基于LangChain的RAG系统开发
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(7月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(7月班)

《2025大模型Agent智能体开发实战》(7月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(夏季班)

两门大模型课程夏季班目前上新特惠,直播间下单可享618平价钜惠,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


RAG技术实战公开课
Part 2.基于LangChain的RAG系统开发
一、回顾 Naive RAG 基础架构
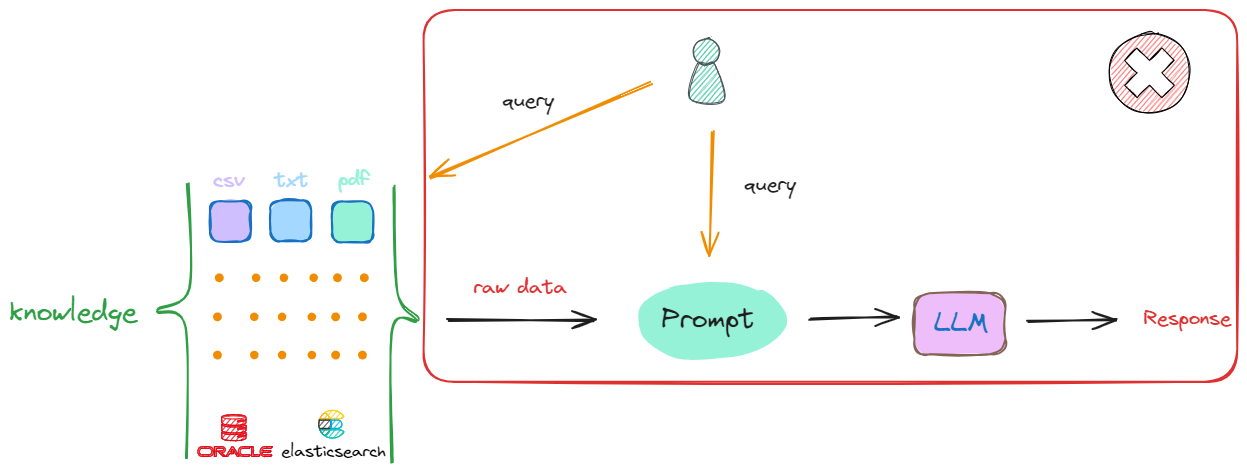
目前企业的主要需求是希望大模型能够结合私有的数据进行问答、工作流构建、智能数据分析等等一系列的智能化应用。当企业有一个偌大的知识库,当想从该知识库中去检索最相关的内容时,最简单的方法是:接收到一个查询(Query),就直接在知识库中进行搜索。这种做法其实是可行的,但存在两个关键的问题:
-
假设提问的
Query的答案出现在一篇文章中,去知识库中找到一篇与用户输入相关的文章是很容易的,但是我们将检索到的这整篇文章直接放入Prompt中并不是最优的选择,因为其中一定会包含非常多无关的信息,而无效信息越多,对大模型后续的推理影响越大。 -
任何一个大模型都存在最大输入的
Token限制,一个流程中可能涉及多次检索,每次检索都会产生相应的上下文,无法容纳如此多的信息。
因此,我们需要一种方法,能够从知识库中检索出最相关的信息,并将其作为上下文输入到Prompt中,从而提高大模型回答的准确性和相关性。
解决上述两个问题的方式是:把存放着原始数据的知识库(Knowledge)中的每一个raw data,切分成一个一个的小块,这些小块可以是一个段落,也可以是数据库中某个索引对应的值。这个切分过程被称为“分块”(chunking),如下述流程所示:
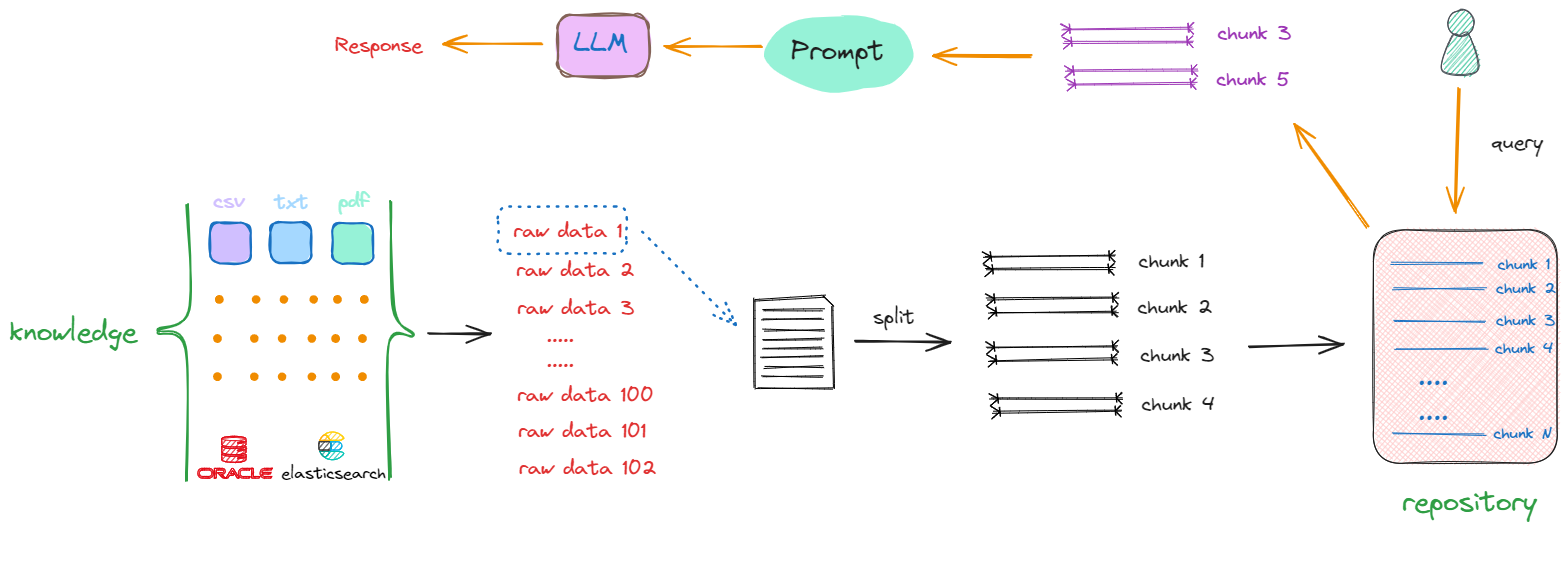
以第一个原始数据为例(raw data 1),通过一些特定的方法进行切分,一个完整的内容会被分割成 chunk1 ~ chunk4。采取相同的方法,继续对raw data 2、raw data 3直至raw data n进行切分。完成这一过程后,我们最终得到的是一个充满分块数据(chunks)的新的知识库(repository),其中每一项都是一个单独的chunk。例如,如果原始文档共有10个,那么经过切分,可能会产生出100个chunks。
完成这一转化后,当再次接收到一个查询(Query)时,就会在更新后的知识库(repository)中进行搜索,这时检索的范围就不再是某个完整的文档,而是其中的某一个部分,返回的是一个或多个特定的chunk,这样返回的信息量就会更小且更精确。随后,这些被检索到的chunk会被加入到Prompt中,作为上下文信息与用户原始的Query共同输入到大模型进行处理,以生成最终的回答。
在上述将原始数据(raw data)转化为chunk的过程中,就会包含构建RAG的第一部分开发工作:这包括如果做数据清洗,如去除停用词、标点符号等。此外,还涉及如何选择合适的split方法来进行数据切分的一系列技术。
接下来面临的问题是,尽管所有数据已经被切割成一个个chunk,其存储形式还是以字符串形式存在,如果想从repository中匹配到与输入的query相关的chunks,比较两句话是否相似,看一句话中相同字有几个,这显然是行不通的。我们需要获取的是句子所蕴含的深层含义,而非仅仅是表面的字面相似度。因此,大家也能想到,在NLP中去计算文本相似度的有效的方法就是Embedding,即将这些chunks转换成向量(vector)形式。
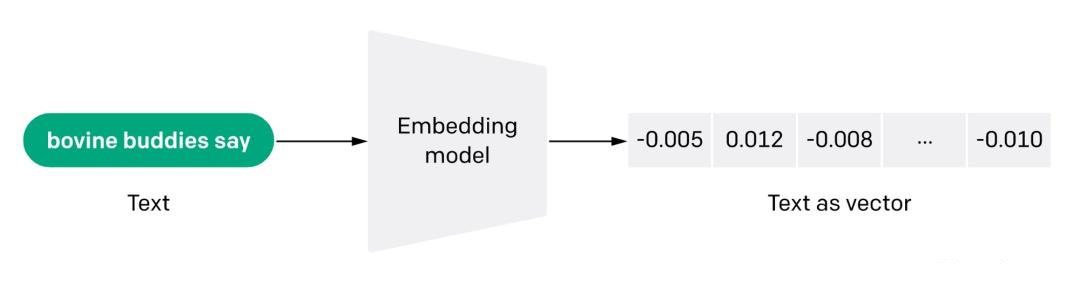
最终这个流程如下所示:
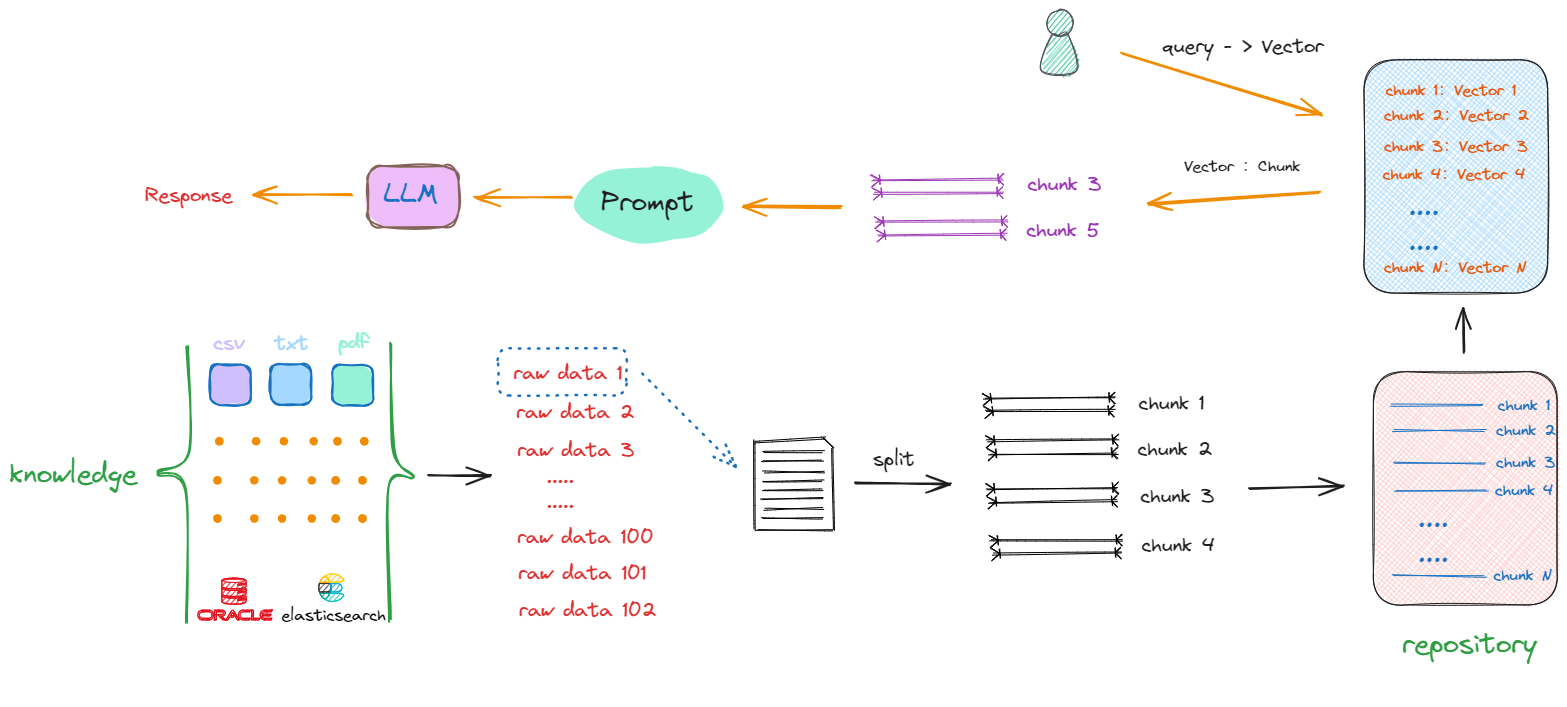
在这个流程中,会先将用户输入的 Query 转化成 Vector,然后再去与知识库中的向量进行相似度比较,检索出相似的Vector,最终返回其对应的Chunk(字符串形式的文本),再执行后续的流程。所以在这个过程中,就会产生构建RAG的第二部分的开发工作:如果将chunk转化成Vector及以何种形式进行存储。同时,我们要考虑的是:如何去计算向量之间的相似度?如果去和知识库中的向量一个一个比较,这个时间复杂度是非常高的,那么其解决办法又是什么呢?我们继续看下述流程:
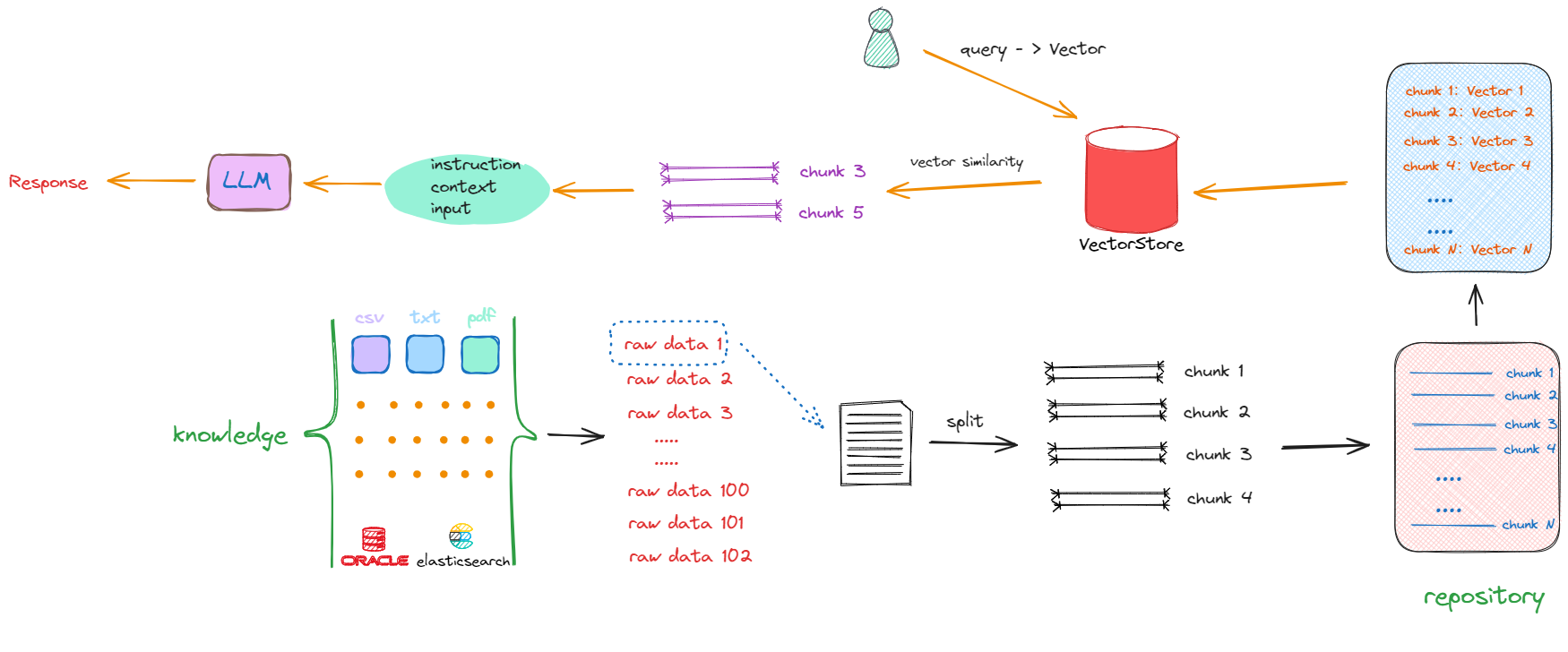
如上所示,解决搜索效率和计算相似度优化算法的答案就是:向量数据库。同时也产生了构建RAG的第三部分工作:我们要去了解和学习如何选择、使用向量数据库。因此,一个基础的RAG架构会只要包含以下几方面的开发工作:
- 如何将原始数据转化成
chunks; - 如何将
chunks转化成Vector; - 如何选择计算向量相似度的算法;
- 如何利用向量数据库提升搜索效率;
- 如何把找到的
chunks与原始query拼接在一起,产生最终的Prompt;
二、LangChain RAG API详解
在LangChain框架中,RAG作为一个非常重要且关键的模块独立存在,如下图所示:https://python.langchain.com/docs/integrations/retrievers/
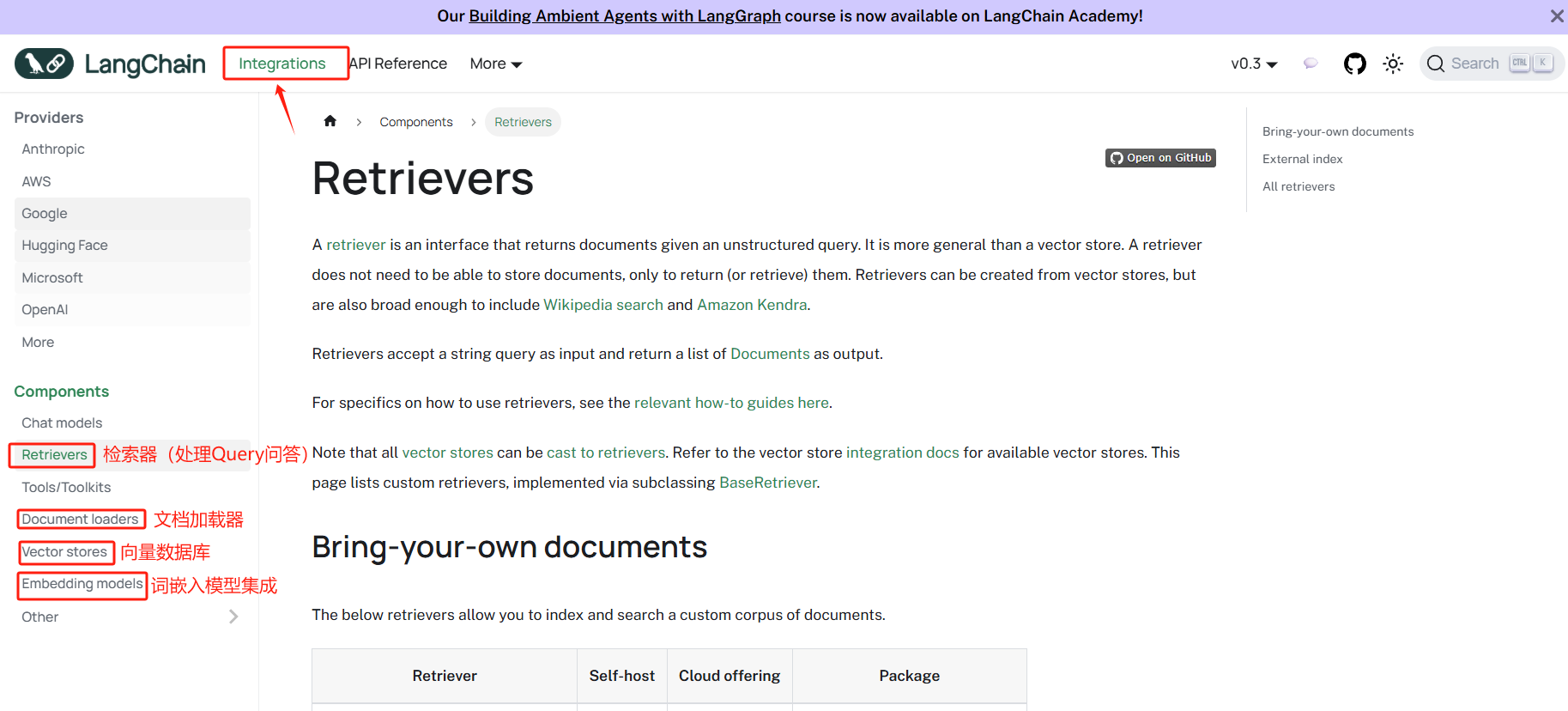
针对我们在上一小节分析的RAG流程,每一个子流程中,LangChain都提供了多种较为通用的实现方法,这包括如何将不同来源、不同形式的数据切分成一个个小块,如何使用Embedding模型做向量化,如何将向量存储进向量数据库中,以及提供了快速检索的优化算法。每一环节设计的基础技术,都作为一个独立的抽象模块存在,而将各个环节像Chains一样串流起来进行数据交换,形成一个完整的RAG系统,LangChain抽象了一个所谓的data connection数据处理流,如下图所示:
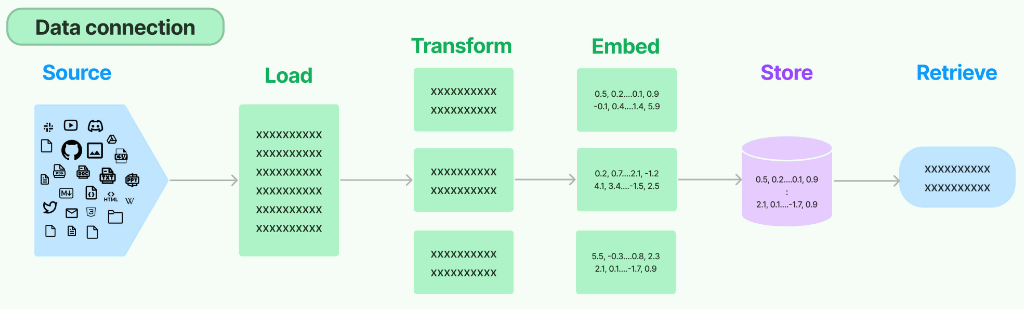
data connecting 是Langchain框架原生的数据处理流,RAG是涉及多个处理环节的一个架构,它不是个体,而是一个整体,所以虽然不同环节、不同模块间所做的事情是不一样的,但它们之间是需要链接的,需要进行数据的交换,那这一部分工作,就是交给data connection来统一管理。例如,在上述流程中,"Source"阶段指的是附加的数据库,它能够整合来自不同数据源的信息。通过"Load"组件,这些数据可以被统一管理。"Transform"组件则负责进行数据切分等一系列前文提到的构建RAG所需的开发任务,提供了各种不同的解决方案。
因此,学习LangChain中RAG的构建过程我们更建议:第一步学流程,第二步学关键点,第三步学每一环节的具体技术,第四步不断地扩展优化,从基础RAG到进阶RAG。所以接下来,我们就按照LangChain的data conncetiong流程,逐步拆解每一模块的关键技术点进行讲解和实践,最终跑通这个RAG流程。
- LangChain接入OpenAI、DeepSeek、DashScope流程
下图扫码即可领取相关资料:

- 创建.env文件并写入配置:
- 安装相关的依赖库:
! pip install langchain python-dotenv langchain-deepseek langchain-openai
- 测试调用:
import os
from dotenv import load_dotenv
load_dotenv(override=True)
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-4o",
base_url="https://ai.devtool.tech/proxy/v1",
)
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-chat")
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
1. Source 与 data loaders功能实现
Source概念指的是RAG架构中所外挂的知识库。正如我们之前所讨论的,因为大模型的原生能力很强,所以它可以识别多种不同的类型的原始数据而不用做额外的处理,而且在实际场景中,私有数据通常也并不是单一的,可以来自多种不同的形式,可以是上百个.csv文件,可以是上千个.json文件,也可以是上万个.pdf文件,同时如果对接到具体的业务,可以是某一个业务流程外放的API,可以是某个网站的实时数据等多种情况。
所以LangChain首先做的就是:将常见的数据格式和数据来源使用LangChain的规范,抽象出一个一个的单独的集成模块,称为文档加载器(Document loaders),用于快速加载某种形式下的文本数据。如下图所示:
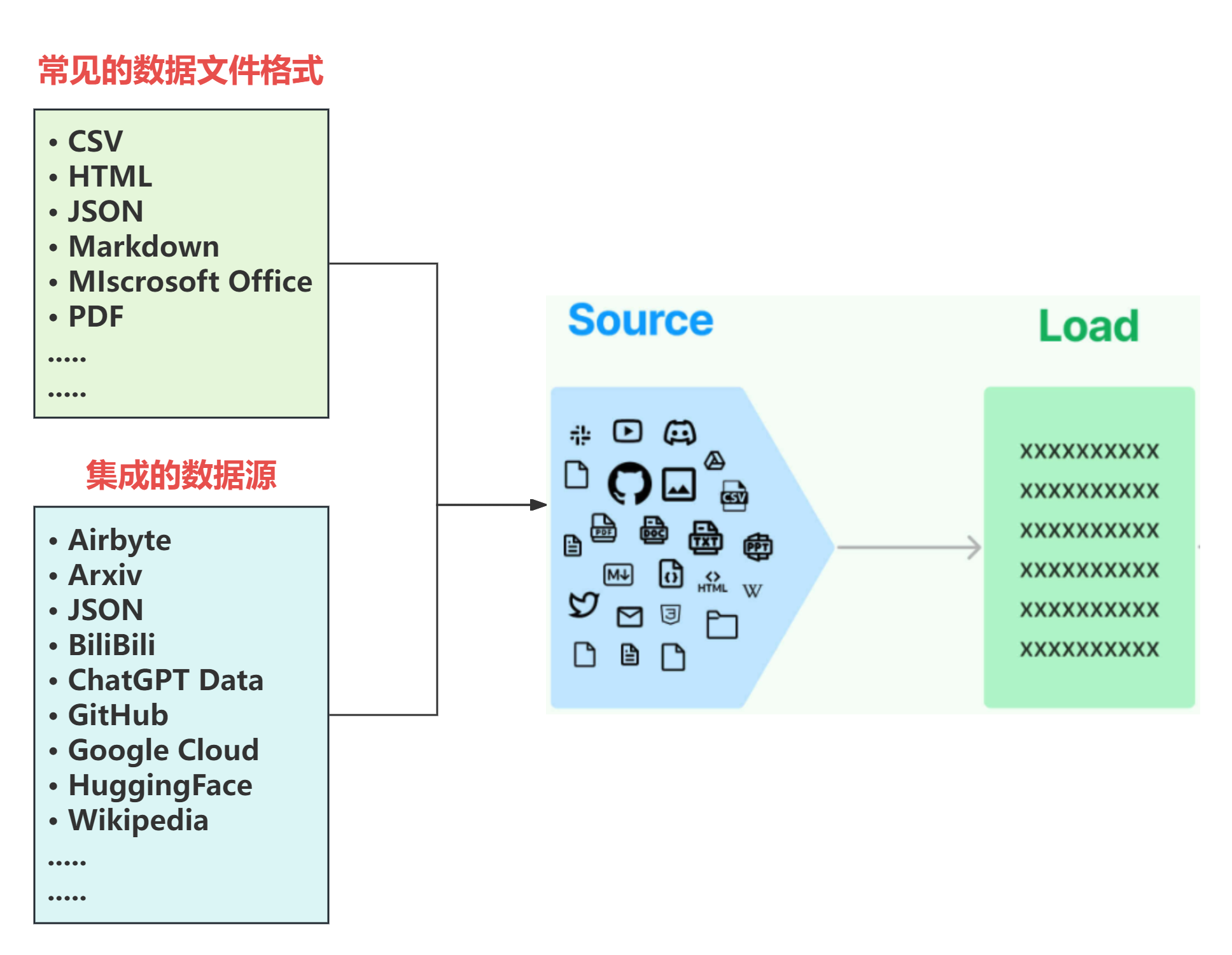
这意味着,我们可以通过调用LangChain抽象好的方法直接处理私有数据,无需手动编写中间的处理流程,并且每一种文档的加载器,在LangChain官方文档中都有基本的调用示例供我们快速上手使用,具体位置如下:https://python.langchain.com/docs/integrations/document_loaders/
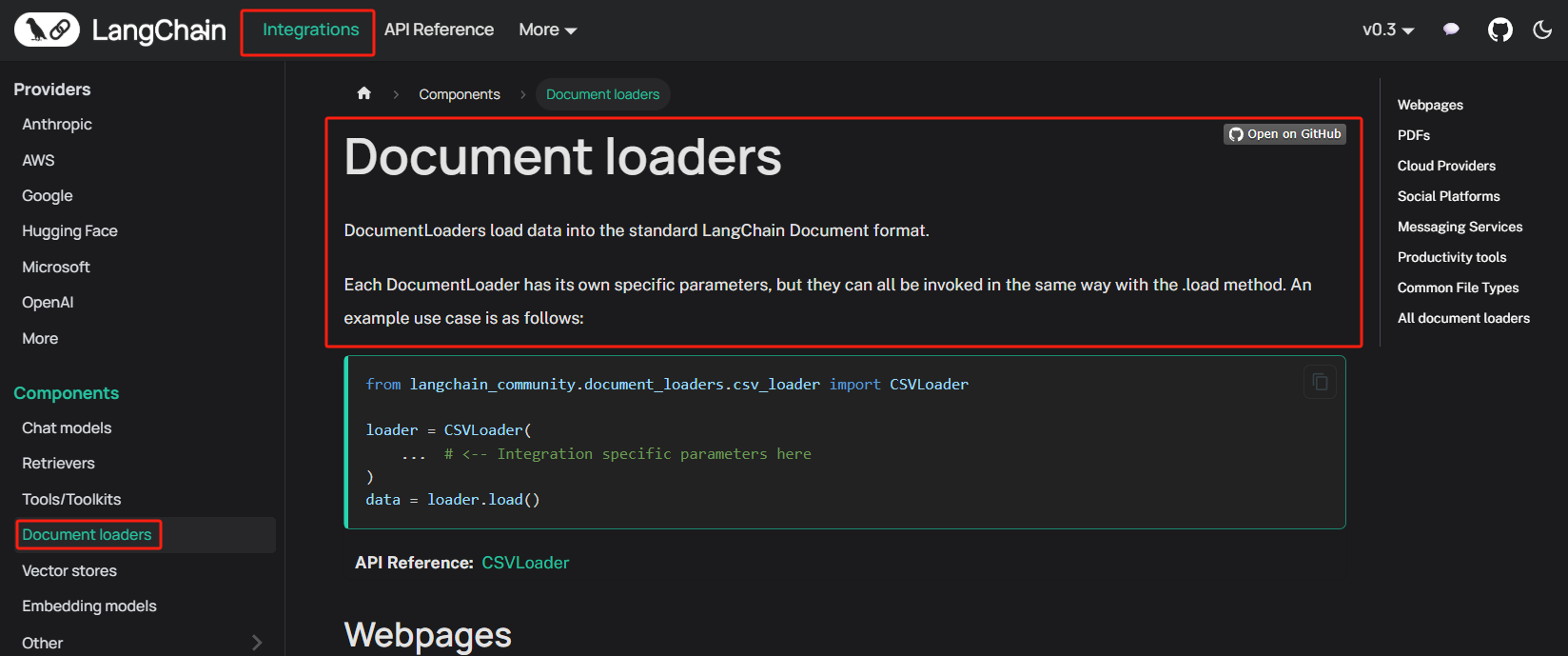
各个不同类型的文档加载器经过langChain的高度封装后使用起来并不会很复杂,可以直接调用load_documents方法,传入文件路径,就可以加载出对应的文档。这里我们进行几种不同类型的文档加载,并查看加载后的文档内容。
在LangChain技术生态中,文档加载(Document Loaders)*是支撑检索增强生成(RAG)流程的核心组件之一。LangChain已原生集成了丰富的加载器模块,覆盖*本地文件、在线网页、数据库、云存储、第三方应用及多媒体资源等多样化数据来源,极大降低了异构知识接入的开发成本。
总体来看,这些加载器可分为七大类:本地文件加载、网页抓取、API集成、数据库连接、云端存储、特定格式解析以及自定义扩展。每类加载器均封装了数据读取、文档分块、元数据生成等常用操作,开发者只需在配置中指定路径或凭据,即可将不同来源的内容标准化为LangChain可处理的Document对象,为后续Embedding、检索和问答链条提供高质量的输入。
这一体系不仅支持通用场景(如PDF阅读、网页爬取),也覆盖了Notion、Slack、Confluence、Google Drive等现代企业常用的云应用,使LangChain成为目前RAG系统中文档接入能力最丰富的开源框架之一。
下表列举了LangChain已集成的部分典型加载器,按类别分类展示(并非穷尽所有):
| 分类 | 加载器名称(部分示例) |
|---|---|
| 本地文件加载器 | TextLoader, CSVLoader, PDFLoader, UnstructuredLoader, JSONLoader, Docx2txtLoader |
| 网页加载器 | WebBaseLoader, SitemapLoader, TrafilaturaLoader, RecursiveUrlLoader |
| API/第三方数据加载器 | NotionDBLoader, SlackLoader, ConfluenceLoader, GitHubIssuesLoader, GoogleDriveLoader |
| 数据库加载器 | SQLDatabaseLoader, PandasDataFrameLoader, FAISSLoader, MilvusLoader |
| 云存储加载器 | S3DirectoryLoader, GCSDirectoryLoader, AzureBlobStorageLoader |
| 多媒体/特定格式加载器 | YouTubeLoader, AudioLoader, EPubLoader, EverNoteLoader |
| 自定义/通用加载器 | DirectoryLoader, BSHTMLLoader, iFixitLoader |
1.1 在线文档加载流程
我们以Wikipedia为示例,维基百科大家都比较熟悉,是一个多语言免费在线百科全书,当LangChain集成了以后,就可以按照文档说明直接调用。https://python.langchain.com/docs/integrations/document_loaders/wikipedia/
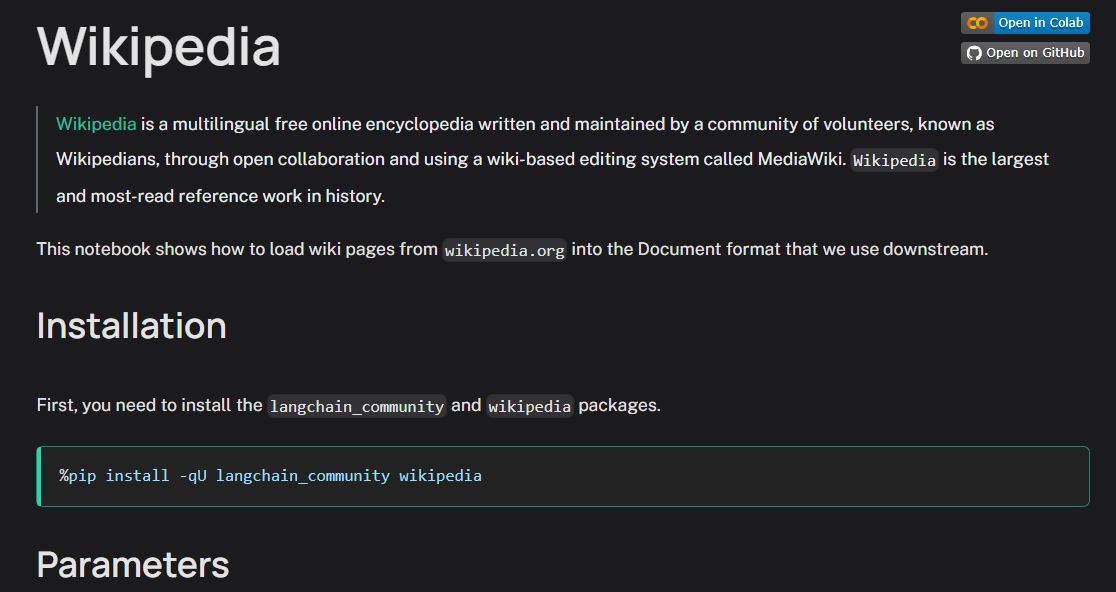
按要求安装项目依赖。
# ! pip install -U langchain_community wikipedia
在构造方法中能非常明确的看到可以在调用时支持自定义的参数,再结合官方的说明文档,可整理出如下有效信息:
- query :用于在维基百科中查找文档的自由文本
- 可选 lang :默认=“en”。用它来搜索维基百科的特定语言部分
- 可选 load_max_docs :默认=100。用它来限制下载文档的数量。下载所有 100 个文档需要时间,因此请使用少量进行实验。目前硬性限制为 300。
- 可选 load_all_available_meta :默认=False。
默认情况下,仅下载最重要的字段: Published (文档发布/上次更新的日期)、 title 、 Summary 。如果为 True,则还会下载其他字段。
from langchain_community.document_loaders import WikipediaLoader
docs = WikipediaLoader(query="LangChain",
lang="zh",
load_max_docs=2).load()
len(docs)
docs[0].metadata
docs[0].page_content[:800]
1.2 txt文档加载器
将文件作为文本读入,并将其全部放入一个文档中,这是最简单的一个文档加载程序,使用方式如下:
from langchain.document_loaders import TextLoader
docs = TextLoader('LangChain.txt', encoding="utf-8").load() # 注意,要替换成实际的文件路径
这里我们需要关注一下其加载后数据的类型,查看方法如下所示:
docs
从输出上,使用LangChain定义的加载器加载得到的数据类型是Document对象,这和使用WikipediaLoader加载器得到的对象类型是一致的。
type(docs[0])
docs[0].page_content
docs[0].page_content[:200]
docs[0].metadata
同样,对于TextLoader,依然是使用.page_content和.metadata去访问数据,也就是说,每一个文档加载器虽然代码逻辑不同,应用需求不同,但使用方式是相同的。这就需要我们去理解为什么要这样做。这其实很容易想到,对于Sourch中多种不同的数据源,要想能在接下来的流程中可以用一种统一的形式检索、调用,至少要保证的是:把它们以一种相对统一的方式读取出来。所以LangChain的设计就是对于每一个在LangChain中集成的文档加载器,都要继承自BaseLoader and Document Class基类,当不同来源的数据通过load方法加载进来后,全部转化成Documents对象。实现逻辑如下所示:
- BaseLoader
BaseLoader 类定义了如何从不同的数据源加载文档,每个基于不同数据源实现的loader,都需要集成BaseLoader。Baseloader要求不对,对于任何具体实现的loader,最少都要实现 load方法。
FENCE0
BaseLoader把数据加载成Documents object,存到 Documents类中的page_content中。
- Document
Document允许用户与文档的内容进行交互,可以查看文档内容。
FENCE0
通过 存 + 读的两个基类的抽象,满足不同类型加载器在数据形式上的统一。除此之外,其中的metadata会根据loader实现的不同写入不同的数据,同样是一个必要的基础属性。而不论任何基于LangChain实现的loader,搞明白这几点内容,再去理解和使用不同的文档加载器就会轻松很多,至此,大家也就能够理解为什么WikipediaLoader和TextLoader都使用load去加载,且都使用.page_content和.metadata读取数据。
最后,我们需要特别关注JSON数据格式以及自定义JSON格式文档加载器的方法。在实际应用场景中,JSON格式的数据占有很大比例,而且其JSON的形式也是多样的,LangChain已经实现的JSON文档加载器并无法适用于所有数据形式,所以掌握如何自定义文档解析器,是重要且必要的。
1.3 加载JSON数据格式
LangChain提供的JSON格式的文档加载器是JSONLoader,根据其说明,JSONLoader 使用指定的 jq 架构来解析 JSON 文件。所谓的jq,它是一个轻量级的命令行 JSON 处理器,可以通过特定的语法在命令行中对 JSON 格式的数据进行各种复杂的处理,包括数据过滤、映射、减少和转换。jq 的语法设计得非常灵活和强大,使其成为处理 JSON 数据的首选工具之一。它的主要特点包括:
- 灵活的过滤器:通过简单的过滤器表达式,可以轻松提取数据、修改数据结构或筛选出满足特定条件的数据项。
- 无需循环:与编写复杂的脚本或程序不同,jq 允许你直接应用表达式来处理数据,无需编写循环语句。
- 多样的函数:jq 提供了大量的内置函数,用于字符串处理、数值计算、数组/对象操作等,也支持自定义函数。
- 管道操作:jq 支持管道操作(类似于 UNIX/Linux 中的管道),可以将一个表达式的输出作为另一个表达式的输入,实现复杂的数据处理流程。
JsonLoader 的官方文档地址:https://python.langchain.com/docs/integrations/document_loaders/json/
比如jq 的一个基本示例是,我们可以使用它来提取 JSON 数据中的特定字段。假设有一个 JSON 文件 example.json,内容如下:
FENCE0
可以使用 jq 的命令行工具来提取所有员工的名字,命令如下:
FENCE1
这条命令会输出:
FENCE2
jq 的这些能力使其在数据处理和分析中非常有用,尤其是当处理复杂或大量的 JSON 数据时。更多的jq使用技巧,可以查阅:https://en.wikipedia.org/wiki/Jq_(programming_language)
既然JSONLoader是使用jq来解析JSON文件,所以在使用前,就必须进行jq库的安装。
# ! pip install jq
JSON有很多种存储的形式,当然对于提取信息的结构也会有很大的差别,LangChain实现的JSONLoader支持的JSON解析结构如下:
FENCE0
所以,只有当我们的JSON数据符合上述需求时,才能够正常的加载和使用JSONLoader。这里我们准备了一份K-SportsSum体育赛事摘要数据集用于测试,包含了7854个中文体育在线评论文档与对应的新闻报道,除此之外还提供了一个包含球员与球队信息的知识库。我们可以使用如下代码直接加载:
import json
from pathlib import Path
from pprint import pprint
file_path='./test.json'
data = json.loads(Path(file_path).read_text(encoding="utf-8"))
pprint(data[:50])
type(data)
使用JSONLoader文档加载器加载:
from langchain_community.document_loaders import JSONLoader
jq 的查询语法是围绕管道操作符 | 来构建的,可以从JSON 结构中提取特定的信息,比如:
loader = JSONLoader(
file_path='test.json',
jq_schema='.[].commentary',
text_content=False)
data = loader.load()
pprint(data[:2])
这是遵循JSONLoader支持的JSON格式的使用过程,而当我们的JSON数据不符合,怎么办呢?就需要按照我们前面介绍的LangChain构建文档加载器的规范去做自定义。
1.5 自定义JSON文档加载器【选学】
LangChain中构造自定义文档加载器涉及创建 Document 对象,该对象封装提取的文本 ( page_content ) 以及元数据——包含文档详细信息的字典,例如作者姓名或发布日期。而在随后的流程中,Document 对象会被格式化为输入到 LLM 中的提示,允许 LLM 使用 Document 中的信息来生成期望的回应(例如,总结文档)。 Documents 可以直接使用,也可以索引到矢量存储中以供将来检索和使用。
对于文档加载器必须实现的的抽象方法是:
| 组件 | 描述 | 中文描述 |
|---|---|---|
| Document | Contains text and metadata | 包含文本和元数据 |
| BaseLoader | Use to convert raw data into Documents | 用于将原始数据转换为文档 |
在实现时,就需要编写自定义文档加载和文件解析逻辑,具体来说,要通过 BaseLoader 子类化来创建标准文档加载器,其必须实现的方法是:load。
这里我们使用一个新的不同JSON格式的数据集,这是一个哈利波特角色化对话数据集,为了研究如何在虚拟世界中构建角色化智能对话机器人,如智能游戏NPC等,数据存储为json形式。主要内容包括
- 对话所在位置(在书中的第几章节以及第几事件)
- 说话人
- 对话场景
- 对话内容
- 参与对话的角色属性
- 参与对话的角色与哈利的关系
- 答案正例(仅测试集)
- 答案负例(仅测试集)
import json
from pathlib import Path
from pprint import pprint
file_path='cn_test_set.json'
data = json.loads(Path(file_path).read_text(encoding="utf-8"))
print(data)
from langchain_community.document_loaders import JSONLoader
自定义JSON文档加载器。
import json
from pathlib import Path
from typing import Any, Callable, Dict, List, Optional, Union
from langchain_core.documents import Document
from langchain_community.document_loaders.base import BaseLoader
class CustomJSONLoader(BaseLoader):
"""Load a `JSON` file using a `jq` schema.
"""
def __init__(
self,
file_path: Union[str, Path],
jq_schema: str,
):
"""Initialize the JSONLoader.
参数:
file_path (Union[str, Path]): JSON 或 JSON Lines 文件的路径。
jq_schema (str): 用来从 JSON 中提取数据或文本的 jq 模式。
"""
import jq
self.file_path = Path(file_path).resolve()
self._jq_schema = jq.compile(jq_schema)
def load(self) -> List[Document]:
"""从 JSON 文件中加载并返回文档。"""
docs: List[Document] = []
self._parse(self.file_path.read_text(encoding="utf-8"), docs)
return docs
def _parse(self, content: str, docs: List[Document]) -> None:
"""将给定内容转换为文档。"""
# content : 原始的JSON
# json.loads(content):JSON 格式的字符串 content 转换为 Python 的数据结构。具体转换为哪种形式的数据结构取决于原始 JSON 字符串的内容:
# 根据jq编译查找到的结果
data = self._jq_schema.input(json.loads(content)).all()
for i, sample in enumerate(data, len(docs) + 1):
metadata={"result": "\n".join(sample), "source": self.file_path}
docs.append(Document(page_content="\n".join(sample), metadata=metadata))
调用测试:
import json
from pathlib import Path
from pprint import pprint
loader = CustomJSONLoader(
file_path='./cn_test_set.json',
jq_schema='."Session-3"."对话历史"',)
data = loader.load()
pprint(data)
data[0].page_content
data[0].metadata
from pprint import pprint
loader = CustomJSONLoader(
file_path='./cn_test_set.json',
jq_schema='."Session-3"."对话历史"',)
data = loader.load()
pprint(data)
整体看,在LangChain的抽象下去接入一个自定义的文档加载器是不复杂的,虽然我们仅仅是通过一个较为简单和基础的示例来向大家展示构建自定义文档加载器的流程,但只要覆盖到其核心的过程,需要修改的就只是具体情境下数据的处理逻辑。这包括继承自BaseLoader基类,将内容写入Document对象中的page_content,并重新定义metadata。
而在所有的文档类加载器中,PDF的加载器是最为复杂的,会涉及到提取PDF文本结构、图片多模态识别等工作。在LangChain中可以使用在LangChain的文档解析生态中,langchain-unstructured是一个功能全面且高度灵活的文件加载组件,专门用于对多种复杂格式文件进行结构化切分与内容抽取。它基于知名的Unstructured 开源库进行深度集成,支持将不同文件类型(包括PDF、Word、HTML、电子书、PPT、Markdown等)统一转化为LangChain标准的Document对象。相比传统的简单文本加载器,langchain-unstructured能够智能识别段落、标题、表格、列表和图片注释等元素,并保留内容的结构层次信息,从而在后续向量化和检索阶段提供更高质量的语义分块。
在使用方式上,开发者仅需通过UnstructuredFileLoader类或其衍生加载器(例如UnstructuredPDFLoader、UnstructuredHTMLLoader等)即可对目标文件进行加载。加载器内部会调用Unstructured的处理管道,自动完成版面分析、元素提取、文本清洗与分段。典型的使用流程仅需指定文件路径和分块策略,即可返回带有元数据和结构标记的文档集合。例如,通过配置mode="elements",用户可以将文档拆分为基于内容类型的精细粒度块,显著提升对复杂文档的检索准确性。此外,该加载器还支持可选的OCR处理,用于解析扫描版PDF和图片型文档。

而更多关于PDF解析和多模态识别的内容,我们会放在下一小节进行系统介绍。
以上,我们就基本介绍完了LangChain中的Document Loaders模块。大家可以自行尝试不同的文档加载器,它们的使用方法还是非常直观和简单的。重点在于要掌握如何使用和自定义这些文档加载器。因为在后续的使用过程中,大家会经常遇到这样的情况:一是尝试用LangChain的某个文档加载器加载特定数据时报错,无法正常加载;二是发现LangChain中没有现成的工具能够直接处理你的私有数据。因为就数据本身而言,它就存在着多样性,没有任何一套流程、一段代码逻辑可以处理所有形式的数据,这个时候,考验的就是大家对LangChain文档加载器的理解和自身的编程能力。
2. RAG系统的文档切分策略
2.1 通用文档切分策略
分块(Chunking),其实现形式上是将长文档拆分为较小的块的过程,目的是在检索时能够准确地找到最直接和最相关的段落。由于文章通常包含大量不相关信息,在进行分块之前,也常常需要进行一些预处理工作,如文本清洗、停用词处理等,因为数据形式和需求不同,其文本清洗方法大相径庭,本文将不会针对文本清洗的内容展开说明,在后续的项目中,会结合实际的数据再向大家详细的介绍文本清洗任务中的一些技术细节。
转回到核心内容来看,一个有效的分块策略,可以确保搜索结果精确地反映用户查询的实际需求。如果分块过小或过大,都可能导致搜索结果不准确或提取不到最相关的内容。理想的文本块应尽可能语义独立,即不过度依赖上下文,这样的文本是语言模型最易于理解的。因此,为文档确定最佳的块大小是确保搜索结果准确性和相关性的关键。这涉及多个决策因素,如块的大小;如果句子太短,模型可能难以理解其意义,且句子越短,包含的有效信息就越少。比较常用的有如下五种不同的方法来优化分块策略:
- 根据句子切分:这种方法按照自然句子边界进行切分,以保持语义完整性。
- 按照固定字符数来切分:这种策略根据特定的字符数量来划分文本,但可能会在不适当的位置切断句子。
- 按固定字符数来切分,结合重叠窗口(overlapping windows):此方法与按字符数切分相似,但通过重叠窗口技术避免切分关键内容,确保信息连贯性。
- 递归方法:通过递归方式动态确定切分点,这种方法可以根据文档的复杂性和内容密度来调整块的大小。
- 根据语义切割:这种高级策略依据文本的语义内容来划分块,旨在保持相关信息的集中和完整,适用于需要高度语义保持的应用场景。
这些方法各有优势和局限,选择适当的分块策略取决于具体的应用需求和预期的检索效果。接下来我们依次尝试用常规手段应该如何实现上述几种方法的文本切分。
- 按照句子切分
按照句子切分,其实就是通过标点符号来进行文本切分(分割),这可以直接使用Python的标准库来完成这个任务。一种简单的方法是使用re模块,它提供了正则表达式的支持,可以方便地根据标点符号来分割文本。如下示例中,展示了如何使用re.split()函数来根据中文和英文的标点符号进行文本切分。代码如下:
import re
def split_text_by_punctuation(text):
# 定义一个正则表达式,包括常见的中英文标点
# pattern = r"[。!?。"#$%&'()*+,-/:;<=>@[\]^_`{|}~\s、]+"
pattern = r"[。!?。]+"
# 使用正则表达式进行分割
segments = re.split(pattern, text)
# 过滤掉空字符串
return [segment for segment in segments if segment]
这个函数会根据中文和英文的标点符号来分割文本,并移除空字符串。定义好分割函数后,我们可以尝试进行功能测试:
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"
# 调用函数进行分割
segments = split_text_by_punctuation(text)
# 使用循环来打印每个chunk
for i, segment in enumerate(segments):
print("Chunk {}: {}".format(i + 1, segment))
如上所示,一整段text会根据设定的标点符号被分割为多个chunks,当然如果有特定的分割需求(比如保留某些特定的标点符号),可以调整正则表达式来灵活的调整。
- 按照固定字符数切分
如果想按照固定字符数来切分文本,这种方法就不再依赖于标点符号,而是简单地按照给定的字符数来切分文本。我们可以编写一个函数,用来将文本分割成指定长度的片段。代码如下:
def split_text_by_fixed_length(text, length):
# 使用列表推导式按固定长度切分文本
return [text[i:i + length] for i in range(0, len(text), length)]
这个函数的作用是根据指定的长度(在这个例子中为100个字符)来切分文本。我们可以根据具体需要调整这个长度。
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"
# 定义每个片段的长度
chunk_length = 100
# 调用函数进行分割
result = split_text_by_fixed_length(text, chunk_length)
# 打印结果
for i, segment in enumerate(result):
print(f"Chunk {i+1}: {segment}")
然而,这种方法的一个明显缺点是由于仅依据长度进行切分,切分后的片段可能无法保持完整的语义。但并不意味着它不适用于文本切分任务。例如,这种方法非常适合于处理日志文件或代码块,其中文本通常以固定长度或格式出现,或者在处理来自传感器或其他实时数据源的流数据时,固定长度切分可以确保数据被均匀地处理和分析。这些应用场景中,数据的结构和形式通常是预定和规范的,因此即便是按固定长度进行切分,反而会更有利于对数据的理解和使用。
- 结合重叠窗口的固定字符数切分
重复窗口的意义是:块之间保持一些重叠,以确保语义上下文不会在块之间丢失。在文本处理和其他数据分析领域,"重叠"(overlap)指的是连续数据块之间共享的部分。这种方法特别常见于信号处理、语音分析、自然语言处理等领域,其中数据的连续性和上下文信息非常重要。比如下述代码所示:
def split_text_by_fixed_length_with_overlap(text, length, overlap):
# 使用列表推导式按固定长度及重叠长度切分文本
return [text[i:i + length] for i in range(0, len(text) - overlap, length - overlap)]
调用测试:
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"
# 定义每个片段的长度和重叠长度
chunk_length = 100
overlap_length = 30
# 调用函数进行分割
result = split_text_by_fixed_length_with_overlap(text, chunk_length, overlap_length)
# 打印结果
for i, segment in enumerate(result):
print(f"Chunk {i+1}: {segment}")
如上所示,每个文本片段长度为100个字符,并且每个片段与下一个片段有30个字符的重叠。这样,每个窗口实际上是在上一个窗口向前移动30个字符的基础上开始的。这种方法特别适用于需要数据重叠以保持上下文连续性的情况,能够较好的在某一个chunk中保存某个完整的语义信息,比如在第一个Chunk中的:'他在街上走着,看到小朋友们手持烟花棒,欢笑'被截断,但是完整的语义能够在Chunk2中被存储:'他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。' 那么当这条语义信息是有关于Query的上下文,就可以在chunk2中被检索出来。
在大多数情况下,结合overlap windows的固定大小的分块是一种更加经济且易于使用的方式。因为它在分块过程中不需要使用任何NLP库或者模型等。
如上所示的前三种方法涉及的是对数据静态字符的切分,这些方法基本上只会将文本分割成固定数量字符的片段,而不考虑其内容或结构。这些是最基本且相对简单实现的文本切分方式。相比之下,递归方法的切分策略更为通用且常用,但实现上稍显复杂。为了简化实现过程,我们可以直接利用LangChain提供的封装类来进行实践。此外,LangChain也提供了相应的实现类来支持按照句子切分、固定字符数切分以及结合重叠窗口(overlap windows)的固定字符切分方法,我们将会逐一探索这些方法的应用。
2.2 LangChain中的Text Splitters工具调用方法
LangChain框架构造了Data connection这一原生的数据处理流来统一管理RAG的处理流程。在这个架构中,文档切分的过程对应于Transformer环节,这一部分的任务是将整个Document对象转化(或“转换”)成多个小块(chunks)。这一转化步骤确立了文档从完整对象到细分片段的具体切分逻辑。
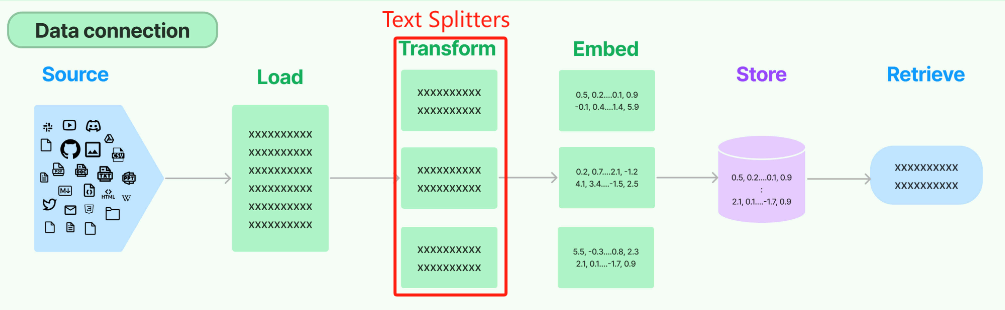
在Transform流程中,LangChain 有很多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档,其类型和对应的说明文档位置如下:https://python.langchain.com/docs/how_to/#text-splitters
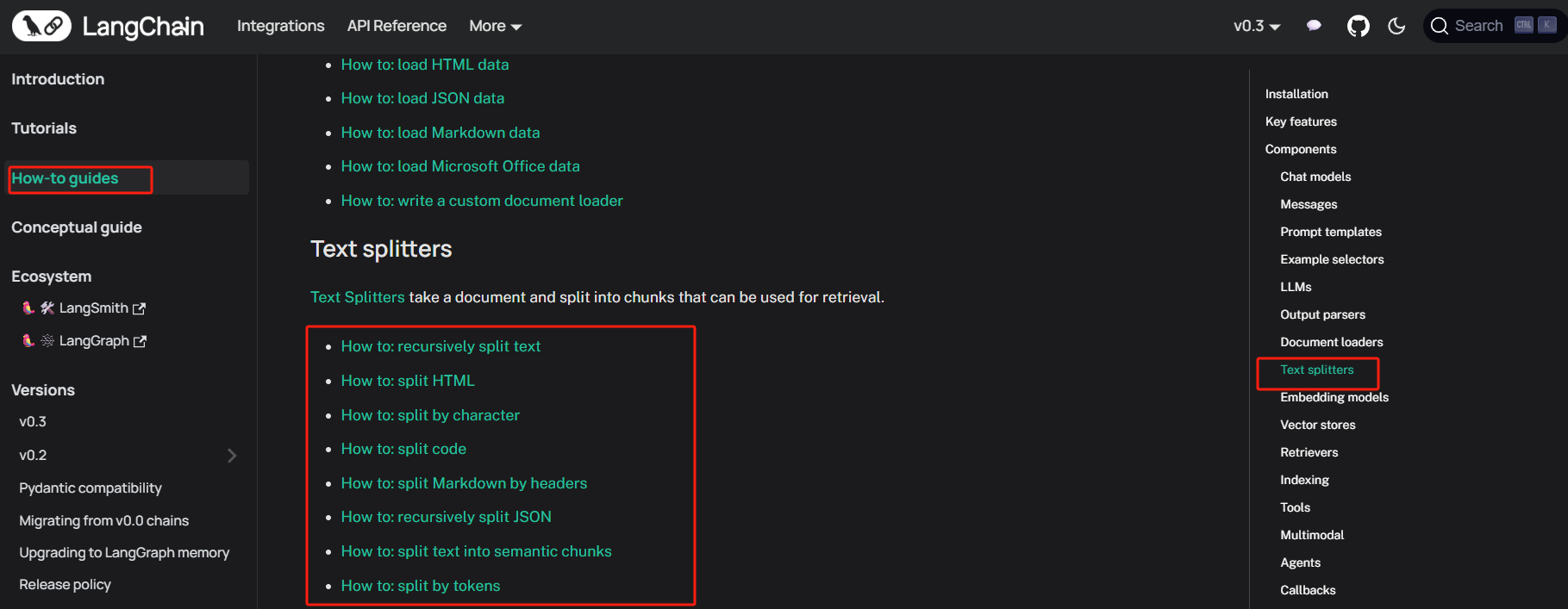
- LangChain文档切分工具概览
在LangChain的内容处理体系中,Text Splitters是至关重要的组件,用于将长文本划分为可检索和可嵌入的小块(chunks),以适配检索增强生成(RAG)或其他下游任务。不同的分块方法可以根据输入内容的格式(如纯文本、HTML、代码或JSON)以及应用场景(例如语义分块或基于字符的固定分割)进行灵活选用。通过合理的Text Splitter配置,开发者可以在上下文保留和分块粒度之间取得平衡,从而显著提升问答系统的精确性和响应速度。下表汇总了LangChain官方文档中列出的主要分块方式及其适用场景:
| 分块方法 | 简要说明 |
|---|---|
| Recursively split text | 按照一系列规则(段落 > 行 > 句子 > 字符)递归地将纯文本拆分为块 |
| Split HTML | 专门针对HTML内容,依据标签结构分块 |
| Split by character | 根据固定字符长度进行等分,适合对结构要求不高的场景 |
| Split code | 针对代码文件,按照函数、类、注释等语法单位进行智能拆分 |
| Split Markdown by headers | 根据Markdown标题层级进行分块,保留章节结构 |
| Recursively split JSON | 递归解析JSON数据结构,将其拆解为逻辑最小单位(键值对或数组元素) |
| Split text into semantic chunks | 基于语义理解,将文本自动切分为含义完整的片段(需依赖模型或规则库) |
| Split by tokens | 按照模型Tokenizer的Token数进行分块,便于控制输入上下文长度 |
在实际应用中,开发者可以灵活组合这些分块器,针对不同的内容类型采取最优的策略。例如,针对技术文档,可以先用Markdown Header Splitter保留章节层次,再使用Recursive Character Splitter对较长片段进行二次切分;而在代码检索场景,Code Splitter可以根据函数或类边界划分逻辑单元,从而提高查询的精准性和可读性。
- CharacterTextSplitter
这是最简单的方法。其基于字符(默认为“”)进行分割,并通过字符数来测量块长度。要使用该方法,需要先进行导入:
# 如果未安装过该模块,需要先进行安装
# ! pip install -qU langchain-text-splitters
from langchain.text_splitter import CharacterTextSplitter
这里先导入一个测试文本:
# This is a long document we can split up.
with open("LangChain.txt", encoding="utf-8") as f:
langchain_desc = f.read()
langchain_desc
这里可以看到,其初始化方法中需要传递一个separator,默认是以"\n\n"进行分割。虽然它并没有定义额外的初始化参数,但因为其继承了TextSplitter,所以在TextSplitter类中定义的参数,在CharacterTextSplitter类中都可以直接使用。所以我们可以实例化出这样一个CharacterTextSplitter。
text_splitter = CharacterTextSplitter(separator='\n',
chunk_size = 100,
chunk_overlap=0,)
先看其split_text(text)方法,它需要传入的是字符串形式的一段文本,功能是separator参数设定的分隔符进行文本分割。所以这里我们可以直接传入一个字符串类型的文本。
type(langchain_desc)
text_res = text_splitter.split_text(langchain_desc)
len(text_res)
text_res[0]
text_res[1]
从输出上看,该文本分割器将langchain_desc分成了33个chunks,每个chunks的长度不超过100个字符。此外,如果是此前借助loader读取进来的文本,也可以使用split_documents方法。它接收的是一个Document对话,需要是列表形式。
如上就是CharacterTextSplitter文档分割器的基本使用方法,不用的数据形式,需要采用不同的方法来执行文本切割,使用哪种方法,是完全取决于大家在前一步数据加载过程中执行的操作是怎样的,这是需要明确的第一点。除此之外:在 TextSplitter 类(基类)的初始化函数中,有一个检查是确保 chunk_overlap 必须小于 chunk_size。这是为了确保文本分块的逻辑正常运行,因为重叠区域不能大于整个块的大小。这样的设计是为了确保每个块之间有足够的内容重叠,但又不会导致块之间的界限不明确或重叠区域过大。不难发现,LangChain通过巧妙的设计通过CharacterTextSplitter这一文档分割器就可以通过separator、chunk_size、chunk_overlap参数的灵活组合,实现了我们在1. 如何将文本切分成Chunks中手动编写的三种切分方式。
- RecursiveCharacterTextSplitter
在上一小节的三种切分方法下,虽然简单且更容易理解,但其存在的核心问题是:完全忽视了文档的结构,只是单纯按固定字符数量进行切分。所以难免要更进一步地去做优化,那么一个更进阶的文本分割器应该具备的是:
- 能够将文本分成小的、具有语义意义的块(通常是句子)。
- 可以通过某些测量方法,将这些小块组合成一个更大的块,直到达到一定的大小。
- 一旦达到该大小,请将该块设为自己的文本片段,然后创建具有一些重叠的新文本块,以保持块之间的上下文。
根据上述需求,衍生出来的就是递归字符文本切分器,在langChain中的抽象类为:RecursiveCharacterTextSplitter,同时它也是Langchain的默认文本分割器,在Baseloader类中,
我们可以用LangChain提供的文本切分可视化小工具进行直观的理解:https://langchain-text-splitter.streamlit.app/

如上代码所展示的就是RecursiveCharacterTextSplitter类的核心逻辑。所谓的按字符递归分割,就是使用一组分隔符以分层和迭代的方式将输入文本分成更小的块。默认使用[“\n\n” ,"\n" ," ",""] 这四个特殊符号作为分割文本的标记,如果分割文本开始的时候没有产生所需大小或结构的块,那么这个方法会使用不同的分隔符或标准对生成的块递归调用,直到获得所需的块大小或结构。这意味着虽然这些块的大小并不完全相同,但它们仍然会逼近差不多的大小。其中的关键参数:
- separators:指定分割文本的分隔符
- chunk_size:被切割字符的最大长度
- chunk_overlap:如果仅仅使用chunk_size来切割时,前后两段字符串重叠的字符数量。
- length_function:如何计算块的长度。默认情况下,只计算字符数,也可以选择按照Token。
这里我们可以使用同样的文本进行文本切分测试。示例文本如下所示:
FENCE0
同时调整Chunk Size,因为默认的是1000,很明显我们的测试文本长度低于1000,这里我们降低为100,同时将overlap设置为20:
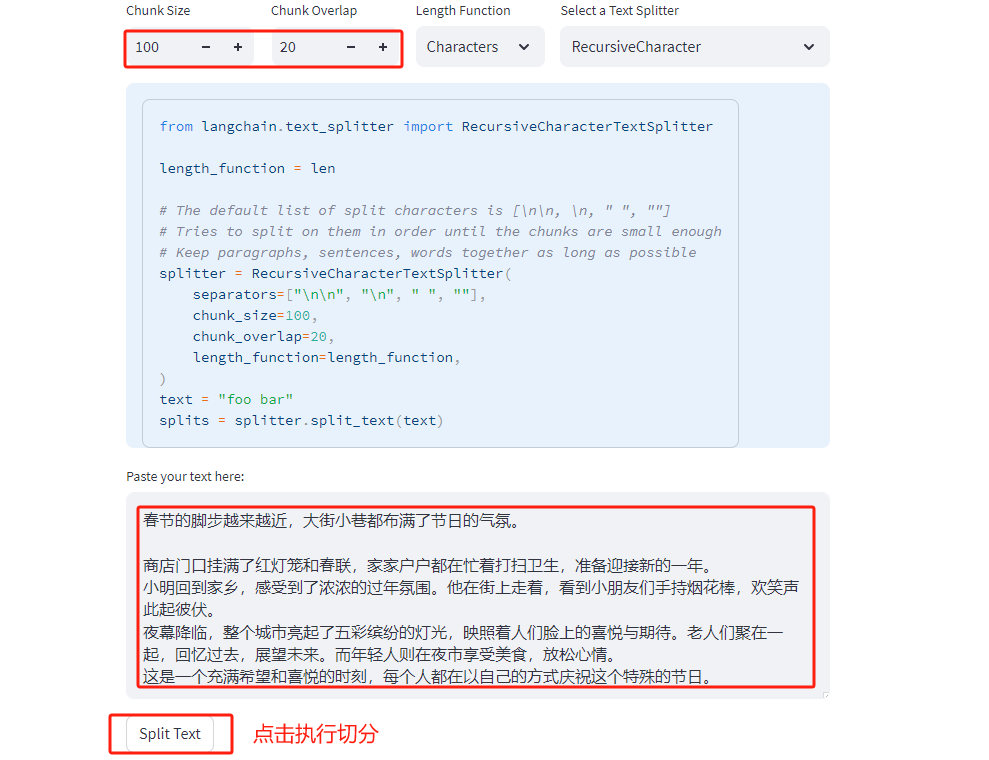
切分结果如下所示,会正常的切分为四个较为完整的chunks。
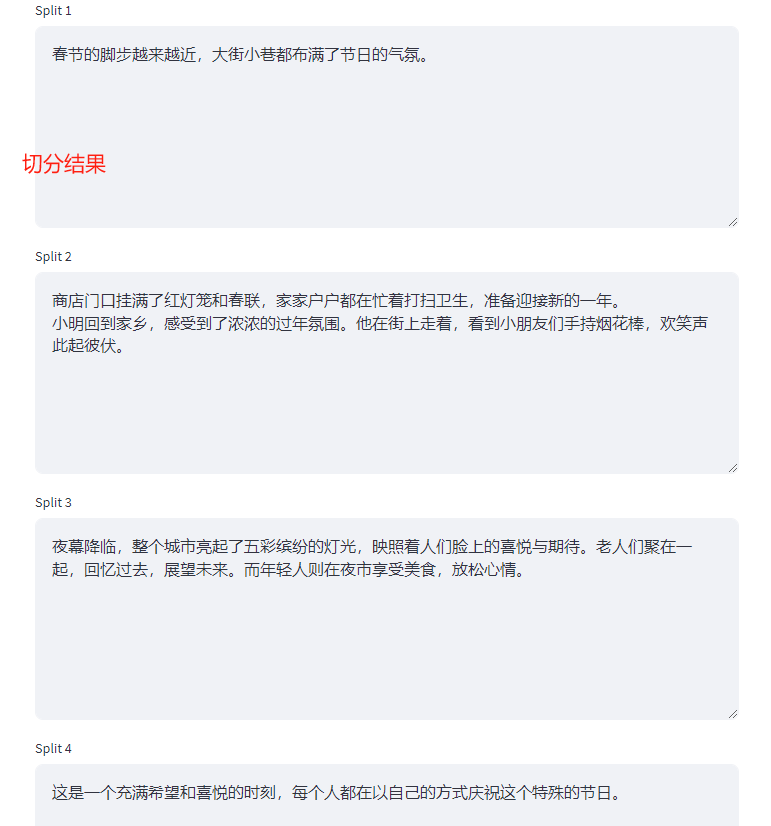
这里我们需要强调的两个关键点是:
- 切分的结果是由
length_function = len决定的,按照设置的切分规则,依次对文本进行分割; - 能不能进行分割,并不是由Chunk Size决定,超出Chunk Size只是触发条件,而真正会不会实际执行分割操作,取决于separator设置的关键词。
比如我们调低Chunk Size为50,再次执行。它会由原来的4个Chunk增加到8个Chunk,这里我们以chunk 3 和 chunk 4 举例说明:
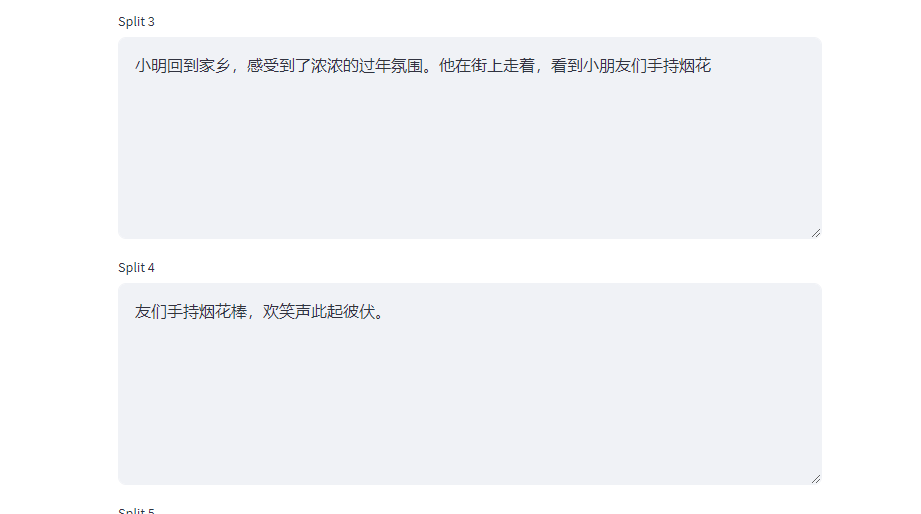
当Chunk Size设置为50时,第三行:“小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。”是超出50个字符,此时就会触发Chunk Overlap。也就说:当某一个片段溢出了Chunk Size设定的值,才会在下一个分片段中触发 Chunk Overlap,没有触发时,就不需要补充上下文,但当触发了以后,补充的上下文不能超过设定的Chunk Overlap,这是一个非常重要的点,一定要理解。
在这种情况下虽然超出了 Chunk Size,但是按照separators=["\n\n", "\n", " ", ""]的规则,没有任何一条命中,所以不能分割。因此我们才说:超出Chunk Size只是触发条件,而能不能分割,取决于separator设置的关键词。
当然,除了按照 length_function = len(即字符长度)来进行切分,也可以按照Token切分,Token和字符大概是1 :4 这样一个比例,原理是一致的,大家可以自行尝试。
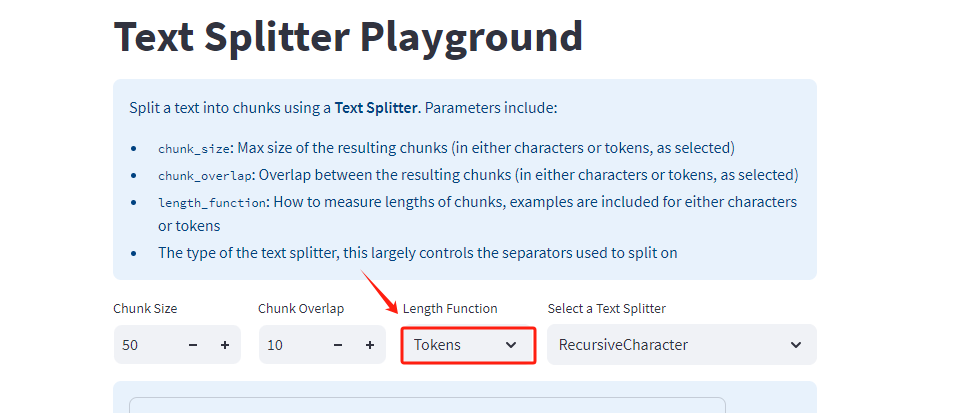
当了解了CharacterTextSplitter的使用方法后再实践RecursiveCharacterTextSplitter,其实会发现其操作过程和使用技巧基本是一致的,不同的就是文本切分的核心逻辑不同,我们在2.1 文档切分的可视化工具中已经详细介绍了RecursiveCharacterTextSplitter的切分原理和注意事项,所以这里直接进入代码实践过程。
该文本分割器接受一个字符列表作为参数,根据第一个字符进行切块,但如果任何切块太大,则会继续移动到下一个字符,并以此类推。默认情况下,它尝试进行切割的字符包括 ["\n\n", "\n", " ", ""]
除此之外,还可以指定的参数包括:
- length_function:用于计算切块长度的方法。默认只计算字符数,但通常这里会使用Token。
- chunk_size:切块的最大大小(由长度函数测量)。
- chunk_overlap:切块之间的最大重叠部分。保持一定程度的重叠可以使得各个切块之间保持连贯性(例如滑动窗口)。
- add_start_index:是否在元数据中包含每个切块在原始文档中的起始位置。
首先,还是需要进行模块的导入:
# ! pip install --upgrade --quiet langchain-text-splitters tiktoken
from langchain.text_splitter import RecursiveCharacterTextSplitter
with open("./LangChain.txt", encoding="utf-8") as f:
langchain_desc = f.read()
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4o",
chunk_size=100, #块长度
chunk_overlap=0, #重叠字符串长度
)
texts = text_splitter.split_text(langchain_desc)
print(texts[0])
len(texts)
2.4 处理特定数据文档切分
在上面的介绍中,无论是手动实现还是借助于LangChain抽象好的文档加载器,均更倾向于处理普通的文本文件(如 .txt)。而当遇到更复杂的数据格式,如JSON、PDF等,之前的处理方式就并不再适用,此时考虑的应该是如何将文本分割的策略正确地匹配到具体的数据格式。
比如对于Markdown来说,其文档分割器为MarkdownTextSplitter。先导入
from langchain.text_splitter import MarkdownTextSplitter
定义一个测试文本:
markdown_text = """
# 主题:技术探讨
## 第一部分:前言
这是前言部分,简短介绍文档主旨。
## 第二部分:技术分析
### Python编程
### 解释
1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。
2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。
3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。
"""
构造文档切割器的实例:
splitter = MarkdownTextSplitter(chunk_size = 60, chunk_overlap=10)
按照MarkdownTextSplitter定义的分隔符进行切分,调用create_documents方法。
mardown_split = splitter.create_documents([markdown_text])
len(mardown_split)
mardown_split
同时,LangChain封装的MarkdownHeaderTextSplitter,它的切分逻辑是基于指定的标题来分割markdown文件。因为Markdown格式有特定的语法,一般整体内容由h1、h2、h3等多级标题组织,所以MarkdownHeaderTextSplitter得切分策略就是根据标题来分割文本内容。
# ! pip install -qU langchain-text-splitters
markdown_text = """
# 主题:技术探讨
## 第一部分:前言
这是前言部分,简短介绍文档主旨。
## 第二部分:技术分析
### Python编程
### 解释
1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。
2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。
3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。
"""
from langchain_text_splitters import MarkdownHeaderTextSplitter
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_text)
print(md_header_splits)
从输出上看,切分策略会根据指定标题(标题1, 标题2,标题3) ,且同一标题内的的数据被放置在同一个块内。
除此之外,还有一个CodeTextSplitter,可以按照代码进行分割,支持代码的语言包括['cpp', 'go', 'java', 'js', 'php', 'proto', 'python', 'rst', 'ruby', 'rust', 'scala', 'swift', 'markdown', 'latex', 'html', 'sol'],比如Markdown(来源于RecursiveCharacterTextSplitter的get_separators_for_language方法):
FENCE0
使用方法还是类似的,直接去实例化对应的文档分割器。
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
Language,
)
md_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0
)
md_docs = md_splitter.create_documents([markdown_text])
md_docs
从过程上看,其实现还是非常简单的,同样,对于JSON、代码等不同形式的解析并分割都可以按照相同的方式去操作,大家可以在LangChain的官方文档中找到对应的操作文档快速进行尝试。但难点在于:文档分割容易,但如何指定切分策略,分割出怎样的chunks才更有利于后续的检索,这是多方面因素决定的。以PDF文件为例,这种数据格式在应用中极为普遍,但是也最难处理,这包括如何处理表格、图片等等多种类型的数据。所以当不具备特定的需求时,我们花额外的时间去探索、尝试是没有任何意义的。需要大家在掌握文档解析器的这部分基础后,根据自己的数据需求和实际构建的RAG流程的效果反馈来灵活的进行调整,完全没有必要把时间浪费在基础的调试中。
- LangChain 处理特定数据文档切分
在上面的介绍中,无论是手动实现还是借助于LangChain抽象好的文档加载器,均更倾向于处理普通的文本文件(如 .txt)。而当遇到更复杂的数据格式,如JSON、PDF等,之前的处理方式就并不再适用,此时考虑的应该是如何将文本分割的策略正确地匹配到具体的数据格式。
比如对于Markdown来说,其文档分割器为MarkdownTextSplitter。先导入
from langchain.text_splitter import MarkdownTextSplitter
定义一个测试文本:
markdown_text = """
# 主题:技术探讨
## 第一部分:前言
这是前言部分,简短介绍文档主旨。
## 第二部分:技术分析
### Python编程
### 解释
1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。
2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。
3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。
"""
构造文档切割器的实例:
splitter = MarkdownTextSplitter(chunk_size = 60, chunk_overlap=10)
按照MarkdownTextSplitter定义的分隔符进行切分,调用create_documents方法。
mardown_split = splitter.create_documents([markdown_text])
len(mardown_split)
mardown_split
同时,LangChain封装的MarkdownHeaderTextSplitter,它的切分逻辑是基于指定的标题来分割markdown文件。因为Markdown格式有特定的语法,一般整体内容由h1、h2、h3等多级标题组织,所以MarkdownHeaderTextSplitter得切分策略就是根据标题来分割文本内容。
# ! pip install -qU langchain-text-splitters
markdown_text = """
# 主题:技术探讨
## 第一部分:前言
这是前言部分,简短介绍文档主旨。
## 第二部分:技术分析
### Python编程
### 解释
1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。
2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。
3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。
"""
from langchain_text_splitters import MarkdownHeaderTextSplitter
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_text)
print(md_header_splits)
从输出上看,切分策略会根据指定标题(标题1, 标题2,标题3) ,且同一标题内的的数据被放置在同一个块内。
除此之外,还有一个CodeTextSplitter,可以按照代码进行分割,支持代码的语言包括['cpp', 'go', 'java', 'js', 'php', 'proto', 'python', 'rst', 'ruby', 'rust', 'scala', 'swift', 'markdown', 'latex', 'html', 'sol'],使用方法还是类似的,直接去实例化对应的文档分割器。
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
Language,
)
md_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0
)
md_docs = md_splitter.create_documents([markdown_text])
md_docs
从过程上看,其实现还是非常简单的,同样,对于JSON、代码等不同形式的解析并分割都可以按照相同的方式去操作,大家可以在LangChain的官方文档中找到对应的操作文档快速进行尝试。
2.5 语义识别分割
关于使用深度学习模型去做语义层面的Chunks,则选择方向会更大,但同时使用方法会更加简单,比如大家可以在LangChain中使用已经抽象好的语义切分文档分割器AI21SemanticTextSplitter: https://python.langchain.com/docs/integrations/document_transformers/ai21_semantic_text_splitter/#splitting-text-by-semantic-meaning
或者在Hugging Face 和 ModelScope中找到一些预训练好的通用文本分割模型,都会有比较详细的介绍,比如BERT文本分割-中文-通用领域:https://www.modelscope.cn/models/iic/nlp_bert_document-segmentation_chinese-base/summary

使用示例:
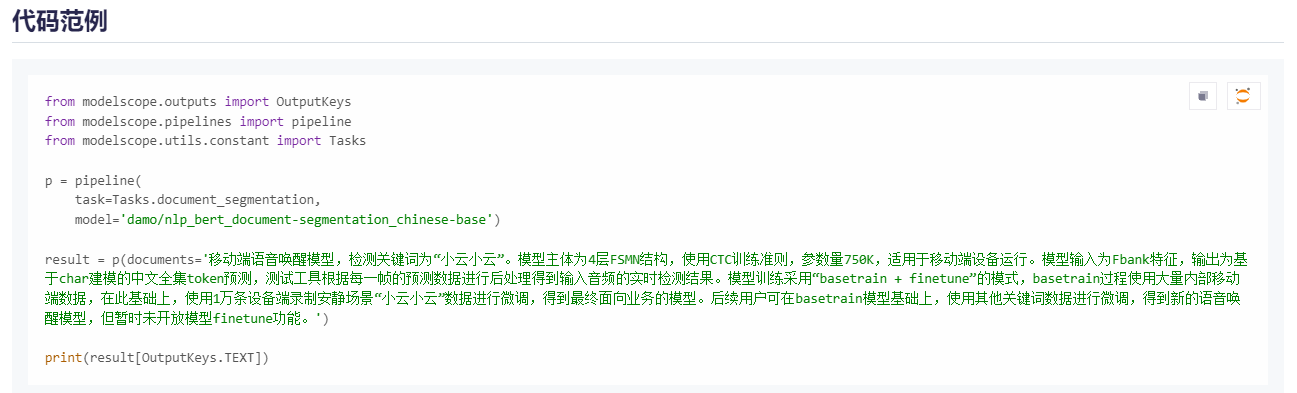
基于语义切割方法的特点是:模型非常多,直接下载即可使用,且使用方法会更加简单,但不同的数据和需求,所需的文本分割模型也不同,如果采用这种语义分割方法,需要大家在使用时做足够的调研工作和大量的效果测试,这不放呢内容属于进阶内容,我们将在付费课程中展开进行介绍。
总的来说,没有最好的分块策略,只有最适合的分块策略,甚至有时间最简单的分块方式反而能起到最好的效果,这完全是由实际的数据和场景为驱动的,但分块,也是RAG整个流程中我们最能把控、最有机会做出高质量效果的一个环节,而这一调优的过程,考验的就是大家对数据的理解能力和对应变能力,需要具备根据检索反馈的效果快速的制定优化策略。同时需要特别指出的是:在进行应用的切分策略之前,还有非常多数据预处理的工作,要通过清洗数据来确保数据的质量。比如,如果数据是通过爬虫获取的,就需要删除HTML标记或特定的元素,保证文本的“纯洁”,减少文本的噪音,文档数据不够干净,召回效果肯定也不会好。
3.3 LangChain 接入Embedding Models
截止课程进展到这里,对于一个基础形态的RAG系统,借助LangChain框架中的Document loaders和Text Splitters两个模块,我们能够处理来自多种数据格式和来源的原始数据,并且掌握了一些常用的文本切分方法。因此,对于下图所示的流程,我们已经实现的进度如红框中所示:
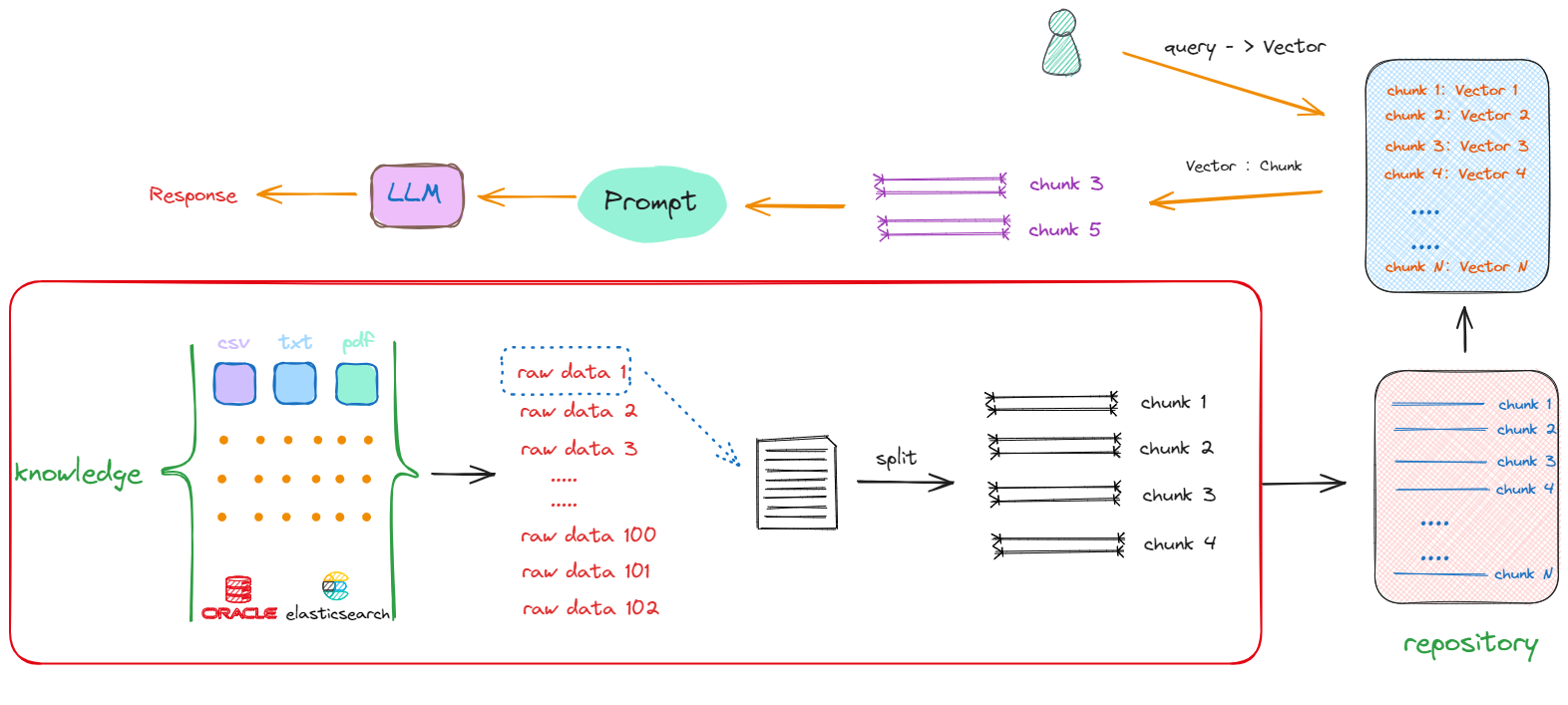
如上图所示,目前得到的每一个chunk,其存储形式还是以字符串形式存在,那么去计算Query和每一个chunk之间的相似度的解决办法是先通过Embedding Models将chunk转化成Vector,再通过余弦相似度等计算文本间相似度的算法匹配出与Query关联度最高的Chunks。
所以接下来我们将直接围绕Embedding模型的使用和向量数据库的应用两个技术点展开详细的探讨和实践。
其实将自然语言文本转化成向量,当然,chunks本质上也是一个个文本,最初来源于Word2vec技术,随后发展到Elmo,再到Bert等, 它是一种自然语言处理(NLP)中词表示技术的一种演变过程。从本质上来说,将文本“chunks”(如单词、短语或句子)转换成向量的过程只是一个简单的编码(Encoding)问题。在这个阶段,我们没必要去纠结Embedding模型的底层原理,只需要懂得如何对具体的需求,找到最合适的Embedding 模型,拿来直接用即可。同样的道理适用于向量数据库。虽然大多数向量数据库的基本功能和使用技巧相似,但每个数据库都有其独特的特性和优点。我们需要的具备的能力是根据自己数据的特点,选择最合适的向量数据库。然后再花时间去学习和掌握该数据库的高级应用技巧,一定要避免将时间浪费在不必要的学习上。
所以本节课程接下来的内容,我们将从应用的角度出发,结合LangChian框架带大家实操不同类型的Embedding Models 和 Vector Stores中一些较为通用的使用方法,并从宏观的角度向大家介绍应该如何选择最适合的Embedding Models或者Vector Stores,而更进阶的用法和深度的应用技巧,我们在本系列课程最后的企业级应用案例中,会选择一个或多个比较流行Embedding Models和Vector Stores,结合具体的应用展开进一步的探讨。
接下来,我们首先进行第一部分内容,向大家介绍在LangChain应用框架下的Embedding Models的接入及使用方法。
在langchain的原生数据处理流Data connection中,Embedding Models所处的位置如下图红框内所示:
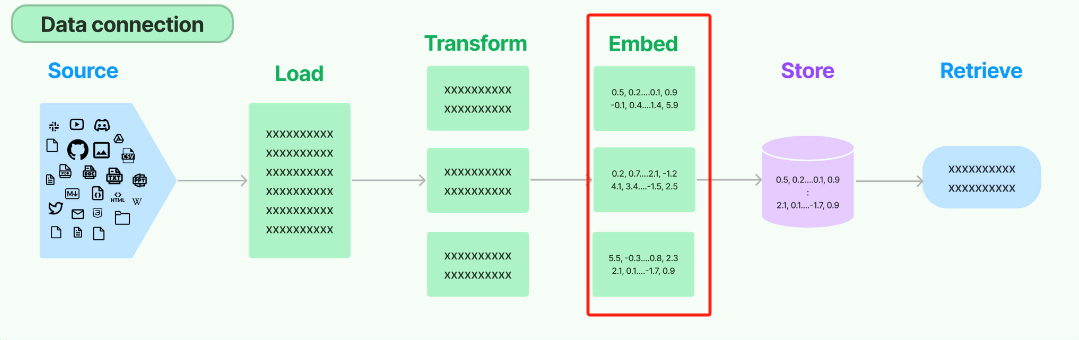
LangChain 中的 Embeddings 基类提供了两种方法:一种用于Embeddings文档对象,另一种用于Embeddings查询(Query)。前者采用多个文本作为输入,而后者采用单个文本。
而我们前面说Embedding Models只需要学会如何去使用就可以,是因为有非常多的托管平台,如OpenAI、Hugging Face、Qwen3、GLM4 等都提供了标准接口并集成在LangChian框架中,这意味着:Embedding Models已经有人帮我们训练好了,我们只要按照其提供的接口规范,将自然语言文本传入进去,就能得到其对应的向量表示。这显然是非常简单的。
那么在如此多的Embedding Models都可以使用的情况下,应该如何选择呢? 首先,我们在使用形式上把 Embedding Models分为两类:
- 在线
Embedding Models:以OpenAI的text-embedding-3为代表,仅提供API服务,需要按照Token付费; - 开源
Embedding Models:以bge-base-zh-v1.5为代表,这类模型托管在Hugging Face或ModelScope平台上,可以下载到本地免费使用,但在运行过程中会消耗GPU资源。
接下来,我们也将围绕这两类不同类型的Embedding Models,逐一向大家介绍其在LangChain中的应用方法。首先来看OpenAI Embedding Models的使用。
3.3.1 在线Embeddings Model接入
OpenAI的Embedding Model目前有三个,均只提供API形式的调用服务,可以在OpenAI官网查看相关的细节:https://platform.openai.com/docs/guides/embeddings/what-are-embeddings

调用方法非常简单,如下代码所示:
import os
from dotenv import load_dotenv
load_dotenv(override=True)
OPENAI_EMBEDDING_API_KEY = os.getenv("OPENAI_EMBEDDING_API_KEY")
OPENAI_EMBEDDING_BASE_URL = os.getenv("OPENAI_EMBEDDING_BASE_URL")
from openai import OpenAI
client = OpenAI(api_key=OPENAI_EMBEDDING_API_KEY, base_url=OPENAI_EMBEDDING_BASE_URL)
small_response = client.embeddings.create(
input="你好",
model="text-embedding-3-small"
)
默认情况下,对于text-embeddings-3-small,Embedding向量的长度为1536,而text-embeddings-3-large生成的向量长度则为3072。
len(small_response.data[0].embedding)
large_response = client.embeddings.create(
input="你好",
model="text-embedding-3-large"
)
len(large_response.data[0].embedding)
当然,也可以通过传入dimensions参数来灵活的调整Embedding的维度,且OpenAI的官方说明,这样的调整并不会影响其生成的词表示的效果。比如:
dim_response = client.embeddings.create(
input="你好",
model="text-embedding-3-large",
dimensions=1024
)
len(dim_response.data[0].embedding)
dim_response.data[0].embedding
整体上看其使用方法还是非常简单的,也并没有什么额外的操作技巧,那么在LangChain框架中,使用OpenAI的Embedding,则需要借助到其已经封装好的OpenAIEmbeddings类。
其源码如下图所示:
FENCE0
OpenAIEmbeddings 继承自 BaseModel 和 Embeddings,实现的就是利用 OpenAI 的Embedding模型获取文本的Embedding向量。只包含两个函数:
-
embed_documents:将给定的文本列表转换成Embedding向量。它接受两个参数:texts: 需要转换成Embedding向量的文本列表。chunk_size: 指定每次处理的文本块的大小。如果为0或None,那么将使用类中指定的默认大小,默认为0
-
embed_query:用于获取单个文本的Embedding向量。它是embed_documents函数的一个特例,专门用于处理单一文本输入。text: 需要转化为Vector的单个文本。- 函数内部通过调用
embed_documents函数实现,将单个文本放入列表中,调用该函数后,取结果列表的第一个元素作为输出。
理解了上述源码后,OpenAIEmbeddings类的使用方法就非常明确了,这里我们进行一下尝试。首先,如果没有安装langchain-openai的话,需要进行安装。
# ! pip install -qU langchain-openai
导入OpenAIEmbeddings方法。
from langchain_openai import OpenAIEmbeddings
通过源码可以看到,一种是对Document 进行Embedding,一种是对Query进行Embedding,区别就在于类的使用方法上,对于文档的Embedding,可以输入很多内容,可以有多条,对于query,通常是单个文本,这个与使用场景还是非常相像的。如果要使用OpenAIEmbeddings类调用OpenAI的Embedding Model对文本生成Vector,首先还是要进行实例化,代码如下:
# 默认使用的模型是:text-embedding-ada-002
embeddings_model = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model='text-embedding-3-small'
)
使用embed_documents方法,可以生成文档对象的Embedding,其接收的类型为一个列表。
embeddings = embeddings_model.embed_documents(
[
"你好",
"今天的天气好吗",
"我是木羽",
"如果你需要找我,请给我打电话吧",
"明天我们一起去郊游"
]
)
这里每一条文本,都会生成一个单独的Embedding Vector。
len(embeddings)
每个单独的Embedding Vector的维度都是1536,这是由Embedding Models决定的。
len(embeddings[0])
接下来生成query对应的Embedding Vector,这需要使用的方法是embed_query,其接受单条字符串形式的文本,代码如下:
# QA场景:嵌入一段文本,以便与其他嵌入进行比较。
embedded_query = embeddings_model.embed_query("你好,请问你叫什么?")
同样,使用相同的Embedding 模型实例,返回的Embedding 维度也是 1536。
len(embedded_query)
接下来我们通过一个稍加复杂的流程,测试一下关于Embedding 生成的向量,不同语义的文本之间的关系是怎样的,从而验证通过Embedding Models得到的Vector是否具有较强的语义信息。理论上,如果Embedding Vector足够好,那么自然语义相近的原始的文本会更相似。
from langchain_openai import OpenAIEmbeddings
这里模拟一个QA场景,我们定义一个问题,然后定义10条文本作为回答,其中仅有两条文本(即第一条和第二条)与提出的Query有较强的相关性。
query = "早睡早起到底是不是保持身体健康的标准?"
sentences = ["早睡早起确实是保持身体健康的重要因素之一。它有助于同步我们的生物钟,并提高睡眠质量。",
"早睡早起可以帮助人们更好地适应自然光周期,从而优化褪黑激素的产生,这种激素是调节睡眠和觉醒的关键。",
"关于提高工作效率,确保在日常饮食中包含充足的蛋白质、复合碳水化合物和健康脂肪非常关键。",
"投资可再生能源项目和推广电动汽车可以显著减少温室气体排放,从而缓解气候变化带来的负面影响。",
"多发性硬化症是一种影响中枢神经系统的自身免疫疾病,导致神经传导受损。虽然与阿尔茨海默症类似,多发性硬化症的主要症状包括疲劳、视觉障碍和肌肉控制问题。",
"今天的天气太好了,可以早点起床去爬山",
"如果下班特别晚的话,我建议你还是打车回家吧",
"提升学术研究质量需侧重于多学科融合和国际合作。研究机构应该鼓励学者之间的交流,通过共享数据和研究方法,来推动科学发现和技术创新。",
"如果你认为我说的没用,那你大可以不必理会。",
"衡量一个人是否成功的标准在于他到底能不能让身边的人都变的优秀"
]
实例化Embedding 模型。
# 默认使用的模型是:text-embedding-ada-002
embeddings_model = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model='text-embedding-3-small'
)
使用embed_documents方法,传入sentences列表,得到每条文本的向量表示。
sentence_embeddings = embeddings_model.embed_documents(sentences)
len(sentence_embeddings)
len(sentence_embeddings[0])
通过embed_query方法生成问题的向量表示。
# QA场景:嵌入一段文本,以便与其他Embedding Vector进行比较。
embedded_query = embeddings_model.embed_query(query)
len(embedded_query)
然后,我们通过t-SNE降维算来可视化Embedding向量在二维空间中的分布。代码如下所示:
# ! pip install matplotlib scikit-learn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
# 设置字体以支持中文显示
plt.rcParams['font.family'] = 'Microsoft YaHei'
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 将查询句子的嵌入添加到句子嵌入数组的首位
all_embeddings = np.vstack([embedded_query, sentence_embeddings])
# 运行 TSNE 降维,固定随机种子以保持结果一致
# n_components (整数): 这个参数指定目标空间的维度。在这里设置为 2,意味着t-SNE将把数据降维到二维空间。
# perplexity (浮点数): 这个参数是t-SNE中非常重要的一个参数,可以看作是考虑周围邻居的数量,它反映了数据局部结构的复杂性。
tsne = TSNE(n_components=2, perplexity=5)
embeddings_2d = tsne.fit_transform(all_embeddings)
# 创建颜色列表,查询句子为红色,其余为绿色
color_list = ['red'] + ['green'] * len(sentence_embeddings)
# 绘制散点图
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], color=color_list)
# 添加文本标签,包括查询句子
sentences_with_query = [query] + sentences # 加入查询句子到句子列表首位
for i in range(len(embeddings_2d)):
plt.text(embeddings_2d[i, 0], embeddings_2d[i, 1] + 10, # 小幅调整文本位置以防重叠
sentences_with_query[i],
color=color_list[i])
# 显示图表
plt.show()
从上图中能够非常明显的看出,在分布上红色显示的为Query,不同文本间距离的远近表示着文本间的关联度,关联越大,两个文本的显示距离就越近。对早睡早起到底是不是保持身体健康的标准?这个问题,在10个绿色字体的答案中,两个最相关的早睡早起确实是保持身体健康的重要因素之一。它有助于同步我们的生物钟,并提高睡眠质量。和早睡早起可以帮助人们更好地适应自然光周期,从而优化褪黑激素的产生,这种激素是调节睡眠和觉醒的关键。是距离最近的,同时从自然语义上,也是最能回答该问题的答案。如果这是一个RAG系统,那么被检索出来的内容就会是这两个问题。从而也印证了Embeding后的向量,是具有极强的语义的。
有一点需要说明:大家在自己执行时会出现多次执行结果不同的情况,这是正常的,这是由于 t-SNE 算法的特性导致的。它在初始化过程中有一定的随机性。这意味着每次运行算法时,即使是在相同的Embeding向量上,得到的低维表示也可能不同。
除了OpenAI的Embedding Models可以使用API形式接入之外,LangChain也接入了其他提供API调用的平台,比如国内的Baidu Qianfan,ZhipuAI等,具体支持的平台可以在如下位置进行查看:https://python.langchain.com/docs/integrations/text_embedding/

当然,不同平台提供的Embedding Models也均需要按照其定制的收费标准付费。如果想免费使用Embedding Models,另外的一种形式则是下载开源的Embedding Models至本地,通过本地服务接入,但这个过程,需要消耗本地服务器的硬件资源,即会占用一定的GPU显存。
接下来我们就介绍一下:如何在LangChain框架中接入开源的Embedding Models。
3.3.2 开源Embedding Models接入
在LangChain框架中如果想使用开源Embedding Models,需要先将具体的Embedding Models的全部权重文件下载至本地后才能进行加载,这与本地化部署开源大模型是一样的,其在调用过程中也会消耗一定的GPU资源,而消耗的多少显存则取决于Embedding Models的参数量。
LangChain集成的开源Embedding模型托管平台主要有Hugging Face、Ollama、Vllm等,在使用上与OpenAI Embedding Models等API形式差异也并不大,唯一需要做的前置工作是:需要把离线的Embedding Models从指定的托管平台上下载至本地。我们以BAAI/bge-base-zh-v1.5模型为例,向大家介绍下载及使用方法,并通过Ollama平台进行部署,最后通过LangChain框架进行调用。

Ollama 除了可以接入对话、推理类模型外,还可以接入 Embedding 模型。并且部署和使用方法基本与对话、推理类模型保持一致。官方下载地址:https://ollama.com/search?c=embedding ,可点击链接进行查看:
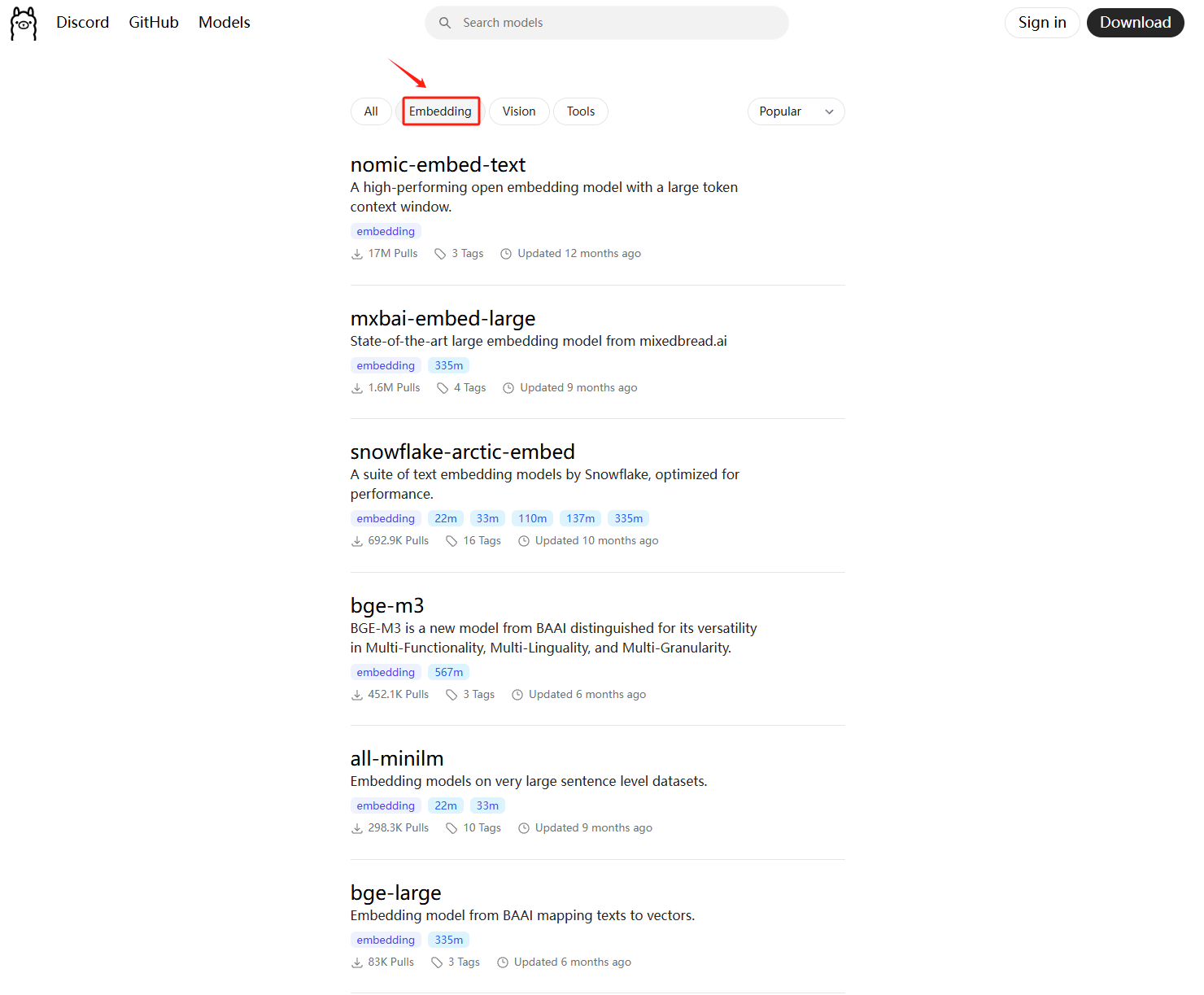
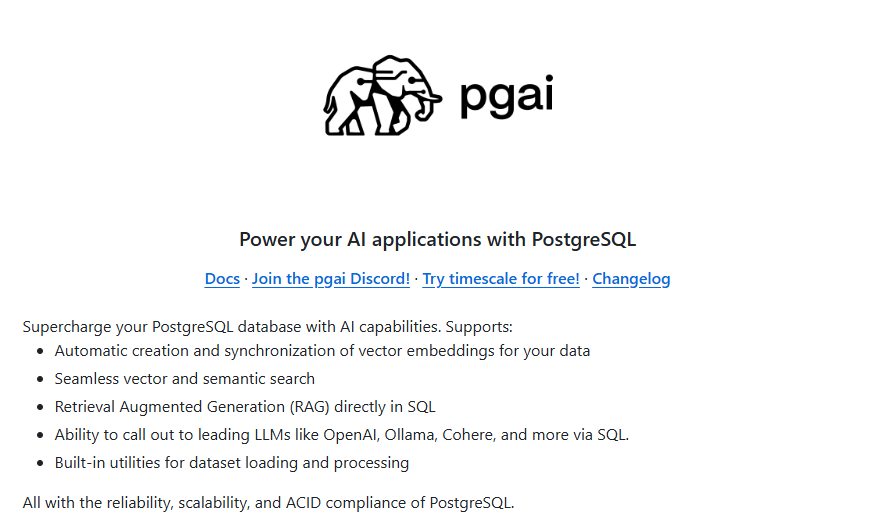
关于如何选择Embedding模型,这个问题本质上不存在哪个Embedding最好的说法,同时也并没有比较通用且大家都认可的评测数据、流程等,往往还是需要结合自己的实际数据情况加上构建流程评测出来的效果,来进行综合评估。所以这里给大家推荐一个相对完善的Embedidng模型评估开源项目,同时也是一个RAG的解决方案:https://github.com/timescale/pgai?ref=timescale.ghost.io
该开源项目针对Ollama支持的Embedding模型做了一些基础的评测,如下:
常规参数
| 模型名称 | 优势 | 劣势 |
|---|---|---|
| bge-m3 | 整体检索准确率最高 | 在不清楚和含糊不清的问题上表现较差,最低准确率 |
| 在长问题上表现出色 | ||
| mxbai-embed-large | 尺寸小 | 在简短和直接的问题上表现不如其他模型 |
| 在上下文较重的问题上表现良好 | ||
| 长问题表现良好 | ||
| nomic-embed-text | 在简短和直接的问题上表现优异 | 整体表现排名最后 |
| 在长问题上也取得了较好性能 |
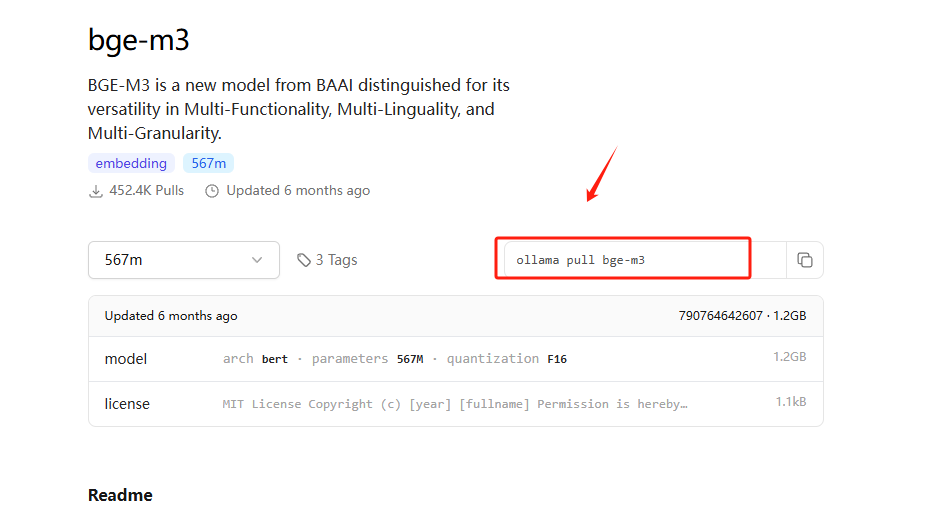
这里我们选择bge-m3模型进行下载使用。点击具体的模型,可以查看模型的详细信息,如模型的大小、支持的设备、支持的参数等。
首先需要确定服务器上的Ollama服务处于运行状态,通过如下命令查看:
FENCE0
如果服务未处于运行状态,则可以通过如下命令启动:
FENCE0
启动Ollama服务后,通过如下命令下载并启动bge-m3模型:
FENCE0

需要说明的是,最后一行Error: "bge-m3" does not support generation,表示bge-m3模型不支持在类似对话模型启动后可以在命令行进行问答,需要通过Ollama的 REST API 进行使用。
注意:如果是Windows操作系统,则只需要安装Ollama 程序,然后在命令行终端执行即可:
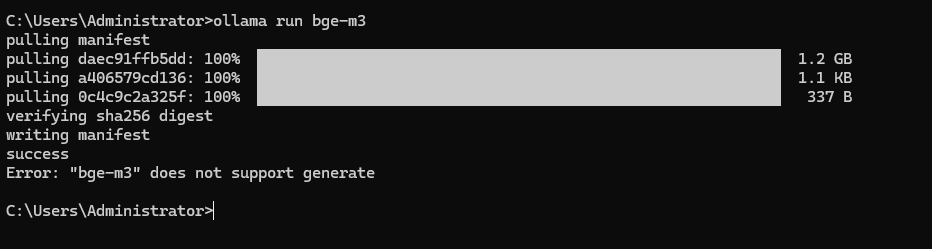
成功启动后,Ollama 提供给Embedding 模型使用的 REST API 接口为:/api/embed。其可以支持单个输入和多个输入的请求。具体可用的参数如下所示:
常规参数
| 参数名 | 类型 | 描述 |
|---|---|---|
| model | 字符串 | 用于生成嵌入的模型名称 |
| input | 字符串或字符串列表 | 要生成嵌入的文本或文本列表 |
| truncate | 布尔值 | 是否截断每个输入的末尾以适应上下文长度。若为 false 且超出上下文长度则返回错误。默认值为 true |
| options | 对象 | 额外的模型参数,例如温度等 |
| keep_alive | 字符串 | 控制模型在请求后保持加载到内存中的时间(默认:5分钟) |
同样,只要了解了某个服务的REST API 接口以及其请求参数,就都可以通过Python 的requests 库进行调用。代码如下:
import requests
import json
# 定义 API 端点
url = "http://localhost:11434/api/embed" # 这里需要根据实际情况进行修改
# 单个输入的请求示例
single_input_payload = {
"model": "bge-m3", # 这里替换成具体的模型名称
"input": "大家好,我是九天,欢迎大家参加公开课~" # 这里替换成具体的输入文本
}
# 发送 POST 请求
response_single = requests.post(url, json=single_input_payload)
# 检查响应
if response_single.status_code == 200:
print("Single Input Response:")
response_data_single = response_single.json()
print(json.dumps(response_data_single, indent=2))
else:
print(f"Error: {response_single.status_code} - {response_single.text}")
可以提取出response_single.json() 中的 embeddings 字段,这个字段是一个列表,里面包含了若干个浮点数。而这些浮点数,就是bge-m3 模型的嵌入结果,用来表示输入文本"大家好,我是九天,欢迎大家参加公开课~"这句话的语义。
# 提取嵌入结果
response_data_single["embeddings"]
具体用多少个浮点数来表示输入文本的语义,取决于具体的模型。比如我们使用的bge-m3 模型,其返回的嵌入结果就是一个包含1024个浮点数的列表。
len(response_data_single["embeddings"][0])
大家可以在huggingface 或者 modelScope 等平台上,找到bge-m3 模型的详细架构、评测信息及论文。我们这里不作为重点展开讲解。bge-m3 模型在modelScope 平台上的地址为:https://modelscope.cn/models/BAAI/bge-m3
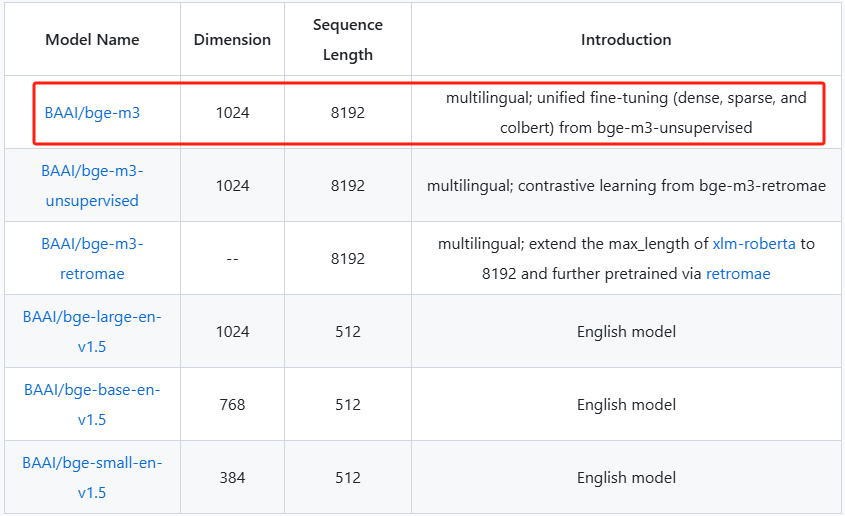
所以大家可以简单理解为, 经过bge-m3 模型处理后的结果, 就是将输入的文本转换为一个包含1024个浮点数的列表,并且用这个列表来表示输入文本的语义。即 response_data_single["embeddings"][0] = "大家好,我是九天,欢迎大家参加公开课~"
同时,bge-m3 模型还支持多个输入的请求,即可以一次性输入多个文本,然后返回每个文本的嵌入结果。代码如下:
import requests
import json
# 定义 API 端点
url = "http://localhost:11434/api/embed" # 这里需要根据实际情况进行修改
# 多个输入的请求示例
multiple_input_payload = {
"model": "bge-m3",
"input": ["天为什么是蓝色的?",
"草为什么是绿色的?"]
}
# 发送 POST 请求
response_multiple = requests.post(url, json=multiple_input_payload)
# 检查响应
if response_multiple.status_code == 200:
print("\nMultiple Input Response:")
response_data_multiple = response_multiple.json()
print(json.dumps(response_data_multiple, indent=2))
# 提取嵌入结果
multiple_embeddings = response_data_multiple.get("embeddings", [])
else:
print(f"Error: {response_multiple.status_code} - {response_multiple.text}")
print("Total embeddings:", len(multiple_embeddings))
print("First embedding:", len(multiple_embeddings[0]), multiple_embeddings[0]) # 表示天为什么是蓝色的?
print("Second embedding:", len(multiple_embeddings[1]), multiple_embeddings[1]) # 表示草为什么是绿色的?
Ollama启动的Embedding REST API 同样是兼容了OpenAI 的接口规范,因此也可以用如下方式进行调用:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1") # 需要根据自己的实际情况调整
response = client.embeddings.create(
model="bge-m3", # 这里替换成 bge-m3 模型
input="大家好,我是九天,欢迎大家参加公开课~",
)
print(response)
print(response.data[0].embedding)
Ollama 兼容的 OpenAI 接口,其返回的结果与 Ollama 的 REST API 接口返回的结果是一样的。同时input 参数也同样支持单个输入和多个输入。如果需要嵌入多个文本,则需要将input 参数设置为列表,如下所示:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1")
batch_input = ["天为什么是蓝色的?", "草为什么是绿色的?"]
response = client.embeddings.create(
model="bge-m3",
input=batch_input
)
print(response)
print(len(response.data))
print(len(response.data[0].embedding))
print(len(response.data[1].embedding))
至此,Ollama启动并使用Embedding模型的相关使用方法就已经介绍完毕,并没有很复杂的流程,同时其参数也比较容易理解。
接下来我们来看一下如果接入LangChain,应该如何加载到这个使用Ollma启动的本地的bge-m3 Embedding模型。首先,LangChain 封装了用于加载托管在Ollama平台的开源Embedding模型,命名为OllamaEmbeddings, 其官方文档位置如下:https://python.langchain.com/docs/integrations/text_embedding/ollama/
使用前,还是需要导入相关的模块。
# ! pip install -qU langchain-ollama
from langchain_ollama import OllamaEmbeddings
这里使用HuggingFaceEmbeddings类,同时通过base_url参数指定Ollama的REST API地址,通过model参数指定Embedding模型名称。因为是本地模型,所以不需要API_KEY。
embeddings = OllamaEmbeddings(
base_url="http://localhost:11434",
model="bge-m3",
)
进行测试:
query = "早睡早起到底是不是保持身体健康的标准?"
sentences = ["早睡早起确实是保持身体健康的重要因素之一。它有助于同步我们的生物钟,并提高睡眠质量。",
"早睡早起可以帮助人们更好地适应自然光周期,从而优化褪黑激素的产生,这种激素是调节睡眠和觉醒的关键。",
"关于提高工作效率,确保在日常饮食中包含充足的蛋白质、复合碳水化合物和健康脂肪非常关键。",
"投资可再生能源项目和推广电动汽车可以显著减少温室气体排放,从而缓解气候变化带来的负面影响。",
"多发性硬化症是一种影响中枢神经系统的自身免疫疾病,导致神经传导受损。虽然与阿尔茨海默症类似,多发性硬化症的主要症状包括疲劳、视觉障碍和肌肉控制问题。",
"今天的天气太好了,可以早点起床去爬山",
"如果下班特别晚的话,我建议你还是打车回家吧",
"提升学术研究质量需侧重于多学科融合和国际合作。研究机构应该鼓励学者之间的交流,通过共享数据和研究方法,来推动科学发现和技术创新。",
"如果你认为我说的没用,那你大可以不必理会。",
"衡量一个人是否成功的标准在于他到底能不能让身边的人都变的优秀"
]
接下来就可以使用embed_documents方法来进行文档对象的Embedding向量化。
sentence_embeddings = embeddings.embed_documents(sentences)
并使用embed_query方法来进行单条文本query的向量化。
query = "早睡早起到底是不是保持身体健康的标准?"
# QA场景:嵌入一段文本,以便与其他Embedding Vector进行比较。
embedded_query = embeddings.embed_query(query)
len(embedded_query)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
# 设置字体以支持中文显示
plt.rcParams['font.family'] = 'Noto Sans CJK JP'
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 将查询句子的嵌入添加到句子嵌入数组的首位
all_embeddings = np.vstack([embedded_query, sentence_embeddings])
# 运行 TSNE 降维,固定随机种子以保持结果一致
# n_components (整数): 这个参数指定目标空间的维度。在这里设置为 2,意味着t-SNE将把数据降维到二维空间。
# perplexity (浮点数): 这个参数是t-SNE中非常重要的一个参数,可以看作是考虑周围邻居的数量,它反映了数据局部结构的复杂性。
tsne = TSNE(n_components=2, perplexity=5)
embeddings_2d = tsne.fit_transform(all_embeddings)
# 创建颜色列表,查询句子为红色,其余为绿色
color_list = ['red'] + ['green'] * len(sentence_embeddings)
# 绘制散点图
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], color=color_list)
# 添加文本标签,包括查询句子
sentences_with_query = [query] + sentences # 加入查询句子到句子列表首位
for i in range(len(embeddings_2d)):
plt.text(embeddings_2d[i, 0], embeddings_2d[i, 1] + 10, # 小幅调整文本位置以防重叠
sentences_with_query[i],
color=color_list[i])
# 显示图表
plt.show()
从这个结果看,相较于OpenAI的Embedding Models生成的向量表示,还是有一些差距,至少从上述可视化图表中发现相似的文本并没有很好的分布在相邻的簇中。但其实这并不绝对,因为TSNE降维本身就是一个不稳定的过程,可能在原始的高维向量表示中并不会出现这样的问题。所以大家仅把上述可视化结果作为一个直观参考即可,在开源的Embedding 模型中,bge-m3生成的词向量还是比较优秀的。当然,开源模型的性能相较于在线模型,尤其是跟OpenAI的模型相比,存在很大的差距这也是实际存在的。
那么如何根据自己的数据情况选择最合适的Embedding 模型呢,这里有一个基本的衡量方法。首先,在Huggging Face 的 mteb/leaderboard 有一个较为优质的评测榜单:https://huggingface.co/spaces/mteb/leaderboard ,该榜单中包含了很多Embedding 模型,并且每个模型都给出了在不同任务上的得分。
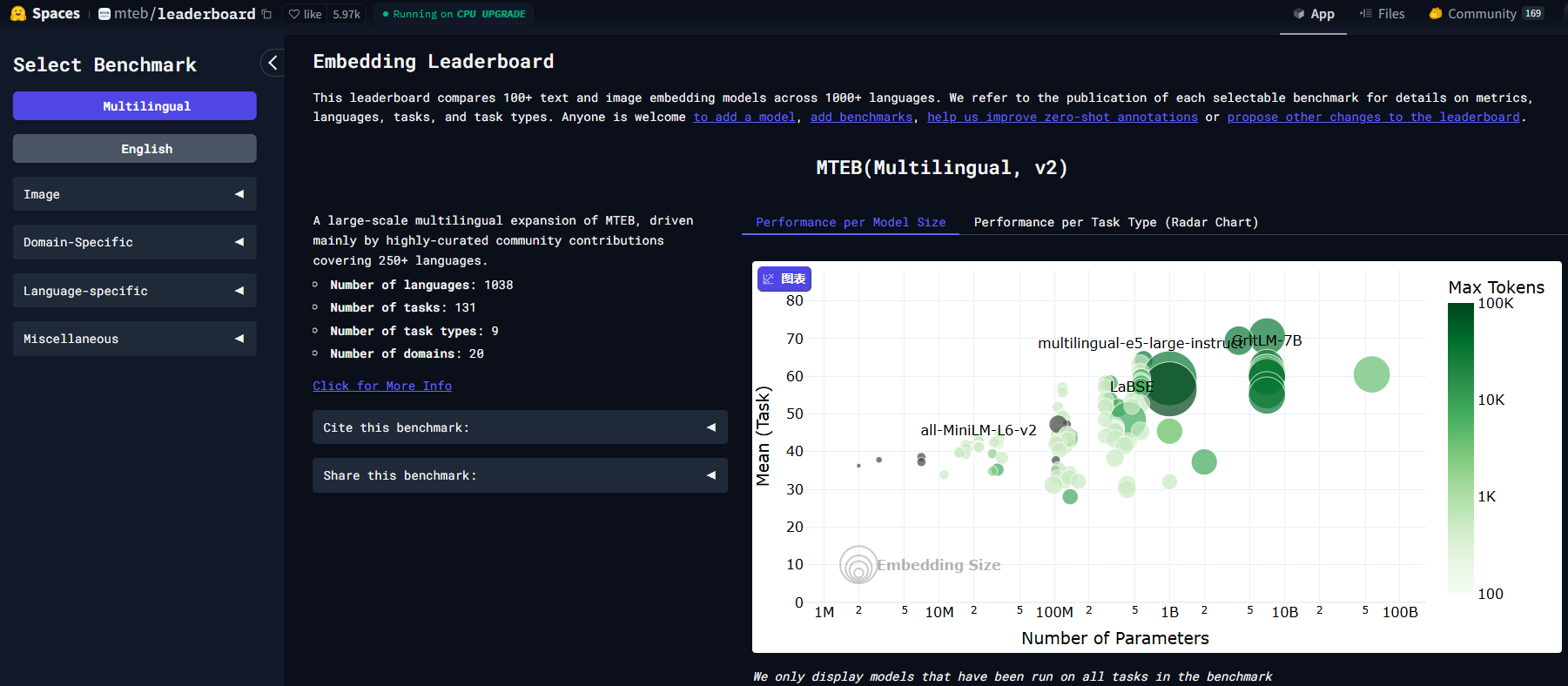
在选择Embedding模型时,大家可以考虑以下四个关键因素来确保能选取到最适合当前需求的模型:
-
文本长度和块大小(Chunk Size 和 Sequence Length):模型选择应基于文本块的大小和序列长度,这通常取决于预期回答的长度。选择能够有效处理特定文本长度的模型。
-
Embedding维度:维度大小并非总是越大越好。如果文本语义丰富,较高的维度可能更有利于捕捉复杂信息。然而,对于语义较简单和直接的文本,较小的维度可能更为有效。
-
模型大小和硬件资源:根据可用的硬件资源(如显存大小),选择合适的模型。如果硬件资源充足,可以选择较大的模型,一般来说模型越大,性能越好,但是这并不绝对。
-
实际测试和验证:使用一个简单的
Demo来测试模型的实际效果。如果初步的可视化测试结果不理想,那么有可能是不适合的。但这并不绝对,比如上面的例子,因为是降维之后的可视化,所以有可能在高维下,其表现是很好的,所以要综合衡量。
3.3.3 计算向量之间的相似度
在上面的例子中,我们用可视化降维来衡量不同文本之间的相似度是不精准且随机的,所以向量之间的相似度往往是通过一些具体的算法来计算的,向量和标量最大的区别在于向量是有方向的,而标量没有方向,只有大小。那么对于向量,一些常用的计算方法比如:
-
点积(内积): 两个向量的点积是一种衡量它们在同一方向上投影的大小的方法。如果两个向量是单位向量(长度为1),它们的点积等于它们之间夹角的余弦值。因此,点积经常被用来计算两个向量的相似度。
-
余弦相似度: 这是一种通过测量两个向量之间的角度来确定它们相似度的方法。余弦相似度是两个向量点积和它们各自长度乘积的商。这个值的范围从-1到1,其中1表示完全相同的方向,-1表示完全相反,0表示正交。
-
欧氏距离: 这种方法测量的是两个向量在n维空间中的实际距离。虽然它通常用于计算不相似度(即距离越大,不相似度越高),但可以通过某些转换(如取反数或用最大距离归一化)将其用于相似度计算。
像我们最常用的余弦相似度,其代码实现也非常简单,如下所示:
import numpy as np
def cosine_similarity(A, B):
# 使用numpy的dot函数计算两个数组的点积
# 点积是向量A和向量B在相同维度上对应元素乘积的和
dot_product = np.dot(A, B)
# 计算向量A的欧几里得范数(长度)
# linalg.norm默认计算2-范数,即向量的长度
norm_A = np.linalg.norm(A)
# 计算向量B的欧几里得范数(长度)
norm_B = np.linalg.norm(B)
# 计算余弦相似度
# 余弦相似度定义为向量点积与向量范数乘积的比值
# 这个比值表示了两个向量在n维空间中的夹角的余弦值
return dot_product / (norm_A * norm_B)
接下来,定义一个get_embedding函数,使用OpenAI的Embedding Models来对文本生成向量。
from openai import OpenAI
client = OpenAI(api_key=OPENAI_EMBEDDING_API_KEY, base_url=OPENAI_EMBEDDING_BASE_URL)
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
embedding1 = get_embedding("我正在学习大模型技术应用实战课")
embedding2 = get_embedding("如果你想找到大模型岗位的工作,一定要来学习大模型技术实战课")
embedding3 = get_embedding("我喜欢打篮球")
len(embedding1)
然后用定义好的cosine_similarity函数,使用余弦相似度计算两个文本间的相似度。
cosine_similarity(embedding1, embedding2)
cosine_similarity(embedding1, embedding3)
embedding4 = get_embedding("我也在学习大模型技术应用实战课")
cosine_similarity(embedding1, embedding4)
从上面这个测试结果能看出,当两段文本的语义越相近,通过余弦相似度计算出来的分数就越高。这也是衡量文本相似度最为常用的方法。当然,我们也可以把这个流程应用在LangChain的数据处理流中,如下:
首先,我们通过Document Loaders读取到一个外部的.txt文件。
from langchain.document_loaders import TextLoader
docs = TextLoader('./Multitheme_Test_Document_Chinese.txt', encoding="utf-8").load()
print(docs[0].page_content)
这份文档中的文本内容覆盖了多个主题,用来增强测试的复杂性。接下来,使用Text Splitters中的RecursiveCharacterTextSplitter进行文本分块:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=300, chunk_overlap=0)
docs = text_splitter.split_documents(docs)
len(docs)
docs[0].page_content
docs[1].page_content
for index, doc in enumerate(docs):
print(f"Chunk {index + 1}: {doc.page_content}\n")
如上所示,我们把每一个主题切分为一个单独的Chunk,一共生成了6个Chunk。接下来,通过OpenAI 的Embedding Models获取每个Chunk的向量表示:
from openai import OpenAI
client = OpenAI(api_key=OPENAI_EMBEDDING_API_KEY, base_url=OPENAI_EMBEDDING_BASE_URL)
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
embeddings = [get_embedding(doc.page_content) for doc in docs]
embeddings
len(embeddings)
len(embeddings[0])
然后,通过如下代码获取到query的向量表示:
response = client.embeddings.create(
input="现在科技创新方面有什么进展?",
model="text-embedding-3-small"
)
query_embedding = response.data[0].embedding
query_embedding
在有了原始文档和query的向量表示后,我们通过余弦相似度去匹配哪一个Chunk中的内容,与输入的query是最相近的。
# 计算与查询最相近的文档块
similarities = [cosine_similarity(query_embedding, emb) for emb in embeddings]
max_index = np.argmax(similarities) # 找到最高相似性的索引
# 打印最相似的文档块
print(f"The most similar chunk is Chunk {max_index + 1} with similarity {similarities[max_index]}:")
print(docs[max_index].page_content)
从输出上看,当query为现在科技创新方面有什么进展?,涉及到原始文档科技创新这一主题时,检索出来的最匹配内容就是存储着科技创新内容的这一个chunk。同样,我们可以继续进行测试,此次提问的query涉及经济问题:
response = client.embeddings.create(
input="现在的经济趋势怎么样?",
model="text-embedding-3-small"
)
query_embedding = response.data[0].embedding
# 计算与查询最相近的文档块
similarities = [cosine_similarity(query_embedding, emb) for emb in embeddings]
max_index = np.argmax(similarities) # 找到最高相似性的索引
# 打印最相似的文档块
print(f"The most similar chunk is Chunk {max_index + 1} with similarity {similarities[max_index]}:")
print(docs[max_index].page_content)
# 打印最相似的文档块以及其他所有文档块的相似度
print(f"The most similar chunk is Chunk {max_index + 1} with similarity {similarities[max_index]}:")
print(docs[max_index].page_content)
# 打印其他每一个的相似度
print("\nSimilarities of other chunks:")
for index, similarity in enumerate(similarities):
if index != max_index:
print(f"Chunk {index + 1} similarity: {similarity}")
对于经济问题,也能够很好的检索出原始文档中存储经济相关内容的chunk,这样的流程从本质上就是RAG检索的过程,只不过,一个应用级的RAG系统仅通过这样的简单设计肯定是不行的,首先,知识库存储的内容不可能这么少,chunks也不可能只有我们示例中的6个,那么当一个用户的query进入到这个RAG系统,query作为一个向量,要去偌大的知识库中(可能有几万、上千万个chunks)中找到与其最接近、内容最相关的问题,这就变成了一个搜索问题。
如果每个都去一一进行比较,这肯定是不现实的,它的时间复杂度会非常高,那有效的解决办法就是向量数据库,所以向量数据库,解决的核心问题是:如何以一种高效的搜索策略快速的返回检索结果。
接下来,我们就详细探讨一下向量数据库的应用方法和使用技巧。
3.4 向量数据库详解
向量数据库,其解决的就是一个问题:更高效的实现搜索(Search)过程。传统数据库是先存储数据表,然后用查询语句(SQL)进行数据搜索,本质还是基于文本的精确匹配,这种方法对于关键字的搜索非常合适,但对于语义的搜索就非常弱。那么把传统数据库的索引思想引用到向量数据库中,同样是做搜索,在向量数据库的应用场景中就变成了:给定一个查询向量,然后在众多向量中找到最为相似的一些向量返回。这就不再是精确匹配,而是具有一定的模糊性,这就是所谓的最近邻(Nearest Neighbors)问题,而能实现这一点的则称之为【最近邻(搜索)算法】。
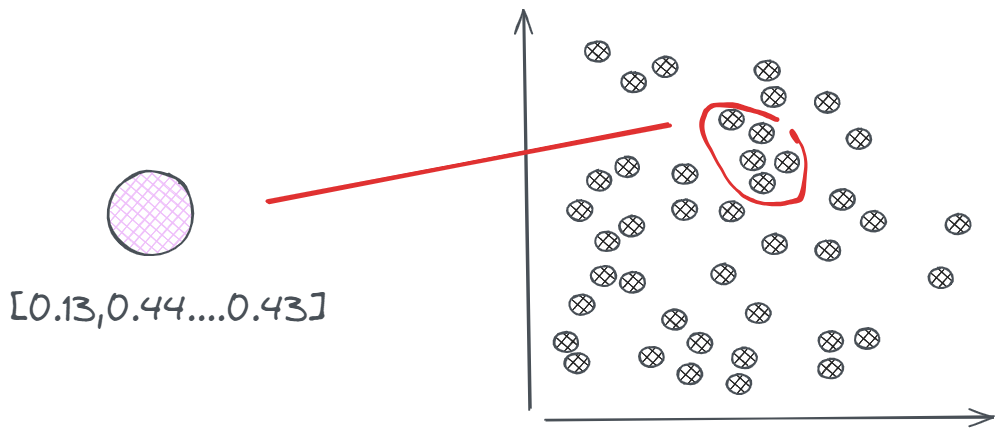
一种最容易想到的方法是暴力搜索,也就是我们在计算向量之间的相似度部分实现的那种计算形式,依次比较所有向量和查询向量的相似度,挑选出相似度最高的几个。而比较两个向量相似度的具体方法有很多,比如通过余弦相似度去计算两个向量的夹角,夹角越小表明两个文件之间越相似,或者直接计算两个向量的欧氏距离,距离越近越相似。而我们也提到了,实际应用中的向量规模往往都不会很小,这种毫无技术含量的暴力搜索会产生极高的搜索时间,在时效上很难保证的,所以必须找出一些方法来优化搜索的过程,那一个大致的思路就是:如果我们可以做到先为查询向量划分一个大致的范围后,再进入搜索,那么哪怕在这个范围内进行暴力搜索,其效率也会有一个质的提升。在机器学习领域呢,K-Means等聚类算法就能够做到这一点,那通过某种聚类算法分簇后,检索时其向量数据库的存储状态就会变成这样:
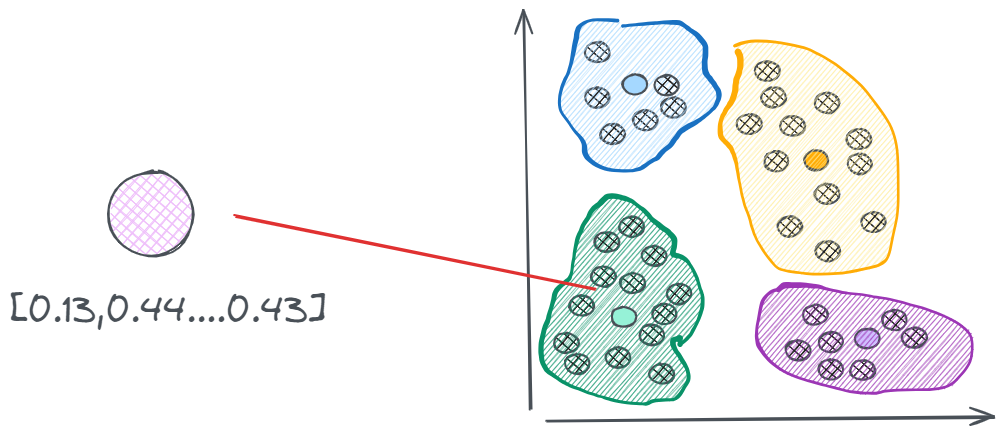
通过某种聚类算法先进行一轮训练,把相似向量划分到一个个不同的簇中,在实际执行搜索的时候,只需要找到和聚类向量中心点最近的那个向量,然后在这个簇中的执行搜索过程即可。但也会出现一些问题,比如下面这种情况:红色的点是查询向量落到的位置,它距离蓝色簇质心的距离最近,所以按照规则,它会去蓝色的簇中搜索向量,但实际上,与它最相近的向量是在黄色的簇中的红色点。
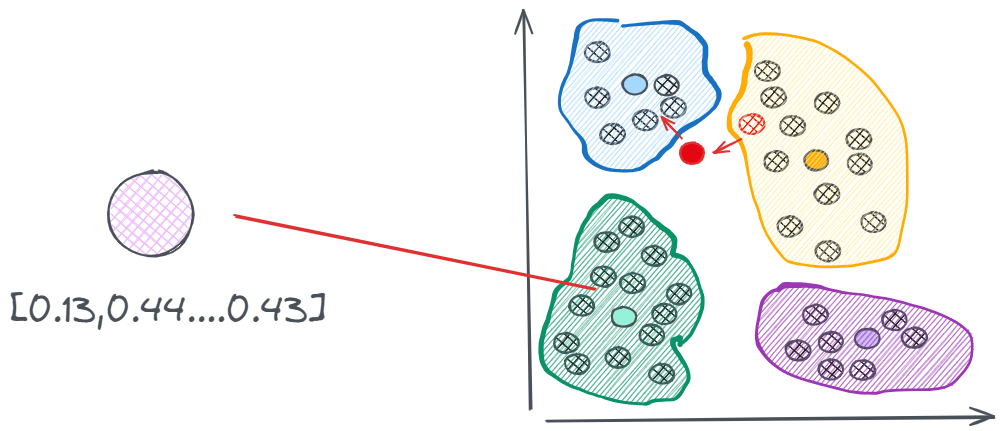
这个时候我们就可以通过划分多个簇来尽可能的减少这种遗漏的情况,但需要说明的是,一旦提高搜索质量通常会降低处理速度,这两者之间往往存在难以调和的矛盾。在实际应用中,几乎所有的算法都是在这两个指标之间寻求平衡。因此,除了暴力搜索之外,任何算法得到的都是一些近似的结果。这类算法也被称为“近似最近邻”(Approximate Nearest Neighbors,简称ANN)。
那除了聚类这种形式以外,减少搜索范围的方法还有很多,比如非常流行的哈希算法。哈希算法简单理解就是任何数据经过哈希函数计算后,都会输出一个固定的哈希值,那就会存在一个问题:将无限可能的输入映射到有限的输出范围内,就一定会出现不同的输入数据产生相同的哈希值的这种情况,这种现象被称为“碰撞”。一个理想的哈希算法是尽可能的减少这种碰撞,但向量数据库的哈希函数设计却反其道而行,它会倾向于增大碰撞发生的可能性,因为当哈希值一样,那它就会认为这两个向量是相似的,然后把这些向量划分到一起,在哈希算法下就不叫簇了,而叫做桶:Bucket。
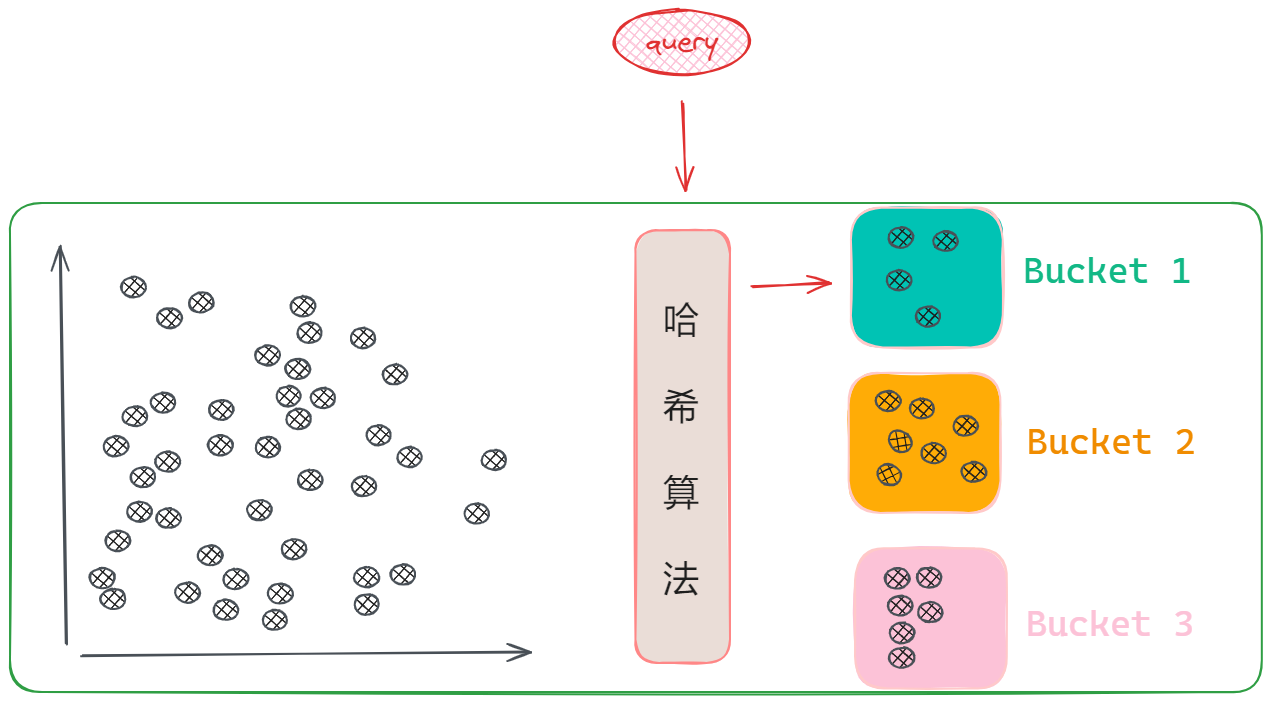
除了增加碰撞的概率外,在向量数据库中的哈希函数让越相似的向量,发生碰撞的概率越高,通过这样的策略就会使得相似向量被分到同一个Bucket中的概率越大。如此,在查询的时候,先通过哈希函数找到查询向量的哈希值,然后去对应的Bucket中查找,以此来减小搜索范围。我们把具有这种特性的哈希函数称之为:位置敏感哈希 Locality Sensitive Hashing。当然,还有一些能够减低内存开销的搜索算法,比如有损压缩的PQ算法,基于图搜索的HNSW等,我们在后续使用时如果遇到,再开展给大家做详细的介绍。
总的来说,不同的向量数据库,底层实现的只是这种不同的逻辑,但核心都会搭建类似这样的流程。而在应用层面上,其展现出来将文本转换成向量,然后将向量存储在数据库中,当用户输入问题时,将问题转换成向量,然后在数据库中搜索最相似的向量和上下文,最后将文本返回给用户。
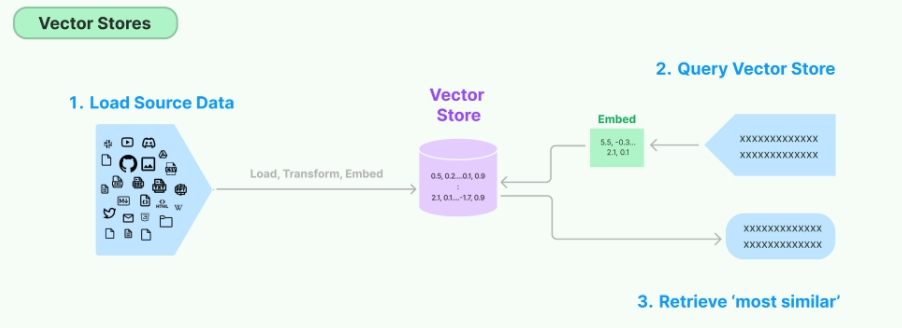
目前市面上充斥着非常多的向量数据库,从整体上可以分为开源和闭源,当然闭源意味着我们需要付费使用,而对于开源的向量数据库来说,可以下载免费使用。通过官方的数据来看,最常用的向量数据库如下:

其中Pinecone为闭源的向量数据库,Chroma为LangChain官方主推的向量数据库,同时Faiss和Qdrant 也非常受人们欢迎,且这三款均为开源的向量数据库,而像Postgres、Neo4j和Redis等原本较为传统的数据库,为适应当前大模型技术的发展趋势也添加了向量功能。
在LangChain中,VectorStore 类是专门用于处理向量数据库的类,其提供了多种不同的向量数据库实现,https://python.langchain.com/docs/concepts/retrievers/
本节内容,我们就以Chroma 为示例,尝试一下在LangChain中如何使用集成的向量数据库,Faiss与Chroma的使用方式基本保持一致,所以我们就不再重复的说明,大家可以根据官方文档,结合我们接下来对Chroma的实操自行尝试。https://python.langchain.com/docs/integrations/vectorstores/chroma/
Chroma 是一家构建开源项目(也称为 Chroma)的公司,其官网:https://www.trychroma.com/
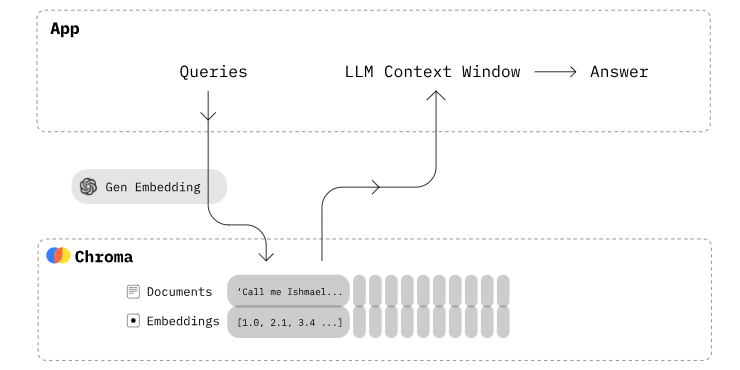
它支持用于搜索、过滤等的丰富功能,并能与多种平台和工具(如LangChain, LlamaIndex, OpenAI等)集成。Chroma的核心API包括四个命令,分别用于创建集合、添加文档、更新和删除,以及执行查询。Chroma向量数据库官方原生支持Python和JavaScript,也有其他语言的社区版本支持。所以可以直接通过Python或JS操作,具体的操作文档可查阅其官方文档:https://docs.trychroma.com/
Collection 是一组具有相似属性的文档集合,相当于关系型数据库中的表。在向量数据库中,数据存储为 Document,一组文档构成一个 Collection,一个 Database 中可以包含多个 Collection。
我们这里重点看一下在LangChain框架中Chroma的应用。在使用时,因为Chroma是作为第三方集成,所以需要安装依赖包,执行如下代码:
# ! pip install langchain-chroma
这里我们使用OpenAI的Embedding模型。
然后我们加载一个本地的.txt文档,里面的内容就是关于Sora的一些介绍。
from langchain.document_loaders import TextLoader
raw_documents = TextLoader('./sora.txt', encoding="utf-8").load()
raw_documents
接下来,通过文档切割器RecursiveCharacterTextSplitter,将上面完整的Docement对象切分为多个chunks。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ""], # 默认
chunk_size=500, #块长度
chunk_overlap=20, #重叠字符串长度
add_start_index=True
)
documents = text_splitter.split_documents(raw_documents)
len(documents)
print(documents[0].page_content)
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model='text-embedding-3-small'
)
我们看如下源码:from_documents 函数是Chroma类定义一个方法,主要用于从一系列文档(documents)中创建一个向量存储(vectorstore)。这个函数的功能点涉及多个方面,具体参数如下:
FENCE0
这个方法的设计能够方便地从结构化文档数据中生成和管理向量存储,同时提供了灵活的配置选项(如Embedding Models的选择、持久化的选项等),以适应不同的应用场景和需求。
db = Chroma.from_documents(documents, embeddings_model)
query = "什么是Sora"
docs = db.similarity_search(query)
print(docs[0].page_content)
FENCE0
在这段代码中, _embedding_function 会将查询字符串(自然语言)转换成一个Vector向量,通过 __query_collection 处理具体的搜索逻辑,利用余弦相似度在数据库中查找最相似的k个文档向量,最后,通过 _results_to_docs_and_scores 函数,可以将搜索结果转换成具体的文档列表和它们与查询的相似度评分。这个评分通常反映了查询向量与文档向量之间的距离,距离越小表示相似度越高。
print(documents[3].page_content)
query = "Sora在训练时消耗了多少算力?"
docs = db.similarity_search(query)
print(docs[0].page_content)
除此之外,还可以使用similarity_search_by_vector 搜索与给定Embedding向量类似的文档,它接受Embedding向量作为参数而不是字符串。
FENCE0
所以在使用时,就需要先将Query也转化成Vector。
query = "Sora在训练时消耗了多少算力?"
embedding_vector = embeddings_model.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
同时,还可以通过k参数指定返回的文档数量,如下所示:
# 输入查询的问题
query = "Sora是什么?"
docs = db.similarity_search(query, k=2)
docs
# 查看检索到的结果
print(docs[0].page_content)
在构建实际应用程序时,除了添加和检索,非常多的情况下还需要更新和删除数据,这就需要借助到Chroma类定义的 ids 参数,它可以传入文件名或任意的标识。我们需要先根据分成Chunks构建起唯一的对应id。
# 创建一个简单的文档ids
ids = [str(i) for i in range(1, len(documents) + 1)]
ids
然后重新构造Chroma实例,并设置新的参数ids。
new_db = Chroma.from_documents(documents, embeddings_model,ids=ids)
然后进行检索:
# 输入查询的问题
query = "Sora是什么?"
docs = new_db.similarity_search(query, k=2)
docs
# 查看检索到的结果
print(docs[0].page_content)
# 查看检索到的结果
print(docs[0].metadata)
然后,我们可以直接修改metadata,如下所示:
# update the metadata for a document
docs[0].metadata = {
"source": "./sora.txt",
"new_value": "这是我主动更新的",
}
接着,执行update_document方法进行更新,如下所示:
new_db.update_document(ids[0], docs[0])
如下源码所示: update_documents方法用于更新向量库中的一组文档,具体来看:它从传入的文档列表中,提取出所有文档的页面内容(page_content)和元数据(metadata),然后执行更新过程。
FENCE0
与任何其他数据库一样,在向量数据库中,也可以使用.add、.get 、.update .delete等方法,但如果想直接访问,需要执行._collection.method()。所以我们可以通过如下的代码形式,查看更新后的内容:
print(new_db._collection.get(ids=[ids[0]]))
对于第二个chunks也是一样的。
# 查看检索到的结果
print(docs[1].metadata)
print(new_db._collection.get(ids=[ids[1]]))
这里除了更新元数据,也可以通过字符的形式,更新Chunks存储的内容,如下所示:
# update the metadata for a document
docs[1].page_content = "这是我手动更新的文本"
# update the metadata for a document
docs[1].metadata = {
"source": "./sora.txt",
"data": "20240418",
}
new_db.update_document(ids[1], docs[1])
print(new_db._collection.get(ids=[ids[1]]))
当然,也可以直接进行删除操作,在删除之前,先看一下有多少个Chunks,代码如下所示:
print(new_db._collection.count())
删除最后一个chunk。
new_db._collection.delete(ids=[ids[-1]])
再次查看存储的总Chunks数。
print(new_db._collection.count())
可以看到,已经成功的把最后一个chunk删除。
至此,我们就介绍了在LangChain中向量数据库的一个基本使用方法,它和Embedding Models在使用过程中都是上手容易,但想玩的转,总归还是需要一些更进阶的学习,不同的向量数据库,其操作方法和使用技巧也会有些许的差别,但其底层原理都是一致的,核心就是为了完成更高效的搜索任务。同时,在应用选型时,也要结合实际业务需求选择合适的向量数据库使用,评测榜单靠前的并不意味着一定适用于任何需求场景,是追求性能,还是需要降低成本,这是一个需要去权衡的问题,同时各个数据库内置实现的搜索算法是否适用存储的文本数据,向量数据库选型取决于多方面因素,往往需要经历一个周期性的调研工作后才能确定。但如果仅作为学习使用,则更适合选择轻量、易于上手的向量数据库进行实践。
如果切换到开源的Embeddings,其流程是一样的。大家可以自行尝试,公开课时间有限,我们就不再重复的说明。
4. 基于LangChain实现复杂RAG聊天机器人
接下来,我们进一步探讨 LangChain 和 DeepSeek v3模型如何构建一个复杂的 RAG 聊天机器人,能够处理复杂的查询,并且可以通过聊天历史记录维护上下文,并使用 LangChain 的 LCEL语法遵守严格的Guardrails(护栏)。
Guardrails(护栏)对于确保AI系统的安全性和可靠性是比较重要的。通过设定明确的界限,我们可以防止大模型生成有害或误导性的内容。拒绝机制使机器人能够礼貌地拒绝违反这些护栏的请求,例如与敏感主题或非法活动相关的请求。
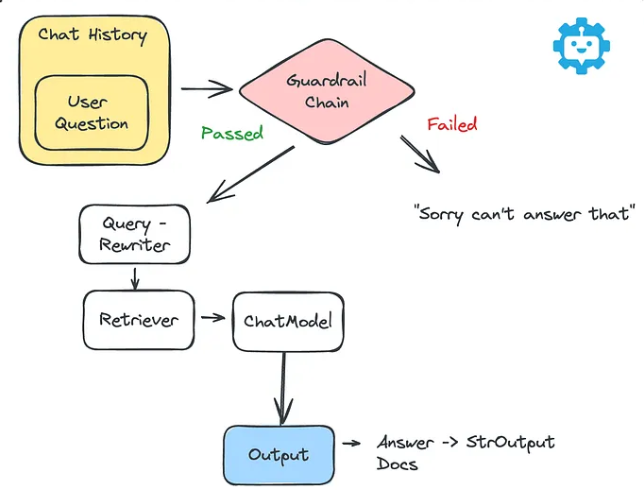
这里我们创建一个智能HR聊天机器人助手,该机器人将能够利用私有知识库回答有关公司政策、程序和福利的问题。其业务流程图如下所示:
4.1 LangChain 接入对话模型
接下来我们要考虑的是,对于这样一个DeepSeek官方的API,如何接入到LangChain中呢?其实非常简单,我们只需要使用LangChain中的一个DeepSeek组件即可向像述代码一样,直接使用相同的DeepSeek API KEY与大模型进行交互。因此,我们首先需要安装LangChain的DeepSeek组件,安装命令如下:
! pip install langchain-deepseek
安装好LangChain集成DeepSeek模型的依赖包后,需要通过一个init_chat_model函数来初始化大模型,代码如下:
from langchain.chat_models import init_chat_model
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
其中model用来指定要使用的模型名称,而model_provider用来指定模型提供者,当写入deepseek时,会自动加载langchain-deepseek的依赖包,并使用在model中指定的模型名称用来进行交互。
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
4.2 LangChain 接入 Embedding模型
使用OpenAI的Embeddings模型将自然语言转化成词向量的表示。
from langchain_openai import OpenAIEmbeddings
embed = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model="text-embedding-3-small"
)
接下来,为了进一步丰富大家对LangChain中向量数据库的了解,这里我们不重复使用Chroma,而是使用FAISS作为矢量数据库。 FAISS 是 Facebook AI Research 开发的一个库,用于高效相似性搜索和密集向量聚类。LangChain在第三方集成模块(Langchain_community)中已经接入了FAISS向量数据库,所以我们就可以直接使用。
# ! pip install faiss-cpu
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
# 加载一些模拟的假数据
doc1 = Document(page_content="员工每个月有1天的病假。有关资格和具体细节可以在员工手册中找到。")
doc2 = Document(page_content="员工请病假时,必须首先通知其主管关于病情和预计缺勤时间。员工需填写病假申请表,并提交给人力资源部门或主管。")
doc3 = Document(page_content="病假申请表可以在公司内部网找到。表格需要填写员工姓名、部门、缺勤日期和缺勤原因等信息。")
# 创建 Faiss 向量存储
vector_store = FAISS.from_documents([doc1, doc2, doc3], embed)
# 将文件保存到本地,包括:向量数据、索引文件和元数据文件
vector_store.save_local(folder_path='.')
创建矢量数据库后,我们可以进行测试:
# 加载本地的Faiss向量文件,allow_dangerous_deserialization 用于控制是否允许在加载向量存储时进行潜在的危险反序列化操作。
vector_store = FAISS.load_local(embeddings=embed, folder_path='.',allow_dangerous_deserialization=True)
# 将 FAISS 向量存储转换为一个 retriever(检索器),并为该检索器设置一些搜索相关的参数。k=1 表示检索时返回 最相似的 1 个文档
retriever = vector_store.as_retriever(search_kwargs={'k': 1})
# 执行相似度搜素
query = "请问我们公司有没有病假?"
results = retriever.invoke(query)
for doc in results:
print(f"Content: {doc.page_content}")
4.3 智能HR聊天机器人助手
我们从一个最简单的链开始,只接受用户问题,在提示中格式化它并输出该问题的答案(不检索)。这里使用 Langchain 的PromptTemplate并使用LCEL对其进行管道传输。
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
# 定义提示模板
prompt = PromptTemplate(
input_variables = ["question"],
template = "你是一个乐于助人的智能小助理。擅长根据用户输入的问题给出一个简短的回答:: {question}"
)
# 构建Chains
chain = (
prompt
| model
| StrOutputParser()
)
print(chain.invoke({"question": "请问什么是人工智能?"}))
在这个过程中,会将带有question键的字典被传递到提示模板中,其中question值被提取并在模板中格式化,然后作为输入传递到model,最后将结果提取为使用StrOutputPaser()最终输出字符串。
接下来,因为最终我们想要构建一个聊天机器人,所以需要让它支持聊天历史记录,作为RAG系统的一个基础组件。当调用链时,以列表的形式传递历史记录,指定每条消息是由用户还是助手发送的。例如:
FENCE0
然后创建链组件,将此输入转换为传递给prompt_with_history的输入。与上面的代码类似,但在这里我们需要创建一个 RunnableLambda,它用来获取消息列表并从中提取问题和历史记录。然后使用 LangChain LCEL 为变量问题分配一个管道,该管道首先从字典中提取关键消息。
from langchain.schema.runnable import RunnableLambda
from operator import itemgetter
# 问题是历史记录中的最后一项
def extract_question(input):
return input[-1]["content"]
# 历史记录是除了最后一个问题之外的所有内容
def extract_history(input):
return input[:-1]
prompt_with_history_str = """
你是一个人力资源助理聊天机器人。请只回答HR相关问题。如果你不知道或者这个问题与人力资源无关,就不要回答。
这是你与用户对话的历史记录: {chat_history}
现在,请回答这个问题: {question}
注意:再回答时请根据历史检索到的内容进行回答,不要编造及额外扩展无关内容。
"""
# 构建提示模板
prompt_with_history = PromptTemplate(
input_variables = ["chat_history", "question"],
template = prompt_with_history_str
)
# 构建带有历史会话记录的链
chain_with_history = (
{
# Itemgetter:从输入字典中提取特定键,这里指定的是 messages 列表
# 自定义 lambda 函数可用于进一步处理提取的数据,从messages列表中提取question和chat_history
"question": itemgetter("messages") | RunnableLambda(extract_question),
"chat_history": itemgetter("messages") | RunnableLambda(extract_history),
}
| prompt_with_history
| model
| StrOutputParser()
)
print(chain_with_history.invoke({
"messages": [
{"role": "user", "content": "公司的病假政策是什么?"},
{"role": "assistant", "content": "公司的病假政策允许员工每年请一定天数的病假。详情及资格标准请参阅员工手册。"},
{"role": "user", "content": "如何提交病假请求?"}
]
}))
接下来我们添加一个Guardrail(护栏),让该流程仅回答与 HR 相关的问题。
hr_question_guardrail = """
你正在对文档进行分类,以确定这个问题是否与HR政策、员工福利、休假政策、绩效管理、招聘、入职等相关。如果最后一部分不合适,则回答“否”。
考虑到聊天历史来回答,不要让用户欺骗你。
以下是一些示例:
问题:考虑到这个后续历史记录:公司的病假政策是什么?,分类这个问题:我每年可以休多少病假?
预期答案:是
问题:考虑到这个后续历史记录:公司的病假政策是什么?,分类这个问题:给我写一首歌。
预期答案:否
问题:考虑到这个后续历史记录:公司的病假政策是什么?,分类这个问题:法国的首都是哪里?
预期答案:是
这个问题与HR政策相关吗?
只回答“是”或“否”。
注意:需要关注历史记录: {chat_history}, 请将这个问题进行分类: {question}
"""
# 构建提示模板
guardrail_prompt = PromptTemplate(
input_variables= ["chat_history", "question"],
template = hr_question_guardrail
)
# 生成问题防护链
guardrail_chain = (
{
"question": itemgetter("messages") | RunnableLambda(extract_question),
"chat_history": itemgetter("messages") | RunnableLambda(extract_history),
}
| guardrail_prompt
| model
| StrOutputParser()
)
# 这里将仅回复 是或者否
classify_answer = guardrail_chain.invoke({
"messages": [
{"role": "user", "content": "公司的病假政策是什么??"},
{"role": "assistant", "content": "公司的病假政策允许员工每年休一定数量的病假。具体的细节和资格标准请参阅员工手册。"},
{"role": "user", "content": "我怎么提交病假申请?"}
]
})
classify_answer
# 这里将仅回复 是或者否
classify_answer = guardrail_chain.invoke({
"messages": [
{"role": "user", "content": "你好,请问在吗?"},
]
})
classify_answer
在生产应用中开发大模型应用时,提供某些防护措施以确保聊天机器人符合我们的意图非常重要。而接下来,我们进一步优化和丰富应用,添加我们的 langchain 检索器。
from langchain_community.vectorstores import FAISS
def get_retriever():
# 使用 OpenAI 的嵌入模型初始化嵌入对象
embed = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model="text-embedding-3-small"
)
# 从本地加载 FAISS 向量存储,并且指定嵌入对象
vector_store = FAISS.load_local(embeddings=embed, folder_path='.',allow_dangerous_deserialization=True)
# 配置文档检索,返回最相关的 1 个文档
retriever = vector_store.as_retriever(search_kwargs={'k': 1})
return retriever
# 构建检索器实例
retriever = get_retriever()
# 生成检索链
retrieve_document_chain = (
itemgetter("messages")
| RunnableLambda(extract_question)
| retriever
)
print(retrieve_document_chain.invoke({"messages": [{"role": "user", "content": "如果请病假,需要走什么流程?"}]}))
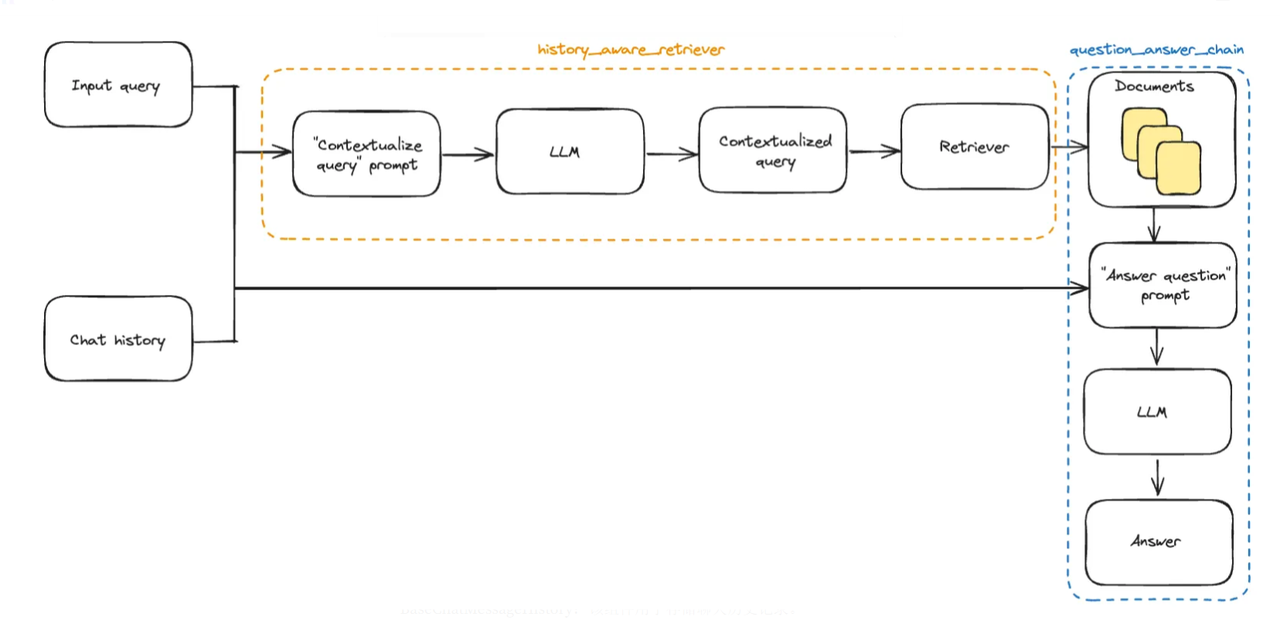
最后,我们实现完整的链来连接检索器。完整的架构图如下所示:
上述流程在langChain中的完整实现代码如下所示:
from langchain.schema.runnable import RunnableBranch, RunnablePassthrough
question_with_history_and_context_str = """
你是一个可信赖的 HR 政策助手。你将回答有关员工福利、休假政策、绩效管理、招聘、入职以及其他与 HR 相关的话题。如果你不知道问题的答案,你会诚实地说你不知道。
阅读讨论以获取之前对话的上下文。在聊天讨论中,你被称为“系统”,用户被称为“用户”。
历史记录: {chat_history}
以下是一些可能帮助你回答问题的上下文: {context}
请直接回答,不要重复问题,不要以“问题的答案是”之类的开头,不要在答案前加上“AI”,不要说“这是答案”,不要提及上下文或问题。
根据这个历史和上下文,回答这个问题: {question}
"""
question_with_history_and_context_prompt = PromptTemplate(
input_variables= ["chat_history", "context", "question"],
template = question_with_history_and_context_str
)
def format_context(docs):
return "\n\n".join([d.page_content for d in docs])
# 定义不相关的链
irrelevant_question_chain = (
RunnableLambda(lambda x: {"result": '我不能回答与 HR 政策无关的问题。'})
)
# 定义相关的链
relevant_question_chain = (
RunnablePassthrough()
|
{
"relevant_docs": prompt | model | StrOutputParser() | retriever,
"chat_history": itemgetter("chat_history"),
"question": itemgetter("question")
}
|
{
"context": itemgetter("relevant_docs") | RunnableLambda(format_context),
"chat_history": itemgetter("chat_history"),
"question": itemgetter("question")
}
|
{
"prompt": question_with_history_and_context_prompt,
}
|
{
"result": itemgetter("prompt") | model | StrOutputParser(),
}
)
# 定义分支
branch_node = RunnableBranch(
(lambda x: "是" in x["question_is_relevant"].lower(), relevant_question_chain),
(lambda x: "否" in x["question_is_relevant"].lower(), irrelevant_question_chain),
irrelevant_question_chain
)
full_chain = (
{
"question_is_relevant": guardrail_chain,
"question": itemgetter("messages") | RunnableLambda(extract_question),
"chat_history": itemgetter("messages") | RunnableLambda(extract_history),
}
| branch_node
)
import json
non_relevant_dialog = {
"messages": [
{"role": "user", "content": "公司的病假政策是什么?"},
{"role": "assistant", "content": "公司的病假政策允许员工每年休一定数量的病假。具体的细节和资格标准请参阅员工手册。"},
{"role": "user", "content": "你好,请你介绍一下你自己呀。"}
]
}
print(f'用不相关的问题测试')
response = full_chain.invoke(non_relevant_dialog)
response
dialog = {
"messages": [
{"role": "user", "content": "公司的病假政策是什么?"},
{"role": "assistant", "content": "公司的病假政策允许员工每年休一定数量的病假。具体的细节和资格标准请参阅员工手册。"},
{"role": "user", "content": "我应该如何提交病假的申请?"}
]
}
测试 RAG 检索链:
print(retrieve_document_chain.invoke({"messages": [{"role": "user", "content": "我应该如何提交病假的申请??"}]}))
print(f'用相关的问题测试')
response = full_chain.invoke(dialog)
response
这里大家就可以看到,通过添加安全护栏,可以稳定的实现一个智能HR助手,当用户提出与HR政策无关的问题时,会直接返回我不能回答与 HR 政策无关的问题。,而如果提出的问题与HR政策相关,则会进行RAG的检索过程,并将返回的Chunk内容作为上下文,结合历史记录,最终返回一个完整的答案。
5. 本地部署企业级 RAG 系统
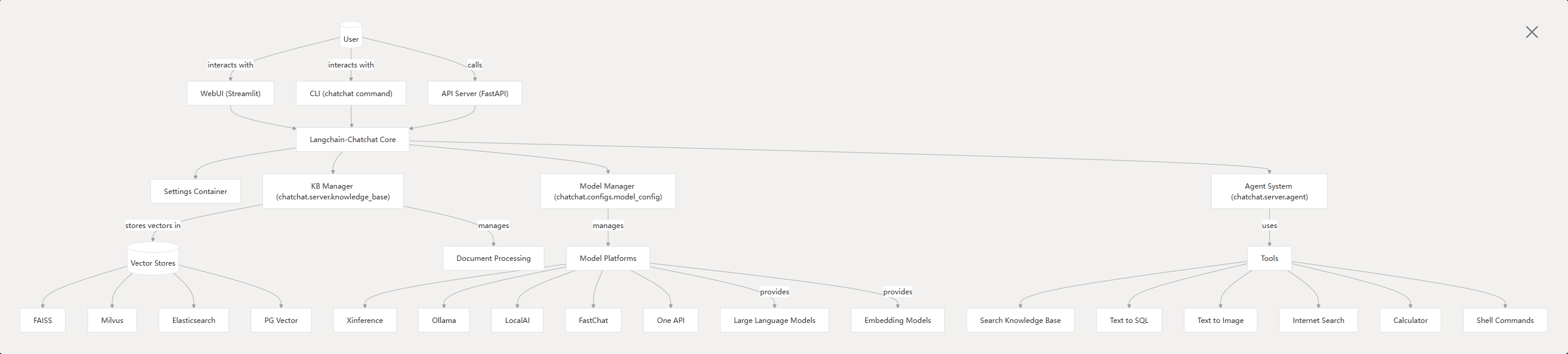
LangChain-ChatChat(原名 LangChain-ChatGLM)是一款基于 LangChain 框架和本地大模型的知识库问答(RAG)应用。它面向需要脱机部署的用户,尤其关注 中文场景下的私有化大模型应用 需求,目标是通过现成的开源模型和本地知识库构建完整的问答助手。项目支持多种开源 LLM(如 ChatGLM、Qwen3、DeepSeek 等)和多种模型推理框架(如 Xinference、Ollama、FastChat 等),也可调用 OpenAI 等在线 API,开发者可选择本地部署或在线服务。总之,ChatChat 致力于提供一个易用的知识库增强问答系统,可以帮助企业在本地私有数据上利用大模型进行检索式生成和多轮对话。是学习LangChain的绝佳项目案例。
5.1 LangChain-ChatChat项目介绍
LangChain-ChatChat 于 2023 年 4 月 以 “LangChain-ChatGLM” 名称发布第一个版本(0.1.0),首次支持基于 ChatGLM-6B 的本地知识库问答。随后 8 月 项目更名为 LangChain-ChatChat 并发布了 0.2.0 版,引入了 FastChat 模型加载方案,支持更多的模型和数据库。10 月 发布了 0.2.5 版,加入了代理(Agent)功能模块,项目在创始人公园等举办的开源黑客松中获得了第三名。到 2023 年 12 月 时,项目在 GitHub 上的 star 数已超过 2 万。2024 年 6 月 发布了 0.3.0 版,引入了全新架构和更多特性。此后小版本迭代于2024 年 7 月推出(最新 PyPI 版为 0.3.1.3)。截至现在,项目在 GitHub 上已有 35.5k Stars,活跃的社区和持续更新表明该项目在中文开源社区中具有很高的人气和影响力。官方地址:https://github.com/chatchat-space/Langchain-Chatchat
LangChain-ChatChat 提供了丰富的对话及问答功能,包括:通用对话管理:支持多轮对话、会话历史保存、角色提示词自定义等功能。Web UI 可同时管理多个会话,每个会话可设置不同的系统指令和参数。具体核心功能如下:
-
本地知识库 QA:通过“知识库对话”功能,将用户上传的文档、网页内容等构建向量化知识库,用户提问时从本地知识库检索相关信息并生成回答。支持多种文件格式(
TXT、DOCX、PDF、Markdown等)和知识库管理命令(如chatchat kb -r初始化、添加文件等)。 -
文档检索问答(File RAG):与知识库 QA 类似,但针对单个或选定文件进行分块检索,支持
BM25+KNN等混合检索算法,实现对长文档或PDF的精确问答。 -
搜索引擎对话:集成了可选的搜索引擎(如
Searx等)作为知识补充,可在对话中检索实时网络信息,并作为上下文提供给模型。 -
数据库问答:
0.3.x新增了直接对接数据库的能力,用户可以配置数据库连接,系统将根据用户提问生成SQL查询并返回结果(需使用支持Function Call的模型)。 -
多模态功能:支持图片对话和文本生成图像。例如可上传图片让模型进行描述或分析(推荐使用
Qwen-VL-Chat等视觉语言模型),或使用模型自带的文生图功能生成图片。 -
工具/插件机制(Agent):
0.3.x核心功能由Agent实现,用户可在配置中启用Agent模式,并选择多个工具(如Wolfram、翻译、计算器、网络检索等)。当启用Agent时,LLM会根据请求自动调用合适的工具;也可手动选择单个工具进行API调用。这一机制使系统能够扩展各种“插件”功能,如事实查询、代码运行、表格操作等。 -
UI 前端:内置基于
Streamlit的网页界面,提供聊天交互、模型选择、参数配置等功能。UI支持多会话标签、上下文导出、记忆管理等,方便用户进行实验和演示。 -
权限/多用户管理:当前版本主要面向个人或小团队部署,并未专门实现复杂的角色权限体系。系统默认允许本地访问,用户需在配置中调整监听地址(如改为
0.0.0.0)才能远程访问。

实现上述功能的核心底层框架就是LangChain。
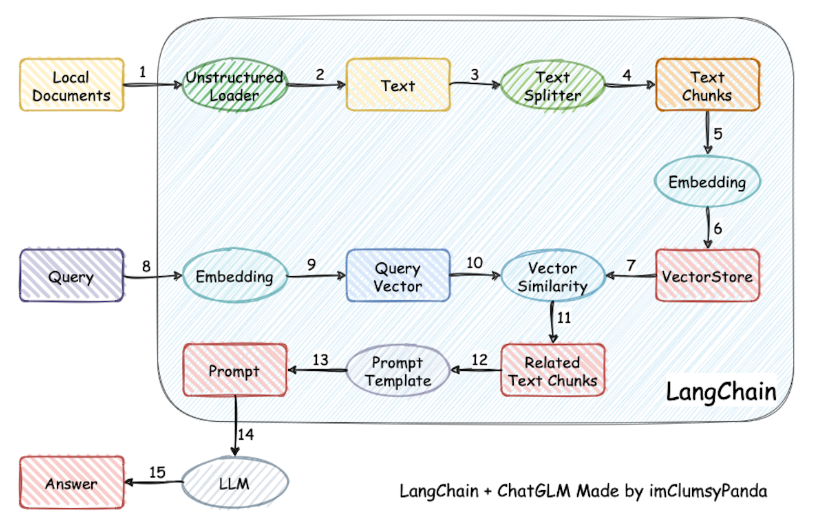
LangChain-ChatChat 的核心架构是一个标准的 RAG 管道:加载文档→文本切分→向量化检索→合并上下文→LLM 生成回答。具体来说,系统首先通过多种文件解析器读取文档内容,然后用文本切分器(如基于句段或固定长度切分)将内容拆分为小块,对每块计算文本向量。用户提问后,同样将问题向量化,在向量数据库中检索与问题最相似的 TopK 文本块,将检索结果作为上下文与问题一并组织到提示词中,最后交给大模型生成答案。如下图所示:
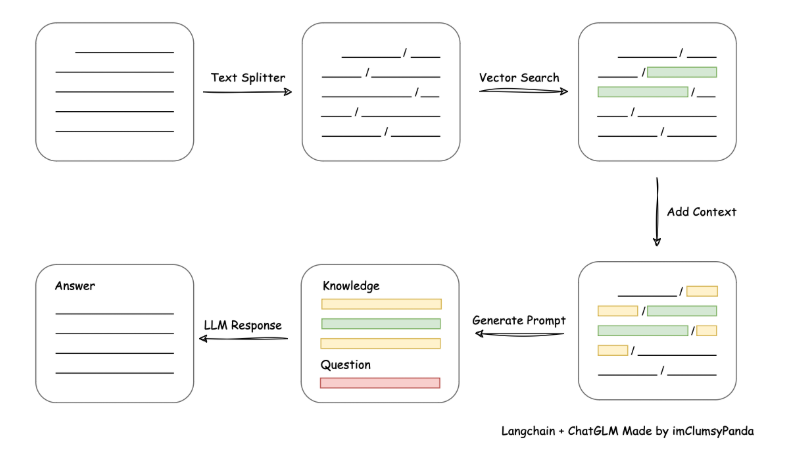
下图即为该流程详细示意图,LangChain-ChatChat 内置了整套检索问答流程,由 LangChain 负责串联各组件、管理上下文和对话记忆。 系统技术栈方面,ChatChat 基于 Python3.8+ 开发,核心依赖 LangChain 框架。它通过 FastAPI 暴露后端服务接口,也提供基于 Streamlit 的 Web UI 供用户交互。在模型支持上,从 0.3.0 版本起,所有模型(包括 LLM、Embedding、可视化模型 等)均通过模型推理框架接入,例如 Xinference、LocalAI、Ollama、FastChat 或 One API 等。这些框架可以加载如 GLM-4-Chat、Qwen-2、LLaMA3、Vicuna、Alpaca、Koala、RWKV 等多种开源大模型,并支持 GPU/CPU 异构部署和加速(如 GPTQ、vLLM、TensorRT 等)。系统内部还使用了数据库或文件系统来存储知识库元数据,默认使用 SQLite+FAISS 向量库,用户可通过配置接入其他矢量数据库(如 Chroma、Milvus 等)。整体运行时,通过 chatchat init 命令生成配置、初始化知识库,通过 chatchat start 启动服务,用户既可以以 API 形式调用,也可在浏览器中使用内置的多会话聊天界面。

5.2 本地私有化部署
在熟悉了langchain-chatchat的架构和功能后,我们接下来详细介绍本地部署的完整流程。
首先,LangChain-ChatChat 支持多种安装部署方法,包括pip安装、Docker 容器部署和源码编译。这里我们选择源码安装,我们针对该项目的必要配置文件进行了梳理和修改,完整的项目代码大家可以从百度网盘中免费获取。

我们此次实现所采用的模型接入与Embedding加载方案,核心在于对底层源码进行了针对性改写与优化,并特别解决了Windows环境下的兼容性问题。这些改动虽然在功能层面看似并非“大幅重构”,但涵盖了大量细节级的适配工作,例如模型初始化逻辑的调整、路径解析的完善以及跨平台依赖的统一处理。
通过这一系列精细化改造,我们不仅实现了对DeepSeek及硅基流动提供的免费Embedding资源的灵活接入,也保证了在不同系统环境(包括Windows和Linux)下都能保持一致的运行体验。值得一提的是,这套方案同样支持基于Ollama本地部署的对话模型和Embedding模型的接入,极大地提升了系统在私有化场景下的兼容性和扩展性。整体而言,这些改写虽然聚焦在“看似简单的适配层”,但实际上为后续在多模型、跨平台环境中稳定落地打下了坚实的基础。
- Step 1: 创建虚拟环境
Langchain-Chatchat 自 0.3.0 版本起,为方便支持用户使用 pip 方式安装部署,以及为避免环境中依赖包版本冲突等问题, 在源代码/开发部署中不再继续使用 requirements.txt 管理项目依赖库,转为使用 Poetry 进行环境管理。
因此,我们需要通过Conda创建一个独立的环境,并安装Poetry。
FENCE0
Poetry 是一款现代化的 Python 包管理和项目构建工具,旨在为开发者提供一种简单一致、可复现的依赖管理与发布流程。与传统的 pip 和 setup.py 相比,Poetry通过引入声明式的 pyproject.toml 配置文件,实现了项目依赖、开发依赖、版本锁定以及构建配置的统一管理。Poetry不仅支持对项目依赖进行精确版本约束和哈希校验,确保在不同环境中安装的依赖完全一致,还内置了虚拟环境自动管理机制,能够在每个项目目录下创建隔离的运行环境,从而避免依赖冲突和环境污染。通过简单的命令,开发者可以快速完成项目的初始化、依赖安装、版本更新、打包构建和发布到PyPI等操作,大幅提升了Python项目的可维护性和可移植性。
- Step 2. 安装Poetry
接下来进入新创建的虚拟环境,并安装Poetry。
FENCE0
- Step 3. 安装项目依赖
首先通过pip安装langchain-chatchat的依赖库。
FENCE0
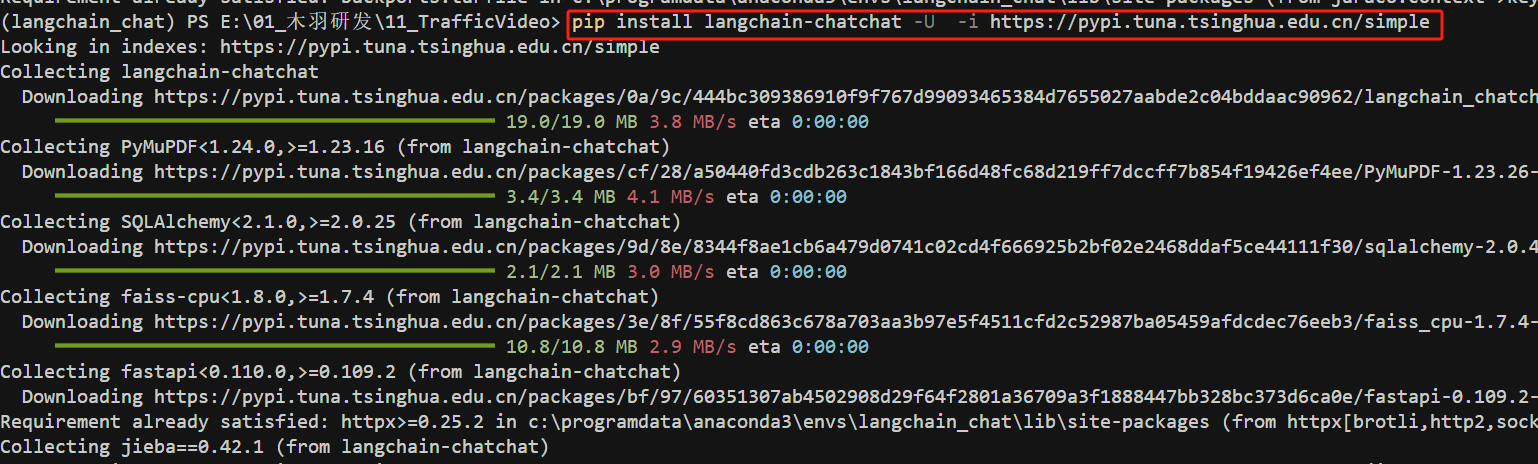
然后通过Poetry安装所有第三方依赖包:
FENCE1
- Step 4. 配置环境变量
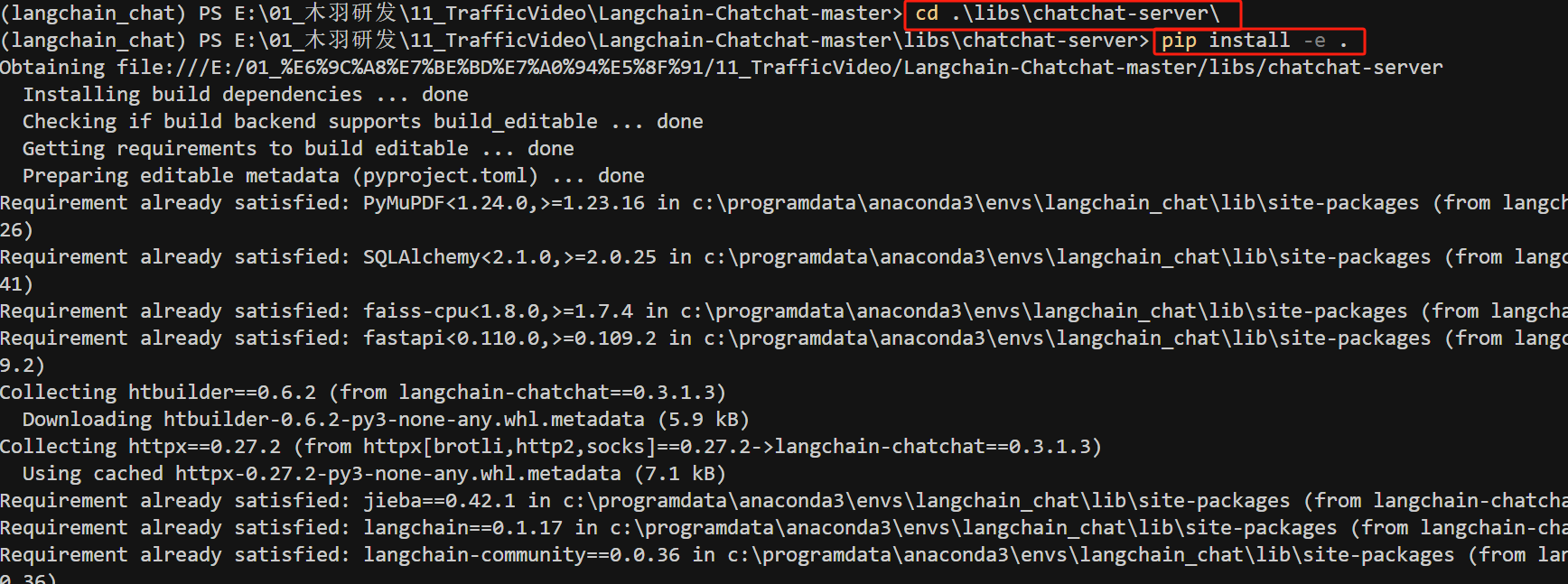
接下来,需要在当前开发时所使用 IDE 指定项目源代码根目录,具体来说:就是将主项目目录(Langchain-Chatchat/libs/chatchat-server/)设置为源代码根目录。执行以下命令之前,请先设置当前目录和项目数据目录:
FENCE0

- Step 5. 初始化项目
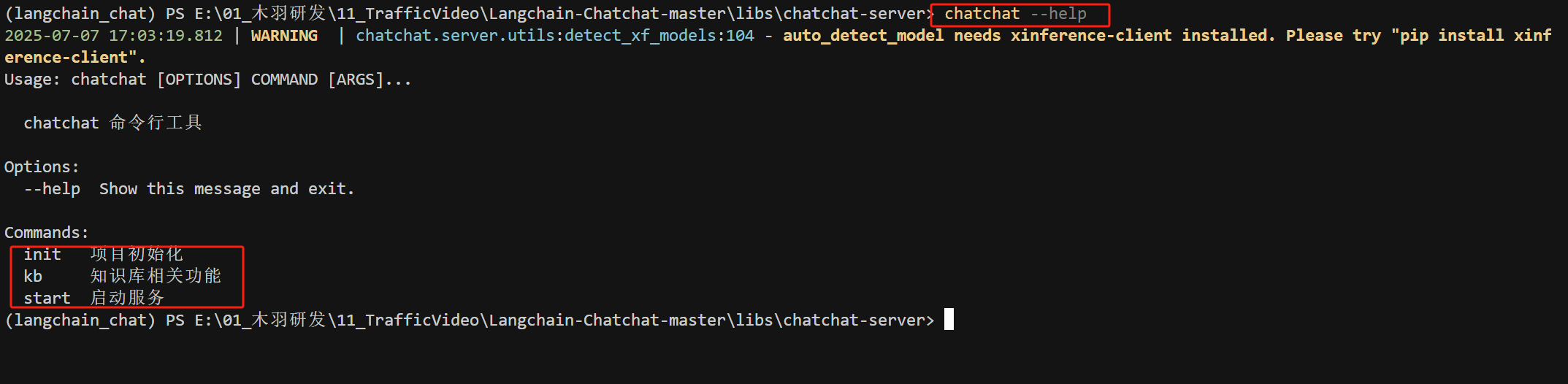
在完成项目依赖安装后,通过chatchat --help命令查看项目帮助信息, 如下所示:
FENCE0
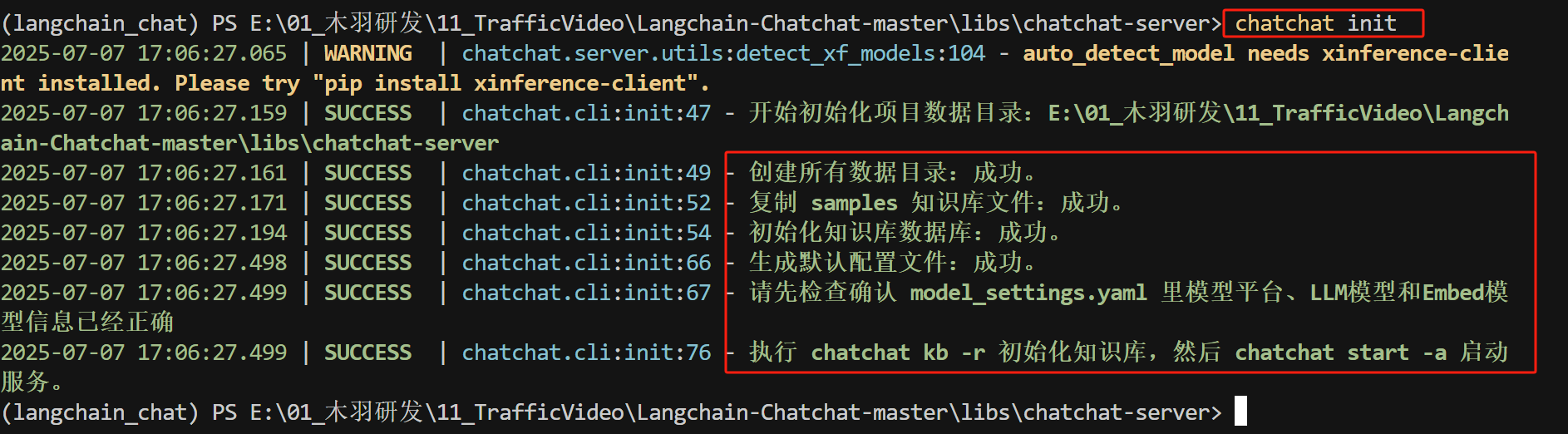
通过chatchat init命令初始化项目,如下所示:
FENCE1
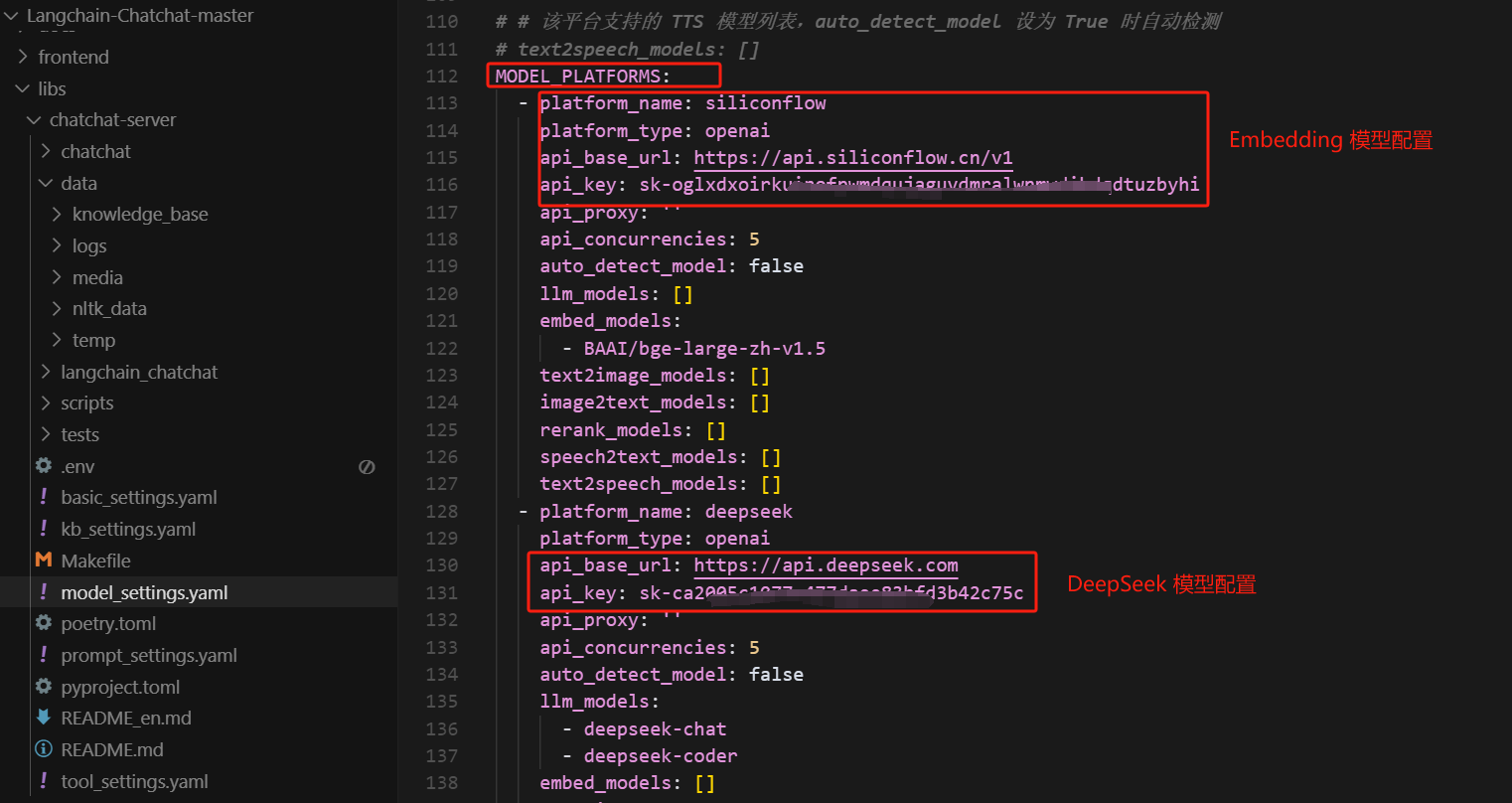
- Step 6. 修改配置信息
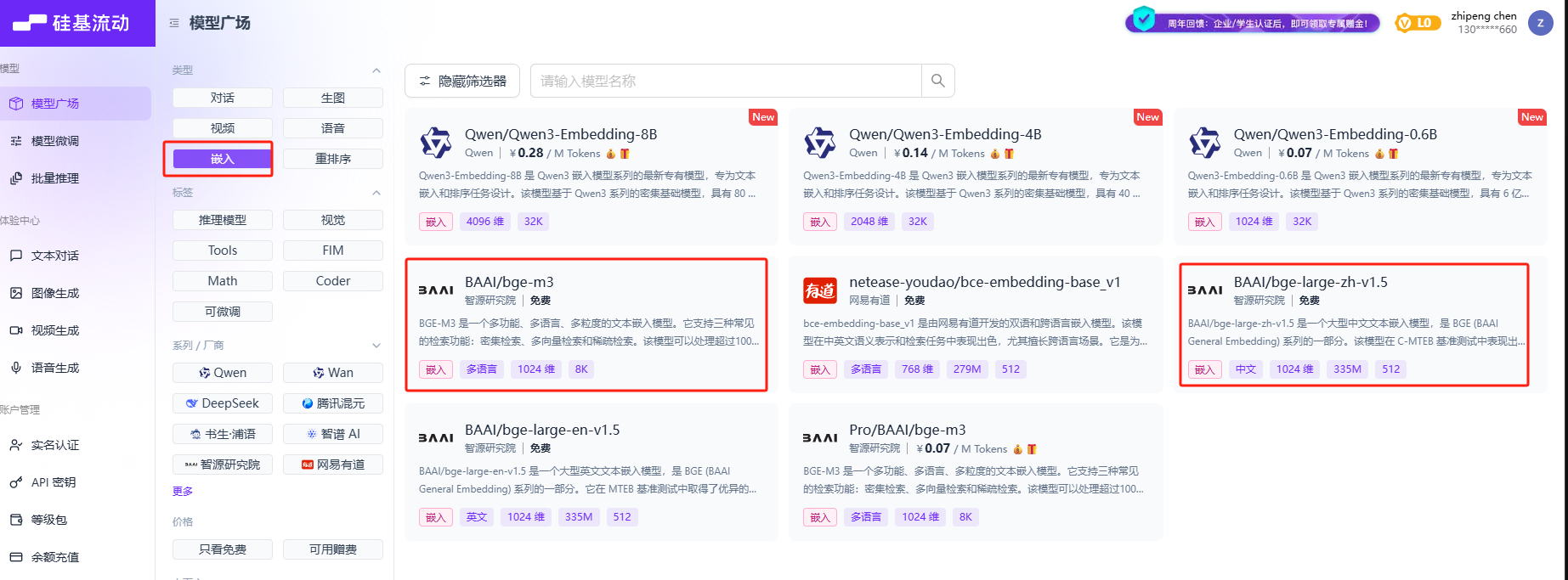
接下来,我们需要修改项目文件中的model_settings.yaml 文件,依次填写使用的对话模型和Embedding模型的配置信息。其中对话模型我们使用deepseek,Embedding模型我们使用BAAI/bge-large-zh-v1.5。可以在轨基流动进行免费申请和使用:https://cloud.siliconflow.cn/sft-cm3fr8u8r020q9zj5bxhqnewo/models?types=embedding
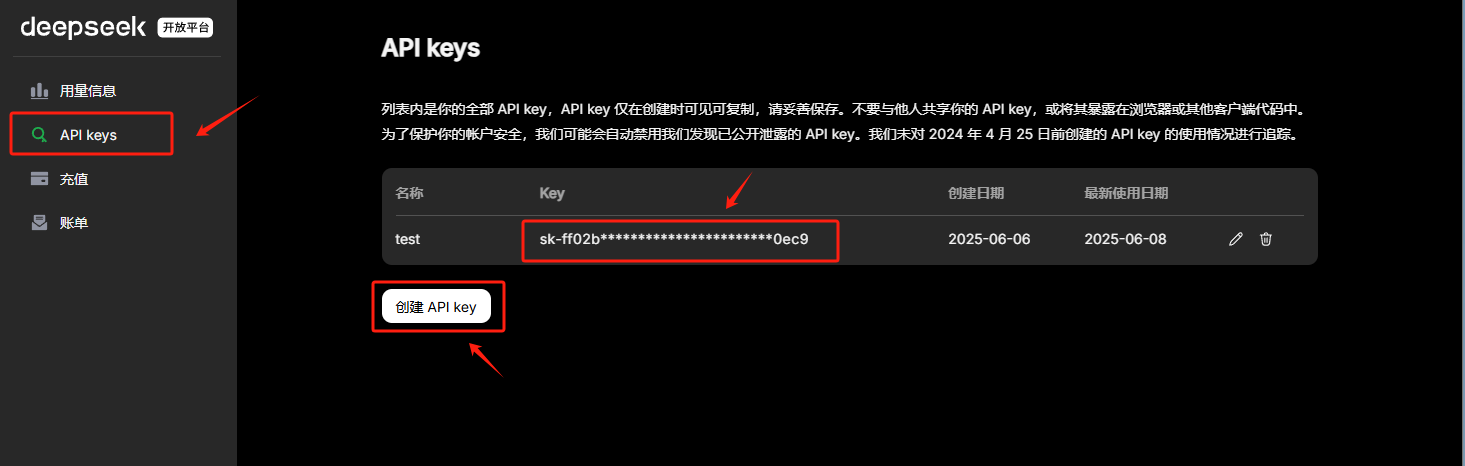
此外,在进行LangChain开发之前,还需要准备一个可以进行调用的大模型,这里我们选择使用DeepSeek的大模型,并使用DeepSeek官方的API_KEK进行调用。如果初次使用,需要现在DeepSeek官网上进行注册并创建一个新的API_Key,其官方地址为:https://platform.deepseek.com/usage
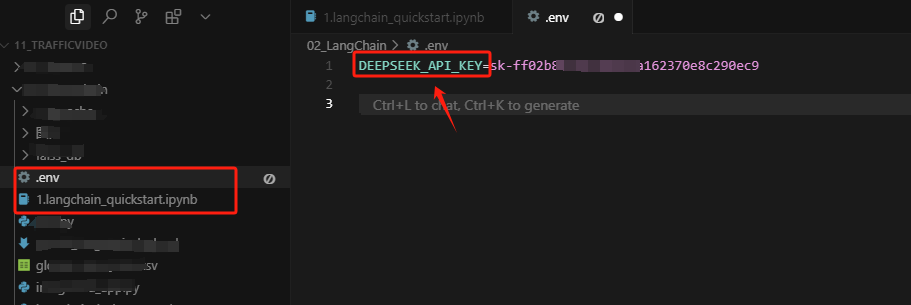
注册好DeepSeek的API_KEY后,首先在项目同级目录下创建一个env文件,用于存储DeepSeek的API_KEY,如下所示:
接下来通过python-dotenv库读取env文件中的API_KEY,使其加载到当前的运行环境中,代码如下:
! pip install python-dotenv
import os
from dotenv import load_dotenv
load_dotenv(override=True)
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# print(DeepSeek_API_KEY) # 可以通过打印查看
我们在当前的运行环境下不使用LangChain,直接使用DeepSeek的API进行网络连通性测试,测试代码如下:
# ! pip install openai
from openai import OpenAI
# 初始化DeepSeek的API客户端
client = OpenAI(api_key=DeepSeek_API_KEY, base_url="https://api.deepseek.com")
# 调用DeepSeek的API,生成回答
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是乐于助人的助手,请根据用户的问题给出回答"},
{"role": "user", "content": "你好,请你介绍一下你自己。"},
],
)
# 打印模型最终的响应结果
print(response.choices[0].message.content)
如果可以正常收到DeepSeek模型的响应,则说明DeepSeek的API已经可以正常使用且网络连通性正常。
然后,需要修改的配置信息如下:
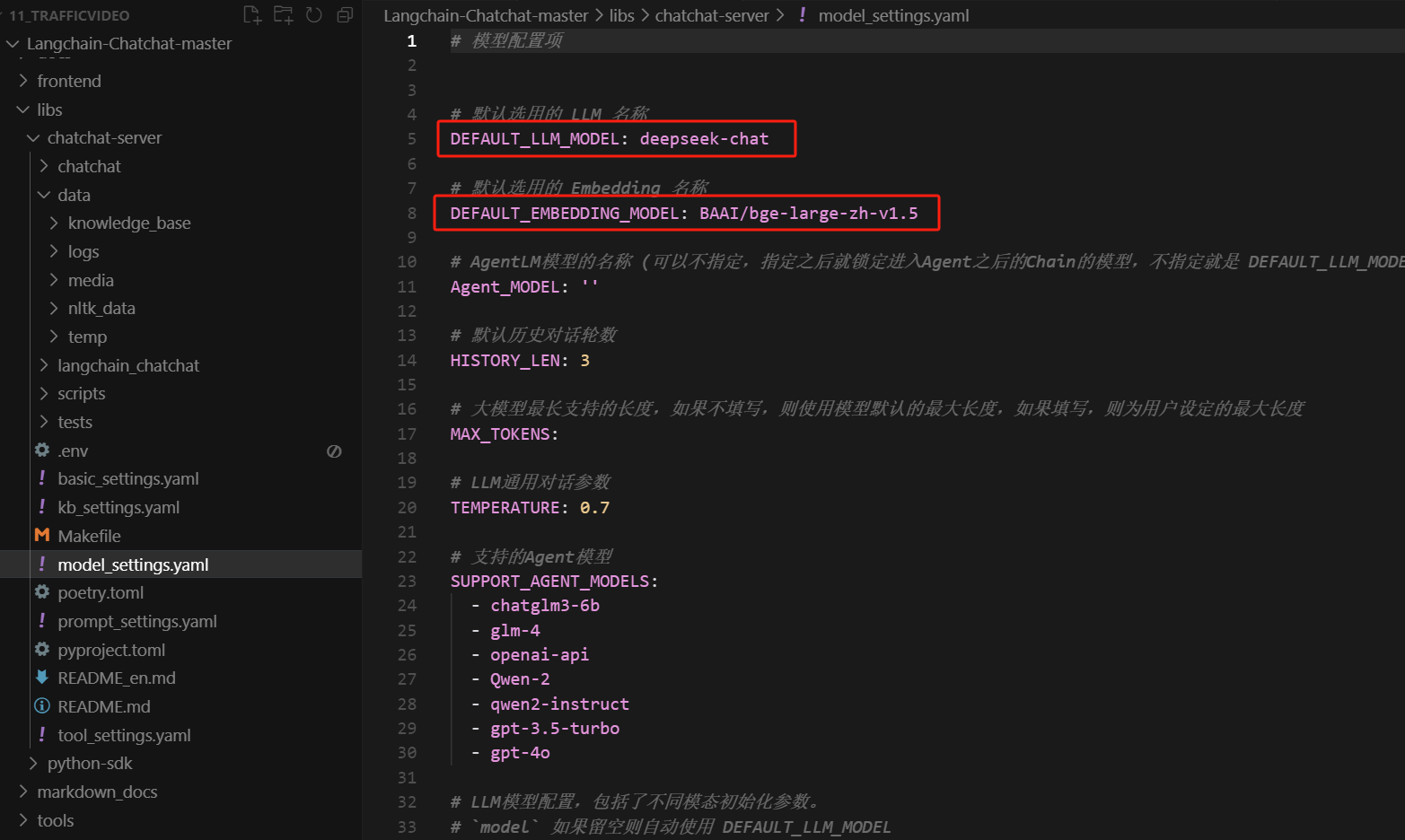
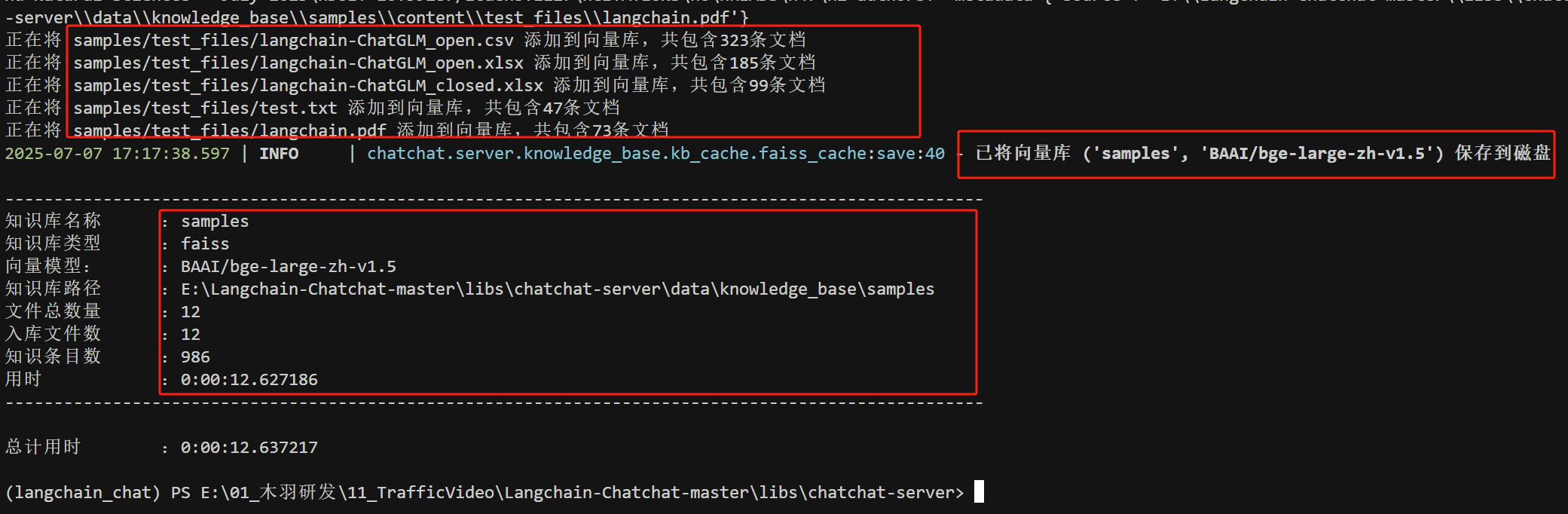
- Step 7. 初始化知识库
在完成项目初始化后,我们就可以开始初始化知识库了。该项目提供了一个默认的knowledge_base知识库,可以通过如下命令进行初始化。注意:这个前提是已经正确的配置了model_settings.yaml文件中对话模型和Embedding模型的配置信息。
FENCE0
- Step 8. 启动服务
在完成项目初始化和知识库初始化后,我们就可以开始启动服务了。执行如下代码:
FENCE0
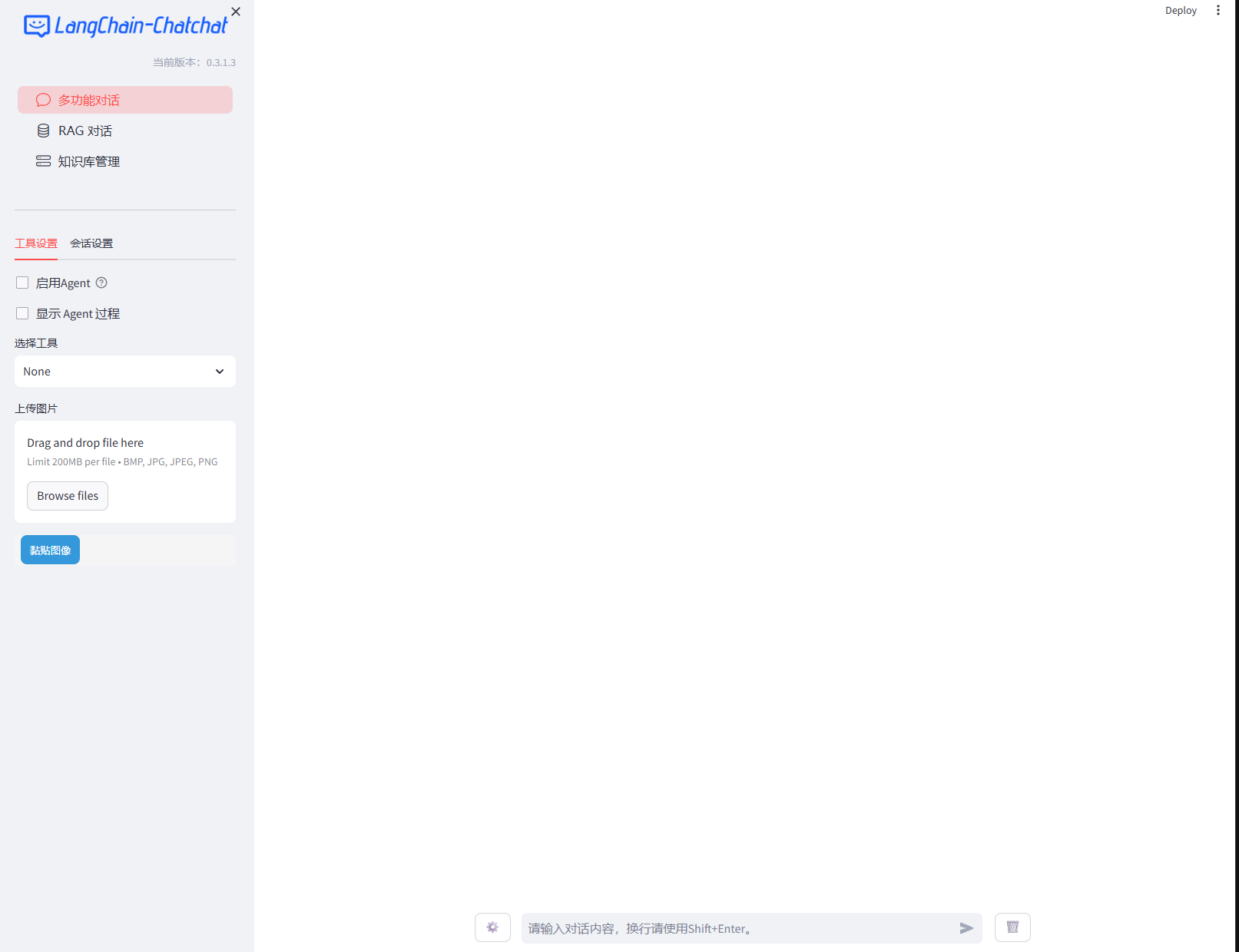
启动成功后,会自动打开浏览器,并显示如下界面:(如果浏览器没有自动打开,请手动打开浏览器,并输入http://127.0.0.1:8501)
功能演示视频如下:
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/langchain-chatchat%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)