AgentScope RAG系统开发入门 (v3)
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(11月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(11月班)

《2025大模型Agent智能体开发实战》(11月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
课程完整介绍

秋季班重磅新增14项实战案例

部分课程成果演示
from IPython.display import Video
- Dify+DeepSeek搭建智能微信语音客服
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- Coze自动图文视频创作流程
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- 可视化数据分析Multi-Agent
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目展示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋季班)



详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

国产开源AgentScope框架技术实战
Part 2.AgentScope RAG系统开发入门
一、RAG(Retrieval-Augmented Generation,检索增强生成)技术综述
RAG,Retrieval-Augmented Generation,也被称作检索增强生成技术,最早在 Facebook AI(Meta AI)在 2020 年发表的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》( https://arxiv.org/abs/2005.11401 )中正式提出,这种方法的核心思想是借助一些文本检索策略,让大模型每次问答前都带入相关文本,以此来改善大模型回答时的准确性。这项技术刚发布时并未引发太大关注,而伴随2022年大模型技术大爆发,RAG技术才逐渐进入人们视野,并且由于早期大模型技术应用均已“知识库问答”为主,而RAG技术是最易上手、并且上限极高的技术,因此很快就成为了大模型技术人必备的技术之一。
1. RAG技术极简实现流程
时至今日,RAG技术已经是非常庞大的技术体系了,从简答的文档切分、存储、匹配,再到复杂的入GraphRAG(基于知识图谱的检索增强),以及复杂文档解析+多模态识别技术等等等等。
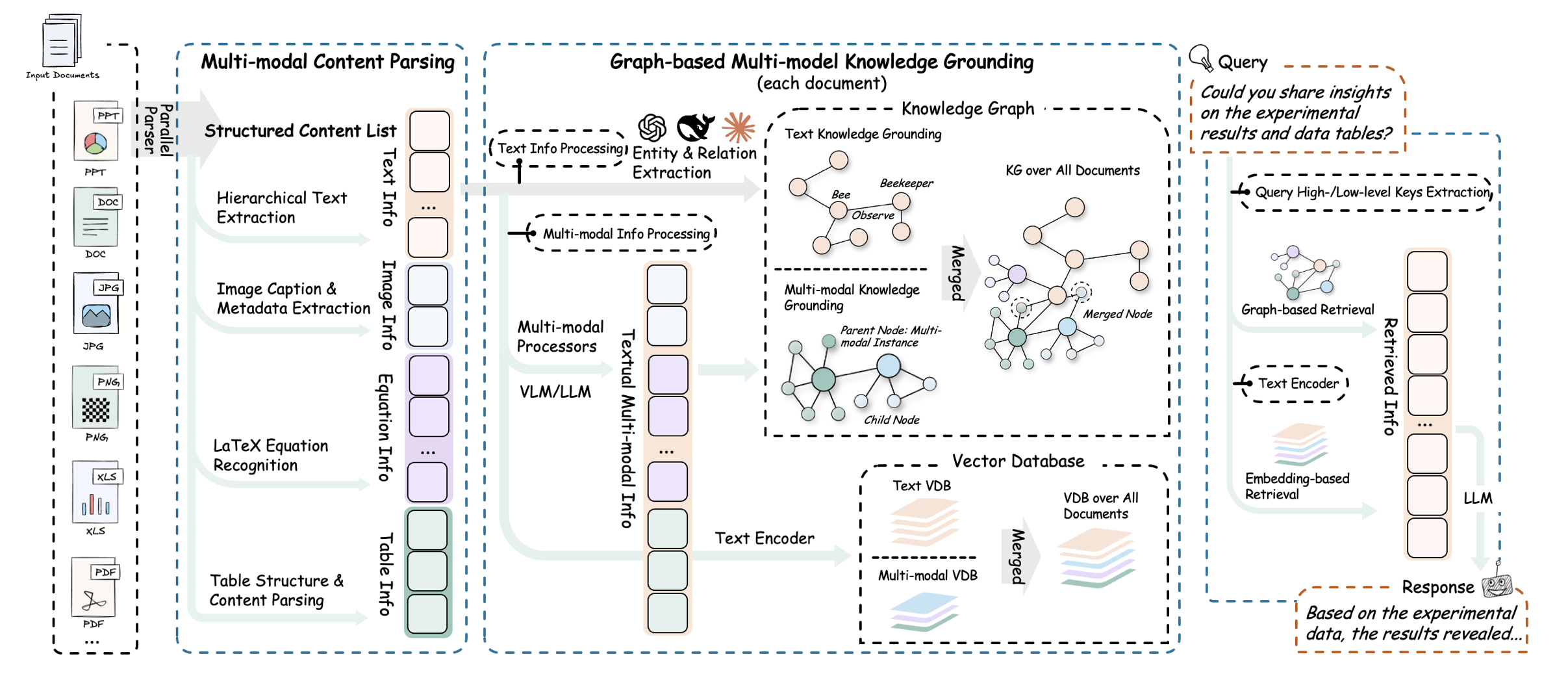
而对于初学者来说,为了更好的上手学习RAG技术,我们首先需要对RAG技术最简单的实现形式有个基础的了解。一个最简单的RAG技术实现流程如下所示:
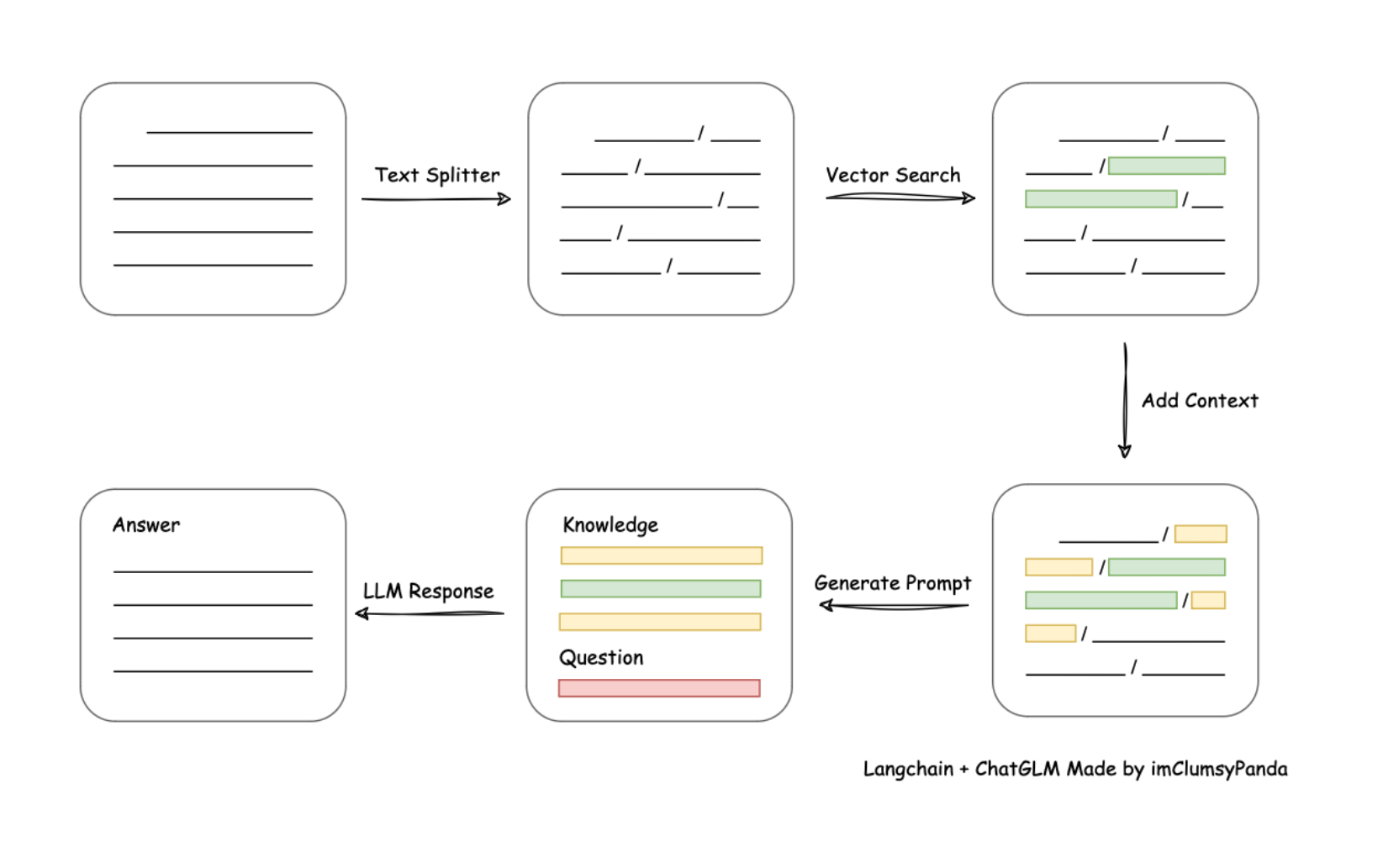
我们需要围绕给定的文档(往往是非常长的文档)先进行切分,然后将切分的文档转化为计算机能识别的形式,也就是将其转化为一个数值型向量(也被称为词向量),然后当用户询问问题的时候,我们再将用户的问题转化为词向量,并和段落文档的词向量进行相似度匹配,借此找出和当前用户问题最相关的原始文档片段,然后将用户的问题和匹配的到的原文片段都带入大模型,进行最终的问答。由此便可实现一次完整的文档检索增强执行流程。a
具体执行过程如下所示:
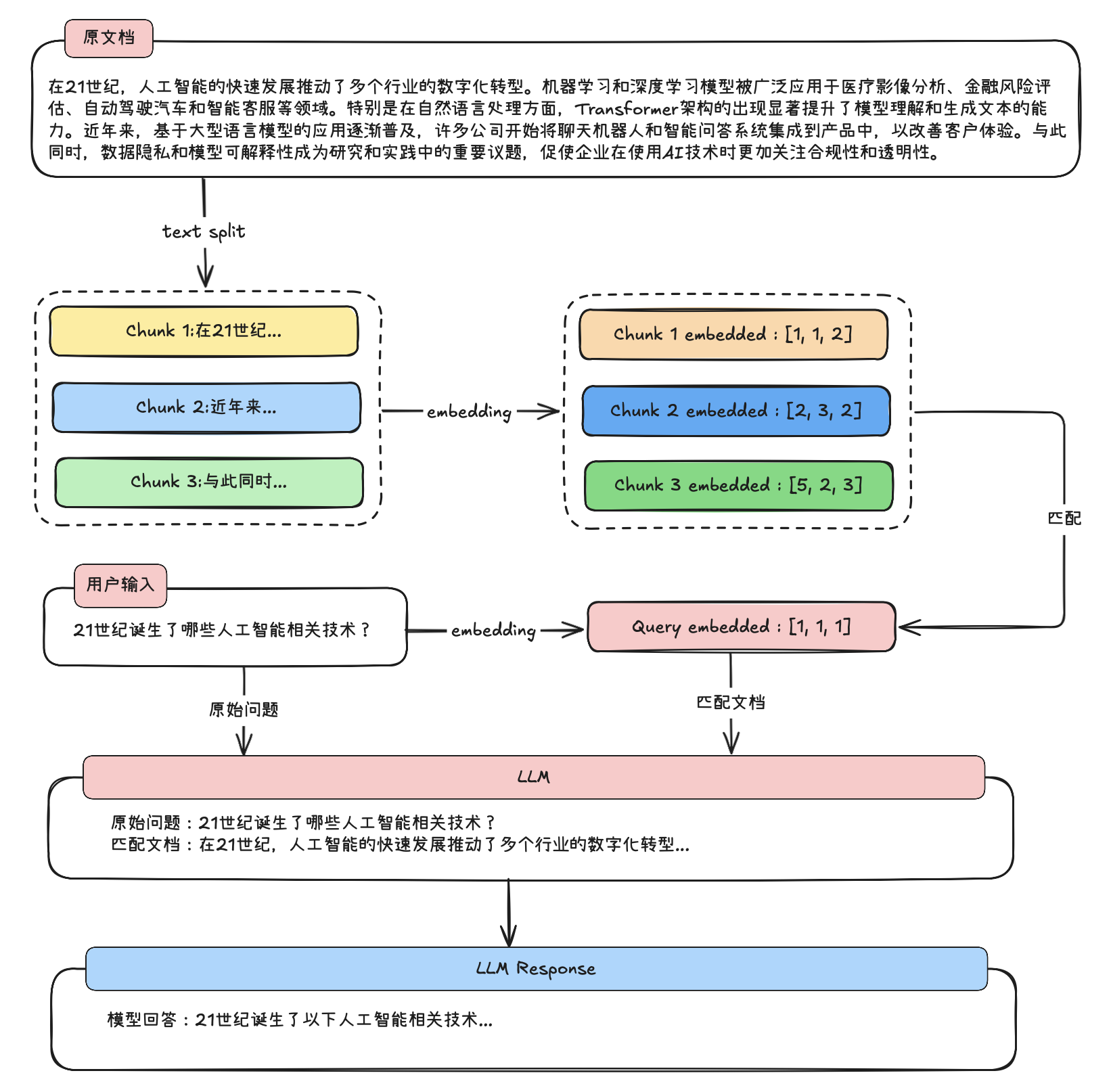
3. RAG技术核心应用场景:拓展模型知识边界与减少问答幻觉
那这样的一个检索增强流程到底有什么用呢?这就不得不从当代大模型本身的三项技术缺陷开始说起了。
- 缺陷一:大模型幻觉
相信大家在使用大模型的时候,都会遇到大模型无中生有胡编乱造答案的情况,例如胡乱生成一些概念、一些论文甚至是一些实时等,这就是所谓的大模型幻觉。
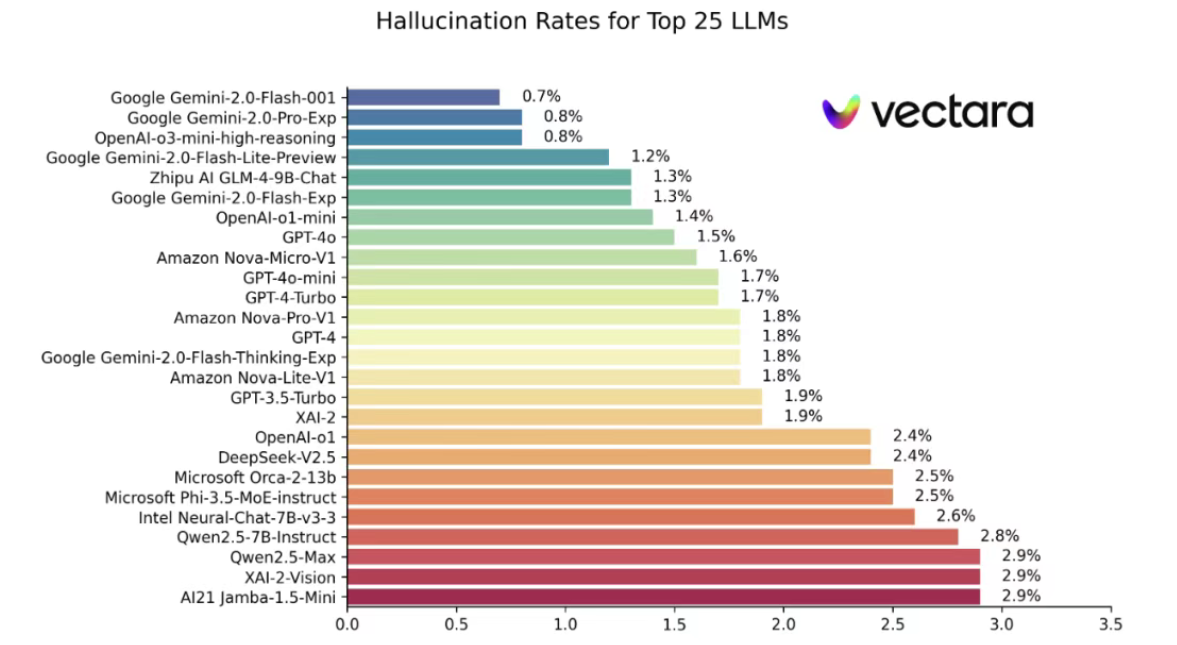
而其中,第一代DeepSeek R1模型的幻觉是非常严重的,平均七次回答中就会有一次的回答存在幻觉,这可以说是第一版R1模型最大的短板。
大型语言模型之所以会产生幻觉,主要是因为它们的训练方式和内在机制决定了它们并不具备真正理解和验证事实的能力。模型在训练过程中,通过分析大规模文本数据来学习不同词语和句子之间的概率关系,也就是在某种程度上掌握“在什么上下文中,什么样的回答听起来更合理”。然而,模型并没有接入实时的知识库或事实核查工具,当它遇到陌生的问题、模糊的描述或者上下文不完整的输入时,就会基于概率和语料库中似是而非的关联去“编造”一个看似正确的答案。由于这些输出往往语法流畅、逻辑连贯,人类读者很容易误以为它是真实可信的内容,这就是我们通常说的“模型幻觉”。
- 缺陷二:有限的最大上下文
而除此之外,大模型在实际应用中还会另一个“障碍”,那就是最大上下文限制。由于大模型的本质其实是一个算法,不管是让大模型“知道”有哪些外部工具,还是要给大模型进行“背景设置”,或者是要给模型添加历史对话消息,以及本次对话的输出,都需要占用这个上下文窗口。这就使得我们在一次对话中能够给大模型灌输的知识(文本)其实是有限的。
大型语言模型还存在最大上下文限制,这是由它们的架构和计算方式决定的。每次生成回答时,模型需要把输入文本转换成固定长度的数字序列(称为token),并在内部一次性加载到模型的“上下文窗口”中进行处理。这个窗口的大小是有限的,不同模型一般在几千到几万token之间。如果输入内容超出这个长度,模型要么截断最前面的部分,要么丢弃部分信息,这就会造成对话历史、长文档或先前提到的重要细节的遗失。因为它无法跨越上下文窗口无限地保留信息,所以在面对长对话或者大量背景知识时,模型常常出现上下文断裂、回答不连贯或者忽略先前条件的情况。
早些时候的大模型普遍是8k最大上下文,相当于是8-10页中文PDF,伴随着大模型预训练技术的不断发展,顶尖的大模型,如Gemini 2.5 Pro和GPT-5等模型,已经达到了1M的最大上下文长度,相当于是一千页的PDF,相当于1.5本《红楼梦》,而普通的模型,也基本达到64K或128K最大上下文,相当于60-100也左右的PDF。
但是,模型上下文的增长也是有限度的,对于开发者来说,能够一次性输入的信息都会有限制。
- 缺陷三:模型专业知识与时效性知识不足
大型语言模型虽然在通用领域展现出令人瞩目的语言理解和生成能力,但其在特定领域的专业知识掌握往往存在明显局限。其根本原因在于,模型的训练依赖于预先收集的大规模语料,这些语料覆盖面虽广,却很难保证在所有专业领域中具有足够的深度和准确性。某些领域,如医学、法律或前沿科技,知识更新速度快且门槛较高,公开可获取的高质量数据本身就有限,模型难以在此基础上形成系统性和权威性的认知。此外,模型训练通常在固定的时间点结束,因此其所掌握的知识具有天然的时效性,无法实时反映新近出现的研究成果、政策变化或行业动态。这种静态的知识存储模式,决定了大模型在面对最新或高度专业化的问题时,往往难以提供全面、精确的解答。

基于此,我们再回顾RAG的技术实现流程,就不难发现其背后的技术价值了:如果我们能在每次对话的时候,为当前模型输入最精准的问题相关的文档,那就能拓展模型的知识边界,无论是提升模型专业知识的准确性、给模型灌输一些时效性的知识、或者消除模型幻觉,都将大有助益,而在其他一些对话场景中,无论是需要围绕海量的文本搭建本地问答知识库、还是在构建无限上下文的聊天机器人,RAG技术都是最佳解决方案。
4. 问答机器人标配:RAG系统
正因为知识库检索的广泛的使用需求,RAG技术几乎成了现在各项聊天机器人的标配,无论是面向普通用户的聊天问答应用Cherry Studio:
还是面向企业应用场景的通用开源前端Open-WebUI:
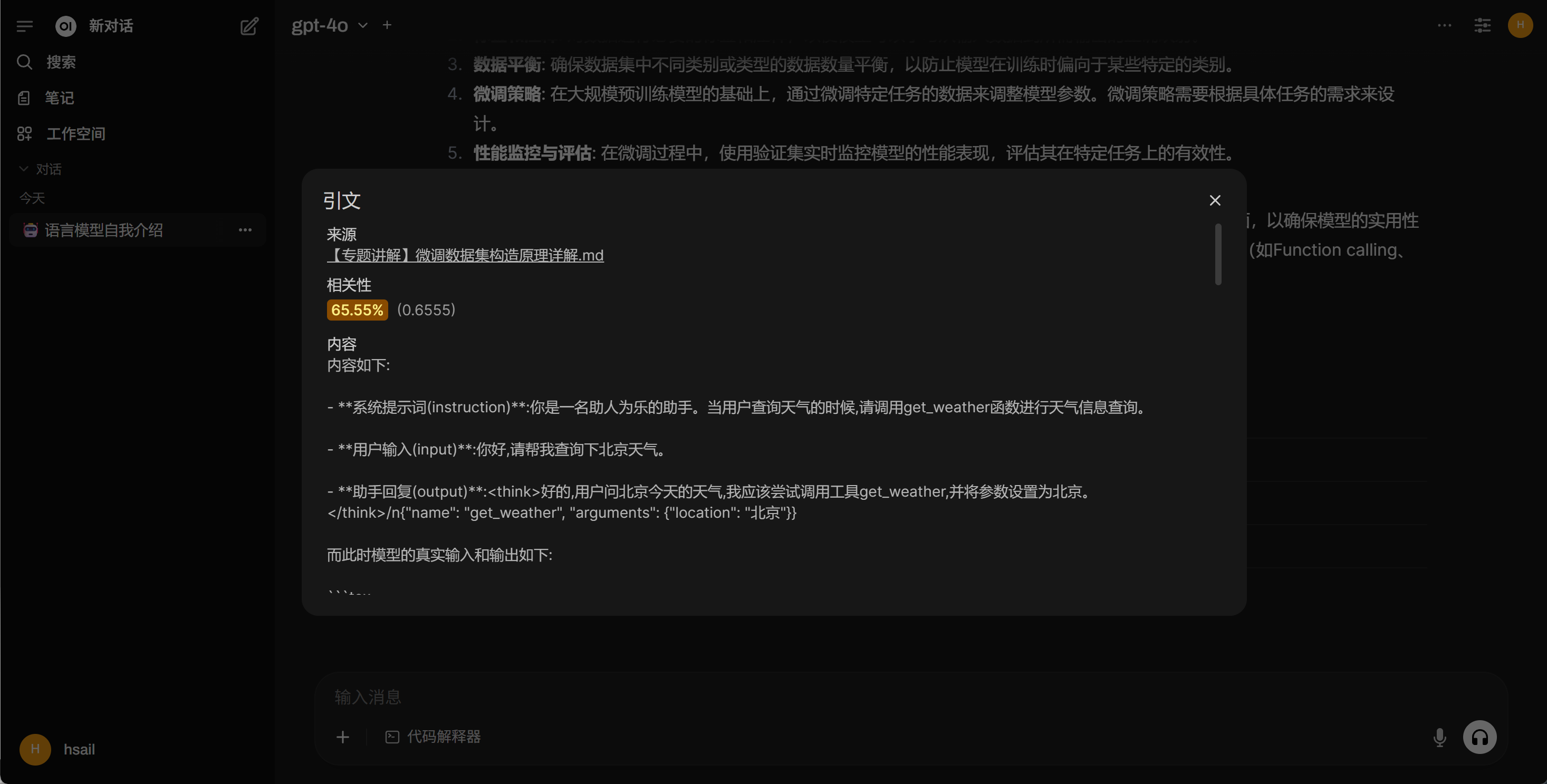
都毫无例外都配置了RAG功能,而对于OpenAI-WebUI这种企业级前端,还为用户展示了RAG检索过程诸多技术细节:
尽管这些项目能让用户更加快速的使用RAG系统,但这种传统的RAG流程(也被称作Native RAG),在长期的应用过程中也逐渐展露出很多问题,例如对于非结构化的文本(例如包含图片、公式的文本)无法进行检索,而对于超大规模文本的检索又会存在精度不足、或者无法提炼总结跨文本概念等问题。为此,近两年的时间里,在无数技术人的共同努力下,RAG技术有了长足的成长和突破。
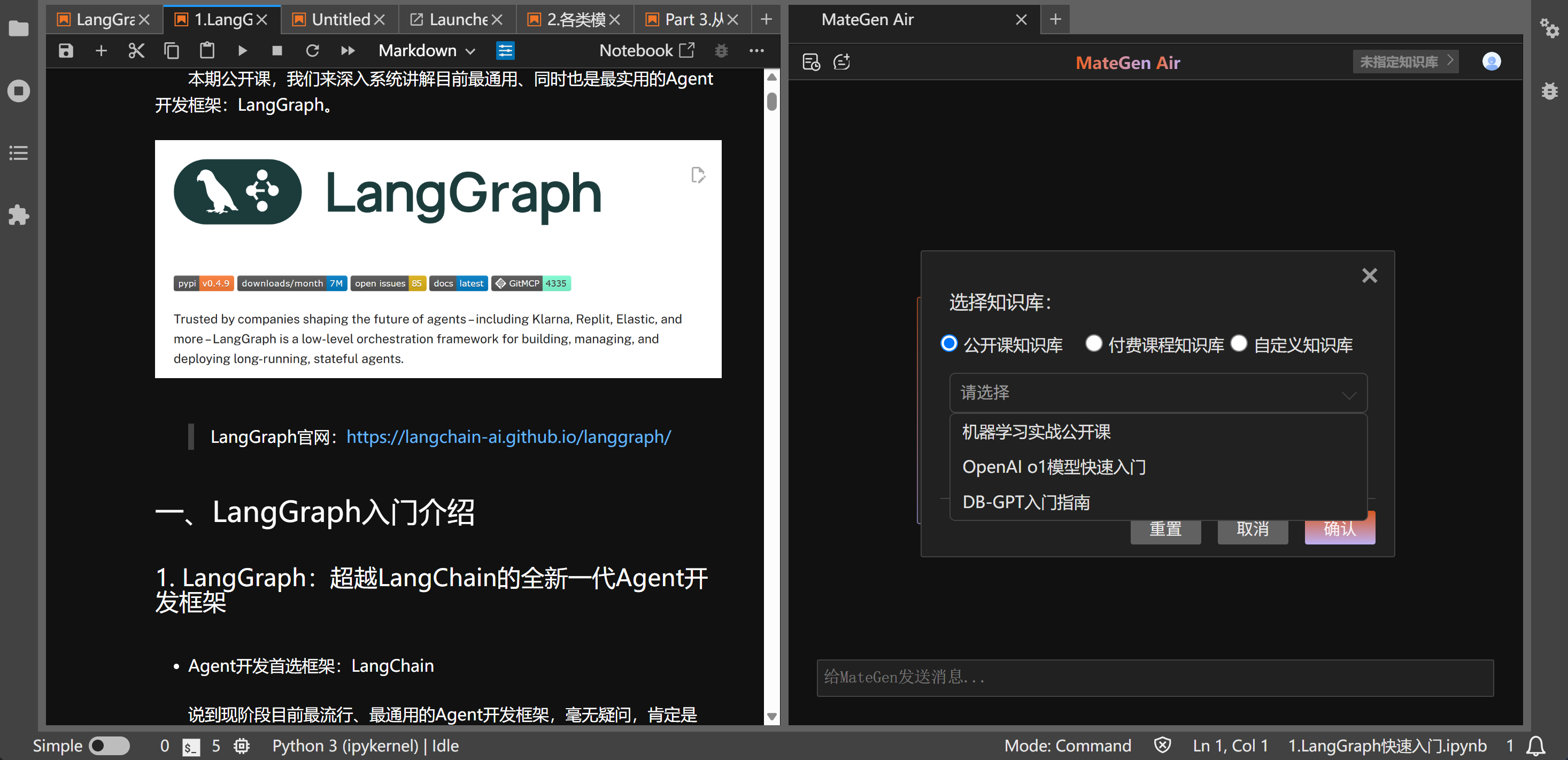
我们团队自研的开源Jupyter智能体助教MateGen Air,也提供了完整的公开课(部分)知识库问答功能:
5. RAG全栈技术体系介绍
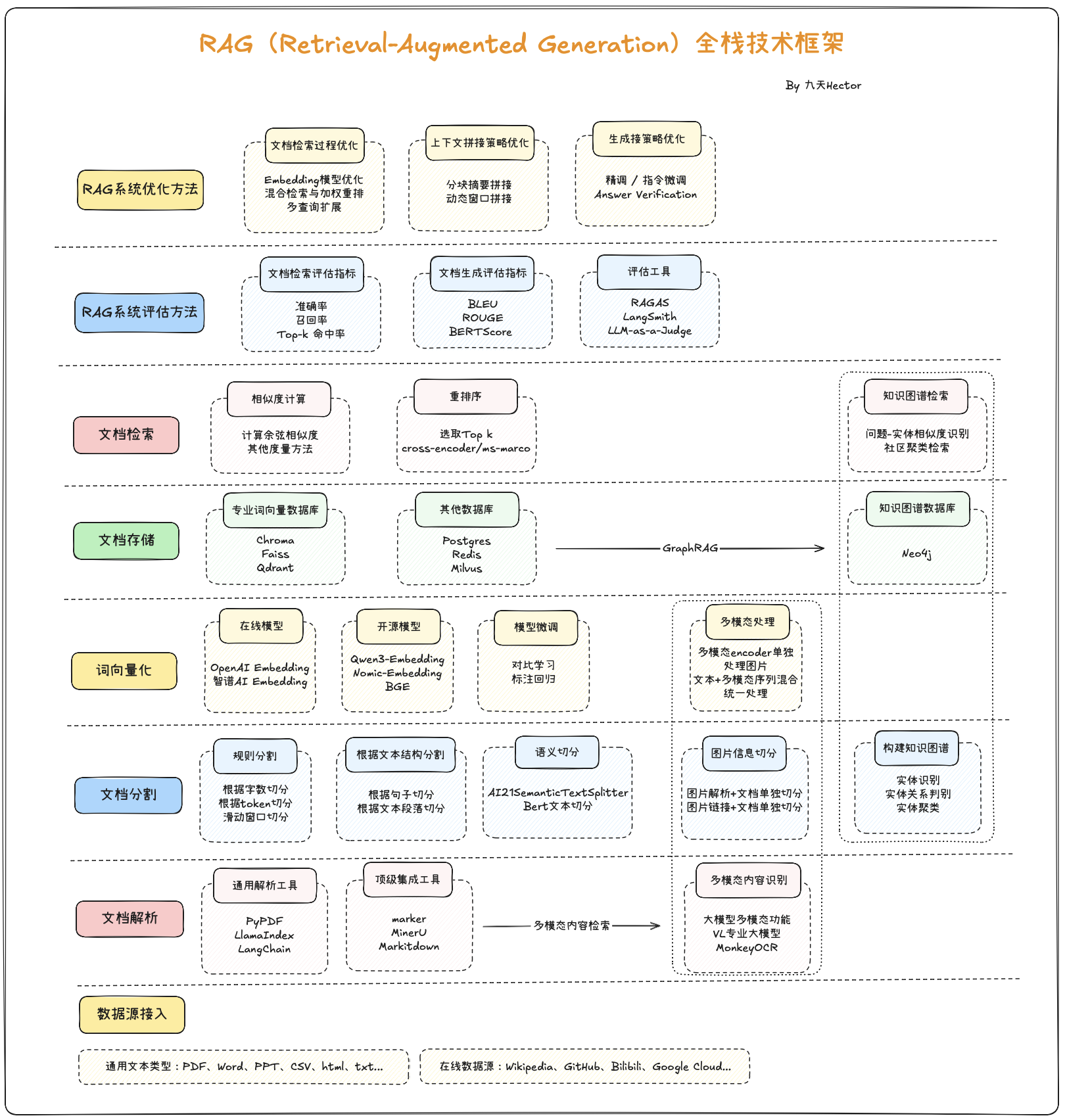
但是,就像前文介绍的那样,RAG技术是一项应用面广、门槛很低、但同时上限也很高的一项技术。历经数年的技术发展,RAG技术的体系已经非常庞大,以下是RAG技术全栈技术框架概览:
- 更多RAG理论入门、LangChain RAG系统开发、多模态RAG系统开发等入门教程,扫码加入赋范大模型技术社区即可免费学习。


二、AgentsScope RAG系统开发流程
1. 基于AgentScope的知识库创建与检索流程
import asyncio
import json
import os
from matplotlib import pyplot as plt
import agentscope
from agentscope.agent import ReActAgent
from agentscope.embedding import (
DashScopeTextEmbedding,
DashScopeMultiModalEmbedding,
)
from agentscope.formatter import DashScopeChatFormatter
from agentscope.message import Msg
from agentscope.model import DashScopeChatModel
from agentscope.rag import (
TextReader,
SimpleKnowledge,
QdrantStore,
Document,
ImageReader,
)
from agentscope.tool import Toolkit
1.1 创建文件读取器
在 AgentScope 的 RAG(Retrieval-Augmented Generation,检索增强生成)模块中,Reader(阅读器) 是知识库构建流程中的第一步组件,负责从不同类型的文件或资源中提取原始内容并将其转换为统一的 Document 对象,供后续的向量化与存储模块使用。
for _ in agentscope.rag.__all__:
if _.endswith("Reader"):
print(f"- {_}")
| Reader 名称 | 作用说明 |
|---|---|
| TextReader | 负责读取纯文本文件(如 .txt),将文本按段落或句子切分后转为 Document 对象。 |
| PDFReader | 用于解析 PDF 文件内容,通常会结合 OCR 或 PDF 解析库提取正文、表格等信息。 |
| ImageReader | 能够处理图片类型的输入(如 .jpg, .png),通过多模态嵌入模型提取图像特征或文本信息。 |
| WordReader | 支持读取 Word 文档(如 .docx),自动分段并提取文本内容。 |
通过这些阅读器,AgentScope 实现了对多模态、多格式数据的统一接入能力。 在实际构建知识库时,用户只需选择合适的 Reader(例如 TextReader() 或 PDFReader()),即可轻松将不同格式的文件转化为模型可理解的语义向量输入。
此外,AgentScope 的 Reader 模块是可扩展的——开发者可以自定义新的阅读器(如 MarkdownReader),从而支持更多数据类型,为后续的检索与生成任务奠定基础。
reader = TextReader(chunk_size=512, split_by="paragraph")
其中,TextReader是 AgentScope 框架中最基础的文本解析器(Reader),用于将纯文本内容按照设定的规则进行分块(chunking)处理。在 RAG 流程中,模型并不会直接读取整篇长文,而是依赖阅读器将大文本拆分成多个可管理的小块,再进行嵌入计算与索引构建。因此,TextReader 的作用相当于一个“文本预处理与切片器”。
TextReader?
核心参数解释如下:
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| chunk_size | int | 512 | 表示每个文本块的最大长度(以字符数为单位)。该值影响切分粒度:数值越小,块越短,检索更精确但存储更多;数值越大,块更长但语义分辨率可能下降。 |
| split_by | 'char' / 'sentence' / 'paragraph' | 'sentence' | 指定分块依据:可以按字符(char)、**句子(sentence)或段落(paragraph)**进行切分。 |
1.2 读取&文本切片
接下来,我们调用了 TextReader 并传入一段包含五句话的文本内容。通过设置 split_by="paragraph",阅读器会以段落(即每个换行符 \n)为切分边界,将整段文字拆分成多个独立的文本块(chunk)。
documents = await reader(
text=(
"我的名字是李明,今年28岁。\n"
"我居住在中国杭州,是一名算法工程师。我喜欢打篮球和玩游戏。\n"
"我父亲的名字是李强,是一名医生,我的母亲是陈芳芳,是一名教师,她总是指导我学习。\n"
"我现在在北京大学攻读博士学位,研究方向是人工智能。\n"
"我最好的朋友是王伟,我们从小一起长大,现在他是一名律师。"
),
)
documents
每个 Document 都对应原文中的一个段落,并包含以下关键信息:
| 字段 | 说明 |
|---|---|
| metadata | 存放原始内容和文档元数据,包括 type(文本类型)和 text(原文段落内容) |
| doc_id | 文档的唯一标识符(由哈希算法自动生成,用于区分不同源文件) |
| chunk_id | 当前段落在文档中的顺序编号,从 0 开始计数 |
| total_chunks | 当前文档被拆分后的总段落数(此处为 5) |
| embedding / score | 向量和得分字段,此阶段为空,后续在嵌入生成与检索阶段会被填充。 |
print(f"文本被分块为 {len(documents)} 个 Document 对象:")
for idx, doc in enumerate(documents):
print(f"Document {idx}:")
print("\tScore: ", doc.score)
print(
"\tMetadata: ",
json.dumps(doc.metadata, indent=2, ensure_ascii=False),
"\n",
)
1.3 创建知识库
接下来继续构建一个基于 Qdrant 的向量知识库(Knowledge Base)。这一步的核心是完成“语义嵌入模型 + 向量数据库”的配对与初始化,为后续的检索增强生成(RAG)提供底层数据支撑。
# 创建一个内存中的 Qdrant 向量存储,以及使用 DashScopeTextEmbedding 作为嵌入模型,初始化知识库
knowledge = SimpleKnowledge(
# 提供一个 embedding 模型用于将文本转换为向量
embedding_model=DashScopeTextEmbedding(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="text-embedding-v4",
dimensions=1024,
),
# 选择 Qdrant 作为向量存储
embedding_store=QdrantStore(
location="http://localhost:6333",
collection_name="test_collection",
dimensions=1024, # 嵌入向量的维度必须与嵌入模型输出的维度一致
),
)
在AgentScope的RAG系统中,知识库的核心组成由两部分构成:
-
Embedding 模型 —— 负责将文本转化为可度量的向量表示;
-
向量数据库(Vector Store) —— 用于存储和检索这些向量。
实际创建知识库过程中,正是通过 AgentScope 的 SimpleKnowledge 类,将这两部分有机地组合在一起,从而实现一个可查询的语义知识
DashScopeTextEmbedding —— 文本嵌入模型参数解释:
| 参数 | 说明 |
|---|---|
| api_key | 从环境变量中读取 DashScope 的 API 密钥 |
| model_name | 指定使用的嵌入模型名称,例如 "text-embedding-v4" |
| dimensions | 向量维度(必须与数据库的维度匹配) |
而Qdrant 是一个高性能的开源向量数据库,用于存储与检索 embedding 向量。在这里,我们通过 location="http://localhost:6333" 指定了本地运行的 Qdrant 服务地址。
| 参数 | 说明 |
|---|---|
| location | Qdrant 服务地址(此处为本地 Docker 容器暴露的端口) |
| collection_name | 存储集合名称(类似于数据库中的表名) |
| dimensions | 嵌入向量维度,必须与上方 embedding_model 一致 |
当 AgentScope 在后续调用 knowledge.add_documents() 时,所有文本片段将被:
-
转换为 1024 维向量;
-
通过 Qdrant API 存入对应的 collection;
-
形成可供相似度检索的语义索引。
Qdrant 的安装与运行(Windows 版)
由于 Qdrant 是一个独立的数据库服务,因此在运行上述代码前,你需要在本地启动 Qdrant。 在 Windows 系统中,推荐使用 Docker 容器 方式进行安装,步骤如下:
前往官方网站下载并安装 Docker Desktop for Windows ;
安装完成后,确保 Docker 正在运行(任务栏中出现小鲸鱼图标 🐳);
打开 PowerShell 或 CMD,输入:
若返回版本号则表示安装成功。
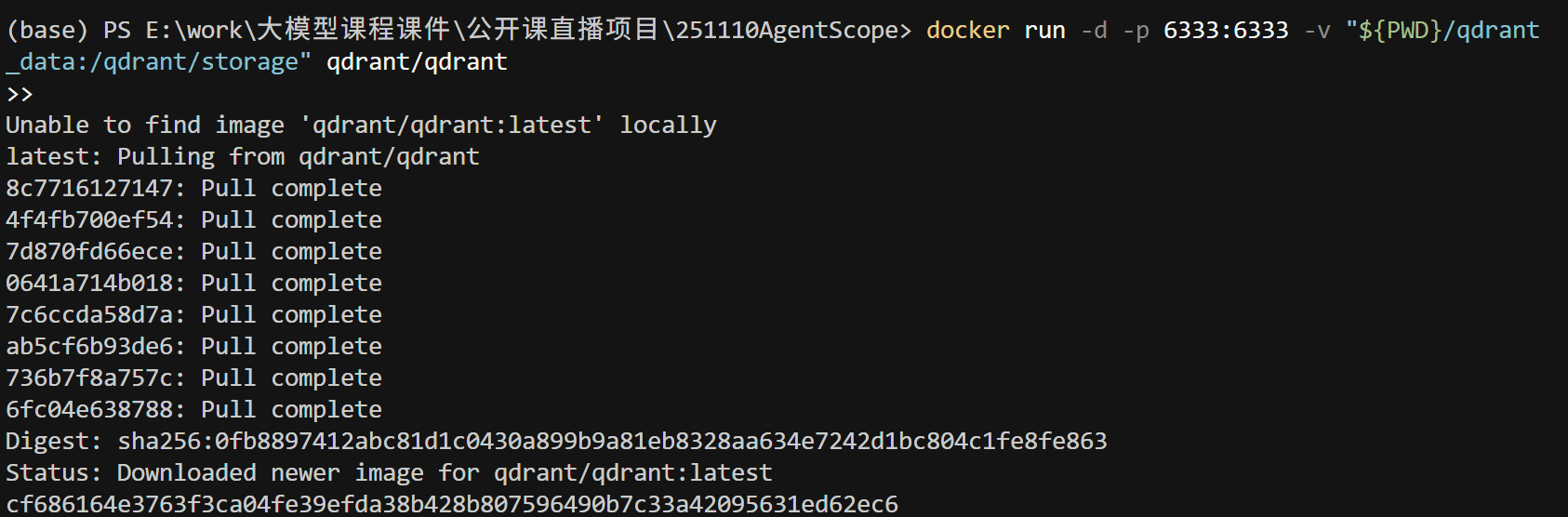
然后在你的项目目录中执行以下命令:
参数解释:
参数 说明 -p 6333:6333将容器的 6333 端口映射到本地 6333(API 访问端口) -v "${PWD}/qdrant_data:/qdrant/storage"将容器数据持久化保存到本地文件夹 qdrant/qdrant官方 Qdrant 镜像名称 运行成功后,可在浏览器访问: http://localhost:6333/dashboard 看到蓝色背景的控制台界面即表示数据库已正常启动。
SimpleKnowledge?
QdrantStore?
QdrantStore?
documents
await knowledge.add_documents(documents)
documents[0]
在 RAG 流程中,add_documents 方法的作用是将读取到的文档(Document 对象)转化为向量并添加到指定的向量存储(如 Qdrant)中,以便后续的检索。在调用 await knowledge.add_documents(documents) 后,文档内容会经过以下几个步骤:
-
文本分割:文档内容已经由 TextReader 等模块切分成多个片段,每个片段(chunk)都会独立处理并生成向量。
-
文本转向量:每个文本块被送入 DashScopeTextEmbedding 嵌入模型,将文本转化为固定维度的向量。例如,将“我的名字是李明,今年28岁”转化为一个 1024 维的浮点数向量。
-
存入数据库:生成的向量和对应的文本内容一起,存储到 Qdrant 向量数据库中。每个向量都会被赋予一个唯一的 doc_id,以便后续检索。
而add_documents 方法不仅将文本内容存储到 Qdrant,还会自动计算并存储每个文本的向量表示,将文本转化为机器可理解和操作的形式。
knowledge
1.4 知识库检索测试
接下来我们使用 await knowledge.retrieve 尝试进行文档检索:
docs = await knowledge.retrieve(
query="李明的父亲是谁?",
limit=3,
score_threshold=0.5,
)
-
query:查询字符串。在这个例子中,我们查询的是「李明的父亲是谁?」,目的是找到与李明相关的背景信息。
-
limit:返回的最大文档数量。limit=3 表示返回前 3 个最相关的文档。
-
score_threshold:相似度得分阈值。这个参数的作用是过滤掉相似度较低的文档,确保返回的文档与查询有足够的相关性。score_threshold=0.5 表示只返回那些得分大于等于 0.5 的文档。
docs
knowledge.retrieve?
print("检索到的 Document 对象:")
for doc in docs:
print(doc, "\n")
1.5 知识库修改流程
knowledge.add_documents?
doc_more = await reader(
text=(
"王伟今年28岁,福建人。\n"
"王伟毕业于厦门大学,目前定居于北京,在一家央企上班。"
),
)
await knowledge.add_documents(doc_more)
docs = await knowledge.retrieve(
query="王伟今年多大?",
limit=3,
score_threshold=0.5,
)
docs
2. 基于知识库的Agentic RAG检索流程
接下来我们继续尝试将整个检索过程封装为一个Agent能够调用的外部工具,方便Agent在适时的时候进行检索,从而实现Agentic RAG流程。
from agentscope.tool import Toolkit
from agentscope.message import Msg
toolkit.clear()
toolkit = Toolkit()
toolkit.register_tool_function(
knowledge.retrieve_knowledge,
func_description=( # 为工具提供清晰的描述
"用于检索与给定查询相关的文档的工具。" "当你需要查找有关李明的信息时使用此工具。"
),
)
这里需要注意:
-
register_tool_function 方法将 retrieve_knowledge 函数注册为一个工具;
-
第一个参数是工具函数本身,第二个参数 func_description 提供了该工具的简短描述。描述将帮助智能体理解何时调用该工具。
import json
print(json.dumps(toolkit.get_json_schemas(), indent=2, ensure_ascii=False))
然后即可在创建react agent的时候带入检索工具了:
# 使用 DashScope 作为模型创建 ReAct 智能体
agent = ReActAgent(
name="智能问答助手",
sys_prompt="你是一名助人为乐的问答助手,会根据知识库进行合理的回答。",
model=DashScopeChatModel(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="qwen-max",
),
formatter=DashScopeChatFormatter(),
toolkit=toolkit,
)
实际检索过程如下:
msg = Msg(
name="user1",
content="请问李明的父亲是谁?",
role="user",
)
res = await agent(msg)
res
msg = Msg(
name="user1",
content="王伟现在在哪里工作呀?",
role="user",
)
res = await agent(msg)
而如果遇到无关的问题,则不会进行检索:
msg = Msg(
name="user1",
content="请问什么是机器学习?",
role="user",
)
res = await agent(msg)
同时需要注意的是,AgentScope还可以在创建react Agent的时候设置knowledge=knowledge参数的方法,让Agent每次运行的时候都强行进行检索:
rag_agent = ReActAgent(
name="智能问答助手",
sys_prompt="你是一名助人为乐的问答助手,会根据知识库进行合理的回答。",
model=DashScopeChatModel(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="qwen-max",
),
formatter=DashScopeChatFormatter(),
knowledge=knowledge,
)
此时无论用户问什么问题,Agent都会先检索、再回答。
msg = Msg(
name="user2",
content="请问什么是机器学习?",
role="user",
)
res = await rag_agent(msg)
res
msg = Msg(
name="user2",
content="请问李明最好的朋友是谁?",
role="user",
)
res = await rag_agent(msg)
res
而此时我们还能额外带入一些工具,以增强Agent的拓展性。
3.PDF检索问答流程
from agentscope.rag import PDFReader
PDFReader?
reader = PDFReader(chunk_size=512, split_by="char")
reader?
documents = await reader('测试文档.pdf')

documents[0]
del knowledge
# 创建一个内存中的 Qdrant 向量存储,以及使用 DashScopeTextEmbedding 作为嵌入模型,初始化知识库
knowledge = SimpleKnowledge(
# 提供一个 embedding 模型用于将文本转换为向量
embedding_model=DashScopeTextEmbedding(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="text-embedding-v4",
dimensions=1024,
),
# 选择 Qdrant 作为向量存储
embedding_store=QdrantStore(
location=":memory:",
collection_name="test_collection",
dimensions=1024, # 嵌入向量的维度必须与嵌入模型输出的维度一致
),
)
await knowledge.add_documents(documents)
documents[0]
toolkit.clear()
toolkit = Toolkit()
toolkit.register_tool_function(
knowledge.retrieve_knowledge,
func_description=( # 为工具提供清晰的描述
"用于检索与给定查询相关的文档的工具。" "当你需要查找有关LangChain的信息时使用此工具。"
),
)
# 使用 DashScope 作为模型创建 ReAct 智能体
agent = ReActAgent(
name="智能问答助手",
sys_prompt="你是一名助人为乐的问答助手,会根据知识库进行合理的回答。",
model=DashScopeChatModel(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="qwen-max",
),
formatter=DashScopeChatFormatter(),
toolkit=toolkit,
)
msg = Msg(
name="user1",
content="请问LangChain是第一代Agent开发框架么?",
role="user",
)
res = await agent(msg)
await agent.memory.clear()
4.AgentScope多模态RAG入门
4.1 AgentScope多模态检索实现流程
而除了能够对文本进行RAG,借助AgentScope的多模态信息格式,也能够非常顺利的对多模态内容进行检索。其核心方法并非普通的对多模态内容进行翻译然后再进行检索,而是借助multimodal-embedding模型直接对图片、音频、视频等内容进行Embedding处理,然后再借助统一的RAG流程进行检索。
- 图像生成
path_image = "./example.png"
plt.figure(figsize=(8, 3))
plt.text(0.5, 0.5, "My name is Ming Li", ha="center", va="center", fontsize=30)
plt.axis("off")
plt.savefig(path_image, bbox_inches="tight", pad_inches=0.1)
plt.close()

- 创建图片类型doc
path_image = "https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20251112173023933.png"
reader = ImageReader()
docs = await reader(image_url=path_image)
docs
- 创建知识库
del knowledge
knowledge = SimpleKnowledge(
embedding_model=DashScopeMultiModalEmbedding(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="multimodal-embedding-v1",
dimensions=1024,
),
embedding_store=QdrantStore(
location=":memory:",
collection_name="test_collection",
dimensions=1024,
),
)
await knowledge.add_documents(docs)
docs
- 知识库检索
docs = await knowledge.retrieve(
query="请问我叫什么名字?",
limit=3,
score_threshold=0.1,
)
docs
- 基于Agent的知识库检索
# 使用 DashScope 作为模型创建 ReAct 智能体
agent = ReActAgent(
name="智能问答助手",
sys_prompt="你是一名助人为乐的问答助手,会根据知识库进行合理的回答。",
model=DashScopeChatModel(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="qwen3-vl-plus",
),
formatter=DashScopeChatFormatter(),
knowledge=knowledge,
)
msg = Msg(
name="user1",
content="你知道我叫什么名字么?",
role="user",
)
res = await agent(msg)
await agent.memory.get_memory()
4.2 复杂图像信息的检索流程
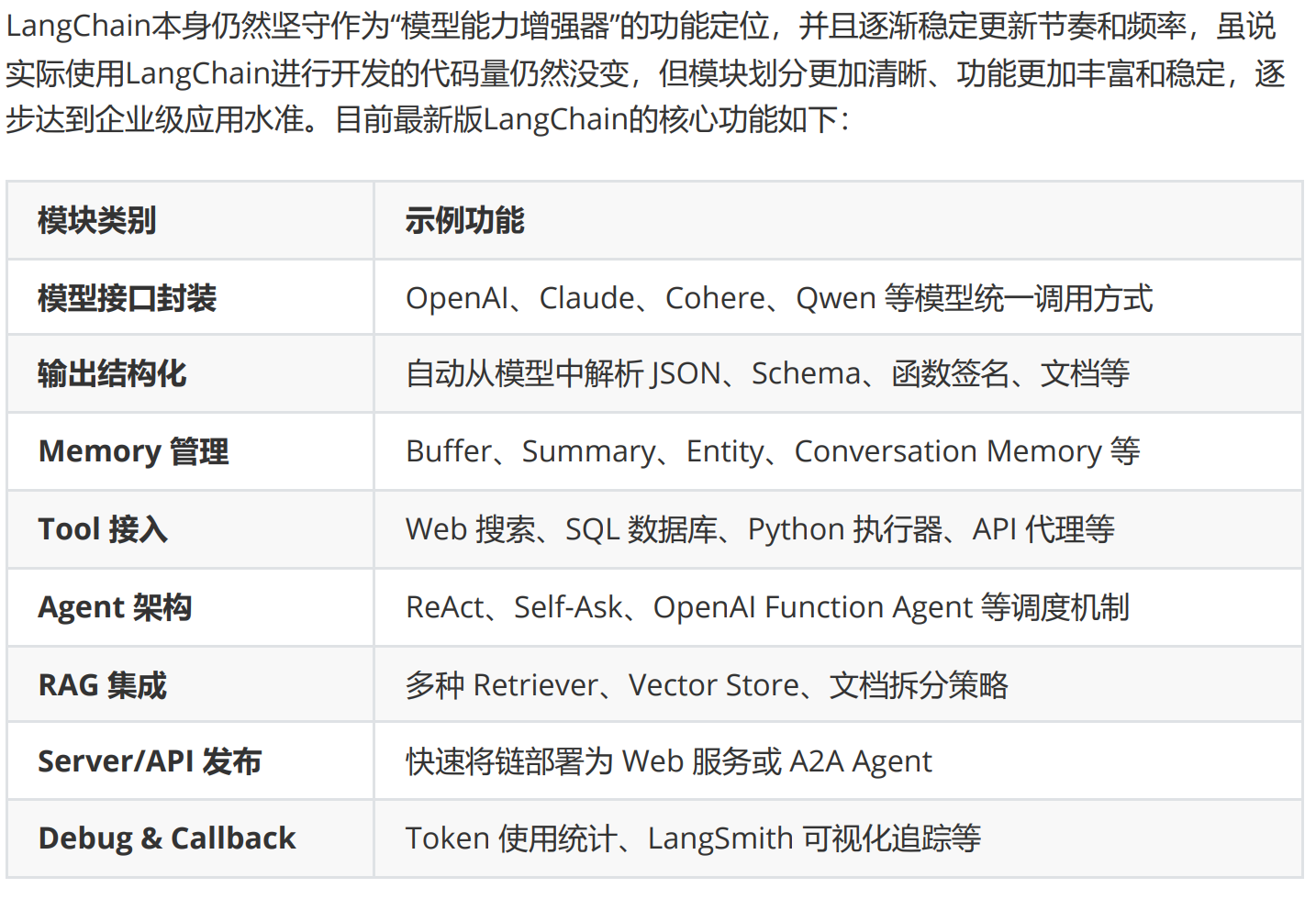
path_image = "https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20251112194126570.png"
reader = ImageReader()
docs = await reader(image_url=path_image)
docs
- 创建知识库
del knowledge
knowledge = SimpleKnowledge(
embedding_model=DashScopeMultiModalEmbedding(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="multimodal-embedding-v1",
dimensions=1024,
),
embedding_store=QdrantStore(
location=":memory:",
collection_name="test_collection",
dimensions=1024,
),
)
await knowledge.add_documents(docs)
docs
- 知识库检索
docs = await knowledge.retrieve(
query="请问LangChain有哪些核心功能?",
limit=3,
score_threshold=0.1,
)
docs
- 基于Agent的知识库检索
# 使用 DashScope 作为模型创建 ReAct 智能体
agent = ReActAgent(
name="智能问答助手",
sys_prompt="你是一名助人为乐的问答助手,会根据知识库进行合理的回答。",
model=DashScopeChatModel(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="qwen3-vl-plus",
),
formatter=DashScopeChatFormatter(),
knowledge=knowledge,
)
msg = Msg(
name="user1",
content="请问LangChain有哪些核心功能?",
role="user",
)
res = await agent(msg)
await agent.memory.get_memory()
- 追加知识库
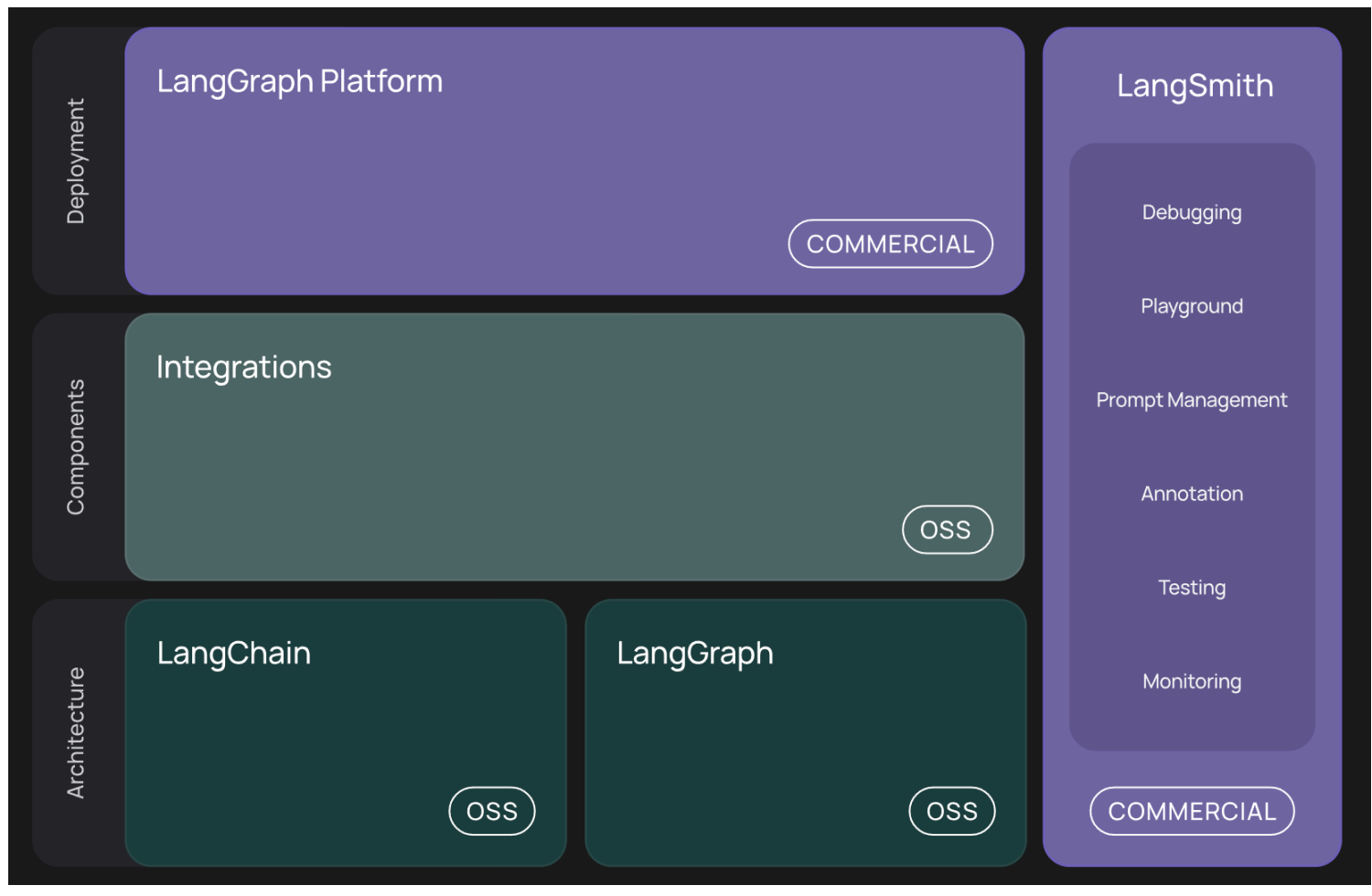
path_image = "https://ml2022.oss-cn-hangzhou.aliyuncs.com/img/image-20251112194400013.png"
reader = ImageReader()
docs = await reader(image_url=path_image)
docs
await knowledge.add_documents(docs)
msg = Msg(
name="user1",
content="请问LangChain和LangGraph是什么关系?",
role="user",
)
res = await agent(msg)
更多多模态RAG相关技术,欢迎报名我主讲的《2025大模型Agent智能体开发实战》(11月班) 进行学习


AgentScope 在 RAG(Retrieval‑Augmented Generation)模块中,为开发者开放的重要接口或组件:
Reader 接口
用来 读取原始文档资源(如文本、PDF、图片、Word 等),并将其拆分成多个“块”(chunks)以供后续处理。
支持设置参数如
chunk_size(每块字符数)、split_by(按 “char/sentence/paragraph” 切分)等。开发者可自行实现自定义 Reader(例如 MarkdownReader)以支持更多文档格式。
Knowledge 接口(知识库管理)
包括
Knowledge或类似组件,用于 向量化文档块、存储索引、以及 检索相关文档。支持设置检索参数如
query: str、limit: int、score_threshold: float等,以控制检索数量与相关度阈值。
多模态支持接口
AgentScope 的 RAG 模块并不仅限于文本,还支持多模态文档(图片/图像/文字混合)检索与问答。
Reader 与 Knowledge 的设计允许处理多模态输入,开发者可配置嵌入模型、读取器、知识库来实现。
工具函数/Agent 结合接口
RAG 模块支持将知识检索功能作为工具(Tool)注册,使得智能体(Agent)能够决定何时检索、用何种查询检索。
在 “Agentic Manner” 模式中,智能体本身可决定是否调用检索接口。 在 “Generic Manner” 模式中,则每次都检索。
扩展数据库与检索后端接口
- 虽然 AgentScope 默认提供某些向量数据库集成(如 Qdrant)作为知识库后端,但其文档明确指出:欢迎开发者 集成更多向量数据库与读取器。
- 这意味着你可以自定义知识库后端(例如使用 other vector stores)、或者自定义检索算法/索引结构。
三、AgentScope的长期记忆管理
Agent 的长期记忆 是指智能体在与用户的长期交互过程中所积累的、用于增强其推理与响应的记忆系统。与短期记忆(如当前会话中的临时数据)不同,长期记忆涉及对历史信息、用户偏好、行为模式和对话背景的长期存储。
长期记忆的核心价值在于:
- 个性化:智能体可以记住用户的兴趣、需求和习惯,从而提供更加个性化、精准的服务;
- 连贯性:通过记忆过去的对话与事件,智能体能在不同会话之间保持话题连贯性,避免重复或错误的回答;
- 推理能力:智能体可以利用历史记忆来进行更复杂的推理与决策,例如在回答多轮问题或进行复杂任务时,能够基于先前的记忆做出更合适的响应。
长期记忆通常是通过专门的存储与检索机制进行管理,能够动态更新和自我优化,从而提高智能体的智能水平和用户体验。
而AgentScope则提供了非常完善的基于mem0和ReMe的长期记忆管理系统,其中Mem0 是一个面向 AI 智能体与助手的长期记忆层(memory layer),其目标在于使得模型不仅能处理当前上下文,还能“记住”过往交互、用户偏好、会话历史、长期状态,从而显著提升连贯性、个性化和效率。
- mem0项目地址:https://github.com/mem0ai/mem0

mem0能实现如下一系列核心功能,包括:
- 多层级记忆维护
- 支持 用户级(User)、会话级(Session) 和 代理/助手级(Agent) 的记忆区分。
- 能将不同粒度的记忆分开管理,使得智能体能够基于不同上下文(例如不同用户、不同任务、不同时间)提取对应记忆。
- 这种分层架构让记忆不仅是简单的会话历史,而是一个结构化、可分类、可检索的长期记忆库。
- 自适应与持续学习能力
- Mem0 不仅存储静态记忆,还具备 自适应更新 的能力:随着用户交互的增长,系统可以记录新的偏好、新的信息、新的状态,并将其纳入记忆体系。
- 在多轮对话或长期使用中,智能体能够基于这些记忆做出更为“了解用户”的响应,从而增强用户体验与个性化程度。
- 混合存储与检索机制
- Mem0 的底层采用混合存储架构:既包括向量数据库(用于语义检索)、键值或关系数据库(用于元数据或结构化状态)、甚至图数据库(用于捕捉复杂关系)等。这样可以根据记忆类型选择最合适的存储和检索方式。
- 检索机制不仅依赖简单匹配,还包括评分(relevance、importance、recency)层,用于选出最“值得回忆”的内容。
- 记忆压缩与成本优化
- Mem0 提供“记忆压缩引擎”(Memory Compression Engine),该机制可在不牺牲关键信息的前提下,压缩历史交互内容,从而减少调用模型时的上下文令牌数(token count)与延迟。
- 这意味着长期记忆不会导致令牌膨胀或显著性能退化,而是通过结构化、智能的保留/淘汰机制实现高效记忆管理。
- 可扩展的开发者体验与集成支持
- Mem0 提供开发者友好的 SDK(包括 Python、JavaScript/TypeScript 等)及统一 API,使其能够与各类 LLM 应用、智能体框架(如你正在使用的 AgentScope)无缝集成。
- 支持托管服务与自托管两种模式:开发者既可以快速使用其托管平台,也可部署在自有基础设施上以满足数据隐私、性能、安全等需求。
- 记忆管理功能(检索、更新、查询)
- Add / Store:允许将用户交互(如对话、行为、偏好)转换为“记忆条目”并存储起来。
- Search / Retrieve:基于查询(如用户当前输入、上下文)检索出相关的历史记忆,从而辅助智能体生成更相关、更连贯的响应。
- Update / Maintain:支持记忆的更新与删除,例如当用户偏好改变、过时信息应淘汰时,系统可以调整记忆内容。 (文档中提及“设置记忆过期”或“控制记忆摄取”模式)
- 结构化关系与图记忆支持
- 除了线性记忆条目外,Mem0 支持使用**图结构(Graph Memory)**来表示记忆中不同实体、事件、关系之间的连接。该功能有助于处理复杂推理、多跳检索等场景。
- 例如,能够记住“用户 A 认识用户 B”、“用户 A 喜欢话题 X”这种关系型记忆,从而智能体可以在后续交互中更透彻地利用这些结构化信息。
- 与主流 LLM 与生态系统高度兼容
- Mem0 自身设计为“通用记忆层”(universal memory layer),可与 OpenAI、Azure、LangGraph、其他智能体框架配合使用。官网明确标示“Works with OpenAI, LangGraph, CrewAI & more”
- 这使得开发者能够在现有的 RAG 或 Agent 架构中将 Mem0 作为长期记忆模块进行插拔,而无需重构整个系统。
而在 AgentScope 中,长期记忆是通过 LongTermMemoryBase 抽象类提供统一接口,而 Mem0 的实现类 Mem0LongTermMemory 实现了该接口,从而将 Mem0 的记忆功能纳入 AgentScope 的生态。
具体而言,AgentScope 支持两种长期记忆管理模式:
- static_control:由开发者显式控制记忆的记录与检索操作;
- agent_control:智能体自主调用记忆工具(如
record_to_memory、retrieve_from_memory)来操控长期记忆。 开发者亦可选择 “both” 模式,将两者结合使用。
在采用 Mem0 作为长期记忆后端的场景中,AgentScope 的流程大致如下:
-
初始化 Mem0 长期记忆实例 使用
Mem0LongTermMemory(agent_name, user_name, model, embedding_model, on_disk…)的构造方式,指定智能体名称、用户 ID、聊天模型(例如 DashScopeChatModel)、嵌入模型(例如 DashScopeTextEmbedding)以及是否持久化存储(on_disk 参数)等。 -
记忆记录(record)与检索(retrieve)接口 Mem0LongTermMemory 提供
record(msgs: List[Msg])和retrieve(msgs: List[Msg])方法用于基础的记忆存储与查询。同时,当处于agent_control模式时,还提供了工具化接口record_to_memory(...)与retrieve_from_memory(...),以供智能体自主调用。 -
工具注册与智能体集成 在 AgentScope 中,当
long_term_memory_mode="agent_control"或"both"时,系统会自动将record_to_memory及retrieve_from_memory注册为工具函数,从而使智能体可以在对话过程中“想起”过去的记忆,或“记录”新的记忆。 -
记忆在对话循环中的作用 在用户与智能体交互的多轮对话中,Mem0 管理的长期记忆可用于保存用户的偏好、行为历史、之前任务信息等。智能体在收到新消息前,先通过
retrieve_from_memory获取相关历史信息,再将其作为上下文输入模型,使得响应不仅基于当下对话,还融合长期记忆信息,从而实现更连贯、更个性化的交互。之后,智能体可将新的有价值信息通过record_to_memory写入长期记忆库。 -
记忆更新与维护机制 Mem0 本身具备多种记忆管理机制,例如根据语义重要性、时间衰减、优先级过滤等来决定哪些信息要保留、哪些应淘汰。AgentScope 通过 Mem0 与其封装接口,使得开发者可以在长期记忆管理中聚焦于“何时记录”、“何时检索”、“何时淘汰”而不需手动管理底层存储细节。
import os
import asyncio
from agentscope.message import Msg
from agentscope.memory import InMemoryMemory, Mem0LongTermMemory
from agentscope.agent import ReActAgent
from agentscope.embedding import DashScopeTextEmbedding
from agentscope.formatter import DashScopeChatFormatter
from agentscope.model import DashScopeChatModel
from agentscope.tool import Toolkit
# 创建 mem0 长期记忆实例
long_term_memory = Mem0LongTermMemory(
agent_name="Friday",
user_name="user_123",
model=DashScopeChatModel(
model_name="qwen-max-latest",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
stream=False,
),
embedding_model=DashScopeTextEmbedding(
model_name="text-embedding-v2",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
),
on_disk=False,
)
# 记录记忆
await long_term_memory.record([Msg("user", "我喜欢住民宿", "user")])
# 检索记忆
results = await long_term_memory.retrieve([Msg("user", "我的住宿偏好", "user")],)
results
基于此长期记忆,我们可以继续创建Agent进行问答对话:
agent = ReActAgent(
name="聊天助手",
sys_prompt="你是一个具有长期记忆功能的助手。",
model=DashScopeChatModel(
api_key=os.environ.get("DASHSCOPE_API_KEY"),
model_name="qwen-max-latest",
),
formatter=DashScopeChatFormatter(),
toolkit=Toolkit(),
memory=InMemoryMemory(),
long_term_memory=long_term_memory,
long_term_memory_mode="static_control", # 使用 static_control 模式
)
# 我们清空智能体的短期记忆,以避免造成干扰
await agent.memory.clear()
# 测试智能体是否会记住之前的对话
msg2 = Msg("user", "我有什么偏好?简要的回答我", "user")
await agent(msg2)
# 对话示例
msg = Msg("user", "我想去杭州旅游,有没有推荐的住处?", "user")
await agent(msg)
1. 如何实现自动记录历史对话并将其封装为长期记忆?
在 AgentScope 中,长期记忆的核心是通过 Mem0 库进行的,特别是在与用户进行对话的过程中,智能体会根据设定的规则自动记录并更新记忆。
自动记录机制:
- 消息记录:每当智能体与用户有交互时,系统会自动将这些对话历史作为“消息(msg)”记录。消息可以是纯文本内容,也可以是带有元数据的结构化内容。
- 调用
record_to_memory:一旦产生新的对话或交互,智能体会通过 Mem0 提供的record_to_memory方法将这些对话消息存储到长期记忆中。具体而言,这些对话会作为“条目”被保存在 Mem0 的存储系统中。
FENCE0
这里的 msgs 是指所有与用户的交互历史,它们会被添加到记忆库中,以便后续访问。
2. 如何根据规则选取并总结对话内容?
长期记忆系统并不会简单地存储每一条对话消息,而是基于特定的 规则 来决定哪些信息值得保留。这些规则可能包括:
-
重要性过滤(Importance Filtering):智能体会评估每个消息的重要性,根据其内容是否与用户需求、偏好、任务目标相关来决定是否存储。例如,智能体在对话中得知用户的兴趣或问题背景时,会判断该信息是否足以影响后续任务决策或生成过程。
-
时间衰减(Temporal Decay):对于较旧的信息,系统会采用“时间衰减”策略。也就是说,随着时间的推移,某些记忆的权重会降低,智能体可能会删除过时的信息或选择不再查询它们。
-
多轮对话(Multi-turn Dialogue):在多轮对话中,系统会根据上下文的相关性选取最具代表性的信息。比如在一次对话中,用户提到的个人信息(如偏好、习惯等)会被记录下来,并在后续对话中加以利用。
-
自适应学习(Adaptive Learning):Mem0 的设计允许智能体随着对话的深入学习用户的新需求或偏好,这意味着它能够动态地调整存储策略,选择保留那些最能帮助生成个性化回应的信息。
3. 长期记忆是如何存储的?
长期记忆的存储和管理主要通过 嵌入(Embedding) 和 向量数据库 来完成。这个过程是通过 Mem0 的存储机制实现的,具体步骤如下:
嵌入存储:
-
文本嵌入(Text Embedding):在 Mem0 中,存储的对话信息首先通过一个 文本嵌入模型(如 DashScopeTextEmbedding)进行嵌入。这意味着,智能体会将每个对话消息转换为一个高维向量,这些向量是该文本内容的语义表示,便于后续进行相似度计算和检索。
-
存储向量与元数据:这些向量(embedding)与原始文本、元数据(如用户 ID、时间戳、对话 ID)一起存储在 Mem0 的数据库中。通过使用 Qdrant 等向量数据库,系统能够高效地进行向量存储和检索。每当查询时,系统会计算查询向量与存储向量的相似度,并返回最相关的记忆信息。
数据模型:
- Mem0 使用混合存储模型:不仅支持向量存储,还支持将嵌入与其他元数据(如用户偏好、任务状态等)一同存储。这样做的好处是,它可以帮助智能体在检索时不仅依赖于向量相似度,还能够利用附加的上下文信息进行更精确的查询。
例子:
当用户在对话中提到 "我的生日是5月1日",Mem0 会将这段文本进行嵌入,并将其与其他对话历史一起存储。随着时间推移,当系统需要生成个性化的响应时,它可以通过相似度匹配从长期记忆中检索到类似的信息(如“5月1日生日”),并在后续的对话中使用。
4. 长期记忆的更新机制
Mem0 允许智能体动态地更新记忆库。每当有新的有价值的信息被记录时,Mem0 会根据当前存储的记忆信息 自动调整,以确保:
- 信息的时效性:过时或无关的记忆将被淘汰,而新的有用信息将被优先存储;
- 存储空间的优化:通过使用智能的 压缩与去重算法,Mem0 可以减少不必要的存储负担,同时确保系统响应速度不受影响。
总结来看:
- Mem0 为 AgentScope 提供了强大的长期记忆管理能力,通过高效的 文本嵌入、多层级记忆结构、自适应学习 和 记忆压缩机制,使得智能体能够在多轮对话中保持连贯性、个性化与响应精度;
- 通过 Qdrant 向量数据库存储嵌入,Mem0 实现了高效的 记忆检索 和 记忆更新;
- 智能体记忆 的管理不仅仅是存储和检索历史对话,它还涉及到自适应学习和动态调整,以更好地满足用户需求。