Llama-Index RAG进阶检索策略介绍
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(12月班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(12月班)

《2025大模型Agent智能体开发实战》(12月班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!
课程完整介绍


部分课程成果演示
from IPython.display import Video
- Dify+DeepSeek搭建智能微信语音客服
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- Coze自动图文视频创作流程
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- 可视化数据分析Multi-Agent
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
- MateGen Pro 项目功能演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目展示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋季班)



详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


最强RAG框架:Llama-Index快速入门实战
Part 2.Llama-Index RAG进阶检索策略介绍
一、Llama-Index进阶RAG策略介绍
在掌握了基础的 RAG 流程后,我们很快就会在实际生产环境中遇到瓶颈。本章将揭示传统 RAG 的局限性,并重点介绍 Llama-Index 提供的三种“破局”策略。这些策略正是我们将 AI 从“玩具”提升为“工具”的关键技术。
1. 传统 RAG 的局限性:为何“Top-K”不够用?
传统的 RAG(即 Naive RAG)架构通常非常简单直接:将文档切分成固定大小的块(Chunk),计算向量,然后根据余弦相似度检索 Top-K 个片段。这种“一刀切”的模式在处理复杂业务文档时,往往面临三大挑战:
- 精度与上下文的矛盾(Granularity Trade-off):
- 如果切片太小,虽然检索精准,但 LLM 看到的上下文支离破碎,容易断章取义。
- 如果切片太大,虽然上下文完整,但包含了大量无关噪声,且检索匹配度会下降。
- “懂意思不懂字面”的盲区(Semantic vs. Keyword):
- 向量检索擅长捕捉语义(如“请假”和“休假”),但对于精确的实体名称(如人名“周云杰”)、专有缩写(如“ROWE”)或具体数字(如“200小时”),往往不如传统的关键词搜索准确。
- 缺乏宏观与微观的判断力(Lack of Intent):
- 系统对待所有问题一视同仁。无论用户问的是“总结全文”(宏观),还是“查某条款”(微观),它都只会呆板地检索几个片段。用“管中窥豹”的方式去回答宏观总结类问题,效果注定失败。
为了解决这些痛点,Llama-Index 引入了一系列高级检索策略。我们将重点学习以下三种核心技术:
2. 进阶策略一:小索引,大窗口 (Small-to-Big Retrieval)
核心思想: “检索粒度”与“生成粒度”的分离。
- 原理: 我们不直接对大段落进行索引,而是将文档切分成极小的颗粒(例如:句子)。检索时,利用句子级的高精度匹配找到目标;但在通过 Prompt 发送给 LLM 之前,系统会自动将这个“小句子”扩展为包含其前后上下文的“大窗口”。
- 解决的问题:
- 解决了“断章取义”的问题。
- 让检索像手术刀一样精准,同时让回答像专家一样全面。
- 典型场景:法律条款查询、规章制度细节问答(如“迟到/旷工后果”)。
- 流程示意图

- 实际运行效果展示

3. 进阶策略二:混合检索 (Hybrid Search)
核心思想: 语义理解(Vector)与 关键词匹配(Keyword)的“双剑合璧”。
- 原理: 系统同时运行两套检索机制:
- 稠密向量检索 (Dense Vector): 负责理解问题的语义和意图。
- 稀疏关键词检索 (BM25): 负责精准匹配专有名词、缩写和人名。
- 最后通过重排序算法(如 RRF - 倒数排名融合)将两路结果的优势结合起来。
- 解决的问题:
- 弥补了向量模型对“生僻词、人名、缩写、ID”不敏感的缺陷。
- 大幅提升了在特定领域(如医疗、法律、内部行政)的召回率。
- 典型场景:查找特定联系人邮箱、查询专有缩写定义(如“法务负责人”和“BYOD”)。
- 流程示意图
- 实际运行效果展示

4. 进阶策略三:智能路由 (Router Query Engine)
核心思想: 给 RAG 系统装上一个“分诊台”(Agentic Behavior)。
- 原理: 我们不再用单一的索引处理所有问题,而是构建多个针对性索引(例如:一个擅长查细节的 Vector Index,一个擅长做总结的 Summary Index)。在检索之前,引入一个“路由层(Router)”,由 LLM 先分析用户意图,再决定分发给哪个索引,甚至同时分发给多个。
- 解决的问题:
- 解决了“用战术动作解决战略问题”的尴尬。
- 实现了按需分配算力,既能快速查细节,又能深度做总结。
- 典型场景:既要回答“某项补贴金额”,又要回答“公司价值观总结”(如复杂多意图场景)。
- 流程示意图
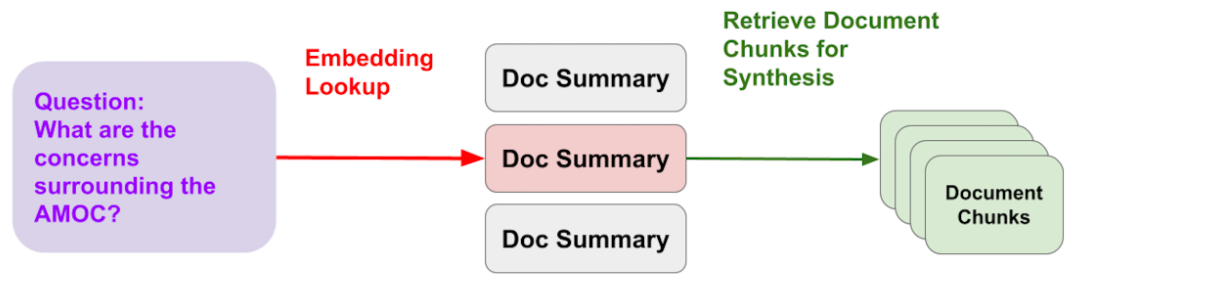
- 实际运行效果展示
5.基本开发环境准备
import os
from dotenv import load_dotenv
import llama_index.core
# 1. 加载环境变量
load_dotenv(override=True)
# 2. 检查 Llama-Index 版本
print(f"Llama-Index Version: {llama_index.core.__version__}")
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
base_url=os.getenv("BASE_URL")
api_key=os.getenv("OPENAI_API_KEY")
# 配置 LLM (大语言模型)
Settings.llm = OpenAI(
model="gpt-4o",
api_key=api_key,
api_base=base_url
)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 1. 数据摄入 (Loading)
documents = SimpleDirectoryReader("data").load_data()
# 2. 索引构建 (Indexing)
index = VectorStoreIndex.from_documents(documents)
# 3. 引擎配置 (Query Engine)
query_engine = index.as_query_engine()
# 4. 执行查询 (Execution)
# 注意:aquery 是异步调用,在 Jupyter 或标准脚本中通常使用同步的 query
response = query_engine.query("请问,我们公司有病假政策么?请用中文进行回复。")
response.response
二、小索引,大窗口RAG策略详解
在 RAG 系统中,我们经常面临一个两难的选择:切片(Chunk)切小了,检索虽然精准,但丢给大模型的上下文支离破碎;切片切大了,上下文虽然完整,但包含大量无关噪声,导致检索准确率下降。
Small-to-Big(小索引,大窗口) 策略,又称 Sentence Window Retrieval,正是为了解决这一痛点而生。该策略的核心思想在于将用于 “搜索” 的数据与用于 “给 LLM 看” 的数据分离开来。
- 小索引 (Small Index for Retrieval): 系统将文档切分为极细颗粒度的**“单句”**。我们在向量库中存储的是这些单句的向量。这样做的好处是,当用户提问时,问题能与最相关的某一句特定的话产生极高的相似度匹配,最大程度减少噪声干扰。
- 大窗口 (Big Window for Generation): 虽然我们搜的是句子,但单句往往缺乏上下文(例如“否则将被解雇”,光看这句不知道“否则”是指什么)。因此,我们在切分时,会预先将这句子前后相邻的 N 句话作为元数据(Metadata)存储起来。
- 偷梁换柱 (Metadata Replacement): 在检索到目标句子后,系统在发送给 LLM 之前,会执行一个“后处理”动作:将这个孤立的句子替换为它预存的“大窗口”内容。
# 3. 检查数据文件是否存在
if not os.path.exists("./data/创新科技股份有限公司员工手册.txt"):
print("❌ 错误:请确保 './data' 目录下存放了员工手册 txt 文件!")
else:
print("✅ 环境检查通过,正在加载数据...")
# 加载文档
documents = SimpleDirectoryReader("./data").load_data()
print(f"📄 成功加载文档,共 {len(documents)} 页/部分。")
# === Cell 2: 构建“普通 RAG” (Baseline) ===
print("🛠️ 正在构建普通 RAG 索引 (使用默认 Chunking)...")
# 1. 建立普通索引
# 默认行为:Chunk Size = 1024, Top-k = 2
base_index = VectorStoreIndex.from_documents(documents)
base_engine = base_index.as_query_engine(similarity_top_k=2)
print("✅ 普通 RAG 就绪!")
# 定义我们的“找茬”问题集
test_questions = [
"Q1: 如果我这个月迟到了 4 次,会受到什么样的具体处理?如果连续 3 天没打卡呢?",
"Q2: 我想周末和春节都来公司加班多赚点钱,工资分别怎么算?我一年最多能加多少小时班,有没有封顶?",
"Q3: 我还在试用期,最近家里有事想请半个月(15天)的假,按规定可以请吗?会不会影响我转正?"
]
# === Cell 3: 构建“黑科技 RAG” (Small-to-Big / Sentence Window) ===
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
import re
print("🚀 正在构建黑科技 RAG 索引 (Small-to-Big)...")
# --- 🛠️ 关键修复:定义一个中文句子切分函数 ---
def chinese_sentence_splitter(text):
# 使用正则表达式,按中文句号、问号、感叹号及换行符进行切分
return re.split(r'(?<=[。?!\n])', text)
# 1. 定义窗口切分器 (加入 sentence_splitter 参数)
node_parser = SentenceWindowNodeParser.from_defaults(
# 告诉它用我们定义的中文切分函数
sentence_splitter=chinese_sentence_splitter,
# 窗口大小
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
# 2. 手动切分文档
nodes = node_parser.get_nodes_from_documents(documents)
print(f"🔪 文档被切分为 {len(nodes)} 个句子节点")
# --- 🔍 验证一下是否切分成功 (如果这里打印的是1,说明还是没切开) ---
if len(nodes) < 10:
print("⚠️ 警告:节点数量过少,可能切分失败!请检查分割符。")
else:
print(f"✅ 切分成功!第一个节点预览: {nodes[0].text[:50]}...")
# 3. 建立索引 (现在每个 Node 都很小,不会报错了)
advanced_index = VectorStoreIndex(nodes)
# 4. 创建引擎
advanced_engine = advanced_index.as_query_engine(
similarity_top_k=5,
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
]
)
print("✅ 黑科技 RAG 就绪!")
这段代码不仅仅是简单的 API 调用,它包含了一个针对中文环境的特殊优化,以及 Llama-Index 中最核心的元数据替换机制。我们将代码拆解为四个关键逻辑块进行讲解。
1. 关键设置:自定义中文分词器 (The Chinese Fix)
FENCE0
- 为什么要写这个函数?
- Llama-Index 的
SentenceWindowNodeParser默认是为英文设计的,它寻找英文句号.来断句。 - 如果直接处理中文文档,解析器会“视而不见”中文的句号
。,导致它把整篇几千字的文档当成一整句话。这不仅会导致检索精度归零,更会直接撑爆 Embedding 模型的 Token 限制(如 OpenAI 的 8192 限制),引发报错。
- Llama-Index 的
- 代码原理解析:
- 我们使用了 Python 的正则表达式
re.split。 (?<=[。?!\n])是一个**“后向断言” (Lookbehind Assertion)。它的意思是:“只要看到中文句号、问号、感叹号或者换行符,就在它们后面**切一刀”。这样能保证标点符号被保留在句子里,而不是被切掉。
- 我们使用了 Python 的正则表达式
2. 定义窗口解析器 (The Architect)
FENCE1
- 核心逻辑:
- 这是该策略的“总设计师”。它决定了数据被切分后的形态。
- 参数详解:
window_size=3:这是策略的灵魂。意味着当系统切分出第 N 句话时,它会同时把 [N-3, N-2, N-1, N, N+1, N+2, N+3] 这 7 句话打包在一起,存储在元数据里。window_metadata_key="window":告诉系统,把打包好的“7句话大窗口”藏在节点的metadata['window']字段里,备用。
3. 切分与验证 (Parsing & Validation)
FENCE2
- 流程变化:
- 在普通 RAG 中,我们直接用
VectorStoreIndex.from_documents()。 - 在这里,我们必须先手动调用
get_nodes_from_documents获得nodes,然后再建索引。这是为了确保我们的切分策略生效。
- 在普通 RAG 中,我们直接用
- 向量化的是谁?
- 关键点: 此时建立索引,Embedding 模型计算的是
node.text(也就是单句)的向量,而不是那个“大窗口”的向量。这保证了检索的极致精准度。
- 关键点: 此时建立索引,Embedding 模型计算的是
4. 引擎构建与“偷梁换柱” (The Magic Swap)
FENCE3
similarity_top_k=5:- 因为我们检索的是“细粒度”的句子,单个节点包含的信息量很小,所以我们需要稍微多找几个(Top-5),以确保覆盖足够的信息。
MetadataReplacementPostProcessor(魔法核心):- 这是 Llama-Index 特有的后处理器。
- 工作流:
- 检索时: 系统用问题去匹配“单句”。
- 命中后: 处理器介入,检查每个命中节点的
metadata。 - 替换(Swap): 它把
metadata['window'](那个包含上下文的大段落)取出来,直接覆盖掉原本的node.text(单句)。 - 合成时: 发送给 LLM 的 Prompt 里,填入的就是替换后的“大窗口”内容。
整体来说基本流程如下:
- 原始文档 $\xrightarrow{中文切分}$ 孤立句子
- 孤立句子 $\xrightarrow{WindowParser}$ 带有“上下文背包”的句子节点
- 索引阶段 $\rightarrow$ 只对 “句子” 做向量化(为了搜得准)
- 检索阶段 $\rightarrow$ 搜到了 “句子”
- 处理阶段 $\xrightarrow{PostProcessor}$ 扔掉句子,打开背包拿出 “大窗口”
- 生成阶段 $\rightarrow$ LLM 阅读 “大窗口” 并回答(为了看得全)
# === Cell 4: 效果对比展示 ===
from IPython.display import display, Markdown
def compare_answers(question):
# 1. 跑普通 RAG
response_base = base_engine.query(question)
# 2. 跑黑科技 RAG
response_adv = advanced_engine.query(question)
# 3. 格式化输出 (使用 Markdown 表格让对比更强烈)
display(Markdown(f"### ❓ 提问: {question}"))
# 构建对比表格
table_md = f"""
| 🤖 普通 RAG (Baseline) | 🚀 黑科技 RAG (Small-to-Big) |
| :--- | :--- |
| {response_base.response} | {response_adv.response} |
"""
display(Markdown(table_md))
# 4. (可选) 展示黑科技到底引用了什么原文,增强可信度
# display(Markdown("**🚀 黑科技引用原文窗口:**"))
# for node in response_adv.source_nodes:
# display(Markdown(f"> ...{node.node.metadata['window']}..."))
display(Markdown("---"))
# 开始循环测试
for q in test_questions:
compare_answers(q)
三、混合检索 (Hybrid Search)执行策略
1. 策略背景:告别“懂意不懂字”的单腿走路
在基础的 RAG 系统中,我们通常完全依赖向量检索(Vector Search)。向量检索的魔法在于它能通过计算高维空间的距离来理解“语义”。例如,用户搜“请假规则”,它能通过语义关联找到“考勤管理”或“休假制度”,即便这几个字没有完全对应。
然而,在企业级落地中,我们很快发现纯向量检索存在一个致命的**“语义盲区”:它对精确匹配(Exact Match)**极不敏感。
- 当用户搜索一个特定的错误码(如“Error 503”)、一个生僻的人名(如“周云杰”)、一个专有的缩写(如“ROWE”)或一个具体的产品型号(如“X-2000”)时,向量模型往往会因为这些词在语义空间中过于稀疏,而检索到一堆“意思相近”但完全不相关的通用描述,导致“张冠李戴”。
混合检索(Hybrid Search) 的诞生,正是为了解决这一痛点。它主张“两条腿走路”,既要 AI 的“脑子”(语义理解),也要传统搜索引擎的“眼睛”(字面匹配)。
2. 核心原理:双路召回与加权融合
混合检索策略在底层构建了两条并行的检索链路,并通过精密的算法将结果合二为一:
- 链路 A:稠密向量检索 (Dense Retrieval)
- 机制: 使用 Embedding 模型将文本转化为向量。
- 强项: 擅长处理模糊查询、概念关联、同义词匹配。
- 角色: 负责“懂你什么意思”。
- 链路 B:稀疏关键词检索 (Sparse Retrieval / BM25)
- 机制: 基于传统的 TF-IDF(词频-逆文档频率)算法演进而来的 BM25 算法。
- 强项: 擅长捕捉生僻词、专有名词、精确数字。它不关心语义,只关心关键词是否在文档中高频出现。
- 角色: 负责“精准定位字面”。
- 融合机制:倒数排名融合 (Reciprocal Rank Fusion, RRF)
- 系统不会简单地把两路结果拼在一起,而是使用 RRF 算法。它像一个公正的裁判,查看两个链路的排名情况。如果一个文档在向量检索中排第 1,在关键词检索中也排第 1,它的最终权重会极高;如果只在单路出现,权重则会降低。
3.执行流程
# !pip install rank_bm25 jieba
# === Cell 1: 初始化与分词器配置 ===
import nest_asyncio
import jieba
from typing import List
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Settings, StorageContext
from llama_index.core.node_parser import SentenceSplitter
nest_asyncio.apply()
# 1. 定义一个中文分词函数 (给 BM25 用)
def chinese_tokenizer(text: str) -> List[str]:
# 使用 jieba 进行分词
return list(jieba.cut(text))
# 2. 加载数据
print("📂 正在加载文档...")
documents = SimpleDirectoryReader("./data").load_data()
# 3. 将文档切分为节点 (标准切分,Chunk Size=512 适中)
# 为什么要手动切分?因为 BM25 和 向量索引 需要共享同一套节点数据
splitter = SentenceSplitter(chunk_size=512, chunk_overlap=50)
nodes = splitter.get_nodes_from_documents(documents)
print(f"✅ 文档已切分为 {len(nodes)} 个标准节点。")
# === Cell 2: 构建“普通 RAG” (纯向量) ===
print("🛠️ 正在构建向量索引 (Vector Index)...")
# 1. 构建向量索引
vector_index = VectorStoreIndex(nodes)
# 2. 创建纯向量检索引擎
# similarity_top_k=2
vector_engine = vector_index.as_query_engine(similarity_top_k=2)
print("✅ 普通 RAG (Vector Only) 就绪!")
# === Cell 3: 构建“黑科技 RAG” (混合检索: Vector + BM25) ===
import inspect
from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
print("🚀 正在构建混合检索系统 (Hybrid Search)...")
# --- 🛠️ 自动侦测修复:从类型提示中提取 FusionMode ---
try:
# 1. 获取 __init__ 函数的签名
sig = inspect.signature(QueryFusionRetriever.__init__)
# 2. 找到 'mode' 参数的类型定义
ModeEnum = sig.parameters['mode'].annotation
print(f"✅ 成功自动侦测到 Mode 类型: {ModeEnum}")
# 3. 获取 RECIPROCAL_RANK 的值
# 如果它是枚举,直接取属性;如果是 Optional[FusionMode],可能需要剥离一层
# 这里做一个简单的容错遍历
if hasattr(ModeEnum, 'RECIPROCAL_RANK'):
target_mode = ModeEnum.RECIPROCAL_RANK
else:
# 如果类型提示没拿到,或者版本太旧是字符串,直接用字符串兜底
print("⚠️ 未找到枚举属性,尝试使用字符串模式...")
target_mode = "reciprocal_rank"
except Exception as e:
print(f"⚠️ 自动侦测失败 ({e}),回退到字符串模式...")
target_mode = "reciprocal_rank"
print(f"👉 最终使用的 mode 参数: {target_mode}")
# 1. 创建 BM25 检索器
bm25_retriever = BM25Retriever.from_defaults(
nodes=nodes,
similarity_top_k=2,
tokenizer=chinese_tokenizer
)
# 2. 创建 向量 检索器
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)
# 3. 创建 融合检索器
fusion_retriever = QueryFusionRetriever(
[vector_retriever, bm25_retriever],
similarity_top_k=4,
num_queries=1,
# 使用我们要么侦测到、要么回退的 mode
mode=target_mode,
use_async=True
)
# 4. 组装成引擎
hybrid_engine = RetrieverQueryEngine.from_args(
retriever=fusion_retriever
)
print("✅ 黑科技 RAG (Hybrid Search) 就绪!")
这段代码展示了如何将关键词检索 (BM25) 与 向量检索 (Vector) 结合,并通过 RRF (倒数排名融合) 算法实现 1+1 > 2 的效果。值得注意的是,代码开头包含了一段处理版本兼容性的“防御性编程”技巧。
我们将代码逻辑拆解为三个核心模块进行讲解:
1. 自动侦测与版本适配 (The Compatibility Fix)
FENCE0
- 为什么要写这段复杂的逻辑?
- 背景: Llama-Index 更新极快,v0.10.x 版本中,
FusionMode从字符串变成了严格的枚举类型(Enum)。直接写字符串"reciprocal_rank"在新版会报错,直接引枚举类在旧版又会报错。 - 原理: 这里使用了 Python 的
inspect(反射) 模块。 - 比喻: 这就像在进门前,先用扫描仪看一眼门锁是“指纹锁”还是“钥匙锁”,然后再决定掏出指纹还是钥匙。这是一种**“防御性编程”**,确保你的代码在不同版本的 Llama-Index 上都能跑通,不至于因为版本升级而崩溃。
- 背景: Llama-Index 更新极快,v0.10.x 版本中,
2. 创建双路检索器 (Two-Stream Retrievers)
FENCE1
- 分工明确:
- BM25Retriever: 它是系统的“眼睛”,负责盯着字面。如果用户搜“周云杰”,它能精准抓取包含这三个字的人名,哪怕语义上这只是一个普通名字。
- VectorIndexRetriever: 它是系统的“脑子”,负责理解含义。如果用户搜“法务负责人”,它能理解这和“周云杰”是关联的。
- 注意点: BM25 必须传入
tokenizer=chinese_tokenizer,否则它会把一整句中文当成一个长单词,无法匹配关键词。
3. 融合与引擎组装 (The Fusion Core)
FENCE2
- 核心组件
QueryFusionRetriever: 它是整个策略的指挥官。 mode=RECIPROCAL_RANK(RRF 算法):- 这是目前业界最流行的无监督融合算法。
- 工作原理: 它不看分数(因为 BM25 的分数和向量的 Cosine 分数无法直接比较),它看排名。
- 举例: 如果文档 A 在关键词检索排第 1,在向量检索也排第 1,它的 RRF 得分就会极高,被置顶。如果文档 B 只在向量检索出现,关键词检索里没影,它的排名就会下降。
- 结果:
hybrid_engine最终吐出的答案,既包含了字面精准的信息,也包含了语义相关的信息,消除了单一检索的盲区。
# === Cell 4: 效果对比展示 ===
from IPython.display import display, Markdown
# 定义“找茬”问题
# 这些问题包含了具体的实体名(Entity)和缩写,是向量检索的弱项
questions = [
"Q1: 请问法务合规部的负责人是谁?我想发邮件给他,邮箱是多少?",
"Q2: 公司关于 BYOD (自带设备) 的具体政策要求是什么?",
"我是研发部的老员工,听说有个‘ROWE’工作制,具体需要满足哪些硬性条件才能申请?",
"如果我遇到紧急情况需要心理支持,公司有没有专门的援助热线?具体的电话号码是多少?",
"公司内部有没有专门支持女性发展的组织?这个小组的准确名称叫什么?"
]
def compare_hybrid(question):
# 1. 普通 RAG
response_base = vector_engine.query(question)
# 2. 混合 RAG
response_hybrid = hybrid_engine.query(question)
# 3. 展示对比
display(Markdown(f"### ❓ 提问: {question}"))
table_md = f"""
| 🤖 普通 RAG (Vector Only) | 🚀 黑科技 RAG (Hybrid: Vector + BM25) |
| :--- | :--- |
| {response_base.response} | {response_hybrid.response} |
"""
display(Markdown(table_md))
# 可选:查看混合检索到底融合了哪些节点
# print("🔍 混合检索命中的节点片段:")
# for node in response_hybrid.source_nodes:
# print(f"[{node.score:.2f}] {node.node.text[:50]}...")
display(Markdown("---"))
# 开始测试
for q in questions:
compare_hybrid(q)
四、路由检索策略介绍
1. 策略背景:打破“一刀切”的检索僵局
在传统的 RAG 架构中,存在一个尴尬的悖论:“宏观与微观的冲突”。
- 如果我们为了回答“总结全文核心思想”这样的宏观问题,而将 Top-K 设得很大或使用摘要索引,那么在回答“某项补贴具体是多少钱”这种微观问题时,就会造成巨大的算力浪费和响应延迟。
- 反之,如果我们为了快速查细节而使用标准的 Top-2 向量检索,那么面对“请概述公司发展历程”这样的问题时,系统就像“管中窥豹”,只能抓取到零星片段,给出的答案往往是片面甚至错误的。
智能路由(Router Query Engine) 的引入,标志着 RAG 系统从“自动化”向**“Agent(智能体)”**迈出了关键一步。它不再机械地执行单一动作,而是学会了“先思考,再行动”。
2. 核心原理:RAG 系统的“前置分诊台”
智能路由策略的核心在于构建了一个决策层,位于用户提问和数据索引之间:
- 构建多元工具箱:
我们不再只维护一个索引,而是针对不同的任务构建不同的索引结构,并将它们封装为“工具(Tools)”。
- 工具 A(向量工具): 基于 VectorStoreIndex,擅长点对点的细节查询(查数据、查条款)。
- 工具 B(摘要工具): 基于 SummaryIndex,擅长遍历全文档构建树状摘要(做总结、看全貌)。
- AI 路由选择器 (LLM Selector):
这是系统的“大脑”。当问题进来时,Selector 会先阅读问题的意图,然后对比手边工具的“功能描述(Description)”,动态决定:
- “这个问题是查细节的 -> 派发给工具 A。”
- “这个问题是做总结的 -> 派发给工具 B。”
- “这个问题既要细节又要总结 -> 同时派发给 A 和 B,最后汇总。”
3.执行流程
# === Cell 1: 初始化与构建双索引 (Vector + Summary) ===
import nest_asyncio
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, SummaryIndex, Settings
from llama_index.core.node_parser import SentenceSplitter
nest_asyncio.apply()
# 1. 加载数据
print("📂 正在加载文档...")
documents = SimpleDirectoryReader("./data").load_data()
# 2. 切分文档 (通用切分)
splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
nodes = splitter.get_nodes_from_documents(documents)
# 3. 构建【向量索引】 (擅长查细节)
print("🛠️ 正在构建向量索引 (Vector Index)...")
vector_index = VectorStoreIndex(nodes)
# 4. 构建【摘要索引】 (擅长做总结)
# SummaryIndex 不做向量化,它把所有节点存成一个列表,查询时会遍历阅读
print("📚 正在构建摘要索引 (Summary Index)...")
summary_index = SummaryIndex(nodes)
print("✅ 双索引构建完毕!")
# === Cell 2: 定义工具与构建 Router ===
from llama_index.core.tools import QueryEngineTool
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.query_engine import RouterQueryEngine
# 1. 定义 Vector 工具 (查细节)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_index.as_query_engine(similarity_top_k=2),
description="专门用于查询具体的、特定的事实细节,例如补贴金额、电话号码、具体政策条款等。"
)
# 2. 定义 Summary 工具 (做总结)
# response_mode="tree_summarize" 是关键,它会构建一棵摘要树,从底向上递归总结
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_index.as_query_engine(response_mode="tree_summarize"),
description="专门用于对文档进行宏观的总结、概括全文主题、分析整体结构或提取跨章节的综合信息。"
)
# 3. 构建 Router 引擎
print("🚦 正在构建智能路由引擎 (Router Engine)...")
router_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[summary_tool, vector_tool],
verbose=True # 开启 verbose,我们可以看到它到底选了哪个工具
)
print("✅ Router 引擎就绪!")
这段代码展示了如何将两个功能迥异的检索引擎(查细节的 Vector 和 查全貌的 Summary)封装成工具,并教会系统如何根据用户的问题自动选择最合适的一个。
1. 定义工具:给系统装上“手脚” (The Tools)
在 Router 模式下,索引(Index)本身不能直接被路由,必须先封装成 QueryEngineTool。
FENCE0
QueryEngineTool:这是 Llama-Index 中的标准工具包装器。description(至关重要!):- 这不仅仅是写给开发者看的注释,它是写给 AI 看的 Prompt(指令)。
- Router 内部的 LLM 会阅读这段文字,来判断:“这个工具是干嘛的?它能解决当前用户的问题吗?”
- 教学点: 描述写得越精准,路由的准确率就越高。
2. 定义摘要工具与合成策略 (The Summary Strategy)
FENCE1
- 为什么要用
SummaryIndex?- 向量索引通过计算距离找 Top-K,会漏掉全局信息。而
SummaryIndex(摘要索引)存储的是节点列表,它允许我们遍历文档的所有内容。
- 向量索引通过计算距离找 Top-K,会漏掉全局信息。而
response_mode="tree_summarize"(树状总结):- 这是处理长文档总结的神器。
- 原理: 如果文档很长,它不会试图一次塞进 LLM。而是先把文档切块,分别总结(叶子节点),然后把这些小总结拼起来再总结(父节点),像爬树一样直到生成最终的根节点摘要。
- 效果: 能够生成覆盖全文档的高质量宏观摘要。
3. 构建大脑:选择器与引擎 (The Brain & Body)
FENCE2
LLMSingleSelector(决策者):- 这是一个小型分类器。它接收用户的问题和工具的描述,然后输出一个最佳工具的名称。
- 注: 还有
LLMMultiSelector,可以同时选择多个工具(例如既查 Google 又查本地文档),但在本例中我们只需要“二选一”。
verbose=True(调试模式):- 在教学和调试中非常有用。开启后,你会在控制台看到系统“思考”的过程,例如:
Selecting query engine 0: ...。这能让你直观地确认 Router 是否变聪明了。
- 在教学和调试中非常有用。开启后,你会在控制台看到系统“思考”的过程,例如:
整体执行逻辑如下:
- 用户提问: “公司有哪些福利?”
- Router (Selector) 思考:
- 看工具 A(Vector)描述:查具体细节、数字。-> 不太匹配。
- 看工具 B(Summary)描述:查宏观总结、概括。-> 匹配!
- 分发任务: 将问题扔给
summary_tool。 - 执行任务:
summary_index启动tree_summarize模式,遍历文档生成总结。 - 返回结果: 用户得到一份全面的福利概览,而不是零星的补贴数字。
# === Cell 3: 定义 5 个测试问题 ===
questions = [
# --- 宏观总结题 (普通 RAG 的死穴) ---
# 1. 全文总结
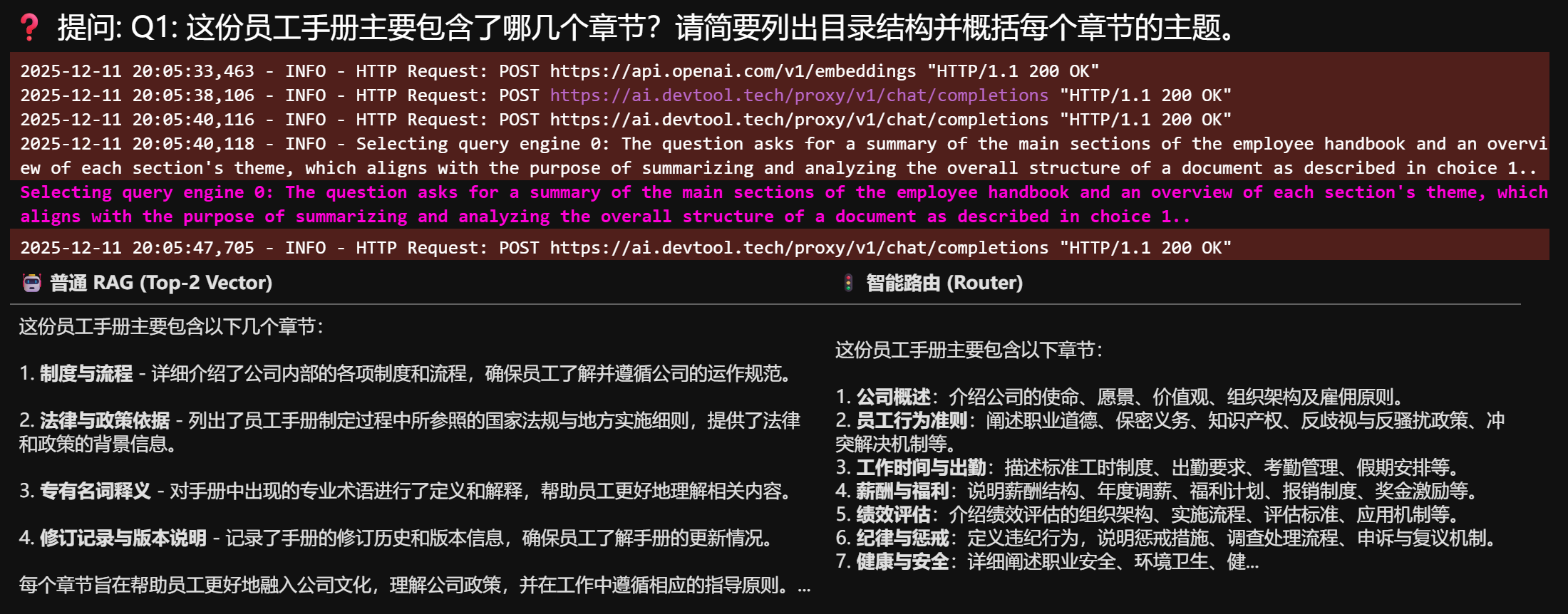
"Q1: 这份员工手册主要包含了哪几个章节?请简要列出目录结构并概括每个章节的主题。",
# 2. 跨章节综合分析
"Q2: 请详细总结一下公司的核心价值观以及我们对待多样性(D&I)的整体策略。",
# --- 微观细节题 (普通 RAG 的强项) ---
# 3. 具体数字
"Q3: 公司的健身房补贴每年最高是多少钱?",
# 4. 具体人名
"Q4: 请问法务合规部的负责人是谁?",
# 5. 具体条款
"Q5: 试用期员工如果累计请假超过 10 天,会有什么具体后果?"
]
# === Cell 4: 效果对比展示 (修复表格渲染版) ===
from IPython.display import display, Markdown
# 准备一个普通的 Vector Engine 作为对照组
base_engine = vector_index.as_query_engine(similarity_top_k=2)
def clean_text(text):
"""
清洗文本:将换行符替换为HTML换行标签,防止Markdown表格崩坏
"""
if not text:
return ""
# 截取前 300 字符,并将换行符替换为 <br>
cleaned = str(text)[:300].replace("\n", "<br>")
return cleaned + "..."
print("🔥 开始 5 轮智能路由测试...")
print("(请耐心等待,Q1 和 Q2 需要总结全文,速度较慢...)")
for q in questions:
display(Markdown(f"### ❓ 提问: {q}"))
# 1. 普通 RAG
response_base = base_engine.query(q)
# 2. Router RAG
# 这一步可能会打印 "Selecting query engine..." 日志,请留意
response_router = router_engine.query(q)
# 3. 提取结果并清洗
base_text = clean_text(response_base.response)
router_text = clean_text(response_router.response)
# 4. 构建严格格式的 Markdown 表格
# 注意:表格每一行开头和结尾都要有 |
table_md = f"""
| 🤖 普通 RAG (Top-2 Vector) | 🚦 智能路由 (Router) |
| :--- | :--- |
| {base_text} | {router_text} |
"""
display(Markdown(table_md))
display(Markdown("---"))