片尺寸,保存为各种格式(PNG、JPG 等)。
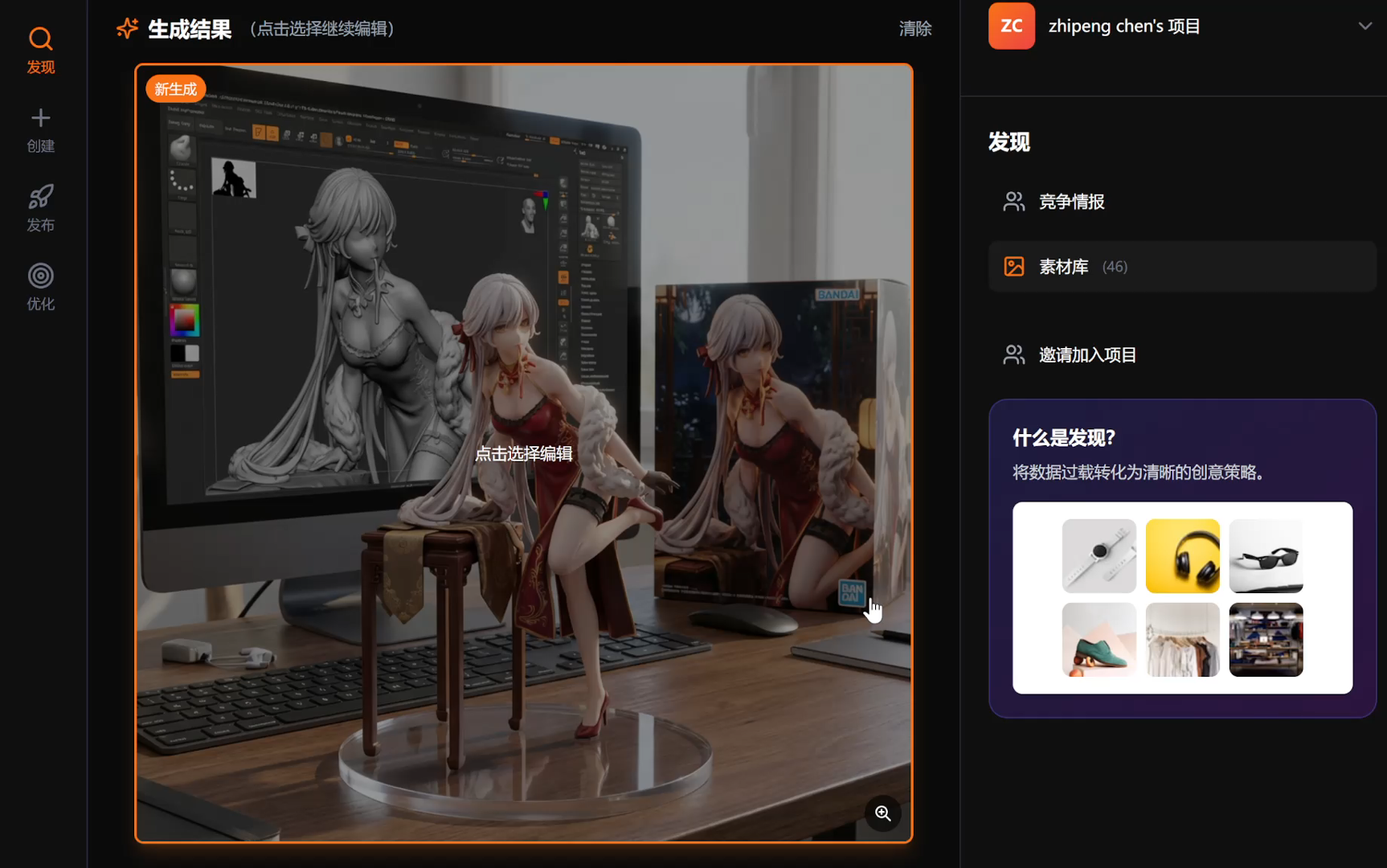
现在让我们测试一下图片生成功能!我会提供几个不同风格的示例:
# 示例 1: 生成自然风景
print("\n【示例 1】生成自然风景")
print("=" * 60)
prompt_1 = "宁静的海面上,夕阳西下,波光粼粼,天空被染成了橙色和粉色。"
image_path_1 = generate_image(prompt_1)
# 显示生成的图片
if image_path_1:
img = Image.open(image_path_1)
display(img)
# 示例 2: 生成科技风格图片
print("\n【示例 2】生成科技风格图片")
print("=" * 60)
prompt_2 = "一位未来主义风格的 AI 机器人在全息电脑屏幕前工作,赛博朋克风格,霓虹灯闪烁。"
image_path_2 = generate_image(prompt_2)
# 显示生成的图片
if image_path_2:
img = Image.open(image_path_2)
display(img)
# 示例 3: 生成架构图
print("\n【示例 3】生成中文描述的图片")
print("=" * 60)
prompt_3 = "请生成一张架构图,内容基于以下描述的三者关系:LiteLLM 是整个调用链最上游的统一 LLM 代理层,是应用端访问所有模型的入口。应用程序发起的所有模型调用请求首先传入 LiteLLM,由它负责提供统一的 OpenAI 兼容接口、API Key 管理、模型切换、负载均衡、回退机制以及成本和使用量追踪等功能。LiteLLM 本身不提供模型推理能力,而是负责将请求路由到下游的平台或模型提供商。OpenRouter 位于 LiteLLM 的下游,是一个模型市场与多模型聚合网关。LiteLLM 可以将请求转发给 OpenRouter,由 OpenRouter 统一管理模型访问、计费、服务商选择、路由策略和备用模型切换。OpenRouter 内部汇集了多家模型提供商,例如 OpenAI、Google、Anthropic 等。OpenRouter 收到来自 LiteLLM 的请求后,会根据所选模型或其内部策略,将请求转交给对应的具体模型。Google Gemini 3 Pro Image Preview 模型是 OpenRouter 平台中的一个具体模型条目,模型 ID 为 google/gemini-3-pro-image-preview。这个模型承担最终的推理任务,支持多模态输入输出(文本和图像),并返回生成结果。在整个链路中,三者的角色分别是:LiteLLM 负责统一代理与调用控制,OpenRouter 负责模型聚合与路由,Google Gemini 3 Pro Image Preview 则负责最终的模型推理。整体调用流程为:应用程序 → LiteLLM → OpenRouter → Google Gemini 3 Pro Image Preview 模型。"
image_path_3 = generate_image(prompt_3)
# 显示生成的图片
if image_path_3:
img = Image.open(image_path_3)
display(img)
其实大家掌握到这里,就已经可以理解项目中输入自然语言,然后生成图片的原理了。源码文件:
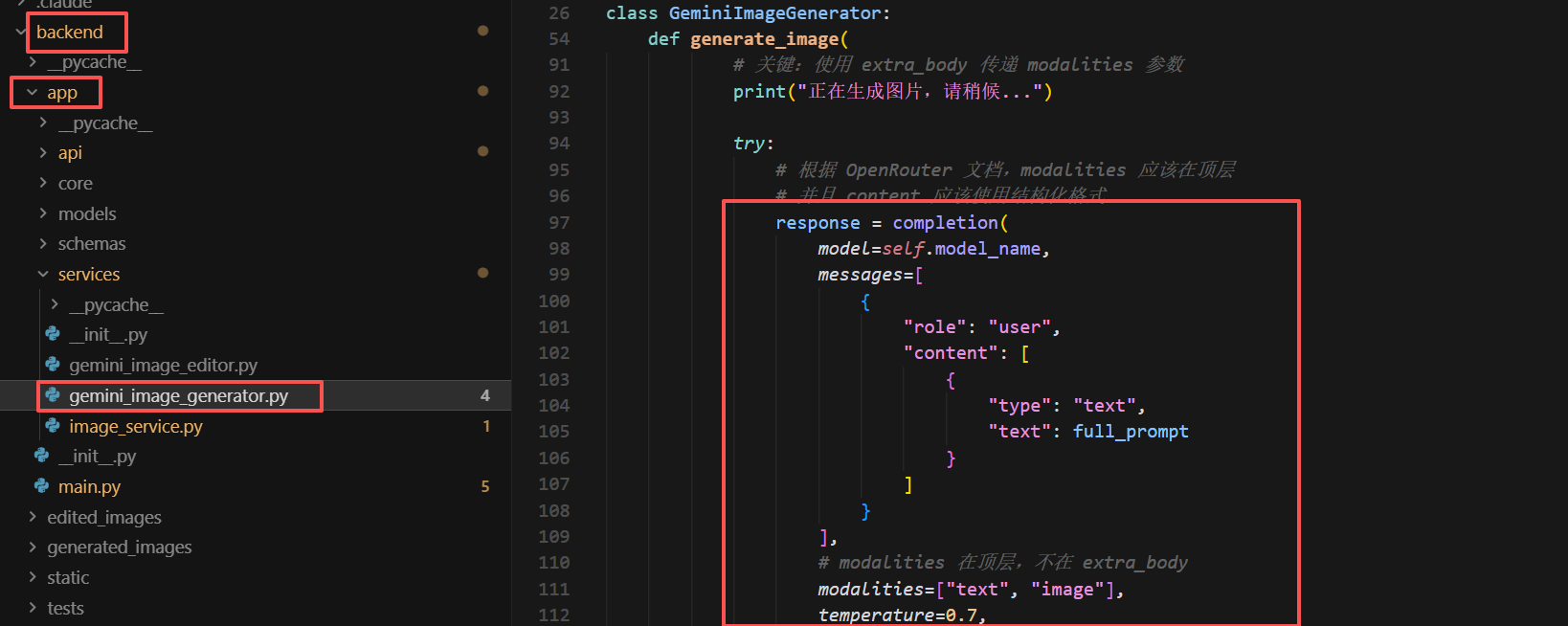
七、Nano Banana Pro 实现多图片混合功能
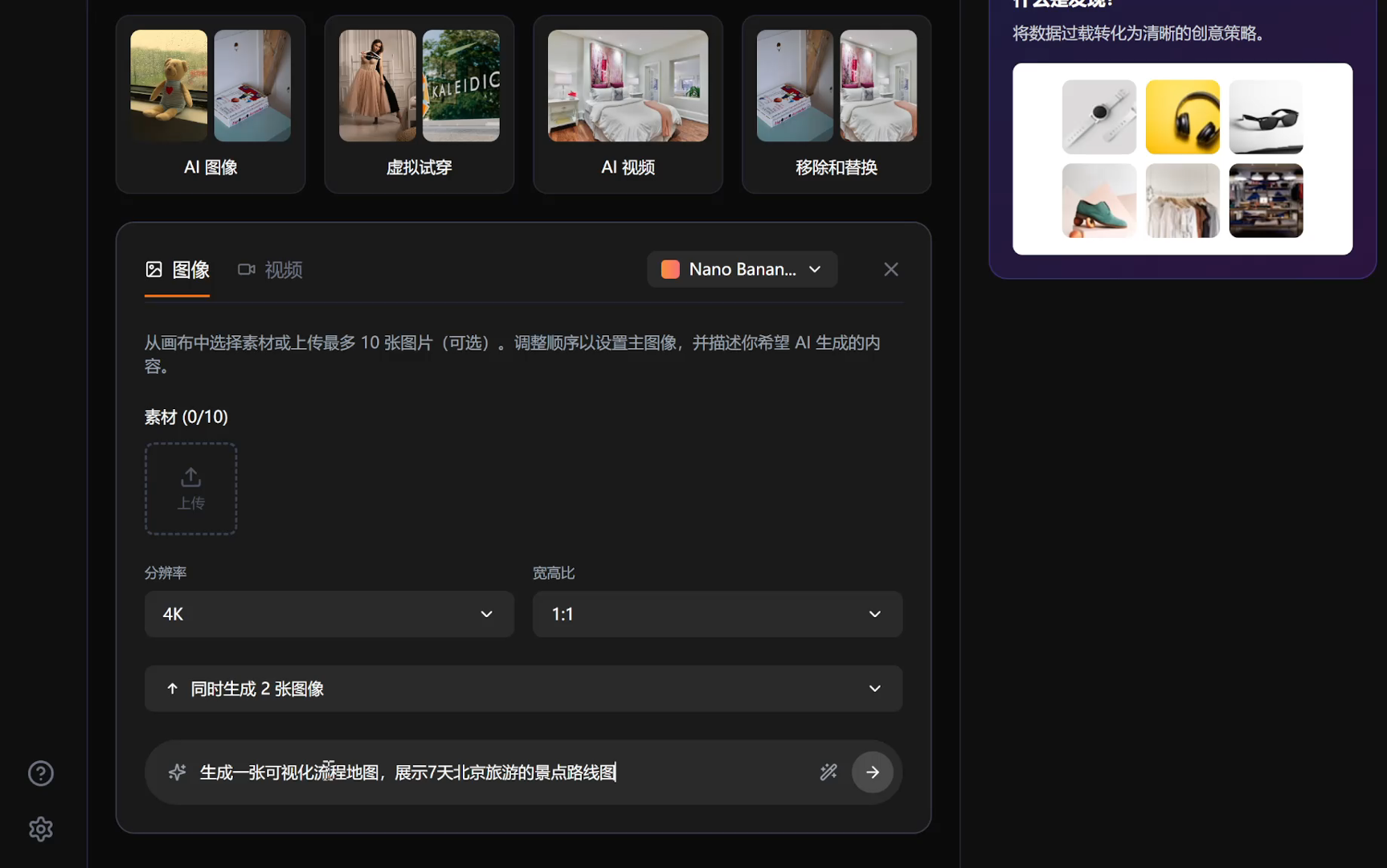
在了解了文本生成图片的原理后,我们再来看一下多图片混合的实现。多图片混合就是将多张图片的元素智能地融合在一起。比如:
- 将二维码放到海报上
- 将产品图放到不同场景中
- 合成多个人物到同一张照片
Gemini 3 Pro Image(代号 Nano Banana Pro)支持 最多 14 张图片同时混合。它会把这些参考整合 —— 角色、构图、风格、光影、背景等 —— “融合 / 混合 / 合成” 成 一张新的图像。
下面我们来看一下具体的实现方法。
首先,我们定义一个函数,用于将图片转换为 Base64 格式:
import base64
def encode_image_to_base64(image_path):
"""将图片转换为 base64 编码"""
with open(image_path, "rb") as f:
image_data = f.read()
base64_str = base64.b64encode(image_data).decode('utf-8')
# 判断图片格式
if image_path.lower().endswith('.png'):
mime = 'image/png'
elif image_path.lower().endswith(('.jpg', '.jpeg')):
mime = 'image/jpeg'
else:
mime = 'image/jpeg'
# 返回 data URL 格式
return f"data:{mime};base64,{base64_str}"
print("Base64 编码函数定义完成")
这个函数做了三件事:
- 读取图片的二进制数据
- 使用
base64.b64encode()编码 - 拼接成
data:image/png;base64,xxx格式
现在定义我们要处理的图片路径。这里我们用这些图进行混合搭配:
# 定义图片路径(请替换为你的实际路径)
image_paths = [
"/home/MuyuWorkSpace/08_Gemini3_to_image/backend/test_image/1.png", # 第1张:主图
"/home/MuyuWorkSpace/08_Gemini3_to_image/backend/test_image/2.png", # 第2张:
"/home/MuyuWorkSpace/08_Gemini3_to_image/backend/test_image/3.png", # 第3张:
"/home/MuyuWorkSpace/08_Gemini3_to_image/backend/test_image/4.png", # 第4张:
"/home/MuyuWorkSpace/08_Gemini3_to_image/backend/test_image/5.png", # 第5张:
"/home/MuyuWorkSpace/08_Gemini3_to_image/backend/test_image/6.png", # 第6张:
]
# 混合指令(用自然语言描述)
instruction = """
根据提供的主体人物照片,根据图片服饰替换主体人物的服饰。使用提供的背景图片作为最终背景,并从背景中移除所有非主体人物。
"""
print(f"准备混合 {len(image_paths)} 张图片")
print(f"混合指令: {instruction.strip()}")
将每张图片都转换为 Base64 格式,并构建 API 请求的内容结构:
# 构建内容列表
content_parts = []
# 添加所有图片
for i, img_path in enumerate(image_paths, 1):
print(f"编码第 {i} 张图片...")
# 转换为 base64
image_base64 = encode_image_to_base64(img_path)
# 添加到内容列表
content_parts.append({
"type": "image_url",
"image_url": {
"url": image_base64
}
})
# 添加文本指令
content_parts.append({
"type": "text",
"text": instruction
})
print(f"准备完成!内容包含:{len(image_paths)} 张图片 + 1 条指令")
这段代码的关键是构建 content_parts 列表,它包含:
- 多个图片对象(每个都是
image_url类型) - 一个文本对象(
text类型,包含我们的指令)
最后,即可调用 Nano Banana Pro 的 API 进行图片混合:
from litellm import completion
print("调用 Gemini API,请稍候...")
# 调用 API
response = completion(
model=model_name,
messages=[
{
"role": "user",
"content": content_parts # 传入图片+文字
}
],
modalities=["text", "image"], # 关键!指定要返回图片
temperature=0.7,
)
print("API 调用成功!")
API 返回的图片是 Base64 格式,我们需要解码并保存:
from PIL import Image
import io
import base64
from datetime import datetime
# 1. 从响应中提取图片数据
message = response.choices[0].message
image_data = message.images[0] # 获取第一张图片
print(f"收到图片数据,类型: {type(image_data)}")
# 2. 处理不同格式的图片数据
if isinstance(image_data, dict):
# OpenRouter 返回的格式:{'image_url': {'url': 'data:image/...'}}
if 'image_url' in image_data:
url = image_data['image_url'].get('url', '')
if url.startswith('data:image'):
# 去掉 data:image/png;base64, 前缀
image_data = url.split(',', 1)[1]
image_bytes = base64.b64decode(image_data)
else:
raise ValueError(f"不支持的 URL 格式: {url[:50]}")
elif 'data' in image_data:
# 直接包含 base64 数据
image_data = image_data['data']
if image_data.startswith('data:'):
image_data = image_data.split(',', 1)[1]
image_bytes = base64.b64decode(image_data)
else:
raise ValueError(f"字典格式不支持: {list(image_data.keys())}")
elif isinstance(image_data, str):
# 字符串格式:可能是 base64 字符串
if image_data.startswith('data:'):
# 去掉 data:image/png;base64, 前缀
image_data = image_data.split(',', 1)[1]
# 解码 base64
image_bytes = base64.b64decode(image_data)
else:
# 假设已经是字节数据
image_bytes = image_data
# 3. 转换为 PIL Image 对象
image = Image.open(io.BytesIO(image_bytes))
print(f"图片尺寸: {image.size}")
# 4. 保存到本地
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
output_path = f"blended_result_{timestamp}.png"
image.save(output_path)
print(f"图片已保存到: {output_path}")
这段代码展示了如何从 API 响应中提取图片:
- 从
response.choices[0].message.images[0]获取图片数据 - 去掉 Base64 的前缀(如果有)
- 使用
base64.b64decode()解码 - 用 PIL 打开并保存
保存后,我们可以直接在 Notebook 中查看效果:
from IPython.display import Image as IPImage, display
# 显示生成的图片
display(IPImage(filename=output_path))
当然,这部分核心代码在项目中是封装在项目的如下位置中:
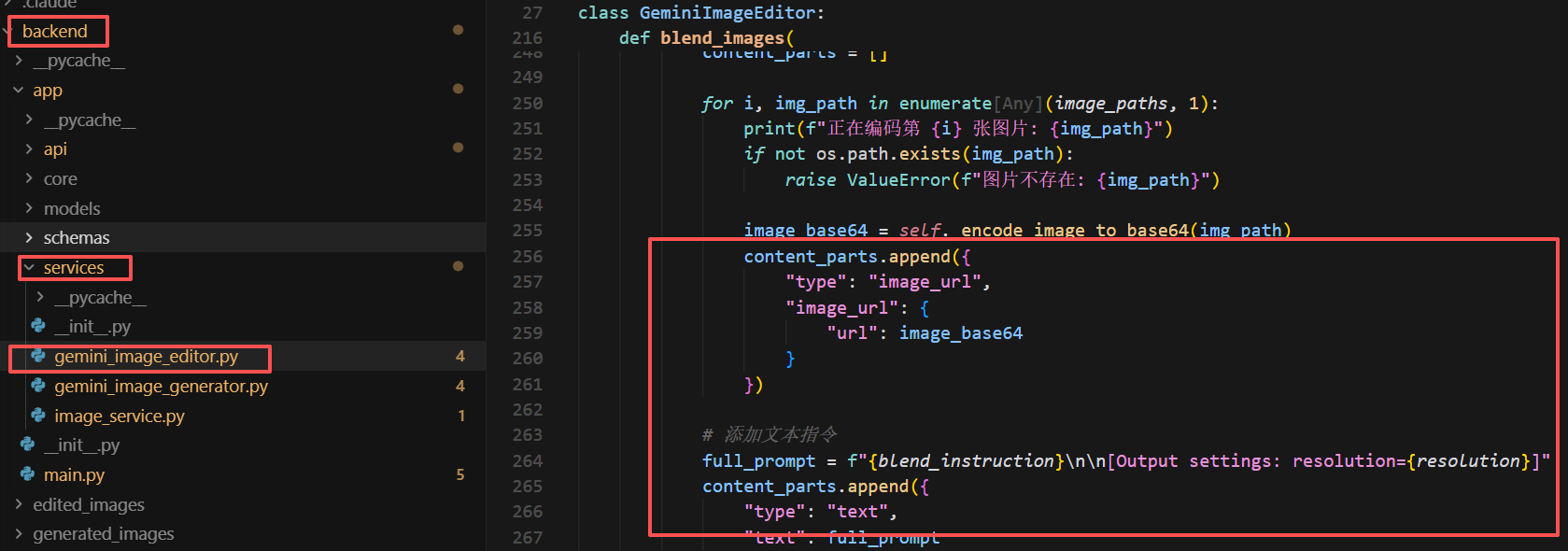
最后,我们将通过分析源码的方式,理解项目的整体架构、模块划分、数据流向,并手把手带领大家完成本地部署和局域网访问配置。
八、本地部署启动Nano Banana Pro文生图设计系统
这是一个前后端分离的全栈 AI 图像生成平台。用户可以通过 Web 界面输入文本提示词,或者上传图片进行编辑和混合,后端调用 Gemini 3 Pro Image 模型生成高质量的图像。
项目的核心亮点包括:
- 多种生成模式:支持纯文本生成、单图编辑、多图混合三种模式
- 现代化技术栈:前端 React + TypeScript + Vite,后端 FastAPI + LiteLLM
- 异步处理:后端采用异步编程,提升并发性能
- 完善的API设计:RESTful API,自动生成 Swagger 文档
- 用户友好的界面:基于 Tailwind CSS 和 Radix UI 的现代化设计
核心技术栈如下:
技术栈总览
| 分类 | 技术 | 版本 | 作用 |
|---|---|---|---|
| 前端框架 | React | 18.3.1 | UI构建 |
| 类型系统 | TypeScript | 5.7.2 | 类型安全 |
| 构建工具 | Vite | 6.3.5 | 快速开发与构建 |
| 样式框架 | Tailwind CSS | 3.4 | 原子化CSS |
| 组件库 | Radix UI | - | 无障碍组件 |
| 后端框架 | FastAPI | 0.109+ | 异步Web框架 |
| AI集成 | LiteLLM | 1.0+ | 统一LLM接口 |
| AI模型 | Gemini 3 Pro Image | - | 图像生成 |
| 图像处理 | Pillow | 10.0+ | Python图像库 |
| 服务器 | Uvicorn | 0.27+ | ASGI服务器 |
在深入分析架构之前,我们先来看看项目的整体目录结构。通过目录结构,我们可以快速了解项目的组织方式。
FENCE0
从这个目录结构可以看出,项目采用了典型的前后端分离架构。前端和后端各自独立,通过 HTTP API 进行通信。接下来,我们将逐层剖析这个架构。
这个项目采用了经典的前后端分离 + 微服务化的架构设计。整体架构可以分为三个主要层次:
- 表现层(Presentation Layer):React 前端应用
- 服务层(Service Layer):FastAPI 后端服务
- AI层(AI Layer):Gemini 3 Pro Image 模型
下面我们用一个架构图来直观地展示这三层之间的关系:
从架构图可以看到,用户通过浏览器访问前端应用,前端调用后端 API,后端再通过 LiteLLM 调用 Gemini 模型,最终将生成的图片返回给用户。
在开始部署之前,我们需要确保本地环境满足以下要求:
环境要求
| 软件 | 最低版本 | 推荐版本 | 用途 |
|---|---|---|---|
| Node.js | 18.0+ | 20.0+ | 前端构建和运行 |
| npm | 8.0+ | 10.0+ | 前端包管理 |
| Python | 3.10+ | 3.11+ | 后端运行 |
| pip | 21.0+ | 23.0+ | Python包管理 |
接下来,我们一步步部署后端服务。
- 步骤 1:下载项目源码并解压后,进入后端目录
FENCE0
- 步骤 2:创建虚拟环境(强烈推荐)
使用虚拟环境可以隔离项目依赖,避免与系统Python环境冲突。
FENCE1
激活成功后,终端提示符前会出现 (venv) 标识。

- 步骤 3:安装依赖
FENCE2
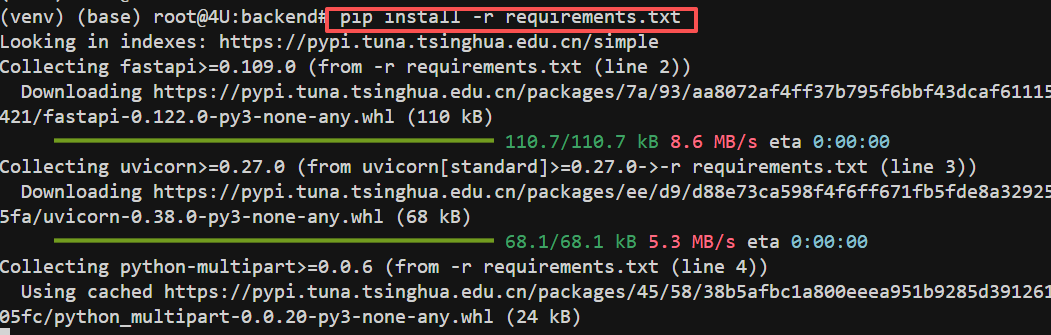
这条命令会安装所有必需的Python包,包括 fastapi、litellm、pillow 等。安装过程可能需要几分钟。
步骤 4:配置 API Key
创建 .env 文件并添加 OpenRouter API Key:
FENCE3
请将 your-api-key-here 替换为你在 OpenRouter 获取的实际 API Key。
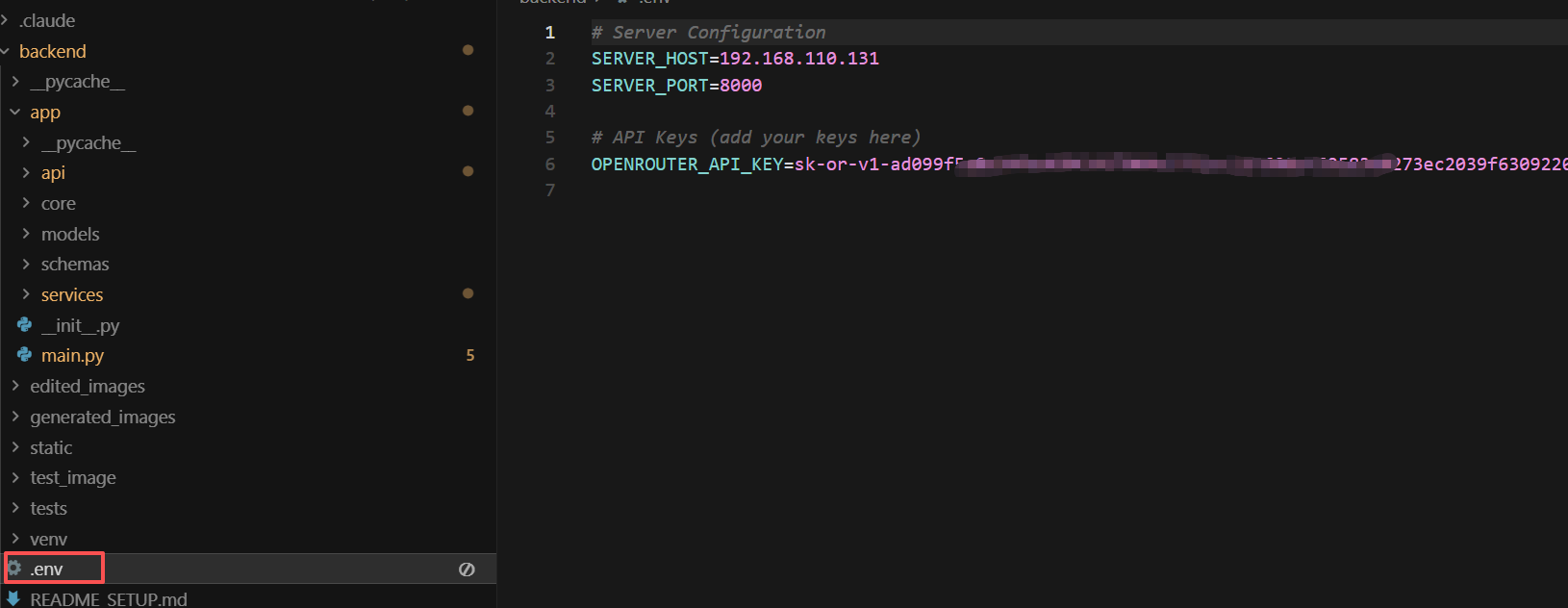
步骤 5:启动后端服务
FENCE4
启动成功后,你会看到类似以下的输出:
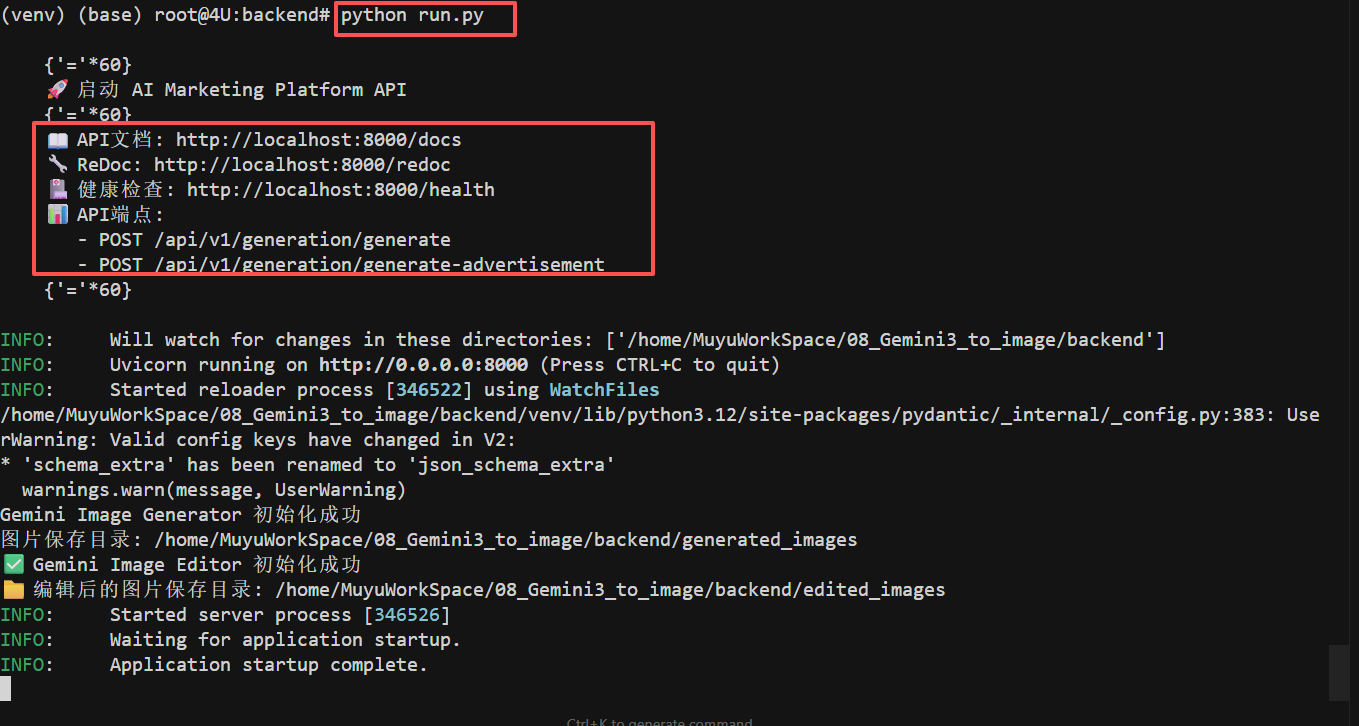
此时,后端服务已经在 http://localhost:8000 成功运行!可以在浏览器中访问 http://localhost:8000/docs 查看 API 文档。
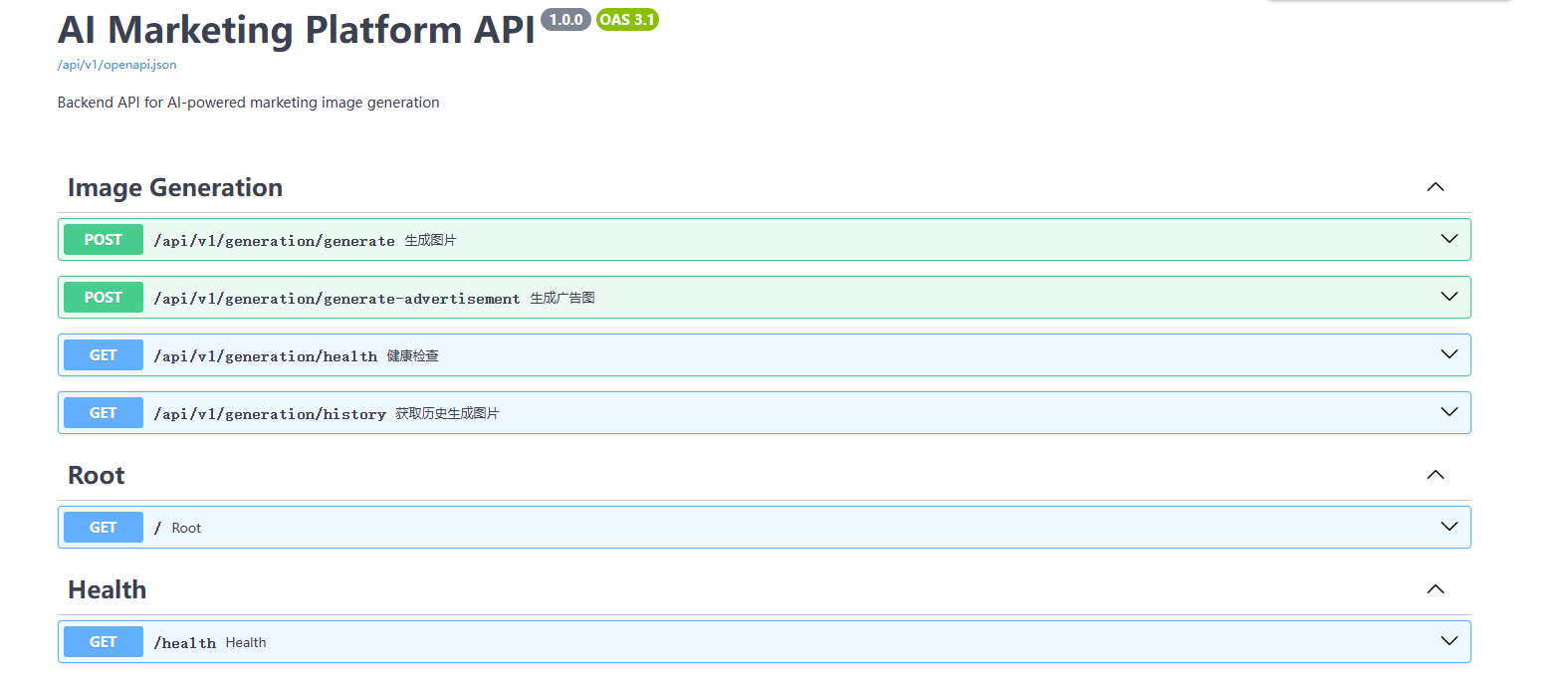
后端启动后,接下来部署前端应用。保持后端服务运行,打开一个新的终端窗口。进入前端目录并安装项目依赖:
FENCE0
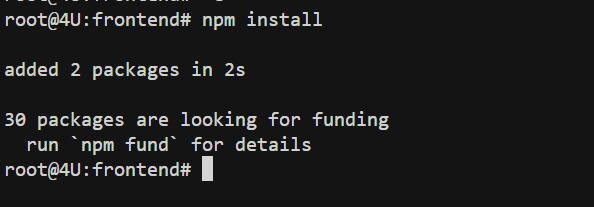
这条命令会安装所有前端依赖包,包括 react、vite、tailwindcss 等。首次安装可能需要几分钟。
启动开发服务器,执行如下命令:
FENCE1
启动成功后,你会看到类似以下的输出:
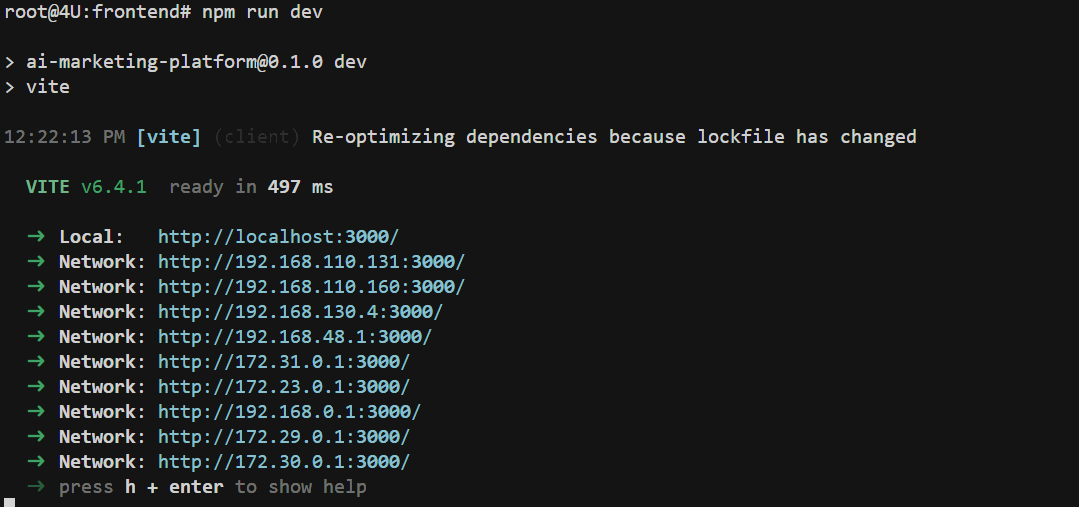
此时,前端应用已经在 http://localhost:3000 成功运行!打开浏览器,访问 http://localhost:3000,你应该能看到主页,显示 6 个创意选项卡片。
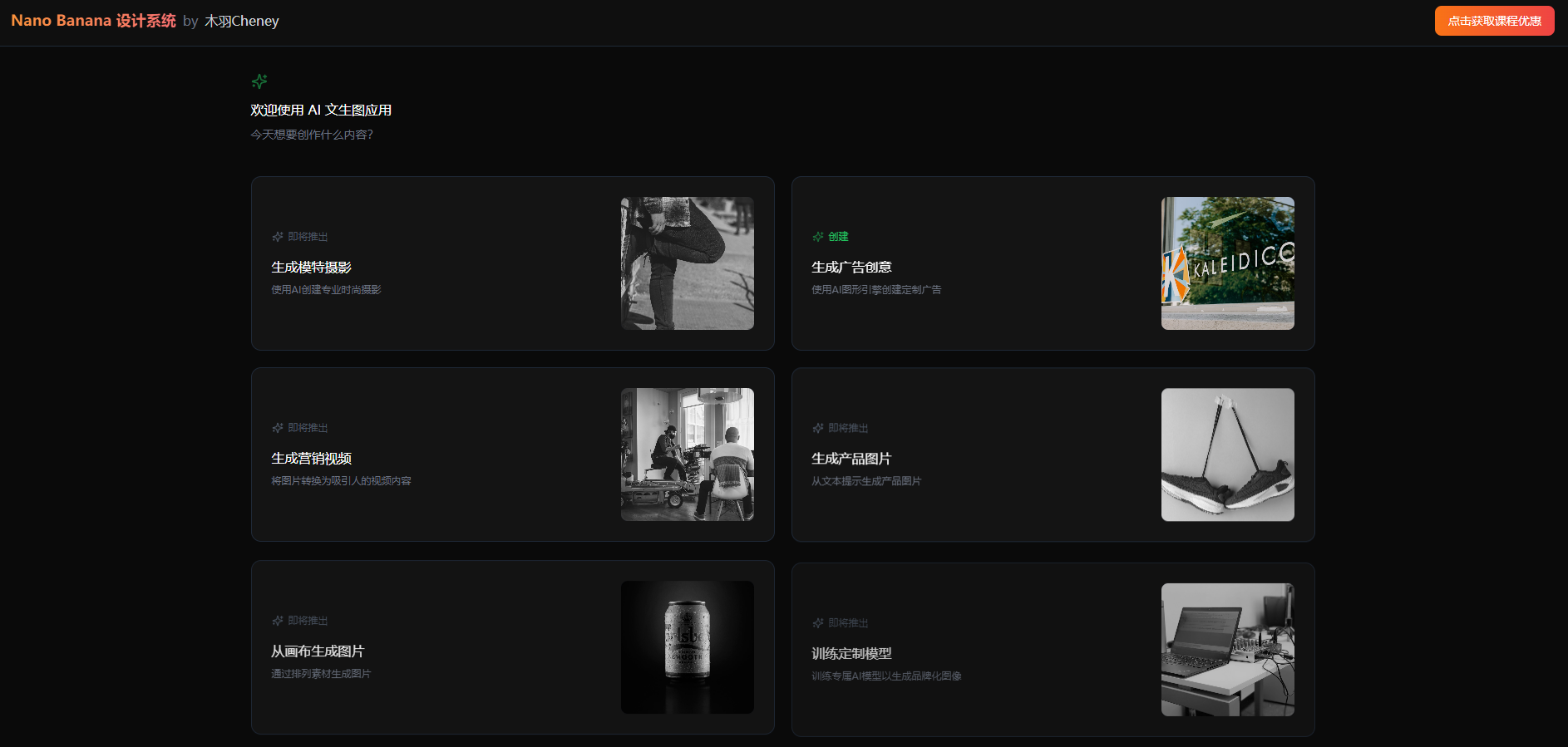
如果以上步骤都顺利完成,恭喜你!项目已经成功在本地部署运行了!
我们下期公开课,再见! 👋