课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(3月DeepSeek强化班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(3月DeepSeek强化班) :

《2025大模型Agent智能体开发实战》(3月DeepSeek强化班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

重磅新增DeepSeek技术应用与智能体开发相关实战内容:

此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(3月班)

两门大模型课程2月班目前上新特惠中,立减2000起,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

《2025大模型Agent智能体开发实战》体验课
OpenAI Responses API快速入门实战
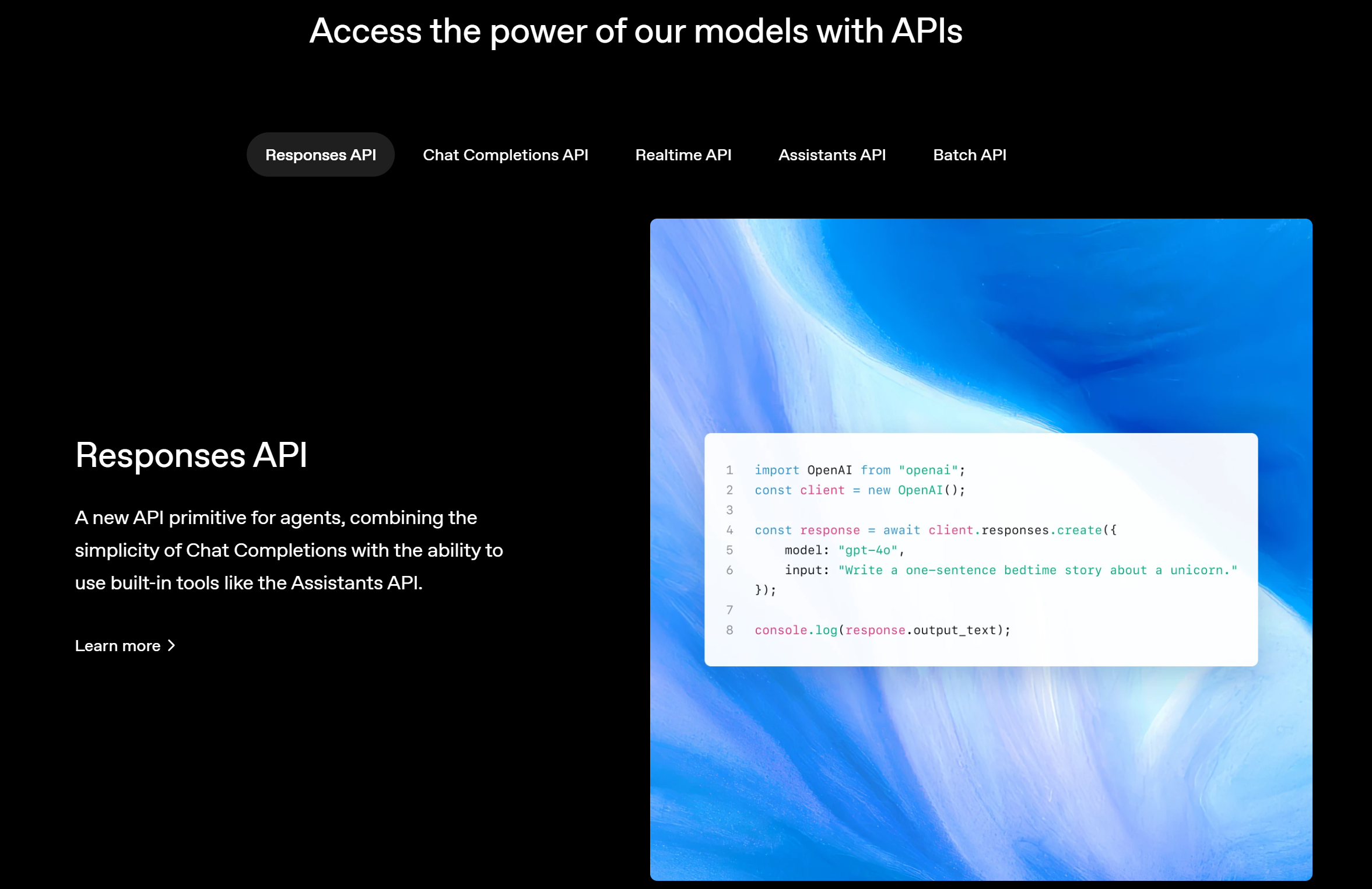
2025年3月11号,OpenAI召开发布会,正式发布全新一代底层调用API:Responses API,并计划在未来一段时间,逐渐代替Chat.Completion API,在如今OpenAI的大模型调用方法已成为业内标准的今天,这一次更新,无疑将对未来的大模型开发生态带来重大影响。
随着发布会一同发布的,还有三项Agent tools和一个开源Agent SDK,分别是:
- Web Search:允许用户联网搜索相关信息;
- File Search:允许用户将文件上传到OpenAI服务器上,并在模型对话时,实时对其进行检索;
- computer use:允许用户借助大模型功能,来操作当前电脑或浏览器。
- Agent SDK:swarm的升级版,一个开源的Multi-Agent开发框架。
对此,我曾专门录制视频进行入门介绍,感兴趣的同学可以戳此观看:https://www.bilibili.com/video/BV1SVQEYqERV/

本届公开课,我们就围绕OpenAI本次更新内容进行详细讲解。
- 课程资料及相关参考材料:OpenAI注册指南&公开课课件&国内反向代理地址,扫码即可领取。


!pip install openai
import openai
openai.__version__
from openai import OpenAI
- 传统chat.completion API调用方法回顾
openai_api_key = "YOUR_API_KEY"
base_url = "国内反向代理地址"
# 实例化客户端
client = OpenAI(api_key=openai_api_key,
base_url=base_url)
# 调用 GPT-4o-mini 模型
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "你好,好久不见!"}
]
)
response
-
GPT4o&o1模型公开课

- OpenAI o1模型入门:https://www.bilibili.com/video/BV1t82UY6Ezh/
一、Responses API基本调用方法介绍
Responses API 是 OpenAI 为智能代理(Agents)提供的全新 API 基础构件,它结合了 Chat Completions API 的简洁性 与 Assistants API 的内置工具能力,使得代理能够更智能地执行任务。
📌 核心特点
- ✅ 简洁易用:继承了 Chat Completions API 的易用性。
- ✅ 增强功能:支持内置工具(Tools),如函数调用(Function Calling)、Web 搜索、文件搜索、计算机控制等。
- ✅ 适用于代理(Agents):可用于构建智能化任务执行系统。
🔗 未来发展:Responses API 旨在成为 OpenAI 代理系统的核心 API,结合 Agents SDK,提供更灵活的任务编排能力。

1.文本生成
使用 OpenAI API,你可以通过一个 简单的提示(prompt) 让模型生成文本,类似于 ChatGPT 的工作方式。
response = client.responses.create(
model="gpt-4o",
input="你好,好久不见,请介绍下你自己!"
)
response
response.output_text
2. 响应结构
OpenAI 的 API 响应包含一个内容数组(output),每个内容项具有以下结构:
FENCE0
📌 重要说明:
output可能包含多个结果,在多轮对话或批量生成时尤其明显。- 一些 SDK 提供
output_text属性,可以直接获取所有文本输出,方便访问文本数据。 - 除了纯文本,模型还可以返回 JSON 结构化数据(称为 Structured Outputs)。
response.output
response.output[0]
response.output[0].content
response.output[0].content[0]
response.output[0].content[0].text
3. 消息角色与指令控制
我们可以使用不同的方式给模型提供指令:
- 使用
instructions参数 提供全局行为指令,如语气、目标等。(权重最高) - 使用
input数组,指定不同角色的消息。
response = client.responses.create(
model="gpt-4o",
instructions="用海盗的口吻说话。",
input="JavaScript 中的分号是可选的吗?",
)
print(response.output_text)
📌 在 instructions 中定义“说话像海盗”后,模型会以海盗风格回答。
此外,也可以使用 input 数组还可以指定多种角色,例如使用developer角色,developer 角色类似于 系统设定,用户输入 user 角色的内容,最终 模型按 developer 设定风格回答。
response = client.responses.create(
model="gpt-4o",
input=[
{
"role": "developer",
"content": "用海盗的口吻说话。"
},
{
"role": "user",
"content": "JavaScript 中的分号是可选的吗?"
}
]
)
print(response.output_text)
4. 消息角色的优先级
OpenAI 规定不同角色的优先级如下:
| 角色 | 优先级 | 说明 |
|---|---|---|
developer | 最高 | 由开发者提供的指令,优先级最高,类似 system。 |
user | 次高 | 由最终用户提供的输入,次于 developer。 |
assistant | 最低 | 由模型生成的响应。 |
5.推理模型调用
- 查看可以调用的模型
models_list = client.models.list()
models_list.data
- 借助o3模型进行调用
response = client.responses.create(
model="o3-mini",
input="你好,请帮我编写一个贪吃蛇小游戏,并能在html中运行。"
)
from IPython.display import display, Code, Markdown
response.output_text
print(response.output_text)
- responses API参数列表
| 参数名 | 类型 | 必填/可选 | 默认值 | 说明 |
|---|---|---|---|---|
| model | string | 必填 | 无 | 指定要使用的模型 ID,例如 gpt-4o 或 gpt-4o-mini。 |
| store | boolean or null | 可选 | false | 是否存储本次对话的输出,供模型精炼或评估产品使用。 |
| metadata | object or null | 可选 | null | 开发者自定义的标签和值,用于过滤仪表盘中的补全结果。 |
| frequency_penalty | number or null | 可选 | 0 | 数值在 -2.0 到 2.0 之间,正值减少重复生成内容的可能性。 |
| logit_bias | map | 可选 | null | 调整某些特定 tokens 出现的可能性,值在 -100 到 100 之间。 |
| logprobs | boolean or null | 可选 | false | 是否返回生成的每个 token 的对数概率。 |
| top_logprobs | integer or null | 可选 | null | 指定返回最有可能出现的前几个 tokens 及其概率,需开启 logprobs。 |
| max_completion_tokens | integer or null | 可选 | null | 指定模型生成的最大 token 数,包括可见文本和推理 tokens。 |
| n | integer or null | 可选 | 1 | 每个输入生成的对话补全选项数量,值越大,生成的回复越多。 |
| presence_penalty | number or null | 可选 | 0 | 数值在 -2.0 到 2.0 之间,正值鼓励生成新的主题和内容。 |
| response_format | object | 可选 | null | 指定生成结果的格式,可以设置为 json_schema 以确保结构化输出,或 json_object 用于 JSON 格式。 |
| seed | integer or null | 可选 | null | 保持生成的一致性,重复相同请求将尽量生成相同的结果。 |
| service_tier | string or null | 可选 | auto | 指定服务延迟等级,适用于付费订阅用户,默认为 auto。 |
| stop | string / array / null | 可选 | null | 最多指定 4 个序列,API 遇到这些序列时会停止生成进一步的 tokens。 |
| stream | boolean or null | 可选 | false | 是否启用流式响应,若启用,生成的 tokens 将逐步返回。 |
| stream_options | object or null | 可选 | null | 流式响应的选项,仅当 stream 为 true 时设置。 |
| temperature | number or null | 可选 | 1 | 控制生成输出的随机性,值越高生成的文本越随机。建议调整此值或 top_p,而不是同时调整。 |
| top_p | number or null | 可选 | 1 | 使用核采样方法,选择最有可能的 tokens,总概率达到 top_p 百分比。建议与 temperature 二选一。 |
| tools | array | 可选 | null | 模型可以调用的工具列表,目前仅支持函数调用。 |
| user | string | 可选 | null | 表示最终用户的唯一标识符,用于监控和检测滥用行为。 |
参数解释:
-
模型和输出相关参数:
model是必填参数,决定使用哪个模型(如gpt-4o或gpt-4o-mini)。store控制是否存储生成的对话结果,便于后续模型训练或评估。metadata用于添加开发者自定义的标签,便于在仪表盘中过滤补全结果。max_completion_tokens和n控制生成内容的数量和长度,帮助管理生成成本。
-
生成行为控制:
frequency_penalty和presence_penalty都用于影响生成结果的内容重复度和新颖性。logit_bias是用于调整特定 token 出现概率的高级控制工具。temperature和top_p通过不同的方式控制生成结果的随机性,建议选其一进行调整。
-
高级功能:
logprobs和top_logprobs用于返回每个 token 的概率信息,适合对模型输出进行更细粒度分析。stream启用后会实时返回生成的结果,适用于需要逐步展示内容的场景。tools允许模型调用外部工具(如函数),适用于扩展模型的功能。
-
服务和用户相关参数:
service_tier控制服务的延迟和稳定性,适合高性能要求的付费用户。user用于标识最终用户,有助于监控使用行为,防止滥用。
三、Web Search(网页搜索)功能实现
OpenAI Agents SDK 支持网页搜索,允许模型在生成回答之前查询最新的信息,类似于 ChatGPT 的搜索功能,并提供清晰的引用来源。
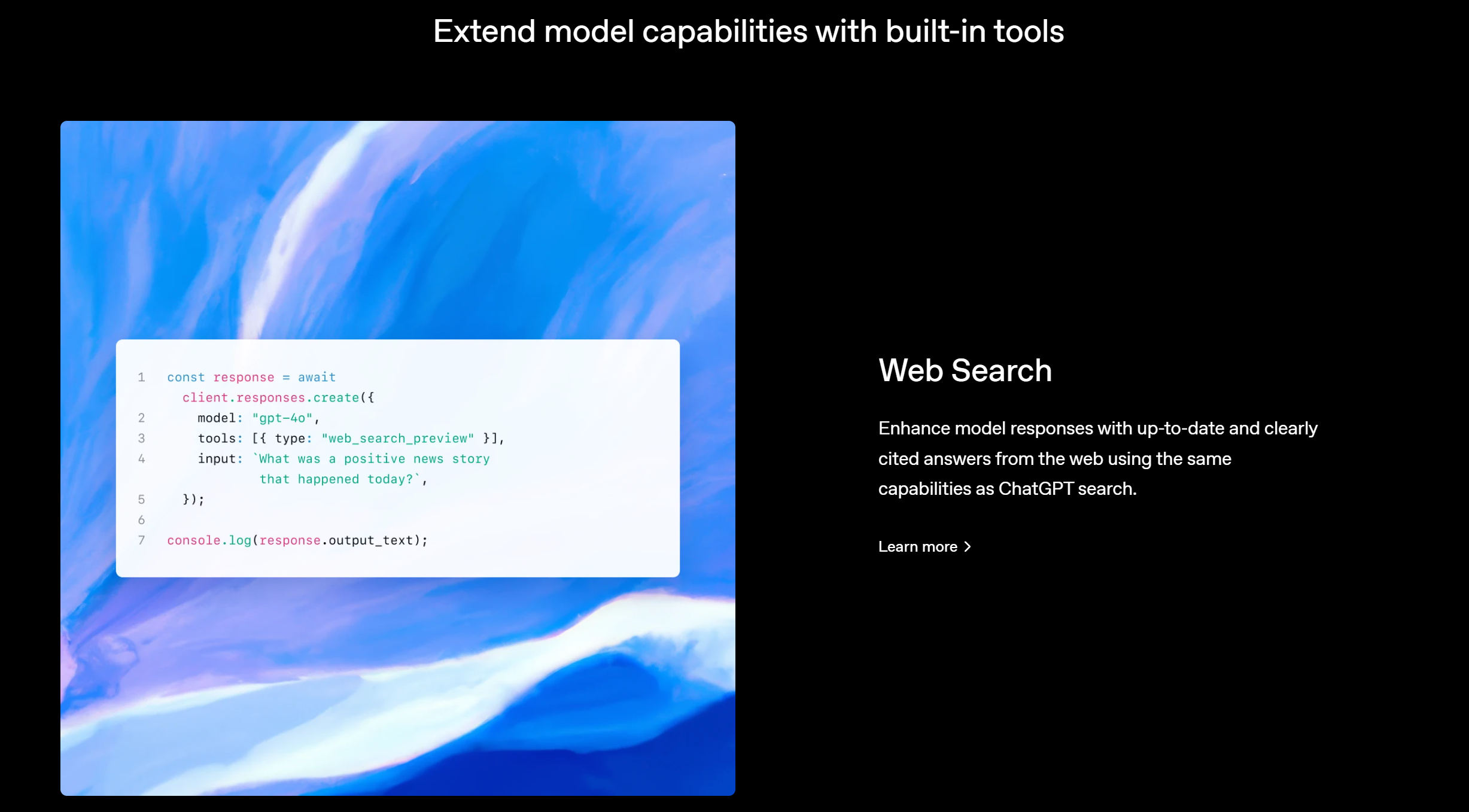
response = client.responses.create(
model="gpt-4o",
tools=[{"type": "web_search_preview"}], # 启用 Web 搜索工具
input="今天有什么正面的新闻吗?"
)
print(response.output_text)
📌 效果:
- 该 API 请求会调用
web_search_preview,允许模型在回答前搜索最新的新闻。 - 但模型可以自行决定是否使用该工具。
response
response1 = client.responses.create(
model="gpt-4o",
tools=[{"type": "web_search_preview"}], # 启用 Web 搜索工具
input="请帮我讲个笑话吧。"
)
print(response1.output_text)
2. 强制使用 Web 搜索
如果希望确保模型一定使用 Web 搜索(避免它仅使用内部知识回答),可以设置 tool_choice 参数:
FENCE0
📌 作用:
- 让 Web 搜索始终执行,而不是让模型决定是否使用搜索工具。
- 提升一致性,但可能会增加查询时间。
3. 输出格式与引用
如果模型调用了 Web 搜索,API 响应将包含两部分:
- Web 搜索调用的 ID
- 模型的回答,并带有网页来源的引用信息
📌 示例输出:
FENCE0
response
response.output
len(response.output)
response.output[0]
response.output[1]
response.output[1].content
response.output[1].content[0]
response.output[1].content[0].annotations
response.output[1].content[0].text
4. 指定位置搜索
Web 搜索可以根据用户的位置优化搜索结果。你可以指定:
country(国家):两字母 ISO 代码,如"US"(美国)、"GB"(英国)。city(城市):如"London"(伦敦)。region(地区):如"California"(加州)。timezone(时区):如"America/Chicago"(芝加哥时间)。
response = client.responses.create(
model="gpt-4o",
tools=[{
"type": "web_search_preview",
"user_location": {
"type": "approximate",
"country": "CN",
"city": "Beijing",
"region": "Beijing",
}
}],
input="北京三里屯附近最好吃的餐厅有哪些?",
)
print(response.output_text)
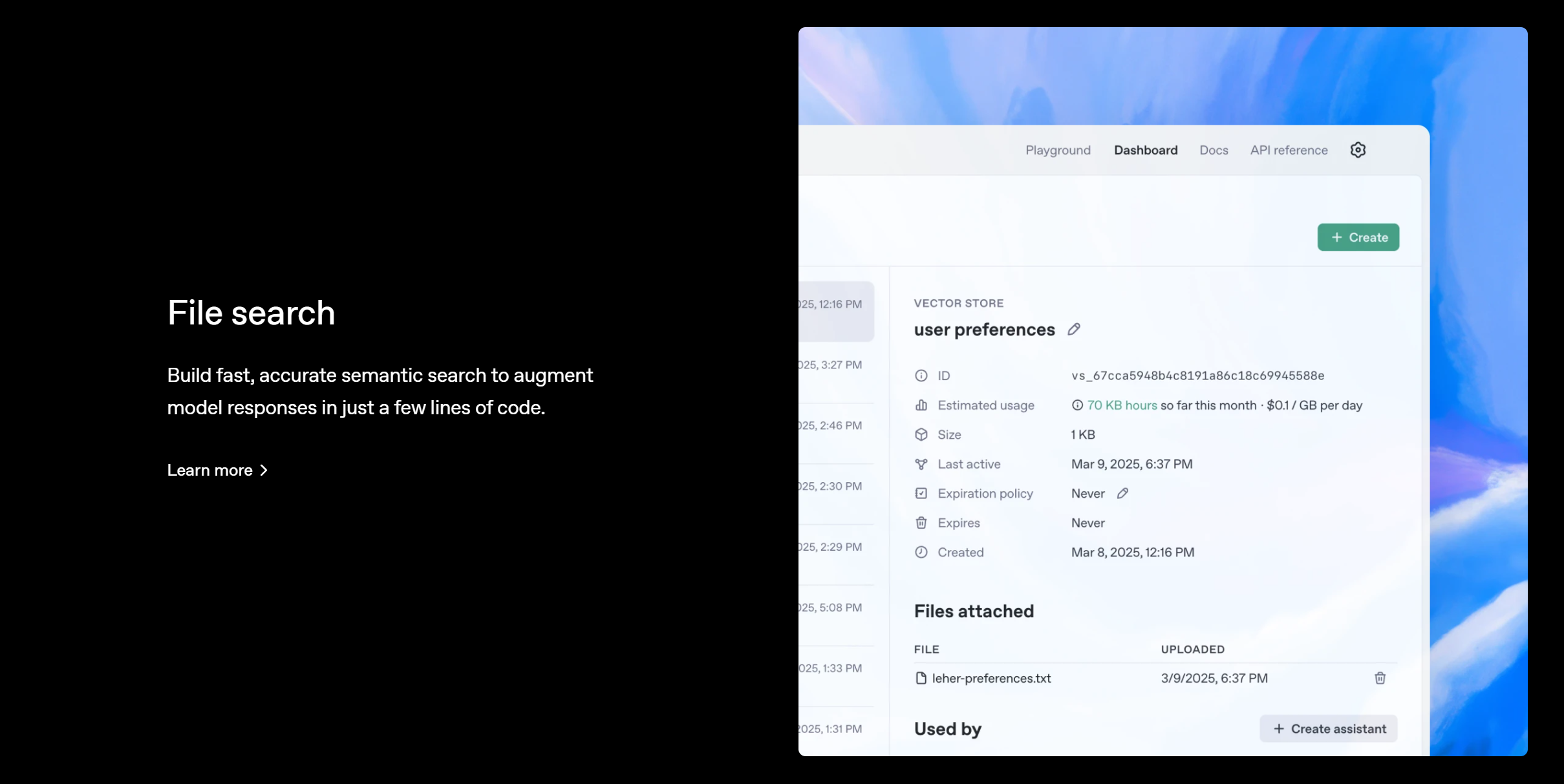
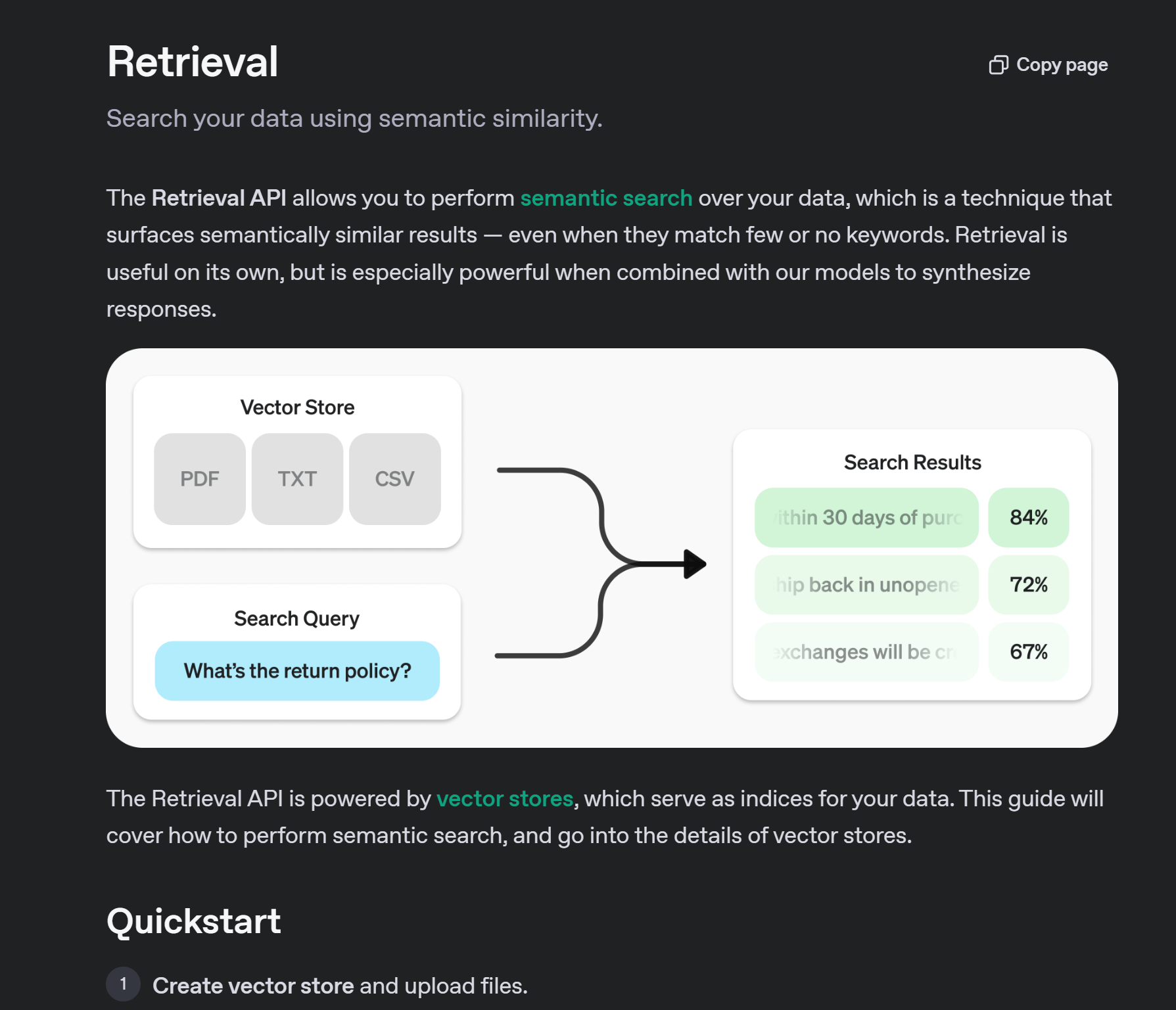
四、文件搜索(File Search)
OpenAI Agents SDK 支持文件搜索功能,允许模型在生成回答之前检索用户上传的文件中的相关信息。
- OpenAI文档检索技术文档:https://platform.openai.com/docs/guides/retrieval
-
创建向量库
-
Vector store:https://platform.openai.com/docs/api-reference/vector-stores
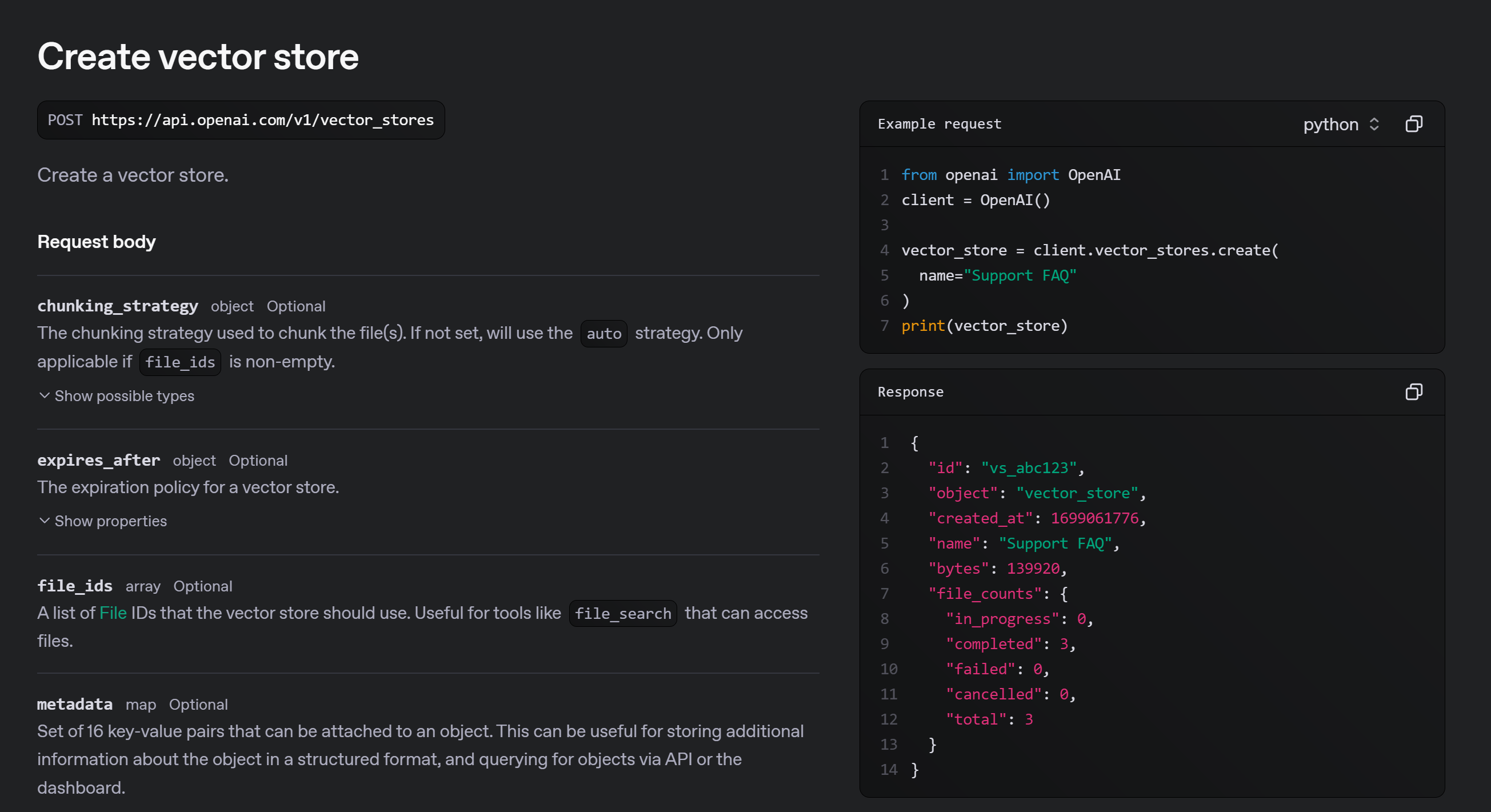
vector_store = client.vector_stores.create(
name="test-file"
)
print(vector_store)
vector_store.id
- 上传文档

# 准备上传到OpenAI的文件
file_paths = ["OpenAI Agents API翻译文档.md"]
file_streams = [open(path, "rb") for path in file_paths]
file_streams
file_batch = client.vector_stores.file_batches.upload_and_poll(
vector_store_id=vector_store.id, files=file_streams
)
print(file_batch.status)
print(file_batch.file_counts)
1. 文件搜索功能概述
file_search 工具可以让模型在已上传的文件知识库(vector stores)中进行语义搜索和关键词搜索,从而扩展模型的内在知识。
📌 特点:
- 托管工具(由 OpenAI 负责管理,无需用户自行实现搜索逻辑)。
- 自动调用:模型决定何时使用该工具进行检索。
- 向量存储支持:通过创建向量存储并上传文件来增强模型的知识。
📌 相关概念:
- Vector Store(向量存储):一个可存储文本向量化数据的数据库,支持语义检索。
- Semantic Search(语义搜索):利用向量表示进行相似性匹配,而不仅仅是关键字匹配。
📌 学习更多:可参考 OpenAI Retrieval Guide(检索指南)。
2. 使用文件搜索
在使用文件搜索前,用户需要:
- 创建向量存储(Vector Store)。
- 上传文件到向量存储。
- 在 API 调用中启用
file_search,并指定向量存储 ID。
📌 ⚠️ 限制:
- 目前 一次搜索仅支持一个向量存储(
vector_store_ids只能包含一个 ID)。
3.启用文件检索
response = client.responses.create(
model="gpt-4o-mini",
input="你知道OpenAI的responses API是什么么?",
tools=[{
"type": "file_search",
"vector_store_ids": ["vs_67d41ac1c3e08191ad00db04996b631f"] # 指定要搜索的向量存储
}]
)
print(response.output_text)
4. API 响应结构
当 file_search 工具被调用后,API 响应将包含两部分:
file_search_call:存储搜索请求的 ID 和查询内容。message:存储模型的回答,并包含文件引用信息(file citations)。
response
📌 解析:
-
file_search_call:存储搜索请求的 ID、状态和查询内容。 -
message:output_text:模型生成的文本。annotations:提供引用文件信息,包括file_id和filename,标明信息的来源。
让 API 响应包含搜索结果
response = client.responses.create(
model="gpt-4o-mini",
input="你知道OpenAI的responses API是什么么?",
tools=[{
"type": "file_search",
"vector_store_ids": ["vs_67d41ac1c3e08191ad00db04996b631f"]
}],
include=["output[*].file_search_call.search_results"]
)
📌 作用:
include参数指定要包含search_results,以便直接获取搜索的原始数据。
print(response)
response.output_text
此时检索到的20个文档片段如下:
response.output[0].results
五、计算机使用(Computer Use)
OpenAI 的 计算机使用代理(Computer-Using Agent, CUA) 允许模型模拟人在计算机上操作,例如点击、输入、滚动等,从而执行自动化任务。
1. 概述
Computer Use(计算机使用) 是 OpenAI 提供的一种增强版 CUA(计算机使用代理),基于 computer-use-preview 模型,结合:
- GPT-4o 的视觉能力(识别屏幕截图)
- 高级推理能力(模拟计算机界面交互)
📌 特点:
- 允许模型执行计算机操作(如点击、输入文本、滚动页面)。
- 通过截图感知界面变化,并决定下一步操作。
- 可用于网页浏览、数据输入、在线购物、表单填写等任务。
📌 当前状态:
- Beta 版,可能存在漏洞或错误。
- 不适用于高安全性任务(如银行交易、个人账户管理)。
- 必须符合 OpenAI 的使用政策 。
📌 适用 API:
- ✅ Responses API
- ❌ 不适用于 Chat Completions
2. 工作原理
计算机使用工具的执行流程是一个循环(loop):
-
发送请求:用户提供目标任务(如“在 Bing 搜索 OpenAI 最新新闻”)。
-
接收响应
:
- 模型可能返回计算机操作(computer_call)(如点击、输入)。
- 也可能返回推理结果(reasoning) 或安全检查(safety_check)。
-
执行操作:应用代码模拟操作,如点击、输入文本。
-
获取更新状态:执行操作后,截图当前界面并传回模型。
-
重复以上步骤,直到模型完成任务或用户停止。
📌 该流程适用于:
- 浏览器操作(
browser) - 本地操作(
mac、windows、ubuntu)
3. 环境设置
为了安全地运行 CUA(计算机使用代理),建议:
- 使用隔离环境(sandbox),避免影响真实系统。
- 创建本地虚拟机 以模拟计算机环境。
📌 示例环境:
| 环境类型 | 适用场景 |
|---|---|
| 本地浏览器 | 网页自动化(如搜索、填表) |
| 虚拟机(VM) | 安全测试,避免破坏主系统 |
| 云端实例 | 远程执行自动化任务 |
本地环境设置方法如下:
如果希望以最小的配置尝试 Computer Use 工具,可以使用 Playwright 或 Selenium 等浏览器自动化框架。
⚠️ 安全提示:
在本地运行浏览器自动化框架 可能存在安全风险,建议按照以下方式进行安全防护:
推荐的安全设置:
- 使用沙盒环境(sandboxed environment)
- 设置
env为一个空对象,以避免暴露主机环境变量给浏览器 - 配置启动标志(flags),以禁用扩展程序和文件系统
- 启动浏览器实例
启动浏览器实例
示例:使用 Playwright 启动浏览器
安装 Playwright SDK:
!pip install playwright
!playwright install chromium
import asyncio
from playwright.async_api import async_playwright
import nest_asyncio
# 允许 Jupyter Notebook 运行异步任务
nest_asyncio.apply()
async def run():
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=False, # 设为 False 以可视化运行浏览器
args=[
"--disable-extensions", # 禁用扩展程序
"--disable-file-system" # 禁用文件系统访问
]
)
page = await browser.new_page()
await page.set_viewport_size({"width": 1024, "height": 768}) # 设置窗口大小
await page.goto("https://bing.com") # 访问 Bing 网站
await page.wait_for_timeout(10000) # 等待 10 秒
await browser.close() # 关闭浏览器
# 运行异步任务
asyncio.run(run())
4. CUA 集成流程
要在你的应用程序中集成 Computer Use 工具,你需要遵循以下步骤:
1️⃣ 向模型发送请求(Send a request to the model)
- 在请求中包含 Computer Use 工具,作为可用工具的一部分。
- 指定显示尺寸(display size)和环境信息(environment)。
- 可选:在首次请求中附加环境的初始状态截图,帮助模型理解当前界面。
2️⃣ 接收模型的响应(Receive a response from the model)
- 检查模型返回的响应中是否包含 computer_call 项目。
- computer_call 代表模型建议的下一步操作,例如:
- 点击(clicking)指定位置
- 输入文本(typing in text)
- 滚动页面(scrolling)
- 等待(waiting)
3️⃣ 执行请求的操作(Execute the requested action)
- 通过代码在计算机或浏览器环境中执行模型建议的操作。
4️⃣ 捕获更新后的界面状态(Capture the updated state)
- 执行操作后,截取当前界面的最新状态作为截图,用于下一步交互。
5️⃣ 循环执行(Repeat)
- 将更新后的状态作为 computer_call_output,并发送新的请求。
- 继续这个循环交互,直到:
- 模型不再请求新操作,或
- 你决定终止执行。
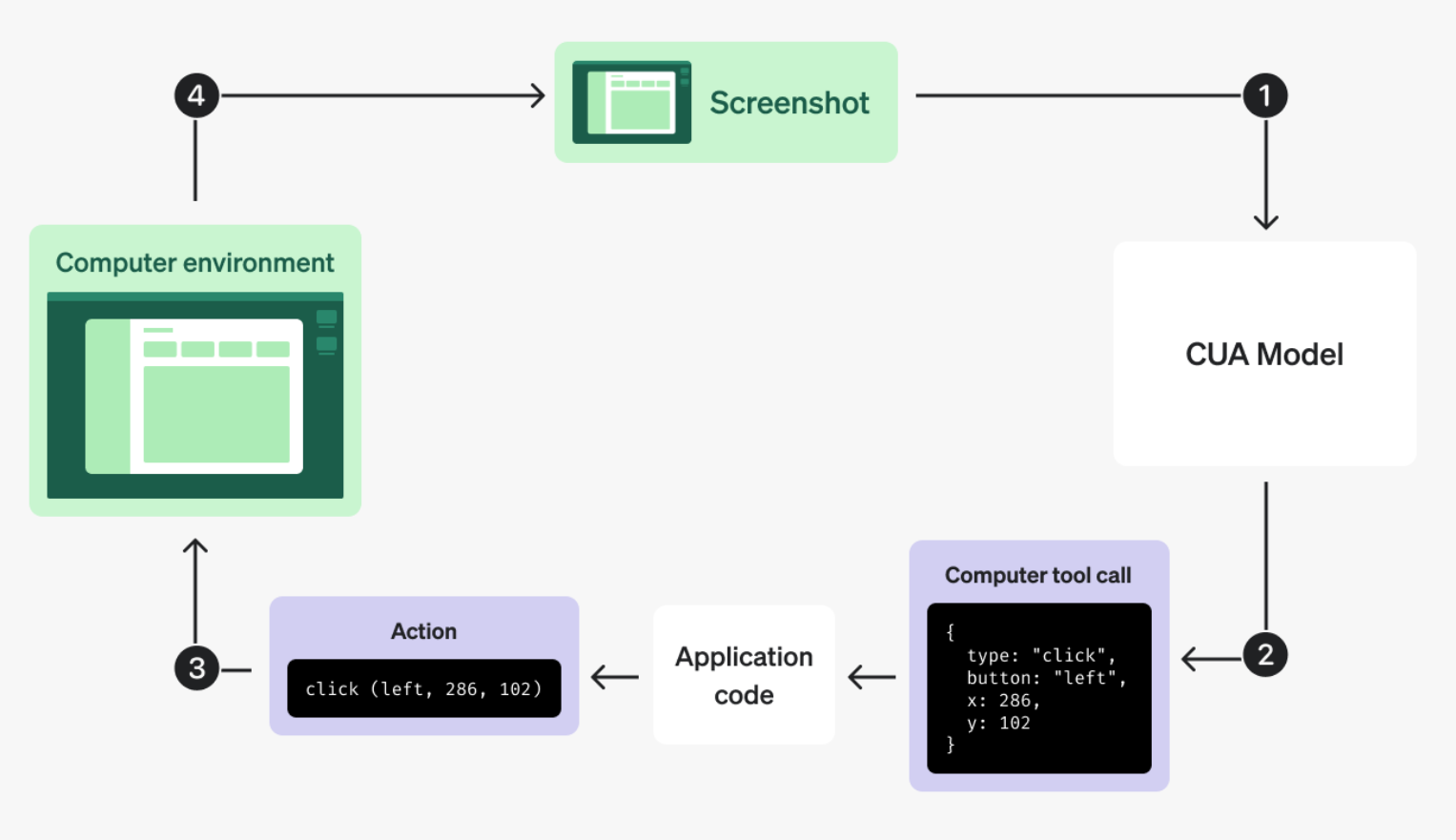
具体代码执行流程如下:
🌟1. 向模型发送请求(Send a request to the model)
发送请求以创建 Response,使用 computer-use-preview 模型,并启用 computer_use_preview 工具。
该请求应包括 环境的详细信息,以及初始输入提示(input prompt)。
📌 可选项:
你可以 附加环境的初始状态截图,帮助模型更好地理解当前界面。
📌 注意:
要使用 computer_use_preview 工具,必须将 truncation 参数 设置为 "auto"。
(默认情况下,truncation 是禁用的)。
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="computer-use-preview",
tools=[{
"type": "computer_use_preview",
"display_width": 1024,
"display_height": 768,
"environment": "browser" # other possible values: "mac", "windows", "ubuntu"
}],
input=[
{
"role": "user",
"content": "Check the latest OpenAI news on bing.com."
}
# Optional: include a screenshot of the initial state of the environment
# {
# type: "input_image",
# image_url: f"data:image/png;base64,{screenshot_base64}"
# }
],
reasoning={
"generate_summary": "concise",
},
truncation="auto"
)
print(response.output)
📌 效果:
- 该 API 请求会启动计算机代理,让它在 Bing 上搜索 OpenAI 新闻。
- 可选:传入界面截图(Base64 编码)以帮助模型理解当前环境。
🌟 2. 接收建议操作
模型的 API 响应可能包含:
- 文本输出
- 计算机操作(computer_call)
- 其他工具调用
📌 示例:模型返回点击操作
FENCE0
📌 解析:
computer_call:告诉应用程序执行点击操作(在x=156, y=50)。reasoning:提供推理过程(如果有)。pending_safety_checks:如果存在安全检查,应用程序需要处理。
🌟 3. 执行操作
在 计算机或浏览器 环境中执行模型建议的操作。
📌 如何通过代码将 computer_call 映射到具体操作 取决于你的环境。
def handle_model_action(page, action):
"""
Given a computer action (e.g., click, double_click, scroll, etc.),
execute the corresponding operation on the Playwright page.
"""
action_type = action.type
try:
match action_type:
case "click":
x, y = action.x, action.y
button = action.button
print(f"Action: click at ({x}, {y}) with button '{button}'")
# Not handling things like middle click, etc.
if button != "left" and button != "right":
button = "left"
page.mouse.click(x, y, button=button)
case "scroll":
x, y = action.x, action.y
scroll_x, scroll_y = action.scroll_x, action.scroll_y
print(f"Action: scroll at ({x}, {y}) with offsets (scroll_x={scroll_x}, scroll_y={scroll_y})")
page.mouse.move(x, y)
page.evaluate(f"window.scrollBy({scroll_x}, {scroll_y})")
case "keypress":
keys = action.keys
for k in keys:
print(f"Action: keypress '{k}'")
# A simple mapping for common keys; expand as needed.
if k.lower() == "enter":
page.keyboard.press("Enter")
elif k.lower() == "space":
page.keyboard.press(" ")
else:
page.keyboard.press(k)
case "type":
text = action.text
print(f"Action: type text: {text}")
page.keyboard.type(text)
case "wait":
print(f"Action: wait")
time.sleep(2)
case "screenshot":
# Nothing to do as screenshot is taken at each turn
print(f"Action: screenshot")
# Handle other actions here
case _:
print(f"Unrecognized action: {action}")
except Exception as e:
print(f"Error handling action {action}: {e}")
🌟 4. 获取更新后的界面状态
执行操作后,截取当前环境的最新状态截图,以反映操作后的界面变化。
📌 注意:
- 截图的获取方式因环境不同而有所不同。
- 你需要根据具体环境选择合适的方法来捕获更新后的界面状态。
def get_screenshot(page):
"""
Take a full-page screenshot using Playwright and return the image bytes.
"""
return page.screenshot()
📌 效果:
- 代码会截图当前屏幕,并将其作为
input_image传给模型,继续执行任务。
🌟5. 循环执行(Repeat)
当你获取到 最新的截图 后,可以将其作为 computer_call_output 发送回模型,以获取下一步操作。
📌 循环执行:
- 只要模型返回
computer_call项目,就继续按照 「发送请求 → 执行操作 → 获取截图」 的流程重复执行,直到模型不再请求新操作。
import time
import base64
from openai import OpenAI
client = OpenAI()
def computer_use_loop(instance, response):
"""
Run the loop that executes computer actions until no 'computer_call' is found.
"""
while True:
computer_calls = [item for item in response.output if item.type == "computer_call"]
if not computer_calls:
print("No computer call found. Output from model:")
for item in response.output:
print(item)
break # Exit when no computer calls are issued.
# We expect at most one computer call per response.
computer_call = computer_calls[0]
last_call_id = computer_call.call_id
action = computer_call.action
# Execute the action (function defined in step 3)
handle_model_action(instance, action)
time.sleep(1) # Allow time for changes to take effect.
# Take a screenshot after the action (function defined in step 4)
screenshot_bytes = get_screenshot(instance)
screenshot_base64 = base64.b64encode(screenshot_bytes).decode("utf-8")
# Send the screenshot back as a computer_call_output
response = client.responses.create(
model="computer-use-preview",
previous_response_id=response.id,
tools=[
{
"type": "computer_use_preview",
"display_width": 1024,
"display_height": 768,
"environment": "browser"
}
],
input=[
{
"call_id": last_call_id,
"type": "computer_call_output",
"output": {
"type": "input_image",
"image_url": f"data:image/png;base64,{screenshot_base64}"
}
}
],
truncation="auto"
)
return response
处理会话历史(Handling conversation history)
你可以使用 previous_response_id 参数,将当前请求与上一次响应关联。
- 如果你不想自己管理会话历史,建议使用此方法。
📌 如果不使用 previous_response_id,请确保:
- 在
inputs数组中包含 上一次请求返回的所有response output项目, - 如果响应中包含
reasoning项目,也需要一并包含。
确认安全检查(Acknowledge safety checks)
OpenAI 在 API 中实施了安全检查,以防止提示词注入(prompt injection) 和 模型错误。
这些安全检查包括:
1️⃣ 恶意指令检测(Malicious instruction detection)
- 评估截图图像,检测是否存在对抗性内容,防止其改变模型行为。
2️⃣ 无关域名检测(Irrelevant domain detection)
- 检查
current_url(如果提供),确定当前访问的域名是否与会话历史相关。
3️⃣ 敏感域名检测(Sensitive domain detection)
- 检查
current_url(如果提供),如果检测到访问了敏感域名,则会触发警告。
📌 如果触发上述一个或多个检查:
- 模型返回
computer_call时,会附带pending_safety_checks参数,指示需要进行安全检查。
五、Computer Use功能展示
- Computer Using Agent Sample App:https://github.com/openai/openai-cua-sample-app
- 基本环境准备
FENCE0
- 设置API-KEY
FENCE0
然后输入OPENAI_API_KEY="YOUR_API_KEY"
- 调用测试
FENCE0
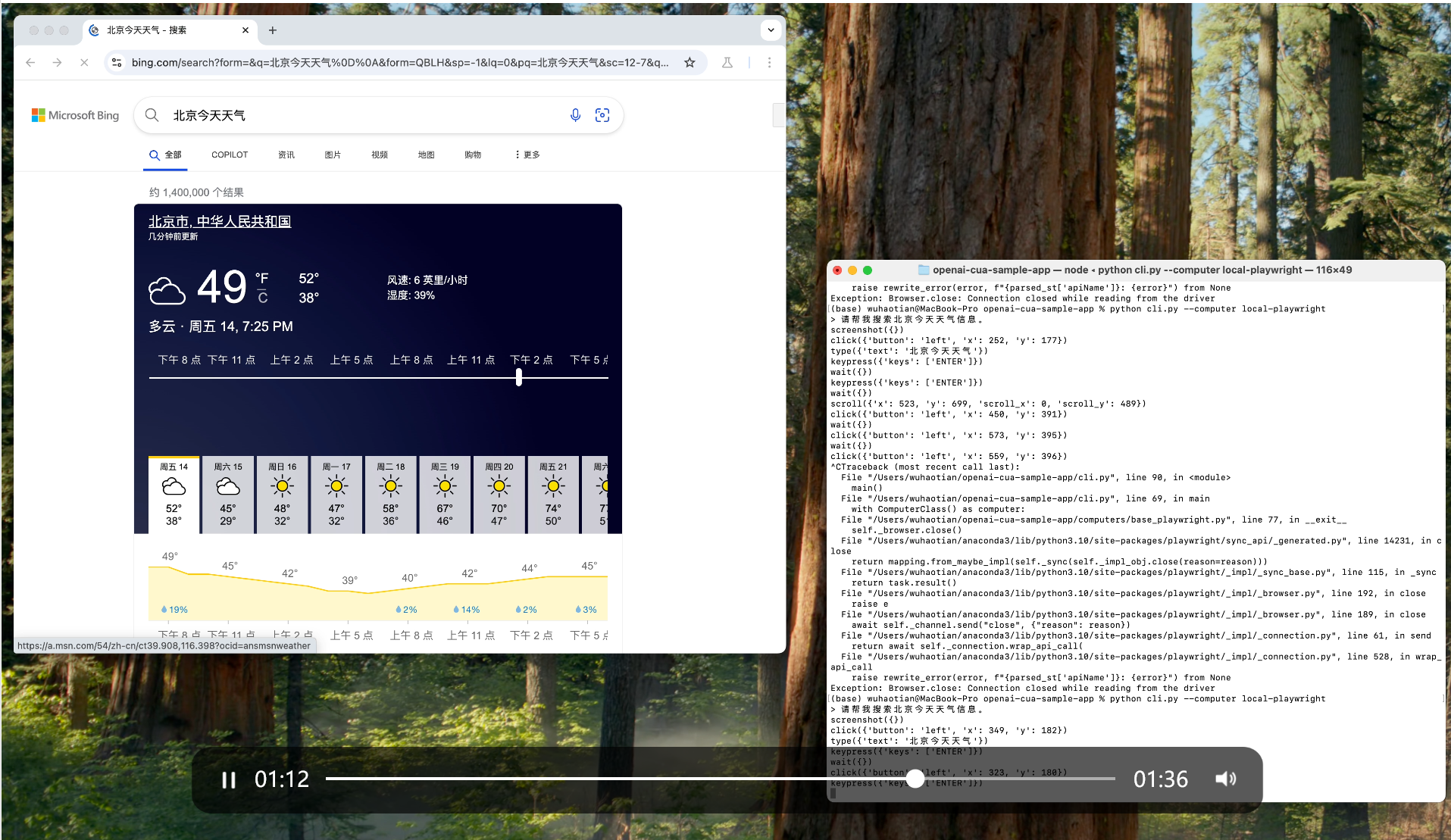
六、MateGen功能演示
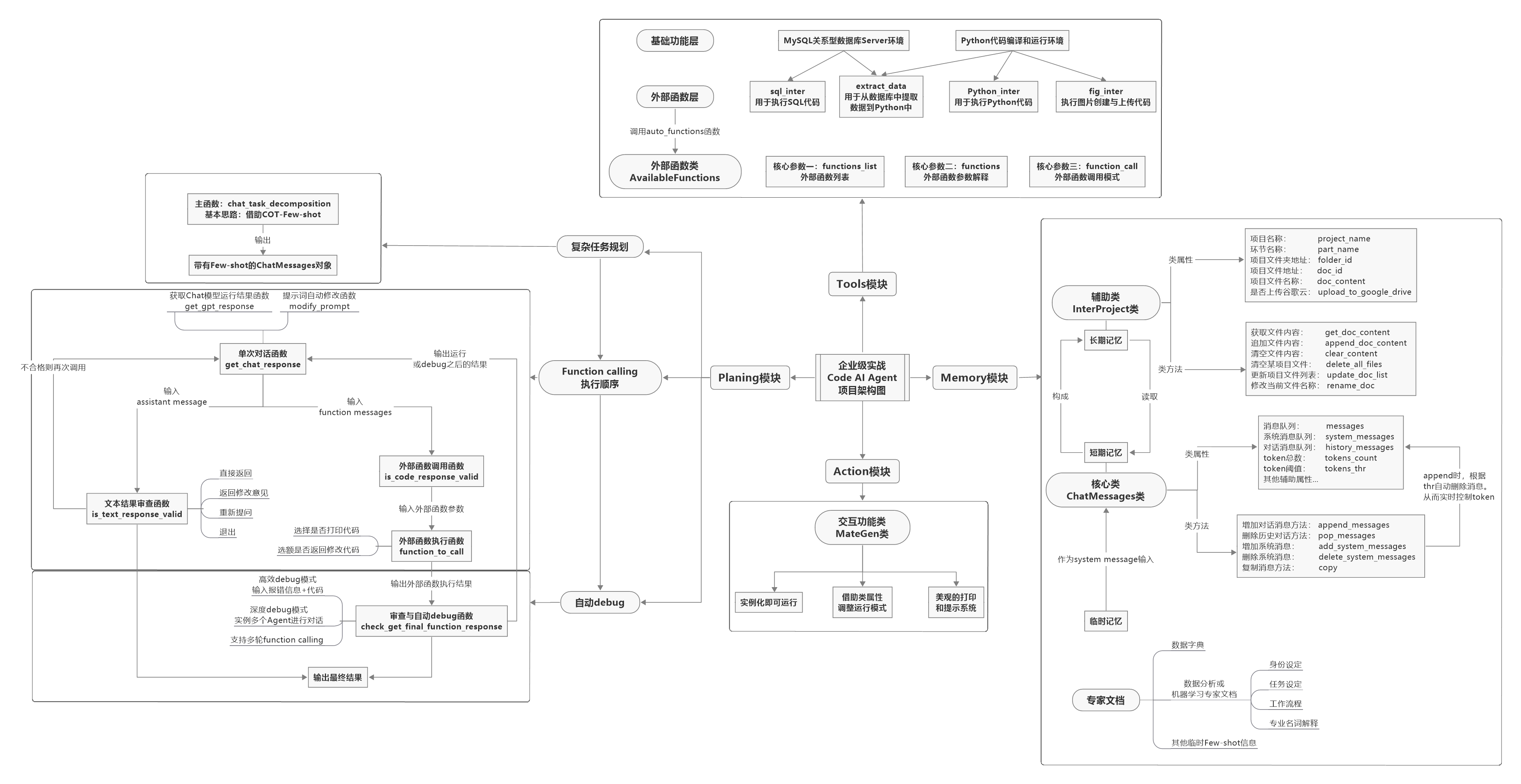
交互式智能编程助手MateGen
功能介绍与入门使用教程

MateGen简介
MateGen是一款由九天老师团队开发的交互式智能编程助手,可以在Python代码环境中运行,核心功能如下
- 多轮对话与无限上下文记忆:可以在对话过程中逐渐深入理解你的需求,并长期记住上下文信息。
- 基于RAG的本地知识库问答:支持在海量文本中进行高精度检索,围绕本地文本进行知识库问答。
- 本地代码解释器:可以连接本地Python环境,编写和执行Python代码,辅助完成编程任务。
- NL2SQL:能够连接本地MySQL环境,根据需求编写和执行SQL代码,帮助完成数据查询和提取任务。
- 图像识别:可以处理用户提供的图片,并针对图片内容进行信息识别和回答问题。
- 联网功能:可以在互联网、知乎或GitHub上搜索相关信息,回答用户提出的问题。
- Kaggle竞赛辅导:能够搜索Kaggle竞赛相关信息,下载热门Kernel,并进行知识库问答,辅导参与竞赛。
- 论文解读和数据分析报告编写:可以帮助解读学术论文或编写数据分析报告。
而在实际使用过程中,九天老师团队秉持实用性优先的原则设计的MateGen还具备如下特性:
- 易用性:MateGen为在线Agent,无需任何网络工具和硬件门槛即可使用,各项功能不用进行参数设置,MateGen会自动根据用户需求开启不同功能;
- 强悍的RAG系统:支持本地文件夹一键同步创建云端词向量数据库,且最大支持1000份文档、10G体量的文本搜索问答;
- 复杂问题拆解与自动debug:面对复杂任务,MateGen会自动进行任务拆解,并在不同环节调用不同工具进行处理,同时,若部分环节运行出问题,MateGen会首先尝试自动优化运行流程,并在多次尝试无法解决问题时向用户寻求帮助;
- 高效率Function calling:MateGen同时具备Multi Function calling(一个任务开启多个功能)和Parallel Function calling(一个功能开多个执行器),借此提高响应效率。
此外,欢迎大家观看《MateGen项目介绍》视频了解更多信息:
目前MateGen已在GitHub上线,欢迎大家关注点星:https://github.com/fufankeji/MateGen
一、MateGen下载与API-KEY获取
1.虚拟环境创建与MateGen安装
MateGen安装非常简单,可以直接通过pip install mategen进行安装,需要注意的是,MateGen运行所需依赖较多,因此推荐借助虚拟环境进行安装。首先创建一个名为mategen的虚拟环境:
FENCE0
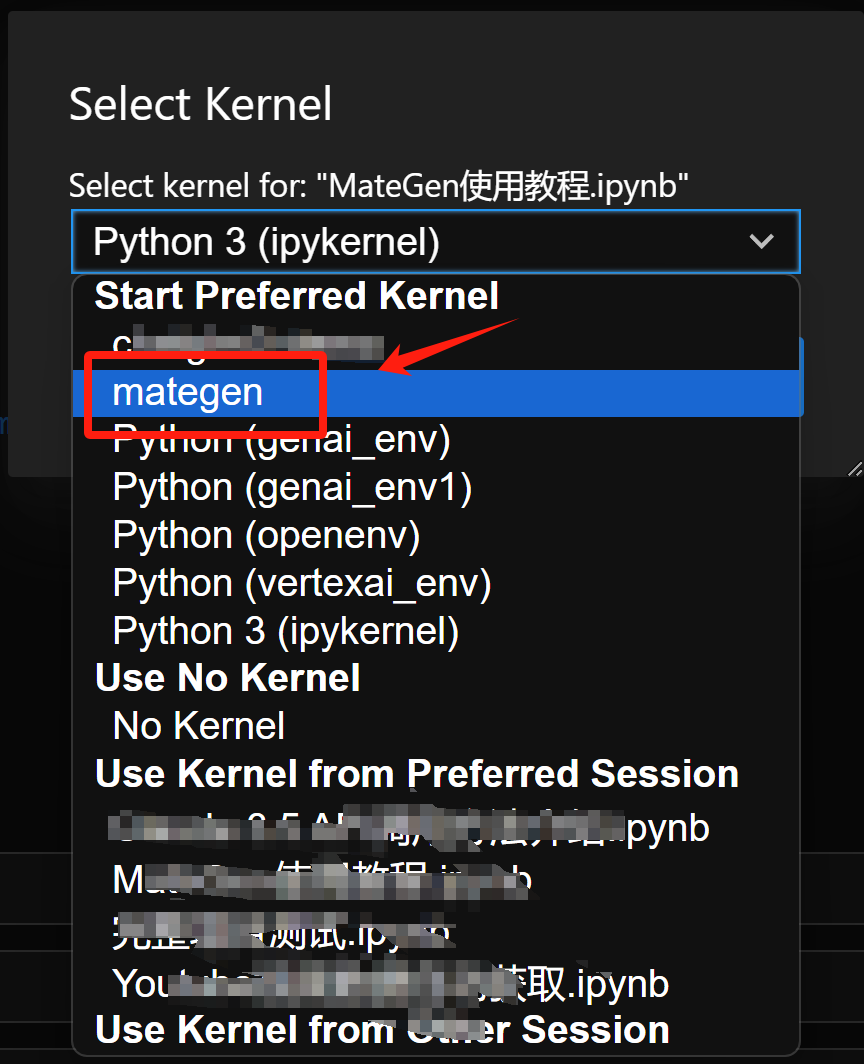
并且将这个虚拟环境添加到Jupyter的Kernel列表中:
FENCE1
若要更新MateGen,则可输入如下命令: FENCE0
以上代码需要在命令行环境中运行
然后在Jupyter的Kernel中选择mategen,即可进入到对应虚拟环境运行MateGen:
然后运行如下代码测试是否安装成功:
!pip install mategen
import MateGen
from MateGen import *
安装后按照如下方式导入即可:
# 查看MateGen版本号
MateGen.__version__
注:最新版本可能随时发生变化,大家安装最新版即可。
2.MateGen API-KEY获取
本部分公开课仅作演示,实际内容为付费课程案例之一:《2025大模型Agent智能体开发实战》(3月DeepSeek强化班) :
二、MateGen对话功能与本地知识库问答功能介绍
- MateGen实例化
MateGen的调用流程和sklearn模型调用流程类似,都是先需要实例化一个MateGen聊天机器人,然后再执行对话。实例化过程如下:
mategen = MateGenClass(api_key = openai_api_key)
每个新的API-KEY实例化MateGen时,需要同步基础指令和调度流程等,因此需要等待一小段时间。此后若不更换API-KEY,则无需重复这个流程。
- 增强模式
MateGen支持两种运行模式,普通模式与增强模式,开启增强模式时MateGen会有更强的性能表现,但同时也会有更长的响应时间以及更高昂的费用。默认情况下MateGen以普通模式运行,当设置参数enhanced_mode为True时则开启增强模式:
mategen = MateGenClass(api_key = 'YOUR_API_KEY',
enhanced_mode = True)
帮助文档的各项实验均基于增强模式运行得到的结果。
1.MateGen基础对话功能介绍
- MateGen对话方式与无限上下文
我们可以使用MateGen.chat()的方式开启对话,MateGen支持单次对话和多次对话两种模式,无论哪种模式,MateGen都具备多轮对话记忆以及拥有无限对话上下文。用户无需担心多轮对话内容总量超出模型最大对话上下文,MateGen会根据用户对话情况,智能截取聊天内容带入模型,并且采用时间衰减和未知信息增加权重等策略,实现无限上下文。
当MateGen.chat()带入对话文本时,即可实现单次对话:
mategen.chat("你好,很高兴见到你!")
而若不带入对话文本,则可以实现多轮对话:
mategen.chat()
并且随时开启MateGen,都拥有多轮对话记忆:
mategen.chat('好的,请问我的上一个问题是?')
甚至当我们删除MateGen或重启代码环境,MateGen仍然可以读取保存在服务器上的对话记录,实现多轮对话:
del mategen
mategen = MateGenClass(api_key = 'YOUR_API_KEY')
mategen.chat("请你帮我总结下咱俩之前的对话内容。")
- 清理消息
若不想保存历史消息,也可调用mategen.clear_messages()清理历史消息:
mategen.clear_messages()
- token消耗统计
同时,无论是否清理消息,MateGen都能实时统计token消耗总量。
mategen.print_usage()
本地token技术可能会因为硬件环境变化而统计有误,实际每个MateGen的token消耗量都会由服务器进行更加准确的统计。
2.借助MateGen进行本地知识库问答
MateGen自带先进的知识库检索(RAG)功能,能够围绕海量文本进行高精度检索问答、文本总结、文本翻译改写等。MateGen为每位用户提供了10G的在线文档存储空间,允许用户上传1000份文档,并且可以围绕PDF、md、ppt、word、txt等主流文档格式进行词向量化存储和读取。在设置了知识库问答的时候,MateGen会根据用户提问,自动判断是否需要进行知识库检索,并不会强制检索再进行回答。
2.1 设置本地知识库地址
MateGen的知识库问答允许用户把本地文件夹的内容批量上传,同时允许创建多个知识库(一个文件夹对应一个知识库),并且可以在问答过程随时切换知识库。首次开启知识库问答之前建议先设置本地知识库的根目录地址,便于存储各个知识库文件夹,若不设置,则MateGen会默认在系统根目录下创建一个知识库文件夹。
我们可以借助如下函数指定知识库根目录地址,例如我们设置E盘下work文件夹为知识库根目录地址:
mategen.set_knowledge_base_url('E:\\work')
注意,Windows下需要通过两个反斜杠来表示文件夹层级关系。修改知识库地址之后,需要重启Jupyter才能生效。
2.2 开启知识库对话
设置完成后即可开启知识库问答,首次开启知识库问答时需要输入知识库名称,例如此处创建一个名为'OpenML'的知识库:
mategen = MateGenClass(api_key = 'YOUR_API_KEY',
knowledge_base_chat=True)
注,此处我们重新实例化了一个MateGen,但正如此前所说,MateGen并不会因为重新实例化而丢失多轮对话记忆,这个实例化过程也可以看成是重新设置参数的过程。
然后即可在E:\work下查看知识库地址,目前知识库地址为E:\work\knowledge_base\OpenML,其中knowledge_base是知识库根目录:
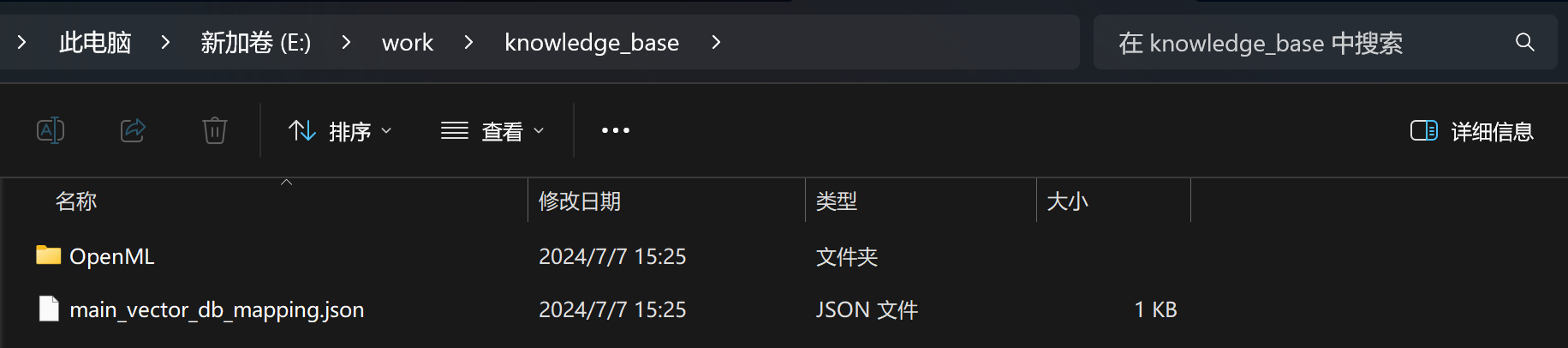
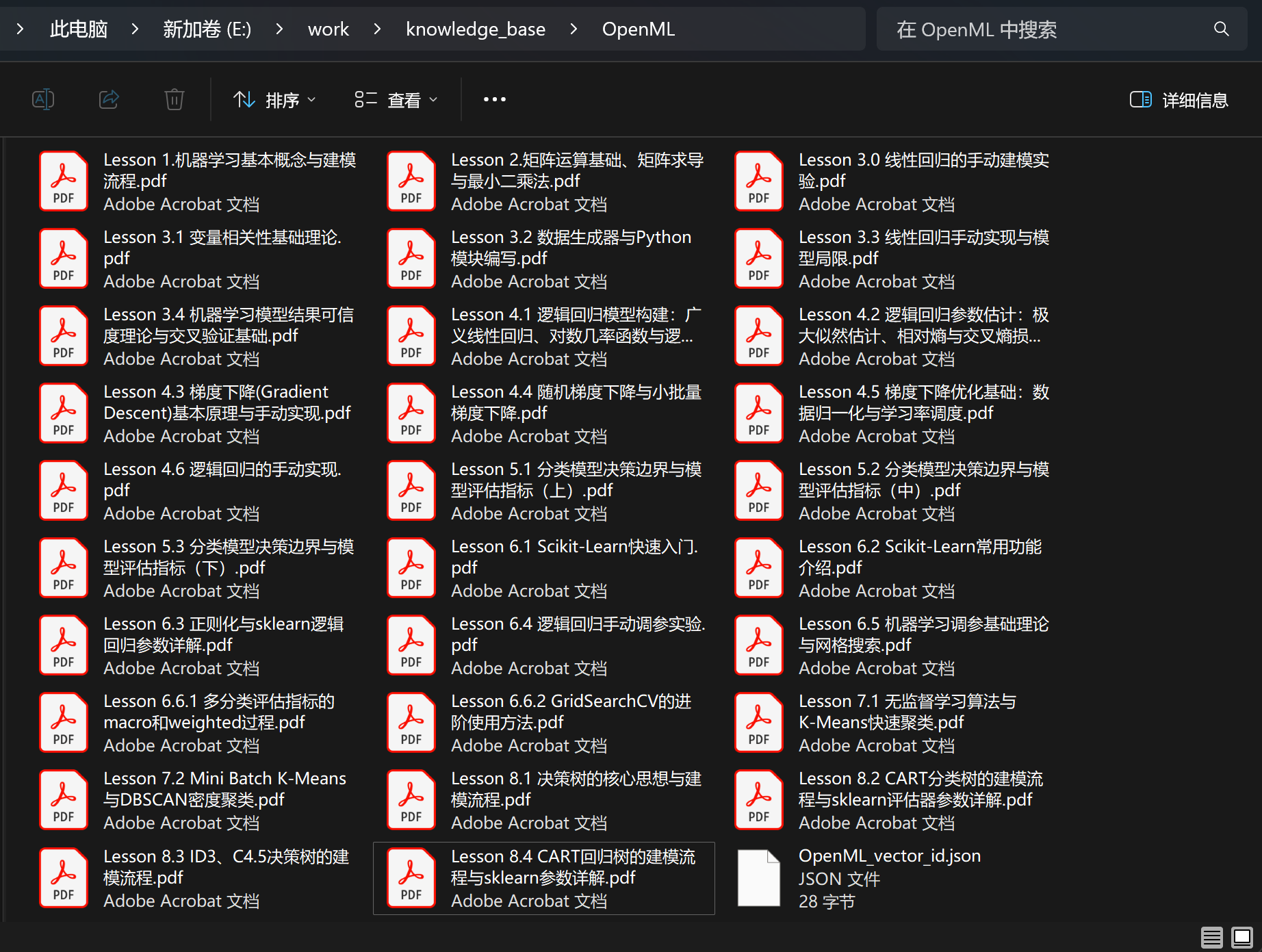
接下来我们将九天老师机器学习公开课课件全部放进去,公开课课件总共636页,属于海量文本专业知识检索:
MateGen知识库问答测试文档下载:链接:https://pan.baidu.com/s/1Gn7vpDHWQYp_x601r5R4yQ?pwd=sst0 提取码:sst0
当然,哪怕是开启了知识库,MateGen也会根据用户提问的内容,决定是否进行知识库检索:
- 自主判断是否需要检索
# 提一个机器学习之外的问题
mategen.chat('请帮我简单介绍下Transformer基本原理')
接下来进一步测试MateGen RAG性能。我们分别从专业知识点(类似大海捞针)、大规模文本总结以及情感判断分析三个方面测试MateGen的RAG性能:
- 知识点提取
首次围绕某知识库对话,系统会先上传知识库文档,并进行词向量化处理,因此首次开启对话会略微耗费一点时间,之后再次开启对话则无需再次进行词向量化处理。
# 专业知识点提取
mategen.chat('请帮我检索下知识库,并详细总结Mini Batch K-Means聚类算法的建模流程。')
- 海量文本总结
# 海量文本总结
mategen.chat('现在你的知识库OpenML包含的文档,是九天老师机器学习公开课课件。请帮我总结下,九天老师在公开课中讲解了几种决策树算法呢?')
- 情感判别
mategen.chat('根据知识库所存储的课件,你觉得九天老师的机器学习公开课质量如何?')
不难看出**MateGen的RAG系统稳定高效,适合各种问答场景。**除了日常问答外,带有课件知识库的MateGen还可以进行教学辅导,例如指导学生课前预习、课中答疑、课后复习等。
2.3 更新知识库
对于相同的知识库,若想增删一些文件,可以先在本地文件夹内操作,然后再调用upload_knowledge_base更新知识库即可:
mategen.upload_knowledge_base(knowledge_base_name='OpenML')
2.4 切换知识库问答
MateGen还支持随时切换知识库进行问答。例如此时我们再创建一个知识库,用于存储MateGen的使用指南文档:
mategen = MateGenClass(api_key = 'YOUR_API_KEY',
knowledge_base_chat=True)
系统会自动创建MateGen文件夹:
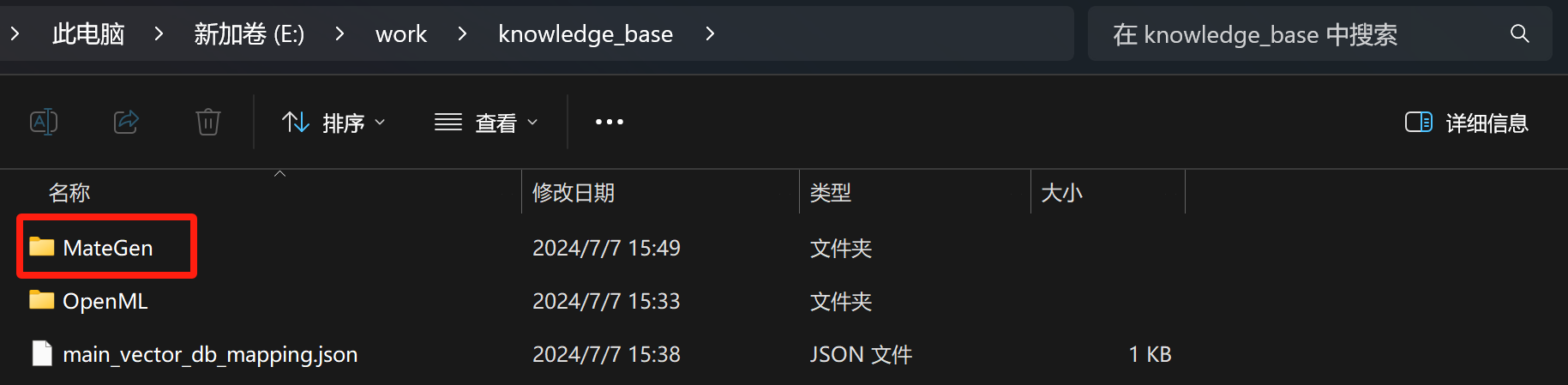
我们在MateGen文件夹中放置MateGen使用指南:
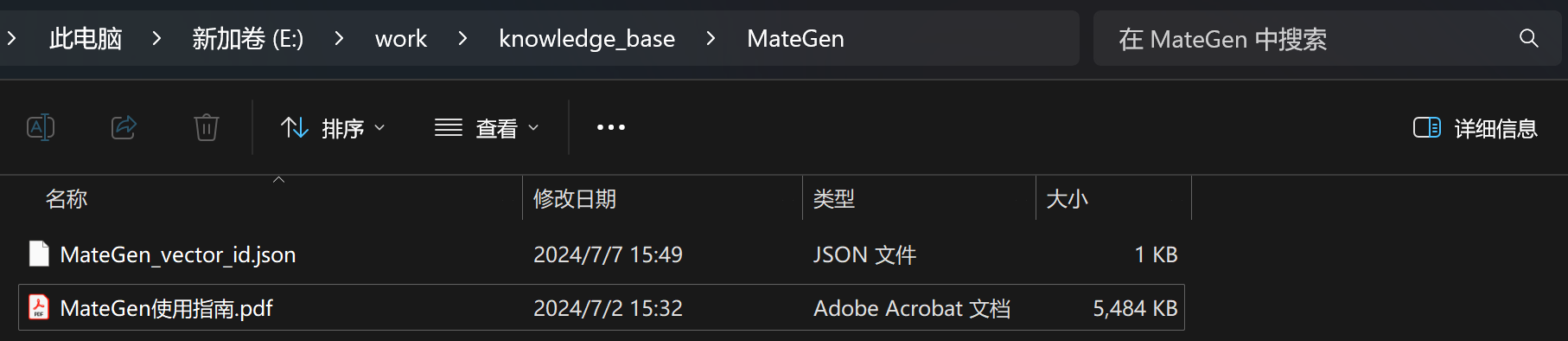
然后开启对话,这里需要注意的是,在切换知识库后,我们需要先清理MateGen历史对话消息,以免历史对话消息影响后续RAG质量:
mategen.clear_messages()
清理完历史消息后再进行知识库问答:
mategen.chat('请检索你的知识库,并告诉我MateGen应该如何查看token消耗情况。')
然后随时可以切换回OpenML知识库进行问答,我们可以直接输入0,然后在知识库序号中选择OpenML进行问答即可:
mategen = MateGenClass(api_key = 'YOUR_API_KEY',
knowledge_base_chat=True)
mategen.chat('请检索你的知识库,并帮我介绍下网格搜索优化算法的优劣势')
并且由于MateGen本身是无限对话长度,因此哪怕现在没有调用MateGen使用方法知识库,但MateGen仍然可以读取此前对话记忆进行回答:
mategen.chat('很好,你是否还记得MateGen应该如何查看token消耗来着?')
2.5 取消知识库问答
关闭知识库问答功能也非常简单,再次实例化MateGen,并取消knowledge_base_chat设置:
mategen = MateGenClass(api_key = 'YOUR_API_KEY')
mategen.clear_messages()
3.借助MateGen实现NL2SQL
MateGen可以连接MySQL数据库,并且可以稳定高效实现NL2SQL。无需额外手动设置,当系统检测到用户需要进行数据库相关操作时,MateGen就会自动开启NL2SQL功能,完成SQL代码编写和运行:
- 输入数据库基本参数
mategen.chat('请帮我查看当前数据库中,总共有几张表。')
mategen.chat('好的,host:localhost,port:3306,ueser:root,password:19920229,database name:telco_db')
目前MateGen只支持MySQL数据库,更多数据库种类连接方式正在开发中。
- 数据库查询
mategen.chat('请帮我查看下,这八张表中,四个不带_new尾缀的数据集,数据量是否相同。')
- 数据查询
mategen.chat('你做得很好,接下来请帮我在user_payments表中,查看月消费金额最高的用户ID,以及对应的总消费金额是多少。')
- 数据读取
mategen.chat('很好,接下来请帮我将user_churn表读取到当前文件夹中,并命名为user_churn.csv')
然后即可在当前代码运行文件夹内找到这个数据集:

4.借助MateGen实现NL2Python:本地代码解释器实现流程
MateGen还可以实现NL2Python,可以连接本地Python环境进行自动编程,进而辅助用户完成数据读取、数据预处理、数据建模、数据可视化等事项。
- 读取数据集
mategen.chat('好的,接下来请帮我将当前文件夹内的user_churn.csv读取到当前Python环境中。')
然后我们即可在当前操作空间中查看读取到的数据集:
# 更新命名空间,即可在本地调用代码操作结果
globals().update(MateGen.export_variables())
user_churn_df.head()
- 数据可视化
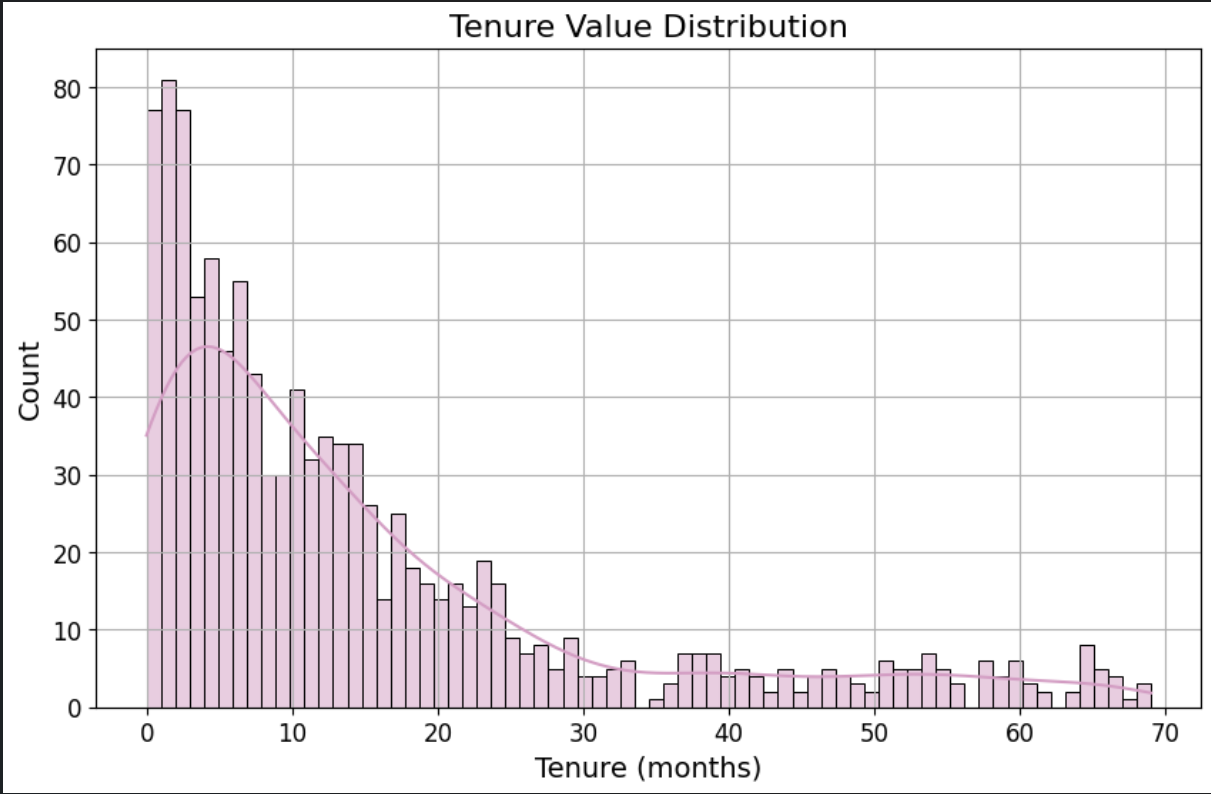
mategen.chat('好的,请用可视化的方式帮我分析下Churn字段的取值分布。')
这里需要注意,当涉及到绘图任务的时候,若设置了阿里云图床,则MateGen会自动将图片上传至oss图床,并保存每张图片的公开访问网址,方便后续组合图片形成数据分析报告。
在没有图床的情况下MateGen绘图功能也可正常使用,阿里云oss图床设置方法见下文《MateGen联网方式设置》部分。
除了可以进行数据清洗和数据可视化相关工作之外,MateGen还可以来进行机器学习建模或深度学习建模等复杂编程任务,并且,若带入企业代码库文档,MateGen还可以模仿企业代码习惯来进行编程。
5.MateGen复杂任务规划执行与自动debug功能
截止目前,我们介绍了MateGen的知识库问答、NL2SQL和NL2Python等功能,在继续介绍MateGen其他进阶功能之前,需要说明的是,MateGen的各项功能支持组合使用。当面对复杂任务的时候,MateGen会自动组合各项功能来构建执行流程,自动逐步执行任务,同时每一步遇到了任何问题都会自动debug。
- NL2SQL+NL2Python联动
例如,我们可以让MateGen直接从MySQL中读取数据集到Python中并本地进行保存,这个简单的例子中就涉及到NL2SQL和NL2Python两个功能的串联实现。
mategen.chat('接下来请帮我将数据库中user_payments读取到当前Python环境中,并在当前文件夹中保存一份user_payments.csv文件')
- 知识库问答+NL2SQL+NL2Python
同时,MateGen也支持在任何处理的环节即时查询知识库,这里我们创建一个telco_db知识库,然后保存一份md文件,其中包含了各数据集字段信息和重要字段列表。我们尝试让MateGen先读取这个知识库,获取重要字段列表信息,然后再从各个数据集中获取重要字段列表组成一个新的数据集,并读取到本地:
mategen = MateGenClass(api_key = 'YOUR_API_KEY',
knowledge_base_chat=True)
其中telco_db文件夹中放置如下文件:
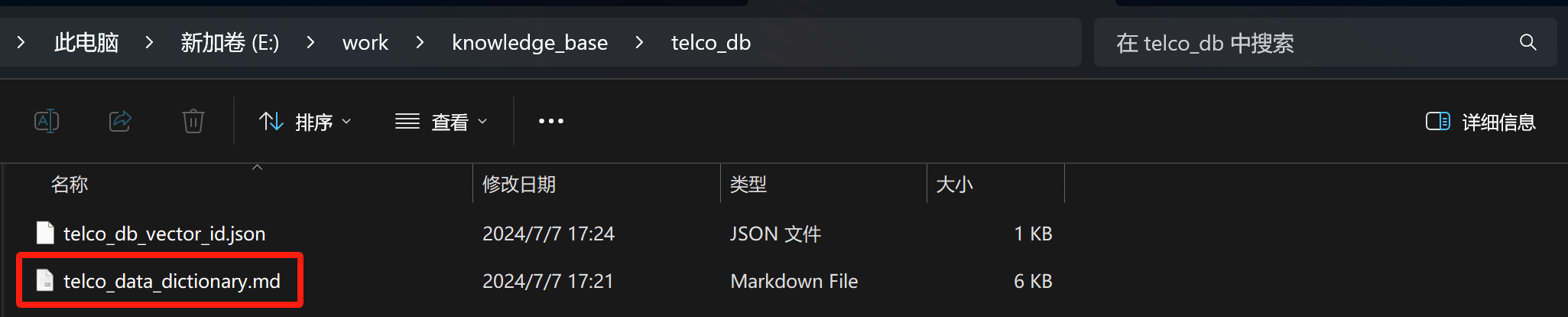
其中telco_data_dictionary内容包含了数据库中每个数据集中所包含的字段情况、以及重要字段说明如下:

接下来让MateGen在这一系列数据集中提取关键字段:
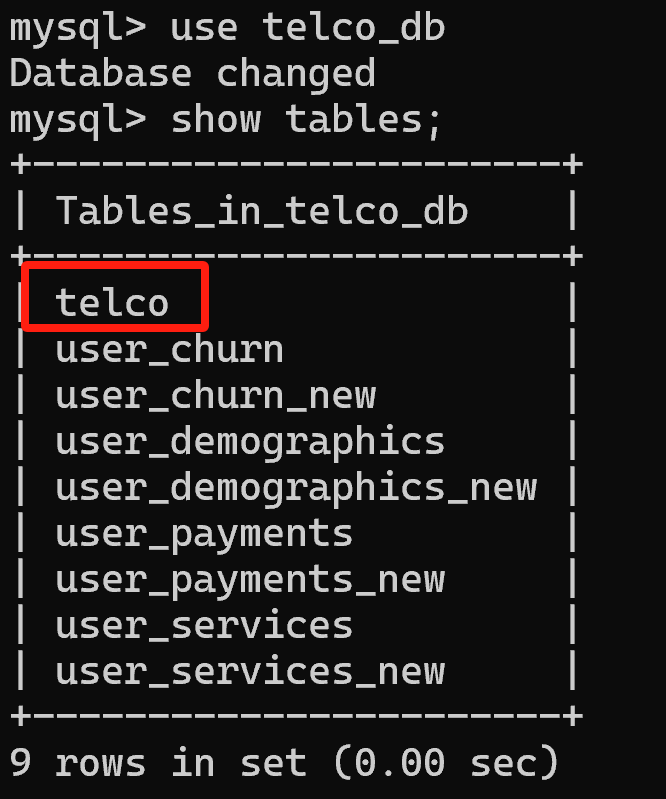
mategen.chat('请查阅你的知识库,确认数据集中最重要的字段,并帮我从不带尾缀_new的几张表中,挑选这些字段组成一张新的表,并保存在MySQL中,取名为telco')
上述流程中,不仅涉及到RAG、NL2SQL、NL2Python,还涉及到自动debug过程,上述过程中第一次将新数据集写入MySQL时遇到了缺失值、第二次操作时由遇到了重名数据集、第三次才顺利将数据集写入。
MateGen会即时自主根据执行结果来调整执行流程,若反复多次都无法尝试成功,并不会无限尝试下去,而是会向用户求助。
然后即可查看当前操作空间中是否已经顺利读取该数据集:
# 更新命名空间,即可在本地调用代码操作结果
globals().update(MateGen.export_variables())
telco_df.head()
数据集中关键字段和知识库中列举关键字段一致:
telco_df.columns

数据库中也成功保存了telco数据集:
除此之外,MateGen还支持Multi Function calling(一个任务开启多个功能)和Parallel Function calling(一个功能开多个执行器),借此提高响应效率。
mategen.clear_messages()
6.MateGen视觉能力
MateGen具备视觉能力,只需要在提问时附带图片连接,就可以调用MateGen的视觉能力、围绕图片进行识别再进行回答:

mategen.chat('请帮我描述下这张图片上的内容:https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20240707212637973.png')
- MateGen视觉+NL2Python联动
同样,MateGen的视觉功能可以和别的功能联动,例如我们可以给MateGen输入一张图片,然后让其模仿绘制一张新的图,并且可以直接通过对话来修改图片。例如有张图片如下:
接下来让MateGen先读取该图片,再借助其Python代码解释器,绘制一张一样的图片。
mategen.chat('请帮我描述下这张图片上的内容:https://ml2022.oss-cn-hangzhou.aliyuncs.com/fig_b92cda8f15534922a7ef72ff329146fb.png')
mategen.chat('非常好!现在,请基于你对这张图片的理解,使用Python代码帮我创建一组数据,使其满足图片上的数据分布,并编写一段Python绘图代码,绘制类似的图片,并直接运行你编写的代码。')
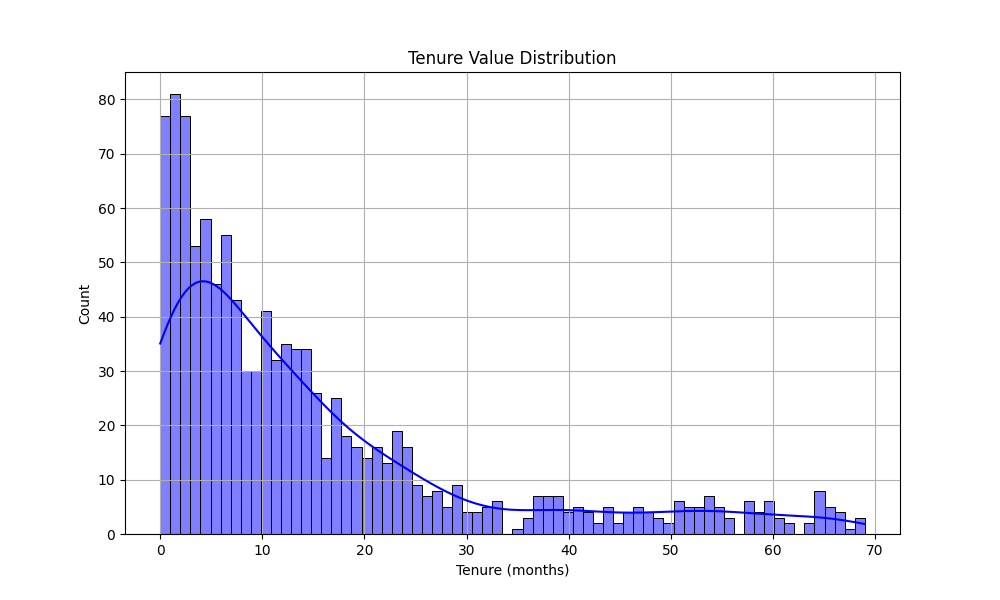
可以看出基本能够对原图进行模仿绘制。接下来尝试对其进行修改,同样,我们让MateGen先参考一张图的配色,然后修改原图。参考图片如下:
mategen.chat('我觉这张图片颜色不够好看,请帮我参考这张图片上的主配色:https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20240701222610915.png,调整原图配色。')
7.MateGen联网能力
注意,由于MateGen会借助爬虫爬取公开数据,爬虫需要用到的cookies经常会失效,因此以下功能
不一定能顺利运行,推荐先使用check_network_environment()函数测试下各项联网功能能否正常运行,并使用internet_config_assistant()获取联网设置帮助,并将自己的cookie输入作为参数,以便顺利实现联网功能。
7.1 MateGen联网功能实现
MateGen自带联网功能,当用户的问题超出MateGen知识库时,MategGen就会开启联网功能,从互联网上获取答案。MateGen的互联网搜索由谷歌搜索API驱动(但无需联网工具即可使用),会从知乎、Github获取相关信息,更适合获取技术相关信息。同时,MateGen还可以调用Kaggle API,若用户有需求,可以从Kaggle上获取竞赛说明和热门Kernel方案构建知识库再来进行问答。
mategen.chat('请帮我介绍下阿里云最新发布的Qwen2大模型。')
mategen.chat('Qwen2可以用vLLM部署么?流程是什么样的呢?')
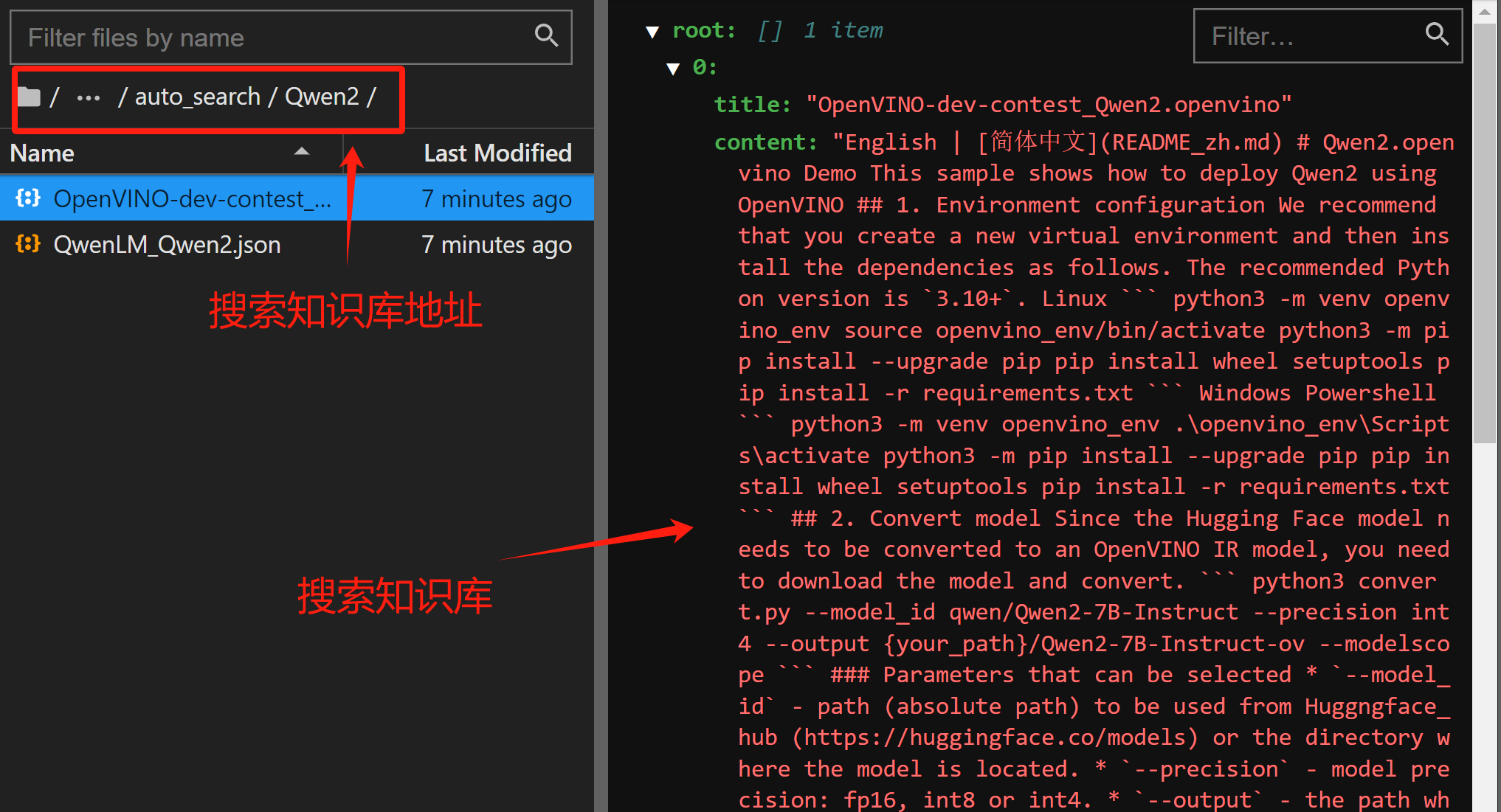
搜索问答的本质是爬取信息创建本地知识库,然后再进行回答,只要开启搜索就会创建一个临时文件夹,并取名为auto_search,保存在knowledge_base中:
若有需要,也可以将其设置为永久知识库。
7.2 MateGen Kaggle竞赛辅导功能
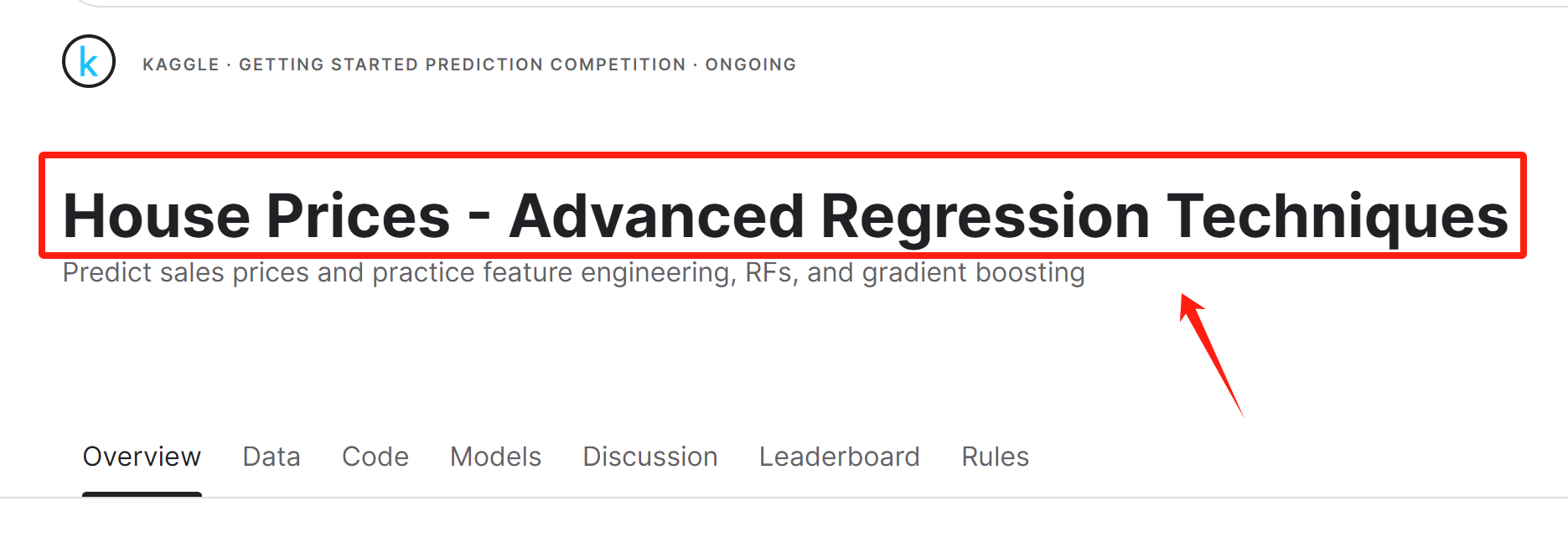
除了能够适时开启联网功能并进行搜索问答外,MateGen还专门围绕Kaggle竞赛信息获取进行了优化。当用户希望了解某项竞赛信息时,只需要在MateGen参数位上输入kaggle_competition_guidance=True即可,并在弹出的对话框中输入感兴趣的Kaggle竞赛名称,MateGen就会自动使用Kaggle API,获取该项比赛的Overview(概览信息)、Data(数据集信息)以及热门Kernels(其他参赛者热门竞赛方案),并在本地创建竞赛同名知识库,并自动开启围绕当前竞赛知识库的问答功能。例如我们想要了解Kaggle上的一项名为House Prices - Advanced Regression Techniques比赛,即可按照如下方式执行:
mategen = MateGenClass(api_key=api_key,
kaggle_competition_guidance=True)
此时当前竞赛的本地知识库位置如下:
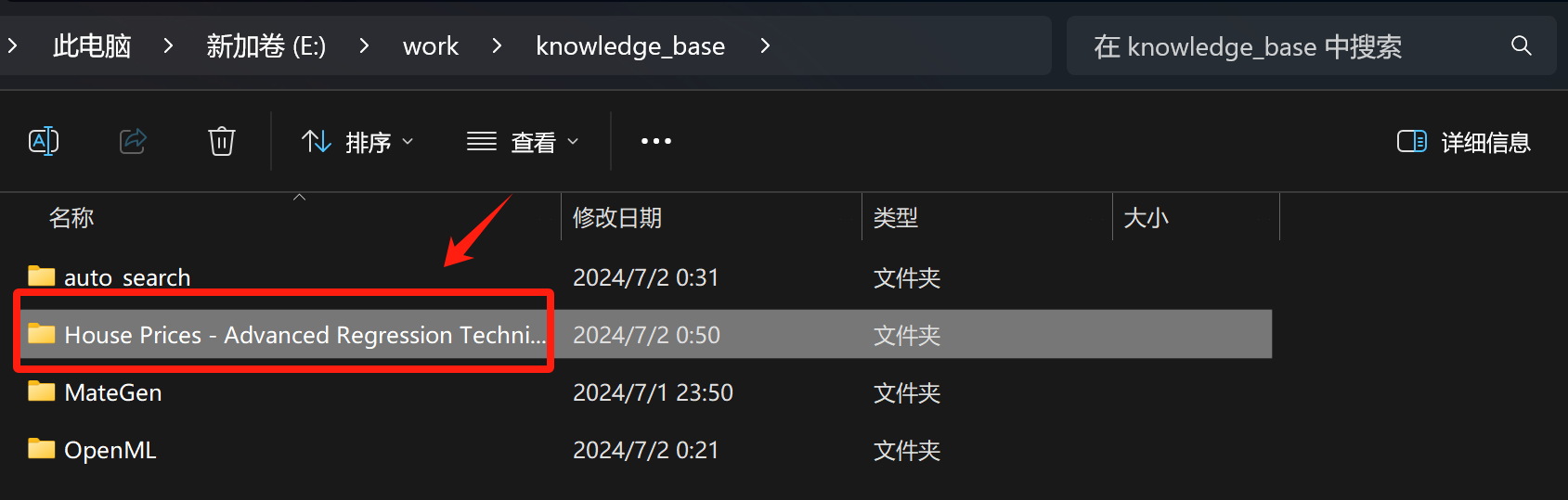
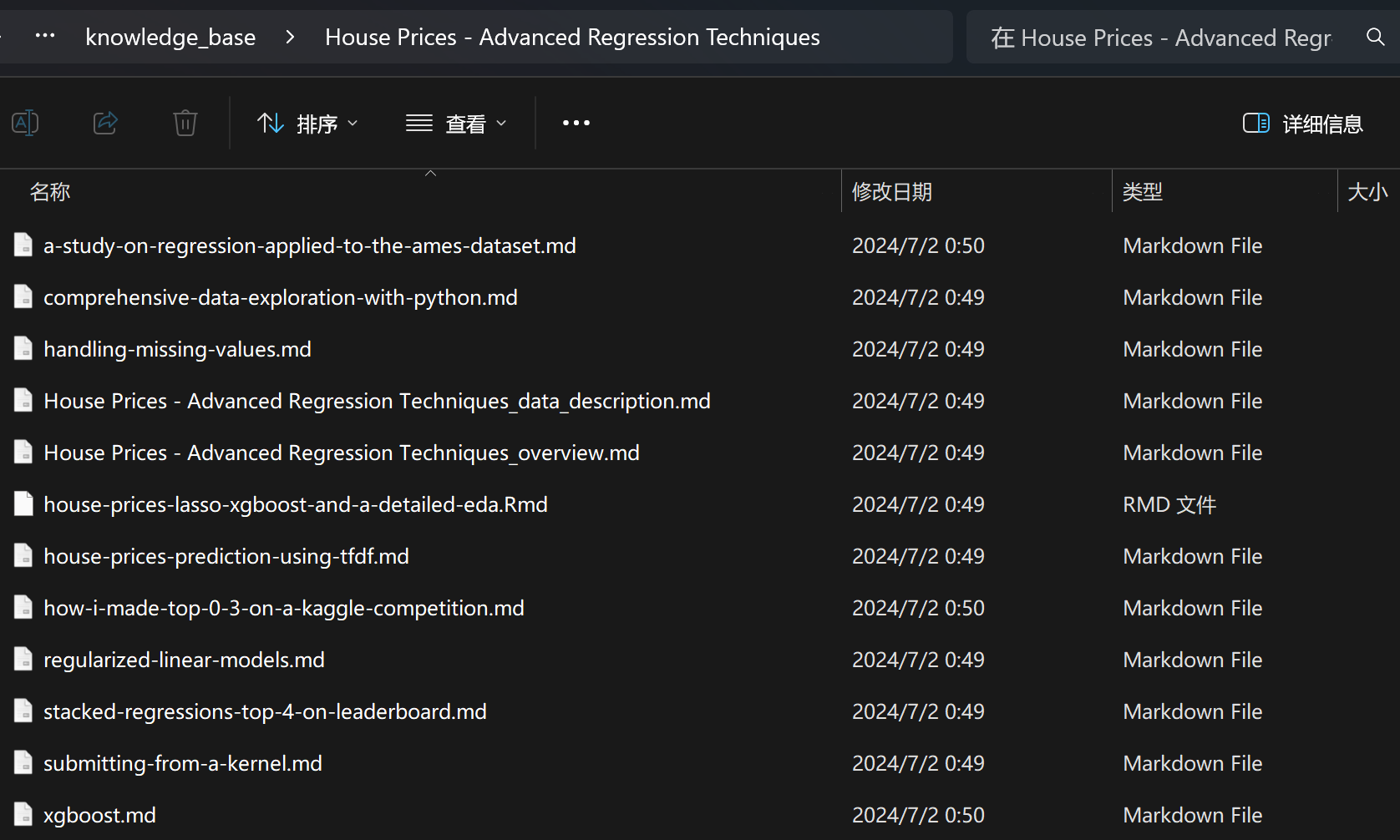
获取的竞赛知识库文件如下,其中包含了比赛介绍、数据集介绍和热门竞赛方案:
接下来MateGen会自动带入该知识库进行问答,从而顺利完成竞赛辅导工作:
mategen.chat('请检索知识库,帮我详细介绍下House Prices这个竞赛')
mategen.chat('在你的知识库中,有什么比较精彩的高分竞赛方案么?能帮我分享下他们的思路么?')
2025年3月11号,OpenAI召开发布会,正式发布全新一代底层调用API:Responses API,并计划在未来一段时间,逐渐代替Chat.Completion API,在如今OpenAI的大模型调用方法已成为业内标准的今天,这一次更新,无疑将对未来的大模型开发生态带来重大影响。
随着发布会一同发布的,还有三项Agent tools和一个开源Agent SDK,分别是:
- Web Search:允许用户联网搜索相关信息;
- File Search:允许用户将文件上传到OpenAI服务器上,并在模型对话时,实时对其进行检索;
- computer use:允许用户借助大模型功能,来操作当前电脑或浏览器。
- Agent SDK:swarm的升级版,一个开源的Multi-Agent开发框架。
对此,我曾专门录制视频进行入门介绍,感兴趣的同学可以戳此观看:https://www.bilibili.com/video/BV1SVQEYqERV/
!pip install openai
import openai
openai.__version__
from openai import OpenAI
- 传统chat.completion API调用方法回顾
openai_api_key = "YOUR_API_KEY"
base_url = "国内反向代理地址"
# 实例化客户端
client = OpenAI(api_key=openai_api_key,
base_url=base_url)
# 调用 GPT-4o-mini 模型
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "你好,好久不见!"}
]
)
response
- Agent SDK安装流程
!pip install openai-agents
from agents import Agent, Runner
Agent?
Runner?
一、各类模型&服务接入Agent SDK流程
1.OpenAI+国内反向代理地址接入Agent SDK
from openai import AsyncOpenAI
from agents import OpenAIChatCompletionsModel,Agent,Runner
from agents.model_settings import ModelSettings
from agents import set_default_openai_client, set_tracing_disabled
external_client = AsyncOpenAI(
base_url = base_url,
api_key=openai_api_key,
)
set_default_openai_client(external_client)
set_tracing_disabled(True)
agent = Agent(name="Assistant", instructions="你是一名助人为乐的助手。")
result = await Runner.run(agent, "请写一首关于编程中递归的俳句。")
俳(pái)句。
print(result.final_output)
2.DeepSeek在线API接入流程
- 测试API能否连接
ds_api_key = 'YOUR_DS_API'
# 实例化客户端
client = OpenAI(api_key=ds_api_key,
base_url="https://api.deepseek.com")
# 调用 deepseekv3 模型
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "你好,好久不见!请介绍下你自己。"}
]
)
# 输出生成的响应内容
print(response.choices[0].message.content)
- 测试接入Agent SDK
external_client = AsyncOpenAI(
base_url = "https://api.deepseek.com",
api_key=ds_api_key,
)
set_default_openai_client(external_client)
set_tracing_disabled(True)
agent = Agent(name="Assistant",
instructions="你是一名助人为乐的助手。",
model=OpenAIChatCompletionsModel(
model="deepseek-chat",
openai_client=external_client,
))
result = await Runner.run(agent, "请写一首关于编程中递归的俳句。")
print(result.final_output)
3.ollama+本地模型接入流程
这里选择QwQ模型作为本地模型进行接入测试,更多QwQ模型本地部署与调用介绍,详见:https://www.bilibili.com/video/BV1hZRTYUEtR/
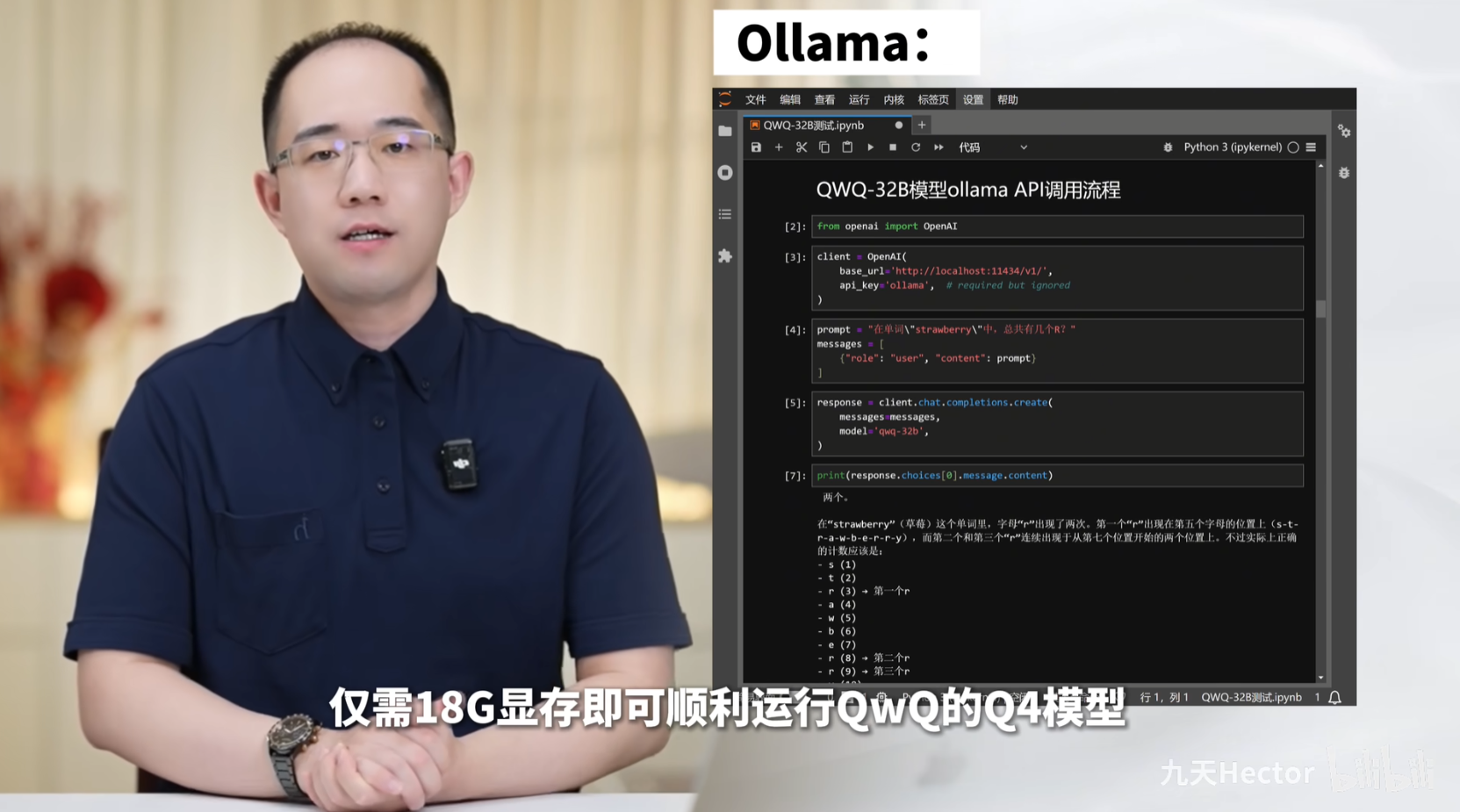
这里需要先启动后台ollama服务,然后进行连接测试
client = OpenAI(
base_url='http://localhost:11434/v1/',
api_key='ollama', # required but ignored
)
prompt = "你好,好久不见!"
messages = [
{"role": "user", "content": prompt}
]
response = client.chat.completions.create(
messages=messages,
model='qwq-32b-bnb',
)
print(response.choices[0].message.content)
- 测试接入Agent SDK
external_client = AsyncOpenAI(
base_url = 'http://localhost:11434/v1',
api_key='ollama',
)
set_default_openai_client(external_client)
set_tracing_disabled(True)
agent = Agent(name="Assistant",
instructions="你是一名助人为乐的助手。",
model=OpenAIChatCompletionsModel(
model="qwq-32b-bnb",
openai_client=external_client,
))
result = await Runner.run(agent, "请写一首关于编程中递归的俳句。")
print(result.final_output)
- Function calling功能测试
ollama_model=OpenAIChatCompletionsModel(
model="qwq",
openai_client=external_client,
)
# 定义代理(Agents)
chinese_agent = Agent(
name="Chinese agent",
instructions="你只能用中文进行回答",
model=ollama_model
)
english_agent = Agent(
name="English agent",
instructions="你只能用英文进行回答",
model=ollama_model
)
triage_agent = Agent(
name="Triage agent",
instructions="根据请求的语言,将任务交给合适的代理。",
handoffs=[chinese_agent, english_agent],
model=ollama_model
)
result = await Runner.run(triage_agent, input="你好,好久不见!")
print(result.final_output)
result = await Runner.run(triage_agent, input="Hello, how are you?")
print(result.final_output)
import requests,json
def get_weather(loc):
"""
查询即时天气函数
:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing';
:return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\
返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息
"""
# Step 1.构建请求
url = "https://api.openweathermap.org/data/2.5/weather"
# Step 2.设置查询参数
params = {
"q": loc,
"appid": open_weather_key, # 输入API key
"units": "metric", # 使用摄氏度而不是华氏度
"lang":"zh_cn" # 输出语言为简体中文
}
# Step 3.发送GET请求
response = requests.get(url, params=params)
# Step 4.解析响应
data = response.json()
return json.dumps(data)
get_weather("Beijing")
import asyncio
from agents import Agent, Runner, function_tool
@function_tool
def get_weather(loc):
"""
查询即时天气函数
:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则loc参数需要输入'Beijing';
:return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\
返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息
"""
# Step 1.构建请求
url = "https://api.openweathermap.org/data/2.5/weather"
# Step 2.设置查询参数
params = {
"q": loc,
"appid": open_weather_key, # 输入API key
"units": "metric", # 使用摄氏度而不是华氏度
"lang":"zh_cn" # 输出语言为简体中文
}
# Step 3.发送GET请求
response = requests.get(url, params=params)
# Step 4.解析响应
data = response.json()
return json.dumps(data)
# 创建一个代理,并添加 `get_weather` 工具
agent = Agent(
name="Hello world",
instructions="You are a helpful agent.",
tools=[get_weather],
model=ollama_model
)
result = await Runner.run(agent, input="你好,请问今天北京天气如何?")
print(result.final_output)
能够发现,各项功能能顺利实现,接下来进入到正式的功能介绍中。为了便于大家运行,这里统一使用deepseek在线API为基础模型进行调用,类似的可以将其更换为ollama模型等。