GraphRAG API开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(7月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(7月班)

《2025大模型Agent智能体开发实战》(7月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(夏季班)

两门大模型课程夏季班目前上新特惠,直播间下单可享618平价钜惠,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


GraphRAG技术实战公开课
Part 3.GraphRAG API开发实战
一、GraphRAG Python API功能介绍
1.GraphRAG Python API高级API调用流程回顾
from pathlib import Path
from pprint import pprint
from IPython.display import Markdown, display
import pandas as pd
import graphrag.api as api
from graphrag.config.load_config import load_config
from graphrag.index.typing.pipeline_run_result import PipelineRunResult
1.1 GraphRAG高级API实现Index流程
- Step 1.准备文档



- Step 2.创建检索项目文件夹
FENCE0
- Step 3.上传数据集

- Step 4.初始化项目文件
FENCE0
# !graphrag init --root ./openl_big
- Step 5.修改项目配置
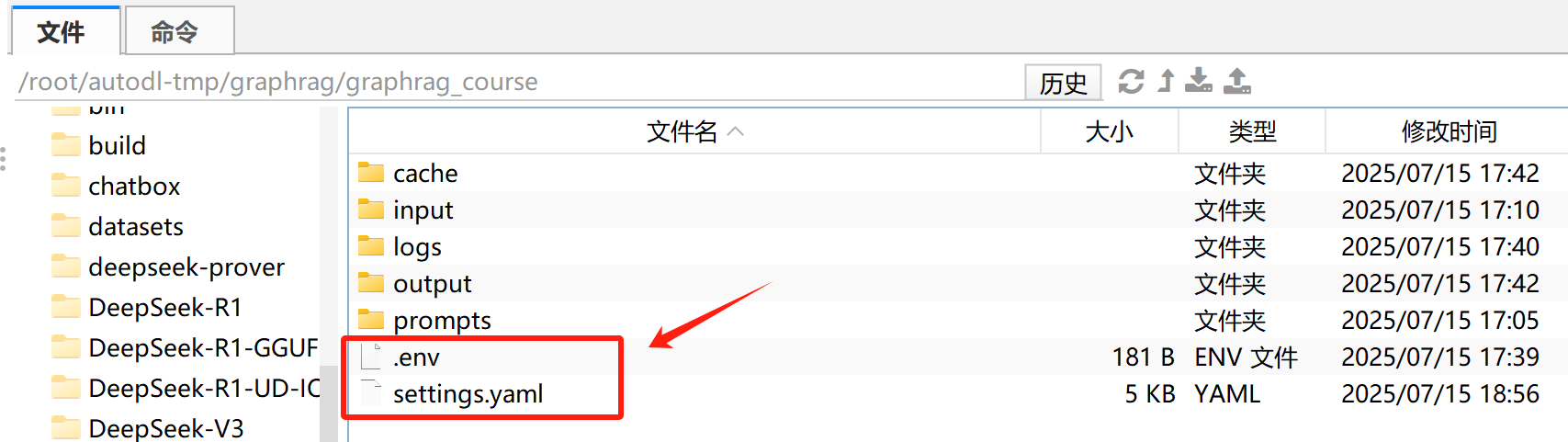
打开.env文件,填写OpenAI API-KEY
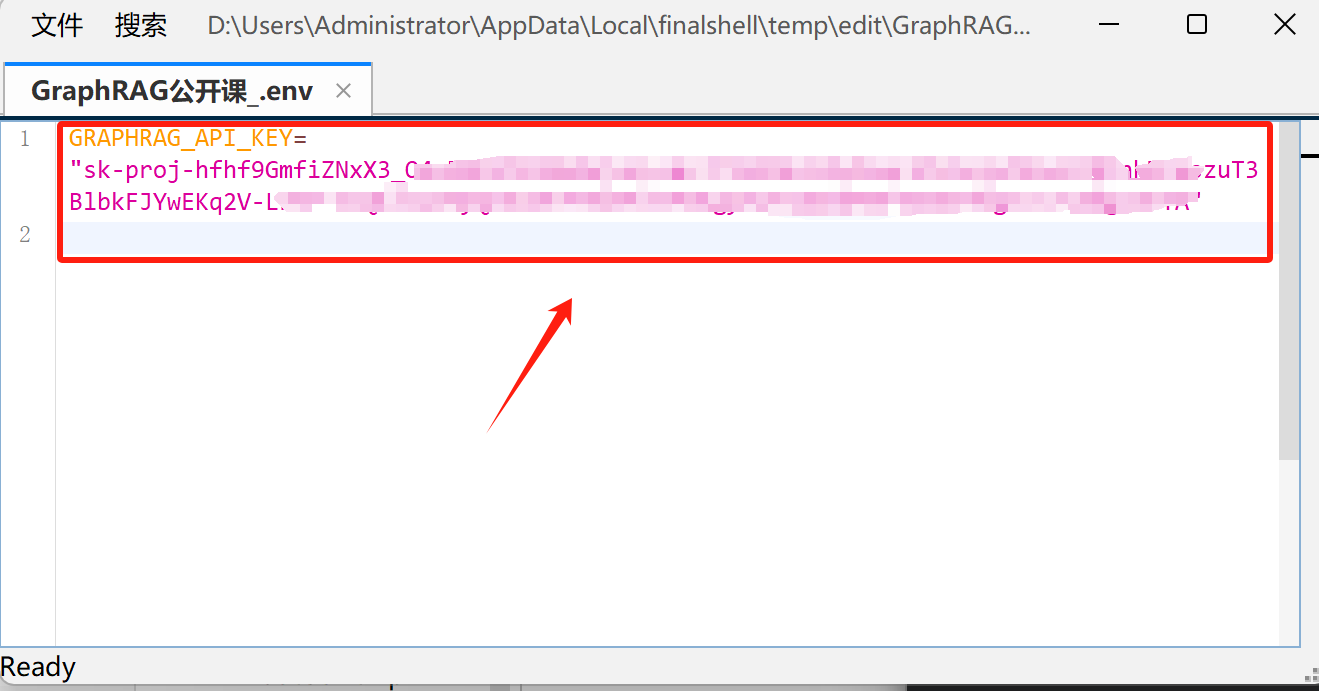
打开setting.yaml文件,填写模型名称和反向代理地址:
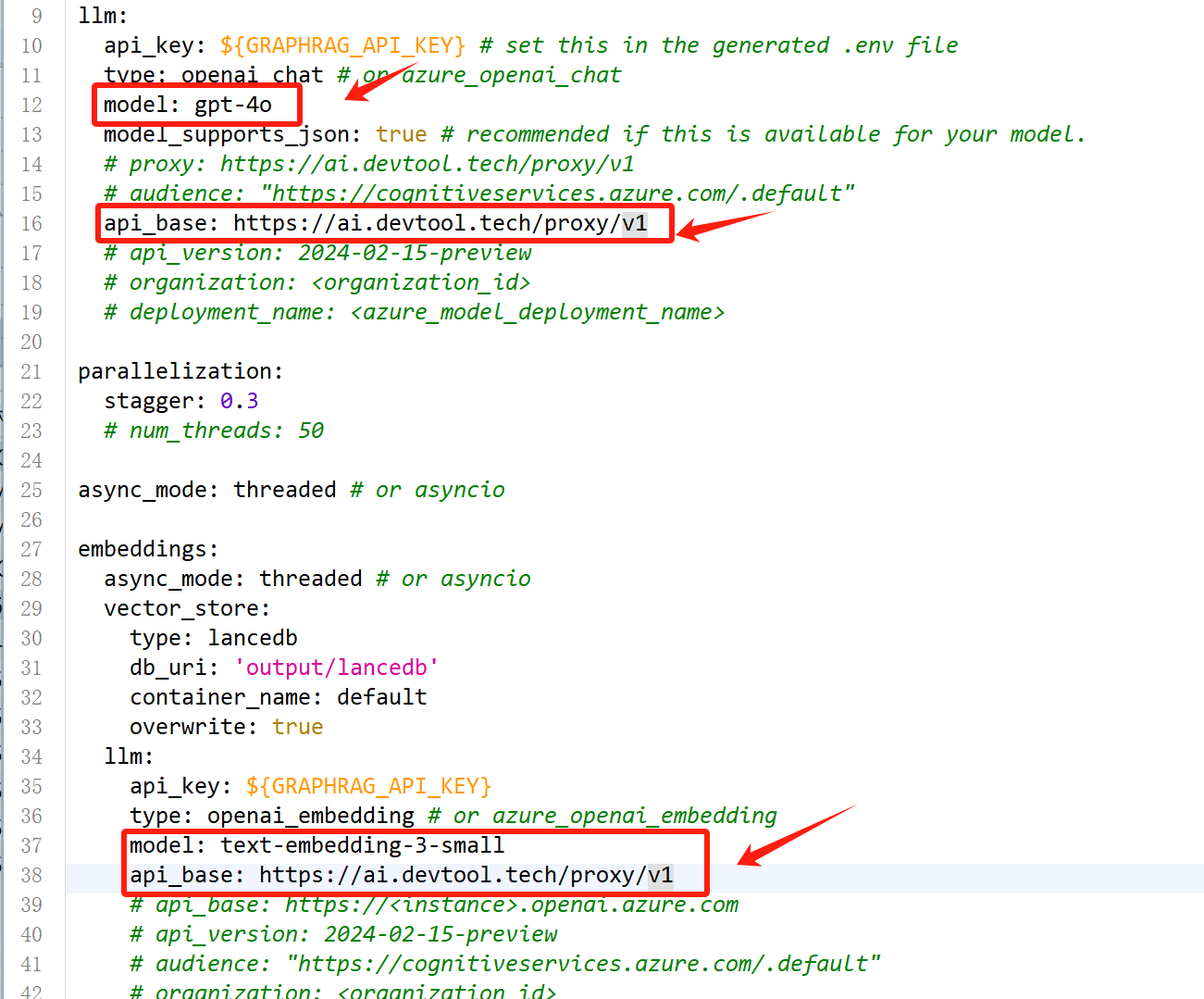
其中反向代理地址为api_base: https://ai.devtool.tech/proxy/v1
- Step 6.执行检索Index
PROJECT_DIRECTORY = "./graphrag_course"
graphrag_config = load_config(Path(PROJECT_DIRECTORY))
index_result: list[PipelineRunResult] = await api.build_index(config=graphrag_config)
# index_result is a list of workflows that make up the indexing pipeline that was run
for workflow_result in index_result:
status = f"error\n{workflow_result.errors}" if workflow_result.errors else "success"
print(f"Workflow Name: {workflow_result.workflow}\tStatus: {status}")
1.2 GraphRAG高级API问答流程
- 全局搜索问答
entities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/entities.parquet")
communities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/communities.parquet")
community_reports = pd.read_parquet(
f"{PROJECT_DIRECTORY}/output/community_reports.parquet"
)
entities.head()
communities
community_reports
community_reports.columns
community_reports['summary']
community_reports['summary'][0]
community_reports['full_content']
community_reports['full_content'][0]
| 字段名 | 类型 | 说明 |
|---|---|---|
id | str | 报告的唯一 ID,通常是哈希或社区 ID 的组合。用于在图谱中唯一定位该社区报告。 |
human_readable_id | str | 可读性更好的社区标识符,通常是 "community-level-{level}-{index}" 格式,便于调试与前端展示。 |
community | int 或 str | 当前社区在该层级下的唯一编号。你可以理解为社区编号 ID。多个节点会共享同一个社区 ID。 |
level | int | 当前报告所属的社区层级。Level 越小,社区越细粒度;Level 越大,聚类越粗。 |
parent | str 或 None | 当前社区在更高一层中的父社区 ID。用于构建社区层级结构(Community Tree)。如果为 None,说明是最高层。 |
children | list[str] | 当前社区在下一层级中包含的子社区 ID 列表。为空表示为叶子社区。 |
title | str | 对该社区内容的自动生成标题(可由模型生成或规则设定)。用于语义检索与 UI 展示。 |
summary | str | 对该社区内容的简要总结(一般为几句话)。用于快速语义匹配,也可以用于向量嵌入。 |
full_content | str | 该社区整合后的完整文段(拼接了该社区内所有实体文档片段,或模型进一步生成)。是 RAG 上下文构造的主要语料。 |
rank | float 或 int | 可选字段,表示该社区在排序(如语义相关性)中的相对重要性分数。常用于调试或模型排序依据。 |
rating_explanation | str | 可选字段,对当前社区的 rank/score 给出解释(如“与查询高相关,因为包含关键词...”)。可能是模型输出。 |
findings | list[str] 或 dict | 可选字段,提取出的关键信息点(如 bullet points),用于 structured 回答或 JSON 输出。 |
full_content_json | dict | 可选字段,将 full_content 拆分为结构化 JSON,按实体、段落、来源组织。用于结构化回答或前端高亮。 |
period | str 或 datetime | 如果图谱包含时间维度,这里表示该社区报告的时间跨度(如“2023-Q1”)。 |
size | int | 该社区包含的实体数量,或构成 full_content 的节点数(chunk数)。可用于过滤过小社区。 |
GraphRAG 会根据文档中实体之间的语义关系网络构建一张实体图(Entity Graph),然后通过图聚类算法(如 Leiden 或 Louvain)划分出多层级社区结构。这些社区层级形成了一棵“社区树(Community Tree)”。
Step-by-step:GraphRAG 社区构建流程(简化)
-
实体提取:识别出如“苹果公司”、“乔布斯”、“iPhone”、“谷歌”、“搜索引擎”等实体。
-
实体关系建图:如“乔布斯 → 苹果公司”、“iPhone 属于苹果”、“谷歌 → Android”,这些组成图结构。
-
图聚类 + 分层:
- Level 0:每个段落或实体形成最基础社区(如每家公司为一级)
- Level 1:按公司维度聚合(如“苹果公司全景”、“谷歌全景”)
- Level 2:聚合成“美国科技巨头”
- Level 3:聚合为“硅谷生态系统”
-
形成树状结构:通过
parent和children字段形成嵌套结构。
📊 示例:你的文本的假想社区聚类结果(树状结构)
我们来列一个例子,用伪结构表示各层级关系:
FENCE0
🧩 说明这个结构里的每层含义:
| 层级 | 含义 | 示例 |
|---|---|---|
| Level 0 | 最细粒度:某一段落、产品或事件 | Apple I 发布、iPhone、AlphaGo |
| Level 1 | 某家公司或单一主题的聚合 | 苹果社区、谷歌社区 |
| Level 2 | 同类型群体整合 | 硅谷科技巨头、前沿技术趋势 |
| Level 3 | 全局主题,覆盖全文的宏观话题 | 全球科技生态系统 |
✅ 在 GraphRAG 中如何体现?
在你的 community_reports.parquet 中:
- 每行代表一个社区
level表示该社区的层级parent字段连接上层社区(如“谷歌社区”是“硅谷科技巨头”的子节点)children是该社区下辖的子社区 ID 列表summary/title是每个社区自动生成的概括信息
api.global_search?
| 参数名 | 类型 | 说明 |
|---|---|---|
config | GraphRagConfig | GraphRAG 的主配置对象,包含模型路径、RAG参数、embedding设置等,一般通过 from_config() 加载 settings.yaml 来生成。 |
entities | pd.DataFrame | 实体识别后的结果,来源通常是 entities.parquet,包括节点信息、类型、embedding等。 |
communities | pd.DataFrame | 图谱中的“社区聚类结构”,从 communities.parquet 加载,表示实体之间的聚类关系。 |
community_reports | pd.DataFrame | 每个社区在不同层级下的摘要信息(或报告),用于组装最终的检索语料。 |
community_level | int | None | 指定使用哪个层级的社区报告(越小越细粒度),设置为 None 表示全部层级或根据 dynamic_community_selection 自动决定。 |
dynamic_community_selection | bool | 如果为 True,系统会根据 query 智能选择哪些社区最相关,而不是用全部报告。适用于大图谱提升效率。 |
response_type | str | 指定返回的格式,常见有 "Single Paragraph", "Multiple Paragraphs", "Structured",甚至有 "Markdown"、"Bullet List" 等(依模型配置支持)。 |
query | str | 用户自然语言查询。 |
callbacks | list[QueryCallbacks] | None | 用于调试或中间日志记录,一般用于开发或观察 pipeline 各步骤的输出。 |
verbose | bool | 是否打印详细执行过程日志,默认为 False,调试时可设为 True。 |
response, context = await api.global_search(
config=graphrag_config,
entities=entities,
communities=communities,
community_reports=community_reports,
community_level=2,
dynamic_community_selection=False,
response_type="Multiple Paragraphs",
query="请帮我介绍下谷歌公司。",
)
📌 community_level概念理解:
community_level 表示你希望查询使用 哪一层的社区聚类(Community Clustering)。
GraphRAG 在构建图谱时,通常会使用如 Louvain 或 Leiden 等算法进行 多层次图聚类(Multilevel Graph Clustering)。这会得到一个社区树(community hierarchy),例如:
FENCE0
📌 参数意义:
community_level=1:选择较细粒度的社区community_level=2:选择中等粒度community_level=3:选择较粗粒度community_level=None:表示不限定层级(可配合dynamic_community_selection=True自适应选择)
📌 实际用途示例:
| 场景 | 建议 community_level 设置 |
|---|---|
| 精细问答,例如“谷歌公司在2023年发布了哪些AI产品?” | community_level=1 |
| 概述问答,例如“介绍一下谷歌公司” | community_level=2 或 3 |
| 模型自动决定最相关的粒度 | 设置为 None,并打开 dynamic_community_selection=True |
📌 response_type概念理解:
response_type 控制的是最终 LLM 生成回答的“格式样式”,比如是:
- 纯段落?
- 多段详细回答?
- markdown 格式?
- 结构化 JSON 输出?
它是传递给 Prompt Template / RAG格式控制器 的一个变量。
📌 可选值(以官方实现为例):
| response_type 选项 | 描述 |
|---|---|
"Single Paragraph" | 输出为一段简洁回答 |
"Multiple Paragraphs" | 输出为多段详细分析(推荐用于总结类问题) |
"Bullet List" | 输出为列表结构(适合列举型回答) |
"Markdown" | 格式为 markdown(适合展示给前端) |
"Structured" | 输出为结构化 JSON(开发用) |
"Chain of Thought" | 模拟思考过程的回答格式 |
"Table" | 返回表格(比如对比多个实体) |
📌 注意:实际支持的
response_type类型,取决于GraphRagConfig中定义的 Prompt 模板。部分格式如果 prompt 没设计好,设置了也不会有效果。
📌 示例应用场景:
| 任务 | 建议 response_type |
|---|---|
| 概括谷歌公司的背景信息 | "Multiple Paragraphs" |
| 总结某人履历 | "Bullet List" 或 "Single Paragraph" |
| 提取结构化信息(如公司财务数据) | "Structured" |
| 输出 markdown 给前端展示 | "Markdown" |
| 做选项对比 | "Table" |
总结:如何选择这两个参数?
| 目标 | community_level | response_type |
|---|---|---|
| 查询具体问题,想要更精准的答案 | 1 或 2 | "Single Paragraph" 或 "Bullet List" |
| 查询广义话题,希望有概括性回答 | 2 或 3 | "Multiple Paragraphs" 或 "Markdown" |
| 不确定社区粒度,让模型自动选 | None + dynamic_community_selection=True | 任意 |
| 想要用在程序中提取结构化数据 | 任意 | "Structured" |
display(Markdown(response))
context
context['reports']
- 拒绝回答情况。
response, context = await api.global_search(
config=graphrag_config,
entities=entities,
communities=communities,
community_reports=community_reports,
community_level=2,
dynamic_community_selection=False,
response_type="Multiple Paragraphs",
query="请帮我介绍下DeepSeek模型。",
)
response
- 局部搜索模式
api.local_search?
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
config | GraphRagConfig | ✅ | 图谱配置对象,一般通过 from_config() 加载 settings.yaml。包含模型配置、索引路径、召回策略等。 |
entities | pd.DataFrame | ✅ | 实体表,通常来源于 entities.parquet,包含所有命名实体及其属性,如 ID、名称、所属社区等。 |
communities | pd.DataFrame | ✅ | 社区聚类结构表,来源于 communities.parquet,定义实体之间的社区归属关系及其多层级结构。 |
community_reports | pd.DataFrame | ✅ | 社区摘要表,来源于 community_reports.parquet,为每个社区生成的 title、summary、full_content 等字段。 |
text_units | pd.DataFrame | ✅ | 原始文本段落表,来源于 text_units.parquet,包含切分后的文本块及其关联的实体和社区。局部搜索会从中选择匹配段落。 |
relationships | pd.DataFrame | ✅ | 实体关系图,来源于 relationships.parquet,定义实体间的边和边类型(如“属于”、“引用”、“提到”)。用于辅助聚类和检索判断。 |
covariates | pd.DataFrame | None | ✅(可以为 None) | 协变量(可选),来源于 covariates.parquet,包含实体或段落的额外属性,如时间戳、文档来源、权重等。可用于过滤。 |
community_level | int | ✅ | 指定在哪一层级的社区中进行搜索。值越小表示越细粒度社区(如 level=0 为最细分粒度)。 |
response_type | str | ✅ | 指定回答的返回格式。常见值有: "Single Paragraph", "Multiple Paragraphs", "Bullet List", "Markdown", "Structured" 等(依模型 prompt 支持)。 |
query | str | ✅ | 用户自然语言查询。局部搜索会基于 query 提取相关实体与社区,在其内部执行文本片段召回与问答。 |
callbacks | list[QueryCallbacks] | None | ❌ | 用于观察 GraphRAG 内部处理过程(中间步骤、实体匹配、检索日志等),适合调试使用。 |
verbose | bool | ❌ | 是否输出详细日志信息。设置为 True 可用于调试和观察每一步流程。 |
text_units = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/text_units.parquet")
relationships = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/relationships.parquet")
text_units.head()
relationships.head()
response, context = await api.local_search(
config=graphrag_config,
entities=entities,
communities=communities,
community_reports=community_reports,
text_units=text_units, # ✅ 必填
relationships=relationships, # ✅ 必填
covariates=None, # ✅ 必填
community_level=2, # ✅ 仍可指定层级
response_type="Multiple Paragraphs", # ✅ 保留格式控制
query="苹果公司推出 iPhone 的时间?"
)
response
context['reports']
2. GraphRAG Python基础API调用流程
- Step 1. 基础库导入
import os
from dotenv import load_dotenv
load_dotenv(override=True)
import pandas as pd
import tiktoken
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
from graphrag.query.indexer_adapters import (
read_indexer_covariates,
read_indexer_entities,
read_indexer_relationships,
read_indexer_reports,
read_indexer_text_units,
)
from graphrag.query.question_gen.local_gen import LocalQuestionGen
from graphrag.query.structured_search.local_search.mixed_context import (
LocalSearchMixedContext,
)
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.vector_stores.lancedb import LanceDBVectorStore
from graphrag.config.enums import ModelType
from graphrag.config.models.language_model_config import LanguageModelConfig
from graphrag.language_model.manager import ModelManager
from graphrag.query.indexer_adapters import (
read_indexer_communities,
read_indexer_entities,
read_indexer_reports,
)
from graphrag.query.structured_search.global_search.community_context import (
GlobalCommunityContext,
)
from graphrag.query.structured_search.global_search.search import GlobalSearch
- Step 2.读取知识图谱全部内容
INPUT_DIR = "./graphrag_course/output"
LANCEDB_URI = f"{INPUT_DIR}/lancedb"
COMMUNITY_REPORT_TABLE = "community_reports"
ENTITY_TABLE = "entities"
COMMUNITY_TABLE = "communities"
RELATIONSHIP_TABLE = "relationships"
COVARIATE_TABLE = "covariates"
TEXT_UNIT_TABLE = "text_units"
COMMUNITY_LEVEL = 2
# read nodes table to get community and degree data
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
community_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_TABLE}.parquet")
entities = read_indexer_entities(entity_df, community_df, COMMUNITY_LEVEL)
# load description embeddings to an in-memory lancedb vectorstore
# to connect to a remote db, specify url and port values.
description_embedding_store = LanceDBVectorStore(
collection_name="default-entity-description",
)
description_embedding_store.connect(db_uri=LANCEDB_URI)
print(f"Entity count: {len(entity_df)}")
entity_df.head()
relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")
relationships = read_indexer_relationships(relationship_df)
print(f"Relationship count: {len(relationship_df)}")
relationship_df.head()
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
reports = read_indexer_reports(report_df, community_df, COMMUNITY_LEVEL)
print(f"Report records: {len(report_df)}")
report_df.head()
text_unit_df = pd.read_parquet(f"{INPUT_DIR}/{TEXT_UNIT_TABLE}.parquet")
text_units = read_indexer_text_units(text_unit_df)
print(f"Text unit records: {len(text_unit_df)}")
text_unit_df.head()
- Step 3.设置模型参数

chat_config = LanguageModelConfig(
api_key=api_key,
api_base="https://ai.devtool.tech/proxy/v1",
type=ModelType.OpenAIChat,
model=llm_model,
max_retries=20,
)
token_encoder = tiktoken.encoding_for_model(llm_model)
embedding_config = LanguageModelConfig(
api_key=api_key,
api_base="https://ai.devtool.tech/proxy/v1",
type=ModelType.OpenAIEmbedding,
model=embedding_model,
max_retries=20,
)
chat_model = ModelManager().get_or_create_chat_model(
name="local_search",
model_type=ModelType.OpenAIChat,
config=chat_config,
)
text_embedder = ModelManager().get_or_create_embedding_model(
name="local_search_embedding",
model_type=ModelType.OpenAIEmbedding,
config=embedding_config,
)
- Step 4.创建LocalSearch上下文构建器
context_builder = LocalSearchMixedContext(
community_reports=reports,
text_units=text_units,
entities=entities,
relationships=relationships,
covariates=None,
entity_text_embeddings=description_embedding_store,
embedding_vectorstore_key=EntityVectorStoreKey.ID,
text_embedder=text_embedder,
token_encoder=token_encoder,
)
- Step 5.创建本地搜索引擎参数组
local_context_params = {
"text_unit_prop": 0.5,
"community_prop": 0.1,
"conversation_history_max_turns": 5,
"conversation_history_user_turns_only": True,
"top_k_mapped_entities": 10,
"top_k_relationships": 10,
"include_entity_rank": True,
"include_relationship_weight": True,
"include_community_rank": False,
"return_candidate_context": False,
"embedding_vectorstore_key": EntityVectorStoreKey.ID,
"max_tokens": 12_000,
}
model_params = {
"max_tokens": 2_000,
"temperature": 0.0,
}
search_engine = LocalSearch(
model=chat_model,
context_builder=context_builder,
token_encoder=token_encoder,
model_params=model_params,
context_builder_params=local_context_params,
response_type="multiple paragraphs",
)
result = await search_engine.search("请问苹果公司什么时候发布的iphone?")
print(result.response)
result
result.context_data["entities"].head()
result.context_data["relationships"].head()
result.context_data["sources"].head()
- Step 6.创建全局搜索模型
global_chat_model = ModelManager().get_or_create_chat_model(
name="global_search",
model_type=ModelType.OpenAIChat,
config=chat_config,
)
- Step 7.创建全局搜索参数组
context_builder = GlobalCommunityContext(
community_reports=reports,
communities=communities,
entities=entities, # default to None if you don't want to use community weights for ranking
token_encoder=token_encoder,
)
context_builder_params = {
"use_community_summary": False, # False means using full community reports. True means using community short summaries.
"shuffle_data": True,
"include_community_rank": True,
"min_community_rank": 0,
"community_rank_name": "rank",
"include_community_weight": True,
"community_weight_name": "occurrence weight",
"normalize_community_weight": True,
"max_tokens": 12_000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 5000)
"context_name": "Reports",
}
map_llm_params = {
"max_tokens": 1000,
"temperature": 0.0,
"response_format": {"type": "json_object"},
}
reduce_llm_params = {
"max_tokens": 2000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 1000-1500)
"temperature": 0.0,
}
GlobalSearch?
- Step 8.执行全局搜索
search_engine = GlobalSearch(
model=global_chat_model,
context_builder=context_builder,
token_encoder=token_encoder,
max_data_tokens=12_000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 5000)
map_llm_params=map_llm_params,
reduce_llm_params=reduce_llm_params,
allow_general_knowledge=False, # set this to True will add instruction to encourage the LLM to incorporate general knowledge in the response, which may increase hallucinations, but could be useful in some use cases.
json_mode=True, # set this to False if your LLM model does not support JSON mode.
context_builder_params=context_builder_params,
concurrent_coroutines=32,
response_type="multiple paragraphs", # free form text describing the response type and format, can be anything, e.g. prioritized list, single paragraph, multiple paragraphs, multiple-page report
)
result = await search_engine.search("请帮我介绍下谷歌公司的核心产品。")
result.response
# inspect the data used to build the context for the LLM responses
result.context_data["reports"]
# inspect number of LLM calls and tokens
print(
f"LLM calls: {result.llm_calls}. Prompt tokens: {result.prompt_tokens}. Output tokens: {result.output_tokens}."
)
unrel_result = await search_engine.search("你知道DeepSeek这个模型么?")
unrel_result.response
search_engine = GlobalSearch(
model=global_chat_model,
context_builder=context_builder,
token_encoder=token_encoder,
max_data_tokens=12_000, # change this based on the token limit you have on your model (if you are using a model with 8k limit, a good setting could be 5000)
map_llm_params=map_llm_params,
reduce_llm_params=reduce_llm_params,
allow_general_knowledge=True, # set this to True will add instruction to encourage the LLM to incorporate general knowledge in the response, which may increase hallucinations, but could be useful in some use cases.
json_mode=True, # set this to False if your LLM model does not support JSON mode.
context_builder_params=context_builder_params,
concurrent_coroutines=32,
response_type="multiple paragraphs", # free form text describing the response type and format, can be anything, e.g. prioritized list, single paragraph, multiple paragraphs, multiple-page report
)
unrel_result = await search_engine.search("你知道DeepSeek这个模型么?")
unrel_result.response
二、从零到一构建GraphRAG完整项目
Microsoft GraphRAG 的Query 一共实现了四个检索方法,分别是local_search、global_search、drift 和basic。其中local_search 和global_search 检索的底层原理我们在公开课中都有详细的介绍,其中Local Search 是基于实体的检索,Global Search 是基于社区的检索。
在实现了Index 和Query 流程的Python 接口后,其实就可以基于一些Python 框架,实现RESTful API 接口的封装,从而提供后端的服务与前端进行对接。这里我们选择FastAPI 框架,来介绍如何实现RESTful API 接口的封装。
在graphrag_course 目录下已经实现了一个app.py 文件,该文件中已经实现了Query 流程的Python 的外部接口封装,如下所示:
FENCE0
存储位置如下:
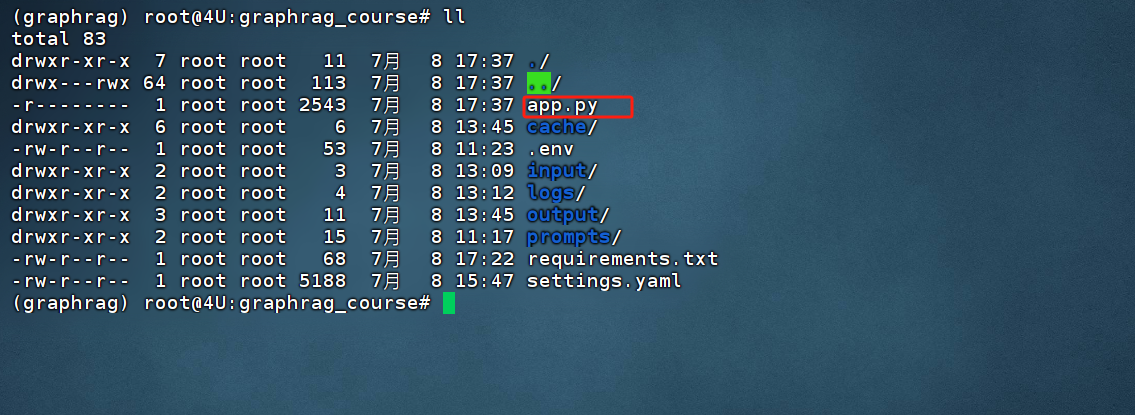
这里我们使用FastAPI 框架,实现一个GraphRAG 的Query 接口,并使用Uvicorn 启动服务。因此,需要先安装requirements.txt 中的依赖。执行如下代码:
FENCE0
安装完依赖后,便可启动服务。这个代码中只有一个地方需要大家根据自己的实际情况进行修改,即通过 --host 和 --port 参数指定服务启动的地址和端口。这里我的服务器地址是192.168.110.131,所以执行代码如下:
FENCE0

成功启动后,即可在浏览器中访问http://192.168.110.131:8000/docs 查看GraphRAG 的Query 接口文档。
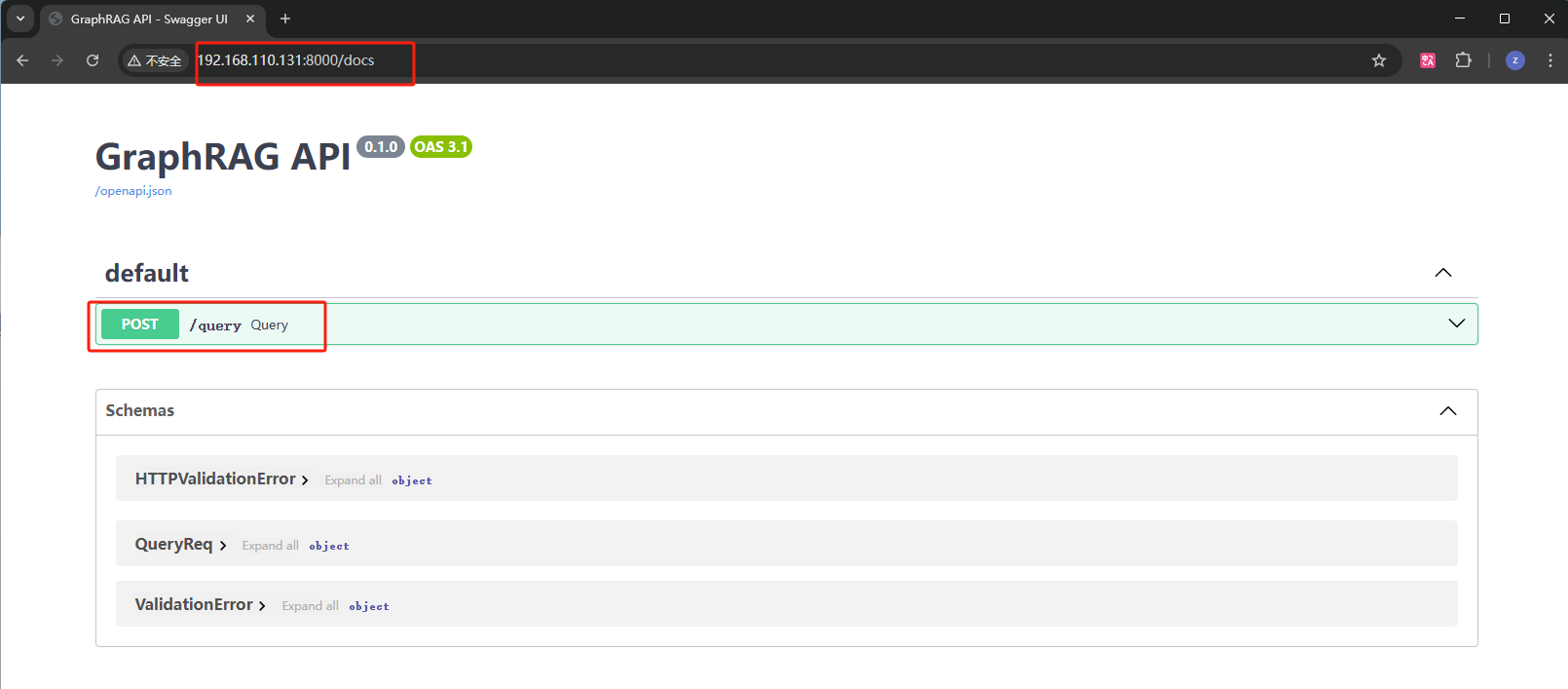
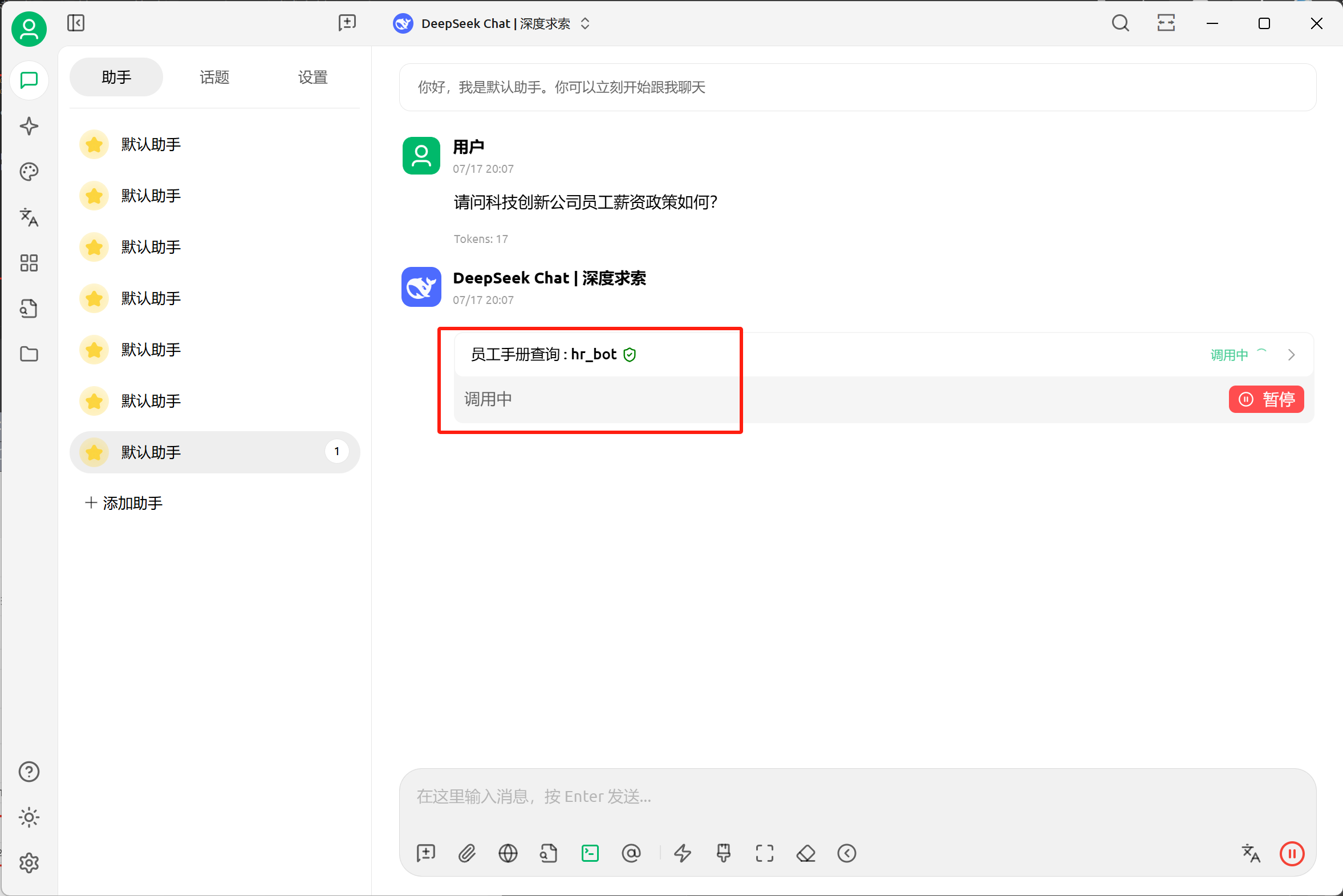
这里我们使用local 方法进行检索测试,即基于本地知识库的检索。点击query 接口,在点击Try it out 按钮,输入query 参数,点击Execute 按钮,即可进行接口请求:
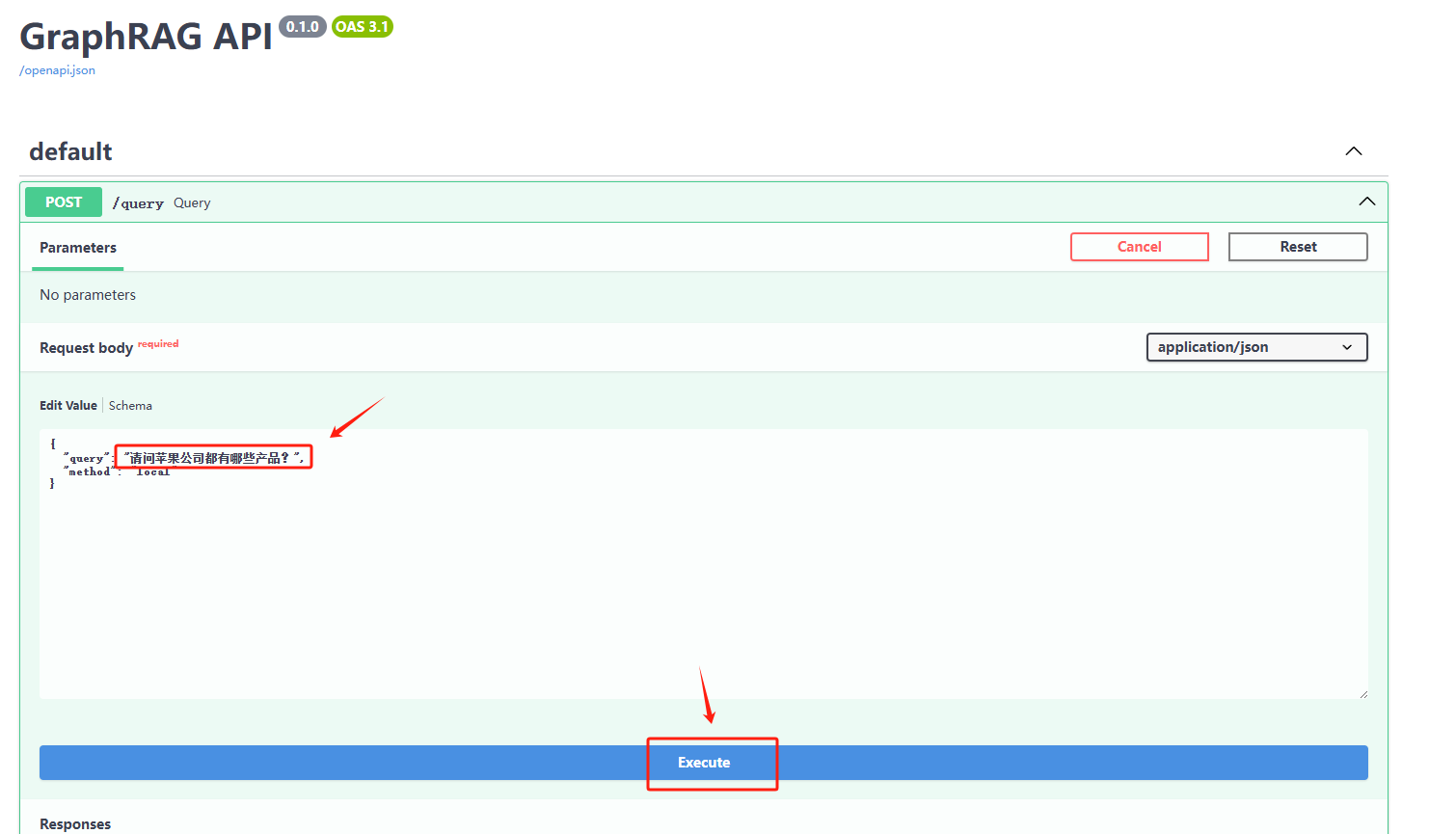
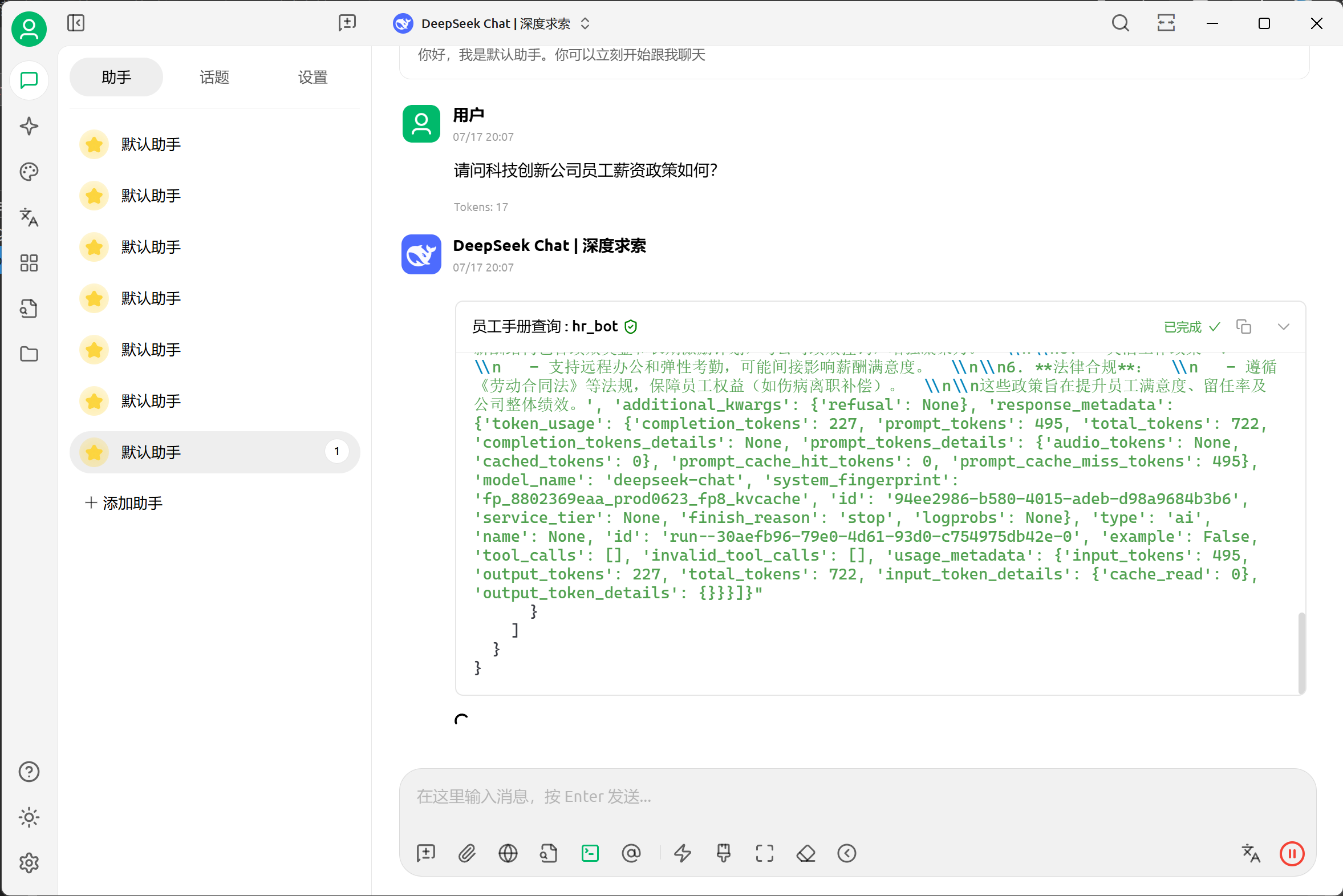
后端服务GraphRAG接收到请求会开始进行检索,检索完成后,会返回检索结果。
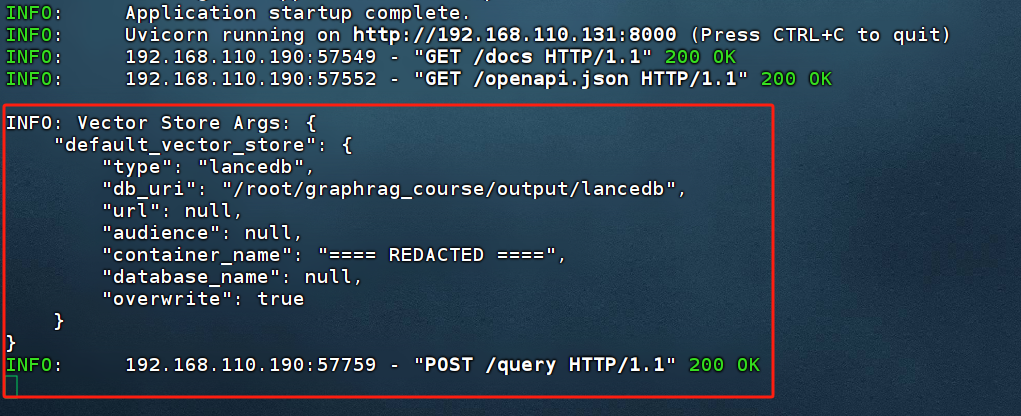
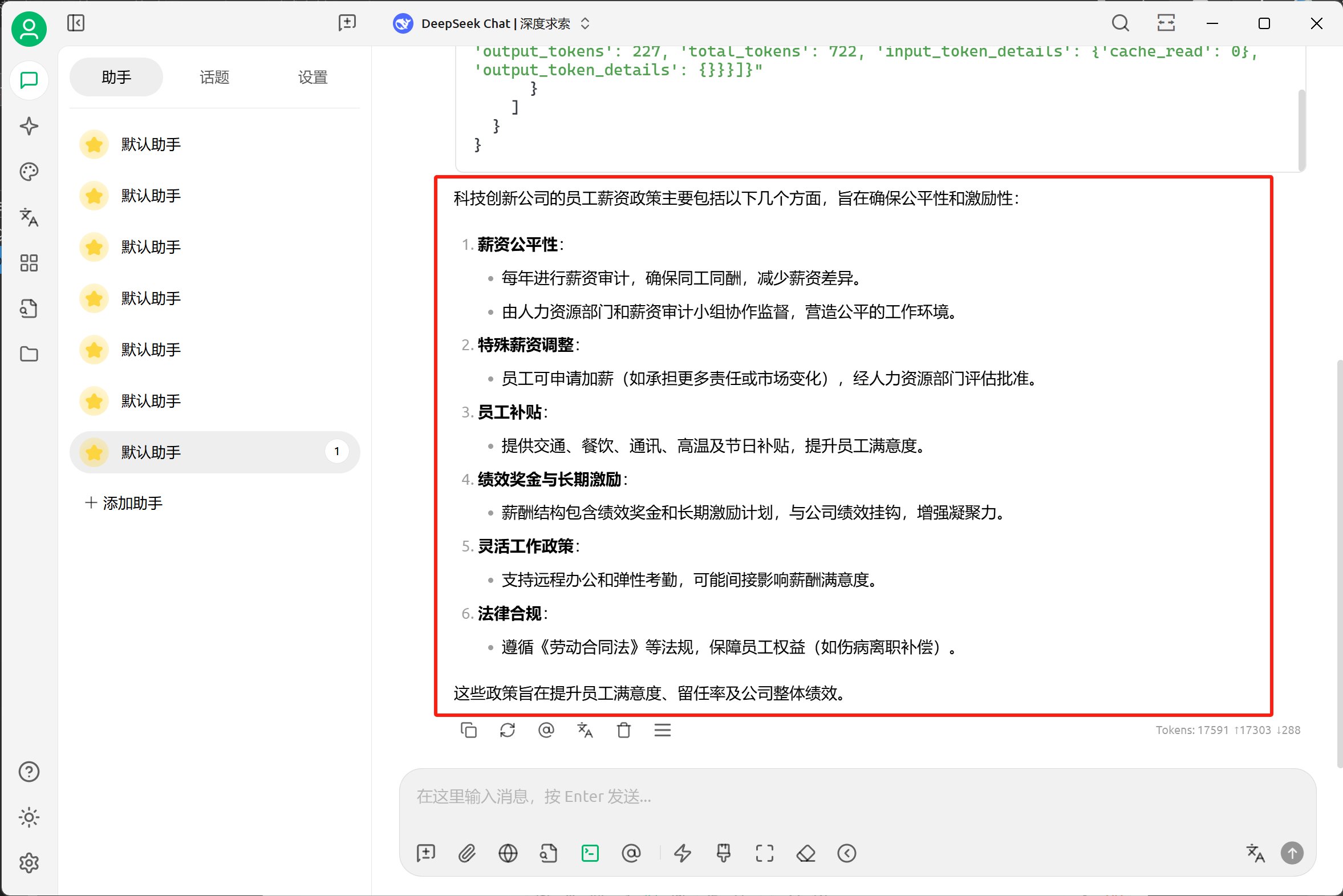
最后,在Swagger 界面中可以实时看到请求的响应状态,以及最终的回复。
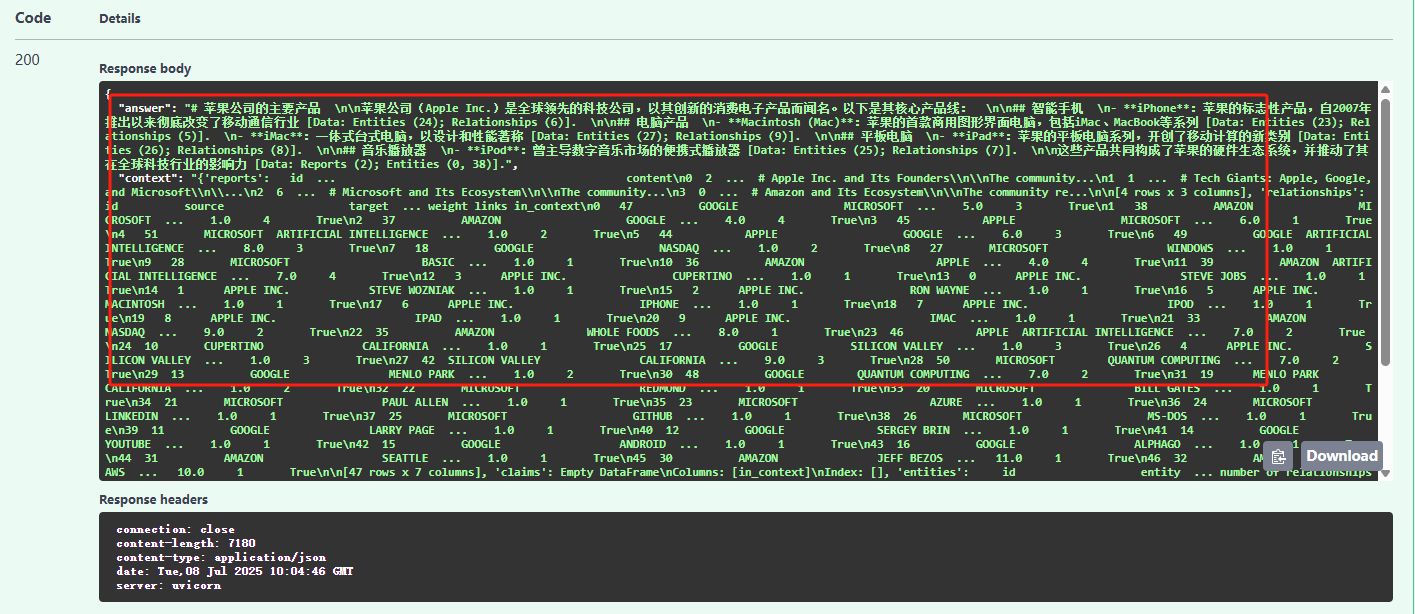
至此,我们便完成了GraphRAG 的Query 接口的实现。
当然,我们可以在这个基础上进一步实现一个交互式的精美前端页面用来展示。首先,我们需要创建一个index.html 文件,用于展示前端页面,并存储static 目录下。结构如下:
graphrag_course/
│── app.py # FastAPI 后端服务
│── settings.yaml # GraphRAG 配置
│── .env # OPENAI_API_KEY 等
│── output/… # graphrag index 生成的 Parquet
│── static/
│ ├── index.html # 前段的展示页面
  然后,修改`app.py` 文件,添加一个路由加载`index.html` 文件,同时通过`/`重定向该`index.html` 文件。
```python
# app.py (放在 /root/graphrag_course/)
from pathlib import Path
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
import graphrag.api as gr_api
from graphrag.config.load_config import load_config
from graphrag.storage.file_pipeline_storage import FilePipelineStorage
from graphrag.utils.storage import load_table_from_storage
import asyncio
import logging, traceback
from fastapi.responses import FileResponse
from fastapi.staticfiles import StaticFiles
ROOT = Path(".") # settings.yaml 所在目录
CFG = load_config(ROOT)
STORE = FilePipelineStorage(ROOT / CFG.output.base_dir)
app = FastAPI(title="GraphRAG API")
from graphrag.utils.storage import load_table_from_storage, storage_has_table
@app.on_event("startup")
async def preload():
global ENTITIES, TEXT_UNITS, COMMUNITIES, COMMUNITY_REP, RELATIONSHIPS, COVARIATES
ENTITIES = await load_table_from_storage("entities", STORE)
TEXT_UNITS = await load_table_from_storage("text_units", STORE)
COMMUNITIES = await load_table_from_storage("communities", STORE)
COMMUNITY_REP = await load_table_from_storage("community_reports", STORE)
RELATIONSHIPS = await load_table_from_storage("relationships", STORE)
# <- 新写法:先判断再加载
if await storage_has_table("covariates", STORE):
COVARIATES = await load_table_from_storage("covariates", STORE)
else:
COVARIATES = None # 或者 pd.DataFrame()
class QueryReq(BaseModel):
query: str = Field(..., description="用户问题")
method: str = Field("local", description="local | global | drift | basic")
BASE_DIR = Path(__file__).parent
app.mount("/static", StaticFiles(directory=BASE_DIR / "static"), name="static") # 这里添加静态文件挂载
@app.get("/", include_in_schema=False)
async def root():
# 直接返回文件
return FileResponse(BASE_DIR / "static" / "index.html", media_type="text/html") # 重定向
@app.post("/query")
async def query(req: QueryReq):
try:
if req.method == "local":
resp, ctx = await gr_api.local_search(
config=CFG,
entities=ENTITIES,
communities=COMMUNITIES,
community_reports=COMMUNITY_REP,
text_units=TEXT_UNITS,
relationships=RELATIONSHIPS,
covariates=COVARIATES,
query=req.query, # 用户问题
community_level=1, # 0=实体级, 1=社区级, 2=跨社区
response_type="text", # 或 "json" / 自定义描述
)
elif req.method == "global":
resp, ctx = await gr_api.global_search(
config=CFG,
entities=ENTITIES,
communities=COMMUNITIES,
community_reports=COMMUNITY_REP,
query=req.query,
)
else:
raise HTTPException(400, f"不支持的 method={req.method}")
return {"answer": resp, "context": str(ctx)}
except Exception as e:
logging.exception("GraphRAG 查询失败") # ← 打印完整回溯
raise HTTPException(500, str(e))
  接下来正常启动`app.py` 文件,通过`ip + port` 即可访问。
FENCE0
<div align=center><img src="https://muyu20241105.oss-cn-beijing.aliyuncs.com/images/202507081847669.png" width=80% /></div>
  启动成功后,直接在浏览器中访问`http://192.168.110.131:8000/`,即可进入前端页面进行交互式问答:
<div align=center><img src="https://muyu20241105.oss-cn-beijing.aliyuncs.com/images/202507081847670.png" width=80% /></div>
```python
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/GraphRAG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
三、借助LangChain搭建GraphRAG检索系统
1. 基础环境搭建
- 创建项目主目录:LangChain_GraphRAG/staff_handbook
- 数据集准备
- 初始化GraphRAG项目
FENCE0
- 上传数据集
FENCE0
- 修改GraphRAG项目配置
打开.env文件,填写OpenAI API-KEY或其他任意模型的API-KEY
打开setting.yaml文件,填写模型名称和反向代理地址:
其中反向代理地址为api_base: https://ai.devtool.tech/proxy/v1
- 进行索引
FENCE0
- 完整项目领取
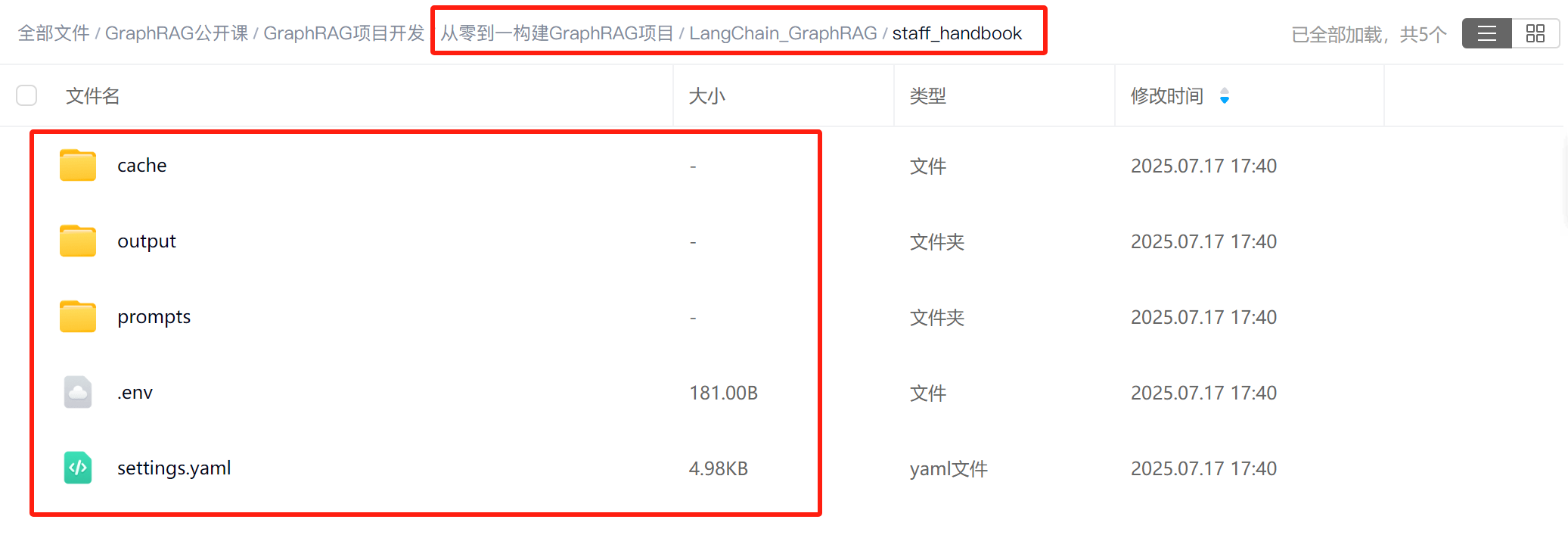
2. 创建基于GraphRAG的知识库检索问答智能体
2.1 LangChain&LangGraph环境准备

- 基础环境安装:
# !pip install pydantic python-dotenv langgraph langchain-core langchain-deepseek langsmith langchain-openai langchain-text-splitters langchain-communityfaiss-cpu
- 设置环境变量:
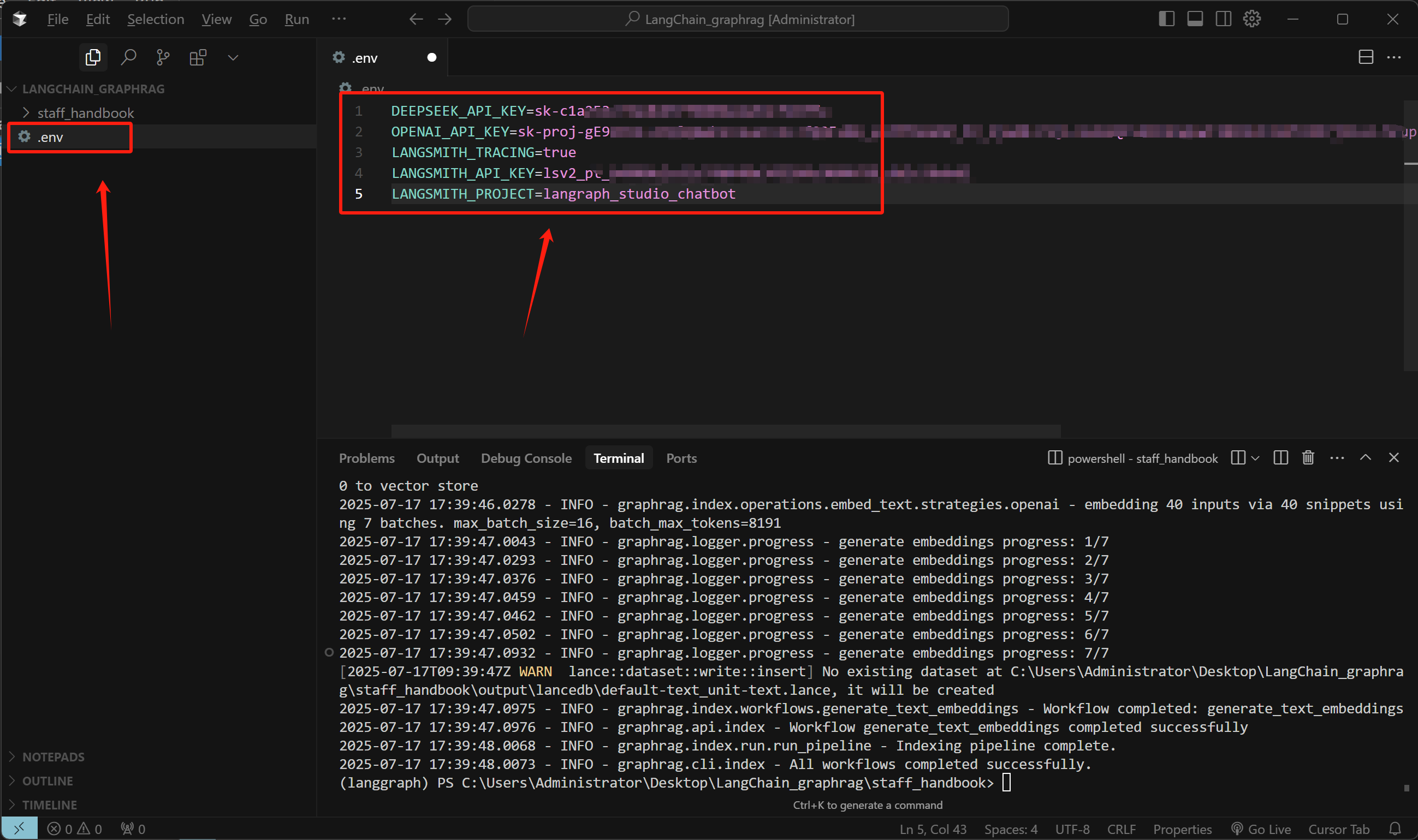
DEEPSEEK_API_KEY=sk-c****
OPENAI_API_KEY=sk-pro-****
LANGSMITH_TRACING=true
LANGSMITH_API_KEY=lsv2_pt_b***
LANGSMITH_PROJECT=langraph_studio_chatbot
2.2 创建基于LangGraph的GraphRAG问答智能体
- 导入基础依赖
from __future__ import annotations
import os
import asyncio
from pathlib import Path
from typing import Literal, Dict, Any
import pandas as pd
from langchain.chat_models import init_chat_model
from langchain.schema import BaseMessage
from langchain.tools import BaseTool
from langchain.tools import tool
from langgraph.graph import MessagesState, StateGraph, START, END
from langgraph.prebuilt import ToolNode, tools_condition
from pydantic import BaseModel, Field
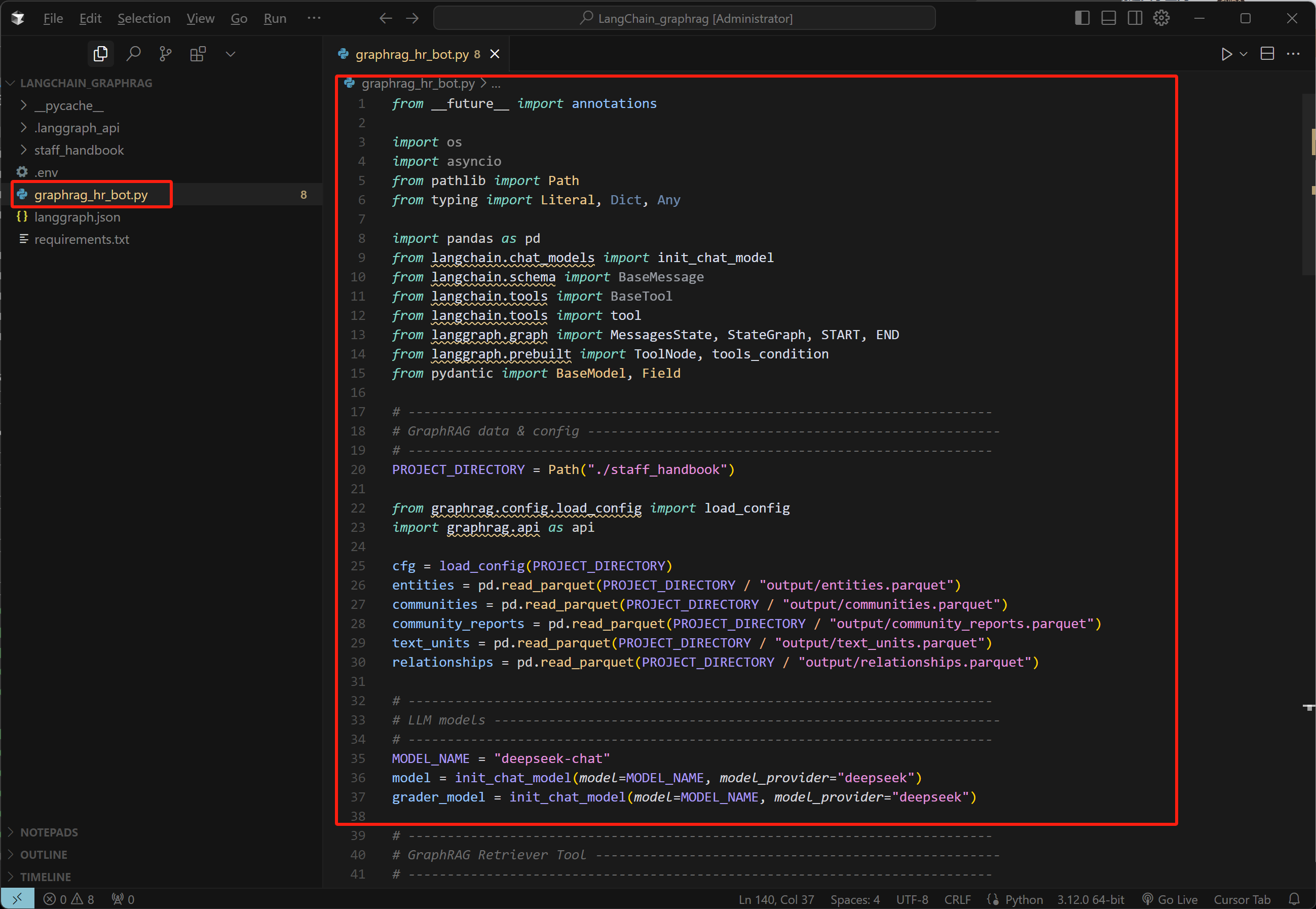
- 设置Agent基座模型
MODEL_NAME = "deepseek-chat"
model = init_chat_model(model=MODEL_NAME, model_provider="deepseek", temperature=0)
grader_model = init_chat_model(model=MODEL_NAME, model_provider="deepseek", temperature=0)
- 导入GraphRAG配置
PROJECT_DIRECTORY = Path("./staff_handbook")
from graphrag.config.load_config import load_config
import graphrag.api as graphrag
cfg = load_config(PROJECT_DIRECTORY)
entities = pd.read_parquet(PROJECT_DIRECTORY / "output/entities.parquet")
communities = pd.read_parquet(PROJECT_DIRECTORY / "output/communities.parquet")
community_reports = pd.read_parquet(PROJECT_DIRECTORY / "output/community_reports.parquet")
text_units = pd.read_parquet(PROJECT_DIRECTORY / "output/text_units.parquet")
relationships = pd.read_parquet(PROJECT_DIRECTORY / "output/relationships.parquet")
- 创建GraphRAG检索函数
# ---------------------------------------------------------------------------
# GraphRAG Retriever Tool ----------------------------------------------------
# ---------------------------------------------------------------------------
@tool
async def graphrag_search(query: str) -> str:
"""
调用GraphRAG进行知识库检索,根据query检索相关有用内容。
"""
response, _ = await api.global_search(
config=cfg,
entities=entities,
communities=communities,
community_reports=community_reports,
community_level=2,
dynamic_community_selection=False,
response_type="Multiple Paragraphs",
query=query,
)
return response
- 创建提示词
SYSTEM_INSTRUCTION = (
"You are an HR‑policy assistant. Answer ONLY questions related to HR policies, benefits, leave, "
"performance evaluation, recruiting, onboarding, etc. If the user question is NOT related to HR, "
"reply exactly: '我不能回答与 HR 政策无关的问题。' You may call the provided tool "
"`graphrag_search` when additional context from the staff handbook is required."
)
你是一名人力资源政策助手。仅回答与人力资源相关的问题,包括政策、福利、请假、绩效评估、招聘、入职等内容。 如果用户的问题与 HR 无关,请严格回复:“我不能回答与 HR 政策无关的问题。” 当需要额外参考员工手册内容时,你可以调用提供的工具 graphrag_search 进行检索。
GRADE_PROMPT = (
"You are a grader assessing relevance of a retrieved document to a user question.\n"
"Retrieved document:\n{context}\n\nUser question: {question}\nReturn 'yes' if relevant, otherwise 'no'."
)
你是一名评估员,负责判断某段检索到的文档是否与用户的问题相关。
REWRITE_PROMPT = (
"Analyze the underlying intent of the question and rewrite it to improve recall.\n"
"Original question:\n{question}\nImproved question:"
)
请你分析用户问题背后的潜在意图,并对其进行改写以提升召回率。
ANSWER_PROMPT = (
"You are an assistant for question‑answering tasks. "
"If unsure say you don't know.\nQuestion: {question}\nContext: {context}"
)
你是一名问答助手。请结合提供的上下文信息,请以尽量详细准确的方式回答用户。
- 创建图节点
async def generate_query_or_respond(state: MessagesState):
"""LLM decides to answer directly or call GraphRAG tool."""
response = await model.bind_tools([retriever_tool]).ainvoke(
[{"role": "system", "content": SYSTEM_INSTRUCTION}, *state["messages"]]
)
return {"messages": [response]}
class GradeDoc(BaseModel):
binary_score: str = Field(description="Relevance score 'yes' or 'no'.")
async def grade_documents(state: MessagesState) -> Literal["generate_answer", "rewrite_question"]:
question = state["messages"][0].content
ctx = state["messages"][-1].content
prompt = GRADE_PROMPT.format(question=question, context=ctx)
res = await grader_model.with_structured_output(GradeDoc).ainvoke([
{"role": "user", "content": prompt}
])
return "generate_answer" if res.binary_score.lower().startswith("y") else "rewrite_question"
async def rewrite_question(state: MessagesState):
question = state["messages"][0].content
resp = await model.ainvoke([
{"role": "user", "content": REWRITE_PROMPT.format(question=question)}
])
return {"messages": [{"role": "user", "content": resp.content}]}
async def generate_answer(state: MessagesState):
question = state["messages"][0].content
ctx = state["messages"][-1].content
resp = await model.ainvoke([
{"role": "user", "content": ANSWER_PROMPT.format(question=question, context=ctx)}
])
return {"messages": [resp]}
workflow = StateGraph(MessagesState)
workflow.add_node("generate_query_or_respond", generate_query_or_respond)
workflow.add_node("retrieve", ToolNode([graphrag_search]))
workflow.add_node("rewrite_question", rewrite_question)
workflow.add_node("generate_answer", generate_answer)
workflow.add_edge(START, "generate_query_or_respond")
workflow.add_conditional_edges("generate_query_or_respond", tools_condition, {"tools": "retrieve", END: END})
workflow.add_conditional_edges("retrieve", grade_documents)
workflow.add_edge("generate_answer", END)
workflow.add_edge("rewrite_question", "generate_query_or_respond")
graphrag_hr_bot = workflow.compile()
完整代码解释如下:
🔧 一、整体结构概览
这个 HR 智能体包含以下五个关键模块:
| 模块名称 | 功能描述 |
|---|---|
| GraphRAG 数据加载 | 加载 Parquet 格式的图数据,为全图搜索做准备 |
| LLM 初始化 | 初始化主模型和评分模型 |
| LangChain Tool 封装 | 将 GraphRAG 检索逻辑封装为异步可调用工具 |
| 各节点函数定义 | 构建四个异步节点(提问/检索/评分/改写) |
| LangGraph 工作流编排 | 构建五节点图结构,连接状态转换逻辑 |
📁 二、模块详解
1️⃣ GraphRAG 数据加载部分
FENCE0
- 用于加载 GraphRAG 构建好的知识图谱数据,这些
.parquet文件通常由 GraphRAG 的索引构建流程生成。 - 涉及的实体包括实体、社区、社区报告、文本单元和关系等。
2️⃣ LLM 初始化部分
FENCE1
-
使用
deepseek-chat初始化两个模型:model:主助手模型,用于回答问题、工具调用、改写问题;grader_model:评估模型,用于判断检索内容是否相关。
3️⃣ Tool 封装部分:异步 GraphRAG 检索工具
FENCE2
- 通过
@tool装饰器,将异步的graphrag_search()注册为 LangChain Tool,可供 LLM function calling 使用。 - 内部调用
api.global_search()实现多段文本召回。
✅ 亮点: 这是 LangGraph 推荐方式之一,可以直接将异步函数暴露为工具,并被 LangGraph 的 ToolNode 所识别。
4️⃣ 四个 LangGraph 节点函数
| 节点名称 | 逻辑说明 |
|---|
✅ generate_query_or_respond
FENCE3
- 利用 LLM 判断用户是否需要调用工具;
- 如果需要,函数会返回一个
tool_call对象,LangGraph 自动跳转到 ToolNode。
✅ grade_documents
FENCE4
- LLM 根据
context + question判断当前内容是否与问题相关; - 若相关 → 跳转生成答案,否则 → 重写问题。
✅ rewrite_question
FENCE5
- 针对召回失败的问题重新改写,提高召回率;
- 改写后会再次返回“user”消息,从而回到
generate_query_or_respond重新处理。
✅ generate_answer
FENCE6
- 使用
context + question生成最终答案。
5️⃣ LangGraph 工作流编排
FENCE7
-
节点添加: 添加四个节点 + 一个 ToolNode
-
路径控制:
- 首节点:
START → generate_query_or_respond - 若调用工具:自动转到
ToolNode - 工具调用完 →
grade_documents→ 分流判断 - 若不调用工具:直接结束
- 首节点:
-
循环机制:
rewrite_question → generate_query_or_respond实现自适应闭环
✅ 最终效果
一个完整的 HR 智能体运行流程如下:
FENCE8
- 支持 自动调用工具 进行文档检索;
- 若文档不相关,自动 改写问题再次尝试;
- 若相关则生成高质量答案;
- 支持 多轮闭环优化。
- 写入代码脚本
在项目主目录下,新建一个langgraph.json文件,在该json文件中配置项目信息,遵循规范如下所示:
- 必须包含
dependencies和graphs字段 graphs字段格式:"图名": "文件路径:变量名"- 配置文件必须放在与Python文件同级或更高级的目录
注意: 项目文件的名称必须为langgraph.json。如下所示:
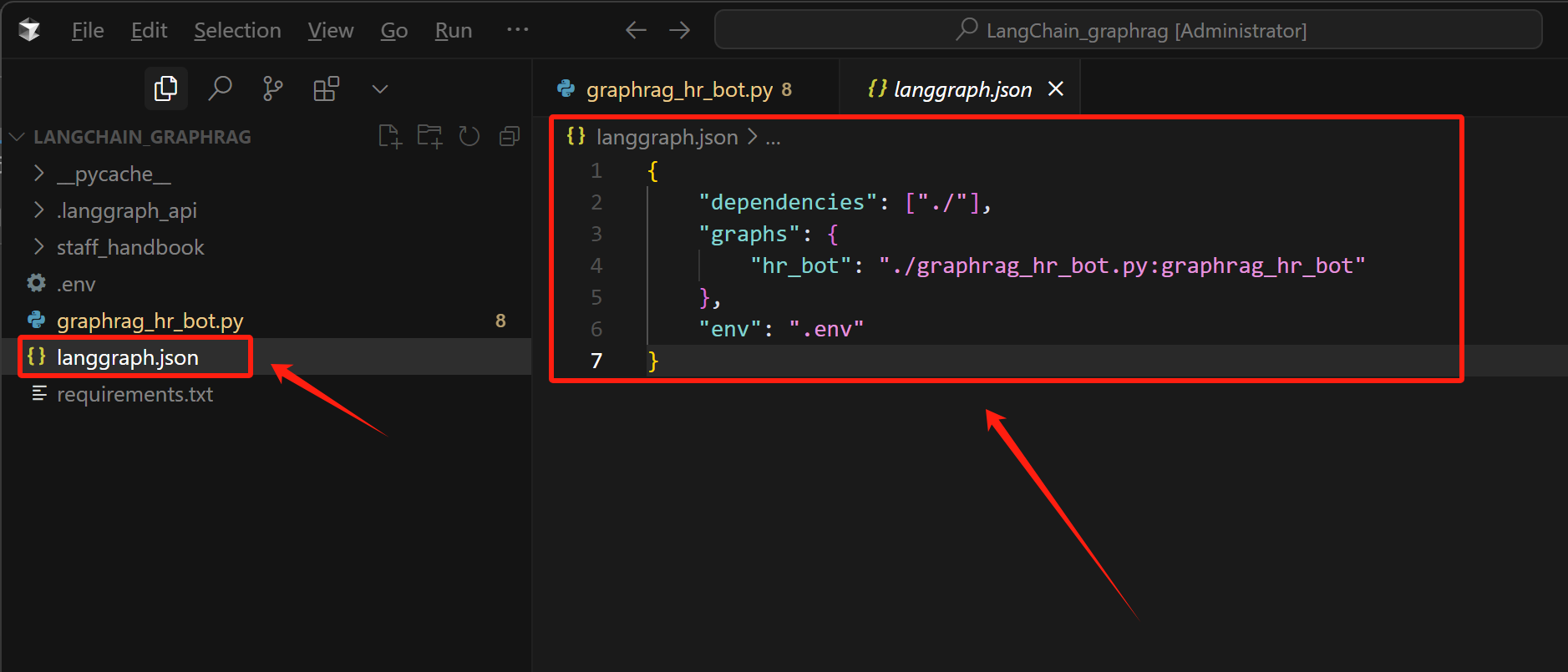
FENCE0
- 安装langgraph cli开发工具
然后,安装langgraph-cli依赖,执行如下代码:
FENCE0
- 编写项目依赖文件
在项目文件夹中,新建一个requirements.txt文件,里面需要填写在运行该项目时需要安装的依赖项,如下所示:
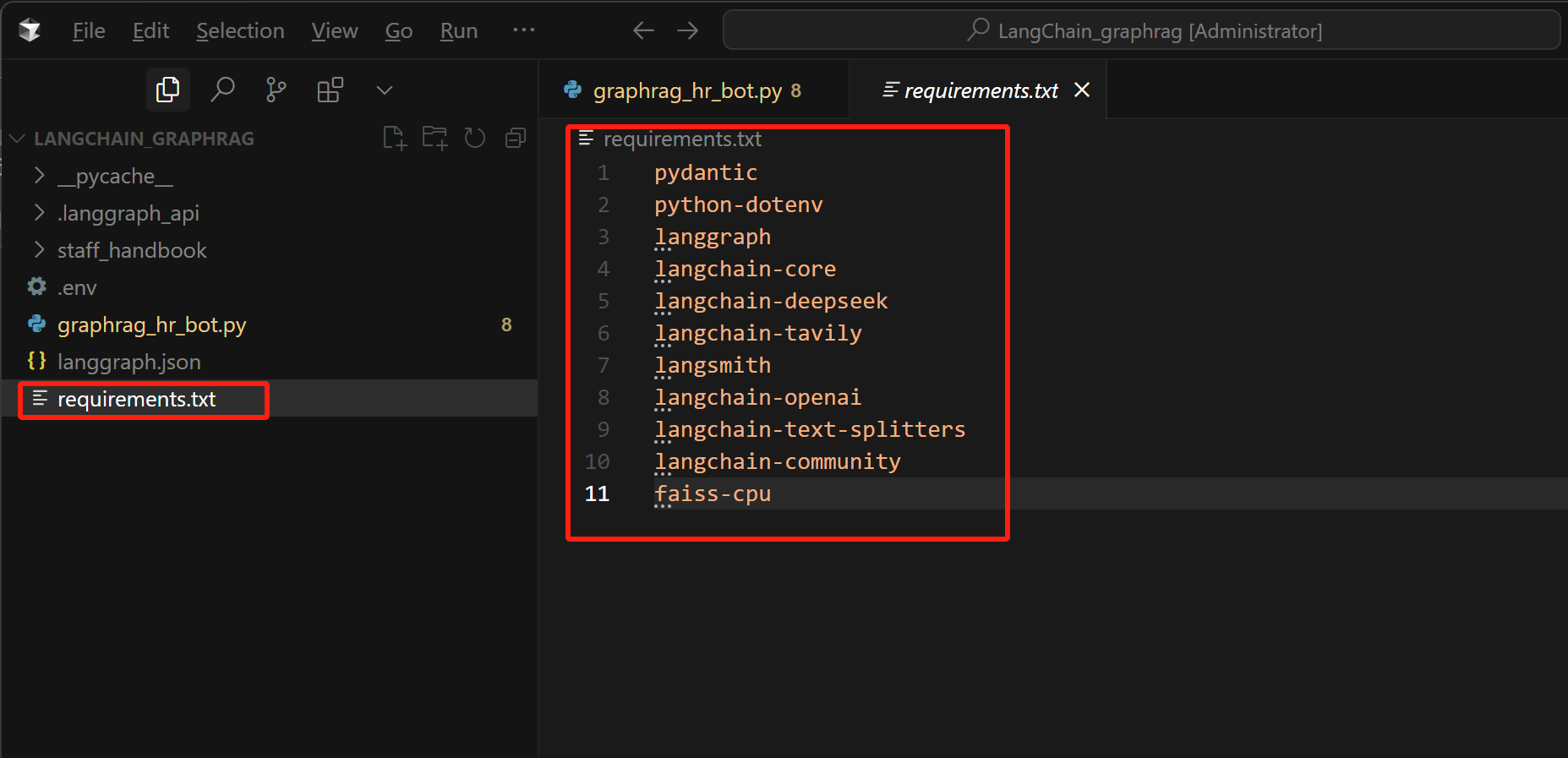
FENCE0
- 启动项目
FENCE0
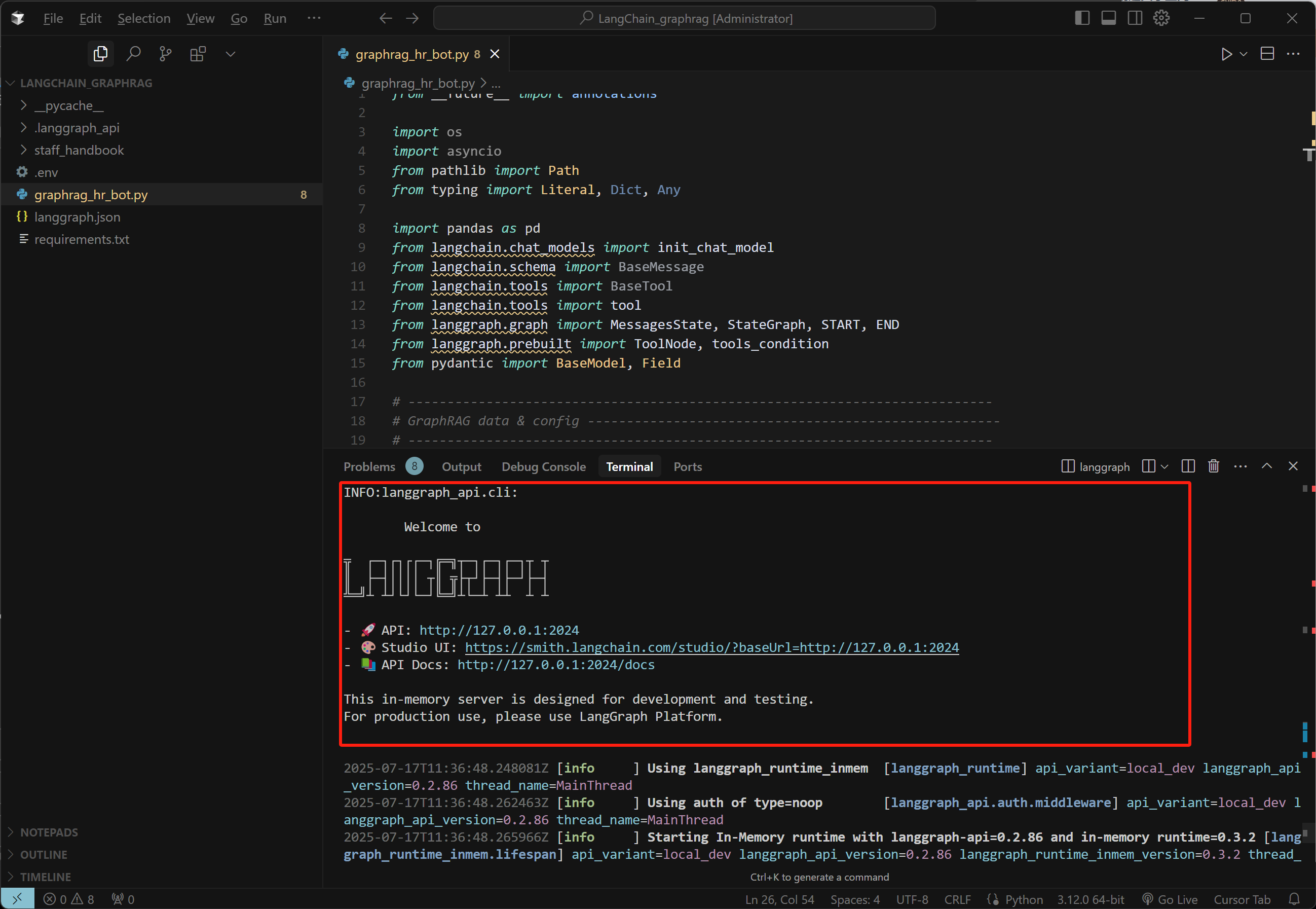
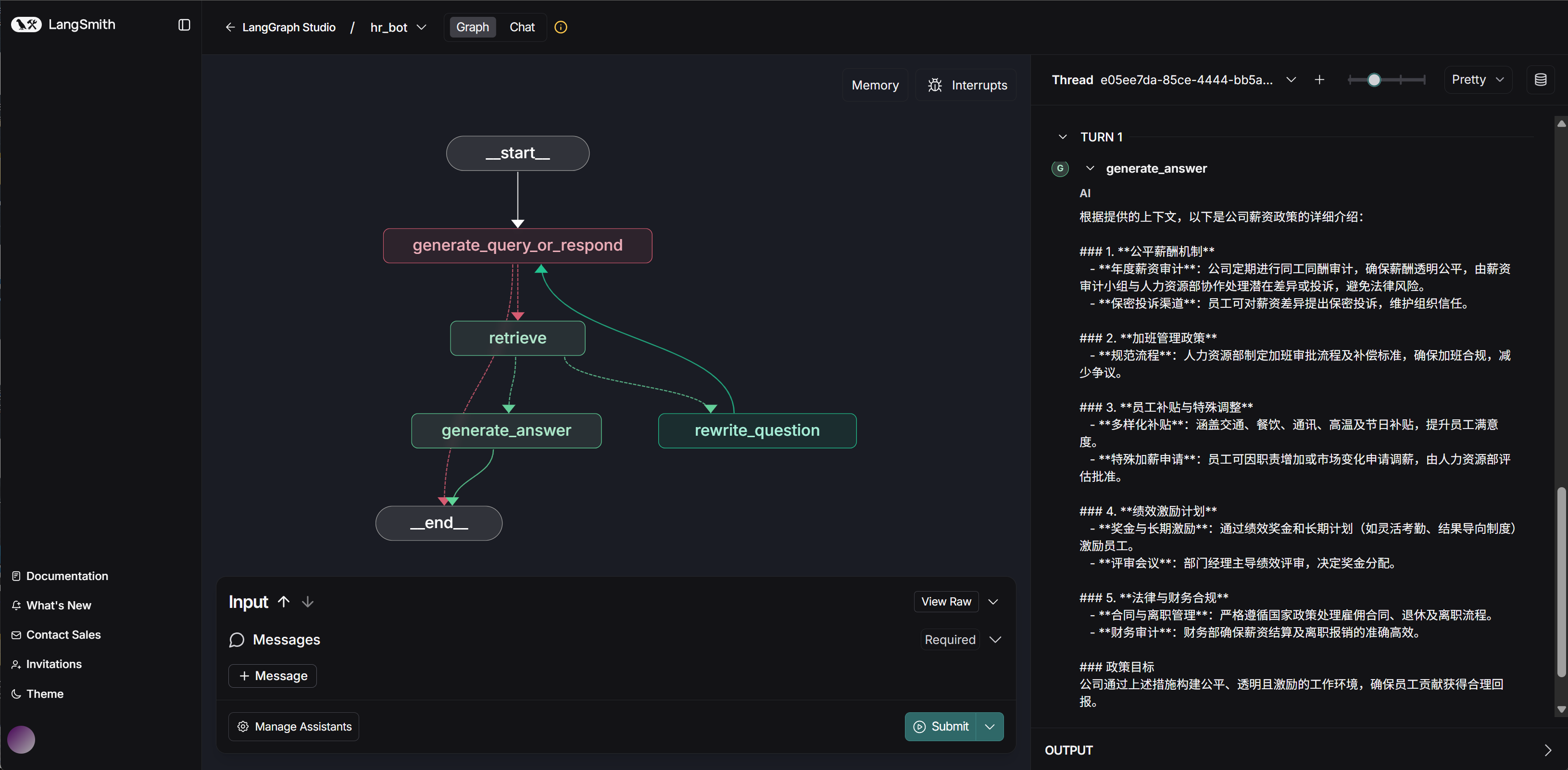
进入:https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024 ,即可查看当前问答系统完整架构:
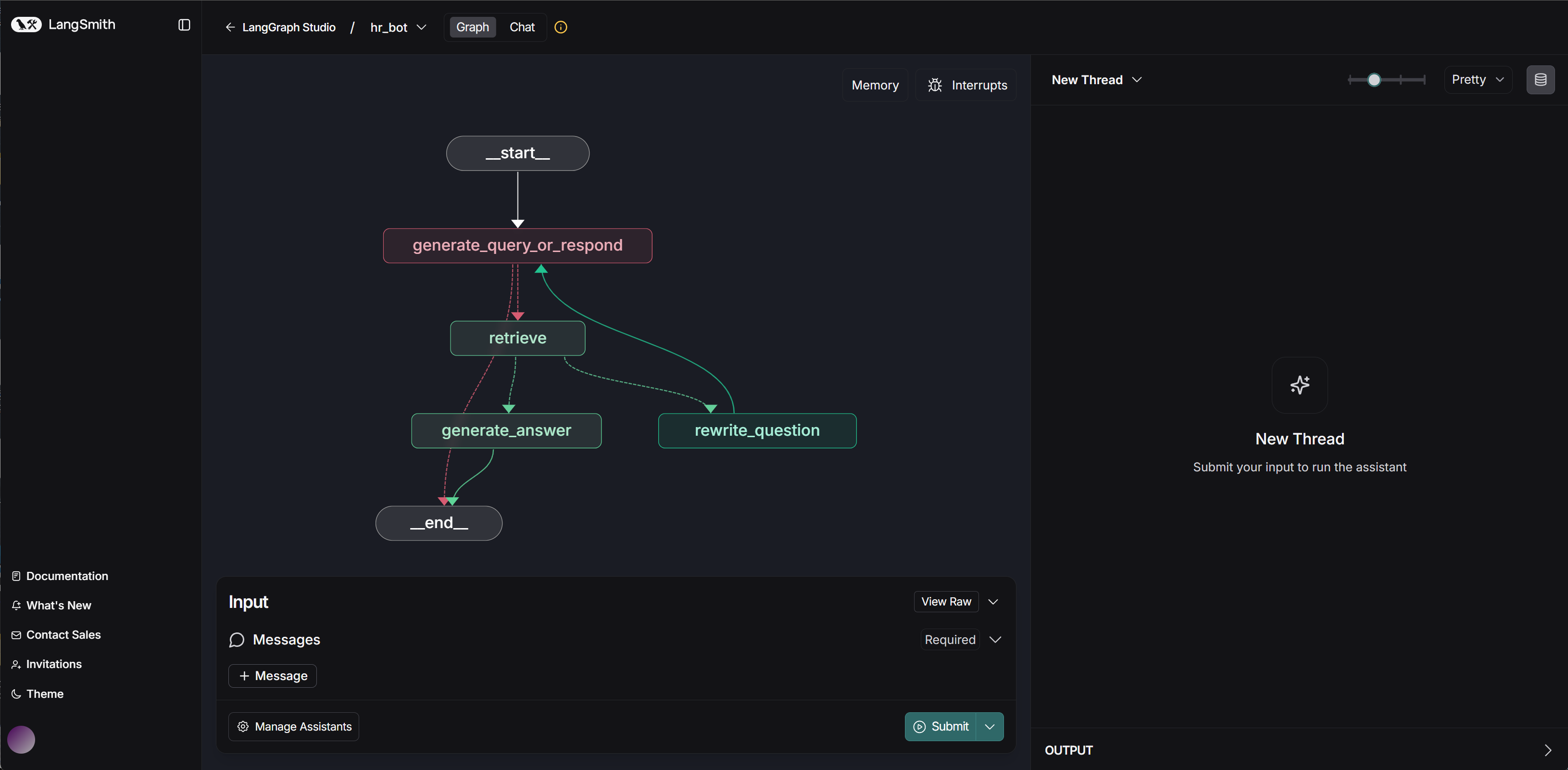
然后即可开始进行提问测试:
2.3 接入Agent Chat UI前端
FENCE0
FENCE0
FENCE0
FENCE0
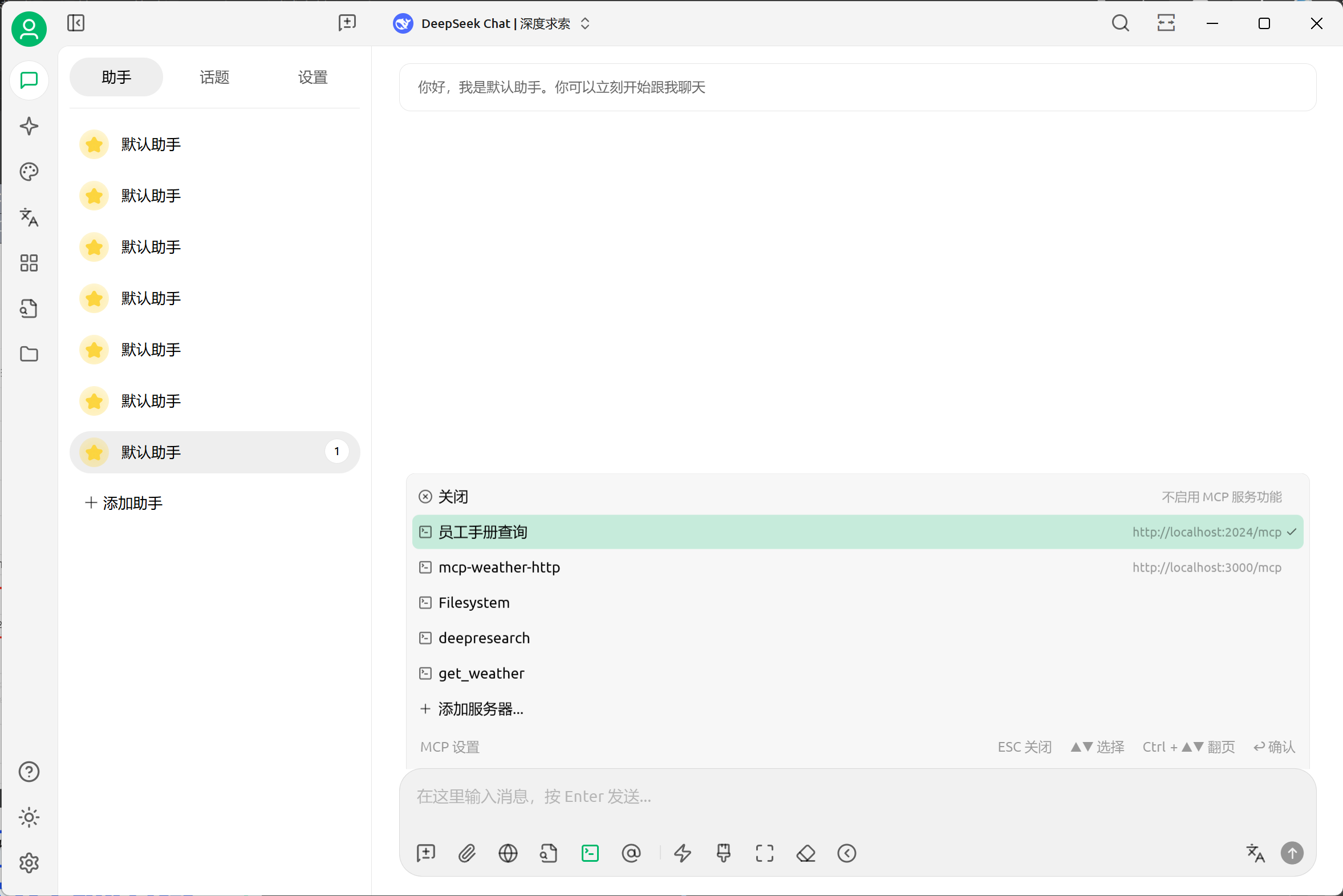
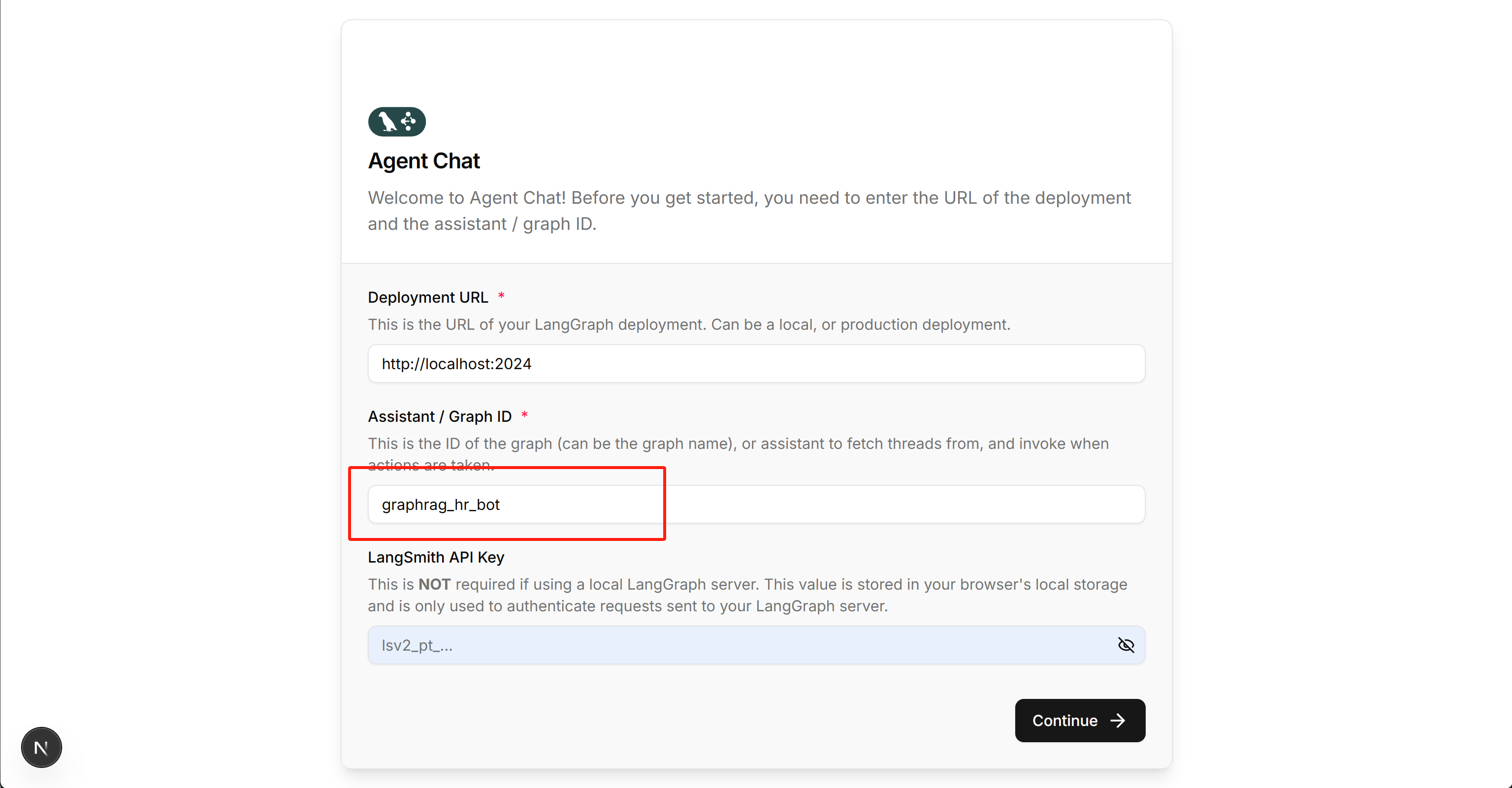
然后在http://localhost:3000/ 即可开启对话
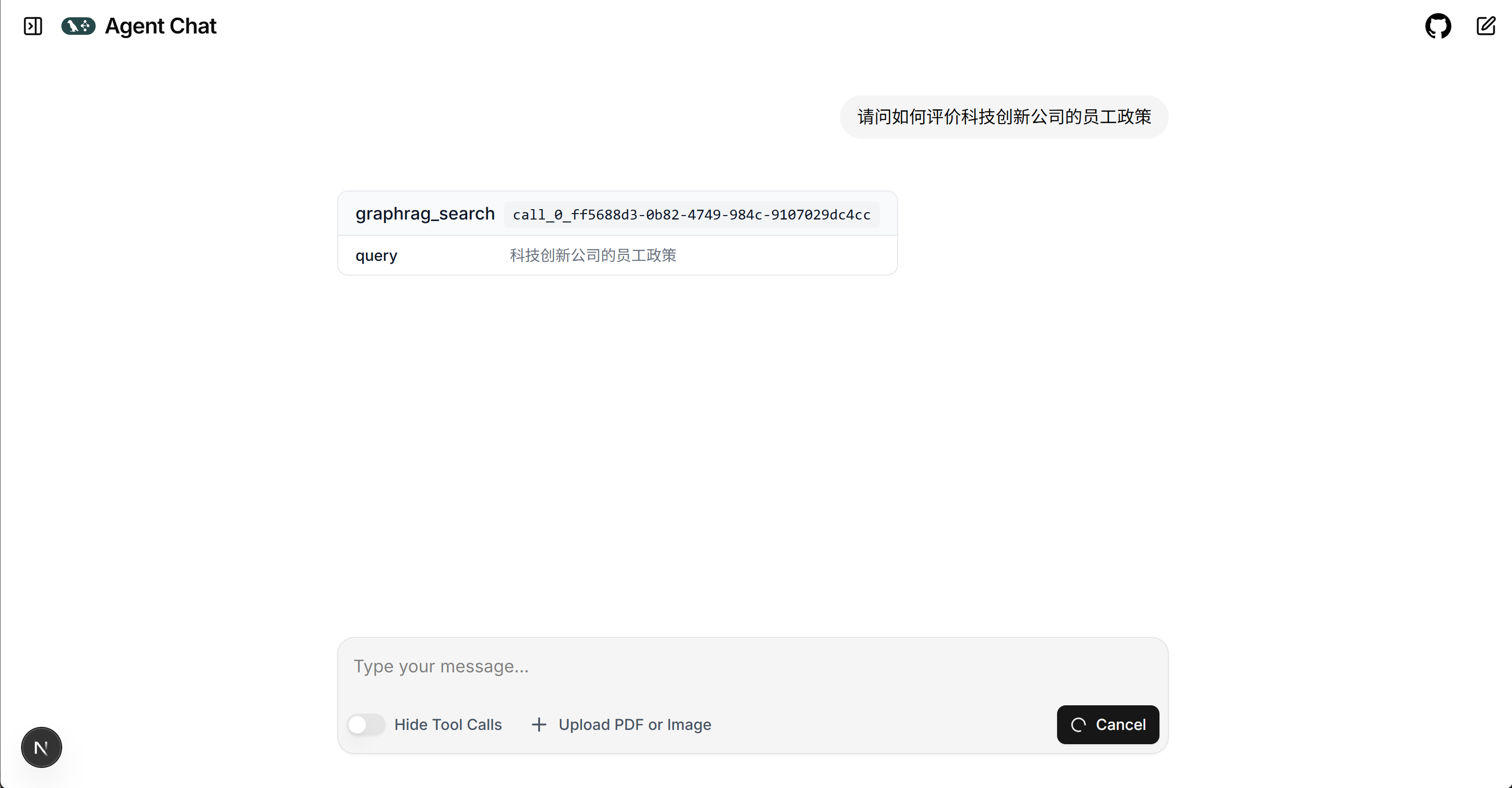
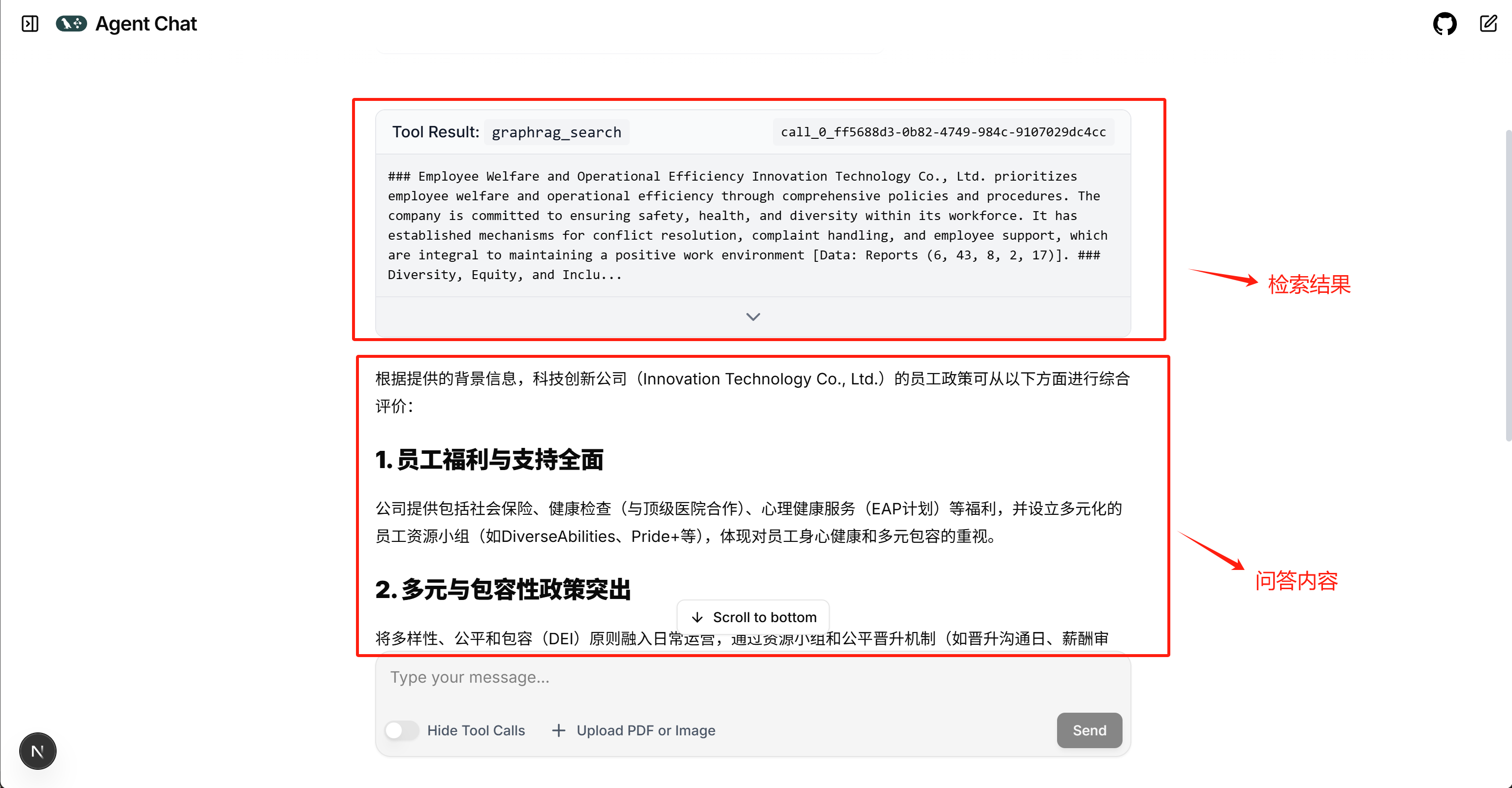
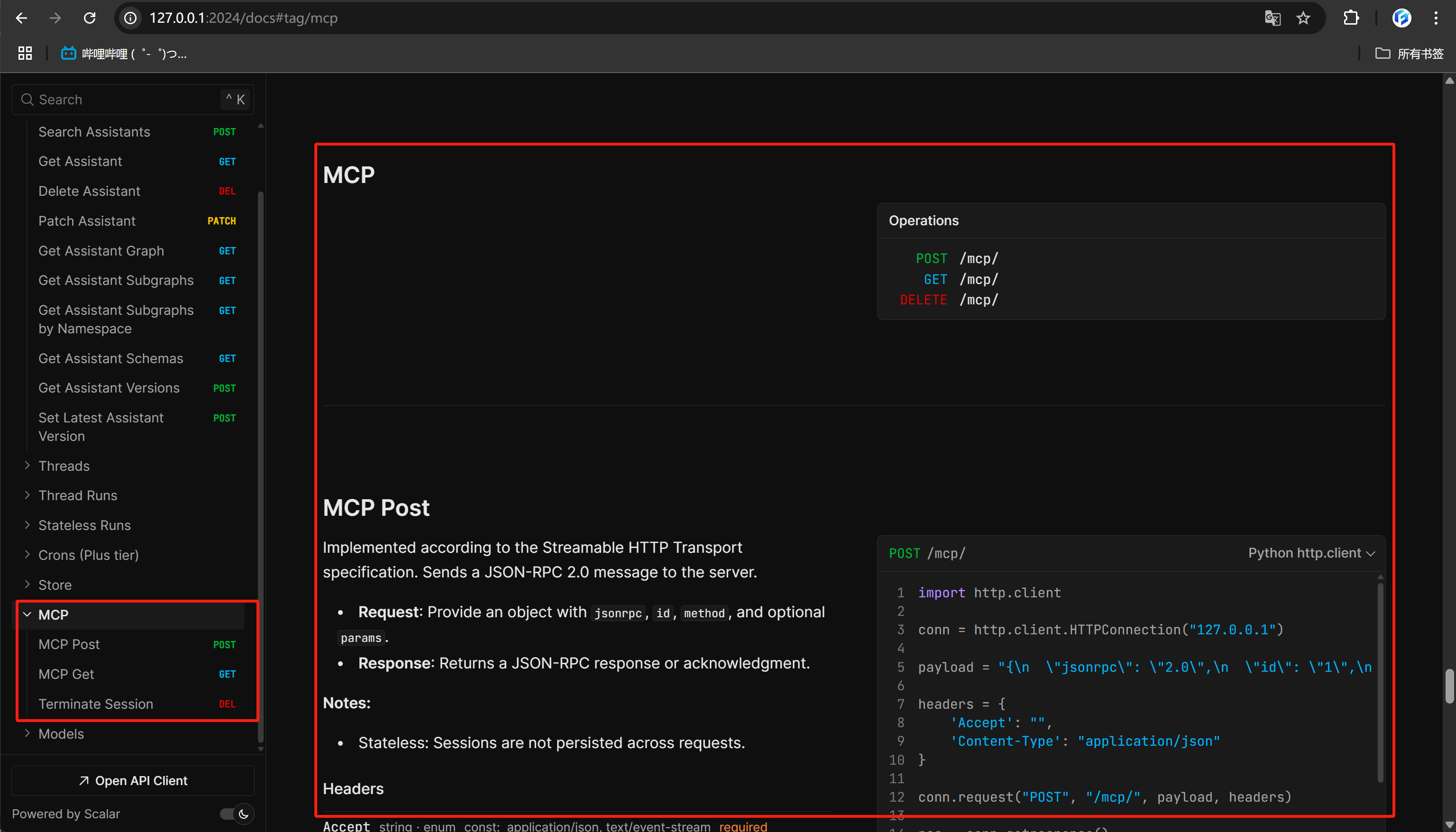
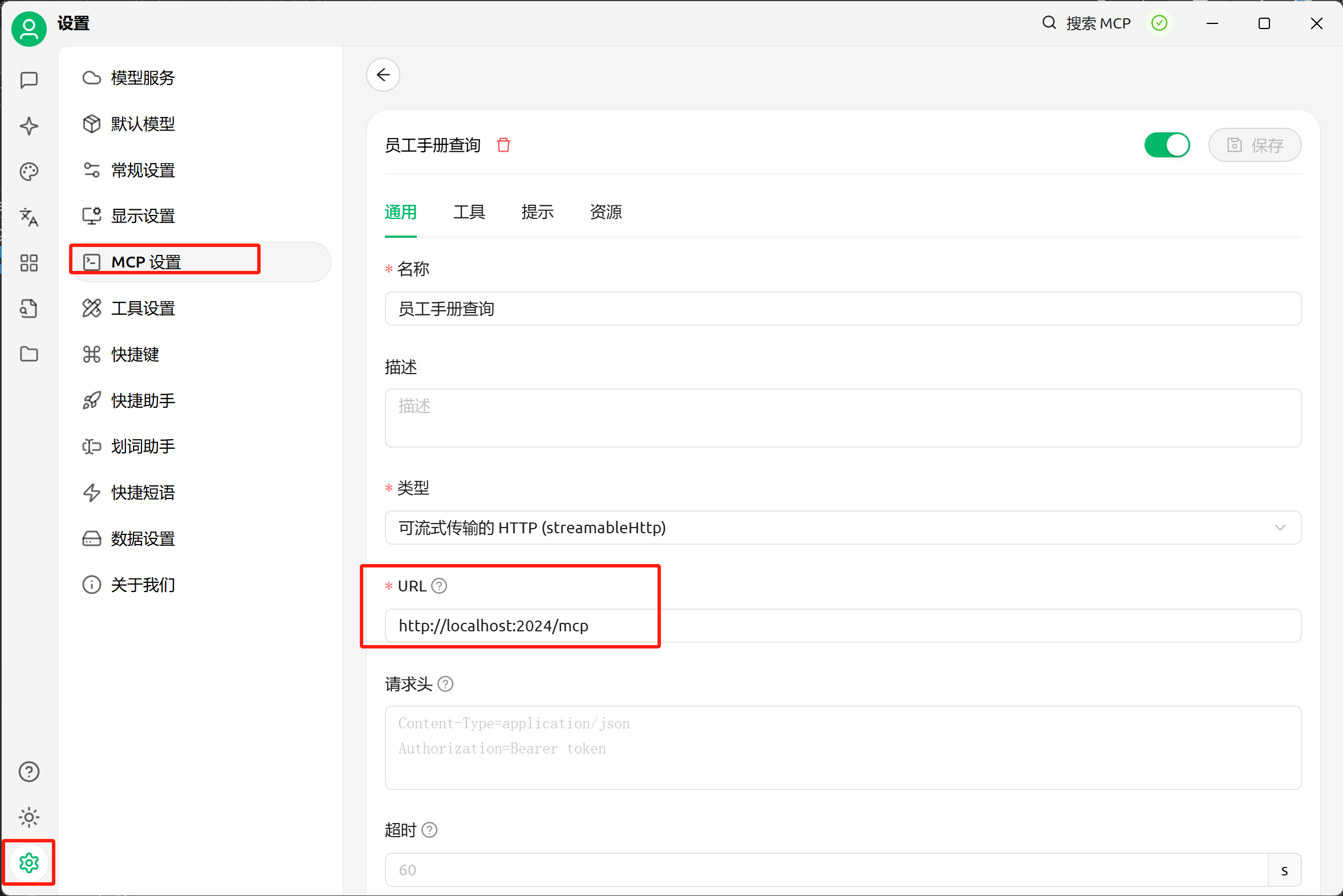
3. 将GraphRAG服务封装为MCP服务器