AgentScope多模态RAG系统开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(11月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(11月班)

《2025大模型Agent智能体开发实战》(11月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
课程完整介绍

秋季班重磅新增14项实战案例

部分课程成果演示
from IPython.display import Video
- Dify+DeepSeek搭建智能微信语音客服
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- Coze自动图文视频创作流程
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- 可视化数据分析Multi-Agent
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目展示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋季班)



详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

国产开源AgentScope框架技术实战
Part 3.AgentScope多模态RAG系统开发实战
一、多模态RAG系统开发思路介绍
在前一节课程中,我们已经系统学习了 AgentScope 多模态检索(Multimodal Retrieval) 的核心流程,包括文档读取、图片解析、向量化编码、知识库存储与检索等基础能力。通过这些内容,我们初步建立了“如何让智能体同时理解文本与图像信息”的整体框架,对多模态知识处理的底层机制有了清晰的认识。
本节课程将进一步在此基础上 迈入实战阶段。我们将以“多模态 RAG 系统(Retrieval-Augmented Generation)开发”为主线,完整演示如何将之前介绍的文档切分、图片 URL 解析、向量存储、检索融合等流程真正整合到一个可运行的系统之中。学习目标不仅是掌握多模态检索的实现,更是让大家理解如何将这些能力 应用到真实业务场景,构建可扩展、可迭代的多模态智能体。
1. 多模态 RAG 系统的主流开发思路
在构建多模态 RAG 系统时,当前主流的技术路径大致可以分为两类:一类是将图像信息 转义为“可检索的文本”;另一类则是将图像 直接作为独立的多模态向量单元 参与检索。这两种范式分别面向不同的场景需求,也体现了多模态知识库在工程层面的两种典型设计模式。
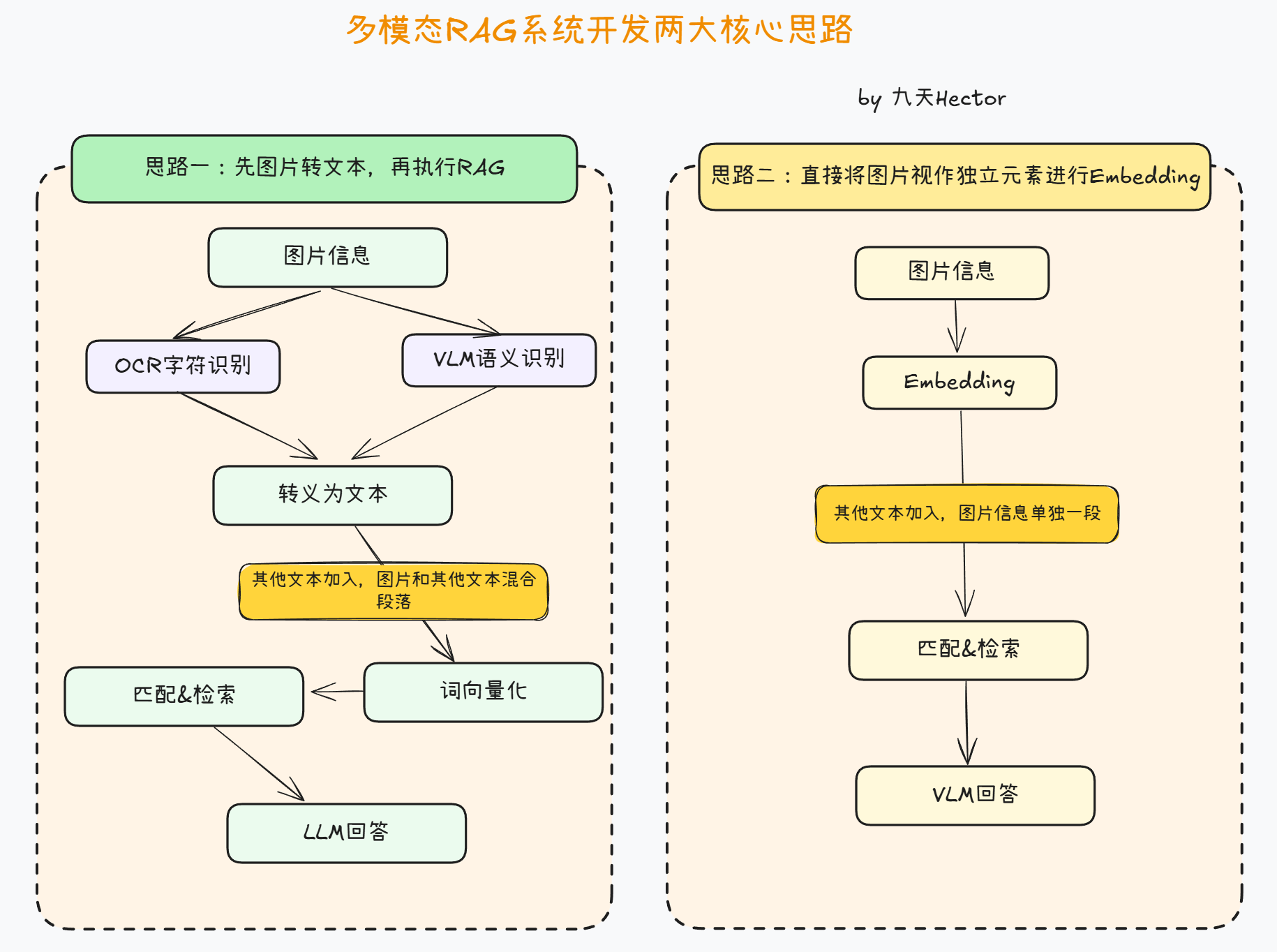
1.1 基于文本化统一处理的检索路径
第一类方法主要强调 “统一模态、统一语义空间” 的思想——无论原始输入是文本还是图片,都在知识库构建前提前转换为文本格式。常见的做法是先通过 OCR、文档解析引擎或通用 VLM(Vision-Language Model)对图像内容进行识别,将图片中包含的文字、图表内容、结构信息等全部提取出来,形成一段与其他文本格式一致的自然语言描述。
在这种方案中,图像信息在进入知识库之前就被“文本化”,因此后续步骤(如分段、向量化、构建向量库、检索匹配)与传统的纯文本 RAG 并无差异。最终被检索出的都是“纯文本片段”,模型回答阶段只需要使用普通的 LLM 即可完成推理,不需要视觉能力支持。
这种方案的特点在于整体流程简洁、对算力要求较低,并且与大多数现有的文本向量引擎高度兼容。然而它也有明显的限制:图像中可能存在无法完整提取的视觉结构特征,或者某些场景中图像的空间布局、图形关系本身就具有语义价值,这些内容在文本化过程中容易丢失。因此,该方案更适用于 文档类图片、扫描件、票据、PPT、OCR 强相关场景,而不太适用于需要理解视觉结构或空间关系的任务。


1.2 基于图像独立建模的多模态检索路径
第二类方法强调 “保持图像的原始模态信息”。在这种方案中,图像并不会提前转义为文本,而是作为独立的内容块,与文本段落一样被视作知识库的基本单元。构建知识库时,图片会单独进行多模态 Embedding,得到与文本 Embedding 能够对齐的向量表示,并以“图像片段”的形式保存到向量库中。
检索阶段,系统会基于查询 prompt 同时检索“文本段落”和“图像段落”,最终得到的结果往往是一个由文本和图片混合组成的文档片段集合。这类片段在生成回答时需要输入支持视觉推理的 VLM 才能进行全面理解和总结。
这种方案的优势在于图片本身的视觉结构、空间组织、非文字信息都可以完整保留,尤其适用于 图表理解、界面截图、CAD 图纸、科学图像、图形数据分析 等任务。但与此同时,它对向量模型、检索模型以及推理模型的能力要求更高,系统整体复杂度也更大。
在实际工程实践中,第二类“图像作为独立模态单元进行检索”的方案,对系统整体的多模态能力有更高要求。它需要模型、向量引擎与消息传递协议三者之间具备高度一致的多模态对齐能力。而这正是 AgentScope 在多模态 RAG 领域展现出明显优势的原因之一。具体而言,AgentScope 能够快速、稳定地构建第二类多模态检索系统,主要得益于以下三项核心能力的组合。
首先,多模态向量化能力由 DashScope 的 multimodal-embedding-v1 模型提供支持。与传统的文本 Embedding 模型不同,该模型能够同时对文本、图片进行向量化编码,并将两种模态映射到共享语义空间中,从而确保文本查询能够准确检索到视觉内容、图像本身也能作为独立的知识片段参与召回。这让多模态检索不再依赖 OCR 或文本转义,而是直接对图像内容进行特征建模,极大提升了视觉信息在检索阶段的语义保真度。
其次,AgentScope 底层拥有 原生多模态消息传输格式。这一机制允许智能体自然地在一次消息中同时处理文本、图片、工具返回值、结构化对象等多种信息,使多模态检索结果能够无缝地输入给推理模型。在第二类多模态 RAG 框架中,检索返回往往包含“文本段落 + 图像片段”的组合,AgentScope 的消息格式能够完整保留这些片段的模态类型与内容结构,为后续推理阶段提供完整的上下文语境,不需要额外的格式转换或中间协议。
最后,在生成回答阶段,AgentScope 可以直接调用 Qwen3-VL 等具备强大视觉推理能力的视觉语言模型。该模型不仅能够理解检索得到的文本内容,还能对返回的图像片段进行视觉分析、区域理解、结构推理,最终实现真正意义上的“图文混合推理式回答”。在第二类多模态检索模式下,模型必须能够同时读懂向量库返回的图像与文字,而 Qwen3-VL 的能力恰好使得 AgentScope 构建的系统在回答阶段无需额外的视觉解析环节,大幅简化系统设计。
二、基于DeepSeek-OCR的PDF转MarkDown过程
DeepSeek-OCR 是面向多模态文档理解与检索而生的 OCR 2.0/VLM 模型:它不仅识别文字,更“读懂”文档。典型能力包括:将多页 PDF 一键转换为结构化 Markdown,高保真解析 表格/公式,理解并描述 图表/示意图/照片 的语义;同时支持区域定位与版面要素标注(如利用 <image>、<|grounding|>、<|ref|>…<|/ref|> 等提示语法)。在多模态 RAG 场景中,DeepSeek-OCR 既是“视觉入口”,也是“结构化输出器”,直接产出可索引、可检索、可复用的文本与结构数据。
- GitHub项目地址:https://github.com/deepseek-ai/DeepSeek-OCR
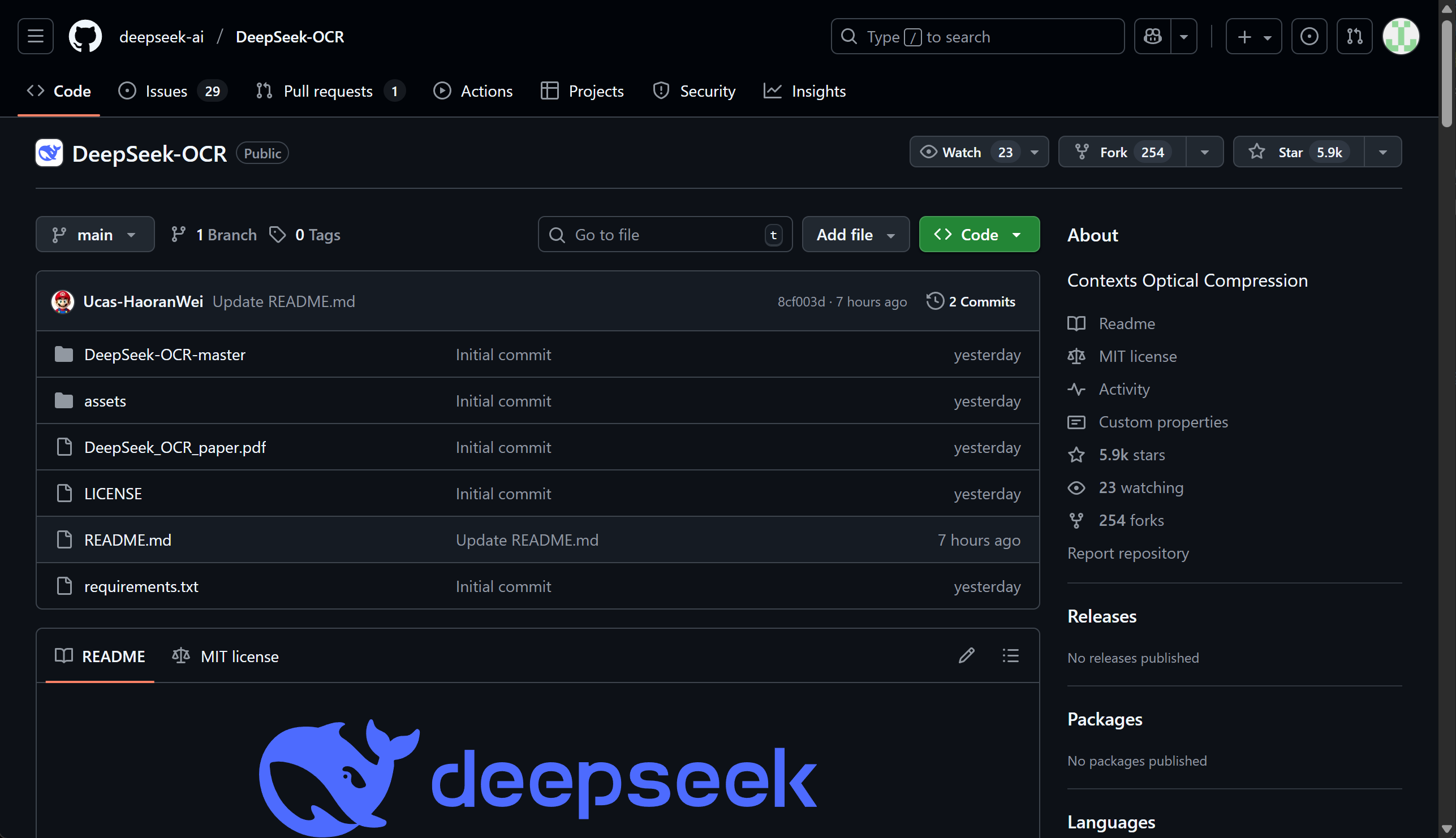
模型采用“视觉编码器 → 投影/对齐(projector)→ 语言解码器”的统一框架:视觉端用 ViT 系列编码图像为高维 token,投影层将视觉表征映射到语言嵌入空间,与 LLM 在同一语义坐标系内对齐,随后由解码器根据指令(prompt)生成 Markdown、LaTeX、JSON 或解释性自然语言。相比传统流水线式 OCR(检测→识别→版面分析),这种端到端的对齐与生成能在一个模型里完成 文本提取 + 结构理解 + 语义生成,减少误差累积,更适合复杂版面与跨页关联的信息抽取。
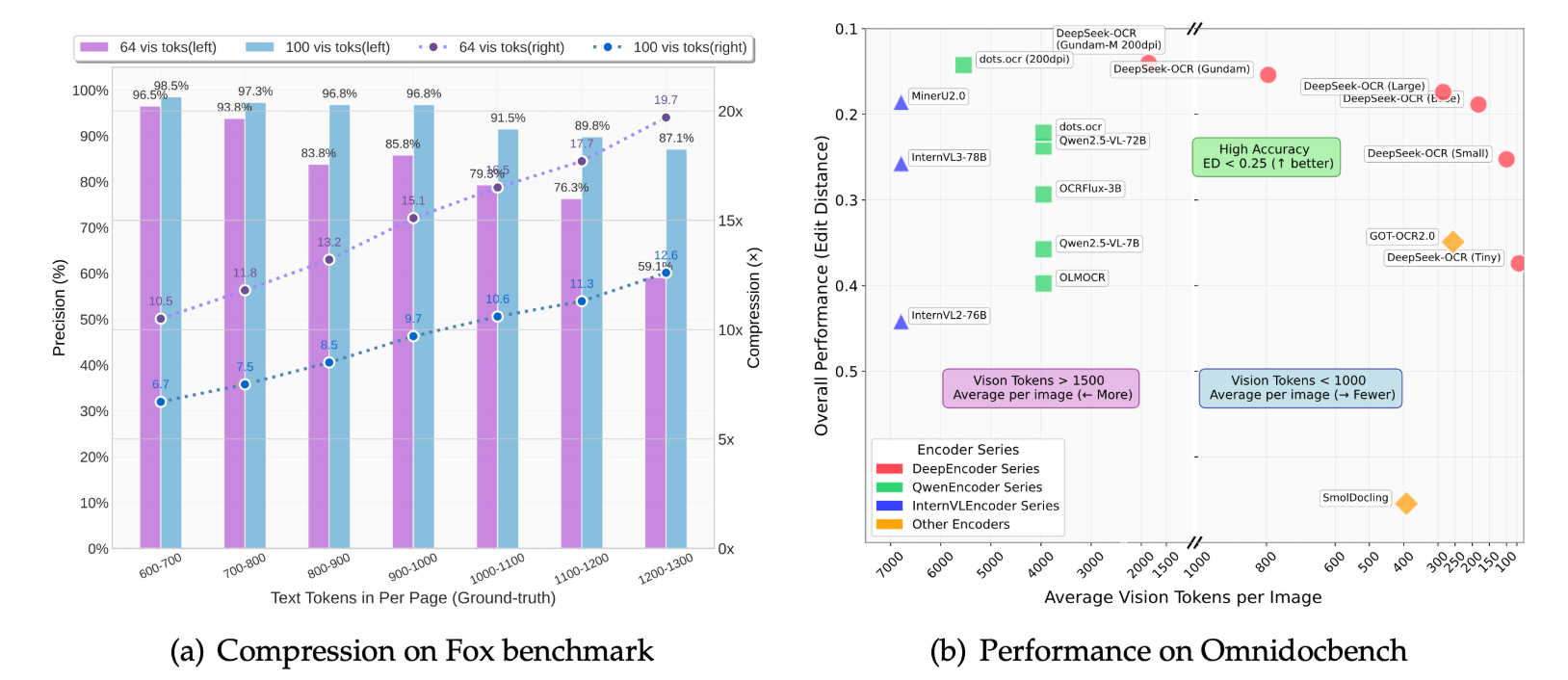
为同时兼顾 效果与效率,DeepSeek-OCR 提出 上下文光学压缩(Contexts Optical Compression):在保持语义判别力的前提下,用更少的“视觉标记”(visual tokens)去“浓缩”文档关键信息,再交给 LLM 的推理能力补全上下文关系。这等于在视觉侧做“语义压缩”,在语言侧做“上下文复原”。其结果是:以小体量模型即可覆盖高难度的版面理解任务,显著降低显存与计算开销,同时在 PDF→Markdown、表格/公式解析、图像语义描述等核心指标上维持高质量输出,成为多模态 PDF RAG 系统中兼顾 精度/吞吐/部署成本 的务实解法。
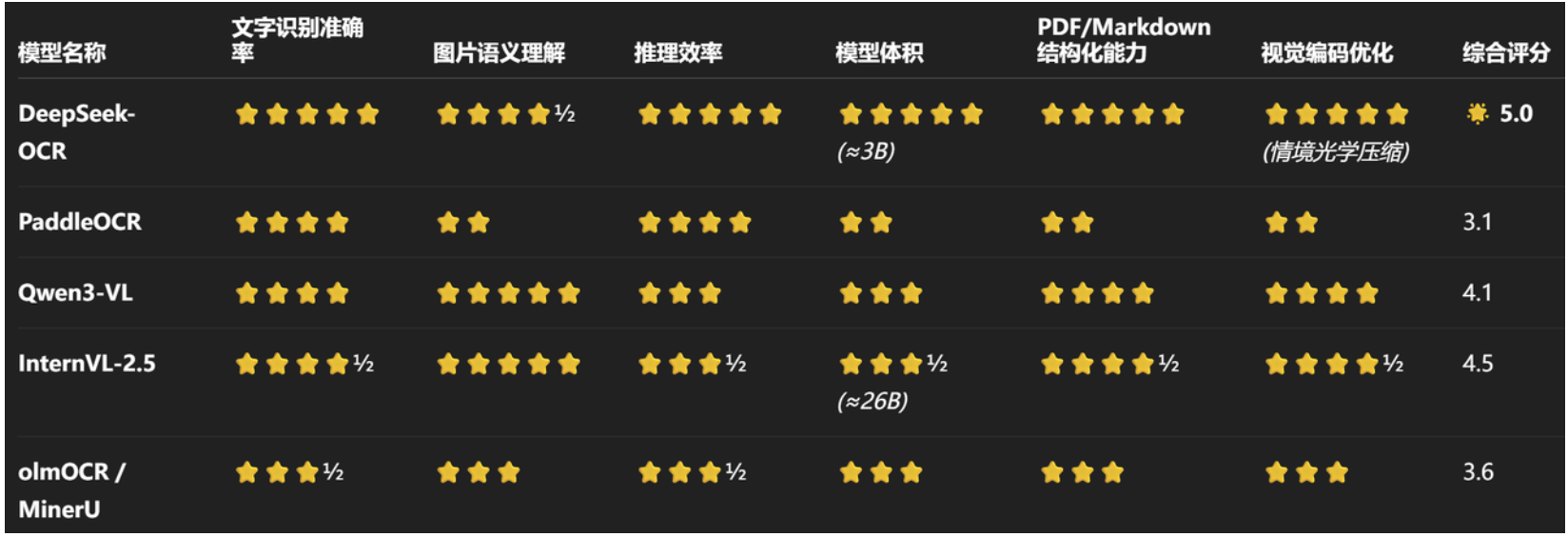
这里我们借助团队自研的DeepSeek-OCR-Web项目进行高效率PDF到MarkDown转化:https://github.com/fufankeji/DeepSeek-OCR-Web
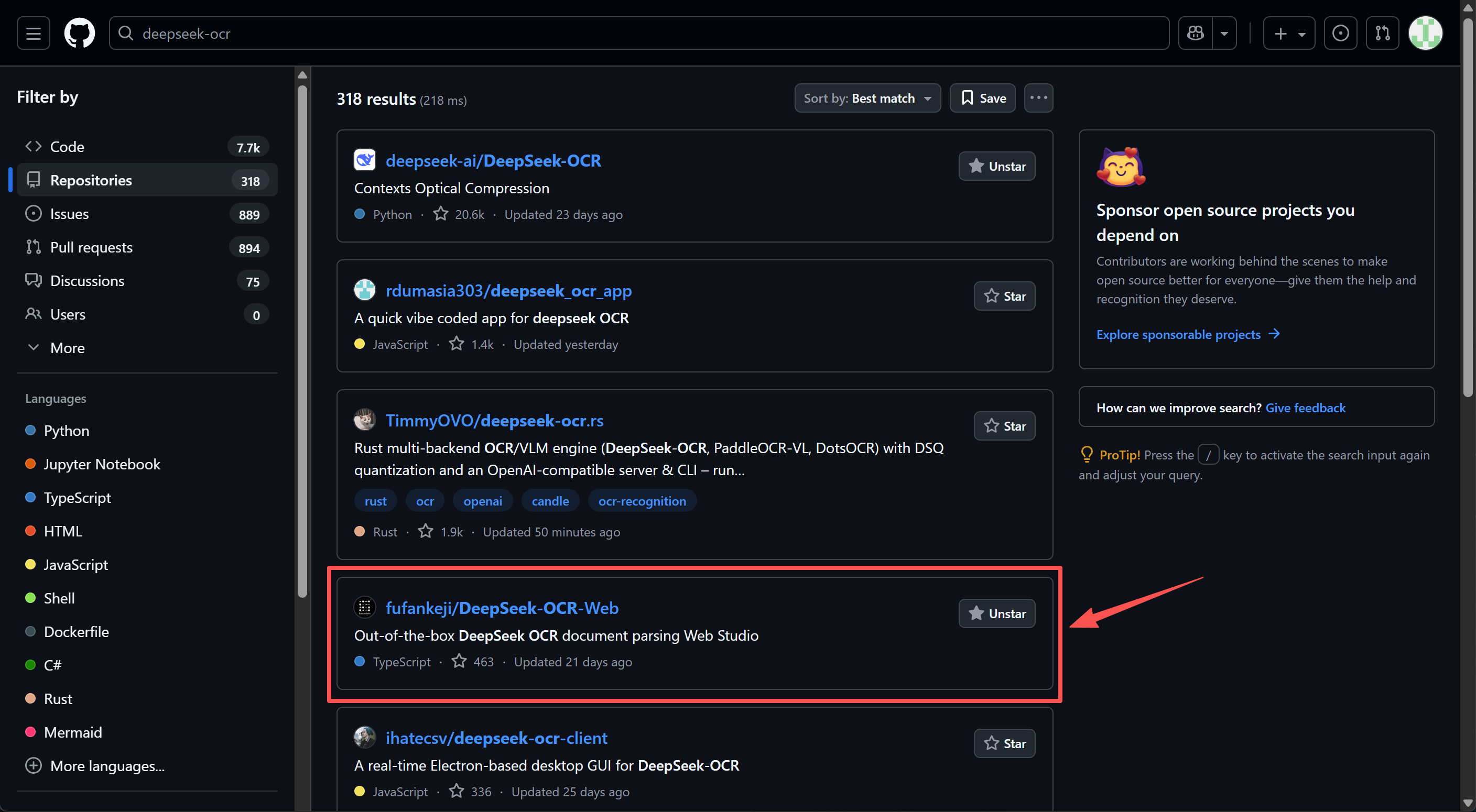
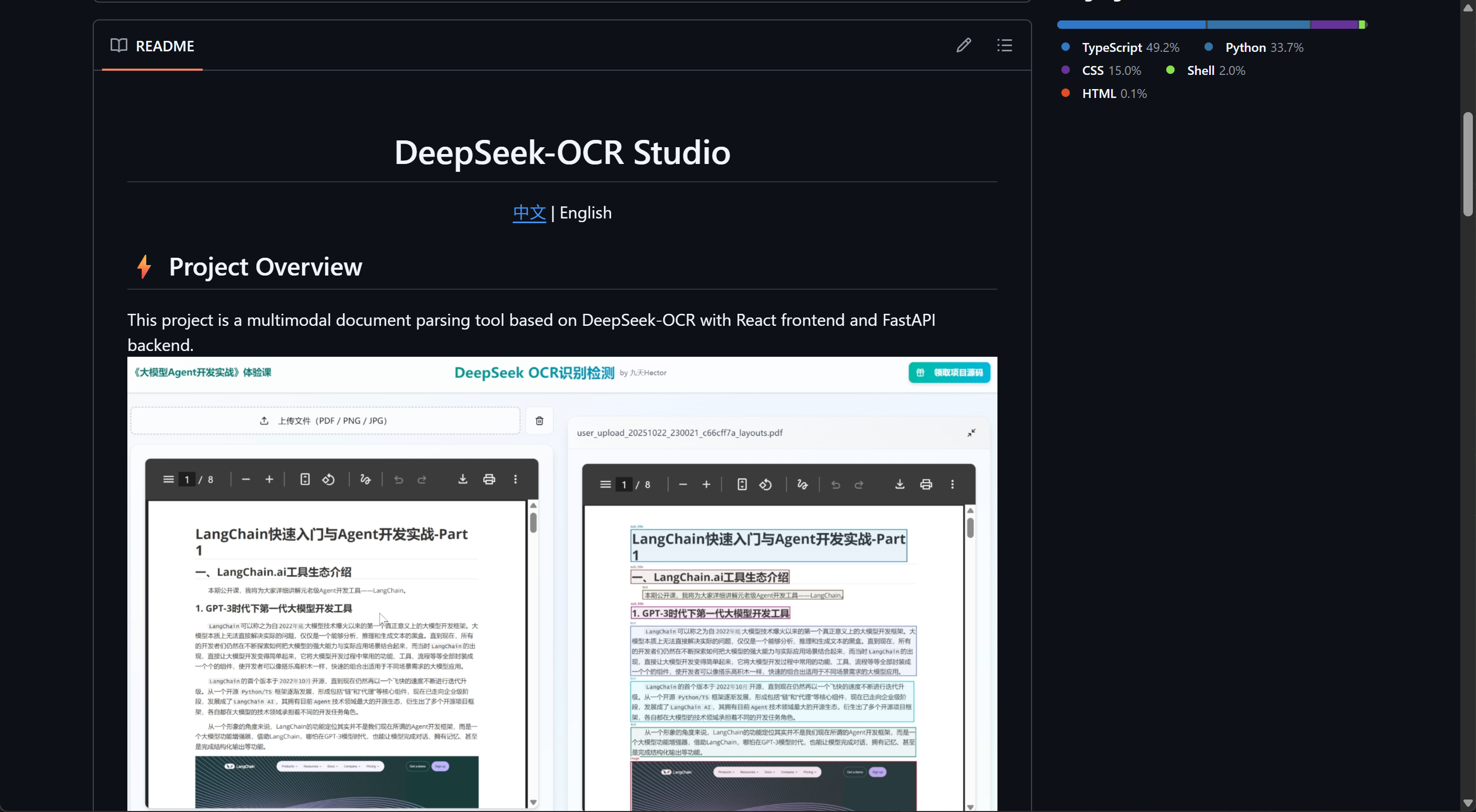
具体实现过程详见项目主页,或相关教程视频:https://www.bilibili.com/video/BV17ks5z7E3U/
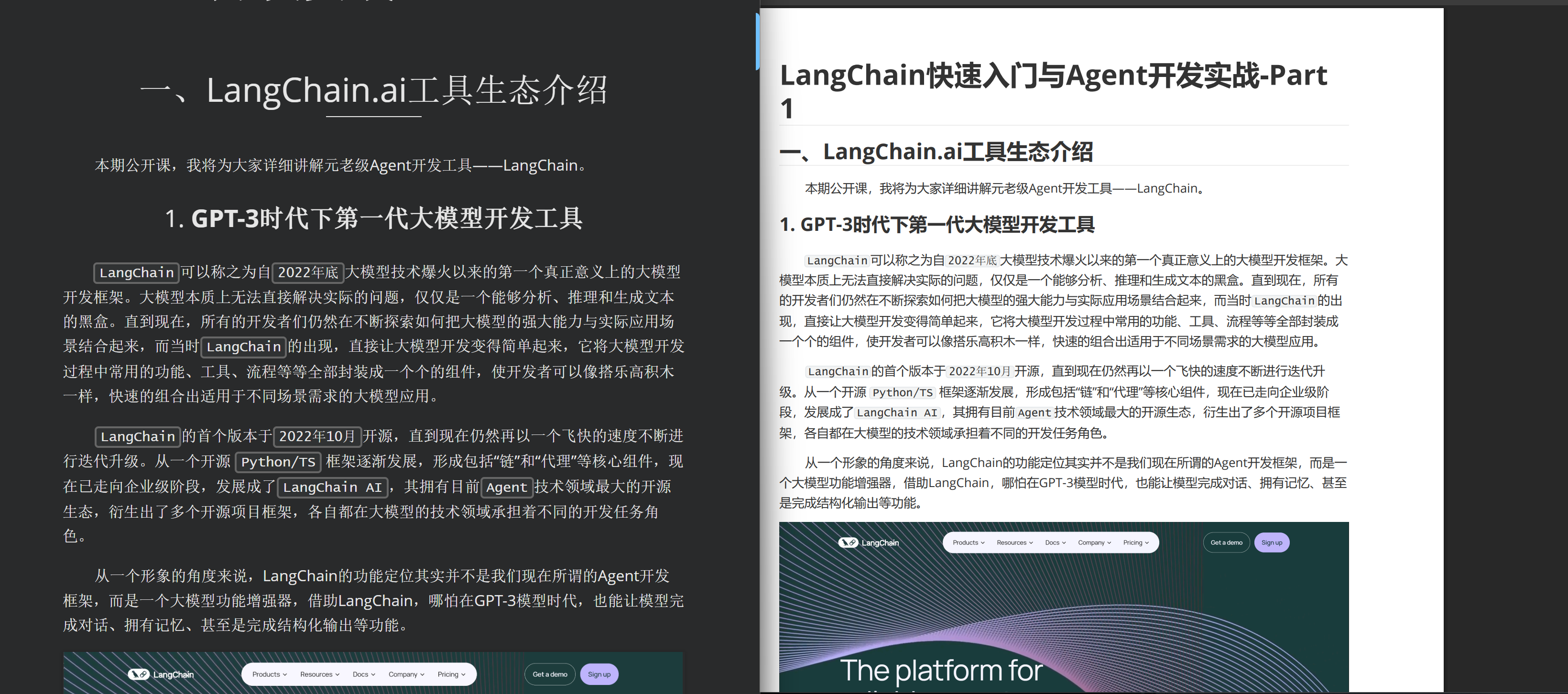
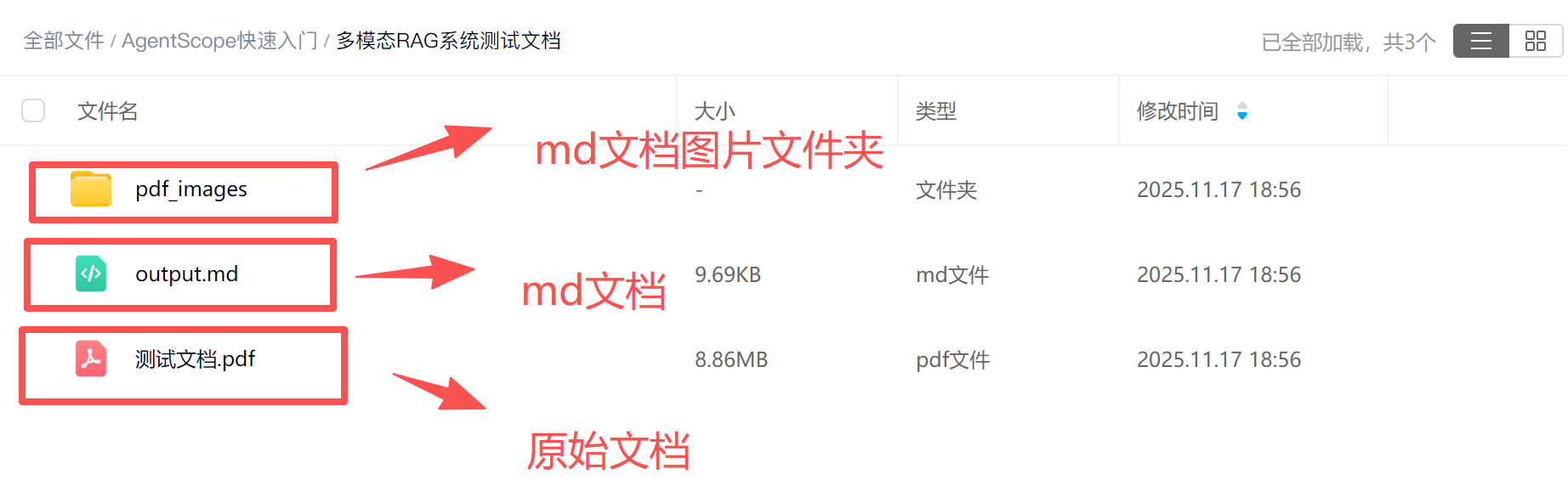
总之,最终需要完成PDF到MarkDown的转化,并对无法识别的图片进行单独保存。不同于语义转化RAG,原生图片识别的RAG流程并不需要对图片进行语义识别,仅需将赌片单独保存即可。最终测试文档的md转化结果和原PDF对比如下:
三、基于AgentScope的多模态RAG系统开发流程
- 整体思路介绍
在完成多模态内容的基础解析后,整个基于 AgentScope 的多模态 RAG 系统将围绕“文档构建—向量检索—多模态推理”三个核心阶段展开协同工作。具体而言,系统的运行链路可以概括为以下几个部分。
-
首先,系统接收包含文本、图片 URL、表格与标题信息的 Markdown 文档,通过预处理模块将整个文档切分为多个粒度较为统一的内容块。在这一阶段,文本段落与图片资源会被分别抽取并标注为不同的内容类型,形成后续向量化和检索所需的基本结构单元。
-
其次,针对文本内容与图像内容分别调用 AgentScope 提供的 TextReader 和 ImageReader 工具进行标准化读取。随后,系统使用 multimodal-embedding-v1 模型对所有内容块进行统一嵌入,将文本与图片映射到相同语义空间中,得到可用于检索的多模态向量表示。所有向量随后存入 QdrantStore,以构建可查询的多模态知识库存储层。
-
当用户提出查询后,系统会先将用户输入同样通过 multimodal-embedding-v1 编码为查询向量,并对向量数据库执行检索操作。借助统一多模态空间的特性,系统能够同时返回与用户查询语义相关的文本段落和图片片段,构成一个跨模态的信息集合。
-
在检索结果返回后,AgentScope 的多模态消息传输格式会将文本和图片片段准确封装为模型输入所需的数据结构,保证模态信息完整地传递到推理阶段。最终,Qwen3-VL 模型基于这些混合输入执行跨模态理解和语义整合,从而生成一段包含视觉理解与文本推理的最终回答。
整体而言,这一流程通过文档切分、双模态向量化、统一检索和视觉语言模型推理的组合,实现了从原始多模态资料到最终回答的端到端处理能力,使 AgentScope 能够有效支撑多模态知识库系统的构建与应用。
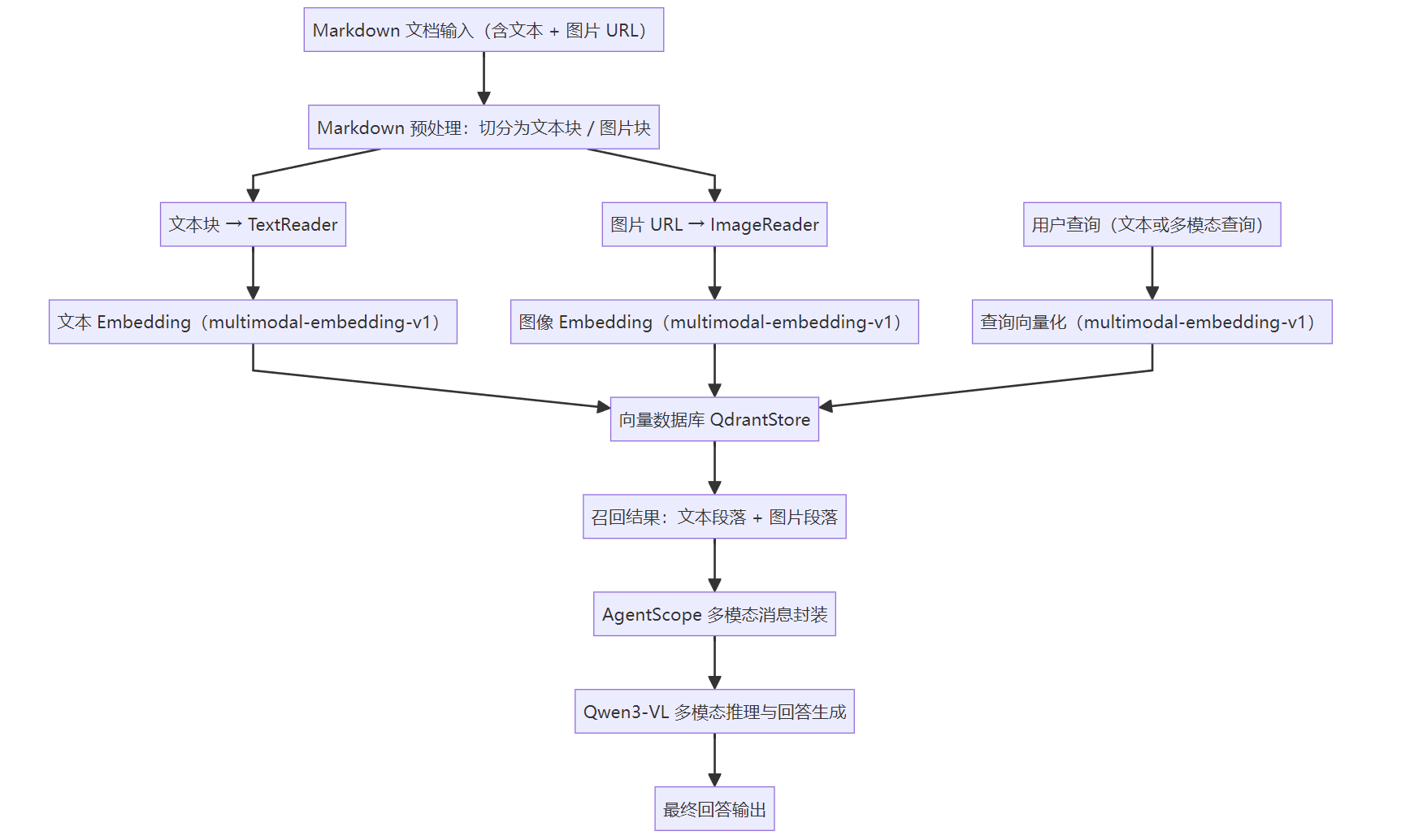
1.markdown文档预处理与分块流程
import asyncio
import json
import os
from matplotlib import pyplot as plt
import agentscope
from agentscope.agent import ReActAgent
from agentscope.embedding import (
DashScopeTextEmbedding,
DashScopeMultiModalEmbedding,
)
from agentscope.formatter import DashScopeChatFormatter
from agentscope.message import Msg
from agentscope.model import DashScopeChatModel
from agentscope.rag import (
TextReader,
SimpleKnowledge,
QdrantStore,
Document,
ImageReader,
)
from agentscope.tool import Toolkit
from bs4 import BeautifulSoup
import markdown
import uuid
import os
import markdown
from bs4 import BeautifulSoup
import uuid
class MdChunk:
def __init__(self, type, content=None, meta=None):
self.id = str(uuid.uuid4())
self.type = type # text / image / table / code
self.content = content
self.meta = meta or {}
def __repr__(self):
return f"<MdChunk type={self.type}, meta={self.meta}, content={str(self.content)[:20]}...>"
def parse_markdown_file(md_path, image_base_url=None):
with open(md_path, "r", encoding="utf-8") as f:
md_text = f.read()
html = markdown.markdown(md_text, extensions=["tables", "fenced_code"])
soup = BeautifulSoup(html, "html.parser")
md_dir = os.path.dirname(os.path.abspath(md_path))
chunks = []
# 遍历 HTML 所有 block element(而不是 children)
for block in soup.find_all(['p', 'h1', 'h2', 'h3', 'h4', 'h5', 'table', 'pre']):
# 1) 表格
if block.name == "table":
chunks.append(MdChunk(type="table", content=str(block)))
continue
# 2) 代码块
if block.name == "pre":
chunks.append(MdChunk(type="code", content=block.get_text()))
continue
# 3) 图片(可能在 block 内部)
images = block.find_all("img")
if images:
for img in images:
src = img.get("src")
abs_path = os.path.abspath(os.path.join(md_dir, src))
url = None
if image_base_url:
url = f"{image_base_url}/{src}".replace("\\", "/")
chunks.append(
MdChunk(
type="image",
meta={
"src": src,
"abs_path": abs_path,
"url": url
}
)
)
# 4) 文本内容
text = block.get_text().strip()
if text:
chunks.append(MdChunk(type="text", content=text))
return chunks
chunks = parse_markdown_file("测试文档.md")
print(chunks)
chunks[0].content
chunks[1].content
chunks[6].content
chunks[7]
chunks[7].meta['src']
len(chunks)
2. MarkDown文档段落Embedding流程
from agentscope.rag import (
TextReader,
SimpleKnowledge,
QdrantStore,
Document,
ImageReader,
)
text_reader = TextReader(chunk_size=2048, split_by="paragraph")
doc1 = await text_reader(chunks[0].content)
doc1
image_reader = ImageReader()
image1 = await image_reader(chunks[7].meta['src'])
image1
knowledge = SimpleKnowledge(
embedding_model=DashScopeMultiModalEmbedding(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="multimodal-embedding-v1",
dimensions=1024,
),
embedding_store=QdrantStore(
location=":memory:",
collection_name="test_collection",
dimensions=1024,
),
)
from agentscope.rag import (
TextReader,
ImageReader,
SimpleKnowledge,
QdrantStore,
)
async def ingest_chunks_into_knowledge(
chunks,
knowledge: SimpleKnowledge,
chunk_size: int = 2048,
split_by: str = "paragraph",
):
"""
将 Markdown 解析出的 chunks 依序写入 AgentScope 的 SimpleKnowledge.
参数:
chunks: parse_markdown_file(...) 返回的列表,每个元素类似 MdChunk
- c.type in {"text", "image", "table", "code"}
- c.content / c.meta["src"]
knowledge: 已初始化好的 SimpleKnowledge 实例
chunk_size: TextReader 的切分长度
split_by: TextReader 的切分策略("paragraph" / "sentence" 等)
"""
text_reader = TextReader(chunk_size=chunk_size, split_by=split_by)
image_reader = ImageReader()
for idx, c in enumerate(chunks):
# ---- 文本类:text / table / code 都统一按文本处理 ----
if c.type in ("text", "table", "code"):
if not c.content or not str(c.content).strip():
continue
try:
# TextReader 是 async __call__,返回 List[Document]
docs = await text_reader(c.content)
if docs:
await knowledge.add_documents(docs)
print(f"[OK] Added {c.type.upper()} chunk #{idx} -> {len(docs)} docs")
except Exception as e:
print(f"[ERROR] Failed to add {c.type} chunk #{idx}")
print(e)
# ---- 图片类:用 ImageReader,直接喂 URL(src) ----
elif c.type == "image":
src = (c.meta or {}).get("src")
if not src:
print(f"[WARN] Image chunk #{idx} missing src, skipped")
continue
# 这里按你的设定:src 就是可访问的 URL(图床地址)
# 不再使用 abs_path,也不依赖本地文件
try:
docs = await image_reader(src)
if docs:
await knowledge.add_documents(docs)
print(f"[OK] Added IMAGE chunk #{idx} -> {len(docs)} docs, url={src}")
except Exception as e:
print(f"[ERROR] Failed to add image chunk #{idx}, url={src}")
print(e)
else:
print(f"[WARN] Unknown chunk type: {c.type}, idx={idx}, skipped")
具体执行词向量化流程如下:
await ingest_chunks_into_knowledge(chunks, knowledge)
3.多模态RAG系统问答流程
3.1 作为知识库问答
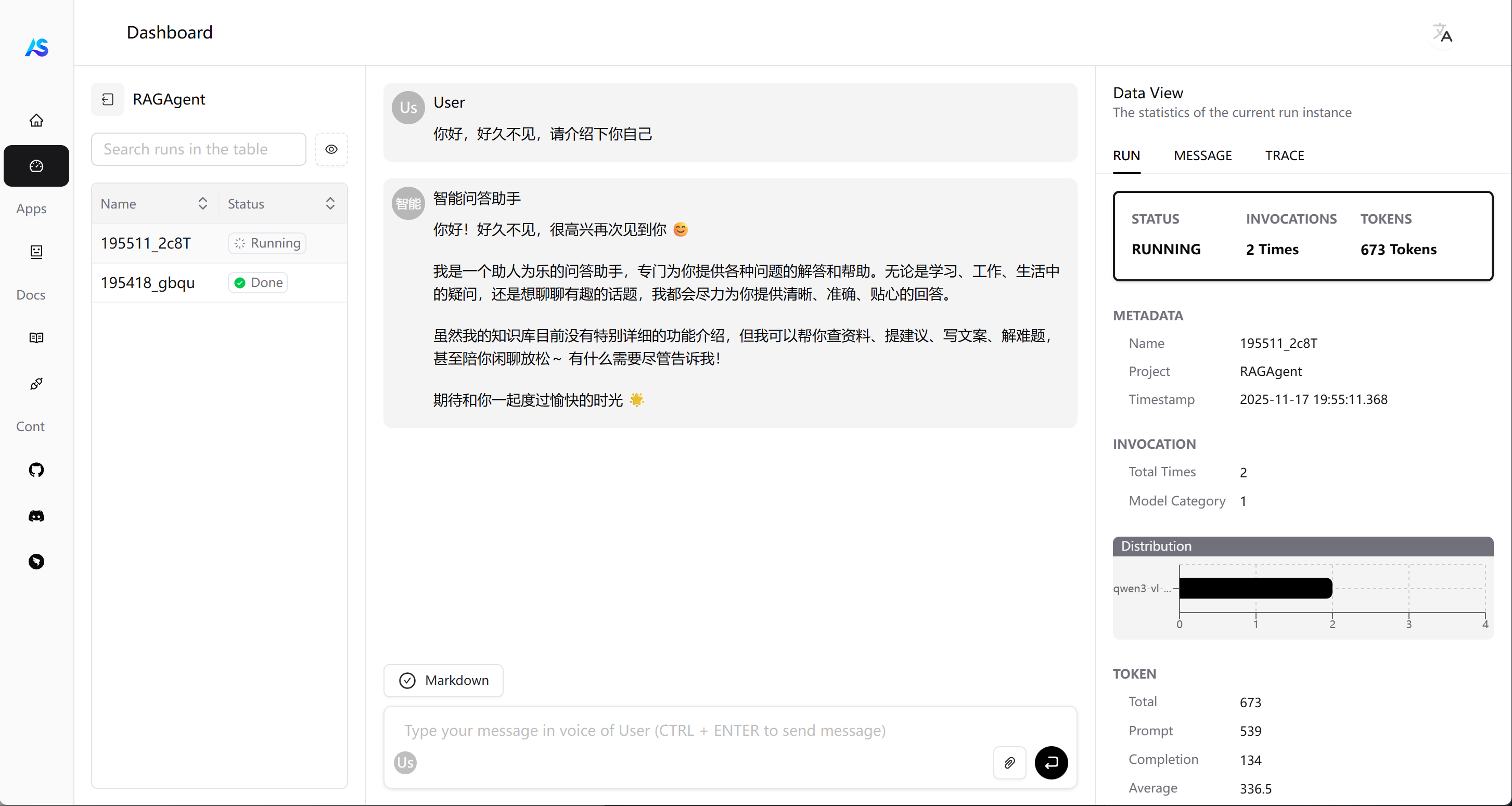
# 使用 DashScope 作为模型创建 ReAct 智能体
agent = ReActAgent(
name="智能问答助手",
sys_prompt="你是一名助人为乐的问答助手,会根据知识库进行合理的回答。",
model=DashScopeChatModel(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="qwen3-vl-plus",
),
formatter=DashScopeChatFormatter(),
knowledge=knowledge,
)
msg = Msg(
name="user1",
content="请问LangChain有哪些核心功能?",
role="user",
)
res = await agent(msg)
await agent.memory.get_memory()
msg = Msg(
name="user1",
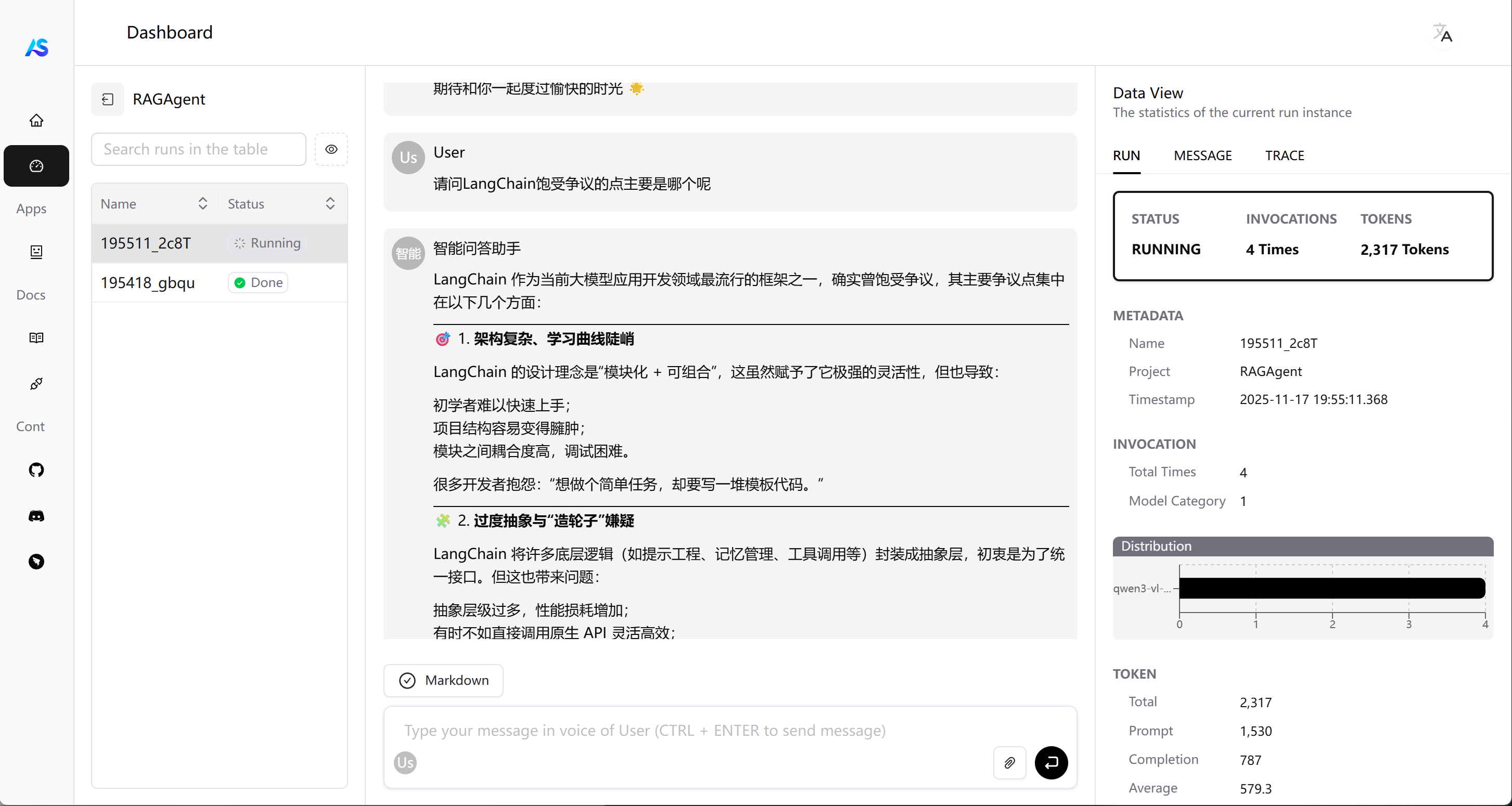
content="你还记得曾经的LangChain饱受争议的地方有哪些么?",
role="user",
)
res = await agent(msg)
await agent.memory.get_memory()
msg = Msg(
name="user1",
content="请帮我介绍下LangGraph-Studio",
role="user",
)
res = await agent(msg)
await agent.memory.get_memory()
3.2 搭建AgenticRAG问答流程
from agentscope.tool import Toolkit
from agentscope.message import Msg
toolkit.clear()
toolkit = Toolkit()
toolkit.register_tool_function(
knowledge.retrieve_knowledge,
func_description=( # 为工具提供清晰的描述
"用于检索与给定查询相关的文档的工具。" "当你需要查找有关LangChain相关信息时请调用本工具进行信息检索。"
),
)
# 使用 DashScope 作为模型创建 ReAct 智能体
agent = ReActAgent(
name="智能问答助手",
sys_prompt="你是一名助人为乐的问答助手,会根据知识库进行合理的回答。",
model=DashScopeChatModel(
api_key=os.environ["DASHSCOPE_API_KEY"],
model_name="qwen-max",
),
formatter=DashScopeChatFormatter(),
toolkit=toolkit,
)
msg = Msg(
name="user1",
content="请问LangChain饱受争议的点主要有哪些?",
role="user",
)
res = await agent(msg)
msg = Msg(
name="user1",
content="请问什么是深度学习?",
role="user",
)
res = await agent(msg)
三、借助AgentScope Studio进行多模态RAG系统部署
FENCE0
输入python RAGAgent.py即可启动项目: