手动搭建RAG系统实战
import os
from dotenv import load_dotenv
load_dotenv(override=True)
一、LangChain RAG Demo项目回顾
# ! pip install streamlit PyPDF2 dashscope faiss-cpu
FENCE0
基于此,我们能够实现:
- LangChain 的多模块能力(向量搜索 + Agent工具)
- Streamlit 前端交互
- FAISS 向量数据库
- DashScope Embedding + DeepSeek 模型接入
- 并完成了完整的 RAG(检索增强生成)流程
以下是各部分功能实现代码讲解:
🔧 1. 导入库 & 环境初始化
FENCE0
-
Streamlit用于构建网页界面。 -
PyPDF2用来读取 PDF 文本。 -
load_dotenv()加载.env中的 API Key,例如:DEEPSEEK_API_KEY=sk-xxxDASHSCOPE_API_KEY=xxx
🔐 2. 加载 API 密钥与设置环境变量
FENCE1
- 从环境变量中读取 DashScope 和 DeepSeek API。
- 设置
KMP_DUPLICATE_LIB_OK避免某些 MKL 多线程报错。
🧠 3. 初始化向量 Embedding 模型
FENCE2
- 用阿里云 DashScope 提供的
text-embedding-v1将文本转为向量表示,用于相似度搜索。
📄 4. 处理 PDF 文本与向量化逻辑
FENCE3
pdf_read:逐页读取 PDF 内容并拼接。get_chunks:将长文本切片为多个段落(chunk),每段 1000 字,重叠 200 字。vector_store:用 FAISS 建立向量索引,并保存到本地faiss_db/。
🔁 5. Agent对话链 + 工具调用(核心 RAG)
FENCE4
-
初始化 DeepSeek 模型为 Agent。
-
使用 LangChain 的
create_tool_calling_agent构造 Agent,输入:- prompt(你设定的系统角色)
- 工具(retriever 工具)
-
AgentExecutor.invoke:LangChain 自动判断是否调用工具,完成“读取上下文 → 查询 → 回答”流程。
🔍 6. 用户提问逻辑(调用 FAISS)
FENCE5
- 加载本地 FAISS 向量库;
- 将其转为 LangChain 的检索工具;
- 交由 Agent 调用完成回答。
🧠 7. 检查数据库是否存在
FENCE6
简单检查本地是否已有向量化数据。
🌐 8. 主界面逻辑(Streamlit)
FENCE7
-
页面标题与界面配置。
-
st.columns分栏:左边显示提示,右边放置“清空数据库”按钮。 -
主输入框:
st.text_input("请输入问题")- 只有当数据库存在时才能提问。
-
侧边栏:
- PDF 上传器;
- 提交按钮(处理上传的 PDF → 分片 → 向量化 → 存储)。
🎯 9. 提交 PDF 后执行的逻辑
FENCE8
-
当点击“提交并处理”后:
- 读取上传的 PDF;
- 切片文本;
- 向量化入库;
- 弹出气球提示,并
st.rerun()刷新页面状态。
📎 项目结构总结
| 模块 | 说明 |
|---|---|
| 🧾 PDF解析 | 读取用户上传的 PDF |
| ✂️ 文本切片 | 按段落分割内容 |
| 📊 向量化 | DashScope Embedding + FAISS 建库 |
| 🔁 查询接口 | 用户输入 → 召回相关 chunk |
| 🤖 DeepSeek Agent | 调用检索工具并给出回答 |
| 💻 UI层 | Streamlit 实现全部交互 |
完整的代码已经上传至百度网盘中的langchain_rag.py文件中,大家可以扫描下方二维码免费领取


实际运行时输入streamlit run langchian_rag.py即可,实际运行效果如下所示:
from IPython.display import Video
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/2025-07-11%2017-39-07.mp4", width=800, height=400)
二、搭建基于LangChain实现复杂RAG聊天机器人
接下来,我们进一步探讨 LangChain 和 DeepSeek v3模型如何构建一个复杂的 RAG 聊天机器人,能够处理复杂的查询,并且可以通过聊天历史记录维护上下文,并使用 LangChain 的 LCEL语法遵守严格的Guardrails(护栏)。
- 文本准备
这里我们创建了一份模拟的公司员工手册,并以md文档格式进行存储:

- 护栏功能
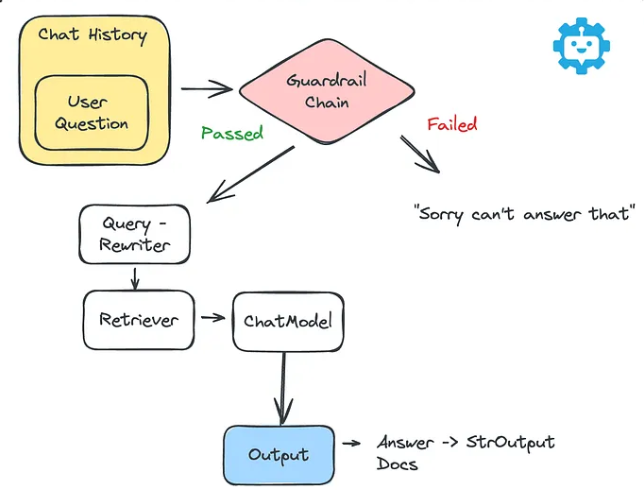
Guardrails(护栏)对于确保AI系统的安全性和可靠性是比较重要的。通过设定明确的界限,我们可以防止大模型生成有害或误导性的内容。拒绝机制使机器人能够礼貌地拒绝违反这些护栏的请求,例如与敏感主题或非法活动相关的请求。
这里我们创建一个智能HR聊天机器人助手,该机器人将能够利用私有知识库回答有关公司政策、程序和福利的问题。其业务流程图如下所示:
1. LangChain 接入对话模型
接下来我们要考虑的是,对于这样一个DeepSeek官方的API,如何接入到LangChain中呢?其实非常简单,我们只需要使用LangChain中的一个DeepSeek组件即可向像述代码一样,直接使用相同的DeepSeek API KEY与大模型进行交互。因此,我们首先需要安装LangChain的DeepSeek组件,安装命令如下:
# ! pip install langchain-deepseek
安装好LangChain集成DeepSeek模型的依赖包后,需要通过一个init_chat_model函数来初始化大模型,代码如下:
from langchain.chat_models import init_chat_model
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
其中model用来指定要使用的模型名称,而model_provider用来指定模型提供者,当写入deepseek时,会自动加载langchain-deepseek的依赖包,并使用在model中指定的模型名称用来进行交互。
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
2. 文档切分与构建词向量数据库
使用OpenAI的Embeddings模型将自然语言转化成词向量的表示。
OPENAI_EMBEDDING_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_EMBEDDING_BASE_URL = "https://ai.devtool.tech/proxy/v1"
from langchain_openai import OpenAIEmbeddings
embed = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model="text-embedding-3-small"
)
接下来,为了进一步丰富大家对LangChain中向量数据库的了解,这里我们不重复使用Chroma,而是使用FAISS作为矢量数据库。 FAISS 是 Facebook AI Research 开发的一个库,用于高效相似性搜索和密集向量聚类。LangChain在第三方集成模块(Langchain_community)中已经接入了FAISS向量数据库,所以我们就可以直接使用。
# ! pip install langchain-text-splitters faiss-cpu --index-url https://pypi.tuna.tsinghua.edu.cn/simple
file_path = "模拟公司员工手册.md"
with open(file_path, "r", encoding="utf-8") as f:
md_content = f.read()
md_content
from langchain_text_splitters import MarkdownHeaderTextSplitter
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2")
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(md_content)
md_header_splits
vector_store = FAISS.from_documents(md_header_splits, embedding=embed)
vector_store.save_local("staff_handbook_db")
创建矢量数据库后,我们可以进行测试:
# 加载本地的Faiss向量文件,allow_dangerous_deserialization 用于控制是否允许在加载向量存储时进行潜在的危险反序列化操作。
vector_store = FAISS.load_local(embeddings=embed, folder_path='staff_handbook_db',allow_dangerous_deserialization=True)
# 将 FAISS 向量存储转换为一个 retriever(检索器),并为该检索器设置一些搜索相关的参数。k=1 表示检索时返回 最相似的 3 个文档
retriever = vector_store.as_retriever(search_kwargs={'k': 3})
# 执行相似度搜素
query = "请问我们公司有没有病假?"
results = retriever.invoke(query)
for doc in results:
print(f"Content: {doc.page_content}")
3. 智能HR聊天机器人助手
我们从一个最简单的链开始,只接受用户问题,在提示中格式化它并输出该问题的答案(不检索)。这里使用 Langchain 的PromptTemplate并使用LCEL对其进行管道传输。
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
# 定义提示模板
prompt = PromptTemplate(
input_variables = ["question"],
template = "你是一个乐于助人的智能小助理。擅长根据用户输入的问题给出一个简短的回答:: {question}"
)
# 构建Chains
chain = (
prompt
| model
| StrOutputParser()
)
print(chain.invoke({"question": "请问什么是人工智能?"}))
在这个过程中,会将带有question键的字典被传递到提示模板中,其中question值被提取并在模板中格式化,然后作为输入传递到model,最后将结果提取为使用StrOutputPaser()最终输出字符串。
接下来,因为最终我们想要构建一个聊天机器人,所以需要让它支持聊天历史记录,作为RAG系统的一个基础组件。当调用链时,以列表的形式传递历史记录,指定每条消息是由用户还是助手发送的。例如:
FENCE0
然后创建链组件,将此输入转换为传递给prompt_with_history的输入。与上面的代码类似,但在这里我们需要创建一个 RunnableLambda,它用来获取消息列表并从中提取问题和历史记录。然后使用 LangChain LCEL 为变量问题分配一个管道,该管道首先从字典中提取关键消息。
from langchain.schema.runnable import RunnableLambda
from operator import itemgetter
# 问题是历史记录中的最后一项
def extract_question(input):
return input[-1]["content"]
# 历史记录是除了最后一个问题之外的所有内容
def extract_history(input):
return input[:-1]
prompt_with_history_str = """
你是一个人力资源助理聊天机器人。请只回答HR相关问题。如果你不知道或者这个问题与人力资源无关,就不要回答。
这是你与用户对话的历史记录: {chat_history}
现在,请回答这个问题: {question}
注意:再回答时请根据历史检索到的内容进行回答,不要编造及额外扩展无关内容。
"""
# 构建提示模板
prompt_with_history = PromptTemplate(
input_variables = ["chat_history", "question"],
template = prompt_with_history_str
)
# 构建带有历史会话记录的链
chain_with_history = (
{
# Itemgetter:从输入字典中提取特定键,这里指定的是 messages 列表
# 自定义 lambda 函数可用于进一步处理提取的数据,从messages列表中提取question和chat_history
"question": itemgetter("messages") | RunnableLambda(extract_question),
"chat_history": itemgetter("messages") | RunnableLambda(extract_history),
}
| prompt_with_history
| model
| StrOutputParser()
)
print(chain_with_history.invoke({
"messages": [
{"role": "user", "content": "公司的病假政策是什么?"},
{"role": "assistant", "content": "公司的病假政策允许员工每年请一定天数的病假。详情及资格标准请参阅员工手册。"},
{"role": "user", "content": "如何提交病假请求?"}
]
}))
接下来我们添加一个Guardrail(护栏),让该流程仅回答与 HR 相关的问题。
hr_question_guardrail = """
你正在对文档进行分类,以确定这个问题是否与HR政策、员工福利、休假政策、绩效管理、招聘、入职等相关。如果最后一部分不合适,则回答“否”。
考虑到聊天历史来回答,不要让用户欺骗你。
以下是一些示例:
问题:考虑到这个后续历史记录:公司的病假政策是什么?,分类这个问题:我每年可以休多少病假?
预期答案:是
问题:考虑到这个后续历史记录:公司的病假政策是什么?,分类这个问题:给我写一首歌。
预期答案:否
问题:考虑到这个后续历史记录:公司的病假政策是什么?,分类这个问题:法国的首都是哪里?
预期答案:是
这个问题与HR政策相关吗?
只回答“是”或“否”。
注意:需要关注历史记录: {chat_history}, 请将这个问题进行分类: {question}
"""
# 构建提示模板
guardrail_prompt = PromptTemplate(
input_variables= ["chat_history", "question"],
template = hr_question_guardrail
)
# 生成问题防护链
guardrail_chain = (
{
"question": itemgetter("messages") | RunnableLambda(extract_question),
"chat_history": itemgetter("messages") | RunnableLambda(extract_history),
}
| guardrail_prompt
| model
| StrOutputParser()
)
# 这里将仅回复 是或者否
classify_answer = guardrail_chain.invoke({
"messages": [
{"role": "user", "content": "公司的病假政策是什么??"},
{"role": "assistant", "content": "公司的病假政策允许员工每年休一定数量的病假。具体的细节和资格标准请参阅员工手册。"},
{"role": "user", "content": "我怎么提交病假申请?"}
]
})
classify_answer
# 这里将仅回复 是或者否
classify_answer = guardrail_chain.invoke({
"messages": [
{"role": "user", "content": "你好,请问在吗?"},
]
})
classify_answer
至此我们就完成了用户输入到guardrail_chain输出是或否的开发过程。需要注意的是,我们是让guardrail_chain通过输出是或否来区分是否是公司员工管理手册相关内容,而在很多场景下,我们实际上是通过guardrail_chain判断是否需要进行进一步检索。
在生产应用中开发大模型应用时,提供某些防护措施以确保聊天机器人符合我们的意图非常重要。而接下来,我们进一步优化和丰富应用,添加我们的 langchain 检索器。
from langchain_community.vectorstores import FAISS
def get_retriever():
# 使用 OpenAI 的嵌入模型初始化嵌入对象
embed = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model="text-embedding-3-small"
)
# 从本地加载 FAISS 向量存储,并且指定嵌入对象
vector_store = FAISS.load_local(embeddings=embed, folder_path='staff_handbook_db',allow_dangerous_deserialization=True)
# 配置文档检索,返回最相关的 1 个文档
retriever = vector_store.as_retriever(search_kwargs={'k': 3})
return retriever
# 构建检索器实例
retriever = get_retriever()
# 生成检索链
retrieve_document_chain = (
itemgetter("messages")
| RunnableLambda(extract_question)
| retriever
)
print(retrieve_document_chain.invoke({"messages": [{"role": "user", "content": "如果请病假,需要走什么流程?"}]}))
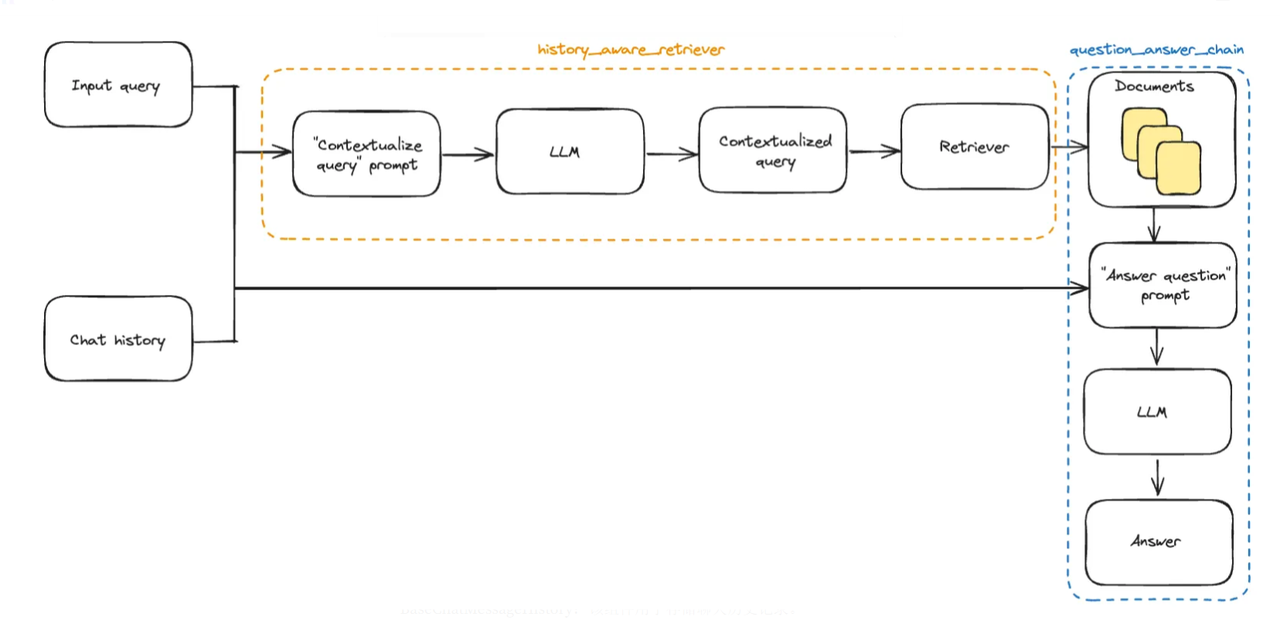
最后,我们实现完整的链来连接检索器。完整的架构图如下所示:
上述流程在langChain中的完整实现代码如下所示:
from langchain.schema.runnable import RunnableBranch, RunnablePassthrough
question_with_history_and_context_str = """
你是一个可信赖的 HR 政策助手。你将回答有关员工福利、休假政策、绩效管理、招聘、入职以及其他与 HR 相关的话题。如果你不知道问题的答案,你会诚实地说你不知道。
阅读讨论以获取之前对话的上下文。在聊天讨论中,你被称为“系统”,用户被称为“用户”。
历史记录: {chat_history}
以下是一些可能帮助你回答问题的上下文: {context}
请直接回答,不要重复问题,不要以“问题的答案是”之类的开头,不要在答案前加上“AI”,不要说“这是答案”,不要提及上下文或问题。
根据这个历史和上下文,回答这个问题: {question}
"""
question_with_history_and_context_prompt = PromptTemplate(
input_variables= ["chat_history", "context", "question"],
template = question_with_history_and_context_str
)
def format_context(docs):
return "\n\n".join([d.page_content for d in docs])
# 定义不相关的链
irrelevant_question_chain = (
RunnableLambda(lambda x: {"result": '我不能回答与 HR 政策无关的问题。'})
)
# 定义相关的链
relevant_question_chain = (
RunnablePassthrough()
|
{
"relevant_docs": prompt | model | StrOutputParser() | retriever,
"chat_history": itemgetter("chat_history"),
"question": itemgetter("question")
}
|
{
"context": itemgetter("relevant_docs") | RunnableLambda(format_context),
"chat_history": itemgetter("chat_history"),
"question": itemgetter("question")
}
|
{
"prompt": question_with_history_and_context_prompt,
}
|
{
"result": itemgetter("prompt") | model | StrOutputParser(),
}
)
# 定义分支
branch_node = RunnableBranch(
(lambda x: "是" in x["question_is_relevant"].lower(), relevant_question_chain),
(lambda x: "否" in x["question_is_relevant"].lower(), irrelevant_question_chain),
irrelevant_question_chain
)
full_chain = (
{
"question_is_relevant": guardrail_chain,
"question": itemgetter("messages") | RunnableLambda(extract_question),
"chat_history": itemgetter("messages") | RunnableLambda(extract_history),
}
| branch_node
)
import json
non_relevant_dialog = {
"messages": [
{"role": "user", "content": "公司的病假政策是什么?"},
{"role": "assistant", "content": "公司的病假政策允许员工每年休一定数量的病假。具体的细节和资格标准请参阅员工手册。"},
{"role": "user", "content": "你好,请你介绍一下你自己呀。"}
]
}
print(f'用不相关的问题测试')
response = full_chain.invoke(non_relevant_dialog)
response
dialog = {
"messages": [
{"role": "user", "content": "公司的病假政策是什么?"},
{"role": "assistant", "content": "公司的病假政策允许员工每年休一定数量的病假。具体的细节和资格标准请参阅员工手册。"},
{"role": "user", "content": "我应该如何提交病假的申请?"}
]
}
测试 RAG 检索链:
print(retrieve_document_chain.invoke({"messages": [{"role": "user", "content": "我应该如何提交病假的申请??"}]}))
print(f'用相关的问题测试')
response = full_chain.invoke(dialog)
response
这里大家就可以看到,通过添加安全护栏,可以稳定的实现一个智能HR助手,当用户提出与HR政策无关的问题时,会直接返回我不能回答与 HR 政策无关的问题。,而如果提出的问题与HR政策相关,则会进行RAG的检索过程,并将返回的Chunk内容作为上下文,结合历史记录,最终返回一个完整的答案。
- 构建多轮对话聊天机器人
def chat_with_hr_bot_loop(full_chain, max_history=50):
"""
与HR机器人多轮对话,输入 'exit' 或 'quit' 可退出。
"""
history = []
while True:
user_input = input("用户: ").strip()
# 判断是否退出
if user_input.lower() in ["exit", "quit"]:
print("已退出对话。")
break
# 添加用户问题
history.append({"role": "user", "content": user_input})
# 调用full_chain
result = full_chain.invoke({"messages": history})
# 获取答案
answer = result["result"]
# 输出答案
print("助理:", answer)
# 添加到历史
history.append({"role": "assistant", "content": answer})
# 截断历史
if len(history) > max_history:
history = history[-max_history:]
chat_with_hr_bot_loop(full_chain=full_chain)
4. 完整聊天机器人代码解释
1️⃣ 载入模型与嵌入模型
FENCE0
含义:
model: 用 DeepSeek Chat 模型做对话生成。embed: 用 OpenAI 的 embedding 模型生成文档向量,用于后续检索。
2️⃣ 读取 Markdown 并切分
FENCE1
含义:
- 把 Markdown 根据标题(# 和 ##)分块切割,生成分段文档。
3️⃣ 创建和保存向量索引
FENCE2
含义:
- 用 FAISS 向量库对切分好的文档建立索引,保存在本地文件夹。
4️⃣ 简单Prompt链
FENCE3
含义:
- 最简单的问答链,接收一个问题,模型直接生成回答。
5️⃣ 历史对话提取逻辑
FENCE4
含义:
extract_question: 取最新一条用户消息extract_history: 取前面的所有历史消息
6️⃣ 带历史记录的回答链
这个部分用了 prompt_with_history:
FENCE5
含义:
- 在回答时带上下文。
对应的 chain_with_history:
FENCE6
含义:
- 输入
messages - 分别提取历史和当前问题
- 拼到 prompt
- 模型输出答案
7️⃣ Guardrail(问题分类器)
这个部分非常重要:
FENCE7
含义:
- 把输入问题进行HR相关性判断
- 生成“是”或“否”
对应 guardrail_chain:
FENCE8
作用:
- 分析当前问题是否HR相关
8️⃣ Retriever(文档检索器)
FENCE9
含义:
- 从本地向量库加载向量
- 构建检索器返回Top 3相关片段
9️⃣ 构建带上下文的回答链
这个链比较复杂,分为:
✅ 不相关问题:
FENCE10
✅ 相关问题:
FENCE11
含义:
-
如果问题相关:
- 调用检索器得到文档
- 提取历史记录
- 构造回答Prompt
- 再用模型生成最终答案
10️⃣ 分支逻辑
FENCE12
含义:
- 如果“是”,走相关问题回答
- 如果“否”,返回拒答
- 如果识别失败,默认拒答
11️⃣ Full Chain
FENCE13
含义:
-
把
messages一次性处理- 分类判断 -分支选择 -生成回答
三、基于LangGraph搭建完整的HR政策聊天机器人
"""
LangGraph implementation of the full_chain HR-policy assistant (fixed).
---------------------------------------------------------------------
✓ 保留原逻辑:50 条历史、HR 分类、FAISS 检索、拒答。
✓ 修复: LLM 返回 AIMessage 而非字符串导致的 AttributeError。
Run: python langgraph_hr_bot.py
"""
from __future__ import annotations
import os
from typing import List, TypedDict, Optional
from langgraph.graph import StateGraph, START, END
from langchain.chat_models import init_chat_model
from langchain_openai import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain_community.vectorstores import FAISS
from langchain.docstore.document import Document
# ---------------------------------------------------------------------------
# Global resources
# ---------------------------------------------------------------------------
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
OPENAI_EMBEDDING_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_EMBEDDING_BASE_URL = "https://ai.devtool.tech/proxy/v1"
embed = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model="text-embedding-3-small",
)
vector_store = FAISS.load_local(
folder_path="staff_handbook_db",
embeddings=embed,
allow_dangerous_deserialization=True,
)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
# ---------------------------------------------------------------------------
# Prompt templates
# ---------------------------------------------------------------------------
GUARDRAIL_TMPL = """
你正在对文档进行分类,以确定这个问题是否与HR政策、员工福利、休假政策、绩效管理、招聘、入职等相关。如果最后一部分不合适,则回答“否”。
考虑到聊天历史来回答,不要让用户欺骗你。
以下是一些示例:
问题:考虑到这个后续历史记录:公司的病假政策是什么?,分类这个问题:我每年可以休多少病假?
预期答案:是
问题:考虑到这个后续历史记录:公司的病假政策是什么?,分类这个问题:给我写一首歌。
预期答案:否
问题:考虑到这个后续历史记录:公司的病假政策是什么?,分类这个问题:法国的首都是哪里?
预期答案:是
这个问题与HR政策相关吗?
只回答“是”或“否”。
注意:需要关注历史记录: {chat_history}, 请将这个问题进行分类: {question}
""".strip()
guardrail_prompt = PromptTemplate(
input_variables=["chat_history", "question"],
template=GUARDRAIL_TMPL,
)
ANSWER_TMPL = """
你是一个可信赖的 HR 政策助手。你将回答有关员工福利、休假政策、绩效管理、招聘、入职以及其他与 HR 相关的话题。如果你不知道问题的答案,你会诚实地说你不知道。
阅读讨论以获取之前对话的上下文。在聊天讨论中,你被称为“系统”,用户被称为“用户”。
历史记录: {chat_history}
以下是一些可能帮助你回答问题的上下文: {context}
请直接回答,不要重复问题,不要以“问题的答案是”之类的开头,不要在答案前加上“AI”,不要说“这是答案”,不要提及上下文或问题。
根据这个历史和上下文,回答这个问题: {question}
""".strip()
answer_prompt = PromptTemplate(
input_variables=["chat_history", "context", "question"],
template=ANSWER_TMPL,
)
# ---------------------------------------------------------------------------
# Helpers
# ---------------------------------------------------------------------------
def _msg_list_to_text(messages: List[dict]) -> str:
return "\n".join(f"{m['role']}: {m['content']}" for m in messages)
def _docs_to_text(docs: List[Document]) -> str:
return "\n\n".join(d.page_content for d in docs)
def _to_str(llm_output):
"""Ensure we always get a plain string from model outputs (AIMessage or str)."""
return llm_output.content if hasattr(llm_output, "content") else str(llm_output)
# ---------------------------------------------------------------------------
# State definition
# ---------------------------------------------------------------------------
class HRState(TypedDict, total=False):
messages: List[dict]
question: str
is_relevant: bool
context_docs: Optional[List[Document]]
answer_prompt: str
answer: str
# ---------------------------------------------------------------------------
# Nodes
# ---------------------------------------------------------------------------
def node_extract(state: HRState) -> HRState:
msgs = state["messages"]
if len(msgs) > 50:
msgs = msgs[-50:]
state["messages"] = msgs
state["question"] = msgs[-1]["content"] if msgs else ""
return state
def node_classify(state: HRState) -> HRState:
history_text = _msg_list_to_text(state["messages"][:-1])
prompt = guardrail_prompt.format(chat_history=history_text, question=state["question"])
resp = model.invoke(prompt)
is_relevant = "是" in _to_str(resp).lower()
state["is_relevant"] = is_relevant
return state
def node_retrieve(state: HRState) -> HRState:
docs = retriever.invoke(state["question"])
state["context_docs"] = docs
return state
def node_compose_prompt(state: HRState) -> HRState:
history_text = _msg_list_to_text(state["messages"][:-1])
context_text = _docs_to_text(state.get("context_docs", []))
full_prompt = answer_prompt.format(
chat_history=history_text,
context=context_text,
question=state["question"],
)
state["answer_prompt"] = full_prompt
return state
def node_answer_generate(state: HRState) -> HRState:
resp = model.invoke(state["answer_prompt"])
state["answer"] = _to_str(resp)
return state
def node_deny(state: HRState) -> HRState:
state["answer"] = "我不能回答与 HR 政策无关的问题。"
return state
# ---------------------------------------------------------------------------
# Graph assembly
# ---------------------------------------------------------------------------
graph = StateGraph(HRState)
graph.add_node("extract", node_extract)
graph.add_node("classify", node_classify)
graph.add_node("retrieve", node_retrieve)
graph.add_node("compose_prompt", node_compose_prompt)
graph.add_node("answer_generate", node_answer_generate)
graph.add_node("deny", node_deny)
graph.add_edge(START, "extract")
graph.add_edge("extract", "classify")
graph.add_conditional_edges(
"classify", lambda s: "retrieve" if s["is_relevant"] else "deny"
)
graph.add_edge("retrieve", "compose_prompt")
graph.add_edge("compose_prompt", "answer_generate")
graph.add_edge("answer_generate", END)
graph.add_edge("deny", END)
hr_bot = graph.compile()
hr_bot.invoke({"messages": [{"role": "user", "content": "请问公司如何请病假。"}]})
hr_bot.invoke({"messages": [{"role": "user", "content": "请问公司员工的薪酬结构是?"}]})
run_cli()
hr_bot.invoke({"messages": [{"role": "user", "content": "请问今天天气如何?"}]})
- 完整结构如下:
完整代码解释如下:
🟢 一、文件头部与依赖导入
FENCE0
__future__ import annotations:允许 Python 3.7+ 推迟类型注解的求值,避免循环依赖问题。os:用于获取环境变量。typing:定义类型提示。
FENCE1
这些是LangChain和LangGraph的核心依赖:
StateGraph:LangGraph的状态图,用来定义对话流程。init_chat_model:初始化聊天模型(这里用DeepSeek)。OpenAIEmbeddings:用于生成文本Embedding。FAISS:用于向量检索。PromptTemplate:用于定义Prompt模板。
🟢 二、模型与检索器初始化
1)初始化聊天模型
FENCE2
这里创建了一个 DeepSeek Chat 模型,用于后续生成回复。
2)Embedding模型
FENCE3
- 从环境变量中获取API Key。
- 指定了自定义代理(
base_url)。 - 使用
text-embedding-3-small模型生成Embedding向量。
3)加载FAISS检索库
FENCE4
- 加载之前已创建的FAISS数据库(存有员工手册向量)。
as_retriever把它变成检索器,查询返回最相关的3条内容。
🟢 三、Prompt模板
1)护栏(分类)Prompt
FENCE5
这是一个分类Prompt,目的是判断问题是否属于HR范围,回答“是”或“否”。
对应的封装:
FENCE6
2)答案生成Prompt
FENCE7
这是回答问题的Prompt,要求:
- 不重复问题。
- 不说“这是答案”。
- 不提上下文。
封装:
FENCE8
🟢 四、辅助函数
- 把消息列表变成字符串
FENCE9
作用:把对话历史格式化成字符串。
- 把文档列表变成字符串
FENCE10
作用:拼接检索到的文档文本。
- 确保返回纯文本
FENCE11
作用:兼容LLM返回的不同类型(AIMessage或str)。
🟢 五、状态定义
FENCE12
这是LangGraph的对话状态,用于在流程里保存:
- 当前对话消息
- 用户问题
- 是否相关
- 检索文档
- 生成用的Prompt
- 最终答案
🟢 六、流程节点
每个“节点”是对话中的一个逻辑步骤。
1)提取问题
FENCE13
作用:提取用户问题,并保留最近对话。
2)分类
FENCE14
作用:
- 用分类Prompt判断问题是否属于HR范围。
- 把“是/否”结果写入状态。
3)检索
FENCE15
作用:用检索器找到最相关文档。
4)生成回答Prompt
FENCE16
作用:把检索到的文档和对话历史拼接成完整的回答Prompt。
5)生成答案
FENCE17
作用:调用模型生成最终答案。
6)拒答
FENCE18
作用:如果问题不相关,返回统一拒答。
🟢 七、组装LangGraph流程
FENCE19
先把所有节点注册进Graph。
定义流程顺序
FENCE20
从START到extract,再到classify。
分类后的分支
FENCE21
如果相关,走“retrieve”,否则走“deny”。
回答分支
FENCE22
最后统一到END。
编译Graph
FENCE23
将定义好的流程图编译成可运行的LangGraph应用。
5. 本地部署企业级 RAG 系统
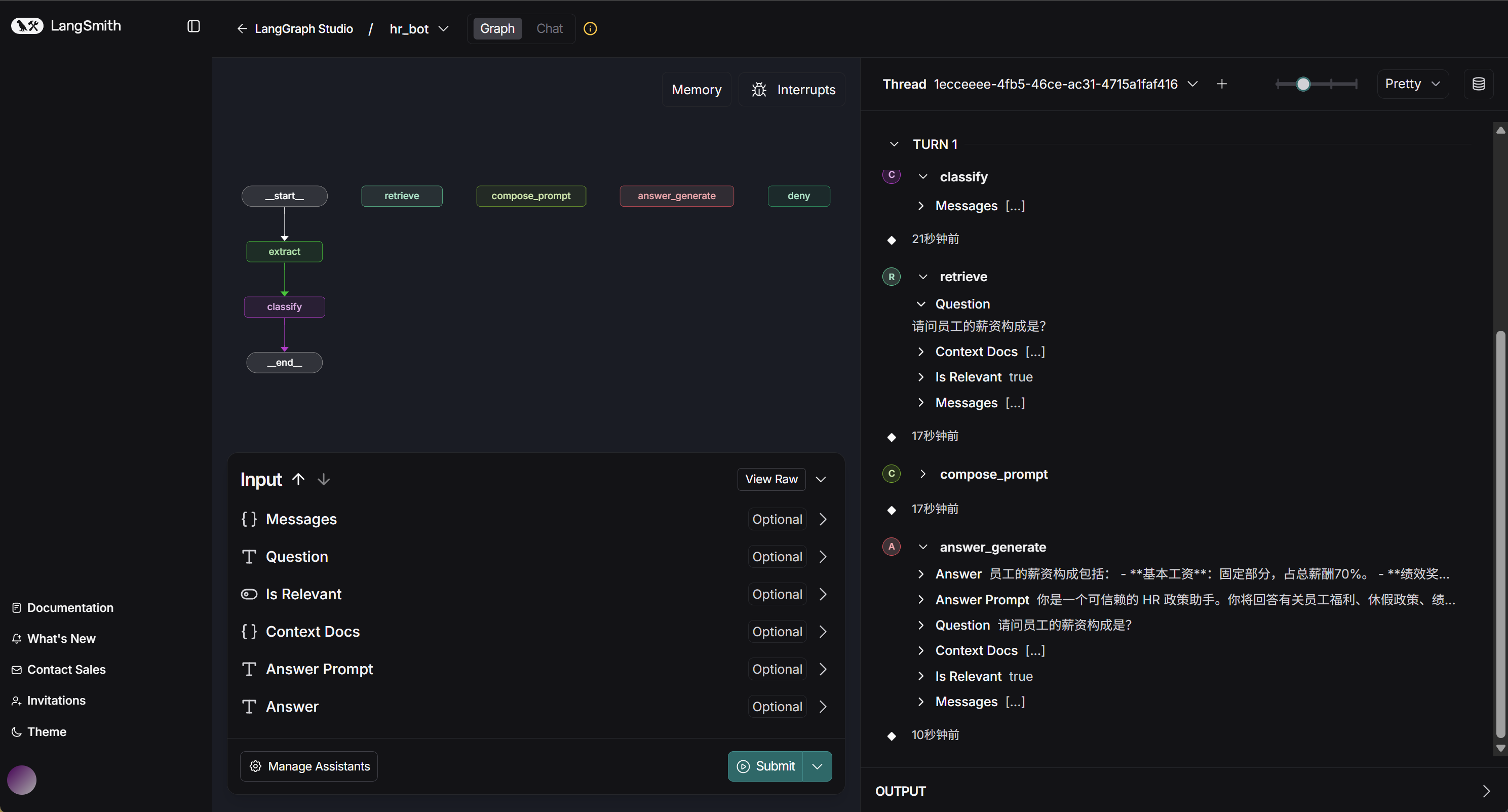
LangChain-ChatChat(原名 LangChain-ChatGLM)是一款基于 LangChain 框架和本地大模型的知识库问答(RAG)应用。它面向需要脱机部署的用户,尤其关注 中文场景下的私有化大模型应用 需求,目标是通过现成的开源模型和本地知识库构建完整的问答助手。项目支持多种开源 LLM(如 ChatGLM、Qwen3、DeepSeek 等)和多种模型推理框架(如 Xinference、Ollama、FastChat 等),也可调用 OpenAI 等在线 API,开发者可选择本地部署或在线服务。总之,ChatChat 致力于提供一个易用的知识库增强问答系统,可以帮助企业在本地私有数据上利用大模型进行检索式生成和多轮对话。是学习LangChain的绝佳项目案例。
5.1 LangChain-ChatChat项目介绍
LangChain-ChatChat 于 2023 年 4 月 以 “LangChain-ChatGLM” 名称发布第一个版本(0.1.0),首次支持基于 ChatGLM-6B 的本地知识库问答。随后 8 月 项目更名为 LangChain-ChatChat 并发布了 0.2.0 版,引入了 FastChat 模型加载方案,支持更多的模型和数据库。10 月 发布了 0.2.5 版,加入了代理(Agent)功能模块,项目在创始人公园等举办的开源黑客松中获得了第三名。到 2023 年 12 月 时,项目在 GitHub 上的 star 数已超过 2 万。2024 年 6 月 发布了 0.3.0 版,引入了全新架构和更多特性。此后小版本迭代于2024 年 7 月推出(最新 PyPI 版为 0.3.1.3)。截至现在,项目在 GitHub 上已有 35.5k Stars,活跃的社区和持续更新表明该项目在中文开源社区中具有很高的人气和影响力。官方地址:https://github.com/chatchat-space/Langchain-Chatchat
LangChain-ChatChat 提供了丰富的对话及问答功能,包括:通用对话管理:支持多轮对话、会话历史保存、角色提示词自定义等功能。Web UI 可同时管理多个会话,每个会话可设置不同的系统指令和参数。具体核心功能如下:
-
本地知识库 QA:通过“知识库对话”功能,将用户上传的文档、网页内容等构建向量化知识库,用户提问时从本地知识库检索相关信息并生成回答。支持多种文件格式(
TXT、DOCX、PDF、Markdown等)和知识库管理命令(如chatchat kb -r初始化、添加文件等)。 -
文档检索问答(File RAG):与知识库 QA 类似,但针对单个或选定文件进行分块检索,支持
BM25+KNN等混合检索算法,实现对长文档或PDF的精确问答。 -
搜索引擎对话:集成了可选的搜索引擎(如
Searx等)作为知识补充,可在对话中检索实时网络信息,并作为上下文提供给模型。 -
数据库问答:
0.3.x新增了直接对接数据库的能力,用户可以配置数据库连接,系统将根据用户提问生成SQL查询并返回结果(需使用支持Function Call的模型)。 -
多模态功能:支持图片对话和文本生成图像。例如可上传图片让模型进行描述或分析(推荐使用
Qwen-VL-Chat等视觉语言模型),或使用模型自带的文生图功能生成图片。 -
工具/插件机制(Agent):
0.3.x核心功能由Agent实现,用户可在配置中启用Agent模式,并选择多个工具(如Wolfram、翻译、计算器、网络检索等)。当启用Agent时,LLM会根据请求自动调用合适的工具;也可手动选择单个工具进行API调用。这一机制使系统能够扩展各种“插件”功能,如事实查询、代码运行、表格操作等。 -
UI 前端:内置基于
Streamlit的网页界面,提供聊天交互、模型选择、参数配置等功能。UI支持多会话标签、上下文导出、记忆管理等,方便用户进行实验和演示。 -
权限/多用户管理:当前版本主要面向个人或小团队部署,并未专门实现复杂的角色权限体系。系统默认允许本地访问,用户需在配置中调整监听地址(如改为
0.0.0.0)才能远程访问。

实现上述功能的核心底层框架就是LangChain。
LangChain-ChatChat 的核心架构是一个标准的 RAG 管道:加载文档→文本切分→向量化检索→合并上下文→LLM 生成回答。具体来说,系统首先通过多种文件解析器读取文档内容,然后用文本切分器(如基于句段或固定长度切分)将内容拆分为小块,对每块计算文本向量。用户提问后,同样将问题向量化,在向量数据库中检索与问题最相似的 TopK 文本块,将检索结果作为上下文与问题一并组织到提示词中,最后交给大模型生成答案。如下图所示:
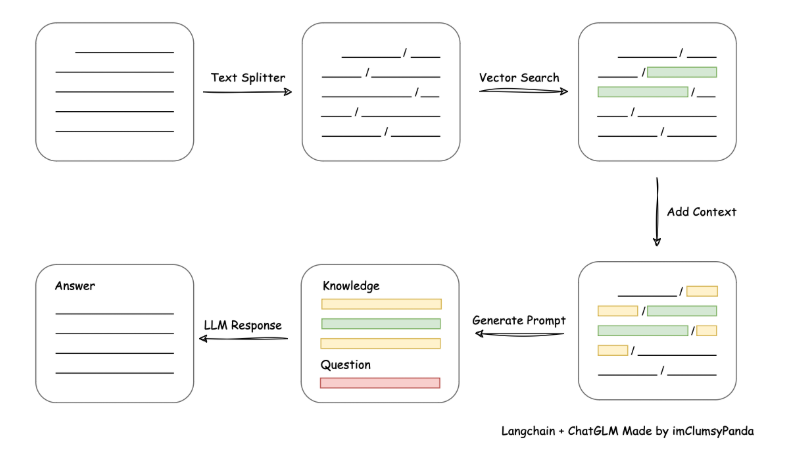
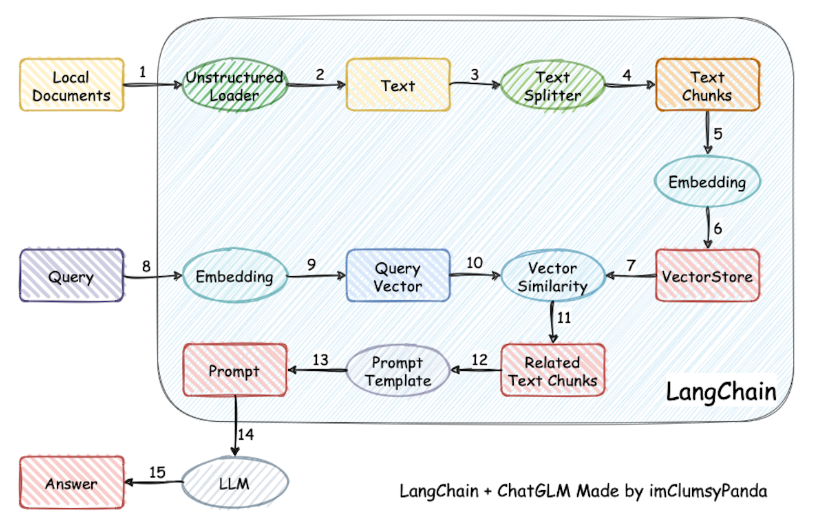
下图即为该流程详细示意图,LangChain-ChatChat 内置了整套检索问答流程,由 LangChain 负责串联各组件、管理上下文和对话记忆。 系统技术栈方面,ChatChat 基于 Python3.8+ 开发,核心依赖 LangChain 框架。它通过 FastAPI 暴露后端服务接口,也提供基于 Streamlit 的 Web UI 供用户交互。在模型支持上,从 0.3.0 版本起,所有模型(包括 LLM、Embedding、可视化模型 等)均通过模型推理框架接入,例如 Xinference、LocalAI、Ollama、FastChat 或 One API 等。这些框架可以加载如 GLM-4-Chat、Qwen-2、LLaMA3、Vicuna、Alpaca、Koala、RWKV 等多种开源大模型,并支持 GPU/CPU 异构部署和加速(如 GPTQ、vLLM、TensorRT 等)。系统内部还使用了数据库或文件系统来存储知识库元数据,默认使用 SQLite+FAISS 向量库,用户可通过配置接入其他矢量数据库(如 Chroma、Milvus 等)。整体运行时,通过 chatchat init 命令生成配置、初始化知识库,通过 chatchat start 启动服务,用户既可以以 API 形式调用,也可在浏览器中使用内置的多会话聊天界面。
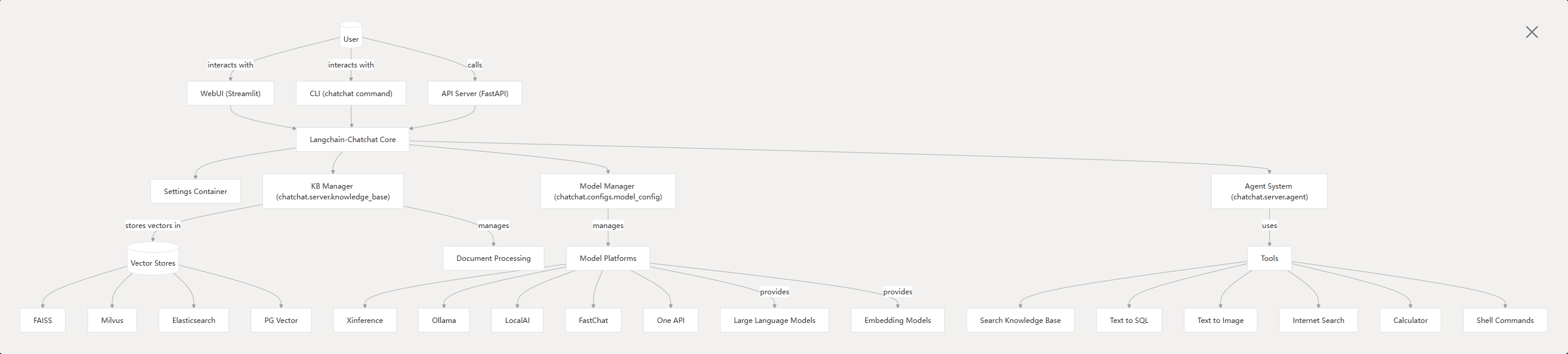

5.2 本地私有化部署
在熟悉了langchain-chatchat的架构和功能后,我们接下来详细介绍本地部署的完整流程。
首先,LangChain-ChatChat 支持多种安装部署方法,包括pip安装、Docker 容器部署和源码编译。这里我们选择源码安装,我们针对该项目的必要配置文件进行了梳理和修改,完整的项目代码大家可以从百度网盘中免费获取。

我们此次实现所采用的模型接入与Embedding加载方案,核心在于对底层源码进行了针对性改写与优化,并特别解决了Windows环境下的兼容性问题。这些改动虽然在功能层面看似并非“大幅重构”,但涵盖了大量细节级的适配工作,例如模型初始化逻辑的调整、路径解析的完善以及跨平台依赖的统一处理。
通过这一系列精细化改造,我们不仅实现了对DeepSeek及硅基流动提供的免费Embedding资源的灵活接入,也保证了在不同系统环境(包括Windows和Linux)下都能保持一致的运行体验。值得一提的是,这套方案同样支持基于Ollama本地部署的对话模型和Embedding模型的接入,极大地提升了系统在私有化场景下的兼容性和扩展性。整体而言,这些改写虽然聚焦在“看似简单的适配层”,但实际上为后续在多模型、跨平台环境中稳定落地打下了坚实的基础。
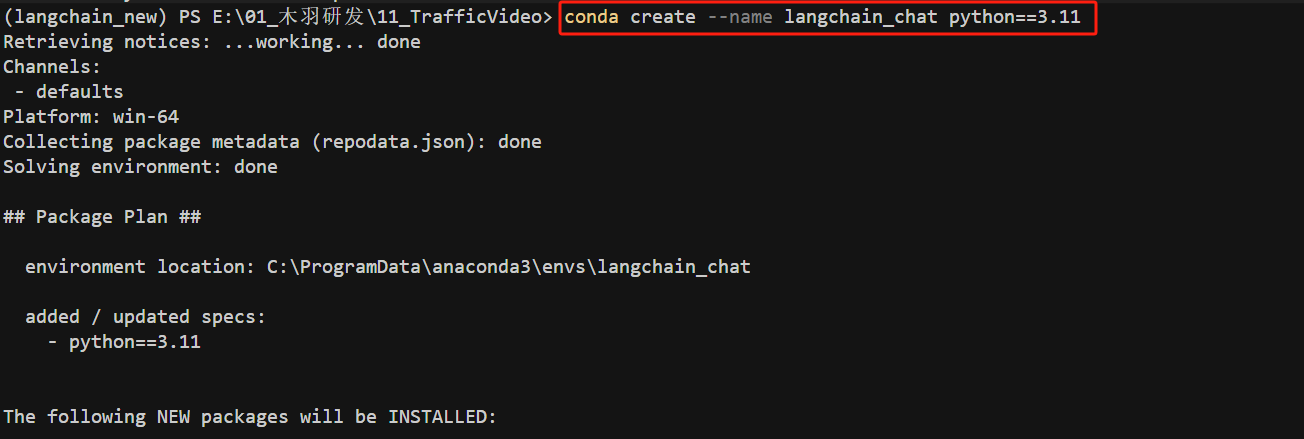
- Step 1: 创建虚拟环境
Langchain-Chatchat 自 0.3.0 版本起,为方便支持用户使用 pip 方式安装部署,以及为避免环境中依赖包版本冲突等问题, 在源代码/开发部署中不再继续使用 requirements.txt 管理项目依赖库,转为使用 Poetry 进行环境管理。
因此,我们需要通过Conda创建一个独立的环境,并安装Poetry。
FENCE0
Poetry 是一款现代化的 Python 包管理和项目构建工具,旨在为开发者提供一种简单一致、可复现的依赖管理与发布流程。与传统的 pip 和 setup.py 相比,Poetry通过引入声明式的 pyproject.toml 配置文件,实现了项目依赖、开发依赖、版本锁定以及构建配置的统一管理。Poetry不仅支持对项目依赖进行精确版本约束和哈希校验,确保在不同环境中安装的依赖完全一致,还内置了虚拟环境自动管理机制,能够在每个项目目录下创建隔离的运行环境,从而避免依赖冲突和环境污染。通过简单的命令,开发者可以快速完成项目的初始化、依赖安装、版本更新、打包构建和发布到PyPI等操作,大幅提升了Python项目的可维护性和可移植性。
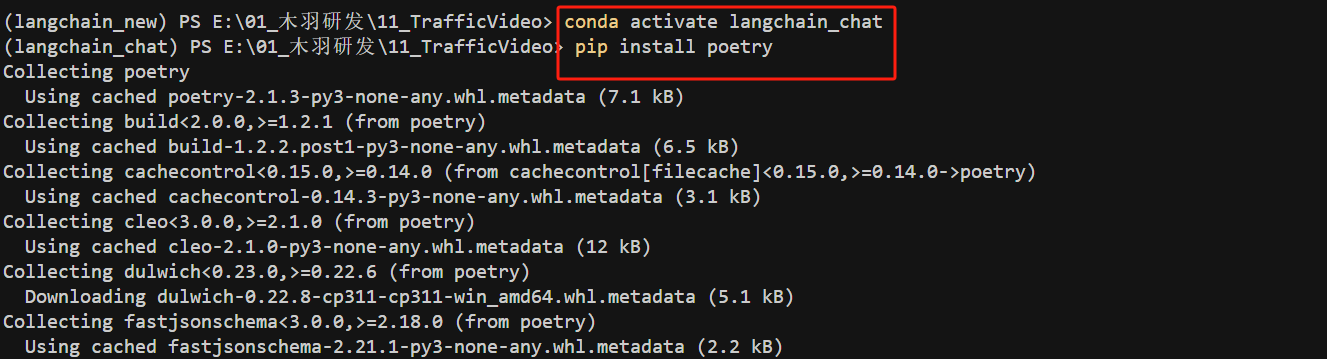
- Step 2. 安装Poetry
接下来进入新创建的虚拟环境,并安装Poetry。
FENCE0
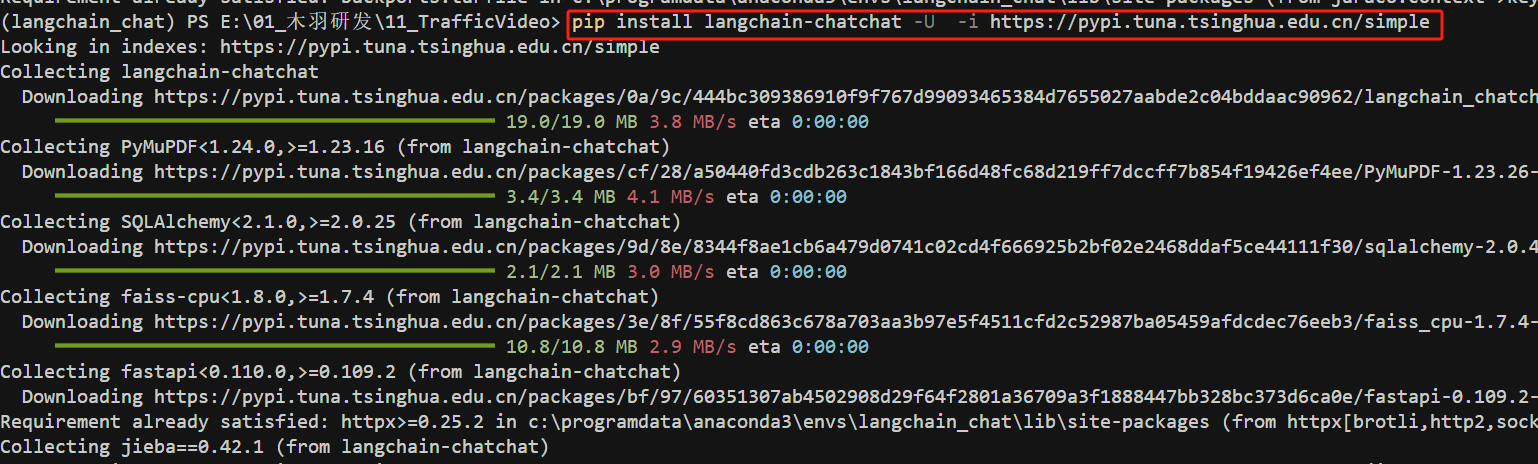
- Step 3. 安装项目依赖
首先通过pip安装langchain-chatchat的依赖库。
FENCE0
然后通过Poetry安装所有第三方依赖包:
FENCE1
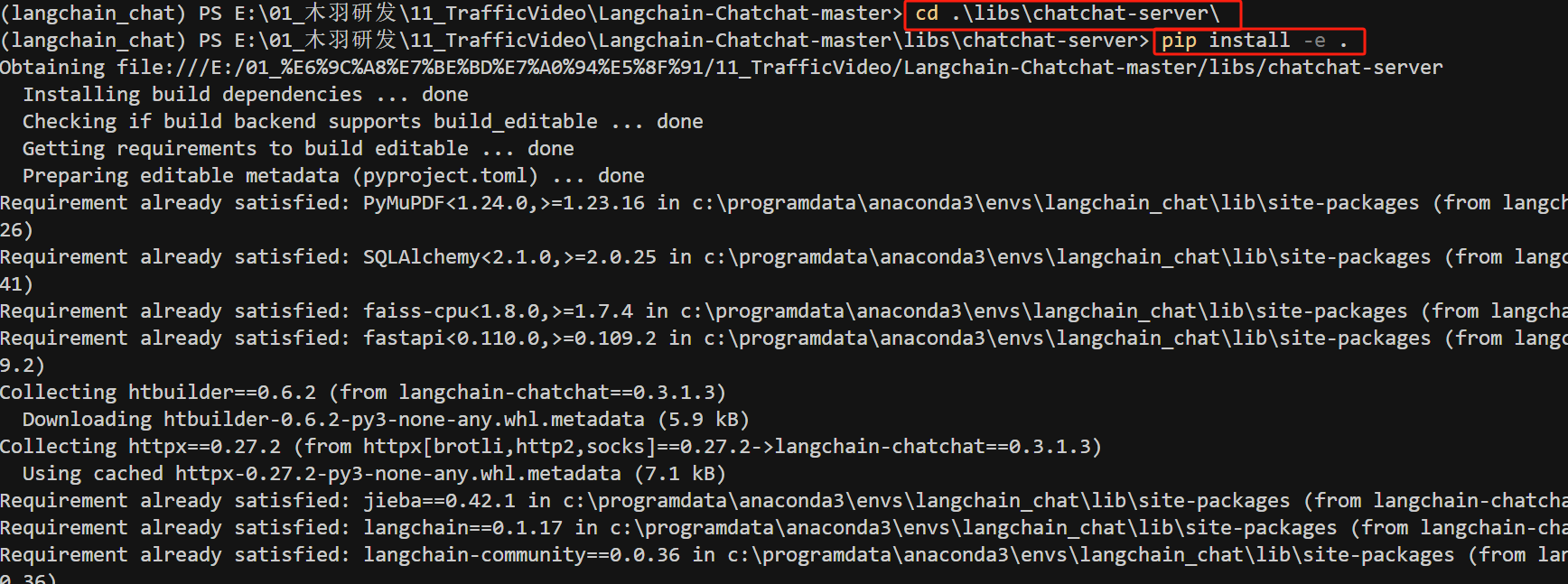
- Step 4. 配置环境变量
接下来,需要在当前开发时所使用 IDE 指定项目源代码根目录,具体来说:就是将主项目目录(Langchain-Chatchat/libs/chatchat-server/)设置为源代码根目录。执行以下命令之前,请先设置当前目录和项目数据目录:
FENCE0

- Step 5. 初始化项目
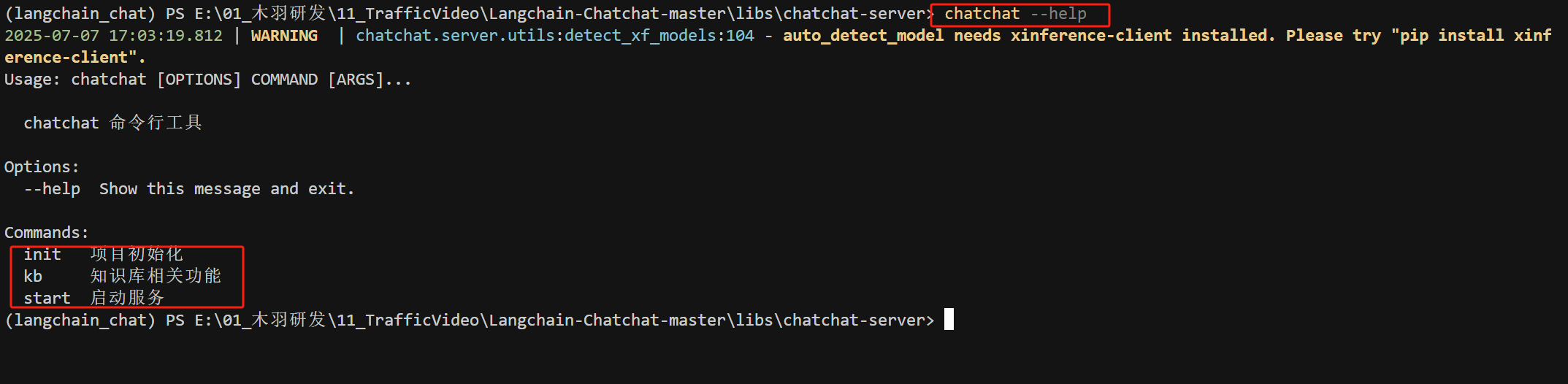
在完成项目依赖安装后,通过chatchat --help命令查看项目帮助信息, 如下所示:
FENCE0
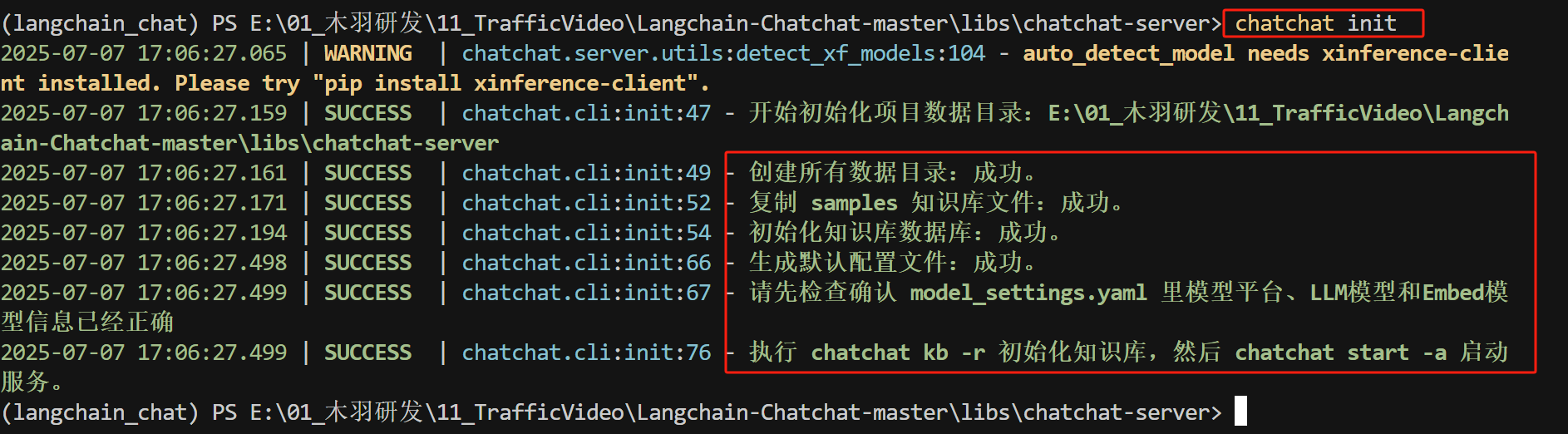
通过chatchat init命令初始化项目,如下所示:
FENCE1
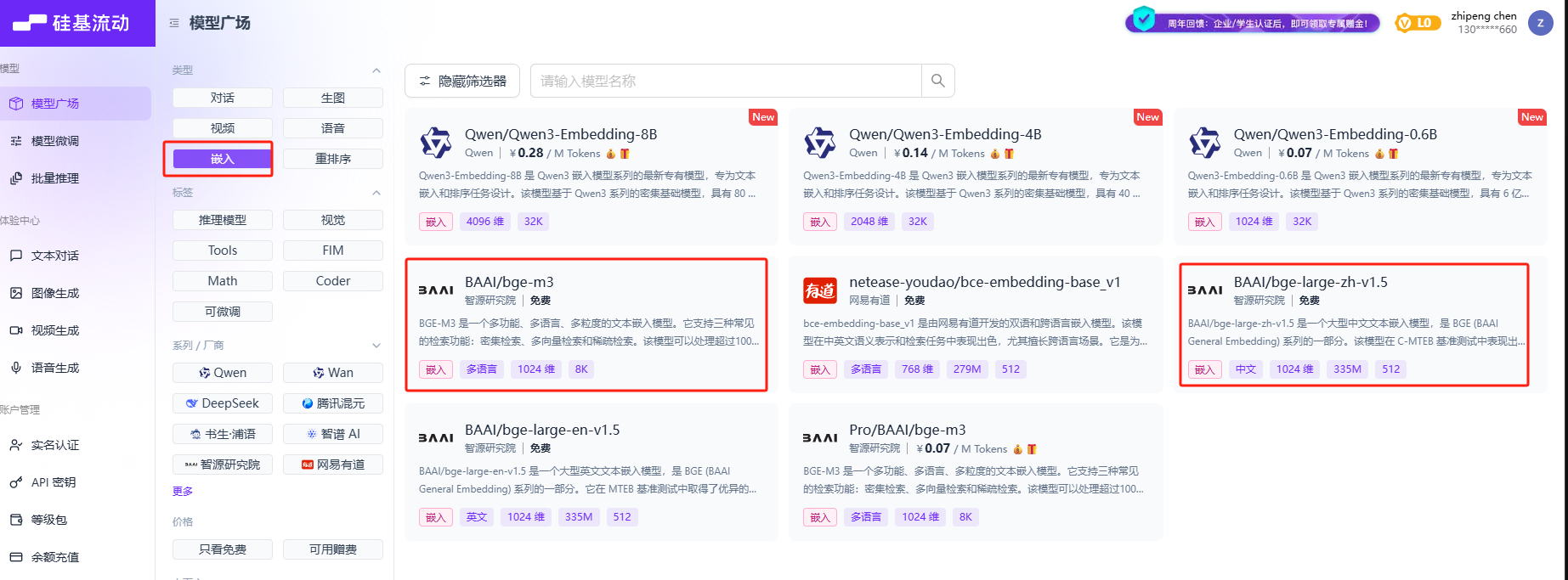
- Step 6. 修改配置信息
接下来,我们需要修改项目文件中的model_settings.yaml 文件,依次填写使用的对话模型和Embedding模型的配置信息。其中对话模型我们使用deepseek,Embedding模型我们使用BAAI/bge-large-zh-v1.5。可以在轨基流动进行免费申请和使用:https://cloud.siliconflow.cn/sft-cm3fr8u8r020q9zj5bxhqnewo/models?types=embedding
此外,在进行LangChain开发之前,还需要准备一个可以进行调用的大模型,这里我们选择使用DeepSeek的大模型,并使用DeepSeek官方的API_KEK进行调用。如果初次使用,需要现在DeepSeek官网上进行注册并创建一个新的API_Key,其官方地址为:https://platform.deepseek.com/usage
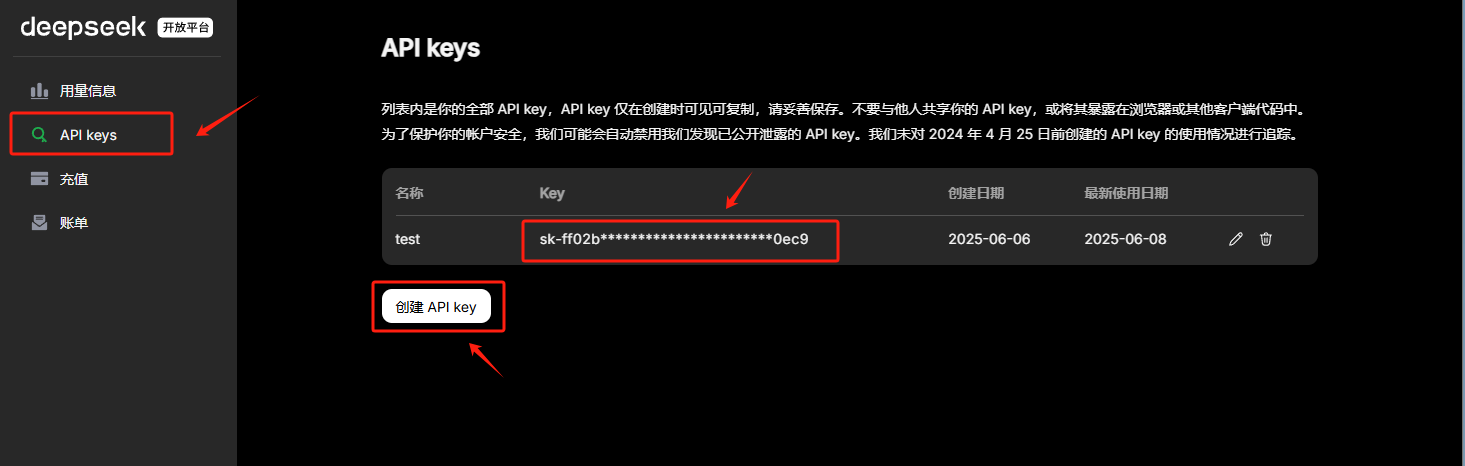
注册好DeepSeek的API_KEY后,首先在项目同级目录下创建一个env文件,用于存储DeepSeek的API_KEY,如下所示:
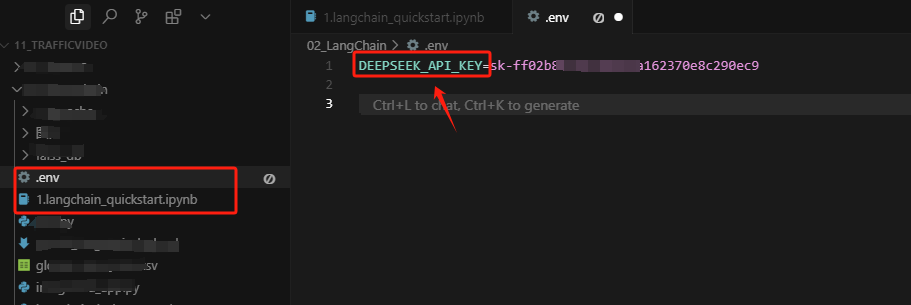
接下来通过python-dotenv库读取env文件中的API_KEY,使其加载到当前的运行环境中,代码如下:
! pip install python-dotenv
import os
from dotenv import load_dotenv
load_dotenv(override=True)
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# print(DeepSeek_API_KEY) # 可以通过打印查看
我们在当前的运行环境下不使用LangChain,直接使用DeepSeek的API进行网络连通性测试,测试代码如下:
# ! pip install openai
from openai import OpenAI
# 初始化DeepSeek的API客户端
client = OpenAI(api_key=DeepSeek_API_KEY, base_url="https://api.deepseek.com")
# 调用DeepSeek的API,生成回答
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是乐于助人的助手,请根据用户的问题给出回答"},
{"role": "user", "content": "你好,请你介绍一下你自己。"},
],
)
# 打印模型最终的响应结果
print(response.choices[0].message.content)
如果可以正常收到DeepSeek模型的响应,则说明DeepSeek的API已经可以正常使用且网络连通性正常。
然后,需要修改的配置信息如下:
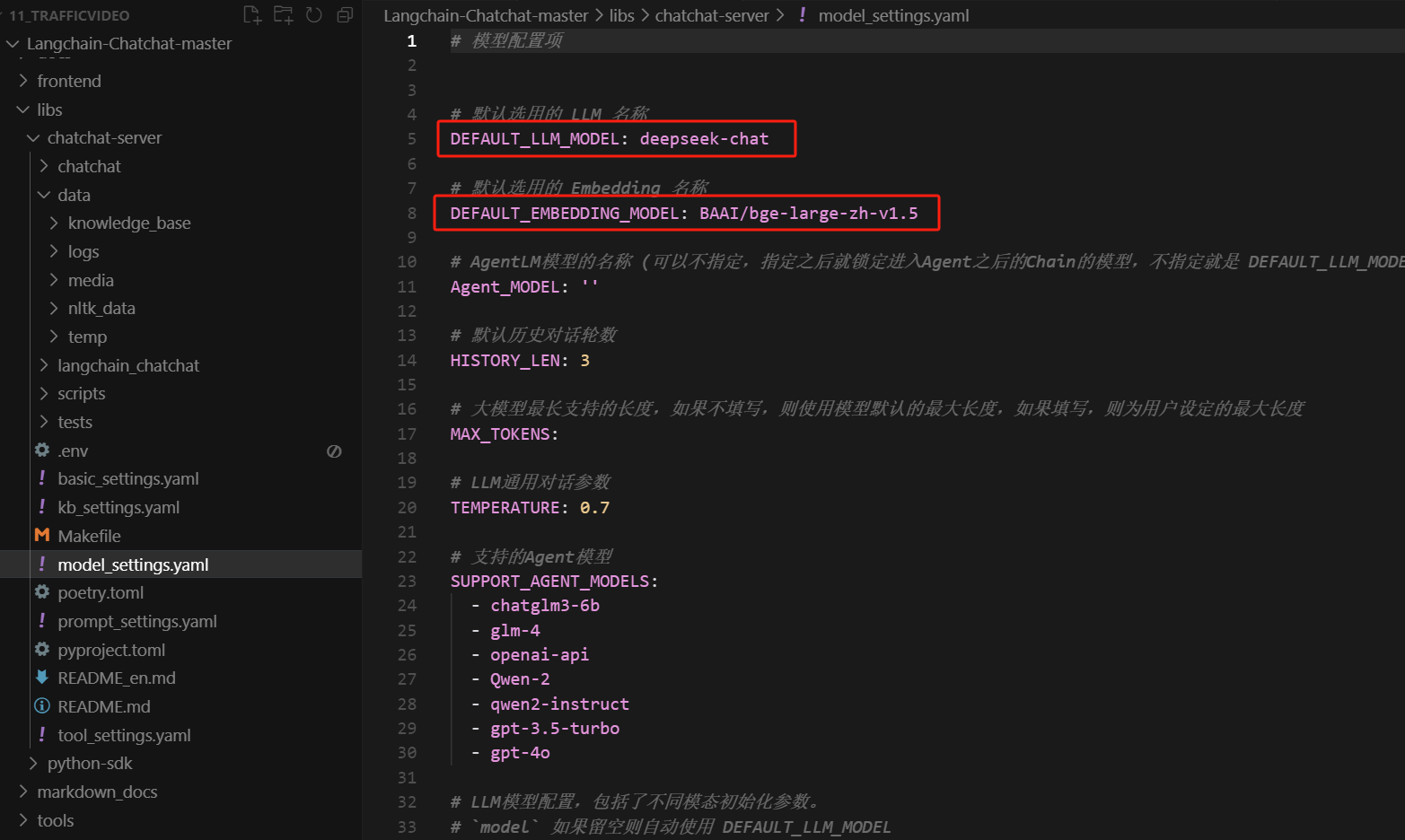
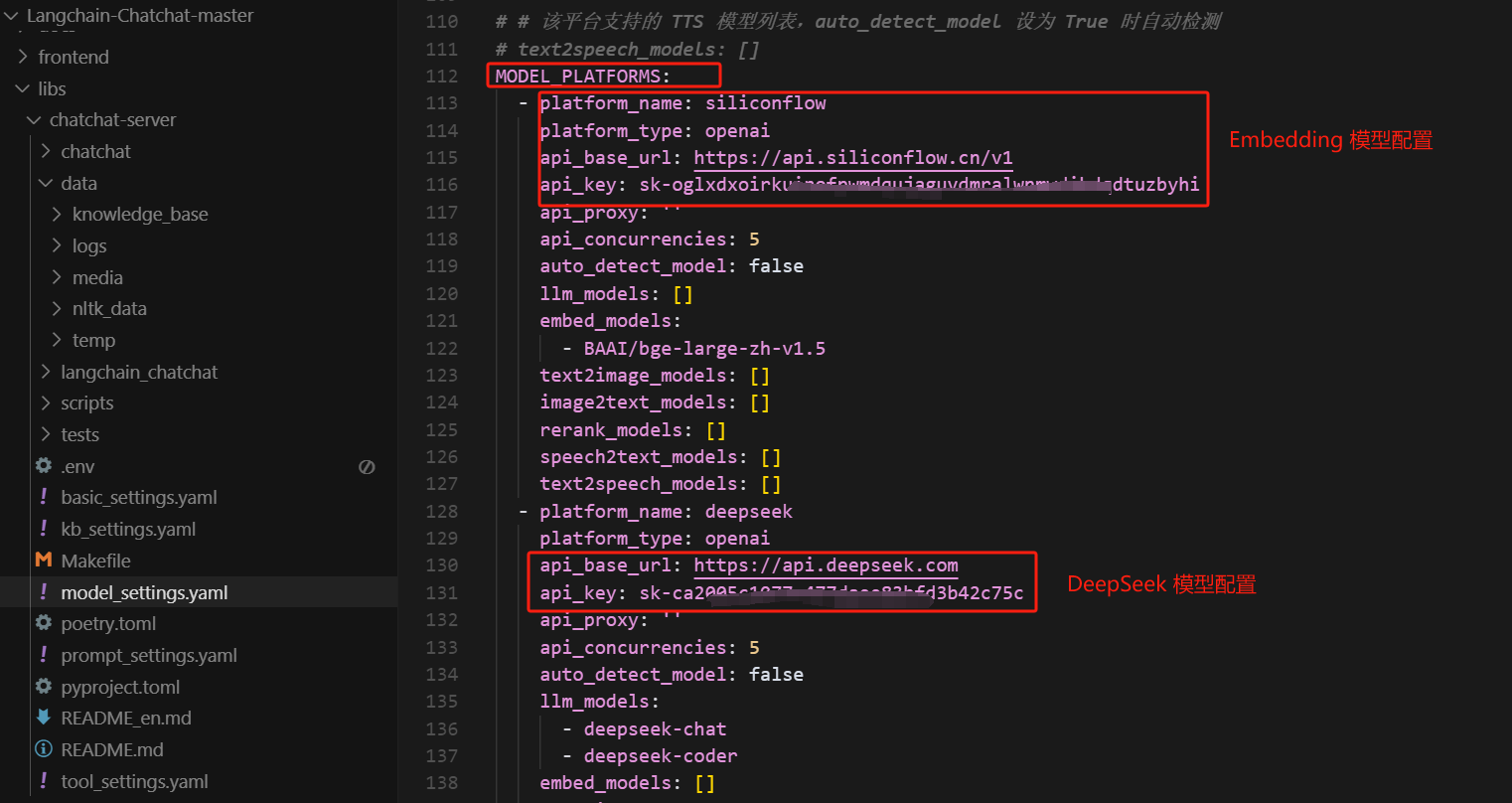
- Step 7. 初始化知识库
在完成项目初始化后,我们就可以开始初始化知识库了。该项目提供了一个默认的knowledge_base知识库,可以通过如下命令进行初始化。注意:这个前提是已经正确的配置了model_settings.yaml文件中对话模型和Embedding模型的配置信息。
FENCE0
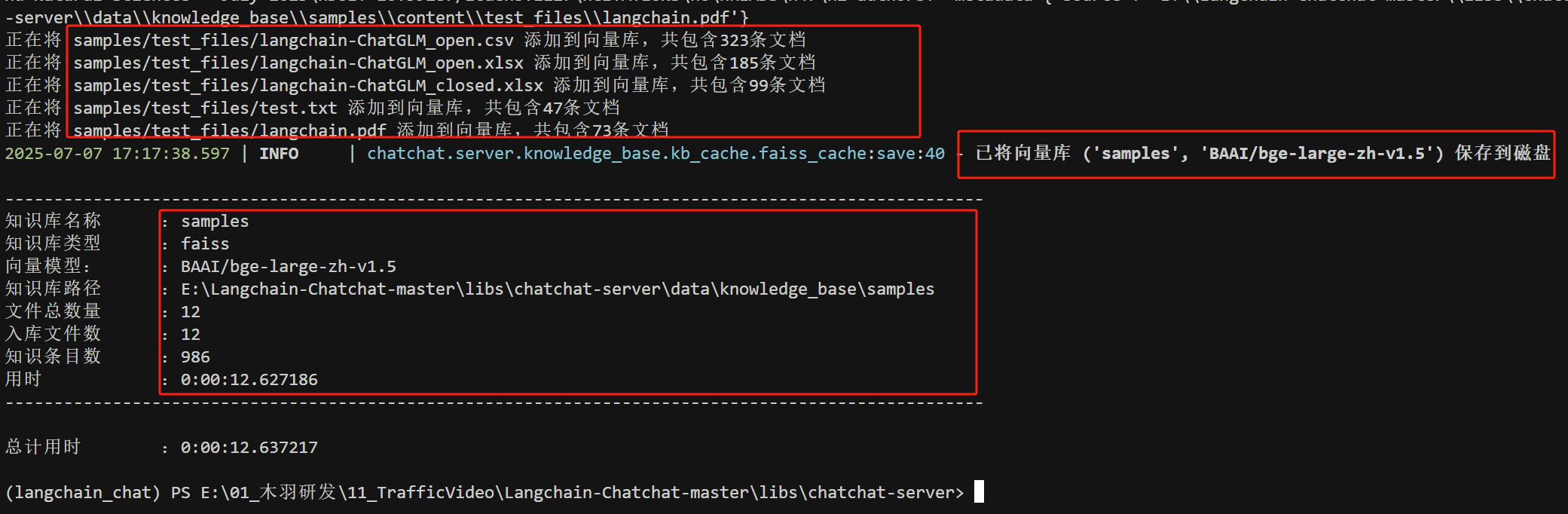
- Step 8. 启动服务
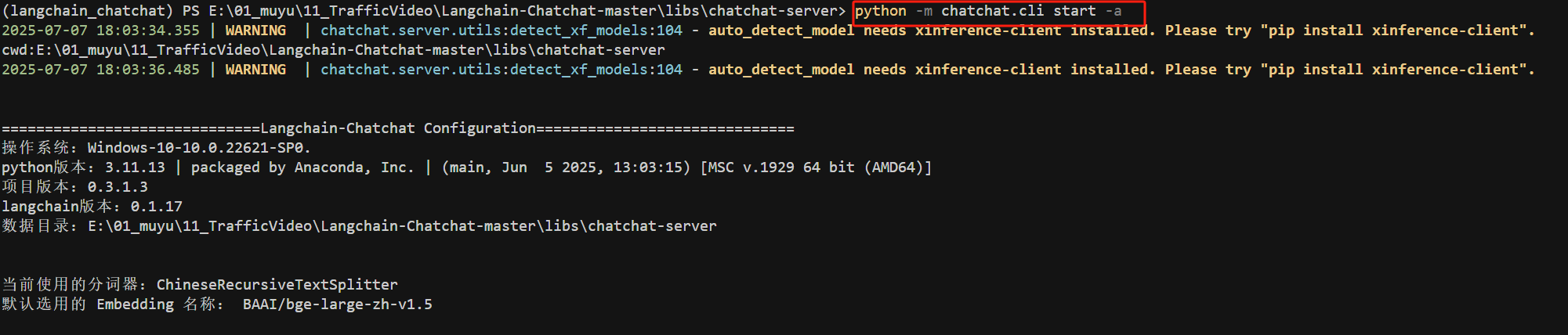
在完成项目初始化和知识库初始化后,我们就可以开始启动服务了。执行如下代码:
FENCE0
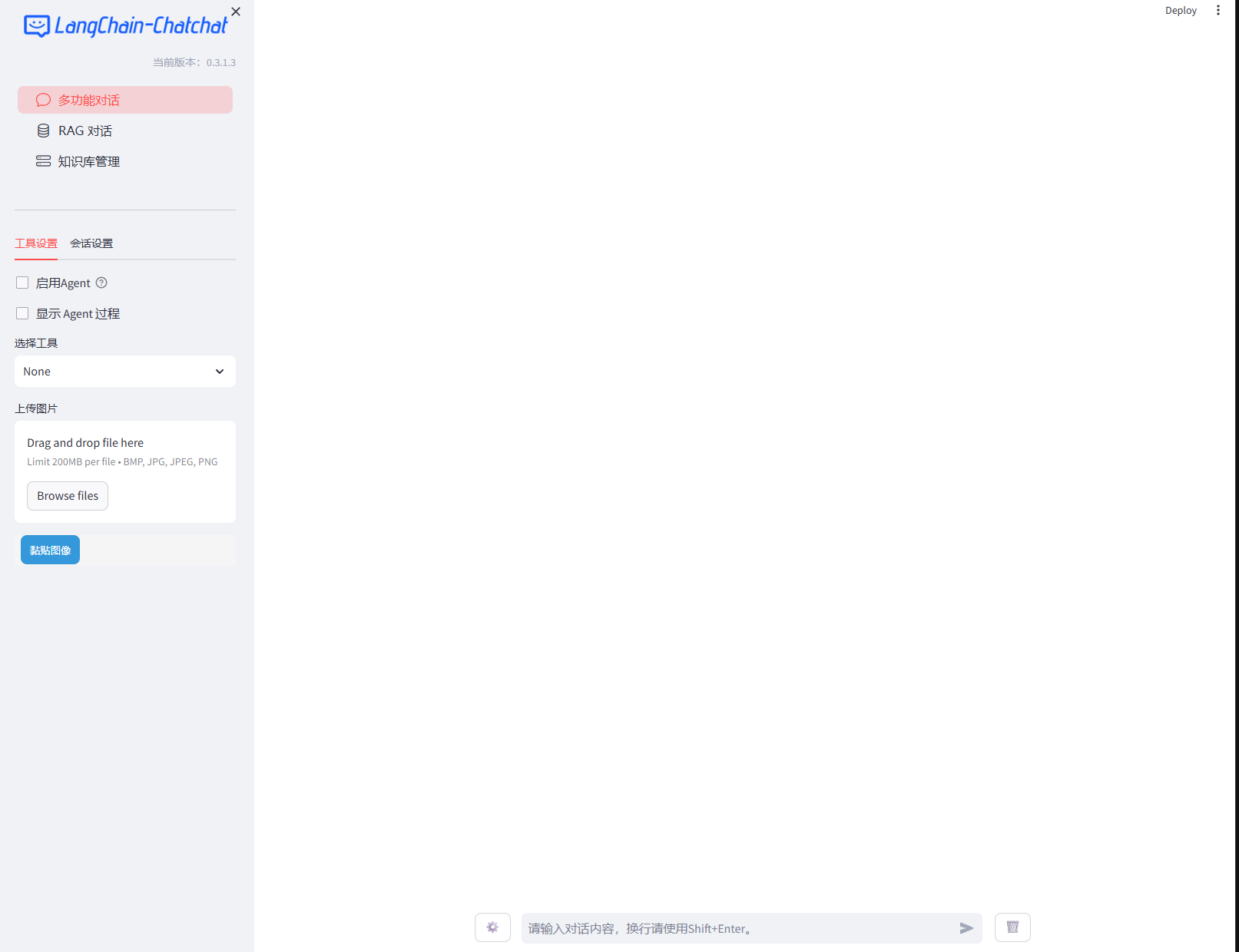
启动成功后,会自动打开浏览器,并显示如下界面:(如果浏览器没有自动打开,请手动打开浏览器,并输入http://127.0.0.1:8501)
功能演示视频如下:
Video("https://ml2022.oss-cn-hangzhou.aliyuncs.com/langchain-chatchat%E6%BC%94%E7%A4%BA%E8%A7%86%E9%A2%91.mp4", width=800, height=400)