DeepSeek-V3.2 RAG系统开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(12月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(12月班)

《2025大模型Agent智能体开发实战》(12月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
课程完整介绍


部分课程成果演示
from IPython.display import Video
- Dify+DeepSeek搭建智能微信语音客服
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- Coze自动图文视频创作流程
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- 可视化数据分析Multi-Agent
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目展示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋季班)


详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

国产最强DeepSeek-V3.2 Agent开发实战
Part 3.DeepSeek-V3.2 RAG系统开发实战
1.RAG全栈技术体系介绍
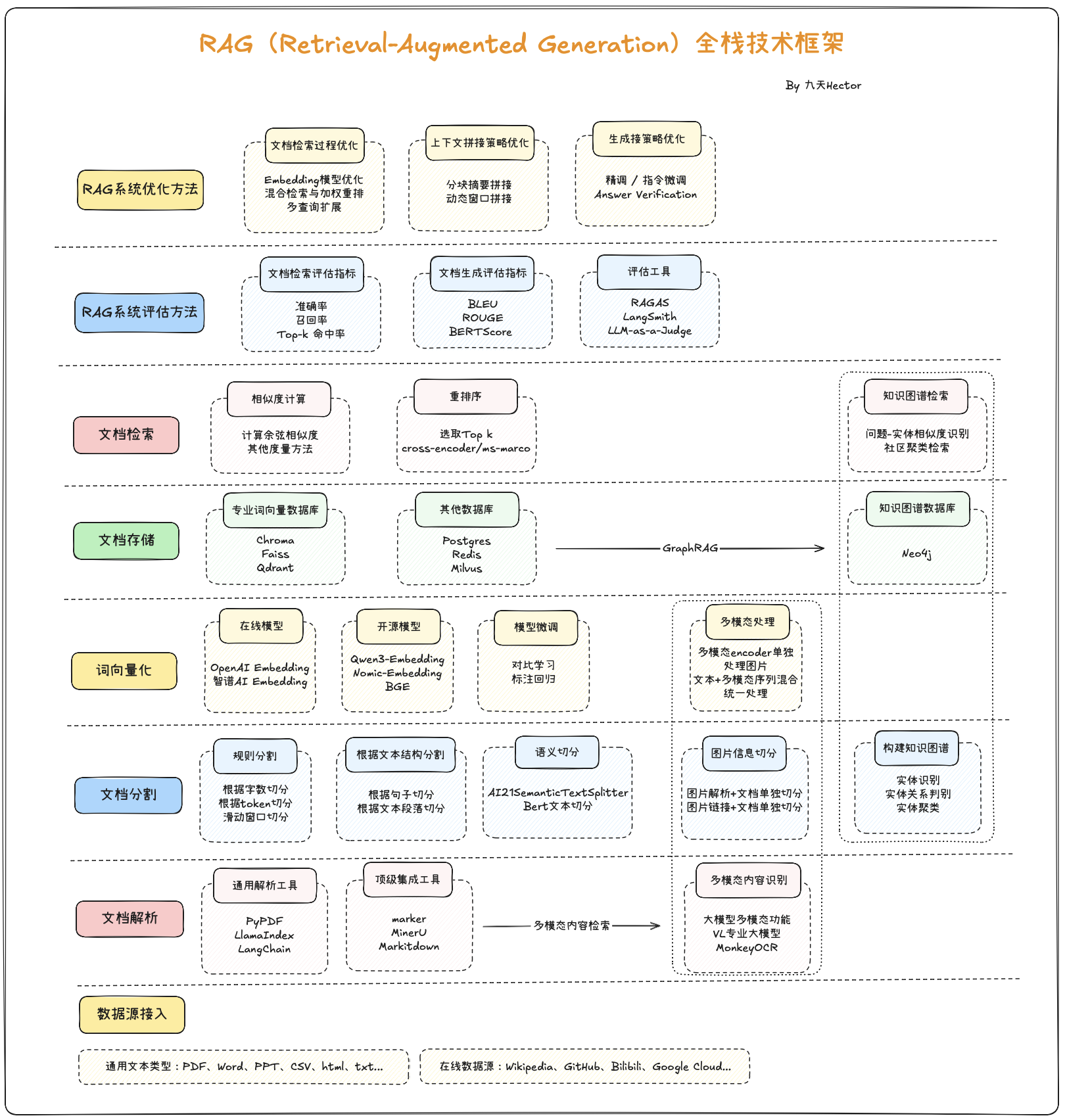
RAG技术是一项应用面广、门槛很低、但同时上限也很高的一项技术。历经数年的技术发展,RAG技术的体系已经非常庞大,以下是RAG技术全栈技术框架概览:


2.LangChain RAG API介绍
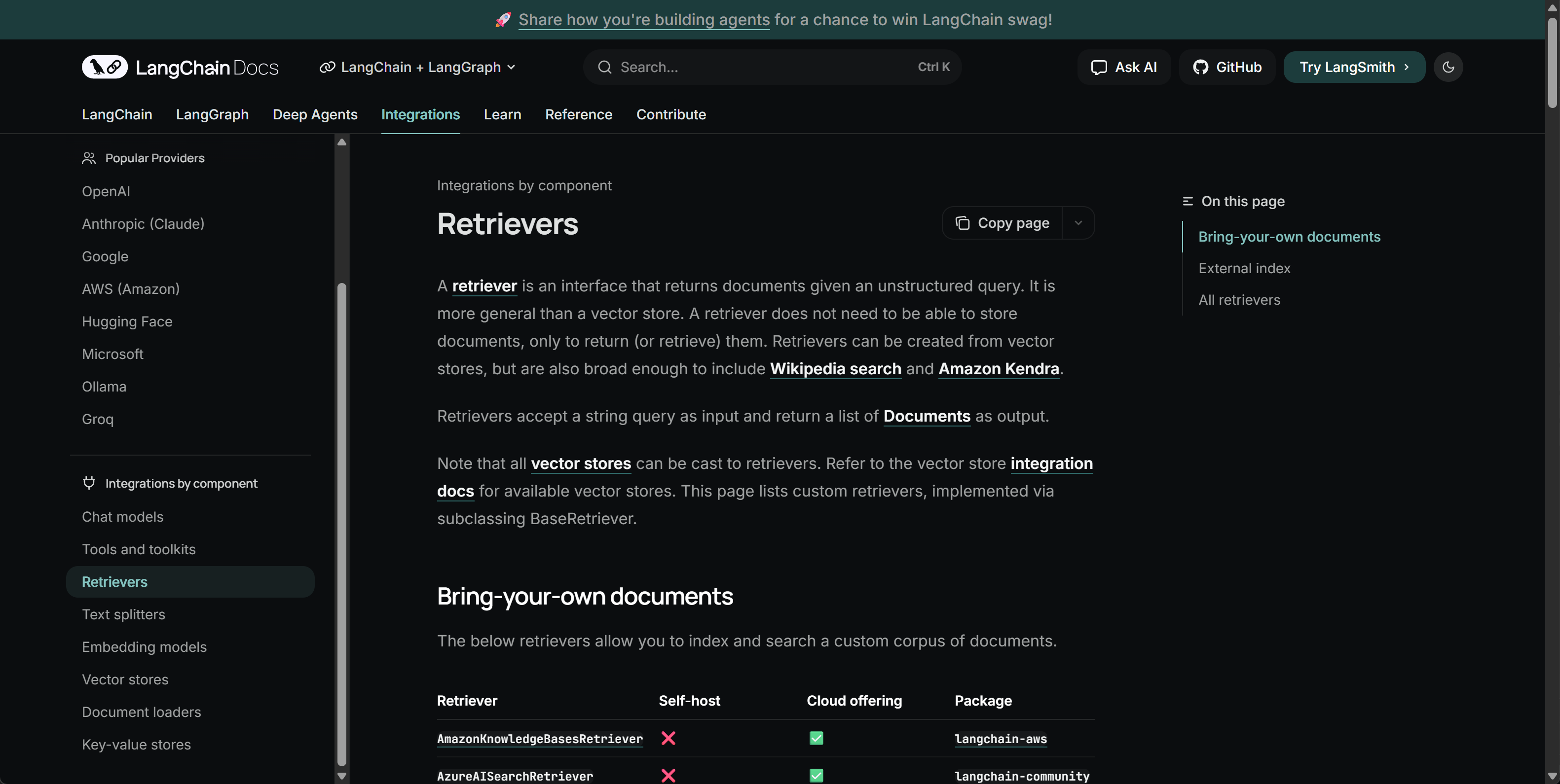
在LangChain框架中,RAG作为一个非常重要且关键的模块独立存在,如下图所示:https://python.langchain.com/docs/integrations/retrievers/
针对我们在上一小节分析的RAG流程,每一个子流程中,LangChain都提供了多种较为通用的实现方法,这包括如何将不同来源、不同形式的数据切分成一个个小块,如何使用Embedding模型做向量化,如何将向量存储进向量数据库中,以及提供了快速检索的优化算法。每一环节设计的基础技术,都作为一个独立的抽象模块存在,而将各个环节像Chains一样串流起来进行数据交换,形成一个完整的RAG系统,LangChain抽象了一个所谓的data connection数据处理流,如下图所示:
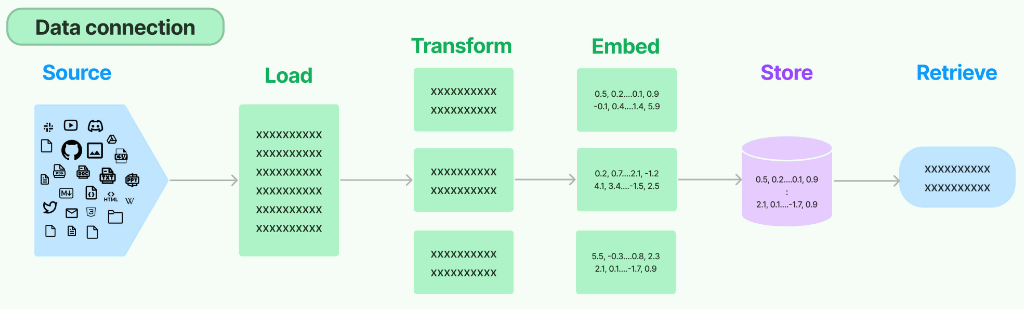
data connecting 是Langchain框架原生的数据处理流,RAG是涉及多个处理环节的一个架构,它不是个体,而是一个整体,所以虽然不同环节、不同模块间所做的事情是不一样的,但它们之间是需要链接的,需要进行数据的交换,那这一部分工作,就是交给data connection来统一管理。例如,在上述流程中,"Source"阶段指的是附加的数据库,它能够整合来自不同数据源的信息。通过"Load"组件,这些数据可以被统一管理。"Transform"组件则负责进行数据切分等一系列前文提到的构建RAG所需的开发任务,提供了各种不同的解决方案。
因此,学习LangChain中RAG的构建过程我们更建议:第一步学流程,第二步学关键点,第三步学每一环节的具体技术,第四步不断地扩展优化,从基础RAG到进阶RAG。所以接下来,我们就按照LangChain的data conncetiong流程,逐步拆解每一模块的关键技术点进行讲解和实践,最终跑通这个RAG流程。
3. LangChain RAG系统开发基础环境搭建
! pip install langchain-text-splitters faiss-cpu langchain-openai langchain_community
- 测试调用:
import os
from dotenv import load_dotenv
load_dotenv(override=True)
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-chat")
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
4. 从零搭建简易Agentic RAG系统
使用OpenAI的Embeddings模型将自然语言转化成词向量的表示。
OPENAI_EMBEDDING_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_EMBEDDING_BASE_URL = "https://ai.devtool.tech/proxy/v1"
from langchain_openai import OpenAIEmbeddings
embed = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model="text-embedding-3-small"
)
接下来,为了进一步丰富大家对LangChain中向量数据库的了解,这里我们使用FAISS作为矢量数据库。 FAISS 是 Facebook AI Research 开发的一个库,用于高效相似性搜索和密集向量聚类。LangChain在第三方集成模块(Langchain_community)中已经接入了FAISS向量数据库,所以我们就可以直接使用。

file_path = "模拟公司员工手册.md"
with open(file_path, "r", encoding="utf-8") as f:
md_content = f.read()

md_content
from langchain_text_splitters import MarkdownHeaderTextSplitter
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2")
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(md_content)
md_header_splits
len(md_header_splits)
md_header_splits[0]
md_header_splits[1]
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(md_header_splits, embedding=embed)
vector_store.save_local("staff_handbook_db")
创建矢量数据库后,我们可以进行测试:
# 加载本地的Faiss向量文件,allow_dangerous_deserialization 用于控制是否允许在加载向量存储时进行潜在的危险反序列化操作。
vector_store = FAISS.load_local(embeddings=embed, folder_path='staff_handbook_db',allow_dangerous_deserialization=True)
# 将 FAISS 向量存储转换为一个 retriever(检索器),并为该检索器设置一些搜索相关的参数。k=1 表示检索时返回 最相似的 3 个文档
retriever = vector_store.as_retriever(search_kwargs={'k': 3})
# 执行相似度搜素
query = "请问我们公司有没有病假?"
results = retriever.invoke(query)
for doc in results:
print(f"Content: {doc.page_content}")

results
# 直接在向量库上搜索并返回相似度
results = vector_store.similarity_search_with_score(query, k=3)
for doc, score in results:
print(f"Score: {score:.4f}")
print(f"Content: {doc.page_content}\n")
然后即可将这个检索过程封装为一个完整的外部工具:
from langchain.tools import tool
@tool(response_format="content_and_artifact")
def retrieve_context(query: str):
"""Retrieve information to help answer a query."""
retrieved_docs = vector_store.similarity_search(query, k=2)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\nContent: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docs
prompt="你是一名助人为了的助手,当用户提问有关员工福利、休假政策、绩效管理、招聘、入职以及其他与 HR 相关的话题时,可以调用retrieve_context工具进行文档检索回答。其他问题则可以调用你的原始知识库进行回答。"
from langchain.agents import create_agent
tools = [retrieve_context]
agent = create_agent(model, tools, system_prompt=prompt)
response = agent.invoke({"messages": [{"role": "user", "content": "请问公司有病假么?"}]})
response
response['messages'][-1].content
而这背后其实就是一次完整的Function calling调用流程:
len(response['messages'])
response['messages'][0]
response['messages'][1]
response['messages'][2]
response['messages'][3]
response['messages'][2].content
二、DeepSeek-V3.2企业级Agentic RAG系统开发流程
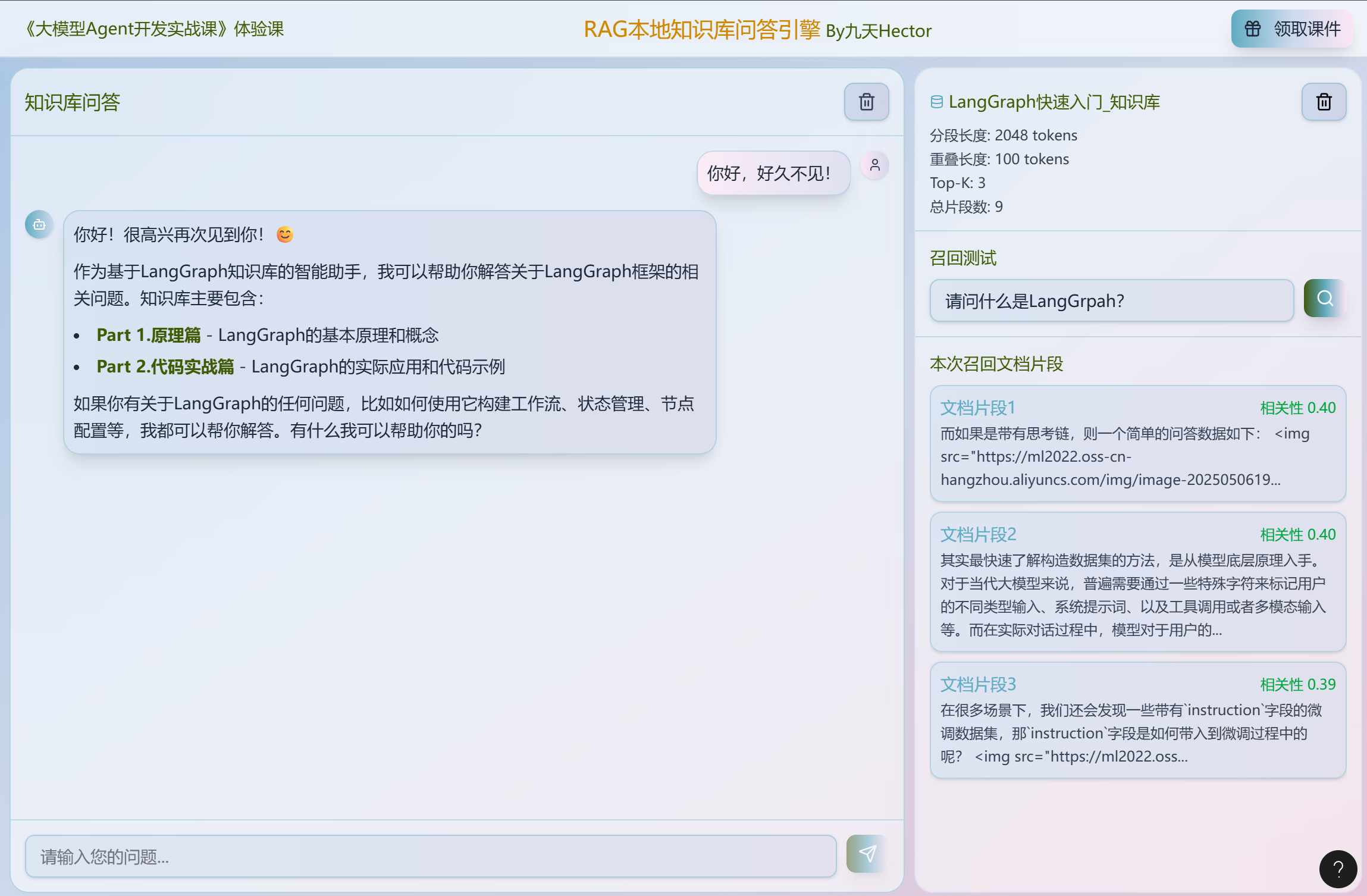
本项目不仅仅是一个简单的文档问答工具,而是基于 LangChain 1.1 最新架构 打造的 Agentic RAG(代理式检索增强生成) 系统。不同于传统 RAG 机械式的“检索-生成”流程,本系统赋予了大模型“自主决策”的能力,并引入了后端中间件机制,实现了真正的智能化知识服务。
核心功能与技术亮点:
-
Agentic RAG 决策架构 (LangChain 1.1 Standard)
- 摒弃过时的 Chain 模式,采用 Agent(智能体) 架构。模型不再是被动接收上下文,而是化身为“决策者”。它能根据用户问题,自主判断是直接进行闲聊,还是调用工具去知识库中检索信息,实现了“所答即所问”的灵活交互。
-
动态中间件与自适应 System Prompt
- 亮点技术:实现了“上下文感知”的中间件机制。
- 核心逻辑:系统在构建向量库时,会自动提取文档的各级标题(Header 1/2)并生成元数据。在对话开启的瞬间,中间件会读取当前挂载知识库的元数据,动态组装 System Prompt。
- 效果:如果用户关联的是《员工手册》,Agent 会自动设定人设为“HR助手”并知晓包含“休假、薪资”等主题;如果关联的是《API文档》,Agent 则立刻切换为“技术专家”。彻底解决了传统 RAG 系统提示词千篇一律、缺乏针对性的痛点。
-
基于 Artifact 的透明化引用机制
- 利用 LangChain 这里的
content_and_artifact特性,实现了检索结果的**“双轨制传输”**:- 给 AI 看:将清洗后的纯文本内容传递给大模型,保证生成的准确性。
- 给用户看:将带有**相关性评分(Score)和元数据(Metadata)**的原始文档片段(Artifact)完整透传至前端。
- 前端不仅能展示 AI 的回答,还能像搜索引擎一样列出带有置信度的“参考来源”,极大地增强了系统的可解释性和用户信任度。
- 利用 LangChain 这里的
-
双重切分与混合检索策略
- 在数据处理层,采用 MarkdownHeader切分 + 递归字符切分 的双重策略,既保留了文档的语义结构(章节归属),又控制了 Token 长度。结合 FAISS 高性能向量库与 DeepSeek-V3 强力底座,确保了在复杂文档场景下的高精度召回。
- 项目结构介绍
项目架构深度解析:基于 LangChain 1.1 的 Agentic RAG 系统
在构建复杂的 AI 应用时,良好的工程结构是成功的基石。本项目采用**分层架构(Layered Architecture)**设计,基于 FastAPI 框架和 LangChain 1.1+ 标准,实现了高内聚、低耦合的后端系统。
1. 项目目录结构全景图
首先,让我们通过目录树来俯瞰整个后端项目(backend/)的物理结构:
FENCE0
2. 核心模块功能详解
我们将系统划分为四个关键层次,每一层都有明确的职责边界:
第一层:接口层 (API Layer)
- 文件:
app/api/endpoints.py - 职责:系统的“门面”。只负责接收 HTTP 请求、验证数据格式(通过 Schemas)、调用下层服务,并返回标准响应。
- 设计原则:不做业务逻辑。你不会在这里看到 LangChain 的代码,只会看到参数解析和函数调用。
第二层:业务逻辑层 (Service Layer) —— 核心大脑
这是本项目最厚重、含金量最高的部分:
-
file_service.py(数据工厂)- ETL 处理:读取 Markdown -> 提取 Header 元数据 -> 双重切分(Header + Character)。
- 向量化:调用 Embedding 模型生成向量。
- 兼容性保障:处理 Windows 路径问题,生成
index.faiss和metadata.json。
-
agent_service.py(智能编排)- 中间件逻辑:在运行时读取
metadata.json,动态生成 System Prompt。 - 动态工具绑定:利用闭包(Closure)在函数内部动态定义
retrieve_context工具,并绑定当前的向量库。 - 执行与解析:运行 Agent,并解析复杂的
content_and_artifact结构,分离出答案和引用来源。
- 中间件逻辑:在运行时读取
第三层:核心配置层 (Core Layer)
- 文件:
app/core/config.py - 职责:管理全局单例。确保 DeepSeek LLM 和 OpenAI Embedding 模型只被初始化一次,避免重复开销。
第四层:数据契约层 (Schemas Layer)
- 文件:
app/schemas/api_schemas.py - 职责:定义“共同语言”。使用 Pydantic 严格定义了前端传什么(如
kb_name)、后端回什么(如DocSource),确保前后端联调顺畅。
3. 数据流转全生命周期 (Data Flow)
当用户发起一次“关联知识库的对话”请求时,数据是如何流转的?
- Request: 前端发送
POST /api/chat,携带{ "query": "病假", "kb_name": "staff_kb" }。 - Routing:
main.py接收请求,转发给endpoints.py。 - Validation:
ChatRequestSchema 验证数据格式是否合法。 - Service Invocation: 接口层调用
AgentService.chat_with_agent()。 - Middleware Execution (AgentService):
- 加载
staff_kb/metadata.json,发现主题包含“休假制度”。 - 生成 System Prompt:“你是一个基于‘休假制度’知识库的助手...”。
- 加载 FAISS 索引,动态创建
retrieve_context工具。
- 加载
- Agent Reasoning: DeepSeek 模型思考 -> 决定调用工具 -> 获得检索结果(含 Score)。
- Response Construction:
AgentService解析执行结果,分离出 Answer 和 Artifacts。 - Return: 接口层将结果封装为 JSON 返回前端。
4. 架构设计总结
- 模块化 (Modularity):文件处理与对话逻辑完全分离,修改向量库逻辑不会影响 Agent 对话逻辑。
- 可扩展性 (Extensibility):如果未来要换成 ChromaDB 或其他 LLM,只需修改
file_service.py或config.py,无需改动上层业务。 - 标准化 (Standardization):严格遵循 FastAPI 和 LangChain 的最佳实践,代码清晰、易读、易维护。
这套架构不仅仅是教学演示,更是一个轻量级企业级 RAG 应用的标准模板。
- 核心代码解释
FENCE0
模块一:动态上下文注入 (Dynamic Context Injection)
核心概念:拒绝千篇一律的 System Prompt,根据知识库内容实时调整 AI 人设。
在 chat_with_agent 函数的开头,我们并没有使用写死的 Prompt,而是引入了一个“中间件”逻辑:
FENCE0
- 技术解读:
- 按需加载:只有当用户指定了
kb_name时,系统才会去加载对应的向量库和元数据。 - Prompt 模板化:利用 Python 的 f-string,将提取到的
topics(如“薪资管理”、“API接口”)嵌入到系统提示词中。 - 价值:这让 Agent 具备了元认知能力。它知道自己“懂什么”,从而在回答问题时更自信,或者在遇到无关问题时能准确拒绝。
- 按需加载:只有当用户指定了
模块二:运行时工具绑定 (Runtime Tool Binding)
核心概念:利用 Python 的闭包 (Closure) 特性,为每一次对话创建专属的检索工具。
请注意 retrieve_context 函数定义的位置——它是在 chat_with_agent 函数内部定义的,而不是全局定义的。
FENCE1
- 技术解读:
- 闭包机制:这个 Tool 捕获了当前请求上下文中的
vector_store和top_k参数。 - 隔离性:用户 A 的请求会生成一个绑定了 A 知识库的 Tool;用户 B 的请求会生成另一个。两者互不干扰,即使并发执行也不会串库。
- 动态挂载:
tools = [retrieve_context]这一行是在运行时决定的。如果没有知识库,tools就是空的,Agent 自动退化为普通聊天模式。
- 闭包机制:这个 Tool 捕获了当前请求上下文中的
模块三:双轨制数据流 (Content & Artifact)
核心概念:LangChain 1.1 的杀手级特性,解决“AI 看的内容”与“前端展示的内容”需求不一致的问题。
我们在 @tool 装饰器中指定了 response_format="content_and_artifact",这是实现引用透明化的关键。
FENCE2
- 技术解读:
- Content (serialized):这是喂给大模型的上下文。我们去掉了不必要的干扰信息,只保留文本和必要的元数据,帮助模型生成答案。
- Artifact (artifacts):这是“副作用”数据。大模型看不到这个列表,但 LangChain 会把它保留在
ToolMessage中。我们利用它将 相关性评分 (Score) 和 原始文档对象 透传给前端,用于渲染“引用来源”卡片。
模块四:标准化执行与解析 (Standard Execution & Parsing)
核心概念:遵循 LangChain 标准协议,精准提取多模态输出。
最后是 Agent 的执行和结果提取环节,这里体现了后端开发的严谨性。
FENCE3
- 技术解读:
create_agent:这是 LangChain 0.2/0.3 (1.1+ API) 推荐的工厂函数,它屏蔽了底层的 Prompt 拼装细节(如AgentScratchPad)。- 消息回溯:由于 Agent 可能进行多轮思考(虽然 RAG 通常是一轮),我们需要遍历
messages列表来找回 Tool 的执行结果(即artifact)。这是获取检索来源最准确的方式,比正则匹配文本要可靠得多。
3.项目运行流程
-
下载源码并解压缩
-
安装后端依赖:
FENCE0
- 开启后端
FENCE0
- 安装前端依赖
FENCE0
- 开启前端
FENCE0
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/d785514f32f7125bd859045b10d3ae3a.mp4", width=800, height=400)