七大场景企业级RAG检索实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(12月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(12月班)

《2025大模型Agent智能体开发实战》(12月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
课程完整介绍


部分课程成果演示
from IPython.display import Video
- Dify+DeepSeek搭建智能微信语音客服
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- Coze自动图文视频创作流程
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- 可视化数据分析Multi-Agent
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目展示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋季班)



详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


Llama-Index进阶实战
七大企业级应用场景RAG检索实战
Part 1.Llama-Index核心功能快速回顾
RAG,Retrieval-Augmented Generation,也被称作检索增强生成技术,最早在 Facebook AI(Meta AI)在 2020 年发表的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》( https://arxiv.org/abs/2005.11401 )中正式提出,这种方法的核心思想是借助一些文本检索策略,让大模型每次问答前都带入相关文本,以此来改善大模型回答时的准确性。这项技术刚发布时并未引发太大关注,而伴随2022年大模型技术大爆发,RAG技术才逐渐进入人们视野,并且由于早期大模型技术应用均已“知识库问答”为主,而RAG技术是最易上手、并且上限极高的技术,因此很快就成为了大模型技术人必备的技术之一。
时至今日,RAG技术已经是非常庞大的技术体系了,从简答的文档切分、存储、匹配,再到复杂的入GraphRAG(基于知识图谱的检索增强),以及复杂文档解析+多模态识别技术等等等等。
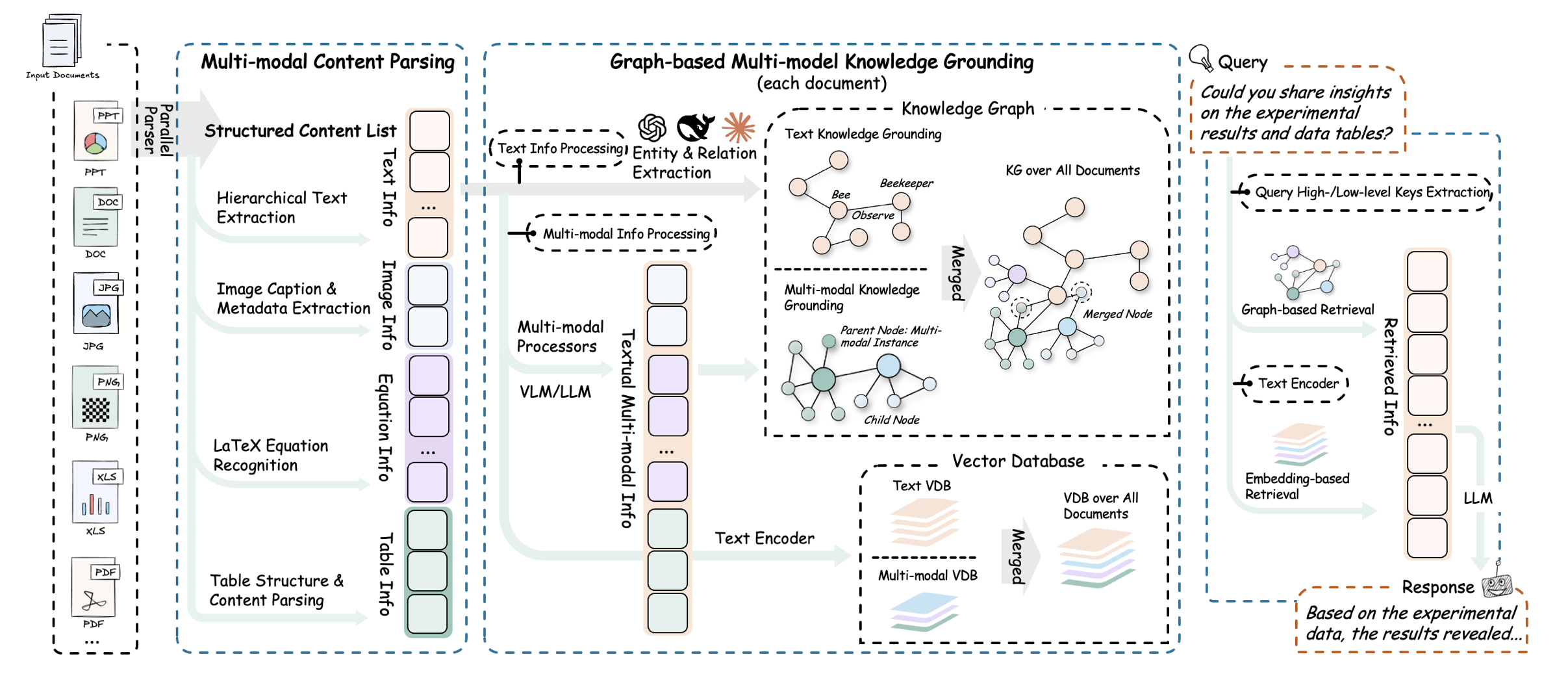
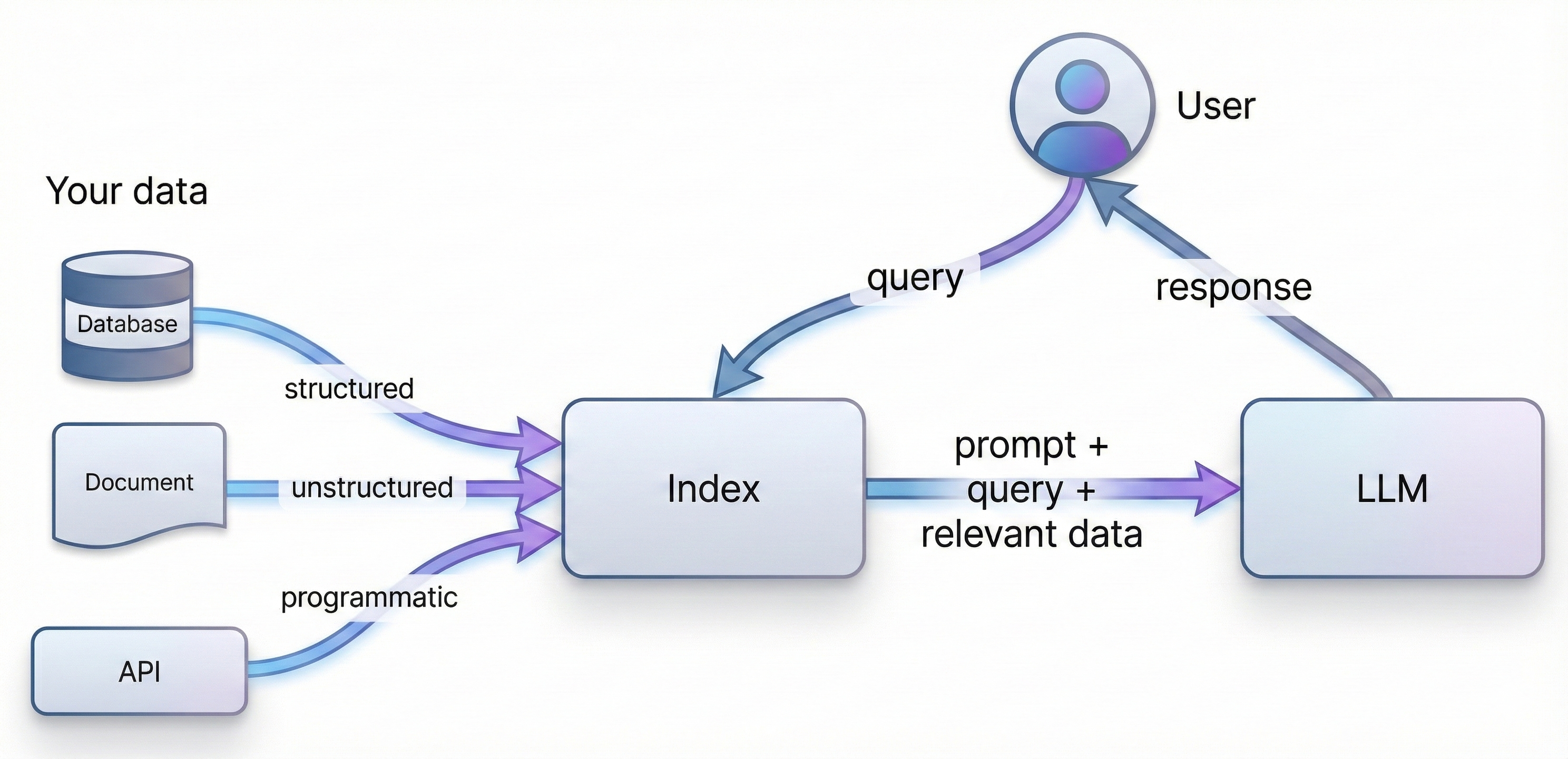
而对于初学者来说,为了更好的上手学习RAG技术,我们首先需要对RAG技术最简单的实现形式有个基础的了解。一个最简单的RAG技术实现流程如下所示:
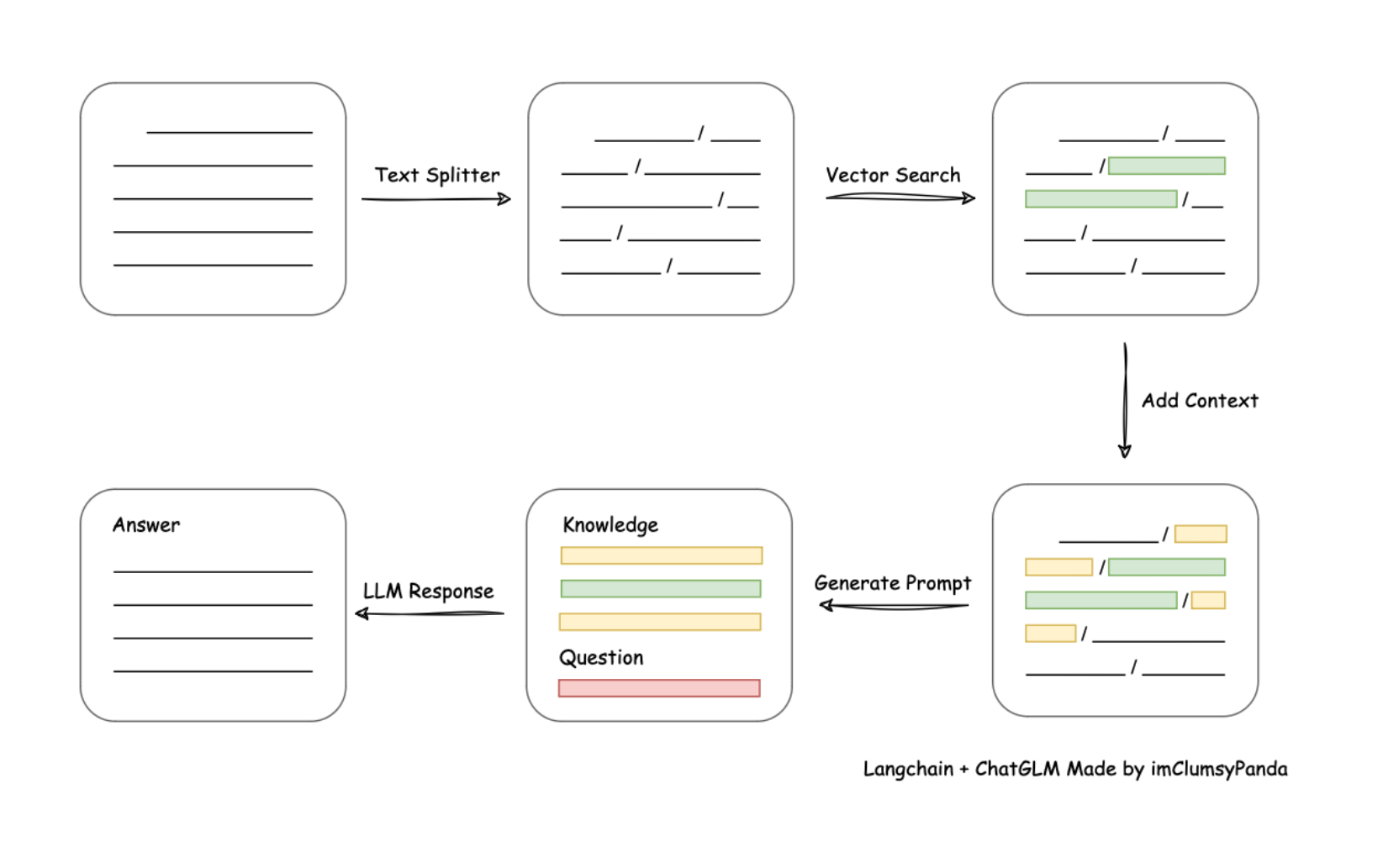
我们需要围绕给定的文档(往往是非常长的文档)先进行切分,然后将切分的文档转化为计算机能识别的形式,也就是将其转化为一个数值型向量(也被称为词向量),然后当用户询问问题的时候,我们再将用户的问题转化为词向量,并和段落文档的词向量进行相似度匹配,借此找出和当前用户问题最相关的原始文档片段,然后将用户的问题和匹配的到的原文片段都带入大模型,进行最终的问答。由此便可实现一次完整的文档检索增强执行流程。a
具体执行过程如下所示:
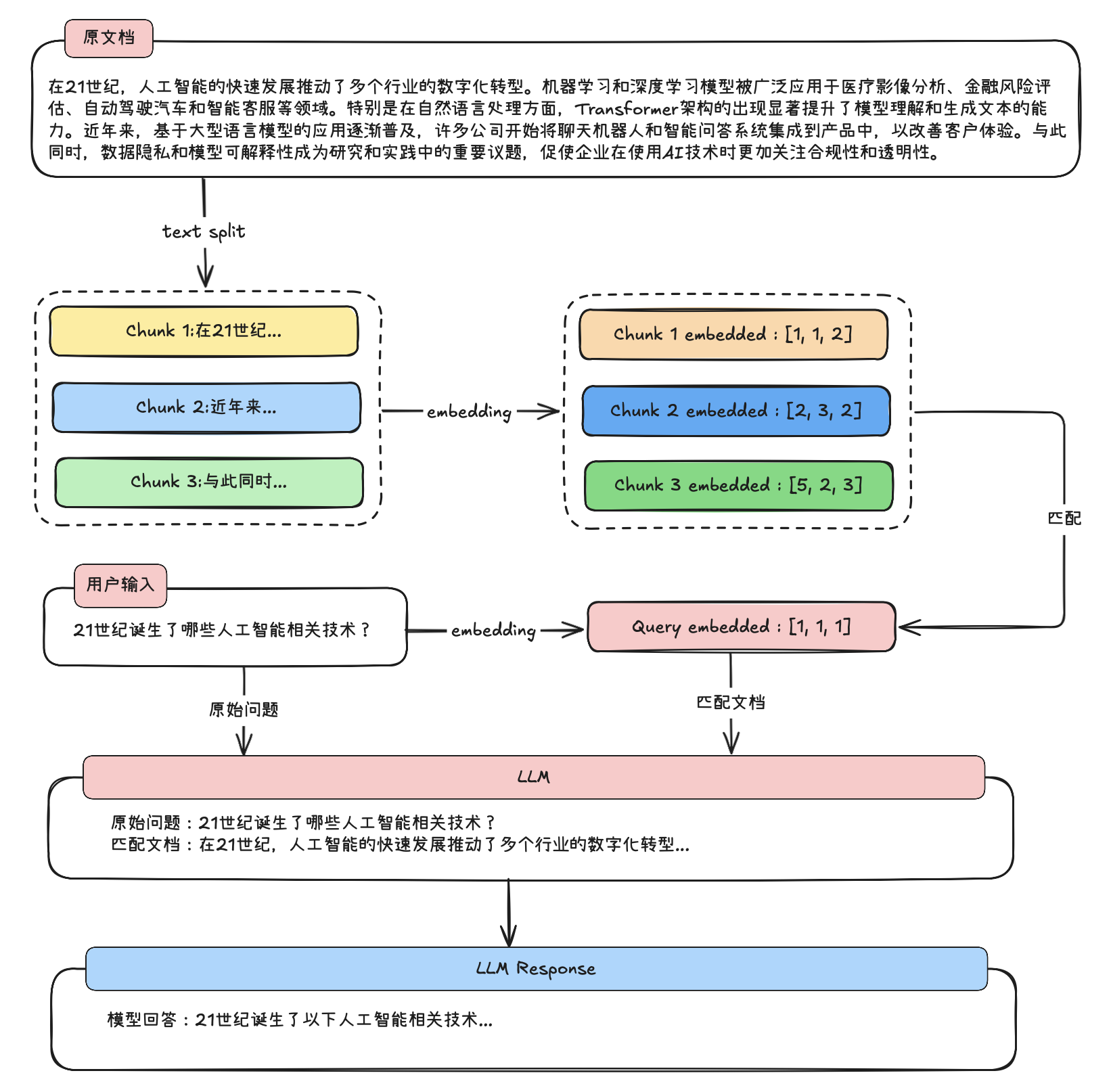
1. Llama-Index 项目介绍
- Llama-Index官方网站:https://www.llamaindex.ai/
- Llama-Index GitHub项目主页:https://github.com/run-llama/llama_index
Llama-Index(前身为 GPT Index)由 Jerry Liu 于 2022 年底发起。项目的诞生背景源于大语言模型(LLM)落地初期的一个核心痛点:模型虽然具备强大的通用推理能力,但缺乏特定领域的私有知识(Private Knowledge),且受限于上下文窗口(Context Window)的长度,无法处理大规模文档。
Llama-Index 最初的初衷非常纯粹:构建一个高效的“接口”,将用户的私有数据(如 PDF、Notion、SQL、API 数据)转化为 LLM 能够理解和利用的格式,从而通过上下文学习(In-context Learning)来增强模型的能力。经过两年的高速迭代,它已从一个简单的索引工具演变为一个完整的**“数据驱动型”大模型应用开发框架**。
如果把大模型比作“大脑”,Llama-Index 的定位就是“记忆增强系统”。它的官方定义是:“用于构建上下文增强型(Context-augmented)LLM 应用程序的数据框架”**。
它不仅仅关注于如何向模型提问(Prompt Engineering),更侧重于数据管理(Data Management)的全生命周期,包括数据的摄入(Ingestion)、结构化索引(Indexing)以及高效检索(Retrieval)。其核心目标是打破私有数据孤岛,让 LLM 能够以最低的成本、最高的精度访问海量外部知识。
目前,Llama-Index 是全球 AI 开源社区中最活跃的项目之一。
- 技术迭代: 保持着极高的更新频率,已发布 v0.10+ 版本,完成了核心架构的模块化重构,具备了企业级生产环境所需的稳定性。
- 生态系统: 拥有庞大的 LlamaHub 数据加载器生态,支持数百种数据源(从文件系统到 SaaS 服务)的开箱即用连接;同时支持 Python 和 TypeScript 双语言版本。
在 LLM 开发领域,通过对比可以更清晰地理解两者的差异:
- LangChain(通用编排者):
- 定位: 通用的 LLM 应用开发框架。
- 强项: 侧重于**“计算逻辑”**的编排。它擅长管理复杂的 Agent 行为链、工具调用(Tool Usage)以及多模态交互的流程控制。它像是一个“胶水”,连接模型与万物。
- Llama-Index(数据专家):
- 定位: 专注于数据处理与检索的垂直框架。
- 强项: 侧重于**“数据结构”**的优化。它在 RAG 领域拥有更深的护城河,特别是在处理非结构化数据切片、层级索引构建、复杂查询路由等方面提供了更精细的控制能力。
相较于其他框架,Llama-Index 在 RAG(检索增强生成)方面展现出显著的专业性优势:
- 更丰富的数据索引结构: 不仅支持简单的向量索引,还原生支持树状索引、关键词表索引、知识图谱索引等多种结构。
- 更高级的检索策略: 提供了递归检索(Recursive Retrieval)、混合检索(Hybrid Search)及元数据过滤等开箱即用的高级功能。
- 数据与 LLM 的深度对齐: 能够更好地处理长文档摘要、跨文档推理等复杂的数据任务。
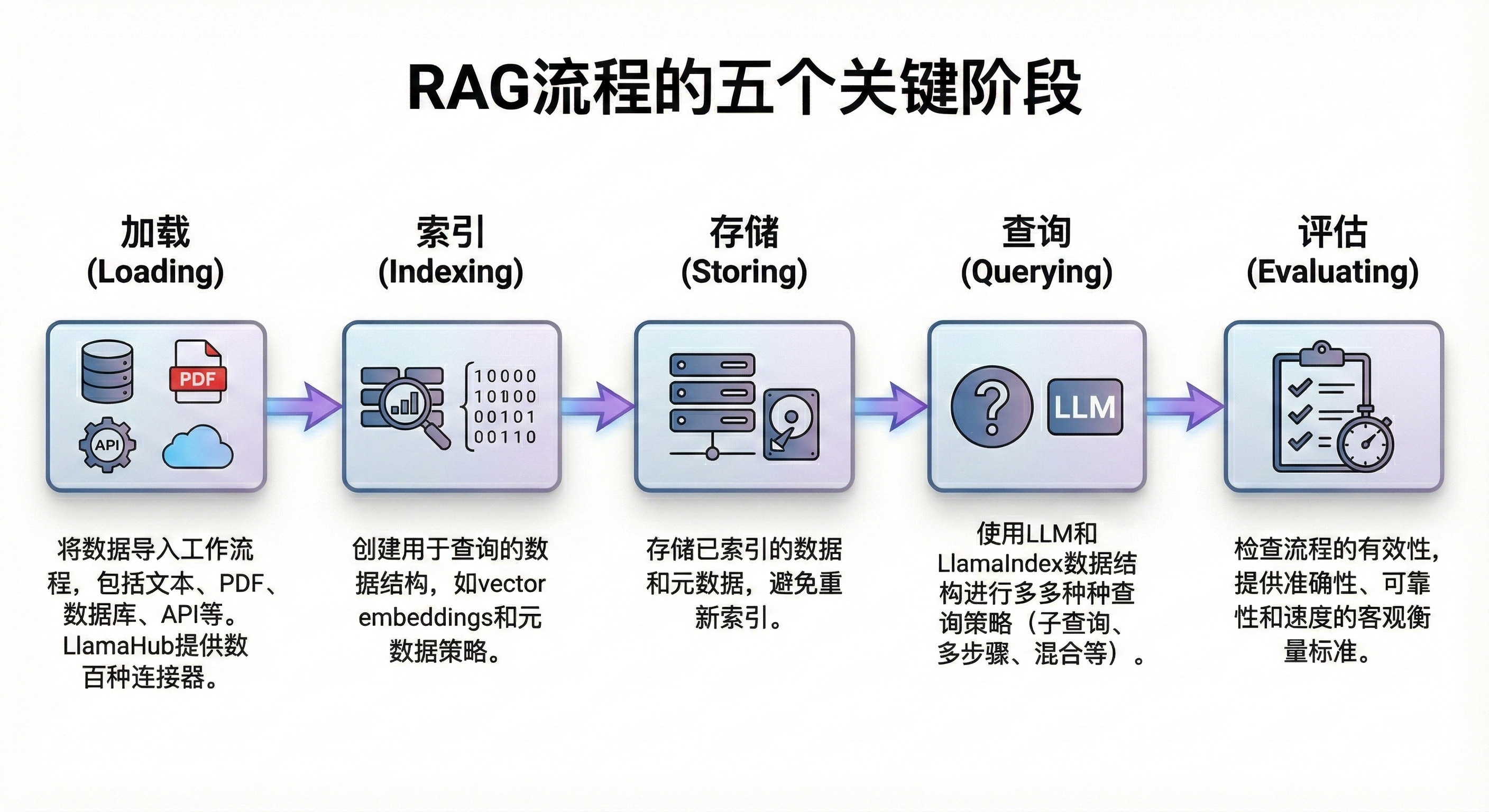
2. Llama-Index RAG核心优势
2.1 RAG 全生命周期(Full-Lifecycle)的闭环支持
与许多仅关注“向量检索”单一环节的工具不同,Llama-Index 提供了从数据源头到最终评估的 RAG 全流程解决方案。它将 RAG 系统抽象为五个标准化的流水线环节,开发者可以在同一个框架内完成所有工作,无需拼凑多个零散的工具库。
- 数据加载 (Loading): 提供统一接口将各类非结构化数据转化为标准的 Document 对象。
- 索引构建 (Indexing): 将文档切分(Chunking)并向量化(Embedding),构建出不仅包含向量、还包含元数据(Metadata)和节点关系(Relationships)的高级索引结构。
- 存储 (Storing): 原生适配数十种主流向量数据库(如 Chroma, Weaviate, Milvus)及图数据库,支持索引的持久化与增量更新。
- 查询 (Querying): 这一环节是 Llama-Index 的核心,它封装了检索、后处理和合成的复杂逻辑,对外提供简洁的查询接口。
- 评估 (Evaluation): 独有的 "Evaluation-First" 理念,内置了基于 LLM 的评估模块,能够对检索的准确性(Retrieval metrics)和生成的质量(Response metrics)进行自动化评分,解决了 RAG 难以优化的痛点。
2.2 极致的定制化空间与丰富的功能接口
Llama-Index 最大的架构优势在于其模块化(Modularity)设计。它将 RAG 的每个步骤都解耦为可插拔的组件,特别是在查询引擎(Query Engine)环节,提供了极高的定制自由度:
- 高级后处理 (Post-Processing):
在检索与生成之间,Llama-Index 允许开发者插入“节点后处理器(Node Postprocessors)”。这使得我们可以轻松实现:
- 重排序(Re-ranking): 集成 Cohere Rerank 或 BGE Rerank 模型,对检索到的 Top-K 结果进行二次精排,大幅提升相关性。
- 元数据过滤(Metadata Filtering): 基于时间、作者或文件类型过滤节点。
- 相似度截断(Similarity Cutoff): 自动丢弃相似度低于阈值的噪声数据。
- 灵活的响应合成 (Response Synthesis):
针对不同的业务场景,提供了多种内置的合成策略,而非单一的拼接:
- Refine(精炼模式): 线性遍历检索结果,逐步迭代优化答案,适合生成详尽的回答。
- Tree Summarize(树状总结): 自底向上构建摘要树,适合处理海量上下文的归纳总结任务。
- Compact(紧凑模式): 最大化利用 Context Window,平衡速度与成本。
2.3 庞大的数据生态:LlamaHub
Llama-Index 拥有目前 AI 社区中最丰富的数据连接器生态——LlamaHub。它解决了 RAG 开发中“最后一公里”的数据获取难题,让开发者无需自行编写爬虫或解析脚本。
- 海量数据加载器 (Data Loaders):
社区维护了超过 400 种数据加载器,覆盖了几乎所有主流数据源:
- 文件类: PDF, Markdown, PowerPoint, Word, Excel, CSV 等。
- SaaS 类: Notion, Slack, Discord, Jira, Salesforce, Google Docs 等。
- 网络类: Wikipedia, YouTube Transcripts, Web Page Reader 等。
- 数据库类: PostgreSQL, MongoDB, SQL Database 等。
- 多模态原生支持: 除了文本,LlamaHub 还提供了针对图像、音频和视频的加载器,支持构建图文混排的 RAG 系统,能够将多模态信息统一映射到向量空间。
2.4 企业级云服务:LlamaCloud
为了满足企业对高性能和免运维的需求,Llama-Index 团队还推出了配套的商业化云服务,进一步补全了开源框架的拼图:
- LlamaParse: 这是目前业界最先进的文档解析服务之一。专为解决 RAG 中的“复杂文档处理”难题而生,能够精准识别和解析 PDF 中的复杂表格、图表、数学公式以及多栏排版,将其转化为 LLM 易于理解的 Markdown 格式,从源头上提升了 RAG 的检索质量。
- Managed Indexing: 提供“检索即服务(Retrieval-as-a-Service)”,开发者无需自行维护向量数据库和索引管道,通过 API 即可直接上传文件并进行高效检索,大幅降低了企业级 RAG 的落地门槛。
import os
from dotenv import load_dotenv
import llama_index.core
# 1. 加载环境变量
load_dotenv()
# 2. 检查 Llama-Index 版本
print(f"Llama-Index Version: {llama_index.core.__version__}")
import os
file_path = "./data/创新科技股份有限公司员工手册.txt"
with open(file_path, "r", encoding="utf-8") as f:
md_content = f.read()
md_content[:1000]

接下来介绍如何从零构建一个能够回答公司内部政策的 AI 助手。请注意,这几行代码虽然简洁,但它们在后台完成了 RAG 系统中最核心的ETL(抽取、转换、加载)、索引构建以及检索生成的全流程。我们将逐行拆解,重点剖析在默认参数下,Llama-Index 到底在后台做了什么,以及如何查看底层结果。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 1. 数据摄入 (Loading)
documents = SimpleDirectoryReader("data").load_data()
# 2. 索引构建 (Indexing)
index = VectorStoreIndex.from_documents(documents)
# 3. 引擎配置 (Query Engine)
query_engine = index.as_query_engine()
# 4. 执行查询 (Execution)
# 注意:aquery 是异步调用,在 Jupyter 或标准脚本中通常使用同步的 query
response = query_engine.query("请问,我们公司有病假政策么?请用中文进行回复。")
response.response

Part 2.三大文本检索进阶策略介绍
import os
from dotenv import load_dotenv
import llama_index.core
# 1. 加载环境变量
load_dotenv(override=True)
# 2. 检查 Llama-Index 版本
print(f"Llama-Index Version: {llama_index.core.__version__}")
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
base_url=os.getenv("BASE_URL")
api_key=os.getenv("OPENAI_API_KEY")
# 配置 LLM (大语言模型)
Settings.llm = OpenAI(
model="gpt-4o",
api_key=api_key,
api_base=base_url
)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 1. 数据摄入 (Loading)
documents = SimpleDirectoryReader("data").load_data()
# 2. 索引构建 (Indexing)
index = VectorStoreIndex.from_documents(documents)
# 3. 引擎配置 (Query Engine)
query_engine = index.as_query_engine()
# 4. 执行查询 (Execution)
# 注意:aquery 是异步调用,在 Jupyter 或标准脚本中通常使用同步的 query
response = query_engine.query("请问,我们公司有病假政策么?请用中文进行回复。")
response.response
二、小索引,大窗口RAG策略详解
在 RAG 系统中,我们经常面临一个两难的选择:切片(Chunk)切小了,检索虽然精准,但丢给大模型的上下文支离破碎;切片切大了,上下文虽然完整,但包含大量无关噪声,导致检索准确率下降。
Small-to-Big(小索引,大窗口) 策略,又称 Sentence Window Retrieval,正是为了解决这一痛点而生。该策略的核心思想在于将用于 “搜索” 的数据与用于 “给 LLM 看” 的数据分离开来。
- 小索引 (Small Index for Retrieval): 系统将文档切分为极细颗粒度的**“单句”**。我们在向量库中存储的是这些单句的向量。这样做的好处是,当用户提问时,问题能与最相关的某一句特定的话产生极高的相似度匹配,最大程度减少噪声干扰。
- 大窗口 (Big Window for Generation): 虽然我们搜的是句子,但单句往往缺乏上下文(例如“否则将被解雇”,光看这句不知道“否则”是指什么)。因此,我们在切分时,会预先将这句子前后相邻的 N 句话作为元数据(Metadata)存储起来。
- 偷梁换柱 (Metadata Replacement): 在检索到目标句子后,系统在发送给 LLM 之前,会执行一个“后处理”动作:将这个孤立的句子替换为它预存的“大窗口”内容。
# 3. 检查数据文件是否存在
if not os.path.exists("./data/创新科技股份有限公司员工手册.txt"):
print("❌ 错误:请确保 './data' 目录下存放了员工手册 txt 文件!")
else:
print("✅ 环境检查通过,正在加载数据...")
# 加载文档
documents = SimpleDirectoryReader("./data").load_data()
print(f"📄 成功加载文档,共 {len(documents)} 页/部分。")
# === Cell 2: 构建“普通 RAG” (Baseline) ===
print("🛠️ 正在构建普通 RAG 索引 (使用默认 Chunking)...")
# 1. 建立普通索引
# 默认行为:Chunk Size = 1024, Top-k = 2
base_index = VectorStoreIndex.from_documents(documents)
base_engine = base_index.as_query_engine(similarity_top_k=2)
print("✅ 普通 RAG 就绪!")
# 定义我们的“找茬”问题集
test_questions = [
"Q1: 如果我这个月迟到了 4 次,会受到什么样的具体处理?如果连续 3 天没打卡呢?",
"Q2: 我想周末和春节都来公司加班多赚点钱,工资分别怎么算?我一年最多能加多少小时班,有没有封顶?",
"Q3: 我还在试用期,最近家里有事想请半个月(15天)的假,按规定可以请吗?会不会影响我转正?"
]
# === Cell 3: 构建“黑科技 RAG” (Small-to-Big / Sentence Window) ===
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
import re
print("🚀 正在构建黑科技 RAG 索引 (Small-to-Big)...")
# --- 🛠️ 关键修复:定义一个中文句子切分函数 ---
def chinese_sentence_splitter(text):
# 使用正则表达式,按中文句号、问号、感叹号及换行符进行切分
return re.split(r'(?<=[。?!\n])', text)
# 1. 定义窗口切分器 (加入 sentence_splitter 参数)
node_parser = SentenceWindowNodeParser.from_defaults(
# 告诉它用我们定义的中文切分函数
sentence_splitter=chinese_sentence_splitter,
# 窗口大小
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
# 2. 手动切分文档
nodes = node_parser.get_nodes_from_documents(documents)
print(f"🔪 文档被切分为 {len(nodes)} 个句子节点")
# --- 🔍 验证一下是否切分成功 (如果这里打印的是1,说明还是没切开) ---
if len(nodes) < 10:
print("⚠️ 警告:节点数量过少,可能切分失败!请检查分割符。")
else:
print(f"✅ 切分成功!第一个节点预览: {nodes[0].text[:50]}...")
# 3. 建立索引 (现在每个 Node 都很小,不会报错了)
advanced_index = VectorStoreIndex(nodes)
# 4. 创建引擎
advanced_engine = advanced_index.as_query_engine(
similarity_top_k=5,
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
]
)
print("✅ 黑科技 RAG 就绪!")
这段代码不仅仅是简单的 API 调用,它包含了一个针对中文环境的特殊优化,以及 Llama-Index 中最核心的元数据替换机制。我们将代码拆解为四个关键逻辑块进行讲解。
1. 关键设置:自定义中文分词器 (The Chinese Fix)
FENCE0
- 为什么要写这个函数?
- Llama-Index 的
SentenceWindowNodeParser默认是为英文设计的,它寻找英文句号.来断句。 - 如果直接处理中文文档,解析器会“视而不见”中文的句号
。,导致它把整篇几千字的文档当成一整句话。这不仅会导致检索精度归零,更会直接撑爆 Embedding 模型的 Token 限制(如 OpenAI 的 8192 限制),引发报错。
- Llama-Index 的
- 代码原理解析:
- 我们使用了 Python 的正则表达式
re.split。 (?<=[。?!\n])是一个**“后向断言” (Lookbehind Assertion)。它的意思是:“只要看到中文句号、问号、感叹号或者换行符,就在它们后面**切一刀”。这样能保证标点符号被保留在句子里,而不是被切掉。
- 我们使用了 Python 的正则表达式
2. 定义窗口解析器 (The Architect)
FENCE1
- 核心逻辑:
- 这是该策略的“总设计师”。它决定了数据被切分后的形态。
- 参数详解:
window_size=3:这是策略的灵魂。意味着当系统切分出第 N 句话时,它会同时把 [N-3, N-2, N-1, N, N+1, N+2, N+3] 这 7 句话打包在一起,存储在元数据里。window_metadata_key="window":告诉系统,把打包好的“7句话大窗口”藏在节点的metadata['window']字段里,备用。
3. 切分与验证 (Parsing & Validation)
FENCE2
- 流程变化:
- 在普通 RAG 中,我们直接用
VectorStoreIndex.from_documents()。 - 在这里,我们必须先手动调用
get_nodes_from_documents获得nodes,然后再建索引。这是为了确保我们的切分策略生效。
- 在普通 RAG 中,我们直接用
- 向量化的是谁?
- 关键点: 此时建立索引,Embedding 模型计算的是
node.text(也就是单句)的向量,而不是那个“大窗口”的向量。这保证了检索的极致精准度。
- 关键点: 此时建立索引,Embedding 模型计算的是
4. 引擎构建与“偷梁换柱” (The Magic Swap)
FENCE3
similarity_top_k=5:- 因为我们检索的是“细粒度”的句子,单个节点包含的信息量很小,所以我们需要稍微多找几个(Top-5),以确保覆盖足够的信息。
MetadataReplacementPostProcessor(魔法核心):- 这是 Llama-Index 特有的后处理器。
- 工作流:
- 检索时: 系统用问题去匹配“单句”。
- 命中后: 处理器介入,检查每个命中节点的
metadata。 - 替换(Swap): 它把
metadata['window'](那个包含上下文的大段落)取出来,直接覆盖掉原本的node.text(单句)。 - 合成时: 发送给 LLM 的 Prompt 里,填入的就是替换后的“大窗口”内容。
整体来说基本流程如下:
- 原始文档 $\xrightarrow{中文切分}$ 孤立句子
- 孤立句子 $\xrightarrow{WindowParser}$ 带有“上下文背包”的句子节点
- 索引阶段 $\rightarrow$ 只对 “句子” 做向量化(为了搜得准)
- 检索阶段 $\rightarrow$ 搜到了 “句子”
- 处理阶段 $\xrightarrow{PostProcessor}$ 扔掉句子,打开背包拿出 “大窗口”
- 生成阶段 $\rightarrow$ LLM 阅读 “大窗口” 并回答(为了看得全)

# === Cell 4: 效果对比展示 ===
from IPython.display import display, Markdown
def compare_answers(question):
# 1. 跑普通 RAG
response_base = base_engine.query(question)
# 2. 跑黑科技 RAG
response_adv = advanced_engine.query(question)
# 3. 格式化输出 (使用 Markdown 表格让对比更强烈)
display(Markdown(f"### ❓ 提问: {question}"))
# 构建对比表格
table_md = f"""
| 🤖 普通 RAG (Baseline) | 🚀 黑科技 RAG (Small-to-Big) |
| :--- | :--- |
| {response_base.response} | {response_adv.response} |
"""
display(Markdown(table_md))
# 4. (可选) 展示黑科技到底引用了什么原文,增强可信度
# display(Markdown("**🚀 黑科技引用原文窗口:**"))
# for node in response_adv.source_nodes:
# display(Markdown(f"> ...{node.node.metadata['window']}..."))
display(Markdown("---"))
# 开始循环测试
for q in test_questions:
compare_answers(q)
三、混合检索 (Hybrid Search)执行策略
1. 策略背景:告别“懂意不懂字”的单腿走路
在基础的 RAG 系统中,我们通常完全依赖向量检索(Vector Search)。向量检索的魔法在于它能通过计算高维空间的距离来理解“语义”。例如,用户搜“请假规则”,它能通过语义关联找到“考勤管理”或“休假制度”,即便这几个字没有完全对应。
然而,在企业级落地中,我们很快发现纯向量检索存在一个致命的**“语义盲区”:它对精确匹配(Exact Match)**极不敏感。
- 当用户搜索一个特定的错误码(如“Error 503”)、一个生僻的人名(如“周云杰”)、一个专有的缩写(如“ROWE”)或一个具体的产品型号(如“X-2000”)时,向量模型往往会因为这些词在语义空间中过于稀疏,而检索到一堆“意思相近”但完全不相关的通用描述,导致“张冠李戴”。
混合检索(Hybrid Search) 的诞生,正是为了解决这一痛点。它主张“两条腿走路”,既要 AI 的“脑子”(语义理解),也要传统搜索引擎的“眼睛”(字面匹配)。
2. 核心原理:双路召回与加权融合
混合检索策略在底层构建了两条并行的检索链路,并通过精密的算法将结果合二为一:
- 链路 A:稠密向量检索 (Dense Retrieval)
- 机制: 使用 Embedding 模型将文本转化为向量。
- 强项: 擅长处理模糊查询、概念关联、同义词匹配。
- 角色: 负责“懂你什么意思”。
- 链路 B:稀疏关键词检索 (Sparse Retrieval / BM25)
- 机制: 基于传统的 TF-IDF(词频-逆文档频率)算法演进而来的 BM25 算法。
- 强项: 擅长捕捉生僻词、专有名词、精确数字。它不关心语义,只关心关键词是否在文档中高频出现。
- 角色: 负责“精准定位字面”。
- 融合机制:倒数排名融合 (Reciprocal Rank Fusion, RRF)
- 系统不会简单地把两路结果拼在一起,而是使用 RRF 算法。它像一个公正的裁判,查看两个链路的排名情况。如果一个文档在向量检索中排第 1,在关键词检索中也排第 1,它的最终权重会极高;如果只在单路出现,权重则会降低。
3.执行流程
# !pip install rank_bm25 jieba
# === Cell 1: 初始化与分词器配置 ===
import nest_asyncio
import jieba
from typing import List
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Settings, StorageContext
from llama_index.core.node_parser import SentenceSplitter
nest_asyncio.apply()
# 1. 定义一个中文分词函数 (给 BM25 用)
def chinese_tokenizer(text: str) -> List[str]:
# 使用 jieba 进行分词
return list(jieba.cut(text))
# 2. 加载数据
print("📂 正在加载文档...")
documents = SimpleDirectoryReader("./data").load_data()
# 3. 将文档切分为节点 (标准切分,Chunk Size=512 适中)
# 为什么要手动切分?因为 BM25 和 向量索引 需要共享同一套节点数据
splitter = SentenceSplitter(chunk_size=512, chunk_overlap=50)
nodes = splitter.get_nodes_from_documents(documents)
print(f"✅ 文档已切分为 {len(nodes)} 个标准节点。")
# === Cell 2: 构建“普通 RAG” (纯向量) ===
print("🛠️ 正在构建向量索引 (Vector Index)...")
# 1. 构建向量索引
vector_index = VectorStoreIndex(nodes)
# 2. 创建纯向量检索引擎
# similarity_top_k=2
vector_engine = vector_index.as_query_engine(similarity_top_k=2)
print("✅ 普通 RAG (Vector Only) 就绪!")
# === Cell 3: 构建“黑科技 RAG” (混合检索: Vector + BM25) ===
import inspect
from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
print("🚀 正在构建混合检索系统 (Hybrid Search)...")
# --- 🛠️ 自动侦测修复:从类型提示中提取 FusionMode ---
try:
# 1. 获取 __init__ 函数的签名
sig = inspect.signature(QueryFusionRetriever.__init__)
# 2. 找到 'mode' 参数的类型定义
ModeEnum = sig.parameters['mode'].annotation
print(f"✅ 成功自动侦测到 Mode 类型: {ModeEnum}")
# 3. 获取 RECIPROCAL_RANK 的值
# 如果它是枚举,直接取属性;如果是 Optional[FusionMode],可能需要剥离一层
# 这里做一个简单的容错遍历
if hasattr(ModeEnum, 'RECIPROCAL_RANK'):
target_mode = ModeEnum.RECIPROCAL_RANK
else:
# 如果类型提示没拿到,或者版本太旧是字符串,直接用字符串兜底
print("⚠️ 未找到枚举属性,尝试使用字符串模式...")
target_mode = "reciprocal_rank"
except Exception as e:
print(f"⚠️ 自动侦测失败 ({e}),回退到字符串模式...")
target_mode = "reciprocal_rank"
print(f"👉 最终使用的 mode 参数: {target_mode}")
# 1. 创建 BM25 检索器
bm25_retriever = BM25Retriever.from_defaults(
nodes=nodes,
similarity_top_k=2,
tokenizer=chinese_tokenizer
)
# 2. 创建 向量 检索器
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)
# 3. 创建 融合检索器
fusion_retriever = QueryFusionRetriever(
[vector_retriever, bm25_retriever],
similarity_top_k=4,
num_queries=1,
# 使用我们要么侦测到、要么回退的 mode
mode=target_mode,
use_async=True
)
# 4. 组装成引擎
hybrid_engine = RetrieverQueryEngine.from_args(
retriever=fusion_retriever
)
print("✅ 黑科技 RAG (Hybrid Search) 就绪!")
这段代码展示了如何将关键词检索 (BM25) 与 向量检索 (Vector) 结合,并通过 RRF (倒数排名融合) 算法实现 1+1 > 2 的效果。值得注意的是,代码开头包含了一段处理版本兼容性的“防御性编程”技巧。
我们将代码逻辑拆解为三个核心模块进行讲解:
1. 自动侦测与版本适配 (The Compatibility Fix)
FENCE0
- 为什么要写这段复杂的逻辑?
- 背景: Llama-Index 更新极快,v0.10.x 版本中,
FusionMode从字符串变成了严格的枚举类型(Enum)。直接写字符串"reciprocal_rank"在新版会报错,直接引枚举类在旧版又会报错。 - 原理: 这里使用了 Python 的
inspect(反射) 模块。 - 比喻: 这就像在进门前,先用扫描仪看一眼门锁是“指纹锁”还是“钥匙锁”,然后再决定掏出指纹还是钥匙。这是一种**“防御性编程”**,确保你的代码在不同版本的 Llama-Index 上都能跑通,不至于因为版本升级而崩溃。
- 背景: Llama-Index 更新极快,v0.10.x 版本中,
2. 创建双路检索器 (Two-Stream Retrievers)
FENCE1
- 分工明确:
- BM25Retriever: 它是系统的“眼睛”,负责盯着字面。如果用户搜“周云杰”,它能精准抓取包含这三个字的人名,哪怕语义上这只是一个普通名字。
- VectorIndexRetriever: 它是系统的“脑子”,负责理解含义。如果用户搜“法务负责人”,它能理解这和“周云杰”是关联的。
- 注意点: BM25 必须传入
tokenizer=chinese_tokenizer,否则它会把一整句中文当成一个长单词,无法匹配关键词。
3. 融合与引擎组装 (The Fusion Core)
FENCE2
- 核心组件
QueryFusionRetriever: 它是整个策略的指挥官。 mode=RECIPROCAL_RANK(RRF 算法):- 这是目前业界最流行的无监督融合算法。
- 工作原理: 它不看分数(因为 BM25 的分数和向量的 Cosine 分数无法直接比较),它看排名。
- 举例: 如果文档 A 在关键词检索排第 1,在向量检索也排第 1,它的 RRF 得分就会极高,被置顶。如果文档 B 只在向量检索出现,关键词检索里没影,它的排名就会下降。
- 结果:
hybrid_engine最终吐出的答案,既包含了字面精准的信息,也包含了语义相关的信息,消除了单一检索的盲区。
# === Cell 4: 效果对比展示 ===
from IPython.display import display, Markdown
# 定义“找茬”问题
# 这些问题包含了具体的实体名(Entity)和缩写,是向量检索的弱项
questions = [
"Q1: 请问法务合规部的负责人是谁?我想发邮件给他,邮箱是多少?",
"Q2: 公司关于 BYOD (自带设备) 的具体政策要求是什么?",
"我是研发部的老员工,听说有个‘ROWE’工作制,具体需要满足哪些硬性条件才能申请?",
"如果我遇到紧急情况需要心理支持,公司有没有专门的援助热线?具体的电话号码是多少?",
"公司内部有没有专门支持女性发展的组织?这个小组的准确名称叫什么?"
]
def compare_hybrid(question):
# 1. 普通 RAG
response_base = vector_engine.query(question)
# 2. 混合 RAG
response_hybrid = hybrid_engine.query(question)
# 3. 展示对比
display(Markdown(f"### ❓ 提问: {question}"))
table_md = f"""
| 🤖 普通 RAG (Vector Only) | 🚀 黑科技 RAG (Hybrid: Vector + BM25) |
| :--- | :--- |
| {response_base.response} | {response_hybrid.response} |
"""
display(Markdown(table_md))
# 可选:查看混合检索到底融合了哪些节点
# print("🔍 混合检索命中的节点片段:")
# for node in response_hybrid.source_nodes:
# print(f"[{node.score:.2f}] {node.node.text[:50]}...")
display(Markdown("---"))
# 开始测试
for q in questions:
compare_hybrid(q)
四、路由检索策略介绍
1. 策略背景:打破“一刀切”的检索僵局
在传统的 RAG 架构中,存在一个尴尬的悖论:“宏观与微观的冲突”。
- 如果我们为了回答“总结全文核心思想”这样的宏观问题,而将 Top-K 设得很大或使用摘要索引,那么在回答“某项补贴具体是多少钱”这种微观问题时,就会造成巨大的算力浪费和响应延迟。
- 反之,如果我们为了快速查细节而使用标准的 Top-2 向量检索,那么面对“请概述公司发展历程”这样的问题时,系统就像“管中窥豹”,只能抓取到零星片段,给出的答案往往是片面甚至错误的。
智能路由(Router Query Engine) 的引入,标志着 RAG 系统从“自动化”向**“Agent(智能体)”**迈出了关键一步。它不再机械地执行单一动作,而是学会了“先思考,再行动”。
2. 核心原理:RAG 系统的“前置分诊台”
智能路由策略的核心在于构建了一个决策层,位于用户提问和数据索引之间:
- 构建多元工具箱:
我们不再只维护一个索引,而是针对不同的任务构建不同的索引结构,并将它们封装为“工具(Tools)”。
- 工具 A(向量工具): 基于 VectorStoreIndex,擅长点对点的细节查询(查数据、查条款)。
- 工具 B(摘要工具): 基于 SummaryIndex,擅长遍历全文档构建树状摘要(做总结、看全貌)。
- AI 路由选择器 (LLM Selector):
这是系统的“大脑”。当问题进来时,Selector 会先阅读问题的意图,然后对比手边工具的“功能描述(Description)”,动态决定:
- “这个问题是查细节的 -> 派发给工具 A。”
- “这个问题是做总结的 -> 派发给工具 B。”
- “这个问题既要细节又要总结 -> 同时派发给 A 和 B,最后汇总。”
3.执行流程
# === Cell 1: 初始化与构建双索引 (Vector + Summary) ===
import nest_asyncio
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, SummaryIndex, Settings
from llama_index.core.node_parser import SentenceSplitter
nest_asyncio.apply()
# 1. 加载数据
print("📂 正在加载文档...")
documents = SimpleDirectoryReader("./data").load_data()
# 2. 切分文档 (通用切分)
splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
nodes = splitter.get_nodes_from_documents(documents)
# 3. 构建【向量索引】 (擅长查细节)
print("🛠️ 正在构建向量索引 (Vector Index)...")
vector_index = VectorStoreIndex(nodes)
# 4. 构建【摘要索引】 (擅长做总结)
# SummaryIndex 不做向量化,它把所有节点存成一个列表,查询时会遍历阅读
print("📚 正在构建摘要索引 (Summary Index)...")
summary_index = SummaryIndex(nodes)
print("✅ 双索引构建完毕!")
# === Cell 2: 定义工具与构建 Router ===
from llama_index.core.tools import QueryEngineTool
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.query_engine import RouterQueryEngine
# 1. 定义 Vector 工具 (查细节)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_index.as_query_engine(similarity_top_k=2),
description="专门用于查询具体的、特定的事实细节,例如补贴金额、电话号码、具体政策条款等。"
)
# 2. 定义 Summary 工具 (做总结)
# response_mode="tree_summarize" 是关键,它会构建一棵摘要树,从底向上递归总结
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_index.as_query_engine(response_mode="tree_summarize"),
description="专门用于对文档进行宏观的总结、概括全文主题、分析整体结构或提取跨章节的综合信息。"
)
# 3. 构建 Router 引擎
print("🚦 正在构建智能路由引擎 (Router Engine)...")
router_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[summary_tool, vector_tool],
verbose=True # 开启 verbose,我们可以看到它到底选了哪个工具
)
print("✅ Router 引擎就绪!")
这段代码展示了如何将两个功能迥异的检索引擎(查细节的 Vector 和 查全貌的 Summary)封装成工具,并教会系统如何根据用户的问题自动选择最合适的一个。
1. 定义工具:给系统装上“手脚” (The Tools)
在 Router 模式下,索引(Index)本身不能直接被路由,必须先封装成 QueryEngineTool。
FENCE0
QueryEngineTool:这是 Llama-Index 中的标准工具包装器。description(至关重要!):- 这不仅仅是写给开发者看的注释,它是写给 AI 看的 Prompt(指令)。
- Router 内部的 LLM 会阅读这段文字,来判断:“这个工具是干嘛的?它能解决当前用户的问题吗?”
- 教学点: 描述写得越精准,路由的准确率就越高。
2. 定义摘要工具与合成策略 (The Summary Strategy)
FENCE1
- 为什么要用
SummaryIndex?- 向量索引通过计算距离找 Top-K,会漏掉全局信息。而
SummaryIndex(摘要索引)存储的是节点列表,它允许我们遍历文档的所有内容。
- 向量索引通过计算距离找 Top-K,会漏掉全局信息。而
response_mode="tree_summarize"(树状总结):- 这是处理长文档总结的神器。
- 原理: 如果文档很长,它不会试图一次塞进 LLM。而是先把文档切块,分别总结(叶子节点),然后把这些小总结拼起来再总结(父节点),像爬树一样直到生成最终的根节点摘要。
- 效果: 能够生成覆盖全文档的高质量宏观摘要。
3. 构建大脑:选择器与引擎 (The Brain & Body)
FENCE2
LLMSingleSelector(决策者):- 这是一个小型分类器。它接收用户的问题和工具的描述,然后输出一个最佳工具的名称。
- 注: 还有
LLMMultiSelector,可以同时选择多个工具(例如既查 Google 又查本地文档),但在本例中我们只需要“二选一”。
verbose=True(调试模式):- 在教学和调试中非常有用。开启后,你会在控制台看到系统“思考”的过程,例如:
Selecting query engine 0: ...。这能让你直观地确认 Router 是否变聪明了。
- 在教学和调试中非常有用。开启后,你会在控制台看到系统“思考”的过程,例如:
整体执行逻辑如下:
- 用户提问: “公司有哪些福利?”
- Router (Selector) 思考:
- 看工具 A(Vector)描述:查具体细节、数字。-> 不太匹配。
- 看工具 B(Summary)描述:查宏观总结、概括。-> 匹配!
- 分发任务: 将问题扔给
summary_tool。 - 执行任务:
summary_index启动tree_summarize模式,遍历文档生成总结。 - 返回结果: 用户得到一份全面的福利概览,而不是零星的补贴数字。
# === Cell 3: 定义 5 个测试问题 ===
questions = [
# --- 宏观总结题 (普通 RAG 的死穴) ---
# 1. 全文总结
"Q1: 这份员工手册主要包含了哪几个章节?请简要列出目录结构并概括每个章节的主题。",
# 2. 跨章节综合分析
"Q2: 请详细总结一下公司的核心价值观以及我们对待多样性(D&I)的整体策略。",
# --- 微观细节题 (普通 RAG 的强项) ---
# 3. 具体数字
"Q3: 公司的健身房补贴每年最高是多少钱?",
# 4. 具体人名
"Q4: 请问法务合规部的负责人是谁?",
# 5. 具体条款
"Q5: 试用期员工如果累计请假超过 10 天,会有什么具体后果?"
]
# === Cell 4: 效果对比展示 (修复表格渲染版) ===
from IPython.display import display, Markdown
# 准备一个普通的 Vector Engine 作为对照组
base_engine = vector_index.as_query_engine(similarity_top_k=2)
def clean_text(text):
"""
清洗文本:将换行符替换为HTML换行标签,防止Markdown表格崩坏
"""
if not text:
return ""
# 截取前 300 字符,并将换行符替换为 <br>
cleaned = str(text)[:300].replace("\n", "<br>")
return cleaned + "..."
print("🔥 开始 5 轮智能路由测试...")
print("(请耐心等待,Q1 和 Q2 需要总结全文,速度较慢...)")
for q in questions:
display(Markdown(f"### ❓ 提问: {q}"))
# 1. 普通 RAG
response_base = base_engine.query(q)
# 2. Router RAG
# 这一步可能会打印 "Selecting query engine..." 日志,请留意
response_router = router_engine.query(q)
# 3. 提取结果并清洗
base_text = clean_text(response_base.response)
router_text = clean_text(response_router.response)
# 4. 构建严格格式的 Markdown 表格
# 注意:表格每一行开头和结尾都要有 |
table_md = f"""
| 🤖 普通 RAG (Top-2 Vector) | 🚦 智能路由 (Router) |
| :--- | :--- |
| {base_text} | {router_text} |
"""
display(Markdown(table_md))
display(Markdown("---"))
Part 3.结构化数据检索实战
# === Cell 1: 加载数据与初始化引擎 ===
import pandas as pd
import os
from llama_index.experimental.query_engine import PandasQueryEngine
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
import os
import sys
from dotenv import load_dotenv
# 1. 加载本地 .env 文件
# override=True 确保如果系统环境变量里有冲突,以 .env 为准
load_dotenv(override=True)
Settings.llm = OpenAI(model="gpt-4o")
csv_path = "telco_data.csv"
df = pd.read_csv(csv_path)
# 3. 构建 PandasQueryEngine
# verbose=True 会让我们看到它生成的 Python 代码,非常适合调试
query_engine = PandasQueryEngine(
df=df,
verbose=True,
synthesize_response=True # 让 LLM 最后把代码运行结果翻译成自然语言
)
# 问题 1: 简单的统计
query_str_1 = "流失用户(Churn='Yes')的平均月费(MonthlyCharges)是多少?"
print(f"❓ 问题: {query_str_1}")
response = query_engine.query(query_str_1)
print("\n🤖 分析结果:")
print(response)
print("-" * 50)
# 问题 2: 复杂的分组统计
query_str_2 = "Show me the count of churned vs non-churned customers grouped by Contract type."
# 中文: "按合同类型(Contract)分组,统计流失和未流失用户的数量。"
print(f"\n❓ 问题: {query_str_2}")
response = query_engine.query(query_str_2)
print("\n🤖 分析结果:")
print(response)
response
import matplotlib.pyplot as plt
# 我们修改一下提示词,明确要求它用代码画图
# 注意:这需要 LLM 具备写 Matplotlib 代码的能力
query_str_viz = (
"Visualize the churn count by Contract type using a bar chart. "
"Use distinct colors for Churn vs Non-Churn. "
"Make sure to set the title as 'Churn Distribution by Contract Type'."
)
print(f"❓ 画图指令: {query_str_viz}")
# 使用之前定义的 query_engine
response_viz = query_engine.query(query_str_viz)
print("\n🤖 AI 回复:")
print(response_viz)
# 注意:PandasQueryEngine 有时会直接执行绘图代码并弹窗,
# 有时代码虽然执行了但图像没显示在 Jupyter 里。
# 如果没看到图,我们可以手动检查生成的代码:
print("\n📝 AI 生成的绘图代码:")
print(response_viz.metadata.get("pandas_instruction_str"))
# 获取当前的 prompt 模板
prompts = query_engine.get_prompts()
prompts
# 打印出 Text-to-Pandas 的核心指令
# 注意:这只是模板,运行时会自动填入 df.head()
print("📋 核心指令模板 (Pandas Instruction):")
print(prompts["pandas_prompt"].template)
print("\n" + "="*50 + "\n")
# 如果想看填入数据后的完整 Prompt,我们可以模拟一下
# LlamaIndex 内部会把 df_str 注入进去
df_head_str = df.head().to_markdown()
instruction_str = prompts["pandas_prompt"].format(
df_str=df_head_str,
query_str="你的问题在这里",
instruction_str="Select the most relevant dataframe..."
)
print("🕵️♂️ 实际发送给 LLM 的完整 Prompt :")
print(instruction_str)
df
chinese_instruction_str = (
"你是一位精通 Python Pandas 的数据分析专家。\n"
"你的任务是将用户的自然语言问题转换为可执行的 Python 代码,并基于执行结果回答问题。\n"
"请严格遵守以下规则:\n"
"1. 代码必须是有效的 Pandas 操作。\n"
"2. 代码的最后一行必须是一个返回结果的表达式(Expression),不要用 print()。\n"
"3. **最终的自然语言分析结果(Synthesis Response)必须强制使用中文回答**。\n"
"4. 如果结果是数据表,请简要总结关键发现。"
)
# 3. 初始化引擎
engine = PandasQueryEngine(
df=df,
verbose=True, # 显示思考过程(生成的代码)
synthesize_response=True, # 关键:开启结果总结,否则只会丢给你一个 DataFrame
instruction_str=chinese_instruction_str # <--- 注入我们的中文指令
)
# 4. 运行测试
print("🤔 正在提问...")
response = engine.query("请对比流失和非流失用户的月均消费金额。")
# 5. 输出结果
print("\n📝 AI 回复:")
print(response)
# 6. 查看生成的代码 (考古乐趣所在)
print("\n💻 生成的 Pandas 代码:")
print(response.metadata["pandas_instruction_str"])
Part 4.图文混排PDF检索实战
import os
import sys
from dotenv import load_dotenv
# 1. 加载本地 .env 文件
# override=True 确保如果系统环境变量里有冲突,以 .env 为准
load_dotenv(override=True)
# 2. 检查 Key 是否存在
dashscope_key = os.getenv("DASHSCOPE_API_KEY")
mineru_key = os.getenv("MINERU_API_KEY")
openai_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("BASE_URL")
if not dashscope_key or not mineru_key:
print("❌ 错误:未找到 API Key,请检查 .env 文件!")
else:
print(f"✅ 成功加载 DashScope Key: {dashscope_key[:6]}******")
print(f"✅ 成功加载 MinerU Key: {mineru_key[:6]}******")
# 3. 检查必要的库是否安装
try:
import llama_index.core
import requests
import dashscope
print("✅ 依赖库检查通过")
except ImportError as e:
print(f"❌ 缺少依赖库: {e}")
print("请运行: pip install llama-index-core llama-index-multi-modal-llms-openai python-dotenv requests dashscope")
# === Cell 2: 终极适配版 MinerUAPIReader (适配 full.md) ===
import time
import requests
import zipfile
import shutil
import os
import json
from pathlib import Path
from typing import List
from llama_index.core import Document
from llama_index.core.schema import ImageDocument
class MinerUAPIReader:
def __init__(self, api_key: str, output_dir="./mineru_output"):
self.api_key = api_key
self.base_url = "https://mineru.net/api/v4"
self.output_dir = Path(output_dir)
def load_data(self, pdf_url: str) -> List[Document]:
"""
核心方法:传入 PDF URL -> 轮询 -> 下载 ZIP -> 提取 full.md 和图片
"""
if not pdf_url.startswith("http"):
raise ValueError("❌ 请传入有效的公网 URL (http/https)")
# 1. 提交解析任务
print(f"🚀 [MinerU] 提交解析任务 URL: {pdf_url[:50]}...")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
data = {
"url": pdf_url,
"model_version": "vlm", # 保持 VLM 模式
"is_ocr": True,
"lang": "auto"
}
try:
resp = requests.post(f"{self.base_url}/extract/task", headers=headers, json=data)
resp_json = resp.json()
if resp.status_code != 200 or resp_json.get('code') != 0:
print(f"❌ 提交失败响应: {resp.text}")
raise Exception(f"API 请求失败: {resp_json.get('msg', '未知错误')}")
task_id = resp_json['data'] # 获取 task_id 字符串 (v4 接口直接返回 ID)
# 如果 data 是字典,尝试获取 task_id 字段 (容错)
if isinstance(task_id, dict):
task_id = task_id.get('task_id')
print(f"⏳ [MinerU] 任务 ID: {task_id},正在解析中...")
except Exception as e:
raise Exception(f"提交任务出错: {e}")
# 2. 轮询结果
result_url = None
start_time = time.time()
timeout = 600 # 10分钟超时,防止大文件解析慢
while True:
if time.time() - start_time > timeout:
raise TimeoutError("解析超时")
time.sleep(3)
try:
status_resp = requests.get(f"{self.base_url}/extract/task/{task_id}", headers=headers)
if status_resp.status_code != 200:
continue
status_json = status_resp.json()
# 容错处理:确保 data 存在
if 'data' not in status_json:
continue
status_data = status_json['data']
state = status_data['state']
if state == 'done':
result_url = status_data['full_zip_url']
print("") # 换行
break
elif state in ['failed', 'error', 'cancelled']:
raise Exception(f"解析最终失败,状态: {state}")
else:
print(f".", end="", flush=True) # 打印进度点
except Exception as e:
# 网络波动不中断,继续重试
print(f"⚠️ 轮询波动: {e}")
time.sleep(2)
continue
print(f"\n✅ [MinerU] 解析完成,开始处理结果包...")
return self._process_zip(result_url, str(task_id))
def _process_zip(self, url, task_id) -> List[Document]:
# 清理并创建目录
extract_path = self.output_dir / task_id
if extract_path.exists():
shutil.rmtree(extract_path)
extract_path.mkdir(parents=True, exist_ok=True)
# 下载 Zip
zip_path = extract_path / "result.zip"
try:
print(f"📥 正在下载结果包...")
with requests.get(url, stream=True) as r:
r.raise_for_status()
with open(zip_path, 'wb') as f:
shutil.copyfileobj(r.raw, f)
except Exception as e:
raise Exception(f"下载结果 zip 失败: {e}")
# 解压
try:
with zipfile.ZipFile(zip_path, 'r') as z:
z.extractall(extract_path)
except Exception:
raise Exception("文件解压失败")
# 封装 Document
documents = []
try:
# === 关键修正:根据您的截图寻找 full.md ===
# 使用 rglob 递归查找,因为 full.md 可能在 task_id 同名子目录里
md_files = list(extract_path.rglob("full.md"))
if not md_files:
# 容错:如果找不到 full.md,尝试找任何 .md 文件
md_files = list(extract_path.rglob("*.md"))
if not md_files:
print(f"⚠️ 警告:解压目录中未找到 full.md。目录内容: {[p.name for p in extract_path.rglob('*')]}")
return []
target_md_file = md_files[0]
print(f"📖 锁定核心文档: {target_md_file.name} (路径: {target_md_file.parent.name})")
except Exception as e:
print(f"⚠️ 文件结构错误: {e}")
return []
# 1. 读取 Markdown 文本
with open(target_md_file, 'r', encoding='utf-8') as f:
documents.append(Document(
text=f.read(),
metadata={"file_name": "mineru_doc.pdf", "task_id": task_id}
))
# 2. 读取图片 (images 文件夹通常和 full.md 在同一级)
images_dir = target_md_file.parent / "images"
if images_dir.exists():
valid_images = [
img for img in images_dir.iterdir()
if img.suffix.lower() in ['.jpg', '.png', '.jpeg'] and img.stat().st_size > 2048 # 过滤小图
]
print(f"📸 [MinerU] 成功提取图表: {len(valid_images)} 张")
for img in valid_images:
documents.append(ImageDocument(
image_path=str(img),
metadata={"file_name": "mineru_doc.pdf", "task_id": task_id}
))
else:
print("ℹ️ 未发现 images 文件夹,可能是纯文本文档。")
return documents
print("✅ 终极适配版 MinerUAPIReader 定义完成!")
# === Cell 2 (Qwen2.5-VL 适配版): 定义 DashScopeEmbedding 类 ===
from typing import Any, List
from llama_index.core.embeddings import MultiModalEmbedding
from llama_index.core.schema import ImageType
import dashscope
from http import HTTPStatus
import asyncio
from pathlib import Path
class DashScopeMultiModalEmbedding(MultiModalEmbedding):
"""
适配阿里百炼最新 Qwen2.5-VL-Embedding 模型
"""
def __init__(self, api_key: str, model_name: str = "qwen2.5-vl-embedding"):
super().__init__(model_name=model_name)
dashscope.api_key = api_key
# --- 通用调用逻辑 (私有方法) ---
def _call_api(self, input_data: list) -> List[float]:
"""
统一处理 API 调用与结果解析
input_data 示例: [{'text': 'hello'}] 或 [{'image': 'file://...'}]
"""
try:
resp = dashscope.MultiModalEmbedding.call(
model=self.model_name,
input=input_data
)
if resp.status_code == HTTPStatus.OK:
# 适配新版返回结构: output -> embeddings -> [0] -> embedding
if 'embeddings' in resp.output and len(resp.output['embeddings']) > 0:
return resp.output['embeddings'][0]['embedding']
else:
print(f"⚠️ API 返回结果为空: {resp}")
return [0.0] * 1536 # 假设维度,避免程序崩溃
else:
print(f"⚠️ API 调用失败: {resp.message}")
return [0.0] * 1536
except Exception as e:
print(f"⚠️ 网络或处理异常: {e}")
return [0.0] * 1536
# --- 1. 图片向量化 ---
def _get_image_embedding(self, img_file_path: ImageType) -> List[float]:
# 必须转换为绝对路径并加 file:// 前缀
abs_path = Path(img_file_path).absolute()
input_data = [{'image': f"file://{abs_path}"}]
return self._call_api(input_data)
# --- 2. 文档文本向量化 ---
def _get_text_embedding(self, text: str) -> List[float]:
input_data = [{'text': text}]
return self._call_api(input_data)
# --- 3. 查询文本向量化 ---
def _get_query_embedding(self, query: str) -> List[float]:
input_data = [{'text': query}]
return self._call_api(input_data)
# --- 4. 异步方法 ---
async def _aget_image_embedding(self, img_file_path: ImageType) -> List[float]:
return self._get_image_embedding(img_file_path)
async def _aget_text_embedding(self, text: str) -> List[float]:
return self._get_text_embedding(text)
async def _aget_query_embedding(self, query: str) -> List[float]:
return self._get_query_embedding(query)
print(f"✅ Qwen2.5-VL 适配版 Embedding 类定义完成!")
# === Cell 3 (Step 1): 单独测试 MinerU 解析 ===
from llama_index.core.schema import ImageDocument
import os
# 1. 准备测试数据
test_url = "https://ml2022.oss-cn-hangzhou.aliyuncs.com/0.LangChain%E6%8A%80%E6%9C%AF%E7%94%9F%E6%80%81%E4%BB%8B%E7%BB%8D.pdf"
# 2. 实例化读取器 (确保 mineru_key 已正确加载)
if 'mineru_key' not in globals():
mineru_key = os.getenv("MINERU_API_KEY")
# 2. 实例化 (确保 mineru_key 存在)
reader = MinerUAPIReader(api_key=mineru_key)
print(f"🔄 开始测试解析 URL: {test_url}")
try:
documents = reader.load_data(test_url)
print(f"\n✅ 解析成功!")
print(f"📊 获得节点总数: {len(documents)}")
# 打印前几个节点的类型
for i, doc in enumerate(documents[:3]):
doc_type = "图片节点 (Image)" if isinstance(doc, ImageDocument) else "文本节点 (Text)"
print(f" - 节点 {i+1}: {doc_type}")
if not isinstance(doc, ImageDocument):
print(f" 文本预览: {doc.text[:100]}...")
except Exception as e:
print(f"\n❌ 测试失败: {e}")
import traceback
traceback.print_exc()
# === Cell 4: 索引构建 (最终测试) ===
from llama_index.core.indices.multi_modal import MultiModalVectorStoreIndex
from llama_index.core import StorageContext, load_index_from_storage
import os
# 1. 实例化新版 Embedding
embed_model = DashScopeMultiModalEmbedding(api_key=dashscope_key)
persist_dir = "./storage_qwen_vl"
if os.path.exists(persist_dir):
print(f"📂 加载本地索引: {persist_dir} ...")
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
index = load_index_from_storage(storage_context)
print("✅ 加载完成")
else:
print("🧠 正在调用 Qwen2.5-VL 构建图文索引...")
# 关键:同时指定 embed_model 和 image_embed_model
index = MultiModalVectorStoreIndex.from_documents(
documents,
embed_model=embed_model, # 文本 -> Qwen2.5
image_embed_model=embed_model # 图片 -> Qwen2.5
)
print(f"💾 保存索引至 {persist_dir} ...")
index.storage_context.persist(persist_dir=persist_dir)
print("✅ 构建并保存完成")
# --- 简单验证一下维度 ---
print("🎉 RAG 引擎就绪!")
# === Cell 5: 多模态问答 (最新标准版 - 无警告) ===
import os
# 1. 改用标准 OpenAI 类 (它现在已经内置了多模态支持)
from llama_index.llms.openai import OpenAI
from IPython.display import display, Image, Markdown
# 2. 配置 GPT-4o (支持国内反代)
openai_api_key = os.getenv("OPENAI_API_KEY")
openai_base_url = os.getenv("BASE_URL")
if not openai_base_url:
print("⚠️ 警告: 未找到 OPENAI_BASE_URL,尝试官方直连...")
else:
print(f"🌍 使用 OpenAI 反代地址: {openai_base_url}")
# 3. 实例化模型 (注意:不再使用 OpenAIMultiModal)
# LlamaIndex 的 OpenAI 类会自动识别 gpt-4o 并开启视觉能力
llm = OpenAI(
model="gpt-4o",
api_key=openai_api_key,
api_base=openai_base_url # 设置反代
)
# 4. 构建查询引擎
# 注意:在 MultiModalIndex 中,我们将其传递给 llm 参数即可
# 系统会自动检测这个 LLM 是否支持多模态
query_engine = index.as_query_engine(
llm=llm, # 传入通用的 OpenAI 对象
similarity_top_k=2, # 2 段文本
image_similarity_top_k=1 # 1 张图片
)
# 3. 发起提问
# 针对我们刚才解析的 LangChain 文档,问一个图文结合的问题
query_str = "根据文档内容,LangChain 的整体架构包含哪几个核心层?请结合架构图进行说明。"
print(f"\n❓ [提问]: {query_str}")
print("⏳ 正在检索上下文并进行视觉推理...")
response = query_engine.query(query_str)
# 4. 结果可视化展示 (核心教学环节)
print("\n" + "="*50)
display(Markdown(f"### 🤖 AI 回答:\n\n{response.response}"))
print("="*50 + "\n")
print("🔍 --- [RAG 检索证据展示] ---")
# 遍历所有检索到的节点 (Source Nodes)
for i, node_with_score in enumerate(response.source_nodes):
node = node_with_score.node
score = node_with_score.score
print(f"\n🏷️ [证据 #{i+1}] 相似度: {score:.4f}")
# 判断是图片还是文本
# 注意:LlamaIndex 的 ImageNode 通常包含 image_path
if hasattr(node, "image_path") and node.image_path:
print(f"📸 类型: 图片节点")
print(f"📂 路径: {node.image_path}")
try:
display(Image(filename=node.image_path, width=500))
except:
print("⚠️ 图片无法显示")
else:
print(f"📄 类型: 文本节点")
# 截取前 200 字展示,避免刷屏
preview_text = node.text[:200].replace('\n', ' ')
print(f"📝 内容片段: \"{preview_text}...\"")
print("\n🎉 恭喜!全链路多模态 RAG 完美跑通!")
Part 5.多模态文搜图、图搜图RAG检索实战
# === Cell 1: 升级版 Qwen2.5-VL Embedding (带自动压缩功能) ===
import os
import dashscope
import tempfile
from typing import List, Any
from pathlib import Path
from http import HTTPStatus
from PIL import Image
from llama_index.core.embeddings import MultiModalEmbedding
from llama_index.core.schema import ImageType
# 确保安装了 dashscope
# !pip install dashscope pillow
class DashScopeMultiModalEmbedding(MultiModalEmbedding):
"""
适配阿里百炼 Qwen2.5-VL-Embedding 模型
✨ 新增特性:上传前自动压缩图片,提升速度并减少 Token 消耗
"""
def __init__(self, api_key: str, model_name: str = "qwen2.5-vl-embedding"):
super().__init__(model_name=model_name)
dashscope.api_key = api_key
def _call_api(self, input_data: list) -> List[float]:
try:
resp = dashscope.MultiModalEmbedding.call(
model=self.model_name,
input=input_data
)
if resp.status_code == HTTPStatus.OK:
if 'embeddings' in resp.output and len(resp.output['embeddings']) > 0:
return resp.output['embeddings'][0]['embedding']
else:
print(f"⚠️ API 返回结果为空: {resp}")
return [0.0] * 1024
else:
print(f"⚠️ API 调用失败: {resp.message}")
return [0.0] * 1024
except Exception as e:
print(f"⚠️ 网络或处理异常: {e}")
return [0.0] * 1024
# --- ✨ 新增:图片压缩辅助函数 ---
def _compress_image(self, image_path: str, max_size: int = 1024, quality: int = 85) -> str:
"""
读取图片,压缩大小和质量,保存到临时文件,返回临时文件路径。
"""
try:
with Image.open(image_path) as img:
# 1. 转换格式:如果是 PNG 透明图,转为 RGB,防止保存为 JPEG 出错
if img.mode in ('RGBA', 'P'):
img = img.convert('RGB')
# 2. 调整尺寸:保持比例,长边不超过 max_size
# thumbnail 方法是原地修改,且只有当图片大于指定尺寸时才缩放
img.thumbnail((max_size, max_size))
# 3. 创建临时文件
# delete=False 确保我们可以把路径传给 API,用完后再手动删
temp_file = tempfile.NamedTemporaryFile(suffix=".jpg", delete=False)
img.save(temp_file.name, format="JPEG", quality=quality)
# print(f"📉 图片已压缩: {os.path.basename(image_path)} -> {os.path.getsize(temp_file.name)/1024:.1f} KB")
return temp_file.name
except Exception as e:
print(f"⚠️ 图片压缩失败,将使用原图: {e}")
return image_path
# --- 1. 图片向量化 (修改版) ---
def _get_image_embedding(self, img_file_path: ImageType) -> List[float]:
# 1. 先进行本地压缩,获取临时文件路径
compressed_path = self._compress_image(img_file_path)
try:
# 2. 转换为绝对路径并加 file:// 前缀
abs_path = Path(compressed_path).absolute()
input_data = [{'image': f"file://{abs_path}"}]
# 3. 调用 API
return self._call_api(input_data)
finally:
# 4. 清理:如果 compressed_path 是临时文件(和原图路径不同),则删除
if compressed_path != img_file_path and os.path.exists(compressed_path):
try:
os.remove(compressed_path)
except:
pass
# --- 2. 文档文本向量化 ---
def _get_text_embedding(self, text: str) -> List[float]:
input_data = [{'text': text}]
return self._call_api(input_data)
# --- 3. 查询文本向量化 ---
def _get_query_embedding(self, query: str) -> List[float]:
input_data = [{'text': query}]
return self._call_api(input_data)
# --- 4. 异步方法 ---
async def _aget_image_embedding(self, img_file_path: ImageType) -> List[float]:
return self._get_image_embedding(img_file_path)
async def _aget_text_embedding(self, text: str) -> List[float]:
return self._get_text_embedding(text)
async def _aget_query_embedding(self, query: str) -> List[float]:
return self._get_query_embedding(query)
print(f"✅ Qwen2.5-VL 适配版 (带自动压缩) 定义完成!")
# === Cell 2: 使用 Qwen 构建多模态索引 ===
from llama_index.core import SimpleDirectoryReader
from llama_index.core.indices import MultiModalVectorStoreIndex
# 1. 设置您的阿里云 API Key
# 建议直接替换字符串,或者从环境变量读取
my_api_key =os.environ["DASHSCOPE_API_KEY"]
# 2. 初始化我们的自定义模型
print("🚀 正在初始化 Qwen2.5-VL Embedding 模型...")
qwen_embed_model = DashScopeMultiModalEmbedding(api_key=my_api_key)
# 2. 初始化我们的自定义模型
print("🚀 正在初始化 Qwen2.5-VL Embedding 模型...")
qwen_embed_model = DashScopeMultiModalEmbedding(api_key=my_api_key)
# 3. 加载本地图片数据
image_dir = "test_images"
if not os.path.exists(image_dir):
print(f"⚠️ 警告: 目录 {image_dir} 不存在,请先运行上一轮的下载图片代码!")
else:
print(f"📂 正在读取目录: {image_dir} ...")
documents = SimpleDirectoryReader(image_dir).load_data()
# 4. 构建索引 (关键一步)
# image_embed_model 指定为我们的 qwen 对象
print("🧠 正在调用阿里百炼 API 构建索引 (这会消耗 token)...")
index = MultiModalVectorStoreIndex.from_documents(
documents,
image_embed_model=qwen_embed_model
)
print("✅ 基于 Qwen2.5-VL 的多模态索引构建完成!")
# === Cell: 修复 Matplotlib 中文显示问题 (Windows 环境) ===
import matplotlib.pyplot as plt
import platform
# 判断系统类型,自动选择合适的字体
system_name = platform.system()
if system_name == "Windows":
# Windows 系统常用字体:SimHei (黑体), Microsoft YaHei (微软雅黑)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
elif system_name == "Darwin":
# Mac 系统常用字体:Arial Unicode MS, PingFang SC
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'PingFang SC']
else:
# Linux 系统 (通常是服务器环境),如果没有中文字体,可能需要安装
# 这里尝试一种通用的 fallback
plt.rcParams['font.sans-serif'] = ['WenQuanYi Micro Hei', 'SimHei']
# 解决负号 '-' 显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
print(f"✅ Matplotlib 字体已配置为适配 {system_name} 环境。")
# 辅助显示函数
def display_results(nodes, title="Results"):
if not nodes:
print("⚠️ 未找到匹配结果。")
return
fig, ax = plt.subplots(1, len(nodes), figsize=(10, 5))
if len(nodes) == 1: ax = [ax]
for i, node in enumerate(nodes):
path = node.node.metadata['file_path']
score = node.score
img = mpimg.imread(path)
ax[i].imshow(img)
ax[i].axis('off')
ax[i].set_title(f"Score: {score:.4f}\n{path}")
plt.suptitle(title)
plt.show()
# --- 测试 ---
# 可以尝试更复杂的中文描述
query_str = "最近家里装修,希望推荐一些好看的家具"
print(f"❓ [文搜图] 正在搜索: '{query_str}'")
# 1. 获取检索器
retriever = index.as_retriever(image_similarity_top_k=1)
# 2. 执行检索 (会自动调用 _get_query_embedding)
retrieval_results = retriever.text_to_image_retrieve(query_str)
# 3. 显示结果
display_results(retrieval_results, title=f"Query: {query_str}")
# --- 测试 ---
# 可以尝试更复杂的中文描述
query_str = "男士穿搭推荐。"
print(f"❓ [文搜图] 正在搜索: '{query_str}'")
# 1. 获取检索器
retriever = index.as_retriever(image_similarity_top_k=2)
# 2. 执行检索 (会自动调用 _get_query_embedding)
retrieval_results = retriever.text_to_image_retrieve(query_str)
# 3. 显示结果
display_results(retrieval_results, title=f"Query: {query_str}")
# --- 测试 ---
# 可以尝试更复杂的中文描述
query_str = "请帮我查询四室一厅的户型图纸。"
print(f"❓ [文搜图] 正在搜索: '{query_str}'")
# 1. 获取检索器
retriever = index.as_retriever(image_similarity_top_k=2)
# 2. 执行检索 (会自动调用 _get_query_embedding)
retrieval_results = retriever.text_to_image_retrieve(query_str)
# 3. 显示结果
display_results(retrieval_results, title=f"Query: {query_str}")
# === Cell 4: 图搜图 (Image-to-Image) ===
import requests
# 1. 准备一张不在库里的图片 (Query Image)
query_image_path = "./test_images/Image_rm5lrzrm5lrzrm5l.png"
if not os.path.exists(query_image_path):
print("📥 下载查询图片...")
resp = requests.get(query_url)
with open(query_image_path, "wb") as f:
f.write(resp.content)
# 显示查询图
print("🖼️ 查询图片 (Input):")
plt.figure(figsize=(3,3))
plt.imshow(mpimg.imread(query_image_path))
plt.axis('off')
plt.show()
# 2. 执行检索
# 这一步会自动调用 _get_image_embedding 对查询图进行向量化
print(f"🔍 [图搜图] 正在库中寻找相似图片...")
retrieval_results = retriever.image_to_image_retrieve(query_image_path)
# 3. 显示结果
display_results(retrieval_results, title="Image-to-Image Results")
Part 6.多模态视频检索实战
目前工业界在解决视频 RAG 问题时,形成了三种主流的技术范式。我们需要深入理解它们的底层逻辑差异,以便在实际业务中做出正确的架构选型。
1. 离散化流水线模式 (The Discretization Pipeline / Slicing)
这是早期最常见的处理方案,其核心思想是**“降维”**——将视频问题退化为图像和文本问题来处理。
- 技术原理: 该方案采用“分而治之”的策略。首先通过**抽帧(Frame Extraction)**将连续视频离散化为静态图片序列,利用 CLIP 等视觉模型提取图像特征;同时剥离音频轨道,利用 ASR(如 Whisper)生成文本。最终,RAG 系统检索的是这些“切片”后的图文向量。
- 架构评价:
- 优势:工程实现成熟,可复用现有的图文检索基础设施。
- 缺陷:存在严重的时序语义丢失(Temporal Semantic Loss)。由于切片之间相互独立,模型难以捕捉跨帧的动作逻辑(如“拿起”与“放下”的区别)和因果关系。它检索的是“瞬间”,而非“过程”。
2. 原生长窗口 LLM 模式 (Native Long-Context LLM)
以 Google Gemini 3 Pro 为代表的端到端方案。
- 技术原理: 这是一种非索引化的处理方式。得益于 Transformer 架构上下文窗口的突破(1M+ Tokens),这类模型可以直接摄入原生的视频流数据。模型内部通过对 Video Token 的注意力机制计算,实现对视频内容的完整理解。
- 架构评价:
- 优势:理解能力最强,具备极高的推理上限,能够理解复杂的叙事结构和隐喻,无需构建中间索引。
- 缺陷:**推理成本与延迟(Latency & Cost)**是最大瓶颈。在 RAG 场景下,如果面对海量视频库,无法将所有视频实时塞入 Context 进行检索。它更适合作为检索后的“重排序(Rerank)”或“精读生成”环节,而非底层的召回环节。
3. 时空对齐向量索引模式 (Spatiotemporal Vector Indexing)
以 Twelve Labs (Marengo/Pegasus) 为代表的专用模型方案。
- 技术原理: 该方案旨在构建一个视频-语言对齐(Video-Language Alignment)的共享向量空间。不同于 CLIP 只能对齐静态图片,Twelve Labs 的模型引入了时空模块(Time-Space Module),将视频的视觉特征、时间变化和音频信息压缩进同一个多维向量中。
- 架构评价:
- 核心突破:实现了细粒度的时间定位(Fine-grained Temporal Grounding)。当用户通过自然语言检索“汽车发生碰撞的瞬间”时,系统可以通过向量距离计算,直接返回精确到秒的时间戳(Timestamp),而不仅仅是返回整个视频文件。
- 定位:它在“理解深度”和“检索效率”之间取得了最佳平衡,是目前构建大规模视频 RAG 知识库的首选索引方案。
import os
import sys
from dotenv import load_dotenv
# 1. 加载本地 .env 文件
# override=True 确保如果系统环境变量里有冲突,以 .env 为准
load_dotenv(override=True)
# 2. 检查 Key 是否存在
tl_api_key = os.getenv("TL_API_KEY")
import os
# 1. 设置本地代理 (VPN 端口 10080)
# 这行代码必须在 import 其他网络库之前运行
proxy_url = "http://127.0.0.1:10080"
os.environ["HTTP_PROXY"] = proxy_url
os.environ["HTTPS_PROXY"] = proxy_url
# === 测试 Twelve Labs API 连通性 ===
import requests
import os
# 随便写个 API Key 或者留空,我们只是测网络通不通,不是测鉴权
url = "https://api.twelvelabs.io/v1.2/indexes"
try:
print(f"📡 正在尝试连接 {url} ...")
# 设置 timeout=5,如果 5 秒没反应就是被墙了
resp = requests.get(url, timeout=5)
# 如果返回 401 (Unauthorized),说明连上了(只是没 Key),这是好消息!
# 如果返回 200,说明连上了。
# 如果报错 ConnectionError,说明被墙了。
print(f"✅ 连接成功!状态码: {resp.status_code}")
print(f" (提示: 返回 401 是正常的,说明网络通了,只是缺 Key)")
except Exception as e:
print(f"❌ 连接失败: {e}")
print("💡 建议:请确保您的 VPN 开启了 'TUN模式' 或在代码中配置了 proxies 参数。")
# === Cell 2: 自定义 Twelve Labs 检索器 (SDK v0.5 终极通关版) ===
import os
import time
from typing import List
from llama_index.core import QueryBundle
from llama_index.core.retrievers import BaseRetriever
from llama_index.core.schema import NodeWithScore, TextNode
# SDK 导入
from twelvelabs import TwelveLabs
from twelvelabs.indexes import IndexesCreateRequestModelsItem
from twelvelabs.tasks import TasksRetrieveResponse
class TwelveLabsRetriever(BaseRetriever):
def __init__(self, api_key: str, index_name: str = "demo_rag_v6"): # 使用您已创建成功的索引名
self.client = TwelveLabs(api_key=api_key)
self.index_name = index_name
self.index_id = self._get_or_create_index()
super().__init__()
def _get_or_create_index(self):
"""检查是否有索引,没有就新建"""
try:
# 尝试查找现有索引
existing_indexes = self.client.indexes.list(page_limit=50)
for idx in existing_indexes:
current_name = getattr(idx, "name", None) or getattr(idx, "index_name", None)
if current_name == self.index_name:
print(f"✅ 找到现有索引: {current_name} ({idx.id})")
return idx.id
except Exception as e:
print(f"⚠️ 获取索引列表提示: {e}")
# 如果没找到,创建新的 (虽然您的 v6 已经存在,但这段逻辑保留以防万一)
print(f"🆕 正在云端创建新索引: {self.index_name} ...")
try:
new_index = self.client.indexes.create(
index_name=self.index_name,
models=[
IndexesCreateRequestModelsItem(
model_name="marengo2.7", # 或 marengo3.0
model_options=["visual", "audio"]
),
IndexesCreateRequestModelsItem(
model_name="pegasus1.1", # 或 pegasus1.2
model_options=["visual", "audio"]
)
]
)
print(f"✅ 索引创建成功: {new_index.id}")
return new_index.id
except Exception as e:
raise Exception(f"创建索引失败: {e}")
def ingest_video(self, video_path: str):
"""上传并索引视频"""
print(f"🚀 [TwelveLabs] 正在上传视频: {video_path} ...")
try:
# 1. 提交任务 (关键修正 1: file -> video_file)
with open(video_path, "rb") as f:
task = self.client.tasks.create(
index_id=self.index_id,
video_file=f
)
print(f"⏳ 任务已提交 (ID: {task.id}),等待云端处理...")
# 2. 轮询等待
def on_task_update(task: TasksRetrieveResponse):
percent = task.process.percentage if task.process else 0
print(f" 进度: {percent}% (状态: {task.status})", end="\r")
finished_task = self.client.tasks.wait_for_done(
task_id=task.id,
callback=on_task_update
)
if finished_task.status != "ready":
raise Exception(f"视频处理失败: {finished_task.status}")
print(f"\n✅ 视频索引构建完成!")
except Exception as e:
if "already exists" in str(e) or "409" in str(e):
print(f"\nℹ️ 视频看起来已经存在,跳过上传。")
else:
print(f"\n❌ 上传过程异常: {e}")
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""执行搜索"""
query_str = query_bundle.query_str
print(f"🔍 [TwelveLabs] 云端视觉搜索: '{query_str}'")
# Search 接口 (关键修正 2: options -> search_options)
try:
search_results = self.client.search.query(
index_id=self.index_id,
query_text=query_str,
search_options=["visual", "audio"] # <--- 修正点:参数名必须是 search_options
)
except TypeError as e:
# 双重保险:如果 SDK 版本极新,有时也会用 options,但 v0.5 通常是 search_options
print(f"⚠️ 搜索参数尝试失败,正在重试: {e}")
raise e
nodes = []
# 获取数据
results_list = getattr(search_results, "data", search_results)
for clip in results_list:
# 封装结果
# 注意:v0.5 返回的时间戳可能是 start/end 属性
start_ts = getattr(clip, "start", 0)
end_ts = getattr(clip, "end", 0)
score = getattr(clip, "score", 0)
node_text = f"Segment: {start_ts}s - {end_ts}s. Confidence: {score}"
node = TextNode(
text=node_text,
metadata={
"start": start_ts,
"end": end_ts,
"score": score,
"video_id": getattr(clip, "video_id", "")
}
)
nodes.append(NodeWithScore(node=node, score=score))
return nodes
# 辅助函数
def build_video_index(video_path):
retriever = TwelveLabsRetriever(api_key=os.environ["TL_API_KEY"])
retriever.ingest_video(video_path)
return retriever
print("✅ SDK v0.5 终极修正版 (video_file + search_options) 定义完成!")
# === Cell 2: 自定义 Twelve Labs 检索器 (SDK v0.5 完美通关版) ===
import os
import time
from typing import List
from llama_index.core import QueryBundle
from llama_index.core.retrievers import BaseRetriever
from llama_index.core.schema import NodeWithScore, TextNode
# SDK 导入
from twelvelabs import TwelveLabs
from twelvelabs.indexes import IndexesCreateRequestModelsItem
from twelvelabs.tasks import TasksRetrieveResponse
class TwelveLabsRetriever(BaseRetriever):
def __init__(self, api_key: str, index_name: str = "demo_rag_v9_final"):
# 建议换个新名字 v8,确保从零开始验证
self.client = TwelveLabs(api_key=api_key)
self.index_name = index_name
self.index_id = self._get_or_create_index()
super().__init__()
def _get_or_create_index(self):
"""检查是否有索引,没有就新建"""
try:
existing_indexes = self.client.indexes.list(page_limit=50)
for idx in existing_indexes:
current_name = getattr(idx, "name", None) or getattr(idx, "index_name", None)
if current_name == self.index_name:
print(f"✅ 找到现有索引: {current_name} ({idx.id})")
return idx.id
except Exception as e:
print(f"⚠️ 获取索引列表提示: {e}")
print(f"🆕 正在云端创建新索引: {self.index_name} ...")
try:
new_index = self.client.indexes.create(
index_name=self.index_name,
models=[
IndexesCreateRequestModelsItem(
model_name="marengo3.0",
model_options=["visual", "audio"]
),
IndexesCreateRequestModelsItem(
model_name="pegasus1.2",
model_options=["visual", "audio"]
)
]
)
print(f"✅ 索引创建成功: {new_index.id}")
return new_index.id
except Exception as e:
raise Exception(f"创建索引失败: {e}")
def ingest_video(self, video_path: str):
"""上传并索引视频"""
print(f"🚀 [TwelveLabs] 正在上传视频: {video_path} ...")
try:
# 1. 提交任务
with open(video_path, "rb") as f:
task = self.client.tasks.create(
index_id=self.index_id,
video_file=f
# ❌ 已移除 language="en",避免报错
)
print(f"⏳ 任务已提交 (ID: {task.id}),等待云端处理...")
# 2. 轮询等待 (修复版)
def on_task_update(task: TasksRetrieveResponse):
# 🛡️ 安全获取进度:task.process 可能是 None
if hasattr(task, 'process') and task.process:
percent = task.process.percentage
else:
percent = 0
print(f" 进度: {percent}% (状态: {task.status})", end="\r")
finished_task = self.client.tasks.wait_for_done(
task_id=task.id,
callback=on_task_update
)
if finished_task.status != "ready":
raise Exception(f"视频处理失败: {finished_task.status}")
print(f"\n✅ 视频索引构建完成!")
except Exception as e:
if "already exists" in str(e) or "409" in str(e):
print(f"\nℹ️ 视频看起来已经存在,跳过上传。")
else:
print(f"\n❌ 上传过程异常: {e}")
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""执行搜索"""
query_str = query_bundle.query_str
print(f"🔍 [TwelveLabs] 云端视觉搜索: '{query_str}'")
# Search 接口
try:
search_results = self.client.search.query(
index_id=self.index_id,
query_text=query_str,
search_options=["visual", "audio"]
)
except Exception as e:
print(f"⚠️ 搜索请求失败: {e}")
return []
nodes = []
# 获取结果列表
results_list = getattr(search_results, "data", search_results)
for clip in results_list:
# 安全获取属性
start = getattr(clip, "start", 0)
end = getattr(clip, "end", 0)
score = getattr(clip, "score", 0)
video_id = getattr(clip, "video_id", "")
node_text = f"Segment: {start}s - {end}s. Confidence: {score}"
node = TextNode(
text=node_text,
metadata={
"start": start,
"end": end,
"score": score,
"video_id": video_id
}
)
nodes.append(NodeWithScore(node=node, score=score))
return nodes
# 辅助函数
def build_video_index(video_path):
retriever = TwelveLabsRetriever(api_key=os.environ["TL_API_KEY"])
retriever.ingest_video(video_path)
return retriever
print("✅ SDK v0.5 完美修复版 (进度条补丁) 定义完成!")
# === Cell 3: 执行检索 ===
from IPython.display import display, HTML
video_file = "DeepSeek-V3.mp4"
retriever = build_video_index(video_file)
# 提问
query_str = "找到解释模型架构的部分。"
print(f"\n❓ [提问]: {query_str}")
retrieved_nodes = retriever.retrieve(query_str)
retrieved_nodes
# === Cell 4: 结果可视化 (让数据动起来) ===
from IPython.display import display, HTML
# 确保我们要播放的视频文件路径正确
video_file = "DeepSeek-V3.mp4"
# retrieved_nodes 是你刚才 Cell 3 运行出来的结果变量
# 如果 Cell 3 报错中断了,请确保先运行 Cell 3 拿到 retrieved_nodes
if 'retrieved_nodes' in locals() and retrieved_nodes:
print(f"🎉 成功检索到 {len(retrieved_nodes)} 个相关片段!\n")
# 构建 HTML 播放器
html_content = f"""
<div style="border: 1px solid #ddd; padding: 15px; border-radius: 8px; background-color: #f9f9f9;">
<h3 style="margin-top: 0;">📺 视频检索结果</h3>
<video id="videoPlayer" width="100%" height="auto" controls style="border-radius: 5px; background: black;">
<source src="{video_file}" type="video/mp4">
您的浏览器不支持 Video 标签。
</video>
<div style="margin-top: 15px;">
<strong>点击下方按钮跳转到精彩瞬间:</strong>
</div>
<div style="display: flex; flex-direction: column; gap: 8px; margin-top: 10px;">
"""
# 遍历检索结果生成按钮
for i, node_w_score in enumerate(retrieved_nodes):
# 从 metadata 中提取时间
meta = node_w_score.node.metadata
start_sec = meta.get('start', 0)
end_sec = meta.get('end', 0)
# 即使 score 是 None,列表也是有序的,第一个就是最匹配的
rank_label = "🥇 最佳匹配" if i == 0 else f"片段 #{i+1}"
html_content += f"""
<button onclick="jumpTo({start_sec})"
style="text-align: left; padding: 10px; cursor: pointer;
background-color: white; border: 1px solid #ccc; border-radius: 5px;
transition: background-color 0.2s;">
<span style="font-weight: bold; color: #007bff;">{rank_label}</span>
<span style="margin-left: 10px; color: #333;">
⏱️ {start_sec:.1f}s - {end_sec:.1f}s
</span>
</button>
"""
html_content += """
</div>
</div>
<script>
function jumpTo(time) {
var vid = document.getElementById("videoPlayer");
vid.currentTime = time;
vid.play();
}
</script>
"""
display(HTML(html_content))
else:
print("⚠️ 没有找到检索结果 (retrieved_nodes),请先运行上一个 Cell 进行检索。")
# === Cell 5: 让 Pegasus "开口说话" (Analyze API 适配版) ===
from IPython.display import display, Markdown
def generate_answer_from_video(query_str, nodes):
if not nodes:
print("⚠️ 没有检索到视频片段,无法生成答案。")
return
# 1. 获取 Video ID
target_video_id = nodes[0].node.metadata.get('video_id')
if not target_video_id:
print("⚠️ 无法从检索结果中提取 Video ID。")
return
print(f"🤖 正在请求 Pegasus 模型分析视频 (ID: {target_video_id})...")
print(f"❓ 问题: {query_str}")
try:
# 2. 调用 Analyze API (核心修正点)
# 根据您找到的公告:generate.text is now analyze
# 参数通常还是 video_id 和 prompt
res = retriever.client.analyze(
video_id=target_video_id,
prompt=query_str
)
# 3. 解析结果
# Analyze 接口返回的对象通常直接包含 text 或者 data
# 我们这里做一个安全的提取
answer = getattr(res, "data", None) or getattr(res, "text", None)
# 如果还是没拿到,可能是对象结构,直接打印看一眼
if not answer:
answer = str(res)
print("\n" + "="*40)
display(Markdown(f"### 🧠 Pegasus 回答:\n\n{answer}"))
print("="*40)
except AttributeError:
print("❌ 依然报错: client 似乎没有 analyze 方法?")
print("💡 调试建议: 请尝试运行 `dir(retriever.client)` 查看可用方法列表。")
except Exception as e:
print(f"❌ 生成请求异常: {e}")
# 运行生成
if 'retrieved_nodes' in locals():
# 使用 Cell 3 定义的问题
generate_answer_from_video(query_str, retrieved_nodes)
else:
print("⚠️ 请先运行 Cell 3 完成检索!")