GraphRAG快速入门与原理详解
GraphRAG快速入门与原理详解

一、GraphRAG快速入门介绍
当前阶段大模型的应用落地亟需解决的核心问题有一个是:如何与私域数据交互。而私域数据主要的问题是:需要有效地将企业数据整合进大语言模型中,但由于大模型的上下文处理能力有限,必须精准的选择出哪些数据在当前对话上下文中是有效的。一个系统是否能成功地商业化落地,在很大程度上取决于复杂的市场环境,大模型的核心优势在于其内容生成的多样性和创新性,但这同样也是其最大的问题,因为大模型生成的内容是不可控的,尤其是在金融和医疗领域等领域,一次金额评估的错误,一次医疗诊断的失误,哪怕只出现一次都是致命的。此外,大模型有时也会输出看似合理但实则错误的信息,这对于非专业人士来说可能难以辨识,但从专业角度来看却存在着不小的问题。这些都是大模型当前面临的挑战,而且目前还没有能够百分之百解决这种情况的方案。
通过人们不断地对大模型领域的探索,非常多的实验能够证明,当为大模型提供一定的上下文信息后,其输出会变得更稳定。那么,将知识库中的信息或掌握的信息先输送给大模型,再由大模型服务用户,就是大家普遍达成共识的一个结论和方法。传统的对话系统、搜索引擎等核心依赖于检索技术,如果将这一检索过程融入大模型应用的构建中,既可以充分利用大模型在内容生成上的能力,也能通过引入的上下文信息显著约束大模型的输出范围和结果,同时还实现了将私有数据融入大模型中的目的,达到了双赢的效果。所以我们才看到RAG的实现是包括两个阶段的:检索阶段和生成阶段。在检索阶段,从知识库中找出与问题最相关的知识,为后续的答案生成提供素材。在生成阶段,RAG会将检索到的知识内容作为输入,与问题一起输入到语言模型中进行生成。这样,生成的答案不仅考虑了问题的语义信息,还考虑了相关私有数据的内容。
1. 传统RAG技术实现流程与技术瓶颈
检索增强生成(Retrieval-Augmented Generation)技术是一种结合了检索和生成两个阶段的自然语言处理技术,它由 Facebook AI 团队在 2020 年提出。这种方法的核心思想是利用大规模的预训练语言模型生成技术,并结合信息检索的策略,以改善回答的准确性和相关性。其核心流程如下:
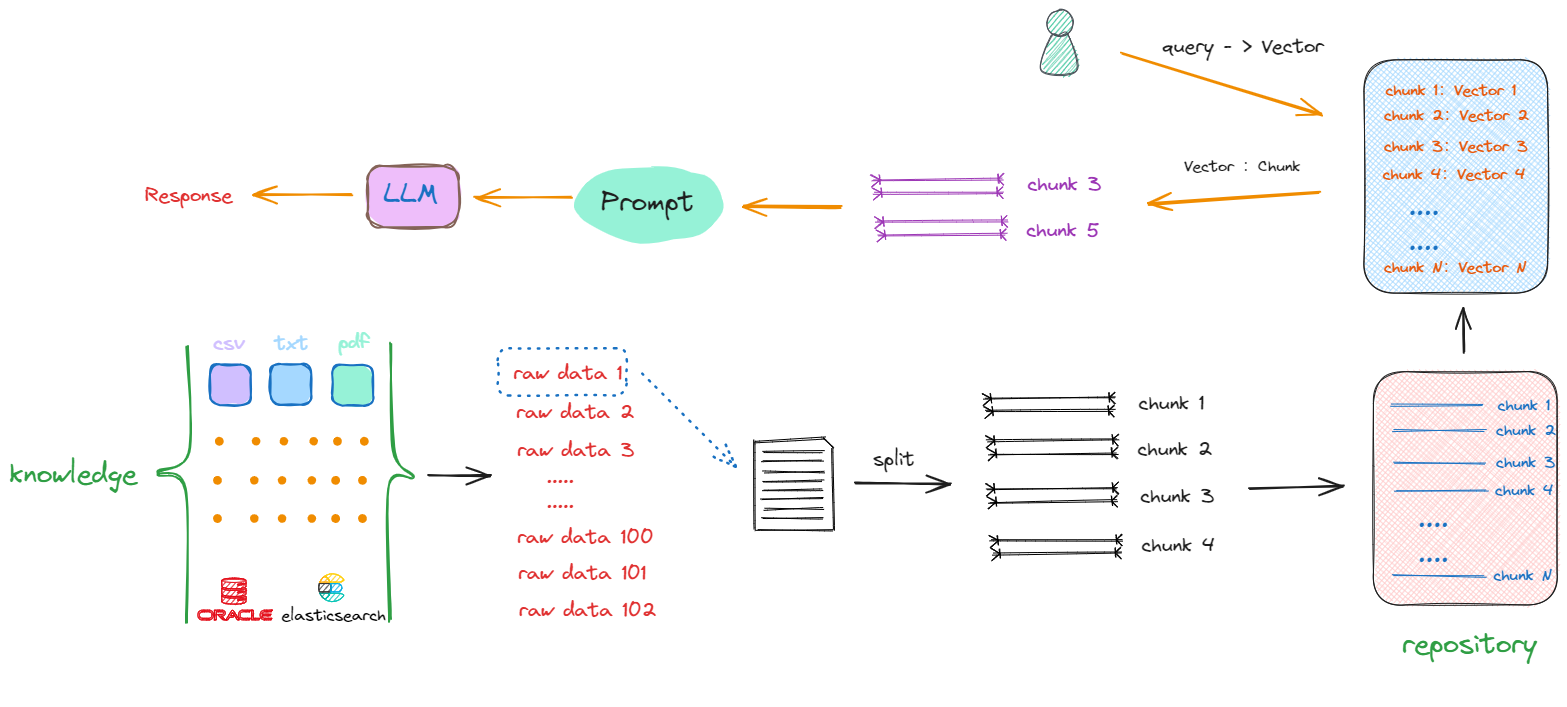
图节选自《大模型与Agent开发实战课》课程RAG板块

此外,我还开设过RAG专题公开课,详细介绍RAG技术基础概念,并从零开始手把手搭建一个RAG入门系统,感兴趣请戳👉https://www.bilibili.com/video/BV1H22DYqEqV/
这种传统的 RAG 通过 Text2Vec 检索的方式通过将生成的响应与现实世界的数据联系起来来减少幻觉,但准确回答复杂问题是另一回事。这在于每个文本嵌入都表示非结构化数据集中的一个特定块,通过最近邻算法搜索查找表示在语义上与传入用户查询相似的块的嵌入,这也意味着搜索是语义性的,但仍然高度具体。因此,候选块的质量在很大程度上取决于查询质量。就像翻阅一本食谱书一样。使用关键字搜索“炒鸡蛋”或“西红柿鸡蛋面”并找到说明,它速度很快,对于简单的问题非常有效。但是,如果你对这些菜肴背后的文化背景或是想知道为什么某些成分能够协同作用增加风味感兴趣,仅仅关键字搜索可能就显得力不从心。例如,西红柿和鸡蛋为何能搭配得如此完美?
同时,对于已经熟悉 RAG 的小伙伴来说,可能都会遇到类似的问题:
- 上下文在文本块之间丢失
- 随着检索到的文档的增长,性能会下降
- 基准RAG难以连接不同的信息点。这种情况发生在回答一个问题时,要求通过共享的属性将分散的信息片段连接起来,从而提供新的综合见解。
- 基准RAG在被要求全面理解大规模数据集或单个大型文档中总结出的语义概念时表现较差。
2. GraphRAG技术方案提出
为了解决这些问题,2024年2月微软研究院正式提出一种基于知识图谱的RAG方法——GraphRAG,这种新方法利用LLM基于私人数据集创建知识图谱。然后,这个图谱与图机器学习技术结合,在查询时执行提示增强。GraphRAG在回答上述两类问题时展现出了显著的提升,显示出超越先前应用于私人数据集的其他方法的智能或掌握能力。

该方法一经推出就受到业内广泛关注,经过一段时间的研究,微软研究院与2024年4月正式发布名为《From Local to Global: A Graph RAG Approach to
Query-Focused Summarization》的论文,详细阐述了GraphRAG方法的基本流程和卓越性能:

论文已同步至本节公开课的课件包,扫码添加老师助理即可领取:
论文中描述GraphRAG(Graph Retrieval-Augmented Generation)是一种结合图数据库和生成模型的技术,旨在通过构建和查询知识图谱来增强自然语言生成(NLG)的能力。它通过利用知识图谱的结构化信息来为生成模型提供更精确和背景丰富的上下文,从而改进生成模型的表现,尤其在复杂问题解答和文本生成方面。
在GraphRAG的实现中,首先会进行索引构建阶段,其中包含多个步骤:从原始文本中提取实体和关系、进行文本切分、生成实体的嵌入(embedding),并使用图机器学习算法进行聚类,进而构建一个基于实体、关系和社区报告的知识图谱。具体来说,GraphRAG通过分割文本为多个单元(如句子或段落),利用大语言模型(如GPT)进行实体识别和关系挖掘,并为每个实体分配嵌入向量来描述它们的语义信息。接着,GraphRAG通过计算实体之间的关系,填充关系表,并生成关于实体的社区报告来总结不同实体之间的关联与上下文。
完成知识图谱构建后,GraphRAG的查询引擎阶段才得以启动。用户可以通过自然语言查询来请求图谱中的信息,GraphRAG通过搜索相关文本单元、实体、关系以及社区报告来提供高度相关的上下文信息。查询引擎不仅能基于当前输入的查询返回相关实体和信息,还能进一步通过生成模型生成多段文本回答,从而提供对复杂问题的深度理解。
GraphRAG的创新在于它通过结合传统的图数据库查询和强大的生成模型,能够在多个领域中提供强大的推理能力,尤其是在需要从大规模文本数据中提取知识的应用中,表现出色。通过灵活的查询和语义嵌入,GraphRAG使得自然语言处理(NLP)不再局限于简单的检索,而是实现了更具推理能力的对话和生成。

图节选自《大模型与Agent开发实战课》课程RAG板块
3. GraphRAG vs NativeRAG快速实现与效果对比
目前九天老师团队自研的两款交互式智能编程与问答Agent产品,分别是MateGen Air与MateGen Pro,其中MateGenAir的问答系统就是基于传统RAG进行的构建,而MateGen Pro则是基于GraphRAG构建的问答系统。两款产品均可在JupyterLab中运行,并直接使用pip安装,无需任何网络和硬件门槛即可运行。

3.1 MateGenAir:基于NativeRAG的问答系统性能测试
-
MateGenAir安装
MateGenAir是一款基于JupyterLab的插件,旨在帮助Jupyter环境下的编程人员进行智慧编程以及围绕课程内容进行智能问答,也是付费课程中的智能助教:
!pip install mategenair
Looking in indexes: http://mirrors.aliyun.com/pypi/simple
Requirement already satisfied: mategenair in /root/miniconda3/envs/graphrag/lib/python3.11/site-packages (0.2.2)