基于PaddleOCR-VL+DeepSeek-ocr搭建企业级多模态RAG系统
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(秋季班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(秋季班)

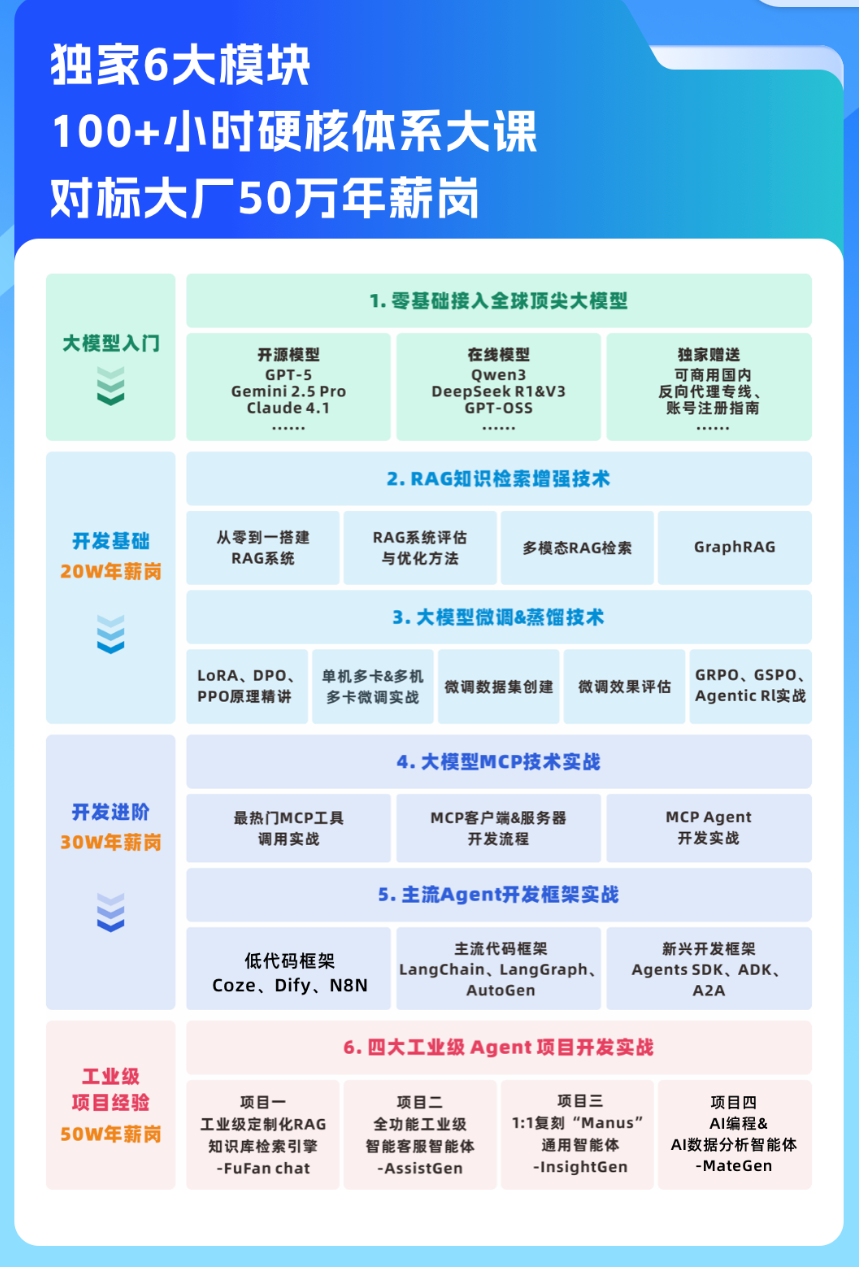
《2025大模型Agent智能体开发实战》(秋招冲刺班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
- 夏季班成果:



- 秋季班新增:


完整课程介绍:

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由九天老师和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋招班)

大模型秋季班·封班倒计时24小时,直播间特惠进行时,直播间享五折特价+全套SVIP新班特定福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇




《大模型Agent开发实战》(体验课)
基于PaddleOCR-VL搭建企业级多模态RAG系统
- 本期公开课案例功能介绍
核心功能一:使用PaddleOCR-VL + DeepSeek-OCR实现复杂图像、PDF、扫描件、手写笔记、旧试卷等文档高精度一键解析;

- 核心功能二:多模态RAG在线解析及提取信息可视化,支持复杂PDF和图片文件类型,并支持文档结构和可视化对比;
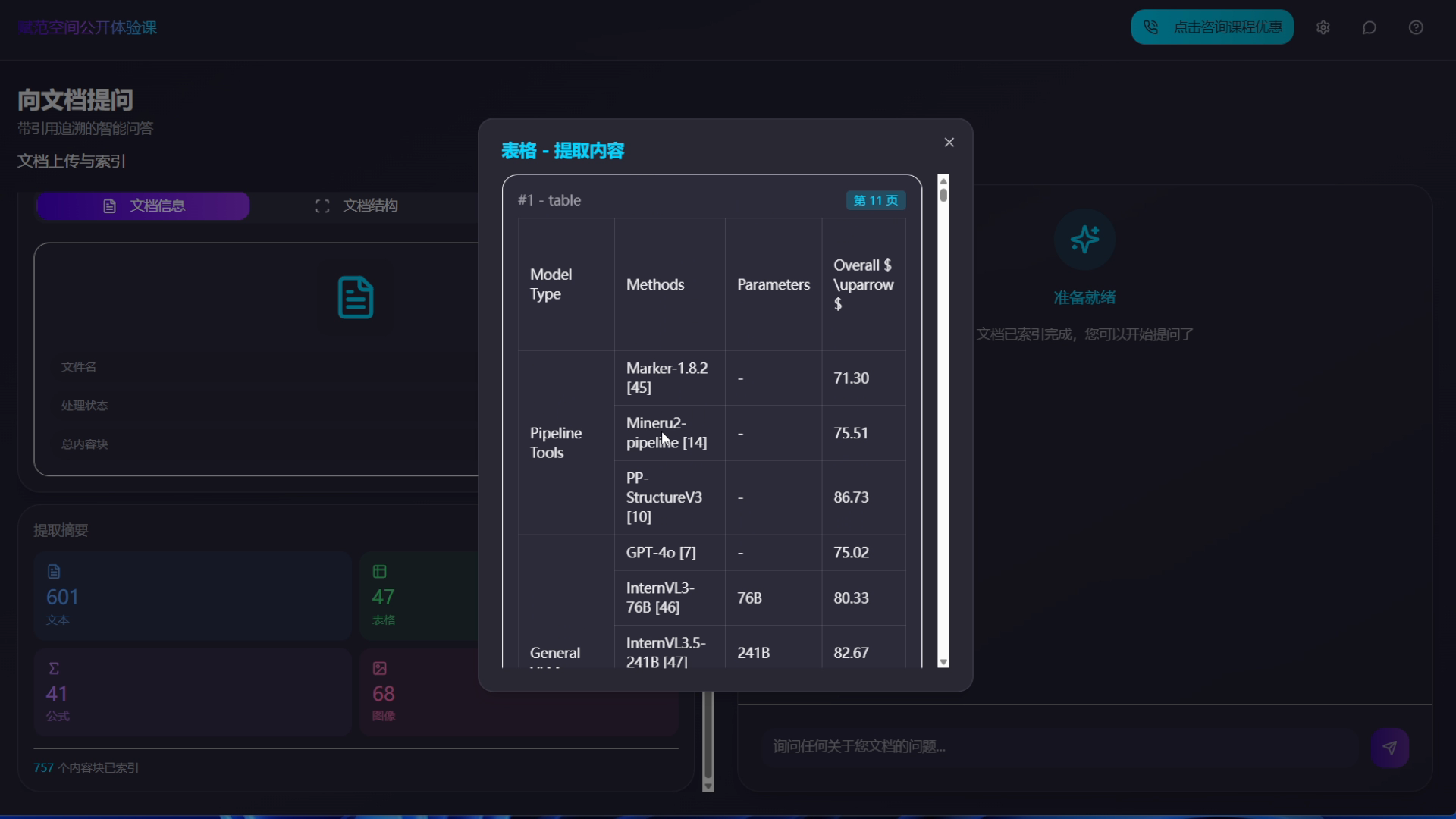
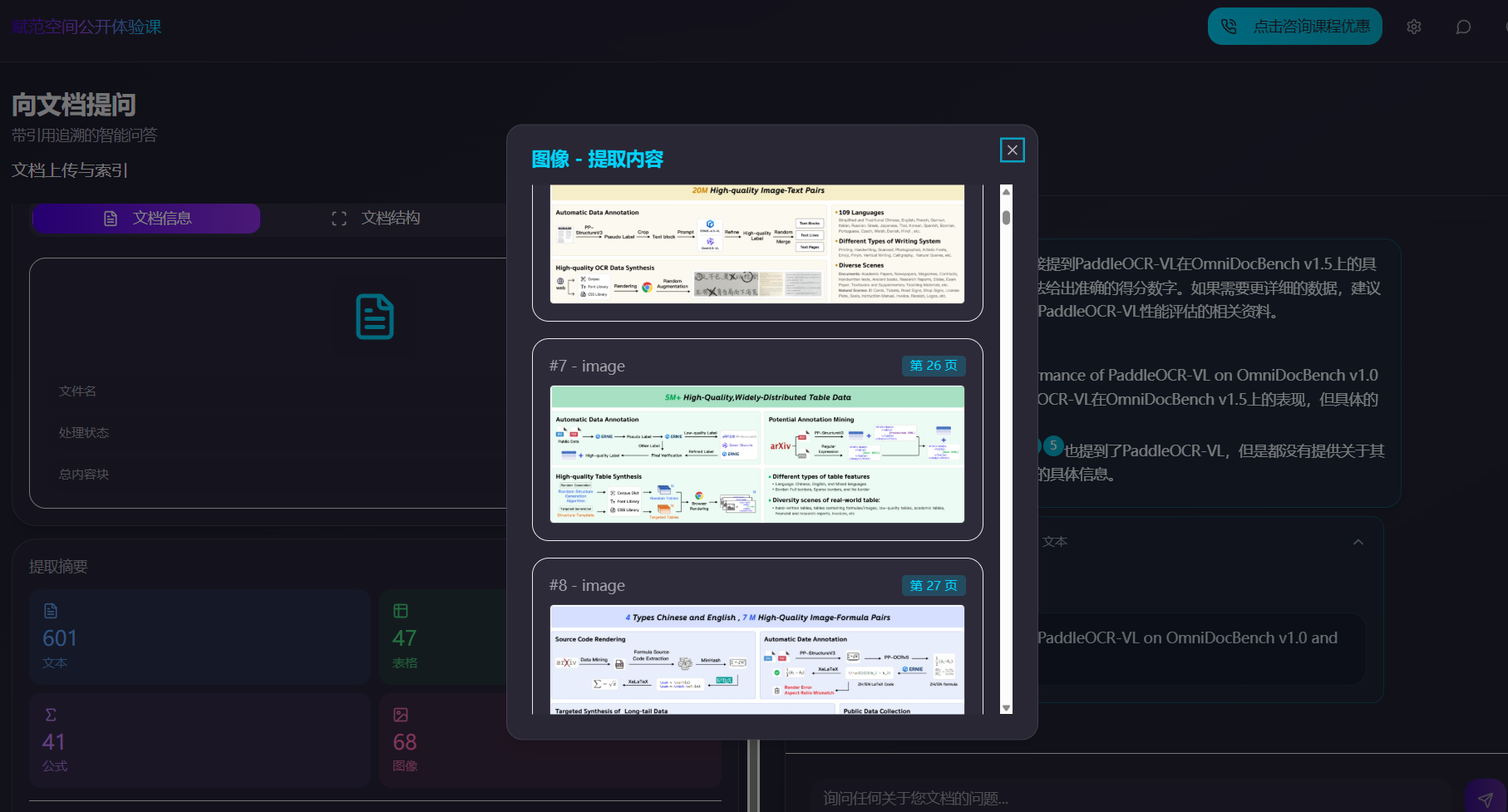
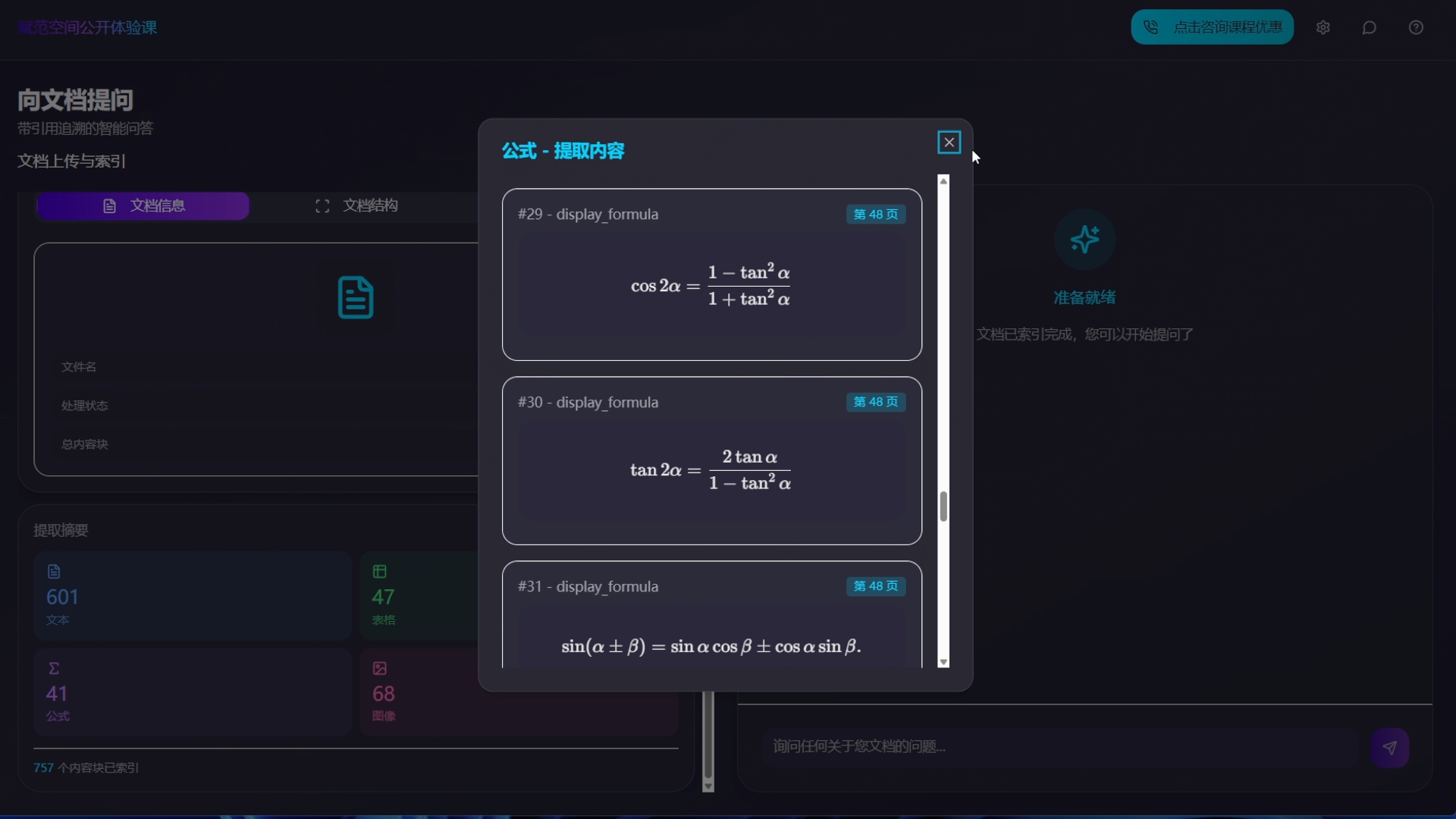
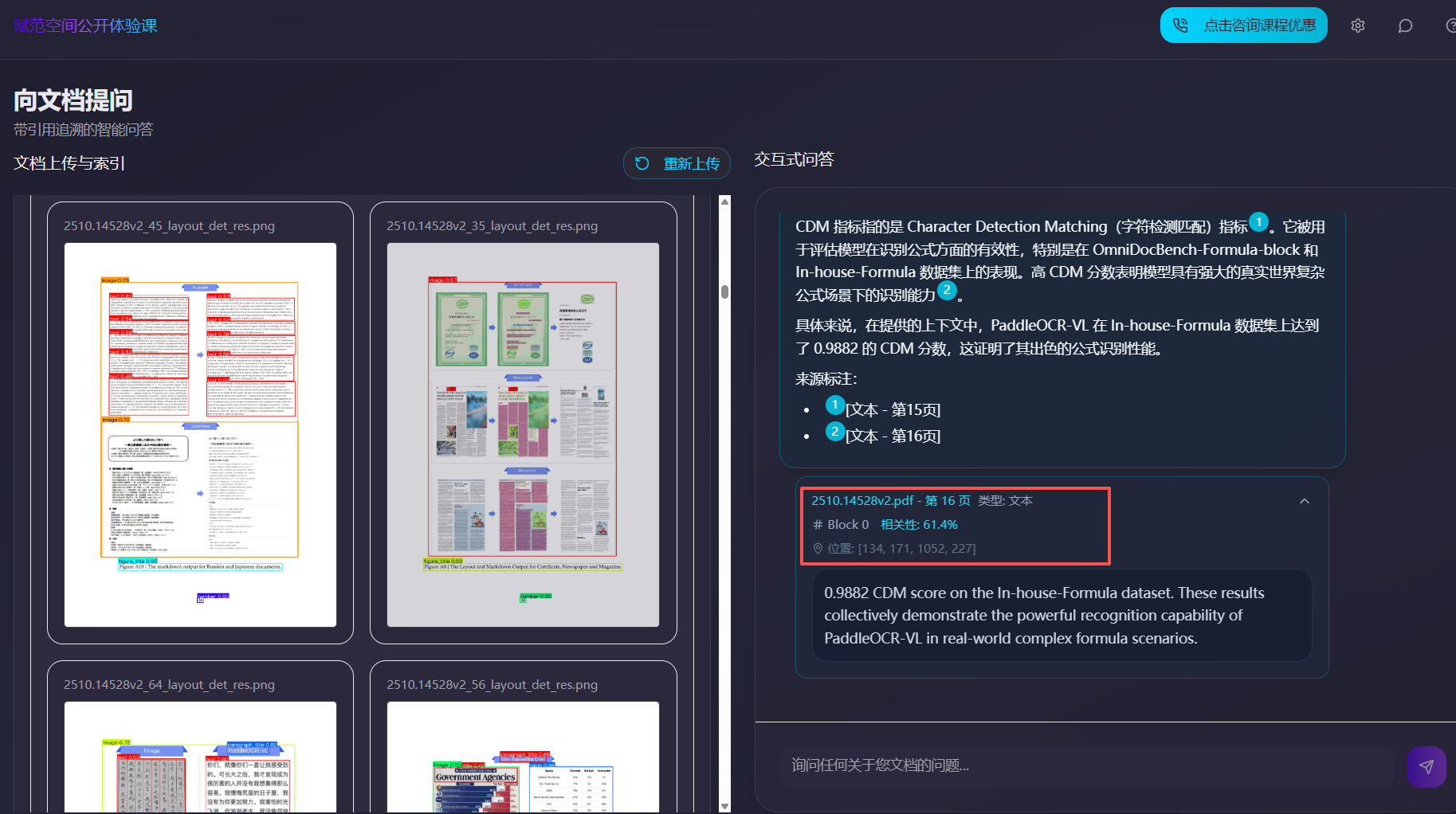
- 核心功能三:多模态 Agentic RAG 问答系统搭建,并支持图片、表格、文本框、公式级细粒度的精准溯源;
一、OCR技术兴起的背景
随着大模型技术的兴起,OCR 技术也迎来了新的快速发展机遇。2025年10月16日发布的 PaddleOCR-VL 模型直接屠榜,在全球权威榜单OmniDocBench V1.5中以92.6分夺得综合性能第一,横扫文本识别、公式识别、表格理解与阅读顺序四项SOTA。

而紧接其后,DeepSeek 也于 2025年10月21日发布了 DeepSeek-OCR 模型,仅需7G的显存,就能完成高精度的表格、公式识别,图片语义识别,并且在多项评测指标中一举拿下SOTA成绩。
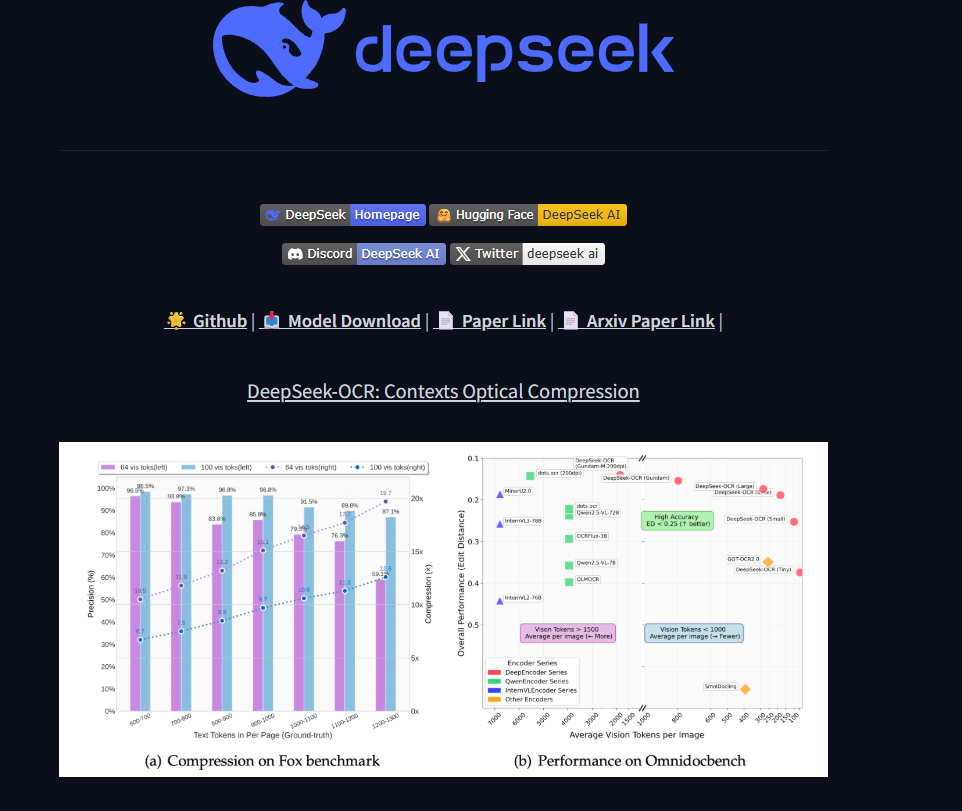
这类模型的兴起,完全是源于真实应用需求的驱动。
OCR(全称:Optical Character Recognition,光学字符识别)是将包含文本的图像(如扫描文档、照片、表单、书页)转换成 机器可读的文本格式的技术,如下图所示:

这类模型并不是传统的OCR模型,而是拥有大模型多模态能力的OCR模型,这种模型被称为VLM(Vision-Language Model)模型、或者OCR 2.0模型。其中最本质的区别,就是多模态大模型在进行图像识别之前,会借助一个名叫视觉编码器的算法,将图像视觉信息映射到文本空间中,然后再借助大模型对文本语义的理解能力,间接的去理解图像信息。
简单理解就是:你有一张扫描的图片,上面写满了打印或手写的文字,OCR 技术可以把这些“文字图像”变成“真实的文本数据”(可以编辑、搜查、分析)而不是只是“一个图片”而已。
目前企业在做的大部分业务场景都是以正确识别不同文档类型的内容为前提,比如处理大量纸质文档(发票、合同、报表、表单、收据等),需要通过 OCR 可以把这些纸质/图像文档转换为电子数据,从而更便于存储、检索、分析。 在数字化、智能化流程(例如自动化数据输入、档案管理、人工智能分析)中,它同样也是一个基础环节。
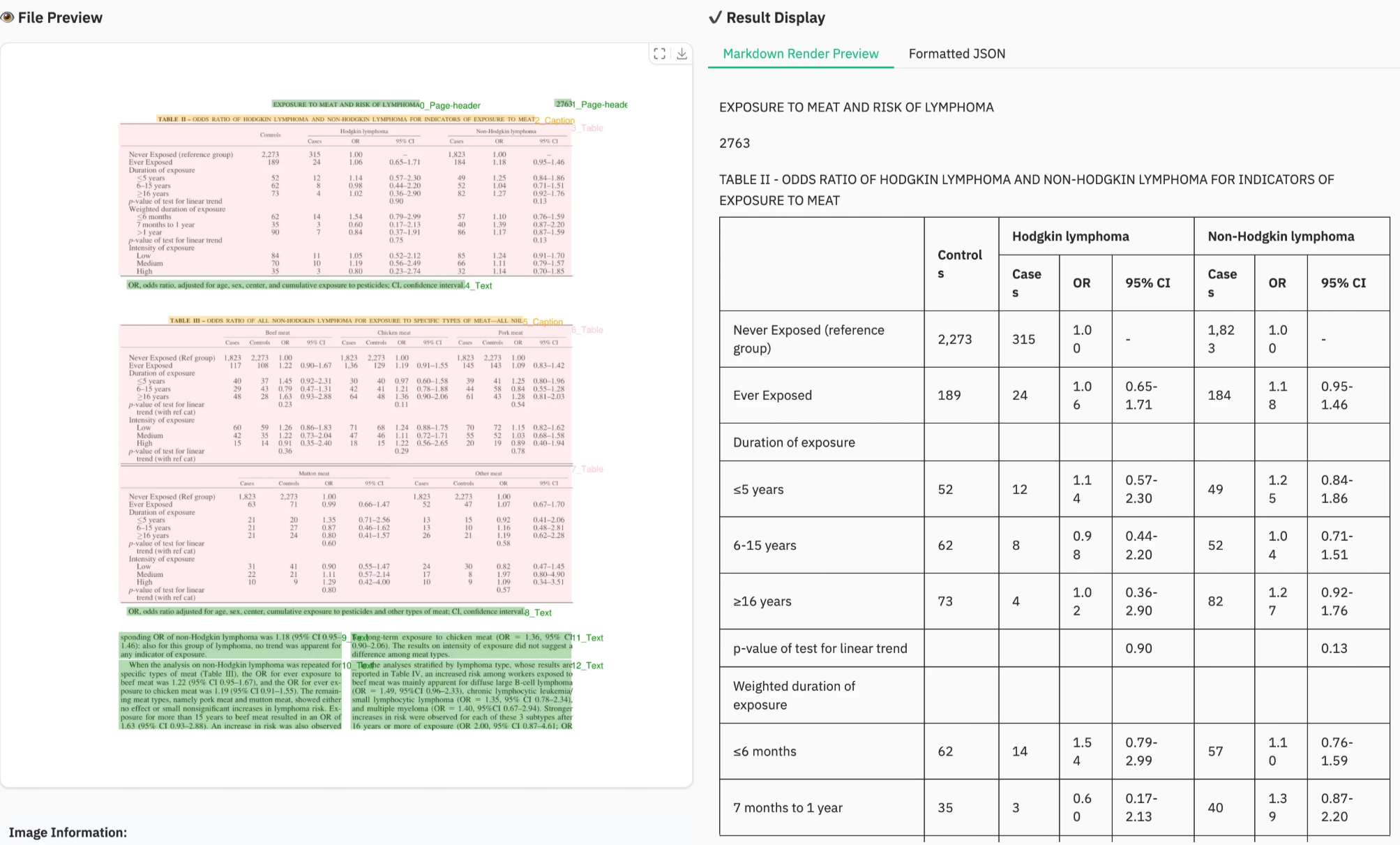
是否能正确解析内容的这个过程对基于大模型落地的应用技术是非常关键的。大家耳熟能详的RAG技术,其构建的第一步,就是完成从各类数据格式的精准解析:
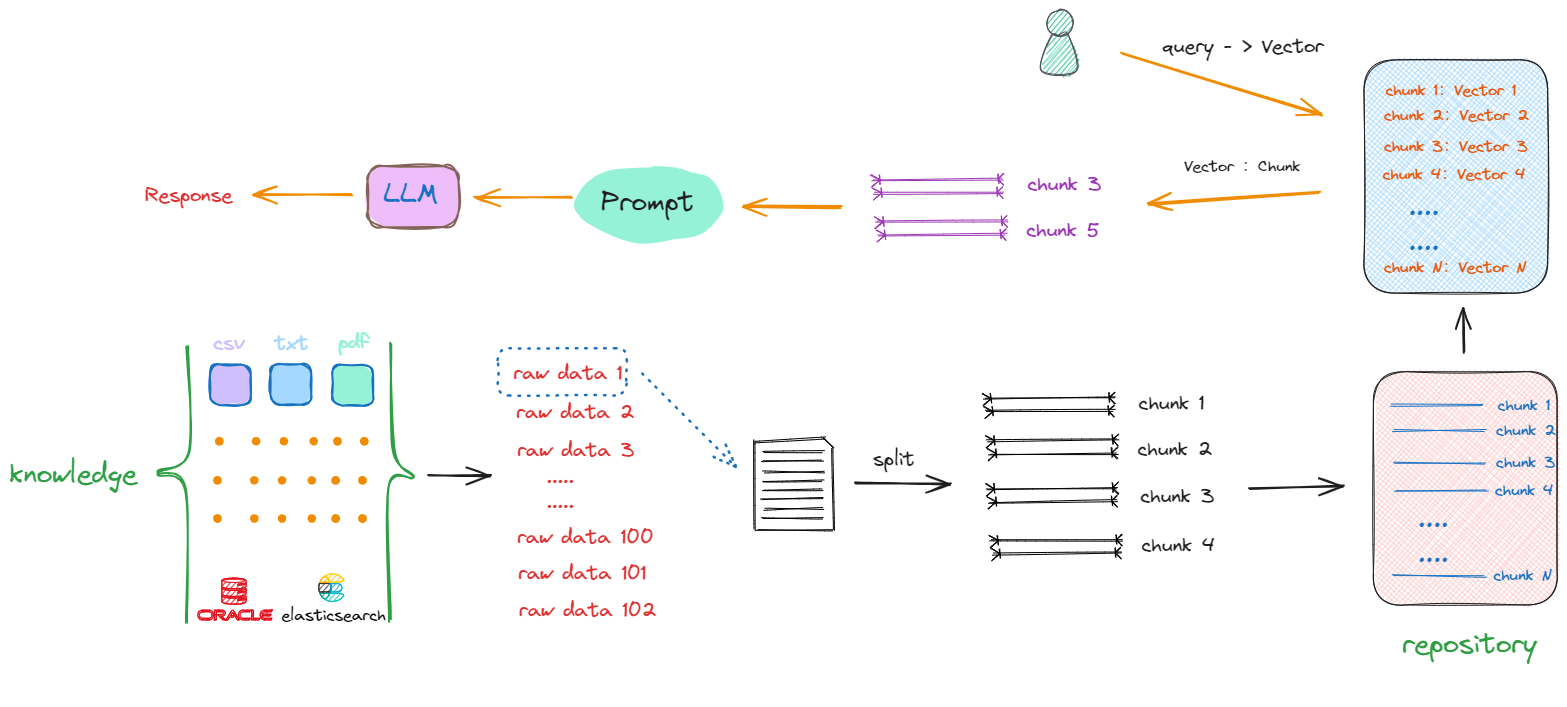
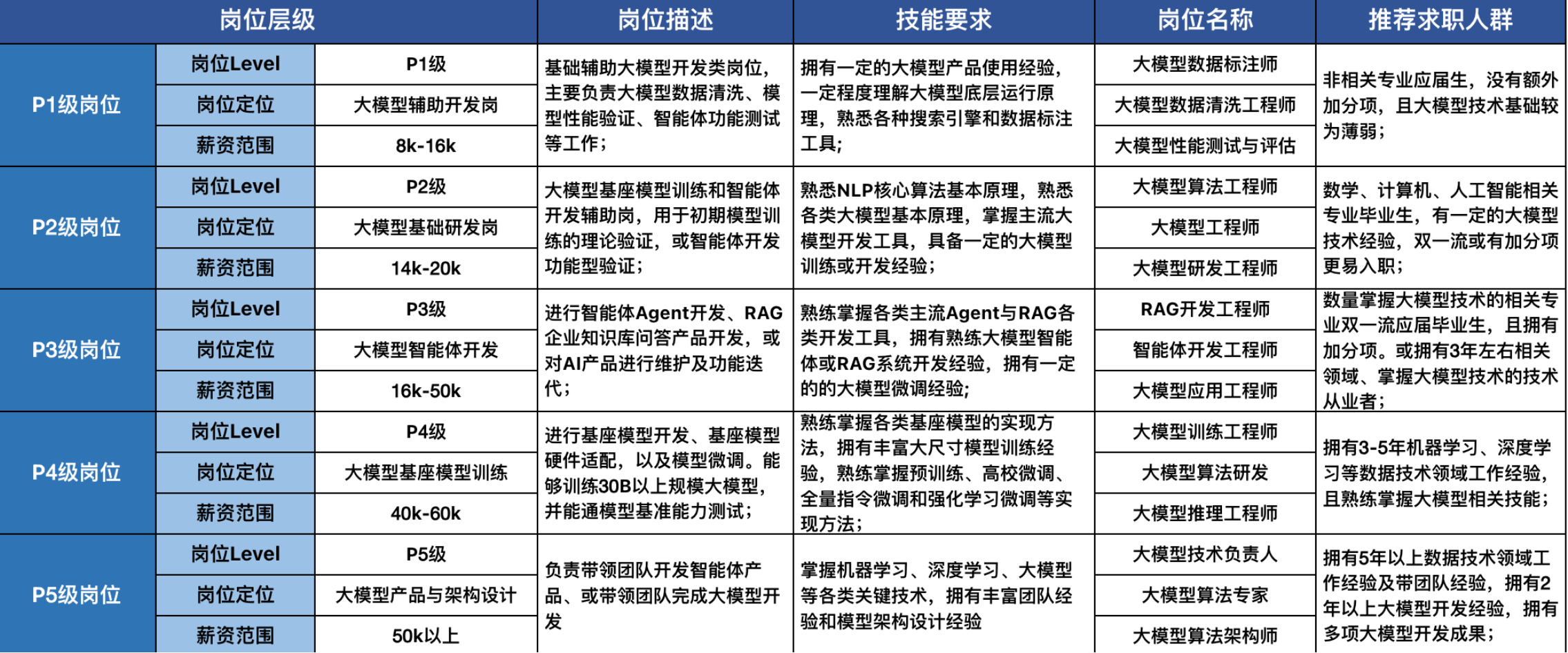
- 大模型开发岗位的敲门砖 - 多模态RAG
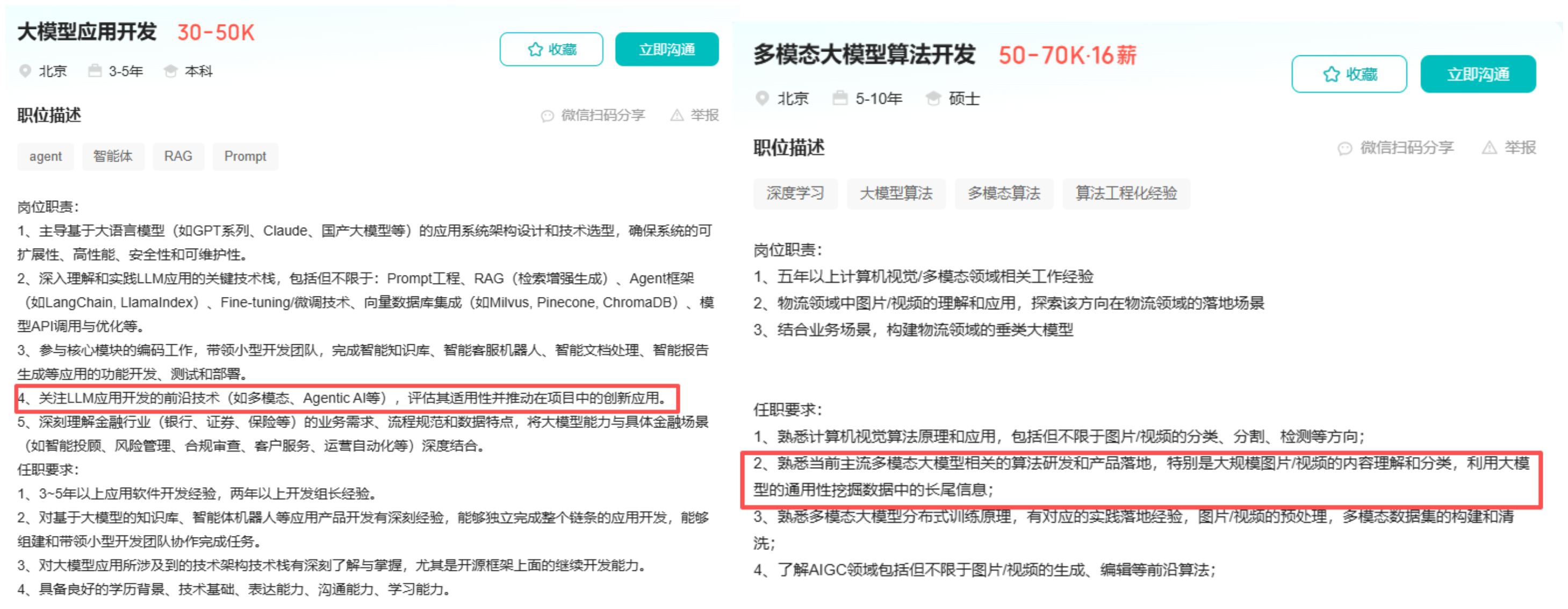
这类岗位做的核心工作其实就是在对多模态数据如PDF、图片、音频、视频的预处理后,再开展基于大模型的智能问答/Agent工作流编排工作。
大模型秋季班·即将封班,直播间特惠进行时,直播间享五折特价+全套SVIP新班特定福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

二、主流OCR项目介绍
就目前的发展来看,OCR 与 RAG 的技术结合并不像简单的传统 OCR 是“你给我一张图像,我把文字提取出来”就可以了,重点不能仅仅放在去提取文字,而是要在 OCR 的基础上,不仅仅是“图像中的文字”被识别,还需要结合 视觉(图像)、语言(文本)、版面结构(布局)、场景环境/上下文 等多个模态(modalities)一起分析,使得识别和理解更强、更智能。
这其实就是我们今天要谈论的主题:多模态RAG。在大模型、视觉-语言模型(Vision‐Language Models, VLMs)兴起的背景下,多模态 OCR 是一个重要方向。
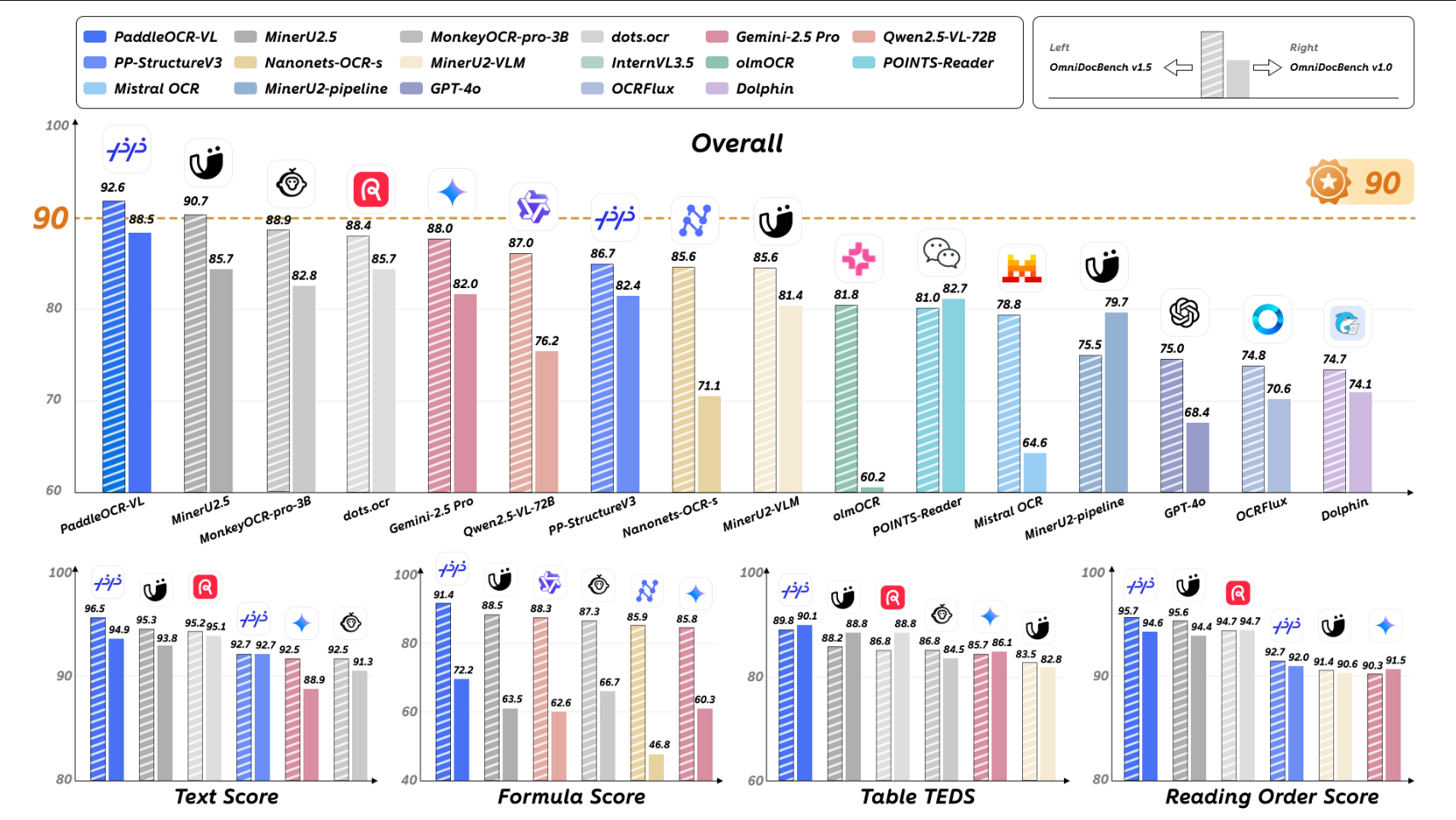
现代文档不仅仅是文本。它们包含多列布局、数学公式、半扫描表格、多语言文本以及分辨率奇数的图表。像 GPT-4o 或 Qwen-VL 这样的端到端模型可以解析它们,但它们速度慢、布局混乱,并且耗费 GPU 内存。所以企业环境下往往会选择更小、更紧凑的视觉模型来为解析工作提供支持。主流的企业级OCR项目应用如下:
- MinerU:点击进入
MinerU 是由 OpenDataLab(上海人工智能实验室下属团队)发起的一个开源工具,目标是将 PDF(含扫描件、复杂版式、多栏、多表格、多公式)转换为可机读的结构化格式(如 Markdown、JSON)以便进一步下游使用。项目的定位更偏「文档内容抽取/结构化」而不仅仅是传统 OCR。其取向是“将 PDF → Markdown/JSON”这一流程,而不仅“图片 → 文字”。
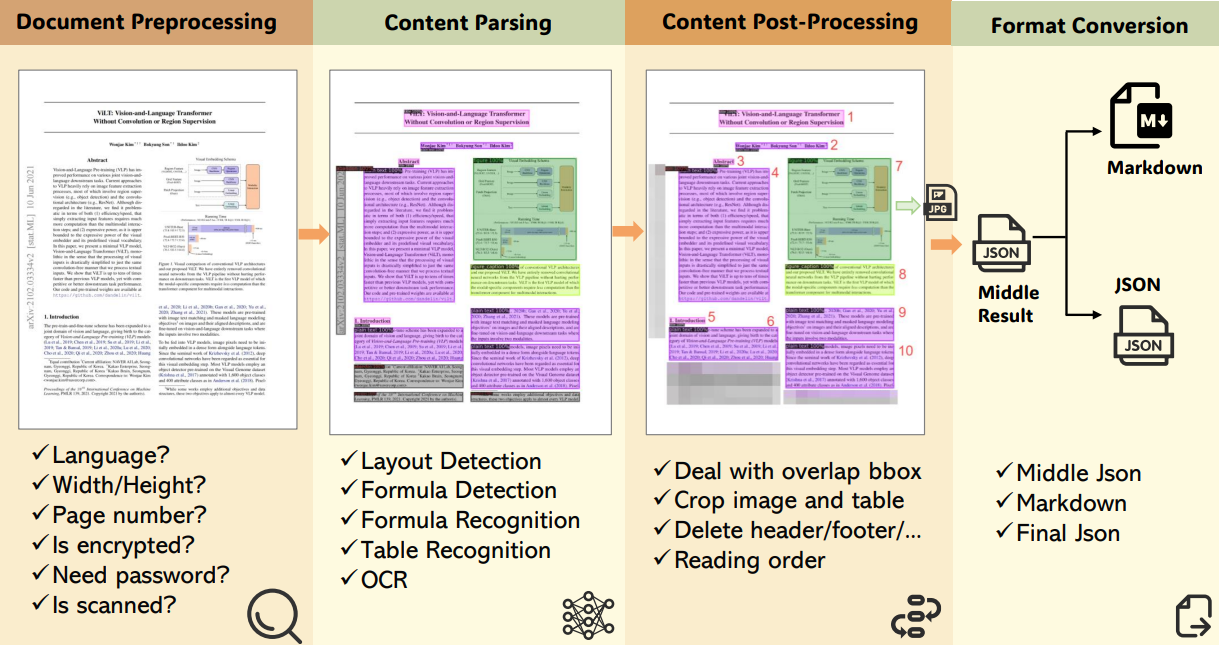
MinerU的主要工作流程分为以下几个阶段:
- 输入:接收
PDF格式文本,可以是简单的纯文本,也可以是包含双列文本、公式、表格或图等多模态PDF文件; - 文档预处理(Document Preprocessing):检查语言、页面大小、文件是否被扫描以及加密状态;
- 内容解析(Content Parsing):
- 局分析:区分文本、表格和图像。
- 公式检测和识别:识别公式类型(内联、显示或忽略)并将其转换为
LaTeX格式。 - 表格识别:以
HTML/LaTeX格式输出表格。 - OCR:对扫描的
PDF执行文本识别。
- 内容后处理(Content Post-processing):修复文档解析后可能出现的问题。比如解决文本、图像、表格和公式块之间的重叠,并根据人类阅读模式重新排序内容,确保最终输出遵循自然的阅读顺序。
- 格式转换(Format Conversion):以
Markdown或JSON格式生成输出。 - 输出(Output):高质量、结构良好的解析文档。
如下是MinerU项目官方给出的配置参考:

VLM-Transformer则是直接利用transformers库中的Vision-Language模型处理图像+文本的多模态输入,其流程如下:

而VLM-Sglang后端则是利用sglang高性能推理引擎,优化了GPU加速及分布式部署的基础上同时支持实时流式输出,其流程如下:

MinerU 项目非常适用于:
-
需要从大量 PDF 文档中抽取结构化内容(例如学术文献、技术白皮书、报告)用于知识库或训练语料。
-
对版式结构(如章节、列表、表格、公式)要求较高,而不只是 OCR 文本识别。
-
希望输出 Markdown/JSON 供后续自动化流水线使用。
-
dots.ocr:点击进入
dots.ocr 是由 rednote‑hilab(HiLab团队)开源的多语种文档布局解析工具。官方介绍中强调:“一个统一的 Vision-Language 模型(≈1.7 B 参数)即可完成布局检测 + 内容识别 +阅读顺序排序”。支持文本、表格、公式、以及多语言输入。

dots.ocr 的特点是用一个 VLM(1.7 B 参数)来统一布局解析+内容识别,而不是传统将检测、识别、结构分开。用户可通过不同 prompt 来切换任务(如“请输出版式元素的 bbox、类别、文本”)→ 即说明模型采用 prompt + VLM 的方式。
非常适合需要快速处理多语种、混版式文档,且希望用一个统一模型/prompt 来搞定。虽然表现不错,但对于极复杂的表格(如跨页表、合并单元格)或特殊版式效果并不是很理想。
- PaddleOCR:点击进入
PaddleOCR 是由 Baidu (及其生态) 基于其深度学习框架 PaddlePaddle 提供的开源 OCR 工具箱。支持从 PDF 或图像文档转为结构化数据(适配 AI 场景),支持 100+ 语言。最新版本 3.0 在其技术报告中提出:PP-OCRv5、PP-StructureV3、PP-ChatOCRv4 三大解决方案,覆盖文字识别、多版式文档解析、关键 信息提取。

在早期版本(如 PP-OCRv3)中,其结构可概括为:“检测 (Detection) → 分类 (Classification of orientation) → 识别 (Recognition)”。使用多种模型,例如检测模型(DBNet 等)、识别模型(如 SVTR),在 3.0 版本中,其“PP-StructureV3”整合了布局分析、表格识别、结构抽取。同时还最新推出了还推出了PaddleOCR-VL 的 Vision-Language 模型版本(0.9B 参数的 VLM),用于多语种文档解析。
PaddleOCR-VL 是推出的一个专注于“文档解析/视觉-语言模型 (Vision-Language Model, VLM)”功能的新模块,采用了视觉-语言模型架构以应对更高阶的需求。在解析多模态数据方面,PaddleOCR将这项工作分为两部分:
- 首先检测并排序布局元素。
- 使用紧凑的视觉语言模型精确识别每个元素。
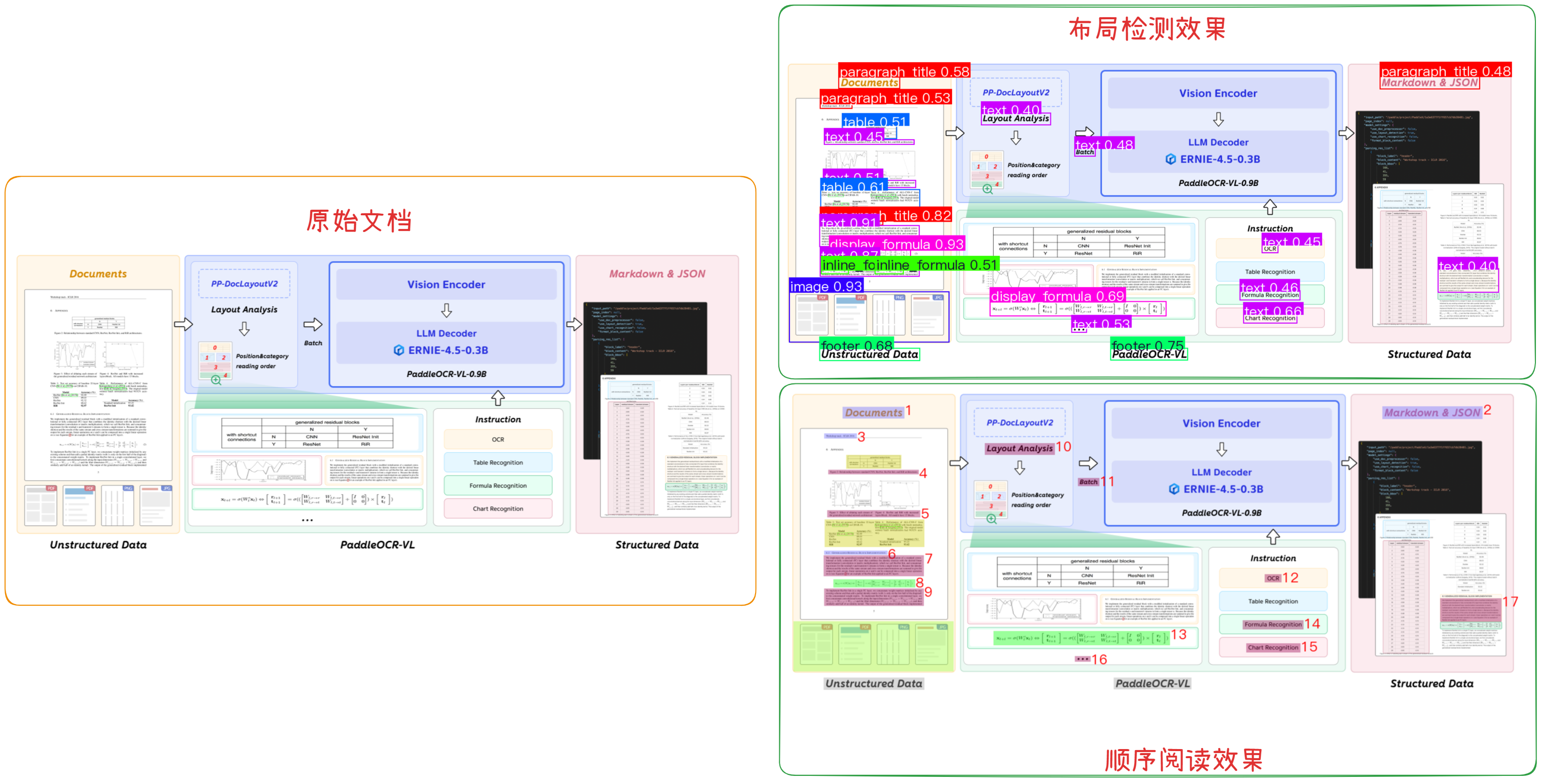
该系统分为两个明确的阶段运行。
第一阶段是执行布局分析(PP-DocLayoutV2),此部分标识文本块、表格、公式和图表。它使用:
- RT-DETR 用于物体检测(基本上是边界框 + 类标签)。
- 指针网络 (6 个转换器层)可确定元素的读取顺序 ,从上到下、从左到右等。
最终输出统一模式的图片标注数据,如下图所示:
第二阶段则是元素识别(PaddleOCR-VL-0.9B),这就是视觉语言模型发挥作用的地方。它使用:
- NaViT 风格编码器 (来自 Keye-VL),可处理动态图像分辨率。无平铺,无拉伸。
- 一个简单的 2 层 MLP, 用于将视觉特征与语言空间对齐。
- ERNIE-4.5–0.3B 作为语言模型,该模型规模虽小但速度很快,并且采用 3D-RoPE 进行位置编码
最终模型输出结构化 Markdown 或 JSON 格式的文件用于后续的处理。
这个小小的设计决策, 将布局和识别分离,使得 PaddleOCR-VL 比通常的一体化系统更快、更稳定。同时根据实际的测试,其运行和解析速度也更快。在 A100 GPU 上, 吞吐量为 1.22 页/秒,。比 MinerU2.5 快 15.8%, VRAM 比 dots.ocr 少约 40%。
三、本地部署 PaddleOCR-VL 实战
本小节课程,我们将从零开始,详细介绍如何在本地环境中完整部署 PaddleOCR-VL 并完成 OCR 功能测试。
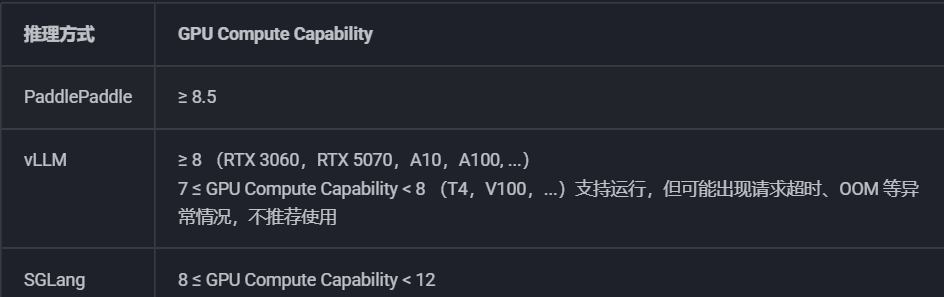
对于硬件要求,官方给出了如上说明。其中使用原生的PaddlePaddle方式,需要GPU算力≥8.5(RTX 3090/4090、A100 等),最稳定。使用vLLM方式,需要GPU算力≥8(RTX 3060 及以上),速度最快,但算力7-8之间(T4/V100)虽可运行但不推荐,易超时或OOM。使用SGLang方式,需要GPU算力8-12之间(RTX 3060-4090),性能与稳定性的平衡选择。
注意:表格里的 "≥8" 指的是 GPU Compute Capability(GPU 算力版本号),不是显存大小!根据实测,根据PaddleOCR-VL-0.9B 模型(模型文件约 3.8GB):
- 最低要求:6GB 显存(勉强够用,单张图)
- 推荐配置:8GB+ 显存(运行舒适)
- 理想配置:12GB+ 显存(可以批处理多张图)
所以:8GB 显存 + RTX 30 系列以上达到高效运行是完全没问题的。整个过程主要包括以下几个核心步骤:
- 创建 Python 虚拟环境 - 隔离项目依赖,避免环境冲突;
- 安装 PaddlePaddle 深度学习框架 - PaddleOCR 的底层依赖;
- 安装 PaddleOCR 库 - 核心 OCR 功能库;
- 下载预训练模型 - PaddleOCR-VL-0.9B 和 PP-DocLayoutV2;
- 验证安装 - 运行测试确保环境正常;
公开课所使用的硬件环境为:Ubuntu 22.04 + 4 * 3090,共计显存96G显存,运行起来非常流畅。
3.1 创建虚拟环境
首先,我们需要创建一个独立的 Python 虚拟环境。虚拟环境可以隔离项目依赖,避免与系统其他 Python 项目产生冲突。执行如下命令 FENCE0
其中:
--name ocr_rag:虚拟环境名称,可以自定义python==3.11:指定 Python 版本为 3.11(PaddleOCR 推荐版本)
执行效果如下图所示:
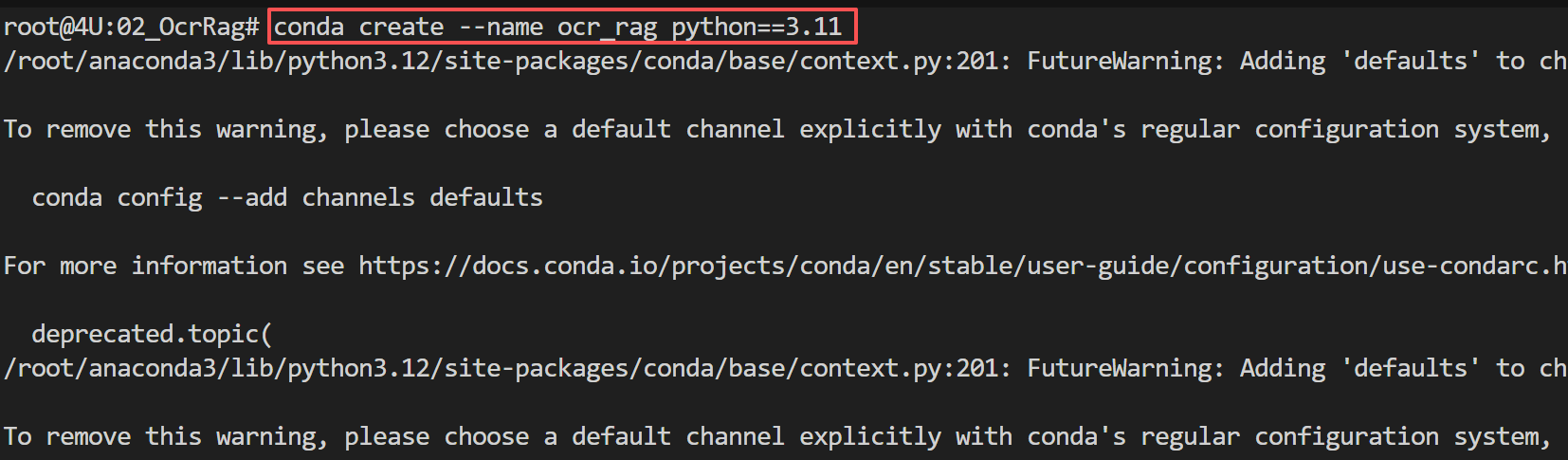
接下来激活虚拟环境: FENCE0
激活后,命令行提示符前会显示 (ocr_rag),表示已进入虚拟环境。
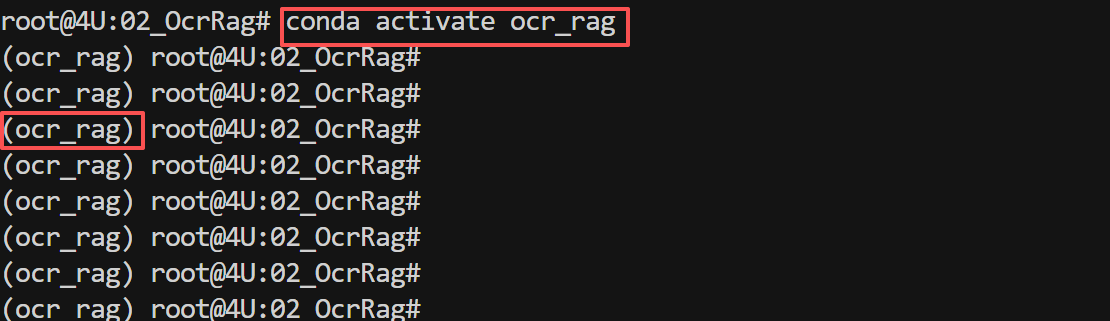
3.2 安装 PaddleOCR 工具框架
首先需要区分PaddleOCR 和 PaddleOCR-VL 两个之间的区别和联系。首先。PaddleOCR 是一个较为成熟、功能全面的 OCR+文档理解开源工具库,其开源地址:https://github.com/PaddlePaddle/PaddleOCR/tree/main
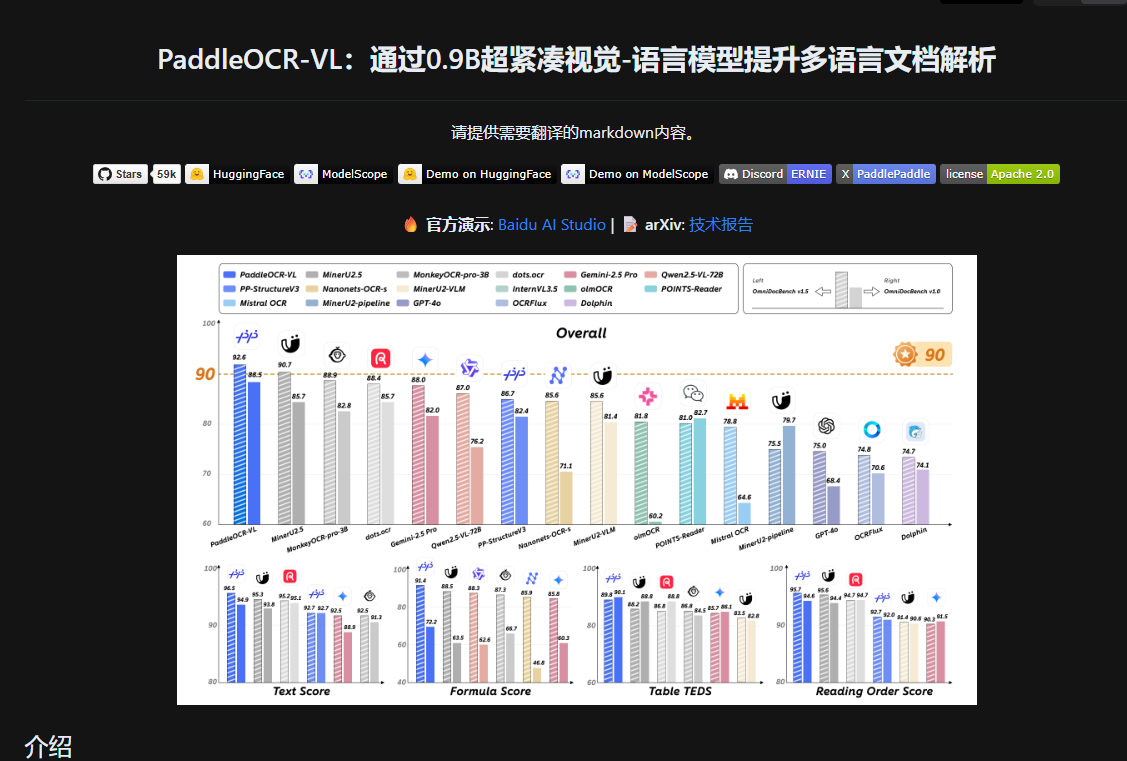
PaddleOCR-VL 是在这个生态内新发布的一个专注于“文档解析/视觉-语言模型 (Vision-Language Model, VLM)”功能的新模块。比如在 README 中提到:「PaddleOCR-VL – Multilingual Document Parsing via a 0.9B VLM」就是被列为 PaddleOCR 3.0 的核心特性之一。
简单来说,PaddleOCR 是一个“全面且成熟”的 OCR+文档理解工具箱,而 PaddleOCR-VL 是在这个工具箱里“专门为复杂文档解析”设计的新模块,采用了视觉-语言模型架构以应对更高阶的需求。
因此,在使用PaddleOCR-VL 时,我们首先需要安装 PaddleOCR 工具框架。https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html
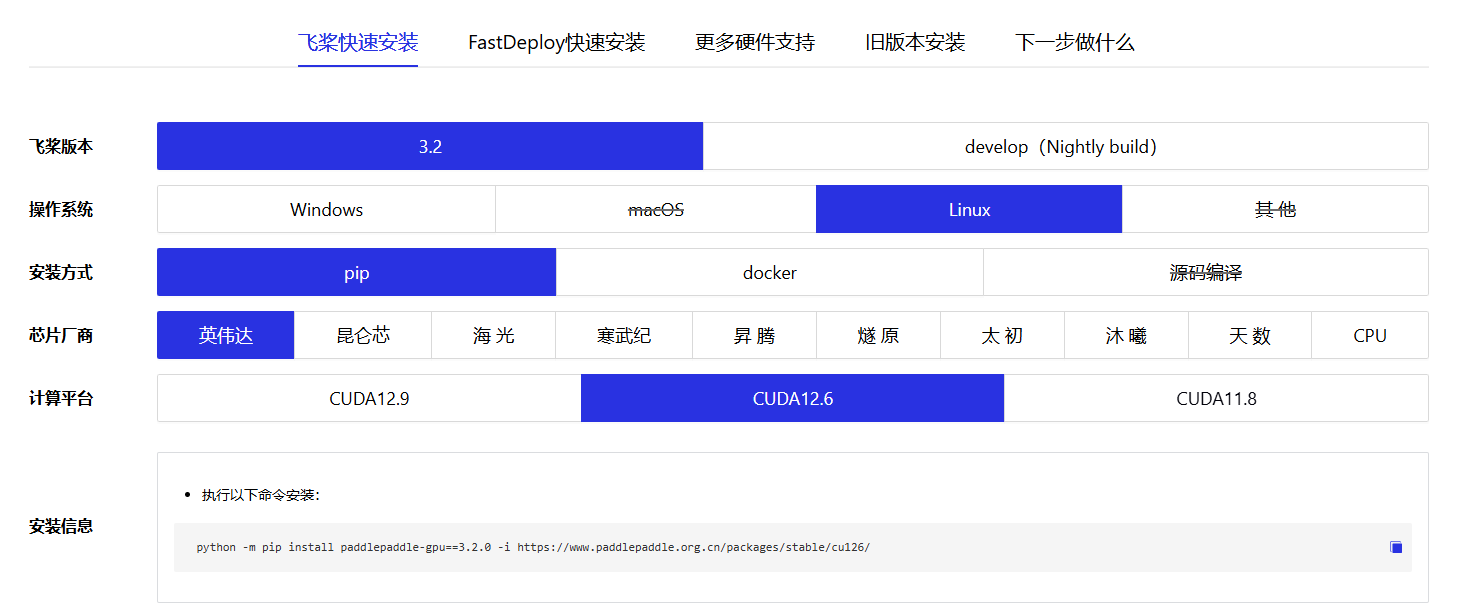
这里安装 PaddlePaddle 3.2.0 版本。执行如下命令:
FENCE0
其中:
paddlepaddle-gpu==3.2.0:GPU 版本的 PaddlePaddle 3.2.0-i https://...:使用百度官方镜像源,下载速度更快cu126:对应 CUDA 12.6 版本
安装过程如下图所示:
安装结束后,需要验证 PaddlePaddle 安装状态,依次运行以下命令验证:
FENCE0
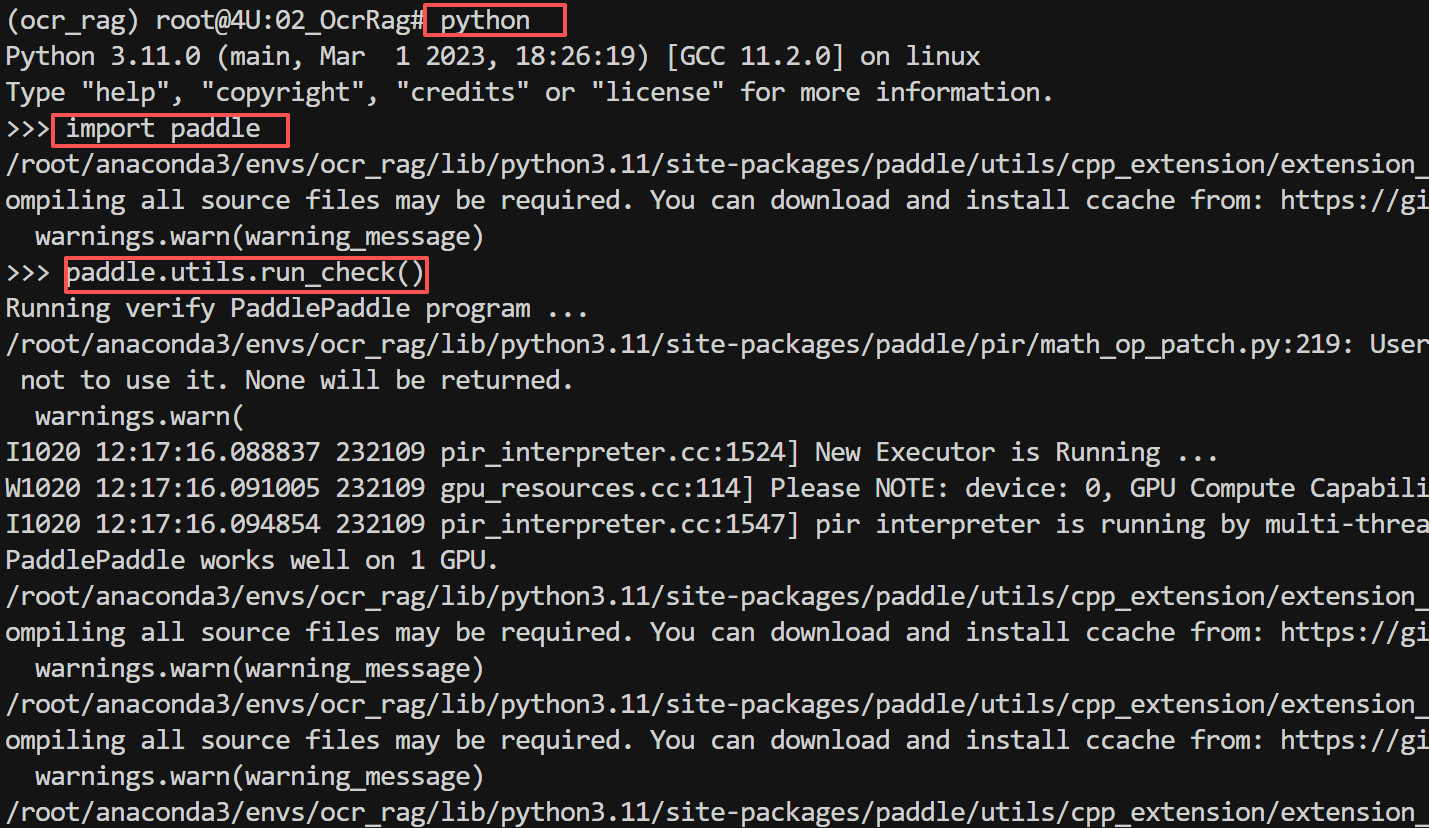
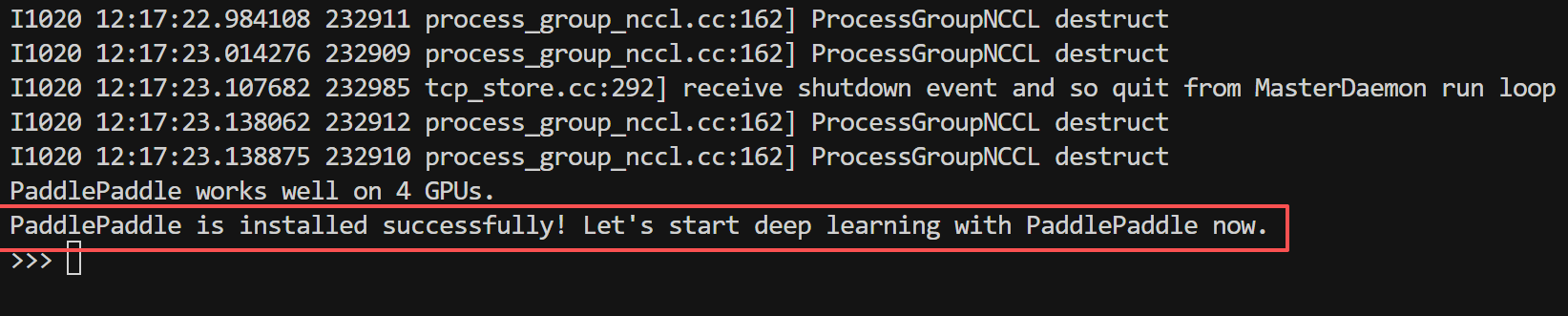
如果看到如下“”信息,说明 PaddlePaddle 已成功安装。
接下来要重点关注的是:PaddleOCR-VL 使用 safetensors 格式存储模型权重,需要额外安装,同时需要安装指定版本的,执行如下命令
FENCE0
这是兼容最新PaddleOCR-Vl 的 safetensors 版本,安装很快。
3.3 下载PaddleOCR-VL模型
使用 PaddleOCR-VL 解析功能需要两个预训练模型,其中:
- PaddleOCR-VL-0.9B - 视觉语言模型(用于文本识别)
- PP-DocLayoutV2 - 文档布局检测模型(用于布局分析)
该模型权重的HuggingFace 地址为:https://huggingface.co/PaddlePaddle/PaddleOCR-VL ,
此外,对于我们国内用户来说,更建议通过 ModelScope 下载(推荐)。https://modelscope.cn/models/PaddlePaddle/PaddleOCR-VL/summary
ModelScope 是阿里云的模型托管平台,国内访问速度快。首先执行如下命令:
FENCE0
新建一个 download_paddleocr_vl.py 文件,写入如下代码:
FENCE0
其中:
'PaddlePaddle/PaddleOCR-VL':模型仓库 IDlocal_dir='.':下载到当前目录(也可以指定其他路径,如'./models')
接下来执行如下代码进行模型权重安装:
FENCE0
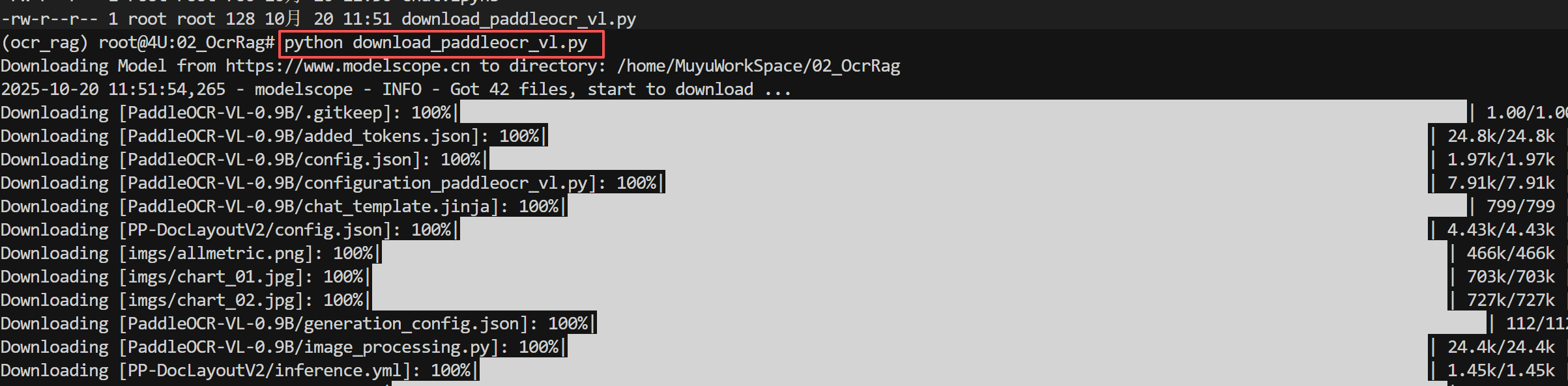
下载完成后的模型目录结构如下所示:
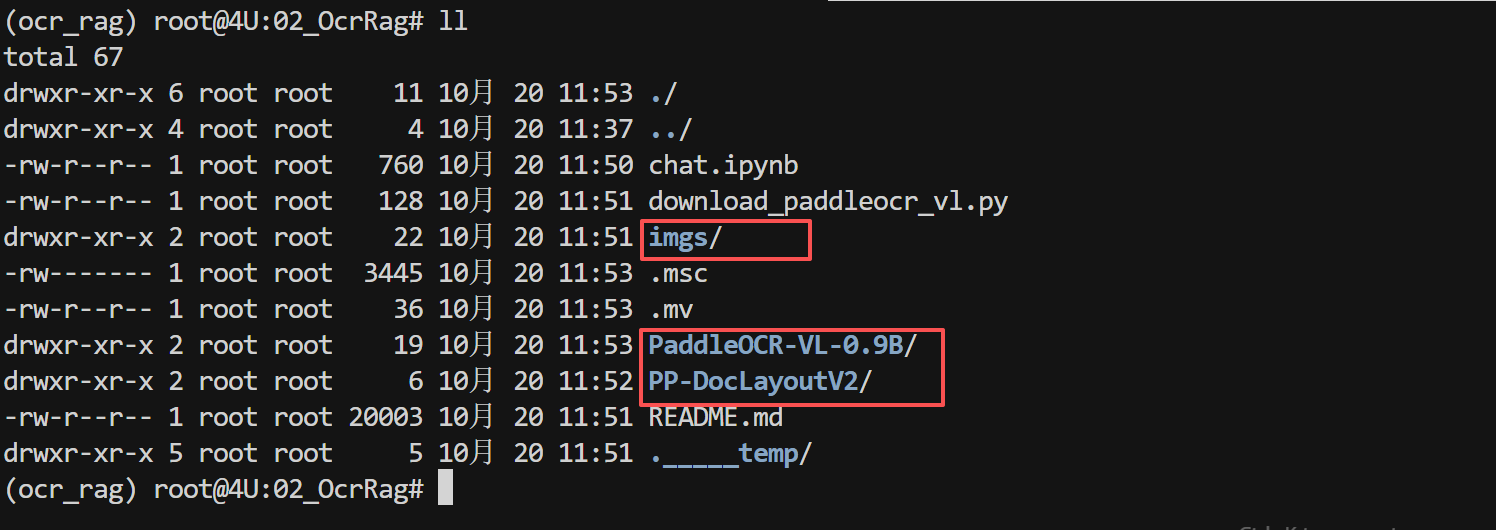
其中 PaddleOCR-VL-0.9B 文件夹中存储的就是本次最新开源的超紧凑视觉语言模型,具有以下特点:
PaddleOCR-VL-0.9B 模型特性
| 特性 | 说明 |
|---|---|
| 模型规模 | 0.9B 参数(极小,推理速度快) |
| 语言支持 | 109 种语言(包括中文、英文、日语、韩语等) |
| 识别能力 | 文本、表格、公式、图表等复杂元素 |
| 输出格式 | Markdown、JSON、HTML |
| 资源消耗 | GPU 显存 4GB+,推理速度 1.22 页/秒(A100) |
| 优势 | 比 MinerU 快 15.8%,显存占用比 dots.ocr 少 40% |
3.4 本地运行测试
在执行完成所有组件安装完成后,在进行运行前需要依次安装如下两个依赖包,首先是paddleocr[all], 其中:
FENCE0
这里我们安装所有功能依赖,如下图所示:
其次,安装LangChain依赖包,执行如下命令:
FENCE0
注意:这里需要保证langchainx版本小于1.0.0,否则会出现兼容问题。
一切准备就绪后,接下来便可以快速进行文档解析测试,输入如下代码:
FENCE0
如下图所示:
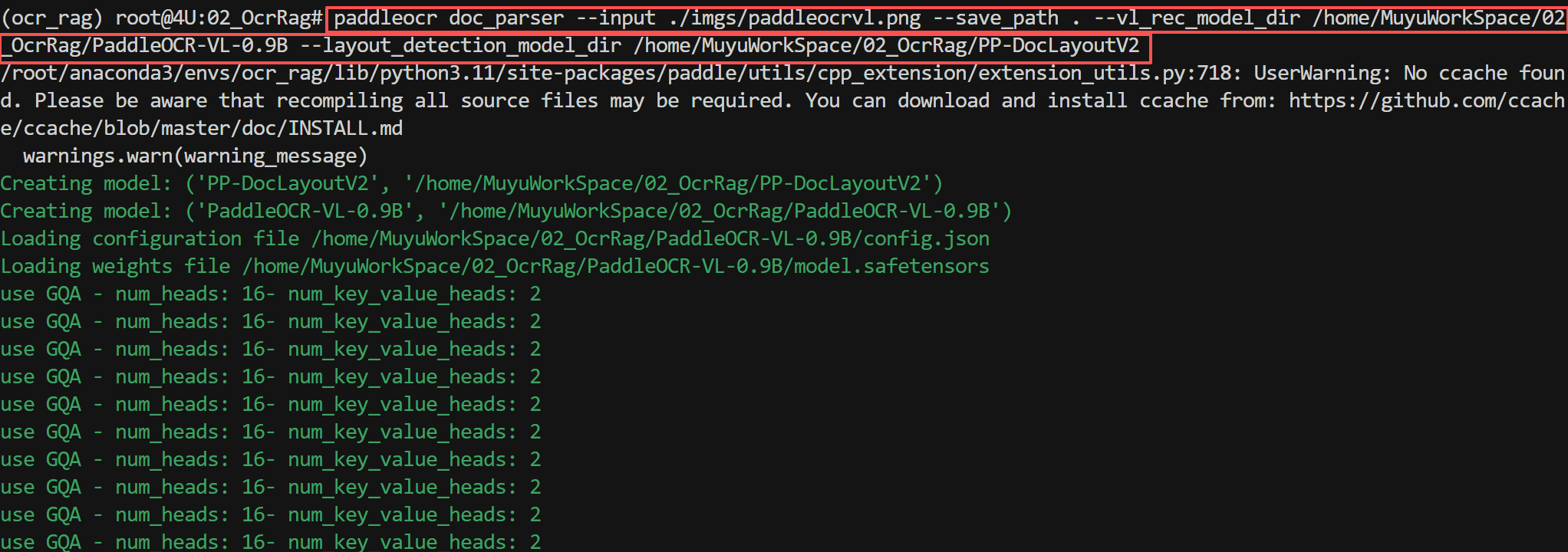
首次运行注意事项:
- 如果未提前下载模型,会自动下载到
~/.paddlex/official_models/目录- 首次运行需要加载模型,耗时约 10-30 秒
- 后续运行会快很多(模型已缓存)
等待程序运行结束后,程序会在当前目录生成以下文件:
paddleocrvl_demo_res.json- 识别结果(JSON 格式)paddleocrvl_demo.md- 识别结果(Markdown 格式)paddleocrvl_demo_layout_det_res.png- 布局检测可视化图paddleocrvl_demo_layout_order_res.png- 阅读顺序可视化图
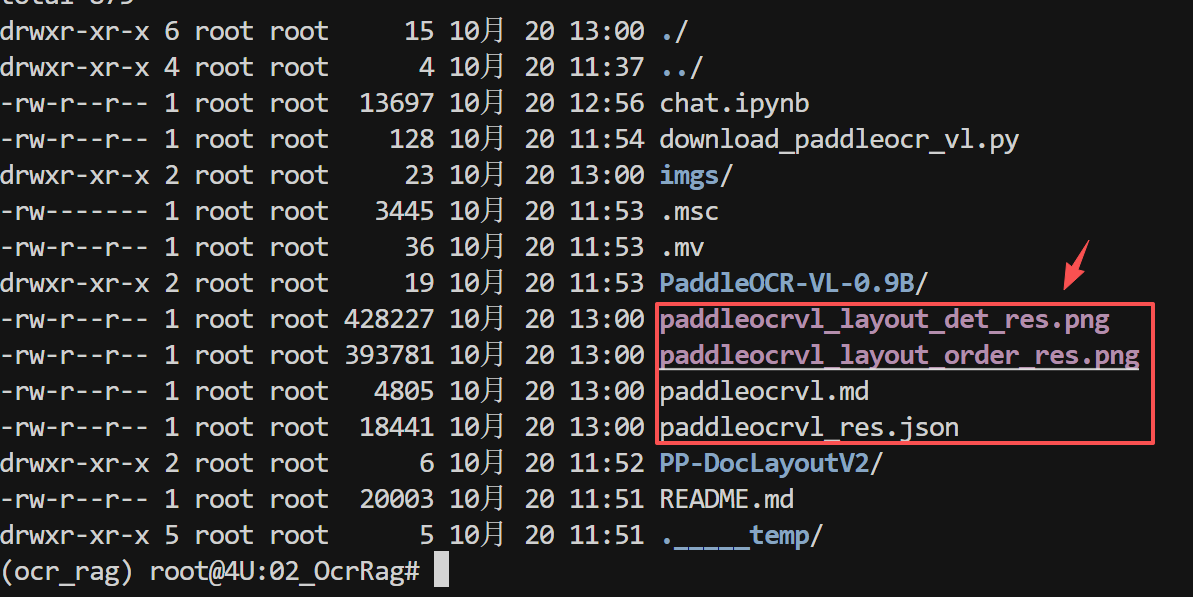
效果如下所示:
PaddleOCR Doc Parser 命令参数如下表所示:
基础参数
| 参数名 | 说明 |
|---|---|
-i INPUT, --input INPUT | 输入路径或 URL(必需) |
--save_path SAVE_PATH | 输出目录路径 |
布局检测参数
| 参数名 | 说明 |
|---|---|
--layout_detection_model_name | 布局检测模型名称 |
--layout_detection_model_dir | 布局检测模型目录路径 |
--layout_threshold | 布局检测模型的分数阈值 |
--layout_nms | 是否在布局检测中使用 NMS(非极大值抑制) |
--layout_unclip_ratio | 布局检测的扩展系数 |
--layout_merge_bboxes_mode | 重叠框过滤方法 |
VL识别模型参数
| 参数名 | 说明 |
|---|---|
--vl_rec_model_name | VL 识别模型名称 |
--vl_rec_model_dir | VL 识别模型目录路径(指定本地 PaddleOCR-VL-0.9B 模型路径) |
--vl_rec_backend | VL 识别模块使用的后端(native, vllm-server, sglang-server) |
--vl_rec_server_url | VL 识别模块使用的服务器 URL |
--vl_rec_max_concurrency | VLM 请求的最大并发数 |
文档处理模型
| 参数名 | 说明 |
|---|---|
--doc_orientation_classify_model_name | 文档图像方向分类模型名称 |
--doc_orientation_classify_model_dir | 文档图像方向分类模型目录路径 |
--doc_unwarping_model_name | 文本图像矫正模型名称 |
--doc_unwarping_model_dir | 图像矫正模型目录路径 |
功能开关参数
| 参数名 | 说明 |
|---|---|
--use_doc_orientation_classify | 是否使用文档图像方向分类 |
--use_doc_unwarping | 是否使用文本图像矫正 |
--use_layout_detection | 是否使用布局检测 |
--use_chart_recognition | 是否使用图表识别 |
--format_block_content | 是否将块内容格式化为 Markdown |
--use_queues | 是否使用队列进行异步处理 |
VLM生成参数
| 参数名 | 说明 |
|---|---|
--prompt_label | VLM 的提示标签 |
--repetition_penalty | VLM 采样中使用的重复惩罚系数 |
--temperature | VLM 采样中使用的温度参数 |
--top_p | VLM 采样中使用的 top-p 参数 |
--min_pixels | VLM 图像预处理的最小像素数 |
--max_pixels | VLM 图像预处理的最大像素数 |
硬件与性能参数
| 参数名 | 说明 |
|---|---|
--device | 用于推理的设备,例如 cpu、gpu、npu、gpu:0、gpu:0,1。如果指定多个设备,将并行执行推理。注意:并非所有情况都支持并行推理。默认情况下,如果可用将使用 GPU 0,否则使用 CPU |
--enable_hpi | 启用高性能推理 |
--use_tensorrt | 是否使用 Paddle Inference TensorRT 子图引擎。如果模型不支持 TensorRT 加速,即使设置此标志也不会使用加速 |
--precision | 使用 Paddle Inference TensorRT 子图引擎时的 TensorRT 精度(fp32, fp16) |
--enable_mkldnn | 为推理启用 MKL-DNN 加速。如果 MKL-DNN 不可用或模型不支持,即使设置此标志也不会使用加速 |
--mkldnn_cache_capacity | MKL-DNN 缓存容量 |
--cpu_threads | 在 CPU 上用于推理的线程数 |
--paddlex_config | PaddleX 管道配置文件路径 |
四、复杂多模态文档本地解析实战
对于企业级应用开发来说,在客户端通过命令行的方式肯定是不能满足需求的,更常用的则是通过 Python 代码集成到业务系统中。
from paddleocr import PaddleOCRVL
# 关键:模型路径参数要在初始化时传入,而不是在 predict() 中
pipeline = PaddleOCRVL(
vl_rec_model_dir="/home/MuyuWorkSpace/02_OcrRag/PaddleOCR-VL-0.9B",
layout_detection_model_dir="/home/MuyuWorkSpace/02_OcrRag/PP-DocLayoutV2"
)
# predict 只需要传入输入文件和保存路径
# save_path 参数会自动保存可视化图片(布局检测结果和阅读顺序图)
output = pipeline.predict(
input="./imgs/paddleocrvl.png",
save_path="./output"
)
for res in output:
res.print() # 打印识别结果
res.save_to_json(save_path="./output") # 保存JSON格式
res.save_to_markdown(save_path="./output") # 保存Markdown格式
res.save_to_img(save_path="./output") # 保存可视化图片(带标注框)
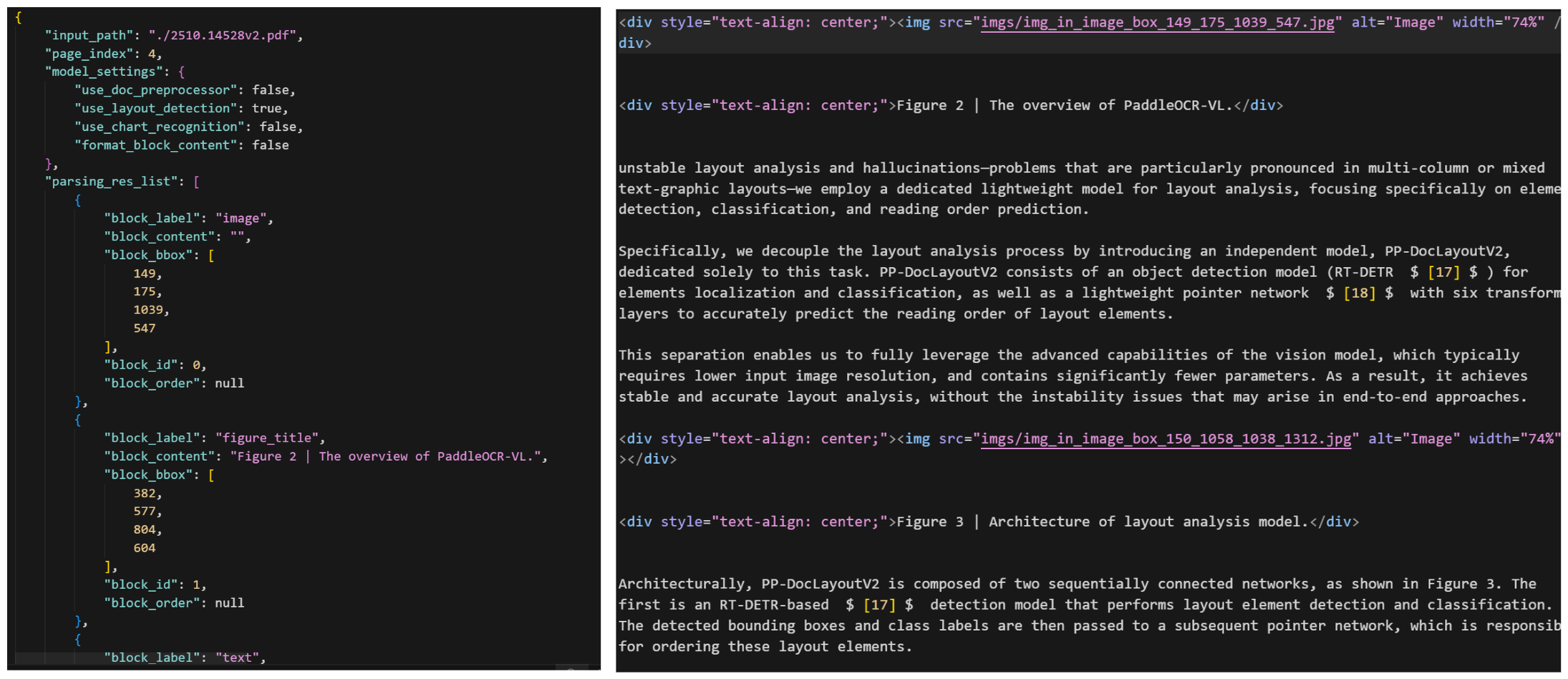
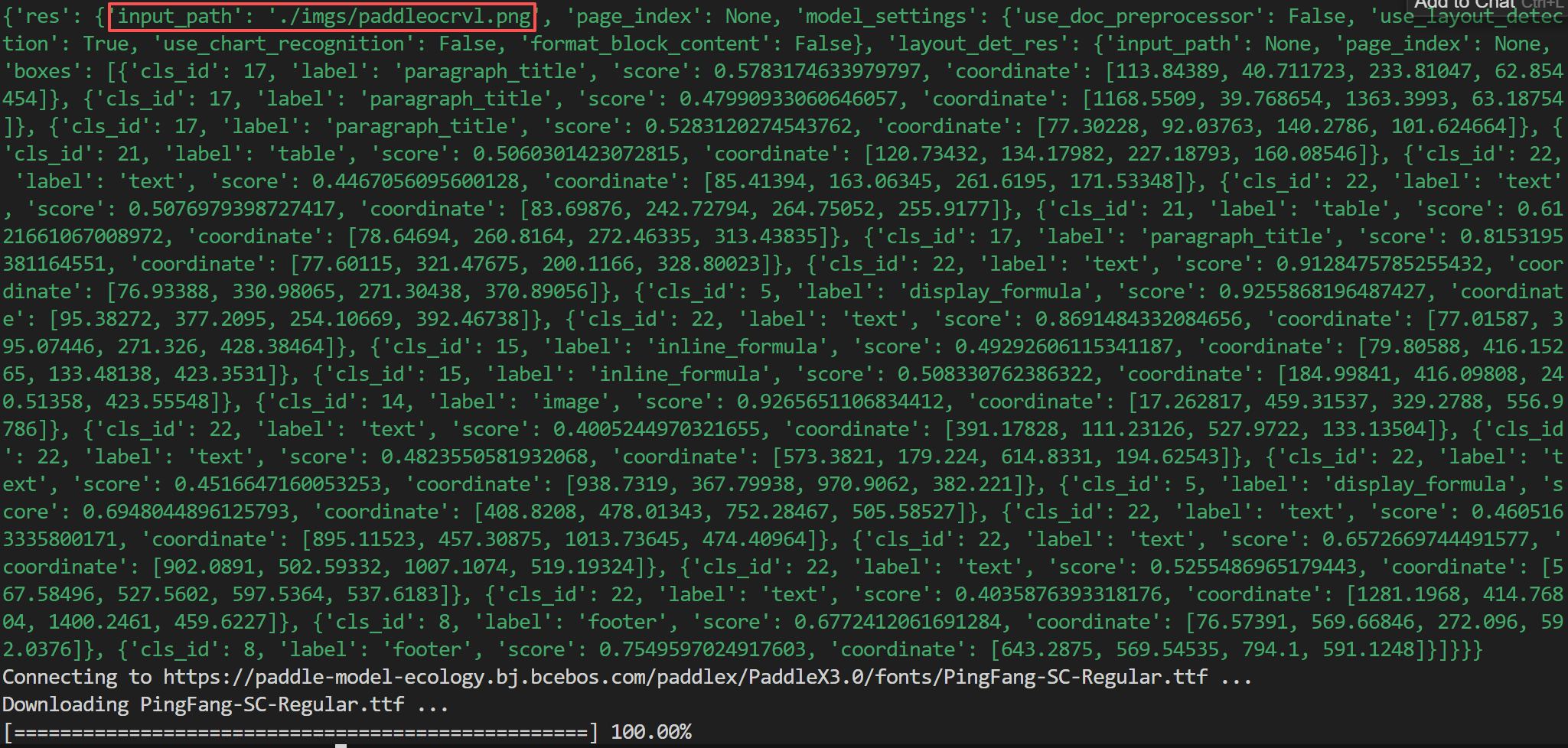
经过 PaddleOCR-VL 解析后,会生成一个 JSON 文件,核心构成如下:
FENCE0
Paddle OCR 关键字段
| 字段 | 说明 | RAG 用途 |
|---|---|---|
block_label | 元素类型(text/table/image/formula等) | 分类索引、差异化处理 |
block_content | 文本内容或 HTML 标签 | 向量化的主要内容 |
block_bbox | 边界框坐标 [x1, y1, x2, y2] | 溯源定位、可视化标注 |
block_id | 块的唯一标识 | 引用关系、溯源ID |
block_order | 阅读顺序(1, 2, 3...) | 上下文关联、chunk排序 |
Paddle OCR 不同 block_label 类型及其特点
| 类型 | 英文标签 | 内容特点 | RAG 处理建议 |
|---|---|---|---|
| 段落标题 | paragraph_title | 简短标题文本 | 作为元数据,增强语义检索 |
| 正文 | text | 普通文本段落 | 直接向量化,标准chunk |
| 表格 | table | HTML <table> 标签 | 提取+结构化+文本描述 |
| 公式 | display_formula | LaTeX 数学公式($$ ... $$) | 保留格式+文本解释 |
| 行内公式 | inline_formula | 行内 LaTeX($ ... $) | 嵌入上下文处理 |
| 图片 | image | 空内容或图片路径 | 多模态向量+标题描述 |
| 页脚 | footer | 页码、来源等信息 | 作为元数据,通常不向量化 |
import json
from collections import Counter
# 加载 JSON 结果
with open('./output/paddle_images/paddleocrvl_res.json', 'r', encoding='utf-8') as f:
ocr_result = json.load(f)
# 统计各类型元素数量
block_types = [block['block_label'] for block in ocr_result['parsing_res_list']]
type_counts = Counter(block_types)
print("=" * 60)
print("元素类型统计")
print("=" * 60)
for block_type, count in type_counts.most_common():
print(f"{block_type:20s}: {count:3d} 个")
print("\n" + "=" * 60)
print("阅读顺序分析")
print("=" * 60)
ordered_blocks = [b for b in ocr_result['parsing_res_list'] if b['block_order'] is not None]
unordered_blocks = [b for b in ocr_result['parsing_res_list'] if b['block_order'] is None]
print(f"有序元素: {len(ordered_blocks)} 个(主要内容)")
print(f"无序元素: {len(unordered_blocks)} 个(通常是表格、图片、页脚等辅助内容)")
# 查看不同类型的具体示例
print("\n" + "=" * 60)
print("各类型内容示例")
print("=" * 60)
for block_type in type_counts.keys():
example = next(b for b in ocr_result['parsing_res_list'] if b['block_label'] == block_type)
content = example['block_content']
# 截断过长内容
if len(content) > 100:
content = content[:100] + "..."
print(f"\n【{block_type}】")
print(f" 内容: {content}")
print(f" 坐标: {example['block_bbox']}")
print(f" 顺序: {example['block_order']}")
接下来我们快速测试 Deepseek-OCR 的本地运行效果。当然,本期公开课我们就不详细介绍 Deepseek-OCR 的本地部署流程,大家可以从百度网盘中领取详细的本地部署及运行测试文档。
import os
import re
import base64
import tempfile
import shutil
import uuid
import json
from io import BytesIO
from typing import List, Optional, Dict, Any, Tuple
from dataclasses import dataclass
import torch
from PIL import Image
from transformers import AutoTokenizer, AutoModel
MODEL_PATH = "/home/data/nongwa/workspace/model/OCR/DeepSeek-OCR" # 修改为你的模型路径
IMAGE_PATH = "./imgs/paddleocrvl.png" # 修改为你的图片路径
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"加载模型: {MODEL_PATH}")
print(f"使用设备: {device}")
# 判断数据类型
if torch.cuda.is_available() and torch.cuda.is_bf16_supported():
dtype = torch.bfloat16
elif torch.cuda.is_available():
dtype = torch.float16
else:
dtype = torch.float32
tokenizer = AutoTokenizer.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
local_files_only=True
)
model = AutoModel.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
local_files_only=True,
use_safetensors=True,
torch_dtype=dtype
).eval().to(device)
if tokenizer.pad_token_id is None and tokenizer.eos_token_id is not None:
tokenizer.pad_token = tokenizer.eos_token
print("模型加载成功\n")
print(f"加载图片: {IMAGE_PATH}")
image = Image.open(IMAGE_PATH).convert("RGB")
img_width, img_height = image.size
print(f"尺寸: {img_width} x {img_height}\n")
print("执行 OCR...")
prompt = "<image>\n<|grounding|>Convert the document to markdown."
# 保存临时图片
img_tmp = tempfile.NamedTemporaryFile(suffix=".png", delete=False)
img_tmp_path = img_tmp.name
img_tmp.close()
image.save(img_tmp_path, format="PNG")
out_dir = tempfile.mkdtemp(prefix="dpsk_ocr_")
with torch.inference_mode():
ocr_output = model.infer(
tokenizer=tokenizer,
prompt=prompt,
image_file=img_tmp_path,
output_path=out_dir,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=False,
test_compress=False,
eval_mode=True,
)
# 清理临时文件
try:
os.remove(img_tmp_path)
shutil.rmtree(out_dir, ignore_errors=True)
except:
pass
print("OCR 完成\n")
print("="*60)
print("原始输出:")
print(ocr_output)
print("="*60 + "\n")
# 清理统计信息
cleaned_text = re.sub(r'={50,}.*?={50,}', '', ocr_output, flags=re.DOTALL)
# 按 <|ref|> 标签分割
segments = re.split(r'(<\|ref\|>.*?<\|/ref\|>)', cleaned_text)
# 存储解析结果
parsed_blocks = []
extracted_images = {}
# 逐段解析
i = 0
while i < len(segments):
segment = segments[i].strip()
if not segment:
i += 1
continue
# 查找 ref 标签
ref_match = re.match(r'<\|ref\|>(.*?)<\|/ref\|>', segment)
if ref_match:
block_type = ref_match.group(1).strip()
# 查找下一段
if i + 1 < len(segments):
next_segment = segments[i + 1]
# 提取 bbox 和内容
det_match = re.match(r'<\|det\|>\[\[(.*?)\]\]<\|/det\|>\s*(.*)', next_segment, re.DOTALL)
if det_match:
bbox_str = det_match.group(1).strip()
content = det_match.group(2).strip()
# 解析 bbox
try:
bbox = [float(x.strip()) for x in bbox_str.split(',')]
if len(bbox) != 4:
bbox = [0, 0, 0, 0]
except:
bbox = [0, 0, 0, 0]
# 创建块数据
block_data = {
'type': block_type,
'bbox': bbox,
'content': content
}
# 如果是图片类型,裁切并保存
if block_type == 'image':
x0, y0, x1, y1 = int(bbox[0]), int(bbox[1]), int(bbox[2]), int(bbox[3])
x0 = max(0, min(x0, img_width))
y0 = max(0, min(y0, img_height))
x1 = max(x0, min(x1, img_width))
y1 = max(y0, min(y1, img_height))
if x1 > x0 and y1 > y0:
cropped_img = image.crop((x0, y0, x1, y1))
# 转 base64
buffered = BytesIO()
cropped_img.save(buffered, format="PNG")
img_base64 = base64.b64encode(buffered.getvalue()).decode('utf-8')
img_filename = f"image_{uuid.uuid4().hex[:12]}.png"
extracted_images[img_filename] = img_base64
block_data['image_file'] = img_filename
# 如果是表格,提取 HTML
if block_type == 'table':
html_match = re.search(r'<table>.*?</table>', content, re.DOTALL)
if html_match:
block_data['html'] = html_match.group(0)
parsed_blocks.append(block_data)
i += 2
continue
i += 1
print(f"✓ 解析完成: {len(parsed_blocks)} 个内容块")
print(f"✓ 提取图片: {len(extracted_images)} 张\n")
for block in parsed_blocks:
if block['type'] == 'image' and 'image_file' in block:
img_filename = block['image_file']
# 获取图片数据
img_base64 = extracted_images[img_filename]
img_data = base64.b64decode(img_base64)
cropped_img = Image.open(BytesIO(img_data)).convert("RGB")
# 保存临时图片
img_tmp = tempfile.NamedTemporaryFile(suffix=".png", delete=False)
img_tmp_path = img_tmp.name
img_tmp.close()
cropped_img.save(img_tmp_path, format="PNG")
out_dir = tempfile.mkdtemp(prefix="dpsk_img_desc_")
try:
# 使用 VQA 模式生成描述(不用 <|grounding|>)
desc_prompt = "<image>\n请详细描述这张图片的内容,包括主要元素、颜色、布局等。"
with torch.inference_mode():
description = model.infer(
tokenizer=tokenizer,
prompt=desc_prompt,
image_file=img_tmp_path,
output_path=out_dir,
base_size=512,
image_size=512,
crop_mode=False,
save_results=False,
test_compress=False,
eval_mode=True,
)
# 清理特殊标签
if description:
description = re.sub(r'<\|.*?\|>', '', description).strip()
block['description'] = description
print(f" - {img_filename}: {description[:60]}...")
except Exception as e:
print(f" {img_filename} 描述生成失败: {e}")
finally:
try:
os.remove(img_tmp_path)
shutil.rmtree(out_dir, ignore_errors=True)
except:
pass
print("✓ 图片描述生成完成\n")
for idx, block in enumerate(parsed_blocks):
print(f"\n【块 {idx+1}】")
print(f" 类型: {block['type']}")
print(f" 位置: {block['bbox']}")
if block['type'] == 'image':
if 'image_file' in block:
print(f" 图片: {block['image_file']}")
if 'description' in block:
desc_preview = block['description']
print(f" 描述: {desc_preview}")
elif block['type'] == 'table':
if 'html' in block:
print(f" HTML: {block['html'][:100]}...")
else:
print(f" 内容: {block['content'][:100]}...")
else:
content_preview = block['content'][:100] if len(block['content']) > 100 else block['content']
print(f" 内容: {content_preview}")
五、项目:PaddleOCR-VL 构建多模态RAG系统
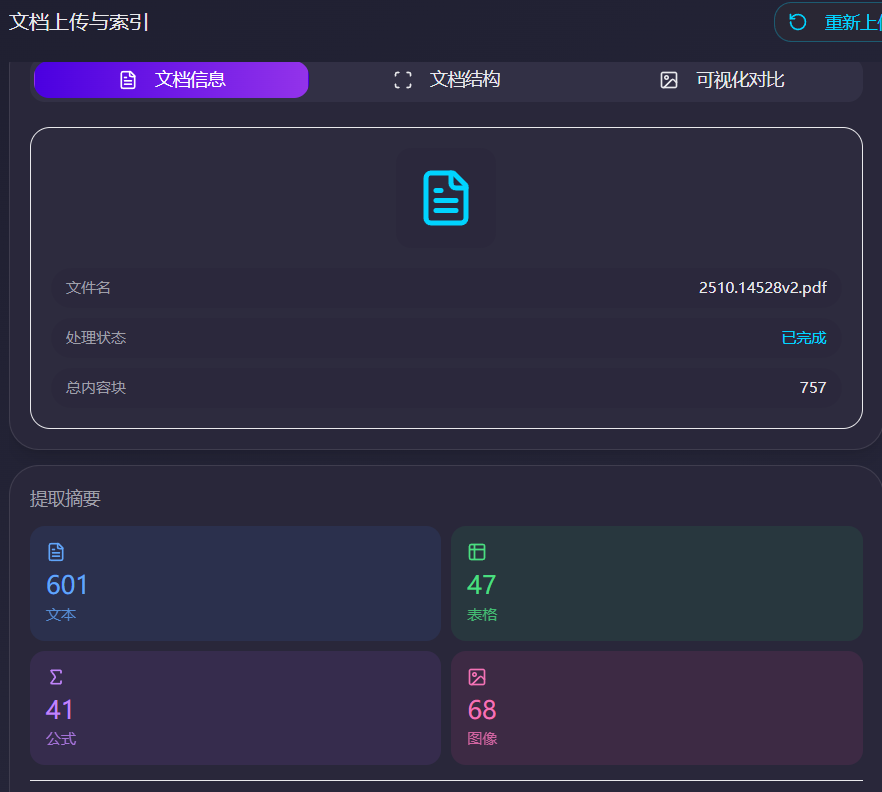
本节内容,我们将详细介绍如何部署和运行这个基于PaddleOCR-VL的多模态AgenticRAG智能问答系统。该系统支持复杂PDF文档、图片、表格、公式等多种格式的智能分析和问答,并具备精准的溯源能力。
5.1 项目核心模块代码详解
PaddleOCR-VL 的输出格式非常适合构建多模态 RAG 系统,如果想要明确的区分出图像、表格、普通文本等信息,一个基本的处理流程是这样的:
FENCE0
首先第一步做的就是完成PaddleOCR-VL模型的接入及实现解析过程。核心代码文件为:
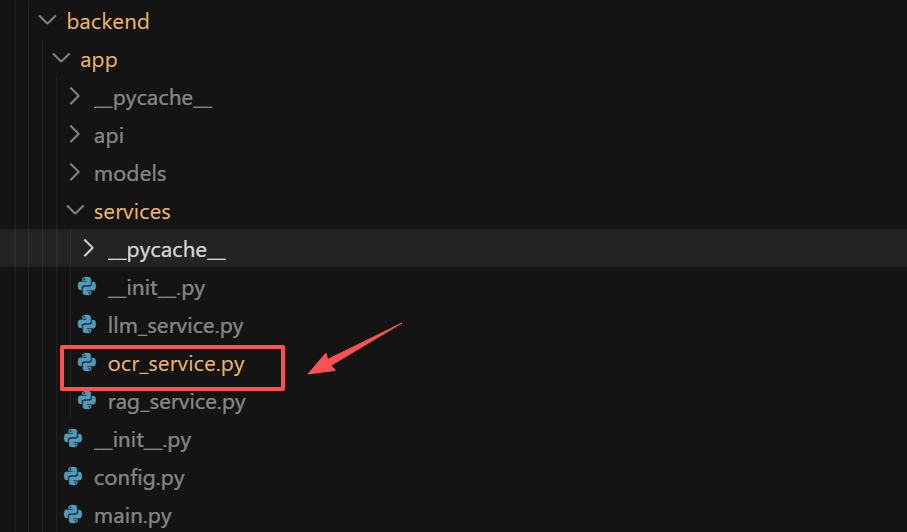
这个服务的核心流程是:初始化时异步加载 PaddleOCRVL 模型到,然后在 parse_document() 中通过线程池执行阻塞的 OCR 调用,PaddleOCR 会将文档解析为多页结果并保存为 JSON/Markdown/可视化图片到磁盘。服务优先从生成的 *_res.json 文件中读取每页的 parsing_res_list,将其中的每个 block(包含 block_id、block_label、block_content、block_bbox、block_order 等字段)转换为 ParsedBlock 对象,最后通过 calculate_stats() 按 label 关键词(table/image/formula/其他)统计各类型块的数量并返回 DocumentStats。即:
- 初始化 → 加载 PaddleOCR 模型
- 执行 OCR → 调用 pipeline.predict() 生成 JSON/Markdown/图片
- 解析结果 → 从 JSON 文件转为 ParsedBlock 对象
- 计算统计 → 按类型分类统计块数量
分类逻辑
| 判断条件 | 分类结果 | 示例 label |
|---|---|---|
'table' in label | table_blocks | table, table_cell |
'image/figure/chart' in label | image_blocks | image, figure, chart |
'formula/equation' in label | formula_blocks | display_formula, inline_formula |
| 其他 | text_blocks | text, paragraph_title, footer |
接下来,在第二步我们要封装 AgenticRAG 的构建逻辑,核心代码文件为:
其中核心的分块策略是根据内容类型差异化处理
分块策略
| 内容类型 | 分块策略 | 原因 |
|---|---|---|
长文本 (text) | ✂️ 分块(chunk_size=500) | 避免单个向量损失局部语义 |
| 短文本 | ✅ 不分块 | 保持完整性 |
表格 (table) | ✅ 整体存储 | 表格结构不能拆分 |
公式 (formula) | ✅ 整体存储 | LaTeX 公式语义完整 |
图片 (image) | ✅ 整体存储 | 图片标题/caption 整体索引 |
每个 chunk 存储以下元数据:
FENCE0
其次,对于溯源的策略,则主要是通过对元数据的格式化处理 + 大模型生成描述的引用来完成。核心代码文件:
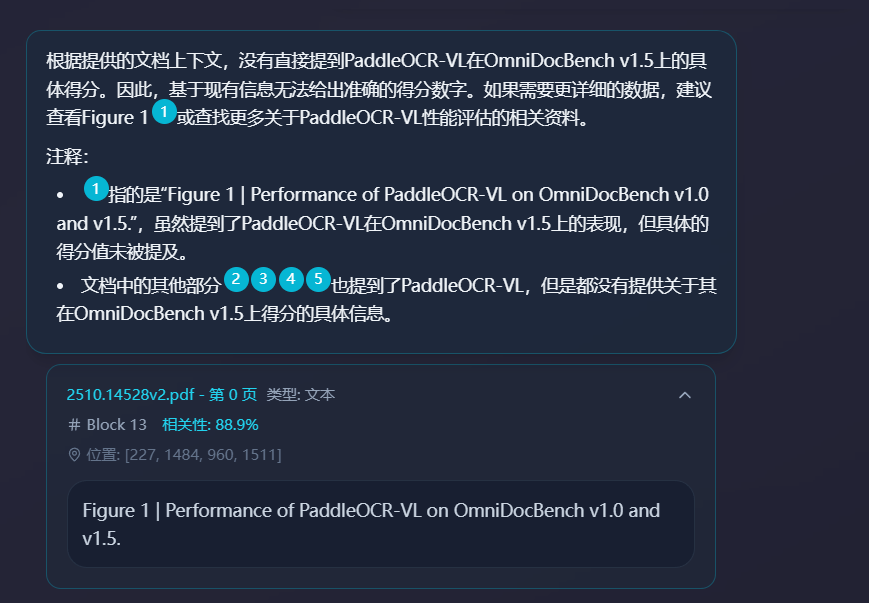
在 Prompt 中明确引用:
FENCE0
5.2 项目架构介绍
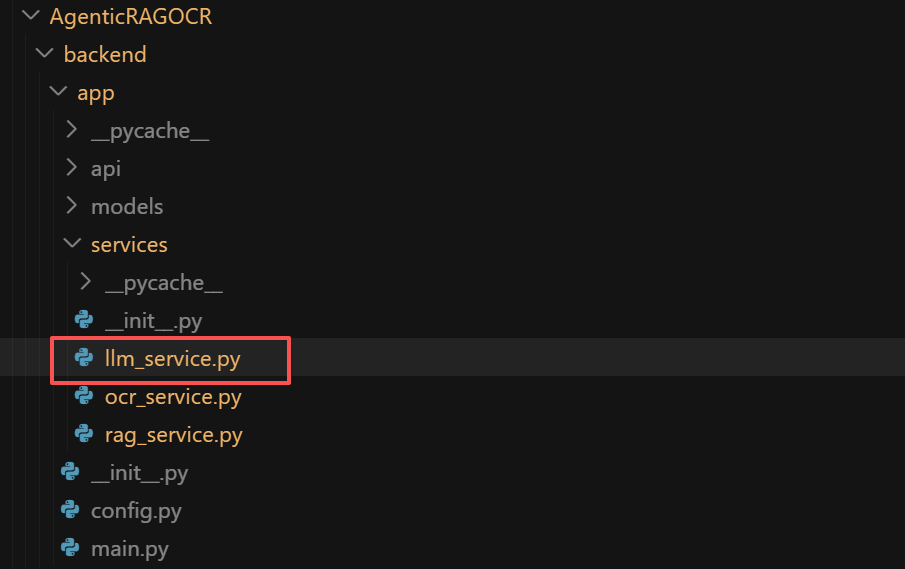
AgenticRAGOCR 项目采用前后端分离的模块化设计,核心结构如下:
FENCE0
核心组件功能说明
| 层级 | 技术栈 | 主要功能 | 关键文件 |
|---|---|---|---|
| API服务层 | FastAPI + Pydantic | RESTful API、文件上传、智能问答 | main.py |
| OCR解析层 | PaddleOCR-VL-0.9B | 文档解析、布局检测、内容识别 | ocr_service.py |
| 向量检索层 | ChromaDB + Qwen Embeddings | 语义检索、相似度计算、分块策略 | rag_service.py |
| 问答生成层 | 通义千问大模型 | 智能问答、溯源引用、上下文理解 | llm_service.py |
| 数据存储层 | 文件系统 + 向量数据库 | 原文件存储、向量索引、元数据管理 | uploads/ + chroma_db/ |
| 前端界面层 | React + TypeScript + Vite | 文档可视化、问答交互、溯源展示 | frontend/ |
5.3 本地部署环境配置
系统基于Python 3.11+开发,需要确保环境满足以下要求:
环境要求
| 组件 | 版本要求 | 安装方式 | 验证命令 |
|---|---|---|---|
| Python | ≥ 3.11 | 官网下载或conda | python --version |
| Node.js | ≥ 18.0 | 官网下载或nvm | node --version |
| pip | 最新版 | 随Python安装 | pip --version |
| npm | ≥ 9.0 | 随Node.js安装 | npm --version |
| GPU | 推荐8GB+ | CUDA 12.6 | nvidia-smi |
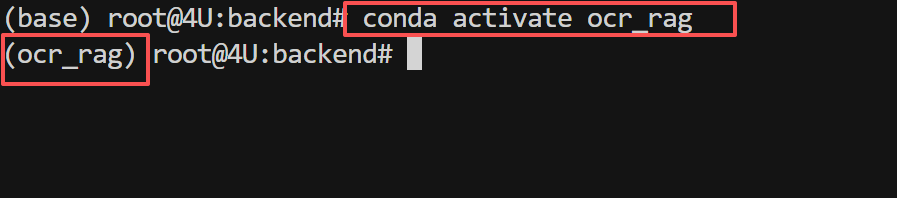
本项目使用 ocr_rag 虚拟环境(与之前的PaddleOCR环境一致):
FENCE0
激活后,命令行提示符前会显示 (ocr_rag),表示已进入虚拟环境。
5.4 后端项目配置与启动
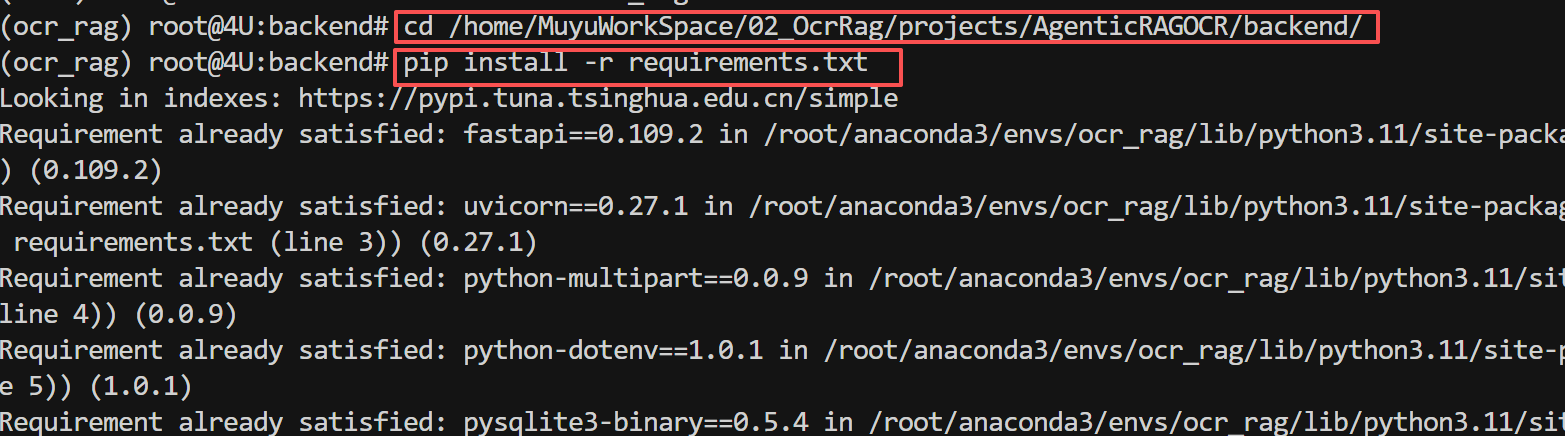
进入项目后端目录,安装Python依赖:
FENCE0
核心Python依赖
| 依赖包 | 版本 | 用途 |
|---|---|---|
| fastapi | 0.109.2 | Web框架 |
| uvicorn | 0.27.1 | ASGI服务器 |
| dashscope | 1.19.0 | 阿里云百炼SDK(Qwen模型) |
| chromadb | 0.4.22 | 向量数据库 |
| langchain | 0.1.7 | LLM应用框架 |
| paddleocr[all] | 最新版 | OCR工具(已在前面安装) |
| paddlepaddle-gpu | 3.2.0 | 深度学习框架(已在前面安装) |
项目的环境变量配置已经在 backend/.env 文件中定义,主要包含以下配置:
FENCE0
重要提示:
DASHSCOPE_API_KEY:必须配置,用于调用通义千问模型和Embedding服务PADDLEOCR_VL_MODEL_DIR和LAYOUT_DETECTION_MODEL_DIR:指向已下载的模型路径
配置完成后,启动FastAPI后端服务:
FENCE0
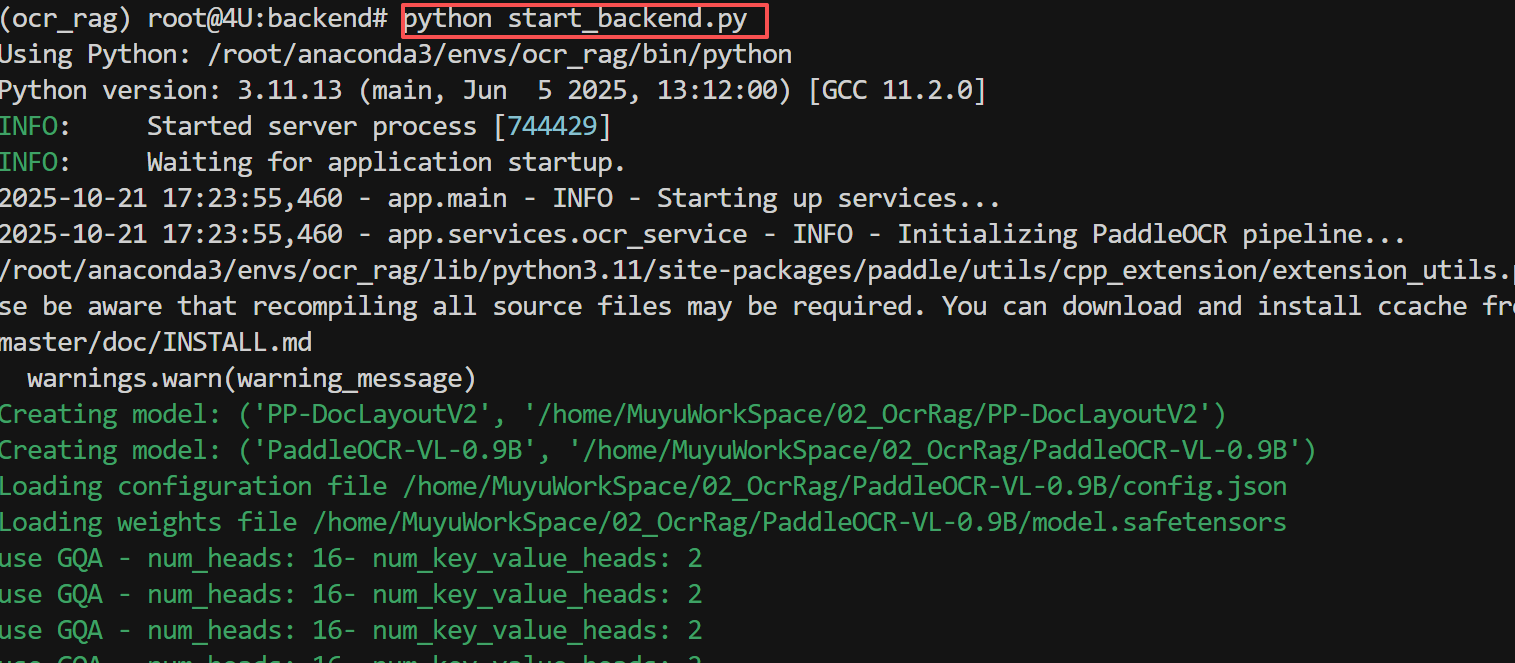
启动成功后,终端会显示如下信息:
FENCE1
此时可以访问 http://localhost:8100/docs 查看API文档。
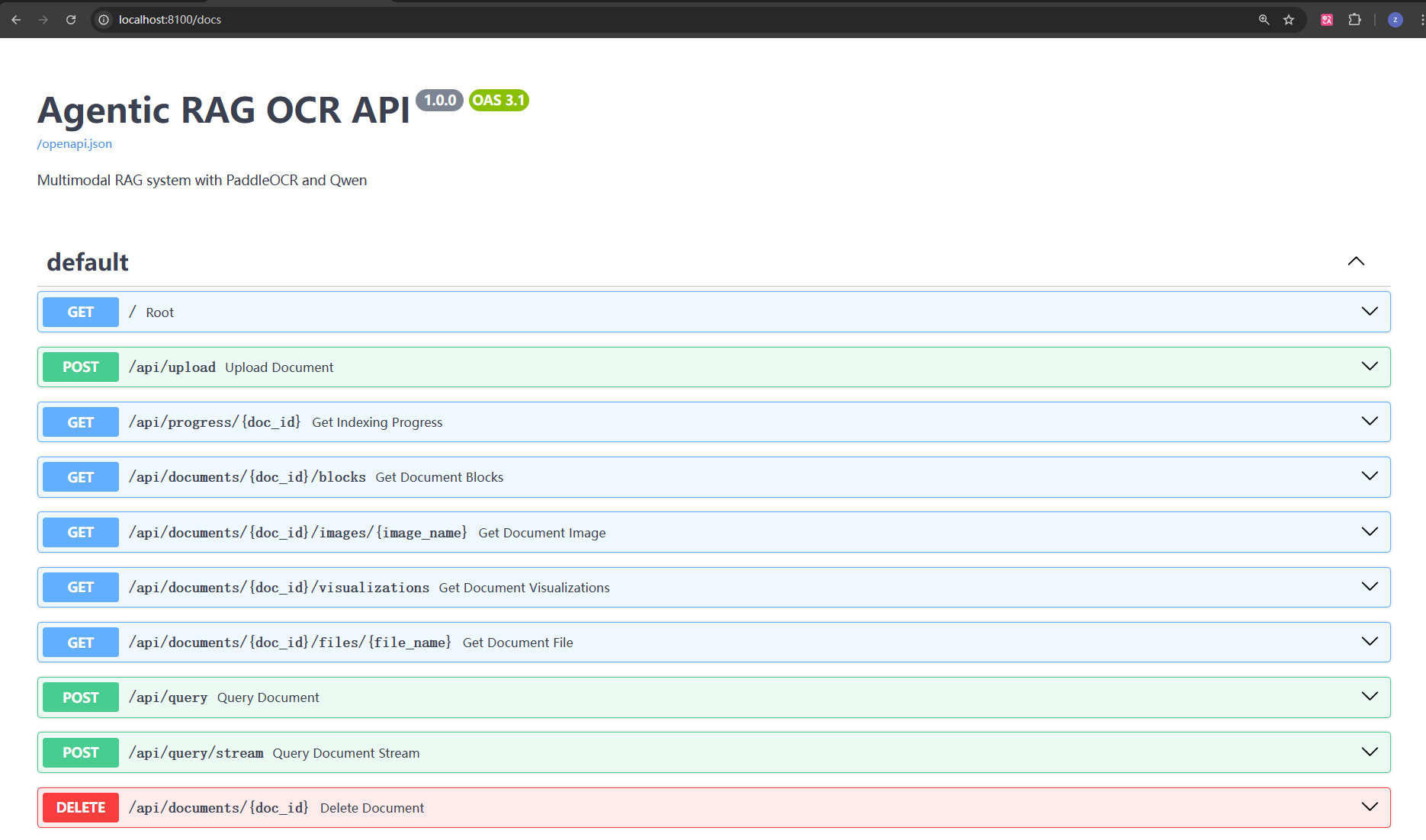
主要API接口
| 接口路径 | 方法 | 功能 | 说明 |
|---|---|---|---|
/api/documents/upload | POST | 文档上传 | 支持PDF、图片等格式,自动OCR解析 |
/api/documents/{doc_id}/index | POST | 文档索引 | 将OCR结果向量化并存入ChromaDB |
/api/documents/{doc_id}/query | POST | 语义检索 | 基于向量检索的语义搜索 |
/api/documents/{doc_id}/qa | POST | 智能问答 | 多模态问答,支持溯源引用 |
/api/documents | GET | 文档列表 | 获取已上传的文档列表 |
/api/documents/{doc_id}/blocks | GET | 获取文档块 | 获取解析后的文档块(可按类型过滤) |
/api/documents/{doc_id}/pages/{page_index} | GET | 获取页面信息 | 获取特定页的OCR结果 |
/api/documents/{doc_id}/visualizations/{img_name} | GET | 获取可视化图 | 获取布局检测和阅读顺序可视化图 |
5.5 前端服务配置与启动
进入前端目录,安装Node.js依赖:
FENCE0
核心前端技术栈:
前端技术栈
| 技术 | 版本 | 用途 |
|---|---|---|
| React | 18.3.1 | UI框架 |
| TypeScript | 5.6.3 | 类型系统 |
| Vite | 5.4.11 | 构建工具 |
| TailwindCSS | 3.4.15 | CSS框架 |
| Radix UI | 最新版 | 组件库 |
| React Markdown | 10.1.0 | Markdown渲染 |
| KaTeX | 0.16.25 | 公式渲染 |
依赖安装完成后,启动Vite开发服务器:
FENCE0
启动成功后,终端会显示如下信息:
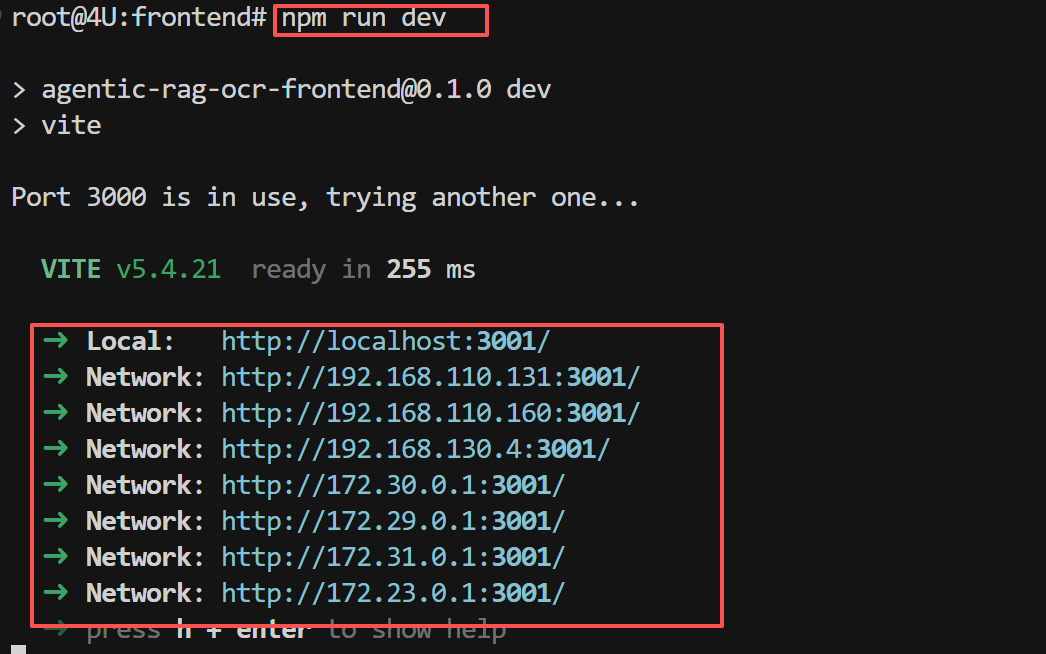
打开浏览器访问 http://localhost:5173,即可看到AgenticRAGOCR系统的前端界面。
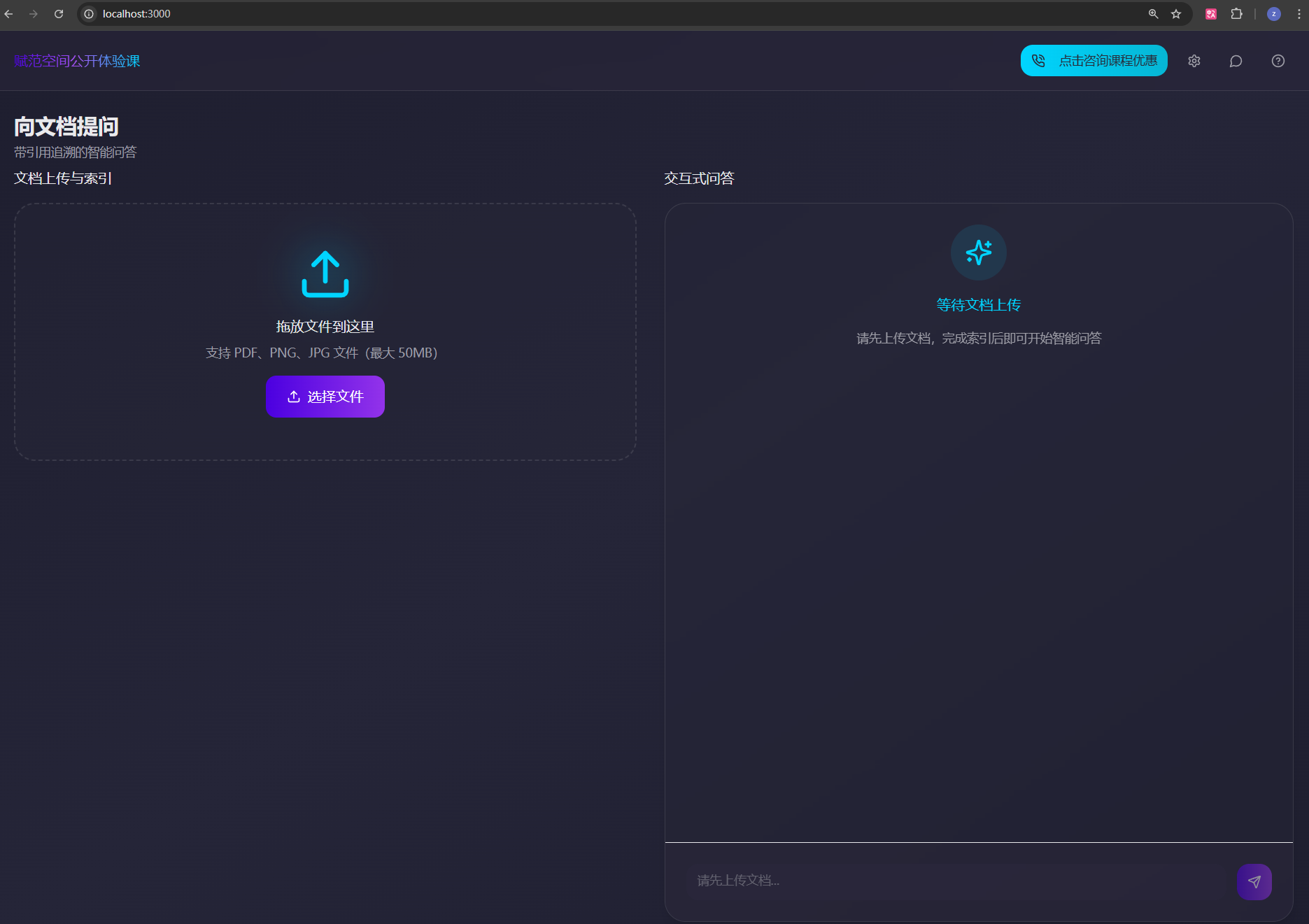
至此,我们就完整实现了 PaddleOCR-VL 的本地部署,到复杂文档解析,再到企业级 AgenticRAG 系统的完整搭建,相信通过本节课程的学习,大家已经基本掌握了多模态 RAG 技术的核心实现。
我们下期公开课,再见! 👋