(课件)Agentic_RAG
公开课内容节选自《大模型与Agent开发》完整版付费课程!
公开课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《大模型与Agent开发实战课》 :

《大模型与Agent开发实战课》 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
公开课直播特惠,全年最低价!低至 5 折 !扫码咨询课程信息哦👇

Agentic RAG 架构的基本原理与应用入门
在大模型领域技术的发展历程中,提高信息检索的效率和准确性是各行各业都在亟需解决的应用难题。在 2023 年占据主导技术地位的是检索增强生成 (RAG)技术,通过将大模型 ( LLMs ) 与外部数据检索相集成,彻底改变了人工智能系统,从而可以做出更明智、上下文更准确的响应。然而,随着需求变得更加复杂,传统的 RAG 系统通常无法处理细致入微的查询、多步骤推理和动态变化的上下文。而随着2024年AI Agent在工作流程方面有了巨大进步,才有了现在我们正在提及的代理检索增强生成(Agentic RAG) —— RAG 范式的创新演变。通过将智能、自主代理纳入检索过程,Agentic RAG 提升了传统系统的功能,使它们能够更有效地适应、推理和响应。这些代理不仅仅是被动的检索者,而且是主动的参与者,能够规划、决策并利用专门的工具来实现其目标。
顾名思义,Agentic RAG 是结合了 RAG 和 AI Agent 两大技术领域而形成的新范式,接下来的内容,我们就针对这样的一个新范式展开详细的介绍和实践。为了帮助大家更好地理解 Agentic RAG,我将首先分别介绍 RAG 和 AI Agent 架构的独立工作原理,然后再将它们结合起来,展示如何最终形成 Agentic RAG。
1. 什么是RAG?
Retrieval-Augmented Generation (RAG) 是帮助大模型更好地回答问题的一种方式。在大模型的应用场景中,一个非常常见的需求是:我们手里有一堆文档,当遇到一个问题时,希望通过其中的一段文本来找到答案。这时,RAG(检索增强生成)技术就能派上用场。它的作用就是从这些文档中找到最相关的信息,然后利用大模型生成精准的回答。简单来说,RAG 就是帮助大模型‘找到’并‘利用’最相关的信息来回答你的问题,就像一个聪明的助手快速翻阅资料给你最合适的答案。如下图所示:
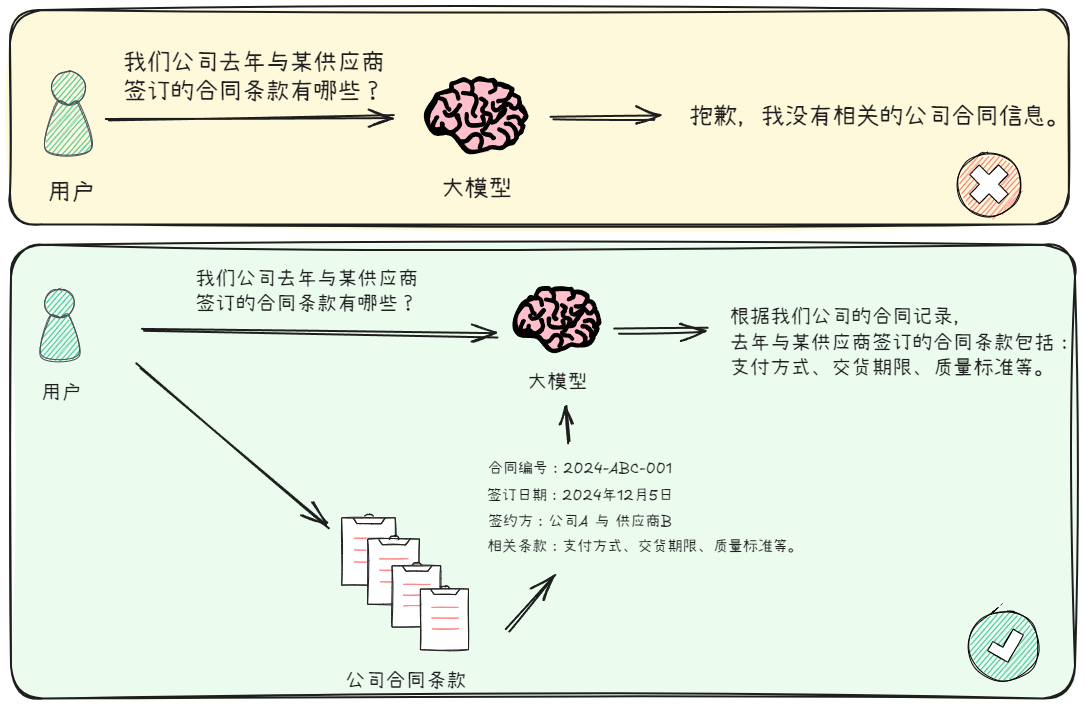
能这样实现的原因在于已经有非常多的实验论文能够证明,当为大模型提供一定的上下文信息后,其输出会变得更稳定。那么,将知识库中的信息或掌握的信息先输送给大模型,再由大模型服务用户,就是大家普遍达成共识的一个结论和方法。传统的对话系统、搜索引擎等核心依赖于检索技术,如果将这一检索过程融入大模型应用的构建中,既可以充分利用大模型在内容生成上的能力,也能通过引入的上下文信息显著约束大模型的输出范围和结果,同时还实现了将私有数据融入大模型中的目的,达到了双赢的效果。
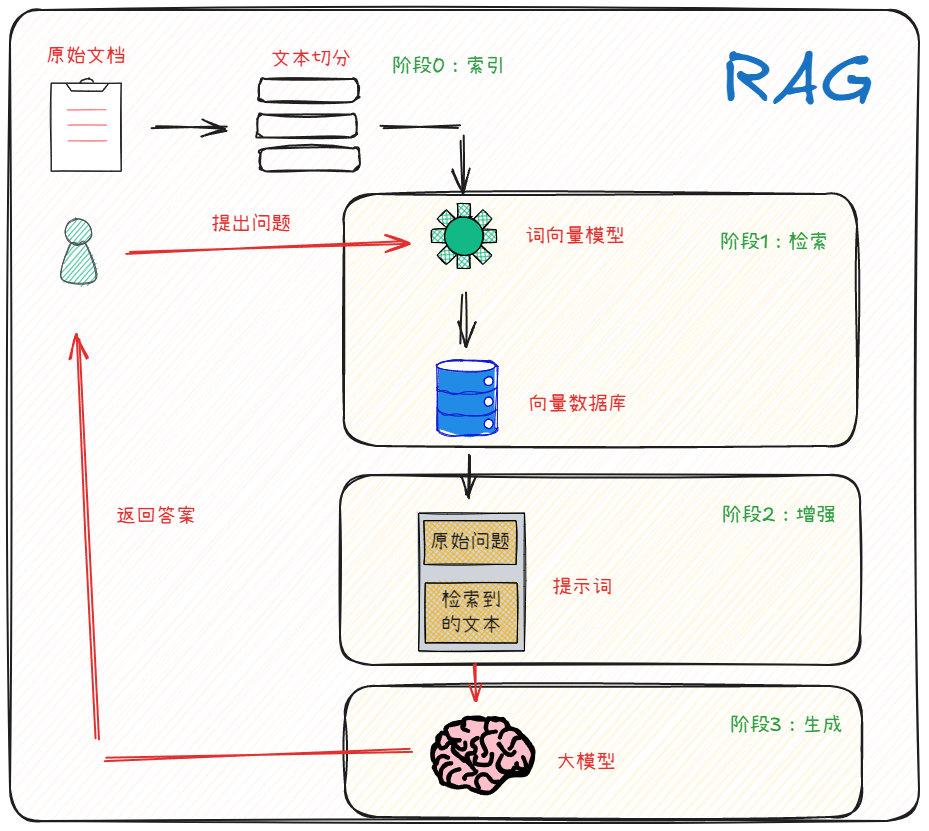
从技术实现细节上看,RAG的实现是包括两个阶段的:检索阶段和生成阶段。在检索阶段,从知识库中找出与问题最相关的知识,为后续的答案生成提供素材。在生成阶段,RAG会将检索到的知识内容作为输入,与问题一起输入到语言模型中进行生成。这样,生成的答案不仅考虑了问题的语义信息,还考虑了相关私有数据的内容。如下图所示:
为什么要搞得这个复杂呢?还是在于大模型本身的以下两个特性:
-
如果用户提出的问题,其对应的答案出现在一篇文章中,去知识库中找到一篇与用户输入相关的文章是很容易的,但是我们将检索到的这整篇文章直接放入
Prompt中并不是最优的选择,因为其中一定会包含非常多无关的信息,而无效信息越多,对大模型后续的推理影响越大。 -
任何一个大模型都存在最大输入的Token限制,如果将一整个文本去全部传入大模型,无法容纳如此多的信息。
而RAG构建的关键,则是由检索组件(通常由Embedding模型和向量数据库组成)和生成组件( 大模型 )组成。在推理时,用户查询用于对索引文档运行相似性搜索,以检索与查询最相似的文档,并为大模型提供额外的上下文。因此,我们在构建RAG的过程中,也往往是遵循着这种流程去做定制化的开发。那么每个环节中我们应该掌握哪些知识呢?我们来看下面的这个思维导图:
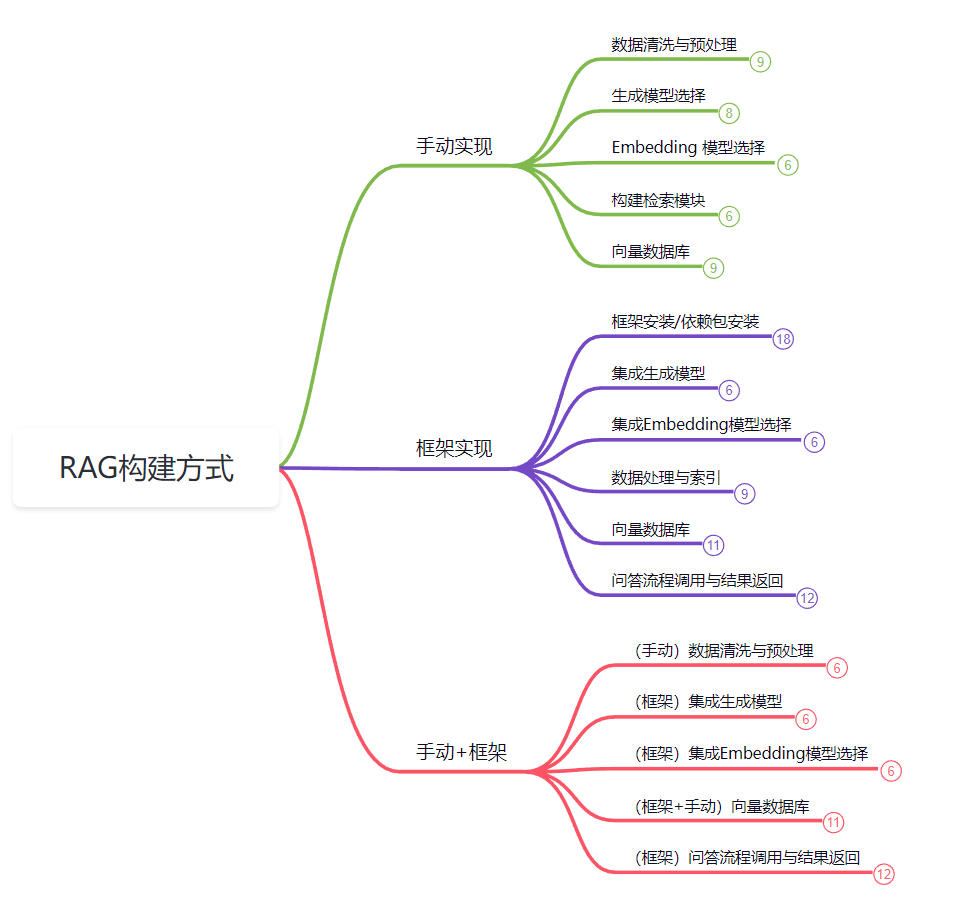
在实现RAG系统时,主要有三种方式:手动实现、框架实现和手动+框架结合的方式。通常,企业中不会选择完全手动实现,因为这样不仅工作量大,而且维护复杂。而手动+框架结合的方式,因其灵活性和高效性,会是90%以上开发者的首选。
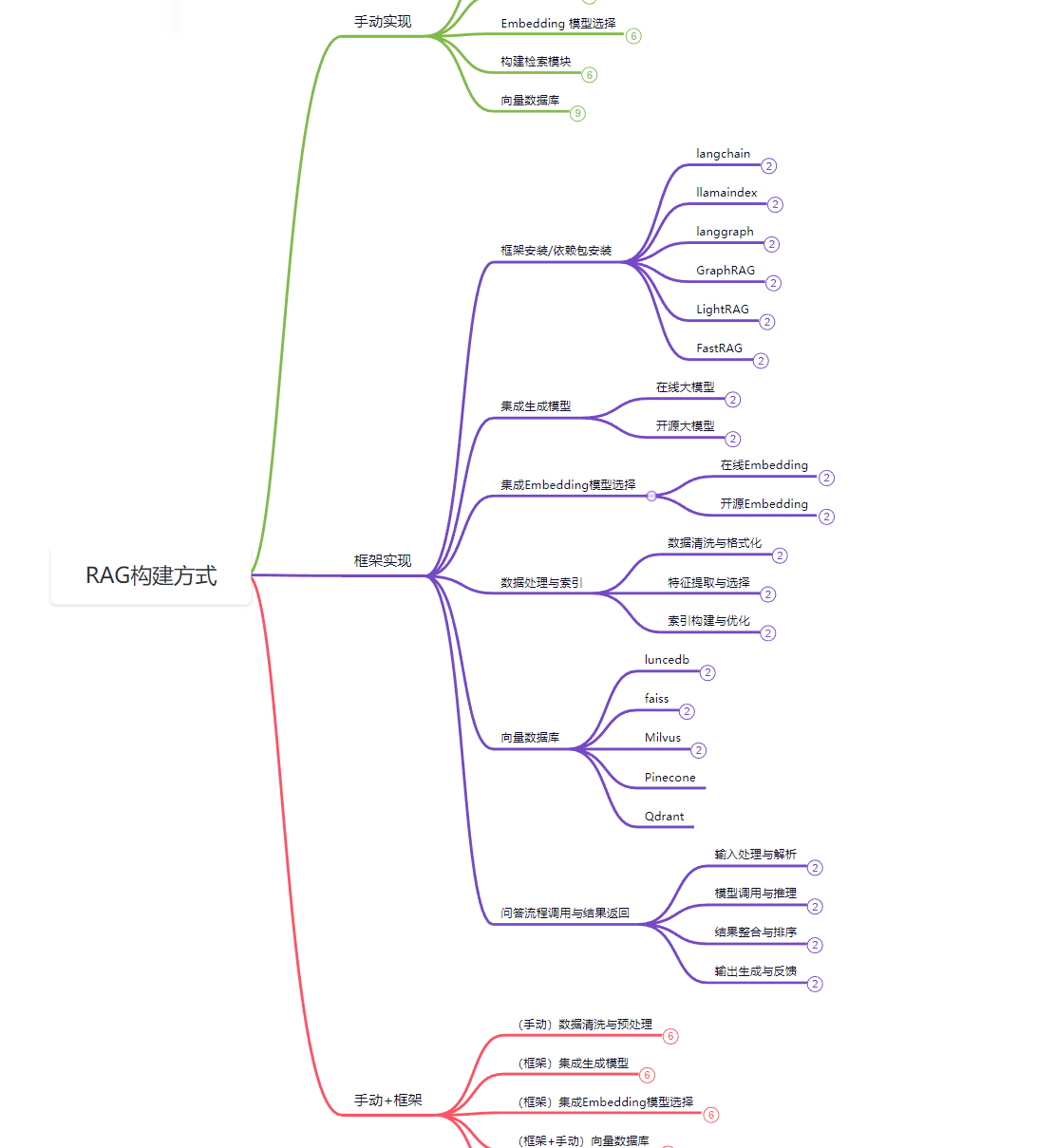
完整的的思维导图请扫码下方的二维码进行领取,同时思维导图中的全部内容在正式课程《大模型与Agent开发实战课》 均有保姆级的讲解,想系统学习的小伙伴可以扫码咨询课程信息哦👇
2. 使用LangChain实现RAG问答
# ! pip install PyPDF2==3.0.1 langchain==0.3.9 langchain-ollama==0.2.1 langchain_community==0.3.9 langchain_milvus==0.1.7 langgraph==0.2.56
这里我们选择其中一个框架:Langchain,并结合手动实现的方式,来帮助大家一步步实现RAG的d过程,既能利用框架加速开发,又能定制化地满足特定需求。我们就严格按照如下流程图中的全流程进行一个快速的复现。
2.1 文档切分
在构建 RAG系统的过程中,第一步是从文档中提取有用的信息。在这里,我们选择.pdf的文件类型进行实践。通过使用 PyPDF2 库的 PdfReader 类来实现从 PDF 文件中提取文本。
from PyPDF2 import PdfReader
def pdf_read(pdf_doc):
text = ""
for pdf in pdf_doc:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
然后, 将['./01_大模型应用发展及Agent前沿技术趋势.pdf'] 作为参数传递给 pdf_read 函数,读取并提取文件中的文本。
content = pdf_read(['./01_大模型应用发展及Agent前沿技术趋势.pdf'])
返回值 content 将包含该 PDF 文件的所有文本内容。
content
这里需要创建了一个 Document 对象,其属性 page_content 被设置为之前从 PDF 文件中提取的文本 content。这种封装方式是为了将文本数据标准化为一个可以在 LangChain 框架中处理的格式。
from langchain_core.documents import Document
documents = [Document(page_content=content)]
documents
然后,使用 LangChain 的 RecursiveCharacterTextSplitter 模块可以根据指定的块大小和重叠部分将文档文本分割成多个较小的部分,完成文本切分。
from langchain_text_splitters import RecursiveCharacterTextSplitter
chunk_size = 1000
chunk_overlap = 300
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
# 切分
splits = text_splitter.split_documents(documents)
splits
2.2 加载Embedding模型
LangChain 作为构建大语言模型应用的框架,提供了与不同Embedding的接入方式。这里通过使用 OllamaEmbeddings接入一个开源的 Embedding 模型 bge-m3。
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(
base_url = "http://192.168.110.131:11434", # 注意:这里需要替换成自己本地启动的endpoint
model="bge-m3",
)
text = "大模型 AI Agent 开发实战 \nCh.1 大模型应用发展及 Agent 前沿技术趋势"
single_vector = embeddings.embed_query(text)
print(str(single_vector)[:100]) # 显示前100个 词向量的表示, Bge-m3 是 1024 维度
print(len(single_vector))
领取Ollama本地部署详细指南,同时Ollama、vllm等框架的全体系介绍在正式课程《大模型与Agent开发实战课》 均有保姆级的讲解,想系统学习的小伙伴可以扫码咨询课程信息哦👇
2.3 存入向量数据库
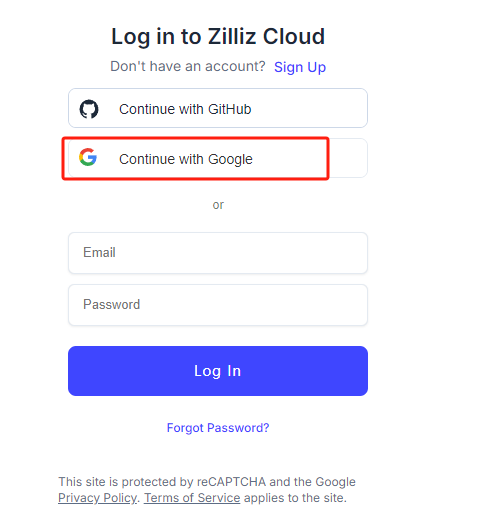
这里我们使用免费的在线milvus实例,地址如下:https://cloud.zilliz.com/login?redirect=/orgs , 先注册登录:
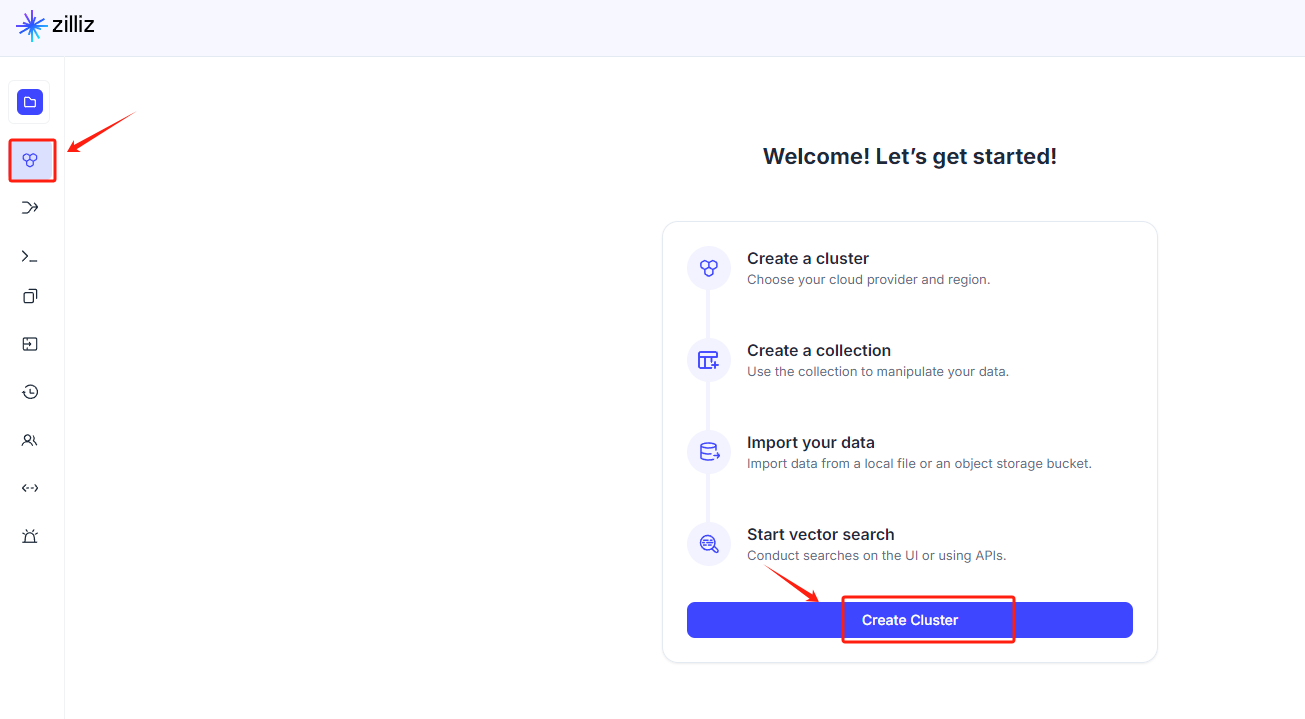
然后创建索引:
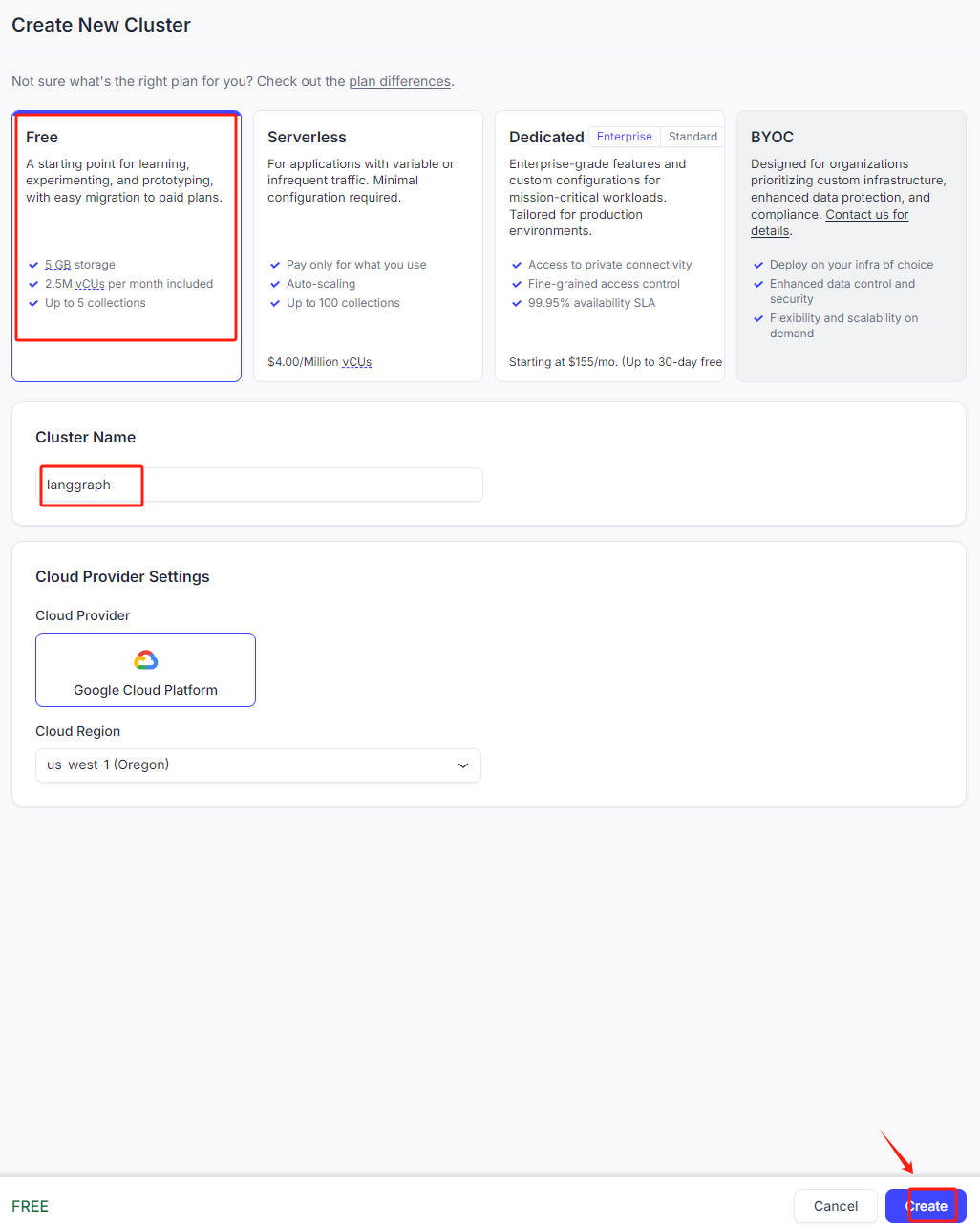
选择免费实例:
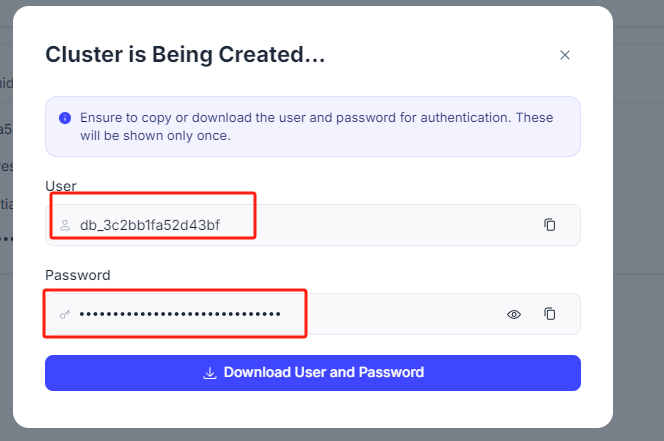
注意:这里需要保存好用户名和密码,用于接下来的远程连接。
等待创建完成后,注意关注如下信息:
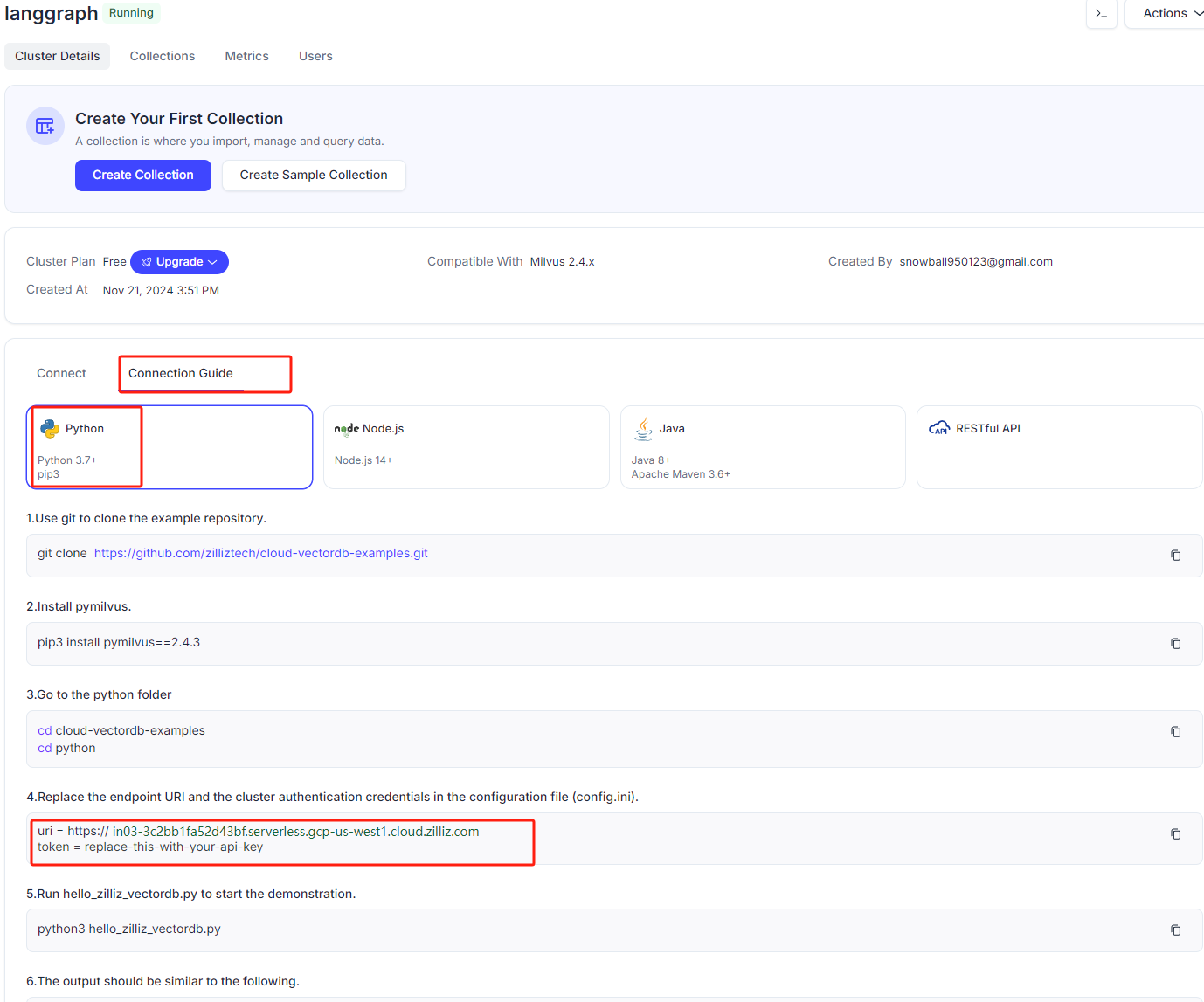
通过如下代码构建向量索引,并存储到云端的Milvus向量数据库中。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_milvus import Milvus
# 添加到向量数据中
vectorstore = Milvus.from_documents(
documents=splits,
collection_name="fufan_rag_milvus",
embedding=embeddings,
connection_args={
"uri": "https://in03-b9ed7b460b5d89f.serverless.gcp-us-west1.cloud.zilliz.com",
"user": "db_b9ed7b460b5d89f",
"password": "Ua3;qLNjSKWmGl6F",
}
)
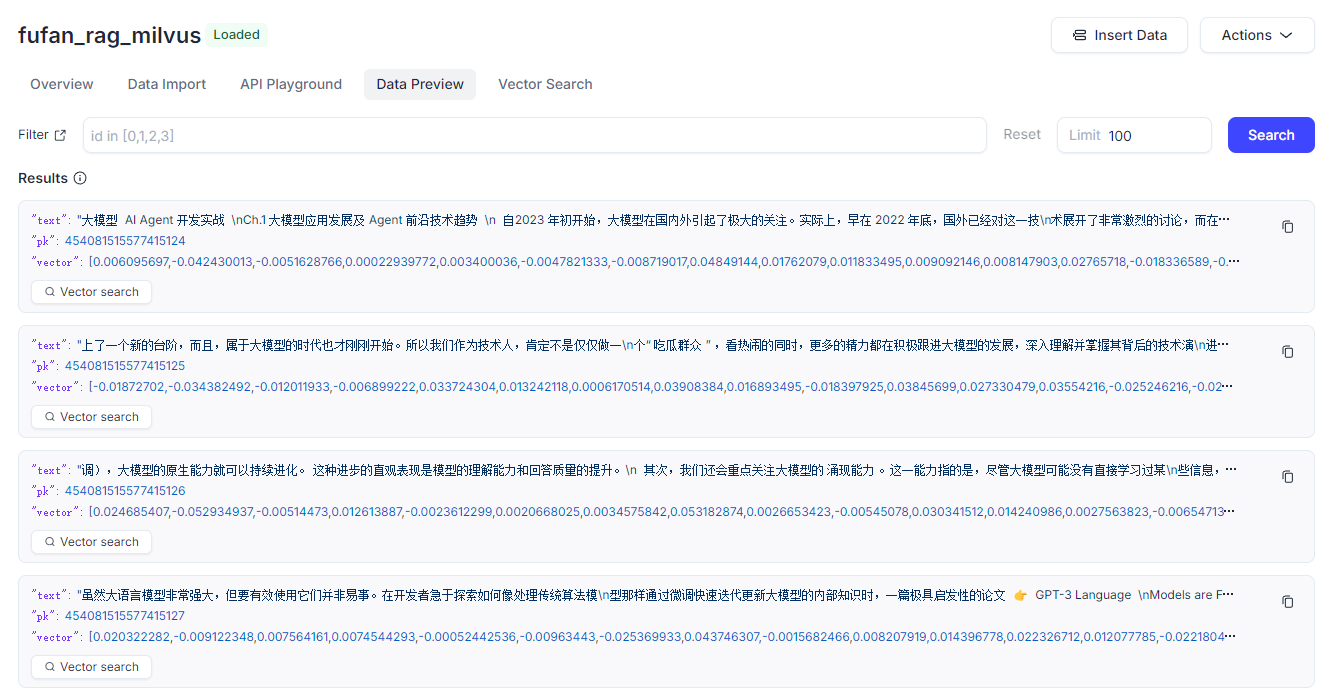
同时可以登录网页端进行确认:
2.4 接入生成模型
LangChain支持接入在线模型或者本地开源模型。这里我们使用Ollama接入通义千问最新推出的推理大模型QWQ:32B,当然大家也可以根据自己的实际使用情况进行灵活选择。
# 如果用开源模型,可以用Ollama 接入
from langchain_ollama import ChatOllama
qwq_llm = ChatOllama(
base_url = "http://192.168.110.131:11434", # 注意:这里需要替换成自己本地启动的endpoint
model="qwq:latest",
)
print(qwq_llm.invoke("你好,请你详细的介绍一下你自己。").content)

领取QWQ推理大模型的本地部署、性能评测保姆级课件,同时各类大模型全体系介绍在正式课程《大模型与Agent开发实战课》 均有保姆级的讲解,想系统学习的小伙伴可以扫码咨询课程信息哦👇
2.4 构建问答流程
在完成RAG的indexing过程后,接下来我们就可以开始构建问答流程了。其中,PromptTemplate 是 LangChain 用来定义提示的类。我们定义了一个用于问答任务的提示模板。模板的内容规定了如何使用检索到的上下文回答用户的问题。{question} 和 {context} 是输入变量,分别代表用户提出的问题和检索到的相关文档内容。Answer则表示后面的部分是生成的答案,规定了返回简洁的三句话以内的回答。
from langchain.prompts import PromptTemplate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# 提示
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Context: {context}
Answer:
""",
input_variables=["question", "document"],
)
然后通过管道运算符 | 将 PromptTemplate、LLM 模型 (qwq_llm) 和输出解析器 (StrOutputParser) 结合起来,构建了一个问答链。该链接收问题和文档内容,并生成简洁的回答。
# 构建传统的RAG Chain
rag_chain = prompt | qwq_llm | StrOutputParser()
接下来进行测试,提问了一个问题 "请问什么是 AI Agent?",该问题将作为输入传递给链,作为问答任务的起点。vectorstore.as_retriever() 方法会将当前的向量数据库(Milvus)转换为一个检索器,可以在给定的向量空间中执行检索操作。search_kwargs={"k": 3} 设置检索器返回前 3 个最相关的文档。
# 运行
question = "请问什么是 AI Agent?"
# 构建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 执行检索
docs = retriever.invoke("question")
docs
运行 RAG_chain,生成最终的回复。
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)
以上就是通过手动 + 框架快速构建一个 RAG 问答流程的完整代码,大家也能够发现相较于全手动实现,其效率和便捷性对开发者是非常友好的。
完整的的思维导图请扫码下方的二维码进行领取,同时思维导图中的全部内容在正式课程《大模型与Agent开发实战课》 均有保姆级的讲解,想系统学习的小伙伴可以扫码咨询课程信息哦👇
这样的 RAG 应用有两个相当大的限制:
- 仅考虑一个外部知识源。但是,某些解决方案可能需要两个外部知识源,而某些解决方案可能需要外部工具和 API,例如 Web 搜索。
- 它们是一次性解决方案,这意味着上下文被检索一次。没有对检索到的上下文的质量进行推理或验证。
而AI Agent 架构,则主要解决的就是如何集成外部的工具,自主规划完成任务所需的步骤并实际采取行动来完成任务。
3. 什么是 AI Agent
AI Agent 整个过程是一个动态循环。代理不断从环境中学习,通过其行动影响环境,然后根据环境的反馈继续调整其行动和策略。这种模式特别适用于那些需要理解和生成自然语言的应用场景,如聊天机器人、自动翻译系统或其他形式的自动化客户支持。
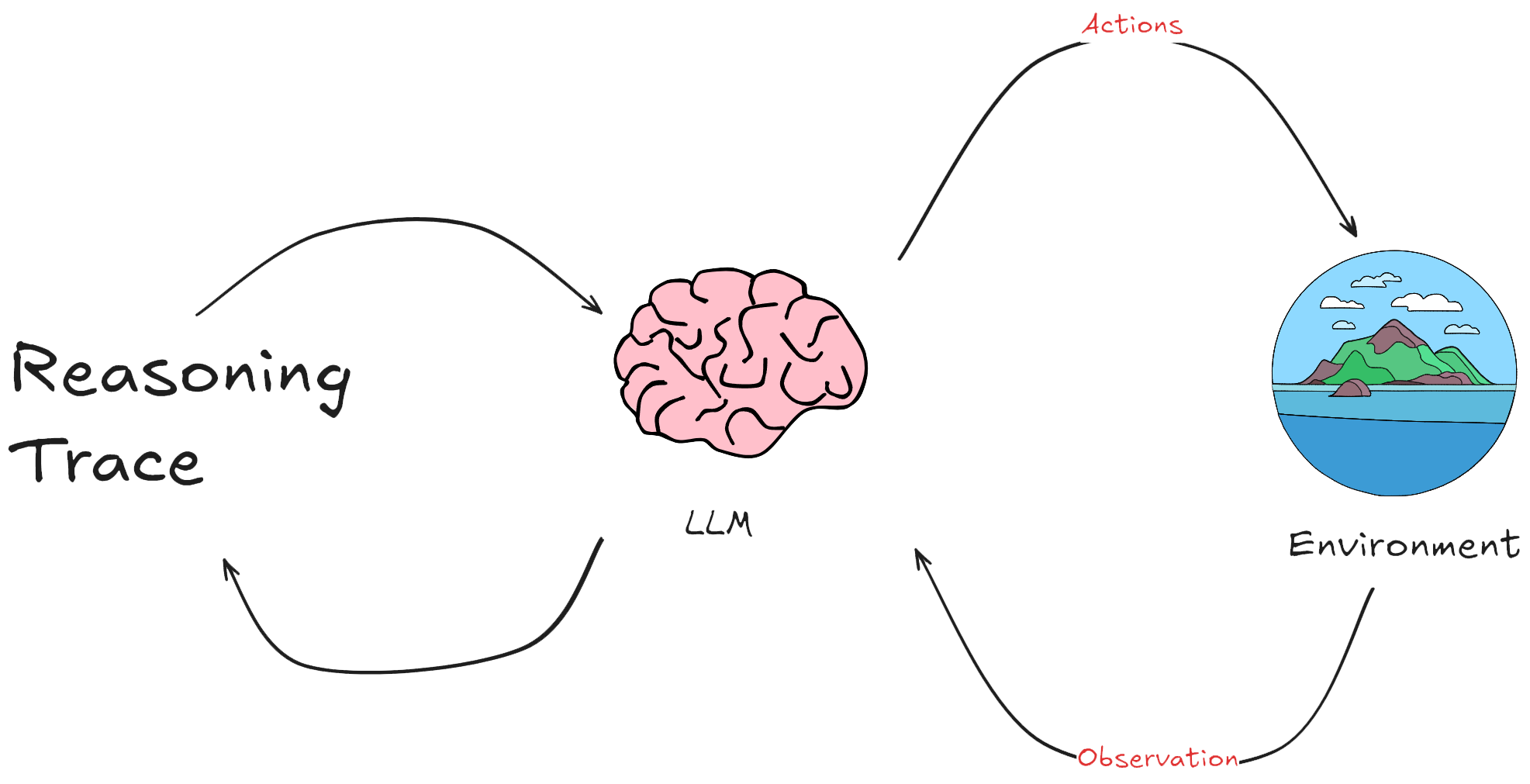
一个这是更加感官性的认知如下图所示:

如上图所示,展示了一个人工智能代理的基本架构,包括它与环境的互动、感知输入、大脑处理及其决策过程。具体来说:
- 环境(Environment): AI代理接收来自其周围环境的信息。环境可以是一个网站、数据库或任何其他类型的系统。
- 感知(Perception): 即输入。AI代理通过多种方式感知环境,如视觉(图像)、听觉(声音)、文本(文字信息)和其他传感器输入(如位置、温度等)。这些输入帮助代理理解当前的环境状态。
- 大脑(Brain):
- 存储(Storage):
- 记忆(Memory):存储先前的经验和数据,类似于人类的记忆。
- 知识(Knowledge):包括事实、信息和代理用于决策的程序。
- 决策制定(Decision Making):
- 总结(Summary)、回忆(Recall)、学习(Learn)、检索(Retrieve):这些功能帮助AI在需要时回顾和利用存储的知识。
- 规划/推理(Planning/Reasoning):基于当前输入和存储的知识,制定行动计划。
- 存储(Storage):
- 行动(Action):代理基于其感知和决策过程产生响应或行动。这可以是物理动作、发送API请求、生成文本或其他形式的输出。
一种最流行的思想就是 ReAct 。 ReAct 代理可以处理顺序的多部分查询,同时通过将路由、查询规划和工具使用组合到单个实体中来维护状态(在内存中)。
ReAct Agent 也称为 ReAct,是一个用于提示大语言模型的框架,它首次在 2022 年 10 月的论文《ReAct:Synergizing Reasoning and Acting in Language Models》 中引入,并于2023 年 3 月修订。该框架的开发是为了协同大语言模型中的推理和行动,使它们更加强大、通用和可解释。通过交叉推理和行动,ReAct 使智能体能够动态地在产生想法和特定于任务的行动之间交替。
ReAct 框架有两个过程,由 Reason 和 Act 结合而来。从本质上讲,这种方法的灵感来自于人类如何通过和谐地结合思维和行动来执行任务,就像我们上面“我想去北京旅游”这个真实示例一样。
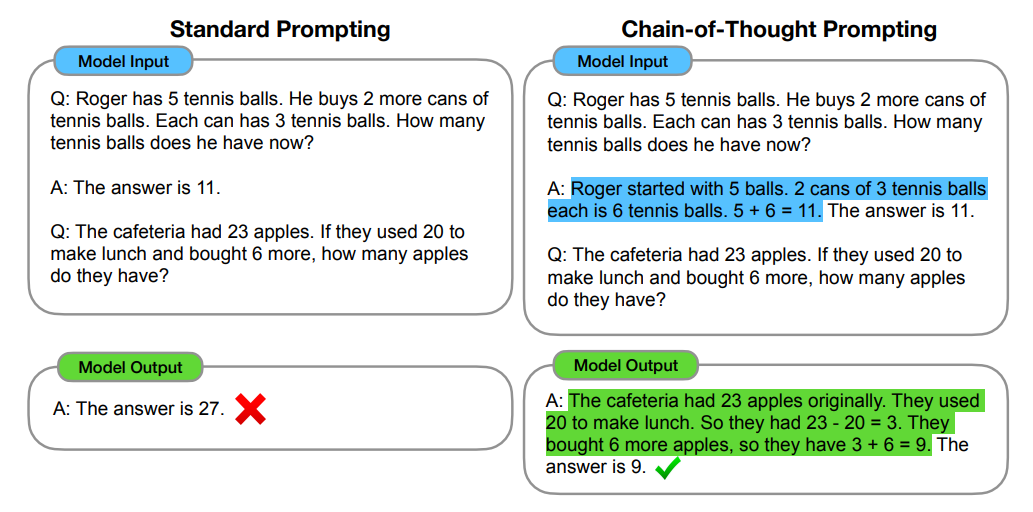
首先第一部分 Reason,它基于一种推理技术——思想链(CoT) , CoT是一种提示工程,通过将输入分解为多个逻辑思维步骤,帮助大语言模型执行推理并解决复杂问题。这使得大模型能够按顺序规划和解决任务的每个部分,从而更准确地获得最终结果,具体包括:
- 分解问题:当面对复杂的任务时,CoT 方法不是通过单个步骤解决它,而是将任务分解为更小的步骤,每个步骤解决不同方面的问题。
- 顺序思维:思维链中的每一步都建立在上一步的结果之上。这样,模型就能从头到尾构造出一条逻辑推理链。
比如,一家商店以 100 元的价格出售产品。如果商店降价20%,然后加价10%,产品的最终价格是多少?
- 步骤 1 — 计算降价20%后的价格:如果原价是100元,商店降价20%,我们计算降价后的价格: 10 x (1–0.2) = 80.
- 步骤 2 — 计算上涨 10% 后的价格:降价后,产品价格为 80 元。现在商店涨价10%:80 x (1 + 0.1) = 88.
- 结论:先降价后加价后,产品最终售价为88元。
# 如果用开源模型,可以用Ollama 接入
from langchain_ollama import ChatOllama
qwq_llm = ChatOllama(
base_url = "http://192.168.110.131:11434", # 注意:这里需要替换成自己本地启动的endpoint
model="qwq:latest",
)
print(qwq_llm.invoke("罗杰有5个网球,他又买了2罐网球,每罐有3个网球,他现在有多少个网球?").content)
但是,在 CoT 提示工程的限定下,大模型仍然会产生幻觉。因为经过长期的使用,大家发现在推理的中间阶段会产生不正确的答案或上下游的传播错误,所以,Google DeepMind 团队开发了ReAct的技术来弥补这一点。ReAct 采用的是 思想-行动-观察循环的思路,其中代理根据先前的观察进行推理以决定行动。这个迭代过程使其能够根据其行动的结果来调整和完善其方法。如下图所示:👇
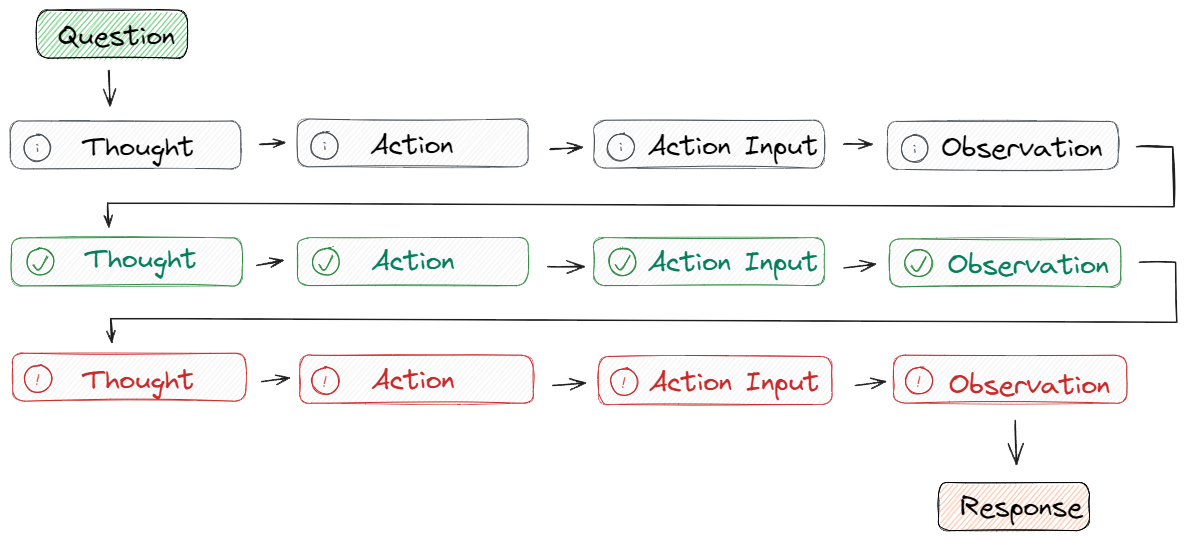
在这个过程中,Question指的是用户请求的任务或需要解决的问题,Thought用来确定要采取的行动并向大模型展示如何创建/维护/调整行动计划,Action Input是用来让大模型与外部环境(例如搜索引擎、维基百科)的实时交互,包括具有预定义范围的API。而Observation阶段会观察执行操作结果的输出,重复此过程直至任务完成。
与RAG的构建方法一样,目前AI Agent开发形式也可以从手动实现、框架实现和 手动+框架实现三种方式来选择,当然,手动 + 框架结合的方法依然是目前最高效的方法。
AI Agent开发完整的的思维导图请扫码下方的二维码进行领取,同时思维导图中的全部内容在正式课程《大模型与Agent开发实战课》 均有保姆级的讲解,想系统学习的小伙伴可以扫码咨询课程信息哦👇
4. 使用LangGraph实现ReAct代理
这里我们选择LangGrah从零开始实现 ReAct 代理。
从名字上看,LangGraph应该是和Langchain有着非常紧密的关系,而事实也确实是这样。因为LangGraph 就是以 LangChain 表达式语言为基础而构建起来的用于开发AI Agent的一个框架。所以我们上面提到的关于LangGragh在大模型的支持、接入和AI Agent构建方面的优势,都可以非常自然的从LangChain中迁移过来。
from typing import (
Annotated,
Sequence,
TypedDict,
)
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
"""The state of the agent."""
messages: Annotated[Sequence[BaseMessage], add_messages]
然后,定义实时联网检索外部工具,通过该函数获取最新的网络数据信息。
from langchain_core.tools import tool
from typing import Union, Optional
from pydantic import BaseModel, Field
import requests
import json
class SearchQuery(BaseModel):
query: str = Field(description="Questions for networking queries")
@tool(args_schema = SearchQuery)
def fetch_real_time_info(query):
"""Get real-time Internet information"""
url = "https://google.serper.dev/search"
payload = json.dumps({
"q": query,
"num": 3,
})
headers = {
'X-API-KEY': '63b0f2e139c8aef1cb3e76406d947e562e522241', # 这里需要替换成自己的 Serper API Key
'Content-Type': 'application/json'
}
response = requests.post(url, headers=headers, data=payload)
data = json.loads(response.text) # 将返回的JSON字符串转换为字典
if 'organic' in data:
return json.dumps(data['organic'], ensure_ascii=False) # 返回'organic'部分的JSON字符串
else:
return json.dumps({"error": "No organic results found"}, ensure_ascii=False) # 如果没有'organic'键,返回错误信息
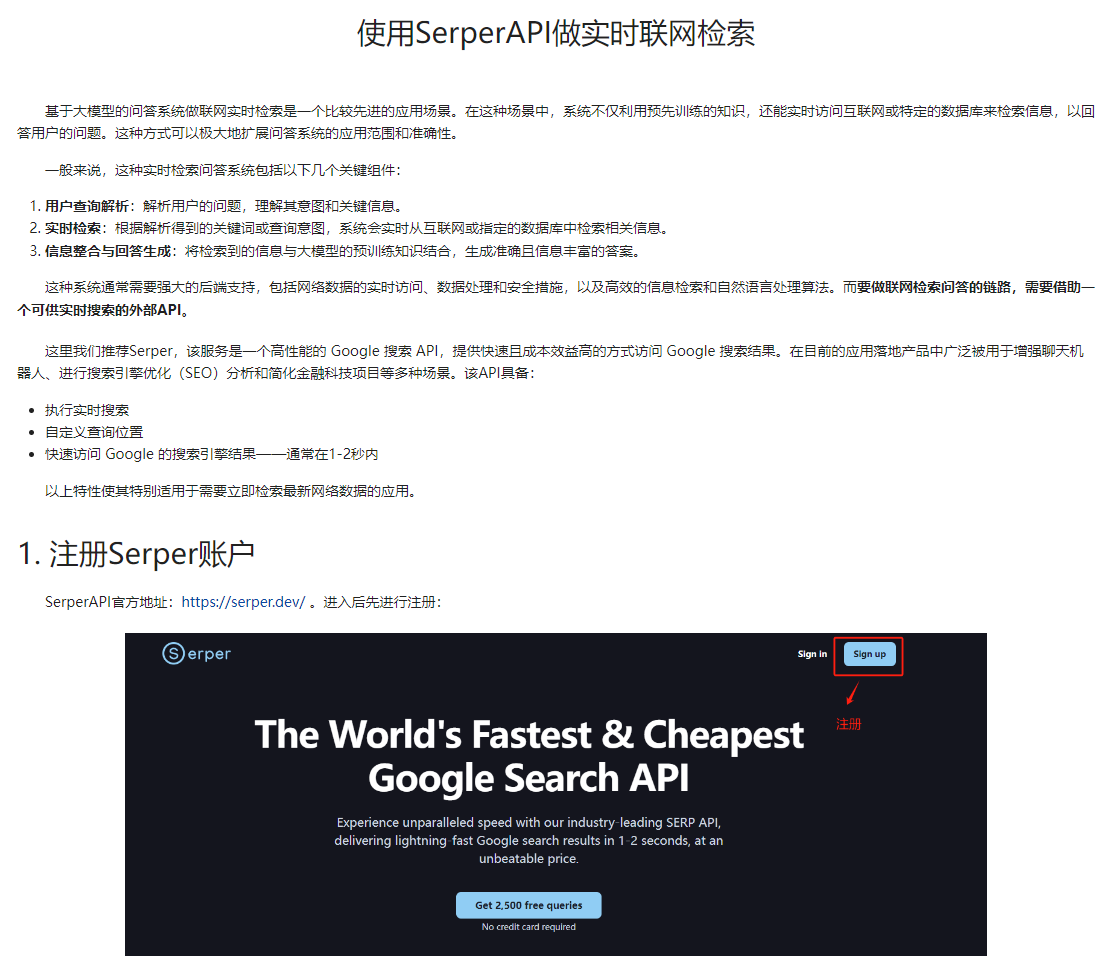
实时联网检索及在AI Agent 中的详细应用在正式课程《大模型与Agent开发实战课》 均有保姆级的讲解,想系统学习的小伙伴可以扫码咨询课程信息哦👇
测试一下fetch_real_time_info函数的有效性,正常情况下可以根据提出的问题返回相关网页的url。测试代码如下所示:
fetch_real_time_info("什么是 AI Agent ?")
# 如果用开源模型,可以用Ollama 接入
from langchain_ollama import ChatOllama
qwq_llm = ChatOllama(
base_url = "http://192.168.110.131:11434", # 注意:这里需要替换成自己本地启动的endpoint
model="qwq:latest",
)
tools = [fetch_real_time_info]
model = qwq_llm.bind_tools(tools)
import json
from langchain_core.messages import ToolMessage, SystemMessage, HumanMessage
from langchain_core.runnables import RunnableConfig
tools_by_name = {tool.name: tool for tool in tools}
# 定义工具节点
def tool_node(state: AgentState):
outputs = []
for tool_call in state["messages"][-1].tool_calls:
tool_result = tools_by_name[tool_call["name"]].invoke(tool_call["args"])
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
# 定义问答模型
def call_model(
state: AgentState,
):
system_prompt = SystemMessage(
"You are a helpful AI assistant, please respond to the users query to the best of your ability!"
)
response = model.invoke([system_prompt] + state["messages"])
return {"messages": [response]}
# 定义路由节点
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return "end"
else:
return "continue"
from langgraph.graph import StateGraph, END
# 定义一个图结构
workflow = StateGraph(AgentState)
# 在图结构中添加节点
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
# 设置启动点是 agent
workflow.set_entry_point("agent")
# 添加路由边
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"end": END,
},
)
# 添加返回边
workflow.add_edge("tools", "agent")
# 编译图
graph = workflow.compile()
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
# 定义问答的流
def print_stream(stream):
for s in stream:
message = s["messages"][-1]
if isinstance(message, tuple):
print(message)
else:
message.pretty_print()
inputs = {"messages": [("user", "你好,请你介绍一下你自己?")]}
print_stream(graph.stream(inputs, stream_mode="values"))
inputs = {"messages": [("user", "如何理解AI Agent?")]}
print_stream(graph.stream(inputs, stream_mode="values"))
inputs = {"messages": [("user", "OpenAI 最近在互联网上有什么大动作?")]}
print_stream(graph.stream(inputs, stream_mode="values"))
4. Agentic RAG
Agentic RAG(Agent-based Retrieval-Augmented Generation)是指在传统的 RAG(Retrieval-Augmented Generation)框架中引入了 Agent(智能体)作为核心组件的变体。在标准的 RAG 系统中,主要是通过检索相关文档或信息来增强生成模型的能力,而 Agentic RAG 则通过集成一个智能体,帮助系统在搜索和生成过程中进行更智能的决策和交互。
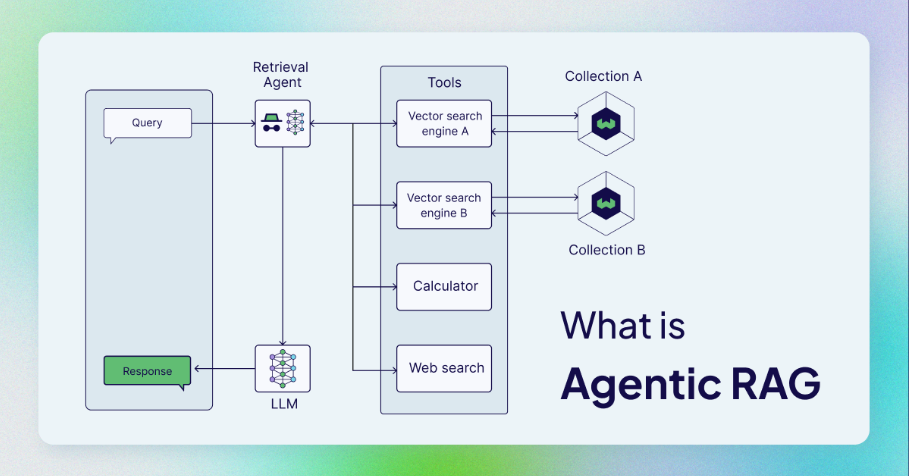
具体来说:它将 AI 代理合并到 RAG 管道中,以编排其组件并执行简单信息检索和生成之外的其他操作,以克服非代理管道的限制。代理 RAG 最常见的是指在检索组件中使用代理。件通过使用可访问不同检索器工具的检索代理而变得代理,例如:
- 矢量搜索引擎(也称为查询引擎),通过矢量索引执行矢量搜索(如典型的 RAG 管道)
- Web search 网页搜索
- 任何以编程方式访问软件的 API,例如电子邮件或聊天程序
这里我们用 Agentic RAG 去整合 Web 搜索和传统的 RAG。首先 构建传统 RAG 的Agent节点:
# 如果用开源模型,可以用Ollama 接入
from langchain_ollama import ChatOllama
qwq_llm = ChatOllama(
base_url = "http://192.168.110.131:11434", # 注意:这里需要替换成自己本地启动的endpoint
model="qwq:latest",
)
@tool
def vec_kg(question:str):
"""
Personal knowledge base, which stores the interpretation of AI Agent project concepts
"""
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Context: {context}
Answer:
""",
input_variables=["question", "document"],
)
# 构建传统的RAG Chain
rag_chain = prompt | qwq_llm | StrOutputParser()
# 构建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
# 执行检索
docs = retriever.invoke("question")
generation = rag_chain.invoke({"context": docs, "question": question})
return generation
tools = [fetch_real_time_info, vec_kg]
model = qwq_llm.bind_tools(tools)
tools
import json
from langchain_core.messages import ToolMessage, SystemMessage, HumanMessage
from langchain_core.runnables import RunnableConfig
tools_by_name = {tool.name: tool for tool in tools}
# 定义工具节点
def tool_node(state: AgentState):
outputs = []
for tool_call in state["messages"][-1].tool_calls:
tool_result = tools_by_name[tool_call["name"]].invoke(tool_call["args"])
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
# 定义问答模型
def call_model(
state: AgentState,
):
system_prompt = SystemMessage(
"You are a helpful AI assistant, please respond to the users query to the best of your ability!"
)
response = model.invoke([system_prompt] + state["messages"])
return {"messages": [response]}
# 定义路由节点
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return "end"
else:
return "continue"
from langgraph.graph import StateGraph, END
# 定义一个图结构
workflow = StateGraph(AgentState)
# 在图结构中添加节点
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
# 设置启动点是 agent
workflow.set_entry_point("agent")
# 添加路由边
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"end": END,
},
)
# 添加返回边
workflow.add_edge("tools", "agent")
# 编译图
graph = workflow.compile()
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
# 定义问答的流
def print_stream(stream):
for s in stream:
message = s["messages"][-1]
if isinstance(message, tuple):
print(message)
else:
message.pretty_print()
inputs = {"messages": [("user", "OpenAI 最近在互联网上有什么新闻?注意,请使用中文回复。")]}
print_stream(graph.stream(inputs, stream_mode="values"))
inputs = {"messages": [("user", "请检索我的知识库并总结一下什么是 AI Agent, 注意,请使用中文回复。")]}
print_stream(graph.stream(inputs, stream_mode="values"))
inputs = {"messages": [("user", "请检索我的知识库,并实时联网检索,结合两部分的信息帮我总结:什么是 AI Agent?注意,请使用中文回复。")]}
print_stream(graph.stream(inputs, stream_mode="values"))
当然,也会存在一些问题,比如:推理模型仅做步骤拆解,但不会触发访问web检索或者RAG的操作,如下所示:
inputs = {"messages": [("user", "请检索我的知识库,并实时联网检索,结合两部分的信息帮我总结:什么是 AI Agent。注意:请使用中文回答我")]}
print_stream(graph.stream(inputs, stream_mode="values"))
或者产生幻觉,直接说自己无法访问知识库。如下所示:
inputs = {"messages": [("user", "请检索我的知识库,帮我总结一下什么是 AI Agent, 注意,请使用中文回复。")]}
print_stream(graph.stream(inputs, stream_mode="values"))
以上存在的问题使我们在做AI Agent 开发过程中基本都会遇到的情况,同时也是根据实际业务做特定优化的主要工作。
实践到这里,大家应该已经对大模型目前最前沿技术有了一个基本的认识,而接下来的这样一个大模型技术栈全景指南,一定能进一步的提升大家对大模型的理解,和指明学习的思路,涵盖在线模型的调用和参数详解,开源模型的部署和调用,RAG、AI Agent 的手动实现和各个热门框架的详解,以及四大企业级落地项目的从零到一构建。

公开课内容节选自《大模型与Agent开发》完整版付费课程!
公开课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《大模型与Agent开发实战课》 :
《大模型与Agent开发实战课》 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
公开课直播特惠,全年最低价!低至 5 折 !扫码咨询课程信息哦👇