多模态Multi-Agent视觉RAG系统开发实战
课程说明:
- 体验课内容节选自《2025大模型Agent智能体开发实战》(秋招冲刺班) 完整版付费课程
体验课时间有限,若想深度学习大模型技术,欢迎大家报名由我主讲的《2025大模型Agent智能体开发实战》(秋招冲刺班)

《2025大模型Agent智能体开发实战》(秋招冲刺班) 为【100+小时】体系大课,总共20大模块精讲精析,零基础直达大模型企业级应用!

部分项目成果演示
from IPython.display import Video
- MateGen项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/MG%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- 智能客服项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E6%A1%88%E4%BE%8B%E8%A7%86%E9%A2%91.mp4", width=800, height=400)
- Dify项目演示
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2f1b47f42c65fd59e8d3a83e6cb9f13b_raw.mp4", width=800, height=400)
- LangChain&LangGraph搭建Multi-Agnet
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/%E5%8F%AF%E8%A7%86%E5%8C%96%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90Multi-Agent%E6%95%88%E6%9E%9C%E6%BC%94%E7%A4%BA%E6%95%88%E6%9E%9C.mp4", width=800, height=400)
此外,若是对大模型底层原理感兴趣,也欢迎报名由我和菜菜老师共同主讲的《2025大模型原理与实战课程》(秋招冲刺班)

两门大模型课程秋招冲刺班即将封班,直播间享五折特价+全套SVIP新班特定福利,合购还有更多优惠哦~详细信息扫码添加助教,回复“大模型”,即可领取课程大纲&查看课程详情👇


《大模型Agent开发实战》(体验课)
Part 3. 多模态Multi-Agent视觉RAG系统开发实战
一、Google ADK 大模型生态介绍
Google ADK(Agent Development Kit)在设计上是 model-agnostic / deployment-agnostic:除了与自家 Gemini 的一线适配(多模态、工具编排、示例最全),也支持把外部或本地模型接进来。主流路径包括:
- 直接指向 Vertex AI 上的模型端点(含自家与第三方/自部署模型);
- 通过 LiteLLM(SDK/Proxy)把 OpenAI、Anthropic、OpenRouter、Ollama/vLLM 等供应商统一为“OpenAI 兼容”接口供 ADK 调用;
- 借助 LangChain/CrewAI 对大量第三方/本地模型的访问;
- 通过 MCP(Model Context Protocol)把外部服务/工具标准化接入,间接扩展增强模型能力。
ADK 接入外部/非 Gemini 模型的路径对比
| 接入路径 | 适用模型/来源 | 多模态支持与数据承载 | 优点 | 常见限制/坑位 |
|---|---|---|---|---|
| 原生 Gemini(Python/Java) | Gemini 2.x/2.5(Flash/Pro/Live 等) | 原生支持图像/音频/视频/文档;配合 Artifacts 传文件/二进制 | 官方最佳路径:工具/示例/Dev UI 最完善,稳定度高 | 厂商锁定;费用/配额受限 |
| Vertex AI 端点直连 | Vertex 上托管的自家或第三方/自训练模型(含微调) | 由目标模型决定;ADK 侧用 Artifacts 携带二进制 | 企业合规/网络统一;便于治理与监控 | 需要先在 Vertex 部署端点;多模态能力依赖目标模型 |
| LiteLLM(SDK/Proxy) | OpenAI(GPT-4o 等)、Anthropic、OpenRouter、Ollama/vLLM、DashScope/Qwen 等 | 走 OpenAI-style 的 image_url/base64 等格式;ADK 用 LiteLlm 包装;配合 Artifacts | 一套接口打通多家模型;可本地/混合路由、降级回退 | 个别供应商/版本对视觉或 tool-call 兼容不齐,需配置 supports_vision 或升级版本;偶见代理图像转发问题 |
| LangChain4j(ADK Java 集成) | 通过 LangChain4j 支持的 LLM(OpenAI、Anthropic、Mistral、本地等) | 由目标模型与连接器决定;二进制可由 ADK/应用层承载 | Java 生态友好;一次集成覆盖多模型 | 新特性刚发布,示例/文档在完善中;多模态链路仍看具体模型 |
| 自托管 HTTP/本地运行(vLLM/Ollama) | 开源基座(Llama/Qwen/Gemma 等)本地/容器化服务 | 需按模型协议封装视觉入参;Artifacts 传文件 | 成本可控,数据不外流;离线/私有化 | 需自建推理与扩展工具层;多模态性能/格式自己兜底 |
| MCP(Model Context Protocol)工具接入 | 任何暴露 MCP 的服务/数据源/“功能” | 非直接“模型接入”,但可把检索/数据库/业务 API 作为工具供任意模型用 | 工具标准化、即插即用;增强“能做事”的广度 | 要维护 MCP server 与权限;不解决模型本身的视觉能力 |
多种模型接入方法,推荐的选择是:
- 要“开箱稳定的多模态+工具编排”:先选 Gemini;
- 要“多供应商/本地化/成本优化”:用 LiteLLM;
- 要“把外部能力即插即用”:补 MCP;
目前国内外开闭源主流模型供应商包括:
| 排名 | 模型 /系列名称 | 开源 vs 闭源 | 支持模态 /亮点功能 | 性能或 benchmark 强项 /使用程度 | 适用场景建议 |
|---|---|---|---|---|---|
| 1 | Gemini(Google) | 闭源优先 | 图像 + 文本 +视频 +音频等多模态输入支持;工具调用稳定,context window 长 | 在多个 benchmark 上表现优异,是 ADK 官网示例中多模态支持最全面的模型 | 要求稳定性/效果好/工具丰富/做示范/企业级的场景 |
| 2 | GPT-4 Vision / GPT-4V (OpenAI) | 闭源 | 图像 + 文本混合输入;自然语言 + 视觉问答能力强 | 在 Roboflow 的比较中,Qwen-VL 和 GPT-4V 在不同测试中各有赢面;GPT-4V 在若干视觉分类任务中表现很好 | 若有权限使用,可以做高端示范或闭源 API 调用;不一定适合对成本敏感或需要完全控制的环境 |
| 3 | Qwen-VL / Qwen2.5-VL(阿里云/DashScope) | 半开源 /可部署 /商用接口 | 图像 +文本 +OCR +视频帧支持;中文理解强;对图表/文档/扫描件等任务表现好 | 在多个国内外 benchmark 上对比 GPT-4V/Gemini,有些任务超过或相近;有用户测试说“在某些 Chinese QA & 文本理解任务上超过 GPT-4V / Gemini” | 本地化中文场景/对成本/控制权有要求的用途很合适;适合图像识别、视觉问答、文档 OCR 等 |
| 4 | MiniCPM-Llama3-V 2.5 | 开源 /研究型 /部分部署 | 高分辨率图像感知能力;OCR 强;表格转换任务优秀 | 在 OpenCompass benchmark 与 OCRBench 上击败 GPT-4V-1106 和 Gemini Pro 等模型;性能/误报率 /图像细节识别表现不错。( | 图像 +文档重度 OCR /表格解析 /需要识别细节图像任务的场景很适用 |
| 5 | Pixtral-12B | 开源 | 文档 +自然图像理解;支持任意分辨率图像 +长上下文(128K tokens) | 在多个多模态 benchmark 中 “比某些大模型更小却表现强”) | 较适合资源有限但希望多模态能力强的开发环境/嵌入式/轻量部署场景 |
| 6 | Molmo(Allen Institute) | 开源 | 有多个参数版本(1B /7B /72B);视觉语言理解任务强 | 在一些学术 benchmark 中与 closed-source 的 Gemma / Claude 等比肩,特别在中小模型下性价比高) | 用于教学 /原型 /成本敏感但还要有视觉任务能力的场景 |
| 7 | Aria | 开源 | 混合专家(Mixture-of-Experts)架构;语言 +视觉 +长上下文 +指令遵守度好 | 在多个多模态任务中强劲;比某些类似规模模型如 Pixtral / Llama3.2 在视觉任务上有领先表现 | 如果你的项目中要处理多个视觉输入 +语言指令 +长上下文 +高质量输出,这类模型很适用 |
| 8 | Valley2(ByteDance /开放) | 开源 | 专注电商/短视频等视觉 +语言任务;参数规模适中;设计上考虑实用性 | 在电商 benchmark 上表现很好,OpenCompass 排行在 <10B 参数模型中排名高 | 电商图像识别 /短视频内容分析 /图像 +标签自动生成等场景推荐使用 |
| 9 | LLaVA /类似开源 VLM 项目 | 开源 | 图像问答 /图像说明能力不错;社区支持强;可做 fine-tune | 虽然在某些细节/OCR/视频长时间理解上可能不如闭源或最新模型,但整体性能与可改造性好 | 适合入门/教学示例/快速原型构建+可自定义/可 debug 场景 |
| 10 | EVA-CLIP-18B | 开源 | 专注图像分类/视觉先验 +语言描述的组合;零样本分类能力强 | 在多个图像分类 benchmark 中零样本 top-1 准确度很高;对自然图像任务执行好 | 如果场景偏自然图像识别/分类/标签任务(不强 OCR 或复杂结构化输出)很合适 |
主流的如DeepSeek v3.1 & r1、Qwen3系列等在线API或本地部署的开源模型接入,其接入的规范主要包含以下两个方面:
- 符合
OpenAI RESTFUL API规范的在线API,比如 DeepSeek官方API, 阿里云百炼应用开发平台 等; - 通过
vLLM、Ollama等框架部署启动的模型,可以使用其OpenAI兼容的REST API地址实现接入; - 通过
LiteLLM 框架集成的在线API & 本地部署的开源模型;
二、LiteLLM 快速入门
除了上述直接通过OpenAIChatCompletionsModel类接入符合OpenAI RESTFUL API规范的大模型端点(EndPoint)以外,OpenAI Agents SDK官方兼容了使用LiteLLM项目托管的模型服务接入。LiteLLM 是一个开源项目,于2023年7月27日开源。该项目集成了 100+ 主流模型,Github上开源地址:https://github.com/BerriAI/litellm
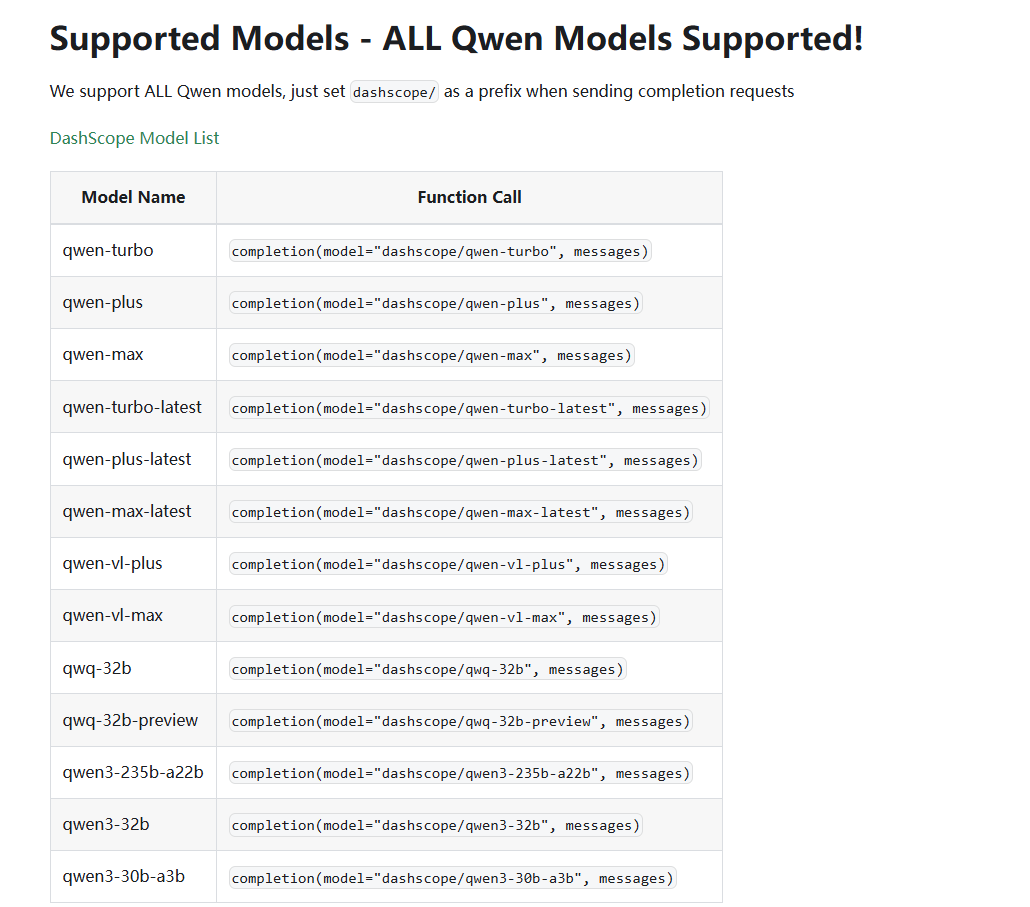
其中该项目框架支持模型的完整列表可以在这里找到:https://docs.litellm.ai/docs/providers
因此,如果想要使用LiteLLM接入其他外部模型,我们首先需要安装litellm依赖项组,执行如下命令:
# ! pip install "openai-agents[litellm]"
我们这里选择Qwen-VL模型作为多模态模型进行接入。首先在官方注册API_Key,注册链接如下:https://bailian.console.aliyun.com/?spm=5176.29597918.J_SEsSjsNv72yRuRFS2VknO.2.29bf7b08zi7Shx&tab=model#/model-market
快速进行测试:
"""
OpenAI version: 1.107.3
"""
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key="sk-e3275257e49848758b1169e1e2044193",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-vl-plus", # 此处以qwen-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[{"role": "user","content": [
{"type": "image_url",
"image_url": {"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"}},
{"type": "text", "text": "请你描述一下图片中的内容"},
]}]
)
print(completion.model_dump_json())
print(completion.choices[0].message.content)
三、Google ADK 接入多模态大模型
在使用 Google ADK 接入 LiteLLM 托管的多模态大模型之前,首先安装必要的依赖包:
FENCE0
对于阿里云百炼平台的Qwen-VL模型,我们需要了解 LiteLLM 中对应的模型调用格式。接入多模态大模型的两个核心关键点是:
- 模型前缀规范:在
LiteLLM中调用阿里云百炼的模型,必须使用openai/前缀,如:openai/qwen-vl-plus - 图片数据格式:ADK 支持两种图片输入方式:
inline_data:适用于本地图片文件(推荐)from_uri:适用于网络图片URL
无论处理本地图片还是网络图片,我们都需要先完成通用配置部分:
import asyncio
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from google.genai import types
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
import os
import mimetypes
import os
from dotenv import load_dotenv
load_dotenv(override=True)
QWEN_MODEL_NAME = os.getenv("QWEN_MODEL_NAME")
QWEN_API_KEY = os.getenv("QWEN_API_KEY")
QWEN_BASE_URL = os.getenv("QWEN_BASE_URL")
# 配置全局变量
APP_NAME = "multimodal_chatbot"
USER_ID = "user_1"
SESSION_ID = "session_001"
每个导入模块的作用如下
| 导入模块 | 功能说明 | 关键作用 |
|---|---|---|
google.adk.agents.Agent | ADK智能体核心类 | 创建和配置智能体,绑定模型和指令 |
google.adk.models.lite_llm.LiteLlm | LiteLLM模型适配器 | 让ADK可以调用LiteLLM托管的外部模型 |
google.genai.types | ADK数据类型模块 | 提供Content, Part, Blob等多模态数据结构 |
google.adk.runners.Runner | 对话执行器 | 管理智能体与用户的异步对话流程 |
google.adk.sessions.InMemorySessionService | 会话服务 | 在内存中管理对话历史和上下文 |
mimetypes | Python标准库 | 自动识别文件的MIME类型(如image/jpeg) |
接下来创建多模态智能体:
# 创建多模态智能体
vision_agent = Agent(
name="qwen_vision_agent", # 智能体名称
model=LiteLlm( # 关键:使用LiteLlm适配器
model = os.getenv("QWEN_MODEL_NAME"), # 须加 openai/ 前缀!
api_key = os.getenv("QWEN_API_KEY"), # 阿里云百炼兼容接口
base_url = os.getenv("QWEN_BASE_URL") # API密钥
),
description="多模态视觉理解专家", # 智能体描述
instruction="""
你是专业的多模态助手,擅长图像分析和视觉问答。
主要能力:
1. 图像内容描述:准确描述图片中的主体、场景、细节
2. OCR文字识别:提取图片中的文字信息
3. 视觉问答:基于图片内容回答用户问题
4. 结构化输出:按要求整理信息并给出要点
回答格式:
- 首先整体描述图像
- 然后提供具体分析要点
- 最后给出实用建议(如适用)
请始终保持专业、准确、有条理的回答风格。
"""
)
print("多模态智能体配置完成!")
print(f"智能体名称: {vision_agent.name}")
print(f"使用模型: openai/qwen-vl-plus")
print(f"API端点: 阿里云百炼平台")
大模型配置 LiteLlm
FENCE0
加 openai/ 前缀的原因是LiteLLM内部需要通过前缀识别调用哪个供应商的接口转换器。openai/qwen-vl-plus 告诉LiteLLM使用OpenAI兼容模式来调用阿里云的Qwen模型,这在ADK框架中兼容的仅是OpenAI规范。其次,**指令设计 instruction**是智能体的"行为准则",定义了:
- 能力范围:图像分析、OCR、视觉问答、结构化输出
- 回答风格:专业、准确、有条理
- 输出格式:整体描述 → 要点分析 → 实用建议
3.1 本地图片识别开发实战
现在我们实现本地图片版本,这是生产环境中最常用的方式。本地图片处理的优势比较多,主要如下:
- 数据安全:图片不需要上传到外部服务器
- 处理稳定:不依赖网络连接质量
- 批量处理:可以轻松处理本地图片文件夹
- 格式支持:支持各种本地图片格式
首先我们需要实现一个专门的本地图片加载函数:
def load_local_image(image_path: str) -> tuple[bytes, str]:
"""
本地图片加载函数
功能说明:
- 读取本地图片文件的二进制数据
- 自动识别图片的MIME类型
- 提供详细的加载信息反馈
Args:
image_path (str): 本地图片文件路径
Returns:
tuple: (图片二进制数据, MIME类型)
Raises:
FileNotFoundError: 图片文件不存在时抛出
"""
# 第一步:检查文件是否存在
if not os.path.exists(image_path):
raise FileNotFoundError(f"图片文件不存在: {image_path}")
print(f"开始加载本地图片: {image_path}")
# 第二步:读取图片二进制数据
try:
with open(image_path, 'rb') as f:
image_data = f.read()
print(f"图片读取成功,文件大小: {len(image_data):,} bytes")
except Exception as e:
raise Exception(f"读取图片失败: {str(e)}")
# 第三步:自动识别MIME类型
mime_type, _ = mimetypes.guess_type(image_path)
# 如果无法识别或不是图片类型,使用默认值
if not mime_type or not mime_type.startswith('image/'):
print("无法识别MIME类型,使用默认值 image/jpeg")
mime_type = 'image/jpeg'
print(f"MIME类型: {mime_type}")
return image_data, mime_type
# 测试本地图片加载函数
print("本地图片加载函数已定义完成!")
print("支持的图片格式: .jpg, .jpeg, .png, .gif, .webp, .bmp 等")
print("使用示例: image_data, mime_type = load_local_image('my_image.jpg')")
ADK的types.Part支持两种图片输入方式:
from_uri- 适用于网络图片URLinline_data- 适用于本地图片文件(推荐)
对于本地图片,在进行解析时我们需要依次执行如下步骤:
- 读取文件的二进制数据
- 识别正确的MIME类型
- 将数据包装为ADK的
Blob对象
因此我们设计的函数执行流程为: FENCE0
支持的图片格式
支持的图片格式
| 格式 | MIME类型 | 说明 |
|---|---|---|
.jpg/.jpeg | image/jpeg | 最常用的图片格式 |
.png | image/png | 支持透明背景 |
.gif | image/gif | 支持动画(但ADK会处理为静态) |
.webp | image/webp | Google的现代图片格式 |
.bmp | image/bmp | Windows位图格式 |
接下来实现完整的本地图片处理流程:
async def process_local_image(image_path: str, question: str = "请描述图中主体、场景,并给出三条要点。"):
"""
本地图片处理主函数
完整流程:
1. 加载本地图片文件
2. 创建ADK会话
3. 构造多模态消息
4. 发送给智能体处理
5. 实时显示响应结果
Args:
image_path (str): 本地图片文件路径
question (str): 要问的问题
"""
print("开始本地图片处理流程...")
try:
# 步骤1:加载本地图片
print("步骤1:加载本地图片")
image_data, mime_type = load_local_image(image_path)
# 🔗 步骤2:创建ADK会话服务
print("\n 步骤2:初始化ADK会话服务")
session_service = InMemorySessionService()
await session_service.create_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID
)
print(f"会话创建成功: {SESSION_ID}")
# 步骤3:构造多模态消息
print("\n步骤3:构造多模态消息")
user_message = types.Content(
role="user",
parts=[
# 文本部分
types.Part(text=question),
# 图片部分 - 使用 inline_data 方式(本地图片推荐)
types.Part(
inline_data=types.Blob(
data=image_data, # 图片二进制数据
mime_type=mime_type # MIME类型
)
)
]
)
print(f"消息构造完成:")
print(f"文本: {question}")
print(f"图片: 本地文件 ({len(image_data):,} bytes, {mime_type})")
# 步骤4:创建Runner并执行对话
print("\n步骤4:智能体处理中...")
runner = Runner(
agent=vision_agent,
session_service=session_service,
app_name=APP_NAME,
)
print("正在调用 Qwen-VL 模型...")
print("=" * 60)
# 步骤5:异步处理响应流
async for event in runner.run_async(
user_id=USER_ID,
session_id=SESSION_ID,
new_message=user_message,
):
# 显示事件来源
print(f"事件来源: {event.author}")
if event.content and event.content.parts:
# 检查工具调用(如果有)
if event.get_function_calls():
print("工具调用:")
for call in event.get_function_calls():
print(f"{call.name}: {call.args}")
# 检查工具响应(如果有)
elif event.get_function_responses():
print("工具响应:")
for response in event.get_function_responses():
print(f"{response.name}: {response.response}")
# 最终的AI响应
elif event.content.parts[0].text:
print("AI分析结果:")
print("-" * 40)
print(event.content.parts[0].text)
print("-" * 40)
# 显示响应详情(调试信息)
print(f"\n响应详情:")
print(f"响应长度: {len(event.content.parts[0].text)} 字符")
print(f"Parts数量: {len(event.content.parts)}")
print("\n本地图片处理完成!")
except FileNotFoundError as e:
print(f"文件错误: {e}")
print("解决方案:")
print(" 1. 检查图片文件路径是否正确")
print(" 2. 确认图片文件确实存在")
print(" 3. 检查文件权限")
except Exception as e:
print(f"处理失败: {str(e)}")
print("本地图片处理函数已定义完成!")
接下来进行本地图片处理测试,我们需要先下载一张测试图片到当前目录下,然后修改下面的 image_path 变量为你的图片文件名,然后运行:
# 配置测试参数
LOCAL_IMAGE_PATH = "dog_and_girl.jpeg" # 这里可以修改为你的图片文件名!
TEST_QUESTION = "请详细描述这张图片中的内容,包括人物、动物、环境等,并给出三个关键观察要点。"
print("本地图片处理测试")
print("=" * 60)
print(f"目标图片: {LOCAL_IMAGE_PATH}")
print(f"测试问题: {TEST_QUESTION}")
print("=" * 60)
# 检查文件是否存在
if os.path.exists(LOCAL_IMAGE_PATH):
print(f"找到图片文件: {LOCAL_IMAGE_PATH}")
# 执行本地图片处理
await process_local_image(LOCAL_IMAGE_PATH, TEST_QUESTION)
else:
print(f"图片文件不存在: {LOCAL_IMAGE_PATH}")
print("\n解决方案:")
print("1. 下载一张测试图片到当前目录")
print("2. 或者修改 LOCAL_IMAGE_PATH 变量为现有图片的路径")
print("3. 支持的格式: .jpg, .jpeg, .png, .gif, .webp, .bmp")
# 提供一个下载示例图片的建议
print("\n下载测试图片的Python代码:")
print("```python")
print("import requests")
print("url = 'https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg'")
print("response = requests.get(url)")
print("with open('dog_and_girl.jpeg', 'wb') as f:")
print(" f.write(response.content)")
print("print('图片下载完成!')")
print("```")
3.2 云端/网络图片URL实战
接下来实现网络图片版本,适用于处理网络上的图片资源。网络图片处理的优势:
- 无需下载:直接使用图片URL,节省本地存储
- 实时处理:可以处理动态生成的图片链接
- API集成:容易与其他Web服务集成
- 共享便利:URL可以轻松分享和复制
但需要注意的是:需要稳定的网络连接以及URL可能失效或图片被删除等诸多问题。
首先实现一个图片URL验证函数,确保链接有效:
import requests
from urllib.parse import urlparse
def validate_image_url(url: str) -> bool:
"""
验证图片URL的有效性
功能说明:
- 检查URL格式是否正确
- 验证图片是否可以访问
- 检查响应的Content-Type
Args:
url (str): 图片URL地址
Returns:
bool: URL是否有效
"""
try:
# 第一步:检查URL格式
parsed = urlparse(url)
if not parsed.scheme or not parsed.netloc:
print("URL格式不正确")
return False
print(f"验证URL: {url}")
# 📡 第二步:发送HEAD请求(只获取头信息,不下载完整文件)
response = requests.head(url, timeout=10, allow_redirects=True)
# 第三步:检查HTTP状态码
if response.status_code != 200:
print(f"HTTP错误: {response.status_code}")
return False
# 第四步:检查Content-Type
content_type = response.headers.get('content-type', '').lower()
if not content_type.startswith('image/'):
print(f"Content-Type不是图片: {content_type}")
# 不直接返回False,因为有些服务器可能不正确设置Content-Type
# 第五步:检查文件大小(如果有)
content_length = response.headers.get('content-length')
if content_length:
size_mb = int(content_length) / (1024 * 1024)
print(f"图片大小: {size_mb:.2f} MB")
# 警告过大的图片
if size_mb > 50:
print("图片文件较大,处理可能需要更多时间")
print(f"URL验证成功: {content_type}")
return True
except requests.exceptions.Timeout:
print("请求超时,请检查网络连接")
return False
except requests.exceptions.RequestException as e:
print(f"网络请求失败: {str(e)}")
return False
except Exception as e:
print(f"URL验证异常: {str(e)}")
return False
print("URL验证函数已定义完成!")
print("功能: 验证图片URL的可访问性和有效性")
接下来实现完整的网络图片处理流程。
async def process_url_image(image_url: str, question: str = "请描述图中主体、场景,并给出三条要点。"):
"""
网络图片URL处理主函数
完整流程:
1. 验证图片URL有效性
2. 创建ADK会话
3. 构造多模态消息(使用from_uri)
4. 发送给智能体处理
5. 实时显示响应结果
Args:
image_url (str): 网络图片URL地址
question (str): 要问的问题
"""
print("开始网络图片处理流程...")
print("=" * 60)
try:
# 步骤1:验证图片URL
print("步骤1:验证图片URL")
if not validate_image_url(image_url):
print("图片URL验证失败,停止处理")
return
#步骤2:创建ADK会话服务
print("\n步骤2:初始化ADK会话服务")
session_service = InMemorySessionService()
# 使用不同的session_id以区分本地图片和URL图片的会话
url_session_id = SESSION_ID + "_url"
await session_service.create_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=url_session_id
)
print(f"会话创建成功: {url_session_id}")
# 步骤3:构造多模态消息
print("\n步骤3:构造多模态消息")
# 自动识别图片MIME类型(基于URL扩展名)
url_lower = image_url.lower()
if url_lower.endswith(('.png', '.PNG')):
mime_type = "image/png"
elif url_lower.endswith(('.gif', '.GIF')):
mime_type = "image/gif"
elif url_lower.endswith(('.webp', '.WEBP')):
mime_type = "image/webp"
else:
mime_type = "image/jpeg" # 默认JPEG
print(f"推测MIME类型: {mime_type}")
user_message = types.Content(
role="user",
parts=[
# 文本部分
types.Part(text=question),
# 图片部分 - 使用 from_uri 方式(网络图片推荐)
types.Part.from_uri(
file_uri=image_url, # 图片URL
mime_type=mime_type # MIME类型
)
]
)
print(f"消息构造完成:")
print(f"文本: {question}")
print(f"图片: 网络URL ({mime_type})")
print(f"URL: {image_url[:50]}{'...' if len(image_url) > 50 else ''}")
# 步骤4:创建Runner并执行对话
print("\n步骤4:智能体处理中...")
runner = Runner(
agent=vision_agent,
session_service=session_service,
app_name=APP_NAME,
)
print("正在调用 Qwen-VL 模型处理网络图片...")
print("=" * 60)
# 🔄 步骤5:异步处理响应流
async for event in runner.run_async(
user_id=USER_ID,
session_id=url_session_id,
new_message=user_message,
):
# 显示事件来源
print(f"事件来源: {event.author}")
if event.content and event.content.parts:
# 检查工具调用(如果有)
if event.get_function_calls():
print("工具调用:")
for call in event.get_function_calls():
print(f" 🛠️ {call.name}: {call.args}")
# 检查工具响应(如果有)
elif event.get_function_responses():
print("工具响应:")
for response in event.get_function_responses():
print(f" 📋 {response.name}: {response.response}")
# 最终的AI响应
elif event.content.parts[0].text:
print("AI分析结果:")
print("-" * 40)
print(event.content.parts[0].text)
print("-" * 40)
# 📊 显示响应详情(调试信息)
print(f"\n响应详情:")
print(f" 响应长度: {len(event.content.parts[0].text)} 字符")
print(f" Parts数量: {len(event.content.parts)}")
print(f" 处理的URL: {image_url}")
print("\n网络图片处理完成!")
except Exception as e:
print(f"处理失败: {str(e)}")
print("可能的原因:")
print(" 1. 图片URL无法访问")
print(" 2. 网络连接不稳定")
print(" 3. API Key无效或过期")
print(" 4. 图片格式不受支持")
print(" 5. 模型服务暂时不可用")
print("网络图片处理函数已定义完成!")
接下来运行网络图片处理测试代码。需要保证网络连接正常,同时修改下面的 image_url 变量为你想处理的图片URL。
# 配置测试参数
TEST_IMAGE_URL = "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"
URL_TEST_QUESTION = "请分析这张图片,描述其中的人物互动、环境背景和情感氛围,并总结三个要点。"
print("网络图片处理测试")
print("=" * 60)
print(f"目标URL: {TEST_IMAGE_URL}")
print(f"测试问题: {URL_TEST_QUESTION}")
print("=" * 60)
# 执行
await process_url_image(TEST_IMAGE_URL, URL_TEST_QUESTION)
# print("\n更多测试URL示例:")
# test_urls = [
# "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg",
# ]
# for i, url in enumerate(test_urls, 1):
# print(f" {i}. {url}")
3.3 图片解析综合使用示例
以下是完整的综合示例,展示如何在实际项目中同时使用两种图片处理方式:
async def comprehensive_image_demo():
"""
综合演示:本地图片和网络图片处理
这个函数展示了如何在实际应用中同时使用两种图片处理方式
"""
print("Google ADK 多模态图片处理综合演示")
print("=" * 70)
# 测试场景配置
scenarios = [
{
"name": "本地图片分析",
"type": "local",
"path": "dog_and_girl.jpeg",
"question": "这张图片展现了什么样的情感?请分析人与动物的互动关系。"
},
{
"name": "网络图片分析",
"type": "url",
"path": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg",
"question": "请从构图、光线、色彩三个角度分析这张照片的摄影技巧。"
}
]
# 依次处理每个测试场景
for i, scenario in enumerate(scenarios, 1):
print(f"\n场景 {i}: {scenario['name']}")
print("-" * 50)
if scenario['type'] == 'local':
# 本地图片处理
if os.path.exists(scenario['path']):
await process_local_image(scenario['path'], scenario['question'])
else:
print(f"跳过本地图片测试: 文件 {scenario['path']} 不存在")
elif scenario['type'] == 'url':
# 网络图片处理
await process_url_image(scenario['path'], scenario['question'])
# 场景间间隔
if i < len(scenarios):
print("\n" + "等待 3 秒后进行下一个场景...")
await asyncio.sleep(3)
print("运行 await comprehensive_image_demo() 开始完整测试")
await comprehensive_image_demo()
理解了基础图像识别处理流程后,接下来我们将其应用于实际的工作场景中。
四、从零实现多智能体图像分析系统
接下来,我们就基于Google ADK的多模态大模型应用能力构建一个完整多智能体图像理解系统:
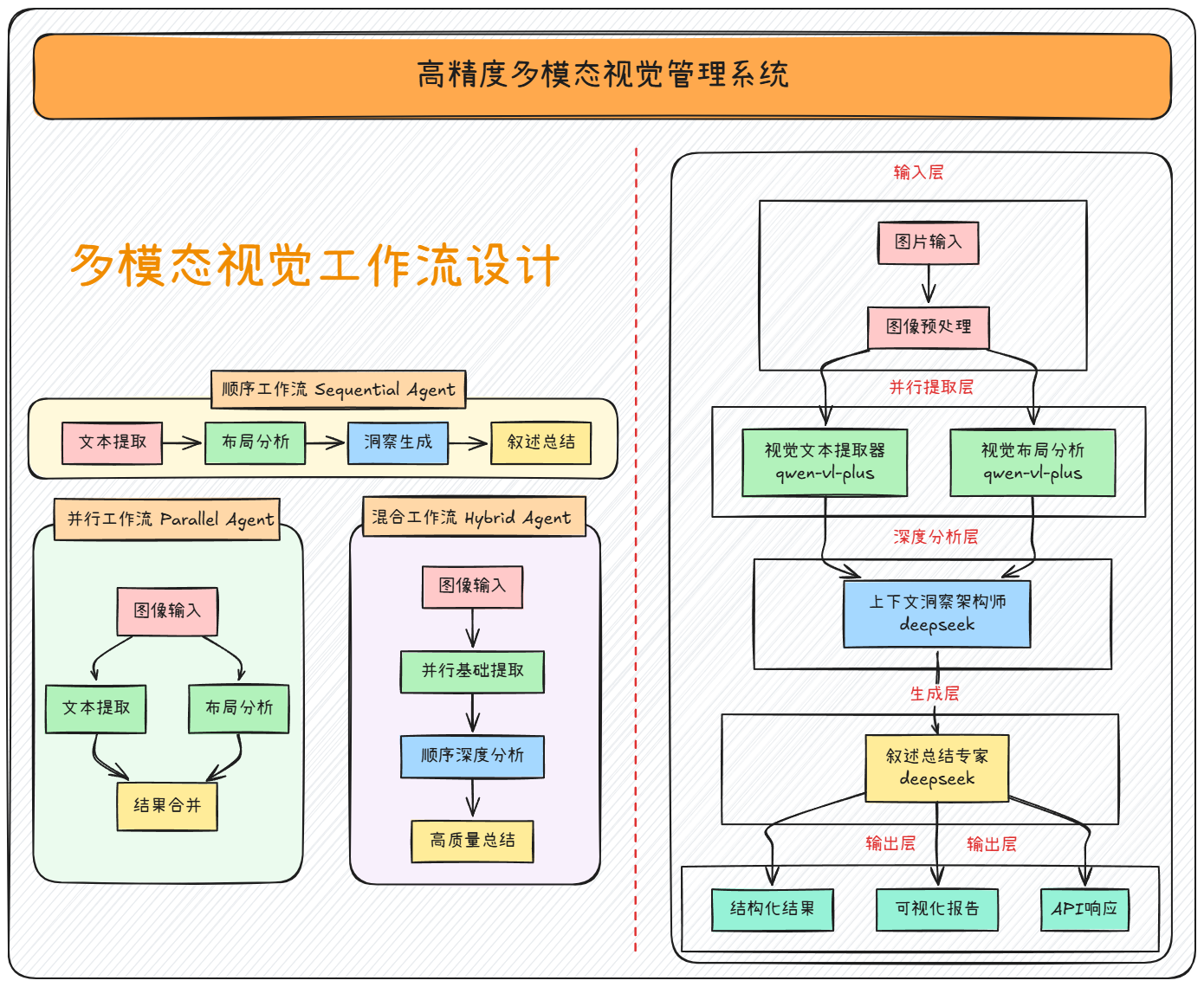
定义的多智能体架构如下:
多智能体架构
| 智能体 | ADK类型 | 模型选择 | 专业能力提升 |
|---|---|---|---|
| VisionTextExtractor | LLM Agent | openai/qwen-vl-plus | OCR + 空间理解 + 多语言 |
| VisualLayoutAnalyzer | LLM Agent | openai/qwen-vl-plus | 布局识别 + 视觉流程 + 设计理解 |
| ContextInsightArchitect | LLM Agent | deepseek/deepseek-v3.1 | 领域识别 + 趋势分析 + 异常检测 |
| NarrativeSummarizer | LLM Agent | deepseek/deepseek-v3.1 | 故事化叙述 + 决策支持 |
每个智能体都有明确的专业领域和优化的提示词,同时支持三种支持3种不同的执行模式,可根据场景需求灵活选择:
- 顺序模式:深度分析
- 并行模式:高速处理
- 混合模式:平衡质量与速度
此外,基于ADK的模块化设计,可以轻松添加新的智能体类型和工具。这个系统可以为图像理解任务提供企业级的解决方案。
五:进阶-多智能体智能图像分析与报告系统
基于上述基础架构,我们可以将其进一步扩展为适用于企业主流需求的落地场景,比如在企业/知识密集型行业中,大量业务文档、合同、发票、表格、报告等内容以扫描件、图片或混合格式存在。这些文档往往包含结构化信息(如表格、关键字段)、文本内容与视觉信息(布局、图表、图片等)。用户希望快速从这些文档中查询关键信息(例如“营业收入”、“合同期限”、“发票金额”),而不是逐页阅读或人工归纳。若将这些内容自动提取,再结合可检索的知识库 + 多模态大模型进行问答,则能显著提升效率、精度与用户体验。
整个的架构设计如下:
-
阶段一:文档分析与结构化提取 — 输入图片/PDF/扫描件 → 文档分析模块做 OCR(提取文字)、表格识别、布局解析/视觉元素定位 → 输出结构化数据(文本块、表格、元数据、位置信息/置信度)。
-
阶段二:知识库存储与索引 — 将文本块向量化存储到向量数据库;表格等结构化部分存入结构化数据库;元数据用于路由 / 提示优化 /上下文过滤。
-
阶段三:检索增强 + 多模态 RAG 问答 — 用户查询时,根据 key 或 vec 检索相关文本 +视觉元素;把文本 +图像描述/视觉元素作为上下文,调用多模态大模型生成回答;支持精确查询 +混合检索 +报告分析等不同模式。
5.1 第一阶段:文档分析与内容提取
输入:图片文档 (.jpg/.png/.pdf等) ↓ 专业文档分析系统 ↓ 输出:结构化数据
- 文本内容 (OCR提取)
- 表格数据 (结构化表格)
- 元数据 (文档类型、置信度)
- 位置信息 (布局分析)
示例输出为: FENCE0
第一阶段:文档分析与内容提取 FENCE0
第二阶段:数据传递给多模态RAG FENCE1
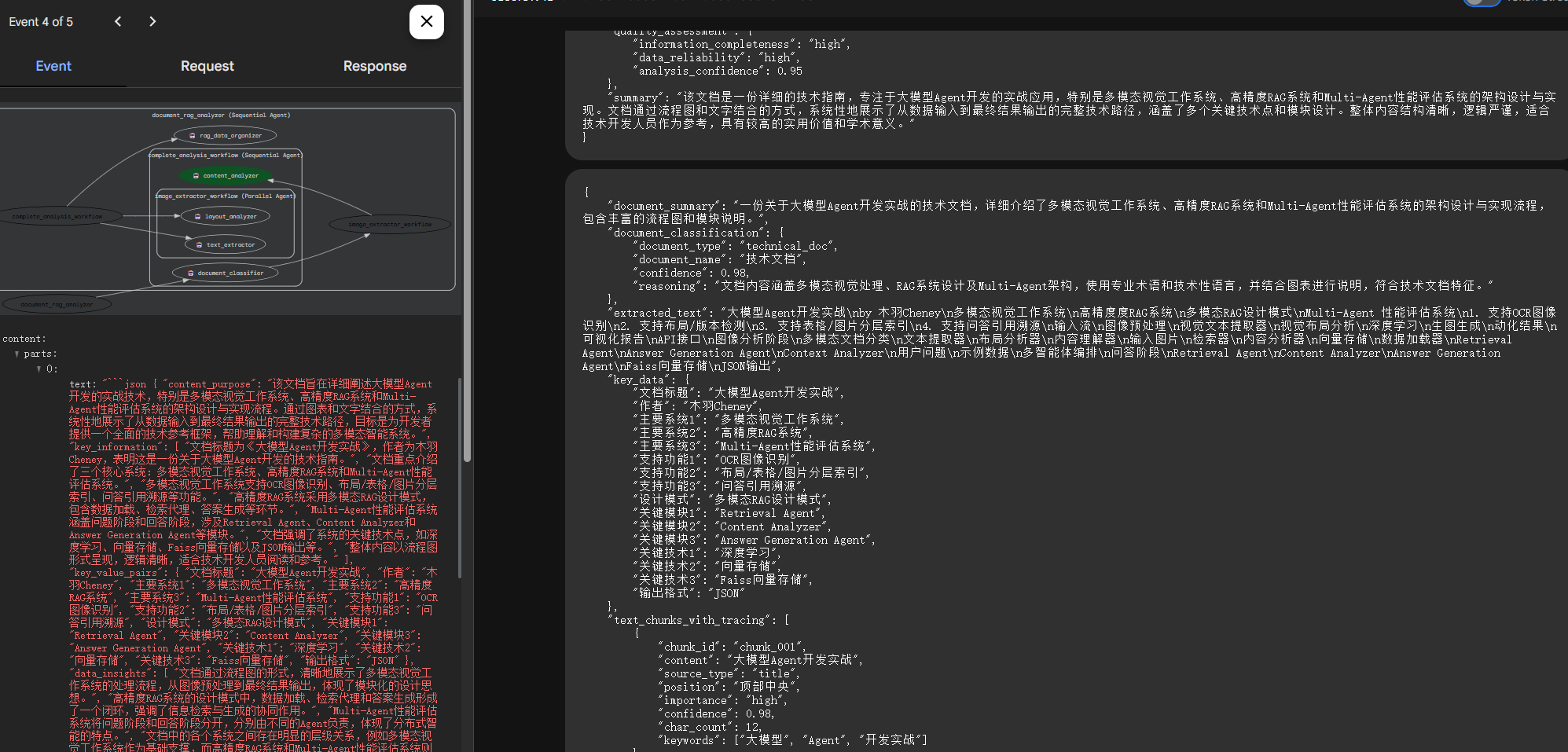
图像内容解析效果如下:
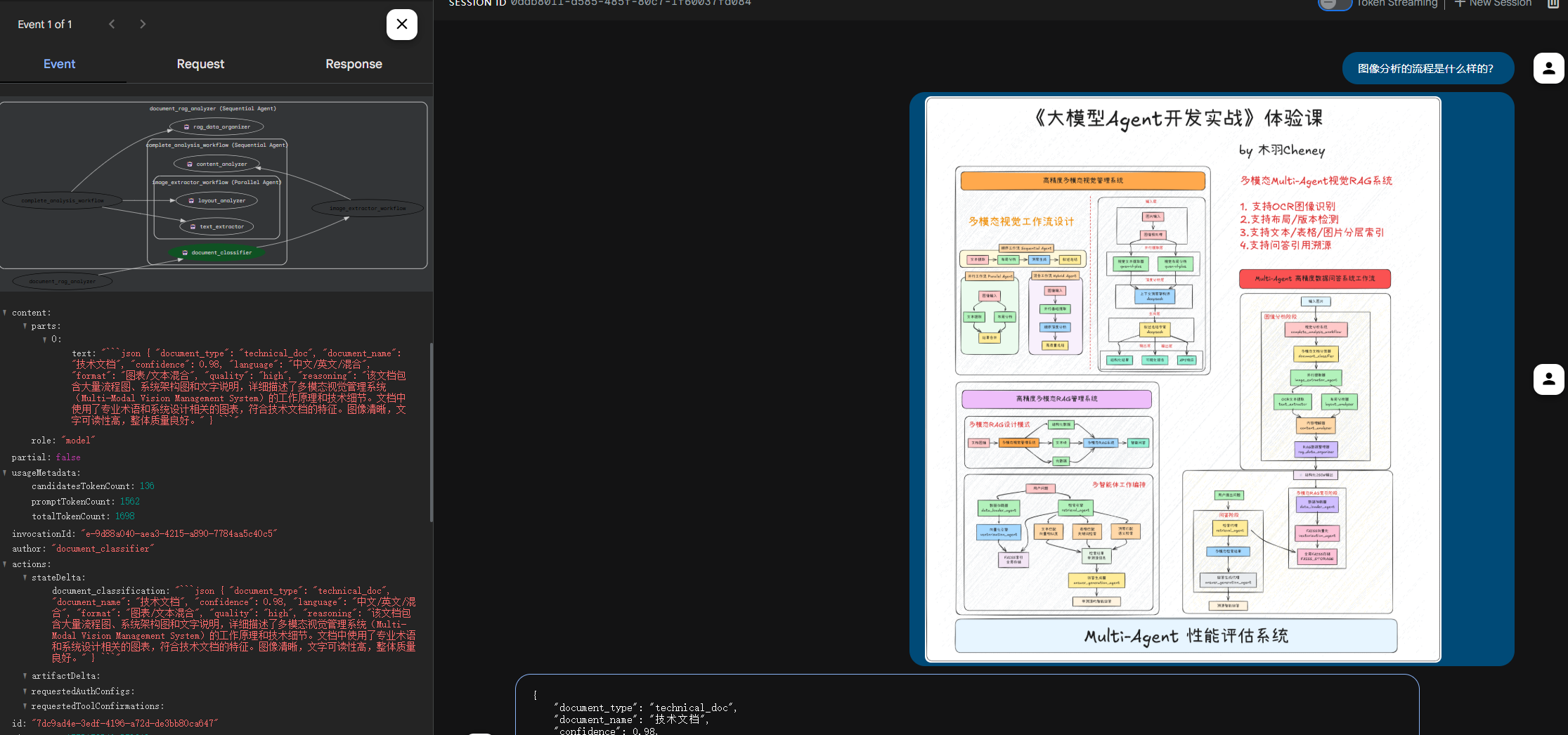
RAG 问答溯源效果如下:

六、Multi-Agent性能评估体系
在构建多智能体图像分析系统的过程中,我们不仅要关注系统的功能实现,更要建立科学的评估体系来衡量Agent的性能表现。Google ADK提供了一套完整的Agent评估框架,帮助开发者系统性地评价Agent在真实任务中的表现,确保系统的可靠性和实用性。
ADK的评估体系围绕四个核心维度展开:正确性、效率、鲁棒性和覆盖率。这套评估框架不仅提供标准化的度量指标,还支持灵活的自定义评估逻辑,让开发者能够根据具体业务需求来优化Agent性能。
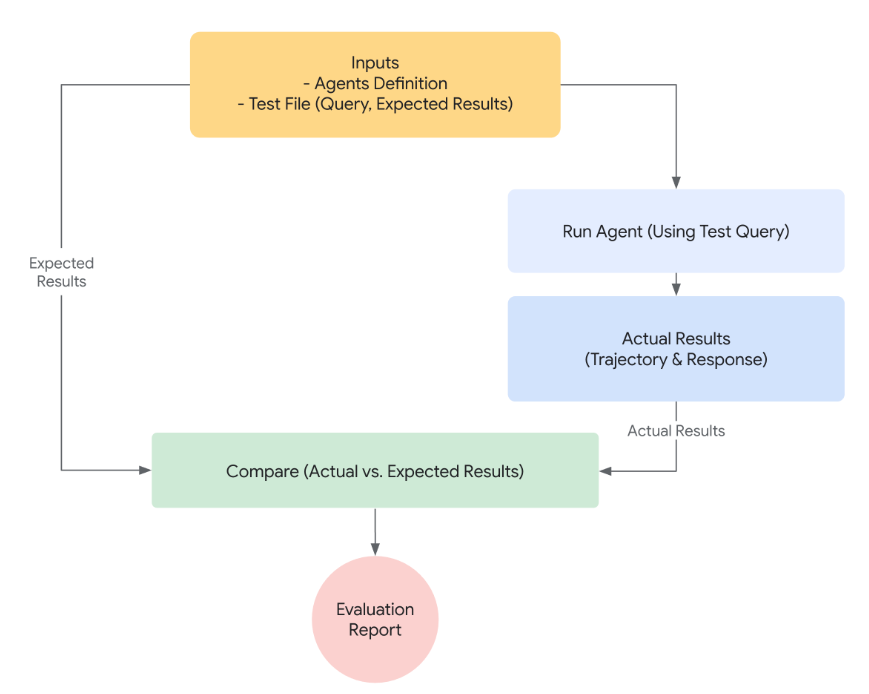
6.1 评估指标详解
- 正确性(Correctness)
正确性衡量Agent输出内容与期望结果的吻合程度,确保输出答案的准确可靠。这包括对最终回复内容的准确性评估,以及决策过程是否走对了路。ADK通过对最终响应与参考答案比对来评估正确性。例如内置的response_match_score利用ROUGE算法计算Agent最终回答与预期答案的相似度。得分越高表示回复越贴近参考答案,1.0表示完全匹配(常用于检查事实准确性)。
同时,ADK也评估Agent执行过程的正确性:例如tool_trajectory_avg_score衡量工具调用轨迹是否符合预期。它将Agent实际调用的工具序列与理想序列逐步比对,每个步骤匹配记1分,不匹配记0分,最后取平均作为轨迹正确率。示例:如果理想步骤是调用API获取数据再生成报告,而Agent实际步骤一致,则轨迹得分1.0,反之若漏调或错调工具则得分降低,表示决策路径不正确。
- 效率(Efficiency)
效率关注Agent达到目标的资源和步骤开销,即是否用最简洁有效的方式完成任务。一方面体现在动作步骤的精简——理想上Agent应按最短路径解决问题,如不进行多余的查询或迂回。ADK支持通过对比实际与理想轨迹来发现Agent流程中的低效之处。例如ADK的轨迹评估可以采用"顺序匹配"或"无序匹配"允许有多余步骤存在,这些多余步骤虽不影响最终正确性但反映了效率问题。
如果Agent执行了额外的不必要工具调用(超出预期序列),尽管最终答案正确,也会在严格的"Exact match"或效率指标下被视为低效。另一方面效率也涉及响应速度和资源使用等(如API调用次数、计算消耗),虽然ADK默认未直接提供此类数值指标,但在实际评估中可通过记录日志来推断。示例:对于需要计算的任务,Agent一次计算得到结果属高效;若多次重复调用工具才得到结果,则流程显得低效。开发者可以据此优化Agent策略,减少无效循环。
- 鲁棒性(Robustness)
鲁棒性表示Agent在不同输入和场景下稳定发挥的能力,即抗干扰能力。理想的Agent应对各种措辞、边缘情况都能做出合理反应,不轻易出错。ADK的评估体系通过多样化测试用例来检验鲁棒性。开发者应设计包括异常或极端情况的案例,例如输入缺失信息、故意刁钻的问题、无效指令等,观察Agent是否仍能正确处理。
此外,由于LLM响应具有随机性,ADK支持对同一案例重复测试多次(通过EvaluationGenerator设置repeat_num),评估Agent输出的一致性。如果多次运行结果差异很大,说明Agent策略不够稳健。示例:针对同一用户请求,Agent有时正确有时错误,或稍微修改措辞它就无法回答,这都暴露了鲁棒性问题。提高鲁棒性通常要改进Prompt使Agent理解核心意图,以及在工具失败或异常时加入降级处理。
- 覆盖率(Coverage)
覆盖率指标有两层含义:(1)测试覆盖率:评估用例集合对Agent功能点的覆盖程度;(2)任务覆盖率:Agent输出/行为对问题要求的覆盖程度。首先,一个全面的评估应当涵盖Agent的所有关键任务和场景。开发者需确保评估用例既包含常规路径也包括异常分支,实现对Agent能力的广泛覆盖。相比大量重复的简单输入,更重要的是有代表性的多样输入集合,强调覆盖广度而非数量。
其次,在单个案例内部,也要看Agent是否面面俱到地解决了用户问题。例如对于需要执行多步操作的任务,Agent是否执行了每一步(对应工具调用)的覆盖检查很重要。ADK评估提供Precision/Recall等细粒度度量:Precision衡量预测动作的相关性/正确性,Recall衡量应做的关键动作是否都做了。Recall本质上就是任务要点的覆盖率指标。示例:用户问一个百科问题,期望回答包含若干要点。如果Agent回答漏掉了一些关键信息,则覆盖率不佳;又如多工具协作任务中,Agent少用了一个本该用的工具,也属于覆盖不全。这些都会导致Recall/coverage评分下降,提示需增加该场景测试并改进Agent处理能力。
- 自动化评估 vs 人工评估(Automatic vs Human Evaluation)
由于LLM Agent性能评估涉及一定主观性,ADK在追求自动化的同时,也融入了接近人工判断的思路。它提供可自动计算的明确指标(如Rouge分数、精确匹配等)以实现客观、一致的评分。这些指标能大规模运行、快速产出结果,适合集成到CI流程中。不过,完全的自动化可能无法涵盖响应的所有质量维度。
对此,ADK在框架设计上预留了空间:一方面,支持利用LLM自身进行评价,如response_evaluation_score通过让另一个模型对Agent回答做出评分,从而在一致性、连贯性等软指标上接近人工评价;另一方面,ADK提供的Web UI让开发者可方便地人工检查评估细节。当自动评估判定某些案例失败时,UI中可以展开对比实际输出和期望输出,甚至打开执行轨迹(Trace)查看Agent每步推理情况。这相当于让人类评审参与进来找问题。总的来说,ADK鼓励将自动和人工手段结合:先用自动评估筛出大部分问题,再由开发者对疑难案例做人工分析,从而既保证评估效率,又不遗漏主观质量问题。
与仅对LLM输出文本打分不同,我们需要先明确Agent任务目标和成功标准。评估用例的设计基于具体业务场景,模拟真实用户与Agent的互动。这种任务驱动体现为:每个测试用例(EvalCase)通常是Agent解决某个实际问题的完整对话流程,包括可能的工具使用和中间步骤。
通过在评估中重现关键任务,可以验证Agent在这些任务上的表现是否达标。ADK不仅评估最终答案对不对,还评估任务过程中每一步是否合理,这正是因为评估以任务流程为基准。比如在工单助手Agent场景,会有提交工单、更新状态、通知用户等不同任务,用对应的EvalCase去评估Agent能否正确完成每个任务环节。这样的评估体系确保结果面向任务:如果Agent在模拟的真实任务中表现良好,我们才认为它真的准备好部署。