课程说明:
- 体验课内容节选自《大模型与Agent开发》完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《大模型与Agent开发实战课》 :

《大模型与Agent开发实战课》 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!



《大模型与Agent开发实战》(12月班)体验课
微软GraphRAG快速部署与调用方法详解
一、微软GraphRAG项目介绍与GraphRAG流程回顾
检索增强生成(RAG) 是一种通过结合真实世界的信息来提升大型语言模型(LLM)输出质量的技术。RAG 技术是大多数基于 LLM 的工具中的一个重要组成部分。大多数 RAG 方法使用 向量相似性 作为检索技术,我们将其称为 基线 RAG(Baseline RAG)。
GraphRAG 则使用 知识图谱 来在推理复杂信息时显著提升问答性能。当需要对复杂数据进行推理时,GraphRAG 展示了优于基线 RAG 的性能,特别是在 知识图谱 的帮助下。
RAG 技术在帮助 LLM 推理私有数据集方面显示了很大的潜力——例如,LLM 没有在训练时接触过的、企业的专有研究、业务文档或通信数据。基线 RAG 技术最初是为了解决这个问题而提出的,但我们观察到,在某些情况下,基线 RAG 的表现并不理想。以下是几个典型的场景:
-
基线 RAG 很难将信息串联起来:当一个问题的答案需要通过多个不同的信息片段,并通过它们共享的属性来连接,进而提供新的综合见解时,基线 RAG 表现得很差。
例如,在回答类似“如何通过现有的数据推断出新结论”这种问题时,基线 RAG 无法很好地处理这些散布在不同文档中的相关信息,它可能会遗漏一些关键联系点。
-
基线 RAG 无法有效理解大型数据集或单一大文档的整体语义概念:当被要求在大量数据或复杂文档中进行总结、提炼和理解时,基线 RAG 往往表现不佳。
例如,如果问题要求对整个文档或多篇文档的主题进行总结和理解,基线 RAG 的简单向量检索方法可能无法处理文档间的复杂关系,导致对全局语义的理解不完整。
为了应对这些挑战,技术社区正在努力开发扩展和增强 RAG 的方法。微软研究院(Microsoft Research)提出的 GraphRAG 方法,使用 LLM 基于输入语料库构建 知识图谱。这个图谱与社区总结和图谱机器学习输出结合,能够在查询时增强提示(prompt)。GraphRAG 在回答以上两类问题时,展示了 显著的改进,尤其是在 复杂信息的推理能力 和 智能性 上,超越了基线 RAG 之前应用于私有数据集的其他方法。
1.GraphRAG项目简介
GraphRAG 是微软研究院开发的一种先进的增强检索生成(RAG)框架,旨在提升语言模型(LLM)在处理复杂数据时的性能。与传统的 RAG 方法依赖向量相似性检索不同,GraphRAG 利用 知识图谱 来显著增强语言模型的问答能力,特别是在处理私有数据集或大型、复杂数据集时表现尤为出色。
2.GraphRAG核心特点
传统的 Baseline RAG 方法在某些情况下表现不佳,尤其是当查询需要在不同信息片段之间建立联系时,或是当需要对大规模数据集进行整体理解时。GraphRAG 通过以下方式克服了这些问题:
- 更好的连接信息点:GraphRAG 能够处理那些需要从多个数据点合成新见解的任务。
- 更全面的理解能力:GraphRAG 更擅长对大型数据集进行全面理解,能够更好地处理复杂的抽象问题。
而借助微软开源的GeaphRAG项目,我们可以快速做到以下事项:
- 基于图的检索:传统的 RAG 方法使用向量相似性进行检索,而 GraphRAG 引入了知识图谱来捕捉实体、关系及其他重要元数据,从而更有效地进行推理。
- 层次聚类:GraphRAG 使用 Leiden 技术进行层次聚类,将实体及其关系进行组织,提供更丰富的上下文信息来处理复杂的查询。
- 多模式查询:支持多种查询模式:
- 全局搜索:通过利用社区总结来进行全局性推理。
- 局部搜索:通过扩展相关实体的邻居和关联概念来进行具体实体的推理。
- DRIFT 搜索:结合局部搜索和社区信息,提供更准确和相关的答案。
- 图机器学习:集成了图机器学习技术,提升查询响应质量,并提供来自结构化和非结构化数据的深度洞察。
- Prompt 调优:提供调优工具,帮助根据特定数据和需求调整查询提示,从而提高结果质量。
3.GraphRAG运行流程
索引(Indexing)过程
- 文本单元切分:将输入文本分割成 TextUnits,每个 TextUnit 是一个可分析的单元,用于提取关键信息。
- 实体和关系提取:使用 LLM 从 TextUnits 中提取实体、关系和关键声明。
- 图构建:构建知识图谱,使用 Leiden 算法进行实体的层次聚类。每个实体用节点表示,节点的大小和颜色分别代表实体的度数和所属社区。
- 社区总结:从下到上生成每个社区及其成员的总结,帮助全局理解数据集。
查询(Query)过程
索引完成后,用户可以通过不同的搜索模式进行查询:
- 全局搜索:当我们想了解整个语料库或数据集的整体概况时,GraphRAG 可以利用 社区总结 来快速推理和获取信息。这种方式适用于大范围问题,如某个主题的总体理解。
- 局部搜索:如果问题关注于某个特定的实体,GraphRAG 会向该实体的 邻居(即相关实体)扩展搜索,以获得更详细和精准的答案。
- DRIFT 搜索:这是对局部搜索的增强,除了获取邻居和相关概念,还引入了 社区信息 的上下文,从而提供更深入的推理和连接。
Prompt 调优
为了获得最佳性能,GraphRAG 强烈建议进行 Prompt 调优,确保模型可以根据你的特定数据和查询需求进行优化,从而提供更准确和相关的答案。
4.GraphRAG核心原理回顾

二、GraphRAG安装与Indexing检索流程实现
注,以下实验环境均为Ubuntu系统,以更好的模拟真实企业应用场景,其中大多数方法也可以直接迁移至Windows操作系统中。
【补充阅读】在线算力租赁平台AutoDL使用指南与虚拟环境创建方法
from IPython.display import Markdown, display
with open('【补充材料】在线算力租赁平台AutoDL使用指南与虚拟环境创建方法.md', 'r') as file:
md_content = file.read()
display(Markdown(md_content))
1.GraphRAG安装与项目创建
- Step 1.使用pip安装graphrag
FENCE0
!pip install graphrag
- Step 2.创建检索项目文件夹
FENCE0

- Step 3.上传数据集
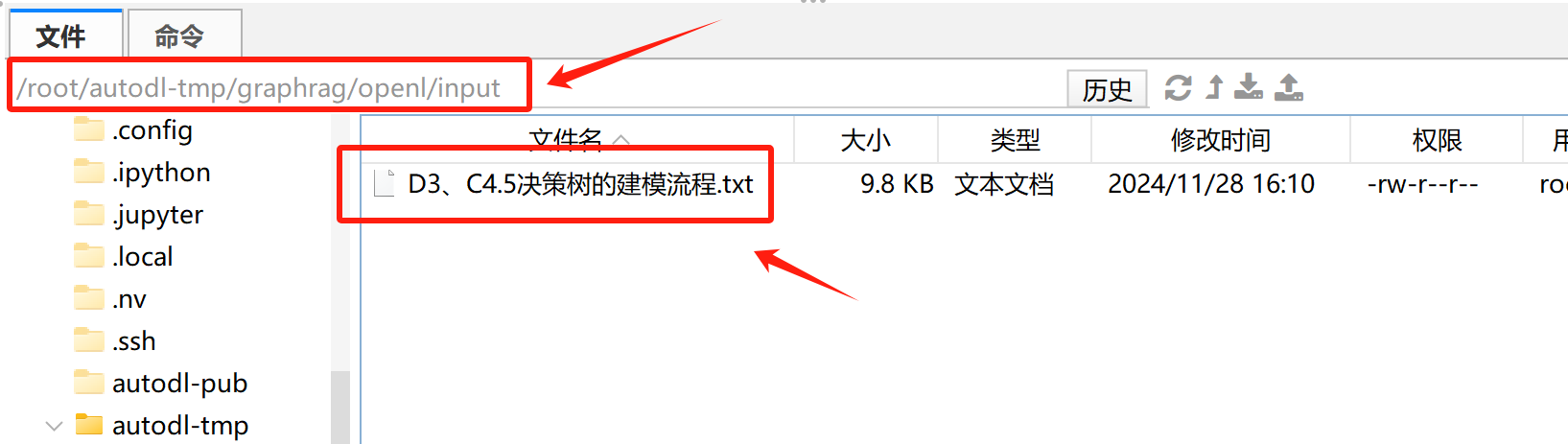
相关数据集已同步至本节公开课的课件包,扫码添加老师助理即可领取:
- Step 4.初始化项目文件
FENCE0
!graphrag init --root ./openl
- Step 5.修改项目配置
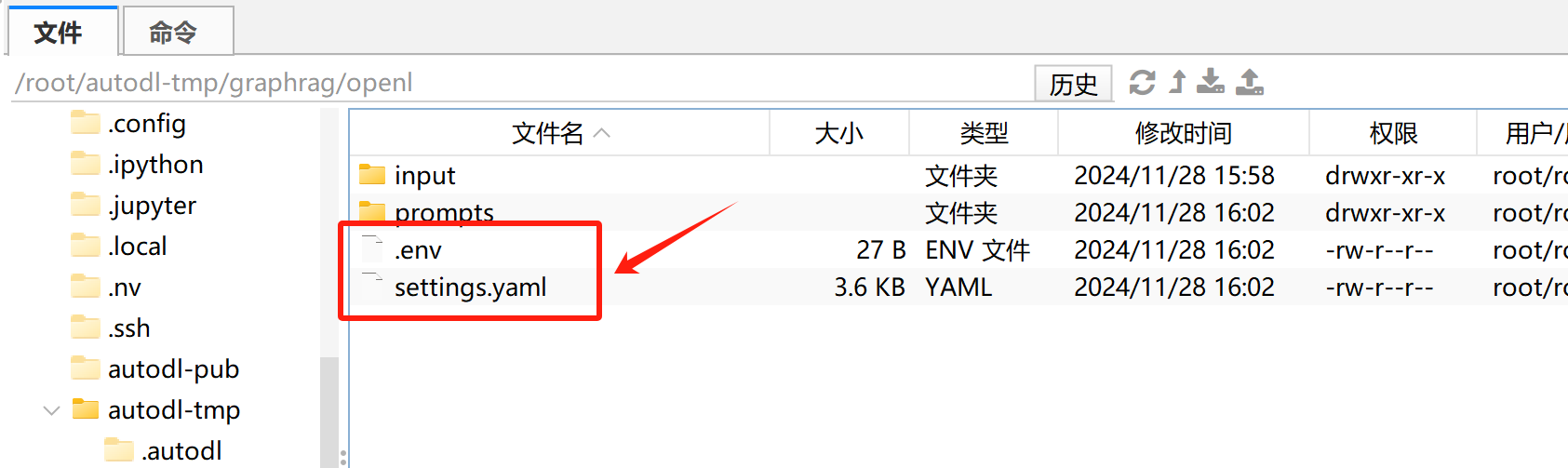
打开.env文件,填写OpenAI API-KEY
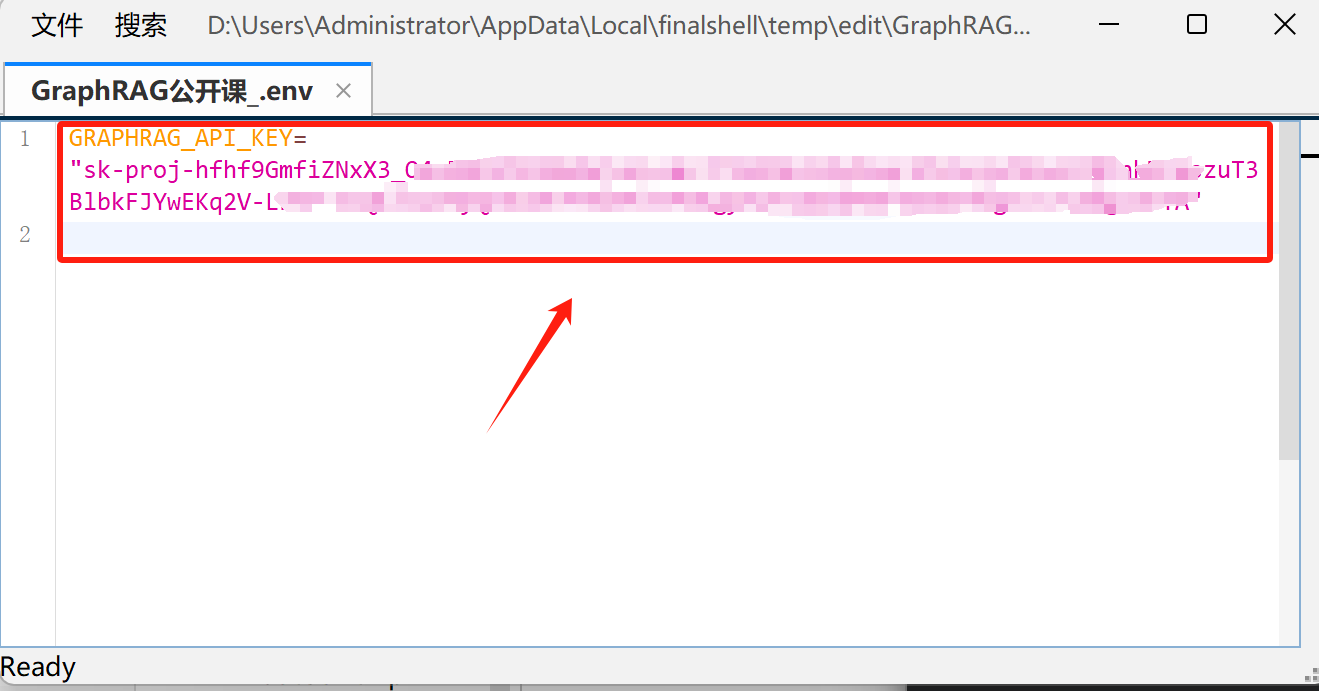
打开setting.yaml文件,填写模型名称和反向代理地址:
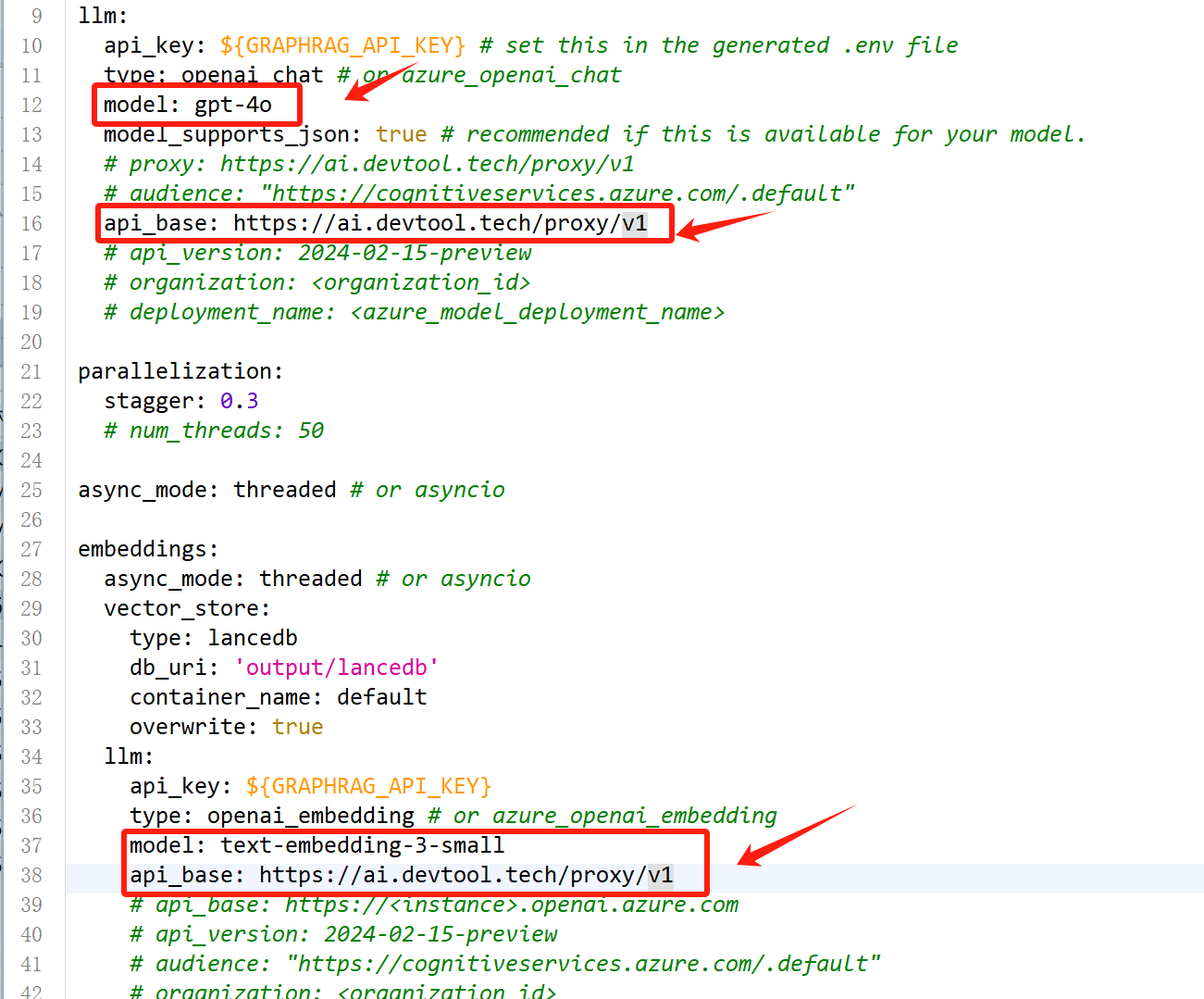
其中反向代理地址为api_base: https://ai.devtool.tech/proxy/v1
- 【可选】Step 6.验证API-KEY和反向代理地址是否可以正常运行
from openai import OpenAI
api_key = 'your-openai-api-key'
# 实例化客户端
client = OpenAI(api_key=api_key,
base_url="https://ai.devtool.tech/proxy/v1")
# 调用 GPT-4o-mini 模型
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "你好,好久不见!"}
]
)
# 输出生成的响应内容
print(response.choices[0].message.content)
然后查看当前API-KEY可以调用的模型:
models_list = client.models.list()
models_list.data
2.GraphRAG索引Indexing过程执行
一切准备就绪后,即可开始执行GraphRAG索引过程。
- Step 7.借助GraphRAG脚本自动执行indexing
!graphrag index --root ./openl
该命令也可以在终端内运行,结果如图:
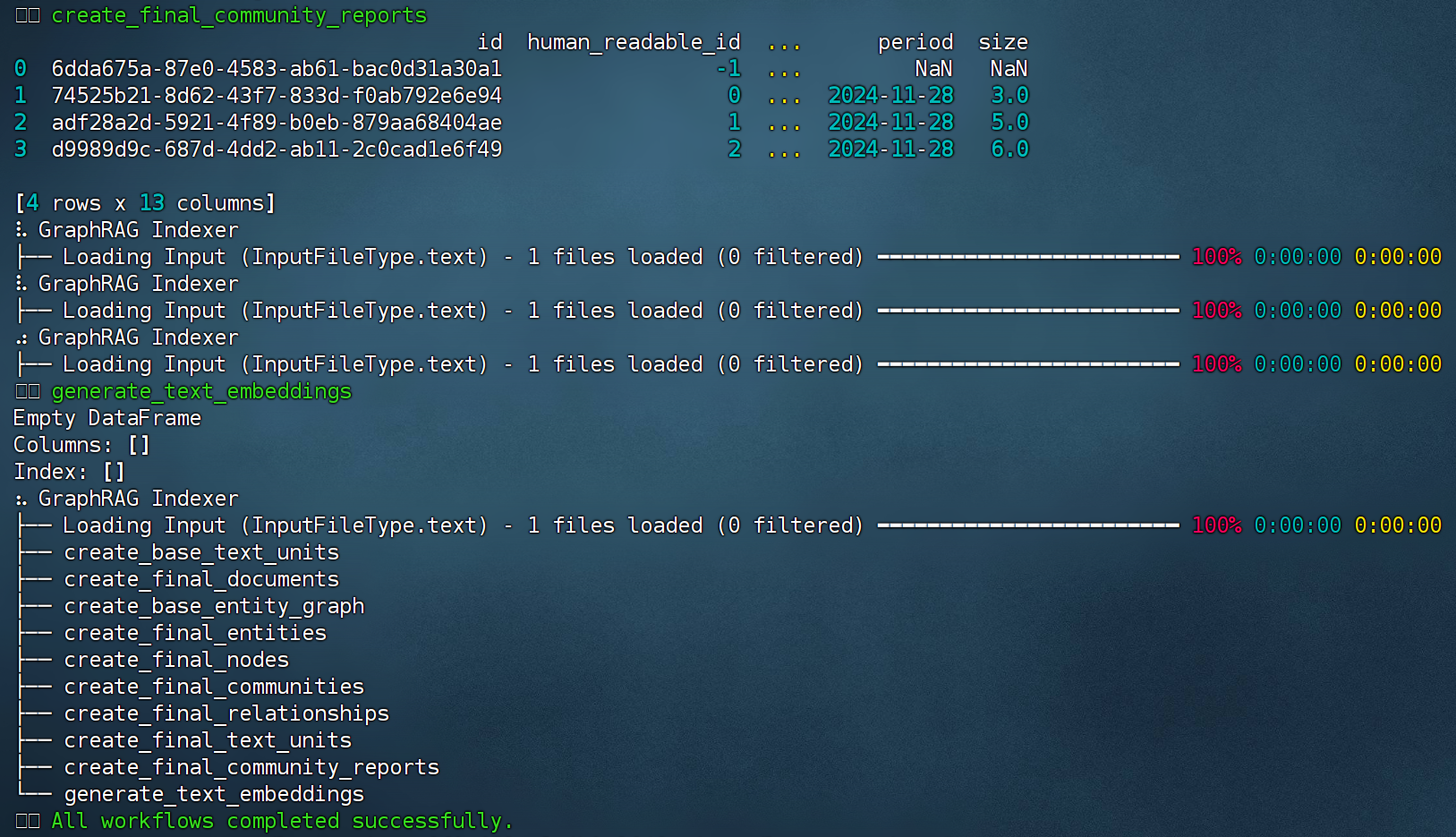
运行结束后,各知识图谱相关数据集都保存在output文件夹中:
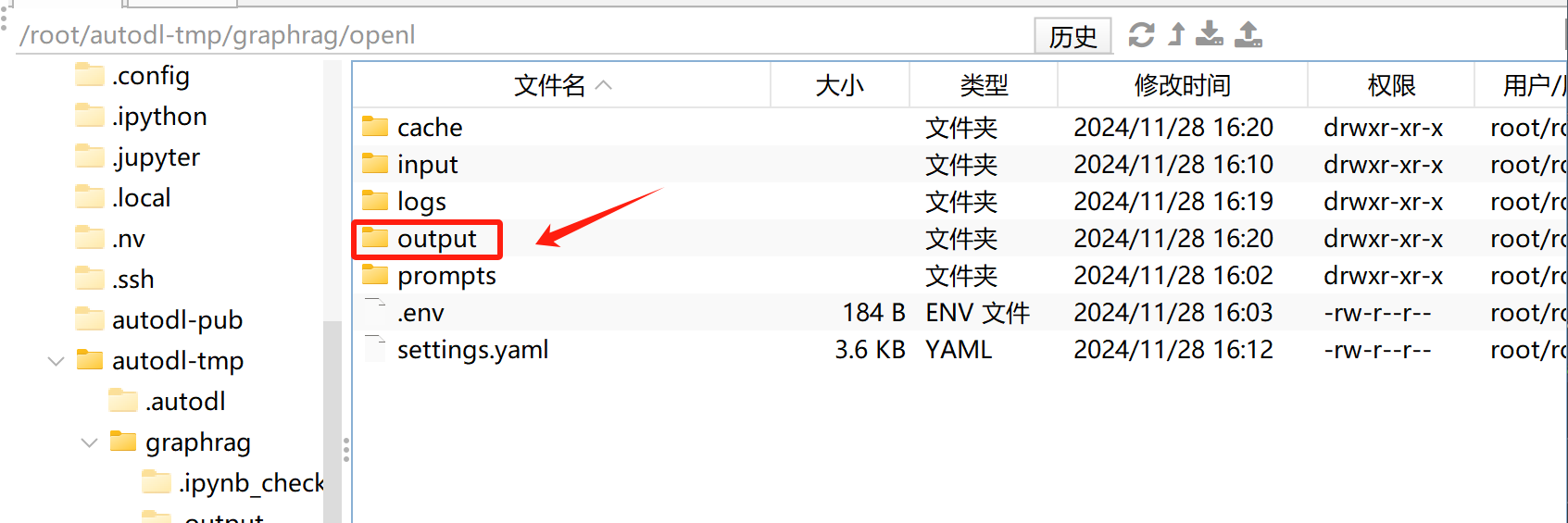
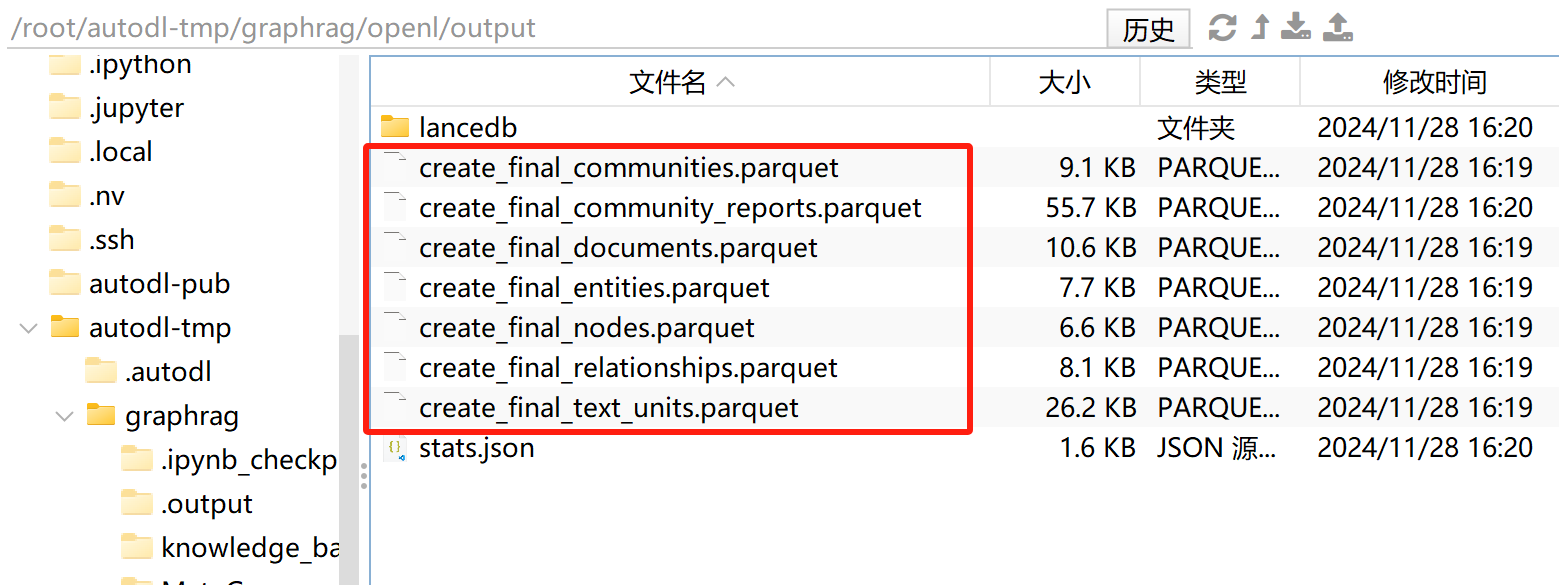
GraphRAG在索引阶段构建的知识图谱的确是以 Parquet 格式保存的!索引阶段的输出文件中,Parquet 文件存储了知识图谱的各个核心组成部分,例如实体、关系、社区信息以及文本单元等。这些文件共同组成了一个完整的知识图谱。
索引阶段的主要输出内容如下:
-
实体表(Nodes Table)
- 文件名:
create_final_nodes.parquet - 内容:知识图谱中的实体节点(例如:人、地点、组织)。
- 包含信息:
- 实体的名称(如 "John Doe")。
- 实体的类别(如 "PERSON", "ORGANIZATION", "LOCATION")。
- 与社区相关的信息(如实体所属的社区)。
- 实体的度数(degree),表示该实体在图谱中的连接数。
- 文件名:
-
关系表(Relationships Table)
- 文件名:
create_final_relationships.parquet - 内容:知识图谱中实体之间的关系(即图谱的边)。
- 包含信息:
- 两个实体之间的关系描述(例如 "works for", "lives in")。
- 关系的强度(数值化,用于衡量关系的显著性或重要性)。
- 文件名:
-
嵌入向量表(Entity Embedding Table)
- 文件名:
create_final_entities.parquet - 内容:实体的语义嵌入,用于表示实体的语义信息。
- 用途:支持语义搜索(通过嵌入计算实体之间的相似性)。
- 文件名:
-
社区报告表(Community Reports Table)
- 文件名:
create_final_community_reports.parquet - 内容:社区的摘要信息。
- 用途:支持全局搜索(通过社区信息回答关于数据集整体的问题)。
- 文件名:
-
文本单元表(Text Units Table)
- 文件名:
create_final_text_units.parquet - 内容:被切分的原始文本单元(TextUnits)。
- 用途:将知识图谱和原始文本结合,为 LLM 提供上下文支持。
- 文件名:
-
社区表(Community Table)
- 文件名:
create_final_Communities.parquet - 内容:每个社区基本情况。
- 文件名:
-
文件表(Documents Table)
- 文件名:
create_final_documents.parquet - 内容:用于记录所有参与知识图谱构建的文件情况。
- 文件名:
为什么用 Parquet 格式保存知识图谱?
- 高效存储:
知识图谱中的数据通常是结构化的,包含大量的实体、关系、嵌入等。
Parquet 的列式存储能够显著减少磁盘占用,同时提高读取效率。
- 快速读取:
查询阶段需要快速加载实体、关系、嵌入等数据到内存中。
Parquet 支持按需加载所需的列,避免了不必要的数据读取。
- 兼容性好:
- Parquet 是一个开放的标准,广泛支持各种数据处理工具(如 Pandas、Spark、Hadoop)。
- GraphRAG 可以在 Python 中使用 Pandas 或其他工具轻松读取这些文件。
3.查看知识图谱相关表格
import pandas as pd
- 文件表(Documents Table)
documents_df = pd.read_parquet("./openl/output/create_final_documents.parquet")
documents_df
- 文本单元表(TEXT UNIT Table)
text_unit_df = pd.read_parquet("./openl/output/create_final_text_units.parquet")
text_unit_df
- 实体嵌入表(ENTITIES Table)
entity_embedding_df = pd.read_parquet("./openl/output/create_final_entities.parquet")
entity_embedding_df.head()
- 实体表(Nodes Table)
entity_df = pd.read_parquet("./openl/output/create_final_nodes.parquet")
entity_df.head()
entity_df
关系表(Relationships Table)
relationships_df = pd.read_parquet("./openl/output/create_final_relationships.parquet")
relationships_df.head()
社区表(Community Table)
community_df = pd.read_parquet("./openl/output/create_final_communities.parquet")
community_df.head()
community_report_df = pd.read_parquet("./openl/output/create_final_community_reports.parquet")
community_report_df.head()
是社区报告(Community Reports) 每一行代表一个社区的摘要信息,包含了与该社区相关的标题、摘要、实体、关系等详细内容。这些信息是 GraphRAG 在索引阶段基于知识图谱生成的高层次语义总结,用于帮助回答关于数据集整体的问题(例如全局搜索)。
表格字段的含义
-
id- 每个社区的唯一标识符(UUID)。
- 这是系统内部生成的,通常用于追踪社区记录。
-
human_readable_id- 更容易理解的人类可读ID(数字化或短标识符)。
- 通常用于直观地区分社区。
-
community- 社区的编号,代表社区的分类或标识。
-
level- 社区层级(
COMMUNITY_LEVEL)。 - 表示社区的聚类粒度。较低的值表示更抽象的层级,较高的值表示更具体的细分社区。
- 社区层级(
-
title- 社区的标题。
- 对该社区的简要描述,用于表示该社区的主题核心。例如:
ID3 Decision Tree Algorithm CommunityC4.5 and Sklearn Integration
-
summary- 社区的摘要。
- 对该社区内容的进一步扩展描述,解释其主题或涵盖的主要内容。
-
full_content- 社区报告的完整内容。
- 包括更详细的信息,可能包含标题、摘要、重要发现等。
-
rank- 社区的排名或评分。
- 可能用来表示社区的重要性、影响力或相关性。
-
rank_explanation- 对排名的解释。
- 例如,“影响严重性从中等到高”。
-
findings- 社区的主要发现(JSON 格式)。
- 包含详细的解释或分析。例如:
- ID3 算法是该社区的核心主题。
- C4.5 是 ID3 的改进版本,结合了 Sklearn 的功能。
-
full_content_json- 社区完整内容的 JSON 表示。
- 如果需要以结构化方式处理社区内容,这个字段是关键。
-
period- 报告的时间戳或周期。
- 在你的示例中,是
2024-11-26,表示报告生成的日期。
-
size- 社区的大小。
- 表示该社区包含的实体或内容的数量。例如:
- 社区 0 包含 8 个内容。
- 社区 1 包含 2 个内容。
结果解释 从你的结果中可以看出:
-
社区 0:
- 标题是“ID3 Decision Tree Algorithm Community”。
- 主题围绕 ID3 决策树算法。
- 内容提到了该算法的重要性,以及其对机器学习领域的影响。
- 社区大小为 8。
-
社区 1:
- 标题是“C4.5 and Sklearn Integration”。
- 主题是 C4.5 算法和 Sklearn 的集成。
- 该社区比社区 0 更小(仅有 2 个内容)。
- 排名评分为 4.5,影响程度适中。
用途 社区报告在查询阶段可以用于:
- 全局搜索(Global Search):
- 回答关于数据集整体的问题,例如“这些文档的主要主题是什么?”
- 快速理解社区:
- 帮助用户快速了解数据集中不同部分的主题和相关信息。
- 可视化与调试:
- 将这些社区报告与知识图谱结合起来,可以直观地呈现社区的结构和语义关系。
三、GraphRAG问答流程
1.导入核心关系组
import os
import pandas as pd
import tiktoken
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
from graphrag.query.indexer_adapters import (
read_indexer_covariates,
read_indexer_entities,
read_indexer_relationships,
read_indexer_reports,
read_indexer_text_units,
)
from graphrag.query.input.loaders.dfs import (
store_entity_semantic_embeddings,
)
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.embedding import OpenAIEmbedding
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.question_gen.local_gen import LocalQuestionGen
from graphrag.query.structured_search.local_search.mixed_context import (
LocalSearchMixedContext,
)
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.vector_stores.lancedb import LanceDBVectorStore
与索引器相关的模块
-
read_indexer_*
从不同的索引文件中读取数据(例如实体、关系、摘要等)。这些模块负责加载索引器生成的数据到 Python 中,供后续搜索或分析使用:read_indexer_covariates: 读取与数据协变量(附加属性)相关的信息。read_indexer_entities: 读取从数据中提取的实体。read_indexer_relationships: 读取实体间的关系。read_indexer_reports: 读取生成的社区报告摘要。read_indexer_text_units: 读取切分后的文本单元(TextUnits)。
-
store_entity_semantic_embeddings
将实体的语义嵌入存储到向量数据库中。GraphRAG 用嵌入向量来表示实体间的语义关系。
与 LLM(大型语言模型)相关的模块
-
ChatOpenAI
一个封装了 OpenAI 聊天模型(如 GPT 系列)的接口,允许你通过编程与 OpenAI 模型交互(如提出问题、获取回答)。 -
OpenAIEmbedding
用于生成文本的嵌入向量的模块,通过调用 OpenAI 的嵌入 API,将文本转换为语义向量表示。 -
OpenaiApiType
定义 OpenAI API 的具体类型,可能包括“聊天模型”、“嵌入模型”等。
与本地搜索相关的模块
-
LocalSearch
GraphRAG 的本地搜索引擎,专注于通过上下文和邻近信息回答关于特定实体的问题。 -
LocalSearchMixedContext
允许混合使用不同上下文数据(例如实体及其邻居的关系)来丰富本地搜索的结果。 -
LocalQuestionGen
用于在本地搜索中生成问题的模块,帮助生成更相关的问题。
与向量存储相关的模块
LanceDBVectorStore
GraphRAG 使用的向量存储解决方案之一,支持存储和检索语义嵌入向量。可以快速高效地查找与查询向量最相似的嵌入。
INPUT_DIR = "./openl/output"
LANCEDB_URI = f"{INPUT_DIR}/lancedb"
COMMUNITY_REPORT_TABLE = "create_final_community_reports"
ENTITY_TABLE = "create_final_nodes"
ENTITY_EMBEDDING_TABLE = "create_final_entities"
RELATIONSHIP_TABLE = "create_final_relationships"
TEXT_UNIT_TABLE = "create_final_text_units"
COMMUNITY_LEVEL = 2
定义输入目录与文件路径 FENCE0
INPUT_DIR:索引器输出文件的存放目录。在这里,索引器输出的路径为./openl/output。LANCEDB_URI:存放向量存储(LanceDB 数据库)的目录路径。在 GraphRAG 中,实体嵌入向量通常被存储在 LanceDB 中,以便后续搜索时高效检索。
定义数据表文件名 FENCE1
COMMUNITY_REPORT_TABLE:存储社区报告的文件名。社区报告是基于知识图谱生成的每个社区的摘要。ENTITY_TABLE:存储实体的文件名(知识图谱中的节点)。每个节点代表一个实体,例如人、地点或组织。ENTITY_EMBEDDING_TABLE:存储实体的嵌入向量。嵌入表示实体的语义信息,用于计算实体之间的相似性。RELATIONSHIP_TABLE:存储实体间关系的文件名(知识图谱中的边)。关系表示两个实体之间的交互或连接。TEXT_UNIT_TABLE:存储文本单元的文件名(原始文本数据被切分为的小块)。COMMUNITY_LEVEL:指定加载的社区层级。社区层级表示知识图谱的聚类粒度(层次化结构中的第2层)。
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)
description_embedding_store = LanceDBVectorStore(
collection_name="default-entity-description",
)
description_embedding_store.connect(db_uri=LANCEDB_URI)
entity_description_embeddings = store_entity_semantic_embeddings(
entities=entities, vectorstore=description_embedding_store
)
print(f"Entity count: {len(entity_df)}")
entity_df.head()
relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")
relationships = read_indexer_relationships(relationship_df)
print(f"Relationship count: {len(relationship_df)}")
relationship_df.head()
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
print(f"Report records: {len(report_df)}")
report_df.head()
text_unit_df = pd.read_parquet(f"{INPUT_DIR}/{TEXT_UNIT_TABLE}.parquet")
text_units = read_indexer_text_units(text_unit_df)
print(f"Text unit records: {len(text_unit_df)}")
text_unit_df.head()
2.设置模型参数
- GraphRAG v 0.5版本bug修复
GraphRAG最新版 v0.5版本当使用OpenAI的Embedding模型时,会出现运行报错,此时需要修改lancedb.py文件才可正常运行。在Ubuntu服务器下,脚本文件地址如下:
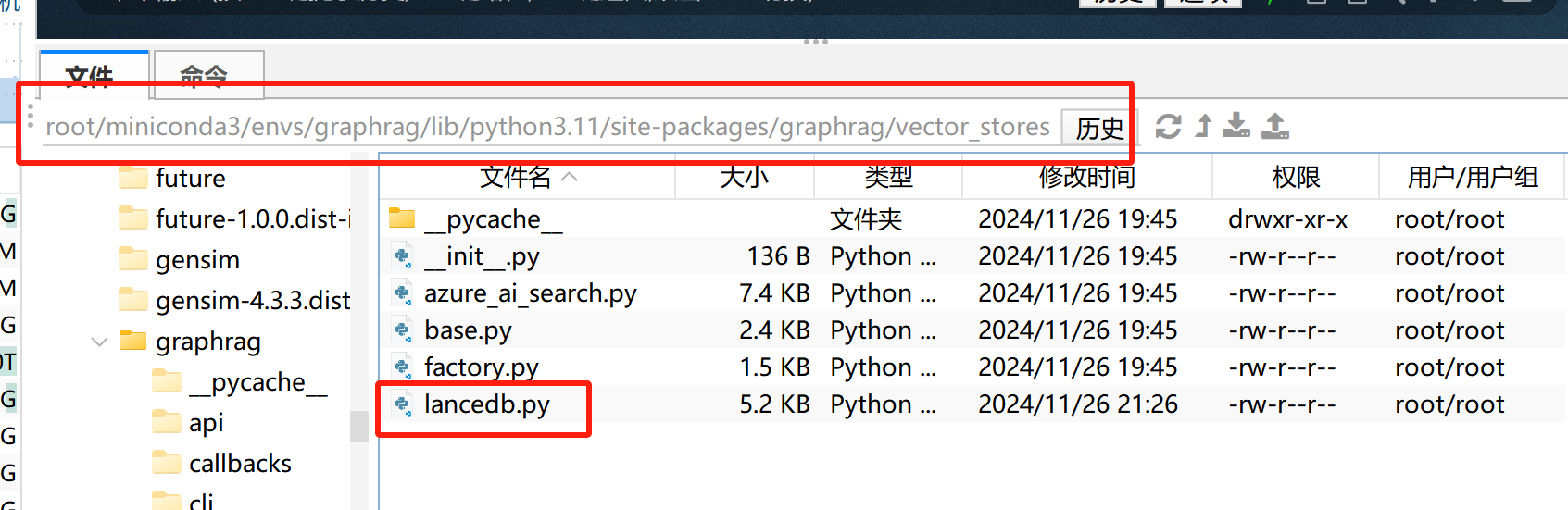
打开脚本文件后需修改如下内容:

当使用OpenAI text-embedding-3-small时,需手动设置N=1536,而若使用text-embedding-3-large,则需要将N设置为3072:

- 设置模型参数
api_key = "YOUR_API_KEY"
llm_model = "gpt-4o"
embedding_model = "text-embedding-3-small"
llm = ChatOpenAI(
api_key=api_key,
model=llm_model,
api_base="https://ai.devtool.tech/proxy/v1",
api_type=OpenaiApiType.OpenAI,
max_retries=20,
)
token_encoder = tiktoken.get_encoding("cl100k_base")
text_embedder = OpenAIEmbedding(
api_key=api_key,
api_base="https://ai.devtool.tech/proxy/v1",
api_type=OpenaiApiType.OpenAI,
model=embedding_model,
deployment_name=embedding_model,
max_retries=20,
)
初始化 Chat 模型
ChatOpenAI:- 用于与 OpenAI 或 Azure OpenAI 的聊天模型(如 GPT 系列)交互。
- 参数说明:
api_key:访问 OpenAI 或 Azure OpenAI 的密钥。model:指定 LLM 模型名称(如gpt-4)。-
api_base:API 的基础路径,可以填写反向代理地址
api_type:API 类型,可以是:OpenaiApiType.OpenAI:OpenAI 直连服务。OpenaiApiType.AzureOpenAI:Azure OpenAI 服务。
max_retries:最大重试次数,以处理网络或服务中断。
初始化文本分词器
tiktoken:- 用于对输入文本进行分词或令牌化操作。
cl100k_base:一种令牌编码方式,适用于 GPT 系列模型(如gpt-3.5-turbo和gpt-4)。- 用途:
- 计算输入文本的令牌数量,确保不超过模型的上下文窗口限制。
初始化嵌入生成器
OpenAIEmbedding:- 用于生成文本的嵌入向量。
- 参数说明:
api_key:用于访问 OpenAI 嵌入 API 的密钥。api_base:API 的基础路径,可以填写反向代理地址api_type:API 类型,与 LLM 相同。model:指定嵌入模型名称,例如text-embedding-ada-002。deployment_name:Azure 模型部署名称(如果使用 Azure)。max_retries:最大重试次数。
3.构建LocalSearch(本地搜索)搜索引擎并进行问答
- 创建LocalSearch上下文构建器
context_builder = LocalSearchMixedContext(
community_reports=reports,
text_units=text_units,
entities=entities,
relationships=relationships,
covariates=None,
entity_text_embeddings=description_embedding_store,
embedding_vectorstore_key=EntityVectorStoreKey.ID,
text_embedder=text_embedder,
token_encoder=token_encoder,
)
本段代码的主要功能是创建本地搜索的上下文构建器(Context Builder)。上下文构建器的作用是整合所有加载的数据(如社区报告、文本单元、实体、关系等),为后续的本地搜索提供语义丰富的上下文。
参数解析
-
community_reports- 传入之前加载的社区报告数据(
reports)。 - 用于补充社区级别的背景信息,在本地搜索中提供更多上下文。
- 传入之前加载的社区报告数据(
-
text_units- 传入已加载的文本单元数据(
text_units)。 - 提供来自原始文档的小块文本,用于回答具体问题或补充答案的上下文。
- 传入已加载的文本单元数据(
-
entities- 传入知识图谱中的实体(
entities)。 - 提供实体的详细信息和属性,帮助本地搜索定位特定实体。
- 传入知识图谱中的实体(
-
relationships- 传入知识图谱中的关系(
relationships)。 - 用于描述实体之间的交互和连接,有助于构建更复杂的答案。
- 传入知识图谱中的关系(
-
covariates- 传入协变量数据(
covariates),如果索引阶段未启用协变量,设置为None。 - 用途:
- 提供附加声明性元数据或上下文信息。
- 如果协变量未启用,仍可正常运行本地搜索,但答案可能少一些附加的语义信息。
- 传入协变量数据(
-
entity_text_embeddings- 传入实体嵌入的存储对象(
description_embedding_store)。 - 用途:
- 将实体的文本嵌入存储在向量数据库中。
- 用于通过语义搜索快速找到相关实体。
- 传入实体嵌入的存储对象(
-
embedding_vectorstore_key- 设置嵌入向量存储的键类型。
EntityVectorStoreKey.ID:- 如果向量存储中的实体是按 ID 存储的,使用此键。
EntityVectorStoreKey.TITLE:- 如果向量存储按实体标题存储,则改为设置为
TITLE。
- 如果向量存储按实体标题存储,则改为设置为
-
text_embedder- 传入嵌入生成器对象(
text_embedder)。 - 用于生成文本或问题的语义嵌入,支持与存储的实体嵌入进行相似度比较。
- 传入嵌入生成器对象(
-
token_encoder- 传入分词器(
token_encoder)。 - 用途:
- 确保生成的上下文不会超过 LLM 的上下文窗口限制。
- 有助于在构建查询时分配合理的上下文。
- 传入分词器(
上下文构建器的作用 上下文构建器是本地搜索的核心组件,它负责将加载的数据整合成结构化的上下文,包括:
-
结合社区级摘要(Community Reports):
- 提供更高层次的背景信息,用于回答主题性问题。
-
整合文本单元(Text Units):
- 使用来自原始文档的文本片段,为问题构建直接的上下文。
-
集成知识图谱的实体和关系:
- 为本地搜索中的实体相关问题提供详细的语义信息。
-
利用嵌入和分词:
- 嵌入存储和分词器确保上下文生成语义准确,符合 LLM 的上下文限制。
- 创建本地搜索引擎参数组
local_context_params = {
"text_unit_prop": 0.5,
"community_prop": 0.1,
"conversation_history_max_turns": 5,
"conversation_history_user_turns_only": True,
"top_k_mapped_entities": 10,
"top_k_relationships": 10,
"include_entity_rank": True,
"include_relationship_weight": True,
"include_community_rank": True,
"return_candidate_context": True,
"embedding_vectorstore_key": EntityVectorStoreKey.ID,
"max_tokens": 12_000,
}
llm_params = {
"max_tokens": 2_000,
"temperature": 0.0,
}
参数解析:
-
text_unit_prop:- 上下文窗口中分配给文本单元(Text Units)的比例(50%)。
- 控制原始文档中的文本内容在上下文中的权重。
-
community_prop:- 上下文窗口中分配给社区报告(Community Reports)的比例(10%)。
- 用于为回答提供更高层次的社区背景。
-
conversation_history_max_turns:- 上下文中包含的最大对话轮数(5轮)。
- 控制是否包括之前的对话历史,以及保留的对话轮数。
-
conversation_history_user_turns_only:- 如果为
True,则只包括用户的提问,而忽略模型的回答。
- 如果为
-
top_k_mapped_entities:- 从嵌入向量存储中检索的相关实体的数量(10个)。
-
top_k_relationships:- 检索到上下文窗口中的最大关系数(10个)。
-
include_entity_rank:- 是否在上下文中包含实体的排名(默认是根据实体的节点度数)。
-
include_relationship_weight:- 是否在上下文中包含关系权重(例如,表示关系的重要性)。
-
include_community_rank:- 是否在上下文中包含社区排名。这里设置为
False。
- 是否在上下文中包含社区排名。这里设置为
-
return_candidate_context:- 如果为
True,返回一个数据帧集合,包含所有可能相关的实体、关系和协变量记录。这些记录的上下文中会有一列in_context表示是否被纳入上下文窗口。
- 如果为
-
embedding_vectorstore_key:- 嵌入向量存储的键类型。
- 如果向量存储的标识符是实体标题而非 ID,则设置为
EntityVectorStoreKey.TITLE。
-
max_tokens:- 上下文窗口允许的最大令牌数(12,000个)。
- 需要根据所用 LLM 的令牌限制调整(例如,GPT-4 支持 8,192 或 32,768)。
-
创建本地搜索引擎
search_engine = LocalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
llm_params=llm_params,
context_builder_params=local_context_params,
response_type="multiple paragraphs",
)
参数解析:
-
llm:- 已初始化的 LLM 对象(
ChatOpenAI),用于生成答案。
- 已初始化的 LLM 对象(
-
context_builder:- 上一段代码中创建的上下文构建器(
LocalSearchMixedContext),负责生成语义丰富的上下文。
- 上一段代码中创建的上下文构建器(
-
token_encoder:- 分词器,用于计算上下文和生成回答的令牌数,确保不会超过 LLM 的限制。
-
llm_params:- 用于 LLM 的参数,包括生成答案时的令牌数和温度。
-
context_builder_params:- 上下文构建器的配置,控制上下文中每种数据的比例和数量限制。
-
response_type:- 指定回答的格式。
- 此处为
"multiple paragraphs",表示生成的回答以多段文字形式呈现。 - 可以根据需求设置为
"single paragraph"或"prioritized list"等。
-
基于本地搜索的问答流程
result = await search_engine.asearch("请帮我介绍下ID3决策树算法")
display(Markdown(result.response))
4.构建GlobalSearch(全局搜索)搜索引擎并进行问答
- 导入知识图谱相关内容
from graphrag.query.indexer_adapters import (
read_indexer_communities,
read_indexer_entities,
read_indexer_reports,
)
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.structured_search.global_search.community_context import (
GlobalCommunityContext,
)
from graphrag.query.structured_search.global_search.search import GlobalSearch
COMMUNITY_TABLE = "create_final_communities"
COMMUNITY_REPORT_TABLE = "create_final_community_reports"
ENTITY_TABLE = "create_final_nodes"
ENTITY_EMBEDDING_TABLE = "create_final_entities"
community_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_TABLE}.parquet")
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
communities = read_indexer_communities(community_df, entity_df, report_df)
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)
- 创建Global Search模式的上下文构建器 (context_builder)
context_builder = GlobalCommunityContext(
community_reports=reports,
communities=communities,
entities=entities,
token_encoder=token_encoder,
)
代码解释如下:
-
GlobalCommunityContext:- 这是一个为 Global Search 模式创建的上下文构建器。它负责从不同的数据源(如社区报告、实体、社区信息等)中提取相关数据,并构建一个用于查询的大范围上下文。
- 这个构建器帮助为整个文档集合(而不是某个特定实体)构建一个全局的知识背景,以便模型能够对广泛的问题做出响应。
-
community_reports=reports:- 这里传入的是之前从文件中读取的
reports数据(也就是COMMUNITY_REPORT_TABLE表格的数据)。 - 这些报告包含了关于不同社区的详细信息,如主题、摘要、影响力、发现等。
- 在全局搜索中,这些社区报告有助于构建整个数据集的高层次概览。
- 这里传入的是之前从文件中读取的
-
communities=communities:communities数据包含社区的结构和信息。在图谱中,社区可能代表了不同的主题、领域或相关性较高的实体群体。- 这部分数据通常用于在全局搜索时进行分组和排名,比如通过社群的重要性或与查询的相关性来排序。
-
entities=entities:-
entities是从之前的索引步骤中提取的实体数据(来自ENTITY_TABLE表)。 -
这些实体(如人物、地点、事件等)可以用来扩展全局搜索的范围。它们提供了具体的名词、对象和概念,有助于为全局查询提供上下文。
-
注意: 如果不希望在全局搜索中使用社区权重来影响排名(例如,不考虑某个社区对某个实体的影响),可以将
entities参数设为None。
-
-
token_encoder=token_encoder:token_encoder是用于对文本进行编码的工具。它将文本转化为可以输入到模型中的 token 序列。- 在之前的代码中,我们已经看到
token_encoder是通过tiktoken.get_encoding("cl100k_base")获取的,它的作用是把文本切分为一定的 token 数量,以便在模型中使用。
- 配置全局搜索参数
context_builder_params = {
"use_community_summary": False,
"shuffle_data": True,
"include_community_rank": True,
"min_community_rank": 0,
"community_rank_name": "rank",
"include_community_weight": True,
"community_weight_name": "occurrence weight",
"normalize_community_weight": True,
"max_tokens": 12_000,
"context_name": "Reports",
}
map_llm_params = {
"max_tokens": 1000,
"temperature": 0.0,
"response_format": {"type": "json_object"},
}
reduce_llm_params = {
"max_tokens": 2000,
"temperature": 0.0,
}
- 构建全局搜索引擎
search_engine = GlobalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
max_data_tokens=12_000,
map_llm_params=map_llm_params,
reduce_llm_params=reduce_llm_params,
allow_general_knowledge=False,
json_mode=True,
context_builder_params=context_builder_params,
concurrent_coroutines=32,
response_type="multiple paragraphs",
)
这里创建了一个 全局搜索(Global Search) 引擎,利用前面配置的上下文构建器 (context_builder)、语言模型 (llm)、以及其它相关的参数进行搜索。对应参数详解如下:
-
llm:- 这个参数传入的是已经配置好的语言模型(LLM),即你之前定义的
ChatOpenAI模型。全局搜索引擎将使用这个模型来生成回答。
- 这个参数传入的是已经配置好的语言模型(LLM),即你之前定义的
-
context_builder:- 上下文构建器,之前我们已经讨论了
GlobalCommunityContext,它负责根据社区报告、社区等信息来构建查询的上下文。
- 上下文构建器,之前我们已经讨论了
-
token_encoder:token_encoder是用来处理文本的编码工具,通常是一个模型专用的 tokenizer。在这里,我们使用了tiktoken.get_encoding("cl100k_base"),它是 OpenAI 模型的一个编码器,用来将文本转化为 token 格式。
-
max_data_tokens:- 最大数据 token 数量。它控制了模型可以处理的最大上下文大小。你可以根据实际使用的模型的最大 token 限制来设置(例如,如果模型最大 token 限制是 8K,则可以设置为 5000,留一些余量)。这个设置控制了全局搜索时在上下文窗口内所使用的最大 token 数。
-
map_llm_params和reduce_llm_params:- 这两个参数分别传入了映射和归约阶段的 LLM 配置(之前我们已经详细分析过这些参数)。这些参数会影响 LLM 在不同阶段生成内容的方式(例如,
max_tokens和temperature等)。
- 这两个参数分别传入了映射和归约阶段的 LLM 配置(之前我们已经详细分析过这些参数)。这些参数会影响 LLM 在不同阶段生成内容的方式(例如,
-
allow_general_knowledge:- 这个参数控制是否允许模型在回答中加入通用知识。如果设置为
True,LLM 会尝试将 外部知识 加入到查询的结果中。这对于需要广泛知识背景的任务可能有帮助,但也有可能导致模型生成 虚假信息(hallucinations)。为了避免这个问题,默认值设置为False。
- 这个参数控制是否允许模型在回答中加入通用知识。如果设置为
-
json_mode:- 这个参数控制结果的格式。如果设置为
True,LLM 会生成结构化的 JSON 格式 输出。如果设置为False,则返回的是更自由形式的文本回答。对于结构化数据的处理,通常使用 JSON 格式。
- 这个参数控制结果的格式。如果设置为
-
context_builder_params:- 这是传入给上下文构建器的参数,用来进一步配置如何构建查询上下文(例如是否使用社区简要摘要、是否包含社区排名等)。我们在之前的代码分析中已经详细介绍了这些参数。
-
concurrent_coroutines:- 这个参数控制并发协程的数量。全局搜索引擎支持并发处理多个查询,如果你需要同时处理多个请求,可以增加这个值。比如设置为
32,意味着最多可以同时处理 32 个查询。
- 这个参数控制并发协程的数量。全局搜索引擎支持并发处理多个查询,如果你需要同时处理多个请求,可以增加这个值。比如设置为
-
response_type:- 这个参数定义了模型生成的响应的类型和格式。它是一个自由文本的描述,指明返回的内容应该是什么样的格式。在这里,
"multiple paragraphs"表示模型会生成多段文字的回答,适合长篇的说明或报告。
- 这个参数定义了模型生成的响应的类型和格式。它是一个自由文本的描述,指明返回的内容应该是什么样的格式。在这里,
-
执行全局搜索
result = await search_engine.asearch("请帮我介绍下ID3决策树算法")
display(Markdown(result.response))
- 查看全局搜索调用的社区报告
result.context_data["reports"]
report_df
- 社区报告最终形成的参考文档
result.context_text[0]
- 模型调用次数和使用的token数量
print(
f"LLM calls: {result.llm_calls}. Prompt tokens: {result.prompt_tokens}. Output tokens: {result.output_tokens}."
)
四、GraphRAG中知识图谱可视化方法
!pip install yfiles_jupyter_graphs
yfiles-jupyter-graphs是一个用于在Jupyter Notebook环境中进行交互式图形可视化的Python库,专为图形数据的展示、交互和分析设计。它基于yFiles,一个功能强大的图形绘制引擎,能够生成、布局和展示各种复杂的图形数据结构。yfiles-jupyter-graphs使得开发者和数据科学家能够便捷地在Jupyter Notebook中创建、分析和可视化网络图、知识图谱、社交网络等各种图形数据。
from yfiles_jupyter_graphs import GraphWidget
- Step 1.读取实体与关系并转化为yfiles_jupyter_graphs可读取的字典格式
def convert_entities_to_dicts(df):
"""Convert the entities dataframe to a list of dicts for yfiles-jupyter-graphs."""
nodes_dict = {}
for _, row in df.iterrows():
# Create a dictionary for each row and collect unique nodes
node_id = row["title"]
if node_id not in nodes_dict:
nodes_dict[node_id] = {
"id": node_id,
"properties": row.to_dict(),
}
return list(nodes_dict.values())
函数解释:
该函数将GraphRAG的实体数据(df)转换为字典格式,方便yfiles-jupyter-graphs进行图形渲染。每个实体(如人、组织、地点等)被转换为一个字典,包含实体的属性数据。
-
具体步骤:
df.iterrows():逐行遍历实体数据的DataFrame,每行代表一个实体。node_id = row["title"]:假设实体的ID(如实体名称、标题等)保存在title这一列中,用它来标识每个节点。nodes_dict[node_id]:使用实体的title作为唯一标识符(node_id),将该实体的属性以字典形式保存到nodes_dict中。row.to_dict()将每行的所有列转换为字典。return list(nodes_dict.values()):返回所有节点的字典列表。
-
返回:
该函数返回一个包含所有实体的列表,每个元素是一个字典,表示一个实体和它的属性。
def convert_relationships_to_dicts(df):
"""Convert the relationships dataframe to a list of dicts for yfiles-jupyter-graphs."""
relationships = []
for _, row in df.iterrows():
# Create a dictionary for each row
relationships.append({
"start": row["source"],
"end": row["target"],
"properties": row.to_dict(),
})
return relationships
函数解释:
该函数将GraphRAG的关系数据(df)转换为适合yfiles-jupyter-graphs格式的字典。
-
具体步骤:
df.iterrows():逐行遍历关系数据的DataFrame,每行代表一个关系。relationships.append(...):对于每一行数据,创建一个包含关系信息的字典。每个关系有:start:关系的起始实体(source列)。end:关系的结束实体(target列)。properties:将整个行的内容转换为字典,存储附加属性。
return relationships:返回一个包含所有关系字典的列表。
-
返回:
该函数返回一个包含所有关系的列表,每个元素是一个字典,表示一个关系及其属性。
relationship_df.head()
convert_relationships_to_dicts(relationship_df)[0]
w = GraphWidget() # 创建GraphWidget对象
w.directed = True # 设置图形为有向图
w.nodes = convert_entities_to_dicts(entity_df) # 将实体数据转换为节点
w.edges = convert_relationships_to_dicts(relationship_df) # 将关系数据转换为边
w.node_label_mapping = "title" # 设置节点标签显示
# 社区到颜色的映射
def community_to_color(community):
"""Map a community to a color."""
colors = [
"crimson",
"darkorange",
"indigo",
"cornflowerblue",
"cyan",
"teal",
"green",
]
try:
return colors[int(community) % len(colors)] if community is not None else "lightgray"
except (ValueError, TypeError):
# 如果 community 不是整数或其他错误,返回默认颜色
return "lightgray"
本段代码定义了一个函数community_to_color,用于将一个社区(community)映射为颜色。它首先定义了一个颜色列表colors,然后根据社区的编号将其映射到列表中的颜色。如果社区编号无效(例如不是整数),则返回默认颜色lightgray。如果社区编号为None,则也返回lightgray。这样每个社区的节点将根据其所属的社区被赋予不同的颜色。
def edge_to_source_community(edge):
"""Get the community of the source node of an edge."""
source_node = next(
(entry for entry in w.nodes if entry["properties"]["title"] == edge["start"]),
None,
)
source_node_community = source_node["properties"]["community"]
return source_node_community if source_node_community is not None else None
本段代码定义了一个函数edge_to_source_community,用于获取一条边的源节点所属的社区。具体步骤如下:
- 函数从节点列表
w.nodes中查找与边的start节点ID匹配的节点。 - 然后获取该源节点的
community属性,即该节点所属的社区。 - 如果该节点没有社区信息,返回
None,否则返回社区的编号。
w.node_color_mapping = lambda node: community_to_color(
node["properties"].get("community", None) # 使用 .get 方法获取属性,避免 KeyError
)
w.edge_color_mapping = lambda edge: community_to_color(edge_to_source_community(edge))
w.node_scale_factor_mapping = lambda node: 0.5 + node["properties"].get("size", 1) * 1.5 / 20
w.edge_thickness_factor_mapping = "weight"
设置边颜色、节点大小和边厚度等。
w.circular_layout()
display(w)
五、大量文本下的GraphRAG问答实战
- Step 1.准备文档
这里我们准备另一篇名为《机器学习决策树算法详解》的文档,进行进一步的检索问答测试:
相关数据集已同步至本节公开课的课件包,扫码添加老师助理即可领取:
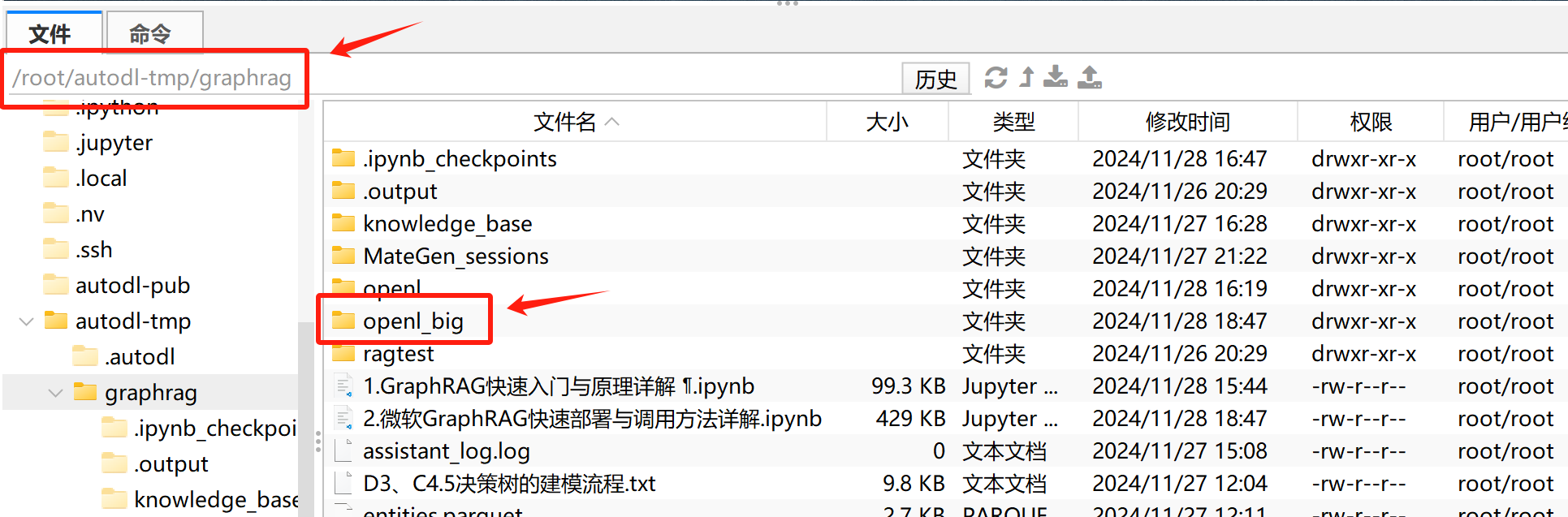
- Step 2.创建检索项目文件夹
FENCE0

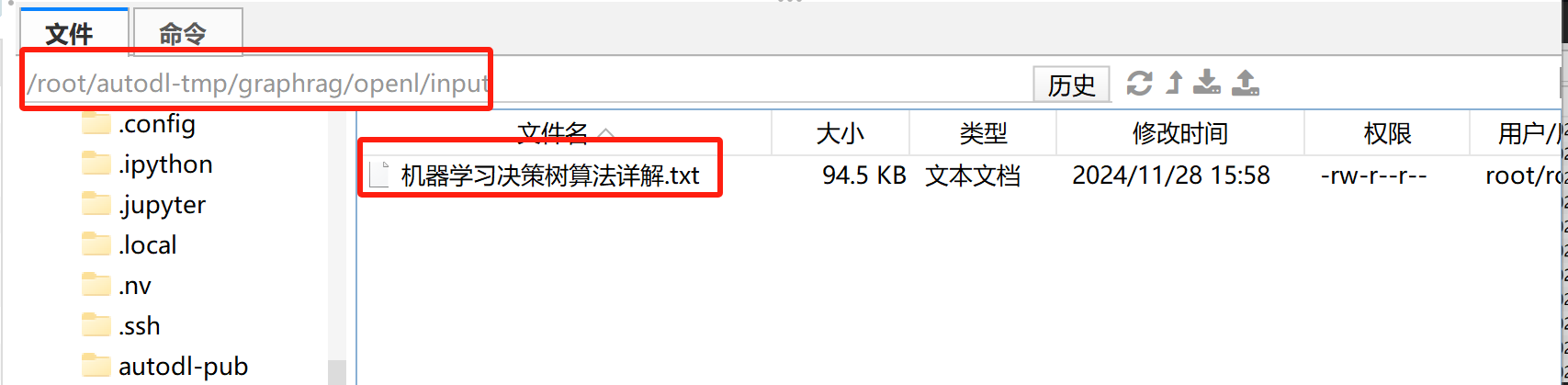
- Step 3.上传数据集
- Step 4.初始化项目文件
FENCE0
!graphrag init --root ./openl_big
- Step 5.修改项目配置
打开.env文件,填写OpenAI API-KEY
打开setting.yaml文件,填写模型名称和反向代理地址:
其中反向代理地址为api_base: https://ai.devtool.tech/proxy/v1
- Step 6.借助GraphRAG脚本自动执行indexing
!graphrag index --root ./openl_big
- Step 7.读取知识图谱
import os
import pandas as pd
import tiktoken
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
from graphrag.query.indexer_adapters import (
read_indexer_covariates,
read_indexer_entities,
read_indexer_relationships,
read_indexer_reports,
read_indexer_text_units,
)
from graphrag.query.input.loaders.dfs import (
store_entity_semantic_embeddings,
)
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.embedding import OpenAIEmbedding
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.question_gen.local_gen import LocalQuestionGen
from graphrag.query.structured_search.local_search.mixed_context import (
LocalSearchMixedContext,
)
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.vector_stores.lancedb import LanceDBVectorStore
INPUT_DIR = "./openl_big/output"
LANCEDB_URI = f"{INPUT_DIR}/lancedb"
COMMUNITY_REPORT_TABLE = "create_final_community_reports"
ENTITY_TABLE = "create_final_nodes"
ENTITY_EMBEDDING_TABLE = "create_final_entities"
RELATIONSHIP_TABLE = "create_final_relationships"
TEXT_UNIT_TABLE = "create_final_text_units"
COMMUNITY_LEVEL = 2
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)
description_embedding_store = LanceDBVectorStore(
collection_name="default-entity-description",
)
description_embedding_store.connect(db_uri=LANCEDB_URI)
entity_description_embeddings = store_entity_semantic_embeddings(
entities=entities, vectorstore=description_embedding_store
)
print(f"Entity count: {len(entity_df)}")
entity_df.head()
relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")
relationships = read_indexer_relationships(relationship_df)
print(f"Relationship count: {len(relationship_df)}")
relationship_df.head()
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
print(f"Report records: {len(report_df)}")
report_df.head()
text_unit_df = pd.read_parquet(f"{INPUT_DIR}/{TEXT_UNIT_TABLE}.parquet")
text_units = read_indexer_text_units(text_unit_df)
print(f"Text unit records: {len(text_unit_df)}")
text_unit_df.head()
- Step 8.设置模型参数
api_key = "YOUR_API_KEY"
llm_model = "gpt-4o"
embedding_model = "text-embedding-3-small"
llm = ChatOpenAI(
api_key=api_key,
model=llm_model,
api_base="https://ai.devtool.tech/proxy/v1",
api_type=OpenaiApiType.OpenAI,
max_retries=20,
)
token_encoder = tiktoken.get_encoding("cl100k_base")
text_embedder = OpenAIEmbedding(
api_key=api_key,
api_base="https://ai.devtool.tech/proxy/v1",
api_type=OpenaiApiType.OpenAI,
model=embedding_model,
deployment_name=embedding_model,
max_retries=20,
)
- Step 9.创建LocalSearch上下文构建器
context_builder = LocalSearchMixedContext(
community_reports=reports,
text_units=text_units,
entities=entities,
relationships=relationships,
covariates=None,
entity_text_embeddings=description_embedding_store,
embedding_vectorstore_key=EntityVectorStoreKey.ID,
text_embedder=text_embedder,
token_encoder=token_encoder,
)
- Step 10.创建本地搜索引擎参数组
local_context_params = {
"text_unit_prop": 0.5,
"community_prop": 0.1,
"conversation_history_max_turns": 5,
"conversation_history_user_turns_only": True,
"top_k_mapped_entities": 10,
"top_k_relationships": 10,
"include_entity_rank": True,
"include_relationship_weight": True,
"include_community_rank": True,
"return_candidate_context": True,
"embedding_vectorstore_key": EntityVectorStoreKey.ID,
"max_tokens": 12_000,
}
llm_params = {
"max_tokens": 2_000,
"temperature": 0.0,
}
- Step 11.创建本地搜索引擎
search_engine_local = LocalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
llm_params=llm_params,
context_builder_params=local_context_params,
response_type="multiple paragraphs",
)
- Step 12.基于本地搜索的问答流程
result = await search_engine_local.asearch("请帮我介绍下CART决策树算法")
display(Markdown(result.response))
result
然后我们再尝试使用全局搜索
- Step 13.全局搜索时导入知识图谱相关内容
from graphrag.query.indexer_adapters import (
read_indexer_communities,
read_indexer_entities,
read_indexer_reports,
)
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.structured_search.global_search.community_context import (
GlobalCommunityContext,
)
from graphrag.query.structured_search.global_search.search import GlobalSearch
COMMUNITY_TABLE = "create_final_communities"
COMMUNITY_REPORT_TABLE = "create_final_community_reports"
ENTITY_TABLE = "create_final_nodes"
ENTITY_EMBEDDING_TABLE = "create_final_entities"
community_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_TABLE}.parquet")
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
communities = read_indexer_communities(community_df, entity_df, report_df)
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)
- Step 14.创建Global Search模式的上下文构建器 (context_builder)
context_builder = GlobalCommunityContext(
community_reports=reports,
communities=communities,
entities=entities,
token_encoder=token_encoder,
)
- Step 15.配置全局搜索参数
context_builder_params = {
"use_community_summary": False,
"shuffle_data": True,
"include_community_rank": True,
"min_community_rank": 0,
"community_rank_name": "rank",
"include_community_weight": True,
"community_weight_name": "occurrence weight",
"normalize_community_weight": True,
"max_tokens": 12_000,
"context_name": "Reports",
}
map_llm_params = {
"max_tokens": 1000,
"temperature": 0.0,
"response_format": {"type": "json_object"},
}
reduce_llm_params = {
"max_tokens": 2000,
"temperature": 0.0,
}
- Step 16.构建全局搜索引擎
search_engine = GlobalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
max_data_tokens=12_000,
map_llm_params=map_llm_params,
reduce_llm_params=reduce_llm_params,
allow_general_knowledge=False,
json_mode=True,
context_builder_params=context_builder_params,
concurrent_coroutines=32,
response_type="multiple paragraphs",
)
- Step 17.执行全局搜索
result1 = await search_engine.asearch("请帮我介绍下CART决策树算法")
display(Markdown(result1.response))
- 查看全局搜索调用的社区报告
result1.context_data["reports"]
report_df
- 社区报告最终形成的参考文档
result1.context_text[0]
- 模型调用次数和使用的token数量
print(
f"LLM calls: {result1.llm_calls}. Prompt tokens: {result1.prompt_tokens}. Output tokens: {result1.output_tokens}."
)
- Step 18.大文本下知识图谱可视化
def convert_entities_to_dicts(df):
"""Convert the entities dataframe to a list of dicts for yfiles-jupyter-graphs."""
nodes_dict = {}
for _, row in df.iterrows():
# Create a dictionary for each row and collect unique nodes
node_id = row["title"]
if node_id not in nodes_dict:
nodes_dict[node_id] = {
"id": node_id,
"properties": row.to_dict(),
}
return list(nodes_dict.values())
def convert_relationships_to_dicts(df):
"""Convert the relationships dataframe to a list of dicts for yfiles-jupyter-graphs."""
relationships = []
for _, row in df.iterrows():
# Create a dictionary for each row
relationships.append({
"start": row["source"],
"end": row["target"],
"properties": row.to_dict(),
})
return relationships
w = GraphWidget() # 创建GraphWidget对象
w.directed = True # 设置图形为有向图
w.nodes = convert_entities_to_dicts(entity_df) # 将实体数据转换为节点
w.edges = convert_relationships_to_dicts(relationship_df) # 将关系数据转换为边
w.node_label_mapping = "title" # 设置节点标签显示
# 社区到颜色的映射
def community_to_color(community):
"""Map a community to a color."""
colors = [
"crimson",
"darkorange",
"indigo",
"cornflowerblue",
"cyan",
"teal",
"green",
]
try:
return colors[int(community) % len(colors)] if community is not None else "lightgray"
except (ValueError, TypeError):
# 如果 community 不是整数或其他错误,返回默认颜色
return "lightgray"
def edge_to_source_community(edge):
"""Get the community of the source node of an edge."""
source_node = next(
(entry for entry in w.nodes if entry["properties"]["title"] == edge["start"]),
None,
)
source_node_community = source_node["properties"]["community"]
return source_node_community if source_node_community is not None else None
w.node_color_mapping = lambda node: community_to_color(
node["properties"].get("community", None) # 使用 .get 方法获取属性,避免 KeyError
)
w.edge_color_mapping = lambda edge: community_to_color(edge_to_source_community(edge))
w.node_scale_factor_mapping = lambda node: 0.5 + node["properties"].get("size", 1) * 1.5 / 20
w.edge_thickness_factor_mapping = "weight"
w.circular_layout()
display(w)
五、GraphRAG提问测试
# 本地检索引擎
search_engine_local
# 全局检索引擎
search_engine
- 总结性质问题
# 本地检索
result = await search_engine_local.asearch("请问文档中总共介绍了几种决策树算法?")
display(Markdown(result.response))
# 全局检索
result = await search_engine.asearch("请问文档中总共介绍了几种决策树算法?")
display(Markdown(result.response))
result.context_data["reports"]
- 综合评价类问题
# 本地检索
result = await search_engine_local.asearch("你觉得文档中介绍的决策树算法,哪个算法最有应用前景?")
display(Markdown(result.response))
# 全局检索
result = await search_engine.asearch("你觉得文档中介绍的决策树算法,哪个算法最有应用前景?")
display(Markdown(result.response))
result.context_data["reports"]
- 主观评价类问题
# 本地检索
result = await search_engine_local.asearch("你觉得这篇文档写得如何?")
display(Markdown(result.response))
# 全局检索
result = await search_engine.asearch("你觉得这篇文档写得如何?")
display(Markdown(result.response))
result.context_data["reports"]
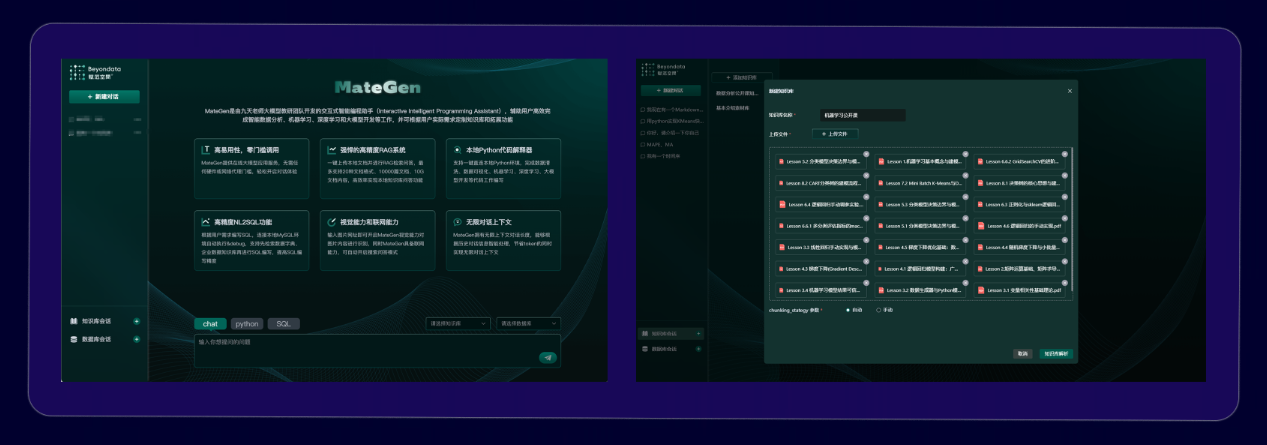
推荐尝试MateGen内置GraphRAG问答系统,零门槛体验GraphRAG问答效率!

!pip install --upgrade mategen -i https://pypi.org/simple
import MateGen
from MateGen import *
mategen = MateGenClass(api_key = 'YOUR_API_KEY',
enhanced_mode = True)
公开课前30席添加微信扫码助教,即可领取300w token MateGen API-KEY!报名正式课程还有更多额度赠送哦~
mategen.chat("你好,很高兴见到你!请介绍下你自己。")
mategen = MateGenClass(api_key = 'YOUR_API_KEY',
enhanced_mode = True,
knowledge_base_chat=True)
mategen.chat('现在你的知识库里面的内容是九天老师机器学习公开课的课件,其中总共介绍了多少种机器学习算法?')
mategen.chat('你觉得九天老师的机器学习公开课质量如何?')
更多MateGen相关信息,戳此查看:https://kq4b3vgg5b.feishu.cn/docx/Wfnida03mol6mZxmxJ3cw11dnsg?from=from_copylink
团队自研MateGen项目课程已在中上线!报名《大模型与Agent开发实战课》 即可完整学习企业级Agent项目开发: