Part 三、LangChain RAG知识库问答系统开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(秋季班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(秋季班)

《2025大模型Agent智能体开发实战》(秋季班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!


部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify&Coze项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/Coze%E5%8A%A8%E6%80%81%E8%A7%86%E9%A2%91%E7%94%9F%E6%88%90%E5%AE%9E%E4%BE%8B.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
- 高效微调全自动数据集创建
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/easy_daset_yanshi.mp4", width=800, height=400)
GraphRAG+多模态文档检索
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/7%E6%9C%8817%E6%97%A5%281%29%20%E8%BF%9B%E5%BA%A6%E6%9D%A1.mp4", width=800, height=400)
详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇

《大模型Agent开发实战课》(秋季班)体验课
大模型零基础入门开发实战
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2025-09-22%2013-58-30.mp4", width=800, height=400)
Part 三、LangChain RAG知识库问答系统开发实战
RAG,Retrieval-Augmented Generation,也被称作检索增强生成技术,最早在 Facebook AI(Meta AI)在 2020 年发表的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》( https://arxiv.org/abs/2005.11401 )中正式提出,这种方法的核心思想是借助一些文本检索策略,让大模型每次问答前都带入相关文本,以此来改善大模型回答时的准确性。这项技术刚发布时并未引发太大关注,而伴随2022年大模型技术大爆发,RAG技术才逐渐进入人们视野,并且由于早期大模型技术应用均已“知识库问答”为主,而RAG技术是最易上手、并且上限极高的技术,因此很快就成为了大模型技术人必备的技术之一。
1. RAG技术极简实现流程
时至今日,RAG技术已经是非常庞大的技术体系了,从简答的文档切分、存储、匹配,再到复杂的入GraphRAG(基于知识图谱的检索增强),以及复杂文档解析+多模态识别技术等等等等。
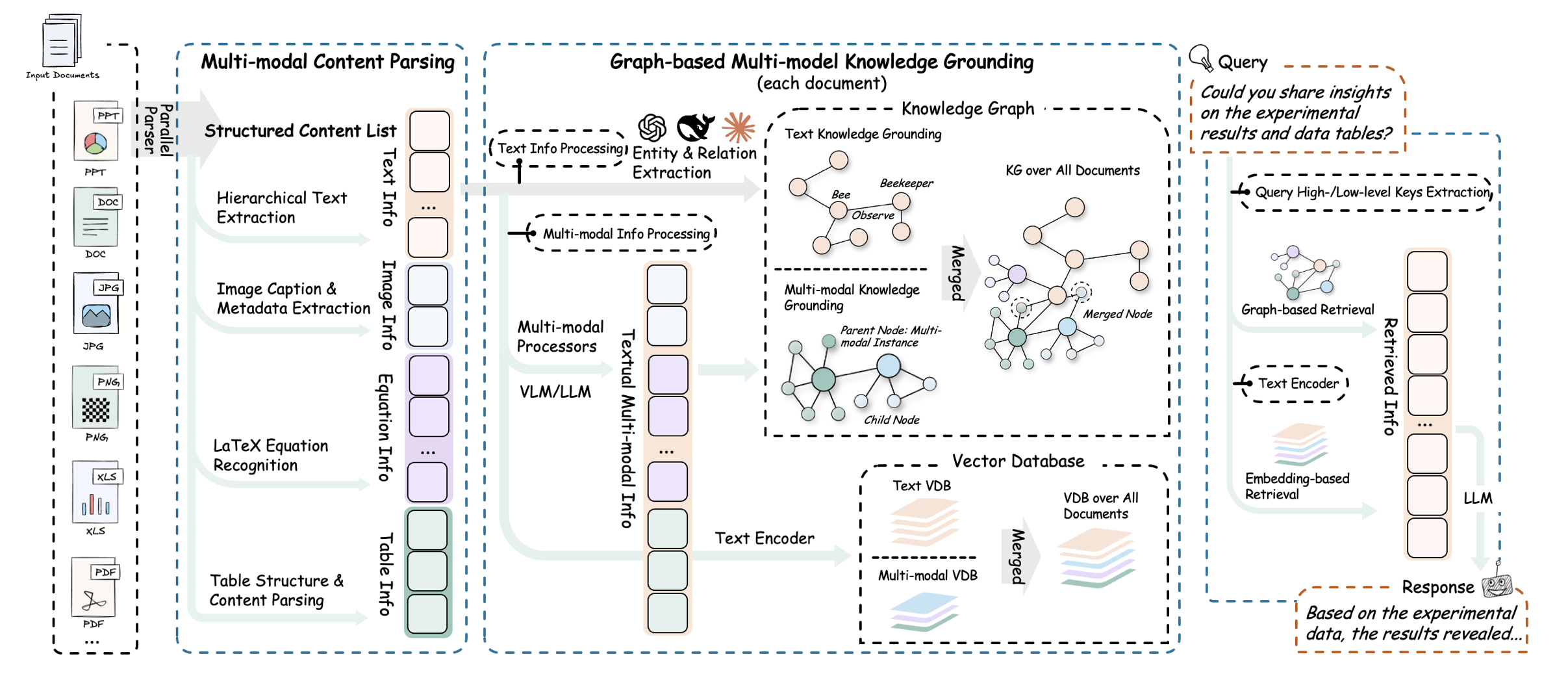
而对于初学者来说,为了更好的上手学习RAG技术,我们首先需要对RAG技术最简单的实现形式有个基础的了解。一个最简单的RAG技术实现流程如下所示:
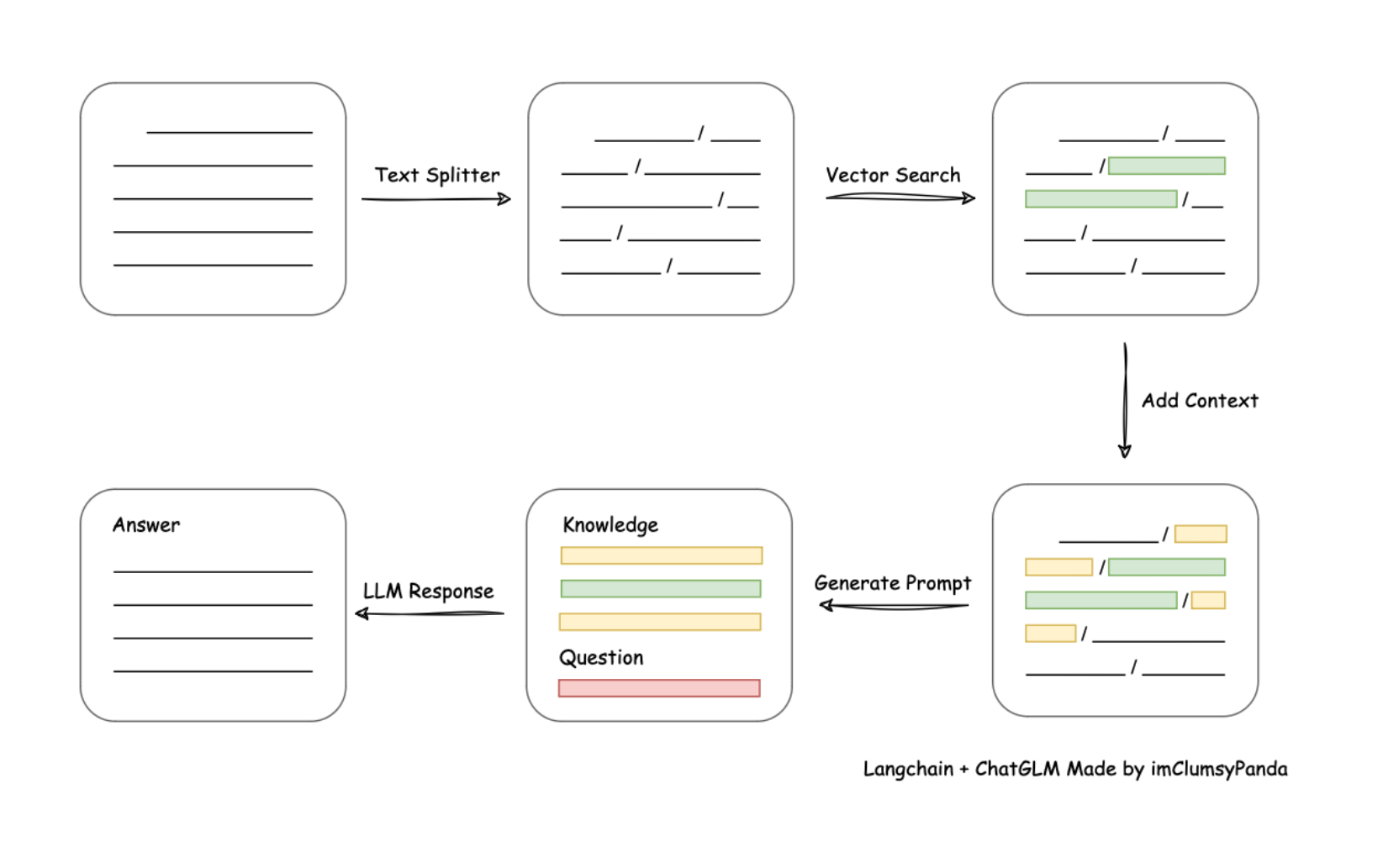
我们需要围绕给定的文档(往往是非常长的文档)先进行切分,然后将切分的文档转化为计算机能识别的形式,也就是将其转化为一个数值型向量(也被称为词向量),然后当用户询问问题的时候,我们再将用户的问题转化为词向量,并和段落文档的词向量进行相似度匹配,借此找出和当前用户问题最相关的原始文档片段,然后将用户的问题和匹配的到的原文片段都带入大模型,进行最终的问答。由此便可实现一次完整的文档检索增强执行流程。
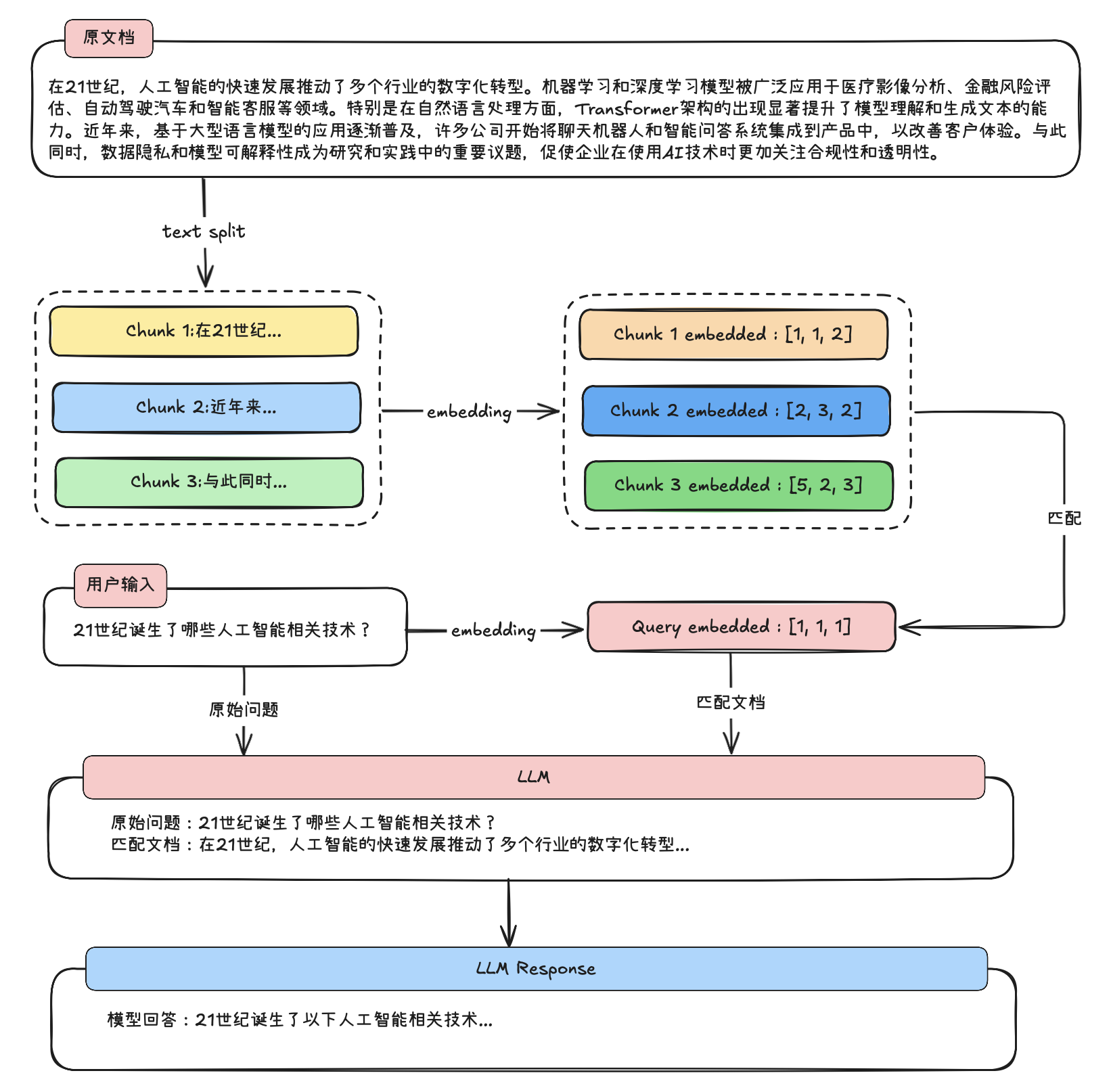
具体执行过程如下所示:
2. RAG技术核心应用场景:拓展模型知识边界与减少问答幻觉
那这样的一个检索增强流程到底有什么用呢?这就不得不从当代大模型本身的三项技术缺陷开始说起了。
- 缺陷一:大模型幻觉
相信大家在使用大模型的时候,都会遇到大模型无中生有胡编乱造答案的情况,例如胡乱生成一些概念、一些论文甚至是一些实时等,这就是所谓的大模型幻觉。
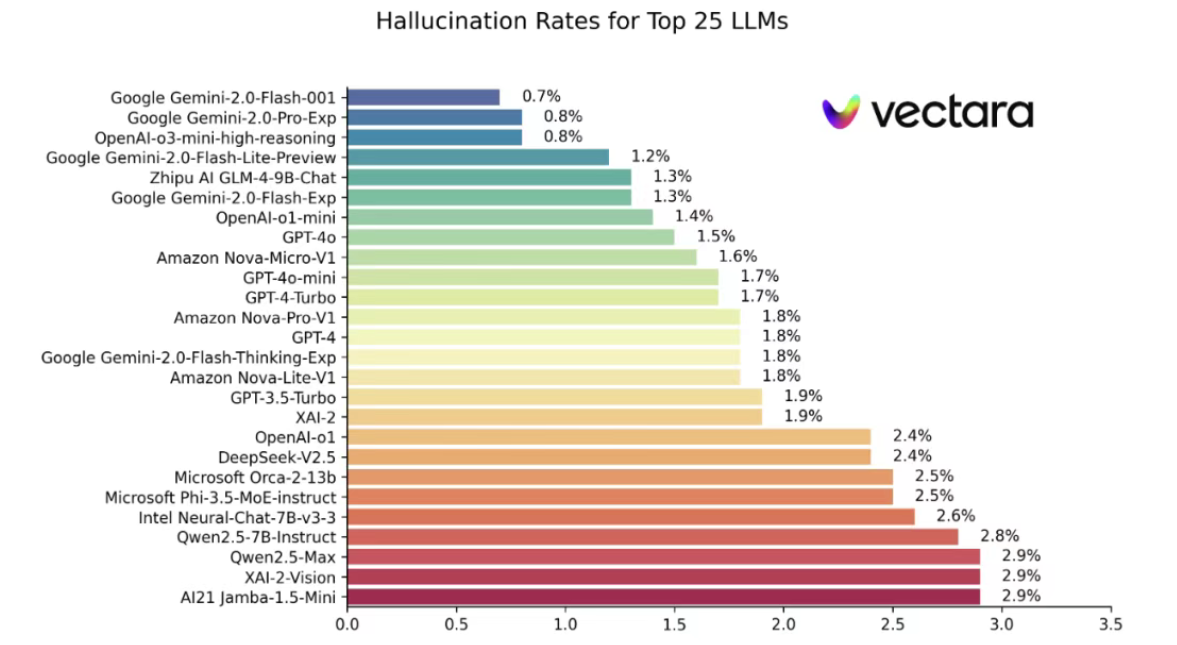
而其中,第一代DeepSeek R1模型的幻觉是非常严重的,平均七次回答中就会有一次的回答存在幻觉,这可以说是第一版R1模型最大的短板。
大型语言模型之所以会产生幻觉,主要是因为它们的训练方式和内在机制决定了它们并不具备真正理解和验证事实的能力。模型在训练过程中,通过分析大规模文本数据来学习不同词语和句子之间的概率关系,也就是在某种程度上掌握“在什么上下文中,什么样的回答听起来更合理”。然而,模型并没有接入实时的知识库或事实核查工具,当它遇到陌生的问题、模糊的描述或者上下文不完整的输入时,就会基于概率和语料库中似是而非的关联去“编造”一个看似正确的答案。由于这些输出往往语法流畅、逻辑连贯,人类读者很容易误以为它是真实可信的内容,这就是我们通常说的“模型幻觉”。
- 缺陷二:有限的最大上下文
而除此之外,大模型在实际应用中还会另一个“障碍”,那就是最大上下文限制。由于大模型的本质其实是一个算法,不管是让大模型“知道”有哪些外部工具,还是要给大模型进行“背景设置”,或者是要给模型添加历史对话消息,以及本次对话的输出,都需要占用这个上下文窗口。这就使得我们在一次对话中能够给大模型灌输的知识(文本)其实是有限的。
大型语言模型还存在最大上下文限制,这是由它们的架构和计算方式决定的。每次生成回答时,模型需要把输入文本转换成固定长度的数字序列(称为token),并在内部一次性加载到模型的“上下文窗口”中进行处理。这个窗口的大小是有限的,不同模型一般在几千到几万token之间。如果输入内容超出这个长度,模型要么截断最前面的部分,要么丢弃部分信息,这就会造成对话历史、长文档或先前提到的重要细节的遗失。因为它无法跨越上下文窗口无限地保留信息,所以在面对长对话或者大量背景知识时,模型常常出现上下文断裂、回答不连贯或者忽略先前条件的情况。
早些时候的大模型普遍是8k最大上下文,相当于是8-10页中文PDF,伴随着大模型预训练技术的不断发展,顶尖的大模型,如Gemini 2.5 Pro和GPT-4.1等模型,已经达到了1M的最大上下文长度,相当于是一千页的PDF,相当于1.5本《红楼梦》,而普通的模型,也基本达到64K或128K最大上下文,相当于60-100也左右的PDF。
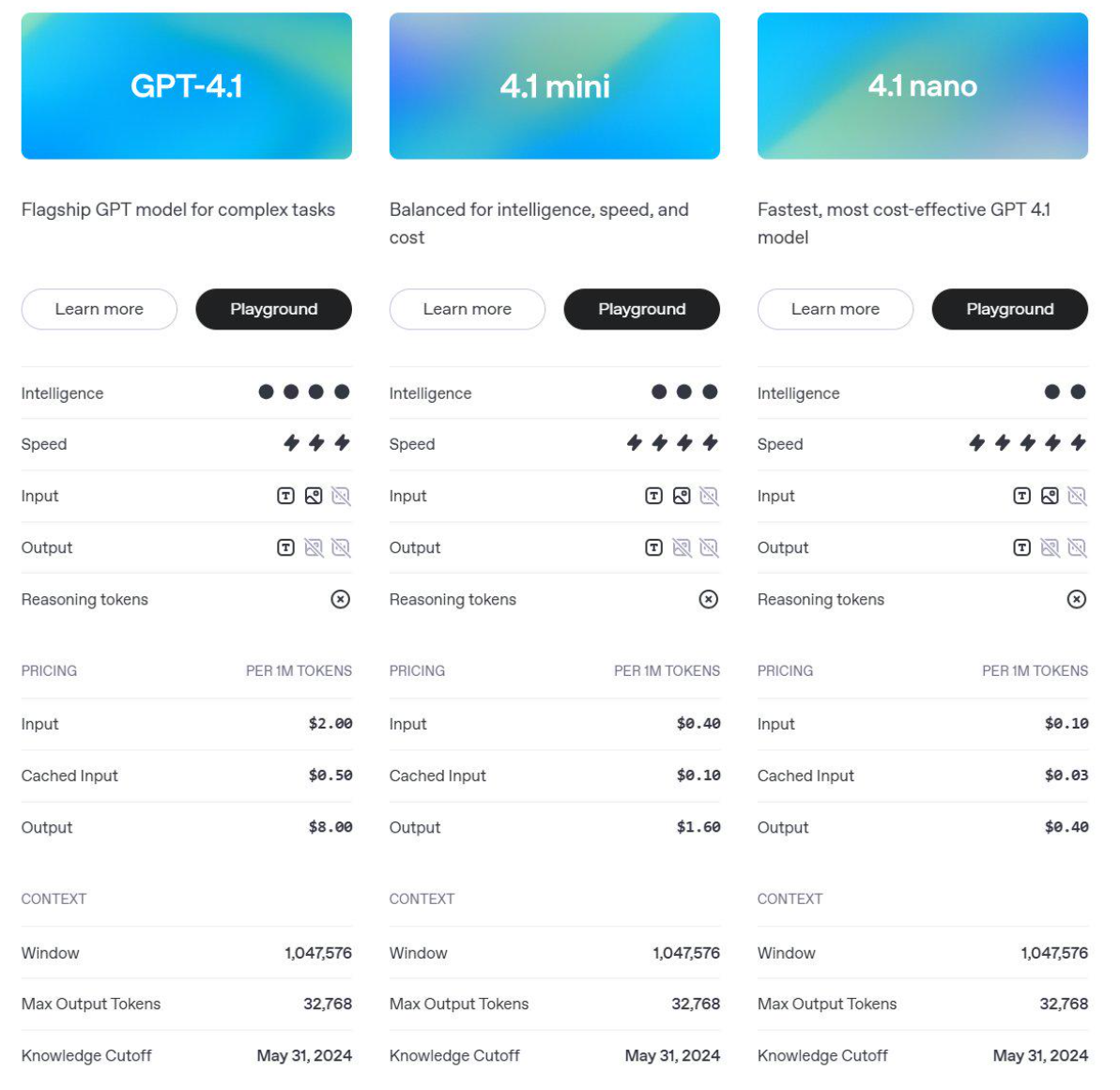
但是,模型上下文的增长也是有限度的,对于开发者来说,能够一次性输入的信息都会有限制。
- 缺陷三:模型专业知识与时效性知识不足
大型语言模型虽然在通用领域展现出令人瞩目的语言理解和生成能力,但其在特定领域的专业知识掌握往往存在明显局限。其根本原因在于,模型的训练依赖于预先收集的大规模语料,这些语料覆盖面虽广,却很难保证在所有专业领域中具有足够的深度和准确性。某些领域,如医学、法律或前沿科技,知识更新速度快且门槛较高,公开可获取的高质量数据本身就有限,模型难以在此基础上形成系统性和权威性的认知。此外,模型训练通常在固定的时间点结束,因此其所掌握的知识具有天然的时效性,无法实时反映新近出现的研究成果、政策变化或行业动态。这种静态的知识存储模式,决定了大模型在面对最新或高度专业化的问题时,往往难以提供全面、精确的解答。

基于此,我们再回顾RAG的技术实现流程,就不难发现其背后的技术价值了:如果我们能在每次对话的时候,为当前模型输入最精准的问题相关的文档,那就能拓展模型的知识边界,无论是提升模型专业知识的准确性、给模型灌输一些时效性的知识、或者消除模型幻觉,都将大有助益,而在其他一些对话场景中,无论是需要围绕海量的文本搭建本地问答知识库、还是在构建无限上下文的聊天机器人,RAG技术都是最佳解决方案。
3. RAG全栈技术体系介绍
但是,就像前文介绍的那样,RAG技术是一项应用面广、门槛很低、但同时上限也很高的一项技术。历经数年的技术发展,RAG技术的体系已经非常庞大,以下是RAG技术全栈技术框架概览:
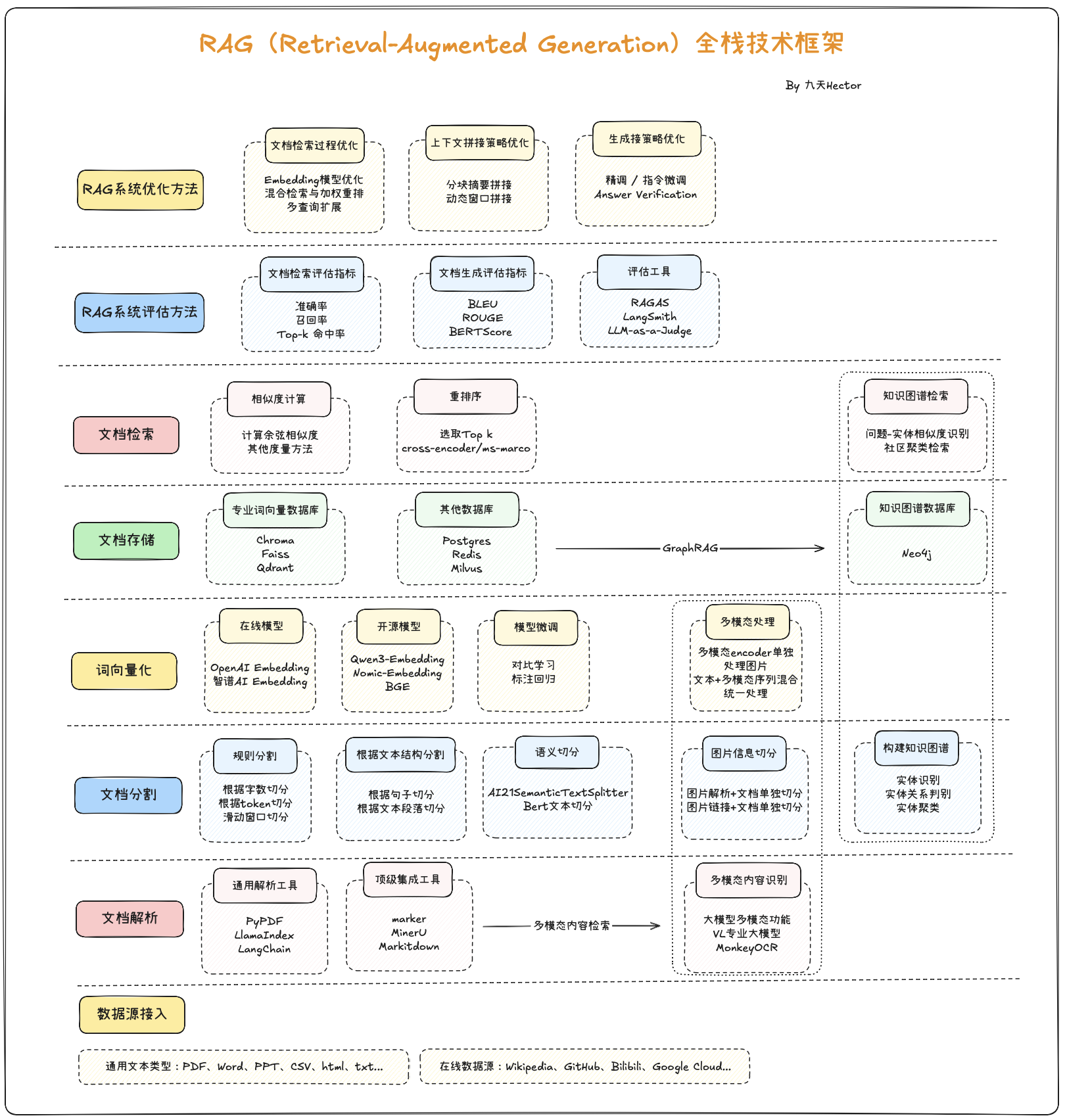
4.LangChain RAG API介绍
在LangChain框架中,RAG作为一个非常重要且关键的模块独立存在,如下图所示:https://python.langchain.com/docs/integrations/retrievers/
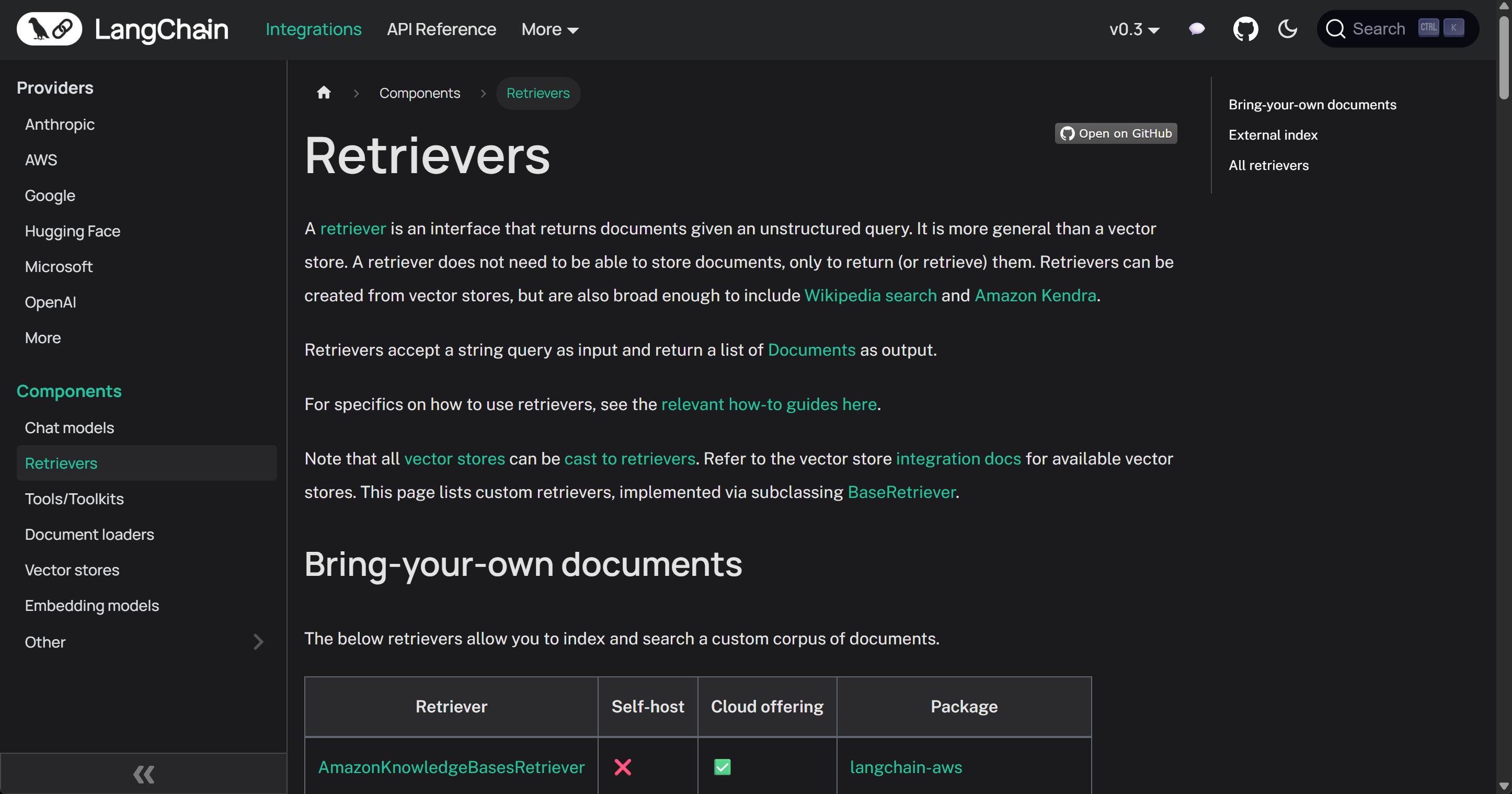
针对我们在上一小节分析的RAG流程,每一个子流程中,LangChain都提供了多种较为通用的实现方法,这包括如何将不同来源、不同形式的数据切分成一个个小块,如何使用Embedding模型做向量化,如何将向量存储进向量数据库中,以及提供了快速检索的优化算法。每一环节设计的基础技术,都作为一个独立的抽象模块存在,而将各个环节像Chains一样串流起来进行数据交换,形成一个完整的RAG系统,LangChain抽象了一个所谓的data connection数据处理流,如下图所示:
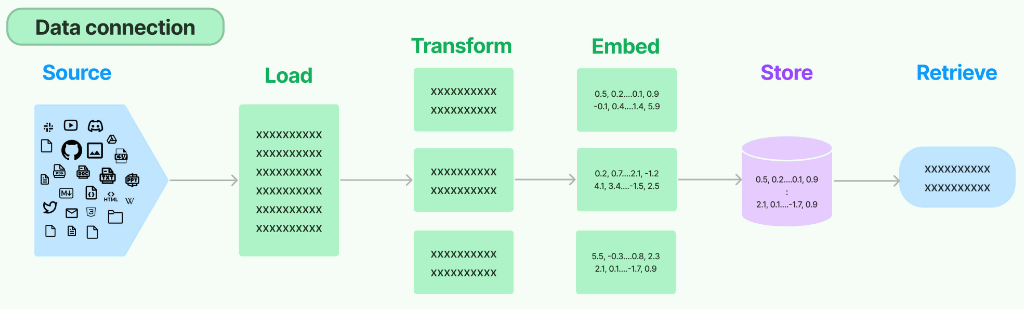
data connecting 是Langchain框架原生的数据处理流,RAG是涉及多个处理环节的一个架构,它不是个体,而是一个整体,所以虽然不同环节、不同模块间所做的事情是不一样的,但它们之间是需要链接的,需要进行数据的交换,那这一部分工作,就是交给data connection来统一管理。例如,在上述流程中,"Source"阶段指的是附加的数据库,它能够整合来自不同数据源的信息。通过"Load"组件,这些数据可以被统一管理。"Transform"组件则负责进行数据切分等一系列前文提到的构建RAG所需的开发任务,提供了各种不同的解决方案。
因此,学习LangChain中RAG的构建过程我们更建议:第一步学流程,第二步学关键点,第三步学每一环节的具体技术,第四步不断地扩展优化,从基础RAG到进阶RAG。所以接下来,我们就按照LangChain的data conncetiong流程,逐步拆解每一模块的关键技术点进行讲解和实践,最终跑通这个RAG流程。
5. LangChain RAG系统开发基础环境搭建
! pip install langchain-text-splitters faiss-cpu langchain-openai langchain_community
- 测试调用:
import os
from dotenv import load_dotenv
load_dotenv(override=True)
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-5",
base_url="https://ai.devtool.tech/proxy/v1",
)
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-chat")
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
6. 从零搭建简易Agentic RAG系统
使用OpenAI的Embeddings模型将自然语言转化成词向量的表示。
OPENAI_EMBEDDING_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_EMBEDDING_BASE_URL = "https://ai.devtool.tech/proxy/v1"
from langchain_openai import OpenAIEmbeddings
embed = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model="text-embedding-3-small"
)
接下来,为了进一步丰富大家对LangChain中向量数据库的了解,这里我们使用FAISS作为矢量数据库。 FAISS 是 Facebook AI Research 开发的一个库,用于高效相似性搜索和密集向量聚类。LangChain在第三方集成模块(Langchain_community)中已经接入了FAISS向量数据库,所以我们就可以直接使用。

file_path = "模拟公司员工手册.md"
with open(file_path, "r", encoding="utf-8") as f:
md_content = f.read()

md_content
from langchain_text_splitters import MarkdownHeaderTextSplitter
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2")
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(md_content)
md_header_splits
len(md_header_splits)
md_header_splits[0]
md_header_splits[1]
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(md_header_splits, embedding=embed)
vector_store.save_local("staff_handbook_db")
创建矢量数据库后,我们可以进行测试:
# 加载本地的Faiss向量文件,allow_dangerous_deserialization 用于控制是否允许在加载向量存储时进行潜在的危险反序列化操作。
vector_store = FAISS.load_local(embeddings=embed, folder_path='staff_handbook_db',allow_dangerous_deserialization=True)
# 将 FAISS 向量存储转换为一个 retriever(检索器),并为该检索器设置一些搜索相关的参数。k=1 表示检索时返回 最相似的 3 个文档
retriever = vector_store.as_retriever(search_kwargs={'k': 3})
# 执行相似度搜素
query = "请问我们公司有没有病假?"
results = retriever.invoke(query)
for doc in results:
print(f"Content: {doc.page_content}")

results
# 直接在向量库上搜索并返回相似度
results = vector_store.similarity_search_with_score(query, k=3)
for doc, score in results:
print(f"Score: {score:.4f}")
print(f"Content: {doc.page_content}\n")
然后即可将这个检索过程封装为一个完整的外部工具:
from langchain.tools.retriever import create_retriever_tool
# 3. 包装成一个 tool
retriever_tool = create_retriever_tool(
retriever,
name="staff_handbook_search",
description="用于检索有关员工福利、休假政策、绩效管理、招聘、入职以及其他与 HR 相关的话题",
)
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(model=model,
tools=[retriever_tool],
prompt="你是一名助人为了的助手,当用户提问有关员工福利、休假政策、绩效管理、招聘、入职以及其他与 HR 相关的话题时,可以调用staff_handbook_search工具进行文档检索回答。其他问题则可以调用你的原始知识库进行回答。")
response = agent.invoke({"messages": [{"role": "user", "content": "请问公司有病假么?"}]})
response
response['messages'][-1].content
而这背后其实就是一次完整的Function calling调用流程:
len(response['messages'])
response['messages'][0]
response['messages'][1]
response['messages'][2]
response['messages'][3]